Embed Size (px)
Citation preview

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
MLPR: Thinking about DataMachine Learning and Pattern Recognition
Amos Storkey
Amos Storkey — MLPR: Thinking about Data 1/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Outline
1 Thinking about Data
2 Learning and Inference
3 Technical Background
4 Some Distributions
5 Summary
Amos Storkey — MLPR: Thinking about Data 2/45
Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Tutorials
Please check your tutorial allocations.1 tutorial a week. Tutorial rules:Do work before the tutorial. Learn from one another. Email your tutor 1 or 2 days before your tutorial. In this
email, each question should be answered or have a quick summary of the answer, have a description your
best guess as to why you feel you are having difficulty answering it, or a statement that you know all this
already and you consider it a waste of time answering this question (that is fine). You will receive either
verbal or written feedback in the tutorial.
Tutorials start Monday week 3.Also you MUST sign up with the Teaching Officehttp://www.inf.ed.ac.uk/admin/ITO/registration/sem2-registration.html
Amos Storkey — MLPR: Thinking about Data 3/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Data? What You See is What You Get
Data types:Real valued, positive, vector (geometric), bounded,thresholded.Categorical data, hierarchical classes, multiplemembership, etc.Ordinal data, binary data, partially ordered sets.Mixed, scale related, scale unrelated, hierarchicalimportance.Missing, with known error, with error bars (knownmeasurement error).Internal dependencies, conditional categories.Raw, preprocessed, normalised, transformed etc.Biased, corrupted, just plain wrong, in unusable formats.Possessed, promised, planned, non-existent.
Amos Storkey — MLPR: Thinking about Data 5/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Attributes and Values
Simple datasets can be thought of as attribute value pairs.For example “state of weather” is an attribute and “raining”is a value.“Height” is an attribute, and “4ft 6in” is a value.For analysis purposes it is handy to re-represent values asnumerical quantities.
Amos Storkey — MLPR: Thinking about Data 6/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Example Attribute Possibilities
1,2,3,4,5,6,7,8,9,10Red, Blue, Green, Yellow, Pink1.7556, 3.449432, 2.34944, etcStrongly Disagree, Disagree, Neither Disagree or Agree,Agree, Strongly Agree...,-3,-2,-1,0,1,2,3,...
Amos Storkey — MLPR: Thinking about Data 7/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Categorical Data
Each observation belongs to one of a number ofcategories. Orderless. E.g. type of fruit.1-of-M encoding. Represent each category by a particularcomponent of an attribute vector.
0 1 0 01 0 0 01 0 0 00 0 0 10 1 0 00 0 1 0
Only one component can be ‘on’ at any one time.Attributes cannot be independent.
Amos Storkey — MLPR: Thinking about Data 8/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Other Data
Offline: consider the representations you would use forOrdinal data, e.g. university grade: (3,2ii,2i,1).Contingent data (an attribute only occurs when anotherattribute takes a certain value).Numeric real valued dataTwo dimensional vectors of length 1.
Amos Storkey — MLPR: Thinking about Data 9/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Know your data and assumptions
Example1 1 1 1 1 0 0 0 0 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1
Brightness of astronomical objects.Stars and Galaxies quite different.Propose a two source model - different models forbrightness for each source type.
Position of 40 points on a robot arm.Robot arm only has a few degrees of freedom - expect alower dimensional representation.
Loan defaulting.Expect people in similar circumstances to be at similar riskof defaulting.
Smoothness. Relational structure. Linearity. Distribution.Noise levels. Dimensionality (degrees of freedom).Sources.
Amos Storkey — MLPR: Thinking about Data 10/45
Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Learning?
So what is this course about? Analogy with humanlearning.
Learning: obtaining general knowledge about the worldaround us.Inference: Using our knowledge to work out what is goingon in a specific scenario.
(In fact learning is just the same as inference, but aboutmore general information.)Learn models from given data. Use models to infer thingsabout new data.
Amos Storkey — MLPR: Thinking about Data 12/45
Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Dasher
ExampleDasher Demo.
Amos Storkey — MLPR: Thinking about Data 13/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Dasher
Dasher learns a model for the patterns occurring in texts.Can train with your own past writing.Given what you have ‘typed’ (specific instance) need towork out what you are about to ‘type’.Learn models from given data. Use models to infer thingsabout new data.In Dasher the uncertainty regarding the future words arerepresented using probabilities.Did you read up on Cox’s axioms?We need to know and use probability distributions.Give examples of probability models you know of?
Amos Storkey — MLPR: Thinking about Data 14/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Event Space
The set of all possible future states of affairs is called theevent space or sample space and is denoted by Ω.A σ-field F is a collection of subsets of the event spacewhich includes the empty set ∅, and which is closed undercountable unions and set complements.Intuitively... The event space is all the possibilities as towhat could happen (but only one will). σ-fields are all thebunches of possibilities that we might be collectivelyinterested in.σ-fields are what we define probabilities on.A probability measure maps each element of a σ-field to anumber between 0 and 1 (ensuring consistency).
Amos Storkey — MLPR: Thinking about Data 16/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Interpretation
Probability Theory is a mathematical abstraction. To use it(i.e. apply it) you need an interpretation of how “real world”concepts relate to the mathematics.Did you read up on Cox’s axioms?Probability as degree of belief. P = 1 is certainty. P = 0 isimpossibility.
Amos Storkey — MLPR: Thinking about Data 17/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Random Variables
Random variables assign values to events in a way that isconsistent with the underlying σ-field (X ≤ x ∈ F) – thebunch of possibilities we might be interested in.We will almost exclusively work with random variables. Wewill presume that there is a suitable underlying event spaceand σ-field for each variable we use.P(X ≤ x) maps to our degree of belief that randomvariable X takes a value less than or equal to x .Don’t worry. Be happy.
Amos Storkey — MLPR: Thinking about Data 18/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Distribution Functionsof Random Variables
The Cumulative Distribution Function F (x) isF (x) = P(X ≤ x)
The Probability Mass Function for a discrete variable isP(x) = P(X = x)
The Probability Density Function for a continuous variableis the function P(x) such that
P(X ≤ x) =
∫ x
−∞P(u)du
Think in terms of probability mass per unit length.We will use the term Probability Distribution to informallyrefer to either of the last two: it will be obvious which fromthe context.
Amos Storkey — MLPR: Thinking about Data 19/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Distribution Functionsof Random Variables
We write P(X = x) for the probability distribution (densityor mass) that random variable X takes value x .
Sloppier notations for brevity
P(X) Sometimes we conflate the notation for therandom variable and the value it takes.
P(x) Sometimes we implicitly assume the underlyingrandom variable.
P(X = x) If there is any doubt we will specify the full form.
Amos Storkey — MLPR: Thinking about Data 20/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Distributions
Briefly introduce some useful distributions.Note: Probability mass functions or probability densityfunctions.
Amos Storkey — MLPR: Thinking about Data 22/45
Thinking about Data Learning and Inference Technical Background Some Distributions Summary
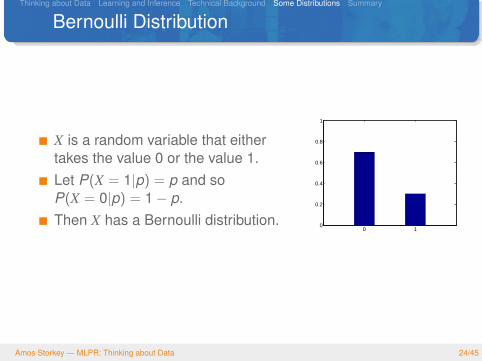
Bernoulli Distribution
X is a random variable that eithertakes the value 0 or the value 1.Let P(X = 1|p) = p and soP(X = 0|p) = 1− p.Then X has a Bernoulli distribution.
0 10
0.2
0.4
0.6
0.8
1
Amos Storkey — MLPR: Thinking about Data 24/45
Thinking about Data Learning and Inference Technical Background Some Distributions Summary
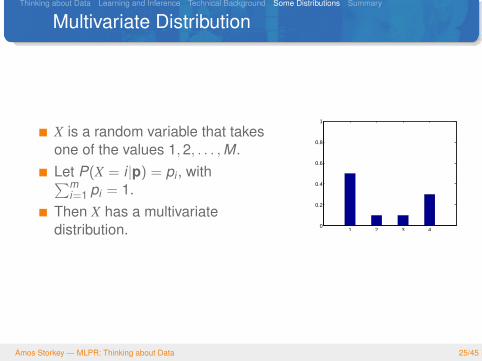
Multivariate Distribution
X is a random variable that takesone of the values 1,2, . . . ,M.Let P(X = i |p) = pi , with∑m
i=1 pi = 1.Then X has a multivariatedistribution. 1 2 3 4
0
0.2
0.4
0.6
0.8
1
Amos Storkey — MLPR: Thinking about Data 25/45
Thinking about Data Learning and Inference Technical Background Some Distributions Summary
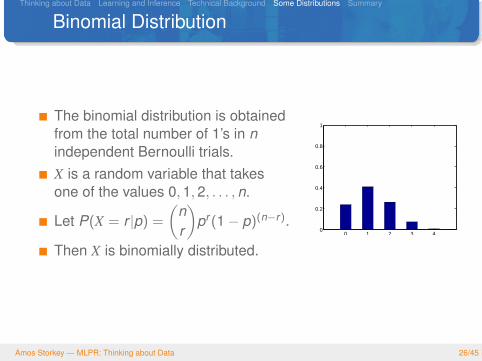
Binomial Distribution
The binomial distribution is obtainedfrom the total number of 1’s in nindependent Bernoulli trials.X is a random variable that takesone of the values 0,1,2, . . . ,n.
Let P(X = r |p) =
(nr
)pr (1− p)(n−r).
Then X is binomially distributed.0 1 2 3 4
0
0.2
0.4
0.6
0.8
1
Amos Storkey — MLPR: Thinking about Data 26/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Multinomial Distribution
The multinomial distribution is obtained from the total countfor each outcome in n independent multivariate trials withm possible outcomes.X is a random vector of length m taking values x withxi ∈ Z+ (non-negative integers) and
∑mi=1 xi = n.
LetP(X = x|p) =
n!
x1! . . . xm!px1
1 . . . pxmm
Then X is multinomially distributed.
Amos Storkey — MLPR: Thinking about Data 27/45
Thinking about Data Learning and Inference Technical Background Some Distributions Summary
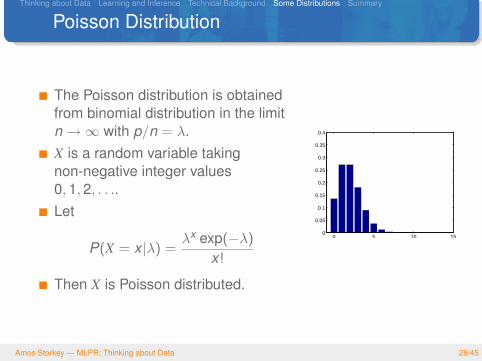
Poisson Distribution
The Poisson distribution is obtainedfrom binomial distribution in the limitn→∞ with p/n = λ.X is a random variable takingnon-negative integer values0,1,2, . . ..Let
P(X = x |λ) =λx exp(−λ)
x!
Then X is Poisson distributed.
0 5 10 150
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
Amos Storkey — MLPR: Thinking about Data 28/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Uniform Distribution
X is a random variable taking valuesx ∈ [a,b].Let P(X = x) = 1/[b − a]
Then X is uniformly distributed.
NoteCannot have a uniform distribution on anunbounded region.
0 2 4 6 8 100
0.2
0.4
0.6
0.8
1
Amos Storkey — MLPR: Thinking about Data 30/45
Thinking about Data Learning and Inference Technical Background Some Distributions Summary
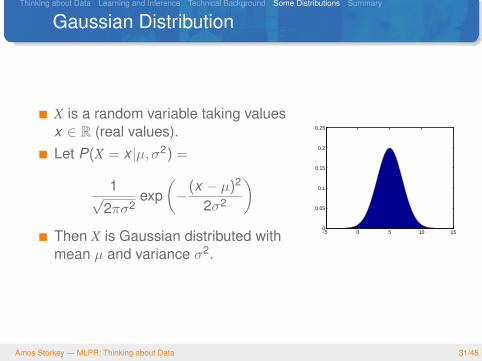
Gaussian Distribution
X is a random variable taking valuesx ∈ R (real values).Let P(X = x |µ, σ2) =
1√2πσ2
exp(−(x − µ)2
2σ2
)Then X is Gaussian distributed withmean µ and variance σ2.
−5 0 5 10 150
0.05
0.1
0.15
0.2
0.25
Amos Storkey — MLPR: Thinking about Data 31/45
Thinking about Data Learning and Inference Technical Background Some Distributions Summary
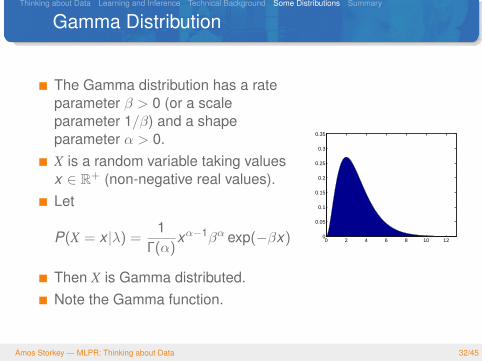
Gamma Distribution
The Gamma distribution has a rateparameter β > 0 (or a scaleparameter 1/β) and a shapeparameter α > 0.X is a random variable taking valuesx ∈ R+ (non-negative real values).Let
P(X = x |λ) =1
Γ(α)xα−1βα exp(−βx)
Then X is Gamma distributed.Note the Gamma function.
0 2 4 6 8 10 120
0.05
0.1
0.15
0.2
0.25
0.3
0.35
Amos Storkey — MLPR: Thinking about Data 32/45
Thinking about Data Learning and Inference Technical Background Some Distributions Summary
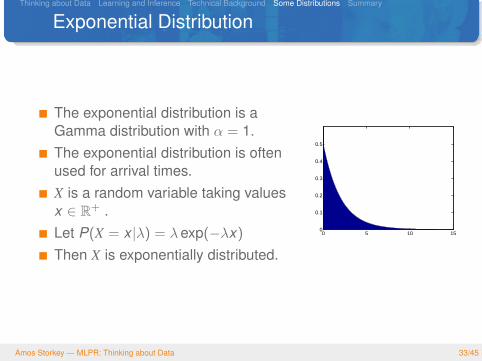
Exponential Distribution
The exponential distribution is aGamma distribution with α = 1.The exponential distribution is oftenused for arrival times.X is a random variable taking valuesx ∈ R+ .Let P(X = x |λ) = λexp(−λx)
Then X is exponentially distributed.
0 5 10 150
0.1
0.2
0.3
0.4
0.5
Amos Storkey — MLPR: Thinking about Data 33/45
Thinking about Data Learning and Inference Technical Background Some Distributions Summary
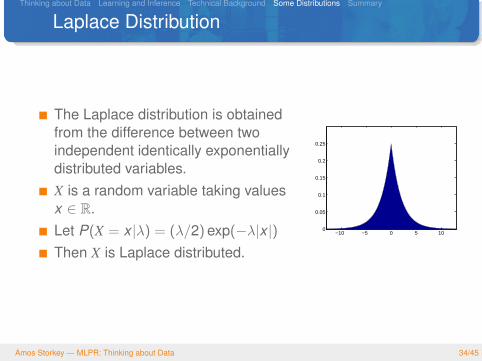
Laplace Distribution
The Laplace distribution is obtainedfrom the difference between twoindependent identically exponentiallydistributed variables.X is a random variable taking valuesx ∈ R.Let P(X = x |λ) = (λ/2) exp(−λ|x |)Then X is Laplace distributed.
−10 −5 0 5 100
0.05
0.1
0.15
0.2
0.25
Amos Storkey — MLPR: Thinking about Data 34/45
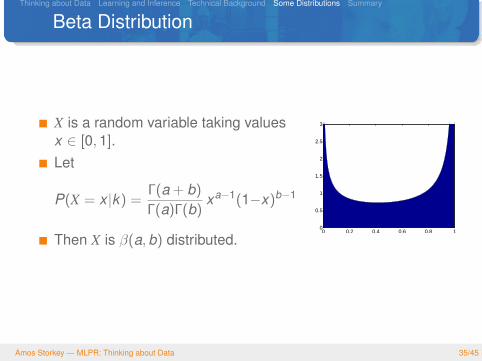
Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Beta Distribution
X is a random variable taking valuesx ∈ [0,1].Let
P(X = x |k) =Γ(a + b)
Γ(a)Γ(b)xa−1(1−x)b−1
Then X is β(a,b) distributed.0 0.2 0.4 0.6 0.8 1
0
0.5
1
1.5
2
2.5
3
Amos Storkey — MLPR: Thinking about Data 35/45
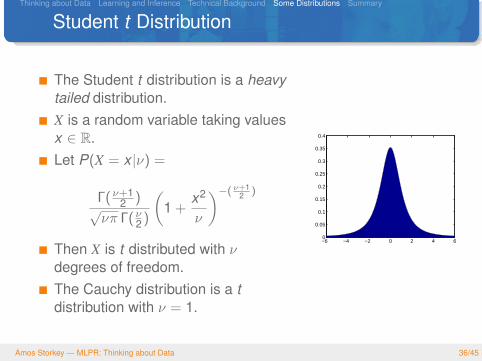
Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Student t Distribution
The Student t distribution is a heavytailed distribution.X is a random variable taking valuesx ∈ R.Let P(X = x |ν) =
Γ(ν+12 )
√νπ Γ(ν
2 )
(1 +
x2
ν
)−( ν+12 )
Then X is t distributed with νdegrees of freedom.The Cauchy distribution is a tdistribution with ν = 1.
−6 −4 −2 0 2 4 60
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
Amos Storkey — MLPR: Thinking about Data 36/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
The Kronecker Delta
Think of a discrete distribution with all its probability masson one value. So P(X = i) = 1 iff (if and only if) i = j .We can write this using the Kronecker Delta:
P(X = i) = δij
δij = 1 iff i = j and is zero otherwise.
Amos Storkey — MLPR: Thinking about Data 38/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
The Dirac Delta
Think of a real valued distribution with all its probabilitydensity on one value.There is an infinite density peak at one point (lets call thispoint a).We can write this using the Dirac delta:
P(X = x) = δ(x − a)
which has the properties δ(x − a) = 0 if x 6= a,δ(x − a) =∞ if x = a,∫ ∞
−∞dx δ(x − a) = 1 and
∫ ∞−∞
dx f (x)δ(x − a) = f (a).
You could think of it as a Gaussian distribution in the limitof zero variance.
Amos Storkey — MLPR: Thinking about Data 39/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Other Distributions
Chi-squared distribution with k degrees of freedom is aGamma distribution with β = 1/2 and k = 2/α.Dirichlet distribution: will be used on this course.Weibull distribution (a generalisation of the exponential)Geometric distributionNegative binomial distribution.Wishart distribution (a distribution over matrices).distributions.Use Wikipedia and Mathworld. Good summaries fordistributions.
Amos Storkey — MLPR: Thinking about Data 41/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Things you must never (ever) forget
Probabilities must be between 0 and 1 (though probabilitydensities can be greater than 1).Distributions must sum (or integrate) to 1.Probabilities must be between 0 and 1 (though probabilitydensities can be greater than 1).Distributions must sum (or integrate) to 1.Probabilities must be between 0 and 1 (though probabilitydensities can be greater than 1).Distributions must sum (or integrate) to 1.
Amos Storkey — MLPR: Thinking about Data 42/45

Thinking about Data Learning and Inference Technical Background Some Distributions Summary
Summary
Data is messy and complicated. Respect.Thinking generatively.Learning and Inference.Swot up on probabilities.
Amos Storkey — MLPR: Thinking about Data 44/45
Thinking about Data Learning and Inference Technical Background Some Distributions Summary
To Do
Examinable ReadingNotes: Mathematics and Data. These slides. Bishop 1.1, 1.2.
Preparatory ReadingBishop 2.
Extra Reading
Cox’s Axioms. Yeah I know you didn’t do it last time.
Amos Storkey — MLPR: Thinking about Data 45/45