Embed Size (px)
Citation preview

PERCEPTUAL INTELLIGENCE
SEMINAR REPORT
submitted by
AMITH K P
EPAHECS009
for the award of the degree
of
Bachelor of Technology
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
GOVERNMENT ENGINEERING COLLEGE SREEKRISHNAPURAM
PALAKKAD
December 2010

CERTIFICATE
This is to certify that the mini seminar report entitled PERCEPTUAL
INTELLIGENCE submitted by AMITH K P, to the Department Of Com-
puter Science and Engineering, Government Engineering College, Sreekr-
ishnapuram, Palakkad-679513, in partial fulfilment of the requirement for the
award of B.Tech Degree in Computer Science and Engineering is a bonafide record of
the work carried out by him during year 2010.
Dr P C Reghu Raj Dr P C Reghu Raj
Staff Co-ordinator Head of the Department
Place: Sreekrishnapuram
Date: 24-10-2010

Acknowledgement
It stands to reason that the completion of a seminar of this scope
needs the support of many people. I take this opportunity to express my
boundless thanks and commitment to each and every one,who helped me in
successful completion of my seminar. I am so happy to acknowledge the help
of all the individuals to fulfil my attempt.
First and foremost I wish to express wholehearted indebtedness to
God Almighty for his gracious constant care and magnanimity showered bliss-
fully over me during this endeavour.
I thank to Dr P C Reghu Raj, Head of Department of Computer
Science and Engineering, Govt. Engineering College Sreekrishnapuram, for
providing and availing me all the required facilities for undertaking the semi-
nar in a systematic way .I express my heartfelt gratitude to him for working
as a seminar coordinator and guide ,who corrected me and gave valuable sug-
gestions.
Gratitude is extended to all teaching and non teaching staffs of De-
partment of Computer Science and Engineering, Govt Engineering College
Sreekrishnapuram for the sincere directions imparted and the cooperation in
connection with the project.
I am also thankful to my parents for the support given in connection
with the project. Gratitude may be extended to all well-wishers and my
friends who supported us to complete the seminar in time.
ii

Table of Contents
List of Figures v
Abstract 1
1 Introduction 2
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Why Perceptual Intelligence ? . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Organisation of the Report. . . . . . . . . . . . . . . . . . . . . . . . 3
2 Perceptual Intelligence 4
2.1 Perception . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.1 The filters that make up perception are as follows: . . . . . . . 4
2.2 Perceptual User Interfaces . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2.1 Information flow in Perceptual User Interfaces . . . . . . . . . 7
2.2.1.1 Perceptive User Interface/Perceptual Interface . . . 7
2.2.1.2 Multimodal Interfaces . . . . . . . . . . . . . . . . . 10
2.2.1.3 Multimedia Interfaces . . . . . . . . . . . . . . . . . 13
2.3 Perceptual Intelligence . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.4 Perceptual Intelligent Systems . . . . . . . . . . . . . . . . . . . . . 21
2.4.1 Gesture Recognition System . . . . . . . . . . . . . . . . . . . 21
2.4.1.1 Gesture Recognition . . . . . . . . . . . . . . . . . . 21
2.4.1.2 Working of Gesture Recognition System . . . . . . . 22
2.4.1.3 Challenges of Gesture Recognition . . . . . . . . . . 26

2.4.2 Speech Recognition System . . . . . . . . . . . . . . . . . . . 27
2.4.2.1 Types of Speech Recognition . . . . . . . . . . . . . 29
2.4.2.2 Working of Speech Recognition Systems . . . . . . . 30
2.4.2.3 Performance of speech recognition systems . . . . . . 32
2.4.3 Nouse Perceptual Vision Interface . . . . . . . . . . . . . . . . 33
2.4.3.1 Computer Control Actions . . . . . . . . . . . . . . . 33
2.4.3.2 Tools Used In Nouse Perceptual Vision Interface . . 34
2.4.3.3 Working Of Nouse Perceptual Vision Interface . . . . 35
3 Applications 41
3.1 SMART ROOMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.2 SMART CLOTHES . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
iv

List of Figures
2.1 Perception . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Perceptual User Interface . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 Information flow in Perceptual User Interface . . . . . . . . . . . . . . 8
2.4 Human Computer Interaction . . . . . . . . . . . . . . . . . . . . . . 9
2.5 Perceptual Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.6 Phantom input/output device . . . . . . . . . . . . . . . . . . . . . . 13
2.7 Different Medias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.8 User cancels video by pressing Cancel push button . . . . . . . . . . 15
2.9 User adjusts sound volume with slider and turns off sound with Sound
off push button . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.10 Suggested sizes for touch areas and visual targets . . . . . . . . . . . 19
2.11 Background subtracted mask . . . . . . . . . . . . . . . . . . . . . . . 24
2.12 image illustrating body center and arm algorithim . . . . . . . . . . . 25
2.13 Selecting Shift, selecting H . . . . . . . . . . . . . . . . . . . . . . . . 39
3.1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42

Abstract
Human computer interaction has not changed fundamentally for nearly two
decades. Most users interact with computers by typing, clicking and pointing. Now
most of the research works are concentrating on interaction techniques that com-
bine an understanding of natural human capabilities with computer I/O devices and
machine perception and reasoning.
Perceptual Intelligence is the knowledge and understanding that everything we
experience (especially thoughts and feelings) are defined by our perception. Its im-
portant to realize that this is an active, not passive, process and therefore we have
the ability to control it or change it. Computers need to share our perceptual en-
vironment before they can be really helpful. They need to be situated in the same
world that we are; they need to know much more than just the text of our words.
They also need to know who we are, see our expressions and gestures, and hear the
tone and emphasis of our voice.

CHAPTER 1
Introduction
Inanimate things are coming to our life. That is the simple objects that surround
us are gaining sensors,computational powers, and actuators.Consequently,desks and
doors, TVs and telephones, cars and trains,eyeglasses and shoes, and even the shirts
on our backs are changing from static, inanimate objects into adaptive, reactive sys-
tems that can be more friendly, useful, and efficient. Or, of course,these new systems
could be even more difficult to use than current systems;it depends how we design
the interface between the world of humans and the world of this new generation of
machines.
1.1 Motivation
The main problem with todays systems are,they are both deaf and blind.They
mostly experience the world around them through a slow serial line to a keyboard
and mouse. Even multimedia computers, which can handle signals like sound and
image,do so only as a transport device that knows nothing. Hence these objects are
still static and inanimate.
To change inanimate objects like offices,houses, cars, or glasses into smart, active
help-mates,they need some kind of Intelligence.This kind of intelligence what they
need here is Perceptual Intelligence. Perceptual Intelligence is paying attention to
people and the surrounding situation in the same way another person would, thus
allowing these new devices to learn to adapt their behavior to suit us,rather than
adapting to them as we do today.

1.2 Why Perceptual Intelligence ?
The problem with current computers is they are incredibly isolated. If
you imagine yourself living in a closed, dark, soundproof box with only a telegraph
connection to the outside world, you can get some sense of how difficult it is for
computers to act intelligently or be helpful.They exist in a world almost completely
disconnected from ours, so how can they know what they should do in order to be
helpful?
Computers need to share our perceptual environment before they can be really
helpful.They need to be situated in the same world that we are; they need to know
much more than just the text of our words of the signals content.Once the computer
has the perceptual ability to know who, what, when, where, and why, by understand-
ing,learning and interacting with the physical world sufficent for the computer to
determine a good course of action.If the systems have the ability to learn perception,
they can act in a smart way.Perceptual intelligence is actually a learned skill.
1.3 Organisation of the Report.
Each chapter begins with a brief introduction to its content. Chapter 2 gives a brief
background information on the various functions of the system and discusses other
related work in this area. Chapter 3 describes the Perceptual Intelligence in detail.
Chapter 4 discusses the Applications of Perceptual Intelligence. Chapter 5 includes
the conclusion and future scope.
3

CHAPTER 2
Perceptual Intelligence
2.1 Perception
Perception is the process of receiving information about and making sense
of the world around us. It involves deciding which information to notice, how to
categorize this information and how to interpret it within the framework of existing
knowledge.A process by which individuals organize and interpret their sensory im-
pressions in order to give meaning to their environment.For instance ,as shown in Fig
3.1,in perception ,process firstly recieve stimuli and select them accordingly.Now after
selecting,it organises and interprets proceeding to give response.
Perception is the end result of a thought that begins its journey with the senses.
We see, hear, physically feel, smell or taste an event. After the event is experienced
it must then go through various filters before our brains decipher what exactly has
happened and how we feel about it. Even though this process can seem instantaneous,
it still always happens.
2.1.1 The filters that make up perception are as follows:
• What we know about the subject or event.I saw an orange and knew it was
editable.
• What our previous experience (and/or knowledge) with the subject or event
was. Last time I ate an orange I peeled it first (knowledge to peel an or-
ange before eating it) and it was sweet. Our previous experience forms our
expectations.

Figure 2.1: Perception
• Our current emotional state. How we are feeling at the time of the event does
affect how we will feel after the event. I was in a bad mood when I ate the
orange and it angered me that it was sour and not sweet (my expectation).
• In the end my intellectual and emotional perception regarding the eating of an
orange was an unpleasant experience. Depending on how strong that experience
was, determines how I will feel next time I eat an orange. For example, if I got
violently sick after eating an orange, the next time I see an orange, I probably
wont want to eat it. If I had a pleasant experience eating an orange, the next
time I see an orange, Ill likely want to eat it.
Even though emotions seemly occur as a result of an experience, they are actually
the result of a complicated process. This process involves interpreting action and
thought and then assigning meaning to it. The mind attaches meaning with prejudice
as the information goes through the perceptual filters we mentioned above.
Our perceptual filters also determine truth, logic along with meaning though they
dont always do this accurately. Only when we become aware that a bad feeling could
5

be an indication of a misunderstanding (error in perception).we can begin to make
adjustments to our filters and change the emotional outcome.
When left alone and untrained, the mind chooses emotions and reactions based
on a ”survival” program which does not take into account that we are civilized beings
its only concerned with survival.
A good portion of this program is faulty because the filters have created distor-
tions, deletions and generalizations which alter perception. For example,jumping to
a conclusion about ”all” or ”none” of something based on one experience.The uncon-
scious tends to think in absolutes and supports ”one time” learnings from experience
(this is the survival aspect of learning).
2.2 Perceptual User Interfaces
A perceptual interface is one that allows a computer user to interact with the
computer without having to use the normal keyboard and mouse. These interfaces are
realised by giving the computer the capability of interpreting the user’s movements
or voice commands.
Perceptual Interfaces are concerned with extending human computer interaction
to use all modalities of human perception. All current research efforts are focused at
including vision, audition, and touch in the process. The goal of perceptual reality is
to create virtual and augmented versions of the world, that are perceptually identical
to the human with the real world. The goal of creating perceptual user interfaces
is to allow humans to have natural means of interacting with computers, appliances
and devices using voice, sounds, gestures, and touch.
Perceptual User interfaces (PUI) are characterised by interaction techniques that
combine an understanding of natural human capabilities with computer I/O devices
and machine perception and reasoning. They seek to make the user interface more
natural and compelling by taking advantage of the ways in which people naturally in-
teract with each other and with the world-both verbally and nonverbally. Devices and
6

Figure 2.2: Perceptual User Interface
sensors should be transparent and passive if possible, and machines should perceive
relevant human communication channels as well as generate output that is naturally
understood. This is expected to require integration at multiple levels of technologies
such as speed and sound recognition and generation, computer vision, graphical ani-
mation and visualization, language understanding, touch based sensing and feedback
learning, user modelling and dialogue management.
2.2.1 Information flow in Perceptual User Interfaces
PUI integrates perceptive, multimodal, and multimedia interfaces to bring
our human capabilities to bear on creating more natural and intuitive interfaces.
2.2.1.1 Perceptive User Interface/Perceptual Interface
A perceptive user interface is one that adds human-like perceptual capabil-
ities to the computer, for example, making the computer aware of what the user is
7

Figure 2.3: Information flow in Perceptual User Interface
saying or what the users face, body and hands are doing. These interfaces provide in-
put to the computer while leveraging human communication and motor skills.Unlike
traditional passive interfaces that wait for users to enter commands before taking any
action, perceptual interfaces actively sense and perceive the world and take actions
based on goals and knowledge at various levels. Perceptual interfaces move beyond
the limited modalities and channels available with a keyboard, mouse, and monitor,
to take advantage of a wider range of modalities, either sequentially or in parallel.
The general model for perceptual interfaces is that of human-to-human commu-
nication. While this is not universally accepted in the Human Computer Interaction
community as the ultimate interface model,there are several practical and intuitive
reasons why it makes sense to pursue this goal. Human interaction is natural and
in many ways effortless; beyond an early age, people do not need to learn special
techniques or commands to communicate with one another.
Figure 1.2 depicts natural interaction between people and, similarly, between
8
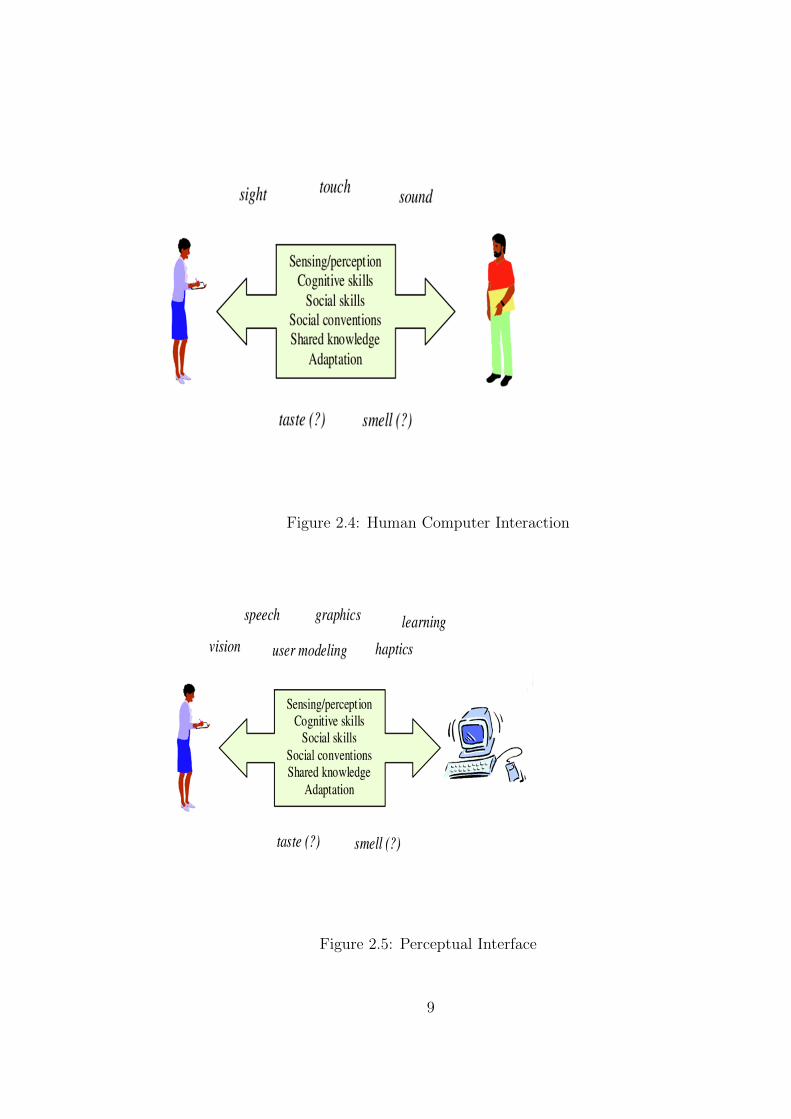
Figure 2.4: Human Computer Interaction
Figure 2.5: Perceptual Interface
9

humans and computers. Perceptual interfaces can potentially effect improvements in
the human factors objectives mentioned earlier in the section, as they can be easy
to learn and efficient to use,they can reduce error rates by giving users multiple and
redundant ways to communicate, and they can be very satisfying and compelling for
users.
2.2.1.2 Multimodal Interfaces
A multimodal user interface is closely related emphasizing human commu-
nication skills.It is a system that combines two or more input modalities in a coor-
dinated manner.Humans interact with the world by way of information being sent
and received, primarily through the five major senses of sight, hearing, touch, taste,
and smell.A modality refers to a particular sense. A communication channel is a
course or pathway through which information is transmitted. In typical HCI usage, a
channel describes the interaction technique that utilizes a particular combination of
user and computer communication i.e., the user output/computer input pair or the
computer output/user input pair . This can be based on a particular device, such as
the keyboard channel or the mouse channel, or on a particular action, such as spoken
language, written language, or dynamic gestures. In this view, the following are all
channels: text (which may use multiple modalities when typing in text or reading
text on a monitor), sound, speech recognition, images/video, and mouse pointing and
clicking.
So are multimodal interfaces or multi-modality or multi-channel. Certainly every
command line interface uses multiple modalities, as sight and touch (and sometimes
sound) are vital to these systems. The same is true for graphical user interfaces, which
in addition use multiple channels of keyboard text entry, mouse pointing and clicking,
sound, images, etc.We use multiple modalities when we engage in face to face com-
munication leading to more effective communication. Most work on multimodal User
Interface as focused on computer input(for example using speech together with pen
10

based gestures).Multimodal output uses different modalities, like visual display, audio
and tactile feedback to engage human perceptual, cognitive and communication skills
in understanding what is being presented. In multimodal UI various modalities are
sometimes used independently or simultaneously or tightly coupled.Multimodal inter-
faces focus on integrating sensorrecognition based input technologies such as speech
recognition, pen gesture recognition, and computer vision, into the user interface.
Multimodal interface systems have used a number of non-traditional modes and
technologies. Some of the most common are the following:
• Speech recognition Speech is a very important and flexible communication
modality for humans, and is much more natural than typing or any other
way of expressing particular words, phrases, and longer utterances. Despitethe
decades of research in speech recognition and over a decade of commercially
available speech recognition products, the technology is still far from perfect,
due to the size, complexity, and subtlety of language, the limitations of micro-
phone technology, the plethora of disfluencies in natural speech, and problems
of noisy environments. Systems using speech recognition have to be able to
recover from the inevitable errors produced by the system.
• Language understanding Natural language processing attempts to model and
understand human language,whether spoken or written. In multimodal inter-
faces, language understanding may be hand-in-hand with speech recognition ,
or it may be separate, processing the users typed or handwritten input. Typi-
cally the more a system incorporates natural language, the more users will ex-
pect sophisticated semantic understanding from the system. Current systems
are unable to deal with completely unconstrained language, but can do quite
well with limited vocabularies and subject matter. Allowing for user feedback
to clarify and disambiguate language input can help language understanding
systems significantly.
• Pen-based gesture Pen-based gesture has been popular in part because of com-
11

puter form factors that include a pen or stylus as a primary input device. Pen
input is particularly useful for pointing gestures,defining lines, contours, and
areas, and specially-defined gesture commands e.g., minimizing a window by
drawing a large M on the screen. Pen-based systems are quite useful in mobile
computing,where a small computer can be carried.
• Haptic input and force feedback Haptic, or touch-based, input devices measure
pressure, velocity, locationessentially perceiving aspects of a users manipulative
and explorative manual actions. These can be integrated into existing devices
e.g., keyboards and mouse that know when they are being touched, and possi-
bly by whom. Or they can exist as standalone devices, such as the well-known
PHANTOM device by SensAble Technologies in Fig.1.4 or the DELTA device
by Force Dimension.4 These and most other haptic devices integrate force feed-
back and allow the user to experience the touch and feel of simulated artifacts
as if they were real. Through the mediator of a hand-held stylus or probe, hap-
tic exploration can now receive simulated feedback including rigid boundaries
of virtual objects, soft tissue, and surface texture properties. A tempting goal
is to simulate all haptic experiences and to be able to recreate objects with all
their physical properties in virtual worlds so they can be touched and handled
in a natural way.
• Computer vision Computer vision has many advantages as an input modality
for multimodal or perceptual interfaces. Visual information is clearly impor-
tant in human-human communication, as meaningful information is conveyed
through identity, facial expression,posture, gestures, and other visually ob-
servable cues. Sensing and perceiving these visual cues from video cameras
appropriately placed in the environment is the domain of computer vision.
12

Figure 2.6: Phantom input/output device
2.2.1.3 Multimedia Interfaces
Multimedia User Interface uses perceptual and cognitive skills to interpret
information presented to the user .Multimedia user interfaces combine several kinds
of media to help people use a computer. These media can include text, graphics, an-
imation, images, voice, music,and touch.Multimedia user interfaces are gaining pop-
ularity because they are very effective at keeping the interest of their users, improve
the amount of information users remember, and can be very cost-effective.
Successful multimedia designers build their products with primary emphasis on
the user. Multimedia designers determine which human sensory system is most effi-
cient at receiving specific information, then use the media that involves that human
sensory system. For example, to teach someone how to fixa part on a jet engine it is
probably most efficient for the student to watch someone else fixing the part rather
than hearing a lecture on how to fix the part. The human visual system is better
at receiving this complex information. So, the designer for this multimedia product
13

Figure 2.7: Different Medias
should probably usevideo as the medium of communication.
This heavy emphasis on the user’s senses, rather than the media, means that
we should probably call these product user interfaces multisensory rather than mul-
timedia. The human senses that designers use most frequently in their multimedia
products are sight, sound, and touch. Multimedia products often stimulate these
senses simultaneously. For example, a user can see and hear a video, and then touch
a graphical button to freeze the video image. Since so many media are available to the
multimedia user interface designer, it is very easy to overwhelm and confuse the users
of these products. The following guidelines are based on the way people think and
perceive information. Theseguidelines will help you build multimedia user interfaces
that are easy and comfortable for people to learn and use.
General Gudilines
some general guidelines of multimedia user interfaces are as follows:
• Keep the user interface simple This is the most important guideline to remem-
14

Figure 2.8: User cancels video by pressing Cancel push button
ber when you design multimedia user interfaces. Don’t show off what you can
do with multimedia technology. Instead, give the users only what they need to
do their tasks.
• Be consistent Use similar objects to perform similar functions throughout. That
way, what users learn in one place they can use in other places . This quality
helps users learn quickly and builds their confidence.
• Let the user control the interaction Let the user, rather than the computer,
control what happens next. Let the user decide where to go, what to see, and
when to leave. For example, when watching a video, let the user cancel the
video rather than watching the whole thing before being able to move on. That
way, if the user saw the video during an earlier interaction, he or she does not
have to see it all over again. This feature is shown in Figure 1.
• Give immediate, obvious feedback for every user action Let the user know that
15

the computer is working and that it received and is responding to the user
action. For example, when the user selects a push button, change the button
to inverse video, and have the computer emit a short beep and process the
action on the push button. This design characteristic will help keep the user
interested.
• Use familiar metaphors Take advantage of the user’s prior learning by using fa-
miliar objects and actions. This characteristic improves learning and increases
user comfort. For example, if the user needs to dial a telephone number, provide
an image of a telephone with a touch-sensitive key pad. The user recognizes the
telephone and knows how to make it work. Other familiar metaphors include
televisions,video cassette recorders, and calculators.
• Let the user safely explore your product The user should be able to navigate
through your product without worrying about breaking or deletingsomething.
If appropriate, don’t provide a delete function. If the user needs to delete
objects, design your user interface so the user can confirm or cancel a deletion.
Let the user undo actions that are not easy to reverse. Let the user go back to
the previous screen from the current screen. Make obvious what the user can
do next. These design characteristics help to make user interface inviting and
comfortable.
Medias of Multimedia Interfaces
Sight The medium of sight is helpful when you need to communicate detailed
information, such as instructions, that the user may need to refer to later. Here are
some guidelines that involve sight.
• Use pastel colors Except for videos and black and white text, it is generally a
good idea to use slightly washed out, desaturated, impure colors. This is most
important for the small objects that you put on screens. Scientists believe that
these kinds of colors let people focus on small objects better and are lesslikely
to cause objects to appear to float on the display. In your videos, stick with
16

the original colors in which the video was shot. Use high-contrast foreground-
background colors for text.
• Use fonts that have serifs Serifs are small lines that finish off the main strokes
of a letter and often appear at the top or bottom of a letter. The text you
are reading has a serif font. Use fonts with serifs because these fonts may help
readers differentiate letters and because readers seem to prefer fonts with serifs.
Sound The medium of sound is helpful when you need to communicate short,
simple information, such as confirmation beeps, that users don’t have to refer to
later. Here are some guidelines that involve sound.
• Limit your use of sound A product that is constantly buzzing, beeping, chat-
tering, and singing to its users quickly becomes annoying. The user is working
with your product to get a job done. Limit your use of sound to those instances
where sound informs, rather than simply entertains, the user.
• Use lower frequency sounds High-frequency sounds can be shrill and annoying
, especially when the user has to hear them repeatedly. Generally, try to use
lower frequency sounds, around 100 hertz to 1000 hertz.
• Let the user control sound volume quickly and easily The user may want to
make the sound louder or softer for personal preference or to avoid disturbing
people nearby.Design so the user can adjust the sound volume. Make sound
controls large and obvious and let the user turn the sound off. These features
are shown in Figure 2.
Touch The medium of touch is helpful when you need to ask the user to make
simple choices, such as navigation decisions, without using a keyboard. Here are some
guidelines that involve touch.
• Use large touch areas If your product has a touch-sensitive screen, make it easy
for the users to activate the touch areas by making those areas fairly large. One
17

Figure 2.9: User adjusts sound volume with slider and turns off sound with Sound off
push button
18

Figure 2.10: Suggested sizes for touch areas and visual targets
study (Hall, Cunningham, Roache, and Cox, 1988) suggests using rectangular
touch areas that are 40 mm wide and 36 mm high surrounding smaller visual
targets, such as push buttons, that are 27 mm wide and 22 mm high. This is
shown in Figure 3.
• Use consistent colors and shapes to designate touch areas To make it obvious
which objects can be selected with touch, use the same color (Christ and Corso,
1975; Teichner, Christ, and Corso, 1977) and shape for those objects that can
be selected with touch.For example, always use a blue square to designate
buttons that the user can select with touch.
• Use different touch styles where appropriate Depending on the touch technology
you use, there are three general ways to design the touch interaction. First,
you can process the touch command when the user’s finger touches down on
the touch area. This technique is useful when you have just a few large touch-
selectable objects, such as push buttons, on the screen and the user can easily
19

recover after selecting the wrong object. Second, you can process the touch
command when the user’s finger goes up from a touch area. This technique
allows the user to highlight touch areas, such as push buttons, by touching or
sliding a finger over them until the desired touch area is highlighted. The user
can select the highlighted touch area command by lifting the finger off it. This
technique reduces errors when your touch areasare close together. Third, you
can add a cursor that appears on the screen, say, half an inch above the user’s
finger location. This technique is useful when the user has to select text. Since
the user’s finger is not blocking the text, the user can read the text before
selecting it with the cursor.
2.3 Perceptual Intelligence
Perceptual Intelligence is the knowledge and understanding that every-
thing we experience (especially thoughts and feelings) are defined by our percep-
tion.Perceptual intelligence is paying attention to people and the surrounding situa-
tion in the same way another person would, thus allowing these new devices to learn
to adapt their behaviour to suit us, rather than adapting to them as we do today.In
the language of cognitive science, perceptual intelligence is the ability to deal with the
frame problem; it is the ability to classify the current situation,so that it is possible
to know what variables are important and thus can take appropriate action. Once a
computer has the perceptual ability to know who, what,when, where, and why, then
the probabilistic rules derived by statistical learning methods are normally sufficient
for the computer to determine a good course of action.
The key to perceptual intelligence is making machines aware of their environment,
and in particular, sensitive to the people who interact with them.They should know
who we are, see our expressions and gestures, and hear the tone and emphasis of
our voice. People often confuse perceptual intelligence with ubiquitous computing
or artificial intelligence,but in fact they are very different.The goal of the perceptual
20

intelligence approach is not to create computers with the logical powers envisioned
in most Artificial Intelligence research, or to have computers that are ubiquitous and
networked, because most of the tasks we want performed do not seem to require
complex reasoning or a gods-eye view of the situation.One can imagine, for instance,
a well-trained dog controlling most of the functions we envision for future smart
environments. So instead of logic or ubiquity, we strive to create systems with reliable
perceptual capabilities and the ability to learn simple responses.
2.4 Perceptual Intelligent Systems
We have developed computer systems that can follow peoples actions,recognizing
their faces, gestures, and expressions.
Some of the systems are:
• Gesture recognition system
• Speech recognition system
• Nouse perceptual vision interface
2.4.1 Gesture Recognition System
2.4.1.1 Gesture Recognition
Gesture Recognition deals with the goal of interpreting human gestures via
mathematical algorithms. Gestures can originate from any bodily motion or state
but commonly originate from the face or hand. Current focuses in the field include
emotion recognition from the face and hand gesture recognition. Many approaches
have been made using cameras and computer vision algorithms to interpret sign lan-
guage.Gesture Recognition can be seen as a way for computers to begin to understand
human body language, thus building a richer bridge between machines and humans
21

than primitive text user interfaces or even GUIs (Graphical User Interfaces), which
still limit the majority of input to keyboard and mouse.
Gesture Recognition enables humans to interface with the machine (HMI) and
interact naturally without any mechanical devices. Using the concept of Gesture
Recognition, it is possible to point a finger at the computer screen so that the cursor
will move accordingly. This could potentially make conventional input devices such
as mouse, keyboards and even touch-screens redundant.Gesture Recognition can be
conducted with techniques from computer vision and image processing.Often the term
gesture interaction is used to refer to inking ormouse gesture interaction, which is
computer interaction through the drawing of symbols with a pointing device cursor.
Strictly speaking the term mouse strokes should be used instead of mouse gesture
since this implies written communication,making a mark to represent a symbol.
2.4.1.2 Working of Gesture Recognition System
The system must be able to look at a user, and determine where they are
pointing. Such a system would be integral to an intelligent room, in which a user
interacts with a computer by making verbal statements accompanied by gestures to
inform the computer of, for example, the location of a newly filed,physical document.
The system was written in c++ using components in c.The operation of the
system proceeds in four basic steps:
• Image input
• Background subtraction
• Image processing and Data extraction
• Decision tree generation/parsing
Initial training of the system requires the generation of a decision tree,however sub-
sequent use of the system only requires the parsing of the decision tree to classify the
image.
22

Image input
To input image data into the system, an SGI IndyCam(Silicon Graphics Inc was
used, with an SGI image capture program used to take the picture. The camera was
used to take first a background imageand then to take subsequent images of a person
pointing in particular directions.
Background subtraction
Once images are taken, the system performs a background subtraction of the im-
age to isolate the person and create a mask. The background subtraction proceeds in
two steps.First, each pixel from the background image is channelwise subtracted from
the corresponding pixel from the foreground image. The resulting channel differences
are summed, and if they are above a threshold, then the corresponding image of the
mask is set white, otherwise it is set black.The resulting image is a mask that outlines
the body of the person (figure ).
Two important features of the image are the existence of a second right arm, which
is the result of a shadow of the right arm falling on the wall behind the person, and
the noise in the generated mask image. This phantom arm is the result of the poor
image quality of the input image, but could be corrected for by the conversion of the
color space of the images and the use of another method of background subtraction. If
the images were converted from RGB to HSB color space, than the subtracted values
of the pixels (before being set to white or black, could be inspected, and those pixels
that have a very low brightness could be discarded as well (set to black). Since a
shadow tends to be very dark when compared to the body of a person (in an image),
those pixels that have a low brightness can be inferred to be part of a shadow.The
noise in the mask image can be reduced significantly by running an averaging filter
over the mask data. The GRS runs two such filters over the mask data, one with a
radius of one pixel, and another of a radius of three pixels.
Image processing and Data extraction
Once a mask is generated, then that image can be processed for data to extract
23

Figure 2.11: Background subtracted mask
24

Figure 2.12: image illustrating body center and arm algorithim
into a decision tree.Two strategies for extracting data from the image were tried.
The first was to find the body and arms. Each column of pixels from the mask was
summed,and the column with the highest sum was assumedto be the an equalized
backg round subcenter of the body. This is a valid criteria for determining the tracted
image body center, based on the assumptions of the input image.In all of the samples
this technique was tried , it was successful in finding the center of the body, within a
few pixels.From the center of the body, horizontal rows are traced out to the left and
right until the edge of the mask is reached (pixels turn from white to black). The row
of pixels that extends the furthest is assumed to be the arm that is pointing. This
again is a valid decision based on the assumptions about the input image. Only one
arm is pointing at a time, and the arm is pointing in a direction. For this , algorithm
created was successful at finding the pointing arm to within a few pixel for all images
tested, including those with shadows.
// find the maximum distances left and right from the middle, and call them
arms for (y = 0; y ¡ mask-¿y(); y++)
if (mask-¿Red(xMiddle, y) != 0)
// left first
25

for (x = xMiddle; mask-¿Red(x, y) != 0; x);
if (x ¡ xLeftMax)
xLeftMax = x + 1;
yLeftMax = y;
// then right
for (x = xMiddle; mask-¿Red(x, y) != 0; x++);
if (x ¿ xRightMax)
xRightMax = x - 1;
yRightMax = y;
Decision tree generation/parsing
Once the data vectors are written to disk, is executed to create the decision tree.
This process is straightforward, involving only the manual classification of the test
vectors into six categories representing the images: right-up, right-middle, rightdown,
left-up, left-middle,left-down. The decision to use only these six vectors was a result of
the use of a decision tree, as well as the difficulty in classifying the and arm algorithim
images with more granularity. Since the system usesa decision tree, the method of
learning must be supervised. Besides being tedious, the manual classification of the
images is difficult to classify into more categories.Figure 6 - a mask converted to
vertical bar representation.The system as presented here is a combination of two
algorithms for image data extraction.To use the system, instead of generating the
tree,a single image is processed, and then run through the decision tree , resulting in
the classification of the image into one of the six mentioned categories.
2.4.1.3 Challenges of Gesture Recognition
There are many challenges associated with the accuracy and usefulness of
Gesture Recognition software. For image-based gesture recognition there are limita-
tions on the equipment used and image noise. Images or video may not be under
consistent lighting, or in the same location. Items in the background or distinct
26

features of the users may make recognition more difficult. The variety of implemen-
tations for image-based gesture recognition may also cause issue for viability of the
technology to general usage. For example, recognition using stereo cameras or depth-
detecting cameras are not currently commonplace. Video or web cameras can give
less accurate results based on their limited resolution.
2.4.2 Speech Recognition System
Speech recognition converts spoken words to machine-readable input (for
example, to the binary code for a string of character codes). The term voice recog-
nition may also be used to refer to speech recognition, but more precisely refers to
speaker recognition, which attempts to identify the person speaking, as opposed to
what is being said.
The following definitions are the basics needed for understanding speech recogni-
tion technology.
• Utterance
An utterance is the vocalization (speaking) of a word or words that represent a
single meaning to the computer. Utterances can be a single word, a few words,
a sentence, or even multiple sentences.
• Speaker Dependance
Speaker dependent systems are designed around a specific speaker. They gener-
ally are more accurate for the correct speaker, but much less accurate for other
speakers. They assume the speaker will speak in a consistent voice and tempo.
Speaker independent systems are designed for a variety of speakers. Adap-
tive systems usually start as speaker independent systems and utilize training
techniques to adapt to the speaker to increase their recognition accuracy.
• Vocabularies
Vocabularies (or dictionaries) are lists of words or utterances that can be rec-
27

ognized by the SR system. Generally, smaller vocabularies are easier for a
computer to recognize, while larger vocabularies are more difficult. Unlike nor-
mal dictionaries, each entry doesn’t have to be a single word. They can be
as long as a sentence or two. Smaller vocabularies can have as few as 1 or 2
recognized utterances (e.g.”Wake Up”), while very large vocabularies can have
a hundred thousand or more!
• Accuract
The ability of a recognizer can be examined by measuring its accuracy or how
well it recognizes utterances. This includes not only correctly identifying an
utterance but also identifying if the spoken utterance is not in its vocabulary.
Good ASR systems have an accuracy of 98acceptable accuracy of a system
really depends on the application.
• Training
Some speech recognizers have the ability to adapt to a speaker. When the
system has this ability, it may allow training to take place. An ASR system
is trained by having the speaker repeat standard or common phrases and ad-
justing its comparison algorithms to match that particular speaker. Training a
recognizer usually improves its accuracy. Training can also be used by speak-
ers that have difficulty speaking, or pronouncing certain words. As long as
the speaker can consistently repeat an utterance, ASR systems with training
should be able to adapt.
The speech recognition process is performed by a software component known as
the speech recognition engine. The primary function of the speech recognition engine
is to process spoken input and translate it into text that an application understands.
The application can then do one of two things:
• The application can interpret the result of the recognition as a command. In
this case, the application is a command and control application. An example
28

of a command and control application is one in which the caller says check
balance, and the application returns the current balance of the callers account.
• If an application handles the recognized text simply as text, then it is considered
a dictation application. In a dictation application, if you said check balance,
the application would not interpret the result, but simply return the text check
balance.
2.4.2.1 Types of Speech Recognition
Speech recognition systems can be separated in several different classes by
describing what types of utterances they have the ability to recognize. These classes
are based on the fact that one of the difficulties of ASR is the ability to determine
when a speaker starts and finishes an utterance. Most packages can fit into more
than one class, depending on which mode they’re using.
• Isolated Words
Isolated word recognizers usually require each utterance to have quiet (lack of
an audio signal) on BOTH sides of the sample window. It doesn’t mean that it
accepts single words, but does require a single utterance at a time. Often, these
systems have ”Listen/NotListen” states, where they require the speaker to
wait between utterances (usually doing processing during the pauses). Isolated
Utterance might be a better name for this class.
• Connected Words
Connect word systems (or more correctly ’connected utterances’) are similar
to Isolated words, but allow separate utterances to be ’runtogether’ with a
minimal pause between them.
• Continuous Speech
Continuous recognition is the next step. Recognizers with continuous speech
capabilities are some of the most difficult to create because they must utilize
29

special methods to determine utterance boundaries. Continuous speech recog-
nizers allow users to speak almost naturally, while the computer determines
the content. Basically, it’s computer dictation.
• Spontaneous Speech
There appears to be a variety of definitions for what spontaneous speech actu-
ally is. At a basic level, it can be thought of as speech that is natural sounding
and not rehearsed. An ASR system with spontaneous speech ability should
be able to handle a variety of natural speech features such as words being run
together, ”ums” and ”ahs”, and even slight stutters.
• Voice Verification/Identification
Some ASR systems have the ability to identify specific users. This document
doesn’t cover verification or security systems.
2.4.2.2 Working of Speech Recognition Systems
The speech recognition process is performed by a software component known
as the speech recognition engine. The primary function of the speech recognition
engine is to process spoken input and translate it into text that an application un-
derstands. The application can then do one of two things:
• The application can interpret the result of the recognition as a command. In
this case, the application is a command and control application. An example
of a command and control application is one in which the caller says check
balance, and the application returns the current balance of the callers account.
• If an application handles the recognized text simply as text, then it is considered
a dictation application. In a dictation application, if you said check balance,
the application would not interpret the result, but simply return the text check
balance.
30

Recognition systems can be broken down into two main types. Pattern Recog-
nition systems compare patterns to known/trained patterns to determine a match.
Acoustic Phonetic systems use knowledge of the human body (speech production, and
hearing) to compare speech features (phonetics such as vowel sounds). Most modern
systems focus on the pattern recognition approach because it combines nicely with
current computing techniques and tends to have higher accuracy. Most recognizers
can be broken down into the following steps:
1. Audio recording and Utterance detection
2. PreFiltering (preemphasis, normalization, banding, etc.)
3. Framing and Windowing (chopping the data into a usable format)
4. Filtering (further filtering of each window/frame/freq. band)
5. Comparison and Matching (recognizing the utterance)
6. Action (Perform function associated with the recognized pattern)
Although each step seems simple, each one can involve a multitude of different
(and sometimes completely opposite) techniques.
(1) Audio/Utterance Recording: can be accomplished in a number of ways. Start-
ing points can be found by
comparing ambient audio levels (acoustic energy in some cases) with the sample
just recorded. Endpoint detection is harder because speakers tend to leave ”artifacts”
including breathing/sighing,teeth chatters, and echoes.
(2) PreFiltering: is accomplished in a variety of ways, depending on other features
of the recognition
system. The most common methods are the ”BankofFilters” method which uti-
lizes a series of audio filters to prepare the sample, and the Linear Predictive Coding
method which uses a prediction function to calculate differences (errors). Different
forms of spectral analysis are also used.
(3) Framing/Windowing involves separating the sample data into specific sizes.
This is often rolled into step 2 or step 4. This step also involves preparing the sample
31

boundaries for analysis (removing edge clicks, etc.)
(4) Additional Filtering is not always present. It is the final preparation for each
window before comparison and matching. Often this consists of time alignment and
normalization.
(5), Comparison and Matching. Most involve comparing the current window
with known samples. There are methods that use Hidden Markov Models (HMM),
frequency analysis, differential analysis, linear algebra techniques/shortcuts, spectral
distortion, and time distortion methods. All these methods are used to generate a
probability and accuracy match.
(6) Actions can be just about anything the developer wants.
2.4.2.3 Performance of speech recognition systems
The performance of speech recognition systems is usually specified in terms of
accuracy and speed. Most speech recognition users would tend to agree that dictation
machines can achieve very high performance in controlled conditions. There is some
confusion, however, over the interchangeability of the terms ”speech recognition” and
”dictation”.
Commercially available speaker-dependent dictation systems usually require only
a short period of training (sometimes also called ‘enrollment’) and may successfully
capture continuous speech with a large vocabulary at normal pace with a very high
accuracy. Most of experiments claim that recognition software can achieve more than
75 percentage accuracy if operated under optimal conditions. Optimal conditions
usually assume that users:
• have speech characteristics which match the training data,
• can achieve proper speaker adaptation, and
• Work in a noise free environment (e.g. quiet office or laboratory space).
This explains why some users, especially those whose speech is heavily accented, might
32

achieve recognition rates much lower than expected. Speech recognition in video has
become a popular search technology used by several video search companies. Limited
vocabulary systems, requiring no training, can recognize a small number of words
(for instance, the ten digits) as spoken by most speakers. Such systems are popular
for routing incoming phone calls to their destinations in large organizations. Both
acoustic modeling and language modeling are important parts of modern statistically-
based speech recognition algorithms. Hidden Markov models (HMMs) are widely used
in many systems.
2.4.3 Nouse Perceptual Vision Interface
Evolved from the original Nouse ie Nose as Mouse. Nouse PVI has several
unique features that make it preferable to other hands-free vision-based computer
input alternatives. natives. Its original idea of using the nose tip as a single refer-
ence point to control a computer has been confirmed to be very convenient.The nose
literally becomes a new finger which can be used to write words, move a cursor on
screen, click or type. Being able to track the nose tip with subpixel precision within
a wide range of head motion, makes performing all control tasks possible.
2.4.3.1 Computer Control Actions
Nouse PVI is a perceptual vision interface program that offers a complete
solution to working with a computer in Microsoft Windows OS hands-free. Using a
camera connected to a computer, the program analyzes the facial motion of the user
to allow him/her to use it instead of a mouse and a keyboard. As such Nouse- PVI
allows a user, to perform the basic three computer-control actions:
• cursor control: includes
a) Cursor positioning
b) Cursor moving, and
33

c) Object drugging - which are normally performed using mouse motion
• clicking: includes
a) right-button click
b) left-button click
c) Double-click, and
d) Holding the button down - which are normally performed using the mouse
buttons
• key/letter entry: includes
a) typing of English letters
b) Switching from capital to small letters, and to functional keys
c) entering basic MS Windows functional keys as well as Nouse functional keys
- which would normally be performed using a keyboard
2.4.3.2 Tools Used In Nouse Perceptual Vision Interface
The program is equipped with such tools as:
1. Nousor (Nouse Cursor) - the video-feedback-providing cursor that is used to
point and to provide the feeling of ” touch” with a computer.
2. NouseClick - a nose-operated mechanism to simulate types of clicks
3. NouseCodes - configurable Nouse tool that allows entering computer commands
and operate the program using head motion codes.
4. NouseEditor - provides an easy way of typing and storing messages hands-free
using face motion. Typed messages are automatically stored in Clipboard (as with
CNTR+A, CNTR+C)
5. NouseBoard- a specially designed for face-motion-based typing on-screen key-
board that automatically maps to the user’s facial motion range.
34

6. NouseTyper - a configurable Nouse tool that allows typing letters by drawing
them inside the cursor (instead of using the NouseBoard)
7. NouseChalk - a configurable Nouse tool that allows writing letters as with a
chalk on a piece of paper. Written letters are automatically saved on hard- drive as
images that can be opened and emailed.
2.4.3.3 Working Of Nouse Perceptual Vision Interface
Once a camera is selected you will be in the inactive sleep state. You can
tell you are in this state because the nouse icon is white and turned to the left. Also
the buttons on the Nouse Cursor (in the top right corner of the screen) are red.
The program remains in this state until a user showing facial motion is detected by
camera.When user is detected, we switch to the inactive wake up state. You can
tell you are in this state because the nouse icon turns to face straight up. Also,
the buttons on the Nouse Cursor turn white. In this state the system verifies that
position of users face. If this position is not consistent over 10-20 secs, Nouse goes
back to sleep state.
Working in NouseCursor State
1. Sleep:Start nouse cursor. (Bring it to ”put face in centre mode”)
When you initially go to NouseCursor state, you are in the Nouse Sleep states all
Nousor buttons colours all red. To Make up control - produce significant face motion.
2. Wake-up: Putting nose (face) in center of nouse cursor to activate it.
The two middle buttons will remain red, while side buttons become bllue. This is
the indication that you must now put your face in the center of the cross-hair. Once
you have done so successfully, the buttons will be blue and you are ready to start
nousing.
3. Crude navigation:Move the cursor to a point on the screen as with a joystick.
When all of the buttons are blue, this means that you are in a general mouse
movement state. The nouse cursor works as a joystick. If your nose is in the center,
35

the nouse cursor will not move. Then as you get farther away from the center in
any direction, the nouse cursor will move proportionally faster is that direction. You
can use the mode to place the cursor approximately near where you’ll want to click.
There is no need to be exact. Once you are satisfied, move your nose back to the
center of the cross-hair and then wait for the buttons to change to yellow.
4. Fine navigation: Move the cursor as by pushing a mouse.
When the buttons are all yellow this means that we are in the precise movement
state. This state can be analogized to moving an actual mouse cursor when the mouse
pad is very small. In order to move to the right for example, you must nudge your
nose to the right and then move back to center and repeat this process. The mode is
used to place the cursor exactly where you would like to click. Once you are satisfied,
stay still and wait for the the cursor to switch to clicking mode.
It is important to note that when placing the cursor you should make note of
which corner of the nouse cursor will be used to make the click. This is indicated by
purple lines protruding from the clicking corner. If you wish to change the clicking
corner, enter the correct code as described later.
5. Prepare to Click:Now that the cursor has been placed, you move into the final
state; that of clicking.
This is indicated by all of the buttons being coloured green. A countdown starting
at 3 will count down and to click all you need to do is move. After you click, you will
go back to the putting face in center mode .
6. Performing different types of Clicking
a. Choose not to click.
b. Do a left click
To do a left click, move down and to the left.
c. Do a right click
To do a right click, move down and to the right.
d. Do a double click.
36

To do a double click, move up and to the left.
e. Drag an item.
If you select drag, the will emulate pressing down on the left mouse button and
holding it down. Once you select drag, a ’D’ will be drawn in the nouse cursor. When
you choose you next place to click, the action will be to release the mouse no matter
what direction you move.
7. Entering motion codes with nousor - NouseCode
Aside from clicking and moving the cursor, there are some actions that you may
want to perform while in the nouse cursor state. The way this can be done is using
the nousor motion coding scheme. Whenever you move your position to a corner of
the range, that corner’s corresponding number will be remembered and shown inside
Nousor as green dot. To enter a code, simply move to the correct corners in order.
So for example, if you want to enter the code 1-2-3-4, you need to move to the top
left, bottom left, bottom right and top right in that order. After any code is entered,
you need to confirm wether or not you actually want to enter that code. A letter
corresponding to that code will appear on the nouse cursor to let you know that you
are in confirmation mode. To confirm you must move in a vertical direction (if you
are up, move down and if you are down, move up). To cancel the code, move in the
horizontal direction.
a. Open Nouse Board
To open Nouse Board enter the code 1-2-3-4. Then to confirm go to 3.
b. Choose to not open nouse board
To cancel opening Nouse Board, go to 1.
c. Change clicking corner
If you don’t move, no click will be made and you will go back to the general
mouse movement state. To change the conner of the Nouse Cursor that will be used
for clicking (this is represented by purple lines protruding from the corder) enter code
1-2-1-2. Then to confirm go to 1.
37

d. Choose to not change clicking corner
To cancel changing the clicking corner, go to 3.
e. Glue/un-glue cursor to nousor
To glue the actual cursor to the nouse cursor, enter Glue code. The same code is
used to un-glue the cursor from the nousor.
f.Chose to not glue cursor to nouser
To cancel gluing the cursor, go to 2.
g. Press enter
To simulate hitting the enter key, enter code 4-1-4-3. Then to confirm go to 4.
h. Choose to not press enter
To cancel hitting the enter key, go to 2.
8. Reconnecting with nouse
Sometimes the nouse program will lose track of your nose. You will notice that
this is happening when you observe that the blue blob that normally appears on your
nose in the nouse cursor will stray. We have implemented many techniques to try to
regain the nose once it is lost. If none of these methods seem to work and the blob
keeps on straying from the nose, this is likely a case of bad callibration. The best
option in this case is to go through the express calibration once again. a. Try putting
nose back where blue is. This is the most intuitive way to get the nose back. If you
see the blue blob stray away from the nose, simply move your nose back to where the
blue blob is. Once you move your nose under it, the blob will likely start to follow
the nose once again. b. Move left right to go back to face in center mode. If you
quickly move your head all the way to the left of your range and then all the way to
the right, you will go back to the face in center mode. Once you put your face in the
center, the nouse program should put the blue blob back on nose nose. Working in
NouseBoard state
• Motion-based key entry using virtual (on-screen) NouseBoard and NousePad.
38

Figures/Chap3/nui2.png
Figure 2.13: Selecting Shift, selecting H
When you first open NouseBoard you will be in the state where you need
to put your face in the center of the nouse cursor. Once you do this, the
NouseBoard and NousePad will popup (see Figure) and youll be ready to type.
The first state of the NouseBoard is one where the whole board in coloured
white. This indicates that no key have been selected yet. Note that for each
cell of the NouseBoard, there are four characters (or commands), one at each
corner. The first thing you need to do is decide which corner the character you
would like to type resides in. When you move the NouseBoard selector to a
corner, all of the cells will have their respective characters in that corner stay
white while the rest of the NouseBoard turns gray. Now that a corner has been
selected, you can move the NouseBoard selector around to select the character
you would like to type. Once you have moved the selector to the requested cell,
stay still for a couple of seconds. This will cause the character or command to
turn green. Once a character has turned green you simply need to move the
selector to another cell and that character will be typed in the NousePad. The
NouseBoard will return to its initial all white state.
• Choosing to not type a letter.
If you have a character coloured green but you dont want to type it, simple
stay still in the same cell for a couple of seconds. This will cause the letter not
to be typed and the NouseBoard to return to its initial all white state.
• Getting back nouse after losing it.
All three methods described for the Nouse Cursor state will work equally here.
See section 6.6.
39

• Cancelling corner selection.
If you select a corner and then realize that the character you want to type is
not in that corner of its cell, there are two ways to cancel the corner selection.
The first is to highlight a letter and then not type it, as in section 7.b. The
other option is to move your face to left and to the right as described in section
6.6.b. This will cause the program to ask you to put your face in the center of
the NouseCursor. Once you do so, the keyboard will be reset to the all white
state.
• Exiting NousePad (copying to clipboard) Once your are satisfied with the text
in the NousePad, you can exit the NouseBoard state by selecting mouse on the
NouseBoard. This will cause the NouseBoard to close and the text in NousePad
to be copied to your systems clipboard. This text can then be accessed using
the paste option of what ever application you are using.
40

CHAPTER 3
Applications
There are some applications currently using Perceptual Intelligence technique for
future development.some of these applications are given below
3.1 SMART ROOMS
The idea of a smart room is little like having a butler; that is a passive
observer who usually stands quietly in the corner but who is constantly looking for
opportunities to help. Both smart rooms and smart clothes are instrumented with
sensors that allow the computer to see, hear, and interpret users actions (currently
mainly cameras, microphones, and electromagnetic field sensors, and also biosensors
like heart rate and muscle action.)People in a smart room can control programs,
browse multimedia information, and experience shared virtual environments without
keyboards, special sensors, or special googles.The key idea is smart room or clothing
can know something about what is going on, it can react intelligently.
Our first smart room was developed in 1989.Now there are smart rooms in Japan,
England, and throughout places in U.S.They can be linked together by ISDN tele-
phone lines to allow shared virtual environment and cooperative work experiments.
Some of the perceptual capabilities are available to smart rooms. To act intelli-
gently in a day to day environment, the first thing we need to know is: where are the
people? The human body is a complex dynamic system, whose visual features are
time varying, noisy signals.
Object tracking can be used to detect the location. Once the person is located,
and visual and auditory attention has been focused on them, the next question to
ask is: who is it? The question of identity is central to adaptive behaviour because

Figure 3.1:
who is giving a command is often as important as the command itself. Perhaps the
best way to answer the question is to recognize them by their facial appearance and
by their speech. For general perceptual interfaces, person recognition systems will
need to recognize people under much less constrained conditions. One method of
achieving greater generality is to employ multiple sensory inputs; audio and-video-
based recognition systems in particular have the critical advantage of using the same
modalities that humans use for recognition.
We have developed computer systems for speech-recognition, hand gesture recog-
nition face recognition etc. After a person is identified, next crucial factor is facial
expression. For instance a car should know if the driver is sleepy, and a teaching pro-
gram should know if the student looks bored.So, just as we can recognize a person once
42

we have accurately located their face, we can also analyse the persons facial motion
to determine their expression. The lips are of particular importance in interpreting
facial expression, so we are giving more importance to tracking and classification of
lip shape. First step of processing is to detect and characterize the shape of the lip
region. For this task, a system called LAFTER is developed. Online algorithms are
used to make maximum posteriori estimates of 2D head pose and lip shape. Using
lip shape features derived from LAFTER systems we can train Hidden Markov Mod-
els for various mouth configurations.HMMs are well developed statistical modelling
techniques for modelling time series data, and are used widely in speech recognition.
3.2 SMART CLOTHES
In the case of a smart room, cameras and microphones are watching people
from a third person perspective.However,when we build the computers,cameras,microphones
and other sensors into our clothes ,the computers view moves from a passive third
person to an active first person vantage point. That means smart clothes can be more
intimately and actively involved in the users activities. If these wearable devices have
sufficient understanding of the users situation-that is-enough perceptual intelligence-
then they should be able to act as an intelligent personal agent, proactively providing
the wearer with information relevant to the current situation.
Eg: suppose we are placing a GPS (Global Position Sensor) into our belt, then
navigation software can help us to find our way around by whispering directions in
your ear or showing a map on a display built into our glasses. Similarly body worn ac-
celerometers and tilt sensors can distinguish walking from standing from sitting, and
bio sensors such as galvanic skin response (GSR) are correlated with mental arousal,
allowing construction of wearable medical monitors. A simple but important applica-
tion for a medical wearable is to give people feedback about their alertness and stress
level. Centre for Future health at the University of Rochester has developed early
warning systems for people with high risk medical problems, and eldercare wearable
43

to help keep seniors out of nursing homes. These wearable devices are examples of
personalized perceptual intelligence, allowing proactive fetching and filtering of in-
formation for immediate use by the wearer. With the development of new self care
technology, tiny wearable health monitors may one day continuously collect signals
from the body and transmit data to a base station at home. Predictive software may
identify trends and make specific health predictions, so users can prevent crisis and
better manage daily routines and health interventions.
Consider that we have built wearables that continuously analyze background
sound to detect human speech. Using this information, the wearable is able to know
when you and another person are talking, so that they wont interrupt. Now researches
are going a step further, using microphones built into a jacket to allow wod-spotting
software to analyze your conversation and remind you of relevant facts. Cameras
make attractive candidates for a wearable, perceptual intelligent interface, because
a sense of environmental contexts may be obtained by pointing the camera in the
direction of users gaze. For instance, by building a camera into your eye glasses, face
recognition software can help you remember the name of the person you are looking
at.
44





























