Embed Size (px)
DESCRIPTION
MIPSI 指令集 32 位 CPU MiniCore 设计实例. 赵继业. 处理器特性介绍. 全 32 位操作, 32 个 32 位通用寄存器,所有指令和地址全为 32 位 静态流水线 ( 3 ~ 5 级) Forwarding 技术 片内 L1 Cache ,指令、数据各 4KByte ,硬件初始化 没有 TLB ,但 系统控制协处理器( CP0 )具有除页面映射外的全部功能. MIPSI 指令格式介绍. 1 、 R 类型指令(寄存器) OP rs rt rd shamt funct 2 、 I 类型指令(立即数) OP rs rt Imm - PowerPoint PPT Presentation
Citation preview

MIPSI 指令集 32 位 CPUMiniCore 设计实例
赵继业
处理器特性介绍• 全 32 位操作, 32 个 32 位通用寄存器,所
有指令和地址全为 32 位• 静态流水线( 3 ~ 5 级)• Forwarding 技术• 片内 L1 Cache ,指令、数据各 4KByte ,
硬件初始化• 没有 TLB ,但系统控制协处理器( CP0 )
具有除页面映射外的全部功能

MIPSI 指令格式介绍1 、 R类型指令(寄存器)
OP rs rt rd shamt funct
2 、 I类型指令(立即数)OP rs rt Imm
3 、 J类型指令(跳转)OP target

MiniCore 所支持的指令• 算术逻辑类指令
– ADD 、 ADDI 、 SUB 、 AND 、 OR 、 NOR 、SLL 、 SRL 、 SRA
• 访存类指令– LW 、 SW 、 MTC0 、 MFC0 、 CACHE ( 0 、
1 )• 跳转类指令
– J 、 JR 、 BEQ
• 其他指令– ERET 、 TEQ

MiniCore 流水线结构单条指令运行步骤• Fetch & Decode( 取指并译码 )• Issue (发射)• Execute & Writeback (执行并写回)
取指并译码 发射 执行并写回取指并译码 发射 访存 写回
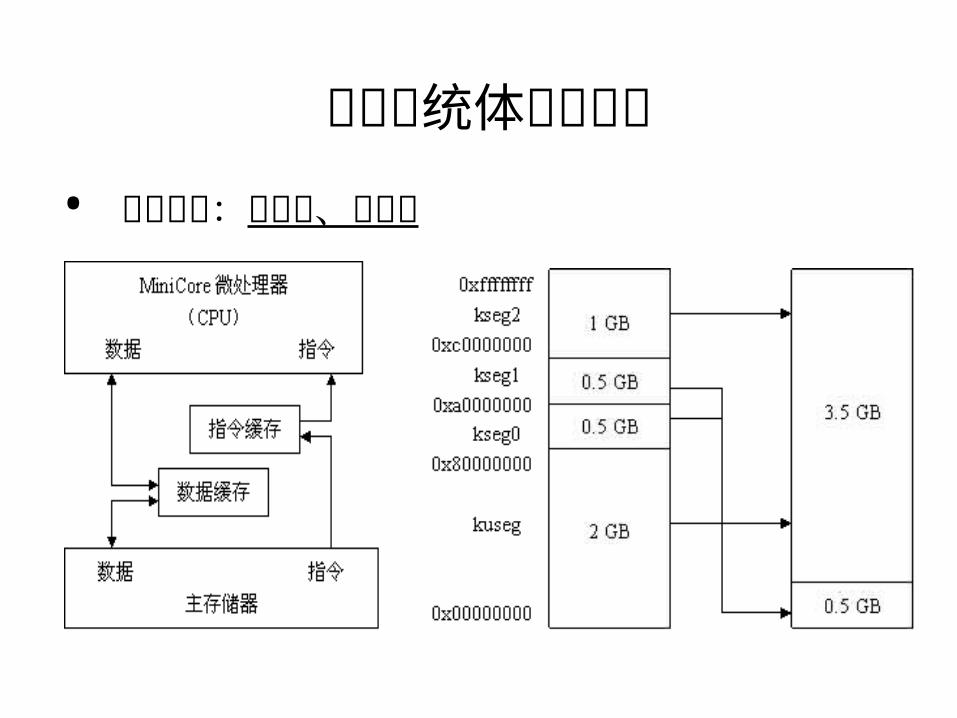
存储系统体系和管理• 操作方式:用户态、核心态
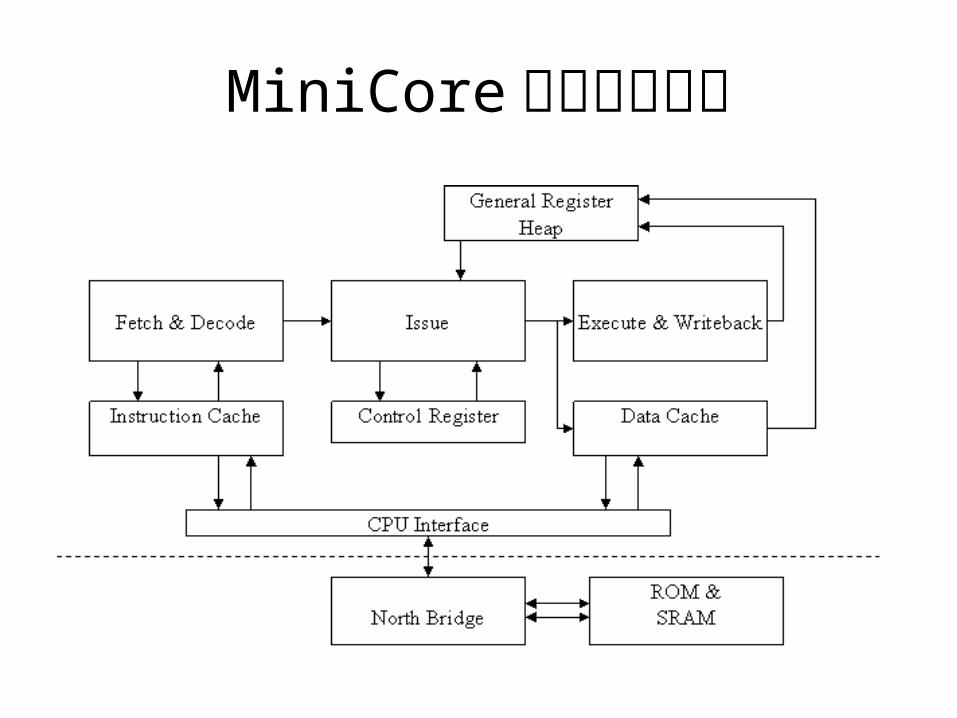
MiniCore 功能模块结构
取指模块( Fetch )• PC - > 指令 Cache - > 指令- > 译码• PC 的来源: PC + 4 (通常)、跳转指令(目标地
址)、例外处理(例外处理向量入口地址、 EPC 内容)• 停止取指的情况(发射堵塞、特殊指令)
• 跳转指令的 Delay Slot (延迟槽)• 指令 Cache 的实现问题(同步与异步 RAM )
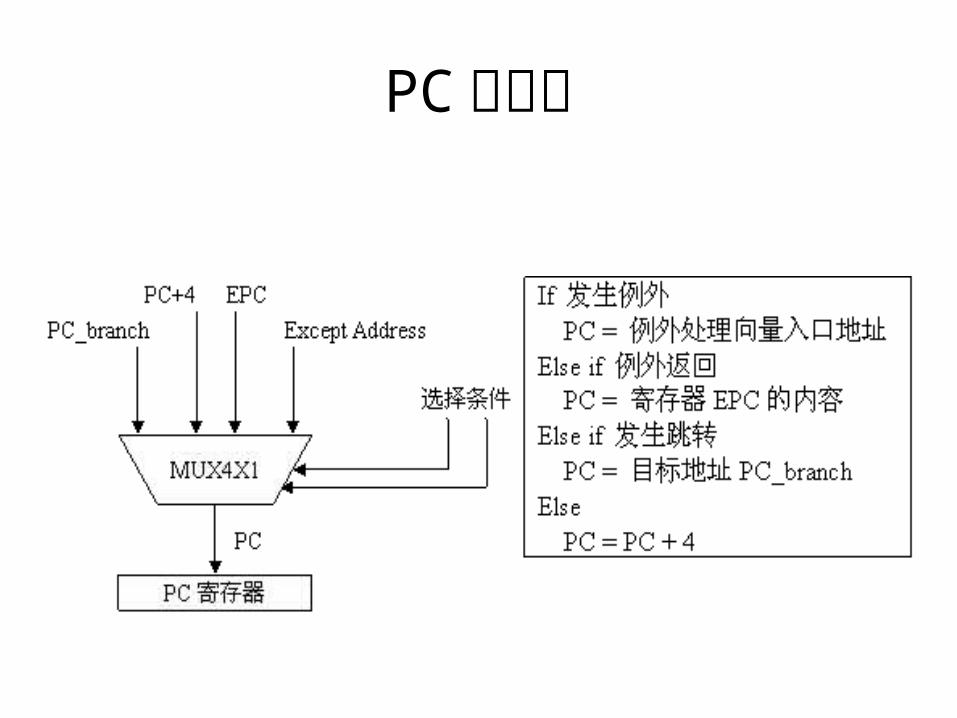
PC 的来源

停止取指的情况• 发射堵塞( Issue_stall )
– 出现指令有相关情况• 特殊指令( Special Instruction )
– 有些情况需要停止取指,如 Cache0 、跳转指令(无转移预测)、出现取指地址错例外等等
• 如何处理– 设置 PC 的有效位,一旦停止取指,有效位置无效
跳转指令的延迟槽( Delay Slot )
• 延迟槽的意义– MIPS 指令系统的规定,由编译器自动处理
• 处理跳转指令的方法– 遇见跳转指令就停止取指,直到获得目标地址
(流水线的要求)– 采用分支预测– J 指令的处理,在 ALU 模块中计算转移地址
• 原则:必须保证处在延迟槽的指令被运行!

指令 Cache 对取指模块的影响• RAM 的同步、异步问题
– 同步写入,读出的同步、异步问题• 指令 Cache 必须保证一拍结果返回
– 采用异步读 RAM 的处理方式(正常方式)• 解决方法
– 提前将 PC 的内容放入 RAM 中– 相应的考虑
•指令 Cache 的比较对象(必须一致)•设置 PC 备份寄存器•设置 pc_in_en ,决定 PC 是否可以进入寄存器•pc_valid 的考虑(实际上提前一拍)
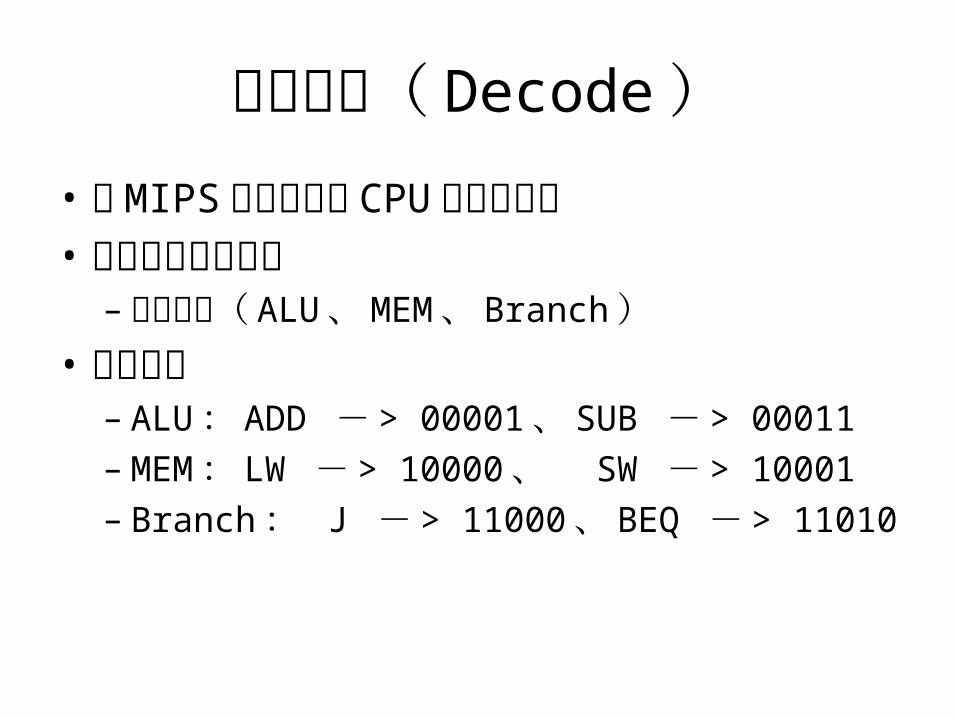
译码模块( Decode )• 由 MIPS 指令转化为 CPU 内部操作码• 内部操作码的定义
– 应当分组( ALU 、 MEM 、 Branch )• 分组示例
– ALU : ADD - > 00001 、 SUB - > 00011– MEM : LW - > 10000 、 SW - > 10001– Branch : J - > 11000 、 BEQ - > 11010

发射模块( Issue )• 静态流水线
– 遇到相关情况就停止发射,直到相关解决• 相关情况分析
– ALU 和跳转指令一拍完成,即使出现这些指令间的相关也没有问题
– MFC0 、 MTC0 、 CACHE0 和 CACHE1 指令也是一拍完成
– 访存指令中的 LW 、 SW 指令执行时间不确定,其后指令有相关必须停止发射
• 停止发射也必须同时停止取指

发射模块中必须考虑的问题• 两个功能部件( ALU 和数据 Cache )• 区别:执行指令的周期数不同• 结果:指令的结束顺序被打乱(前面访存
指令的结果尚未返回,后面与之不相关的 ALU 指令已经完成)
• 必须考虑:一旦指令(包括 ALU 指令和访存指令)运行中出现例外,如何处理?

修改发射策略• 访存等待
– 一旦遇到访存指令,必须等访存指令结果返回后,下一条指令才能发射出去
• 优点:顺序发射,顺序结束,例外处理比较简单方便
• 缺点:指令间没有相关也必须等待!

乱序执行时的精确例外处理• 两种方式:
– 乱序发射,顺序结束(龙芯- 1 采用的方式)• 指令执行完后,等待,直到允许写回才能写入到寄
存器中– 顺序发射,乱序结束( MiniCore 采用的方式)
• 分析乱序结束出现的情况– 一条访存指令运行结束前,之后数条 ALU 指令已经执行完毕

MiniCore 的解决方式• ALU 指令出现例外
– 停止取指,停止发射,停止写回,直到访存结果返回之后,进入例外处理程序
• 访存指令出现例外– 例外种类,地址错例外– 处理方式,判断地址错例外的时机,一拍完成
•优缺点– 优点:不出现前后指令相关则无需等待– 缺点:例外处理比较复杂

Forwarding 技术• 什么是 Forwarding ?
– 发射时必须判断寄存器内容是否可用– 运算指令即便一拍完成,该指令结果也必须在下一拍对发射可用
– 实现对运算结果的侦听,一旦结果总线上结果可用就直接取值用于发射
• 效率较高,在“龙芯- 1” 中使用 Forwarding 技术前后性能差距超过 10 %
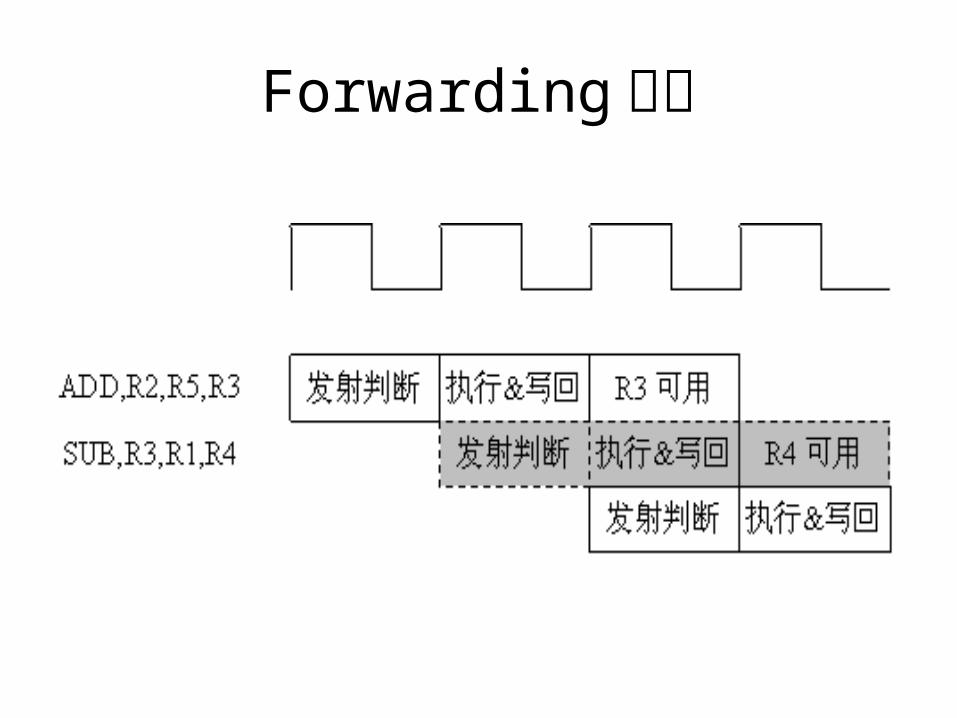
Forwarding 图解

算术及逻辑模块( ALU )• 是一个运算单元• 根据发射来的指令码判断所应当做的操作• 不同指令的结果存储寄存器不同( Rd 或 R
t )• 判断指令执行所导致的例外(溢出、自陷)• 主要目标:尽量节省硬件开销
控制寄存器模块( Control Register )
• 主要进行例外处理• 所能够处理的例外
– 复位、地址错(取指、访存读、访存写)、溢出、自陷、保留指令、中断
• 所实现的例外处理寄存器– 计数( Count )、比较( Compare )、状态
( Status )、原因( Cause )、例外地址( EPC )、版本标识( Prid )
需要考虑到的问题• 两个操作: MTC0 、 MFC0
– 必须一拍完成并且返回结果• EPC 内容
– 当一条指令发生例外时,如果前一条指令不是跳转指令,则 EPC 内容为发生例外的指令 PC值,否则是前一条指令的 PC 值,同时 Cause寄存器中的 BD 位置 1
• 原则:必须全面考虑所有例外情况

地址错例外的处理• 三种地址错情况(取指、访存读、访存写)• 取指
– 例外作为取指的结果送回,并当作一条特殊指令对待,直到送入控制寄存器模块,发生例外
– 取指模块判断地址错后,停止取指• 访存读、写
– 在 ALU 模块中直接判断是否发生访存地址错例外,如果发生,直接进入控制寄存器模块,而不进入 Cache 模块
– 同时清除在发射模块中标志访存操作的标志位

例外之前的指令结果尚未返回• 停止之后指令的取指、发射、写回• 将当前指令的内容和 PC 值放入控制寄存器
模块中储存起来• 待前面指令内容返回之后,发出例外信号,
转入例外处理程序的入口地址• 发出例外信号的同时,判断 EPC 中应存放
的例外地址并置入

Cache 模块• 指令 Cache 和数据 Cache 独立• 直接映射• 写回机制• 虚地址低位查找( Index 、 Offset )• 物理地址高位比较• 各 4KByte 大小• Cache Line 是 32Byte ( 256bit )
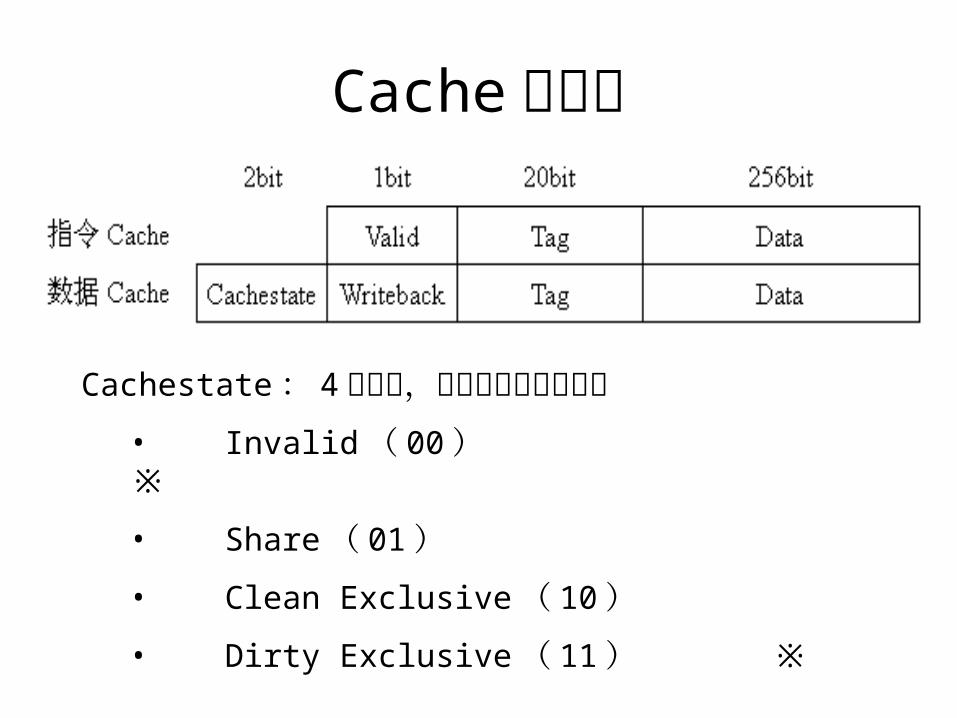
Cache 的组织
Cachestate : 4 种状态,单处理器只使用两种• Invalid ( 00 ) ※• Share ( 01 )• Clean Exclusive ( 10 )• Dirty Exclusive ( 11 ) ※

32bit 物理地址的划分• Tag ( 20 位):比较是否命中• Index ( 7 位):查找哪一个 Cacheline• Offset ( 5 位):定位 Cacheline 中哪一个字节

Cache 的工作流程(读)• 目的: 32bit 物理地址- > 访存结果( 32bit )

Cache 的工作流程(写)• 只有数据 Cache 才需要写内存• 如果 Tag 比较命中,直接写入 Cacheline 中• 如果没有命中,需要先把内存中的相同物理
地址内容读入 Cache 中,再写入• 如果 Cacheline 中原有状态位为 Dirty ,则还
需要把原有内容按该物理地址写入到内存中去
• 理解 Writeback 与 Writethrough 的区别

块操作( Block )• 在 CPU 使用 Cache 时,所有的 Cache 访
存操作都是块操作,一次一个 Cacheline
• 与单字操作相比,块操作提高了效率• CPU 直接访存,不使用 Cache 时,采用单字操作
• MiniCore 中使用 Cache 硬件初始化,都是块操作,如果是操作系统软件初始化,就必须存在单字操作

接口模块• 连接 CPU 与外部设备(北桥、内存、外设
等)• 允许 CPU 访问 Cache 未命中所需的外部资源,同时也允许外设访问 CPU 内部资源
• 信号转换( Reset 、 Interrupt )和信息交换(访存请求、访存结果)
• CPU 内外频率配合(内频=外频 × 倍频)

接口模块设计要求• 与北桥连接为双向三态总线( 0 、 1 、 Z )• 能够提供内外频率转换• 将 Cache 发出的块操作转化为八个地址请求,
并连续发出• 将北桥返回的访存结果拼成一个 Cacheline
( 256bit ),送至 Cache 模块• 外部信号( Reset 、 Interrupt )锁存后,送往 CPU 内部

北桥接口信号说明• Oe : CPU 输出使能, 1bit
• Ie :北桥输入使能, 1bit
• Iee : CPU 允许北桥输入使能, 1bit
• Sys_con :系统双向传递总线, 65bit– Sys_con[64] : 1 - >CPU 写操作, 2 - >CPU 读
操作– Sys_con[63:32] : 32bit 地址信号– Sys_con[31:0] : 32bit 数据信号

北桥接口信号• Oe = 1 ,表示 CPU 发出访存请求,此时 i
ee = 0 , ie = 0
• Oe = 0 ,表示 CPU 所发的访存请求结束,此时 iee=1 ,允许北桥传送数据
• Ie = 0 ,表示北桥发送访存结果,此时 oe= 0 , iee = 0
• CPU 、北桥均无请求, sys_con 总线置高阻态

实验说明( 1 )• MiniCore 所使用的北桥仅仅是一个初级的
SRAM 控制器,连接 CPU 和 SRAM 及 ROM
• SRAM 大小为 2MB , ROM 大小为 1MB
• 实验提供北桥和 SRAM 及整个系统顶层的Verilog 代码,实验者自行设计 CPU 内部所有模块

实验说明( 2 )• 设计 CPU 内部电路所使用的 Verilog 代码
必须均为可综合方式• 所有时序器件必须使用同步逻辑(时钟上
跳沿触发),不能使用异步逻辑(电平触发)
• 提供 Cache 模块中 SRAM 的仿真用 Verilog 文件,不能自行用寄存器搭建

实验说明( 3 )• 在完成 CPU 设计之后,将对其进行进一步
的综合( Synthesis ),生成网表( netlist )文件
• 对网表文件进行零延迟仿真和时序反标仿真( back annotation )
• 观察综合及三次仿真(包括行为级仿真)结果,完成实验最终报告





























