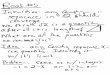-
7/29/2019 Lecture 4 Statictik
1/7
Prof. Thistleton STA100 Statistical Methods Lecture 4
Text Sections: Chapter 3 Sections 2
Computing Formula for Standard Deviation
So far we have seen how to describe a data set with just a few
numbers: the mean and the mediantell you where the data are
centered and provide an insight to the data set with just one
number.
If you also know the standard deviation or the Inter-Quartile
Range (IQR) you know how spread
out the data are. As a reminder, suppose you have the following
toy data set, and assume the data
come from a sample (not the whole population):
100 112 121 95 97
You can easily calculate thesample mean, as
(1)
Note a few things:
weve used the symbol x bar since our data are drawn from a
sample. If they had come
from a population we would have used the Greek letter or mu.
Also, since they come from a sample we have denoted the number
of data points (thesample size) as little or lower case n.
Finally, just as our text book does, Ive used the Greek letter
upper case sigma or
to indicate that we are adding some numbers up. What we are
saying is that we haveseveral numbers where the first is a 100, the
second is 112, etc. A compact way to write
this which clearly indicates which number is first, second, all
the way to fifth is to say
. Then since these are all
individual data points from the variable write sum of the xs as
. Greek lettersigma forsum.
-
7/29/2019 Lecture 4 Statictik
2/7
Some people like to draw a dot plot showing the data on a
horizontal scale:
o o o o o
80 90 100 110 120
If you draw in a small triangle under the line at the point 105
you can see that the (arithmetic)
mean shows where a collection of numbers would balance or if you
prefer has its center of
mass. (Just think of kids on a see-saw).
Now when we try to see how spread out the data are by
calculating the standard deviation.
Remember that to do this we calculate the mean (105) and then
calculate the deviations, etc.
Data points, x Deviations, Deviations2
100 100-105 = -5 (100-105) = (-5)
= 25
112 112-105 = 7 (112-105) = (7)
= 49121 121-105 = 16 (121-105) = (16)
= 256
95 95-105 = -10 (95-105)
= (-10)= 100
97 97-105 = -8 (97-105) = (-8)= 64
sums 525 0 494
Once we add up all the squared deviations we take their average.
As we noted before, some
books at this point just divide by the number of data points, .
Our book (and many others)
divide by when the data come from a sample. They do this for the
following reason.Remember that we usually form a sample because we
cant get to all the data in the population.
If you would like to know the average number of text messages
sent by a 12 year old each day
you cant get this info for all kids in America (not even Verizon
can do this!) but will have tofind a sample of, say, 100 kids and
work from that. Dividing by tends to underestimate the true
population variability, so we boost it a little by dividing by a
little less, We can be more
technical about this later. Thus the sample variance,
And the sample standard deviation (average deviation)
-
7/29/2019 Lecture 4 Statictik
3/7
The Computational Formula
There is a formula that many people find easier to work with. A
little algebra shows that you can
calculate the sum of the squares as follows:
We can set up a table for this as well. First notice that you
need to square all the terms and then
add them up ( , and also add up all the terms themselves .
Data points, x Data points squared,100 10000
112 12544
121 1464195 9025
97 9409
sums
This gives us
And so
See if you can reproduce these tables in your spreadsheet.
-
7/29/2019 Lecture 4 Statictik
4/7
Chebyshev's Theorem.
Pafnuty Chebyshev was an 19th
century Russian mathematician who is probably most famous
for
the following idea. Given any set of numbers you can think of,
the standard deviation gives us away of organizing the data in our
mind. Consider the following data, expressed as a dot plot.
o o o o o
o-------------------------------------------------------------------------------------------------------
5 10 15 20 25 30 35 40 45 50 55 60 65 70
We can calculate the mean as
Put a marker on your graph at
Now calculate the standard deviation by filling in the missing
figures in the table:
10 100
25
30
40 1600
45
55 3025
sums
And obtain
Now start to orient your data set by putting little markers one,
two and three standard deviationsaway from the mean to each side.
This is just like walking one, two, or three yards in either
direction to mark out a garden. This gives us
-
7/29/2019 Lecture 4 Statictik
5/7
If you mark your dotplot with these numbers you should see
that
o o o o o o5 10 15 20 25 30 35 40 45 50 55 60 65 70
Four of your numbers (25, 30, 40, and 45) lie between 18.22406
and 50.10927
All of your numbers lie between 2.281456 and 66.05188
Chebyshev told us that this isnt a coincidence. Heres what is
always true: if you have a
collection of numbers you are guaranteedto see
At least 75% (3/4) of your data within 2 standard deviations of
the meanAt least 89% (8/9) of your data within 3 standard
deviations of the mean
At least 93.75% (15/16) of your data within 4 standard
deviations of the mean.
In general, you will see at least
Of your data within standard deviations of the mean. Note: You
will probably see more. Thisis a worst case scenario.
-
7/29/2019 Lecture 4 Statictik
6/7
Why do we care?
If I told you that I had a data set with a mean of 100 and a
standard deviation of 15 (this is true
for a certain type of IQ data) and if I then told you I knew
someone with an IQ of 180 you could
reason as follows:
According to our friend Pafnuty,
at least 75% of all people have an IQ between 70 and 130 (do you
see that 70 = 100-2*15
and 130 = 100+2*15?)
at least 89% of all people have an IQ between 55 and 145
(why?)
at least 93.75% of all people have an IQ between 40 and 160
(why?)
at least 96% of all people have an IQ between 25 and 175 (Please
note that this is a little
silly at this point- weve pushed the IQ idea too far.)
So an IQ of 180 is really quite high.
-
7/29/2019 Lecture 4 Statictik
7/7
The Normal Distribution
IQ data tend to have the distribution shown in the histogram
above. This is called the Normal or
Gaussian distribution and has a characteristic bell shape. Many
real world data sets have this
shape.
As you can see Chebyshev is really very conservative. There is
an Empirical Rule in our text that
tells us, when data are normall y distr ibuted:
Approximately 68.27% of data will lie within one standard
deviation of the mean
(between 85 and 115 above).
Approximately 95.45% of data will lie within one standard
deviation of the mean
(between 70 and 130 above).
Approximately 99.73of data will lie within one standard
deviation of the mean (between
55 and 145 above).
So thats pretty much the whole show. Using the normal
distribution we will later compute that
the chances that someone randomly selected from the population
has an IQ as high as 180 are
actually 1 in 20,741,279 (if you believe the model).
25 40 55 70 85 100 115 130 145 160 1750
0.005
0.01
0.015
0.02
0.025
0.03
The Normal Distribut ion, =100, =15