Embed Size (px)
Citation preview

Rachunek Prawdopodobieństwa i statystyka
W 10: Analizy zależności pomiędzy zmiennymi
losowymi (danymi empirycznymi)
Dr Anna ADRIANPaw B5, pok [email protected]

Odkrywanie i analiza zależności pomiędzy
zmiennymi ilościowymi (liczbowymi)
Przedmiotem kolejnych dwóch wykładów będą zależności dla– Zmiennych jednowymiarowych
• Korelacja liniowa– Korelacja liniowa– – test istotności współczynnika korelacji liniowej
• regresja prosta– Współczynniki regresji, wyznaczanie ich MNK– Ocena dopasowania modelu Współczynnik determinacji– Standardowy błąd estymacji– Współczynnik zmienności losowej
– Zmiennych wielowymiarowych• Macierz korelacji• Korelacje cząstkowe• regresja wieloraka

Metody statystyczne stosuje się do badania struktury zbiorowości i zależności pomiędzy jej cechami
• Metody statystyczne dotyczące analizy struktury zbiorowości opierały się na obserwacjach tylko jednej cechy, a jeśli brano pod uwagę kilka cech, to każdą analizowano oddzielnie.
• W wielu przypadkach, do poznania całokształtu zagadnienia potrzebna jest analiza zbiorowości z punktu widzenia kilku cech, pomiędzy którymi występują pewne zależności
• Odkrywanie postaci i siły zależności występujących pomiędzy cechami zbiorowości są przedmiotem analizy korelacji i regresji.
• Uwzględniając liczbę zmiennych (analizowanych cech zbiorowości) rozróżnia się następujące odmiany zależności
wiele zmiennychwielowymiarowa
jedna zmienna wielowymiarowa
wiele zmiennychjednowymiarowa
jedna zmienna jednowymiarowa
niezależna (objaśniająca)zależna (objaśniana)
Rodzaj zmiennej

Wprowadzenie do analizy zależności pomiędzy danymi statystycznymi
• Celem analizy jest stwierdzenie, czy między badanymi zmiennymi zachodzą jakieś zależności, jaka jest ich:– siła (współczynnik determinacji , współczynnik korelacji)
– postać ( dopasowanie funkcji reprezentujących zależność - aproksymacja)
– kierunek (monotoniczność)
• Współzależność między zmiennymi może być dwojakiego rodzaju: – funkcyjna
– stochastyczna (probabilistyczna).

Przykłady związków funkcyjnychi statystycznych

Rodzaje zależności pomiędzy danymi -zależność funkcyjna
• Istota zależności funkcyjnej polega na tym, że zmiana wartości jednej zmiennej powoduje ściśle określoną zmianę wartości drugiej zmiennej.
• W przypadku zależności funkcyjnej: y = f (x), każdej wartości zmiennej (X) odpowiada jedna i tylko jedna wartość zmiennej (Y).
• Symbolem X oznaczamy zmienną objaśniającą(niezależną), natomiast symbolem Y - zmiennąobjaśnianą (zależną ).

Postać związków – przykłady dlajednowymiarowej zmiennej objaśnianej (y), gdy jedna jest zmienna objaśniająca (x)
y=2x+1
0
1
2
3
4
5
6
0 0,5 1 1,5 2 2,5
y=1+xcos(x)
-3,00
-2,00
-1,00
0,00
1,00
2,00
0 1 2 3 4
x
y= EXP(x)
0,00
1,00
2,00
3,00
4,00
5,00
6,00
7,00
8,00
0 0,5 1 1,5 2 2,5
x
a b
c d
y=log x
-1,50
-1,00
-0,50
0,00
0,50
1,00
0 0,5 1 1,5 2 2,5 3 3,5 4

Rodzaje zależności pomiędzy danymi Zależność korelacyjna
• Zależność stochastyczna występuje wtedy, gdy wraz ze zmianą wartości jednej zmiennej zmienia się rozkład prawdopodobieństwa drugiej zmiennej
• Szczególnym przypadkiem zależności stochastycznej jest zależność korelacyjna (statystyczna).
• Zależność korelacyjna polega na tym, że określonym wartościom jednej zmiennej odpowiadają ściśle określone średnie wartości drugiej zmiennej.
• Związki typu statystycznego są możliwe do wykrycia oraz ilościowego opisu w przypadku, kiedy mamy do czynienia z wieloma obserwacjami, opisującymi badane obiekty, zjawiska czy też procesy


Badanie zależności statystycznych pomiędzy danymi empirycznymi
• W badaniach statystycznych zależności pomiędzy cechami najczęściej sprowadza się do funkcji liniowych.
• Nieliniowe związki pomiędzy zmiennymi mogą byćopisywane przez wielomiany drugiego i wyższych stopni albo przez inne funkcje (wykładnicze, logarytmiczne, trygonometryczne itp.) .
• Przy podejmowaniu decyzji o wyborze funkcji aproksymacyjnej, opisującej w przybliżeniu związek pomiędzy analizowanymi cechami, pomocne jest sporządzenie wykresu rozrzutu wartości badanych zmiennych.
• Jeśli okaże się, że pomiędzy zmiennymi widoczna jest zależność i nie jest ona liniowa, wówczas trzeba znaleźćodpowiednie rozwiązanie nieliniowe

Miarą siły i kierunku zależności liniowej jest współczynnik korelacji liniowej
• Statystyką, która opisuje siłę liniowego związku pomiędzy dwiema zmiennymi jest współczynnik korelacji z próby (ρ∼r).
• Przyjmuje on wartości z przedziału domkniętego <-1; 1>.
• Wartość -1 oznacza występowanie doskonałej korelacji ujemnej (to znaczy sytuację, w której punkty leżądokładnie na prostej, skierowanej w dół), a wartość 1 oznacza doskonałą korelację dodatnią (punkty leżądokładnie na prostej, skierowanej w górę).
• Wartość 0 oznacza brak korelacji liniowej
)()(
),cov(
YDXD
YX=ρ

Przykłady układów punktów przy różnych wartościach współczynnika korelacji liniowej

Wzór do obliczania empirycznego współczynnika korelacji ma postać
gdzie:• xi oraz yi oznaczają empiryczne wartości zmiennych,
odpowiednio, X i Y, natomiast• x oraz y oznaczają średnie wartości tych zmiennych.
Współczynnik korelacji daje też informację o kierunku zależności, bo jeśli małym wartościom X odpowiadają przeważnie małe wartości zmiennej Y, a dużym wartościom X duże wartości Y, to licznik wyrażenia dla r będzie dodatni, mianownik jest zawsze dodatni, zatem r>0 oznacza zależność rosnącą, r<0 –malejącą.

Test istotności współczynnika korelacji liniowej (Pearsona)
Badane zmienne (X, Y) mają dwuwymiarowy rozkład normalny, o nieznanym współczynniku korelacji ρ.
Z populacji wylosowano n – elementową próbę i wyliczono rZweryfikować hipotezę H0: ρ = 0 wobec jednej z hipotez alternatywnych
H1: ρ ≠ 0 lub H1: ρ < 0 albo H1: ρ > 0
Funkcja testowa ma postać:
a gdy n>100 to
zmienna t ma rozkład Studenta z n-2 stopniami swobody; u ma rozkład normalny. Hipotezę H 0 odrzucamy ilekroć wartość
obliczona funkcji testowej znajdzie się w obszarze krytycznym (zdefiniowanym przez hipotezę H1)
21 2
−−
= nr
rt n
r
ru
21−=

Niejednoznaczno ść informacji przekazywanej przez współczynnik korelacji - przykład
Zale żność pomi ędzy licz ą bocianow i liczb ą urodzin dzieci
y = 0,182x + 1,3015
R2 = 0,9654
0
2
4
6
8
10
12
14
16
18
20
0 20 40 60 80 100
Liczba bocianow
Licz
ba u
rodz
onyc
h dz
ieci
Interpretacja: przez analogię do filmu Seksmisja: jeśli bociany to miejsce wybrały musi to być „zdrowy” region –pomyśleli młodzi i postanowili się tu osiedlić
R=0.9825

Regresja prosta (regresja liniowa)
Analiza regresji stanowi w stosunku do analizy korelacji dalszy krok w zakresie ilościowego opisu powiązań zachodzących między zmiennymi.
• Model regresji liniowej prostej przyjmuje postać:
Y = β 0+ β1 x + εgdzie β 0 oznacza wyraz wolny, β1 współczynnik kierunkowy, a ε błąd.
• Zazwyczaj nie wszystkie punkty układają się dokładnie na prostej regresji. Źródłem błędu są wpływy innych nie uwzględnionych w modelu zmiennych, takich jak np. błędy pomiarowe.
• Zakłada się przy tym, że błędy mają średnią wartość równą zero i nieznaną wariancję oraz, że błędy nie są nawzajem skorelowane.
• Współczynniki regresji β 0 β1 można wyznaczyć korzystając z metody najmniejszych kwadratów.

Istota metody najmniejszych kwadratów -MNK
• Wprowadzona przez Legendre'a i Gaussa, jest najczęściej stosowaną w praktyce metodą statystyczną
• Jej istota jest następująca:– Wynik kolejnego pomiaru yi można przedstawić jako sumę (nieznanej)
wielkości mierzonej y oraz błędu pomiarowego εi ,
• Od wielkości oczekujemy, aby suma kwadratów była jak najmniejsza:
( ) minˆ 22 =−=∑∑i
iii
i yyε

Ocena stopnia dopasowania modelu do danych rzeczywistych
• Zasadniczy cel analizy regresji polega na ocenie nieznanych parametrów modelu regresji. Ocena ta jest dokonywana za pomocą metody najmniejszych kwadratów (MNK).
• MNK sprowadza się do minimalizacji sum kwadratów odchyleńwartości teoretycznych od wartości rzeczywistych (czyli tzw. reszt modelu).
• Dopasowany model regresji prostej, który daje punktową ocenęśredniej wartości y dla określonej wartości x przyjmuje postać:
• gdzie f(x) oznacza teoretyczną wartość zmiennej zależnej, • b 0 i b1 odpowiednio oceny wyrazu wolnego i współczynnika
kierunkowego, uzyskane na podstawie wyników z próby.
xbbxfy 10)(ˆ +==

MNK
( )∑ =+−−=∂∂
iii xbby
b
y0)(2 10
0
( ) ( ) min)(ˆ 210
2 →+−=− ∑∑i
iii
ii xbbyyy
Wyrażenie
Osiągnie min wtedy i tylko wtedy gdy
( )∑ =+−−=∂∂
iiii xbbyx
b
y0)(2 10
1

Współczynniki równania regresji liniowej
2
1
11
11
11
0
)(
))((
1
∑
∑
∑∑
=
=
==
−
−−=
−=
−=
n
ii
n
iii
n
ii
n
ii
xx
yyxxb
xbyxbyn
b

Interpretacja współczynników regresji
• b0 jest punktem przecięcia prostej regresji z osia wartości y (rzędnych)
• b1 oznacza przyrost wartości prostej przy jednakowym przyroście argument

Interpretacja równania regresji (r r l)
• b0 jest punktem przecięcia prostej regresji z osia wartości y (rzędnych)
• b1 oznacza przyrost wartości prostej przy jednakowym przyroście argumentu
• Łatwo wyliczyć związek współczynnika b1 z wartosciąwspółczynnika korelacji próbkowej
xx
xbbxbbb
−++−++=
)1(
)())1(( 10101
x
y
x
y
yx
n
iii
x
n
iii
n
ii
n
iii
s
sr
s
s
ssn
yyxx
sn
yyxx
xx
yyxxb =
−
−−=
−
−−=
−
−−=
∑∑
∑
∑==
=
=
)1(
))((
)1(
))((
)(
))((1
21
2
1
11

Interpretacja równania regresji (r r l)
• Prosta regresji przechodzi przez punkt o współrzędnych odpowiadającym średnim wartościom zmiennych X i Y
• Z faktu, że MNK minimalizuje sumę kwadratów różnic ei
• wynika, ze
• Stąd wynika, że reszty nie mogą być dowolne, w szczególności nie mogą być jednakowego znaku
yxbxbyxbbxy =+−=+= 1110 )()(ˆ
iii yye ˆ−=
0)(()ˆ( 10111
=+−=−= ∑∑∑===
xbbyyye i
n
iii
n
i
n
ii

Typowanie postaci zale żności- Statistica/wykresy/ wykresy rozrzutu 2W
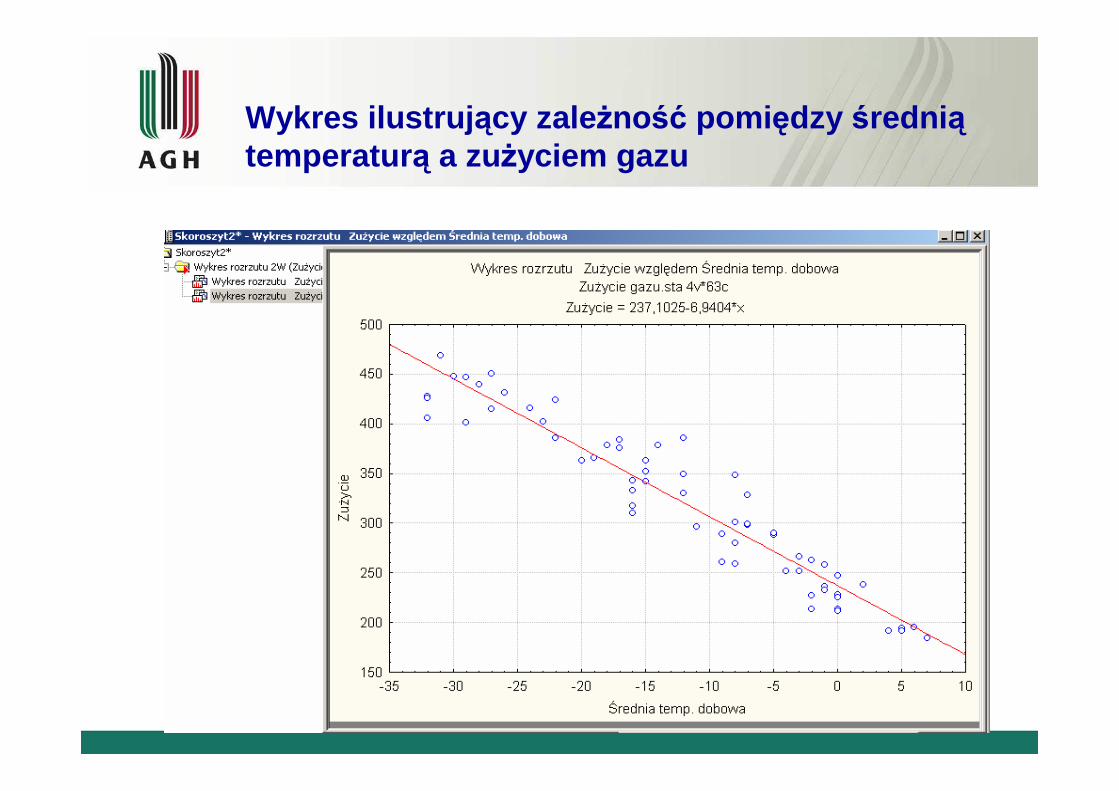
Wykres ilustruj ący zale żność pomi ędzy średni ątemperatur ą a zużyciem gazu

Regresja wieloraka


Regresja wielomianowa dla n=2
( ) ( ) minˆ22
2102 →−−−=− ∑∑
iii
iii xbxbbyyy
2210)(ˆ xbxbbxfy ++==
Współ
Współczynniki b0, b1 i b2 wyznaczymy z układu trzech równań utworzonych z trzech pochodnych obliczonych względem zmiennych b0 , b1 i b2 i przyrównanych do zera

Regresja wielomianowa


Linearyzacja funkcji nieliniowych
bxay =
baxy =
bxey =

Ocena dopasowania modelu do danych Współczynnik determinacji R 2
• Jeśli wartość współczynnika determinacji R2 (wielkość ta oznacza kwadrat współczynnika korelacji) jest duża, to oznacza , że błędy dla przyjętego modelu są stosunkowo małe i w związku z tym model jest dobrze dopasowany do rzeczywistych danych
• Licznik reprezentuje tu zmienność wielkości y obliczonej z modelu, a mianownik jest miarą zmienności empirycznych wartości yi
• Współczynnik R2 , przyjmujący wartości z przedziału [0,1], jest zatem miarą stopnia w jakim model wyjaśnia kształtowanie się zmiennej Y.Im jego wartość jest bliższa 1, tym lepsze dopasowanie modelu do danych empirycznych
∑
∑
=
=
−
−=
n
ii
n
ii
yy
yyR
1
2
1
2
2
)(
)ˆ(

Analiza reszt
• Reszta odpowiadająca i-tej obserwacji wyraża się wzorem
, gdzie i=1,2,....,n
• Wariancja resztowa będąca oceną wariancji składnika losowego wyraża się wzorem
Pierwiastek z wariancji resztowej, czyli odchylenie standardowe reszt Se
, zwane standardowym błędem estymacji jest najczęściej stosowanąmiarą zgodności modelu z danymi empirycznymi.
iii yye ˆ−=
21
2
2
−−=∑
=
mn
eS
n
ii
e

Współczynnik zmienno ści losowej
• Wielkość Se2 wskazuje na przeciętną różnicę między zaobserwowanymi wartościami
zmiennej objaśnianej
i wartościami teoretycznymi obliczonymi z prostej regresji.
• Współczynnik W , obliczany według wzoru
informuje o tym jaką część średniej wartości zmiennej objaśnianej stanowi błąd
standardowy estymacji.
• Po wyznaczeniu równania regresji ( modelu) należy sprawdzić hipotezę o istotności
otrzymanych współczynników regresji,
• W tym celu przeprowadzamy testy istotności t .
y
SW e=

Podsumowanie
• Analiza zależności pomiędzy badanymi cechami polega
na określeniu
– Siły
– Kierunku
– Postaci – modelu matematycznego
Analiza stopnia dopasowania modelu
matematycznego do danych empirycznych





























![INFORMATYKA W CHEMII · REGRESJA LINIOWA [podstawy, regresja ważona, analiza reszt, współczynnik korelacji, błąd standardowy] ... OPTYMALIZACJA I PLANOWANIE DOŚWIADCZEŃ](https://img.pdfslide.net/doc/110x75/5c77706a09d3f2a94e8bd6d0/informatyka-w-chemii-regresja-liniowa-podstawy-regresja-wazona-analiza-reszt.jpg)