Embed Size (px)
Citation preview

Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1584–1594Florence, Italy, July 28 - August 2, 2019. c©2019 Association for Computational Linguistics
1584
Open Vocabulary Learning for Neural Chinese Pinyin IME
Zhuosheng Zhang1,2, Yafang Huang1,2, Hai Zhao1,2,∗
1Department of Computer Science and Engineering, Shanghai Jiao Tong University2Key Laboratory of Shanghai Education Commission for Intelligent Interaction
and Cognitive Engineering, Shanghai Jiao Tong University, Shanghai, China{zhangzs, huangyafang}@sjtu.edu.cn, [email protected]
Abstract
Pinyin-to-character (P2C) conversion is thecore component of pinyin-based Chinese in-put method engine (IME). However, the con-version is seriously compromised by the am-biguities of Chinese characters correspondingto pinyin as well as the predefined fixed vocab-ularies. To alleviate such inconveniences, wepropose a neural P2C conversion model aug-mented by an online updated vocabulary witha sampling mechanism to support open vocab-ulary learning during IME working. Our ex-periments show that the proposed method out-performs commercial IMEs and state-of-the-art traditional models on standard corpus andtrue inputting history dataset in terms of multi-ple metrics and thus the online updated vocab-ulary indeed helps our IME effectively followsuser inputting behavior.
1 Introduction
Chinese may use different Chinese characters upto 20,000 so that it is non-trivial to type the Chi-nese character directly from a Latin-style key-board which only has 26 keys (Zhang et al.,2018a). The pinyin as the official romanizationrepresentation for Chinese provides a solution thatmaps Chinese character to a string of Latin al-phabets so that each character has a letter writingform of its own and users can type pinyin in termsof Latin letters to input Chinese characters into acomputer. Therefore, converting pinyin to Chinesecharacters is the most basic module of all pinyin-based IMEs.
As each Chinese character may be mapped to apinyin syllable, it is natural to regard the Pinyin-to-Character (P2C) conversion as a machine trans-
∗ Corresponding author. This paper was partially sup-ported by National Key Research and Development Programof China (No. 2017YFB0304100) and Key Projects of Na-tional Natural Science Foundation of China (U1836222 and61733011).
lation between two different languages, pinyin se-quences and Chinese character sequences (namelyChinese sentence). Actually, such a translation inP2C procedure is even more straightforward andsimple by considering that the target Chinese char-acter sequence keeps the same order as the sourcepinyin sequence, which means that we can decodethe target sentence from left to right without anyreordering.
Meanwhile, there exists a well-known challengein P2C procedure, too much ambiguity mappingpinyin syllable to character. In fact, there are onlyabout 500 pinyin syllables corresponding to tenthousands of Chinese characters, even though theamount of the commonest characters is more than6,000 (Jia and Zhao, 2014). As well known, thehomophone and the polyphone are quite commonin the Chinese language. Thus one pinyin may cor-respond to ten or more Chinese characters on theaverage.
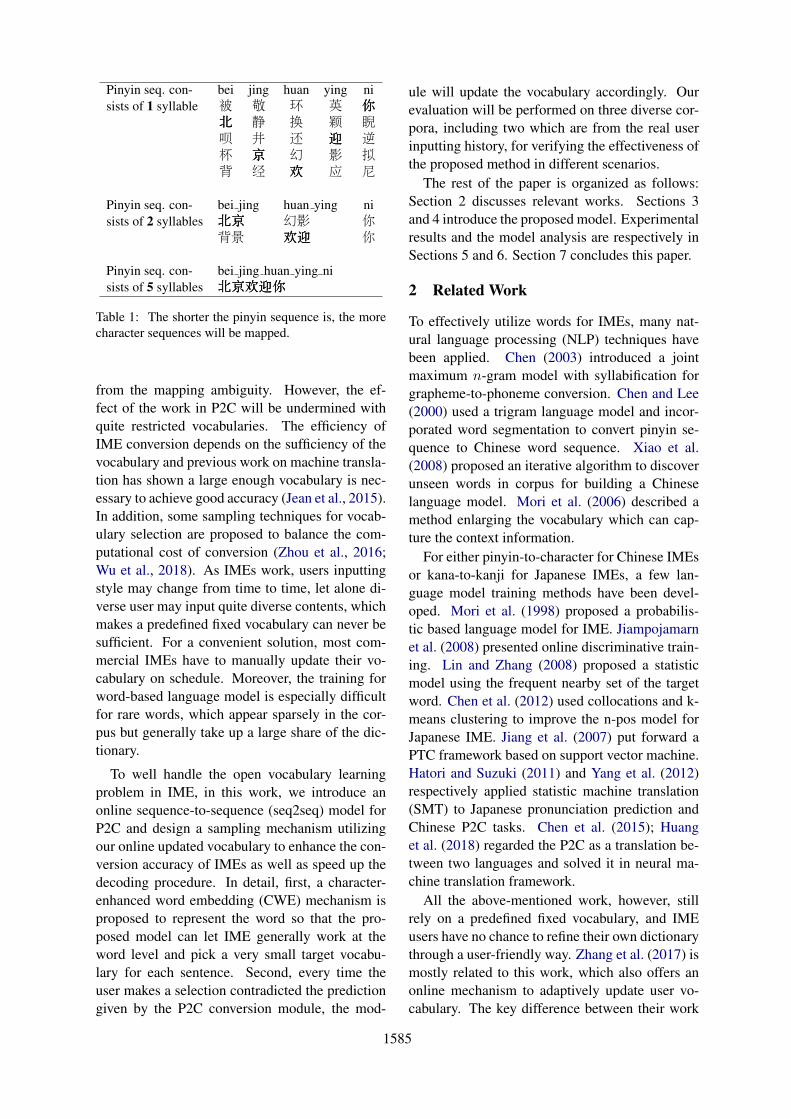
However, pinyin IME may benefit from decod-ing longer pinyin sequence for more efficient in-putting. When a given pinyin sequence becomeslonger, the list of the corresponding legal charactersequences will significantly reduce. For example,IME being aware of that pinyin sequence bei jingcan be only converted to either 背景(background)or北京(Beijing) will greatly help it make the rightand more efficient P2C decoding, as both pinyinbei and jing are respectively mapped to dozens ofdifference single Chinese characters. Table 1 illus-trates that the list size of the corresponding Chi-nese character sequence converted by pinyin se-quence bei jing huan ying ni (北京欢迎你, Wel-come to Beijing) is changed according to the dif-ferent sized source pinyin sequences.
To reduce the P2C ambiguities by decodinglonger input pinyin sequence, Chinese IMEs mayoften utilize word-based language models sincecharacter-based language model always suffers
1585
Pinyin seq. con- bei jing huan ying nisists of 1 syllable 被 敬 环 英 你你你
北北北 静 换 颖 睨呗 井 还 迎迎迎 逆杯 京京京 幻 影 拟背 经 欢欢欢 应 尼
Pinyin seq. con- bei jing huan ying nisists of 2 syllables 北北北京京京 幻影 你
背景 欢欢欢迎迎迎 你
Pinyin seq. con- bei jing huan ying nisists of 5 syllables 北北北京京京欢欢欢迎迎迎你你你
Table 1: The shorter the pinyin sequence is, the morecharacter sequences will be mapped.
from the mapping ambiguity. However, the ef-fect of the work in P2C will be undermined withquite restricted vocabularies. The efficiency ofIME conversion depends on the sufficiency of thevocabulary and previous work on machine transla-tion has shown a large enough vocabulary is nec-essary to achieve good accuracy (Jean et al., 2015).In addition, some sampling techniques for vocab-ulary selection are proposed to balance the com-putational cost of conversion (Zhou et al., 2016;Wu et al., 2018). As IMEs work, users inputtingstyle may change from time to time, let alone di-verse user may input quite diverse contents, whichmakes a predefined fixed vocabulary can never besufficient. For a convenient solution, most com-mercial IMEs have to manually update their vo-cabulary on schedule. Moreover, the training forword-based language model is especially difficultfor rare words, which appear sparsely in the cor-pus but generally take up a large share of the dic-tionary.
To well handle the open vocabulary learningproblem in IME, in this work, we introduce anonline sequence-to-sequence (seq2seq) model forP2C and design a sampling mechanism utilizingour online updated vocabulary to enhance the con-version accuracy of IMEs as well as speed up thedecoding procedure. In detail, first, a character-enhanced word embedding (CWE) mechanism isproposed to represent the word so that the pro-posed model can let IME generally work at theword level and pick a very small target vocabu-lary for each sentence. Second, every time theuser makes a selection contradicted the predictiongiven by the P2C conversion module, the mod-
ule will update the vocabulary accordingly. Ourevaluation will be performed on three diverse cor-pora, including two which are from the real userinputting history, for verifying the effectiveness ofthe proposed method in different scenarios.
The rest of the paper is organized as follows:Section 2 discusses relevant works. Sections 3and 4 introduce the proposed model. Experimentalresults and the model analysis are respectively inSections 5 and 6. Section 7 concludes this paper.
2 Related Work
To effectively utilize words for IMEs, many nat-ural language processing (NLP) techniques havebeen applied. Chen (2003) introduced a jointmaximum n-gram model with syllabification forgrapheme-to-phoneme conversion. Chen and Lee(2000) used a trigram language model and incor-porated word segmentation to convert pinyin se-quence to Chinese word sequence. Xiao et al.(2008) proposed an iterative algorithm to discoverunseen words in corpus for building a Chineselanguage model. Mori et al. (2006) described amethod enlarging the vocabulary which can cap-ture the context information.
For either pinyin-to-character for Chinese IMEsor kana-to-kanji for Japanese IMEs, a few lan-guage model training methods have been devel-oped. Mori et al. (1998) proposed a probabilis-tic based language model for IME. Jiampojamarnet al. (2008) presented online discriminative train-ing. Lin and Zhang (2008) proposed a statisticmodel using the frequent nearby set of the targetword. Chen et al. (2012) used collocations and k-means clustering to improve the n-pos model forJapanese IME. Jiang et al. (2007) put forward aPTC framework based on support vector machine.Hatori and Suzuki (2011) and Yang et al. (2012)respectively applied statistic machine translation(SMT) to Japanese pronunciation prediction andChinese P2C tasks. Chen et al. (2015); Huanget al. (2018) regarded the P2C as a translation be-tween two languages and solved it in neural ma-chine translation framework.
All the above-mentioned work, however, stillrely on a predefined fixed vocabulary, and IMEusers have no chance to refine their own dictionarythrough a user-friendly way. Zhang et al. (2017) ismostly related to this work, which also offers anonline mechanism to adaptively update user vo-cabulary. The key difference between their work

1586
and ours lies on that this work presents the firstneural solution with online vocabulary adaptationwhile (Zhang et al., 2017) sticks to a traditionalmodel for IME.
Recently, neural networks have been adoptedfor a wide range of tasks (Li et al., 2019; Xiaoet al., 2019; Zhou and Zhao, 2019; Li et al.,2018a,b). The effectiveness of neural models de-pends on the size of the vocabulary on the targetside and previous work has shown that vocabular-ies of well over 50K word types are necessary toachieve good accuracy (Jean et al., 2015) (Zhouet al., 2016). Neural machine translation (NMT)systems compute the probability of the next tar-get word given both the previously generated tar-get words as well as the source sentence. Estimat-ing this conditional distribution is linear in the sizeof the target vocabulary which can be very largefor many translation tasks. Recent NMT work hasadopted vocabulary selection techniques from lan-guage modeling which do not directly generate thevocabulary from all the source sentences (L’Hostiset al., 2016; Wu et al., 2018).
The latest studies on deep neural network provethe demonstrable effects of word representationon various NLP tasks, such as language model-ing (Verwimp et al., 2017), question answering(Zhang and Zhao, 2018; Zhang et al., 2018b), di-alogue systems (Zhang et al., 2018c; Zhu et al.,2018) and machine translation (Wang et al.,2017a,b, 2018; Wang et al., 2018; Chen et al.,2018). As for improved word representation inIMEs, Hatori and Suzuki (2011) solved Japanesepronunciation inference combining word-basedand character-based features within SMT-styleframework to handle unknown words. Neubiget al. (2013) proposed character-based SMT tohandle sparsity. Okuno and Mori (2012) in-troduced an ensemble model of word-based andcharacter-based models for Japanese and ChineseIMEs. All the above-mentioned methods usedsimilar solution about character representation forvarious tasks.
Our work takes inspiration from (Luong andManning, 2016) and (Cai et al., 2017). The for-mer built a novel representation method to tacklethe rare word for machine translation. In detail,they used word representation network with char-acters as the basic input units. Cai et al. (2017)presented a greedy neural word segmenter withbalanced word and character embedding inputs. In
the meantime, high-frequency word embeddingsare attached to character embedding via averagepooling while low-frequency words are computedfrom character embedding. Our embeddings alsocontain different granularity levels of embedding,but the word vocabulary is capable of being up-dated in accordance with users’ inputting choiceduring IME working. In contrast, (Cai et al., 2017)build embeddings based on the word frequencyfrom a fixed corpus.
3 Our Models
For a convenient reference, hereafter a characterin pinyin language also refers to an independentpinyin syllable in the case without causing confu-sion, and word means a pinyin syllable sequencewhich may correspond to a true word written inChinese characters.
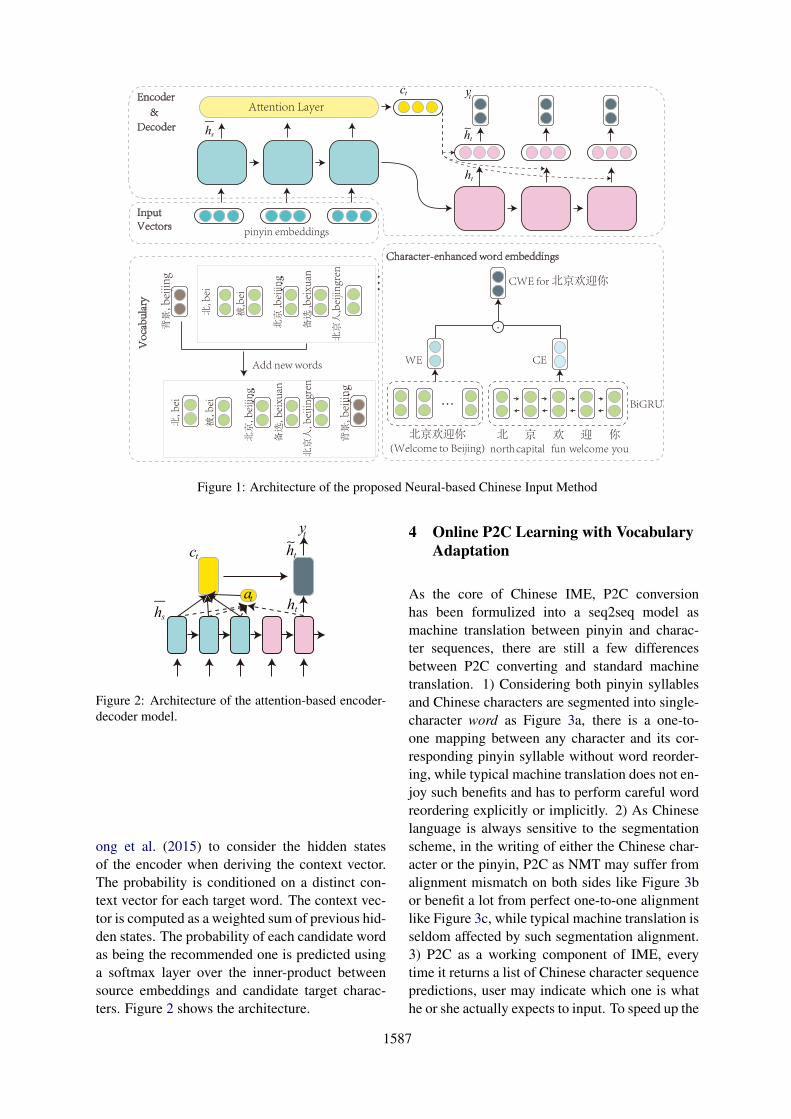
As illustrated in Figure 1, the core of our hybridP2C is a seq2seq model (Cho et al., 2014) in termsof the encoder-decoder framework. Given a pinyinsequence X and a Chinese character sequence Y ,the encoder of our neural P2C model utilizes anetwork for pinyin representation in which bothword-level and character-level embedding are ex-ploited, and the decoder is to generate the Chinesetarget sequence which maximizes P (Y |X) usingmaximum likelihood training.
Starting from an initial vocabulary with indica-tor from each turn of the user inputting choice, theonline learning module helps update the word vo-cabulary by minimizing empirical prediction risk.
3.1 Pinyin-Character Parallel Corpus
Pinyin-character parallel corpus can be conve-niently generated by automatically annotatingChinese character text with pinyin as introducedin (Yang et al., 2012). Using standard Chineseword segmentation methods, we may segmentboth character and pinyin text into words with thesame segmentation for each sentence pair.
3.2 Encoder-Decoder
The encoder is a bi-directional long short-term memory (LSTM) network (Hochreiter andSchmidhuber, 1997). The vectorized inputs arefed to forward and backward LSTMs to obtain theinternal representation of two directions. The out-put for each input is the concatenation of the twovectors from both directions. Our decoder is basedon the global attentional models proposed by Lu-
1587
Character-enhanced word embeddings
Decoder
EncoderAttention Layer
h
c
h
h
y
Vocabulary
&
BiGRU
WE
...
北京欢迎你(Welcome to Beijing)
北north
京capital
欢fun
迎welcome
你you
CE
CWE for 北京欢迎你
Add new words
北京人, beijingren
⋯
北, bei
被, bei
北京, beijing
备选, beixuan
背景, beijing
北, bei
被,bei
北京 ,beijing
⋯备选 ,beixuan
Input Vectors pinyin embeddings
背景, beijing
s
t t
t
t
⋯
北京人,beijingren
⋯
Figure 1: Architecture of the proposed Neural-based Chinese Input Method
hs
ct
yt
ht
at ht
Figure 2: Architecture of the attention-based encoder-decoder model.
ong et al. (2015) to consider the hidden statesof the encoder when deriving the context vector.The probability is conditioned on a distinct con-text vector for each target word. The context vec-tor is computed as a weighted sum of previous hid-den states. The probability of each candidate wordas being the recommended one is predicted usinga softmax layer over the inner-product betweensource embeddings and candidate target charac-ters. Figure 2 shows the architecture.
4 Online P2C Learning with VocabularyAdaptation
As the core of Chinese IME, P2C conversionhas been formulized into a seq2seq model asmachine translation between pinyin and charac-ter sequences, there are still a few differencesbetween P2C converting and standard machinetranslation. 1) Considering both pinyin syllablesand Chinese characters are segmented into single-character word as Figure 3a, there is a one-to-one mapping between any character and its cor-responding pinyin syllable without word reorder-ing, while typical machine translation does not en-joy such benefits and has to perform careful wordreordering explicitly or implicitly. 2) As Chineselanguage is always sensitive to the segmentationscheme, in the writing of either the Chinese char-acter or the pinyin, P2C as NMT may suffer fromalignment mismatch on both sides like Figure 3bor benefit a lot from perfect one-to-one alignmentlike Figure 3c, while typical machine translation isseldom affected by such segmentation alignment.3) P2C as a working component of IME, everytime it returns a list of Chinese character sequencepredictions, user may indicate which one is whathe or she actually expects to input. To speed up the

1588
inputting, IME always tries to rank the user’s in-tention at the top-1 position. So does IME, we saythere is a correct conversion or prediction. Differ-ent from machine translation job, users’ inputtingchoice will always indicate the ‘correct’ predictionright after IME returns the list of its P2C conver-sion results.
(a)
(b)
(c)
Figure 3: Different segmentations decide differentalignments
Therefore, IME working mode implies an on-line property, we will let our neural P2C modelalso work and evaluate in such a way. Meanwhile,online working means that our model has to trackthe continuous change of users’ inputting contents,which is equally a task about finding new words ineither pinyin sequence or character sequence.
However, the word should be obtained throughthe operation of word segmentation. Note thatas we have discussed above, segmentation overpinyin sequence is also necessary to alleviate theambiguity of pinyin-to-character mapping. Thusthe task here for IME online working actually re-quires an online word segmentation algorithm ifwe want to keep the aim of open vocabulary learn-ing. Our solution to this requirement is adopting avocabulary-based segmentation approach, namely,the maximum matching algorithm which greedilysegments the longest matching in the given vocab-ulary at the current segmentation point of a givensequence. Then adaptivity of the segmentationthus actually relies on the vocabulary online up-dating.
Algorithm 1 gives our online vocabulary updat-ing algorithm for one-turn IME inputting. Notethe algorithm maintains a pinyin-character bilin-gual vocabulary. Collecting the user’s inputtingchoices through IME, our P2C model will performonline training over segmented pinyin and charac-ter sequences with the updated vocabulary. Theupdating procedure introduces new words by com-paring the user’s choice and IME’s top-1 predic-tion. The longest mismatch n-gram characters willbe added as new word.
Algorithm 1 Online Vocabulary Updating Algo-rithmInput:
• Vocabulary: V = {(Pyi, Chi)|i =1, 2, 3, · · · };• Input pinyin sequence: Py = {pyi|i =1, 2, 3, · · · };• IME predicted top-1 character sequence:Cm = {cmi|i = 1, 2, 3, · · · };• User choosing character sequence: Cu ={cui|i = 1, 2, 3, · · · }.
Output:
• The Updated Vocabulary: V̂ .
1: � Adding new words2: for n = 6 to 2 do3: Compare n-gram of Cu and Cm4: if Mismatch Ch is found // both the first and
last characters are different at least then5: if Ch is not in V̂ then6: V = V ∪ {Ch}7: end if8: end if9: if no mismatch is found then
10: break11: end if12: end for13: return V̂ ;
We adopt a hybrid mechanism to balanceboth words and characters representation, namely,Character-enhanced Word Embedding (CWE). Inthe beginning, we keep an initial vocabulary withthe most frequent words. The words inside the vo-cabulary are represented as enhanced-embedding,and those outside the list are computed from char-acter embeddings. A pre-trained word2vec model(Mikolov et al., 2013) is generated to representthe word embedding WE(w)(w ∈ V̂ ). At thesame time we feed all characters of each wordto a bi-gated recurrent unit (bi-GRU) (Cho et al.,2014) to compose the character level representa-tion CE(w) (w = {ci|i = 1, 2, 3, · · · }).
The enhanced embedding CWE(w) is tostraightforwardly integrate word embedding andcharacter embedding by element-wise multiplica-tion,
CWE(w) = WE(w)� CE(w)

1589
5 Target Vocabulary Selection
In this section, we aim to prune the target vocabu-lary V̂ as small as possible to reduce the comput-ing time. Our basic idea is to maintain a separateand small vocabulary V̂ for each sentence so thatwe only need to compute the probability distribu-tion over a small vocabulary for each sentence.
We first generate a sentence-level vocabularyVs to be one part of our V̂ , which includes themapped Chinese words of each pinyin in thesource sentence. As the bilingual vocabulary Vconsists of the pinyin and Chinese word pair ofall the words that ever appeared, it is natural touse a prefix maximum matching algorithm to ob-tain a sorted list of relevant candidate translationsD(x) = [Ch1, Ch2, ...] for the source pinyin.Thus, we generate a target vocabulary Vs for a sen-tence x = (Py1, Py2, ...) by merging all the can-didates of all pinyin.
In order to cover target un-aligned functionalwords, we also need top n most common targetwords Vc.
In training procedure, the target vocabulary V̂for a sentence x needs to include the target wordsVt in the reference y, V̂ = Vs ∪ Vc ∪ Vy.
In decoding procedure, the V̂ may only containtwo parts, V̂ = Vs ∪ Vc.
6 Experiment
6.1 Datasets and Evaluation Metrics
We adopt two corpora for evaluation. The People’sDaily corpus is extracted from the People’s Dailyfrom 1992 to 1998 by Peking University (Emer-son, 2005). The bilingual corpus can be straight-forwardly produced by the conversion proposedby (Yang et al., 2012). Contrast to the style ofthe People’s Daily, the TouchPal corpus (Zhanget al., 2017) is a large scale of user chat historycollected by TouchPal IME, which are more col-loquial. Hence, we use the latter to simulate user’schatting input to verify our online model’s adapt-ability to different environments. The test set sizeis 2,000 MIUs in both corpora. Table 2 shows thestatistics of two corpora1.
Two metrics are used for our evaluation byfollowing previous work: Maximum Input Unit(MIU) Accuracy and KeyStroke Score (KySS) (Jiaand Zhao, 2013). The former measures the con-
1The two corpora along with our codes are available athttps://github.com/cooelf/OpenIME .
version accuracy of MIU, which is defined as thelongest uninterrupted Chinese character sequenceinside a sentence. As the P2C conversion aimsto output a rank list of corresponding charactersequences candidates, the top-K MIU accuracymeans the possibility of hitting the target in thefirst K predict items. We will follow the defi-nition of (Zhang et al., 2017) about top-K accu-racy. The KySS quantifies user experience by us-ing keystroke count. An IME with higher KySSis supposed to perform better. For an ideal IME,there will be KySS = 1.
6.2 Settings
IME works giving a list of character sequence can-didates for user choosing. Therefore, measuringIME performance is equivalent to evaluating sucha rank list. In this task, we select 5 convertedcharacter sequence candidates for each pinyin se-quence. Given a pinyin sequence and candidatecharacters, our model is designed to rank the char-acters in an appropriate order.
Here is the model setting we used: a) pre-trained word embeddings were generated on thePeople’s Daily corpus; b) the recurrent neural net-works for encoder and decoder have 3 layers and500 cells, and the representation networks have 1layer; c) the initial learning rate is 1.0, and we willhalve the learning rate every epoch after 9 epochs;d) dropout is 0.3; e) the default frequency filter ra-tio for CWE establishment is 0.9. The same settingis applied to all models.
For a balanced treatment over both corpora, weused baseSeg (Zhao et al., 2006) to segment alltext, then extract all resulted words into the ini-
Chinese Pinyin
PD# MIUs 5.04M# Word 24.7M 24.7M# Vocab 54.3K 41.1K# Target Vocab (train) 2309 -# Target Vocab (dec) 2168 -
TP# MIUs 689.6K# Word 4.1M 4.1M# Vocab 27.7K 20.2K# Target Vocab (train) 2020 -# Target Vocab (dec) 2009 -
Table 2: MIUs count, word count and vocab size statis-tics of our training data. PD refers to the People’sDaily, TP is TouchPal corpus.
1590
System EDPD TP
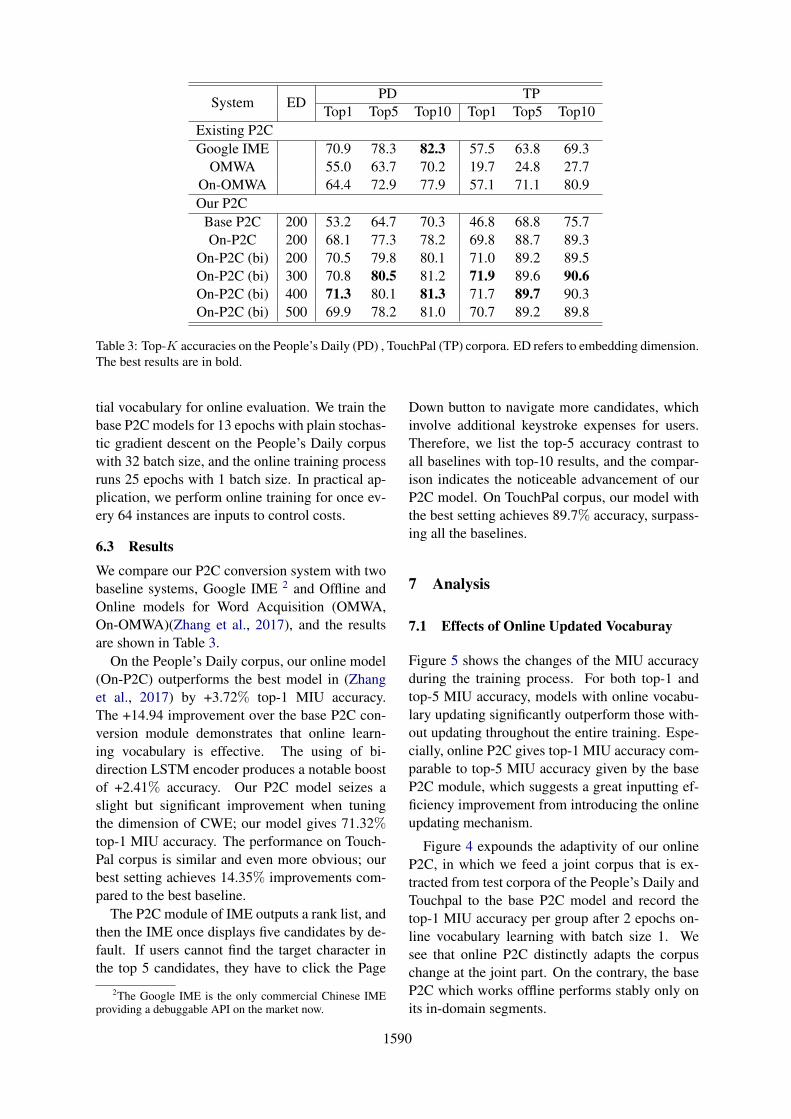
Top1 Top5 Top10 Top1 Top5 Top10Existing P2CGoogle IME 70.9 78.3 82.3 57.5 63.8 69.3
OMWA 55.0 63.7 70.2 19.7 24.8 27.7On-OMWA 64.4 72.9 77.9 57.1 71.1 80.9Our P2C
Base P2C 200 53.2 64.7 70.3 46.8 68.8 75.7On-P2C 200 68.1 77.3 78.2 69.8 88.7 89.3
On-P2C (bi) 200 70.5 79.8 80.1 71.0 89.2 89.5On-P2C (bi) 300 70.8 80.5 81.2 71.9 89.6 90.6On-P2C (bi) 400 71.3 80.1 81.3 71.7 89.7 90.3On-P2C (bi) 500 69.9 78.2 81.0 70.7 89.2 89.8
Table 3: Top-K accuracies on the People’s Daily (PD) , TouchPal (TP) corpora. ED refers to embedding dimension.The best results are in bold.
tial vocabulary for online evaluation. We train thebase P2C models for 13 epochs with plain stochas-tic gradient descent on the People’s Daily corpuswith 32 batch size, and the online training processruns 25 epochs with 1 batch size. In practical ap-plication, we perform online training for once ev-ery 64 instances are inputs to control costs.
6.3 Results
We compare our P2C conversion system with twobaseline systems, Google IME 2 and Offline andOnline models for Word Acquisition (OMWA,On-OMWA)(Zhang et al., 2017), and the resultsare shown in Table 3.
On the People’s Daily corpus, our online model(On-P2C) outperforms the best model in (Zhanget al., 2017) by +3.72% top-1 MIU accuracy.The +14.94 improvement over the base P2C con-version module demonstrates that online learn-ing vocabulary is effective. The using of bi-direction LSTM encoder produces a notable boostof +2.41% accuracy. Our P2C model seizes aslight but significant improvement when tuningthe dimension of CWE; our model gives 71.32%top-1 MIU accuracy. The performance on Touch-Pal corpus is similar and even more obvious; ourbest setting achieves 14.35% improvements com-pared to the best baseline.
The P2C module of IME outputs a rank list, andthen the IME once displays five candidates by de-fault. If users cannot find the target character inthe top 5 candidates, they have to click the Page
2The Google IME is the only commercial Chinese IMEproviding a debuggable API on the market now.
Down button to navigate more candidates, whichinvolve additional keystroke expenses for users.Therefore, we list the top-5 accuracy contrast toall baselines with top-10 results, and the compar-ison indicates the noticeable advancement of ourP2C model. On TouchPal corpus, our model withthe best setting achieves 89.7% accuracy, surpass-ing all the baselines.
7 Analysis
7.1 Effects of Online Updated Vocaburay
Figure 5 shows the changes of the MIU accuracyduring the training process. For both top-1 andtop-5 MIU accuracy, models with online vocabu-lary updating significantly outperform those with-out updating throughout the entire training. Espe-cially, online P2C gives top-1 MIU accuracy com-parable to top-5 MIU accuracy given by the baseP2C module, which suggests a great inputting ef-ficiency improvement from introducing the onlineupdating mechanism.
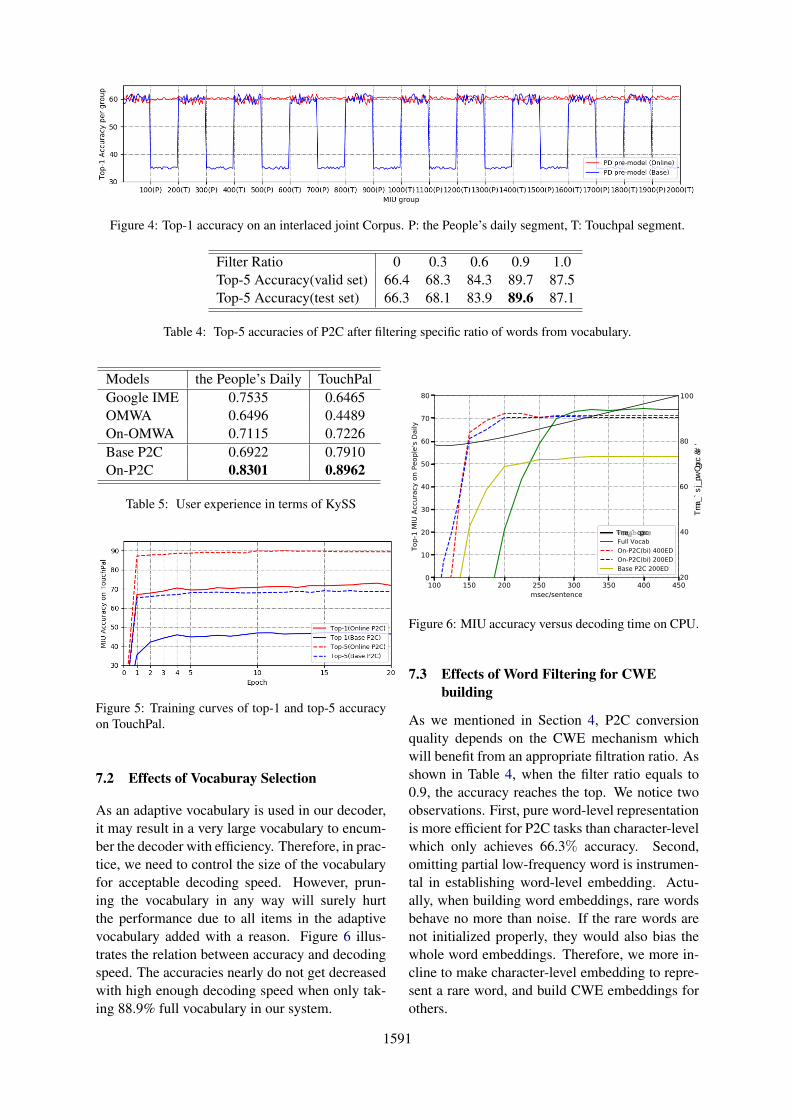
Figure 4 expounds the adaptivity of our onlineP2C, in which we feed a joint corpus that is ex-tracted from test corpora of the People’s Daily andTouchpal to the base P2C model and record thetop-1 MIU accuracy per group after 2 epochs on-line vocabulary learning with batch size 1. Wesee that online P2C distinctly adapts the corpuschange at the joint part. On the contrary, the baseP2C which works offline performs stably only onits in-domain segments.
1591
Figure 4: Top-1 accuracy on an interlaced joint Corpus. P: the People’s daily segment, T: Touchpal segment.
Filter Ratio 0 0.3 0.6 0.9 1.0Top-5 Accuracy(valid set) 66.4 68.3 84.3 89.7 87.5Top-5 Accuracy(test set) 66.3 68.1 83.9 89.6 87.1
Table 4: Top-5 accuracies of P2C after filtering specific ratio of words from vocabulary.
Models the People’s Daily TouchPalGoogle IME 0.7535 0.6465OMWA 0.6496 0.4489On-OMWA 0.7115 0.7226Base P2C 0.6922 0.7910On-P2C 0.8301 0.8962
Table 5: User experience in terms of KySS
Figure 5: Training curves of top-1 and top-5 accuracyon TouchPal.
7.2 Effects of Vocaburay Selection
As an adaptive vocabulary is used in our decoder,it may result in a very large vocabulary to encum-ber the decoder with efficiency. Therefore, in prac-tice, we need to control the size of the vocabularyfor acceptable decoding speed. However, prun-ing the vocabulary in any way will surely hurtthe performance due to all items in the adaptivevocabulary added with a reason. Figure 6 illus-trates the relation between accuracy and decodingspeed. The accuracies nearly do not get decreasedwith high enough decoding speed when only tak-ing 88.9% full vocabulary in our system.
Vocabulary Size (%)
Vocab size
Figure 6: MIU accuracy versus decoding time on CPU.
7.3 Effects of Word Filtering for CWEbuilding
As we mentioned in Section 4, P2C conversionquality depends on the CWE mechanism whichwill benefit from an appropriate filtration ratio. Asshown in Table 4, when the filter ratio equals to0.9, the accuracy reaches the top. We notice twoobservations. First, pure word-level representationis more efficient for P2C tasks than character-levelwhich only achieves 66.3% accuracy. Second,omitting partial low-frequency word is instrumen-tal in establishing word-level embedding. Actu-ally, when building word embeddings, rare wordsbehave no more than noise. If the rare words arenot initialized properly, they would also bias thewhole word embeddings. Therefore, we more in-cline to make character-level embedding to repre-sent a rare word, and build CWE embeddings forothers.

1592
7.4 User Experience
Jia and Zhao (2013) proposed that the user-IMEinteraction contains three steps: pinyin input, can-didate index choice and page turning. In Table 3,the 89.7% top-5 accuracy on TouchPal means thatusers have nearly 90% possibilities to straightlyobtain the expected inputs in the first page (usu-ally 5 candidates per page for most IME interfacesetting), so that user experiment using IMEs canbe directly measured by KySS. Table 5 shows themean KySS of various models. The results indi-cate that our P2C conversion module further facil-itates the interaction.
8 Conclusion
This paper presents the first neural P2C converterfor pinyin-based Chinese IME with open vocab-ulary learning as to our best knowledge. Weadopt an online working-style seq2seq model forthe concerned task by formulizing it as a machinetranslation from pinyin sequence to Chinese char-acter sequence. In addition, we propose an on-line vocabulary updating algorithm for further per-formance enhancement by tracking users behav-ior effectively. The evaluation on the standardlinguistic corpus and true inputting history showthe proposed methods indeed greatly improve userexperience in terms of diverse metrics comparedto commercial IME and state-of-the-art traditionalmodel.
ReferencesDeng Cai, Hai Zhao, Zhisong Zhang, Yuan Xin,
Yongjian Wu, and Feiyue Huang. 2017. Fast andaccurate neural word segmentation for Chinese. InProceedings of the 55th Annual Meeting of the Asso-ciation for Computational Linguistics (ACL), pages608–615.
Kehai Chen, Rui Wang, Masao Utiyama, EiichiroSumita, and Tiejun Zhao. 2018. Syntax-directed at-tention for neural machine translation. In Proceed-ings of the AAAI Conference on Artificial Intelli-gence (AAAI), pages 4792–4799.
Long Chen, Xianchao Wu, and Jingzhou He. 2012. Us-ing collocations and k-means clustering to improvethe n-pos model for japanese ime. In Proceedingsof the Second Workshop on Advances in Text InputMethods, pages 45–56.
Shenyuan Chen, Rui Wang, and Hai Zhao. 2015. Neu-ral network language model for Chinese pinyin in-put method engine. In Proceedings of the 29th Pa-
cific Asia Conference on Language, Information andComputation (PACLIC), pages 455–461.
Stanley F. Chen. 2003. Conditional and joint mod-els for grapheme-to-phoneme conversion. In EighthEuropean Conference on Speech Communicationand Technology, pages 2033–2036.
Zheng Chen and Kai Fu Lee. 2000. A new statisticalapproach to Chinese pinyin input. In Proceedingsof the 38th Annual Meeting of the Association forComputational Linguistics (COLING), pages 241–247.
Kyunghyun Cho, Bart Van Merrienboer, Caglar Gul-cehre, Dzmitry Bahdanau, Fethi Bougares, HolgerSchwenk, and Yoshua Bengio. 2014. Learningphrase representations using RNN encoder-decoderfor statistical machine translation. In Proceedings ofthe 2014 Conference on Empirical Methods in Nat-ural Language Processing (EMNLP), pages 1724–1734.
Thomas Emerson. 2005. The second international Chi-nese word segmentation bakeoff. In Proceedings ofthe fourth SIGHAN workshop on Chinese languageProcessing, pages 123–133.
Jun Hatori and Hisami Suzuki. 2011. Japanese pro-nunciation prediction as phrasal statistical machinetranslation. In Proceedings of 5th InternationalJoint Conference on Natural Language Processing(IJCNLP), pages 993–1004.
Yafang Huang, Zuchao Li, Zhuosheng Zhang, andHai Zhao. 2018. Moon IME: neural-based chinesepinyin aided input method with customizable asso-ciation. In Proceedings of the 56th Annual Meet-ing of the Association for Computational Linguistics(ACL), System Demonstration, pages 140–145.
Sebastien Jean, Kyunghyun Cho, Roland Memisevic,and Yoshua Bengio. 2015. On using very largetarget vocabulary for neural machine translation.In Proceedings of the 53rd Annual Meeting of theAssociation for Computational Linguistics and the7th International Joint Conference on Natural Lan-guage Processing (ACL-IJCNLP), pages 1–10.
Zhongye Jia and Hai Zhao. 2013. Kyss 1.0: a frame-work for automatic evaluation of Chinese inputmethod engines. In Proceedings of the Sixth In-ternational Joint Conference on Natural LanguageProcessing (IJCNLP), pages 1195–1201.
Zhongye Jia and Hai Zhao. 2014. A joint graph modelfor pinyin-to-chinese conversion with typo correc-tion. In Proceedings of the 52nd Annual Meet-ing of the Association for Computational Linguistics(ACL), pages 1512–1523.
Sittichai Jiampojamarn, Colin Cherry, and GrzegorzKondrak. 2008. Joint processing and discriminativetraining for letter-to-phoneme conversion. In Pro-ceedings of ACL-08: HLT, pages 905–913.

1593
Wei Jiang, Yi Guan, Xiao Long Wang, and Bing QuanLiu. 2007. Pinyin to character conversion modelbased on support vector machines. Journal of Chi-nese Information Processing, 21(2):100–105.
Gurvan L’Hostis, David Grangier, and Michael Auli.2016. Vocabulary selection strategies for neural ma-chine translation. arXiv preprint arXiv:1610.00072.
Zuchao Li, Jiaxun Cai, Shexia He, and Hai Zhao.2018a. Seq2seq dependency parsing. In Pro-ceedings of the 27th International Conference onComputational Linguistics (COLING), pages 3203–3214.
Zuchao Li, Shexia He, Jiaxun Cai, Zhuosheng Zhang,Hai Zhao, Gongshen Liu, Linlin Li, and Luo Si.2018b. A unified syntax-aware framework for se-mantic role labeling. In Proceedings of the 2018Conference on Empirical Methods in Natural Lan-guage Processing (EMNLP), pages 2401–2411.
Zuchao Li, Shexia He, Hai Zhao, Yiqing Zhang, Zhu-osheng Zhang, Xi Zhou, and Xiang Zhou. 2019. De-pendency or span, end-to-end uniform semantic rolelabeling. arXiv preprint arXiv:1901.05280.
Bo Lin and Jun Zhang. 2008. A novel statistical Chi-nese language model and its application in pinyin-to-character conversion. In Proceedings of the 17thACM conference on Information and knowledgemanagement, pages 1433–1434.
Minh-Thang Luong and Christopher D. Manning.2016. Achieving open vocabulary neural machinetranslation with hybrid word-character models. InProceedings of the 54th Annual Meeting of the Asso-ciation for Computational Linguistics (ACL), pages1054–1063.
Minh Thang Luong, Hieu Pham, and Christopher DManning. 2015. Effective approaches to attention-based neural machine translation. In Proceedings ofthe 2015 Conference on Empirical Methods in Nat-ural Language Processing (EMNLP), pages 1412–1421.
Tomas Mikolov, Kai Chen, Greg Corrado, and Jef-frey Dean. 2013. Efficient estimation of wordrepresentations in vector space. arXiv preprintarXiv:1301.3781.
Shinsuke Mori, Daisuke Takuma, and Gakuto Kurata.2006. Phoneme-to-text transcription system with aninfinite vocabulary. In Proceedings of the 21st In-ternational Conference on Computational Linguis-tics and the 44th annual meeting of the Associa-tion for Computational Linguistics (ACL-COLING),pages 729–736.
Shinsuke Mori, Masatoshi Tsuchiya, Osamu Yamaji,and Makoto Nagao. 1998. Kana-Kanji conversionby a stochastic model. Information Processing So-ciety of Japan (IPSJ), pages 2946–2953.
Graham Neubig, Taro Watanabe, Shinsuke Mori, andTatsuya Kawahara. 2013. Machine translation with-out words through substring alignment. In Proceed-ings of the 50th Annual Meeting of the Associationfor Computational Linguistics (ACL), pages 165–174.
Yoh Okuno and Shinsuke Mori. 2012. An ensemblemodel of word-based and character-based modelsfor Japanese and Chinese input method. In Proceed-ings of the Second Workshop on Advances in TextInput Methods, pages 15–28.
Lyan Verwimp, Joris Pelemans, Hugo Van Hamme,and Patrick Wambacq. 2017. Character-word LSTMlanguage models. In Proceedings of the 15th Con-ference of the European Chapter of the Associationfor Computational Linguistics (EACL), pages 417–427.
Rui Wang, Andrew Finch, Masao Utiyama, and Ei-ichiro Sumita. 2017a. Sentence embedding for neu-ral machine translation domain adaptation. In Pro-ceedings of the 55th Annual Meeting of the Asso-ciation for Computational Linguistics (ACL), pages560–566. Association for Computational Linguis-tics.
Rui Wang, Masao Utiyama, Andrew Finch, LemaoLiu, Kehai Chen, and Eiichiro Sumita. 2018. Sen-tence selection and weighting for neural machinetranslation domain adaptation. IEEE/ACM Transac-tions on Audio, Speech, and Language Processing,26(10):1727–1741.
Rui Wang, Masao Utiyama, Lemao Liu, Kehai Chen,and Eiichiro Sumita. 2017b. Instance weightingfor neural machine translation domain adaptation.In Proceedings of the 2017 Conference on Em-pirical Methods in Natural Language Processing(EMNLP), pages 1482–1488. Association for Com-putational Linguistics.
Rui Wang, Masao Utiyama, and Eiichiro Sumita. 2018.Dynamic sentence sampling for efficient training ofneural machine translation. In Proceedings of the56th Annual Meeting of the Association for Compu-tational Linguistics (ACL), pages 298–304.
Yu Wu, Wei Wu, Dejian Yang, Can Xu, Zhoujun Li,and Ming Zhou. 2018. Neural response generationwith dynamic vocabularies. In Thirty-Second AAAIConference on Artificial Intelligence (AAAI), pages5594–5601.
Fengshun Xiao, Jiangtong Li, Hai Zhao, Rui Wang, andKehai Chen. 2019. Lattice-Based Transformer En-coder for Neural Machine Translation. In Proceed-ings of the 57th Annual Meeting of the Associationfor Computational Linguistics (ACL).
Jinghui Xiao, Bing Quan Liu, and XiaoLong WANG.2008. A self-adaptive lexicon construction algo-rithm for Chinese language modeling. Acta Auto-matica Sinica, 34(1):40–47.

1594
Shaohua Yang, Hai Zhao, and Bao-liang Lu. 2012. Amachine translation approach for Chinese whole-sentence pinyin-to-character conversion. In Pro-ceedings of the 26th Asian Pacific conference on lan-guage and information and computation (PACLIC),pages 333–342.
Xihu Zhang, Chu Wei, and Hai Zhao. 2017. Tracinga loose wordhood for Chinese input method engine.arXiv preprint arXiv:1712.04158.
Zhuosheng Zhang, Yafang Huang, and Hai Zhao.2018a. Subword-augmented embedding for clozereading comprehension. In Proceedings of the 27thInternational Conference on Computational Lin-guistics (COLING), pages 1802–1814.
Zhuosheng Zhang, Yafang Huang, Pengfei Zhu, andHai Zhao. 2018b. Effective character-augmentedword embedding for machine reading comprehen-sion. In Proceedings of the Seventh CCF Interna-tional Conference on Natural Language Processingand Chinese Computing (NLPCC), pages 27–39.
Zhuosheng Zhang, Jiangtong Li, Pengfei Zhu, andHai Zhao. 2018c. Modeling multi-turn conversationwith deep utterance aggregation. In Proceedings ofthe 27th International Conference on ComputationalLinguistics (COLING), pages 3740–3752.
Zhuosheng Zhang and Hai Zhao. 2018. One-shotlearning for question-answering in gaokao historychallenge. In Proceedings of the 27th InternationalConference on Computational Linguistics (COL-ING), pages 449–461.
Hai Zhao, Chang-Ning Huang, Mu Li, and Taku Kudo.2006. An improved Chinese word segmentation sys-tem with conditional random field. In Proceedingsof the Fifth SIGHAN Workshop on Chinese Lan-guage Processing, pages 162–165.
Jie Zhou, Ying Cao, Xuguang Wang, Peng Li, and WeiXu. 2016. Deep recurrent models with fast-forwardconnections for neural machine translation. Trans-actions of the Association for Computational Lin-guistics (TACL), 4:371–383.
Junru Zhou and Hai Zhao. 2019. Head-Driven PhraseStructure Grammar Parsing on Penn Treebank. InProceedings of the 57th Annual Meeting of the As-sociation for Computational Linguistics (ACL).
Pengfei Zhu, Zhuosheng Zhang, Jiangtong Li, YafangHuang, and Hai Zhao. 2018. Lingke: A fine-grainedmulti-turn chatbot for customer service. In Proceed-ings of the 27th International Conference on Com-putational Linguistics (COLING), System Demon-strations, pages 108–112.










![[Pinyin Test]](https://img.pdfslide.net/doc/110x75/549eed7bac79593d768b486f/pinyin-test.jpg)


















