Embed Size (px)
Citation preview

Learning Modular Structures from Network Data and Node Variables
Elham Azizi [email protected]
Bioinformatics Program, Boston University, Boston, MA 02215 USA
Edoardo M. Airoldi [email protected]
Department of Statistics, Harvard University, Camrbdige, MA 02138 USA
James E. Galagan [email protected]
Departments of Biomedical Engineering and Microbiology, Boston University, Boston, MA 02215 USA
AbstractA standard technique for understanding underly-ing dependency structures among a set of vari-ables posits a shared conditional probability dis-tribution for the variables measured on individ-uals within a group. This approach is often re-ferred to as module networks, where individualsare represented by nodes in a network, groupsare termed modules, and the focus is on estimat-ing the network structure among modules. How-ever, estimation solely from node-specific vari-ables can lead to spurious dependencies, and un-verifiable structural assumptions are often usedfor regularization. Here, we propose an ex-tended model that leverages direct observationsabout the network in addition to node-specificvariables. By integrating complementary datatypes, we avoid the need for structural assump-tions. We illustrate theoretical and practical sig-nificance of the model and develop a reversible-jump MCMC learning procedure for learningmodules and model parameters. We demonstratethe method accuracy in predicting modular struc-tures from synthetic data and capability to learnregulatory modules in the Mycobacterium tuber-culosis gene regulatory network.
1. IntroductionThere is considerable interest in modeling dependencystructures in a variety of applications. Examples include re-constructing regulatory relationships from gene expressiondata in gene networks or identifying influence structures
Proceedings of the 31 st International Conference on MachineLearning, Beijing, China, 2014. JMLR: W&CP volume 32. Copy-right 2014 by the author(s).
from activity patterns such as purchases, posts, tweets,etc in social networks. Common approaches for learningdependencies include using Bayesian networks and factoranalysis (Koller & Friedman, 2009).
Module networks (Segal et al., 2005; 2003) have beenwidely used to find structures (e.g. gene regulation) be-tween groups of nodes (e.g. genes) denoted as modules,based on measurements of node-specific variables in a net-work (e.g. gene expression). The motivation lies in thatnodes that are influenced or regulated by the same par-ent node(s), have the same conditional probabilities fortheir variables. For example, in gene regulatory networks,groups of genes respond in concert under certain environ-mental conditions (Qi & Ge, 2006) and are thus likely tobe regulated by the same mechanism. In other domains,such as social networks, communities with similar inter-ests or affiliations may have similar activity in posting mes-sages (e.g. in twitter) in response to news-outbreaks orsimilar purchases in response to marketing advertisements(Kozinets, 1999; Aral et al., 2009).
However, inferring dependencies merely from node-specific variables can lead to higher rate of false posi-tives (Michoel et al., 2007). For example, a dependencymight be inferred between two unrelated nodes due to ex-isting confounding variables. This can introduce arbitraryor too many parents for a module. To avoid over-fitting ininferring module networks, additional structural assump-tions such as setting the maximum number of modules ormaximum number of parents per module may be required.This in turn presents additional inductive bias and resultsbecome sensitive to assumptions. Moreover, searchingthrough the entire set of candidate parents for each mod-ule is computationally infeasible.
Alternatively, we can take advantage of existing networkdata and by integrating node interactions with node vari-ables, we can avoid structural assumptions. For exam-

Learning Modular Structures from Network Data and Node Variables
a b
d
c e
a b
d
c e
a b
d
c e
Context (i) (iii) (ii)
Pa1: Activator
Pa2: Repressor
Nod
e Va
riabl
es
γHi1γ
Lo1
γLo2
γHi2
γHi1
+
+
+
µPa2c
µPa1c
µM4c
0
0
0
Com
bina
toria
l Pro
gram
> 0
< 0
γHi2
Model for variables
π41
π42
Net
wor
k D
ata
Model for network data
b
a
e
dM4
b
ab
cM3 M4
M1M2a
d eNetwork Data (B)
Node Variable Data (X)
(i) (ii) (iii)
Node VariablesModel
Network Data
Model
Modular Structures
e
d
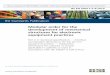
Figure 1. Illustration of proposed model: Modular structures are learned from node variables (e.g. gene expression) and network data(e.g. protein-DNA interactions). Node variables are color-coded ranging from green (low) to red (high). A number of parents areassigned to each module (orange links). A combinatorial program is inferred for each module; example shown for module M4.
ple, to learn gene regulatory networks, we can use protein-DNA interaction data, which shows physical interactionsbetween proteins of genes (known as Transcription Factors)with promoter regions of other genes, leading to regulationof transcription (and expression) of the latter genes. Thisdata can be measured using chromatin immunoprecipita-tion of DNA-bound proteins, i.e. ChIP-ChIP or ChIP-Seqtechnologies, which have shown to be informative of regu-lation (Galagan et al., 2013; Liu et al., 2013; Celniker et al.,2009). As another example, to learn influence structures ina twitter network, we can integrate the network of who-follows-who with measurements of users activities.
Identifying modules or block structures from network datahas been well-studied, e.g., using stochastic blockmodels(Wang & Wong, 1987; Snijders & Nowicki, 1997; Airoldiet al., 2008; 2013a) in the area of social network modeling(Goldenberg et al., 2009; Azari Soufiani & Airoldi, 2012;Choi et al., 2012). Stochastic blockmodels assume thatnodes of a network are members of latent blocks, and de-scribe their interactions with other nodes with a parametricmodel. However, models for inferring modular structuresfrom both node variables and network data are relativelyunexplored and of interest in many applications.
1.1. Contributions
In this paper, we propose an integrated probabilistic modelinspired by module networks and stochastic blockmodels,to learn dependency structures from the combination ofnetwork data and node variables data. We consider networkdata in terms of directed edges (interactions) and modelnetwork data using stochastic blockmodels. Intuitively, byincorporating complementary data types, a node which is
likely to have directed edges to members of a module aswell as correlation with variables of module will be as-signed as parent. A shorter version of this work was pre-sented in (Azizi, 2013). The use of network data enhancescomputational tractability and scalability of the method byrestricting the space of possible dependency structures. Wealso show theoretically that the integration of network dataleads to model identifiability, whereas node variables alonecan not, without extra structural assumptions.
Our model captures two types of relationships betweenvariables of modules and their parents, including smallchanges of variables due to global dependency structureand condition-specific large effects on variables based onparent activities in each condition.
For estimation of parameters, we use a Gibbs sampler in-stead of the deterministic algorithm employed by Segal etal. to overcome some of the problems regarding multi-modality of model likelihood (Joshi et al., 2009). Wealso solve the problem of sensitivity to choice of maxi-mum number of modules using a reversible-jump MCMCmethod which infers the number of modules and parentsbased on data. The probabilistic framework infers poste-rior distributions of assignments of nodes to modules andthus does not face restrictions of non-overlapping modules(Airoldi et al., 2008; 2013b).
1.2. Related Work
Other works have also proposed integrating different datatypes, mostly as prior information, for improvement inlearning structures (Werhli & Husmeier, 2007; Imoto et al.,2003; Mitra et al., 2013). It is more natural to consideradditional data types also as observations from a model

Learning Modular Structures from Network Data and Node Variables
of dependency structures. Our model thus considers bothnetwork edges and node variables as data observed fromthe same underlying structure, providing more flexibility.Moreover, we utilize data integration to identify structuresbetween groups of nodes (modules) as opposed to individ-ual nodes. Despite the similarity in the framework of ourmodel to module networks, our model for variables has dif-ferences in relating modules to their parents, giving moreaccurate and interpretable dependencies. Also, the integra-tion of network data is novel. Regarding the learning proce-dure, prior work has been done on improving module net-work inference by using a Gibbs sampling approach (Joshiet al., 2009). We take a step further and use a reversible-jump MCMC procedure to learn the number of modulesand parents from data as well as parameter posteriors. Ourmethod can also allow restricting the number of modulesbased on context, with a narrow prior. By adjusting thisprior, we have multi-resolution module detection.
2. Model of Modular StructuresIn the framework of module networks, dependencies arelearned from profiles of node variables (e.g. gene ex-pressions) for each node (e.g. gene), as random variables{X1, ..., XN}. The idea is that a group of nodes withcommon parents (e.g. co-regulated genes) are representedas a module and have similar probability distributions fortheir variables conditioned on their shared parents (regula-tors). Figure 1 shows a toy example where node variabledata are shown in green-to-red heatmaps and network datawith dashed arrows (Airoldi, 2007). A module assignmentfunction A maps nodes {1, ..., N} to K non-overlappingmodules. A dependency structure function S assigns a setof parents Paj from {1, ..., R} known candidate parents(possible regulators/influencers), which are a subset of theN nodes, to module Mj (figure 1). In the toy example,nodes d, e are assigned to the same module M4 and b, aare assigned as their parents. In cases where multiple par-ents drive a module, e.g. a, b affecting M4, combinatorialeffects are represented as a decision tree (regulatory pro-gram) and each combination of parents activities, definedas a context, is assigned to a cluster of conditions (experi-ments). In figure 1, parent b has an activating effect whilea represses M4, hence, e, d are active in context (ii) whereonly b is active and a is not. Inferring this decision treein the context of different applications shows how multipleparents act together in influencing a group of nodes, e.g.in a gene network, multiple transcription-factors (TFs) acttogether to express a group of genes.
Given this framework, our model considers variables andnetwork data as two types of observation from the same un-derlying modular structure. This structure is encoded basedon assignments to modules (A) and parents for each mod-
ule (S). In the example of gene networks, in each module,TF-gene interactions are likely to be observed between TFsand upstream regions of genes in the module while combi-nations of expressions of TFs explain expressions of genes.
2.1. Modeling Node Variables
We model variables for nodes {1, ..., N} in each conditionor sample c ∈ 1, ..., C with a multivariate normal repre-sented as Xc ∼ N (µc,Σ), where Xc is a N × 1 vector,with N being the total number of nodes. The covarianceand mean capture two different aspects of the model re-garding global dependency structures and context-specificeffects of parents, respectively, as described below.
We define the covariance Σ to be independent of condi-tions and representing the strength of potential effects ofone variable upon another, if the former is assigned as aparent of the module containing the latter. In the exam-ple of gene expressions, Σ may represent the affinity of aTranscription-Factor protein to a target gene promoter. Themodular dependencies between variables imposes a struc-ture on Σ. To construct this structure, we relate node vari-ables to their parents through a regression Xc = WXc + εwhere ε = N (mc, I). W is a N × N sparse matrix inwhich element Wnr is nonzero if variable r is assigned asa parent of the module containing variable n. Here we as-sume Wnr has the same value for ∀n ∈ Mk,∀r ∈ Pak,which leads to identifiability of model (as explained insection 3. Then, assuming I − W is invertible, Xc =(I −W )−1ε which implies Σ = (I −W )−T (I −W )−1.Therefore, we impose the modular dependency structureover Σ through W , which is easier to interpret based onA,S assignments.
We define variable means µc, based on parents as describedbelow. First, based on the modular structure of nodes, wecan partition the mean vector as µc = [µ1
c ...µKc ]T , where
each µkc for k = 1, ...,K is a 1×Nk vector with Nk equalto the number of nodes in module k. In modules wherethere is more than one parent assigned, combinations ofdifferent activities of parents, creating a context, can leadto different effects. The binary state of parent r ∈ Pak isdefined by comparing its mean to a split-point zrk, corre-sponding to a mixture coefficient for that state γrLo or γrHi,as: γrc = γrLoH(zrk − µrc) + γrHiH(µrc − zrk), where H(·)is a unit step function.
The combination of different activities are represented asa decision tree for each module k (figure 1). We repre-sent a context-specific program as dependencies of variablemeans on parents activities in each context, such that µkcfor module k is a linear mixture of means for parents ofthat module: µkc =
∑Rk
r=1 γrcµ
Parkc where Rk is the num-
ber of parents Pak and γrc are similar for all conditionsc occurring in the same context. Thus, in general we can

Learning Modular Structures from Network Data and Node Variables
WXΣ
µc
c
µcR
πrk
Br n
Γc
CRkNk
K
Z
Figure 2. Graphical representation of model: The assignmentsof nodes to modules A and parents for modules S represent mod-ular dependency structures, from which we observe node vari-ables Xc in each condition c and network data Br→n betweena parent r and a node n. Means of node variables µc are deter-mined from parent means µR
c with mixing coefficients Γ deter-mined based on parent split-points Z.
write µc = ΓcµRc , where µRc contains the means of parents
1, ..., R in condition c. The N ×R matrix Γc has identicalrows for all variables in one module based on the assign-ment functions A,S. The graphical model is summarizedin figure 2. Thus the model for object variables would be:Xc ∼ N (Γcµ
Rc , (I −W )−T (I −W )−1).
Given independent conditions, the probability of dataX = [X1, ...,XC] for C conditions given parameters canbe written as multiplication of multivariate normal dis-tributions for each condition: P (X|A,S,Θ,Σ, ZS) =∏Cc=1 P (Xc|A,S, θc,Σ, ZS), where Θ = {θ1, ..., θC}
denotes the set of condition-specific parameters θc ={µRc ,Γc} for c = 1, ..., C and ZS denotes theset of parent split-points for all modules. Then foreach condition we have: P (Xc|A,S, θc,Σ, ZS) =
1(2π)N/2|Σ1/2|exp(−
12 (Xc − µc)
TΣ−1(Xc − µc)).
Hence, this model provides interpretations for two types ofinfluences of parents. By relating the distribution mean forvariables in each module and in each condition to meansof their assigned parents (figure 1.B), we model condition-specific effects of parents. Based on the states of parents indifferent contexts (partitions of conditions), this leads to abias or large signal variations in node variables. Whereas,small signal changes (linear term) are modeled through thecovariance matrix Σ which is independent of condition andis only affected by the global wiring imposed by depen-dency structures.
2.2. Modeling Network Data
Network data, as a directed edge between a parent r ∈{1, ..., R} and node n ∈Mk, when r is assigned as a parentof the module r ∈ Pak is defined as a directed link Br→nwhere
P (Br∈Pak→n∈Mk|A,S, πrk) ∼ Bernoulli(πrk) (1)
The parameter πrk defines the probability of parentr influencing module Mk (figure 2). In the genenetwork example, an interaction between a Transcrip-tion Factor protein binding to a motif sequence, up-stream of target genes, which is common in allgenes of a module can be observed using ChIP data.Therefore, directed interactions from parents to allnodes in a module would be P (BMk
|A,S,πk) =∏r∈Pak
∏n∈Mk
P (Br→n|A,S, πrk), where πk is the vec-tor of πrk for all r ∈ Pak and for all nodes we have:
P (B|A, S,π) =
K∏k=1
∏r∈Pak
∏n∈Mk
P (Br→n|A,S, πrk)
=
K∏k=1
∏r∈Pak
(πrk)srk(1− πrk)|Mk|−srk
∏r′ 6∈Pak
(π0)sr′k(1− π0)|Mk|−sr′k (2)
with π = {π1, ...,πK} and srk =∑n∈Mk
(Br→n) is thesufficient statistic for the network data model and |Mk| isthe number of nodes in module k and π0 is the probabilitythat any non-parent can have interaction with a module. Ingene regulatory networks, π0 can be interpreted as basallevel of physical binding that may not necessarily affectgene transcription and thus regulate a gene.
In the context of stochastic blockmodels, the group of par-ents assigned to each module can be considered as an in-dividual block and thus our model can represented as over-lapping blocks of nodes.
The likelihood of the model M = {A,S,Θ,Σ, ZS ,π}given the integration of node variables and network datais: P (X,B|M) = P (X|A,S,Θ,Σ, ZS)P (B|A,S,π).With priors for parameters M the posterior likelihood is:P (M|X,B) ∝ P (M)P (X,B|M).
3. Theory: Model IdentifiabilityOur method uses network data to avoid extra structural as-sumptions. In this section we formalize this idea throughthe identifiability of the proposed model. This property isimportant for interpretability of learned modules. Modulenetworks and generally multivariate normal models for ob-ject variables can be un-identifiable, and imposing extrastructural assumptions is necessary to overcome this. Here,we illustrate that the integrated learning proposed in thispaper resolves the un-identifiability issue. First, we showthat modeling node variables alone is identifiable only un-der very specific conditions. Then, we will restate someresults from (Latouche et al., 2011) on the identifiability ofoverlapping block models. Using this result we show theidentifiability of the model under some reasonable condi-tions.

Learning Modular Structures from Network Data and Node Variables
Lemma 1. Node Variables Model: For the model of node-specific variables X, if we have: P (X|{A,S}′,Θ′,Σ′) =P (X|{A,S},Θ,Σ)
1. Then, we can conclude: µ′ = µ and Σ′ = Σ.
2. If we further assume {A,S} = {A,S}′ and thateach module has at least two non parent nodes and∑k |Pak| < N and the covariance matrix Σ is in-
vertible, we can conclude: Θ = Θ′, W = W ′.
Proof presented in (Azizi et al., 2014).The above lemma provides identifiability for the casewhere the structure {A,S} is assumed to be known. How-ever, in the case where we don’t have the structure, the pa-rameterizations of multivariate normal (µ and Σ) can bewritten in multiple ways in terms of Θ and {A,S}. This isdue to existence of multiple decompositions for the covari-ance matrix. In the following, we will use a theorem foridentifiability of overlapping block models from (Latoucheet al., 2011) which is an extension of the results in (Allmanet al., 2009). The results provide conditions for overlappingstochastic block models to be identifiable.Theorem 1. Network Data Model: If we haveP (B|{A, S},π) = P (B|{A, S}′,π′), then: {A, S} ={A, S}′ with a permutation and π = π′ (except in a setof parameters which have a null Lebesgue measure) (Proofdirect result of Theorem 4.1 in Latouche et al. (2011) asdescribed in Azizi et al. (2014)).
Using the above Theorem and Lemma 1 we can have thefollowing Theorem for the identifiability of the model.Theorem 2. Identifiability of Model: If wehave: P (B|{A, S},π) = P (B|{A, S}′,π′) andP (X|{A,S}′,Θ′,Σ′) = P (X|{A,S},Θ,Σ) with as-suming that each module has at least two non-parentnodes and
∑k |Pak| < N and the covariance matrix Σ
is invertible, then: {A, S} = {A, S}′ with a permutation,π = π′ , Θ = Θ′ and W = W ′ (except in a set ofparameters which have a null Lebesgue measure) (Proofin Azizi et al. (2014)).
This Theorem states the theoretical effect of integratedmodeling on identifiability of modular structures, giventhat the sum of number of parents is less than the numberof nodes (as is common in gene regulatory networks).
4. Parameter Estimation using RJMCMCWe use a Gibbs sampler to obtain the posterior distributionP (M|X,B) and design Metropolis-Hastings samplers foreach of the parameters Θ,Σ,π conditioned on the other pa-rameters and data X,B. We use Reversible-Jump MCMC(Green, 1995) for sampling from conditional distributionsof the assignment and structure parameters A,S.
4.1. Learning Parameters Θ,Σ, ZS ,π.
To update the means, we only need to sample one value formeans of parents assigned to the same module. This set ofmeans of distinct parents µR
c are sampled with a Normalproposal (Algorithm 1). Similarly we sample the param-eters γrc , z
rk and πrk, corresponding to parent r ∈ Pak of
module k, from normal distributions. To update covarianceΣ, each distinct element of the regression matrix W corre-sponding to a module k, denoted as wk, is updated. Dueto the symmetric proposal distribution, the proposal is ac-cepted with probability Pmh = min{1, P (M(j+1)|X,B)
P (M(j)|X,B)}.
The conditions required for identifiability (from Theorem1) are enforced in each iteration.
whereM(j) = {A,S,Θ,Σ, ZSπ}(j).
Algorithm 1 RJMCMC for sampling parametersInputs:Node Variables Data XNetwork Data Bfor iterations j = 1 to J do
SampleA(j+1) givenA(j) using Alg 2 in (Azizi et al.,2014)Sample S(j+1) given S(j) using Alg 3 in (Azizi et al.,2014)for modules k = 1 to K(j) do
Propose w(j+1)k ∼ N (w
(j)k , I)
Accept with probability Pmh; update Σ(j+1)
for parents r = 1 to Rk doPropose zr(j+1)
k ∼ N (zr(j)k , I); accept with Pmh
Propose πr(j+1)k ∼ N (π
r(j)k , I); accept with
Pmhend for
end forfor condition c = 1 to C do
Propose µR(j+1)c ∼ N (µ
R(j)c , I); accept with Pmh
Propose γR(j+1)c ∼ N (γ
R(j)c , I); accept with Pmh
end forend for
4.2. Learning assignments A,S.
Learning the assignment of each node to a module, involveslearning the number of modules. Changing the numberof modules however, changes dimensions of the parame-ter space and therefore, densities will not be comparable.Thus, to sample from P (A|S,Θ,Σ, , ZSπ,X,B), we usethe Reversible-Jump MCMC method (Green, 1995), an ex-tension of the Metropolis-Hastings algorithm that allowsmoves between models with different dimensionality. Ineach proposal, we consider three close move schemes ofincreasing or decreasing the number of modules by one, or

Learning Modular Structures from Network Data and Node Variables
not changing the total number. For increasing the numberof modules, a random node is moved to a new module ofits own and for decreasing the number, two modules aremerged. In the third case, a node is randomly moved fromone module to another module, to sample its assignment(Algorithm 2 in (Azizi et al., 2014)).
To sample from the dependency structure (assignment ofparents) P (S|A,Θ,Σ, ZSπ,X,B), we also implement aReversible-Jump method, as the number of parents for eachmodule needs to be determined. Two proposal moves areconsidered for S which include increasing or decreasingthe number of parents for each module, by one (Algorithm3 in (Azizi et al., 2014)).
5. Results5.1. Synthetic Data
We first tested our method on synthetic node-variablesand network data generated from the proposed model. Adataset was generated for N = 200 nodes in K = 4 mod-ules with C = 50 conditions for each node variable. Par-ents were assigned from a total of R = 10 number of can-didates. Parameters π, γ and W were chosen randomly,preserving parameter sharing of modules. The inferenceprocedure was run for 20,000 samples. Exponential priordistributions were used for number of parents assigned toeach module, to avoid over-fitting. Figure 3 shows the au-tocorrelation for samples of variable mean µnc for an ex-ample gene. The samples become independent after a lagand thus we removed the first 10, 000 iterations as burn-inperiod. Samples from posteriors, including the number ofmodules K, exhibit standard MCMC movements aroundthe actual value (actual K = 4). We also calculated thetrue positive rate and false positive rates based on actualdependency links. We repeated the estimation of true pos-itive and false positive rates for 100 random datasets withthe same size as mentioned and computed the average ROCfor the model (figure 3). As comparison, for each gener-ated dataset, we also tested the sub-model for variable data(excluding the model for network data) to infer links. Weperformed bootstrapping on sub-samples with size 1000 tocompute variance of AUC (area under curve) and paired t-tests confirmed improved performance of integrated modelcompared to the variables sub-model (p < 0.05).
The parameter sharing property in modular structures al-lows parallel sampling of parameters wk and γr(k), z
rk,πrk
for each module k, in each iteration and in different con-ditions. We used Matlab-MPI for this implementation. Ittakes an average of 36±8 seconds to generate 100 samplesfor N = 200, C = 50, R = 10 on an i5 3.30GHz In-tel(R). For further enhancement, module assignments wereinitialized by k-means clustering of variables.
0.050.1
0.15
0.2
10,000 20,00015,000
0
2
4
6
8
0 2000 4000 6000 8000 10,000−0.2
0
1
Lag
µ Au
toco
rrela
tion
µ
0.2
Iterations
K
TPR0.5
0.25
0.75
1
010,000 20,00015,000
False Positive Rate
True
Pos
itive
Rat
e
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Variables modelIntegrated model
Figure 3. Results sythetic data: Autocorrelation for an examplevariable mean (top); gibbs samples and posterior after burn-in pe-riod (actual mean shown with red line); number of modules (pur-ple) and true positive rate of recovered links (green), ROC curvefor integrated model and variables model (bottom)
5.2. M. tuberculosis Gene Regulatory Network
We applied our method to identify modular structures in theMycobacterium tuberculosis (MTB) regulatory network.MTB is the causative agent of tuberculosis disease in hu-mans and the mechanisms underlying its ability to persistinside the host are only partially known (Flynn & Chan,2001). We used interaction data identified with ChIP-Seqof 50 MTB transcription factors and expression data fordifferent induction levels of the same factors in 87 experi-ments, from a recent study by (Galagan et al., 2013). Onlybindings of factors to upstream intergenic regions wereconsidered. We tested our method on 3072 MTB geneswhich had binding from at least one of these factors andperformed 100,000 iterations on the combination of the twodatasets. For each gene, we inferred the mode of its assign-ments to modules (after removing burn-in samples) and ob-tained 29 modules in total. The largest modules and theassigned regulators are shown in figure 4. The identifiedmodules are enriched for functional annotations of genes(Azizi et al., 2014).
For each module, the number of assigned genes and ex-

Learning Modular Structures from Network Data and Node Variables
M25
M8
M28Rv2021 Rv3124
M1
M11
M22
6
M9
M13 M14
M20
M5Rv2034
Rv1990 M6
Rv0767
M24
DosR
M27 M10
Lsr2
M7
M29
KstR M23
M18M4
Rv2324
M21
Rv3249c
M3
M17
Rv0494
M2
Rv0081
Energy Production
AA transport/metabolism
Transcription
Cell wall
Cell motility
Transcription
Posttranslationalmodi�cation
Hypoxic/Nitrositivestress response
M26
M13
M11Lipid &
Carbohydrate metabolism
Figure 4. Regulatory structures between largest modules in-ferred for MTB: Regulators assigned to each module are shown;the size of circles are proportional to number of genes assignedto the module. Enriched functional annotations are highlighted;details are in Azizi et al. (2014).
amples of previously studied genes are presented. Theidentified regulators of each module and enriched annota-tions confirm known functions for some regulators, such asthe role of KstR (Rv3574) in regulating lipid metabolism(Kendall et al., 2007), confirmed in modules M26 and M11;and DosR (Rv3133c) in nitrosative stress response (Voskuilet al., 2003) (module M1) and transcription (Rustad et al.,2008) (module M25). Novel functions for other regulatorsand the combinations of regulators acting together are alsopresented.
As shown in figure 4, many modules are controlled by morethan one regulator, highlighting the significance of combi-natorial regulations (see supplemantary material for inter-pretations). One inferred module is M11 shown in figure 5which is regulated by Rv0081 and KstR (Rv3574). Rv0081is known to be involved in hypoxic adaptation (Galaganet al., 2013) while KstR is known to be involved in choles-terol and lipid catabolism (Kendall et al., 2007) and themodule is enriched for ”Energy production and conversion”and ”Lipid transport and metabolism” COG categories (ta-ble 1 in Azizi et al. (2014)). The inferred program in figure5 shows that either of the two regulators can repress theexpression of the 48 genes assigned to this module, whichinclude lipases and genes involved in fatty acid β-oxidationand triacylglycerides cycle metabolic pathways. KstR itselfis also regulated by Rv0081, and thus Rv0081 regulateslipid metabolism genes through KstR. Figure 3 in supple-mantary material shows another module M25 containing161 genes, with two hypoxic adaptation regulators mediat-ing the induction of a second hierarchy of regulators with a
KstR
Gen
e E
xpre
ssio
ns
TF-
Gen
e In
tera
ctio
ns
Rv0081
KstR
Rv0081
context (a) (b) (c)
Figure 5. Inferred regulatory program for module M11 of fig. 4showing that either of Rv0081 and KstR can repress the modulein contexts (a) and (c)
time delay, explaining a late hypoxic response.
We showed in section 3 that integration of network datahas theoretical advantages in terms of model identifiabil-ity. Here, we show that it can also reduce the number offalse positive regulatory links in MTB data. As a gold stan-dard, we used previously validated links (by EMSA, RTq-PCR) for two MTB regulators, including 48 known linksfor DosR from (Voskuil et al., 2003) and 72 known linksfor KstR from (Kendall et al., 2007). We calculated thearea under precision-recall for our method by comparingposterior probabilities for DosR and KstR links to knownlinks (table 1). As comparison, we also applied commonmethods shown to have best performance in DREAM chal-lenge contests (Marbach et al., 2012) in inferring regulatorynetworks from gene expression only. These include MutualInformation between expression profiles (MI), CLR (Faithet al., 2007), GENIE3 (Irrthum et al., 2010). We appliedthese on the above MTB expression data, and comparedthe inferred links to the gold standard set. As the numberof validated links in MTB are small, we also scored thepredictions from co-expression methods to the MTB ChIP-Seq data (Galagan et al., 2013) for the same two regulators.Also, none of these methods assume modular structures.
We then applied Module Networks (Segal et al., 2005)to the same expression dataset and compared predictionsto known links and ChIP-Seq data (table 2). We set themaxmimum number of modules to 10 and constrained thecandidate pool of regulators to the 50 ChIPped regulatorsonly. On average 2.8 ± 0.63 regulators were assigned toeach module, with a mode of 3, whereas the ChIP-Seq net-work shows a mode of 1 for in-degree of genes (Galaganet al., 2013), i.e. most genes have only one regulator bind-ing. As the predicted links from module networks are de-

Learning Modular Structures from Network Data and Node Variables
Table 1. Area under precision-recall AUPR(%) calculated forlink prediction using proposed method and other common co-expression methods, applied to MTB data. The predictions arescored vs known and ChIP-Seq links for two regulators
Gold Standard Validated Links ChIP-Seq LinksRegulator DosR KstR DosR KstRNo. of Targets (48) (72) (528) (503)
MI 39.04 9.24 25.00 17.85
CLR 48.25 9.37 21.44 16.77
GENIE3 62.26 31.37 21.55 19.44
Proposed Model 72.13 65.72 79.62 70.06
terministic, an AUPR score can not be reported, thus wecompared to precision and recall of posterior mode fromour models. Note small precision values are due to smallnumber of validated links, i.e. if a link is not validated ex-perimentally it may not be wrong. For a fair comparison ofmodels without the effect of interaction data, we also com-pared to performance of our model for variables data only(table 2). These results show that module networks and ingeneral co-expression methods have many false positivesand integrating interaction data is necessary for inferenceof direct regulatory relationships.
Table 2. Percentage of Precision (P) and Recall (R) for link pre-diction using module networks and proposed models.
Gold Standard Validated Links ChIP-Seq LinksRegulator DosR KstR DosR KstR
P R P R P R P R
Module Networks 3.8 81.2 6.5 86.1 40.1 76.3 35.8 67.4
Proposed Model forVariables (mode)
4.6 77.1 7.2 77.8 55.0 83.7 52.5 80.5
Proposed IntegratedModel (mode)
6.5 89.6 10.6 84.7 75.4 93.4 83.6 95.6
6. ConclusionWe proposed a model for learning dependency structuresbetween modules, from network data and node variablesdata. We showed that the assumption of shared parentsand parameters for nodes in a module, together with in-tegration of network data deals with under-determinationand un-identifiability, improves statistical robustness andavoids over-fitting. We presented a reversible-jump in-ference procedure for learning model posterior. Our re-sults showed high performance on synthetic data and in-terpretable structures on synthetic data and real data fromM. tuberculosis gene network. Results for MTB generegulatory network revealed feed-forward loops and in-sights into condition-specific regulatory programs for lipidmetabolism and hypoxic adaptation. One future direction isto propose faster algorithms based on generalized method
of moments (Azari Soufiani et al., 2014; 2013; Anandku-mar et al., 2012) for estimators of this model.
AcknowledgmentsWe acknowledge funding from the Hariri Institute forComputing and Computational Science & Engineer-ing, the National Institute of Health under grantsHHSN272200800059C and R01 GM096193, the NationalScience Foundation under grant IIS-1149662, the ArmyResearch Office under grant MURI W911NF-11-1-0036,and from an Alfred P. Sloan Research Fellowship.
ReferencesAiroldi, E.M. Getting started in probabilistic graphi-
cal models. PLoS Computational Biology, 3(12):e252,2007.
Airoldi, E.M., Blei, D.M., Fienberg, S.E., and Xing, E.P.Mixed membership stochastic blockmodels. The Journalof Machine Learning Research, 9:1981–2014, 2008.
Airoldi, E.M., Costa, T.B., and Chan, S.H. Stochasticblockmodel approximation of a graphon: Theory andconsistent estimation. In Advances in Neural Informa-tion Processing Systems (NIPS), volume 26, pp. 692–700, 2013a.
Airoldi, E.M., Wang, X., and Lin, X. Multi-way block-models for analyzing coordinated high-dimensional re-sponses. Annals of Applied Statistics, 7(4):2431–2457,2013b.
Allman, E.S., Matias, C., and Rhodes, J.A. Identifiabilityof parameters in latent structure models with many ob-served variables. The Annals of Statistics, 37(6A):3099–3132, 2009.
Anandkumar, A., Hsu, D., and Kakade, S.M. A method ofmoments for mixture models and hidden markov mod-els. arXiv:1203.0683, 2012.
Aral, S., Muchnik, L., and Sundararajan, A. Distinguishinginfluence-based contagion from homophily-driven diffu-sion in dynamic networks. Proceedings of the NationalAcademy of Sciences, 106(51):21544–21549, 2009.
Azari Soufiani, H. and Airoldi, E.M. Graphlet decomposi-tion of a weighted network. Journal of Machine Learn-ing Research, (W&CP 22 (AISTATS)):54–63, 2012.
Azari Soufiani, H., Chen, W., Parkes, D.C., and Xia, L.Generalized method-of-moments for rank aggregation.In Advances in Neural Information Processing Systems,pp. 2706–2714, 2013.
Azari Soufiani, H., Parkes, D.C., and Xia, L. Computingparametric ranking models via rank-breaking. In Pro-ceedings of The 31st International Conference on Ma-chine Learning, pp. 360–368, 2014.

Learning Modular Structures from Network Data and Node Variables
Azizi, E. Joint learning of modular structures from multipledata types. In NIPS Workshop of Frontiers of NetworkAnalysis: Methods, Models, and Applications, 2013.
Azizi, E., Airoldi, E.M., and Galagan, J.E. Learning mod-ular structures from network data and node variables.arXiv:1405.2566, 2014.
Celniker, S.E., Dillon, L., Gerstein, M.B., Gunsalus, K.C.,Henikoff, S., Karpen, G.H., Kellis, M., Lai, E.C., Lieb,J.D., MacAlpine, D.M., et al. Unlocking the secrets ofthe genome. Nature, 459(7249):927–930, 2009.
Choi, D.S., Wolfe, P.J., and Airoldi, E.M. Stochastic block-models with a growing number of classes. Biometrika,99(2):273–284, Jun. 2012.
Faith, J.J., Hayete, B., Thaden, J.T., Mogno, I.,Wierzbowski, J., et al. Large-scale mapping and vali-dation of escherichia coli transcriptional regulation froma compendium of expression profiles. PLoS biology, 5(1):e8, 2007.
Flynn, J.L. and Chan, J. Tuberculosis: latency and reacti-vation. Infection and immunity, 69(7):4195–4201, 2001.
Galagan, J.E., Minch, K., Peterson, M., Lyubetskaya, A.,Azizi, E., et al. The mycobacterium tuberculosis regula-tory network and hypoxia. Nature, 499(7457):178–183,2013.
Goldenberg, A., Zheng, A. X., Fienberg, S. E., and Airoldi,E. M. A survey of statistical network models. Foun-dations and Trends in Machine Learning, 2(2):129–233,Feb. 2009.
Green, P.J. Reversible jump markov chain montecarlo computation and bayesian model determination.Biometrika, 82(4):711–732, 1995.
Imoto, S., Higuchi, T., Goto, T., Tashiro, K., Kuhara, S.,and Miyano, S. Combining microarrays and biologi-cal knowledge for estimating gene networks via bayesiannetworks. Proc. Computational Systems Bioinformatics,2003.
Irrthum, A., Wehenkel, L., Geurts, P., et al. Inferring reg-ulatory networks from expression data using tree-basedmethods. PLoS One, 5(9):e12776, 2010.
Joshi, A., De Smet, R., Marchal, K., Van de Peer, Y.,and Michoel, T. Module networks revisited: compu-tational assessment and prioritization of model predic-tions. Bioinformatics, 25(4):490–496, 2009.
Kendall, S.L., Withers, M., Soffair, C.N., Moreland, N.J.,Gurcha, S., et al. A highly conserved transcriptional re-pressor controls a large regulon involved in lipid degra-dation in mycobacterium smegmatis and mycobacteriumtuberculosis. Molecular microbiology, 65(3):684–699,2007.
Koller, D. and Friedman, N. Probabilistic Graphical Mod-els: Principles and Techniques. MIT Press, 2009.
Kozinets, R.V. E-tribalized marketing?: The strategic im-plications of virtual communities of consumption. Euro-pean Management Journal, 17(3):252–264, 1999.
Latouche, P., Birmele, E., and Ambroise, C. Overlappingstochastic block models with application to the frenchpolitical blogosphere. The Annals of Applied Statistics,5(1):309–336, 2011.
Liu, Y., Qiao, N., Zhu, S., Su, M., Sun, N., Boyd-Kirkup,J., and Han, J.-D. A novel bayesian network inferencealgorithm for integrative analysis of heterogeneous deepsequencing data. Cell Research, 23(3):440–443, 2013.
Marbach, D., Costello, J.C., Kuffner, R., Vega, N.M., Prill,R.J., et al. Wisdom of crowds for robust gene networkinference. Nature methods, 2012.
Michoel, T., Maere, S., Bonnet, E., Joshi, A.and Saeys, Y.,et al. Validating module network learning algorithms us-ing simulated data. BMC Bioinformatics, 8(Suppl 2):S5,2007.
Mitra, K., Carvunis, A., Ramesh, S.K., and Ideker, T. Inte-grative approaches for finding modular structure in bio-logical networks. Nature Reviews Genetics, 14(10):719–732, 2013.
Qi, Y. and Ge, H. Modularity and dynamics of cellular net-works. PLoS Computational Biology, 2(12):e174, 2006.
Rustad, T.R., Harrell, M.I., Liao, R., and Sherman, D.R.The enduring hypoxic response of mycobacterium tuber-culosis. PLoS One, 3(1):e1502, 2008.
Segal, E., Shapira, M., Regev, A., Pe’er, D., Botstein, D.,Koller, D., and Friedman, N. Module networks: iden-tifying regulatory modules and their condition-specificregulators from gene expression data. Nature genetics,34(2):166–176, 2003.
Segal, E., Pe’er, D., Regev, A., Koller, D., and Friedman, N.Learning module networks. Journal of Machine Learn-ing Research, (6):557–588, 2005.
Snijders, T.A.B. and Nowicki, K. Estimation and predic-tion for stochastic blockmodels for graphs with latentblock structure. Journal of Classification, 14(1):75–100,1997.
Voskuil, M.I., Schnappinger, D., Visconti, K.C., Harrell,M.I., Dolganov, G.M., Sherman, D.R., and School-nik, G.K. Inhibition of respiration by nitric oxide in-duces a mycobacterium tuberculosis dormancy program.The Journal of experimental medicine, 198(5):705–713,2003.
Wang, Y.J. and Wong, G.Y. Stochastic blockmodels fordirected graphs. Journal of the American Statistical As-sociation, 82(397):8–19, 1987.
Werhli, A.V. and Husmeier, D. Reconstructing gene regula-tory networks with bayesian networks by combining ex-pression data with multiple sources of prior knowledge.Statistical Applications in Genetics and Molecular Biol-ogy, 6(1):15, 2007.