Embed Size (px)
Citation preview
Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 1/20
Neural networks
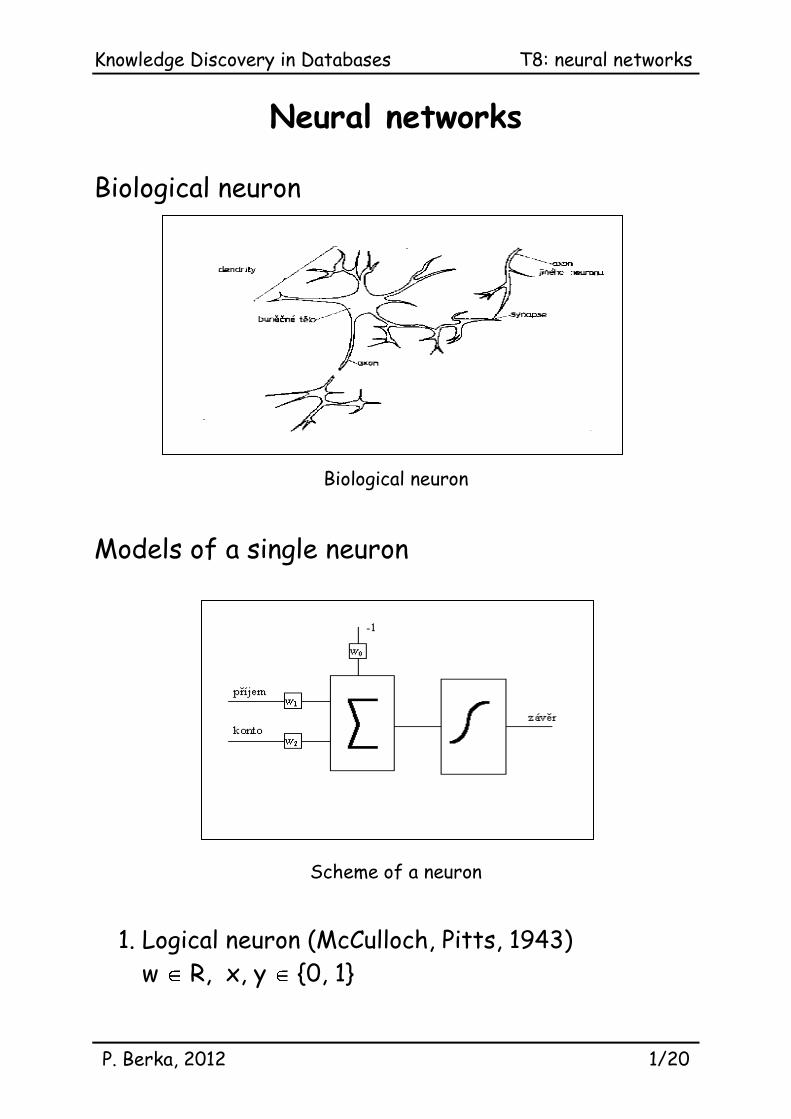
Biological neuron
Biological neuron
Models of a single neuron
Scheme of a neuron
1. Logical neuron (McCulloch, Pitts, 1943)
w R, x, y {0, 1}
Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 2/20
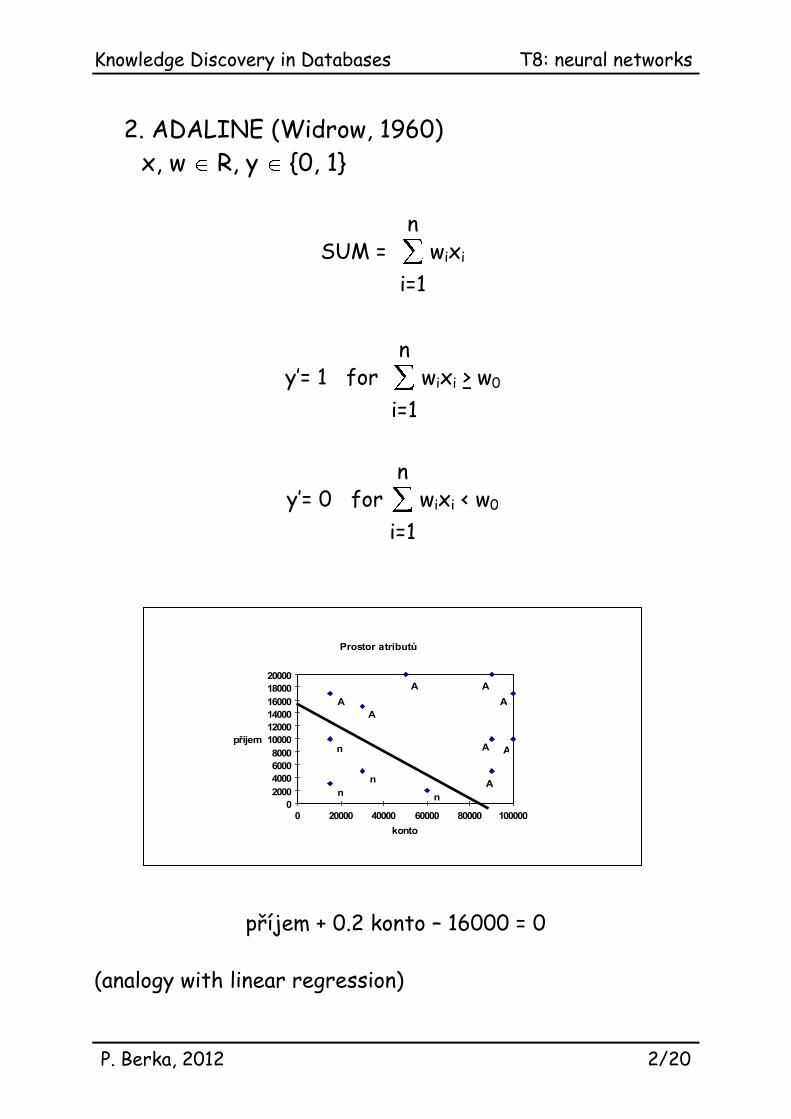
2. ADALINE (Widrow, 1960)
x, w R, y {0, 1}
SUM =
i=1
n wixi
y’= 1 for
i=1
n wixi > w0
y’= 0 for
i=1
n wixi < w0
Prostor atributů
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 20000 40000 60000 80000 100000
konto
příjem
A
A
A A
A
A A
A
n
n
n
n
příjem + 0.2 konto – 16000 = 0
(analogy with linear regression)
Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 3/20
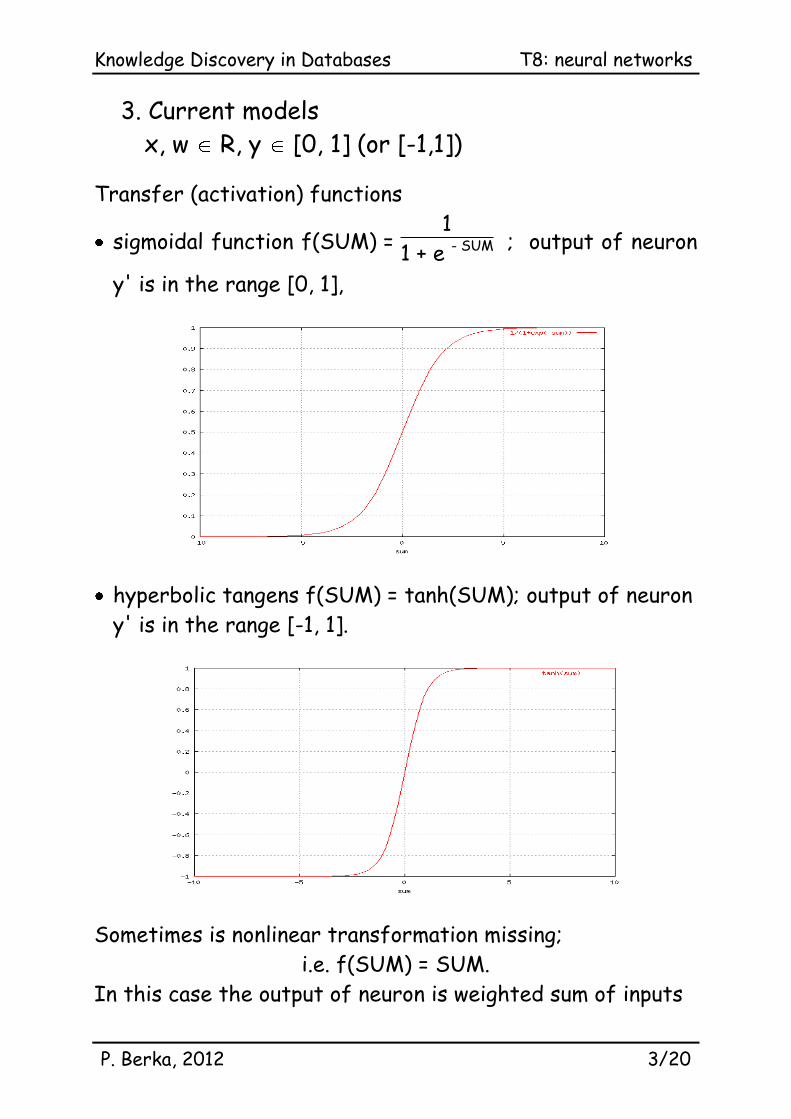
3. Current models
x, w R, y [0, 1] (or [-1,1])
Transfer (activation) functions
sigmoidal function f(SUM) = 1
1 + e - SUM ; output of neuron
y' is in the range [0, 1],
hyperbolic tangens f(SUM) = tanh(SUM); output of neuron
y' is in the range [-1, 1].
Sometimes is nonlinear transformation missing;
i.e. f(SUM) = SUM.
In this case the output of neuron is weighted sum of inputs

Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 4/20
Learning ability
Modification of weights w using training data [xk, yk]
Learning as approximation – looking for parameters
of given function f(x)
Hebb’s law
wk+1 = wk + yk xk
gradient method
Err(w) = 1
2
k=1
N (yk - f(xk))
2
d
dq
k=1
N (yk - f(xk))
2 = 0
wk+1 = wk - Err(w)
w
for y’k = f(xk) = wk xk = i wik xik
wk+1 = wk + (yk - y’k ) xk
F
wi =
1
2
k=1
n
wi(yk -y’k)
2 = 1
2
k=1
n
2(yk -y’k) wi(yk - y’k) =
k=1
n
(yk - y’k) wi(yk - wkxk) =
i=1
n
(yk - y’k)(-xik)
Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 5/20
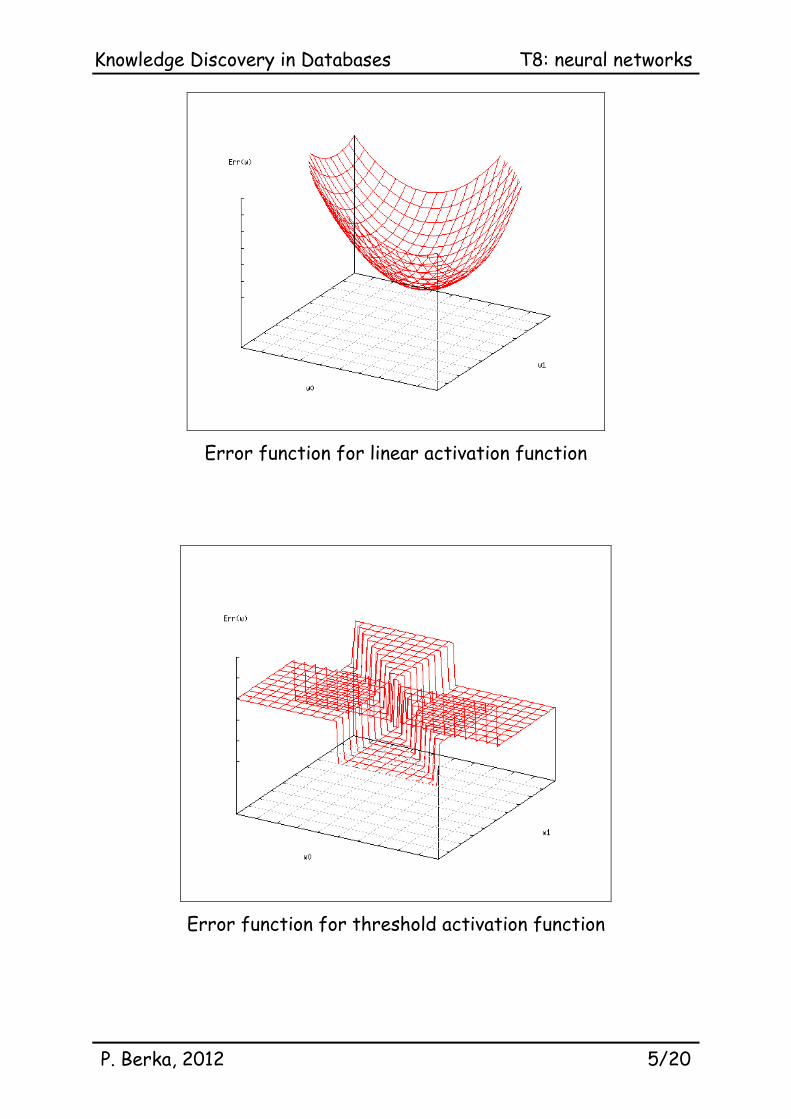
Error function for linear activation function
Error function for threshold activation function
Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 6/20
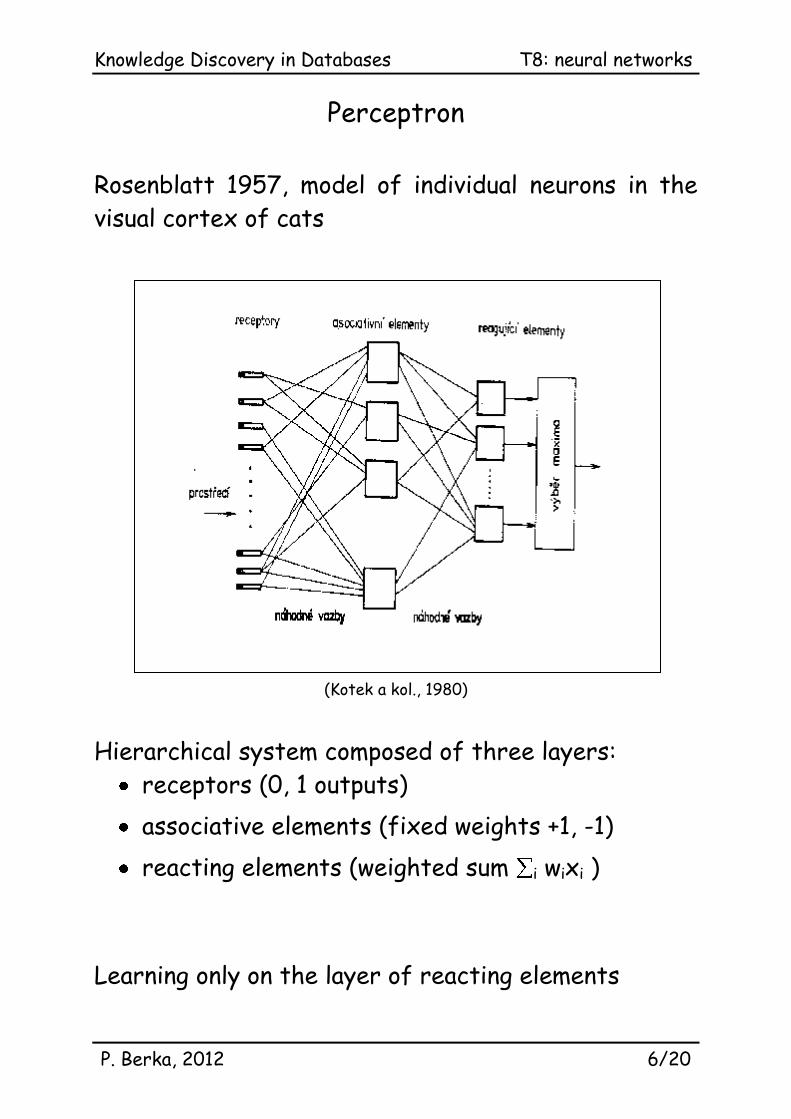
Perceptron
Rosenblatt 1957, model of individual neurons in the
visual cortex of cats
(Kotek a kol., 1980)
Hierarchical system composed of three layers:
receptors (0, 1 outputs)
associative elements (fixed weights +1, -1)
reacting elements (weighted sum i wixi )
Learning only on the layer of reacting elements

Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 7/20
The non-equivalence problem: A B
more general, the problem with tasks that are not
linearly separable
Minsky M., Pappert S.: Perceptrons, an introduction
to computational geometry, MIT Press 1969 –
criticism of neural networks
„Silent years“
A
B
0 1
1 F
F T
T

Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 8/20
Rebirth of neural networks, 1980th
More structured networks - Hopfield, Hecht-Nielsen,
Rumelhart a Kohonen
1. the ability to approximate an arbitrary continuous
function
an arbitrary logical function (in DNF form) can be expressed
using three-layer network consisting of neurons for
conjunction, disjunction and negation
conjunction
disjunction
negation
E.g. nonequivalence A B (A B) ( A B)
2. new learning algorithms
0
-1
2
1 1
1
1 1
Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 9/20
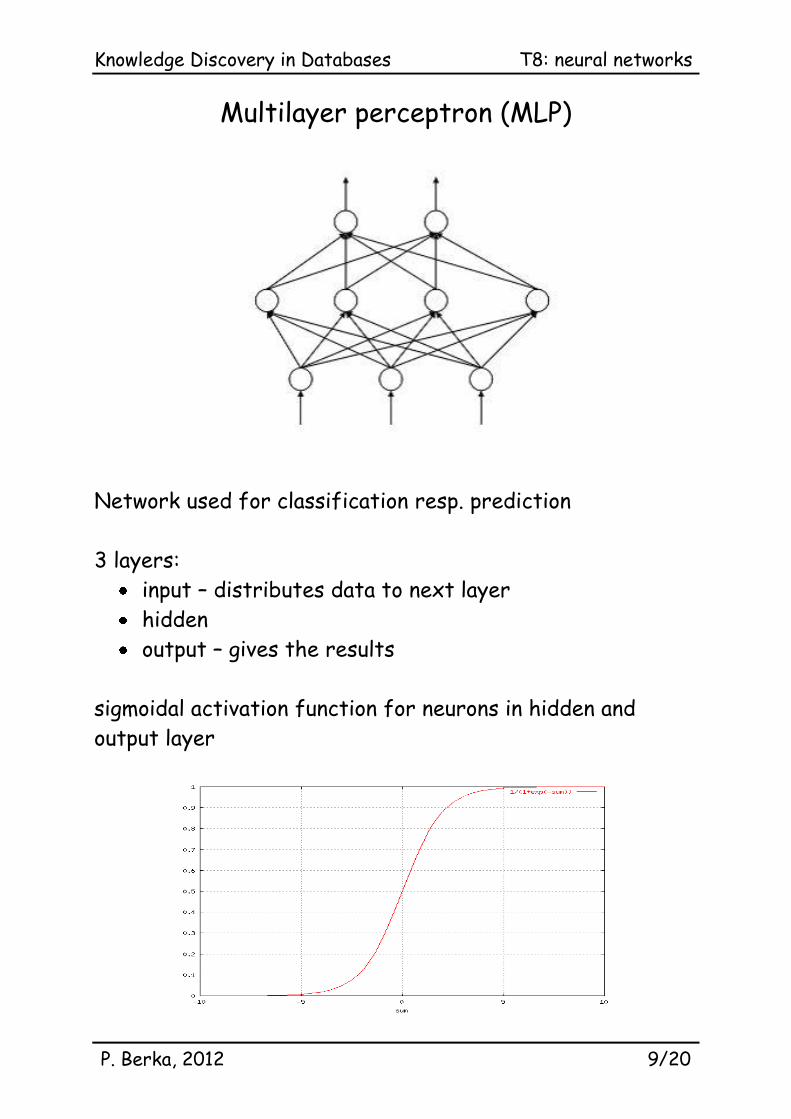
Multilayer perceptron (MLP)
Network used for classification resp. prediction
3 layers:
input – distributes data to next layer
hidden
output – gives the results
sigmoidal activation function for neurons in hidden and
output layer
Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 10/20
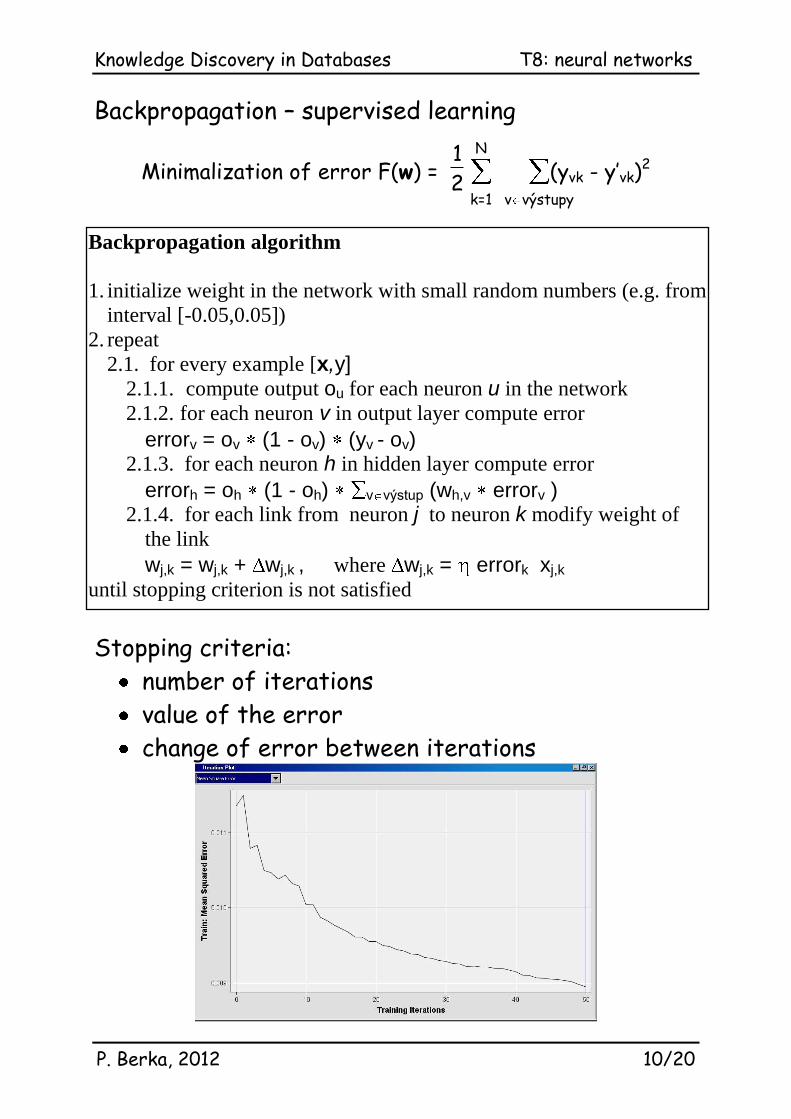
Backpropagation – supervised learning
Minimalization of error F(w) = 1
2 k=1
N
v výstupy
(yvk - y’vk)
2
Stopping criteria:
number of iterations
value of the error
change of error between iterations
Backpropagation algorithm
1. initialize weight in the network with small random numbers (e.g. from
interval [-0.05,0.05])
2. repeat
2.1. for every example [x,y] 2.1.1. compute output ou for each neuron u in the network
2.1.2. for each neuron v in output layer compute error
errorv = ov (1 - ov) (yv - ov) 2.1.3. for each neuron h in hidden layer compute error
errorh = oh (1 - oh) v výstup (wh,v errorv )
2.1.4. for each link from neuron j to neuron k modify weight of
the link
wj,k = wj,k + wj,k , where wj,k = errork xj,k until stopping criterion is not satisfied
Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 11/20
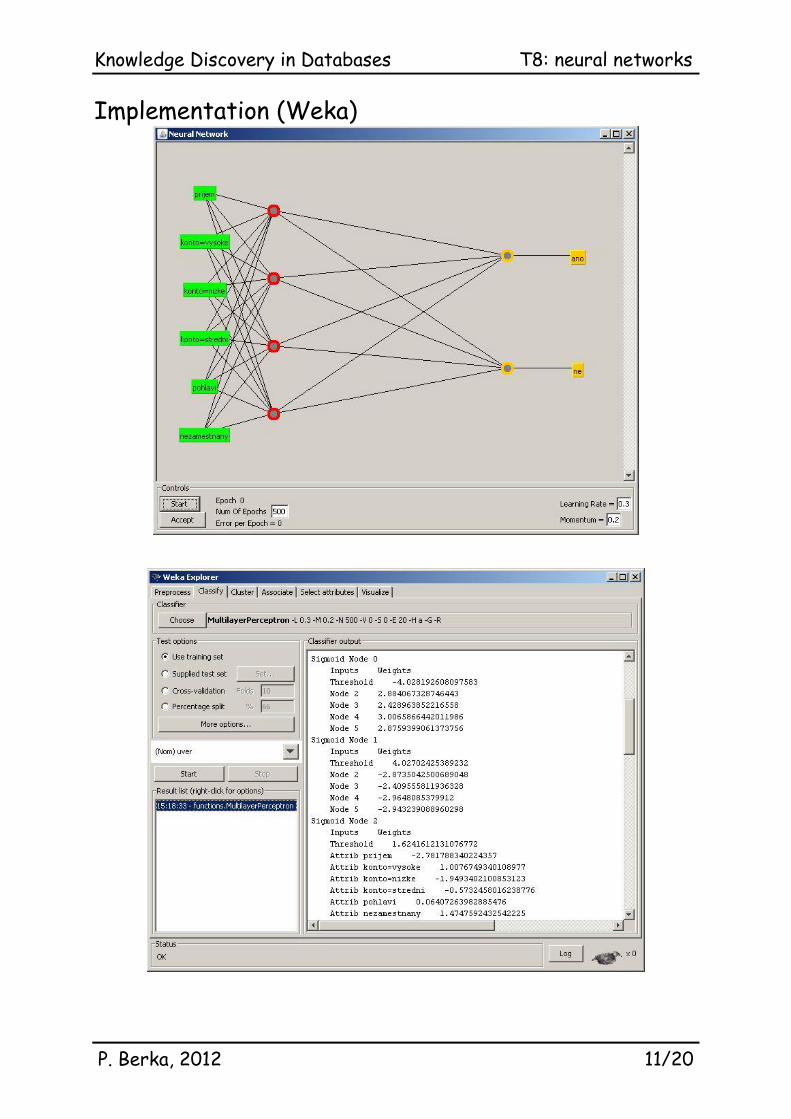
Implementation (Weka)
Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 12/20
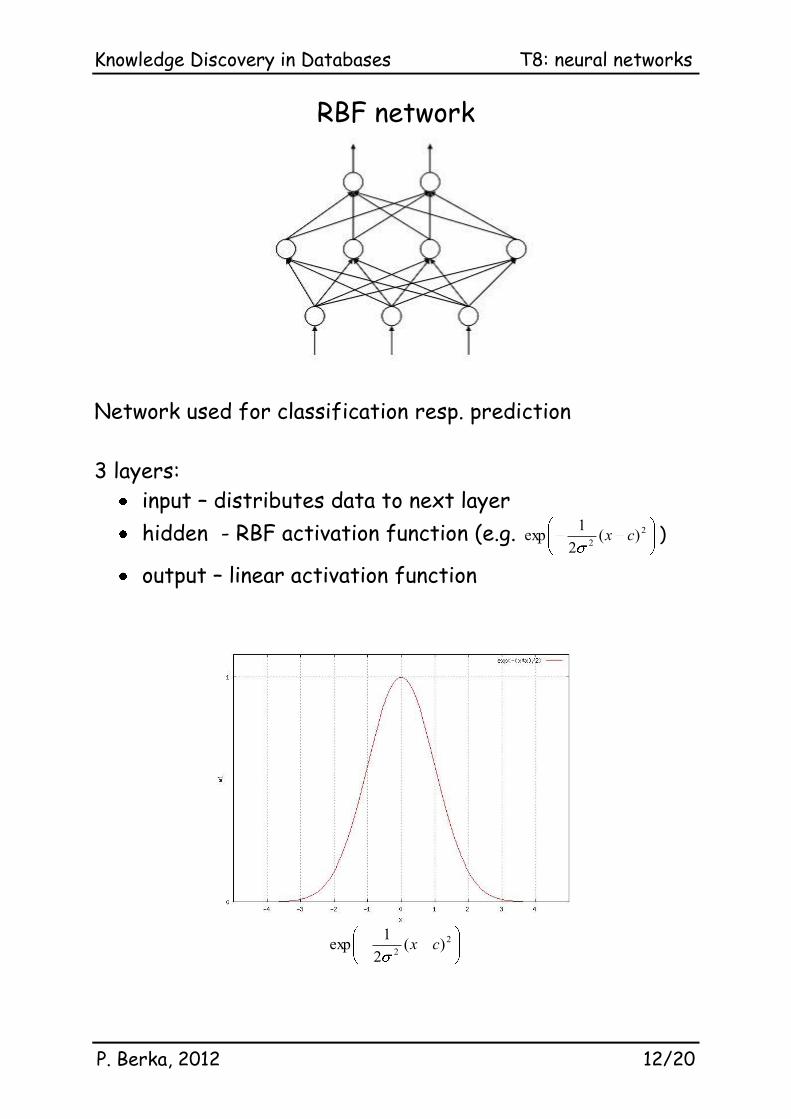
RBF network
Network used for classification resp. prediction
3 layers:
input – distributes data to next layer
hidden - RBF activation function (e.g. 2
2)(
2
1exp cx )
output – linear activation function
2
2)(
2
1exp cx
Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 13/20
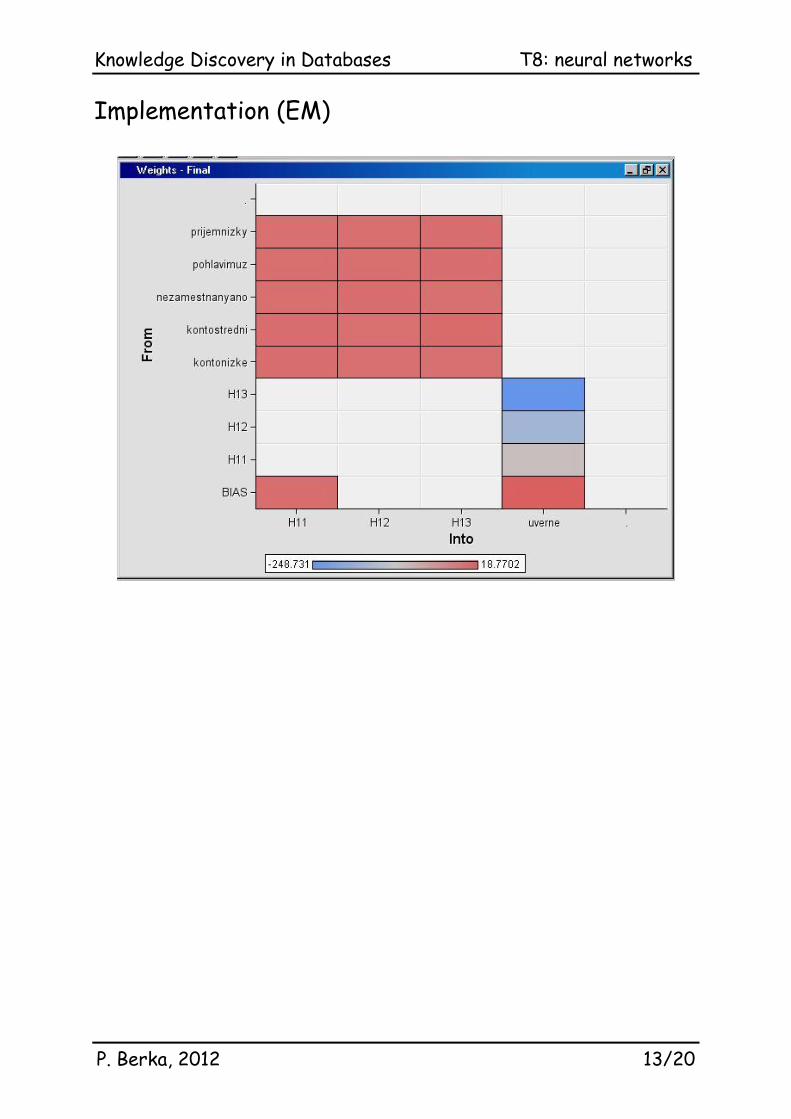
Implementation (EM)
Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 14/20
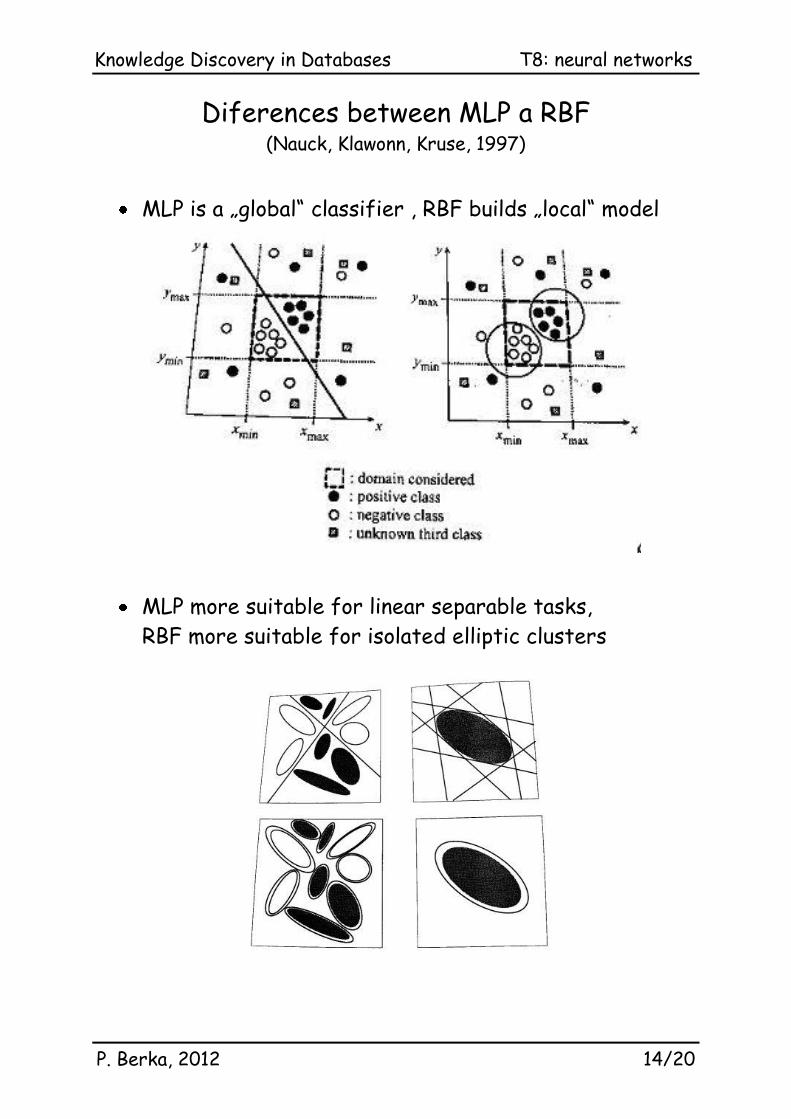
Diferences between MLP a RBF (Nauck, Klawonn, Kruse, 1997)
MLP is a „global“ classifier , RBF builds „local“ model
MLP more suitable for linear separable tasks,
RBF more suitable for isolated elliptic clusters
Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 15/20
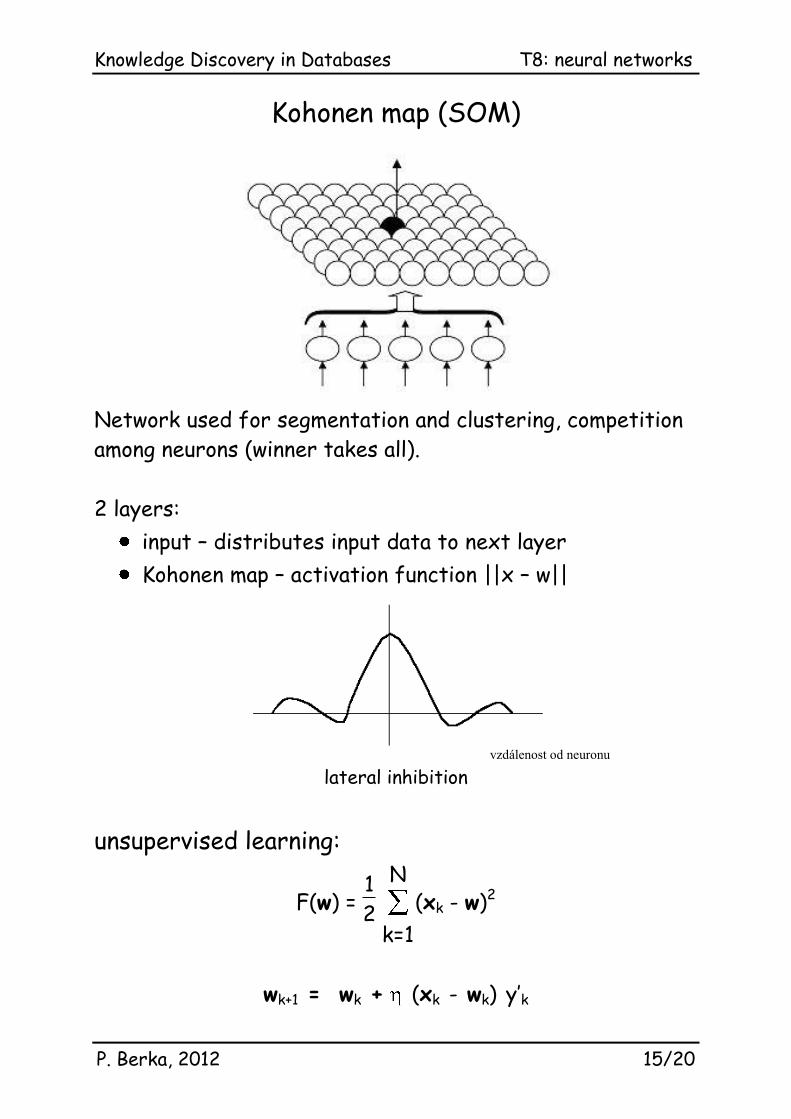
Kohonen map (SOM)
Network used for segmentation and clustering, competition
among neurons (winner takes all).
2 layers:
input – distributes input data to next layer
Kohonen map – activation function ||x – w||
lateral inhibition
unsupervised learning:
F(w) = 1
2
k=1
N (xk - w)2
wk+1 = wk + (xk - wk) y’k
vzdálenost od neuronu
Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 16/20
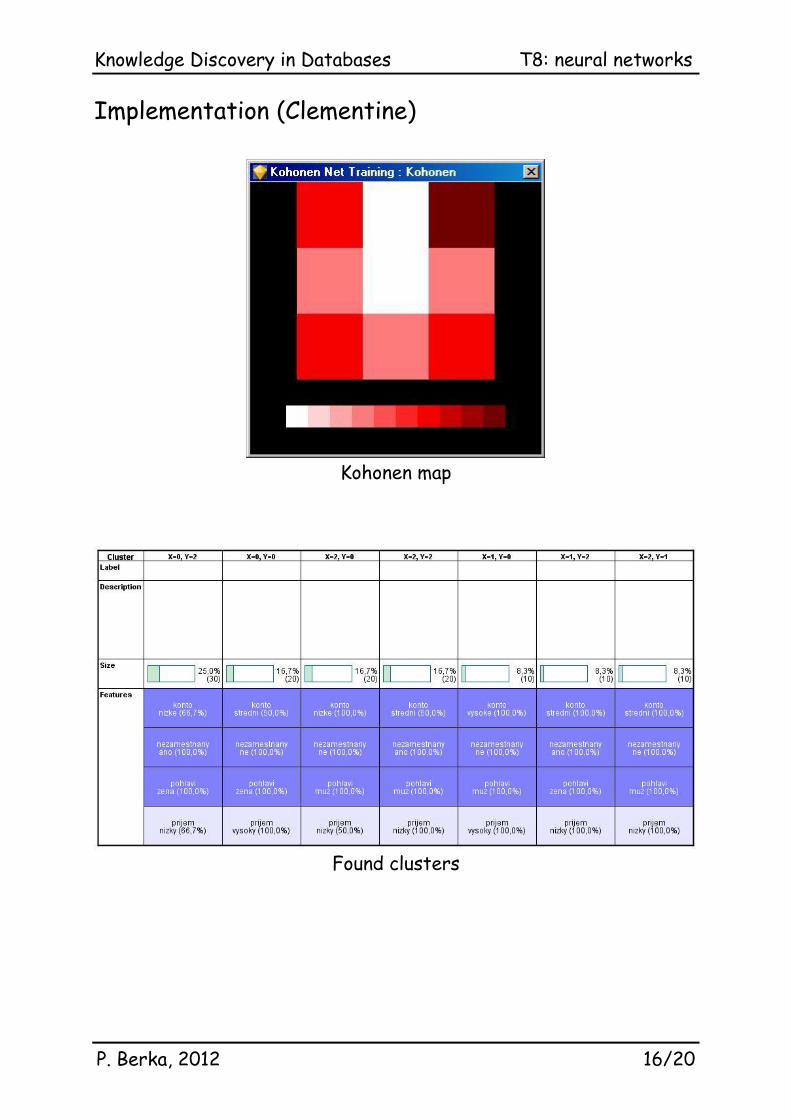
Implementation (Clementine)
Kohonen map
Found clusters

Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 17/20
SVM
1. change (using data transformations) classification
tasks, where classes are not linearly separable into
tasks where, classes are linearly separable
zx ),2,(),()( 2
221
2
121 xxxxxxΦΦ
2. Find separating hyperplane which has maximal distance
from transformed examples in training data (maximal
margin hyperplane). It is sufficient to work only with
examples closest to the hyperplane (support vectors)

Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 18/20
Application of neural network
select the type of network (topology, neurons)
choose training data
learn the network
Types of tasks:
classification
prediction
association
coding
Prostor atributů
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 20000 40000 60000 80000 100000
konto
příjem
A
A
A A
A
A A
A
n
n
n
n
Expressive power of MLP
neural networks suitable for numeric attributes
neural networks can express complex clusters in the
attribute space
found models hard to interpret

Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 19/20
Example 1 - Classification
Task: credit risk assessment of a bank client
Input: data about loan applicant
Output: decision „grant/don’t grant the loan“
Solution:
Network topology: MLP
Input layer: one neuron for each characteristics
of the applicant
Output layer: single neuron (decision)
Hidden layer: ??
Learning: training data consists of information
about past applications together with the decision
of the bank
Knowledge Discovery in Databases T8: neural networks
P. Berka, 2012 20/20
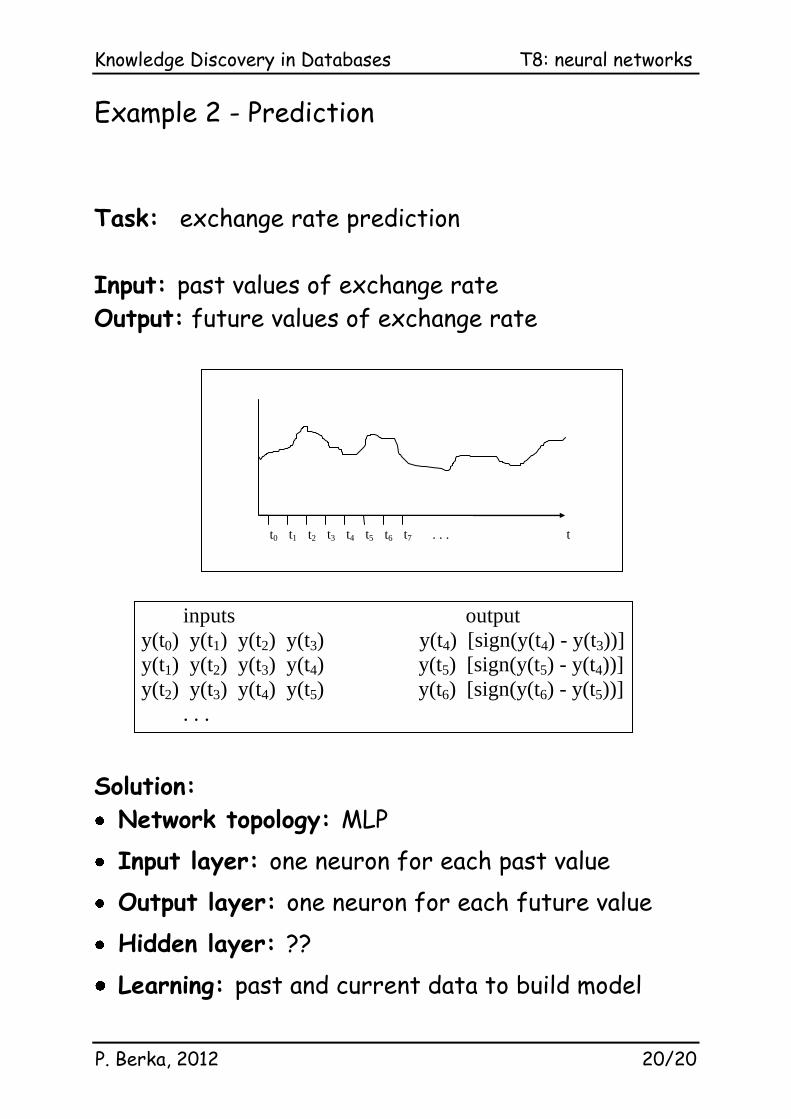
Example 2 - Prediction
Task: exchange rate prediction
Input: past values of exchange rate
Output: future values of exchange rate
Solution:
Network topology: MLP
Input layer: one neuron for each past value
Output layer: one neuron for each future value
Hidden layer: ??
Learning: past and current data to build model
t t0 t1 t2 t3 t4 t5 t6 t7 . . .
y
inputs output
y(t0) y(t1) y(t2) y(t3) y(t4) [sign(y(t4) - y(t3))]
y(t1) y(t2) y(t3) y(t4) y(t5) [sign(y(t5) - y(t4))]
y(t2) y(t3) y(t4) y(t5) y(t6) [sign(y(t6) - y(t5))]
. . .





![Zentralklinik Bad Berka GmbH - Klinikbewertungen.dequalitaetsberichte.klinikbewertungen.de/261600634... · vrzlh ghuhq 4xdolwlw yroovwlqglj grnxphqwlhuw ]x sulvhqwlhuhq xqg vrplw](https://img.pdfslide.net/doc/110x75/5cce589d88c993fb7c8cbbf6/zentralklinik-bad-berka-gmbh-vrzlh-ghuhq-4xdolwlw-yroovwlqglj-grnxphqwlhuw.jpg)























