Embed Size (px)
DESCRIPTION
LHT : A Low-Maintenance Indexing Scheme over DHTs. Yuzhe Tang and Shuigeng Zhou 湯宇哲 , 周水庚 復旦大學 The 28th International Conference on Distributed Computing Systems. 89721001 博一 張睿元. Outline. Introduction Preliminaries Algorithms Experimental Results Conclusion. Introduction. - PowerPoint PPT Presentation
Citation preview

Yuzhe Tang and Shuigeng Zhou湯宇哲 , 周水庚復旦大學
The 28th International Conference on Distributed Computing Systems
89721001 博一 張睿元

Introduction Preliminaries Algorithms Experimental Results Conclusion

DHTs have several outstanding advantages:
--(1) Scalability and efficiency.
--(2) Robustness.
--(3) Load balance.

Basic DHTs do not support complex query processing.
However, complex queries are highly desired and actually gaining popularity in many P2P applications.

The popularity of complex queries poses an urgent need for DHT-based indexing schemes.
Generally speaking, to design an indexing structure, query efficiency comes as the first priority.
As a result, P2P systems have to invest a lot maintenance cost for adjusting their index structures.

This problem, however, has not be effectively resolved in the existing P2P indexing schemes.
Instead, they focused on improving query efficiency, and as a trade-off, sacrificed maintenance efficiency.
For example, in Prefix Hash Tree (PHT), each leaf knows its neighboring leaves.

Based on this observation, in this paper we propose LHT, a Low maintenance Hash Tree for data indexing in DHT based P2P systems.
LHT requires no modification of the underlying DHTs and can be easily adapted to any DHT substrate.
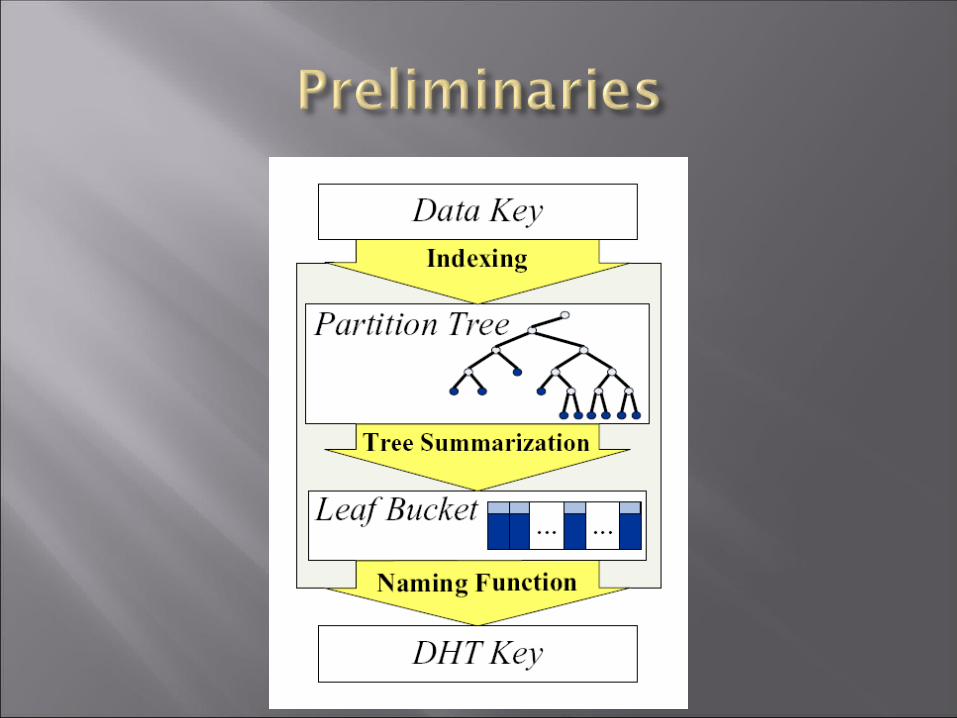
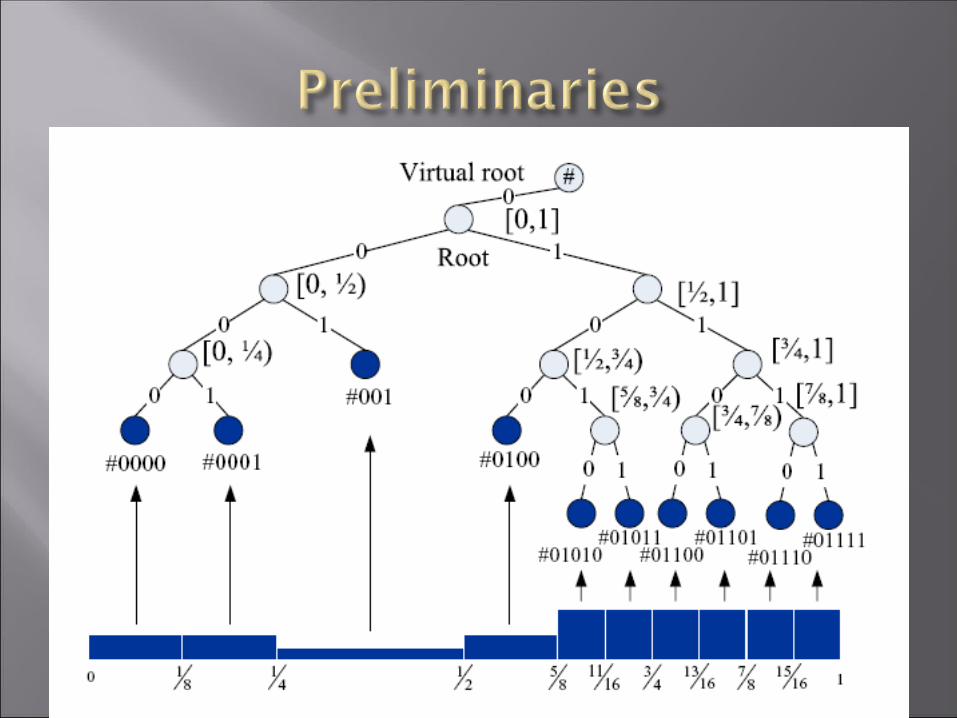
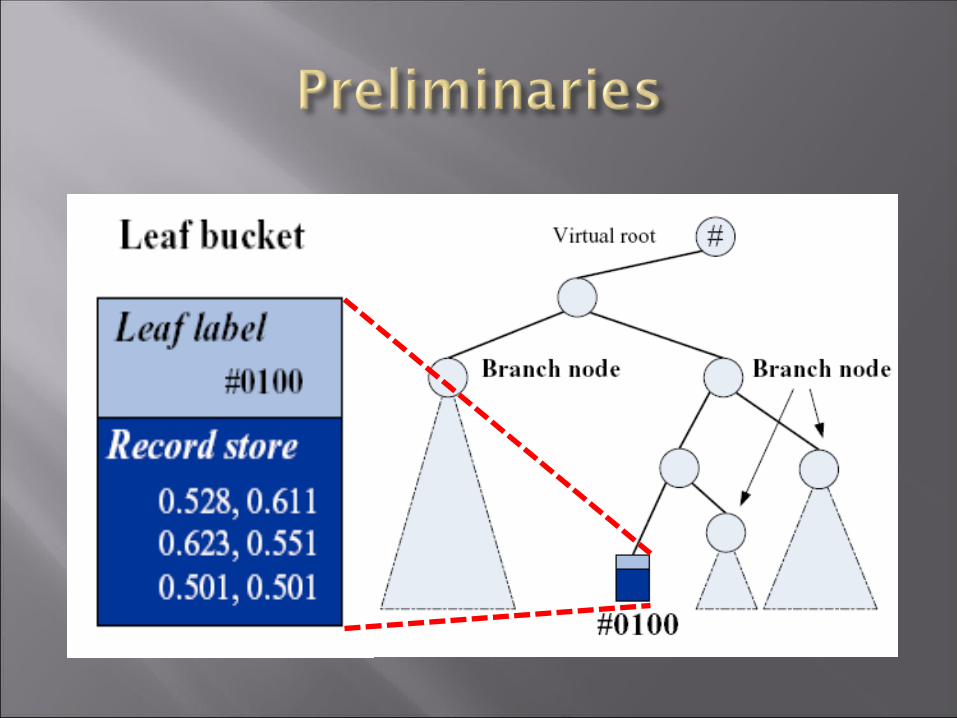
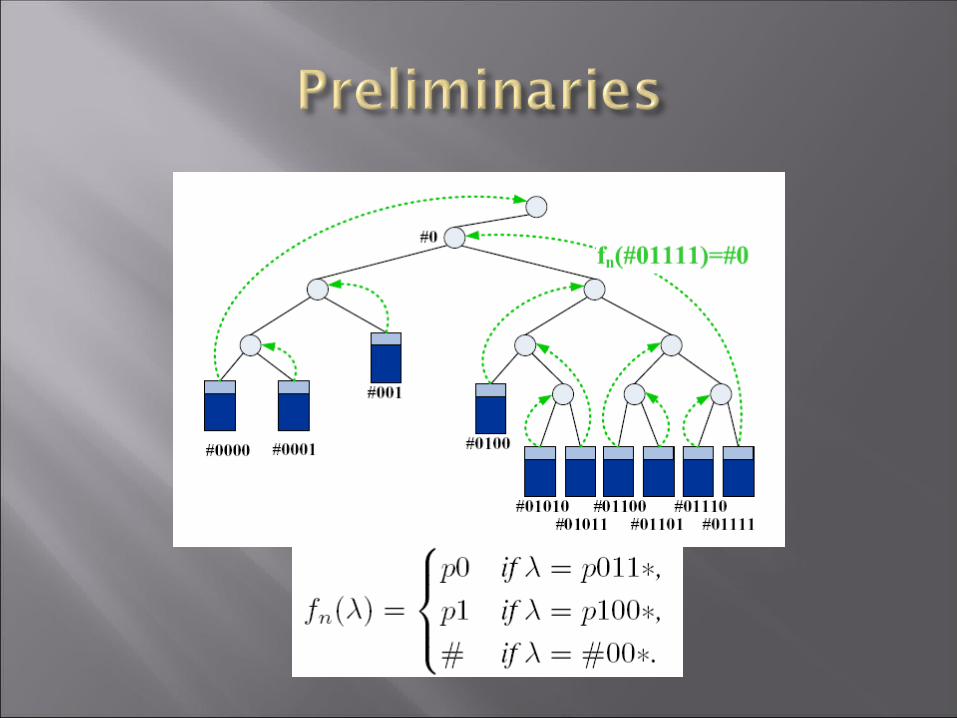

Incremental Tree Growth : --When a data insert and make the
number of data in a leaf bucket exceed θsplit, then we will split this leaf bucket.
#010
0.620.70
#
EX: θsplit=2 and insert 0.72
0.72
#0100
0.62
#0101
0.700.72
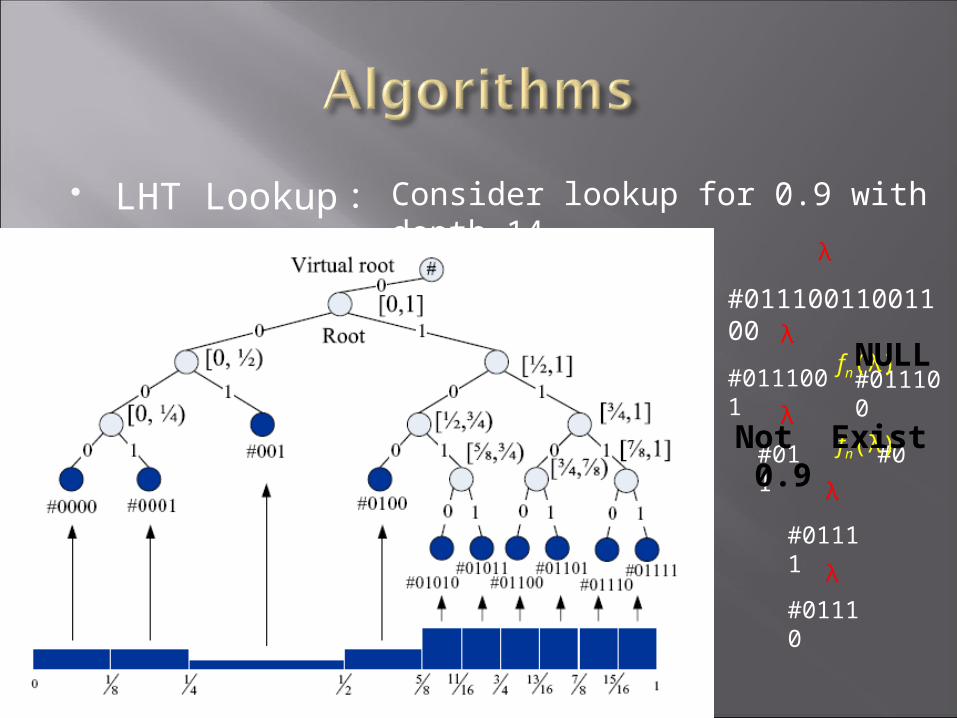
LHT Lookup : Consider lookup for 0.9 with depth 14.
#01110011001100
#0111001
#011100
#011
#0
#01111
#01110
λ fn(λ)
λ
λ fn(λ)
λ
λ
NULL
Not Exist 0.9
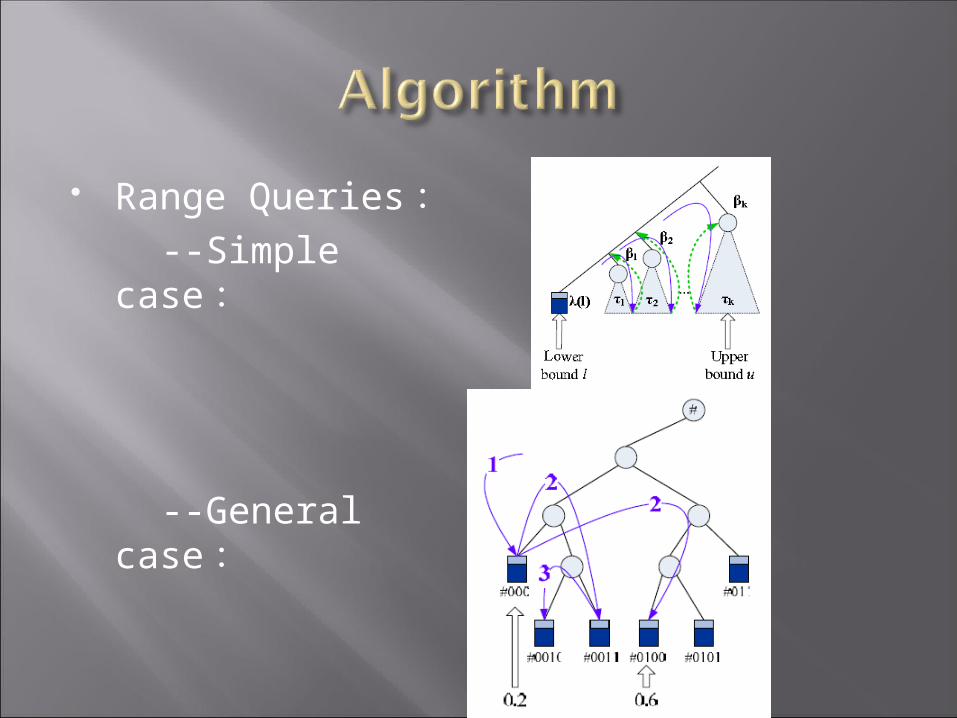
Range Queries : --Simple case :
--General case :
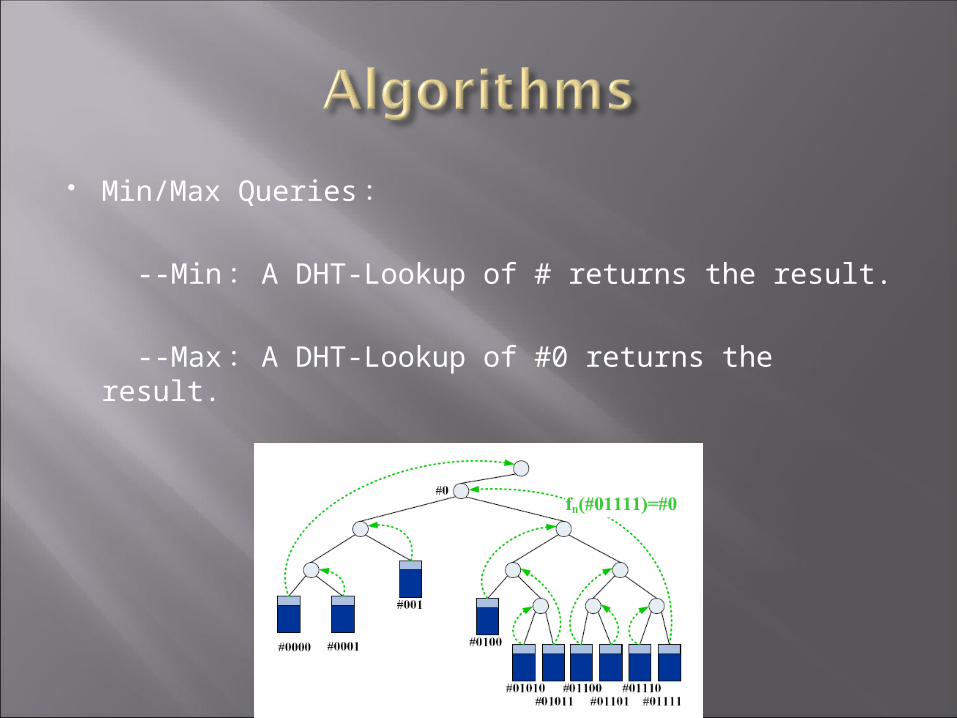
Min/Max Queries :
--Min : A DHT-Lookup of # returns the result.
--Max : A DHT-Lookup of #0 returns the result.

LHT has no need of periodical maintenance for index integrality and consistency.
LHT’s maintenance cost is only paid for its tree structure adjustment, incurred by data insertion/deletion.
This structural adjustment involves leaf split and merge.
In comparison with PHT, LHT’s saving ratio of maintenance cost can be up to 75% and at least 50%.

Both uniform and gaussian datasets were used.
Maintenance Cost : --Data-Movement Cost : LHT is about 50% lower than PHT. --DHT-Lookup Cost : LHT is about 25% lower than PHT.

Lookup Performance : --For uniform data : LHT is about 20% lower than PHT. --For gaussian data : LHT is about 30% lower than PHT.
When data size equals to some special number (ex:212, 216, 220 which lead the tree depth equal to D/2, D/4, 3D/8) the binary search thus can be resolved in the first (fewer) DHT-lookup.

Range Query Performance : --Bandwidth : PHT(parallel)>PHT(sequential)≈ LHT --Latency : PHT(parallel)>PHT(sequential)≈ LHT LHT is about 18% lower than PHT(parallel).
PHT(sequential)’s near-optimal bandwidth consumption is owing to the presence of B+ tree-like leaf link which incurs extra maintenance cost.
PHT(parallel) can achieve competitive time latency, which however deteriorates when data distribution tends to be skewed (like in gaussian data).

This paper proposes LHT for data indexing over DHTs.
As compared with PHT, LHT can save up to 75%(at least 50%) maintenance cost, and achieves better performance in exact-match and range query processing.
LHT is adaptable to any generic DHT, and is easy to be implemented and deployed.





























