Embed Size (px)
Citation preview

LBM for EXA — Ulrich Rüde
Lehrstuhl für Simulation Universität Erlangen-Nürnberg
www10.informatik.uni-erlangen.de
Ulrich Rüde LSS Erlangen and CERFACS Toulouse
1
Lattice Boltzmann methods on the way to exascale
Centre Européen de Recherche et de Formation Avancée en Calcul Scientifique
www.cerfacs.fr

LBM for EXA — Ulrich Rüde
OutlineMotivation Building Blocks for the Direct Simulation of Complex Flows 1. Supercomputing: scalable algorithms, efficient software 2. Solid phase - rigid body dynamics 3. Fluid phase - Lattice Boltzmann method 4. Electrostatics - finite volume 5. Fast implicit solvers - multigrid 6. Gas phase - free surface tracking, volume of fluids
Multi-physics applications Coupling Examples
Perspectives
2

LBM for EXA — Ulrich Rüde
Motivation
Simulating Additive Manufacturing
3
Bikas, H., Stavropoulos, P., & Chryssolouris, G. (2015). Additive manufacturing methods and modelling approaches: a critical review. The International Journal of Advanced Manufacturing Technology, 1-17.
Klassen, A., Scharowsky, T., & Körner, C. (2014). Evaporation model for beam based additive manufacturing using free surface lattice Boltzmann methods. Journal of Physics D: Applied Physics, 47(27), 275303.
LBM for EXA — Ulrich Rüde
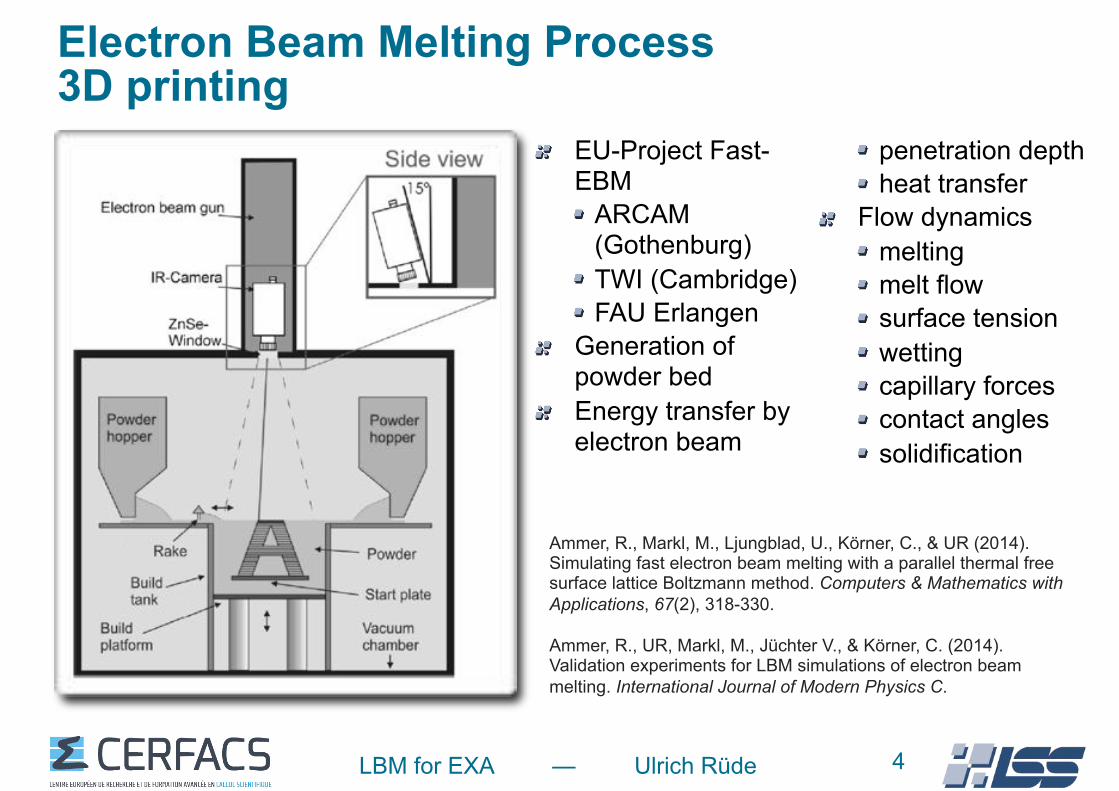
Electron Beam Melting Process 3D printing
EU-Project Fast-EBM
ARCAM (Gothenburg) TWI (Cambridge) FAU Erlangen
Generation of powder bed Energy transfer by electron beam
penetration depth heat transfer
Flow dynamics melting melt flow surface tension wetting capillary forces contact angles solidification
4
Ammer, R., Markl, M., Ljungblad, U., Körner, C., & UR (2014). Simulating fast electron beam melting with a parallel thermal free surface lattice Boltzmann method. Computers & Mathematics with Applications, 67(2), 318-330.
Ammer, R., UR, Markl, M., Jüchter V., & Körner, C. (2014). Validation experiments for LBM simulations of electron beam melting. International Journal of Modern Physics C.

LBM for EXA — Ulrich Rüde
Building Block I:
Current and Future High Performance Supercomputers
5
SuperMuc: 3 PFlops

Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
LBM Methods Ulrich Rüde
Multi-PetaFlops SupercomputersJUQUEEN SuperMUC (phase 1)
Blue Gene/Qarchitecture 458,752 PowerPCA2 cores 16 cores (1.6 GHz)per node 16 GiB RAM per node 5D torus interconnect 5.8 PFlops Peak TOP 500: #13
Intel Xeon architecture 147,456 cores 16 cores (2.7 GHz) per node 32 GiB RAM per node Pruned tree interconnect 3.2 PFlops Peak TOP 500: #27
What is the problem?
SW26010 processor 10,649,600 cores 260 cores (1.45 GHz)per node 32 GiB RAM per node 125 PFlops Peak Power consumption:15.37 MW TOP 500: #1
Sunway TaihuLight
TERRA NEO
TERRA
7
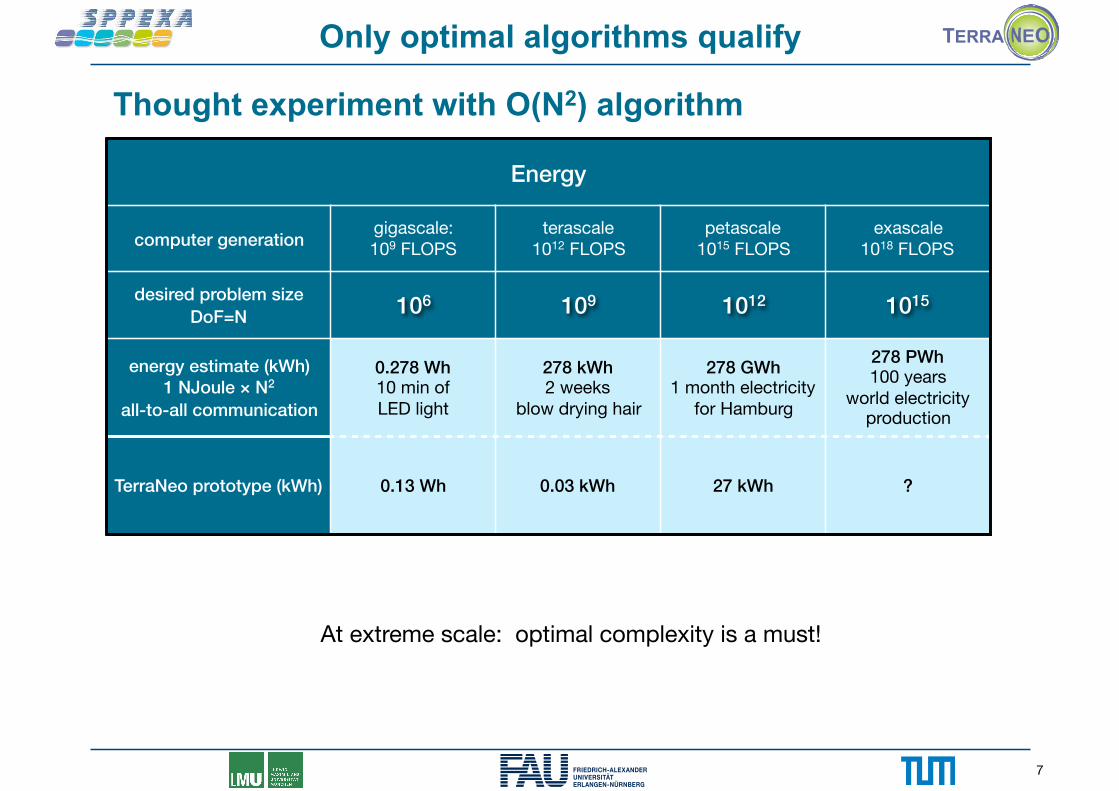
Energy
computer generation gigascale:109 FLOPS
terascale1012 FLOPS
petascale1015 FLOPS
exascale1018 FLOPS
desired problem size DoF=N 106 109 1012 1015
energy estimate (kWh) 1 NJoule × N2
all-to-all communication
0.278 Wh 10 min of LED light
278 kWh 2 weeks
blow drying hair
278 GWh 1 month electricity
for Hamburg
278 PWh 100 years
world electricity production
TerraNeo prototype (kWh) 0.13 Wh 0.03 kWh 27 kWh ?
Only optimal algorithms qualify
At extreme scale: optimal complexity is a must!
Thought experiment with O(N2) algorithm

LBM for EXA — Ulrich Rüde
Building block II:
The Lagrangian View:
Granular media simulations with the physics engine
8
1 250 000 spherical particles 256 processors 300 300 time stepsruntime: 48 h (including data output) texture mapping, ray tracing
Pöschel, T., & Schwager, T. (2005). Computational granular dynamics: models and algorithms. Springer Science & Business Media.

LBM for EXA — Ulrich Rüde
Lagrangian Particle PresentationSingle particle described by
state variables (position x, orientation φ, translational and angular velocity v and ω) a parameterization of its shape S (e.g. geometric primitive, composite object, or mesh) and its inertia properties (mass m, principle moments of inertia Ixx, Iyy and Izz).
9
The Newton-Euler equations of motion for rigid bodies describe the rate of change of the state variables:
Newton-Euler Equations for Rigid Bodies
✓x(t)'(t)
◆=
✓v(t)
Q('(t))!(t)
◆
M('(t))
✓v(t)!(t)
◆=
✓f(s(t), t)
⌧(s(t), t)� !(t)⇥ I('(t))!(t)
◆
• Integrator of order one similar to semi-implicit Euler.
✓x
0(�)'
0(�)
◆=
✓x
'
◆+ �t
✓v
0(�)Q(')!0(�)
◆
✓v
0(�)!
0(�)
◆=
✓v
!
◆+ �tM(')�1
✓f(s, t)
⌧(s, t)� ! ⇥ I(')!
◆
• Integration of positions is implicit in the velocities and integration of ve-locities is explicit.
Contact Detection
• Formal description of contact detection for a pair of convex rigid bodies.
x(t) = argminf2(y)0
f1(y)
n(t) = rf2(x(t))
⇠(t) = f1(x(t))
f1/2 : Signed distance function of body 1/2
⇠ : Minimum signed distance function
n : Function for surface normal
• Time-continuous non-penetration constraint for hard contacts:
⇠(t) � 0 ? �n
(t) � 0
1
Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
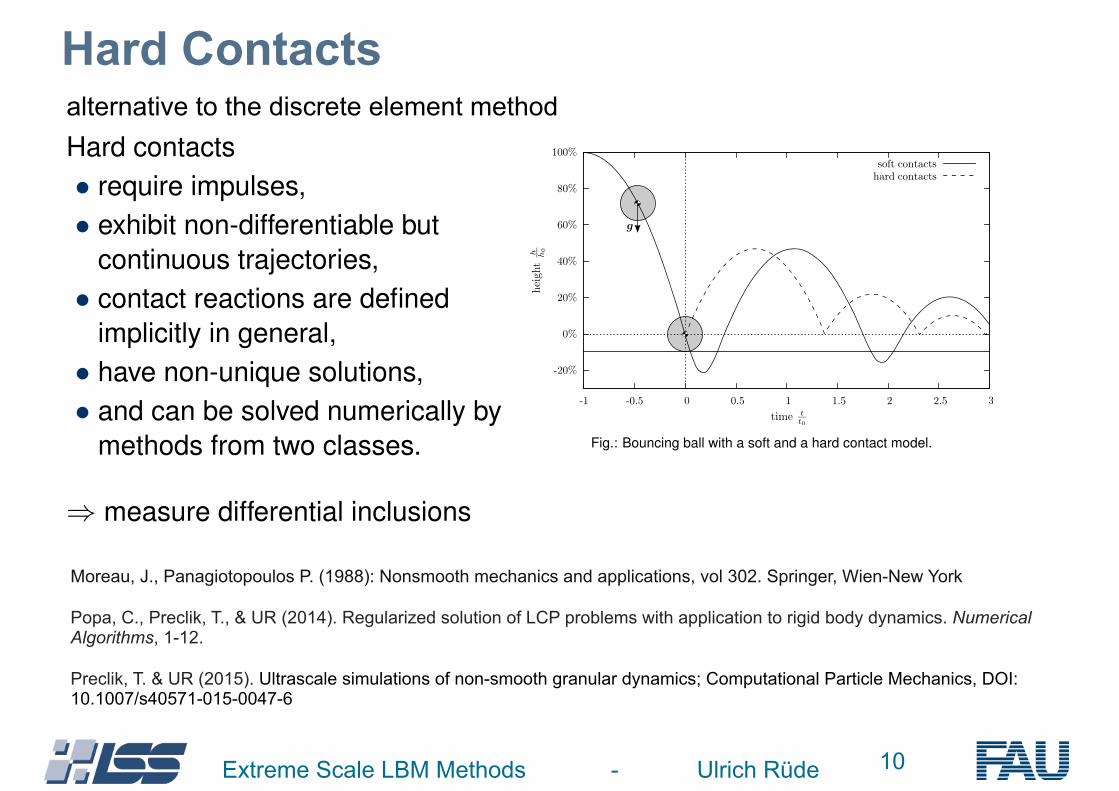
Hard Contacts
10Extreme Scale LBM Methods - Ulrich Rüde
Contact Models
Hard contacts• require impulses,• exhibit non-differentiable but
continuous trajectories,• contact reactions are defined
implicitly in general,• have non-unique solutions,• and can be solved numerically by
methods from two classes.
-1
100%
80%
60%
40%
20%
0%
-20%
-0.5 0 0.5 1 1.5 2 2.5 3
soft contactshard contacts
Fig.: Bouncing ball with a soft and a hard contact model.
) measure differential inclusions
Erlangen, 15.12.2014 — T. Preclik — Lehrstuhl fur Systemsimulation — Ultrascale Simulations of Non-smooth Granular Dynamics 6Moreau, J., Panagiotopoulos P. (1988): Nonsmooth mechanics and applications, vol 302. Springer, Wien-New York
Popa, C., Preclik, T., & UR (2014). Regularized solution of LCP problems with application to rigid body dynamics. Numerical Algorithms, 1-12.
Preclik, T. & UR (2015). Ultrascale simulations of non-smooth granular dynamics; Computational Particle Mechanics, DOI: 10.1007/s40571-015-0047-6
alternative to the discrete element method
LBM for EXA — Ulrich Rüde
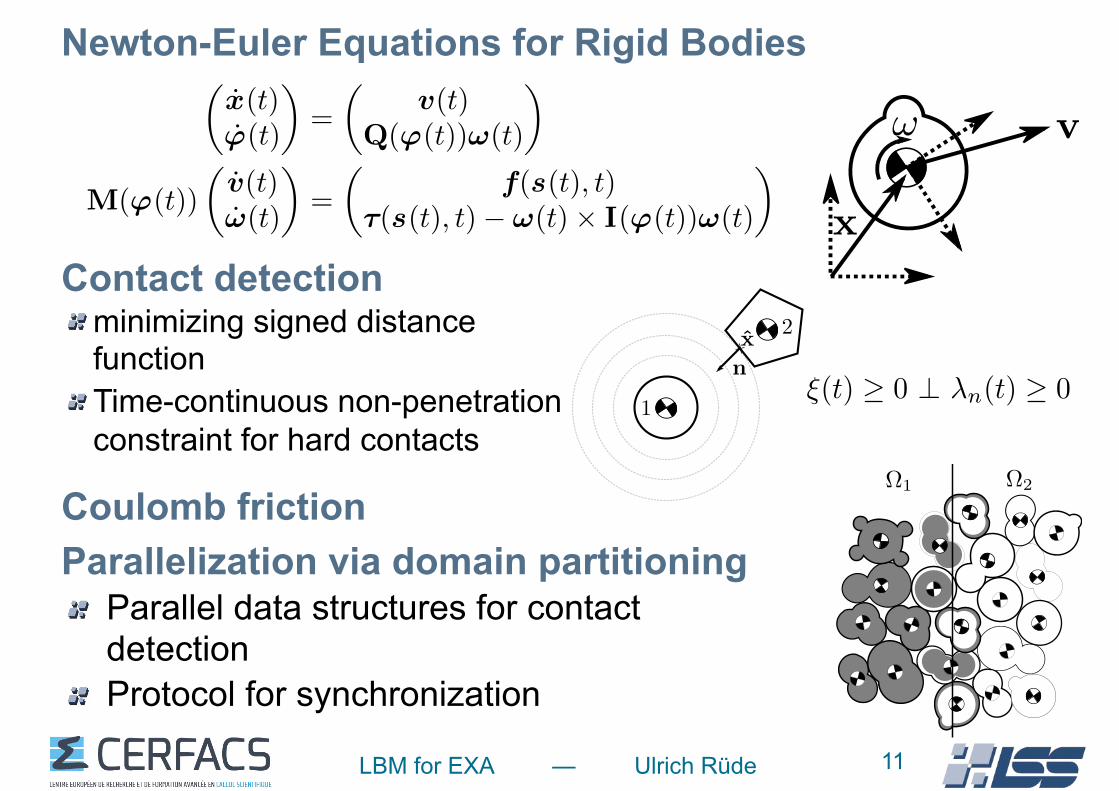
Newton-Euler Equations for Rigid Bodies
11
Newton-Euler Equations for Rigid Bodies
✓x(t)'(t)
◆=
✓v(t)
Q('(t))!(t)
◆
M('(t))
✓v(t)!(t)
◆=
✓f(s(t), t)
⌧(s(t), t)� !(t)⇥ I('(t))!(t)
◆
• Integrator of order one similar to semi-implicit Euler.
✓x
0(�)'
0(�)
◆=
✓x
'
◆+ �t
✓v
0(�)Q(')!0(�)
◆
✓v
0(�)!
0(�)
◆=
✓v
!
◆+ �tM(')�1
✓f(s, t)
⌧(s, t)� ! ⇥ I(')!
◆
• Integration of positions is implicit in the velocities and integration of ve-locities is explicit.
Contact Detection
• Formal description of contact detection for a pair of convex rigid bodies.
x(t) = argminf2(y)0
f1(y)
n(t) = rf2(x(t))
⇠(t) = f1(x(t))
f1/2 : Signed distance function of body 1/2
⇠ : Minimum signed distance function
n : Function for surface normal
• Time-continuous non-penetration constraint for hard contacts:
⇠(t) � 0 ? �n
(t) � 0
1
Contact detectionminimizing signed distance function Time-continuous non-penetration constraint for hard contacts
⇠ : Minimum signed distance function
n : Function for surface normal
• Time-continuous non-penetration constraint for hard contacts:
⇠(t) � 0 ? �n
(t) � 0
• Discretization:
⇠
�t+ n
T�v
0(�) � 0 ? �n
� 0
�v
0(�) =v
01(�) + !
01(�)⇥ (x � x1)
�v
02(�)� !
02(�)⇥ (x � x2)
Coulomb Friction
• Contact reaction must be within friction cone.
• Frictional reaction directly opposes the slip (relative contact velocity intangential plane).
k�to
(t)k2 µ�n
(t)
k�vto
(t)k2�to
(t) = �µ�n
(t)�vto
(t)
• Discretization:
k�to
k2 µ�n
k�v0to
(�)k2�to
= �µ�n
�v
0to
(�)
2
Parallelization via domain partitioningParallel data structures for contact detection Protocol for synchronization
Coulomb friction

Discretization Underlying the Time-Stepping
Non-penetration conditions Coulomb friction conditions
⇠ � 0 ?�
n
� 0 k�to
k2 µ�
n
⇠
+ � 0 ?�
n
� 0 k�v+to
k2�to
= �µ�
n
�v
+to
⇠
+ � 0 ?�
n
� 0 k ˙�v
+to
k2�to
= �µ�
n
˙�v
+to
⇠ � 0 ? ⇤n
� 0 k⇤to
k2 µ⇤n
⇠
+ � 0 ? ⇤n
� 0 k�v+to
k2⇤to
= �µ⇤n
�v
+to
⇠
�t
+ �v
0n
(�) � 0 ? �
n
� 0k�
to
k2 µ�
n
k�v0to
(�)k2�to
= �µ�
n
�v
0to
(�)
Signorini condition impact law friction cone condition frictional reaction opposes slip
⇠ = 0
⇠
+ = 0
⇠ = 0
k�v+to
k2 = 0forc
esim
puls
es
cont
inuo
usdi
scre
te
Erlangen, 15.12.2014 — T. Preclik — Lehrstuhl fur Systemsimulation — Ultrascale Simulations of Non-smooth Granular Dynamics 9
LBM for EXA — Ulrich Rüde
Nonlinear Complementarity and Time Stepping
12
Moreau, J., Panagiotopoulos P. (1988): Nonsmooth mechanics and applications, vol 302. Springer, Wien-New York
Popa, C., Preclik, T., & UR (2014). Regularized solution of LCP problems with application to rigid body dynamics. Numerical Algorithms, 1-12.
Preclik, T. & UR (2015). Ultrascale simulations of non-smooth granular dynamics; Computational Particle Mechanics, DOI: 10.1007/s40571-015-0047-6

LBM for EXA — Ulrich Rüde
Regularizing Multi-Contact Problems
13
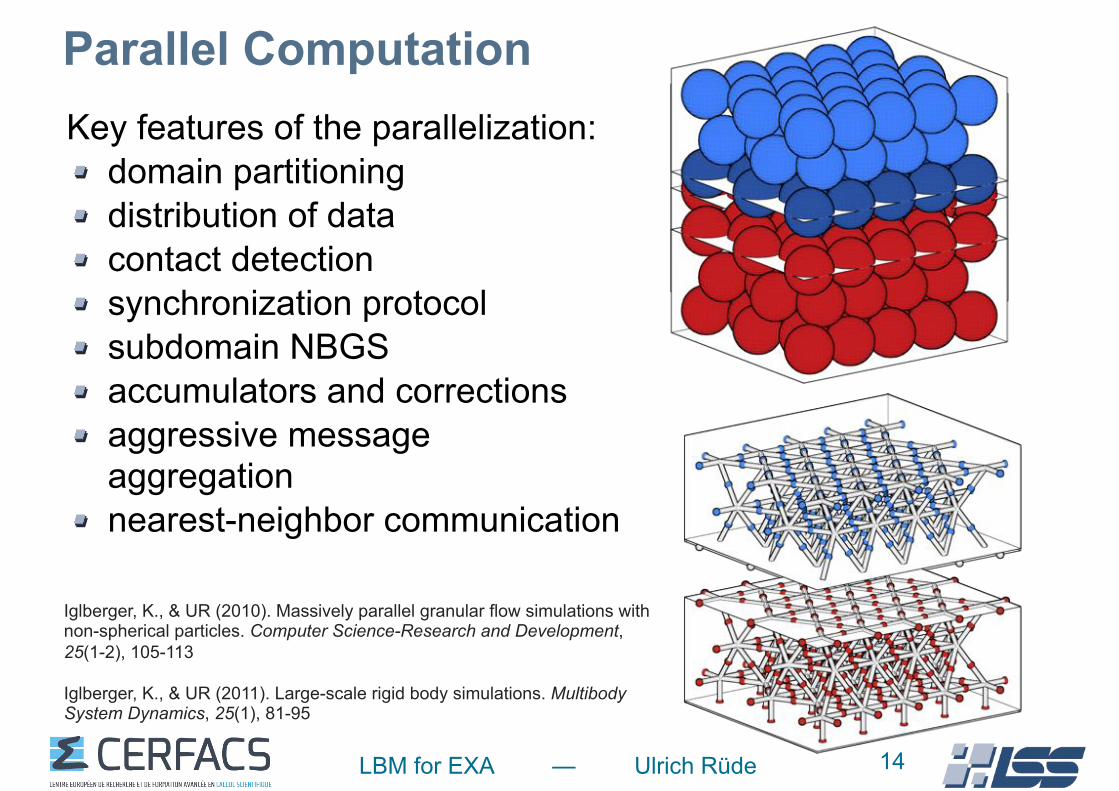
LBM for EXA — Ulrich Rüde
Parallel ComputationKey features of the parallelization:
domain partitioning distribution of data contact detection synchronization protocol subdomain NBGS accumulators and corrections aggressive message aggregation nearest-neighbor communication
14
Iglberger, K., & UR (2010). Massively parallel granular flow simulations with non-spherical particles. Computer Science-Research and Development, 25(1-2), 105-113
Iglberger, K., & UR (2011). Large-scale rigid body simulations. Multibody System Dynamics, 25(1), 81-95
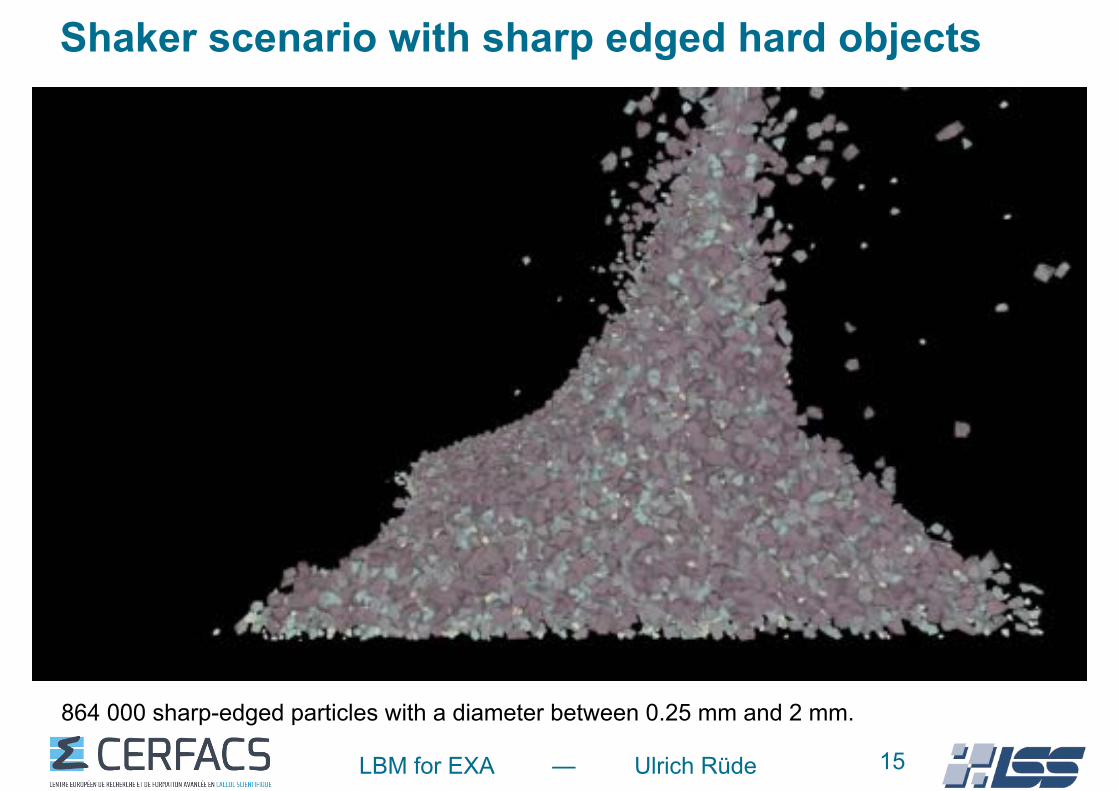
LBM for EXA — Ulrich Rüde 15
Shaker scenario with sharp edged hard objects
864 000 sharp-edged particles with a diameter between 0.25 mm and 2 mm.

LBM for EXA — Ulrich Rüde 16
PE marble run - rigid objects in complex geometry
Animation by Sebastian Eibl and Christian Godenschwager
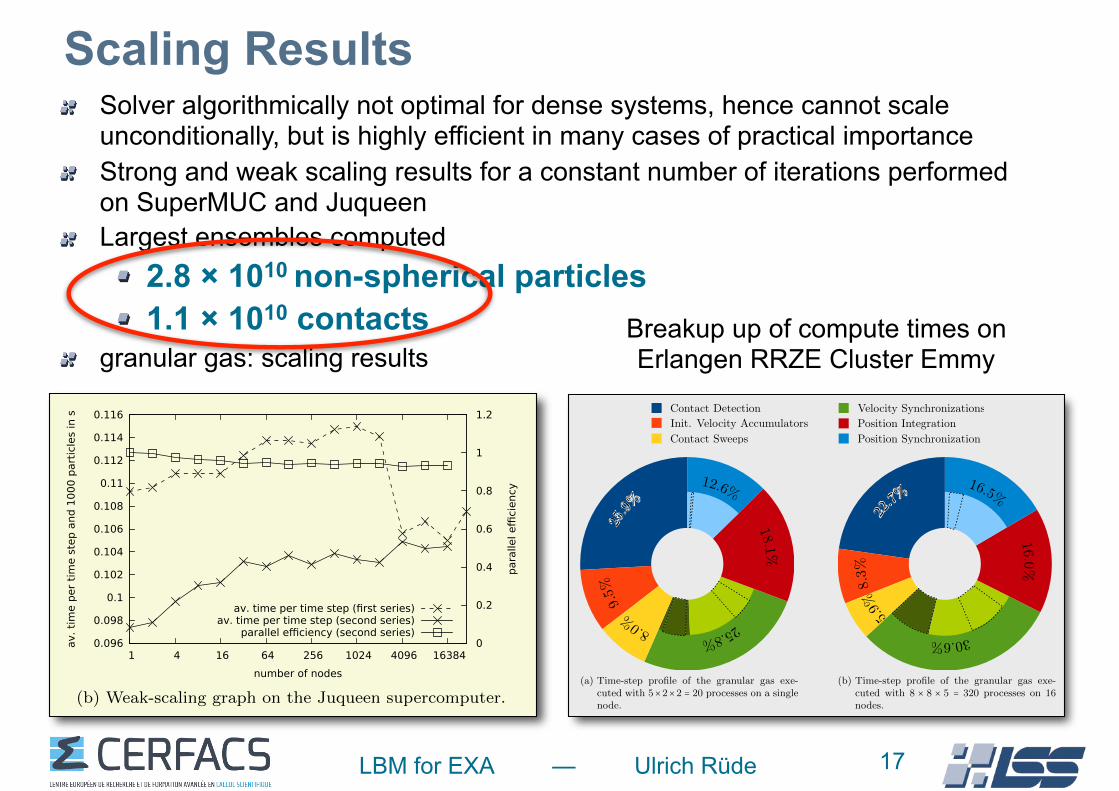
7.1 Scalability of Granular Gases
25.9%
9.5%
8.0% 25.8%
18.1%
12.6%
(a) Time-step profile of the granular gas exe-
cuted with 5×2×2 = 20 processes on a single
node.
16.0%
5.9%
22
.7%
22
.7%
30.6%
16.5%
8.3%
(b) Time-step profile of the granular gas exe-
cuted with 8 × 8 × 5 = 320 processes on 16
nodes.
Figure 7.3: The time-step profiles for two weak-scaling executions of the granular gas onthe Emmy cluster with 253 particles per process.
domain decompositions. The scaling experiment for the one-dimensional domain decom-positions (20×1×1, . . . , 10 240×1×1) performs best and achieves on 512 nodes a parallele�ciency of 98.3% with respect to the single node performance. The time measurementsfor two-dimensional domain decompositions (5 × 4 × 1, 8 × 5 × 1, . . . 128 × 80 × 1) areconsistently slower, but the parallel e�ciency does not drop below 89.7%. The time mea-surements for three-dimensional domain decompositions (5×2×2, 5×4×2, . . . , 32×20×16)come in last, and the parallel e�ciency goes down to 76.1% for 512 nodes. Again thisbehaviour can be explained due to the di↵erences in the communication volumes of one-,two- and three-dimensional domain decompositions. The largest weak scaling setups inthis experiment contained 1.6 ⋅ 108 non-spherical particles.
Fig. 7.3 breaks down the wall clock time of various time step components in two-level piecharts. The times are averaged over all time steps and processes. The dark blue sectioncorresponds to the fraction of the time in a time step used for detecting and filteringcontacts. The orange section corresponds to the time used for initializing the velocityaccumulators. The time to relax the contacts is indicated by the yellow time slice, itincludes the contact sweeps for all 10 iterations without the velocity synchronization. Thetime used by all velocity synchronizations is shown in the green section, which includesthe synchronizations for each iteration and the synchronization after the initialization ofthe velocity accumulators. The time slice is split up on the second level in the time usedfor assembling, exchanging, and processing the velocity correction message (dark green
145
LBM for EXA — Ulrich Rüde
Scaling ResultsSolver algorithmically not optimal for dense systems, hence cannot scale unconditionally, but is highly efficient in many cases of practical importance Strong and weak scaling results for a constant number of iterations performed on SuperMUC and Juqueen Largest ensembles computed
2.8 × 1010 non-spherical particles 1.1 × 1010 contacts
granular gas: scaling results
17
18 Tobias Preclik, Ulrich Rude
(a) Weak-scaling graph on the Emmy cluster.
0.096
0.098
0.1
0.102
0.104
0.106
0.108
0.11
0.112
0.114
0.116
1 4 16 64 256 1024 4096 16384 0
0.2
0.4
0.6
0.8
1
1.2
av. t
ime
per t
ime
step
and
100
0 pa
rtic
les
in s
para
llel e
�ci
ency
number of nodes
av. time per time step (�rst series)av. time per time step (second series)
parallel e�ciency (second series)
(b) Weak-scaling graph on the Juqueen supercomputer.
(c) Weak-scaling graph on the SuperMUC supercomputer.
Fig. 5: Inter-node weak-scaling graphs for a granulargas on all test machines.
The reason why the measured times in the firstseries became shorter for 4 096 nodes and more is re-vealed when considering how the processes get mappedto the hardware. The default mapping on Juqueen isABCDET, where the letters A to E stand for the fivedimensions of the torus network, and T stands for thehardware thread within each node. The six-dimensionalcoordinates are then mapped to the MPI ranks in arow-major order, that is, the last dimension increases
fastest. The T coordinate is limited by the number ofprocesses per node, which was 64 for the above measure-ments. Upon creation of a three-dimensional communi-cator, the three dimensions of the domain partition-ing are mapped also in row-major order. This e↵ects, ifthe number of processes in z-dimension is less than thenumber of processes per node, that a two-dimensionalor even three-dimensional section of the domain parti-tioning is mapped to a single node. However, if the num-ber of processes in z-dimension is larger or equal to thenumber of processes per node, only a one-dimensionalsection of the domain partitioning is mapped to a singlenode. A one-dimensional section of the domain parti-tioning performs considerably less intra-node communi-cation than a two- or three-dimensional section of thedomain partitioning. This matches exactly the situa-tion for 2 048 and 4 096 nodes. For 2 048 nodes, a two-dimensional section 1⇥2⇥32 of the domain partitioning64⇥64⇥32 is mapped to each node, and for 4 096 nodesa one-dimensional section 1⇥1⇥64 of the domain par-titioning 64⇥ 64⇥ 64 is mapped to each node. To sub-stantiate this claim, we confirmed that the performancejump occurs when the last dimension of the domain par-titioning reaches the number of processes per node, alsowhen using 16 and 32 processes per node.
Fig. 5c presents the weak-scaling results on the Su-perMUC supercomputer. The setup di↵ers from thegranular gas scenario presented in Sect. 7.2.1 in that itis more dilute. The distance between the centers of twogranular particles along each spatial dimension is 2 cm,amounting to a solid volume fraction of 3.8% and conse-quently to less collisions. As on the Juqueen supercom-puter only three-dimensional domain partitionings wereused. All runs on up to 512 nodes were running within asingle island. The run on 1 024 nodes also used the min-imum number of 2 islands. The run on 4 096 nodes usednodes from 9 islands, and the run on 8 192 nodes usednodes from 17 islands, that is both runs used one islandmore than required. The graph shows that most of theperformance is lost in runs on up to 512 nodes. In theseruns only the non-blocking intra-island communicationis utilised. Thus this part of the setup is very similarto the Emmy cluster since it also has dual-socket nodeswith Intel Xeon E5 processors and a non-blocking treeInfiniband network. Nevertheless, the intra-island scal-ing results are distinctly worse. The reasons for thesedi↵erences were not yet further investigated. However,the scaling behaviour beyond a single island is decentfeaturing a parallel e�ciency of 73.8% with respect toa single island. A possible explanation of the under-performing intra-node scaling behaviour could be thatsome of the Infiniband links were degraded to QDR,which was a known problem at the time the extreme-
Breakup up of compute times on Erlangen RRZE Cluster Emmy

Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
Building Block III:
Scalable Flow Simulations with the Lattice Boltzmann Method
18Extreme Scale LBM Methods - Ulrich Rüde
Lallemand, P., & Luo, L. S. (2000). Theory of the lattice Boltzmann method: Dispersion, dissipation, isotropy, Galilean invariance, and stability. Physical Review E, 61(6), 6546.
Feichtinger, C., Donath, S., Köstler, H., Götz, J., & Rüde, U. (2011). WaLBerla: HPC software design for computational engineering simulations. Journal of Computational Science, 2(2), 105-112.

Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
19
The Eulerian View : Lattice-BoltzmannDiscretization in squares or cubes (cells) Particles Distribution Functions (PDF)
in 2D: 9 numbers (2DQ9) in 3D: D3Q19 (alternatives D3Q27, etc)
Repeat (many times) stream collide
Extreme Scale LBM Methods - Ulrich Rüde
Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
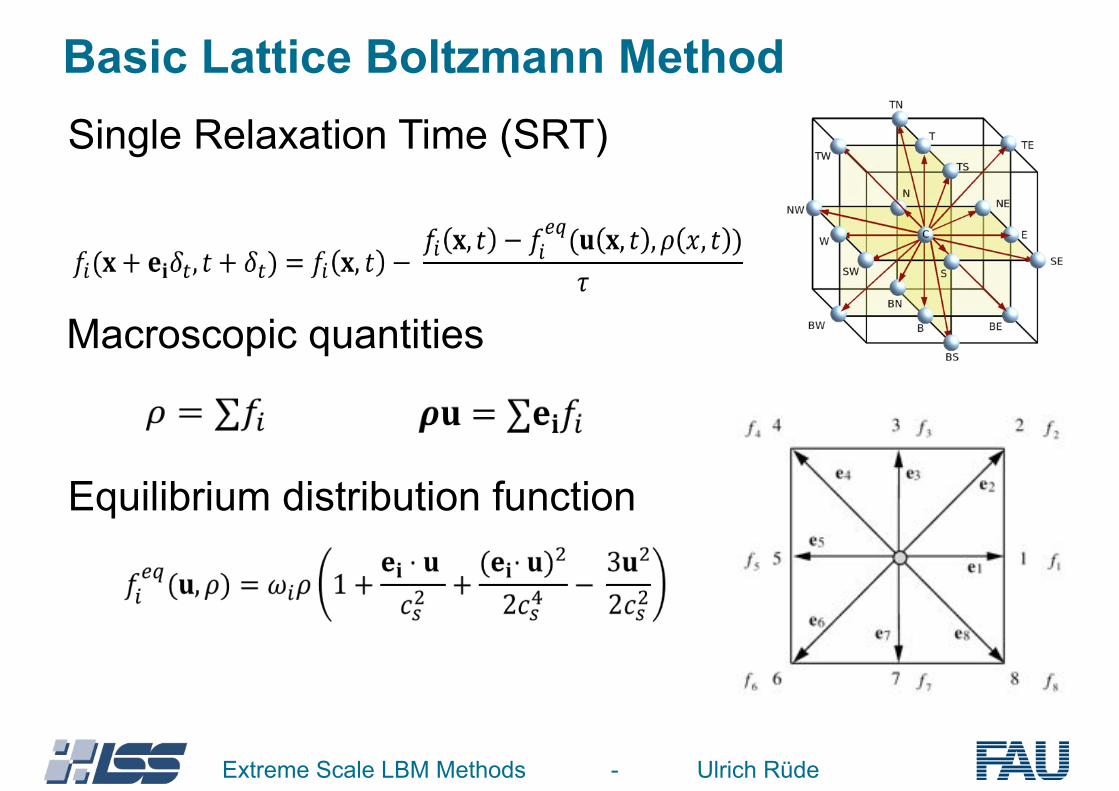
Basic Lattice Boltzmann Method
Extreme Scale LBM Methods - Ulrich Rüde
Single Relaxation Time (SRT)
Equilibrium distribution function
Macroscopic quantities
Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
21
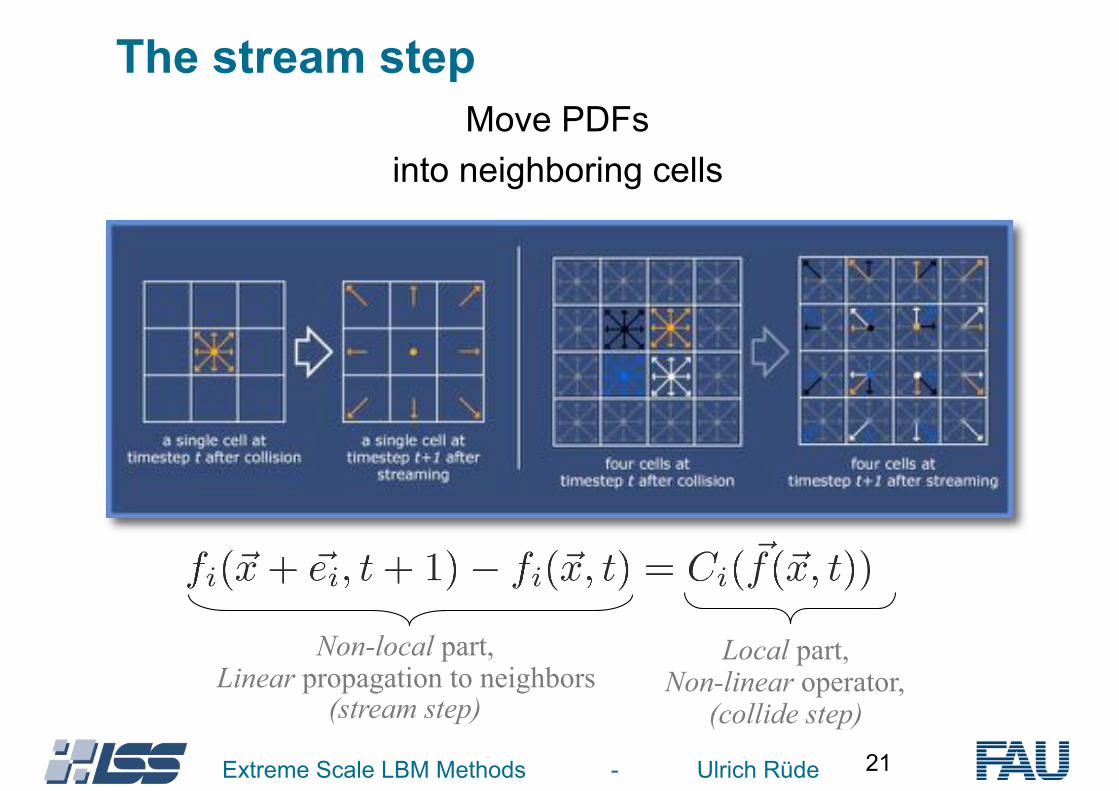
The stream stepMove PDFs
into neighboring cells
Non-local part, Linear propagation to neighbors
(stream step)
Local part, Non-linear operator,
(collide step)
Extreme Scale LBM Methods - Ulrich Rüde

Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
22
The collide stepCompute new PDFs modeling „molecular collisions“Most collision operators can be expressed as
Equilibrium function: non-linear,depending on the conserved moments , , and .
Extreme Scale LBM Methods - Ulrich Rüde
Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
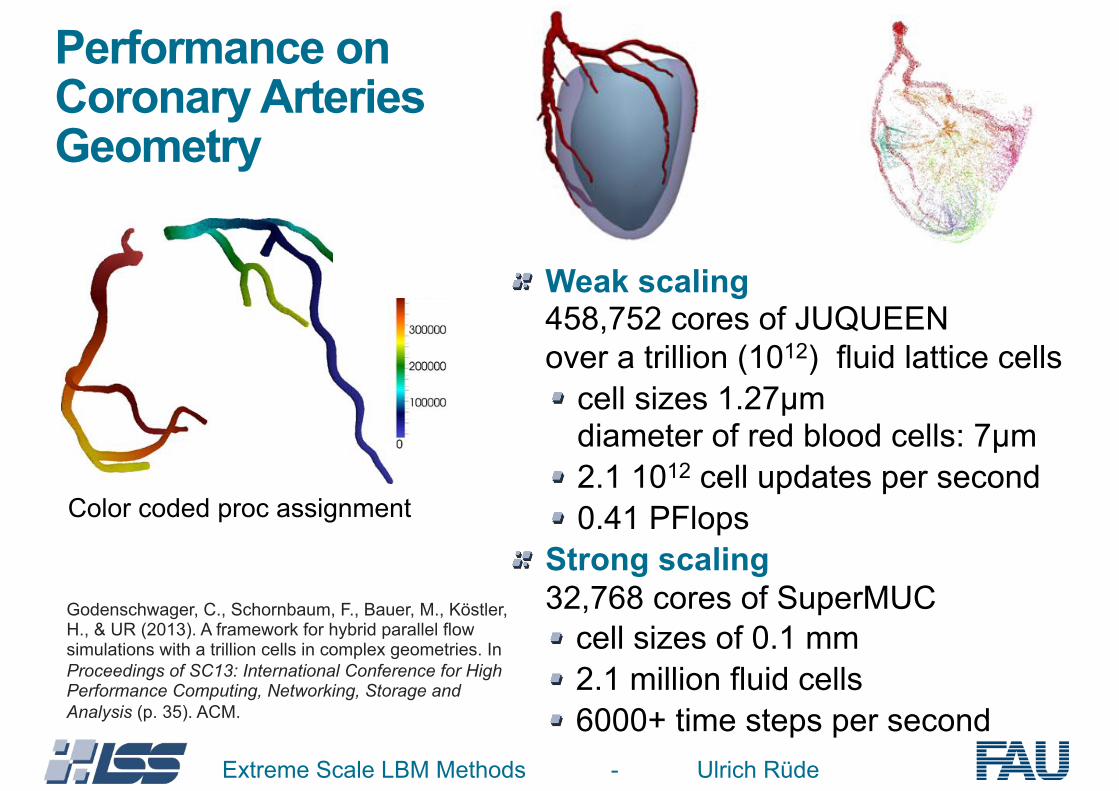
Performance on Coronary Arteries Geometry
Extreme Scale LBM Methods - Ulrich Rüde
Godenschwager, C., Schornbaum, F., Bauer, M., Köstler, H., & UR (2013). A framework for hybrid parallel flow simulations with a trillion cells in complex geometries. In Proceedings of SC13: International Conference for High Performance Computing, Networking, Storage and Analysis (p. 35). ACM.
Weak scaling 458,752 cores of JUQUEENover a trillion (1012) fluid lattice cells
cell sizes 1.27µm diameter of red blood cells: 7µm 2.1 1012 cell updates per second 0.41 PFlops
Strong scaling32,768 cores of SuperMUC
cell sizes of 0.1 mm 2.1 million fluid cells 6000+ time steps per second
Color coded proc assignment

Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
Single Node Performance
Extreme Scale LBM - Ulrich Rüde
SuperMUCJUQUEEN
vectorized
optimized
standard
Pohl, T., Deserno, F., Thürey, N., UR, Lammers, P., Wellein, G., & Zeiser, T. (2004). Performance evaluation of parallel large-scale lattice Boltzmann applications on three supercomputing architectures. Proceedings of the 2004 ACM/IEEE conference on Supercomputing (p. 21). IEEE Computer Society.
Donath, S., Iglberger, K., Wellein, G., Zeiser, T., Nitsure, A., & UR (2008). Performance comparison of different parallel lattice Boltzmann implementations on multi-core multi-socket systems. International Journal of Computational Science and Engineering, 4(1), 3-11.
Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
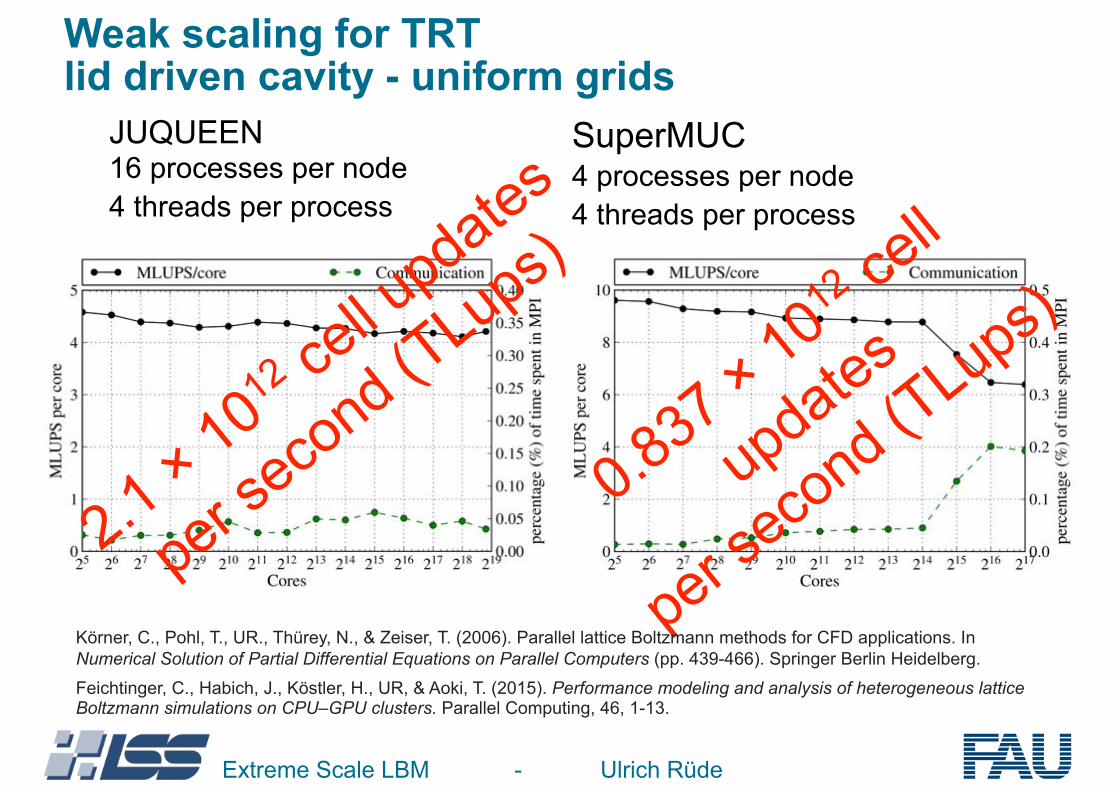
Weak scaling for TRT lid driven cavity - uniform grids
JUQUEEN 16 processes per node 4 threads per process
SuperMUC 4 processes per node 4 threads per process
0.837 × 101
2 cell
updates
per second (T
Lups)
2.1 × 101
2 cell u
pdates
per second (T
Lups)
Extreme Scale LBM - Ulrich Rüde
Körner, C., Pohl, T., UR., Thürey, N., & Zeiser, T. (2006). Parallel lattice Boltzmann methods for CFD applications. In Numerical Solution of Partial Differential Equations on Parallel Computers (pp. 439-466). Springer Berlin Heidelberg.
Feichtinger, C., Habich, J., Köstler, H., UR, & Aoki, T. (2015). Performance modeling and analysis of heterogeneous lattice Boltzmann simulations on CPU–GPU clusters. Parallel Computing, 46, 1-13.
LBM for EXA — Ulrich Rüde
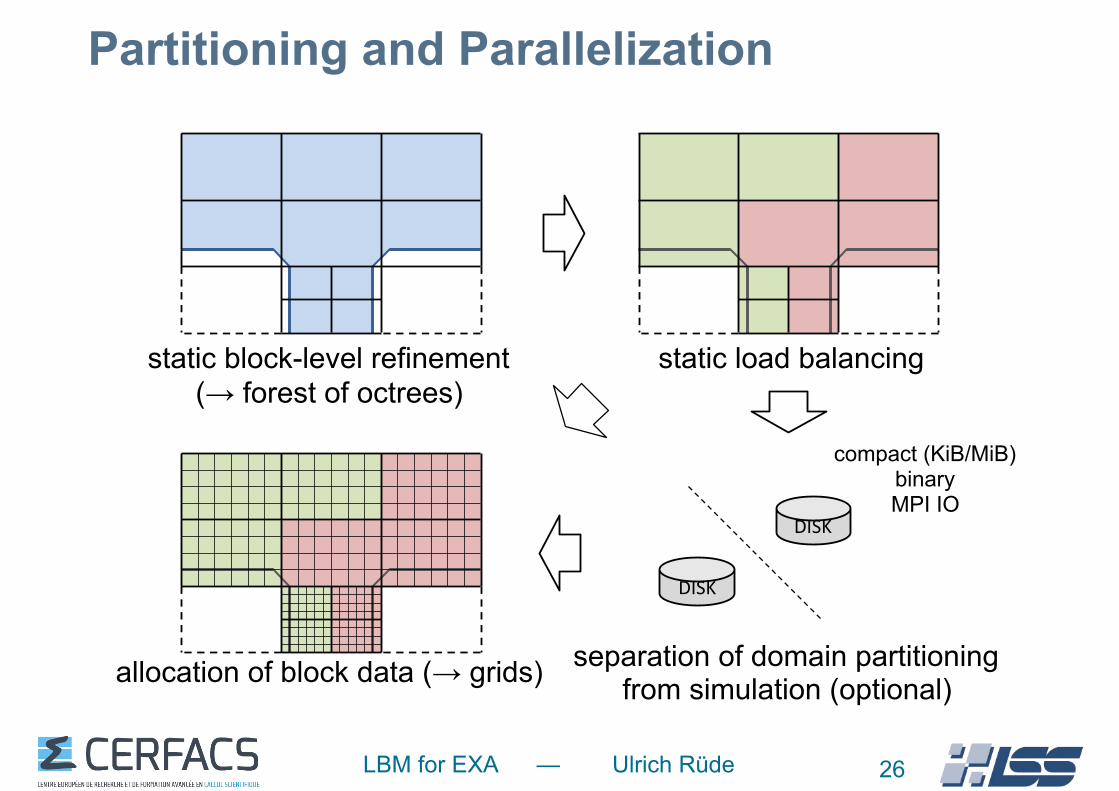
Partitioning and Parallelization
26
static load balancing
allocation of block data (→ grids)
static block-level refinement (→ forest of octrees)
DISK
DISK
separation of domain partitioning from simulation (optional)
compact (KiB/MiB) binary MPI IO
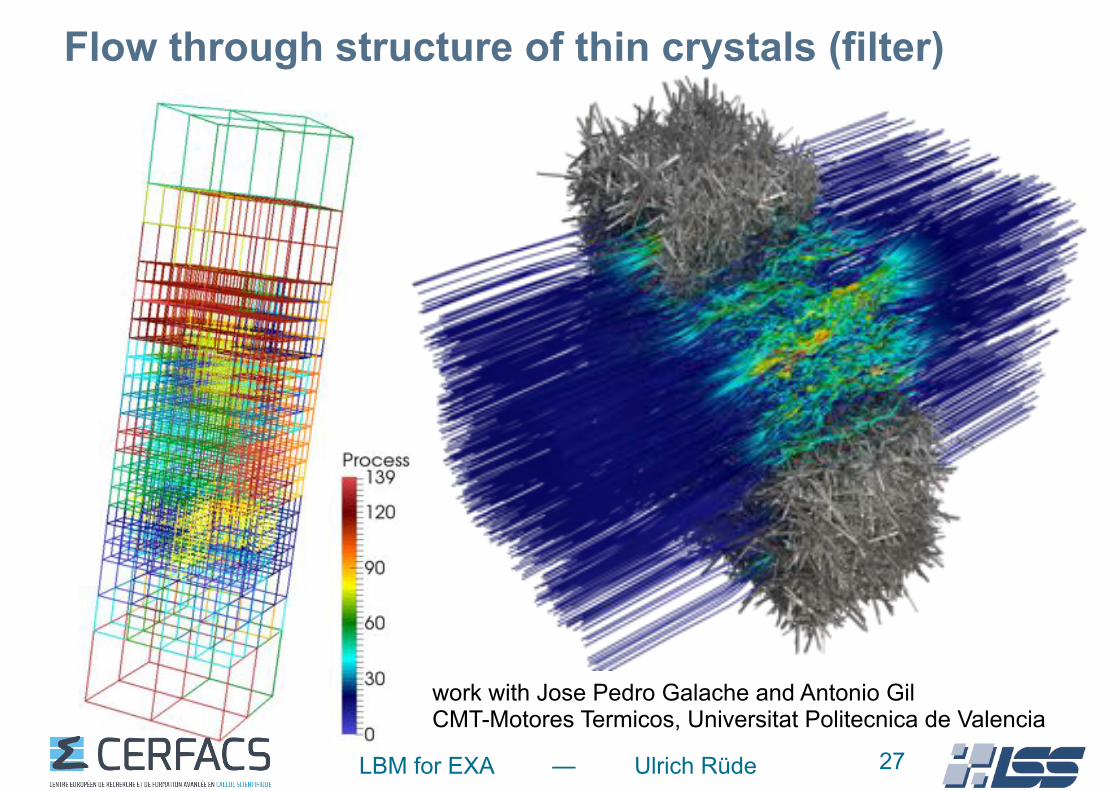
LBM for EXA — Ulrich Rüde
Flow through structure of thin crystals (filter)
27
work with Jose Pedro Galache and Antonio Gil CMT-Motores Termicos, Universitat Politecnica de Valencia
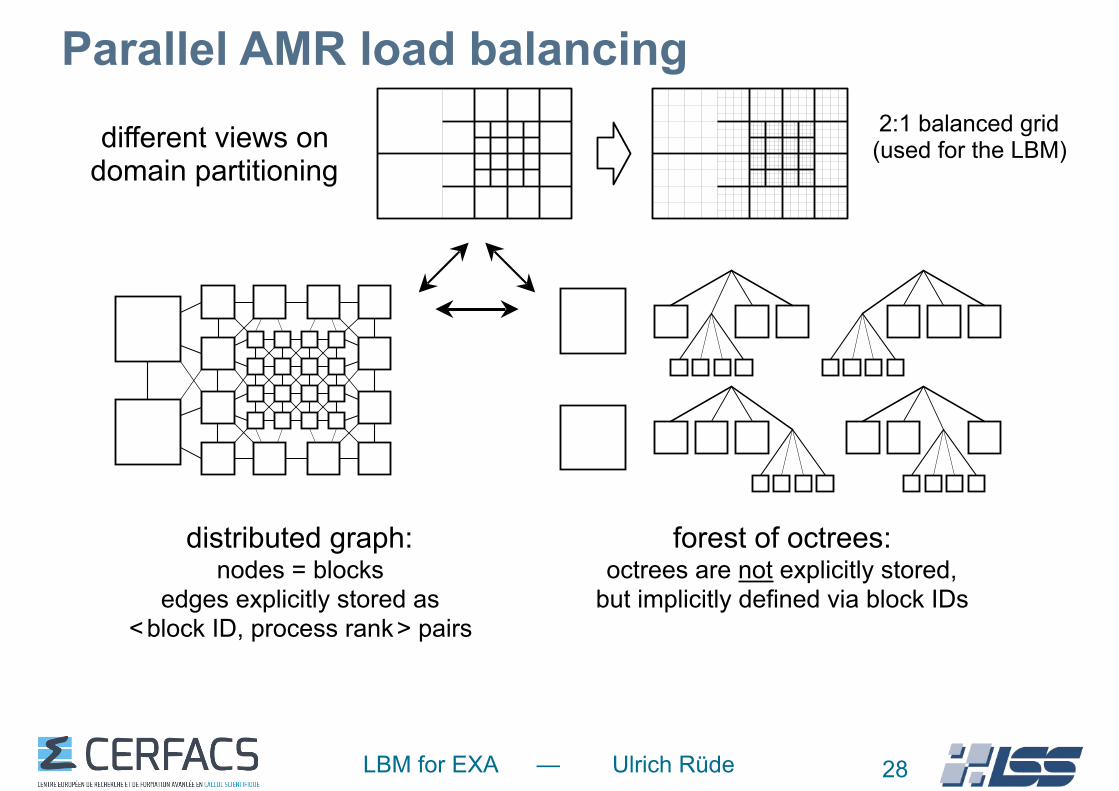
LBM for EXA — Ulrich Rüde
Parallel AMR load balancing
28
forest of octrees: octrees are not explicitly stored,
but implicitly defined via block IDs
2:1 balanced grid(used for the LBM)
distributed graph: nodes = blocks
edges explicitly stored as < block ID, process rank > pairs
different views on domain partitioning

Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
AMR and Load Balancing with waLBerla
29Extreme Scale LBM Methods - Ulrich Rüde
Isaac, T., Burstedde, C., Wilcox, L. C., & Ghattas, O. (2015). Recursive algorithms for distributed forests of octrees. SIAM Journal on Scientific Computing, 37(5), C497-C531.
Meyerhenke, H., Monien, B., & Sauerwald, T. (2009). A new diffusion-based multilevel algorithm for computing graph partitions. Journal of Parallel and Distributed Computing, 69(9), 750-761.
Schornbaum, F., & Rüde, U. (2016). Massively Parallel Algorithms for the Lattice Boltzmann Method on NonUniform Grids. SIAM Journal on Scientific Computing, 38(2), C96-C126.
Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
AMR Performance
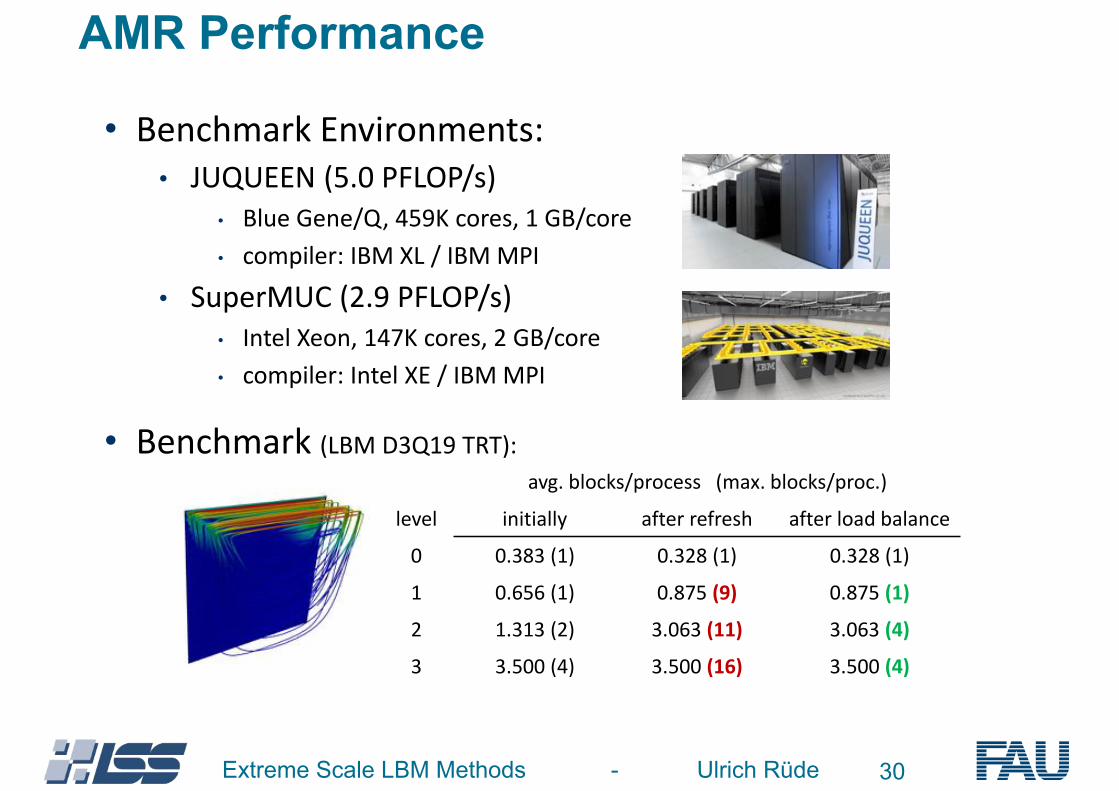
30Extreme Scale LBM Methods - Ulrich Rüde
• Benchmark Environments: • JUQUEEN (5.0 PFLOP/s)
• Blue Gene/Q, 459K cores, 1 GB/core • compiler: IBM XL / IBM MPI
• SuperMUC (2.9 PFLOP/s) • Intel Xeon, 147K cores, 2 GB/core • compiler: Intel XE / IBM MPI
• Benchmark (LBM D3Q19 TRT): avg. blocks/process (max. blocks/proc.)
level initially after refresh after load balance
0 0.383 (1) 0.328 (1) 0.328 (1)
1 0.656 (1) 0.875 (9) 0.875 (1)
2 1.313 (2) 3.063 (11) 3.063 (4)
3 3.500 (4) 3.500 (16) 3.500 (4)
LBM AMR - Performance
33 Peta-Scale Simulations with the HPC Framework waLBerla: Massively Parallel AMR for the LBM Florian Schornbaum - FAU Erlangen-Nürnberg - April 15, 2016

Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
AMR Performance
31Extreme Scale LBM Methods - Ulrich Rüde
• Benchmark Environments: • JUQUEEN (5.0 PFLOP/s)
• Blue Gene/Q, 459K cores, 1 GB/core • compiler: IBM XL / IBM MPI
• SuperMUC (2.9 PFLOP/s) • Intel Xeon, 147K cores, 2 GB/core • compiler: Intel XE / IBM MPI
• Benchmark (LBM D3Q19 TRT):
refine coarsen
LBM AMR - Performance
30 Peta-Scale Simulations with the HPC Framework waLBerla: Massively Parallel AMR for the LBM Florian Schornbaum - FAU Erlangen-Nürnberg - April 15, 2016
• Benchmark Environments: • JUQUEEN (5.0 PFLOP/s)
• Blue Gene/Q, 459K cores, 1 GB/core • compiler: IBM XL / IBM MPI
• SuperMUC (2.9 PFLOP/s) • Intel Xeon, 147K cores, 2 GB/core • compiler: Intel XE / IBM MPI
• Benchmark (LBM D3Q19 TRT):
LBM AMR - Performance
32
during this refresh process …
… all cells on the finest level are coarsened and the same amount of fine cells is created by splitting coarser cells
→ 72 % of all cells change their size
Peta-Scale Simulations with the HPC Framework waLBerla: Massively Parallel AMR for the LBM Florian Schornbaum - FAU Erlangen-Nürnberg - April 15, 2016
Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
AMR Performance
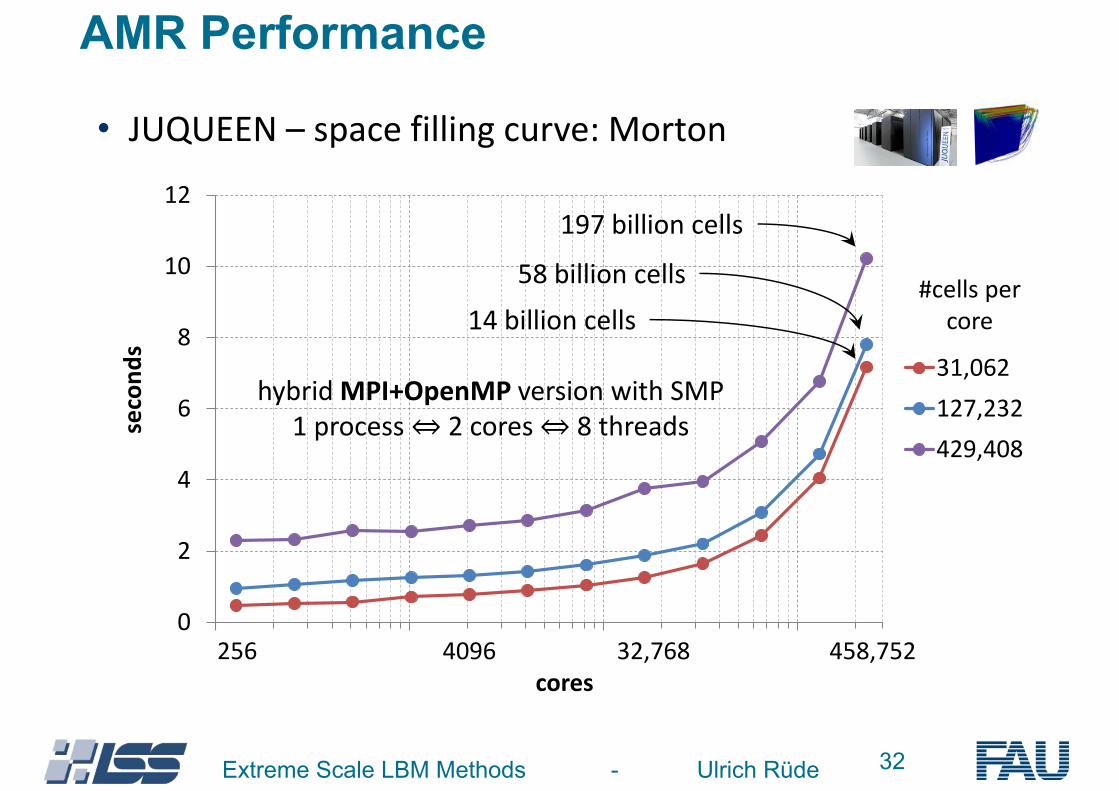
32Extreme Scale LBM Methods - Ulrich Rüde37
• JUQUEEN – space filling curve: Morton
0
2
4
6
8
10
12
seco
nds
31,062
127,232
429,408
256 4096 32,768 458,752 cores
#cells per core 14 billion cells
197 billion cells
58 billion cells
hybrid MPI+OpenMP version with SMP 1 process ⇔ 2 cores ⇔ 8 threads
LBM AMR - Performance
Peta-Scale Simulations with the HPC Framework waLBerla: Massively Parallel AMR for the LBM Florian Schornbaum - FAU Erlangen-Nürnberg - April 15, 2016

Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
AMR Performance
33Extreme Scale LBM Methods - Ulrich Rüde
38
• JUQUEEN – diffusion load balancing
0
2
4
6
8
10
12
seco
nds
31,062
127,232
429,408
256 4096 32,768 458,752 cores
#cells per core 14 billion cells
197 billion cells
58 billion cells
time almost independent of #processes !
LBM AMR - Performance
Peta-Scale Simulations with the HPC Framework waLBerla: Massively Parallel AMR for the LBM Florian Schornbaum - FAU Erlangen-Nürnberg - April 15, 2016

LBM for EXA — Ulrich Rüde 34
Pore scale resolved flow in porous media
Direct numerical simulation of flow through sphere packings
Beetstra, R., Van der Hoef, M. A., & Kuipers, J. A. M. (2007). Drag force of intermediate Reynolds number flow past mono-and bidisperse arrays of spheres. AIChE Journal, 53(2), 489-501.
Tenneti, S., Garg, R., & Subramaniam, S. (2011). Drag law for monodisperse gas–solid systems using particle-resolved direct numerical simulation of flow past fixed assemblies of spheres. International journal of multiphase flow, 37(9), 1072-1092.
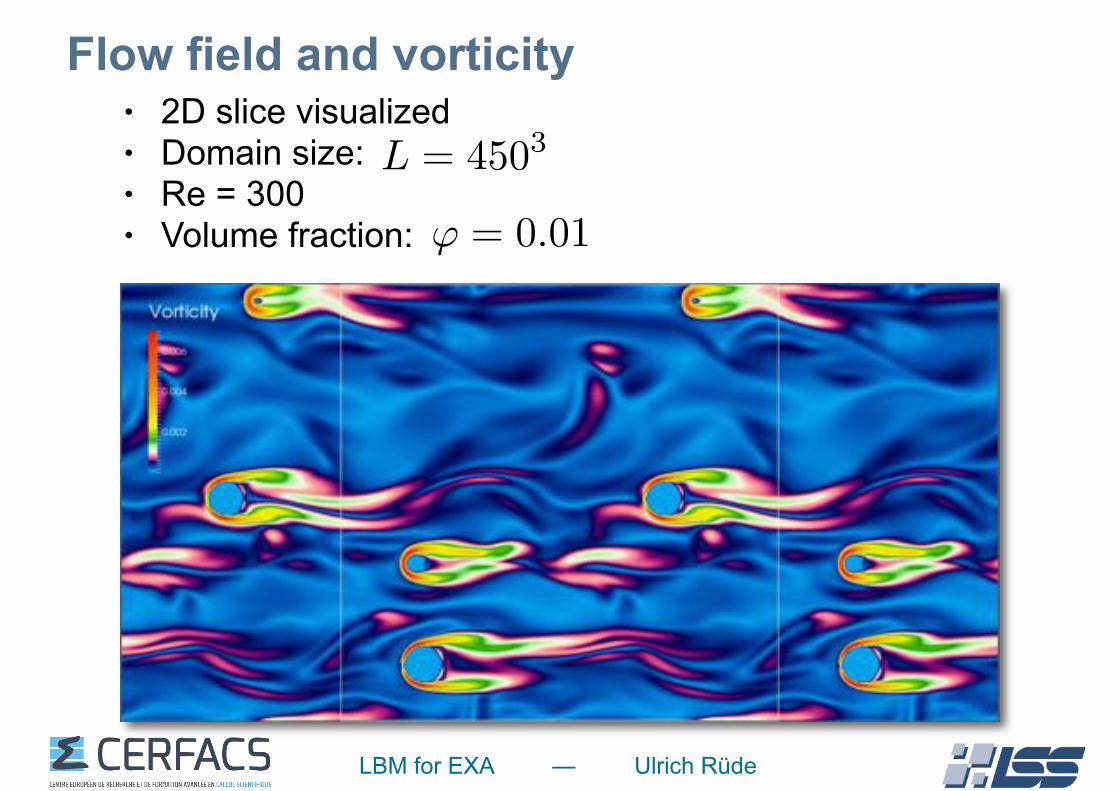
LBM for EXA — Ulrich Rüde
Flow field and vorticity• 2D slice visualized • Domain size: • Re = 300 • Volume fraction:

LBM for EXA — Ulrich Rüde 36
Macroscopic drag correlation
Finally, the drag correlation reads
Average absolute percentage error: 9.7 %
Bogner, S., Mohanty, S., & UR (2015). Drag correlation for dilute and moderately dense fluid-particle systems using the lattice Boltzmann method, International Journal of Multiphase Flow 68, 71-79.

Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
Massively Parallel Multiphysics Simulations - Ulrich Rüde
Setup of random spherical structure for porous media with the PE
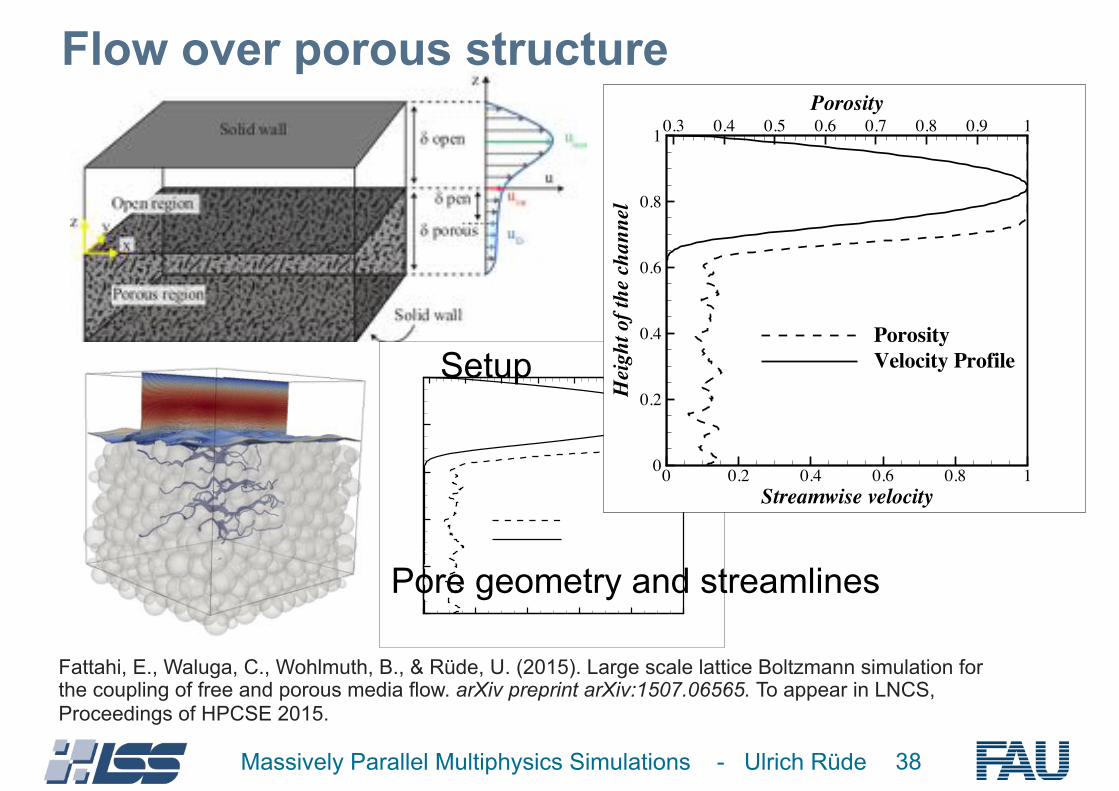
10 Lecture Notes in Computer Science: Authors’ Instructions
(a) pore geometry and streamlinesStreamwise velocity
Porosity
Hei
gh
t of
the
chan
nel
0 0.2 0.4 0.6 0.8 1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0
0.2
0.4
0.6
0.8
1
Porosity
Velocity Profile
(b) planar average of stream-wise velocity
Fig. 4. pore-scale simulation of free flow over porous media.
in the OTW model, the jump coe�cient � and the e↵ective viscosity µe↵ areunknown and in the Br model, the e↵ective viscosity µe↵ is unknown.
By using the DNS solution, we calculate the optimal value for the unknownparameters. The domain that is used is a channel which is periodic in stream-wiseand span-wise directions (Fig. 5). A free fluid flows on the top of a porous media.To make the comparison independent of the setup, all of the flow properties arenon-dimensionalized.
Fig. 5. Schematic of the simulation domain and averaged velocity profile in the openand porous regions.
The value of the interface velocity Uint, can be directly obtained from theaveraged velocity profile of the DNS. In order to obtain the velocity gradient on
Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
Massively Parallel Multiphysics Simulations - Ulrich Rüde
Flow over porous structure
38
Fattahi, E., Waluga, C., Wohlmuth, B., & Rüde, U. (2015). Large scale lattice Boltzmann simulation for the coupling of free and porous media flow. arXiv preprint arXiv:1507.06565. To appear in LNCS, Proceedings of HPCSE 2015.
10 Lecture Notes in Computer Science: Authors’ Instructions
(a) pore geometry and streamlinesStreamwise velocity
Porosity
Hei
gh
t of
the
chan
nel
0 0.2 0.4 0.6 0.8 1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0
0.2
0.4
0.6
0.8
1
Porosity
Velocity Profile
(b) planar average of stream-wise velocity
Fig. 4. pore-scale simulation of free flow over porous media.
in the OTW model, the jump coe�cient � and the e↵ective viscosity µe↵ areunknown and in the Br model, the e↵ective viscosity µe↵ is unknown.
By using the DNS solution, we calculate the optimal value for the unknownparameters. The domain that is used is a channel which is periodic in stream-wiseand span-wise directions (Fig. 5). A free fluid flows on the top of a porous media.To make the comparison independent of the setup, all of the flow properties arenon-dimensionalized.
Fig. 5. Schematic of the simulation domain and averaged velocity profile in the openand porous regions.
The value of the interface velocity Uint, can be directly obtained from theaveraged velocity profile of the DNS. In order to obtain the velocity gradient on
Pore geometry and streamlines
Setup
Streamwise velocity
Porosity
Hei
ght o
f the
cha
nnel
0 0.2 0.4 0.6 0.8 1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0
0.2
0.4
0.6
0.8
1
PorosityVelocity Profile
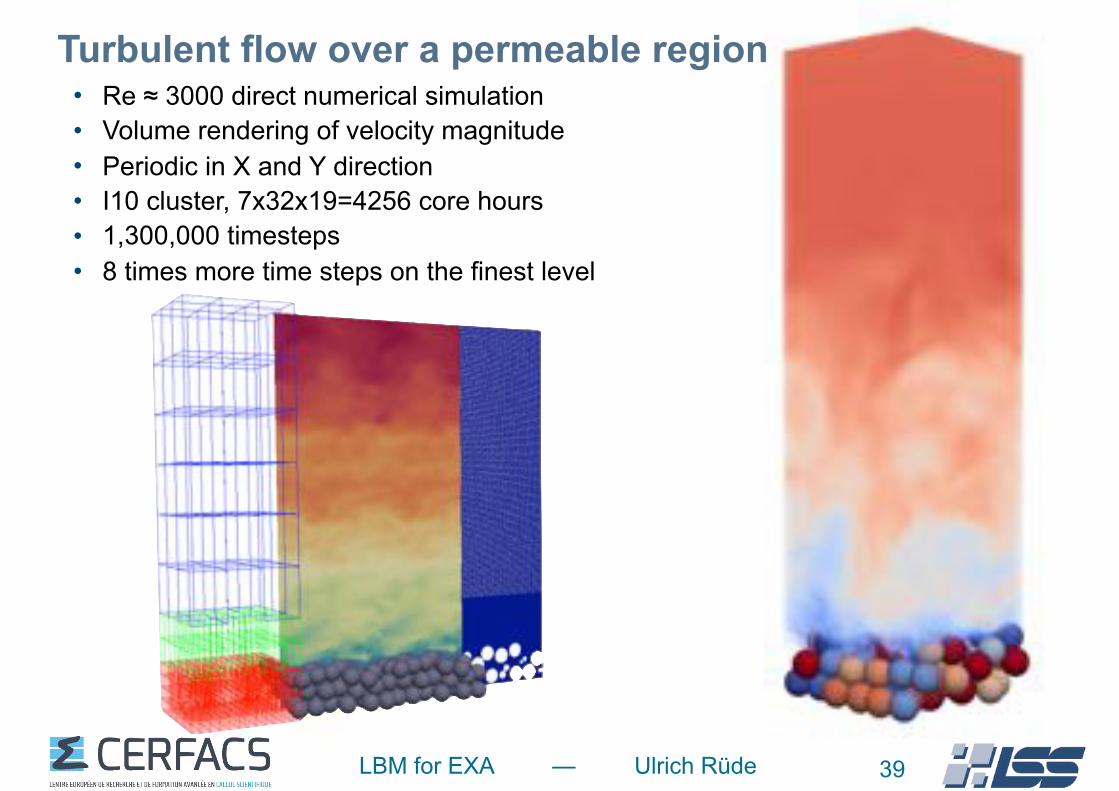
LBM for EXA — Ulrich Rüde
• Re ≈ 3000 direct numerical simulation • Volume rendering of velocity magnitude • Periodic in X and Y direction • I10 cluster, 7x32x19=4256 core hours • 1,300,000 timesteps • 8 times more time steps on the finest level
Turbulent flow over a permeable region
39

LBM for EXA — Ulrich Rüde
Multi-Physics Simulations for Particulate Flows
Parallel Coupling with waLBerla and PE
40
Ladd, A. J. (1994). Numerical simulations of particulate suspensions via a discretized Boltzmann equation. Part 1. Theoretical foundation. Journal of Fluid Mechanics, 271(1), 285-309.
Tenneti, S., & Subramaniam, S. (2014). Particle-resolved direct numerical simulation for gas-solid flow model development. Annual Review of Fluid Mechanics, 46, 199-230.
Bartuschat, D., Fischermeier, E., Gustavsson, K., & UR (2016). Two computational models for simulating the tumbling motion of elongated particles in fluids. Computers & Fluids, 127, 17-35.

LBM for EXA — Ulrich Rüde
Fluid-Structure Interaction direct simulation of Particle Laden Flows (4-way coupling)
41
Götz, J., Iglberger, K., Stürmer, M., & UR (2010). Direct numerical simulation of particulate flows on 294912 processor cores. In Proceedings of Supercomputing 2010, IEEE Computer Society.
Götz, J., Iglberger, K., Feichtinger, C., Donath, S., & UR (2010). Coupling multibody dynamics and computational fluid dynamics on 8192 processor cores. Parallel Computing, 36(2), 142-151.

LBM for EXA — Ulrich Rüde
Simulation of sediment transport
42

LBM for EXA — Ulrich Rüde
Heterogenous CPU-GPU Simulation
43
Particles: 31250, Domain: 400x400x200, Timesteps: 400 000 Devices: 2 x M2070 + 1 Intel „Westmere“, Runtime: 17.5 h
Fluidized Beds:
Direct numerical simulation fully resolved particles
Fluid-structure-interaction
4-way-coupling
C. Feichtinger, J. Habich, H. Köstler, U. Rüde, T. Aoki, Performance modeling and analysis of heterogeneous lattice Boltzmann simulations on CPU–GPU clusters, Parallel Computing, Volume 46, July 2015, Pages 1-13 C. Feichtinger, J. Habich, H. Köstler, G. Hager, U. Rüde, G. Wellein, A flexible Patch-based lattice Boltzmann parallelization approach for heterogeneous GPU–CPU clusters, Parallel Computing, Volume 37, Issue 9, September 2011, Pages 536-549.

100 1000 10000 300000Number of Cores
0.5
0.6
0.7
0.8
0.9
1
Effic
ienc
y
40x40x40 lattice cells per core 80x80x80 lattice cells per core
100 1000 10000 300000Number of Cores
0.5
0.6
0.7
0.8
0.9
1
Effic
ienc
y
40x40x40 lattice cells per core 80x80x80 lattice cells per core
100 1000 10000 300000Number of Cores
0.5
0.6
0.7
0.8
0.9
1
Effic
ienc
y
40x40x40 lattice cells per core 80x80x80 lattice cells per core
Büro
für G
esta
ltung
Wan
gler
& A
bele
04.
Apr
il 20
11
Massively Parallel Multiphysics Simulations - Ulrich Rüde
Weak Scaling experiment
Scaling 64 to 294 912 cores Densely packed particles
150 994 944 000 lattice cells 264 331 905 rigid spherical objects
Largest simulation on
Jugene: 8 Trillion (1012) variables per
time step (LBM alone)
Jugene Blue Gene/P
Jülich Supercomputer
Center
44
Götz, J., Iglberger, K., Stürmer, M., & Rüde, U. (2010, November). Direct numerical simulation of particulate flows on 294912 processor cores. In Proceedings of the 2010 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis (pp. 1-11). IEEE Computer Society.

LBM for EXA — Ulrich Rüde 45
Direct numerical simulation of charged particles in flowMasilamani, K., Ganguly, S., Feichtinger, C., & UR (2011). Hybrid lattice-boltzmann and finite-difference simulation of electroosmotic flow in a microchannel. Fluid Dynamics Research, 43(2), 025501.
Bartuschat, D., Ritter, D., & UR (2012). Parallel multigrid for electrokinetic simulation in particle-fluid flows. In High Performance Computing and Simulation (HPCS), 2012 International Conference on (pp. 374-380). IEEE.
Bartuschat, D. & UR (2015). Parallel Multiphysics Simulations of Charged Particles in Microfluidic Flows, Journal of Computational Science, Volume 8, May 2015, Pages 1-19
Positive and negatively charged particles in flow subjected to transversal electric field
Building Block IV (electrostatics)
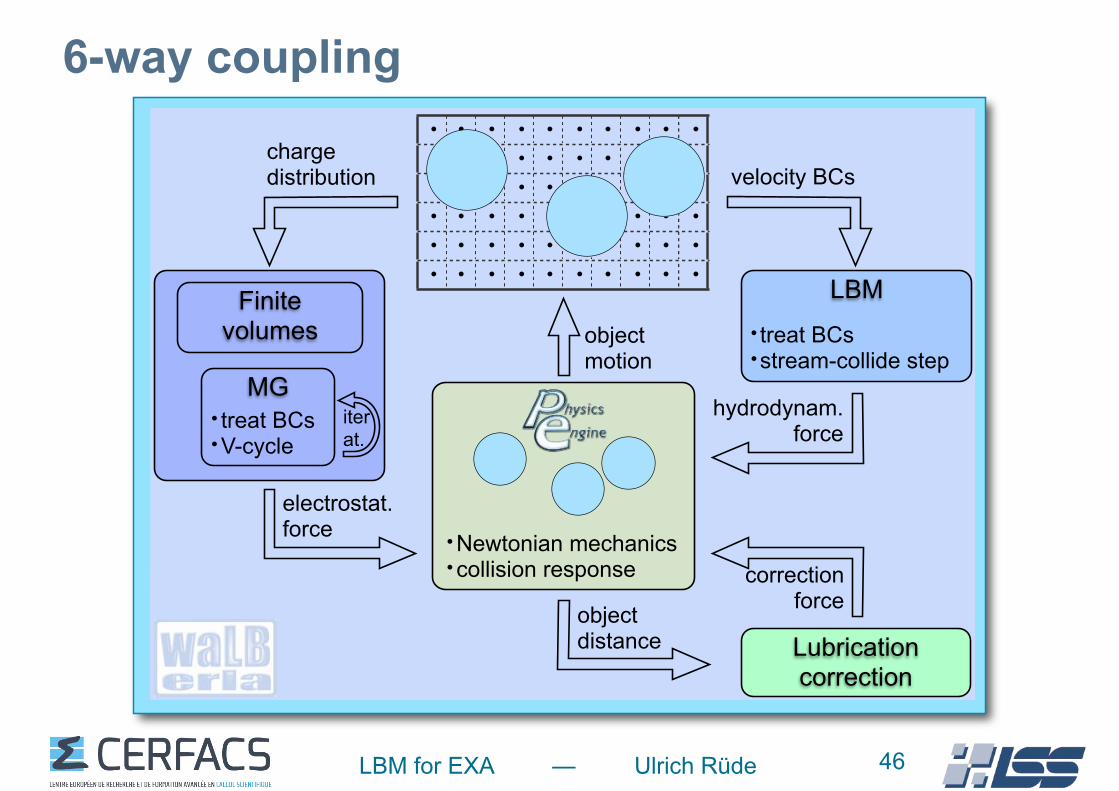
hydrodynam. force
object motion
Lubricationcorrection
electrostat. force
velocity BCs
object distance
LBM
correction force
charge distribution
Newtonian mechanicscollision response
treat BCsstream-collide step
Finite volumes
MGiterat.
treat BCsV-cycle
LBM for EXA — Ulrich Rüde
6-way coupling
46
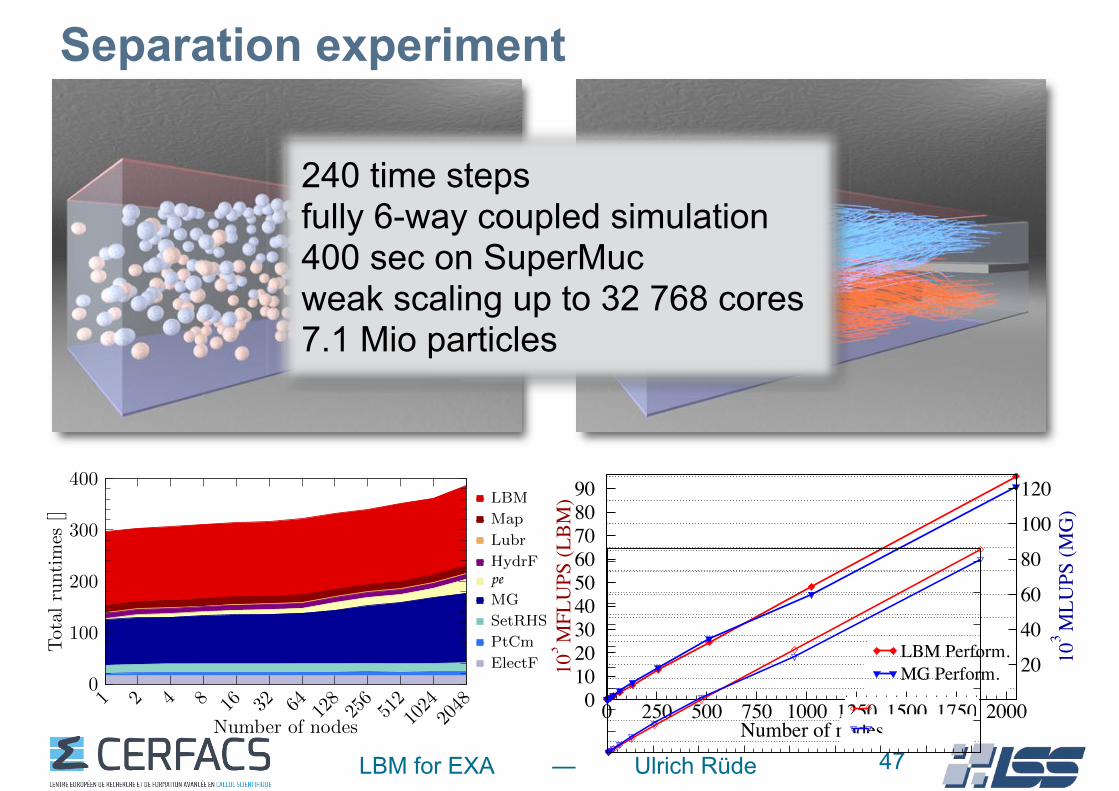
LBM for EXA — Ulrich Rüde
Separation experiment
47
Parallel Multiphysics Simulations of Charged Particles in Microfluidic Flows 17
The SuperMUC single-node performance reported forthe finite element MG solver in Gmeiner and Rude(2014) corresponds to 170 MLUPS. This performance ismeasured for V(3,3)-cycles and CG coarsest grid solverfor a Poisson problem with Dirichlet BCs.
8.3 Weak Scaling
We perform weak scaling experiments for up to 2048nodes on SuperMUC for 240 time steps. The problemsize is successively doubled in all dimensions, as shownin Tab. 6. The number of CG iterations required to solve
Table 6 Number of required CG coarse grid iterations fordi↵erent problem sizes.
#n. size #iter. #n. size #iter.1 2⇥ 2⇥ 4 6 64 8⇥ 8⇥ 16 262 2⇥ 2⇥ 8 10 128 8⇥ 8⇥ 32 524 4⇥ 2⇥ 8 12 256 16⇥ 8⇥ 32 548 4⇥ 4⇥ 8 12 512 16⇥ 16⇥ 32 5416 4⇥ 4⇥ 16 24 1024 32⇥ 16⇥ 64 11432 8⇥ 4⇥ 16 26 2048 32⇥ 32⇥ 64 116
the coarsest grid problem is depicted for di↵erent prob-lem sizes. Doubling the domain in all three dimensions,the number of CG iterations approximately doubles.This corresponds to the expected behaviour that therequired number of iterations scales with the diameterof the problem size Gmeiner et al. (2014) according tothe growth in the condition number Shewchuk (1994).However, when doubling the problem size, CG iterationssometimes stay constant or have to be increased. Thisresults from di↵erent shares of Neumann and DirichletBCs on the boundary. Whenever the relative proportionof Neumann BCs increases, convergence deteriorates andmore CG iterations are necessary.
The runtimes of all parts of the algorithm are shownin Fig. 13 for di↵erent problem sizes, indicating theirshares on the total runtime. This diagram is based on themaximal (for MG, LBM, pe) or average (others) runtimesof the di↵erent sweeps among all processes. The upper
1 2 4 8 16 32 64 12825651210242048
0
100
200
300
400
Number of nodes
Total
runtim
es[]
LBM
Map
Lubr
HydrFpeMG
SetRHS
PtCm
ElectF
Figure 13 Runtimes of charged particle algorithm sweepsfor 240 time steps on increasing number of nodes.
part of the diagram shows the cost of fluid-simulation
related sweeps, such as LBM, moving obstacle mapping(Map), Hydrodynamic force computation (HydrF), andlubrication correction (Lubr) sweep. In the middle, thecost of the pe sweep is shown. Below, the cost of sweepsrelated to the electric potential computation are dis-played. These include MG, setting the RHS of Poisson’sequation (SetRHS), communication of the electric po-tential before the gradient computation (PtCm), and thesweep computing the electrostatic force (ElectF).
For a more precise evaluation, the exact figures areshown in Tab. 7 for one node and 2048 nodes. The totalruntime (Whl) is less than the sum of the individualsweeps, since di↵erent sweeps are slow on di↵erent pro-cesses. Sweeps whose runtimes depend on the problem
Table 7 Time of the whole algorithm and its sweeps for240 time steps on a single and 2048 nodes.
Whl LBM MG pe PtCm Oth#n. t[s] t[s] ([%]) t[s] ([%]) t[s] t[s] t[s]
1 294 143 (48) 88 (30) 2 3 612048 353 157 (41) 136 (35) 27 7 60
size—mainly due to increasing MPI communication—areLBM, MG, pe, and PtCm. Overall, LBM and MG takeup more than 75% of the total time, w.r.t. the runtimesof the individual sweeps.
The sweeps that scale perfectly—HydrF, LubrC,Map, SetRHS, and ElectF—are summarized as ‘Oth‘.For longer simulation times the particles attracted by thebottom wall are no longer evenly distributed, possiblycausing load imbalances. However, they hardly a↵ect theoverall performance. For the simulation for the anima-tion, the relative share of the lubrication correction isbelow 0.1% and each other sweep of ‘Oth‘ is well below4% of the total runtime.
Overall the coupled multiphysics algorithm achieves83% parallel e�ciency on 2048 nodes. Since most timeis spent to execute LBM and MG, we will now turn toanalyse them in more detail. Fig. 14 displays the paral-lel performance for di↵erent numbers of nodes. On 2048nodes, MG executes 121,083 MLUPS, corresponding toa parallel e�ciency of 64%. The LBM performs 95,372MFLUPS, with 91% parallel e�ciency.
0 250 500 750 1000 1250 1500 1750 2000Number of nodes
0102030405060708090
103
MFL
UPS
(LB
M)
LBM Perform.20
40
60
80
100
120
103
MLU
PS (M
G)
MG Perform.
Figure 14 Weak scaling performance of MG and LBMsweep for 240 time steps.
Parallel Multiphysics Simulations of Charged Particles in Microfluidic Flows 17
The SuperMUC single-node performance reported forthe finite element MG solver in Gmeiner and Rude(2014) corresponds to 170 MLUPS. This performance ismeasured for V(3,3)-cycles and CG coarsest grid solverfor a Poisson problem with Dirichlet BCs.
8.3 Weak Scaling
We perform weak scaling experiments for up to 2048nodes on SuperMUC for 240 time steps. The problemsize is successively doubled in all dimensions, as shownin Tab. 6. The number of CG iterations required to solve
Table 6 Number of required CG coarse grid iterations fordi↵erent problem sizes.
#n. size #iter. #n. size #iter.1 2⇥ 2⇥ 4 6 64 8⇥ 8⇥ 16 262 2⇥ 2⇥ 8 10 128 8⇥ 8⇥ 32 524 4⇥ 2⇥ 8 12 256 16⇥ 8⇥ 32 548 4⇥ 4⇥ 8 12 512 16⇥ 16⇥ 32 5416 4⇥ 4⇥ 16 24 1024 32⇥ 16⇥ 64 11432 8⇥ 4⇥ 16 26 2048 32⇥ 32⇥ 64 116
the coarsest grid problem is depicted for di↵erent prob-lem sizes. Doubling the domain in all three dimensions,the number of CG iterations approximately doubles.This corresponds to the expected behaviour that therequired number of iterations scales with the diameterof the problem size Gmeiner et al. (2014) according tothe growth in the condition number Shewchuk (1994).However, when doubling the problem size, CG iterationssometimes stay constant or have to be increased. Thisresults from di↵erent shares of Neumann and DirichletBCs on the boundary. Whenever the relative proportionof Neumann BCs increases, convergence deteriorates andmore CG iterations are necessary.
The runtimes of all parts of the algorithm are shownin Fig. 13 for di↵erent problem sizes, indicating theirshares on the total runtime. This diagram is based on themaximal (for MG, LBM, pe) or average (others) runtimesof the di↵erent sweeps among all processes. The upper
1 2 4 8 16 32 64 12825651210242048
0
100
200
300
400
Number of nodes
Total
runtim
es[]
LBM
Map
Lubr
HydrFpeMG
SetRHS
PtCm
ElectF
Figure 13 Runtimes of charged particle algorithm sweepsfor 240 time steps on increasing number of nodes.
part of the diagram shows the cost of fluid-simulation
related sweeps, such as LBM, moving obstacle mapping(Map), Hydrodynamic force computation (HydrF), andlubrication correction (Lubr) sweep. In the middle, thecost of the pe sweep is shown. Below, the cost of sweepsrelated to the electric potential computation are dis-played. These include MG, setting the RHS of Poisson’sequation (SetRHS), communication of the electric po-tential before the gradient computation (PtCm), and thesweep computing the electrostatic force (ElectF).
For a more precise evaluation, the exact figures areshown in Tab. 7 for one node and 2048 nodes. The totalruntime (Whl) is less than the sum of the individualsweeps, since di↵erent sweeps are slow on di↵erent pro-cesses. Sweeps whose runtimes depend on the problem
Table 7 Time of the whole algorithm and its sweeps for240 time steps on a single and 2048 nodes.
Whl LBM MG pe PtCm Oth#n. t[s] t[s] ([%]) t[s] ([%]) t[s] t[s] t[s]
1 294 143 (48) 88 (30) 2 3 612048 353 157 (41) 136 (35) 27 7 60
size—mainly due to increasing MPI communication—areLBM, MG, pe, and PtCm. Overall, LBM and MG takeup more than 75% of the total time, w.r.t. the runtimesof the individual sweeps.
The sweeps that scale perfectly—HydrF, LubrC,Map, SetRHS, and ElectF—are summarized as ‘Oth‘.For longer simulation times the particles attracted by thebottom wall are no longer evenly distributed, possiblycausing load imbalances. However, they hardly a↵ect theoverall performance. For the simulation for the anima-tion, the relative share of the lubrication correction isbelow 0.1% and each other sweep of ‘Oth‘ is well below4% of the total runtime.
Overall the coupled multiphysics algorithm achieves83% parallel e�ciency on 2048 nodes. Since most timeis spent to execute LBM and MG, we will now turn toanalyse them in more detail. Fig. 14 displays the paral-lel performance for di↵erent numbers of nodes. On 2048nodes, MG executes 121,083 MLUPS, corresponding toa parallel e�ciency of 64%. The LBM performs 95,372MFLUPS, with 91% parallel e�ciency.
0 250 500 750 1000 1250 1500 1750 2000Number of nodes
0102030405060708090
103
MFL
UPS
(LB
M)
LBM Perform.20
40
60
80
100
120
103
MLU
PS (M
G)
MG Perform.
Figure 14 Weak scaling performance of MG and LBMsweep for 240 time steps.
240 time steps fully 6-way coupled simulation 400 sec on SuperMuc weak scaling up to 32 768 cores 7.1 Mio particles

LBM for EXA — Ulrich Rüde
Volume of Fluids Method for Free Surface Flows
48
joint work with Regina Ammer, Simon Bogner, Martin Bauer, Daniela Anderl, Nils Thürey, Stefan Donath, Thomas Pohl, C Körner, A. Delgado
Körner, C., Thies, M., Hofmann, T., Thürey, N., & UR. (2005). Lattice Boltzmann model for free surface flow for modeling foaming. Journal of Statistical Physics, 121(1-2), 179-196. Donath, S., Feichtinger, C., Pohl, T., Götz, J., & UR. (2010). A Parallel Free Surface Lattice Boltzmann Method for Large-Scale Applications. Parallel Computational Fluid Dynamics: Recent Advances and Future Directions, 318. Anderl, D., Bauer, M., Rauh, C., UR, & Delgado, A. (2014). Numerical simulation of adsorption and bubble interaction in protein foams using a lattice Boltzmann method. Food & function, 5(4), 755-763. Bogner, S., Ammer, R., & Rüde, U. (2015). Boundary conditions for free interfaces with the lattice Boltzmann method. Journal of Computational Physics, 297, 1-12.
Building Block V

LBM for EXA — Ulrich Rüde 49
Free Surface FlowsVolume-of-Fluids like approach Flag field: Compute only in fluid
Special “free surface” conditions in interface cells Reconstruction of curvature for surface tension

Körner, C., Thies, M., Hofmann, T., Thürey, N., & UR (2005). Lattice Boltzmann model for free surface flow for modeling foaming. Journal of Statistical Physics, 121(1-2), 179-196. Donath, S., Mecke, K., Rabha, S., Buwa, V., & UR (2011). Verification of surface tension in the parallel free surface lattice Boltzmann method in waLBerla. Computers & Fluids, 45(1), 177-186. Thürey, N., &UR. (2009). Stable free surface flows with the lattice Boltzmann method on adaptively coarsened grids. Computing and Visualization in Science, 12(5), 247-263.
LBM for EXA — Ulrich Rüde
Simulation of Metal FoamsExample application:
Engineering: metal foam simulations Based on LBM:
Free surfaces Surface tension Disjoining pressure to stabilize thin liquid films Parallelization with MPI and load balancing
Other applications: Food processing Fuel cells
50

LBM for EXA — Ulrich Rüde
Simulation for hygiene products (for Procter&Gamble)
capillary pressure inclination
surface tension contact angle
51

LBM for EXA — Ulrich Rüde
Additive Manufacturing Fast Electron Beam Melting
52
Ammer, R., Markl, M., Ljungblad, U., Körner, C., & UR (2014). Simulating fast electron beam melting with a parallel thermal free surface lattice Boltzmann method. Computers & Mathematics with Applications, 67(2), 318-330.
Ammer, R., UR, Markl, M., Jüchter V., & Körner, C. (2014). Validation experiments for LBM simulations of electron beam melting. International Journal of Modern Physics C.

LBM for EXA — Ulrich Rüde
Simulation of Electron Beam Melting
53
Simulating powder bed generation using the PE framework
High speed camera shows melting step for manufacturing a
hollow cylinder
WaLBerla Simulation

LBM for EXA — Ulrich Rüde
Conclusions
54

LBM for EXA — Ulrich Rüde
Research in Computational Science is done by teams
55
Harald Köstler
Christian Godenschwager
Kristina Pickl
Regina Ammer
Simon Bogner
Florian Schornbaum
Sebastian Kuckuk
Christoph Rettinger
Dominik Bartuschat
Martin Bauer
Ehsan Fattahi
Christian Kuschel

LBM for EXA — Ulrich Rüde
Thank you for your attention!
56
Videos, preprints, slides at https://www10.informatik.uni-erlangen.de





























