Embed Size (px)
Citation preview

Online Learning in Perception-Action Systems
Michael Felsberg?, Affan Shaukat, and David Windridge
Dept. of Electrical Engineering, Linkoping University,S-58183 Linkoping, Sweden.
Centre for Vision, Speech and Signal Processing, FEPS,University of Surrey, Guildford, UK.
{a.shaukat,d.windridge}@surrey.ac.uk
Abstract. In this position paper, we seek to extend the layered percepti-on-action paradigm for on-line learning such that it includes an explicitsymbolic processing capability. By incorporating symbolic processing atthe apex of the perception action hierarchy in this way, we ensure thatabstract symbol manipulation is fully grounded, without the necessityof specifying an explicit representational framework. In order to carryout this novel interfacing between symbolic and sub-symbolic processing,it is necessary to embed fuzzy first-order logic theorem proving withina variational framework. The online learning resulting from the corre-sponding Euler-Lagrange equations establishes an extended adaptabilitycompared to the standard subsumption architecture. We discuss an ap-plication of this approach within the field of advanced driver assistancesystems, demonstrating that a closed-form solution to the Euler Lagrangeoptimization problem is obtainable for simple cases.
Key words: Perception-Action systems, Artificial Cognitive systems,Fuzzy logics, Euler Lagrange optimization, First order theorem proving.
1 Introduction: Perception-Action Systems
In this paper we propose a new approach for designing layered perception-action(PA) systems incorporating a logic-based symbolic processing component. Lay-ered PA systems represent a state-of-the art extension of the standard sub-sumption architecture [1]. Whereas the latter has generally been focused onfixed-function finite state machines, layered PA systems are more appropriate toadaptive and embodied systems, for which a fixed representational frameworkwould present a serious constraint on learning. Recently, this concept has beendemonstrated to produce continuous learning by exploration and adaptation [2].
Thus, by employing the action-precedes-perception paradigm [3] it is possibleto entirely bypass the issue of representation; in its place is the issue of thephysical grounding of symbols (a symbol in this context being an abstractionof the low-level perception-action coupling through the progressive levels of the
? Corresponding author: Michael Felsberg, URL: http://www.isy.liu.se/˜mfe/.

2 Michael Felsberg, Affan Shaukat, and David Windridge
subsumption hierarchy until it can be manipulated by an appropriate systeme.g. first order logic). Employing concepts defined in [4], the integration of firstorder logic within a PA hierarchy was successfully demonstrated in [5]. However,this system employed PROGOL for first order logic induction with all of itsattendant instability in a stochastic environment. In the present paper, we setout an approach for integrating a fuzzy logic-based first order theorem proverwithin a variational perception action framework (specifically an Euler-Lagrangeframework) in order to overcome these issues of stability. We further demonstratethat a closed form solution is possible in simple cases.
1.1 States and Mappings in Single Layered System
One difficulty in designing cognitive vision systems is the ambivalent terminol-ogy. Therefore, we start by defining a numbers of terms, in particular differenttypes of states.
Virtual system states are states of the system, which do not have a physicalrealization – except for their physical implementation in terms of memory cells– e.g. variables. These states are called hidden states, internal to the estimatorin [4]. Physical system states are states of the system, which have a physicalrealization, e.g. angles of a robotic arm. These states are called hidden states,internal to the world in [4].
states not belonging to a cognitive system
virtual system statesstate mappings
physical system states
actionspe
rcep
ts
cognitive system
physical interaction
virtual system statesstate mappings
physical system states actions
perc
epts
second cognitive system
physical interaction
"world"
Fig. 1. Illustration of cognitive system(s) and terminology used in this paper.
Percepts are virtual representations of observable physical system states.These states are called visible states, external in [4]. Actions are changes ofphysical system states initiated by virtual states. State mappings are mappingstaking percepts and virtual system states as input and delivering virtual systemstates and actions as output. These mappings are called inverse mappings in [4].

Online Learning in Perception-Action Systems 3
A cognitive system is a system consisting of all previous items, where at leasta part of the mappings is learnable and adaptable. Physical states not belongingto any cognitive system are states of the non-cognitive part of the world, or,what we assume as such, e.g. mechanical devices.
Note that percepts and actions are always with respect to system states, i.e.,the interface between physical entities and virtual entities lies within the system.The system interacts with the world through its physical states, i.e., the interfaceto the world is realized by physical interaction of states, e.g., mechanical lawsor transmission of light. All terms and connections are illustrated in figure 1.
1.2 Learning in Single Layered System
The paradigm of action-precedes-perception learning [3] is based on the follow-ing ratio. The aim is to establish mappings from percepts to actions. For thispurpose, both spaces need to be structured.
For the percept space, we know that it has an extremely high-dimensionalextrinsic dimension. Images of size M×N lie in a vector space RM×N . We knowfurther that natural images form a manifold of significantly smaller dimensionthan their extrinsic dimension, but still of high-dimensional intrinsic dimension.The topology of the manifold of natural images is highly complex, includingdiscontinuities, wormholes etc. caused by e.g. occlusions.
Hence, learning percept space from percepts only is a very hard problem,including many local minima and problems of convergence. The high dimen-sionality requires lots of data for learning and the discontinuities make simplemethods like gradient descent fail in general.
For the action space, we know that it has a low-dimensional extrinsic dimen-sion. Action space usually covers few degrees of freedom. Systems with morethan a few 10 dimensions seldomly occur and more than 100 dimensions arehardly ever seen. Actions are performed in a sequence, which has an intrin-sic dimension of 1 and is parametrized by time. The action manifold is highlyfolded, but continuous due to its connection to the physical layer.
Hence, learning action space is a feasible problem and consequently, it is easierto learn percept-actions mappings backward, i.e., by starting from the actionside. This can be done in three different ways. In cognitive bootstrapping we faceentirely unknown mappings and establish them by performing random actions,observing the corresponding percepts, and adding associations for appropriatepercept-action pairs. This can only be done as offline learning. During explorationwe face incomplete mappings and add new mappings by performing randomactions and continue as in the bootstrapping case. This corresponds to switchingbetween ”working” and ”learning” and thus, this is a type of interleaved learning.Finally, and central to this paper, in adaptation we face non-perfect mappingsand improve them by varying actions and update existing associations. Thisshould happen continuously and corresponds to real online learning.

4 Michael Felsberg, Affan Shaukat, and David Windridge
2 A Layered PA System
In this section we extend the learning-based PA system structure as suggestedin [2] to several layers. This extension is required as adaptation requires top-downcontrol. The presented ideas show large overlap with the structure presentedin [6] with the main difference that the cited work only considers perception.
2.1 States and Mappings in Multi-Layer System
The major change in terminology compared to the previous section is the ex-tension of percepts and actions to higher levels. Furthermore, the terms controland feedback are introduced. Percepts are virtual representations at level n ofobservable system states at level n− 1 if n > 0 or virtual representations of ob-servable physical system states at level 0. Actions are changes of system statesat level n − 1 initiated by virtual states at level n if n > 0 or physical systemstates initiated by virtual states at level 0. Feedback is the output of level n thatis considered as percepts at level n + 1 and control is the input to level n thatis considered as actions at level n+ 1.
level 0 system statesstate mappings
physical system states
a cf
p
cognitive system
level 1 system statesstate mappings a cf
p
level 2 system statesstate mappings a cf
p
level n-1 system statesstate mappings a cf
p
Fig. 2. Layered system architecture and related terminology: percepts (p), actions (a),feedback (f), and control (c).
These concepts allow us to build a system with several layers of virtual statesand mappings, as illustrated in figure 2. Note that level 0 can be considered as aninnate (engineered) level and n grows with time. Note also the similarity to thesubsumption architecture [1] with the major difference that the latter is usingfinite state machines.
2.2 Learning in Multi-Layered System
The considered system does not have distinct modes for learning and working.From the beginning, it has no capabilities except for level 0. This level can be

Online Learning in Perception-Action Systems 5
considered as a (virtual representation of) physical state predictor. Whenever theprediction fails, a feedback is triggered to level 1, indicating a need for changingthe control of level 0, i.e., requesting an action at level 1. In this way, level 1 isembedded in a percept-action cycle and acts as a predictor for level 0 states. Thisleads to bootstrapping of level 1, using the mechanisms described earlier. Whenthe level 1 predictions start to work, bootstrapping of level 1 can be consideredcompleted.
The feedback of level 1 (being sent to level 2), becomes stronger with timeand eventually triggers a similar bootstrapping process at level 2. Meanwhile,level 1 still adapts, continuously trying to improve its predictions. By sendingdifferent control signals from level 2 to level 1, level 1 develops different modesof prediction, i.e., it starts to make different predictions based on the top-downcontrol. If the feedback from level 0 (the percept of level 1) becomes strongerthan a triggering threshold, level 1 will generate a new mode of prediction, thusexploratory learning is applied as described earlier.
Repeating this procedure through more and more levels lead to a system withincreasingly better capabilities w.r.t. solving a task of appropriate complexity.It is important to choose the complexity such that exactly one new level needsto be generated in each step, otherwise learning might become slow or entirelybreak down, very similar to learning in humans.
2.3 Adaption of a Layer
The central part of online learning is the adaptation process performed by asingle layer m. Thus, we restrict our system diagram to a single layer in figure 2.Note the similarity to PAC modules [7] with the difference that in PAC modulesthe feedback is part of the action output, i.e., the percept at level m was givenby a part of the action at level m− 1, instead of the feedback from level m− 1.We call the extended PACs PACFs in what follows.
Similar to the PACs, the PACFs are related to the Neisser perceptual cycle [8]and can be interpreted as an abstract tracking process that is looping throughthe reflexive transitive closure of (state – system model – prediction – matches –observation – update). The matching of predictions and observations (percepts)defines the internal modelling error and drives adaptation and feedback. Smallerrors lead to adaptation, whereas large errors lead to feedback and explorationor bootstrapping at the next higher level.
Let us define: pt is the percept at time t (I in [4]), rt is the internal state attime t, at is the action at time t, ct is the control at time t, ft is the feedbackat time t, and pt is the expected percept a time t. Furthermore, we define twomappings: v is the internal state update
rt+1 = v(ct, ρ(pt − pt), rt) , (1)
where ρ is some error function. u is the prediction generation
pt = u(rt) , (2)

6 Michael Felsberg, Affan Shaukat, and David Windridge
and the action and feedback is given by (a subset of) pt and r(t), respectively.The feedback, i.e., r(t), influences the state vector rt+1 and leads to internal
adaption through (1). Furthermore, it might lead to changes in the control signalfor a future time step (ct+tc). Actions might lead to new percepts with unknowndelay pt+tp . A scheme for two interacting PACFs is illustrated in figure 3.
GM
detec-tions
r
predic-tions
z−1
u
v
ρ
SP
rlog
plog
z−1
u
v
ρ
symbolic output
cf
Fig. 3. State diagram of two interacting PACFs. Note that in the upper part plog
corresponds to f . In the lower part, p corresponds to detections and p to predicteddetections. z−1 denotes a unit time delay.
The goal of each layer is to achieve a low prediction error ρ(pt − pt) and atthe same time to update the internal state as little as possible. The first criterionis obvious: if the prediction error is low, the system provides good predictions ofpercepts caused by its actions, i.e., the system shows a high degree of flexibilityto model percept-action loops. The second point might be less obvious, but haspartly been discussed in [4] and can be further motivated by minimizing effortsto change the system and by implicitly requiring the control to be smooth.
One implication of the action-precedes-perception paradigm is that actionsare continuous for consistent trajectories through percept space. However, per-cept space is discontinuous and therefore it is easier to measure the consistency ofpercept sequences by continuity of actions. Therefore, we consider fewer changes

Online Learning in Perception-Action Systems 7
of the control signals as an indicator for correct feedback. This corresponds tothe generalization capability of the layer under consideration.
Hence, we obtain a classical generalization versus flexibility tradeoff, a typicalbias-variance dilemma.
2.4 An Implementation of Learning
One possibility to formulate the learning problem that we face is in terms ofan objective function that is to be minimized. Obviously, we would like to havea good prediction independently of what the control ct and the percept pt are(fidelity). Furthermore, small changes in the percepts should result in smallchanges of the internal state r. These requirements result in
ε(u, v) =∫Ψ(|∇prt+1|) + ρ(pt − pt) dct dpt , (3)
where Ψ is some error norm applied to the gradient of r, e.g. the L1-norm (whichwill basically count the occurrences of changes of r). In order to optimize thisequation, we plug in (1) and (2)
ε(u, v) =∫Ψ(|∇pv(ct, ρ(u(rt)− pt), rt)|) + ρ(u(rt)− pt) dct dpt . (4)
The control signal ct is obtained from the SP (logic) layer as a function of theprevious state rt−1 (cf. fig. 3): ct = L(rt−1) with the Jacobean J(rt−1) = ∂ct
∂rt−1.
Substituting ct and v(rt−1, u(rt), pt, rt) = v(L(rt−1), ρ(u(rt)−pt), rt), we obtain
ε(u, v) =∫{Ψ(|vp(rt−1, u(rt), pt, rt)|) + ρ(u(rt)− pt)}J(rt−1) drt−1 dpt . (5)
We compute the Euler-Lagrange equations (where we omit the argument of v)
0 = εu = {Ψ ′(|vp|)vp|vp|
vp,u + ρ′(u(rt)− pt)}J(rt−1) (6)
0 = εv = −divp
{Ψ ′(|vp|)
vp|vp|
}J(rt−1) = −Ψ ′′(|vp|)vppJ(rt−1) (7)
In order to get the equations for v instead of v, we substitute v back. Note thatvp = −vρρ′. Finally, we obtain the mappings u and v by gradient descent:
unew = uold − αεu (8)vnew = vold − βεv (9)
for some suitable step-lengths α and β which might also vary with time. Again,terminology is adapted to [4]. If we use a linear model for u giving u(rt) = urrt,the two updates contain (18) and (19) in [4] as special cases.
Looking at the Euler-Lagrange equation (6) and (7) in more detail, we seethat the Jacobian of the next higher level directly influences the updates of

8 Michael Felsberg, Affan Shaukat, and David Windridge
the mapping u and v: it might suppress or amplify updates depending on therelevance for the further processing. How this Jacobean is obtained in a logicsystem will be part of the remainder of the paper.
The influence of internal entities of the subsymbolic part can be understoodas follows: The first term in (6) and the term in (7) have a smoothing effect onv and u, whereas the second term in (7) improves fidelity.
3 The Logic Module
We will demonstrate how fuzzy theorem proving within the SP module maybe linked to the PACF module immediately below it, thereby demonstratinghow symbolic logic can be integrated within the Euler Lagrange framework. Inorder to do this it is necessary to quantify, in closed-form, the effects of logicalresolution with respect to a given query. We do this as follows.
3.1 Fuzzy Theorem Proving
Fuzzy logic is the logic applicable to fuzzy sets, i.e. sets for which there are degreesof membership. This is usually formulated in terms of a membership functionvalued in the real unit interval [0, 1]. Various fuzzy logics are possible withinthis framework; membership functions (and therefore truth values) can be singlevalues, intervals or even (most generally) Borel sets within the unit interval [0,1]. [9] argues that fuzzy logic programming is well suited to the implementationof methodologies relating to reasoning with uncertainty.
The propagation of truth values through logic rules is carried by means of anaggregation operator. The aggregation operators subsumes conjunctive operators(T-norms; min, prod etc) or disjunctive operators (T-conorms; max, sum, etc)and hybrid operators (combination of previous operators) [10].
The concept of aggregation operator also extends to the notion of implication,which is implemented as a residuum of the t-norm. A left-continuous t-norm T(i.e. an intersection of two fuzzy sets say x and y) is generally specified by abinary operation on the unit interval; i.e., it is a function of the form [11],
i : [0, 1]× [0, 1]⇒ [0, 1]thus there is a unique binary operation ⇒ on [0, 1] such that,
T (γ, x) ≤ y iff γ ≤ (x⇒ y), ∀(x, y, γ) ∈ [0, 1]. (10)
The operation above is known as the residuum of the t-norm. The residuum ofa t-norm T is generally denoted by R. The residuum R of a t-norm T forms aright adjoint R(x,−) to the functor T (−, x) for each x in the lattice [0, 1]. Instandard fuzzy logic, conjunction is generally interpreted by a t-norm T whereas the residuum R defines the role of implication. If ⇒ defines the residuum ofa left-continuous t-norm T , then
(x⇒ y) = sup{γ | T (γ, x) ≤ y} (11)

Online Learning in Perception-Action Systems 9
thus, ∀(x, y, γ) ∈ [0, 1],
(x⇒ y) = 1 iff x ≤ y and (1⇒ y) = y (12)
This allows for the representation of clauses as implication of a head predicatewith respect to a conjunct of body literals. Consequently, modus ponens argu-ments and (more generally) theorem proving via resolution are thus achievablewithin fuzzy logic.
3.2 Fuzzy Prolog Syntax
We implement our method within Ciao Prolog or Fuzzy Prolog system, whichprovides a complete library of fuzzy logic semantics amalgamated with completeProlog system supporting ISO-Prolog [10]. Given that A is an atom then a fuzzyfact can be represented as, A← υ, where as υ is a truth value, an element in theBorel Algebra, B([0, 1]), which can be considered as the power set of the sets ofcontinuous subintervals on [0, 1] [12].
If A,X1, ..., Xn are atoms,
A←F X1, ..., Xn (13)
represents a fuzzy clause where F is an interval-aggregation operator of truthvalues in B([0, 1]), defined as constraints over the domain [0, 1]. F here, inducesa union-aggregation [10]:
F′(B1, ..., Bn) = ∪{F (ε1, ..., εn)|εj ∈ Bj} (14)
A fuzzy query is a tuple, if A is an atom, and υ is a variable representing a truthvalue in B([0, 1]), then a fuzzy query is represented as,
υ ← A? (15)
A fuzzy program is a collection of facts and rules (i.e. a subset of the Herbrandbase mapped into B([0, 1]) along with a set of clauses).
Meaning is interpreted as the least model of a program; the concept of ’least’being defined under set inclusion with regard to subsets of the Herbrand baseand under lattice inclusion with respect to fuzzy values within the Borel setB([0, 1]).
This is defined in [10] as follows; if TP is a one-step logical consequenceoperator for the fuzzy program, P such that TP (I) = I ′ with I ′ =< BI′ , VI′ >,then:
BI′ = {A ∈ BP |cond}VI′(A) =
⋃{v ∈ B([0, 1])|cond}
where:cond = A < −v i.e. a ground instance of a fact in P or A < −FA1, A2, . . . An
where F is a ground instance of a clause in P(BP = Herbrand base of P )

10 Michael Felsberg, Affan Shaukat, and David Windridge
The meaning of a fuzzy program, P , is thus its least fixed point, lfp(TP ) = I(TP (I) = I), with respect to the allocation of fuzzy values to predicates from itsHerbrand base, where I is an interpretation i.e. a mapping of truth values to asubset of the Herbrand base.
We thus equate the notion of a least model, I, with stability under theoperation of resolution, such that all facts within I are consistent with eachother, being thus either axiomatic or provable from axioms. This notion willbecome important later when we subsume fuzzy Prolog within a hierarchicalEuler-Lagrange framework, for which I will constitute a set of internal or vir-tual system state representing the logical completion of the sparse fuzzy input’perceptual’ input p. The least model is thus the optimal self-consistent worldmodel on the basis of an Occam’s-razor-like closed world assumption.
3.3 Operational Semantics of Fuzzy Prolog
According to [10], the procedural semantics of Fuzzy Logic incorporating con-straint logic programs can be defined in terms of a virtual interpreter that worksas a sequence of transitions between different states of the system. The state of atransition system in a computation always maintains a tuple 〈A, σ, S〉, where asA is the current goal, σ is a substitution representing the instantiation of vari-ables and S is a constraint store that holds the truth value of the goal at thatspecific state [10]. The current goal A contains the literals that the interpreterhas to prove, along with the constraints it has to satisfy i.e. S; the constraintstore contains all the constraints that have been assumed by the interpreter tothis point. Thus a generic transition is a pair of the tuple (goal/constraint store);〈A, σ, S〉 −→ 〈A′ , σ′ , S′〉. It states the possibility of going from state 〈A, σ, S〉 tostate 〈A′ , σ′ , S′〉.
The computation comprises a sequence of transitions, which starts with A setas the initial goal, σ = Ø and S set to true (with the assumption that there areneither previous instantiations nor initial constraints). The sequential transitionshalt when the first argument A is empty, where as σ and S represent the finalresult. The whole transition process can be more formally defined as follows:
Given that q ← υ is a fact of the program P , and r is a component of thegoal A, θ is the ’most general unifier’ of q and r, and µr is the truth variablefor r,
〈A ∪ r, σ, S〉 −→ 〈Aθ, σ · θ, S ∧ µr = υ〉 (16)
if q ←F B is a rule of the program P , θ is the ’most general unifier’ of q andr, c is the constraint that defines a truth value obtained via the application ofthe aggregator F on the truth variables of B,
〈A ∪ r, σ, S〉 −→ 〈(A ∪B)θ, σ · θ, S ∧ c〉 (17)
if none of the above cases are applicable then the transition fails,
〈A ∪ r, σ, S〉 −→ fail (18)
We implement fuzzy theorem proving within an Euler-Lagrange frameworkas follows.

Online Learning in Perception-Action Systems 11
3.4 Implementing Fuzzy Theorem Proving with a PACF
The complete success set of goals p(x) for a program P is denoted SS(P ) =<B, V > with
B = {p(x)σ| < p(x), ∅, true >→?< ∅, σ, S >}V (p(x)) =
⋃{v| < p(x), ∅, true >→?< ∅, σ, S >}
(→? is the iterated transition sequence from the goal to the empty set).The declarative and operational semantics of Ciao Prolog can be shown to be
equivalent i.e. such that SSP (P ) = lfp(TP ) = I, where the least fixed point I isalso the least model of program P . This means that a self-consistent world modelincorporating the sparse perceptual facts and highwaycode/ECOM rules; (theExtended Control Model i.e., ECOM, suggests that humans employ a hierarchicalperception-action model within the context of driving [13]), can be created viaexhaustive querying. We shall use this to generate the logic-level virtual roadmodel at time t, i.e. V logt , and relate this to a logic-level virtual system state,rlogt used in the PACF.
Thus, V logt = lfp(TP ) where Pt =< ∧t′{Is past(t− t′) ∧ pt−t′ × ft−t′}, R >,such that R is the clause set embodying the highwaycode and ECOM rules ( ∧t′is the union via conjunction over all t′; t′ > 0). P is thus an amalgam of thehistorical perceptual observations and the known a priori rules. ft ∈ {0, 1} is aconsistency-based ’inclusion’ multiplier that determines whether pt is includedin the historical set of percepts (see later). The program Pt is thus regeneratedwith each temporal iteration t = t+ 1. Note that we write pt as a shorthand for< υ′ ← pt, pt > i.e. we always consider the percepts pt along with their fuzzymembership allocations.
We may equate rlogt with Pt via reasoning as follows. A fact g may be amal-gamated with a program P that already embodies the facts F and rules R soas to create a new program P ′ via the relation P ′ = g ∧ P =< g ∧ F,R >. Thelogic-level PACF prediction generation, pt+1 = ulog(rlogt , pt), can thus be mod-elled on the logic layer by updating Pt so as to include the current perceptualobservations pt i.e. P ′t = Is current(t) ∧ pt ∧ Pt.
A query υ ← pt+1? directed at the program P ′t determines the plog, i.e. thepredicted future perceptual state pt+1. We denote this P ′t {pt+1 = υ ← pt+1?}.Hence, the function ulog is defined:
pt+1 = u(rlogt , pt) ≡ P ′t {pt+1 = υ ← pt+1} : P ′t = rlogt ∧ pt ∧ Is current(t)Actions a are passed back to the lower PACF in the form of modified confi-
dences on pt derived from the extrapolation of the globally-consistent model i.e.a = pt.
There is no control specified on the topmost logic layer (if this were to existit would perhaps function as a clause update or rule induction procedure). Thuswe can write rlogt = vlog(f logt−1, r
logt−1). This is thus the temporal update function
conditional on the feedback f logt−1 i.e. rlogt = (pt × ft) ∧ Is past(pt) ∧ rlogt−1.The function ρ(pt−pt) acts as an internal gating function on perceptual mod-
ifications a = pt, so that excessive disparity between prediction and observation|pt − pt| > threshold ’turns off’ an internal confidence flag regarding the global

12 Michael Felsberg, Affan Shaukat, and David Windridge
consistency of the perceptual pt, i.e. such that ft = 0 (it is unity otherwise). Theaction feedback to the lower level is always < υ′ ← pt, pt > (i.e. the predictedpercepts plus their confidences) by default, supplemented by this warning flag.< υ′ ← pt, pt > can thus be treated as a ’logical prior’ on observations.
Thus in the function: [f logt alogt ] = w(ρ(pt − pt), rlogt )we have that:alogt =< υ′ ← pt, pt > and f logt = ft = H(|pt − pt| − threshold)with H the Heaviside step function (or Logistic function for analytic conti-
nuity, if necessary).
3.5 Integration with Euler Lagrange Optimization
As regards the Euler Lagrange optimization, we may omit consideration of Ψ log
(characterizing the cost of changes in rlog with respect to changes in p). Thisis because p is sparse with respect to V log as a whole, as well as being limitedto a single temporal slice, and so we would not expect much change in rlog (the’global’ perceptual picture) unless p is a critical predicate (assuming that p isglobally consistent and not flagged by f). Thus, in general, to a first order ofapproximation, rlog is modified only in terms of the fuzzy truth values refer-ring to p. However, for the cases that will prove quantifiable later, with only afew predicates, the change in rlog is disproportionately large due to the lack ofconstraint on V log.
Ψ log is thus not applicable the logic level; change in rlog with respect to p isdictated by the resolution procedure and will tend to stabilize naturally as morecontext is accrued.
We thus consider only the Jacobean ’interface’ ∂plog
∂alog ≡ ∂c∂f at the logical level.
3.6 The Logic-level Jacobean: A worked example
This process can be elaborated with more perspicuity by the following simpleexample,
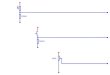
Fig. 4. Graph of the Product T-norm

Online Learning in Perception-Action Systems 13
let the terms pr 1, pr 2, and pr 3 represent the predicates; obj position le-ft road, obj position driver road, and velocity leftwards respectively, where t1 =past and t2 = current;
pr 1(car 1, t2)← 0.7, pr 2(car 1, t1)← 0.9, pr 3(car 1, t2)← 0.8;
driver int(turn left, X)← Tprod pr 1(X, t2), pr 2(X, t1), pr 3(X, t2).
The complete Borel set is confined to discrete confidence values defining thetruth values for each fuzzy predicate (i.e. feature input) by applying a maxoperator to the input predicates. A simple Product T-norm is used for logicalresolution of clauses, Tprod(x, y) = x · y (which is an ordinary product of tworeal numbers). The product T-norm is a strict Archimedean t-norm semanticallyused for strong conjunction in fuzzy logics (refer to figure 4).
Three temporal facts have been provided here, pr 1(car 1,t2), pr 2(car 1,t1),and pr 3(car 1,t2) whose truth values are the unitary intervals [0.7, 0.7], [0.9,0.9], and [0.8, 0.8], respectively, and a fuzzy clause for the driver int predicate,which is defined by an aggregation operator that is a Product T-norm. Letsconsider a fuzzy goal, µ ← driver int(turn left,X)? the first transition in thecomputation would be:
〈{(driver int(turn left, X))}, ξ, true〉 → 〈{pr 1(X, t2), pr 2(X, t1), pr 3(X, t2)},ξ, µ = ((µpr 1 · µpr 2) · µpr 3)〉
the goal is unified with the clause and the constraint corresponding to Prod-uct T-norm is added. The next transition leads to the state:
〈{pr 3(X, t2)}, {pr 2(X, t1)}, {X = car 1}, µ = ((µpr 1 · µpr 2) · µpr 3) ∧ µpr 1 = 0.7〉
after pr 1(X, t2) is unified with pr 1(car 1, t2) and the constraint definingthe truth value of the fact is added, the computation follows towards the nextiteration:
〈{pr 3(X, t2)}, {X = car 1}, µ = ((µpr 1 · µpr 2) · µpr 3) ∧ µpr 1 = 0.7 ∧ µpr 2 = 0.9〉
The computation ends with the following iteration:
〈{}, {X = car 1}, µ = ((µpr 1 · µpr 2) · µpr 3) ∧ µpr 1 = 0.7 ∧ µpr 2 = 0.9 ∧ µpr 3 = 0.8〉
Since µ = ((µpr 1 · µpr 2) · µpr 3) ∧ µpr 1 = 0.7 ∧ µpr 2 = 0.9 ∧ µpr 3 = 0.8entails µ ∈ [0.50, 0.50], the answer to the query driver int(turn left,X) is X =car 1 with its truth value in the unitary interval [0.50, 0.50]. Thus given anyarbitrary truth values for the fuzzy facts pr 1(X,T ), pr 2(X,T ), and pr 3(X,T )i.e. [x1, x1], [x2, x2], and [x3, x3], respectively, the truth value for the driverintention can be summarized into the following general formula:
µint = {Tprod(µpr 1, µpr 2, µpr 3) ∧ µpr 1 = x1 ∧ µpr 2 = x2 ∧ µpr 3 = x3}
where as µint ∈ [0, 1]. Thus µint = x1× x2× x3 in this very simplified case.If we thus treat µint as the simplified output alog from the logical level withrespect to changes in p = {µpr 1, µpr 2, µpr 3}, then the Jacobean ∂p
∂alog becomes:[x1 × x2 + x1 × x3 + x2 × x3]. Hence as such, we can achieve the closed formsolution to a multi-level PACF in terms of a top level jacobean, thereby it ispossible to find a solution to a multi-layer Euler-Lagrange problem.

14 Michael Felsberg, Affan Shaukat, and David Windridge
4 Conclusion and Future Work
Having described the multi-layer PACF and its implementation within an Euler-Lagrange framework, we have demonstrated the closed form solution to a first-order fuzzy theorem proving. Thus it is possible to build a grounded hierarchicalPerception-Action framework with first-order symbol processing capability ofworking in a stochastic environment. The proposed learning structure has beenevaluated in a single layer system using offline learning [14]. What remains is toevaluate the proposed framework for online learning in a multi-layer system.
5 Acknowledgements
This research work has received funding from the European Community’s Sev-enth Framework Programme (FP7/2007-2013) under grant agreement no. 215078(DIPLECS) and 247947 (GARNICS).
References
1. Brooks, R.A.: Intelligence without representation. Artif. Intell. 47 (1991) 139–1592. Felsberg, M., Wiklund, J., Granlund, G.: Exploratory learning structures in arti-
ficial cognitive systems. Image and Vision Computing 27 (2009) 1671–16873. Granlund, G.H.: The complexity of vision. Signal Processing 74 (1999) 101–1264. Rao, R.P.N.: An optimal estimation approach to visual perception and learning.
Vision Research 39 (1999) 1963–19895. Windridge, D., Kittler, J.: Perception-action learning as an epistemologically-
consistent model for self-updating cognitive representation. Advances in Experi-mental Medicine and Biology 657 (2010)
6. Rao, R.P.N., Ballard, D.H.: Predictive coding in the visual cortex: a functionalinterpretation of some extra-classical receptive-field effects. Nature Neuroscience2 (1999) 79–87
7. Felsberg, M., Granlund, G.: Fusing dynamic percepts and symbols in cognitivesystems. In: International Conference on Cognitive Systems. (2008)
8. Neisser, U.: Cognition and Reality: Principles and Implications of Cognitive Psy-chology. W. H. Freeman, San Francisco (1976)
9. Shapiro, E.Y.: Logic programs with uncertainties: a tool for implementing rule-based systems. In: IJCAI’83, San Francisco, CA, USA, Morgan Kaufmann Pub-lishers Inc. (1983) 529–532
10. Vaucheret, C., Guadarrama, S., Mu noz-Hernandez, S.: Fuzzy prolog: A simplegeneral implementation using clp(r). In: Proceedings of the 18th InternationalConference on Logic Programming, London, UK, Springer-Verlag (2002) 469
11. Klir, G.J., Yuan, B.: Fuzzy Sets and Fuzzy Logic: Theory and Applications. 1stedn. Prentice Hall PTR, Upper Saddle River, NJ, USA (1995)
12. Mu noz-Hernandez, S., Sari Wiguna, W.: Fuzzy cognitive layer in robocupsoccer.In: IFSA ’07, Berlin, Heidelberg, Springer-Verlag (2007) 635–645
13. Hollnagel, E., Woods, D.D. In: Joint Cognitive Systems: Foundations of CognitiveSystems Engineering. CRC Press, FL 33487-2742 (2005) 149–154
14. Felsberg, M., Larsson, F.: Learning Bayesian tracking for motion estimation. In:International Workshop on Machine Learning for Vision-based Motion Analysis.(2008)