Embed Size (px)
Citation preview

Overture and MetaChoas for
CISM Developers
M. Wiltberger
With thanks to Bill Henshaw and Alan Sussman

What is Overture?
A Collection of C++ Classes that can be used to solve PDEs on overlapping grids Key Features
High level interface for PDEs on adaptive and curvilinear grids
Provides a library of finite differences operators Conservative/NonConservative 2nd and 4Th order
Uses A++/P++ array class for serial parallel array operations
Extensive grid generation capablities

Overture: A toolkit for solving PDEs
Mappings(geometry)
MappedGridGridCollection
MappedGridFunctionGridCollectionFunction
Operatorsdiv, grad, bc's
Grid Generator Ogen
Adaptive Mesh Refinement
SolversOges, Ogmg, OverBlown
A++P++array class
Data base (HDF)
Graphics (OpenGL)
Boxlib (LBL)

A++ Array Class
Serial and Parallel Array operations
Easily passed to Fortran
Just recompile with different library for parallel code using MPI calls
do j=1,8 do i=1,8 u(i,j)=0.25*(v(i+1,j)+v(i-1,j) +v(i,j+1+v(i,j+1) enddoenddo
Fortran
realArray u(10,10), v(10,10);Range I(8,8), J(8,8);v = 1;u(I,J) =0.25*(v(I+1,J)+v(I-1,J)+
v(I,J+1)+v(I,J-1));
C++

Passing A++ arrays to Fortran
C++
Fortran
extern "C" { void myfortran_( int & m, int & n, real & u); }
realArray u(20,10);
myfortran_( u.getLength(0), u.getLength(1), *u.getDataPointer() );
subroutine myfortran( m,n,u )real u(m,n)...end

A Mapping defines a continuous transformation
xr
Mapping
domainDimensionrangeDimensionmap( r,x,xr )inverseMap( x,r,rx )boundaryConditionssingularities...
SquareMappingAnnulusMappingSphereMappingHyperbolicMappingEllipticTransformMatrixMappingRevolutionMapping etc.
unit square
Each mapping has an optimized map and inverseMap
map

A MappedGrid holds the grid pointsand other geometry info
MappedGrid
gridIndexRangeMappingvertexvertexDerivativecellVolumefaceNormal...
Mapping that defines the geometrygrid pointsjacobian derivatives optionally computed
geometry arrays
Figure here
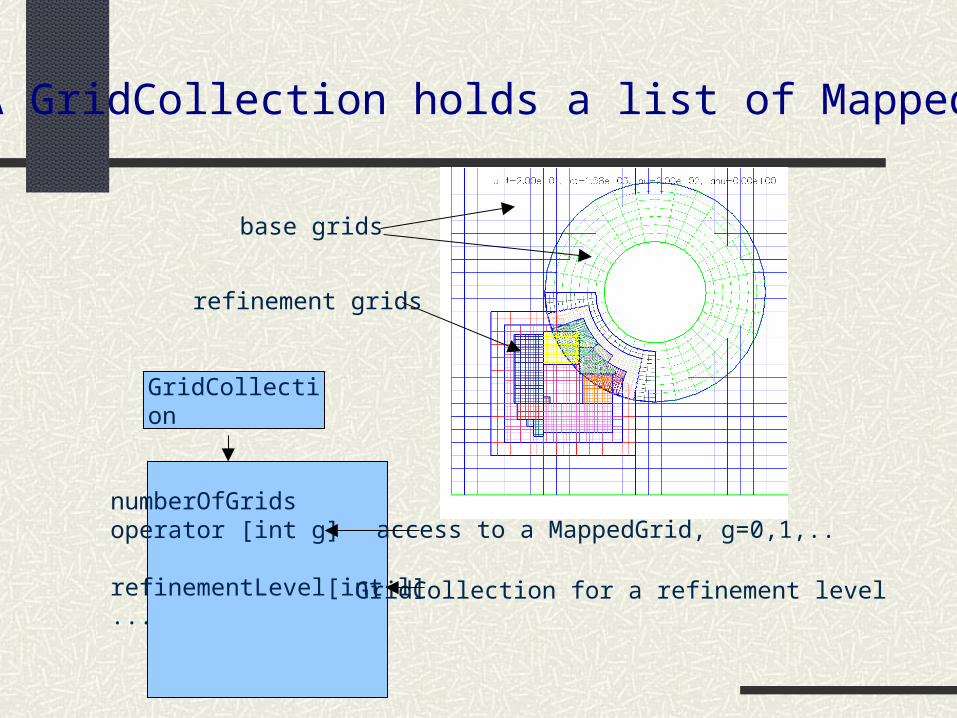
A GridCollection holds a list of MappedGrids
GridCollection
numberOfGridsoperator [int g]
refinementLevel[int l]...
access to a MappedGrid, g=0,1,..
GridCollection for a refinement level
base grids
refinement grids

A MappedGridFunction holds solution values
realMappedGridFunction
numberOfComponentsMappedGridMappedGridOperators
x,y,z,xx,... derivatives
derived from an A++ realArraywhich implies it inherits all A++ operators
scalar, vector, 2-tensor, ..
Grid functions can be vertex-centered,cell-centered, face-centered etc.
MappedGrid mg(mapping);realMappedGridFunction u(mg);u=1.;

A GridCollectionFunction is alist of MappedGridFunctions
GridCollection gc(...);Range all;
realGridCollectionFunction u(gc,all,all,all,2);
u=1.;
for( int grid=0; grid<gc.numberOfGrids(); grid++ ) u[grid]=1.;
realGridCollectionFunction
realMappedGridFunction
realMappedGridFunction

Operators
The Operator classes define differential operators and boundary conditions. - 2nd/4th order approximations plus some conservative approximations
MappedGrid mg(sphere);
MappedGridOperators op(mg);
floatMappedGridFunction u(mg), v(mg), w;
v=u.x()+u.y();
w=u.laplacianCoefficients();
Compute the derivatives directly
Form the sparse matrix for thedifferential operator

Overture can be used at a number of levels
GridCollection gc(...);realGridCollectionFunction u(gc), v(gc);GridCollectionOperators op(gc);
v = u.x();
for( int grid=0; grid<gc.numberOfGrids(); grid++ ) v[grid]=u[grid].x();
for( grid=0; grid<gc.numberOfGrids(); grid++ ) xFortran_( *v[grid].getDataPointer(), *u[grid].getDataPointer(), ...);
Operate at the collection level
Call Fortran
Operate at the single grid level

A sample Overture program
int main() { CompositeGrid cg; // Create a Composite grid getFromADataBaseFile(cg,”mygrid.hdf”); floatCompositeGridFunction u(cg); u = 1.0; // Set initial conditions CompositeGridOperators og(cg); // Create Operators u.setOperators(op); float t=0, dt=0.005, a=1., b=1., nu=0.1; for(int step=0;step<200;step++) { u+=dt*(-a*u.x()-b*u.y()+nu*(u.xx()+u.yy()); t+=dt; u.interpolate(); // Exchange info between grids u.applyBoundaryConditions(dircichelt,allBoundaries); u.finishBoundaryConditions(); } return 0;
}
Solve ut +aux + buy -(uxx+uyy) on overlaping grid

Wave Equation Solver
The Overture primer contains a short codeshowing how to write a solver for the waveequation. This example shows how a waveis able to pass through a grid interface withfew artificial reflections.

Incompressible flow past two cylinders
Fine grids are integrated implicitly, coarse grids explicitly.

What is MetaChoas?
A runtime meta-library that achieves direct data transfers between data structures managed by different parallel libraries Runtime meta-library means that it interacts with data
parallel libraries and languages used for separate applications (including MPI)
Can exchange data between separate (sequential or parallel) applications
Manage data transfers between different libraries in the same application
This often referred to as the MxN problem in parallel programming

How does MetaChaos work?
It starts with the Data Descriptor Information about how the
data is distributed across the processors
Usually supplied by the library/program developer
Sussman et al. are working on generalizing this process
MetaChaos then uses a linearization (LSA
) of the data to be moved (the regions) to determine the optimal method to move data from set of regions in A (SA ) to a set of regions in B (SB)
Moving the data is a three step process
LSA = llibX(SA)
LSB = LSA
SB = l-1libY(LSB
)Only constraint on this operation is each region must have the same number of elements

A Simple Example: Wave Eq Using P++
#include <A++.h>main(int argc, char **argv) { Optimization_Manager::Initialize_Virtual_Machine("",iNPES,argc,argv); doubleArray daUnm1(iNumX+2,iNumY+2),daUn(iNumX+2,iNumY+2); doubleArray daUnp1(iNumX+2,iNumY+2);
Index I(1,iNumX), J(1,iNumY); // Indices for computational domain for(j=1;j<iNumY+1;j++) { daUnm1(I,j) = sin(dW*dTime + (daX(I)*2*dPi)/dLenX); daUn(If,j) = sin(dW*0 + (daX(If)*2*dPi)/dLenX); }
// Apply BC Omitteed for space // Evole a step forward in time for(i=1;i<iNSteps;i++) { daUnp1(I,J) = ((dC*dC*dDT*dDT)/(dDX*dDX))* (daUn(I-1,J)-2*daUn(I,J)+daUn(I+1,J)) + 2*daUn(I,J) - daUnm1(I,J);
// Apply BC Omitted for space
} Optimization_Manager::Exit_Virtual_Machine();}

Split into two using MetaChaos#include <A++.h>main(int argc, char **argv) { Optimization_Manager::Initialize_Virtual_Machine("",NPES,argc,argv); this_pgme = InitPgme(pgme_name,NPES); other_pgme = WaitPgme(other_pgme_name,NPES_other); Sync2Pgme(this_pgme,other_pgme); BP_set = Alloc_setOfRegion(); left[0] = 4; right[0] = 4; stride[0] = 1; left[1] = 5; right[1] = 5; stride[0] = 1; reg = Alloc_R_HDF(DIM,left,right,stride); Add_Region_setOfRegion(reg,BP_Set); BP_da = getPartiDescriptor(&daUn); sched = ComputeScheduleForSender(…,BP_da,BP_set,…);
for(i=1;i<iNSteps;i++) { daUnp1(I,J) = ((dC*dC*dDT*dDT)/(dDX*dDX))* (daUn(I-1,J)-2*daUn(I,J)+daUn(I+1,J)) + 2*daUn(I,J) - daUnm1(I,J); iDataMoveSend(other_pgme,sched,daUn,getLocalArray().getDataPointer); iDataMoveRecv(other_pgme,sched,daUn,getLocalArray().getDataPointer); Sync2Pgme(this_pgme,other_pgme);
} Optimization_Manager::Exit_Virtual_Machine();}
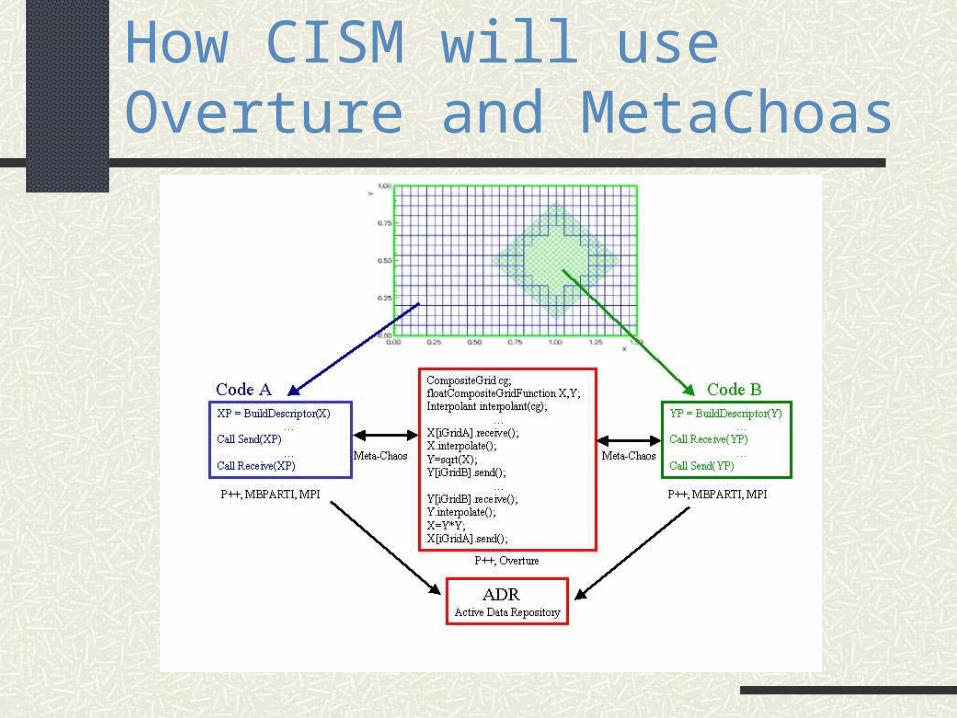
How CISM will use Overture and MetaChoas




![The San Francisco call (San Francisco [Calif.]) 1913 …...Henshaw and Tyler Henshaw and is a? ousin of Mrs. Harry Chickering and Miss Florence Henshaw. In college Mr. Henshaw prepared](https://img.pdfslide.net/doc/110x75/5f330aea5bd653373e409c34/the-san-francisco-call-san-francisco-calif-1913-henshaw-and-tyler-henshaw.jpg)
























