Embed Size (px)
Citation preview

1
FB Automatisierung und Informatik: Parallele Algorithmen 1
Parallele Algorithmen
� Dipl.-Inf., Dipl.-Ing. (FH) Michael Wilhelm
� Hochschule Harz
� FB Automatisierung und Informatik
� Raum 2.202
� Tel. 03943 / 659 338
FB Automatisierung und Informatik: Parallele Algorithmen 2
Inhalt
1. Einführung, Literatur, Motivation2. Architektur paralleler Rechner
3. Software
4. Open MP
5. MIMD
6. Algorithmen
7. Computernumerik
8. PS/3

2
FB Automatisierung und Informatik: Parallele Algorithmen 3
Literatur
� Rauber, Runger, Multicore: Parallele Programmierung, Springer Verlag
� Timothy G. Mattson, Beverly A. Sanders, Berna L. Massingill:Patterns for Parallel Programming (Software Patterns) von
� Akhter, Roberts: Multicore-Programmierung,
� Zhou: Parallel Computing in .NET
� Rauber, Rünger: Parallele und verteilte Programmierung,Springer Verlag, 2000, ISBN 978-3-540-46549-2, 2. Auflage
� W. Huber, Paralleles Rechnen, R. Oldenbourg Verlag, 1997, ISBN 3-486-24383-7
� Theo Ungerer, Parallelrechner und parallele Programmierung, Spektrum Akademischer Verlag, 1997, 3-8274-0231-X
� Ananth Gama, Anshul Gupta: Introduktion to Parallel Computing; ISBN: 0-201-64865-2
FB Automatisierung und Informatik: Parallele Algorithmen 4
Literatur
� Bräunl, Thomas.: Parallele Programmierung, Vieweg: Braunschweig, 1993., ISBN 3-528-05142-6
� Klaus Schmidt, Programmieren von Vektorrechnern und Parallelrechnern, Verlag Harri Deutsch, 1994, 3-8171-1360-9

3
FB Automatisierung und Informatik: Parallele Algorithmen 5
Literatur� Shared Memory Parallel Programming with Open MP
5th International Workshop on Open MP Application and Tools, WOMPAT 2004, Houston, TX, USA, May 17-18, 2004Reihe: Lecture Notes in Computer Science, Band 3349 Chapman, Barbara M. (Hrsg.) 2005, X, 149 p. ISBN: 3-540-24560-X
� http://www.springerlink.com/content/t74brpc87u5q/
� A. S. Tanenbaum: Moderne Betriebssysteme
� Kredel, Yoshida: Thread- und Netzwerkprogammierung mit Java, dPunkt Verlag, ISBN 3-932588-28-2
� Lea, Doug.: Concurrent Programming in Java, Entwurfsprinzipien und Muster, Addison-Wesley: Bonn, 1997, java.sun.com/Series.
� ISBN 3-8273-1243-4
� Horstmann, C.S.: Core Java, Vol. II - Advanced Features, Prentice Hall: Palo Alto, 1998, S. 76-131.
FB Automatisierung und Informatik: Parallele Algorithmen 6
Lernziele� Grundlegende Kenntnisse in parallelen Rechnerarchitekturen
– Multi-Core-Rechner (Threads, Open MP)
– Vektorrechner (SIMD, Parallaxis)
– Multiprozessingrechner (MIMD, MPI, PVM)
� Konzepte der parallelen Programmierung– Synchronisation (Semaphore, Monitore)
– Kommunikation
– Threads
� Parallelrechner mit verteilten Speichern– Message Passing Interface (MPI)
– Parallel Virtuell Machine (PVM)
� Algorithmen– Sortieralgorithmen
– Systolische Matrixmultipikation
� Numerik

4
FB Automatisierung und Informatik: Parallele Algorithmen 7
Motivation
� PC-Software:– Textverarbeitung (Starwriter, WinWord, Tex, LaTex)
– Bildverarbeitung (PhotoShop, Corel Draw, 3D StudioMax)
– CAD (AutoCAD, Microstation, Caddy)
– Mathematik Tools (MathLab, MathCad)
– Steuerung einer Fabrik (Hasseröder)
Geschwindigkeit ausreichend, Dauer der Berechnung 0,1 bis 10 min
� PC-Software:– Statikprogramme (Finite Element Methoden, Gleichungen 3000×3000,
– Bildverarbeitung (Trickfilme, König von Narnia)
– Spezialsoftware (Eagle)
Geschwindigkeit nicht ausreichend, Dauer der Berechnung 1-14 Tage, Jahre
FB Automatisierung und Informatik: Parallele Algorithmen 8
Motivation
� Probleme:– Simulation der Wechselwirkung zwischen Atomen
– Gravitation zwischen Himmelskörpern (2 bis n Körper)
– Wettersimulation (Quadrat 50 km × 50 km, kaum 3D)
– Hydromechanische Simulation (Großstadt Berlin, New York etc.)
– Schach (Deep Blue)
– Erdbebensimulation
– Atomwaffen-Simulation
� Lösungen / Abhilfe:– Erhöhung der Taktfrequenz ?
– Parallelität in der CPU (Pipelines)
– Parallelbetrieb mit 10, 100 oder mehr CPU

5
FB Automatisierung und Informatik: Parallele Algorithmen 9
Beispiel Entwicklung von Medikamenten
Problem:
� Wie bindet sich ein hypothetischer medizinischer Wirkstoff an einem
biologischen Rezeptor (Spektrum der Wissenschaft, März, 1994)
� 8000 Atomen im Wirkstoffmolekül, Lösungsmittel und biologischer
Zielsubstanz
� Pro Atom drei Unbekannte (drei Koordinaten)
� Gleichungssystem mit 24000 Unbekannten
� teilweise ein nichtlinearesGleichungssystem
FB Automatisierung und Informatik: Parallele Algorithmen 10
Beispiel Integration
Problem:
� Integration einer mehrdimensionalen Funktion
� Berechnung eines „Gebirges“
� hohe Anzahl der Variablen
� Numerische Komplexität: 1 / εd
� Beispiel:
– drei Variablen
– acht Stellen Genauigkeit
– Komplexität: 1024
– Rechenzeit eines Teraflop-Computers: eine Billion Sekunden

6
FB Automatisierung und Informatik: Parallele Algorithmen 11
Beispiel Faktorisierung einer Zahl
Problem:
� Ermittlung aller Faktoren einer beliebigen Zahl
� Beispiel:
– 3×3 ×3803 ×3607 = 123 456 789
– Aufwand soll minimal sein
� Aufwand bei einer 200-stelligen Zahl ?
� Komplexität: vermutlich mit nicht polynomialer Rechenzeit lösbar
� Verwendung in Kryptographie
FB Automatisierung und Informatik: Parallele Algorithmen 12
Beispiel Primzahlbestimmung
Problem:
� Ist eine Zahl eine Primzahl?
� Verwendung in der Kryptographie
� Vor dem Computerzeitalter war 2127-1 die höchste bekannte Primzahl

7
FB Automatisierung und Informatik: Parallele Algorithmen 13
Umstieg auf einen Parallelrechner:
� Wie viele Prozessoren?
� Wie werden sie miteinander verbunden?
� Welcher Komplexitätsgrad hat jede CPU?
� Sind alle Prozessoren identisch?
� Lösung des Synchronisationsproblem?
� BUS-Systeme (Anzahl, Unabhängigkeit)
� Speicher (lokal, global, Messages)
� Synchrone Parallelität
� Asynchrone Parallelität
� Koordination des Programms
� Parallele Programmiersprache
� Paralleles Betriebssystem
FB Automatisierung und Informatik: Parallele Algorithmen 14
Parallelität:
Parallele Tätigkeiten bei einer Rechenaufgabe:
� Simultane Eingabe an mehreren PC´s
� Mehrere Programme gleichzeitig starten (1 CPU) ?
� Mehrere Programme gleichzeitig starten (n CPU) ?
� Ein Programm besitzt mehrere Teilaufgaben (Tasks)
� Parallelität in der CPU (Pipeline, IU, FPU, Cache)

8
FB Automatisierung und Informatik: Parallele Algorithmen 15
Parallelität:
Parallele Software erfordert:
� Parallelen Rechner (mindestens 2 CPU)
� Betriebssystem mit parallelen Tasks
� Parallele Programmiersprache
FB Automatisierung und Informatik: Parallele Algorithmen 16
Probleme:
� Aufteilung der Aufgaben
� Synchronisation zwischen den Prozessen
� Datenzugriff der Prozessen (Gemeinsamer Speicher etc).
� Lineare Algorithmen
� Parallele Algorithmen
� Alter Quellcode mit linearen Algorithmen (OpenMP)
� Neuer Quellcode mit parallelen Algorithmen (MPI, PVM)
Parallelität:

9
FB Automatisierung und Informatik: Parallele Algorithmen 17
Dual-Core-Rechner (Intel, AMD):
Threads, Open MP, MPI, C / Fortran
Multi-Core-Rechner:
Open MP, MPI, Unified Parallel C, Fortran
Grafikkarten:
OpenCL, Direct X
Clusterrechner:
MPI, PVM
Vektorrechner:
Parallaxis
Beispiele für Rechnersysteme
FB Automatisierung und Informatik: Parallele Algorithmen 18
Open MP-Projekt:
� Open Multiprozessing
� Standardisiert
�Verwendung beim Multi-Core-Computern
� Kommunikation über Bus
� Neuprogrammierung teilweise notwendig, siehe 1. Labor
Beispielprojekte:

10
FB Automatisierung und Informatik: Parallele Algorithmen 19
PVM-Projekt
� Parallel Virtual Machine
� Plattform übergreifender Standard
� Oak Ridge National Laboratory,1989
� Jeder Rechner hat einen „Daemon“ mit der Library „libpvm“
� Kommunikation über UDP,TCP, Sockets
� Neuprogrammierung notwendig
� http://freshmeat.net/releases/80892
Beispielprojekte:
FB Automatisierung und Informatik: Parallele Algorithmen 20
MPI-Projekt:
� Messing Passing Interface
� Plattform übergreifender Standard
� Kommunikation über UDP,TCP, Sockets
� Neuprogrammierung notwendig, siehe 2. Labor
� http://www.unix.mcs.anl.gov/mpi
Beispielprojekte:

11
FB Automatisierung und Informatik: Parallele Algorithmen 21
■ Die Sapphire HD5870 basiert auf AMDs aktueller High-End GPU Radeon HD5870.
■ Die in 40nm gefertigte GPU taktet mit 850 MHz und verfügt über satte 1600Streamprozessoren, was für eine Rechenleistung von 2,77 TeraFLOPs einfacher Genauigkeit ausreicht.
■ Die Karte ist mit 1024 Mbyte GDDR5-Speicher bestückt (effektiver Takt 4800 MHz), der über ein 256-Bit-Interface angebunden ist.
■ Weitere Eigenschaften: DirectX 11, OpenGL 3.2, ATI Avivo HD Video, ATI Stream (Unterstützung von OpenCL 1.0 und DirectCompute 11), CrossFireX für bis zu vier GPUs und die Multi-Display-Technologie ATI Eyefinity.
Sapphire HD5870: 355.00 €
FB Automatisierung und Informatik: Parallele Algorithmen 22
PCEe-ATI: Asus EAH5970/G/2DIS: 600,00 €
■ Die Asus EAH5970/G/2DIS ist eine Dual-GPU-Karte auf Basis von zwei AMD Radeon HD5870 Chips.
■ Die beiden GPUs auf der EAH5970/G/2DIS arbeiten mit 725 MHz und verfügen zusammen über 3200Streamprozessoren und 160 Textureinheiten für unglaubliche Rechenpower in GPGPU-Anwendungen und Spielen.
■ Jeder GPU stehen 2 GByteGDDR5-Speicher zur Verfügung, der mit 256-Bit angebunden ist und mit 1 GHz taktet (effektive Datenrate 4000 MHz).
■ Dazu bietet die Asus EAH5970/G/2DIS aktuelle Features wie DirectX 11, OpenGL 3.2, ATI Avivo HD Video, ATI Stream (Unterstützung von OpenCL 1.0 und DirectCompute 11) und die Multi-Display-Technologie ATI Eyefinity.
12
FB Automatisierung und Informatik: Parallele Algorithmen 23
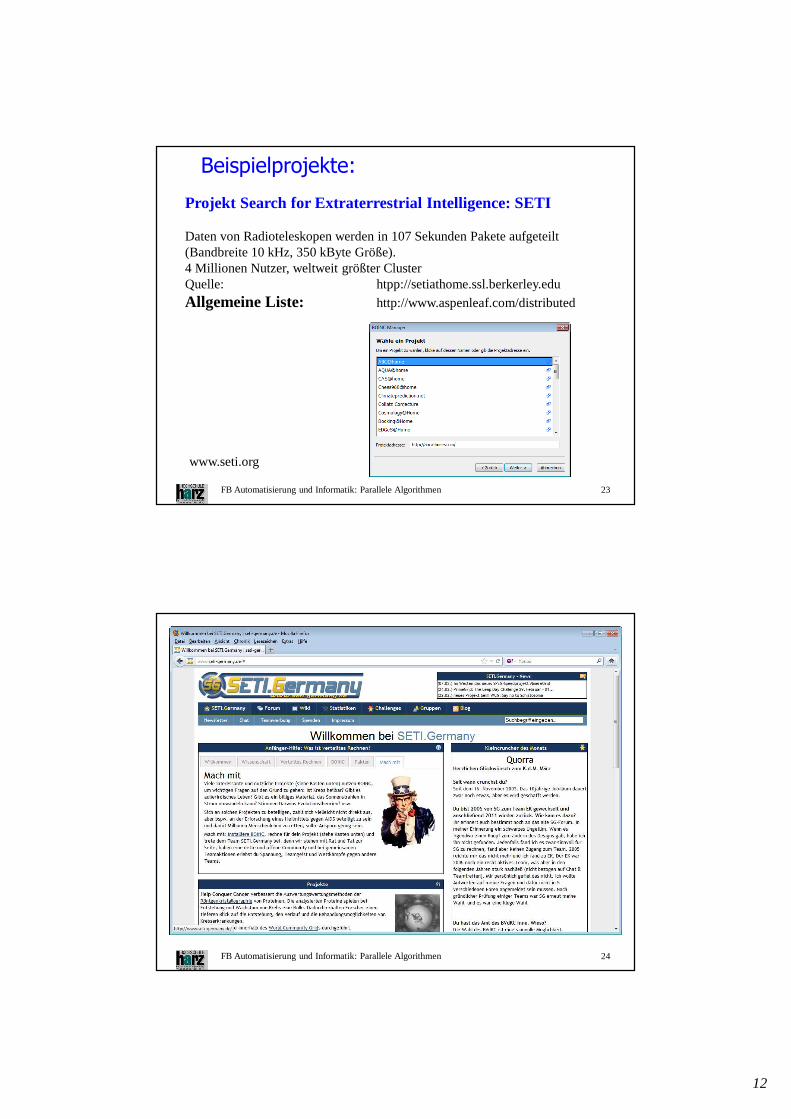
Projekt Search for Extraterrestrial Intelligence: SETI
Daten von Radioteleskopen werden in 107 Sekunden Pakete aufgeteilt (Bandbreite 10 kHz, 350 kByte Größe).4 Millionen Nutzer, weltweit größter ClusterQuelle: htpp://setiathome.ssl.berkerley.edu
Allgemeine Liste: http://www.aspenleaf.com/distributed
Beispielprojekte:
www.seti.org
FB Automatisierung und Informatik: Parallele Algorithmen 24

13
FB Automatisierung und Informatik: Parallele Algorithmen 25
Sun SPARC Enterprise M9000 Server
CPU Choice of as many as 32 SPARC64 VII quad-core or 32 SPARC64 VI dual-core processors (up to 64 processors with expansion cabinet)
Cache per SPARC64 Level 1 • SPARC64 VII: 64 KB D-cache and 64 KB I-Cache
• SPARC64 VI: 128 KB D-cache and 128 KB I-Cache
Cache per SPARC64 Level 2 • SPARC64 VII: 6 MB on chip • SPARC64 VI: 5 MB – 6 MB on chip
Clock speed • SPARC64 VII: 2.88 GHz • SPARC64 VI: 2.28 GHz – 2.4 GHz System
System bus High-speed, low-latency interconnect with redundant data, address, and response crossbar
CPU: Main memory Up to 2 TB CPU: I/O As many as 8 I/O units (IOUs) with 8 PCIe slots
each/64 PCIe slots per system; up to 224 PCIe and PCI-X slots with the optional External I/O Expansion Unit
System bus bandwidth (memory) 368 GB/sec peak, 114,9 GB/sec stream (copy) System bus bandwidth (I/O) 122 GB/sec peak PC : RAM-Durchsatz peak:6 GB/s
FB Automatisierung und Informatik: Parallele Algorithmen 26
The Sun SPARC Enterprise M9000 server features the option to mix and match up to 64 quad-core SPARC64 VII processorsor dual-core SPARC64 VI processors, with up to 256 cores, and 512 threads all in the same system. It comes preinstalled with Solaris 10, the worlds most advanced OS.
14
FB Automatisierung und Informatik: Parallele Algorithmen 27
An all-new, faster backplane interconnect gives you 368 GB/second speedsand acts as a common interconnect between all chips, maximizing address and data bandwidth on one interconnect.
FB Automatisierung und Informatik: Parallele Algorithmen 28
IBM SystemsLab Europe, Mainz

15
FB Automatisierung und Informatik: Parallele Algorithmen 29
IBM SystemsLab Europe, Mainz
FB Automatisierung und Informatik: Parallele Algorithmen 30
IBM SystemsLab Europe, Mainz
16
FB Automatisierung und Informatik: Parallele Algorithmen 31
� 9 KW
� 320 kW
� 80 km Länge des Netzwerkkabels
� 1500 Rechner
� 100 Racks
� Stromkosten: 45000,00 € pro Monat
Mainz, IBM Storage Center
FB Automatisierung und Informatik: Parallele Algorithmen 32
Dhrystone:Nur Integerbefehle. Geeignet für Messungen der Betriebssystem-Performance kleiner und mittlerer Rechner
Whetstone:Standard-Arithmetik. Geeignet für kleine und mittlere Rechner
Livermore Loops:24 For-Schleifen von häufig benutzten Programmen im Lawrence Livermore National Laboratory
Beispiele für synthetische Benchmarks
17
FB Automatisierung und Informatik: Parallele Algorithmen 33
SPECS-Marks:Von der Systems Performance Evaluation Cooperative zusammengestellte Programmsammlung, bestehend aus 6 Fortran und 4 C-Programmen, die Integer- und Floatingpoint-Operationen beinhalten. Die SPEC wurde 1988 von Apollo, HP, MIPS und SUN gegründet. Hauptsächlich für Workstations geeignet.
Slalom-Benchmark:Eine weitere Programmsammlung, die so geschrieben ist, dass der Benchmark auf jedem Rechner ungefähr gleich lange dauert. Er ist somit geeignet auch kleinere Rechner zu testen.
Beispiele für synthetische Benchmarks
FB Automatisierung und Informatik: Parallele Algorithmen 34
Perfect-Benchmark:Sammlung aus verschiedenen Anwendungsprogrammen für Supercomputer. Perfect steht für „Performance Evaluation für Cost-Effective Transformations“. Die Normierung der Version wurde mit der Cray XMP durchgeführt. Es gibt zwei Disziplinen: Bei der „baseline“ wurde der Code eingefroren, und neue Compilerversionen können ihre Leistungsfähigkeit unter Beweis stellen. In der zweiten Disziplin darf der Quellcode beliebig verändert werden, nur die Ergebnisse müssen übereinstimmen.
Beispiele für synthetische Benchmarks

18
FB Automatisierung und Informatik: Parallele Algorithmen 35
Linpack:Der Ur-Benchmark für Supercomputer von Jack Dongerra. Er besteht aus 2 Disziplinen:
Beispiele für synthetische Benchmarks
� Lösen eines 100x100 Gleichungssystems bei vorgegebenen Fortransource
� Lösen eines 1000x1000 Gleichungssystems, wobei beliebige Optimierungen erlaubt sind. Er bestimmt die aktuelle „Hitliste“ von Rechnern. Er ist sehr gut vektorrisierbar, führt keine I/O-Operationen aus und verbraucht wenig Speicher.
FB Automatisierung und Informatik: Parallele Algorithmen 36
NASA-Benchmark
NAS (Numerical Aerodynamic Simulation)
Euro-Ben-Benchmark
Genesis
PAR-Benchmark
Beispiele für synthetische Benchmarks

19
FB Automatisierung und Informatik: Parallele Algorithmen 37
Mips:Millions instruction per second.
Mips bezeichnet hierbei die pro Sekunde von einem Rechner verarbeitbare Anzahl an Befehlen.
Die maximale Mips-Rate (Mips-peak) ergibt sich in Abhängigkeit der Taktfrequenz tc und der Anzahl nm an erforderlichen Taktzyklen pro Befehl zu:
Kriterien für Rechnerarchitekturen
610·m
cpeak n
tMips =
610·
ProgrammeineminnenInstruktioderAnzahl
szeitAusführungMips=
FB Automatisierung und Informatik: Parallele Algorithmen 38
Mflops-Rate:Die maximale Mflop-Rate ergibt sich damit für eine notwendige Anzahl an Taktzyklen nf pro Gleitpunktoperation:
Kriterien für Rechnerarchitekturen
610·f
cpeak n
tMflops =
610·
ProgrammeineminnoperationeGleitpunktAnzahl
szeitAusführungMflops=
20
FB Automatisierung und Informatik: Parallele Algorithmen 39
Adresse� www.top500.org
� www.top500.org/lists/linpack.php
� http://www.top500.org/lists/2004/06/1/
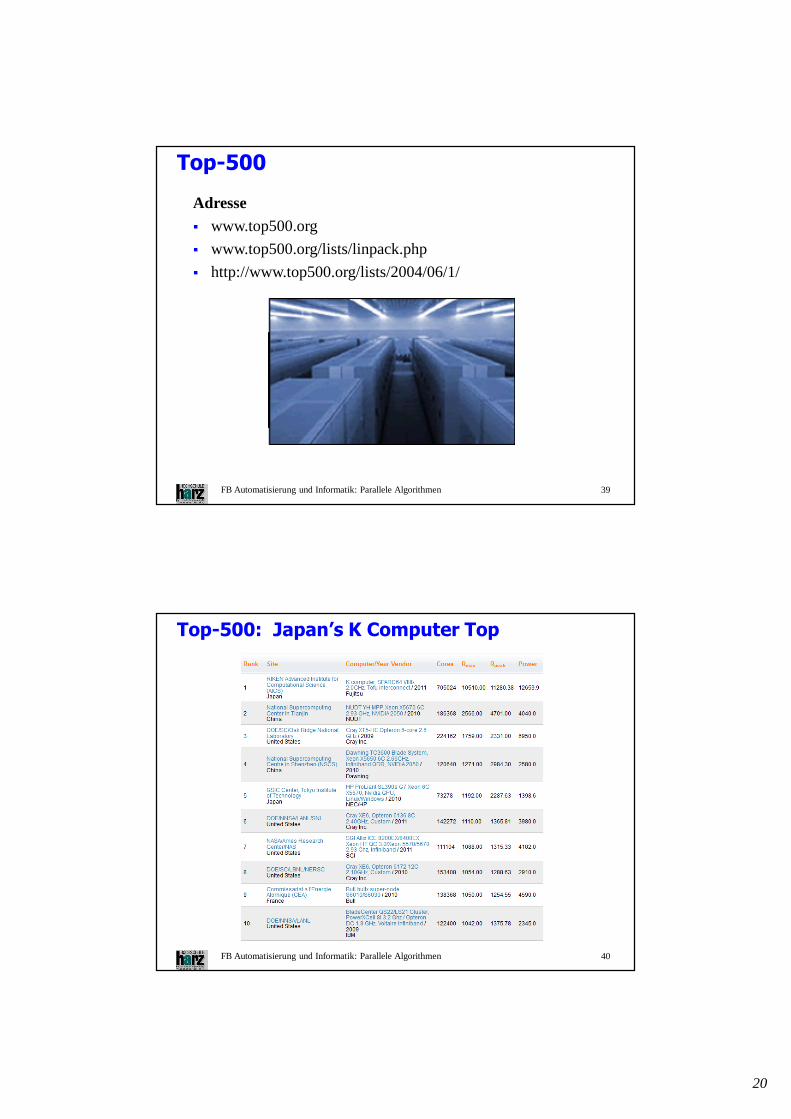
Top-500
FB Automatisierung und Informatik: Parallele Algorithmen 40
Top-500: Japan’s K Computer Top
21
FB Automatisierung und Informatik: Parallele Algorithmen 41
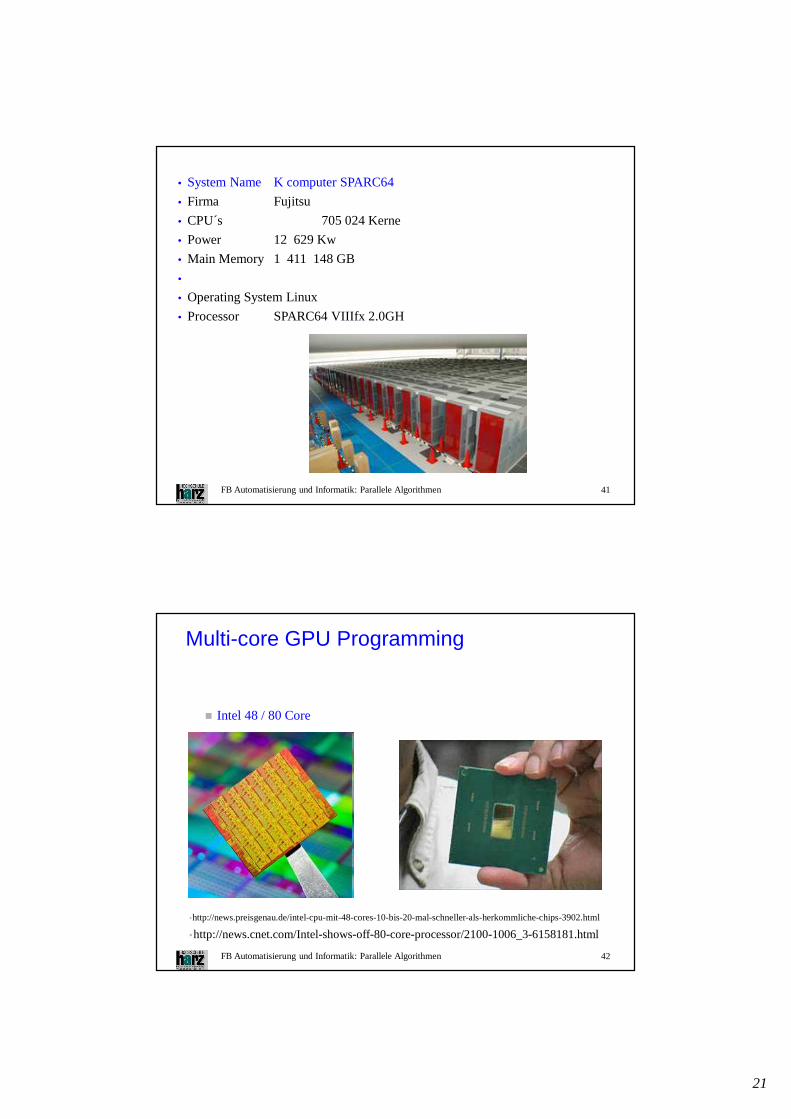
• System Name K computer SPARC64
• Firma Fujitsu
• CPU´s 705 024 Kerne
• Power 12 629 Kw
• Main Memory 1 411 148 GB
•
• Operating System Linux
• Processor SPARC64 VIIIfx 2.0GH
FB Automatisierung und Informatik: Parallele Algorithmen 42
� Intel 48 / 80 Core
Multi-core GPU Programming
•http://news.cnet.com/Intel-shows-off-80-core-processor/2100-1006_3-6158181.html
•http://news.preisgenau.de/intel-cpu-mit-48-cores-10-bis-20-mal-schneller-als-herkommliche-chips-3902.html
22
FB Automatisierung und Informatik: Parallele Algorithmen





























