Embed Size (px)
Citation preview

8/2/2019 Optimization in Image Processing
http://slidepdf.com/reader/full/optimization-in-image-processing 1/13
OPTIMIZATION ALGORITHMS IN IMAGE PROCESSING USED IN
MULTICORE PROCESSORS
Abstract
High quality image and video processing has become an important part in many professional and
consumer applications. Unfortunately, it often comes with a high performance price. In such cases,
software vendors are forced to compromise some of the quality, resort to more powerful hardware,
and invest many programming resources to optimize their code to achieve adequate performance.This paper shares insights and methods gained during a shared work by HP* Labs and Intel®
Software and Services Group on optimizing several useful imaging algorithms. It focuses on how
the multi-core architecture of 5500 series Intel® Xeon® Processors combined with Intel’s SingleInstruction Multiple Data (SIMD) technology can be exploited to achieve a significant
performance boost. The paper includes concrete code examples to demonstrate the optimization process. We start from a serial non-optimized baseline algorithm and apply data layoutmodifications to both make the code more SIMD-friendly and to improve the compiler’s ability to
vectorize it. We employ OpenMP* to gain thread-level parallelism and show its effectiveness in
the transformation of serial to parallel code. We also show how manual Streaming SIMD
Extensions (SSE) intrinsics can be effectively used to gain performance per thread. By using theabove approaches we were able gain 60X improvement of the running time relative to the baseline
implementation.
IntroductionVisual data is becoming an important part of our digital life. Most people have easy access to someform of digital video or camera. This visual data can be easily uploaded to the internet where it can
be shared. In many cases, people would also like to print some of this visual data on paper for
convenient browsing. As the data size increases and as clients expect ever improving levels of
quality, processing this data is becoming more and more time consuming. To maintain adequate performance, software vendors may compromise some of the quality or resort to more powerful
and expensive hardware. We believe that a better solution might be to optimize the existing code to
meet performance needs. This paper shares insights and methods on optimizing several usefulimaging algorithms.
Following Moore’s law, the chip industry was able to increase the performance of CPUs through
the increase in the number of transistors and architectural improvements. However, keeping the
pace of improvement has become ever more difficult from one CPU generation to the next andCPU-designers have turned to multi-core solutions to meet the ever growing performance
demands. With the introduction of the Intel® Core™ microarchitecture, multi-core machines that
were previously restricted to high-end technical markets have become commonplace in consumer-class PCs. To take full advantage of this new processing power requires software developers to
change the way they write computer programs. This paper shows that for image processing

8/2/2019 Optimization in Image Processing
http://slidepdf.com/reader/full/optimization-in-image-processing 2/13
applications, an impressive increase in performance can be achieved by multi-threading (i.e. high
level parallelism). However, to fully utilize the potential performance of modern CPUs, micro data
level parallelism in the form of SIMD, should also be utilized. This work shows that thecombination of thread level parallelism and micro data level parallelism can be highly effective.
The rest of the paper is organized as follows. We start by describing the algorithms that were
optimized. Then, focusing on one of the algorithms, we describe the optimization approaches thatwere used. We continue by giving the performance improvement statistics and conclude with some
lessons and insights that were gained.
Image Processing Algorithms
There are many classes of imaging and printing algorithms. In this work, we are interested in
algorithms which are either compute intensive or memory intensive (or both). We focus on three
classes; namely color conversion, filtering and halftoning and pick three sample algorithms.
1. RGB to CAM color conversionTransforming images between different color spaces is fundamental to many color/image processing algorithms. For example, images are usually stored as a triplet of red, green and blue
(RGB) values. Certain color processing algorithms would not function properly when represented
in this space as they are non-linear. Instead of modifying the algorithms, linear color spaces suchas CIE-CAM [CIECAM02] can be used. Unfortunately, transforming an image from RGB color
space to linear color space can be computationally intensive.
The transform can be described as a two stage process.• First values are transformed from RGB color-space into XYZ color space. This stage is a
simple linear transformation , where is a 3x3 transformation matrix
from XYZ to RGB.
• Once XYZ values are obtained, the non-linear part of the transformation is applied to them.
Each pixel is multiplied by another 3x3 metrics followed by two applications of a power
function, a sine and cosine.The full description of RGB to CIE-CAM color transform can be found in [CIECAM02]. From a
performance point of view, these color space transformations are point operations. This means that
a single input color is transformed into a single output color. The memory requirements for thealgorithm are optimal in the sense that each pixel is loaded once from memory and stored away
once in its transformed value.
2. Bilateral Filter Noise-removal is a very common operation in video and image processing. There are many
available approaches for image denoising ranging from simple linear filters which can effectively
eliminate noise at the expense of blurring details to computationally expensive iterative, non-linear filters.
In this work, we consider bilateral filter [Tomasi98], a non-iterative, non-linear filter, which can
8/2/2019 Optimization in Image Processing
http://slidepdf.com/reader/full/optimization-in-image-processing 3/13
yield good denoising while avoiding blurring of small details at an acceptable computational cost.
For each input pixel, it considers a neighborhood of pixels, which in our work is a square of NxN
pixels (N=11, 13). Conceptually, a bilateral filter operates at the cross domain of spatial and photometric distances. Each output pixel is a weighted average of all neighborhood pixels.
However, different from linear filters, the pixel weights are computed as a function of the
geometric as well as the photometric distance of the center pixel, pi, to each of its neighborhood pixels, p j. Φ,ψ (see Equation 1) are univariate functions that control the amount of noise removal
giving larger weight to neighborhood pixels that are close (both geometric and photometric) to the
center pixel.
Equation 1 : schematic bilateral filter setting.
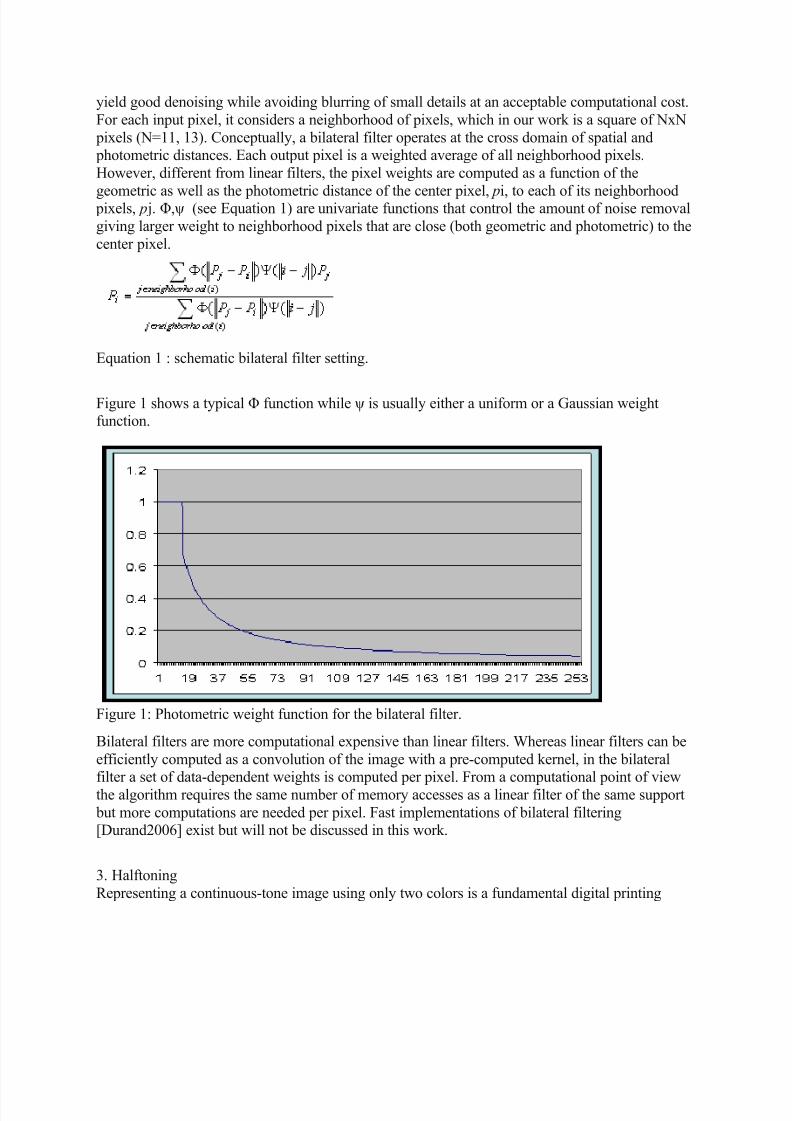
Figure 1 shows a typical Φ function while ψ is usually either a uniform or a Gaussian weightfunction.
Figure 1: Photometric weight function for the bilateral filter.
Bilateral filters are more computational expensive than linear filters. Whereas linear filters can be
efficiently computed as a convolution of the image with a pre-computed kernel, in the bilateralfilter a set of data-dependent weights is computed per pixel. From a computational point of view
the algorithm requires the same number of memory accesses as a linear filter of the same support
but more computations are needed per pixel. Fast implementations of bilateral filtering[Durand2006] exist but will not be discussed in this work.
3. Halftoning
Representing a continuous-tone image using only two colors is a fundamental digital printing

8/2/2019 Optimization in Image Processing
http://slidepdf.com/reader/full/optimization-in-image-processing 4/13
operation, known as “halftoning”. There are many halftoning algorithms with variable levels of
quality and complexity.
In our work, we focus on “screening” which is probably the simplest halftoning algorithm and iswidely used in industrial printing. In screening, a small pre-computed matrix of thresholds (called
a “cell”) is tiled on top of the image. Then, for each image pixel which is above its corresponding
threshold, the algorithm returns one; otherwise it returns zero. It is important to note that in order to reduce printing artifacts; care must be taken when designing cell values and selecting cell values
is done offline. During runtime, the algorithm is very efficient as it only has to do a single
comparison operation per pixel. Pseudo-code for such screening operation is presented in Figure 2;an image of image_width by image_height pixels is compared to the pre-computed values inside
the cell. The typical dimensions of a cell can vary from 64 by 64 to 512 by 512, which is usually
much smaller than the image size, hence the tiling operation on line (3) is required. From a
computational point of view, “screening” almost purely memory bound.
- collapse sourceview plain copy to clipboard print ?
1. for i = 1:image_width
2. for j = 1:image_height3. if cell[i % cell_width] [j % cell_height] > image[i][j]4. binary_image[i][j] = 1;
5. else
6. binary_image[i][j] = 0;
7. endif 8. end
9. end
10.
Figure 2: pseudo-code for a simple screening algorithm
Optimization description steps
In this section we focus on the optimization steps that were applied to the “XYZ to CIE-CAM” and
Bilateral Filter algorithms. Only high and middle level optimizations were considered- no low
level assembly coding. Moreover, we restricted the optimization to local code transformationswithout any significant algorithmic or data layout modifications. Thus the optimization was rather
straightforward, namely things were arranged by the “predicted performance effect divided by
implementation difficulty” ratio, and the steps having this ratio higher were the first to implement.
Parallelization
Since the vast majority of modern CPUs have multiple cores – for example the main optimization
target, Intel® Xeon® processor 5500-based systems, comes with 16 virtual cores and two CPUs--
we were mainly focused on thread level parallelization. We opted for the OpenMP* [OpenMP08]
library due to its low implementation cost, high portability, and scalability. OpenMP is supported by all the common compilers on every major environment and OS; OpenMP programs can scale to
any number of CPU cores. OpenMP, consists of a set of compiler directives, library routines,
and environment variables that influence run-time behavior. In OpenMP, the master thread "forks"a specified number of slave threads and a task is divided among them. The threads then run

8/2/2019 Optimization in Image Processing
http://slidepdf.com/reader/full/optimization-in-image-processing 5/13
concurrently, with the runtime environmentallocating threads to different processors. The section
of code that is meant to run in parallel is marked accordingly, with a preprocessor directive (see
Figure 3) that will cause the threads to form before the section is executed. After the execution of the parallelized code, the threads "join" back into the master thread, which continues onward to the
end of the program. "Work-sharing” constructs can be used to divide a task among the threads so
that each thread executes its allocated part of the code. The runtime environment allocates threadsto processors depending on usage, machine load and other factors. The number of threads can be
assigned by the runtime environment based on environment variables or it can be assigned in code
using OpenMP* API functions.1. XYZ to CAM
We start by splitting the outer pixel processing loop into work-sharing chunks. Due to the fact that
pixels can be processed independently from each other, it doesn’t require much work. Using
OpenMP, this can be done simply by employing the #pragma omp parallel for work sharingdirective. The iteration space of all image pixels will be traversed in parallel.
- collapse sourceview plain copy to clipboard print ?
1. #pragma omp parallel for private(colin,colout)2. for(int i = 0; i < image->width*image->height*3; i+=3)
3. {
4. //for every pixel in the image, apply color transformation
5. //colout from colin6. }
7.
Figure 3: OpenMP code sample. In this algorithm we traverse an image from top to bottom in
parallel.
Since each input pixel is mapped into a distinct output pixel, no synchronization between OpenMP
threads is required. For large images, the thread creation overhead tends to be negligible. In such acase, the expected speedup on a quad-core (with Intel® Hyper-Threading Technology) should be
above 4 times. Unfortunately, the real improvement turned out to be less than 3 times. After doingsome analysis, we could pinpoint the reason for this suboptimal result in the interaction with the
cache. Each pair of hyper-threads that share the same physical core also share L1 and L2 cache. In
a system with Intel® quad-core technology all cores on the same physical core also share the L3cache. As a result, if we load small chunks of data from separate threads on the same physical
core, we can create “cache races”.
In a cache race, one thread would write its data into the cache and data the other threads needed
would be flushed due to capacity constraints. The solution is to load chunks of data into cache
once, change the thread granularity so each thread processes one image line, and have multiplethreads process in the same chunk. In OpenMP, this is done by setting the data schedule clause.
Note: in our case each image line is much larger then a cache line, so we need not be concerned
about false cache sharing (a situation where two threads access adjacent data within the samecache-line casing ping-pong effect). In the general case, this effect should be considered as well
and could influence the thread data chunk. The modified code gave us the expected performance
boost of more than five times compared with the serial version.
- collapse sourceview plain copy to clipboard print ?

8/2/2019 Optimization in Image Processing
http://slidepdf.com/reader/full/optimization-in-image-processing 6/13
1. #pragma omp parallel for private (colin,colout) schedule(dynamic,3*image->width)
2. for(int i = 0; i < image->width*image->height*3; i+=3)
3. {4. //for every pixel get colout from colin, each thread processes an image line.
5. }
6.7.
It is important to note that OpenMP* is not the only available option for managed threading. For
example, Intel® Threading Building Blocks [Intel® TBB] is a C++ runtime library that does
thread management, letting developers focus on proven parallel patterns and take advantageof multi-core processors. Using Intel® TBB, the programmer can avoid some complications
arising from the use of nativethreading packages (e.g. thread creation, synchronization and
termination). In Intel® TBB, operations are treated as "tasks," which are allocated to individualcores dynamically by the library's run-time engine, and by automating efficient use of the cache.
Intel® TBB implements "task stealing" to balance a parallel workload across available processing
cores in order to increase core utilization and therefore scaling. Initially, the workload is evenlydivided among the available processor cores. Intel® TBB would reassign work that lays in the
work queue of busy threads to the work queues of idle cores. Due to its “Task Stealing”
mechanism, Intel® TBB can be more efficient then OpenMP* on managing parallelism. However
in our case where the tasks are “thread symmetric”- they are computationally equal and evenlydivided between threads, OpenMP works fine.
Vectorization
One of the most significant factors in achieving good performance in a multi-core system is
arranging the data layout so as to minimize issues such as cache misses and false sharing.
Important factors to note are cache locality, prefetching and SSE-friendliness. The CPU hardware
prefetcher automatically analyzes information about the locality of expected memory accesses and
pre-fetches data from a higher memory level into the cache for a near future usage. To reducememory access cost, it is important to arrange the data in such a way that helps the prefetcher to
correctly predict data access patterns. Finally, it is useful to ensure the data layout is SSE friendly.Since SSE would process vectors in a uniform way, it makes sense to group data items uniformly.
For example, arranging the data in a Structure of Arrays (SoA) format would enable SSE
operations to load and store uniform data items in a more efficient way then Array of Structures(AoS) format.
Using Intel® C++ Compiler
It is obvious that color conversion is very computationally intensive. And that is why it makes
sense to use a good optimizing compiler for this project. The Intel® C++ Compiler is known togive good results, compared to other compilers, on such workloads since:
• Intel® C++ Compiler uses SVML (Short Vector Math Library) internally for auto SIMDvectorization.
• Intel® C++ Compiler uses LibM Math Library internally for highly optimized scalar mathfunctions as direct replacements for the standard C calls.
• Intel® C++ Compiler uses OpenMP* runtime library underneath to automatically
parallelize qualified loops.Moreover, since Intel® C++ Compiler is seamlessly integrated into common integrated
development environments (e.g. Microsoft* Visual Studio* on Windows*, Eclipse* on Linux*,

8/2/2019 Optimization in Image Processing
http://slidepdf.com/reader/full/optimization-in-image-processing 7/13
XCode* on Mac OS* X), it is very easy to use. The performance gains we got from using Intel®
C++ Compiler were very significant. In one of our sample applications, with maximum
optimization switches on, we were able to improve the execution time by more than 3 times. Therelevant switches used were /O3 (Maximize speed plus high level optimization) and /arch:SSSE3
(in this case SSE4.x were not used in the optimization manually). In addition / Qopenmp (enable
OpenMP) and /Oi (enable intrinsic functions) were used. The complete performance improvementsof switching to Intel® C++ Compiler will be discussed later on in this paper.
SIMD (Single Instruction, Multiple Data)
SSE is a technique for micro level data-level parallelism on x86 architecture. SSE contains eight
128-bit registers, XMM0 through XMM7, where uniform type data can be packed. SSEinstructions operate on all data items in parallel.
The Intel® C++ Compiler and almost all other compilers used in software development today provide a very convenient way to enable SSE usage – so called intrinsic functions that provide
high level wrap for the low level SSE coding without any performance overhead. Intel® C++
Compiler can, in many cases, automatically optimize sequential code into vectorized code that
exploits SSE. When a loop is vectorized, the data is read into SSE registers, computations are performed using vector instructions to the SSE registers, and then the results in the SSE registers
are stored as needed. SSE shines in applications where the same math operations are applied to a
large number of data points such as many multimedia applications.
Manual intrinsic functions based SSE optimization
Considering that complicated math operations were needed in this case (e.g. power functions, sin,
cosine etc), in addition to standard compiler intrinsic functions, we also found the Intel SVMLlibrary functions to be highly effective. SVML was developed for the automatic compiler
vectorization capability of Intel® C++ Compiler but can be also used directly.
Let us focus first on the expected improvement in the XYZ to CAM color conversion algorithm.
Due its intended use, we were forced to use double precision floating point arithmetic. Since SSEregisters are 128 bit, they can only support arithmetical and logical operations on pairs of data units
in parallel. On the original interleaved data layout, processing one pixel at a time, we could only
gain a theoretical improvement of thirty percent. When attempting adding manual optimizationsusing SSE, we were only able to get a seven percent improvement which implies that compiler
optimizations were effective and that the data layout was not SSE friendly.
In order to make the data layout more SSE-friendly we rearranged it a Structure of Arrays (SoA)
format. Pairs of pixels were shuffled so that the data is laid-out in a (R,R,G,G,B,B) setting.Optimally, this data preparation should be done offline. In our case, we had to do it as a first step
to our pixel processing loop. When the pixel processing step was over, the data was scattered to the
original format. Note that this data shuffling could be achieved using SSE scatter and gather

8/2/2019 Optimization in Image Processing
http://slidepdf.com/reader/full/optimization-in-image-processing 8/13
capabilities but in our case it was done on the fly. After the data processing rearrangement (still
without any SSE instructions usage) the performance improved significantly. Unfortunately, due to
the complex pixel processing, the compiler was not able to unroll the processing loop.
Loop unrolling is a loop transformation technique that attempts to optimize a program's executionspeed at the expense of its size. Loop unrolling typically helps compiler with the automatic SIMD
usage. Namely in our case we increase loop counter i (processing 3 color components at a time) by2 (processing 2*3 color components at a time), repeating 3 components processing twicemanually. As can be seen in the example below, the “C” variable is divided into two operations
“C[0]” and “C[1]” as we increase loop counter i by 2. Transforming the code in Figure 4 to the
code in Figure 5.- collapse sourceview plain copy to clipboard print ?
1. void Cam022Lab_f(COLOUR_FPTYPE* camin, COLOUR_FPTYPE* labout, int npixels)
2. {
3. for(int i = 0; i < npixels; i++){4. lab = labout + i * 3;
5. jab = camin + i * 3;6.7. C = ab2C(jab[1], jab[2]);
8. …….
9. }
10. }11.
Figure 4: original pixel processing loop
- collapse sourceview plain copy to clipboard print ?
1.
2. void Cam022Lab_f(COLOUR_FPTYPE* camin, COLOUR_FPTYPE* labout, int npixels)3. {
4. for(int i = 0; i < npixels; i+=2){
5. lab = labout + i * 6;6. jab = camin + i * 6;
7.
8. C[0] = ab2C(jab[1], jab[2]);
9. C[1] = ab2C(jab[4], jab[5]);10.
11. …….12.}13.
14.
Figure 5 : pixel processing loop after manual loop unrolling
After the data layout was modified, automatic compiler optimization gave an impressive fifty

8/2/2019 Optimization in Image Processing
http://slidepdf.com/reader/full/optimization-in-image-processing 9/13
percent improvement. From that point we started to integrate manual SSE intrinsics into the code.
To illustrate the main concepts used in SSE intrinsic implementation of the code, let’s focus on
two examples. The first one demonstrates extensive usage of masking.- collapse sourceview plain copy to clipboard print ?
1. #ifndef __USE_SSE2. xyzt[0][0] = xyz[0][0] < 0.0 ? 0.0 : xyz[0][0];
3. xyzt[1][0] = xyz[0][1] < 0.0 ? 0.0 : xyz[0][1];4. #else
5. xyztSSE = _mm_and_pd(xyztSSE, _mm_cmpgt_pd(xyztSSE, _mm_setzero_pd()) );
6. #endif 7.
8.
Here, we compare xyz[0][0,1] with 0, and if xyz[0][0,1] >0 we have "ones" in the mask otherwise
we have "zeros", then anding xyz[0][0,1] with this mask gives us 0 or xyz[0][0,1]. The second
example focuses on SVML but also demonstrates the use of masking.- collapse sourceview plain copy to clipboard print ?
1. #ifndef __USE_SSE
2. RGBp[0][0] = pow(((27.13 * abs(RGBpa[0][0] - 0.1)) / (400.0-abs(RGBpa[0][0] - 0.1))), (1.0/0.42))*G3;
3. RGBp[0][0] = RGBpa[0][0] < 0.1 ? - RGBp[0][0] : RGBp[0][0];
4.
5. RGBp[0][1] = pow(((27.13 * abs(RGBpa[0][1] - 0.1)) / (400.0-abs(RGBpa[0][1] - 0.1))), (1.0/0.42))*G3;
6. RGBp[0][1] = RGBpa[0][1] < 0.1 ? - RGBp[0][1] : RGBp[0][1];
7. #else8. __declspec(align(16)) static const __int64 ffff[2]= {0x7fffffffffffffffL,0x7fffffffffffffffL} ;
9. static __m128d const01 =_mm_set1_pd(0.1);
10. rgbp[0] = _mm_sub_pd(rgbp[0],const01); //(RGBpa[0][0] - 0.1),(RGBpa[0][1] - 0.1)11. temp1 = _mm_andnot_pd(*(__m128d*)ffff,rgbp[0] ); //sign bit of (RGBpa[0,1] - 0.1)
12. rgbp[0] = _mm_and_pd(*(__m128d*)ffff,rgbp[0] ); //abs(RGBpa[0,1] - 0.1)
13.
14. rgbp[0] = __svml_pow2(_mm_div_pd(_mm_mul_pd(rgbp[0], const2713), _mm_sub_pd( _mm_set1_pd(400.0),rgbp[0])),_mm_set1_pd(1.0/0.42));
15. rgbp[0] = _mm_mul_pd(rgbp[0],G3_SSE); //RGBp[0][0] ,RGBp[0][1] are ready
16.
17. rgbp[0] =_mm_xor_pd(temp1,rgbp[0]); //RGBp[0,1] = RGBpa[0][0,1] < 0.1 ? - RGBp[0][0,1] : RGBp[0][0,1];
18. #endif 19.
20.
21.22.
23.

8/2/2019 Optimization in Image Processing
http://slidepdf.com/reader/full/optimization-in-image-processing 10/13
24.
2. Bilateral Filter We applied most of the optimization steps described above for the XYZ to CIE-CAM to the
Bilateral Filter as well. Now, we will focus on some unique features of the Bilateral Filter optimization process.
For each pixel in Bilateral Filter single UNSIGNED CHAR color intensity component was used.But inside the filter calculations we have SIGNED INT data. It means that the data quadruple
could be processed by the SSE register and therefore we need to group data by four to make them
SSE friendly.
So just moving from this code:
- collapse sourceview plain copy to clipboard print ?
1. for( j = matchWindow; j <= image->width -(matchWindow) ; j ++){
2. *outData = Bfilter(data,image,i,j); //for every pixel do bilateral filter computation3. data++; outData++;
4.5. }
6.
To this code:
- collapse sourceview plain copy to clipboard print ?
1. for( j = matchWindow; j <= image->width -(matchWindow) - 4; j += 4){
2. Bfilter4(data, outData, image,i,j); //for every 4 pixels do bilateral filtercomputation3. data+=4; outData+=4;
4. }
5. for(int jj= j; jj< image->width-(matchWindow); jj++){6. *outData = Bfilter(data,image,i,jj); //for every pixel do bilateral filter computation
7. data++; outData++;
8. }9.
10.
This resulted in approximately a 35% speed-up even before SSE optimization.
Results
In this work, the main optimization and benchmark target was an Intel® Xeon® processor 5500-
based system, a CPU with Intel® quad-core technology and two physical sockets. The platform
can support eight concurrent physical threads. We found that enabling Simultaneous MultiThreading (SMT), the interleaving of two logical threads of execution on a single physical, was
effective. Enabling SMT let the system execute 16 logical threads. In the case of the XYZ to CIE-

8/2/2019 Optimization in Image Processing
http://slidepdf.com/reader/full/optimization-in-image-processing 11/13
CAM algorithm, utilizing these 16 virtual cores (16 threads) gave us a 50 percent performance
boost. A second significant enhancement with the Intel® Xeon® processor 5500 architecture is its
NUMA (Non-Uniform Memory Access). With NUMA, each CPU has a local memory bank and aremote memory bank. Access times to the local memory bank are shorter than for the remote
memory bank. This architectural change improves the overall memory bandwidth. Nevertheless,
since access latency to the remote memory is ~1.7 longer than to local memory, threads shouldstrive to access local memory as much as possible. This requires setting thread affinity and a
careful design of allocations. In the general case, the optimizing applications for NUMA can gain
up to 20 percent performance boost; however, we have witnessed performance drops of up to 50 percent on non-optimized applications. For that reason, and as can be seen from the results, it was
usually better to disable NUMA in the BIOS configurations as recommended for non-NUMA
optimizations.
The following results show our results on three of the algorithms. The performance for the XYZ to
CIE-CAM color conversion and Bilateral Filter algorithms was application run-time in seconds
(smaller numbers are better). The Halftone algorithm performance was measured in MB/second(larger numbers are better). All measurements were done on a dual socket, Intel® Xeon®
processor 5500-based system running at 3.2 GHz. Baseline results are reported for the original,
serial, version of the code and were measured on a previous generation Intel® Xeon® 5400
processor-based system. This platform is a dual socket, quad core platform with clock speed of 2.83 GHz.
Table 1 summarizes the results. Column 2 is the original, serial code, compiled with VisualStudio* 2005 (VS). In column 3 we incorporate software optimizations (i.e. vectorization and
parallelization) and move to the Intel® C++ Compiler. In columns 4 and 5, we switched to the
Intel® Xeon® processor 5500 and tested several different BIOS settings (NUMA on/off, SMTon/off). Column 6 shows the overall speed-up that was gained by moving from the baseline setting
to the best performing setup. Note: for each column, we made several runs and averaged the results
to ensure reproducibility of the results.We observed that the bulk improvement in run time was from incorporating multi-threading
(OpenMP) and vectorization (SSE) to the baseline code. By employing both multi-threading and
vectorization, we gained a performance boost of up to 40X. In addition, the benefits of moving to
the new Intel® Xeon® processor 5500 platform are clearly shown in the table when you comparecolumn 3 with column 6. The best performing setting (SMT on, NUMA off) gave us a 50 percent
performance increase over the older Intel® Xeon® processor 5400 machine. The overall gains
from both software optimization and from moving to the new Intel® Xeon® processor 5500 platform were up to 68X relative to the baseline. A more visual representation of the results can be
seen in Figure 6.

8/2/2019 Optimization in Image Processing
http://slidepdf.com/reader/full/optimization-in-image-processing 12/13
Intel
Xeon5400 +
Visual Studio2005 (serial
version)
Intel
Xeon5400 +
IC + SWoptimizations
(OMP + SSE)
Intel
Xeon5500 +
IC + SWoptimizations
(SMT* Off)
(NUMA OFF)
Intel
Xeon5500
(SMT* ON)(NUMA ON)
Intel
Xeon5500
(SMT* ON)(NUMA
OFF)
speed up
XYZ2CAM 196.3 4.9 4.2 3.6 2.9 68
BilateralFilter
163 4 3.2 2.6 2.6 63
Halftoning(screening)
599 1739 5418 6195 6632 11
SMT* – Simultaneous Multi Threading
Table 1 : This table summarizes the optimization stages that were implemented. We move from a
serial version on an Intel® Xeon® processor 5400 platform to the new Intel® Xeon® processor 5500 platform and optimize the algorithm using OpenMP and SSE intrinsics.
IC: Intel® C++ Compiler for Windows 11.1
Figure 6 : Bar charts of the optimization stages. The left chart shows XYZ to CIE-CAM and
Bilateral Filter benchmarks while the right chart is focused on Halftoning results.
Conclusions
The inherent parallel structure of many image processing algorithms makes them suitable for both
thread level parallelism and low data level parallelism. For the three algorithms we optimized, we
achieved an excellent performance boost, which implies that thread synchronization overheadremains minimal. We showed that OpenMP can be very effective for doing image processing and
that it can be used to incrementally modify a serial implementation into a parallel one. In addition,
since most image processing algorithms apply the same operations to each pixel, utilizing SSE wasrelatively simple and highly effective. Finally, we showed that when the data layout is designed to
be SIMD-friendly, vectorization from the compiler provide a significant performance.

8/2/2019 Optimization in Image Processing
http://slidepdf.com/reader/full/optimization-in-image-processing 13/13





























