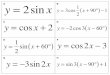Embed Size (px)
Citation preview

R.J. McAulay and T.F. Quatieri
Speech Processing Based ona Sinusoidal Model
Using a sinusoidal model of speech, an analysis/synthesis technique has been developed that characterizes speech in terms of the amplitudes, frequencies, and phases ofthe component sine waves. These parameters can be estimated by applying a simplepeak-picking algorithm to a short-time Fourier transform (STFf) of the input speech.Rapid changes in the highly resolved spectral components are tracked by using afrequency-matching algorithm and the concept of "birth" and "death" of the underlyingsinewaves. For a given frequency track, a cubic phase function is applied to a sine-wavegenerator. whose output is amplitude-modulated and added to the sine waves generatedfor the other frequency tracks. and this sum is the synthetic speech output. Theresulting waveform preserves the general waveform shape and is essentially indistingUishable from the original speech. Furthermore. in the presence ofnoise the perceptualcharacteristics of the speech and the noise are maintained. Itwas also found that highquality reproduction was obtained for a large class of inputs: two overlapping. superposed speech waveforms; music waveforms; speech in musical backgrounds; andcertain marine biologic sounds.
The analysis/synthesis system has become the basis for new approaches to suchdiverse applications as multirate coding for secure communications, time-scale andpitch-scale algorithms for speech transformations, and phase dispersion for theenhancement ofAM radio broadcasts. Moreover, the technology behind the applicationshas been successfully transferred to private industry for commercial development.
Speech signals can be represented with aspeech production model that views speech asthe result of passing a glottal excitation waveform through a time-varying linear filter (Fig. 1),which models the resonant characteristics ofthe vocal tract. In many speech applications theglottal excitation can be assumed to be in one oftwo possible states, corresponding to voiced orunvoiced speech.
In attempts to design high-quality speechcoders at mid-band rates, more general excitation models have been developed. Approachesthat are currentlypopular are multipulse [1] andcode-excited linear predictive coding (CELP) [2).This paper also develops a more general modelfor glottal excitation, but instead of usingimpulses as in multipulse, or code-book excitationsas in CELP, the excitation waveform is assumed to be composed of sinusoidal components of arbitrary amplitudes, frequencies, andphases.
The Lincoln Laboratory Journal, Volume 1, Number 2 (1988)
Other approaches to analysis/synthesis that·are based on sine-wave models have beendiscussed. Hedelin [3] proposed a pitch-independent sine-wave model for use in coding thebaseband signal for speech compression. Theamplitudes and frequencies of the underlyingsine waves were estimated using Kalman fIltering techniques and each sine-wave phase wasdefined to be the integral of the associated in
stantaneous frequency.Another sine-wave-based speech system is
being developed by Almeida and Silva [4]. Incontrast to Hede1in's approach, their systemuses a pitch estimate to establish a harmonic setof sine waves. The sine-wave phases are computed from the STFf at the harmonic frequencies. To compensate for any errors that might beintroduced as a result of the harmonic sinewave representation, a residual waveform iscoded, along with the underlying sine-waveparameters.
153

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
Sine Waves(t)
Generation e(t)h(t, T)
of some of these experiments are discussed andpictorial comparisons of the original and synthetic waveforms are presented.
The above sinusoidal transform system (STS)has found practical application in a number ofspeech problems. Vocoders have beendeveloped that operate from 2.4 kbps to 4.8 kbpsproviding good speech quality that increases
PitchPeriod
W,
ImpulseTrain ---Generator
c Vocal
~TractFilter
RandomSpeech
Noise I--
Generator
~
EXCITATION VOCAL TRACT
Fig. 1- The binary model ofspeech production illustratedhere, r~quires pi~ch, voca~-~ractparameters, en~rgy levels,and vOiced/unvoiced decIsions as inputs.
Speech Production Model
Fig. 2 - The sinusoidal speech model consists of an excitation and vocal-tract response. The excitation waveform ischaracterized by the amplitudes, frequencies, and phasesC!f the underlying sine waves of the speech; the vocal tractIS modeled by the time-varying linear filter, the impulse response of which is h(t; -r).
In the speech production model, the speechwaveform, s(t), is modeled as the output of alinear time-varying filter that has been excitedby the glottal excitation waveform, eft). The filter,which models the characteristics of the vocaltract, has an impulse response denoted by h(t; -r).The speech waveform is then given by
more or less uniformly with increasing bit rate.In another area the STS provides high-qualityspeech transformations such as time-scale andpitch-scale modifications. Finally, a largeresearch effort has resulted in a new techniquefor speech enhancement for AM radiobroadcasting. These applications areconsidered in more detail later in the text.
(1)s(t) = ft hlt- T; t) e(r) dr.o
This paper derives a sinusoidal model for thespeech waveform, characterized by the amplitudes, frequencies, and phases ofits componentsine waves, thatleads to a newanalysis/synthesis technique. The glottal excitation is represented as a sum ofsine waves that, when appliedto a time-varying vocal-tract filter, leads to thedesired sinusoidal representation for speechwaveforms (Fig. 2).
A parameter-extraction algorithm has beendeveloped that shows that the amplitudes, frequencies, and phases of the sine waves can beobtained from the high-resolution short-timeFourier transform (STFT), by locating the peaksof the associated magnitude function. To synthesize speech, the amplitudes, frequencies,and phases estimated on one frame must bematched and allowed to evolve continuouslyinto the set of amplitudes, frequencies, andphases estimated on a successive frame. Theseissues are resolved using a frequency-matchingalgorithm in conjunction with a solution to thephase-unwrapping and phase-interpolationproblem.
A system was built and experiments wereperformed with it. The synthetic speech wasjudged to be of excellent quality - essentiallyindistingUishable from the original. The results
154 TIle Lincoln Laboratory Journal, Volume 1, Number 2 (1988)

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
H(w; t) = M(w; t) exp lj<I>(w; t)l (3)
By combining the effects of the glottal and vocaltract amplitudes and phases. the representation can be written more concisely as
(8)
phases of the component sine waves must beextracted from the original speech waveform.
Estimation of Speech Parameters
The key problem in speech analysis/synthesis is to extract from a speech waveform theparameters that represent a quasi-stationaryportion of that waveform. and to use thoseparameters (or coded versions ofthem) to reconstruct an approximation that is "as close aspossible" to the original speech. The parameterextraction algorithm. or estimator. should berobust. as the parameters must often be extracted from a speech signal that has been contaminated with acoustic noise.
In general. it is diffIcult to determine analytically which of the component sine waves andtheir amplitudes. frequencies. and phases arenecessary to represent a speech waveform.Therefore. an estimator based on idealizedspeech waveforms was developed to extractthese parameters. As restrictions on the speechwaveform were relaxed in order to model realspeech better. adjustments were made to the estimator to accommodate these changes.
In the development of the estimator. the timeaxis was first broken down into an overlappingsequence of frames each of duration T. Thecenter of the analysis window for the k th frameoccurs at time t
k. Assuming that the vocal-tract
and glottal parameters are constant over aninterval of time that includes the duration of theanalysis window and the duration of the vocaltract impulse response. then Eq. 7 can be written as
(4)
(5)L(t)
s(t) = ~AI(t) exp ljl/!I(t)]1=1
represent the time-varying vocal-tract transferfunction and assuming that the excitation parameters given in Eq. 2 are constant throughoutthe duration of the impulse response ofthe filterin effect at time t. then using Eqs. 2 and 3 in Eq.1 leads to the speech model given by
L(t)
s(t) =~ al(t) M!wI(t); tJ1=1
If the glottal excitation waveform is representedas a sum of sine waves of arbitrary amplitudes.frequencies. and phases. then the model can bewritten as
eft) = Re~ al(t) exp {j [~[ WI (a) da + <PI]} (2)
where. for the l th sinusoidal component. Clz{t)and wlt) represent the amplitude and frequency(Fig. 2). Because the sine waves will not necessarily be in phase. f/J1is included to represent afIxed phase-offset. This model leads to a particu1arly simple representation for the speech waveform. Letting
where
l/!I(t) =f t wda) da + <I>[wI(t); tl + <PIo
(6)
(7)
where the superscript kindicates that the parameters of the model may vary from frame toframe. Using Eq. 8. in Eq. 5 the synthetic speechwaveform over frame k can be written as
represent the amplitude and phase of the lthsine wave along the frequency track wlt). Equations 5. 6. and 7 combine to provide a sinusoidalrepresentation ofa speech waveform. In order touse the model, the amplitudes. frequencies. and
where
k-Ak ( 'Ok)YI - I exp J I
(9)
(9A)
The Lincoln Laboratory Journal. Volume 1, Number 2 (l988) 155

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
where
from which it follows that the optimal estimatefor the amplitude and phase is
(16)
(17)
if l = i (13)if l ~ i
Lk
+(N+ 1) ~ [IYlw~)-'Y~12-IYlW~)12I.1=1
sine (w~ - w~) =sine [(l- i) w~l ={6
.y~ = Y(lw;) •
which reduces the error to
where wk = lwk Then the error expression re-I o'
duces to
fk = ~ Iy(n) 12
- 2(N + 1) ReI~ (')'k) * y(wk )In ~1 I 1
~ (14)+ (N+ 1) ~ 1'Y~12
1=1
Ylw) =N: 1~ y(n) exp (-jnw) (15)n
is the STFT of the measurement signal. Bycompleting the square in Eq. 14. the error can bewritten as
From this calculation it follows. therefore, thatthe error is minimized by selecting all of the harmonic frequencies in the speech bandwidth,fl (ie, Lk =fl/w~).
Equations 15 and 17 completely specify thestructure of the ideal estimator and show thatthe optimal estimator depends on the speechdata through the STFT (Eq. 15). Although theseresults are eqUivalent to a Fourier-series representation of a periodic waveform, the resultslead to an intuitive generalization to the morepractical case. This is done by considering thefunctionlY (w) 12 to be a continuous function of w.
For the idealized voiced-speech case, thisfunction (called a periodogram) will be pulse-
Lk
s(n) = ~ 'Y~ exp Unlw~) (12)1=1
represents the 1th complex amplitude for the 1thcomponent of the Lk sine waves. Since themeasurements are made on digitized speech,sampled-data notation [s(n)] is used. In thisrespect the time index n corresponds to theuniform samples of t - t
k; therefore n ranges from
-N/2 to N/2. with n = 0 reset to the center of theanalysis window for every frame and where N+1is the duration of the analysis window. Theproblem now is to fit the synthetic speech waveform in Eq. 9 to the measured waveform. denoted by y(n). A useful criterion for judging thequality of fit is the mean-squared error
fk = ~ Iy(n) _ s(n) ,2n (10)
= ~ Iy(n) ,2 _ 2 Re ~ y(n) s*(n) + ~ Is(n) 12
.n n n
Substituting the speech model of Eq. 9 intoEq. 10 leads to the error expression
Lk
fk = ~ Iy(n) 12
- 2 Re ~ ('Y~)* ~ y(n) exp (-jnw~)n 1=1 n
Lk Lk (11)+ (N + 1) ~ ~ 'Y k ('Y k )* sine (w k - w k )
~ ~ I 1 I 11=1 1=1
where sinc(x) =sin [(N+ l)x/21/[(N+ 1) sin (x/2)].The task of the estimator is to identify a set of
sine waves that minimizes Eq. 11. Insights intothe development of a suitable estimator can beobtained by restricting the class ofinput signalsto the idealization of perfectly voiced speech, ie,speech that is periodic, hence having component sine waves that are harmonically related.In this case the synthetic speech waveform canbe written as
where w~ =21T/T~ and where T~ is the pitchperiod assumed to be constant over the durationof the k th frame. For the purpose of establishingthe structure of the ideal estimator. it is furtherassumed that the pitch period is known and thatthe width of the analysis window is a multiple ofT~ • Under these highly idealized conditions.the sinc (.) function in the last term of Eq. 11reduces to
156 The Lincoln Laboratory Journal. Volume 1. Number 2 (l988)

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
Provided the analysis window is "wide enough"that
(23)
Assuming that the component sine waves havebeen properly resolved, then, in the absence ofnoise, A~ will yield the value of an underlyingsine wave, provided the window is scaled so that
where w(n) represents the temporal weightingdue to the window function, then the practicalversion of the idealized estimator estimates thefrequencies of the underlying sine waves as thelocations of the peaks of I¥(w) I. Letting thesefrequency estimates be denoted by {w~}, thenthe corresponding complex amplitudes aregiven by
nated, by using the weighted STFf. Letting Y"(w)
denote the weighted STFf, ie,
NI2
Y(w) = ~ w(n) y(n) exp (-jnw) (22)n=-NI2
(20)
(19)L
k
Y(w) = ~ 'Y~ sine (w~ - w) .1=1
like in nature, with peaks occurring at all of thepitch harmonics. Therefore, the frequencies ofthe underlying sine waves correspond to the location of the peaks of the periodogram, and theestimates of the amplitudes and phases areobtained by evaluating the STFf at the frequencies associated with the peaks of the periodogram. This interpretation permits the extensionof the estimator to a more generalized speechwaveform, one that is not ideally voiced. Thisextension becomes evident when the STFf iscalculated for the general sinusoidal speechmodel given in Eq. 9. In this case the STFf issimply
Using the Hamming window for the weightedSTFf provided a very good sidelobe structure inthat the leakage problem was eliminated; it didso at the expense of broadening the main lobesof the periodogram. In order to accommodatethis broadening, the constraint implied by Eq.20 must be revised to require that the windowwidth be at least 2.5 times the pitch period. Thisrevision maintains the resolution features thatwere needed to justifY the optimality propertiesof the periodogram processor. Although thewindow width could be set on the basis of theinstantaneous pitch, the analyzer is less sensitive to the performance of the pitch extractor ifthe window width is set on the basis of theaverage pitch instead. The pitch computeddUring strongly voiced frames is averaged usinga 0.25-s time constant, and this averaged pitchis used to update, in real time, the width of theanalysis window. During frames of unvoicedspeech, the window is held fixed at the valueobtained on the preceding voiced frame or 20ms, whichever is smaller.
Once the width for a particular frame has beenspecified, the Hamming window is computed
then the periodogram can be written as
Lk
IY(w)12
= ~ 1'Y~12sine2(w~-w), (21)1=1
and, as before, the location of the peaks of theperiodogram corresponds to the underlyingsine-wave frequencies. The STFf samples atthese frequencies correspond to the complexamplitudes. Therefore, provided Eq. 20 holds,the structure of the ideal estimator applies to amore general class of speech waveforms thanperfectly voiced speech. Since, dUring steadyvoicing, neighboring frequencies are approximately seperated by the width of the pitchfrequency, Eq. 20 suggests that the desiredresolution can be achieved most of the time byrequiring that the analysis window be at leasttwo pitch periods wide.
These properties are based on the assumptionthat the sinc (.) function is essentially zerooutside of the region defmed by Eq. 20. In fact,this approximation is not a valid one, becausethere will be sidelobes outside of this region dueto the rectangular window implicit in the definition ofthe STFf. These sidelobes lead to leakagethat compromises the performance of the estimator' a problem that is reduced, but not elimi-
NI2
~ w(n) = 1 .n=-NI2
(24)
'The Uncoln Laboratory Journal. Volume 1. Number 2 (1988) 157

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
and normalized according to Eq. 24, and theSTIT of the input speech is taken using a 512point fast Fourier transform (FIT) for 4-kHzbandwidth speech. A typical periodogram forvoiced speech. along with the amplitudes andfrequencies that are estimated using the aboveprocedure, is plotted in Fig. 3.
In order to apply the sinusoidal model tounvoiced speech, the frequencies correspondingto the periodogram peaks must be close enoughto satisfy the requirement imposed by theKarhunen-Loeve expansion [5) for noiselikesignals. If the window width is constrained to beat least 20 ms wide, on average, the corresponding periodogram peaks will be approximately100 Hz apart, enough to satisfy the constraintsof the Karhunen-Loeve sinusoidal representation for random noise. A typical periodogram fora frame of unvoiced speech, along with theestimated amplitudes and frequencies, is plotted in Fig. 4.
This analysis provides a justification for representing speech waveforms in terms of theamplitudes, frequencies, and phases of a set ofsine waves. However, each sine-wave represen-
Frame-to-Frame Peak Matching
If the number of periodogram peaks wereconstant from frame to frame, the peaks could
20I
10I
950.0 ms
-10I I I I
-20I
50x"xX
40 ~Xx X
30 ~ X X X XQ)"0
X020 ~X X l¢( X XX X
10 ~ X X X ~
I I I I I I I
0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0
kHz
tation applies only to one analysis frame; different sets of these parameters are obtained foreach frame. The next problem to address, then,is how to associate the amplitudes, frequencies,and phases measured on one frame with thosefound on a successive frame.
20I
10I
1270.0 ms
-10I I I I
-20I
X Denotes Underlying Sine Wave
50
40 X Xx X
X XX
X 'I!-l¢( X X
30 X IQ)
\"0 X X20
X10
o 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0
kHz
X Denotes Underlying Sine Wave
Fig. 3 - This is a typicalperiodogram ofvoicedspeech. Theamplitude peaks of the periodogram determine which frequencies are chosen to represent the speech waveform.The amplitudes of the underlying sine waves are denotedwith an x.
Fig. 4 - This periodogram illustrates how the power isshifted to higher frequencies in unvoiced speech. Theamplitudes of the underlying sine waves are denoted withanx.
simply be matched between frames on a frequency-ordered basis. In practice, however,there are spurious peaks that come and gobecause of the effects of sidelobe interaction.(The Hammingwindow doesn't completely eliminate sidelobe interaction.) Additionally, peaklocations change as the pitch changes and thereare rapid changes in both the location and thenumber of peaks corresponding to rapidly varying regions of speech, such as at voiced/unvoiced transitions. The analysis system canaccommodate these rapid changes through theincorporation of a nearest-neighbor frequencytracker and the concept of the "birth" and
158 The Lincoln Laboratory Journal, Volume 1. Number 2 (1988)

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
"death" of sinusoidal components. A detaileddescription of this tracking algorithm is given inRef.6.
An illustration of the effects of the procedureused to account for extraneous peaks is shownin Fig. 5. The results of applying the tracker to asegment of real speech is shown in Fig. 6, whichdemonstrates the ability of the tracker to adaptqUickly through such transitory speech behavior as voiced/unvoiced transitions and mixedvoiced/unvoiced regions.
The Synthesis System
Frequency
Fig. 6 - These frequency tracks were derived from realspeech using the birth/death frequency tracker.
After the execution of the preceding parameter-extraction and peak-matching procedures,the information captured in those steps can beused in conjunction with a synthesis system toproduce natural-sounding speech. Since a set ofamplitudes, frequencies, and phases are estimated for each frame. it might seem reasonableto estimate the original speech waveform on thek th frame by using the equation
vUnvoiced Segment
Time
I '---v---" -~Voiced
Segment
Fig. 5 - Differentmodes used in the birth/death frequencytrack-matching process. Note the death of two tracks duringframes one and three and the birth ofa track during the second frame.
where n = O. 1.2, ... , S - 1 and where S is thelength of the synthesis frame. Because of th~
time-varying nature ofthe parameters, however.this straightforward approach leads to discontinuities at the frame boundaries. The discontinuities seriously degrade the quality of the
•••
>uc:Q)::::lcQ)...u.. Death
Birth
Death
(25)
•••
Time
synthetic speech. To circumvent this problem.the parameters must be smoothly interpolatedfrom frame to frame.
The most straightforward approach for performing this interpolation is to overlap and addtime-weighted segments of the sinusoidal components. This process uses the measured amplitude. frequency. and phase (referenced to thecenter ofthe synthesis frame) to construct a sinewave. which is then weighted by a triangularwindow over a duration equal to twice the lengthof the synthesis frame. The time-weighted components corresponding to the lagging edge ofthetriangular window are added to the overlappingleading-edge components that were generateddUring the previous frame. Real-time systemsusing this technique were operated with framesseparated by 11.5 ms and 20.0 ms. respectively.
While the synthetic speech produced by thefirst system was quite good. and almost indistingUishable from the original speech, the longerframe interval produced synthetic speech thatwas rough and, though quite intelligible,deemed to be of poor quality. Therefore, theoverlap-add synthesizer is useful only for appli-
The Lincoln Laboratory Journal. Volume 1, Number 2 (1988) 159

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
cations that can support a high frame rate. Butthere are many practical applications, such asspeech coding, that require lower frame rates.These applications require an alternative to theoverlap-add interpolation scheme.
A method will now be described that interpolates the matched sine-wave parameters directly. Since the frequency-matching algorithmassociates all ofthe parameters measured for anarbitrary frame, k, with a corresponding set ofparameters for frame k + I, then letting
1T
-1T
-1T
1T W
(25A)(a)
Experimental Results
and Lk is the number of sine waves estimated forthe k th frame.
(28)
1T W
W
fJ i (n)
(b)
-1T
1T
-1T
Fig. 7 - Requirement for unwrapped phase. (a) Interpolation of wrapped phase. (b) Interpolation of unwrappedphase.
Figure 8 gives a block diagram description ofthe complete analysis/ synthesis system. A nonreal-time floating-point simulation was developed initially to determine the effectiveness ofthe proposed approach in modeling real speech.The speech processed in the simulation was lowpass-filtered at 5 kHz, digitized at 10 kHz, andanalyzed at lO-ms frame intervals. A 512-pointFIT using a pitch-adaptive Hamming window,with a width 2.5 times the average pitch. wasused and found to be sufficient for accurate peak
denote the successive sets of parameters for thel th frequency track, a solution to the amplitudeinterpolation problem is to take
~k+l "kA(n) =Ak + (A S-A) n. (26)
where n =O. I, ... , S - 1 is the time sample intothe k th frame. (The track subscript l has beenomitted for convenience.)
Unfortunately, this simple approach cannotbe used to interpolate the frequency and phasebecause the measured phase, jjk, is obtainedmodulo 2n (Fig. 7). Hence, phase unwrappingmust be performed to ensure that the frequencytracks are "maximally smooth.. across frameboundaries. One solution to this problem thatuses a phase-interpolation function that is acubic polynomial has been developed in Ref. 6.The phase-unwrapping procedure provideseach frequency track with an instantaneous unwrapped phase such that the frequencies andphases at the frame boundaries are consistentwith the measured values modulo 2. The unwrapped phase accounts for both the rapidphase changes due to the frequency of eachsinusoidal component. and to the slowly varyingphase changes due to the glottal pulse and thevocal-tract transfer function.
Letting iizCtl denote the unwrapped phasefunction for the l th track. then the fmal synthetic waveform will be given by
Lk
S(n) = I Al(n) cos [~(n)J (27)1=1
where AzCnl is given by Eq. 26, iizCnl is given by
160 The Uncoln Laboratory Journal Volume 1. Number 2 (1988)

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
ANALYSIS:
tan-1(.)Phases
Speech
In~ OFT
Frequencies
I"Peak
PickingWindow Amplitudes
SYNTHESIS:
Phases Frame-To-FramePhase 8(t) Sine Wave Sum All_ Frequencies Unwrapping & ----..
Generator Sine Waves---.
Interpolation
_ Amplitudes Frame-To-Frame A(t)Linear
Interpolation
SyntheticSpeechOutput
Fig. 8 - This block diagram of the sinusoidal analysis/synthesis system illustrates the major functions subsumed within thesystem. Neither voicing decisions nor residual waveforms are required for speech synthesis.
estimation. The maximum number of peaksused in synthesis was set to a fIxed number(-80); if excess peaks were obtained only thelargest peaks were used.
A large speech data base was processed withthis system, and the synthetic speech was essentially indistinguishable from the original. Avisual examination of the reconstructed passages shows that the waveform structure isessentially preserved. This is illustrated by Fig.9, which compares the waveforms ofthe originalspeech and the reconstructed speech dUring anunvoiced/voiced speech transition. The comparison suggests that the quasi-stationaryconditions imposed on the speech model are metand that the use of the parametric model basedon the amplitudes, frequencies, and phases of aset of sine-wave components is justified for bothvoiced and unvoiced speech.
In another set of experiments it was found
The lincoln Laboratory Journal. Volume 1, Number 2 (l988)
that the system was capable of synthesizing abroad class of signals including multispeakerwaveforms. music, speech in a music background. and marine biologic signals such aswhale sounds. Furthermore. the reconstructiondoes not break down in the presence of noise.The synthesized speech is perceptually indistinguishable from the original noisy speech withessentially no modification of the noise characteristics. Illustrations depicting the performance of the system in the face of the abovedegradations are provided in Ref. 6. More recently a real-time system has been completedusing the Analog Devices ADSP2100 16-bitfixed-point signal-processing chips and performance equal to that of the simulation hasbeen achieved.
Although high-quality analysis/synthesis ofspeech has been demonstrated using the amplitudes, frequencies. and phases of the peaks
161

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
(a) -120 msl-
ample of a waveform synthesized by the magnitude-only system is shown in Fig. 10 (b). Compared to the original speech, shown in Fig. 10 (a),the synthetic waveform is quite different because of the failure to maintain the true sinewave phases. In an additional experiment themagnitude-only system was applied to the synthesis of noisy speech; the synthetic noise tookon a tonal quality that was unnatural andannoying.
Vocoding
~----""",,"'--1,oo~".-"~.~"iIIl·'lit"H""~M""''''''''''-~''''---
(b) -120 msl-
Since the parameters ofthe sinusoidal speechmodel are the amplitudes, frequencies, andphases of the underlying sine waves, and since,for a typical low-pitched speaker there can be asmany as 80 sine waves in a 4-kHz speech
Fig. 10- (a) Original speech. (b) Reconstructed speech.The original speech is compared to the segment that hasbeen reconstructed using the magnitude-onlysystem. Thedifferences brought about by ignoring the true sine-wavephases are clearly demonstrated.
-/20 msl-
-120 msl-
(a)
(b)
bandwidth, it isn't possible to code all of theparameters directly. Attempts at parameterreduction use an estimate of the pitch to establish a set ofharmonically related sine waves thatprovide a best fit to the input speech waveform.
of the high-resolution STFf, it is often arguedthat the ear is insensitive to phase, a propositionthat forms the basis of much of the work innarrowband speech coders. The question ariseswhether or not the phase measurements areessential to the sine-wave synthesis procedure.An attempt to explore this questionwas made byreplacing each cubic phase track by a phasefunction thatwas defined to be the integral oftheinstantaneous frequency [3,7). In this case theinstantaneous frequency was taken to be thelinear interpolation ofthe frequencies measuredat the frame boundaries and the integration,which started from a zero value at the birth ofthetrack and continued to be evaluated along thattrack until the track died. This "magnitudeonly" reconstruction technique was applied toseveral sentences of speech, and, while theresulting synthetic speech was very intelligibleand free of artifacts, it was perceived as beingdifferent from the original speech, having asomewhat mechanical quality. Furthermore,the differences were more pronounced for lowpitched (ie, pitch <-100 Hz) speakers. An ex-
Fig. 9 - (a) Original speech. (b) Reconstructed speech.Both voiced and unvoiced segments are compared to thevoiced/unvoiced segment of speech that has been reconstructed with the sinusoidalanalysis/synthesis system. Thewaveforms are nearly identical, justifying the use of thesinusoidal transform model.
162 TIle Lincoln Laboratory Journal. Volume 1, Number 2 (l988)

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
The amplitudes. frequencies, and phases ofthisreduced set of sine waves are then coded. Sincethe neighboring sine-wave amplitudes are naturally correlated, especially for low-pitchedspeakers. pulse-code modulation is used toencode the differential log amplitudes.
In the earlier versions of the vocoder all thesine-wave amplitudes were coded simply byallocating the available bits to the number to becoded. Since a low-pitched speaker can produceas many as 80 sine waves. then in the limit of 1bit/sine-wave amplitude, 4000 bps would be required at a 50-Hz frame rate. For an 8-kbpschannel. this leaves 4.0 kbps for coding thepitch. energy, and about 12 baseband phases.However, at 4.8 kbps and below, assigning 1bit/amplitude immediately exhausts the codingbudget. so no phases can be coded. Therefore, amore efficient amplitude encoder had to be developed for operation at these lower rates.
The increased efficiency is obtained by allowing the channel separation to increase logarithmically with frequency, thereby exploiting thecritical band properties of the ear. Rather thanimplement a set ofbandpass filters to obtain thechannel amplitudes. as is done in the channelvocoder, an envelope of the sine-wave amplitudes is constructed by linearly interpolatingbetween sine-wave peaks and sampling at thecritical band frequencies. Moreover, the locationof the critical band frequencies was made pitchadaptive whereby the baseband samples arelinearly seperated by the pitch frequency andwith the log-spacing applied to the high-frequency channels as required.
In order to preserve the naturalness at rates at4.8 kbps and below, a synthetic phase modelwas employed that phase-locks all of the sinewaves to the fundamental and adds a pitchdependent quadratic phase dispersion and avoicing-dependent random phase to each sinewave [8). Using this technique at 4.8 kbps, thesynthesized speech achieved a diagnostic rhymetest (DRT) score of94 (for three male speakers).A real-time, 4800-bps system that uses twoADSP2100 signal-processing chips has beensuccessfully implemented. The technology developed from this research has been transferredto the commercial sector (CYLINK, INC). where a
The Lincoln Laboratory Journal. Volume 1. Number 2 (1988)
product is being produced that will be availablein 1989.
Transformations
The goal oftime-scale modification is to maintain the perceptual quality ofthe original speechwhile changing the apparent rate ofarticulation.This implies that the frequency trajectories ofthe excitation (and thus the pitch contour) arestretched or compressed in time and that thevocal tract changes at the modified rate. Toachieve these rate changes, the system amplitudes and phases. and the excitation amplitudes and frequencies, along each frequencytrack are time-scaled. Since the parameter estimates ofthe unmodified synthesis are availableas continuous functions of time. in theory anyrate change is possible. Rate changes rangingbetween a compression oftwo and an expansionoftwo have been implemented with good results.Furthermore, the natural quality and smoothness of the original speech were preservedthrough transitions such as voiced/unvoicedboundaries. Besides the above constant ratechanges, linearly varying and oscillatory ratechanges have been applied to synthetic speech,resulting in natural-sounding speech that is freeof artifacts [9).
Since the synthesis procedure consists ofsumming the sinusoidal waveforms for each ofthe measured frequencies. the procedure isideally suited for performing various frequencytransformations. The procedure has been employed to warp the short-time spectral envelopeand pitch contour of the speech waveform and,conversely, to alter the pitch while preservingthe short-time spectral envelope. These speechtransformations can be applied simultaneouslyso that time- and frequency (or pitch)-scalingcan occur together by simultaneously stretching and shifting frequency tracks. These jointoperations can be performed with a continuously adjustable rate change.
Audio Preprocessing
The problem ofpreprocessing speech that is tobe degraded by natural or man-made distur-
163

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
bances arises in applications such as attemptsto increase the coverage area ofAM radio broadcasts and in improving ground-to-air communications in a noisy cockpit environment. Thetransmitter in such cases is usually constrainedby a peak operating power or the dynamic rangeof the system is limited by the sensitivity characteristics of the receiver or ambient-noise levels. Under these constraints, phase dispersionand dynamic-range compression, along withspectral shaping (pre-emphasis), are combinedto reduce the peak-to-rms ratio of the transmitted signal. In this way, more average power canbe broadcast without changing the peak-poweroutput ofthe transmitter, thus increasing loudness and intelligibility at the receiver whileadhering to peak-output power constraints.
This problem is similar to one in radar inwhich the signal is periodic and given as theoutput of a transmit filter the input of whichconsists ofperiodic pulses. The spectral magnitude of the filter is specified and the phase of thefilter is chosen so that, over one period, thesignal is frequency-modulated (a linear frequency modulation is usually employed) andhas a flat envelope over some specified duration.If there is a peak-power limitation on the transmitter, this approach imparts maximal energyto the waveform. In the case of speech, thevoiced-speech signal is approximately periodicand can be modeled as the output of a vocaltract filter the input ofwhich is a pulse train. Theimportant difference between the radar designproblem and the speech-audio preprocessingproblem is that, in the case ofspeech, there is nocontrol over the magnitude and phase of thevocal-tract filter. The vocal-tract filter is characterized by a spectral magnitude and some natural phase dispersion. Thus, in order to takeadvantage ofthe radar signal design solutions todispersion, the natural phase dispersion mustfirst be estimated and removed from the speechsignal. The desired phase can then be introduced. All three ofthese operations, the estimation of the natural phase, the removal of thisphase, and its replacement with the desiredphase, have been implemented using the STS.
The dispersive phase introduced into thespeech waveform is derived from the measured
164
vocal-tract spectral envelope and a pitch-periodestimate that changes as a function of time; thedispersive solution thus adapts to the timevarying characteristics of the speech waveform.This phase solution is sampled at the sine-wavefrequencies and linearly interpolated acrossframes to form the system phase component ofeach sine wave [10].
This approach lends itself to coupling phasedispersion, dynamic-range compression, andpre-emphasis via the STS. An example of theapplication of the combined operations on aspeech waveform is shown in Fig. 11. A systemusing these techniques produced an 8-dB reduction in peak-to-rms level, about 3 dB betterthan commercial processors. This work is currently being extended for further reduction ofpeak-to-rms level and for further improvementof quality and robustness. Overall system performance will be evaluated by field tests conducted by Voice of America over representativetransmitter and receiver links.
Conclusions
A sinusoidal representation for the speechwaveform has been developed; it extracts theamplitudes, frequencies, and phases of thecomponent sine waves from the short-timeFourier transform. In order to account for spurious effects due to sidelobe interaction andtime-varying voicing and vocal-tract events, sinewaves are allowed to come and go in accordancewith a birth/death frequency-tracking algorithm. Once contiguous frequencies arematched, a maximally smooth phase-interpolation function is obtained that is consistent withall of the frequency and phase measurements.This phase function is applied to a sine-wavegenerator which is amplitude-modulated andadded to the other sine waves to form the outputspeech. It is important to note that, except in updating the average pitch (used to adjust thewidth of the analysis window), no voicing decisions are used in the analysis/synthesis procedure.
In some respects the basic model has similarities to one that Flanagan has proposed [11, 12].Flanagan argues that because of the nature of
The Lincoln Laboratory Journal. Volume 1. Number 2 (I 988)

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
the peripheral auditory system, a speech wavefonn can be expressed as the sum of the outputsof a fixed filter bank. The amplitude, frequency,and phase measurements of the filter outputsare then used in various configurations ofspeech synthesizers. Although the present workis based on' the discrete Fourier transfonn (DFT),which can be interpreted as a filter bank, the useof a high-resolution DFT in combination withpeak picking renders a highly adaptive filterbank since only a subset of all of the DFT filtersare used at anyone frame. It is the use of thefrequency tracker and the phase interpolatorthat allows the filter bank to move with thehighly resolved speech components. Therefore,the system fits into the framework Flanagandescribed but, whereas Flanagan's approach isbased on the properties of the peripheral auditory system, the present system is designed onthe basis of properties of the speech productionmechanism.
Attempts to perfonn magnitude-only reconstruction were made by replacing the cubicphase tracks with a phase that was simply theintegral of the instantaneous frequency. Whilethe resulting speech was very intelligible andfree of artifacts, it was perceived as being different in quality from the original speech; thedifferences were more pronounced for lowpitched (ie, pitch <-100 Hz) speakers. When themagnitude-only system was used to synthesizenoisy speech, the synthetic noise took on a tonalquality that was unnatural and annoying. Itwasconcluded that this latter propertywould renderthe system unsuitable for applications for whichthe speech would be subjected to additive
acoustic noise.While it may be tempting to conclude that the
ear is not phase-deaf, particularly for lowpitched speakers, it may be that this is simply aproperty of the sinusoidal analysis/synthesissystem. No attempts were made to devise anexperiment that would resolve this questionconclusively. It was felt, however, that the system was well-suited to the design and executionof such an experiment, since it provides explicitaccess to a set of phase parameters that areessential to the high-quality reconstruction ofspeech.
Using the frequency tracker and the cubicphase-interpolation function resulted in a functional description of the time-evolution of theamplitude and phase of the sinusoidal components of the synthetic speech. For time-scale,pitch-scale, frequency modification of speech,and speech-coding applications such a functional model is essential. However, if the systemis used merely to produce synthetic speech,using a set of sine waves, then the frequencytracking and phase-interpolation proceduresare unnecessary. In this case, the interpolationis achieved by overlapping and adding timeweighted segments of each of the sinusoidalcomponents. The resulting synthetic speech isessentially indistinguishable from the originalspeech as long as the frame rate is at least100 Hz.
A fixed-point 16-bitreal-timeimplementationof the system has been developed on theLincoln Digital Signal Processors [13] and usingthe Analog Devices ADSP2100 processors. Diagnostic rhyme tests have been perfonned and
Fig. 11-Audiopreprocessing using phase dispersion and dynamic-range compression illustrates the reduction in the peakto-rms level.
The Lincoln Laboratory Journal. Volume 1. Number 2 (1988) 165

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
about one DRr point is lost relative to theunprocessed speech of the same bandwidthwith the analysis/synthesis system operating ata 50-Hz frame rate. The system is used inresearch aimed at the development of a multirate speech coder (14). A practical low-ratecoder has been developed at 4800 bps and2400 bps using two commercially availableDSP chips. Furthermore, the resulting technology has been transferred to private industryfor commercial development. The sinusoidalanalysis/synthesis system has also been applied successfully to problems in time scale,pitch scale, and frequency modification ofspeech (9) and to the problem of speech en-
166
hancement for AM radio broadcasting (10).
Acknowledgments
The authors would like to thank their colleague, Joseph Tierney, for his comments andsuggestions in the early stages of this work. Theauthors would also like to acknowledge thesupport and encouragement of the late AntonSegota of RADC/EEV, who was the Air Forceprogram manager for this research from its inception in September 1983 until his death inMarch 1987.
This work was sponsored by the Departmentof the Air Force.
The Lincoln Laboratory Journal. Volume 1, Number 2 (1988)

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
References
1. B.S. AtalandJ.R Remde. "A New Model ofLPC Excitationfor Producing Natural-Sounding Speech at Low Bit Rates."Int. Conj. on Acoustics, Speech. and Signal Processing 82(IEEE, New York, 1982). p 614.2. M.R Schroeder and B.S. Atal, "Code-Excited LinearPrediction (CELP): High Quality Speech at Very Low BitRates," Int. ConJ on Acoustics, Speech. and Signal Processing 85 (IEEE. New York. 1985). p 937.3. P. Hedelin, "ATone-Oriented Voice-Excited Vocoder," Int.ConI onAcoustics, Speech. and SignalProcessing 81 (IEEE.New York, 1981), p 205.4. L.B. Almeida and F.M. Silva, "Variable-Frequency Synthesis: An Improved Harmonic Coding Scheme." Int. ConIon Acoustics, Speech. and Signal Processing 84 (IEEE, NewYork, 1984). p 27.5.1.5. H. Van Trees, Detection, Estimation and ModulationTheory, Part! (John Wiley, New York. 1968), Chap 3.6. RJ. McAulay and T.F. Quatieri. "Speech Analysis/Synthesis Based on a Sinusoidal Representation." IEEETrans. Acoust. SpeechSignalProcess. ASSP-34, 744 (1986).7. RJ. McAulay and T.F. Quatieri, "Magnitude-Only Reconstruction Using a Sinusoidal Speech Model," Int. ConlonAcoustics, Speech. and Signal Processing 84 (IEEE. NewYork, 1984). p 27.6.1.
The Lincoln Laboratory Journal, Volume 1, Number 2 (1988)
8. RJ. McAulay and T.F. Quatieri. "Multirate SinusoidalTransform Coding at Rates from 2.4 kbps to 8.0 kbps." Int.ConI onAcoustics. Speech. and Signal Processing 87(IEEE,New York. 1987). p 1645.9. T.F. Quatieri and RJ. McAulay. "Speech Transformations Based on a Sinusoidal Representation." IEEE Trans.Acoust. Speech Signal Process. ASSP-34, 1449 (Dec. 1986).10. T.FQuatieri and RJ. McAulay. "Sinewave-based PhaseDispersion for Audio Preprocessing." Int. Conj. onAcoustics,Speech. and Signal Processing 88 (IEEE, New York. 1988),p 2558.11. J. L. Flanagan. "Parametric Coding of Speech Spectra."J. Acoust. Soc. ojAmerica 68. 412 (1980).12. J.L. Flanagan and S.W. Christensen, "Computer Studies on Parametric Coding ofSpeech Spectra," J. Acoust. Soc.ojAmerica 68, 420 (1980).13. P.E. Blankenship. "LDVT: High Performance Minicomputer for Real-Time Speech Processing." EASCON '75(IEEE. New York, 1975). p 214-A.14. RJ. McAulay and T.F. Quatieri, "Mid-Rate CodingBased on a Sinusoidal Representation ofSpeech." Int. ConJon Acoustics. Speech. and Signal Processing 85 (IEEE, NewYork. 1985), p 945.
167

McAulay et aI. - Speech Processing Based on a Sinusoidal Model
ROBERT J. McAULAY is asenior staff member in theSpeech SystemsTechnologyGroup. He received a BASedegree in engineering physics (with Honors) from theUniversity of Toronto in1962, an MSc degree in electrical engineering from the
University of Illinois in 1963, and a PhD degree in electricalengineering from the University of California, Berkeley, in1967. In 1967 he joined Lincoln Laboratory and worked onproblems in estimation theory and signal/filter design using optimal control techniques. From 1970 to 1975 he wasa member of the Air Traffic Control Division and worked onthe development ofaircraft tracking algOrithms. Since 1975he has been involved with the development of robust narrow-band speech vocoders. Bob received the M. BarryCarlton award in 1978 for the best paper published in theIEEE Transactions on Aerospace and Electronic Systems.In 1987 he was a member of the panel on Removal of Noisefrom a Speech/Noise Signal for Bioacoustics and Biomechanics of the National Research Council's Committeeon Hearing.
168
THOMAS F. gUATIERl is astaff member in the SpeechSystems Technology Group.where he is working onproblems in digital signalprocessing and their application to speech enhancement. speech coding. anddata communications. He
received a BS degree (summa cum laude) from Tufts University and SM. EE, and ScD degrees from Massachusetts Institute ofTechnology in 1975, 1977. and 1979. respectively.He was previously a member of the Sensor ProceSSingTechnology group involved in multidimensional digital signal processing and image processing. Tom received the1982 Paper Award of the IEEE Acoustics. Speech and Signal Processing Society for the best paper by an author underthirty years ofage. He is a member of the IEEE Digital SignalProcessing Technical Committee, Tau Beta Pi. Eta KappaNu. and Sigma Xi.
The Lincoln Laboratory Journal, Volume 1. Number 2 (1988)
•