Embed Size (px)
Citation preview

Modeling a Corporate Information System to ImproveKnowledge Management
Birgit Zimmermann1, Melanie Gnasa2, and Karin Harbusch1
1 Department of Computer ScienceUniversity of Koblenz, Germany
{birgit, harbusch}@uni-koblenz.de2 Institute of Computer Science III
University of Bonn, [email protected]
Abstract. Knowledge Management Systems (KMSs)are of increasing interest ineconomy to collect, store and re–use company–relevant knowledge as a resourceto gain productivity. In this paper we demonstrate how to leverage structured in-formation for its efficient re–use. We propose the development ofontologiestorepresent the knowledge to be stored.As it is anyhow the case that in a KMS knowl-edge has to be fostered the step towards a systematic structuring is a solution whichsuggests itself. In the paper we outline our experience with the development of anontological model of the KMS of the IT company sd&m (called K–WEB) in viewof a restructuring process of the whole system. On the basis of the implementedontology we illustrate how frequently asked questions in the company which aredifficult to be answered by the currently deployed full–text retrieval–system (forinstance, experienced colleagues in a specific programming language can only befound if the currently considered list of relevant documents can be classified asthe employee’s home page due to the fact that only on this page a pointer intothe skills hierarchy is provided in the K–WEB whereas a full text retrieval systemcan neither regard the document type nor the physical pointer) become simple ina structural representation.
1 Introduction
In a Knowledge Management System (KMS)knowledge is collected, stored and can bere–used. For instance, companies use KMS to foster their own company knowledge1.From deploying this resource companies expect to gain productivity. For instance, gainedexperience in one project should be re–used in current projects — such as best practices.
We propose the development ofontologiesto represent the knowledge to be stored.As it is anyhow the case that in a KMS knowledge has to be fostered the step towards asystematic structuring is not far out of reach.According to [Gruber, 1993], an ontology isa formal, explicit specification of a shared conceptualization, i.e. it can be characterized
1 In this paper we distinguish betweeninformationandknowledgeaccording to a semiotic pointof view (cf. [Peirce, 1931]) where information has a syntactic and semantic dimension (incontrast todatawhich has only a syntactic dimension) whereas knowledge also comprises apragmatic dimension (cf., e.g., [Dretske, 1981]).
A.B. Chaudhri et al. (Eds.): EDBT 2002 Workshops, LNCS 2490, pp. 435–449, 2002.c© Springer-Verlag Berlin Heidelberg 2002

436 B. Zimmermann, M. Gnasa, and K. Harbusch
as an abstract, simplified view of the world that we wish to represent for some purpose.Every knowledge base, knowledge–based system or knowledge–level agent is committedto some conceptualization, explicitly or implicitly.
In the paper we outline our experience with the development of an ontologicalmodel of the KMS of the IT company sd&m — software, design & managementsee www.sdm.com — (called K–WEB) in view of a restructuring process of the en-tire system. We followed the four steps of developing an ontology according to, e.g.,[Bernaras et al., 1996]:
1. the domain of the ontology was specified,2. the information in this domain was collected, a preliminary concept was developed
and stepwise refined in agreement with the company,3. the ontology became realized and evaluated, and finally,4. the system should to be fostered in the future (under the control of sd&m).
With respect to the evaluation of the implemented ontology, we illustrate here thatfrequently asked questions by employees of sd&m which are difficult to be answeredby the currently deployed full–text retrieval–system (for instance, finding experiencedcolleagues in a specific programming language can only be performed by explicitlyselecting any employee’s home page due to the fact that only on this page a pointerinto the skills hierarchy is provided in the K–WEB) become simple in a structuralrepresentation.
The paper is organized as follows. First we give an overview on recently proposedontological models in the field of knowledge management (cf. section 2). In section 3 thecurrent coverage and use of the KMS K–WEB is described. In section 4 ontologies areformally introduced. In the section 5 the steps developing an ontology and the resultingmodel are outlined. Section 6 illustrates the advantages of an ontological representationcompared to a full–text retrieval–system. The paper ends addressing future work andopen problems.
2 Related Work
The systematic process of finding, selecting, organizing, distilling and presenting infor-mation in a way that improves an employee’s comprehension in a specific area of interestis covered by the termknowledge management. It essentially helps an organization togain insight and understanding from its own experience and helps to protect intellectualassets from decay.Apparently, many facets of research are covered under this term — forinstance, “data–mining”. For reasons of space, let us here only refer to some portal sitesthat represent the broad coverage of the term (see, e.g., [Dieng et al., 1999a] for corporateknowledge management; [Jurisica et al., 1999] for an information–system perspective;[Staab et al., 2001] for knowledge processes and ontologies; [Staab and Maedche, 2001]for ontologies at work) as a starting point for search and give some hints to recent pub-lications. Subsequently, we focus on ontologies in KMS.
With respect to knowledge management systems (also calledcorporate memories;cf. [Steels, 1993], [K¨uhn and Abecker, 1997] and [Gandon, 2001]) [Dieng et al., 1999b]give a good overview to methods and tools for such systems. Focusing on anontology–based KMS our approach is influenced by conceptualisations outlined in

Modeling a Corporate Information System to Improve Knowledge Management 437
[Uschold and King, 1995], [Bernaras et al., 1996], [Gomez-Perez, 1996], [Sure, 2002]and [Gandon, 2001]. In [Uschold and King, 1995] experiences with theskeletal method-ologybuilding enterprise ontologies is described. In [Bernaras et al., 1996] basic steps tobe performed in the development of an ontology are provided (specification of the appli-cation, preliminary design, ontology refinement and structuring). In our framework thesesteps are also performed (cf. the more fine–grained specification in [Gomez-Perez, 1996]or [Sure, 2002]). [Gandon, 2001] accomplishes a fine–grained model (providing differ-ent interrelated levels: terminological, intensional and extensional). In contrast to that,we explicitly decided to remain much simpler for reasons of easier fostering (see stepfour of the development of a KMS which is in our case performed by the companysd&m) of the whole system. Basically, all projects provide convincing results that ledto the endeavor we outline in this paper.
Let us finally mention a system where knowledge is retrieved on the basis of on-tologies although this system does not directly belong to the class of KMS. GETESS[Dusterhoft et al., 2000] is a search engine that applies semantic information and naturallanguage capabilities in order to gather tourist information. In particular is specifies anontology assemantic reference modelthat leverages, on the one hand, inferencing capa-bility of the overall system and, on the other hand, mediation between different modulesof the system. For instance, the system can decomposed terms like the compound noun“Usedom music festival” into its ontological representation, i.e. the concept “Usedom”has the relation “hostsEvent” towards “MusicFestival”. Same as for our application theontology underpins the retrieval system and gives easier access to implicit information.
Another favorably comparing general approach is proposed by [Hahn et al., 1999]who have explored ontologies as an intermediate level between text representation andexternal data bases. This point of view has influenced our considerations here as wedeploy an ontology as an access layer to text documents.
In the next section the currently used knowledge management system by sd&m isoutlined as the collected text documents become underpinned by an ontology in section 4.
3 The Current KMS K–WEB of sd&m
The so–calledK–WEB (knowledge web)servers as internal knowledge managementsystem of sd&m. With this intranet, corporation–wide access to different kinds of doc-uments and databases is provided (e.g., current projects or customers and employee’sskills). It consists of the following six disjunctive collections to a subset of which thesearch can be restricted if desired:
1. company (33,427 documents),2. employees (6,777 documents),3. service (71,901 documents),4. themes (2,633 documents),5. projects (13,390 documents) and6. extern (102,995 documents).
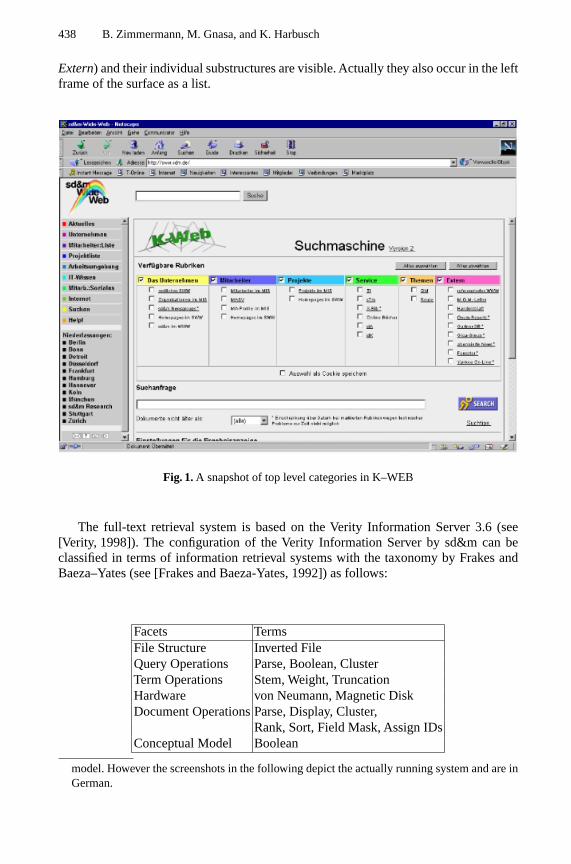
In Fig. 1 the surface of the currently deployed K–WEB2 is outlined. In the middle ofthe figure the six collections (Das Unternehmen, Mitarbeiter, Projekte, Service, Themen,
2 As sd&m is a German company the whole system is in German. Actually the implemented on-tology is specified in German. In this paper we have translated essential parts of the ontological
438 B. Zimmermann, M. Gnasa, and K. Harbusch
Extern) and their individual substructures are visible. Actually they also occur in the leftframe of the surface as a list.
Fig. 1. A snapshot of top level categories in K–WEB
The full-text retrieval system is based on the Verity Information Server 3.6 (see[Verity, 1998]). The configuration of the Verity Information Server by sd&m can beclassified in terms of information retrieval systems with the taxonomy by Frakes andBaeza–Yates (see [Frakes and Baeza-Yates, 1992]) as follows:
Facets TermsFile Structure Inverted FileQuery Operations Parse, Boolean, ClusterTerm Operations Stem, Weight, TruncationHardware von Neumann, Magnetic DiskDocument OperationsParse, Display, Cluster,
Rank, Sort, Field Mask, Assign IDsConceptual Model Boolean
model. However the screenshots in the following depict the actually running system and are inGerman.

Modeling a Corporate Information System to Improve Knowledge Management 439
Here we need not go into these techniques as we only compare — so to speak,as a black–box — the behavior of such a full-text retrieval–system to our ontologicalapproach.
As we shall only describe the ontological modeling within the areas of projects andemployees in more detail in this paper we elaborate these two knowledge sources here.In the area “employees”, the employee’s skills management system (called MASV forMitarbeiterskillv erwaltung) and the personal home pages are yielded. The MASV is astructured knowledge source where the employees can perform the following tasks:
– administer personal gradings according to a predefined lattice of skills and– search for colleagues with special skills.
Fig. 2 depicts the surface of the provided search facilities in MASV. The meta tagsrefer to:
1. On top of the page the navigation list of the MASV is provided.2. In this window in the left half of the screenshot the skill lattice is outlined. Here also
the results are provided (e.g., as a leaf representing an individual employee with therespective profile) of the tree.
3. In this field the search query is written.4. This button starts the respective search.5. This button allows the (un–)suppression of leaves of the skill lattice, i.e. the em-
ployees are listed or not.6. This is the help button.7. By these lists the search can be restricted to sites and (sub–)areas.8. This check box (de–)activates the facility to display the date when the skill was
added by the employee.9. These lists allow the specification of restrictions with respect to how far the skill
lattice actually becomes expanded.10. Human assistance is provided by an email hot line.
All in all an extensive search is provided to the employees. However it is restricted tothe skill lattice.
On their personal home pages employees can specify any skill in a self–definedmanner. Hence, this is the place where preferably experiences gained in projects can befound. However the terminology varies as it is not determined in any respect as for theskills in the MASV. So it cannot be taken for granted that an experienced colleague isactually found on the basis of these two knowledge sources.
The second area we shall go into are “projects”. This branch yields information onapplied techniques (calledTechInfo3). This is again a fine–grained structured knowledgesource containing the following items with respect to any project:
– Author of the report; date; updates.– Name of the project, number of members, head of the project.– Delivery and development platform with respect to hardware, operating system,
programming languages, ...3 Notice that due to the fact that these documents are all provided in German we have omitted a
screenshot of a project here.

440 B. Zimmermann, M. Gnasa, and K. Harbusch
Fig. 2. A screenshot of the employee’s skill management system (MASV)
– Project specification in terms of phases and steps.– Surface specification, portability.– Prototype.– Data base systems.– Internet technology.– Middleware.– Configuration management (tools, sources, contact person).– Re–use.– Test methods.– Re–engineering.– Project–management tools.– Software tools.– Tools.
Even without elaborating the individual items, the list seems not free of redundancy dueto the differing depth of specification granularity. This leads basically to the difficultythat the knowledge is subtle to be fostered. Furthermore, it seems to be hard to findrelated projects under a currently taken perspective. We discuss the difficult and oftenunsuccessful access to these knowledge sources in section 5 when we illustrate frequentlyasked questions by the employees. It becomes obvious there that the answers to thequestions has to be based on a more general structuring of the information to become aknowledge source.
As we propose ontologies for the structuring, we define ontologies in the next section.

Modeling a Corporate Information System to Improve Knowledge Management 441
4 Ontologies
Each discipline defines different requirements for ontologies, resulting in different def-initions, but the usage of ontologies as images of the world or of a relevant domain,respectively, is common to all of them.
According to [Gruber, 1993], an ontology is a formal, explicit specification of ashared conceptualization, i.e. it can be characterized as an abstract, simplified view ofthe world that we wish to represent for some purpose. Every knowledge base, knowledge–based system or knowledge–level agent is committed to some conceptualization, explic-itly or implicitly.
The entire problem with this definition is that the view to the world is always aninterpretation process of the respective human who identifies the relevant concepts ofa phenomenon. The semiotic triangle (cf. [Ogden and Richards, 1923]) based on thetradition from Peirce, Saussure and Frege (see Fig. 3) describes the interaction betweenwords (in general: symbols), concepts (semantic objects) and real things of the world.Words which are used for the transfer of information could not cover the concepts orthe real things of the world completely. Nevertheless, a correspondence between words,concepts and things exists and is approximated by an ontology in the following manner.An ontology is described by a logical theory built of a vocabulary and a set of logicalstatements for the example domain. The logical theory specifies relations between wordsand then restricts the set of possible interpretations of words and their relations to eachother. Hence, an ontology reduces the number of possible correspondences betweenwords and things as the members of the group have arranged with each other aboutthe domain. Hence, ontologies describe the semantic vocabulary, which represents thecontent of a specific domain (here, knowledge within the IT company sd&m).
concept
symbol thing
apply toawakes
represent
Fig. 3. Semantic Triangle
Now, we formally define ontologies according to [Studer et al., 2001]:An ontology Ois a 7–tupleO := {L, C, R, F, G, H, A} where:
1. L = Lc ∪ Lt is thelexiconwhich consists ofLc, a finite set of signs for concepts(lexical entries) andLt a finite set of signs for relations.
2. C is the finite set ofconcepts.3. R is the finite set ofbinary relationsconnecting concepts (i.e.,(Dc, Rc) ∈ R, where
Dc, Rc ∈ C). Dc is thedomain (d)and denotes the concept to which the relationbelongs. Often the relation is calledattribute of the concept Dc. Rc is calledrange

442 B. Zimmermann, M. Gnasa, and K. Harbusch
(r) and denotes the concept the relation targets at. The functionsd andr appliedto the binary relationR are equal to the conceptsDc and Rc, respectively, i.e.d(Dc, Rc) = Dc andr(Dc, Rc) = Dc. At both concepts involved in the relation,restrictionswith respect to the cardinality of can be specified (in terms of the explicitcardinality or intervals such as 0..*).
4. The functionsF : Lc −→ C andG : Lt −→ R relate the lexicon with conceptsand relations, respectively. In general a lexical entry can refer to several concepts orrelations in parallel and vice versa.
5. In ataxonomyH ⊂ C×C concepts are related by a irreflexive, acyclic and transitiverelation.H(Ci, Cj) means thatCi is asub–conceptof Cj .
6. A is the finite set ofaxioms.
In the following example (Fig. 4) the definition of an ontology is exemplified bysome concepts of our example domain (employee, project, employee knowledge, projectknowledgeandknowledge).
Books andBonks Inc.
employee
knowledge
project
employeeknowledge
has has
0..*
1
0..*
1
is_a is_a
is_a
...
JAVA
C++
Jonathan
Using Beans in a B2B scenario
projectknowledge
is_a
...
Fig. 4. Section of the example domain
The illustration contains three relations: (1) the relationhasfrom employeeto em-ployee knowledge, (2) another relationhasfrom project to project knowledge, and (3)the relationis a from knowledgeto employee knowledgeandproject knowledge. In thefigure the relationhasis restricted with respect to the cardinality in that way that an em-ployee or a project, respectively, can have arbitrarily much employee/project knowledge(0..*).
The distinction between concepts and instances is essential. Concepts are designedat the model layer. Their definition is abstract and include all necessary properties of aset of objects. In contrast, aninstancerefers to an actually existing object (e.g., employeeJonathanand projectBooks and Bonks Inc.).
In the next section in line with this definition the ontological model for an essentialsubpart of the K–WEB is modeled.

Modeling a Corporate Information System to Improve Knowledge Management 443
5 The Ontological Model for the K–WEB
Here, we outline our experience with the development of an ontological model of theKMS K–WEB of the IT company sd&m in view of a restructuring process of the entiresystem.
For this endeavor, we accomplished the following four steps of developing an ontol-ogy:
1. the domain of the ontology was specified,2. the information in this domain was collected, a preliminary concept was developed
and stepwise refined in agreement with the company,3. the ontology became realized and evaluated, and finally,4. the system should to be fostered in the future (under the control of sd&m).
The first step was guided by the goal to identify a small, manageable subpart of thewhole K–WEB on the one hand but on the other hand an expressive part to demonstratethe advantages of an ontology later on as the whole K–WEB is too big to be modeled inon step. So we decided to model the K–WEB on its top level and only some subparts indepth. Here we describe a clipping of the overall system.
To find such an essential subpart to be modeled in depth, we basically collectedfrequently asked questions that are difficult to answer by the current search engine. Aninteresting subclass of such typical queries posed to a human colleague (the so called‘information broker’for some restricted domain) basically address the areas of projectsand employee’s skills. They can be grouped as follows:
– Queries about projects, which gain experience with a special problem or solution orused a special product, e.g.:
• Do you know a project, which has successfully automatically tested?• Do you know a project, which has used black box tests?• In which project content management systems are used?
– Queries about employee and their skills, e.g.:• Who knows all about XML?• Who can me help with COBOL?• I am searching for an expert of data warehouses by sd&m, who worked at least
in one project for data warehouses.
If we particularly look at the last question we can see that both areas (projects andemployee’s skills) become intertwined in the question. This question cannot simply beanswered by the search engine. According to these questions the areas of projects andemployees were selected to be describe here to illustrate the advantages of ontologicalmodeling. In the following we only concentrate on these two branches of the K–WEB.
In the second step the current situation in these two areas was investigated. We foundout that the information is spread over various systems with differing, individual accesssystems. As stated in section 3 the areas ‘employees’ and ‘projects’ provide some sortof structuring but it does not suffice to answer the questions listed above substantiallyand convincingly. The questions concerning test methods use search terms that do notnecessarily occur in the project specification. However, the contact person’s home pagecould eventually specify this skill. The last question with respect to projects can end up

444 B. Zimmermann, M. Gnasa, and K. Harbusch
with zero hits due to the fact that this particular technical term is not specified althoughmatching projects exist.
In the area “employees”, the first two questions produce a probably overwhelmingamount of hits according to the skill lattice and the personal home pages but no rankingis provided — for instance according to the fact how long the actual experience laysin the past. As mentioned before the very last question requires further structuring andbasically an interrelation between the two knowledge sources.
From this starting point the ontological concepts and the interrelations where col-lected, revised, extended in agreement with contact persons of sd&m who are responsiblefor fostering the K–WEB and who were familiar with the company’s entire structure.The final result of this process which lasted in fact two to three month is depicted inFig. 5. Let us refer to this model and its implementation asK–ONTO–WEB.
Employee ProjectEmployee
Project
Knowledge
ProjectKnowledge
EmployeeKnowledge
KnowledgeContent
TheoryProgrammingLanguage
Product
ProgrammingTheory
InformationTheory
SoftwareProduct
HardwareProduct
1
1 1..* 1..* 1
1..*
0..*
0..*
1
1
1..*
1..* 1..*
0..*
0..*
0..*
0..*
1..*
works_as has
hashas
has_counterpart
has has
used_by
belongs_to
Fig. 5. Subpart of K–ONTO–WEB: The ontological model for the areas “projects” and “employ-ees”
In the upper left corner the concept “employee” is depicted and in the right uppercorner the concept “project”. Both concepts deploy “has” relations towards specificknowledge which is a sub–concept of “knowledge”. The concept “knowledge” is furtherstructured as outlined in the lower panel of the figure. Within other categories, theoreticaland practical knowledge is separated which helps to specify employee’s skills in a morefine–grained manner as we outline later on.
Modeling a Corporate Information System to Improve Knowledge Management 445
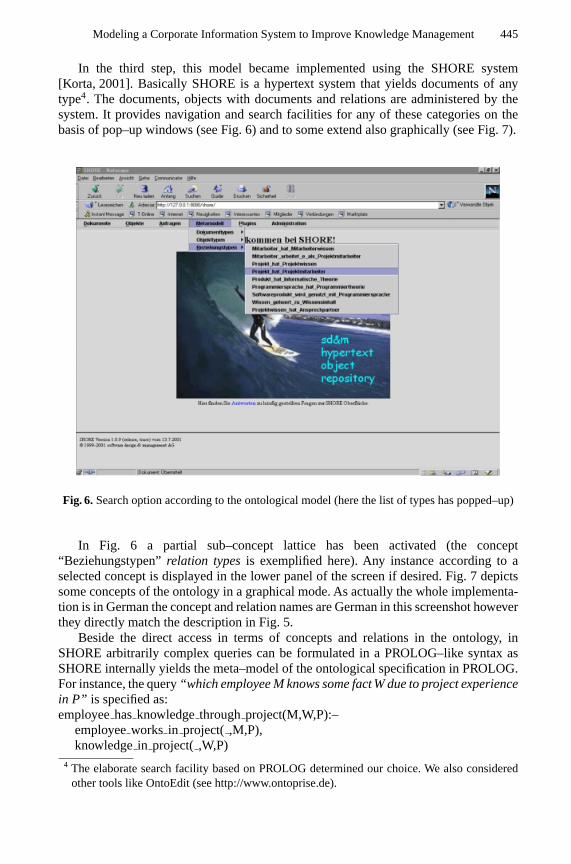
In the third step, this model became implemented using the SHORE system[Korta, 2001]. Basically SHORE is a hypertext system that yields documents of anytype4. The documents, objects with documents and relations are administered by thesystem. It provides navigation and search facilities for any of these categories on thebasis of pop–up windows (see Fig. 6) and to some extend also graphically (see Fig. 7).
Fig. 6. Search option according to the ontological model (here the list of types has popped–up)
In Fig. 6 a partial sub–concept lattice has been activated (the concept“Beziehungstypen”relation typesis exemplified here). Any instance according to aselected concept is displayed in the lower panel of the screen if desired. Fig. 7 depictssome concepts of the ontology in a graphical mode. As actually the whole implementa-tion is in German the concept and relation names are German in this screenshot howeverthey directly match the description in Fig. 5.
Beside the direct access in terms of concepts and relations in the ontology, inSHORE arbitrarily complex queries can be formulated in a PROLOG–like syntax asSHORE internally yields the meta–model of the ontological specification in PROLOG.For instance, the query“which employee M knows some fact W due to project experiencein P” is specified as:employeehasknowledgethroughproject(M,W,P):–
employeeworks in project( ,M,P),knowledgein project( ,W,P)
4 The elaborate search facility based on PROLOG determined our choice. We also consideredother tools like OntoEdit (see http://www.ontoprise.de).

446 B. Zimmermann, M. Gnasa, and K. Harbusch
Fig. 7. Graphical navigation through the ontological model
It is obvious that only users with programming experience in PROLOG can useour system with respect to this search facility but in the future an easier user–interfacefor this search can be developed and would serve as an extensive search engine in theK–ONTO–WEB.
As our system only represents a prototype for the restructuring of the K–WEB wecan skip the last step here. In the next section we illustrate the search behaviour inK–ONTO–WEB in more detail.
6 Evaluation of the New System
The main objective of our work was the improvement of knowledge management forsd&m. The subpart of K–ONTO–WEB we have presented here combines the knowledgeabout projects and employees within one tool and provides a common interface to bothknowledge types. Let us illustrate the leverage of ontologies by investigating how easilythe questions mentioned in the previous section can be answered now.
Let us first discuss questions concerning project which are of the sort:
– Do you know a project, which has successfully automatically tested?– Do you know a project, which has used black box tests?– In which project content management systems are used?
They are translated into search terms of the form “project & application &” combinedwith “automatic test”, “black box test” or “content management system”, respectively.The search results in averagely 50 documents where for any of these it has to be checkedwhether the intended relation actually holds.

Modeling a Corporate Information System to Improve Knowledge Management 447
In terms of the K–ONTO–WEB simply instances of the concept “project–knowledge” targeted by the relation “hasknowledge” which starts at the concepts“project” are searched for. The correctness of the retrieved documents can be takenfor granted without any further check of the individual documents.
The questions aiming at employee’s skills such as:
– Who knows all about XML?– Who can me help with COBOL?
can be directly retrieved from the employee’s skills management system. However, thelist of results is overwhelmingly long as it is not ranked according to factors such asfine grained experience measures (for instance theoretically experienced or experiencein applying the method within a project) or whether the time the knowledge was gainedis recent or not. With K–ONTO–WEB recency and types of accomplishment can bespecified to get a more suitable list. However, it can be the case the PROLOG–basedsearch queries have to be posed to the system.
The questionI am searching for an expert of data warehouses by sd&m, who workedat least in one project for data warehouses.cannot directly be retrieved in the K–WEBbut can simple be stated in K–ONTO–WEB as the concept “project knowledge” is relatedto both, “employee” and “project”.
Let us end addressing future work and open problems.
7 Conclusions
In order to sum up, we have proposed an ontological structure to underpin a knowledgemanagement system in order to get more suitable retrieval results. We have evaluatedour claim by a list of frequently asked questions by the employees which currently canonly be answered by human information broker or by long winded navigation throughdocument lists. The results are promising.
Let us now address open problems and future work.As directly obvious the ontologymight constitute an engineering bottleneck, i.e. the question arises how time and moneyconsuming it is to develop such an ontology. Our modeling has taken two to three person’smonth. Our estimation is that particularly for KMS such as the intranet K–WEB thedevelopment is worthwhile. The re–use factor of knowledge within the company andinteraction between colleagues increases.
To illustrate the tiny little difficulties in developing an ontology, let us briefly men-tion a not yet finally determined concept in our ontology. A problem emerged when weinspected the list of frequently asked questions. Employees often ask for“best prac-tices”. During the development we discussed an explicit modeling of such a concept inmore depth. As a first realization we finally decided to impose it on the ontology onlyas an attribute called “quality”. To become retrievable as a “best practice” instances itshould be checked by some responsible information broker. Whether this is a suitablerealization has to be investigated in the future.
References
[Bernaras et al., 1996] Bernaras, A., Laresgoiti, I., and Corera, J. (1996). Building and reusingontologies for electrical network applications. InProcs. of European Conference on AI.

448 B. Zimmermann, M. Gnasa, and K. Harbusch
[Dieng et al., 1999a] Dieng, R., Corby, O., Giboin, A., and Ribiere, M. (1999a). Methods andtools for corporate knowledge management.Journal of Human-Computer Studies, 51(3):567–598.
[Dieng et al., 1999b] Dieng, R., Corby, O., Giboin, A., and Ribiere, M. (1999b). Methods andtools for corporate knowledge management.International Journal on Human–Computer Stud-ies, 51(3):567–598.
[Dretske, 1981] Dretske, F. (1981).Knowledge and the Flow of Information. MIT Press, Cam-bridge, MA, USA.
[Dusterhoft et al., 2000] D¨usterhoft, A., Neumann, G., Becker, M., Bedersdorfer, J., and Bruder,I. (2000). Getessconstructing a linguistic search index for an internet search engine. InProcs.of 5th International Conference on Applications of Natural Language to Information Systems,Versailles, France.
[Frakes and Baeza-Yates, 1992] Frakes,W. B. and Baeza-Yates, R. (1992).Information Retrieval,Data Structures & Algorithms. Prentice Hall, Hemel Hempstead.
[Gandon, 2001] Gandon, F. (2001). Engineering an ontology for a multi–agents corporate mem-ory system. InProcs. of the 9th International Symposium on the Management of Industrialand Corporate Knowledge, Compienge, France.
[Gomez-Perez, 1996] Gomez-Perez, A. (1996). A framework to verify knowledge sharing tech-nology. Expert Systems with Applications, 11(4):519–529.
[Gruber, 1993] Gruber, T. R. (1993). Towards principles for the design of ontologies used forknowledge sharing. In Guarino, N. and Poli, R., editors,Formal Ontology in ConceptualAnalysis and Knowledge Representation, Dordrecht, Norwell. Kluwer Academic Publishers.
[Hahn et al., 1999] Hahn, U., Romacker, M., and Schulz, S. (1999). How knowledge drivesunderstanding: Matching medical ontologies with the needs of medical language processing.AI in Medicine, 15(1):25–51.
[Jurisica et al., 1999] Jurisica, I., Mylopoulos, J., andYu, E. (1999). Using ontologies for knowl-edge management: An information systems perspective. InProceedings of the 62nd AnnualMeeting of the American Society for Information Science (ASIS’99), Oct. 31 - Nov. 4, 1999,Washington, D.C., pages 482–496.
[Korta, 2001] Korta (2001). Shore — 1.0.8, administration handbook. sd&m, Munich, Germany.[Kuhn and Abecker, 1997] K¨uhn, O. andAbecker,A. (1997). Corporate memories for knowledge
management in industrial practice: Prospects and challenge.Journal of Universal ComputerScience, 3(8):929–954.
[Ogden and Richards, 1923] Ogden, C. K. and Richards, I. A. (1923).The Meaning of Meaning:A Study of the Influence of Language upon Thought and the Science of Symbolism.Routledge& Kegan Paul Ltd., London.
[Peirce, 1931] Peirce, C. (1931).Collected Papers of Charles Sanders Peirce. Harvard UniversityPress, Cambridge, Massachusetts.
[Staab and Maedche, 2001] Staab, S. and Maedche, A. (2001). Knowledge portals — ontologiesat work.
[Staab et al., 2001] Staab, S., Schnurr, H., Studer, R., and Sure, Y. (2001). Knowledge processesand ontologies.IEEE Intelligent Systems, 16(1):26–34.
[Steels, 1993] Steels, L. (1993). Corporate knowledge management. InProcs. of the 2nd Inter-national Symposium on the Management of Industrial and Corporate Knowledge, pages 9–30,Compienge, France.
[Studer et al., 2001] Studer, R., Erdmann, M., M¨adche,A., Oppermann, H., Schnurr, H.-P., Staab,S., Sure, Y., and Tempich, C. (2001). Arbeitsgerechte bereitstellung von wissen – ontologienfur das wissensmanagement.http://www.aifb.uni-karlsruhe.de/WBS/ama/publications/paperheilmann.pdf.

Modeling a Corporate Information System to Improve Knowledge Management 449
[Sure, 2002] Sure, Y. (2002). A tool–supported methodology for ontology–based knowledgemanagement. InSubmitted to 8th International Symposium on Methodologies for IntelligentSystems, Lyon, France.
[Uschold and King, 1995] Uschold, M. and King, M. (1995). Towards a methodology for buildingontologies. InProcs. of Workshop on Basic Ontological Issues in Knowledge Sharing, held inconjunction with IJCAI–95, Montreal, CA.
[Verity, 1998] Verity (1998). Search’97 information server user’s guide v3.6. Verity, Sunnyvale.





























