Embed Size (px)
Citation preview

Technische Universität Hamburg-Harburg Arbeitsbereich Softwaresysteme
Online Help and User Manuals
A Syntactical Analysis using Case Based Reasoning Tools
Project
submitted by Rolando Armuelles
Information and Communication Systems Masters Program
Supervisors: Prof. Dr. Florian Matthes [email protected]
Dipl-Inform. Ulrike Steffens [email protected]
March 1st, 2000

II
Contents
1 Motivation and Goals IV
2 A Grammar for English Phrases 5 2.1 Natural and Artificial Languages……………………………... 5 2.2 Linguistic competence………………………………………... 5 2.3 Word structure………………………………………………... 6 2.4 Syntax………………………………………………………… 6 2.4.1 The Parts of Speech……………………………….. 6 2.4.2 Describing Sentence Structure……………………. 7 2.5 A Grammar for English Phrases ……………………………. 9
3 Syntactical Analysis of Phrases in Tables of Contents 11 3.1 User Manuals…………………………………………………. 11 3.2 Online Help Systems………………………………………….. 14 3.2.1 Windows Help…………………………………….. 14 3.2.2 Getting Help in Windows 98……………………… 15 3.2.3 Analyzing the Syntax……………………………... 17 3.3 Comparing Online Help with Manuals….……………………. 20
4 Semantics Analysis of Verbs used in Information Technology 22 4.1 Defining Semantics…………………………………………… 22 4.2 A Classification of Verbs……………………………………... 22
5 Case Based Reasoning 26 5.1 Cases………………………………………………………….. 26 5.2 Methods………………………………………………………. 26 5.3 Decomposition of CBR……………………………………….. 28 5.4 A Case Based Reasoning Tool………………………………... 29 5.4.1 CBR4 Works Professional………………………… 29 5.5 CBR Applied to Syntax Analysis…………………………….. 31
6 Conclusion 36 Appendix
A List of English Verbs 37 Bibliography 38

III
Figures
2.1 A labelled Constituent Structure Diagram………………………….
8
2.2 A Context Free Grammar……………………………………………..
10
3.1 Style I in Table of Contents of Manuals …………………………….
12
3.2 Style II using Combinations of Nouns………………………………..
13
3.3 a, b Styles III and IV in Software Manuals……………………………….
14
3.4 Main Contents in Word for Windows 98 Help………………………
16
3.5 Style A, The Preferred Construction for Topics in Windows Help..
17
3.6 a, b Style B, Top Level Problem Definitions in Microsoft Word Help…
18
3.7 Style C, Two Nouns Combine to Form an Online Help Topic……...
19
3.8 Style D, „Automatically“ Topics, with an Adverbial Phrase………..
19
4.1 A Classification of Verbs used in Information Technology………...
25
5.1 The Case Based Reasoning Cycle …………………………………….
27
5.2 CBR-Works Application Architecture……………………………….
30
5.3 Basic Structure of a CBR-Works Application……………………….
31
5.4 The CBR-Works 4 Concept Manager……………………………...
33
5.5 Concept Manager’s Graphical View………………………………….
34
5.6 The CBR-Works 4 Type Manager…………………………………… 35

IV
Chapter 1
Motivation and Goals
There is an increasing number of information systems users with a limited computing experience who need easy-to-understand assistance. Likewise, more advanced users and system developers need reliable sources for technical support and learning. Current aids include: access to human experts, user manuals and, more recently, interactive online help systems.
The goal of this project is to ease and improve information retrieval in online help
systems by analyzing the description of problems and solutions they contain, making them closer to the kind of results achieved through direct contact with people and those obtained by learning from user manuals.
The chosen strategy is to find structures and common patterns in the expressions used
for such descriptions, dividing them into smaller constituent terms first, and then to closely examine the types of those components in order to gain a deeper knowledge, possibly improving retrieval results.
By making a syntactical analysis of the Table of Contents of a user manual and
comparing it to that of an equivalent software product, the structural differences and similarities that cause particular patterns of use in humans are to be found. A classification for verbs commonly used in both types of media, based on their semantics, will be proposed.
In addition, as an alternative to traditional grammatical analysis, Case Based
Reasoning is introduced. By definition, it provides not only for fast and accurate retrieval but also for improving a system by direct or indirect feedback.
Chapter 2 introduces a grammar for the analysis of expressions used for problem
definitions in user manuals and online help systems. Chapter 3 applies the rules of the grammar to depict the syntactical structure of the most common styles of problem definitions in printed and online help. Secondly, a comparison of features of both media is depicted. Chapter 4 explores a list of verbs used in information technology and proposes a categorization of them, based on their semantics. In Chapter 5, a Case Based Reasoning tool and development environment is tested and evaluated as a platform for natural language analysis. Finally, the conclusions of this project are summed up and future courses of action are suggested.

5
Chapter 2 A Grammar for Natural Language
2.1 Natural and Artificial Languages
Natural language is something that already exists and fulfils different functions in the process of communicating with other people. It can be used to express anger, grief, commands, questions, ideas, etc. On the other hand, an artificial language is something that has to be defined. An example can be one of the many programming languages existing today. There are three main differences between natural and artificial languages1:
�� The rules introduced in artificial languages leave out ambiguities. This makes them
easier to process than natural languages. �� Statements in programming languages are generally kept simple, because they
generally have a specific objective in mind. �� Natural languages fulfil many functions, thus making it very difficult to represent the
meaning of everything they can be used to express.
But studying the structure of sentences in a natural language is not enough, in order to understand the meaning. The context in which something is expressed also plays an important role. This aspect, however, will not be considered, in the interest of simplicity.
2.2 Linguistic Performance
Studies by Noam Chomsky observed that language use heard in everyday lifes is inconsistent, containing interruptions, mistakes and other features that make it a very poor basis for discovering underlying regularities. He called this type of linguistic behaviour “linguistic performance”. A scientific approach to language involves an explanation of our linguistic competence, not only our linguistic performance.2
Chomsky further argued that a generative grammar must be specified to capture linguistic competence. In general, syntax is a description of how words combine together to form sentences. A grammar can additionally cover sounds (phonology) and meaning (semantics). A generative grammar relates to syntax and is a grammar capable of generating all the sentences in a language and does not generate anything that is ungrammatical3.
The techniques to handle artificial languages provide an efficient base for natural language processing and relate to many other fields of study: theory of grammars, automata theory, data structures, logic programming, psychology and the language philosophy. The
1 [3] Differentiates them in detail. 2 An explanation is given in [4]. 3 [3] page 5.

6
2.3 Word structure
Words are not always atomic. They sometimes can be broken down into pieces with meaning. The word premodifying can be broken down, while the word plot cannot. Yet, you can also derive other words from it, like plotter, plotting, etc.
The parts of words that have meaning are called morphemes. Examples of these are
pre, er, ing, s, ed. Words that contain more than one morpheme are complex. Complex words have a base or stem morpheme and an attached morpheme. Morphemes can be bound or free, depending whether they can be words by themselves.
Bound morphemes can be classified in prefixes and suffixes, by whether they attach to another morpheme at the start or at the end. The most widely used prefixes used in the English language are: Prefixes: a, ante, anti, arch, auto, be, bi, co, counter, de, dis, em, en, ex, extra, fore,
hyper, in inter, mal, mis, non, post, pre, pro, re, semi, sub, super, trans, ultra, un
Suffixes: able, age, al, ance, ate, ation, cy, dom, ed, en, ence, er, ery, est, ful, hood,
ible, ion, ing, ise, ish, ist, ity, ize, less, like, ly, ment, ness, ous, s, ‘s, s’, ship, some, ster, teen, ty, ward, way, wise
The complex words in a language are formed by combining free and bound
morphemes. The different word types are known as parts of speech. They represent a classification of words based on their use within a particular language. A word may have more than one part of speech classification.
For an in-depth coverage of the rules governing the formation of the parts of speech, refer to a textbook by Paul Bennet4 or other books on linguistics.
2.4 Syntax
Syntax studies how words fit together to form structures up to the sentence level. In this section, different kinds of word and their roles in sentence structure are introduced. A context-free grammar to handle the structure of sentences will be presented later. 2.4.1 The Parts of Speech
In modern linguistics, the parts of speech are called syntactic categories. A short explanation of the most common categories will be given: noun, pronoun, determiner, adjective, preposition, verb, adverb, conjunction.
�� Nouns are known as naming words. Proper names are a sub-category of nouns
and are used to name particular things, such as persons or places. Proper names behave differently from other nouns, called common nouns, which name whole classes of things. Proper names are not preceded be the or a. They do not appear
4 [4]; an overview is also present in [3].

7
in the plural form.5 Noun phrases are groups of words based on a noun. They can be used to describe things or classes of things.
�� Pronouns are a special case, because they appear on their own in place of other
noun phrases. Some common pronouns are: I, me, you, he, him, she, her, it, we, us, them. Another type of pronoun, which performs a joining function, is known as a relative pronoun. For example: who, whom, which, that. They allow a noun phrase to be extended by adding a further phrase.
�� Determiners appear at the beginning of a noun phrase and tend to determine the
way the phrase refers. They include the indefinite articles a and an and the definite article the. His and her can also act as determiners6. Quantifiers are words like all, some, as well as the numerals. They can also act as determiners.
�� Adjectives modify a noun, thus providing a more specific description. A noun can
be modified by more than one adjective. �� Prepositions often concern possession, direction or location. Some common
prepositions are: after, at, before, by, down, during, from, in, inside, of, on, outside, to, up, upon, with, without. They sometimes behave in a similar manner as relative pronouns, within noun phrases, in that they allow the modification of a noun phrase by other noun phrases.
�� Verbs are thought of as doing words. That is, they express action. For example,
delay, format, copy, suspend, run. Verbal groups are groups of verbs working together, and are often regarded as the most significant part of the structure of a sentence. In English, verbal groups are used to handle variations of tense, mood and modality. The tense refers to the place in time an event occurs: past, present or future. The aspect of a verb is connected to the tense and can be progressive or perfect. The mood of a verb can be active or passive. The modality indicates possibility or necessity or a degree or certainty. This is usually expressed by auxiliary verbs such as may and can.
�� Adverbs qualify verbs in much the same way that adjectives qualify nouns.
�� Conjunctions are words that connect, e.g. and, but and so. They can be used to
join two simple sentences into a compound sentence and also to enumerate elements of another syntactic category.
2.4.2 Describing Sentence Structure
A sentence can be thought of as being composed of a relatively small number of building blocks, which are called its immediate constituents7. These constituents themselves have their own immediate constituents. This goes on until the level of the word is reached.
A phrase is a constituent smaller than a sentence. Sometimes a constituent of a complex sentence has a sentence-like structure itself. This is commonly called a clause. There can be verbal, noun, prepositional phrases, or others.
5 Refer to [5] for an comprehensive look into nouns and other parts of speech. 6 Although they are classified as possessive pronouns. 7 As described by [8].

8
A good way of representing this is using a tree structure8, where all points that contain a word, or label, are called nodes. The single node at the top is called the root node and the nodes at the bottom, which have no further constituents, are called leaf nodes or terminal nodes. Where two nodes are immediately dominated by the same node, they are siblings. An example of this structure can be seen in Figure 2.1. Note that the words themselves only appear on terminal nodes and the non-terminal nodes contain labels of abstract syntactic categories.
Figure 2.1: A labelled constituent structure diagram
8 [3] uses this tree structure to introduce a parser for natural language.
POST-VERB
VP
VERB
NP
V-ING NOUN
ErrorHandling

9
2.5 A Grammar for English Phrases
To build a grammar powerful enough to analyse all English sentences will not be attempted, for this task would be too large and complex. Yet, a grammar that fulfils the following criteria is needed: a. Able to analyse all of the sentences in our study. b. Should not generate too many sentences that are ungrammatical in English. c. With phrases and rules that are generally applicable, even if in some cases they
involve simplifying the way English works. Although the subset of the English language used for software documentation is
reduced in comparison with all possible expressions, we expect this to change over time, as the evolution of information systems tend to simulate human to human interaction. [3] develops a grammar suitable for our purposes, that is strong enough to cover most problem definitions in user manuals or online help systems. Not all the rules will be used in the analysis, but they can be of interest for discovering structure or parsing within the text of a document or a larger universe of research objects (e.g. English phrases). The rules are shown in Figure 2.2.
Some symbols need to be explained:
::= is read as is defined as. | can be read as or. [ ] means the presence of an item is optional * an asterisk after an item means zero or more occurrences of the item.
A formal explanation of context free grammars is available in most introductory computer science texts. In each of the rules there is one symbol to the left of the ::=, indicating that the re-writing does not depend on surrounding context, hence it is context free.
Some of the rules should be explained further. CLASF refers to classifiers, which are nouns and proper names that are also able to qualify the main noun. PP is a prepositional phrase, simply composed of a preposition and a noun phrase. REL-CL are relative clauses, which begin with a relative pronoun, followed by a verb phrase. A quantifying phrase (QU-PH) can precede a noun phrase and express quantity.
Verbs are expressed according to their tense, primarily: past (V-ED), present (V-PRES) , and future (using V-INF). The future tense is different from the others as it involves an auxiliary verb (will). The progressive aspect is constructed using a form of the verb to be (BE) and the present participle (V-ING) form of the verb that follows. The perfect aspect is constructed from a form of to have (HAVE) and the past participle (V-EN) form of the verb that follows. Passives are created with a form of the verb to be and the past participle. Modal auxiliaries are always followed by a verb in the infinitive form (V-INF)
The purpose of constructing a generative grammar is to generate precisely the sentences of some dialect of a natural language. In the present project, this dialect corresponds to the argot of Information Technology. This should at least bring out the structural ambiguities in sentences of the language.

10
Figure 2.2: A Context Free Grammar

11
Chapter 3
Syntactical Analysis of Phrases in Tables of Contents
3.1 User manuals
There are as many types of printed material in use in computer science and information technology as there is of software and/or hardware products. It would be very difficult to attempt to look into textbooks, magazines, periodicals, manuals, etc., to find an underlying general structure in the way they state problem-solution pairs. This responds to the writing styles of the authors, the established format of the publishers, and a dozen other factors, which vary among languages and countries.
The San Francisco Evaluation Kit (V1R3) user manual from IBM9 has been selected
as the object of our study. It provides the documentation for programmers who want to develop applications using object-oriented methodologies and tools. The results can then be extrapolated to many other similar publication types.
The different problems a programmer or user might encounter are represented in the Table of Contents or Index of the manual, which will be classified according to the style of expressions used. These problems are classified in chapters and subchapters, each with a title. Additionally, an introduction, appendices, etc. and matched to the number of the page where the user can find a description of the solution.
Style I
The most frequent pattern for problem description in the Table of Contents
corresponds to verbal phrases (VP) starting with verbs of progressive aspect (present participle), followed by a post-verb construction. This means that they are not complete sentences, but partial phrases.
An example of this would be:
Uninstalling on Windows 95/98 and Windows NT
where the subject is left out, while implying that the user himself wishes to or must execute the action of uninstalling. The full sentence could actually read
I would like to see how [uninstalling on Windows 95/98 and Windows NT] works.
The choice of this example is also due to the complex syntax, which can be applied to all simpler cases. Rules 5, 8, 12, 20 and 24 of the context free grammar of chapter 2 are applied. Figure 3.1 shows the constituents.
9 See the full index of [14].

12
The simplest item with the same basic structure is titled Handling Errors, which consists of a verb ending in –ing and a noun, and only needs rule 20 of the context free grammar. But by adapting other rules to their substructures, this can also be extended to constructions such as: Using the San Francisco Online Documentation or Administering Access Rights with San Francisco Utilities This structure is equally used to name chapters, or more general problem or concept areas, as well as the sub topics that contain the detailed information itself. Style II
Second in the number of occurrences to the structure described above is one consisting of a noun phrase only (NP). A noun that acts as classifier (CLASF) is followed by another noun, which can be seen in Figure 3.2. It seems to respond to the question How do I configure a (the) Browser? In this case, rule 6 of the context grammar is enough to do the analysis. However, there can be modifications in the sub-structure by applying rule 10, for example: General Ledger Enhancements or Multi-Machine Installation
Figure 3.1: Style I in Table of Contents of Manuals
POST-VERB
VP
VERB
NP
V-ING PROPER
andon Windows 95/98 Uninstalling Windows NT
PROPER
NP and
NPPREP
PP
V-MOD

13
Style III Another frequent structure also requires rules 6 and 10 of the grammar, with slight variations, and is described in Figure 3.3(a). Instead of a whole sentence, a subject expressed by a noun phrase is enough to describe the concept to be explained. The peculiarity in this case is that it begins with the definite article the, a determiner (DET). Items such as The San Francisco Outlook or The Schema Mapping Tool can be classified under this style. Style IV
Last but not least, some topics in the manual subject of our study are described by one noun, as in Figure 3.3(b). Again, rule 6 of the context free grammar serves to describe the most basic of problem descriptions. These usually indicate standard sections of any publication, like Summary, Introduction, Appendix, etc. The above confirms that the context free grammar used is satisfactory for the majority of the sentences or expressions in the user manual. Although it seems that not all the rules have been applied, we must add that such a grammar is suitable for creating a parser that can analyze not only the problem (the phrase in the Table of Contents), but the solution (the documentation itself) as well. In the following section, a similar approach is used with an online help system to understand the expressions used for problem descriptions.
NP
CLASF NOUN
NOUN
Browser Configuration
Figure 3.2: Style II using Combinations of Nouns

14
3.2 Online Help Systems Together with user manuals, online help systems are the basic aids used by information technology product vendors to close the gap between the expectations of the consumers and the company’s technical support staff. Be it in a CD-ROM or on the Internet, these systems can also be used for continuous education, using sophisticated agents that answer the user’s most frequently asked questions, combining regular text with the multimedia capabilities of computers. That is, animation, audio and video are combined, to facilitate the learning process. The Windows operating system was chosen for the present project due to the availability and familiarity that many readers will have with it. Among the most popular applications written for this operative system is the word processor software Word. Before going into the syntax analysis of the online help for Word, the options offered to solve a given problem in the standardized Windows Help for all applications must be explained. 3.2.1 Windows Help
One of Windows’ most popular features is the standardisation of applications; once you have learned to use one Windows application, you have a good idea of how to operate others. Among the most helpful of the standard features is the online help interface, which allows the user to instantly access application-specific information from any point within a program. Online help is not a substitute for printed documentation, but if it is written correctly it can reduce the amount of printed documentation required and also make programs easier to understand and use.
To construct Windows help files, you need an editor that can produce plain ASCII text files, or a word processor which can produce Rich Text Format files. You also need the
The Checkbook Sample
NOUNDET CLASF
NOUN
NP
NP
NOUN
Summary
(a) (b)
Figure 3.3 a, b: Styles III and IV in Software Manuals

15
Microsoft Windows Help Compiler10 in order to convert your help text into a format that Windows Help can read. Graphical tools are needed to edit bitmap images and to write programs that access Windows Help, you need any development system that allows calling Windows API functions.
The most common methods of accessing Windows Help are11: • = Pressing F1 from within an application • = Selecting an item from an application’s Help menu • = Clicking on the Help button in a dialog box • = Executing WINHELP.EXE
Which criteria are used to classify the help topics in the Index?
The search for help topics is based on keywords. Just as a book index is used to quickly find a particular topic, the Search facility allows you to find a help topic without having to go through multiple levels of hypertext links.
The help author defines the search keywords and attaches them to topics, much as a book author would create an index for a printed book. When the user clicks on the Search button, Windows Help displays the Search dialog box and allows the user to select the keyword to search for.
To select a keyword to search, either type the key word into the edit field, or use the list box controls to highlight the keyword that is to be searched. When the edit field is typed in, the list box scrolls automatically to match the input. Case is not significant in keywords.
When the search is finished, the titles of all the topics that were found by the search are displayed in the lower list box. To view a topic, double-click on the topic title12. 3.2.2 Getting Help in Windows 98
The latest version of desktop operating systems by Microsoft introduces some changes to the user interface of its standardised help system. As its predecessors, it maintains the same indexing and search capabilities, but in connection with a network like the Internet, can expand the access to other sources of documentation.
The online option is helpful in most cases, but the World Wide Web version is more
comprehensive. Earlier versions of Windows allowed the user to press the F1 key and get help on the selected dialog box option. This is again the case in Windows 98. Pressing this key brings help on the Desktop or the current action being undertaken.
Online help allows you to select from three different ways of getting help. One is through a search of the Contents of Windows 98, which includes general help categories. Here the category of interest (such as Printing) is selected and then work your way through the selection of options until you find the topic on which you need help. Following the instructions will provide the needed assistance.
10 For a basic tool to produce help files, see [12] 11 Normally, on-line help systems are self-explanatory. You find the instructions for its use in the system itself. 12 We recommend [10] for its explanation on exploiting the Windows Help System.

16
A second way to get help is through selecting the Index tab. This action produces a list of all the topics contained in Windows 98 Help; you can scroll through the list or type in a key word or phrase to find the topic on which you need assistance.
The third way of using online Help is to use the Search tab to look for a particular
term or operation. Windows 98 will find terms that relate to the input and provides help on that topic. The help screen only disappears when you close out of it, so it can stay on the foreground for continuous consulting. The wizards feature can guide the user step by step to perform a task. The list of topics in this version has grown, but contains the same basic expressions for problems encountered by users of the software. The well-known word processor Microsoft Word, an application based on this system, has been selected for analysis. Figure 3.4 shows the high level topics or general problems that are displayed by selecting the Contents tab.
�Getting Help �Installing and Removing Word �Running Programs and Managing Files �Opening, Creating, and Saving Documents �Typing, Navigating, and Selecting �Editing and Sorting �Checking Spelling and Grammar �Formatting �Changing the Appearance of Your Page �Importing Graphics and Creating Drawing Objects �Working with Tables and Adding Borders �Working With Long Documents �Sharing Data with Other Users and Applications �Working with Online and Internet Documents �Creating and Working with Web Pages �Assembling Documents with Mail Merge �Printing �Customizing Microsoft Word �Reference Information �Switching from WordPerfect �Microsoft Word Visual Basic Reference
Figure 3.4: Main Contents in Word for Windows 98 Help

17
3.2.3 Analyzing the Syntax
Pursuing the methodology of our previous syntax analysis, the most common construction in the Contents feature of Word for Windows 95/98 help will be identified. The following primary styles of expressions have been found:
Style A
This corresponds to a verb phrase (VP) composed by a verb in the infinitive form (V-INF) and a post verbal structure (POST-VERB).
Figure 3.5 shows how rules 6, 20 and 26 of the grammar of chapter 2 are used to find
the constituents. It appears to indicate an imperative mood. This means that an item like Copy a file can be interpreted as [I would like to] copy a file, a wish on the side of the user, or [You] copy a file a command directed towards the program.
Style B
The attention should be directed towards the place of these constructions within the overall hierarchy of concepts/problems. Unlike in user manuals, where verbal phrases with V-ING are more abundant, Windows Help systems (including that of Word) use such a formulation almost primarily for high level topics. This would be equivalent to the names of chapters in manuals.
And this is precisely the second most frequent structure, which can be seen in Figures
3.6(a) and 3.6(b), where (b) shows the simplest form, consisting of only one word; in this case, the present participle of a verb. Once again, there is a verb phrase, composed of one verb in progressive form, followed by a post verbal section. Rule 16 and optionally rules 4 and 20 of the context free grammar of chapter 2, deal with these cases.
POST-VERB
VP
VERB
NP
V-INF DET
aCopy
NOUN
File
Figure 3.5: Style A, the preferred construction for topics in Windows Help

18
Style C
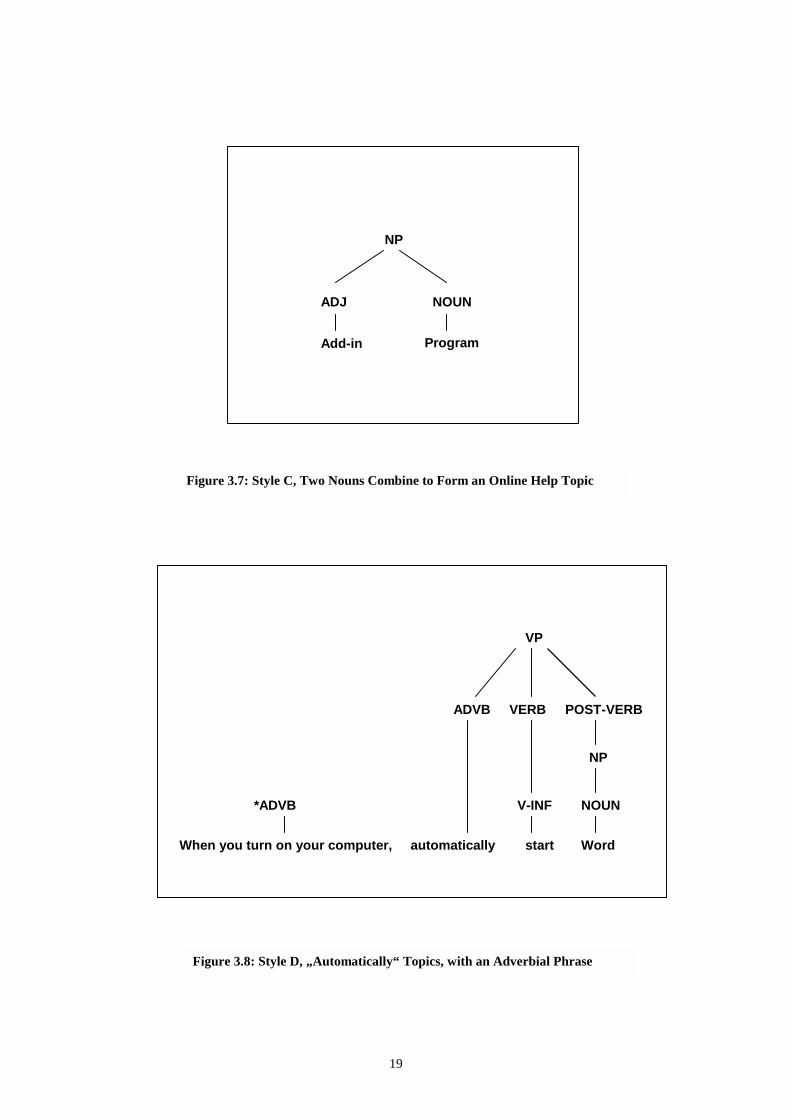
Very simple arrangements are present, although less frequent. Such is the case of a noun phrase with an adjective followed by a noun. Figure 3.7 displays the example
Add-in programs
Style D
Among many other problem formulations, like WH- questions (why, when, where, how, what), one calls our attention because of its complexity. It contains the adverb automatically and an adverbial phrase with when. The adverbial phrase indicates the time of occurrence of an event, and modifies the rest of the sentence.
Consequently, our example shown in Figure 3.8 is a re-stated version of the item
Automatically start Word when you turn on your computer.
It is time to make the observation that Windows Help tends to use whole sentences to
formulate the problems in some occasions, contrasting with the approach in user manuals.
POST-VERB
VP
VERB
NP
V-ING NOUN
CharactersFormatting
POST-VERB
VP
VERB
V-ING
Selecting
(a) (b)
Figure 3.6 a, b: Style B, Top Level Problem Definitions in Microsoft Word Help
19
NP
ADJ NOUN
ProgramAdd-in
POST-VERB
VP
VERB
NP
*ADVB
ADVB
automatically When you turn on your computer, Word start
V-INF NOUN
Figure 3.7: Style C, Two Nouns Combine to Form an Online Help Topic
Figure 3.8: Style D, „Automatically“ Topics, with an Adverbial Phrase

20
3.3 Comparing Online Help with Manuals
Regardless of the experience level of a user of a certain application, all of them make use of online help at some point. Some are able to get the needed help online easily for certain tasks, while others have to scan through several screens of information before they access what they require. Others have considerable difficulties and have to be assisted by someone else.
A study made at the Loughborough University reveals that even experienced users
find some aspects of existing online help systems difficult to use, and current versions are not well received.13
Their research suggests that computer users, especially novice users still find information, about the application they are using, more quickly using printed documentation and/or human experts, than from online help systems. Online help systems are more appreciated for their response to task-related queries rather than their usefulness as tools for learning about the applications.
Experienced users get more out of online help because they are more familiar with the syntax and the semantics of the applications, making it easier for them to formulate meaningful queries.
Another important difference between user manuals and online help systems is ontological. Users, particularly novices, can’t seem to find the right terms in which to express their problems to the system. Also, online help systems cannot be easily browsed.
User manuals are considered more descriptive, more technical and offer detailed examples. They give clear and detailed explanations of concepts, they are easier to scan through, have no restricted pattern of response, and are more procedural. Moreover, they do not compete for screen area, in contrast to online help.
Online Help provides four ways in which to access information: Contents, Find, an Index and a Help Wizard. There is no clear guidance as to which to use in what situation. Contents (or Help Topics) provides a top-down approach. This may require using a Help Wizard later on. In Find, the user supplies a word, and a set of topics are presented. The Index allows the user to scan the words in the help system, and the Wizard takes the user through a worked example.
The most frequent reasons for considering user manuals more effective than online help systems are the ease of reading from paper rather than from the screen, and the fact that online help obscures part of the screen, plus having to scan through many screens. Online help is often given in a non-procedural, not concise and not specific way, and in many cases irrelevant information is displayed. Help systems are rather inflexible and assume too much user knowledge.
On the other hand, if there is no ontological problem when looking for a given solution, the online help information is unidirectional and displays to a sometimes large number of clear answers.
The positive aspects are the rich indices, search facilities, cue cards, and the fact that they can be accessed within the application. 13 See [2] for the full report of this observational study.

21
Typical of users who are assisted by written information, after using an index for primary access, they often exploit the sequential nature of written material, browsing until they find information which appears relevant. This technique often solves ontological problems because the user is able to discover differences in terminology. The human browsing capability is superior to Hypertext links. In addition, there is a clear separation between help source and application.
In contrast to online help, user manuals offer an integrated base of information, which
helps to get around the ontological problem. Nevertheless, there are several possibilities of enriching the results of information retrieval in online help systems. A promising system is the PIA model for interactive product and service catalogs using techniques from fuzzy set theory.14 Based on the initial request from a customer (or online help user, in our case), a match or mismatch between the personal preferences and the available services or products is made.
Similarly, another approach involves steadily improving a given information base by
applying the learning cycle of Case Based Reasoning, and will be attempted in the following chapters.
14 [11].

22
Chapter 4 Semantics Analysis 4.1 Defining Semantics
The study of semantics (meaning) involves developing a structure, similar to the one used for syntax. But this approach leads to certain obstacles. For instance, the ambiguity involved in some verbs that have tens of meanings. Looking into a dictionary for the verb go reflects different senses, sometimes synonyms as different as move, extend, set out, each of which can have several entries as definitions. This leads to a serious problem during semantic interpretation. Fortunately, these different meanings can be organized into a set of broad categories or classes of objects, producing a classification of our reality. This representation is called an ontology.15 The basic categories have already been studied by ancient cultures, and continue to be modified and adapted through the ages, as dynamically as mankind itself. A formal definition of semantic methods will not be undertaken. For the purpose of our study, a more pragmatic angle is undertaken. An analysis of the parts of speech for their meaning should begin with the actions (verbs) that are at the core of any sentence. The following question will be answered: how are the verbs used in information technology related?
4.2 A Classification of Verbs
In this section, a classification of 200 verbs16 selected from the thousands used in information technology to describe various actions will be produced, based on a thesaurus17 and relying on domain knowledge of computer science and communications. The reason for using a thesaurus is that it offers a variety of words in which to express a given meaning, while the dictionary only gives the meaning of a particular word. This arrangement makes both instruments complementary.18
Although a given word can have more than one meaning, more general definitions will be left out. Our aim here is to come up with a taxonomy that can be used to structure the most common tasks and problems encountered by software users, according to a semantic relationship tree. Other diagrams, like nested f-structures19, can be used for such an analysis as well.
These relationships could then be applied to the Find feature of online help systems, as well as catalogue or web based search engines to encounter conceptual dependencies.
15 Refer to [6] for a methodology to build ontologies. 16 Translated from German into English. 17 [9] is the revised edition of the classic by P.M. Roget, first published in 1852. 18 According to [7], a thesaurus can also be built based on syntax analysis. 19 An account of paradigms for grammars is given in [15].

23
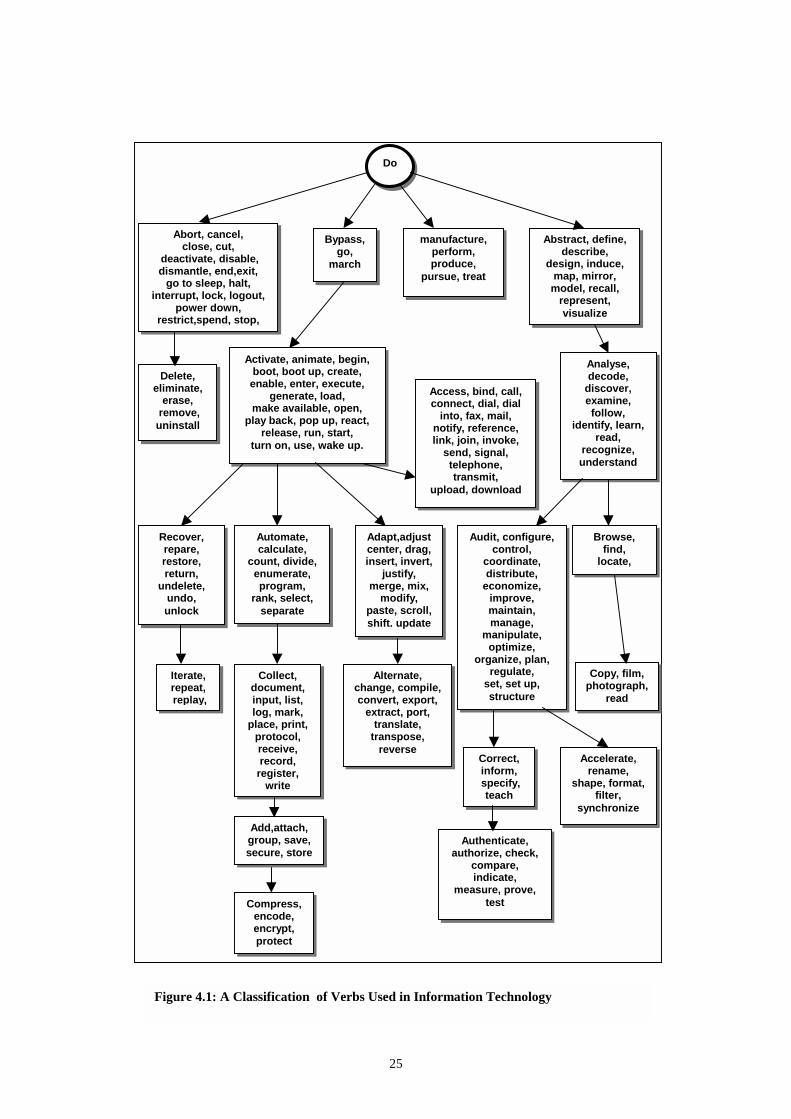
To start, the verbs must be separated into groups that are related in their meaning. The verb (to) do is considered the starting node of the hierarchy, for it describes the most general type of action. The complete list in alphabetical order can be seen in Appendix A. The names of the groups are based on our idea of the main concept behind the verbs, regarding their application within IT. The concept hierarchy describes the is-a relationship between concepts. Sub-concepts of another concept, inherit the structural information. End of a process abort, cancel, close, cut, deactivate, disable, dismantle, end, exit, go to sleep, halt, interrupt, lock, logout, power down, restrict, spend, stop, terminate, turn off. Obliteration delete, eliminate, erase, remove, uninstall. Production manufacture, perform, produce, pursue, treat. Movement bypass, go, march. Creation activate, animate, begin, boot, boot up, create, enable, enter, execute, generate, load, make available, open, play back, pop up, react, release, run, start, turn on, use, wake up. Recovery recover, repair, restore, return, undelete, undo, unlock. Cycles iterate, repeat, replay, rerun, reuse, review. Programming a. Storage: add, attach, group, save, secure, store. b. Hiding : compress, encode, encrypt, protect. c. Statement: collect, document, input, list, log, mark, place, print, protocol, receive,
record, register, write. d. Classification: automate, calculate, count, divide, enumerate, program, rank, select,
separate. Editing a. Internal: adapt, adjust, center, drag, insert, invert, justify, merge, mix, modify, paste,
scroll, shift, update. b. External : alternate, change, compile, convert, export, extract, port, translate,
transpose, reverse.

24
Communications access, bind, call, connect, dial, dial into, fax, mail, notify, reference, link, join, invoke, send, signal, telephone, transmit, upload, download. Knowledge abstract, define, describe, design, induce, map, mirror, model, recall, represent, visualize. Learning analyze, decode, discover, examine, follow, identify, learn, read, recognize, understand. Administrating. a. Instruction: correct, inform, specify, teach b. Verification: authenticate, authorize, check, compare, indicate, measure, prove, test. c. Properties: accelerate, rename, shape, format, filter, synchronize d. Management: audit, configure, control, coordinate, distribute, economize, improve,
maintain, manage, manipulate, optimize, organize, plan, regulate, set, set up, structure. Searching. browse, find, locate, roam, scan, seek, search. Input methods copy, film, photograph, read.
By going through the list of verbs, it is quite obvious that there are several possible cross-references and associations, which can be built among the items. This fact is better understood by looking at Figure 4.1, where an attempt is made to reflect the multiple alternate relations in this empirical classification effort.
Further categorization can be accomplished by going into more particular definitions, arriving in the end at a very complex network.
25
Abort, cancel,close, cut,
deactivate, disable, dismantle, end,exit,
go to sleep, halt, interrupt, lock, logout,
power down, restrict,spend, stop,
Activate, animate, begin, boot, boot up, create, enable, enter, execute,
generate, load, make available, open,
play back, pop up, react, release, run, start,
turn on, use, wake up.
Recover, repare, restore, return,
undelete, undo, unlock
Browse, find,
locate,
Bypass, go,
march
Access, bind, call,connect, dial, dial
into, fax, mail, notify, reference, link, join, invoke,
send, signal, telephone, transmit,
upload, download
Delete, eliminate,
erase, remove, uninstall
Iterate, repeat, replay,
Analyse, decode,
discover, examine, follow,
identify, learn, read,
recognize, understand
manufacture, perform, produce,
pursue, treat
Alternate, change, compile, convert, export,
extract, port, translate,
transpose, reverse
Adapt,adjustcenter, drag, insert, invert,
justify, merge, mix,
modify, paste, scroll, shift. update
Copy, film, photograph,
read
Abstract, define, describe,
design, induce, map, mirror, model, recall,
represent, visualize
Audit, configure, control,
coordinate, distribute,
economize, improve, maintain, manage,
manipulate, optimize,
organize, plan, regulate,
set, set up, structure
Accelerate, rename,
shape, format, filter,
synchronize
Authenticate, authorize, check,
compare, indicate,
measure, prove, test
Correct, inform, specify,
teach
Collect, document, input, list, log, mark,
place, print, protocol, receive, record,
register, write
Automate, calculate,
count, divide, enumerate, program,
rank, select, separate
Compress, encode, encrypt, protect
Add,attach, group, save, secure, store
Do
Figure 4.1: A Classification of Verbs Used in Information Technology

26
Chapter 5 Case Based Reasoning
When faced with a problem situation, human beings often remember how they were able to solve a similar problem, instead of re-thinking the whole situation. Case Based Reasoning (CBR) is motivated precisely by this experience, and constitutes a decision support that uses earlier experiences, or cases, as the basis to make decisions. A definition can be “To solve a new problem by remembering a previous similar situation and by reusing information and knowledge of that situation “20.
Case Based Reasoning is a cyclic and integrated process of solving a problem and learning from this experience.
5.1 Cases
A case is an abstraction of an event, limited in time and space. It can either be a previously encountered and solved problem, or a typical way of solving a problem. The differences in notation will be evident from the different methods of CBR, outlined hereafter.
A case consists of a description, an associated solution, and the justification for the solution where the justification is an explicit representation of the problem solving process. It can refer to other cases, textual explanation or to general rules. Cases can be described in a variety of languages, and be represented as data tables or with a structure such as a tree. Cases can be either positive or negative experiences, or both21.
5.2 Methods
Case Based Reasoning can be divided into different methods, which can be discriminated by their dependency on a large number of cases, domain knowledge and whether they are able to modify solutions to suit new problems. 22 Exemplar-based reasoning: CBR is seen as the task of classifying a new case into a given set of classes which consists of previously experienced (prototypical) cases. The classes represent the set of possible solutions, and it is therefore not possible to modify a solution. This method is useful for weak theory domains. Instance-based reasoning: A highly syntactic specialization of Exemplar-based reasoning without domain knowledge. Memory-based reasoning: The collection of cases is seen as a large memory, and reasoning consists of accessing and searching the memory.
20 Extracted from [1]. 21 [12] gives a thorough definition of cases, with examples. 22 See [1] for details.
27
Case-based reasoning: Typical CBR systems have some richness of information and a certain complexity in their internal organization. They are able to modify, or adapt a retrieved solution when it is used to solve a problem with another context than described in the case. Analogy-based reasoning: Methods that are able to solve problems by using experience from a different domain.
The first three methods typically require more recorded cases than the latter two, because they lack domain knowledge. A Case Based Reasoning method that relies heavily on domain knowledge is called knowledge rich. If the system relies heavily on cases, it is called knowledge poor.
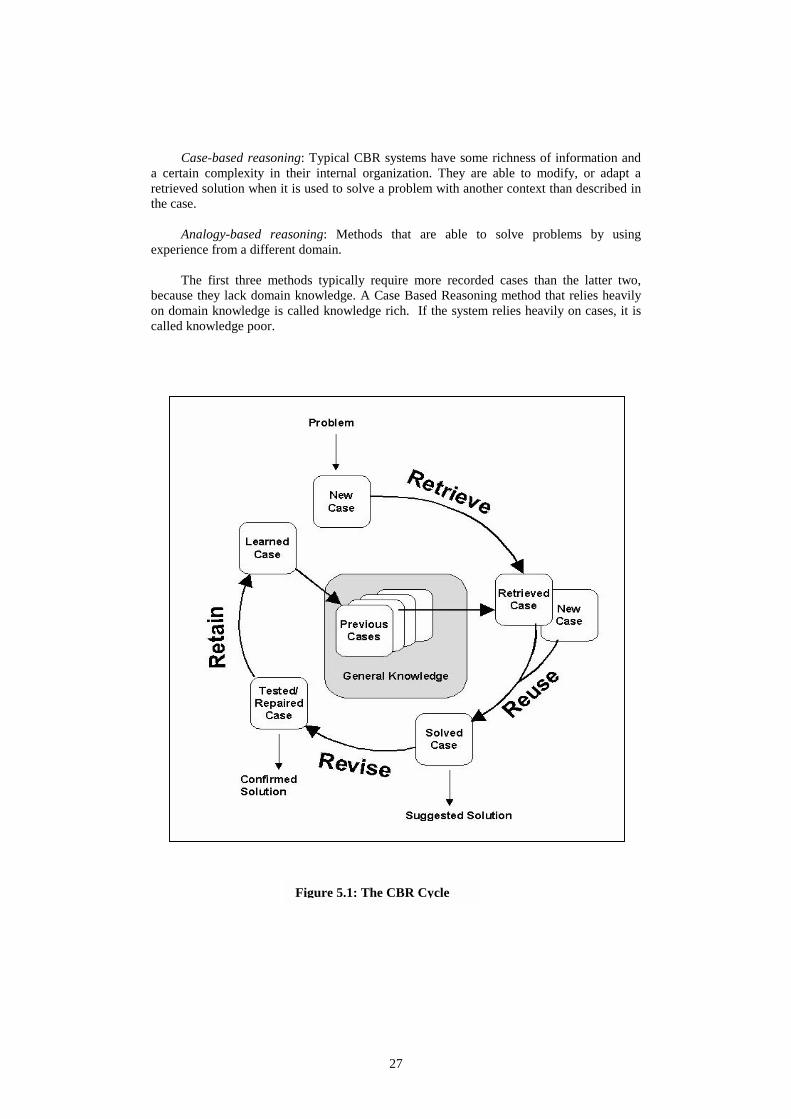
Figure 5.1: The CBR Cycle

28
5.3 Decomposition of CBR
Case Based Reasoning methods can be divided into four steps: �� Retrieve: find the best matching of a previous case, �� Reuse: find what can be reused from old cases, �� Revise: check if the proposed solution is correct, and �� Retain: learn from the problem solving experience.
This decomposition of methods is illustrated in Fig 5.1. 23
Before outlining the substructures, it will be explained how cases are indexed, which is vital for fast retrieval of cases. In order not to search through all cases in the case base (in linear time), some features are selected for organizing the cases into a tree. Similar cases can then be found by traversing the tree instead of searching the whole case base. Retrieve
Retrieving a case means to start with a (partial) new case, and retrieve the best matching previous case. It involves the following subtasks: �� Identify features: this may simply be to notice the feature values for a case, or can be a
more complex evaluation that tries to “understand” the problem in a context. This can be filtering out noisy problem descriptors, inferring other relevant problem features, checking whether the feature values make sense in the given context, or generating expectations of other feature values. The checking might be done against a knowledge model (cases or general knowledge) or by asking the user.
�� Initial match: usually done in two parts. First an initial matching process gives a list of
possible candidates, which are then further examined to select the best. Matching cases can be found by comparing with input features or input features and features inferred from others using domain knowledge. The features can be compared using some similarity measure, which is usually normalized, for instance to the range [0,1], so that it is easy to compare cases based on several or all features. The case based reasoner can try to ``understand'' the problem, and use this understanding in comparing. It can also weigh the input features.
�� Select: select a best match from the cases returned by the initial match. The reasoner
tries to explain away non-identical features. If the match is not good enough, a better one is sought by using links to closely related cases. The selection process can generate consequences and expectations from each retrieved case, by using an internal model or by asking the user.
Reuse
The focus of reuse is to find the difference between the new and the old case, and find what part of the old case that can be used in the new case. It involves either copying the old solution or adapting it: �� Copy: in simple classification, the differences between the old and new case are
abstracted away, and the solution is simply copied from the old case. 23 Depends heavily on [1].

29
�� Adapt: either the solution itself can be (transformed and) reused, or the past method
that produced the solution can be used. Revise
If the solution generated by the last phase is not correct, the system can learn from its failures. This involves: �� Evaluation: try the solution proposed by the reuse-phase in the real environment, and
evaluate it. �� Repair fault: If the solution evaluated badly, find the errors or flaws of the solution,
and generate explanations for them. Retain
Incorporate what is useful to learn from the problem-solving experience into the existing knowledge. The sub-processes are: �� Extract: if the problem was solved using an old case, the system can build a new case,
or generalize an old case to include the new case as well. If the user was asked, a new case should be constructed. Explanations may be included in the case.
�� Index: decide what types of indexes to use for future retrieval. �� Integrate: modify the indexing of existing cases after the experience, strengthen the
weight of features that were relevant, and decrease the weight of features that lead to retrieval of irrelevant cases.
5.4 A Case Based Reasoning Tool
As more individuals, as well as companies, turn to digital media seeking a solution to the dissemination of information, new methods to bridge the gap between very distinct communication modes arises. “One extreme is the direct, one-to-one conversation between an individual customer and a well-trained sales person. The other extreme is the mass distribution of anonymous information to the customer via broadcast media like advertisements, product fact sheets or product catalogs”24.
Several software systems today address human-computer interaction based on artificial intelligence techniques. For a description of advances in research and applications, refer to [1]. A CBR system from TECINNO25 called CBR-Works 4 Professional was chosen to develop a sample application that can analyze syntax and semantics of problem definitions in online help or printed manual indices.
5.4.1 CBR-Works 4 Professional
Based on the idea that information systems should behave as intelligently as human experts, to solve users’ problems, TECINNO develops CBR application development software for database access, text indexing, product catalogs, online shops and customer support. Figure 5.2 shows the architecture of this system
24 [10] Proposed a fuzzy logic approach as decision support for customers of an online catalog. 25 http://www.tecinno.com

30
These applications store and maintain cases, and import cases from standard database
systems. Data stored in such databases can be used to feed a case base with the relevant content. Cases are generated from existing data and may be further refined or enhanced. If no data for the intended application are available from existing sources, then the authoring environment of CBR-Works 4 provides a modeling environment.
The CBR kernel provides the core functionality of all CBR-Works products and
applications and is implemented in an object-oriented manner. As a basis, new applications serve as a set of modules that can be easily tailored for custom solutions.
CBR-Works 4 is designed primarily for decision support with databases. It offers
access with object-oriented models, integration via standard interfaces using an ODBC-DB connection and is configurable for network use.
The user can design knowledge models and application interfaces with its graphical
browsers. It is mainly designed for developers, administrators and experts of CBR solutions, but also has wizards and tools to ease the building of CBR applications. It contains an integrated rule engine for modeling dependencies for concrete applications and an integrated Web server for Intra- and Internet applications.
Figure 5.2: CBR-Works Application Architecture

31
5.5 CBR Applied to Syntax Analysis Before building an application to analyze the previously defined grammar, the terminology used by CBR-Works must be explained. Terminology
• = By domain we denote the subject area of an application. The world of English phrases is the working domain of this project.
• = The application is the software product hat is built using the CBR-Works tools. • = The case base is the database where the case data is stored. In this study a single
help topic in an online or printed medium will be a case. • = The model contains all information describing the relations among case data and
the terminology of a domain. • = A model will be described in terms of concepts, attributes and types. These
correspond to the way phrases were described earlier: a phrase (problem definition) is the concept of our domain. A syntax category is represented by an attribute of the concept. The value range of an attribute is given by a type.
When building an application, the construction of a domain model is the first step. The
second step is the case collection.
Figure 5.3: Basic Structure of a CBR-Works Application

32
User Interface Four separate interfaces provide easy to use elements for modeling concepts and types, case base management, and case based retrieval:
• = Concept Manager: serves as an editor to build the concept part of the model. • = Type Manager: serves as an editor to define the types and their similarity measures
being used in the model. • = Case Explorer: provides the tools to manage the case base. • = Case Navigator: offers operations to retrieve cases either by filling out a query or
being guided by a query wizard. Case Query Language CBR-Works uses the standardized exchange language CQL, developed for CBR applications. It provides communication between CBR-Works servers and clients as well as serving as interface language between the CBR-Works components.26 It is an object oriented language for storing and exchanging the domain model description and cases in form of ASCII files, and transportation of model and cases between servers and clients.
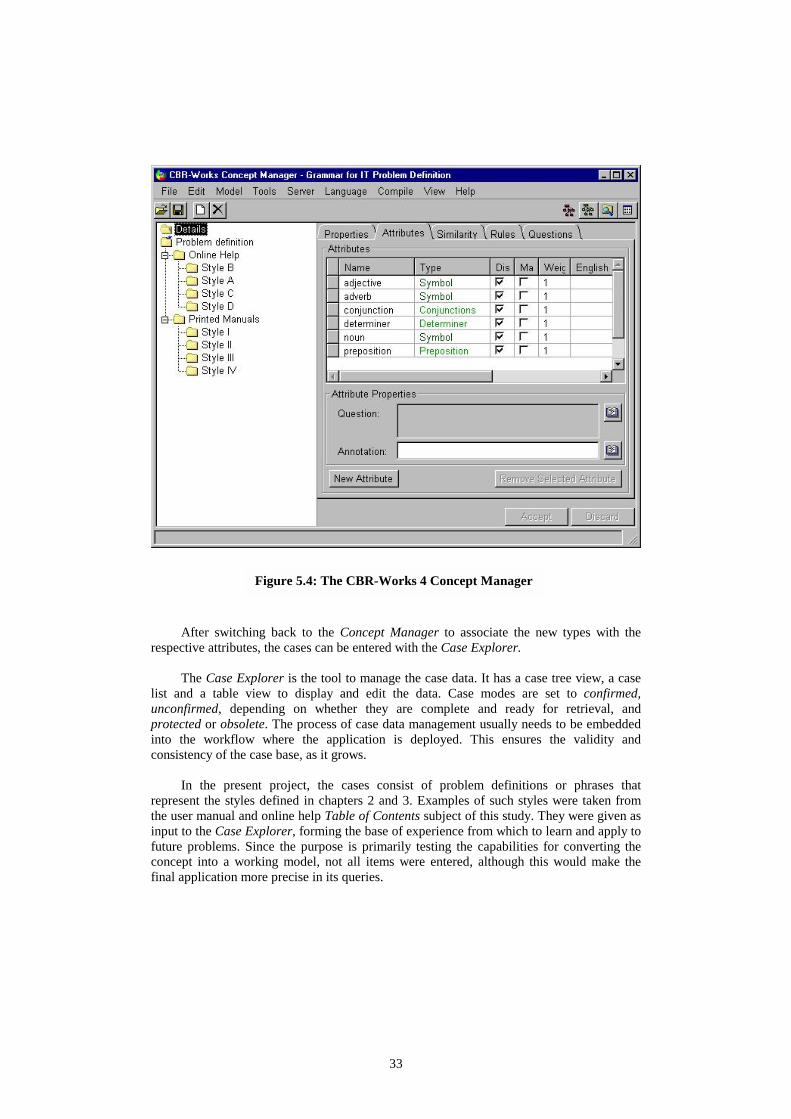
Building an Application First, the Concept Manager must be opened to enter the main information about the features of our application model. It shows the hierarchy of concepts in a tree view. The properties have to be defined, attributes, similarity, rules and questions. The properties include the author and annotations for documentation purposes. The attributes are placed in a table, where its name, type, weight, etc. are specified. The similarities are used in CBR as the similarity between a query (new problem) and a case. Rules are used for completion and adaptation of the cases. Completion rules are used to complete a case or query from the case base. An adaptation rule can be used to derive a new result from the query and retrieved cases. Finally, questions are used when performing queries of the case base. Figure 5.4 displays the Concept Manager screen with a tree view of our case: the expressions used to define problems in IT-related information sources.
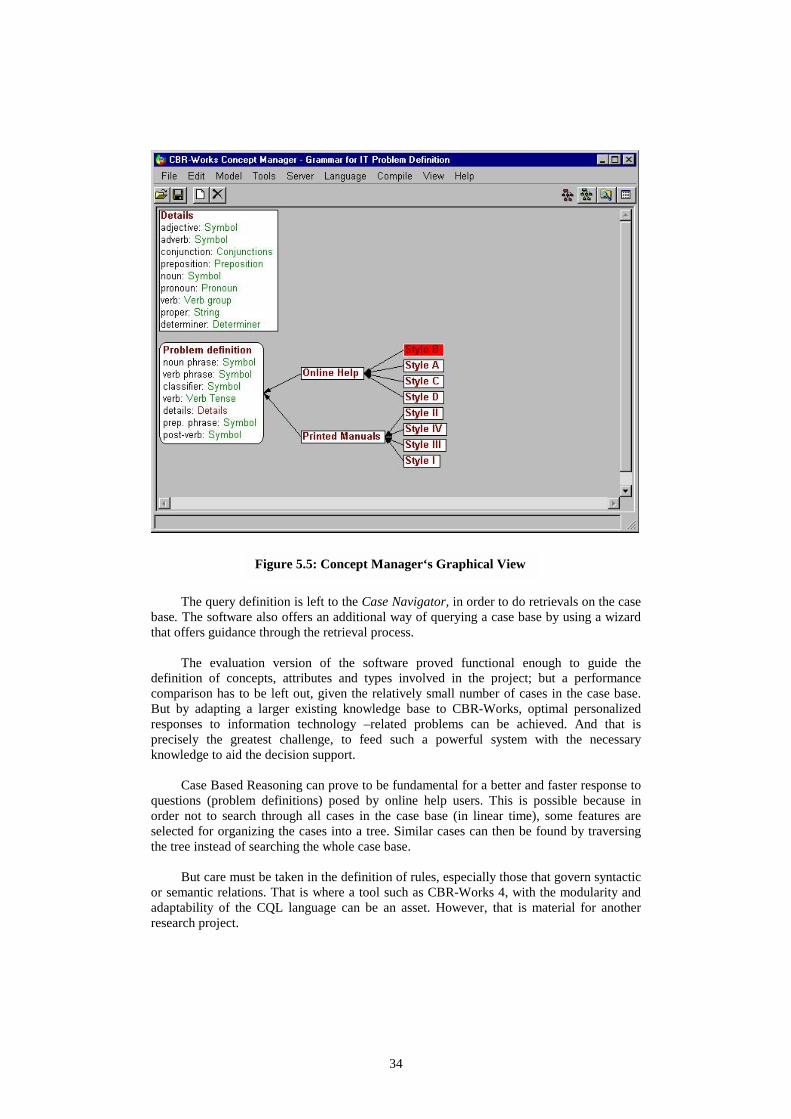
As explained in previous chapters, Information Technology related documentation can be classified in printed and online (computer based). Our study shows there are certain styles that appear more often in each, as reflected in their indices or Table of contents. Figure 5.5 is a graphical representation generated by CBR-Works for our model. Application specific types are always subtypes of some other already defined types, which means there are range restrictions of existing types. The Preposition type is a subtype of the predefined type Symbol that restricts the value range of Symbol to an enumeration of valid preposition symbols like about, at, before, on, over, through, etc
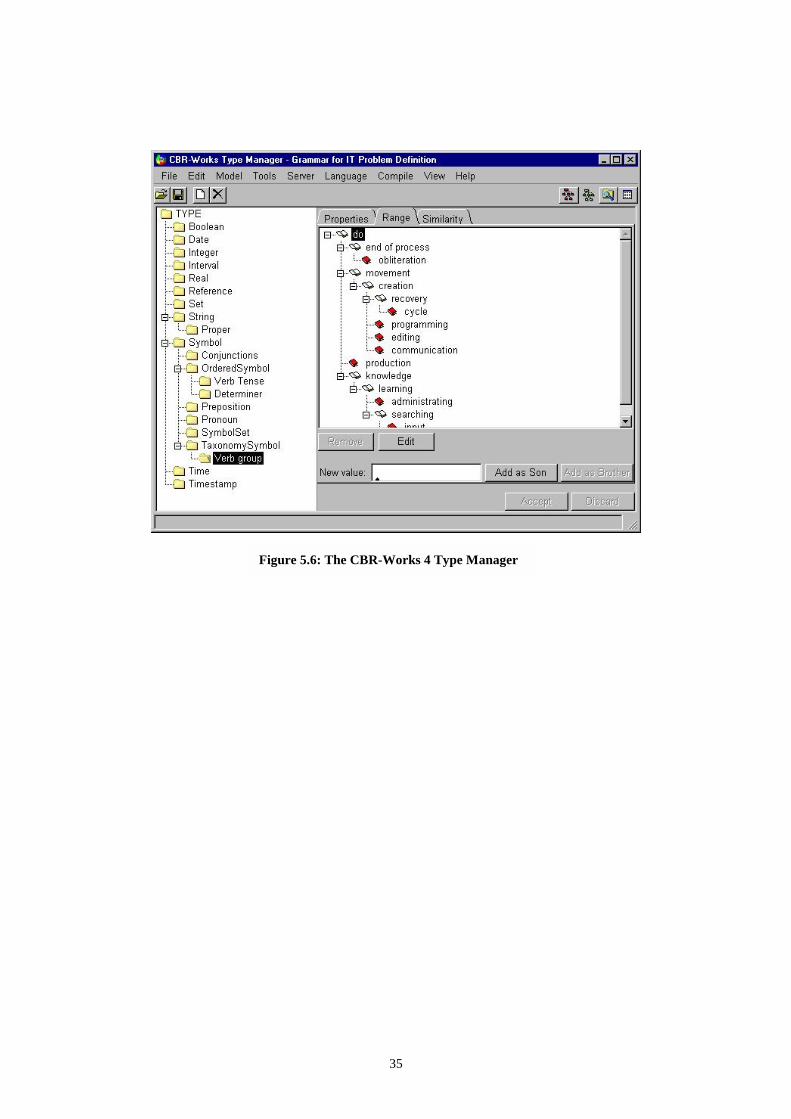
To define a new type the Type Manager must be used, where the predefined types are organized in a tree structure. After selecting the type that will act as super-type, say TaxonomySymbol the properties are set, range and similarity for our application. The type TaxonomySymbol is ideal to pursue a semantics classification of IT related verbs.27 Figure 5.6 shows how CBR-Works displays such a type hierarchy.
26 Taken from the CBR-Works 4 Reference Manual. 27 See Chapter 4.
33
After switching back to the Concept Manager to associate the new types with the
respective attributes, the cases can be entered with the Case Explorer. The Case Explorer is the tool to manage the case data. It has a case tree view, a case
list and a table view to display and edit the data. Case modes are set to confirmed, unconfirmed, depending on whether they are complete and ready for retrieval, and protected or obsolete. The process of case data management usually needs to be embedded into the workflow where the application is deployed. This ensures the validity and consistency of the case base, as it grows.
In the present project, the cases consist of problem definitions or phrases that
represent the styles defined in chapters 2 and 3. Examples of such styles were taken from the user manual and online help Table of Contents subject of this study. They were given as input to the Case Explorer, forming the base of experience from which to learn and apply to future problems. Since the purpose is primarily testing the capabilities for converting the concept into a working model, not all items were entered, although this would make the final application more precise in its queries.
Figure 5.4: The CBR-Works 4 Concept Manager
34
The query definition is left to the Case Navigator, in order to do retrievals on the case base. The software also offers an additional way of querying a case base by using a wizard that offers guidance through the retrieval process. The evaluation version of the software proved functional enough to guide the definition of concepts, attributes and types involved in the project; but a performance comparison has to be left out, given the relatively small number of cases in the case base. But by adapting a larger existing knowledge base to CBR-Works, optimal personalized responses to information technology –related problems can be achieved. And that is precisely the greatest challenge, to feed such a powerful system with the necessary knowledge to aid the decision support.
Case Based Reasoning can prove to be fundamental for a better and faster response to questions (problem definitions) posed by online help users. This is possible because in order not to search through all cases in the case base (in linear time), some features are selected for organizing the cases into a tree. Similar cases can then be found by traversing the tree instead of searching the whole case base.
But care must be taken in the definition of rules, especially those that govern syntactic or semantic relations. That is where a tool such as CBR-Works 4, with the modularity and adaptability of the CQL language can be an asset. However, that is material for another research project.
Figure 5.5: Concept Manager‘s Graphical View
35
Figure 5.6: The CBR-Works 4 Type Manager

36
Conclusion
Together with user manuals, online help systems are the basic aids used by information technology product vendors to close the gap between the expectations of the consumers and the company’s technical support or sales staff.
User manuals are easier to scan through, have no restricted pattern of response, and
are more procedural. They do not compete for screen area. Online help systems are not a substitute for printed documentation, but can reduce the amount of paper required and also make programs easier to understand and use. Often the best results are achieved by using both media together.
Syntax studies how words fit together to form structures up to the sentence level. A
context free grammar was presented, that can analyse all of the phrases in our project: a subset of the English language. But its concepts and rules are generally applicable. The syntactic structure of the most often used expressions in the Table of contents of printed software manuals and online help systems were analysed using a tree structure. These can be classified into eight styles. Complete sentences are rarely used, rather verbal or noun phrases are preferred.
Semantics studies the meaning of words. A taxonomy was developed, which can be
used to structure the most common tasks and problems encountered by software users, according to a semantic relationship tree. These relationships could then be applied to the Find feature of online help systems, as well as catalogs or web based search engines to encounter conceptual similarities.
The underlying principle of Case Based Reasoning (CBR) is expressed by the common life idea that “similar problems have similar solutions”. It tries to model behaviour by experience and its methods can be divided into four steps: retrieve, reuse, revise, and retain a case. A CBR modeling environment called CBR-Works 4 was evaluated. It is also an application development software for database access, text indexing, product catalogs, online shops and customer support.
Case Based Reasoning can lead to a better and faster response to questions (problem
definitions) posed by online help users, if special care is taken in the definition of rules, especially those that govern syntactic or semantic relations. Such improvement can be seen in recently developed business-related applications, such as intelligent assistants for customer support, sales and knowledge management.
A next step would be to port the whole Table of Contents of an online help system, as
a database, into CBR-Works, and measure its query performance versus the usual methods. If an automatic collection of cases and rules from experts in a given topic is accomplished, this would certainly add to the personalization of updated responses to queries on users’ problems with the technology. CBR becomes very useful when the context of an expression change, leading to insufficient criteria for decision support based on syntax or semantics alone.

37
Appendix List of English Verbs
abortabstractaccelerateaccessactivateadaptaddadjustalternateanalyseanimateattachauditauthenticateauthorizeautomatebeginbindbootboot upbrowsebypasscalculatecallcancelcenterchangecheckclosecollectcomparecompilecompressconfigureconnectcontrolconvertcoordinatecopycorrectcountcreatecutdeactivatedecodedefinedefragmentdeletedescribedesigndialdial intodisable
discoverdismantledistributedividedocumentdownloaddrageconomizeeliminateenableencodeencryptendenterenumerateeraseexamineexecuteexitexportextractfaxfilmfilterfindfollowformatgenerategogo to sleepgrouphaltidentifyimproveindicateinduceinforminputinsertinterruptinvertinvokeiteratejoinjustifylearnlinklistloadlocatelockloglogout
mailmaintainmake availablemanagemanipulatemanufacturemapmarchmarkmeasuremergemirrormixmodelmodifymonitornotifyopenoptimizeorganizepasteperformphotographplaceplanplay backpop upportpower downprintproduceprogramprotectprotocolprovepursuerankreactreadrecallreceiverecognizerecordrecoverreferenceregisterregulatereleaseremoverenamereparerepeatreplay
representrerunrestorerestrictreturnreusereversereviewroamrunsavescanscrollsearchsecureseekselectsendseparatesetset upshapeshiftsignalspecifyspendstartstopstorestructuresynchroniseteachtelephoneterminatetesttranslatetransmittransposetreatturn offturn onundeleteunderstandundouninstallunlockupdateuploaduseverifyvisualizewake upwrite

38
Bibliography
[1] Aamodt, A.; Plaza, E. Case-Based Reasoning: Foundational Issues, Methodological Variations, and System Approaches. AICom - Artificial Intelligence Communications, IOS Press, Vol. 7: 1, pp. 39-59. 1994.
[2] Abdullahi, Usman; Alty, James. How Useful is Online Help?: An Observational Study. IEEE Electronic Library. 1998. http://www.ieee.org
[3] Beardon, Colin. Natural Language and Computational Linguistics, an Introduction. Ellis Horwood Limited. London. 1991.
[4] Bennet, Paul. A Course in Generalized Phrase Structure Grammar. Studies in Computational Linguistics. UCL Press, London. 1995.
[5] Darling, Charles. Guide to Grammar and Writing. http://webster.commnet.edu/HP/pages/darling/grammar.htm
[6] Gómez-Pérez, Asunción. Knowledge Sharing and Reuse. The Handbook of Applied Expert Systems. Jay Liebowitz, editor. CRC Press LLC. 1998.
[7] Grefenstette, Gregory. Explorations in Automatic Thesaurus Discovery. Kluwer Academic Publishers. Boston. 1994.
[8] Kolln, Martha. Understanding English Grammar. 4rth Edition. MacMillan Publishing Company: New York. 1994.
[9] Lloyd, Susan. rev. Roget’s Thesaurus by P. M. Roget. Penguin Books, Ltd. England. 1984.
[10] Mansfield, Ron. Working in Microsoft Office. Osborne McGraw-Hill. 1996.
[11] Matthes, Florian; Steffens, Ulrike. PIA- A Generic Model and System for Interactive Product and Service Catalogs. 1999.
[12] Mishel, Jim. The Developer‘s Guide to WINHELP.EXE. John Wiley & Sons Inc. 1994.
[13] Suan Ong, Lean and Desai N., Arcot. Case Based Reasoning. The Handbook of Applied Expert Systems. Jay Liebowitz, editor. CRC Press LLC. 1998.
[14] Weber, Owen et.al. 1998. SanFrancisco Evaluation Kit (V1R3) Getting Started. International Technical Support Organization. IBM. Rochester, MN.
[15] Zarri, Gian Piero. Natural Language Processing Associated with Expert Systems. The Handbook of Applied Expert Systems. Jay Liebowitz, editor. CRC Press LLC. 1998.