Embed Size (px)
Citation preview

UNIVERSIDADE DO VALE DO ITAJAÍ CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
SISTEMA PARA ESTRUTURAÇÃO DE INFORMAÇÕES SOBRE PROTEÍNAS
Área de Bioinformática
por
Thomas Basten
Rafael Luiz Cancian, MSc. Orientador
Itajaí (SC), julho de 2006

UNIVERSIDADE DO VALE DO ITAJAÍ CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
SISTEMA PARA BUSCA E ESTRUTURAÇÃO DE INFORMAÇÕES SOBRE PROTEÍNAS
Área de Bioinformática
por
Thomas Basten Relatório apresentado à Banca Examinadora do Trabalho de Conclusão do Curso de Ciência da Computação para análise e aprovação. Orientador: Rafael Luiz Cancian, MSc.
Itajaí (SC), julho de 2006

SUMÁRIO
LISTA DE ABREVIATURAS...................................................................v
LISTA DE FIGURAS................................................................................vi LISTA DE TABELAS..............................................................................vii RESUMO..................................................................................................viii ABSTRACT................................................................................................ ix
1. INTRODUÇÃO......................................................................................1 1.1. OBJETIVOS ........................................................................................................ 3 1.1.1. Objetivo Geral ................................................................................................... 3 1.1.2. Objetivos Específicos ........................................................................................ 3 1.2. METODOLOGIA................................................................................................ 4 1.3. ESTRUTURA DO TRABALHO ....................................................................... 6
2. FUNDAMENTAÇÃO TEÓRICA ........................................................7 2.1. BIOLOGIA MOLECUAR.................................................................................. 7 2.1.1. DNA .................................................................................................................... 8 2.1.2. NUCLEOTÍDEOS ............................................................................................ 9 2.1.3. ESTRUTURA DO DNA ................................................................................. 10 2.1.4. Genes ................................................................................................................ 12 2.1.4.1. FUNCIONAMENTO DOS GENES ........................................................... 12 2.1.5. RNA .................................................................................................................. 13 2.1.6. AminoácidoS.................................................................................................... 15 2.1.7. PROTEÍNAS ................................................................................................... 15 2.1.7.1. Estrutura das proteínas ................................................................................... 15 2.1.7.1.1. Estrutura Primária ............................................................................................................17 2.1.7.1.2. Estrutura Secundária ........................................................................................................17 2.1.7.1.3. Estrutura Terciária............................................................................................................21 2.1.7.1.4. Estrutura Quaternária .......................................................................................................22 2.1.7.2. Funções das Proteínas .................................................................................... 22 2.1.7.3. Bancos de Dados Biológicos.......................................................................... 24 2.1.7.3.1. Banco de Dados Primários ...............................................................................................24 2.1.7.3.2. Banco de Dados Secundários ...........................................................................................24 2.2. PROTEÔMICA ................................................................................................. 27 2.2.1.1. Ferramentas para Proteômica ......................................................................... 28 2.3. TECNOLOGIA APLICADA ........................................................................... 31 2.3.1. PROCESSAMENTO PARALELO E DISTRIBUÍDO............................... 31 2.3.2. BANCO DE DADOS....................................................................................... 33 2.3.3. ACESSO A BANCO DE DADOS BIOLÓGICOS ...................................... 34 2.3.4. LINGUAGEM DE PROGRAMAÇÃO DELPHI........................................ 38
3. DESENVOLVIMENTO ......................................................................40

iv
3.1. INTRODUÇÃO ................................................................................................. 40 3.2. MODELAGEM.................................................................................................. 40 3.2.1. Casos de Uso .................................................................................................... 41 3.2.2. Diagrama de Classes ....................................................................................... 46 3.2.3. Diagrama de Seqüências................................................................................. 47 3.2.4. Diagrama de Entidades e Relacionamentos ................................................. 49 3.3. PROJETO .......................................................................................................... 50 3.3.1. Janela de Login................................................................................................ 51 3.3.2. Tela Informações de Escravos ....................................................................... 52 3.3.3. Tela de Busca por Proteínas........................................................................... 53 3.3.4. Tela de Progresso da Busca............................................................................ 54 3.3.5. Tela de Banco de Dados Protéico .................................................................. 55 3.3.6. Tela Aplicação Escrava de Busca por Proteínas.......................................... 58 3.4. IMPLEMENTAÇÃO ........................................................................................ 58 3.4.1. Componentes e Funções Utilizadas ............................................................... 59 3.4.1.1. Função de Leitura de Arquivo .ini ................................................................. 59 3.4.1.2. Função de Criação de Lista com IPs da Rede ................................................ 59 3.4.1.3. Função de Download de Arquivos na Internet............................................... 60 3.4.2. Busca em Banco de Dados Protéico............................................................... 60 3.4.3. Comunicação entre a Aplicação Principal e a Aplicação Servidora.......... 61 3.4.4. Inclusão de Resultados no Banco de Dados.................................................. 62 3.5. VALIDAÇÃO E TESTES................................................................................. 63
4. CONSIDERAÇÕES FINAIS ...................Erro! Indicador não definido. REFERÊNCIAS BIBLIOGRÁFICAS ...................................................72
APÊNDICE A – DICIONÁRIO DE DADOS ........................................76
ANEXO I – CÓDIGO FONTE DA APLICAÇÃO PRINCIPAL........79
ANEXO II – CÓDIGO FONTE DA APLICAÇÃO ESCRAVA .........85

LISTA DE ABREVIATURAS
DDBJ DNA Data Bank of Japan DNA DesoxirriboNucleic Acid, ou Ácido Desoxirribonucléico EBI European Bioinformatics Institute EMBOSS European Molecular Biology Open Software Suíte ExPASy EXpert Protein Analysis System FK Foreign Key HTML HyperText Markup Language IP Internet Protocol PDB Protein Data Bank PK Primary Key RNA Ácido Ribonucléico RNAm RNA Mensageiro RNAt RNA Transportador SQL Structured Query Language TCC Trabalho de Conclusão de Curso TCP Transmission Control Protocol UML Unified Modeling Language UNIVALI Universidade do Vale do Itajaí URL Uniform Resource Locator W3C World Wide Web Consortium XML Extensible Markup Language

LISTA DE FIGURAS
Figura 1. Estrutura de um cromossomo, da dupla hélice do DNA e das bases nitrogenadas. .............8 Figura 2. Nucleotídeo Timina. .............................................................................................................9 Figura 3. Bases nitrogenadas que compõe o DNA.............................................................................10 Figura 4. A Dupla hélice do DNA......................................................................................................11 Figura 5. Nucleotídeo Uracila. ...........................................................................................................13 Figura 6. Bases nitrogenadas que compõe o RNA.............................................................................14 Figura 7. Exemplo de estrutura primária de uma proteína. ................................................................17 Figura 8. Exemplo de Estrutura Secundária.......................................................................................17 Figura 10. Estrutura Secundária Folha-�............................................................................................19 Figura 11. Estrutura Secundária Laço (Turn).....................................................................................20 Figura 13. Estrutura terciária..............................................................................................................21 Figura 14. Estrutura quaternária.........................................................................................................22 Figura 15. Sistema de busca no banco de dados PROSITE. ..............................................................26 Figura 16. Resultados obtidos pela busca no banco de dados PROSITE. .........................................27 Figura 16. Página inicial do sistema de busca de domínios PFam.....................................................29 Figura 17. Resultados obtidos pelo sistema de busca de domínios PFam. ........................................30 Figura 18. Sistema de busca no banco de dados Swiss-Prot. .............................................................35 Figura 19. Tela de resultados obtidos pelo Sistema de busca no banco de dados Swiss-Prot. ..........35 Figura 20. Tela de resultados obtidos pelo acesso direto as informações do UniProt. ......................36 Figura 21. Diagrama do Caso de Uso Login no Sistema. ..................................................................42 Figura 22. Diagrama do Caso de Uso Servidores na Rede. ...............................................................43 Figura 23. Diagrama do Caso de Uso Buscar, Visualizar Proteínas e Gravar Dados ........................45 Figura 24. Diagrama de classes Aplicação Principal .........................................................................46 Figura 25. Diagrama de classes Aplicação Escrava ...........................................................................47 Figura 26. Diagrama de Seqüência Inclusão Manual de Escravo. .....................................................48 Figura 27. Diagrama de Seqüência Solicitação de Informações........................................................49 Figura 28. Modelo de entidades e relacionamentos. ..........................................................................50 Figura 29. Janela de Login .................................................................................................................51 Figura 30. Janela Cadastro de Novo Usuário .....................................................................................52 Figura 31. Tela de Informações de Escravos .....................................................................................53 Figura 32. Tela de Busca por Proteínas..............................................................................................54 Figura 33. Tela de Progresso de Busca ..............................................................................................55 Figura 34. Tela de Informações Básicas da Proteína .........................................................................56 Figura 35. Tela de Estrutura da Proteína............................................................................................57 Figura 36. Escravo de Busca por Proteínas........................................................................................58 Figura 37. Busca por ABC Transporters através da ferramenta UniProt Knowledgebase ................63 Figura 38. Resultado da busca por ABC Transporters através da aplicação......................................64 Figura 39. Arquivo no formato Flat da proteína ABCCD_HUMAN. ...............................................65 Figura 40. Tela informações básicas da proteína ABCCD_HUMAN. ..............................................65 Figura 41. Estrutura secundária fornecida pelo banco de dados Uniprot...........................................66 Figura 42. Motivos na proteína ABCCD_HUMAN, conforme a ferramenta PrositeScan. ...............67 Figura 43. Domínios na proteína ABCCD_HUMAN conforme banco de dados PFam....................67 Figura 44. Estrutura secundária, motivos e domínios encontrados através da aplicação...................68

LISTA DE TABELAS
Tabela 1. Lista de aminoácidos que podem compor uma proteína. ...................................................16 Tabela 3. Descrição do Caso de Uso Login no Sistema.....................................................................42 Tabela 4. Descrição do Caso de Uso Inclusão de Novo Escravo.......................................................43 Tabela 4. Descrição do Caso de Uso Solicitação de Informação.......................................................44 Tabela 5. Descrição do Caso de Uso Visualizar Proteínas. ...............................................................44 Tabela 6. Descrição do Caso de Uso Gravar Dados. .........................................................................45 Tabela 7. Dicionário de Dados da Tabela Autor ................................................................................76 Tabela 8. Dicionário de Dados da Tabela Datas ................................................................................76 Tabela 9. Dicionário de Dados da Tabela Domínio. ..........................................................................76 Tabela 10. Dicionário de Dados da Tabela EstruturaSecundária.......................................................76 Tabela 11. Dicionário de Dados da Tabela Gene...............................................................................77 Tabela 12. Dicionário de Dados da Tabela Motivo. ..........................................................................77 Tabela 13. Dicionário de Dados da Tabela Organismo. ....................................................................77 Tabela 14. Dicionário de Dados da Tabela Organismo_Proteína. .....................................................77 Tabela 15. Dicionário de Dados da Tabela Proteína. .........................................................................77 Tabela 16. Dicionário de Dados da Tabela Referência. .....................................................................78 Tabela 17. Dicionário de Dados da Tabela Seqüência.......................................................................78 Tabela 18. Dicionário de Dados da Tabela Taxonomia. ....................................................................78

RESUMO
BASTEN, Thomas. Sistema para busca e estruturação de informações sobre proteínas. Itajaí, 2006. 115 f. Trabalho de Conclusão de Curso (Graduação em Ciência da Computação)–Centro de Ciências Tecnológicas da Terra e do Mar, Universidade do Vale do Itajaí, Itajaí, 2006.
Esse trabalho tem por objetivo o desenvolvimento de uma ferramenta computacional que, numa primeira etapa, busque todos os dados disponíveis em bancos de dados públicos sobre uma proteína, gerando um banco de dados local estruturado. Numa segunda etapa, tal ferramenta deve utilizar ferramentas de proteômica já desenvolvidas para extrair diversas informações que podem não estar contidas em um único banco de dados público, como estruturas secundárias e terciárias, motivos e domínios conservados, incluindo tais informações pós-processadas também no banco de dados. A realização deste projeto pode servir de base a outros projetos que pretendem identificar novas proteínas com base nas características próprias de grupos protéicos já conhecidos. Tal feito pode ser de grande relevância a pesquisadores da área de biologia molecular, uma vez que pode auxiliar a identificação de proteínas hipotéticas e proteínas sem função biológica conhecida.
Palavras-chave: Bioinformática; Proteômica; Banco de dados

ABSTRACT
This work goals the development of a computational tool that, in a first step, retrieves available data about certain protein from public databases and generates a structured local primary protein database. In a second step it will use already developed proteomic tools to extract several information from the primary database that may not exist in just one public database, such as secondary structures, motifs and conserved domains, and then including these extracted information in the local database. Based on this local database one can search for existent patterns in that proteic group that fully characterizes it and allow to identify hypothetic proteins. The development of this works may have great relevance to molecular biology’s researchers because it can help identifying proteins with biologic function still unknown. Keywords: Bioinformatic, Proteomic, Database.

1. INTRODUÇÃO
O uso da bioinformática é imprescindível para atender os desafios científicos relacionados
ao grande volume de dados produzidos pelos atuais projetos na área biológica. Um dos desafios é
determinar a função e o papel biológico das proteínas identificadas nas últimas décadas. Se os
genes, contidos no DNA (DesoxirriboNucleic Acid, ou Ácido Desoxirribonucléico), são os
portadores das instruções que permitem o desenvolvimento de um determinado organismo, as
proteínas são as responsáveis por executarem essas instruções. São essas moléculas que formam os
ossos, músculos e os demais tecidos e comandam o metabolismo (FALCÃO, 2004).
As macromoléculas de DNA são compostas por seqüências de apenas quatro diferentes
nucleotídeos, numa ordem específica. Apesar de serem seqüências muito grandes (milhões a
trilhões de nucleotídeos), apenas alguns trechos do DNA possuem informações que serão traduzidas
em proteínas. Esses trechos são chamados de genes. Por isso diz-se que o DNA é o código genético
(ibidem). Num gene, uma seqüência de três nucleotídeos que podem codificar uma proteína forma
um códon. Cada códon é o código para sua tradução num aminoácido, e vários aminoácidos ligados
em seqüência linear formam uma proteína.
Muitos consideram o conhecimento sobre os genes apenas o primeiro passo da
bioinformática, sendo necessária ainda uma compreensão mais aprofundada dos processos que
ocorrem após o armazenamento, a duplicação e a tradução do material genético. A chamada “era
pós-genômica” começou com a constatação de que os dados trazidos pelo seqüenciamento das
moléculas de DNA, embora relevantes, são limitados. É imprescindível investigar tanto os
processos de transcrição das informações contidas no genoma quanto os seus produtos, as proteínas
(PIMENTA, 2004).
O proteoma é o conjunto de todas as proteínas de um dado organismo, do mesmo modo
como genoma é um conjunto de genes de um dado organismo (CATES, 2004). O ser humano, por
exemplo, tem cerca de meio milhão de proteínas (EXPASY, 2004). O termo “proteoma” foi
originalmente usado por Mark Wilkins para descrever “PROTEIn complement of the genOME”.
Atualmente, esse termo é usado para descrever qualquer técnica usada para analisar as proteínas
expressas por uma célula ou organismo sob determinadas condições. O Instituto Suíço de
Bioinformática (Swiss Institute of Bioinformatics) define proteômica como comparação qualitativa e

2
quantitativa de proteomas sob diferentes condições para posterior resolução de processos biológicos
(CATES, 2004).
Considerando-se que uma célula desempenha suas funções de acordo com as enzimas ali
presentes; que as enzimas atuam em substratos específicos segundo a forma de suas moléculas e
que a forma da molécula de uma enzima é definida pela seqüência de aminoácidos presentes na
cadeia polipeptídica, e que a seqüência de aminoácidos é definida pelos genes, então pode-se
afirmar que os processos vitais que ocorrem na célula dependem, em última instância, do DNA
(FARAH, 1997).
As proteínas contêm uma estrutura em quatro níveis. A seqüência linear dos aminoácidos
em uma cadeia polipeptídica é chamada estrutura primária da proteína. A estrutura secundária
refere-se a inter-relações de aminoácidos que estão unidos em seqüência linear. Essa disposição
especial resulta do fato de que os polipeptídeos podem se dobrar em estruturas que se repetem. Uma
proteína também tem uma arquitetura tridimensional, chamada de estrutura terciária, que é a
maneira pela qual a cadeia polipeptídica encurva-se ou dobra-se em três dimensões, formando a
estrutura compacta firmemente enovelada das proteínas globulares. Em muitos casos, os
aminoácidos que estão distantes na seqüência linear são aproximados na estrutura terciária. Além
disso, geralmente, duas ou mais cadeias polipeptídicas dobradas se ligam para formar uma estrutura
quaternária (GRIFFITHS, MILLER, JSUZIKI, 2001).
A análise proteômica vai muito além da simples anotação de proteínas e pode fornecer
indícios substanciais quanto à organização e à dinâmica dos processos metabólicos, regulatórios e
de sinalização através dos quais a célula se desenvolve. Mais ainda, a análise proteômica pode
mostrar como esses processos se tornam disfuncionais nos estados patológicos e como podem ser
manipulados, mediante, por exemplo, a administração de medicamentos ou a terapia gênica
(PIMENTA, 2004).
Portanto, uma das grandes inovações prometidas pelo conhecimento dos proteomas, além do
mapeamento de intrincados caminhos metabólicos celulares, é a possibilidade de identificar novos
alvos farmacológicos, novas moléculas bioativas e marcadores biológicos que podem ser usados
para diagnósticos clínicos. Pesquisas em bioinformática já produziram inúmeros resultados e
ferramentas, que hoje formam a base necessária a novas pesquisas, resultados e ferramentas mais
avançadas (ibidem).

3
Este projeto objetiva fornecer uma ferramenta que concentre todos os dados a respeito de
um grupo protéico, de forma estruturada, incluíndo as informações geradas por ferramentas de
proteômica e que não estão disponíveis em bancos de dados. Com base nessas informações
estruturadas, pode-se buscar padrões existentes em um grupo protéico de forma a caracterizá-lo, e
possibilitar também a identificação de outras proteínas descobertas, mas ainda não anotadas.
A realização deste projeto pode servir de base a outros projetos que pretendem identificar
novas proteínas com base nas características próprias de grupos protéicos já conhecidos. Tal feito
pode ser de grande relevância a pesquisadores da área de biologia molecular, uma vez que pode
permitir identificar proteínas hipotéticas e proteínas sem função biológica conhecida.
Em relação à Ciência da Computação, este projeto é significante por combinar diversas
técnicas estudadas, como processamento distribuído, banco de dados e soluções para Web. Além
disso, este projeto possui um componente forte de pesquisa científica, por tratar de aspectos
avançados de uma nova área (proteômica) e dar suporte a análises que podem produzir
conhecimentos científicos relevantes.
1.1. OBJETIVOS
1.1.1. Objetivo Geral
O objetivo geral deste trabalho é desenvolver uma ferramenta computacional que, numa
primeira etapa, busque todos os dados disponíveis em bancos de dados públicos sobre proteínas de
determinado grupo e que já tenham função biológica conhecida e comprovada, gerando um banco
de dados local estruturado com dados relacionados a esse grupo protéico. Numa segunda etapa, tal
ferramenta deve utilizar ferramentas de proteômica já desenvolvidas para extrair diversas
informações que podem não estar contidas em bancos de dados públicos, como estruturas
secundárias e terciárias, alinhamentos entre as proteínas do grupo, motivos, domínios conservados,
etc, incluindo tais informações pós-processadas também no banco de dados.
1.1.2. Objetivos Específicos

4
Os objetivos específicos deste projeto de pesquisa são:
• Pesquisar e compreender a formação, estruturas, propriedades físico-químicas,
características e funções de proteínas;
• Pesquisar e compreender o funcionamento de ferramentas para proteômica já
desenvolvidas;
• Pesquisar o acesso a bancos de dados biológicos e ferramentas para proteômica públicos;
• Modelar o banco de dados estruturado de informações proteicas;
• Modelar o sistema para busca, processamento e geração do banco de dados de proteínas;
• Implementar tal sistema; e
• Testar e validar o funcionamento do sistema para estruturação de informações sobre
proteínas;
1.2. METODOLOGIA
Para que este trabalho fosse realizado com sucesso, as tarefas foram divididas em etapas
bem definidas, conforme a metodologia científica hipotetico-dedutiva, que foram seguidas para a
sua realização.
A etapa inicial foi a pesquisa e compreensão de proteínas quanto à sua formação, estrutura,
propriedades, características e funções, pesquisa essa que pode ocorrer em diversas fontes de
informação, tais como livros, artigos, dissertações, anais, periódicos e internet. Após a coleta de
materiais encontrados nas fontes citadas acima, foi feita uma seleção daqueles que são considerados
mais importantes, dando início à confecção da revisão bibliográfica. Paralelamente a essa etapa
ocorria a pesquisa de soluções existentes para a classificação e busca de padrões em proteínas.
Após o término das duas primeiras etapas, foi realizada a pesquisa por ferramentas de
proteômica existentes de maneira que possa se compreender o seu funcionamento. Obteve-se como
resultado uma tabela com suas vantagens e desvantagens.

5
Na quarta, iniciou-se os processos de pesquisa de formas de acesso à banco de dados
biológicos e o uso das ferramentas de proteômica. Essas últimas contaram com a implementação de
protótipo na linguagem de programação escolhida para desenvolvimento.
Ao final das etapas de pesquisa, foi realizada a modelagem do banco de dados protéico, bem
como a definição do banco de dados a ser utilizado e as ferramentas de criação. Em seguida teve-se
o início da modelagem do sistema de busca, processamento e armazenamento das informações
recolhidas, modelagem esta seguindo a metodologia UML.
Como conclusão do trabalho foram desenvolvidas as aplicações principal e escrava com
base no estudo realizado.

6
1.3. ESTRUTURA DO TRABALHO
INTRODUÇÃO. Esse capítulo objetiva introduzir o leitor nos aspectos que serão
obordados nesse trabalho alem de contém os objetivos gerais e específicos e a metodologia utilizada
para a realização do trabalho.
FUNDAMENTAÇÃO TEÓRICA. A fundamentação teórica é composta por três sessões:
Biologia Molecular, Proteômica e Tecnologia Aplicada. Na sessão Biologia Molecular é descrito o
que são as proteínas, como se formam, os tipos de estruturas que as compõe, o que são os seus
motivos e domínios funcionais, assim como o modo que informações sobre proteínas são
armazenadas em bancos de dados públicos e sua forma de acesso. Na sessão de Proteômica é
descrito é que é proteômica e suas ferramentas. Já na sessão Tecnologia Aplicada são descritas as
tecnologias necessárias e aplicadas para o desenvolvimento do trabalho, bem como a justificativa
para o uso de tais tecnologias.
DESENVOLVIMENTO. Esse capítulo contém a análise modelagem e projeto do sistema,
bem como suas características e aspectos de implementação.
CONCLUSÕES. Nas conclusões são feitos comentários sobre os objetivos alcançados com
este trabalho; são apresentados pontos fortes e fracos do mesmo; algumas considerações e uma
relação de possíveis trabalhos futuros.
[FIM DE SEÇÃO. Não remova esta quebra de seção]

2. FUNDAMENTAÇÃO TEÓRICA
2.1. BIOLOGIA MOLECUAR
Em 1869, o bioquímico suíço Friedtich Mieschner constatou pela primeira vez que todos os
núcleos celulares provavelmente possuíam uma química específica. Em anos subseqüentes, ele
descobriu várias substâncias do núcleo, as quais separou em proteínas e moléculas ácidas, daí o
termo “ácidos nucléicos” (FARAH, 1997; GRIFFITHS, MILLER, JSUZIKI, 2001).
Phoebus A. T. Levene, um químico natural da Rússia, também foi um pioneiro no estudo de
ácidos nucléicos. Em 1909, Levene identificou corretamente a ribose como açúcar de um dos dois
tipos de ácido nucléico, o ácido ribonucléico, e certos componentes do outro ácido nucléico, o ácido
desoxirribonucléico. Ele e muitos de seus colaboradores estavam convencidos de que, com os
ácidos nucléicos armazenavam todas as informações genéticas nos cromossomos. A teoria de
Levene sobre o propósito do DNA (meramente manter unidas as moléculas de proteína) revelou-se
incorreta (ibidem).
O trabalho que levou à correção dessa suposição equivocada teve início em 1928 com
bacteriologista inglês Fredrick Griffith (ibidem). Outro bacteriologista, Oswald T. Avery,
juntamente com sua equipe, percebeu a importância do trabalho de Griffith e passou dez anos
tentando identificar o agente que era a essência da transformação genética na bactéria. Finalmente,
em 1944, Avery publicou os resultados de suas extensas pesquisas, os quais mostraram claramente
que era o DNA, e não a proteína ou RNA, que armazena e transporte as informações hereditárias.
Esse trabalho inaugurou a ciência da genética molecular. Na década de 1940, Alfred D. Hershey
confirmou a conclusão do grupo de Avery de que o DNA, e não a proteína, é o material genético
(ibidem).
Segundo Amabis (2002 apud BIBLIOMED, 2002) os ácidos nucléicos são as maiores e as
mais importantes moléculas orgânicas. Existem dois tipos de ácidos nucléicos, que são:
• DNA (que significa, em inglês, DesoxirriboNucleic Acid, ou ácido
desoxirribonucléico). Ele tem esse nome porque o açúcar que o forma é a
desoxirribose.

8
• RNA (que significa, em inglês, RiboNucleic Acid, ou ácido ribonucléico). O seu
nome vem do açúcar que o compõe, que é a ribose.
2.1.1. DNA
O DNA é a molécula na qual estão contidas todas as características de um ser vivo, ou
seja, é o portador da informação que caracteriza qualquer indivíduo (MELEIRO & FONSECA,
2001). O material responsável pelo comando e coordenação de toda a atividade celular e pelas
divisões celulares e transmissões das características hereditárias são os cromossomos. Os
cromossomos contêm os genes que por sua vez são formados por DNA, ilustrado na Figura 1. Estes
genes permitem a transmissão das informações genéticas de geração a geração (BIOMANIA, 2002).
Figura 1. Estrutura de um cromossomo, da dupla hélice do DNA e das bases nitrogenadas. Fonte: Adaptado de Yangene (2000).
Nas células eucarióticas, o cromossomo é formado por DNA associado a moléculas de
histona, que são proteínas básicas. É na molécula de DNA que estão contidos os genes,
responsáveis pelo comando da atividade celular e pelas características hereditárias. Cada molécula
de DNA contém vários genes dispostos linearmente ao longo da molécula. Cada gene, quando em
atividade, é transcrito em moléculas de outros ácidos nucléicos denominados ribonucléicos ou
RNA, que comandarão a síntese de proteínas (ibidem).

9
Nas células procarióticas, o cromossomo é uma única molécula de um ácido nucléico, e
encontram-se imersos no próprio citoplasma formando uma estrutura denominada nucleóide. Nas
células eucarióticas os cromossomos encontram-se separados do citoplasma pela membrana nuclear
ou carioteca, em uma estrutura denominada núcleo. A presença de carioteca é uma característica
típica das células eucarióticas, que as distingue das procarióticas. Além disso, as células
procarióticas não apresentam organelas membranosas, como ocorre com as eucarióticas
(BIOMANIA, 2002).
2.1.2. NUCLEOTÍDEOS
O DNA é uma molécula de ácido nucléico polimérica, como mostra a Figura 2. É composta
de três tipos de unidades: um açúcar de cinco carbonos, a desoxorribose; uma base contendo
nitrogênio; e um grupo fosfato. As bases são de dois tipos: purinas (formadas por dois anéis de
carbono) e pirimidinas (formadas por um simples anel de carbono). No DNA existem duas bases
purínicas, adenina (A) e guanina (G), e duas bases pirimidínicas, timina (T) e citosina (C), como
ilustrado na Figura 3 (THOMPSON, 2000).
Figura 2. Nucleotídeo Timina. Fonte: Adaptado de Thompson (2000).

10
Figura 3. Bases nitrogenadas que compõe o DNA. Fonte: Adaptado de Thompson (2000).
A molécula de açúcar e o fosfato são componentes invariáveis nos nucleotídeos e
apresentam uma função unicamente estrutural na molécula de DNA. A fim de evitar qualquer tipo
de confusão, quando os números referem-se a moléculas de desoxirribose eles são seguidos pelo
sinal linha (‘) (ibidem).
Milhares de nucleotídeos empilham-se em forma linear para construir uma cadeia de DNA.
O grupo fosfato liga o carbono 3’ da desoxirribose de um nucleotídeo ao carbono 5’ da
desoxirribose do nucleotídeo seguinte, por meio de uma ligação fosfodiéster. A quantidade de T é
sempre igual à quantidade de A, e a quantidade de C é sempre igual à quantidade de G. Mas a
quantidade de A + T não é necessariamente igual à quantidade de G + C. Essa proporção varia entre
os organismos diferentes (GRIFFITHS, MILLER, JSUZIKI, 2001).
2.1.3. ESTRUTURA DO DNA
Na dupla hélice do DNA, descrita pela primeira vez por Watson e Crick em 1953, as cadeias
da molécula se dobram em torno de um eixo comum e de modo antiparalelo, ou seja, enquanto uma
vai na direção 5’ para 3’ a outra está orientada na direção oposta, de 3’ para 5’. Cada metade é uma
cadeia de nucleotídeos (ocupando a parte interna da hélice) mantidos juntos por ligações de

11
fosfodiéster, nas quais um grupo fosfato forma uma ponte entre os grupos –OH em duas
desoxirriboses adjacentes (ocupam a parte externa da hélice). As duas hélices são mantidas unidas
por pontes de hidrogênio (GRIFFITHS, MILLER, JSUZIKI, 2001).
As pontes de hidrogênio são formadas entre pares de bases nitrogenadas, uma base purina e
outra pirimidina, combinadas de acordo com a seguinte regra: G combina com C e A combina com
T. A ilustração da dupla hélice do DNA pode ser visto na Figura 4 (FARAH, 1997).
Figura 4. A Dupla hélice do DNA Fonte: (Access, 2001). xxx

12
2.1.4. Genes
Até o final da década de 1970, o gene era considerado simplesmente como um segmento de
uma molécula de DNA que continha o código para a seqüência de aminoácidos de uma cadeia
polipeptídica (proteína) (FARAH, 1997).
Segundo Thompson, Mcinnes e Willard (1998), atualmente sabe-se que a descrição acima é
incompleta. Na verdade, bem poucos genes existem como seqüências codificadas contínuas. Em
eucariontes, por exemplo, essas seqüências são interrompidas por íntrons, seqüências intercalares,
que são inicialmente transcritas em RNA no núcleo mas não estão presentes no mRNA processado,
portanto não são representadas no produto protéico final.
Os íntrons alternam-se com as seqüências codificadoras, ou éxons, que codificam a
seqüência de aminoácidos de uma proteína. Embora alguns genes no genoma humano não possuam
íntrons, a maioria dos genes em eucariontes contém pelo menos um e, em geral, vários (ibidem).
Os genes estão localizados nos cromossomos no núcleo celular e se alinham ao longo de
cada um deles. O material genético é o DNA, uma molécula que representa a "coluna vertebral" do
cromossomo. Como em cada cromossomo o DNA é uma molécula contínua, alongada, simples e
delgada, os genes devem ser parte dela e exercem seus efeitos através das moléculas às quais dão
origem, em sua maioria das proteínas (FARAH, 1997).
2.1.4.1. Funcionamento dos Genes
Os genes controlam a síntese de proteínas que, quando atuam no organismo, determinam as
características fenotípicas dos seres vivos. Cada gene ocupa um lugar certo no cromossomo e este
lugar é chamado de locus. Os genes que ocupam o mesmo lócus em cromossomos homólogos são
denominados alelos (FARAH, 1997; GRIFFITHS, MILLER, JSUZIKI, 2001; THOMPSON,
MCINNES, WILLARD, 1998).
Os genes provêem as instruções para as células produzirem as proteínas essenciais à vida do
organismo. Embora cada célula do corpo contenha genes idênticos, alguns genes somente estão

13
ativados ou "ligados" em certas células ou em certos momentos (por exemplo, não há necessidade
de um gene responsável pela cor dos olhos estar ligado em uma célula do coração, mesmo que esse
gene esteja presente na célula do coração). Alguns genes são ligados somente durante o tempo que
um órgão ou tecido está sendo formado, ou somente durante a puberdade, ou somente durante
períodos de estresse (FARAH, 1997; GRIFFITHS, MILLER, JSUZIKI, 2001; THOMPSON,
MCINNES, WILLARD, 1998).
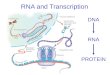
2.1.5. RNA
A composição do RNA é muito semelhante ao do DNA, ilustrado na Figura 5, contudo
apresenta algumas diferenças: o RNA possui uracila no lugar da timina na seqüência de bases; ao
invés de conter a desoxirribose ele contém a ribose; o RNA é formado por uma fita única, com
eventual pareamento de bases intracadeia; a molécula do RNA é muito menor que a do DNA
(THOMPSON, MCINNES, WILLARD, 2000).
A síntese de uma molécula de RNA a partir de um molde de DNA chama-se transcrição.
Essa transcrição ocorre quando uma molécula de DNA abre-se em um determinado ponto.
Nucleotídios livres na célula vão se pareando a esse segmento aberto. Completado o pareamento a
esse segmento aberto, está pronta a molécula do RNA, o DNA que serviu de molde reconstitui a
molécula original (WIKIPEDIA, 2006).
Figura 5. Nucleotídeo Uracila. Fonte: Adaptado de Thompson, Mcinnes, Willard (2000).

14
A Figura 6 mostra os quatro tipos de bases nitrogenadas encontradas em uma cadeia de
RNA.
Figura 6. Bases nitrogenadas que compõe o RNA. Fonte: Adaptado de Thompson, Mcinnes, Willard (2000).
Existem 3 tipos de RNA, cada um com características estruturais e funcionais próprias:
RNA Ribossômico: ou RNAr é encontrado, em associação com várias proteínas diferentes,
na estrutura dos ribossomos, as organelas responsáveis pela síntese protéica. Corresponde a até 80%
do total de RNA da célula (THOMPSON, MCINNES, WILLARD, 2000).
RNA de Transferência: ou RNA Transportador, ou ainda RNAt é a menor molécula dos 3
tipos de RNA. Pode se ligar de forma específica a cada um dos 20 aminoácidos encontrados nas
proteínas. Corresponde a 15% do RNA total da célula. Fazem um extenso pareamento de bases
intracadeia, e atua no posicionamento dos aminoácidos na seqüência prevista pelo código genético,
no momento da síntese protéica (ibidem).
RNA Mensageiro: ou mRNA, corresponde a apenas 5% do total de RNA da célula. Atua
transportando a informação genética do núcleo da célula eucariótica ao citosol, onde ocorrerá a
biossíntese protéica. É utilizado como molde nesta biossíntese. (ibidem).

15
2.1.6. AminoácidoS
Um aminoácido (aa) é molécula composta por um radical amino (NH2), um radical ácido
orgânico (COOH) e uma cadeia lateral, cujas propriedades lhes darão suas características
particulares (GENTIL, 2002).
Os aminoácidos podem se unir em cadeias e combinações químicas, produzindo peptídeos e
proteínas, daí a famosa afirmação de que os aas são os blocos formadores de proteínas. Ao todo
existem 20 tipos básicos de aminoácidos, dentre os quais nove (Isoleucina, Leucina, Valina,
Histadina, Lisina, Metionina, Fenilalanina, Treonina e Triptofano) são considerados essenciais e
devem ser obtidos pela alimentação, pois nosso corpo não é capaz de produzí-los. Todas as
proteínas encontradas em nosso corpo (tecidos, enzimas, alguns hormônios....) são combinações
destes 20 aminoácidos (ibidem).
2.1.7. PROTEÍNAS
As proteínas são as macromoléculas mais abundantes nas células vivas, constituíndo cerca
de 50% de seu peso seco. São encontradas em todas as células do organismo e em todas as partes
das células. Possuem grande diversidade sendo que podem existir centenas de tipos diferentes em
uma única célula.
Um organismo biológico possui milhares de diferentes tipos de proteínas, as quais são
constituídas basicamente de aminoácidos ligados em cadeias lineares por meio de ligações
peptídicas. Forças intramoleculares ativas fazem com que a proteína assuma uma estrutura
tridimensional específica que está diretamente relacionada às suas funções biológicas
(LEHNINGER, NELSON, COX, 1998; FARAH, 1997).
2.1.7.1. Estrutura das proteínas
A estrutura das proteínas é extraordinariamente complexa e seu estudo requer o
conhecimento de vários níveis de organização. Destingem-se quatro níveis de organização

16
existentes nas proteínas, os quais são chamados de estrutura primária, secundária, terciária e
quaternária.
Uma proteína nascente pode ser composta pelos aminoácidos listados na Tabela 1.
Tabela 1. Lista de aminoácidos que podem compor uma proteína.
Símbolo 3 letras Símbolo de 1 letra Nome do Aminoácido Ala A Alanina
Asx R Asparagina
Cis ou Cys C Cisteína
Asp D Aspartato
Glu Q Glutamato
Fen ou Phe F Fenilalanina
Gli ou Gly G Glicina
His H Histidina
Ile I Isoleucina
Lis ou Lys K Lisina
Leu L Leucina
Met M Metionina
Pro P Prolina
Gln E Glutamina
Arg R Arginina
Ser S Serina
Ter ou Thr T Treonina
Val V Valina
Trp W Triptofano
Tir ou Tyr Y Tirosina

17
2.1.7.1.1. Estrutura Primária
A estrutura primária de uma proteína é a seqüência linear dos aminoácidos em uma cadeia
polipeptídica (GRIFFITHS, MILLER, JSUZIKI, 2001; MOTTA, 2004; ALBERTS, BRAY,
LEWIS, 1997). A Figura 7 aponta um exemplo de estrutura primária de uma proteína.
Figura 7. Exemplo de estrutura primária de uma proteína. Fonte: Adaptado de Horton, Moram, Ochs (1995).
2.1.7.1.2. Estrutura Secundária
A estrutura secundária refere-se a inter-relações de aminoácidos que estão unidos em
seqüência linear. Essa disposição especial resulta do fato de que os polipeptídicos podem se dobrar
em estruturas que se repetem. Neste nível de estrutura encontram-se arranjos regulares chamados de
�-hélice e folha-� conforme ilustrado na Figura 8, e outros arranjos não regulares (GRIFFITHS,
MILLER, JSUZIKI, 2001; MOTTA, 2004; ALBERTS, BRAY, LEWIS, 1997). As estruturas
secundárias mais comuns são as hélices e os planos apresentados a seguir.
Figura 8. Exemplo de Estrutura Secundária. Fonte: Adaptado de Horton, Moram, Ochs (1995).

18
�-hélice
Na estrutura �-hélice, ilustrada na Figura 9, a molécula polipeptídica apresenta-se como uma
hélice orientada para a direita como se estivesse em torno de um cilindro, mantida por pontes de
hidrogênio arranjadas entre os grupos C=O e o H-N das ligações peptídicas. Cada volta da hélice
corresponde a 3,6 resíduos de aminoácidos (MOTTA, 2004). Uma �-hélice pode ser composta pelos
aminoácidos Alanina (Ala), Leucina (Leu) e pelo ácido glutâmico (Glu).
A presença dos aminoácidos prolina e hidroxiprolina, cujas estruturas cíclicas relativamente
rígidas não se encaixam à hélice (Figura 9), forçam a cadeia a dobrar-se rompendo a estrutura
secundária regular. Esse dois aminoácidos, também como a glicina, favorecem a formações de
conformação folha-�. Seqüências polipeptídicas com grande número de aminoácidos com carga e
grupos R volumosos são incompatíveis com a estrutura helicoidal pelos efeitos provocados por suas
cadeias laterais (ibidem).
folha-�
A estrutura de folha-� resulta da formação de pontes de hidrogênio entre duas ou mais
cadeias polipeptídicas adjacentes. As pontes de hidrogênio ocorrem entre os grupos C=0 e N-H de
ligações peptídicas pertencentes a cadeias polipeptídicas vizinhas em vez de no interior da cadeia.
Figura 9. Estrutura Secundária �-hélice Fonte: Adaptado de Alberts, Bray, Lewis (1997).

19
Diferentemente das �-hélices, as cadeias polipeptídicas da folha-� estão quase inteiramente
estendidas, como pode ser observado na Figura 10 (MOTTA, 2004). Uma folha-� pode ser
composta pelos aminoácidos Valina (Val), Isoleucina (Ile), Cisteína (Cys) e pelo aminoácido
Fenilalanina (Phe).
Figura 10. Estrutura Secundária Folha-� Fonte: Adaptado de Alberts, Bray, Lewis (1997).
Laço (Turn)
Os laços, ilustrados na Figura 11, são o terceiro tipo das estruturas secundárias clássicas, e
são responsáveis pela reversão da direção da cadeia polipeptídica. Eles são localizados na superfície
polar da proteína, e contêm resíduos com carga (QMCWEB, 2004). Os laços podem ser compostos
pelos aminoácidos Glicina (Gli), Aspartato (Asp) e pelo aminoácido Prolina (Pro).

20
Figura 11. Estrutura Secundária Laço (Turn). Fonte: Adaptado de Horton, Moram, Ochs (1995).
As �-hélices e as folhas-� são classificadas como estruturas secundárias regulares, pois seus
componentes exibem conformações estruturais periódicas. Dependendo da natureza das cadeias
laterais dos aminoácidos presentes, as �-hélices e as folhas-� podem apresentar-se levemente
distorcidas em sua conformação específica.
Muitas proteínas apresentam combinações de estruturas �-hélice e folha-� em proporções
variadas. As combinações produzem vários arranjos denominados de estruturas supersecundárias ou
motivos. Alguns exemplos destas formações podem ser observados na Figura 12, os quais são:
unidade ���, grampo �, � meandro; chave grega; � sanduíche.
Figura 12. Exemplo de Estrutura Supersecundárias. (a) Motivo ���; (b) Motivo Grampo ���; (c) Motivo � Meandro; (d) Motivo Chave grega; (e) Motivo � Sanduíche. Fonte: Motta (2004).

21
2.1.7.1.3. Estrutura Terciária
A maneira pela qual a cadeia polipeptídica encurva-se ou dobra-se em três dimensões,
formando a estrutura compacta firmemente enovelada das proteínas globulares é chamada estrutura
terciária (GRIFFITHS, MILLER, JSUZIKI, 2001; MOTTA, 2004; ALBERTS, BRAY, LEWIS,
1997). A Figura 13 ilustra um exemplo de estrutura terciária de uma proteína.
Figura 13. Estrutura terciária Fonte: Adaptado de Horton, Moram, Ochs (1995).
Por existir apenas um número limitado de maneiras de se combinar �-hélices e folhas-�,
certas combinações destes elementos ocorrem repetidamente no centro de muitas proteínas não-
relacionadas. Várias combinações de motivos formam um domínio protéico, que é tipicamente
uma estrutura compacta, cuja superfície é coberta por alças salientes e tem um formato irregular,
geralmente formando sítios de ligação para outras moléculas (LODISH, BERK, ZIPURSKY, 1999;
ALBERTS, BRAY, LEWIS, 1997).
Um domínio protéico geralmente contém de 40 a 350 aminoácidos e leva a crer que são as
unidades modulares, a partir das quais as proteínas são constituídas. Embora pequenas proteínas
possam conter apenas um domínio, a maioria possui de 2 a 4 domínios, que são geralmente
conectados por regiões de cadeia polipeptídica sem função específica (ibidem).

22
2.1.7.1.4. Estrutura Quaternária
Geralmente, duas ou mais cadeias polipeptídicas dobradas se ligam para formar uma
estrutura quaternária (GRIFFITHS, MILLER, JSUZIKI, 2001; MOTTA, 2004; ALBERTS, BRAY,
LEWIS, 1997). Um exemplo de estrutura quaternária pode ser visto na Figura 14.
Figura 14. Estrutura quaternária Fonte: Adaptado de Horton, Moram, Ochs (1995).
2.1.7.2. Funções das Proteínas
Segundo BIOMANIA (2002) e Farah (1997), as proteínas podem ser classificadas de acordo
com a sua função no organismo, tais como:
• Função Estrutural - As proteínas estruturais participam como matéria-prima na
construção de estruturas celulares.
• Função Hormonal - Muitos hormônios são, na verdade, proteínas especializadas na
função de estimular ou inibir a atividade de determinados órgãos.

23
• Função de Defesa - No sistema imunológico do ser humano, existem células
especializadas na identificação de proteínas presentes nos organismos invasores, que
serão consideradas "estranhas". Estas proteínas invasoras denominam-se antígenos e
estimulam o organismo a produzir outras proteínas especializadas no combate às
invasoras. Estas proteínas de defesa são denominadas anticorpos e combinam-se
quimicamente aos antígenos com o objetivo de neutralizá-los. Deve-se salientar o fato de
que existe uma determinada especificidade entre antígeno e anticorpo. Ou seja, um
anticorpo só neutralizará o antígeno que estimulou a formação desse anticorpo. Os
anticorpos são produzidos em células especializadas do sistema imunológico
denominadas plasmócitos.
• Função Nutritiva - Todos os alimentos ricos em proteína, como as carnes em geral, são
fontes naturais de aminoácidos indispensáveis aos seres vivos para a produção de outras
proteínas.
• Função Reguladora - Esta função é desempenhada por um grupo especial de proteínas
denominadas vitaminas. As células dos vegetais clorofilados e certos microrganismos,
como bactérias, possuem a capacidade de produzirem vitaminas. Nos animais se dá
através do processo de nutrição. Cada vitamina tem um papel biológico próprio, por isso
não pode ser substituída por outra. A carência de uma determinada vitamina faz surgir
um quadro de distúrbios orgânicos denominado hipovitaminose. O excesso de vitaminas
pode acarretar uma hipervitaminose. As vitaminas são classificadas de acordo com a sua
solubilidade em água ou em lipídios. Existem as vitaminas hidrossolúveis, como as do
complexo B (B1, B2, B6 e B12) e a vitamina C. As lipossolúveis são as vitaminas A, D,
E, K.
• Função Enzimática - As enzimas são proteínas especiais com função catalítica, ou seja,
aceleram reações bioquímicas que ocorrem nas células. Assim como os anticorpos,
apresentam especificidade em relação à reação ou substância em que atuam. Isso se deve
ao fato de cada enzima possuir em sua estrutura um ou mais pontos que se encaixam
perfeitamente no seu substrato que sofrerá sua ação.

24
• Coagulação sangüínea - vários são os fatores da coagulação que possuem natureza
protéica.
• Transporte - pode-se citar como exemplo a hemoglobina, proteína responsável pelo
transporte de oxigênio no sangue (BIOMANIA, 2002).
2.1.7.3. Bancos de Dados Biológicos
Os bancos de dados envolvendo seqüências de nucleotídeos, de aminoácidos ou estruturas
de proteínas podem ser classificados em bancos de seqüências primários e secundários
(BIOESFERA, 2001).
2.1.7.3.1. Banco de Dados Primários
Os bancos de dados primários são formados pela deposição direta de seqüências de
nucleotídeos, aminoácidos ou estruturas protéicas, sem qualquer processamento ou análise. Os
principais bancos de dados primários são o GenBank, o EBI (European Bioinformatics Institute), o
DDBJ (DNA Data Bank of Japan) e o PDB (Protein Data Bank). Atualmente a maioria das revistas
científicas exige que as seqüências identificadas pelos laboratórios sejam submetidas a um destes
bancos antes mesmo da publicação do artigo (PROSDOCIMI, CERQUEIRA, BINNECK, 2004).
2.1.7.3.2. Banco de Dados Secundários
Os bancos de dados secundários são aqueles que derivam dos primários, ou seja, são
formados usando as informações depositadas nos bancos primários. Por exemplo, o Swiss-Prot é
um dos principais bancos de dados sobre proteínas, onde as informações sobre seqüências de
proteínas foram anotadas e associadas a informações sobre função, domínios funcionais, proteínas
homólogas e outros (PROSDOCIMI, CERQUEIRA, BINNECK, 2004). Outro exemplo de banco de
dados secundário é o PRODOM, que é um banco de dados de proteínas e consiste de uma
compilação automática de domínios homólogos (PRODOM, 2004).

25
O Swiss-Prot foi criado em 1986 pelo Departamento de Bioquímica Médica da
Universidade de Genebra e EMBL. Atualmente é mantido pelo Swiss Institute of Bioinformatics
(SIB) e EBI/EMBL. Este banco mantém um alto nível de anotações, como a descrição e a função da
proteína, estrutura dos seus domínios, modificações pós-tradução, além de ter uma estrutura que
facilita o acesso computacional a diferentes campos de informações. TrEMBL é um suplemento do
Swiss-Prot que contém todas as traduções das entradas de seqüências de nucleotídeos do EMBL,
ainda integradas ao Swiss-Prot (SWISS-PROT, 2004).
O PROSITE foi o primeiro banco de estruturas a ser desenvolvido e é mantido atualmente
pelo Swiss Institute of Bioinformatics. É baseado na filosofia de que famílias de proteínas podem
ser agrupadas através de motivos, o que pode ser obtido através do alinhamento múltiplo de
seqüências já conhecidas. Esses motivos geralmente estão associados à sua função biológica. No
PROSITE, os motivos são codificados como expressões regulares ou "padrões". O processo usado
para obter estes padrões envolve a construção de alinhamentos múltiplos e a inspeção manual para a
identificação de regiões conservadas. A informação assim obtida é transformada em expressões de
consenso e o resultado é usado como dados de entradas para buscas no Swiss-Prot (LBMP, 2004).
Um exemplo do uso desse banco de dados pode ser visto na Figura 15.

26
Figura 15. Sistema de busca no banco de dados PROSITE.
Como resultado da busca tem-se a Figura 16, que ilustra os motivos encontrados na proteína
3MG_HUMAN.

27
Figura 16. Resultados obtidos pela busca no banco de dados PROSITE.
2.2. PROTEÔMICA
Apenas um número pequeno de proteínas possui sua função bem caracterizada e, devido a
isso, os anotadores de seqüências geralmente classificam-nas em grupos ou famílias a partir de
similaridades encontradas com proteínas de outras espécies, sendo essa uma rica fonte para a
anotação funcional. É bom lembrar, entretanto, que devido à forma como a evolução acontece, nem
sempre proteínas da mesma família possuem funções similares (ALBERTS, BRAY, LEWIS, 1997).
Apesar do fato de várias técnicas recentes terem sido desenvolvidas para identificar
automaticamente as proteínas pertencentes a diferentes grupos ortólogos (proteínas com a mesma
função em diferentes organismos), muitas delas podem ter classificações ambíguas. Na prática, o
que é normalmente feito é a classificação das proteínas preditas com base em domínios funcionais,
configurações espaciais e presença de padrões conservados, além de pesquisa ampla de similaridade
e identidade contra proteínas bem caracterizadas.

28
O desenvolvimento de técnicas para o seqüênciamento de moléculas de DNA permitiu
determinar seqüências de aminoácidos de milhares de proteínas a partir da seqüência de
nucleotídeos de seus genes. Bancos de dados de proteínas estão disponíveis para pesquisa de
possíveis seqüências homólogas entre proteínas “recém-seqüenciadas” e outras previamente
estudadas com estrutura e funções definidas. Como resultado dessa pesquisa é comum encontrar
uma proteína recém-seqüenciada que é homóloga a uma parte de outra proteína, indicando que a
maioria das proteínas devem descender de ancestrais comuns. O campo de análises de seqüências
tornou-se importante, pois a seqüência da biomolécula, DNA ou proteína, possui grande quantidade
de informação sobre sua função e história (LOURENÇO, 2004).
A comparação de seqüências biológicas é baseada no critério de evolução. Quando
seqüências são comparadas ou alinhadas, algumas vezes duas ou mais seqüências mostram-se
similares. Essa similaridade pode ser devida a uma homologia (implica ancestral comum) ou apenas
acaso, sem que as seqüências tenham tido uma origem comum. Comparações entre proteínas são
importantes porque estruturas relacionadas geralmente implicam funções relacionadas. Anos de
pesquisa podem ser poupados pelo descobrimento de uma seqüência de aminoácidos homóloga a
uma proteína de função conhecida.
2.2.1.1. Ferramentas para Proteômica
Segundo EXPASY (2006) em 2006 existiam cerca de 230.000 estruturas de proteínas
disponíveis no banco de dados Swiss-Prot, e este número está aumentando a cada ano. Uma
maneira simples e rápida de acessar toda a informação contida nos bancos de dados de proteínas é
fundamental para trabalhar com esse enorme volume de dados estruturais.
O EMBOSS (European Molecular Biology Open Software Suíte) é um conjunto de
programas com ferramentas para a visualização e análise estrutural de proteínas. Através de um dos
seus diversos módulos disponíveis é possível determinar a estrutura secundária de uma proteína.
Esse módulo é chamado de Garnier, que utiliza como parâmetros de entrada a seqüência da
proteína a ser analisada (EMBOSS, 2004).
O ExPASy (EXpert Protein Analysis System) é um servidor de ferramentas para proteômica
e é dedicado à análise de seqüências e estruturas de proteínas, disponibilizando bancos de dados,
ferramentas computacionais, cursos e serviços educacionais, documentações, hiperlinks diversos e

29
ferramentas de busca em diversos bancos de dados, dentre eles o Swiss-Prot e o PROSITE, os quais
que serão utilizados nesse trabalho (EXPASY, 2004).
O Pfam Search Engine é uma ferramenta de busca de domínios de proteínas nos mais
respeitados bancos de dados, tais como o Prosite, Swiss-Prot e o Protein Data Bank. A busca se dá
através do número do registro. As Figuras 16 a 19 mostram o acesso a essa ferramenta em busca de
domínios da proteína com nome de registro 3MG_HUMAN.
Figura 16. Página inicial do sistema de busca de domínios PFam.

30
Após preenchimento dos campos necessários e executar a busca, o sistema apresenta uma
tela de resultados como a da Figura 17.
Figura 17. Resultados obtidos pelo sistema de busca de domínios PFam.
A Figura 17 mostra os dois domínios encontrados na proteína 3MG_HUMAN representados
por barras horizontais com padrões distintos.

31
2.3. TECNOLOGIA APLICADA
Esta seção descreve as tecnologias a serem utilizadas para desenvolvimento do sistema
proposto.
2.3.1. PROCESSAMENTO PARALELO E DISTRIBUÍDO
Quando se avalia o custo de micros pessoais PC, encontra-se ótima relação
preço/performance. Porém, quando se coloca uma máquina, independente para cada usuário, tem-se
a dificuldade de compartilhar os dados. Além da comunicação necessária entre os usuários, é
desejável o compartilhamento de recursos oferecidos por cada máquina. Este compartilhamento é
possível se as máquinas estiverem interligadas em rede. Assim um sistema distribuído pode ser
implementado com computadores pessoais ligados em rede a servidores, os quais executariam os
processos mais pesados de forma distribuída (LaCPaD, 2006).
Segundo Buyya (1999), “a principal razão para a criação e o uso de computadores paralelos
é que o paralelismo é uma das melhores formas de resolver o problema de gargalo de
processamento em sistemas de um único processador”. A relação preço/performance de um
pequeno sistema de processamento distribuído em rede é muito melhor se comparado com um
minicomputador.
O grande objetivo do processamento paralelo/distribuído é aumentar o desempenho de
aplicações que necessitam de grande poder computacional e que são pouco eficientes quando
executadas seqüencialmente. Para tanto, o aumento de desempenho é obtido particionando-se uma
tarefa em tarefas menores e executando-as em diferentes processadores, paralelamente. Um
conjunto de processadores interconectados é a definição mais simples de um ambiente
paralelo/distribuído (LaCPaD, 2006).
Vários fatores explicam a necessidade do processamento paralelo. O principal deles trata-se
da busca por maior desempenho. As diversas áreas nas quais a computação se aplica, sejam
científicas, industriais ou militares, requerem cada vez mais poder computacional, em virtude dos

32
algoritmos complexos que são utilizados, do tamanho do conjunto de dados a ser processado, ou a
existência de algum tipo de “gargalo” (Kirner apud SANTANA, SOUZA, PIEKARSKI, 1997).
Os sistemas com vários processadores podem ser classificados em função do grau de
integração e acoplamento dos seus componentes: Multiprocessadores que possuem espaço de
endereçamento compartilhado por um pequeno número de processadores; Multicomputadores, onde
cada processador possui sua própria memória privativa e canais de comunicação ligados através de
redes compostas por múltiplos canais bipontuais e Redes de computadores que são formadas por
computadores independentes interconectados através de redes entendidas como canais de
comunicação compartilhados (LaCPaD, 2006).
Aplicações paralelas/distribuídas tem como propósito a execução de uma tarefa em comum
possibilitando o aumento do desempenho. Para a execução de um tarefa em comum, a cooperação
entre processos que compõe um programa paralelo é essencial. Basicamente, a comunicação entre
processos pode ser feita de duas formas: através da troca de mensagens e/ou através de memória
compartilhada. Na comunicação entre processos através de memória compartilhada, os processos
compartilham uma área de memória comum onde dados podem ser lidos e escritos por processos
em execução. Existem mecanismos de sincronização para controlar o acesso a um mesmo dado na
memória. Na comunicação através de troca de mensagens, os processos não compartilham
memória, a troca de dados é feita através de mensagens. Esta troca pode ser síncrona (o processo
emissor é bloqueado até que o receptor aceite a mensagem) ou assíncrona (o processo emissor
continua sua execução, independente do receptor aceitar a mensagem) (ibidem).
A forma mais elementar de interação entre processos baseada em troca de mensagens é a
comunicação ponto a ponto, onde um processo origem envia uma mensagem para um processo
destino. Entretanto, por questões de desempenho e até facilidade de programação, muitas aplicações
paralelas/distribuídas tem como requisito um sistema de passagem de mensagens que suporte
comunicação em grupo. Por exemplo, considere um grupo de servidores de arquivos que tem como
tarefa comum oferecer um serviço de arquivos tolerante a falhas. Neste caso, espera-se que as
requisições de serviço emitidas por clientes sejam recebidas por todos os servidores de arquivos.
Assim, mesmo que um servidor de arquivos não possa atender outros poderão atender o pedido.
Para que isso seja possível é necessário que exista um mecanismo de comunicação alternativo,

33
diferente da comunicação envolvendo apenas dois processos, onde é possível a recepção de uma
mesma mensagem por vários recebedores.
Outro conceito importante é o balanceamento de carga (Load Balancing). A distribuição das
tarefas entre os computadores deve ser realizada de forma que o tempo da execução distribuída seja
eficiente. Se as tarefas não forem bem distribuídas, é possível que ocorra a espera pelo término do
processamento de uma única tarefa por todo o sistema (JACINTO, 2006).
Em relação ao presente trabalho, o uso de processamento distribuído é justificável pela
existência de um “gargalo”, que é o acesso à web já que o volume de dados a ser recuperado é
muito grande. Assim, esse volume pode ser distribuído em diversas estações de trabalho que
retornariam os dados recuperados para uma única estação. Por exemplo: existe a necessidade de se
buscar informações sobre “p” proteínas, a estação do usuário solicitaria a outras “n” estações que
cada uma delas recupere dados sobre “p/n” proteínas e envie-os para a estação solicitante, desta
forma o tempo necessário para a busca é reduzido significativamente.
2.3.2. BANCO DE DADOS
Por se tratar de um sistema onde há a necessidade de armazenamento em um banco de dados
nos quais os dados são organizados em um conjunto de tabelas inter-relacionadas. São dois os
principais tipos de banco de dados a serem utilizados nesse trabalho: servidores de bancos de dados
remotos e sistema com banco de dados local (CARVALHO, 2001).
Os servidores remotos tipicamente ficam instalados em uma ou mais máquinas separadas, e
são capazes de atender a múltiplos clientes conectados a ele simultaneamente. Podem armazenar
grandes volumes de dados e possuem recursos de administração e segurança que nos sistemas locais
são mais simplificados ou até mesmo inexistentes. São também chamados de servidores SQL, pois
todos oferecem como forma de acesso e manipulação de dados, uma interface baseada na
Structured Query Language. Um servidor remoto pode ser instalado numa rede local ou numa rede
de longa distância. As partes que compõe um servidor SQL e os clientes comunicam-se entre si por
meio de mensagens (ibidem).

34
Os sistemas locais de banco de dados ficam tipicamente instalados no mesmo computador
em que a aplicação é executada. Podem, às vezes, ser instalados numa rede local e também admitem
o acesso a múltiplos clientes simultaneamente, usando, nesse caso, recursos do próprio sistema de
arquivos para o controle de eventuais conflitos entre as operações dos clientes.
Em relação os presente trabalho, foi escolhido como banco de dados o MySQL, por se tratar
de um banco de dados, gratuito, robusto, de fácil instalação e configuração. Existem várias formas
de se acessar o MySQL, sendo a mais comum através da linguagem SQL, que foi definida como a
forma de acesso a banco de dados neste trabalho.
2.3.3. ACESSO A BANCO DE DADOS BIOLÓGICOS
O acesso aos principais bancos de dados biológicos na internet se dá através de sistemas de
busca construídos e mantidos pelos próprios bancos de dados. Esses sistemas de busca são
constituídos basicamente de um formulário onde o usuário preenche os campos necessários com
dados do seu interesse, feito isso, o sistema retorna ao usuário uma página web com os dados
resultantes da busca. A Figura 18 retrata o acesso ao banco de dados Swiss-Prot onde o usuário
realiza a busca pela palavra-chave “kinase”. Na Figura 19 é ilustrado resultado de tal busca.

35
Figura 18. Sistema de busca no banco de dados Swiss-Prot.
Figura 19. Tela de resultados obtidos pelo Sistema de busca no banco de dados Swiss-Prot.

36
Embora os principais bancos de dados biológicos permitam o acesso aos seus dados via
formulários, alguns disponibilizam o acesso direto por meio de URLs. Esse tipo de acesso é ideal
para ser utilizado em ferramentas que necessitam desses dados. Em bom exemplo de um banco de
dados que dispõe de tal recurso é o Unitprot, que também permite a escolha do formato dos dados.
O formato de arquivo escolhido foi o formato Flat.
Os registros de uma proteína em formato Flat são estruturados de modo que sua leitura de
utilização possa ser feita tanto por pessoas ou quanto por programas de computador. Cada registro é
composto por linhas. Diferentes tipos de linhas, cada uma com seu próprio formato são usados para
armazenar dados pertinentes a um registro. A Figura 20 mostra a estrutura de um arquivo Flat.
Figura 20. Tela de resultados obtidos pelo acesso direto as informações do UniProt.

37
Cada linha em um arquivo no formato Flat começa por dois caracteres que identificam o
tipo de registro armazenado nessa linha, podendo ser dos seguintes tipos:
• Linha ID (IDentification): Essa sempre é a primeira linha do registro, pois é a
responsável identificar a proteína. Contém os seguinte itens: nome do registro,
classe do registro, tipo de molécula e tamanho da seqüência;
• Linha AC (ACcession number): Contém os números de acesso a essa proteína,
pode contem mais que um registro separados por “;”;
• Linha DT (DaTe): Contém informações sobre as datas de criação do registro e sua
última modificação. As datas são representados no formato dia-mês-ano;
• Linha DE (DEscription): Contém a descrição sobre a proteína do registro,
geralmente é suficiente para identificar o registro;
• Linha GE (Gene Names): Contém os nomes dos genes codificados na seqüência da
proteína. Pode conter nomes e sinônimos para o gene;
• Linha OS (Organism Species): Contém informações a respeito do organismo que
foi ou é a origem do registro. Possui nome científico do organismo e pode conter o
nome vulgar do mesmo;
• Linha OG (OrGanelle): Contém informações a respeito da origem do gene que
codificou a proteína. Pode e geralmente contém mais que um registro;
• Linha OC (Organism Classification): Contém as classificações taxonômicas do
organismo fonte da proteína. Pode e geralmente contém mais que um registro;
• Linha OX (Organism taxonomy cross-reference): É usada para indicar o
identificador do organismo especifico em uma base de dados taxonômica. Contém
o nome da base de dados e o(s) identificador(es);
• Linhas de Referencia RN, RP, RC, RX, RG, RA, RT, RL: Contém informações
sobre publicações a respeito do registro;
• Linhas CC: São utilizadas para armazenas informações úteis sobre o registro,
função, similiaridade e descrição de domínios;
• Linha DR (Database cross-Reference): Contém identificadores desse registro em
outras bases de dados. Pode conter identificadores primários, secundários e
terciários; e

38
• Linha SQ (SeQuence header): Essa linha marca o início dos dados sobre a
seqüência da proteína do registro, contém em seu cabeçalho, o tamanho e peso
molecular aproximado.
2.3.4. LINGUAGEM DE PROGRAMAÇÃO DELPHI
Neste projeto é desenvolvido um sistema que necessita das tecnologias já apresentadas.
Sendo assim, é importante escolher uma ferramenta de desenvolvimento que permita o uso de todas
elas de forma facilitada. Para a implementação deste trabalho foi escolhida a ferramenta Delphi 7.0,
que dispõe de vários tipos de componentes que serão úteis para o desenvolvimento da aplicação.
Em relação ao desenvolvimento dessa ferramenta, o Delphi dispõe de todos os recursos
necessários para tal, já que disponibiliza acesso a web, acesso a banco de dados, permite
desenvolvimento voltado para web, dentre outras utilidades, como a criação de aplicativos
multithread e que se comuniquem através de sockets, possibilitando o processamento paralelo e
distribuído. Possui também componentes que permitem o acesso e manipulação fácil de bancos de
dados. Após o levantamento das tecnologias a serem aplicadas nesse trabalho, a ferramenta
escolhida e utilizada para desenvolvimento foi o Delphi por ser enquadrar no perfil desejado.
O Delphi 7.0 já dispõe alguns componentes que foram utilizados no desenvolvimento do
trabalho são eles:
• IdAntiFreeze: Um dos grandes problemas no uso de TCP em Delphi é o
congelamento (Freeze) da aplicação em diversos momentos: na conexão,
desconexão, entre outros, invariavelmente. A biblioteca Indy traz um componente
que trata especificamente desse problema: IdAntiFreeze. Sua principal função é
priorizar as tarefas da aplicação, evitando o efeito freeze;
• IdTcpServer: Servidor responsável por receber as conexões de clientes
(IdTcpClient), pode receber e enviar dados a clientes conectados a ele;
• IdTcpClient: Responsável por estabelecer a conexão com servidor (IdTcpServer),
pode enviar e receber dados de servidor a qual estão conectado;

39
• IdThreadMgr: Componente que quando associado ao IdTcpServer, cria uma thread
para cada nova conexão efetuada; e
• Timer: Tem a função de repetir uma determinada ação de tempo em tempo.
Além de componentes já disponibilizados pelo Delphi outros são necessários:
• IEHttp3: Componente que recebe uma URL como parâmetro e salva o seu conteúdo
do documento referenciado por essa URL em um StringList;
• SUIPack: Suíte de componentes de interface;
• HtmlParser: Classe que divide um documento HTML em tag’s da linguagem HTML
e objetos de texto; e
• TextFormatter: Classe que elimina os tag’s de documentos gerados pelo HtmlParser,
restando somente os objetos de texto.

40
3. DESENVOLVIMENTO
3.1. INTRODUÇÃO
Neste capítulo são apresentadas as etapas do desenvolvimento deste trabalho, como a
modelagem, projeto, e aspectos importantes da implementação, incluíndo as características do
sistema.
3.2. MODELAGEM
O Sistema de Busca e Estruturação de Dados de Proteínas, também chamada de aplicação
principal, é uma ferramenta que foi desenvolvida para a criação de um banco de dados com
informações de proteínas selecionadas pelo usuário. Informações essas que podem ser retiradas de
bancos de dados públicos ou através de ferramentas de proteômica já desenvolvidas.
Para a coleta das informações necessárias é utilizada a ferramenta de proteômica (Emboss) e
são acessados os seguintes banco de dados protéicos:
• Swiss-Prot: Fonte de informações básicas sobre proteínas;
• Prosite: Fonte de informações sobre motivos de proteínas; e
• PFam: Fonte de dados sobre domínios de proteínas.
O desenvolvimento do sistema iniciou-se a partir de métodos de acesso a banco de dados
públicos, através de uma URL padrão para cada banco de dados. A partir desse momento foi dado
início ao desenvolvimento da aplicação escrava que auxiliará a principal na busca pelas
informações. O principal motivo para a o desenvolvimento dessa aplicação é o aumento de
desempenho na busca por informações de proteínas.

41
Essa aplicação Escrava de Busca por Proteínas deve ser executada em computadores
conectados na mesma rede em que o computador da aplicação principal. Para que essa aplicação
entre em funcionamento basta que ela seja executada.
As aplicações foram desenvolvidas em uma estrutura cliente-servidor, onde a aplicação
principal possuiu a tarefa de controlar as aplicações escravas que estão conectadas a ela. A partir do
momento que o usuário executa a aplicação principal e escolhe o método de inclusão de escravos
(manual ou automática) uma porta TCP é aberta, aguardando a conexão de novos escravos. À
medida que os escravos vão conectando-se, é exibida uma lista de quais estão ativos na rede.
Caso a aplicação principal tenha apenas o acesso a internet, e não esteja conectada a uma
rede de computadores, basta que o Escravo de Busca por Proteínas seja executado juntamente com a
aplicação principal. O Escravo de Busca por Proteínas possui informações como: endereço IP local,
lista de proteínas solicitadas, status da busca, nome do computador que solicitou a busca e um log
de comunicação.
A modelagem do sistema pretende mostrar os aspectos lógicos e de projeto do sistema em
estudo, não levando em consideração o produto final. A modelagem do presente projeto deu-se
através da metodologia de orientação a objetos, utilizando-se a UML como meio de representação.
Após estudo dos diagramas disponíveis pela UML foram considerados utilizáveis os diagramas de
Casos de Uso, Diagrama de Classes, Diagrama de Seqüências e Diagrama de Entidades e
Relacionamentos.
3.2.1. Casos de Uso
Um Caso de Uso descreve uma seqüência de ações que representam um cenário principal e
cenários alternativos com o objetivo de demonstrar o comportamento de um sistema (ou parte dele),
através de interações com atores (MELO, 2004). Como referência ao projeto atual, tem-se a
necessidade de descrever os seguintes casos de uso: login no sistema, busca e visualização de
proteínas e gravação de dados.
A Tabela 3 descreve as seqüências de ações com a interação do usuário, em um cenário em
que o ator (usuário) faz o login no sistema (aplicação principal), a representação gráfica é ilustrada
na Figura 21.

42
Tabela 3. Descrição do Caso de Uso Login no Sistema.
Objetivo Permitir que o usuário tenha acesso aos recursos oferecidos pelo mesmo.
Ator Usuário
Cenário Principal 1. O usuário digita o seu login e sua senha de acesso. 2. O usuário clica no botão “Login” e aguarda a liberação do acesso.
Cenários Alternativos 1a. Caso seja a primeira vez que o usuário acesse o sistema é necessário o preenchimento de um cadastro com alguns dados pessoais.
1b. Caso a senha ou o nome do usuário estejam incorretos o sistema retorna a tela de login, solicitando ao usuário que preencha novamente os campos necessários.
Figura 21. Diagrama do Caso de Uso Login no Sistema.
A Tabela 4 descreve as seqüências de ações com a interação do usuário, em um cenário em
que o ator (usuário) faz a escolha do modo com que sistema tratará os servidores da rede, podendo
ser por inserção manual ou automática.

43
Tabela 4. Descrição do Caso de Uso Inclusão de Novo Escravo
Objetivo Optar por inserção manual ou busca automática por servidores na rede
Ator Usuário
Cenário Principal 1. O usuário informa o endereço IP do servidor e clica no botão incluir.
2. O usuário opta por uma busca automática de servidores na rede.
Cenários Alternativos 1a. O usuário informa o endereço IP do servidor e clica no botão incluir.
1b. O sistema solicita uma confirmação de atividade para o servidor. 1c. Caso o sistema receba a mensagem de confirmação, o servidor
será incluído na lista de ativos. Caso contrário o servidor é considerado inativo.
A Figura 22 ilustra o Caso de Uso Inclusão de Novo Escravo.
Figura 22. Diagrama do Caso de Uso Servidores na Rede.

44
A Tabela 4 descreve as seqüências de ações com a interação do usuário, em um cenário em
que o ator (usuário) faz a busca de proteínas.
Tabela 4. Descrição do Caso de Uso Solicitação de Informação.
Objetivo Realiza a buscar por informações sobre proteínas em banco de dados a partir de argumentos de busca escolhidos pelo usuário.
Ator Usuário
Cenário Principal 3. O usuário informa os argumentos que lhe interessam para a busca de proteínas.
4. O usuário clica no botão prosseguir e aguarda que a busca seja concluída.
5. O sistema informa ao usuário uma lista de proteína com uma breve descrição.
Cenários Alternativos 1. Caso as proteínas que o sistema retornou ao usuário não sejam de interesse do usuário o mesmo pode voltar a tela anterior e realizar uma nova busca.
A Tabela 5 descreve as seqüências de ações com a interação do usuário, em um cenário em
que o ator (usuário) faz a visualização de proteínas.
Tabela 5. Descrição do Caso de Uso Visualizar Proteínas.
Objetivo Permite que o usuário visualize as proteínas contidas no seu banco de dados local.
Ator Usuário
Cenário Principal 1. O usuário informa quais proteínas ele deseja visualizar e clica em mostrar proteínas.
2. O sistema retorna as informações sobre as proteínas selecionadas.

45
A Tabela 6 descreve as seqüências de ações com a interação do usuário, em um cenário em
que o ator (usuário) faz a gravação dos dados obtidos com a busca de proteínas.
Tabela 6. Descrição do Caso de Uso Gravar Dados.
Objetivo Permite que o usuário grave os dados obtidos pela busca de informações sobre proteínas.
Ator Usuário
Cenário Principal 1. O sistema dá a opção ao usuário de gravar ou não os dados obtidos pela busca.
2. O usuário clica no botão gravar e aguarda a confirmação do sistema.
Cenários Alternativos 2a. Caso não seja de interesse do usuário gravar os dados obtidos ele pode cancelar a gravar e fazer uma nova busca.
O diagrama dos casos de uso Solicitação de Informação, Visualizar Proteínas e Gravar
Dados está exposto na Figura 23.
Busca e Visualização
Usuário
Buscar Proteínas
Selecionar Proteínas
Visualizar Proteínas
Grav ar Dados
«extend»
«extend»
«extend»
Figura 23. Diagrama do Caso de Uso Buscar, Visualizar Proteínas e Gravar Dados

46
3.2.2. Diagrama de Classes
Por se tratar de um sistema a ser desenvolvido orientado a objetos, faz-se necessário a
criação de um diagrama onde são detalhadas as classes e seus relacionamentos. Nesse diagrama
também são visíveis outros elementos como interface e pacotes. Para a criação dos modelos e
diagrama foi utilizada a ferramenta CASE Enterprise Architect 4.1.
Na Figura 24 é apresentado o diagrama de classes da aplicação principal contendo as classes
e seus relacionamentos.
Figura 24. Diagrama de classes Aplicação Principal
Na Figura 25 é apresentado o diagrama de classes da aplicação escrava contendo as classes e
seus relacionamentos.

47
Figura 25. Diagrama de classes Aplicação Escrava
3.2.3. Diagrama de Seqüências
Um Diagrama de Seqüências enfatiza o comportamento dos objetos em um sistema
incluindo suas operações, interações, colaborações e histórias de estado em seqüência temporal de
mensagem e representação explícita de ativação de operações. Os objetos são desenhados como
linhas verticais, as mensagens como linhas horizontais, a seqüência de mensagens é lida de cima
para baixo (MELO, 2004).
No Diagrama de Seqüências para o caso de uso Inclusão de Novo Escravo, onde o usuário
opta por incluir manualmente um novo escravo a partir de seu endereço IP a aplicação principal
após a solicitação de inclusão, envia uma mensagem do tipo “1” (solicitação de conexão) para o
endereço IP informado. Uma vez recebida uma mensagem do tipo “1”, a aplicação escrava efetua
uma conexão com a aplicação solicitante.

48
A Figura 26 ilustra o diagrama de seqüências para o Caso de Uso Inclusão de Novo Escravo.
Figura 26. Diagrama de Seqüência Inclusão Manual de Escravo.
No diagrama de seqüências do caso de uso Solicitação de Informação, onde o usuário realiza
a busca por informação a aplicação principal envia uma mensagem do tipo “3” a aplicação escrava
informando o nome de registro da proteína a ser buscada. Uma vez recebida uma mensagem do tipo
“3”, a aplicação escrava inicia a busca por informações e em seguida as envia a aplicação principal
como uma mensagem do tipo “4”, e aguarda a confirmação de recebimento da mesma.
Mensagens do tipo “4” ao serem recebidas pela aplicação principal geram automaticamente
uma mensagem de confirmação de recebimento de registros, tipo “5”, que quando recebida pela
aplicação escrava, encerra a busca por essa proteína.
A Figura 27 ilustra um diagrama de seqüências para o caso de uso Solicitação de
Informações.

49
Figura 27. Diagrama de Seqüência Solicitação de Informações
3.2.4. Diagrama de Entidades e Relacionamentos
Para o armazenamento das informações recuperadas pelo usuário, será necessária a criação
de um banco de dados onde as informações serão armazenados em diferentes tabelas de acordo com
a sua estruturação. O banco de dados escolhido é o MySQL.
O modelo lógico do banco de dados modelado pode ser visto no diagrama de entidades e
relacionamento ilustrado na Figura 28.

50
Figura 28. Modelo de entidades e relacionamentos.
O dicionário de dados, onde estão os atributos existentes em suas respectivas tabelas
(entidades), com o indicador para chave primária (PK) e chave estrangeira (FK) e o tipo de dado,
pode ser visto no Apêndice A.
3.3. PROJETO
Nessa seção são apresentadas algumas funcionalidades que foram desenvolvidas para
facilitar a interação entre o sistema e o usuário. O sistema será apresentado a seguir onde serão
descritas suas principais características e funcionalidades.

51
3.3.1. Janela de Login
Na janela login o usuário digita o seu nome e sua senha de acesso ao sistema. Caso o usuário
ainda não esteja cadastrado deve-se clicar no botão “Novo Usuário” onde serão preenchidas
algumas informações básicas sobre o mesmo.
A Figura 29 apresenta a janela de login com as opções acima descritas.
Figura 29. Janela de Login
Na Figura 30 é apresentada a tela de cadastro de novo usuário, onde é necessário o
preenchimento de nome completo, e-mail, login, senha e a confirmação da senha.

52
Figura 30. Janela Cadastro de Novo Usuário
3.3.2. Tela Informações de Escravos
A Tela Informações de Escravos foi desenvolvida com o intuito de dar ao usuário a
possibilidade de gerenciamento dos escravos na rede, desde a inclusão manual até a busca
automática de escravos ativos na rede ao qual o sistema principal está operando.
As informações de escravos já ativos e conectados no sistema são mostradas nessa tela,
assim como um histórico de conexões já realizadas a partir do momento em que o sistema é
executado. A tela de informações de escravos é ilustrada na Figura 31.

53
Figura 31. Tela de Informações de Escravos
3.3.3. Tela de Busca por Proteínas
Uma vez feita a inclusão de escravos, o usuário tem a opção de buscar por informações de
novas proteínas para inclusão em seu banco de dados. Desenvolvida com esse propósito, a Tela de
Busca por Proteínas dá ao usuário um campo onde deve ser digitada uma palavra-chave a respeito
de uma proteína, podendo ser o grupo protéico a que essa proteína pertença.
Uma vez digitada a palavra-chave o usuário deve clicar no botão buscar, para que o sistema
exiba uma lista de proteínas com o nome e uma breve descrição das mesmas. Com a lista completa
o usuário deve selecionar quais proteínas devem ser buscadas pelo sistema e em seguida clicar no
botão avançar. A Tela de Busca por Proteínas pode ser vista na Figura 32.

54
Figura 32. Tela de Busca por Proteínas
3.3.4. Tela de Progresso da Busca
Uma vez selecionadas as proteínas para buscar e iniciada a busca, o usuário é levado à Tela
de Progresso de Busca onde pode ser feito um acompanhamento da busca. O usuário tem disponível
nessa tela informações como: proteínas a serem buscadas, status individual por proteína, qual
escravo esta cooperando com a busca, inicio e término e tempo gasto na busca.

55
A Tela de Progresso de Busca pode ser vista na Figura 33.
Figura 33. Tela de Progresso de Busca
3.3.5. Tela de Banco de Dados Protéico
A Tela de Banco de Dados Protéico é divida em duas partes: Tela com Informações Básicas
e Tela de Estrutura da Proteína. Na Tela de Informações Básicas são mostrados:
• Nome do Registro;
• Accession Number (código de acesso);
• Informações sobre a origem da proteína (Gene, Sinônimos, Organismo e
Taxonomia); e

56
• Descrição da Proteína com Nome, Sinônimos e Função.
Na Tela de Estrutura da Proteína são mostrados:
• Estrutura Primária;
• Estrutura Secundária;
• Motivos; e
• Domínios da Proteína.
A Tela de Informações Básicas pode ser vista na Figura 34.
Figura 34. Tela de Informações Básicas da Proteína

57
A Figura 35 apresenta a Tela de Estrutura da Proteína.
Figura 35. Tela de Estrutura da Proteína.

58
3.3.6. Tela Aplicação Escrava de Busca por Proteínas
A Figura 36 mostra a única tela disponível na aplicação Escrava de Busca por Proteínas.
Onde são mostrados dados sobre a proteína que está sendo buscada, nome de quem solicitou a
informação e status da busca.
Na mesma tela é apresentado um pequeno histórico de conexões e ações da aplicação
escrava.
Figura 36. Escravo de Busca por Proteínas.
3.4. IMPLEMENTAÇÃO
Tanto a aplicação principal, o Sistema de Busca por Informações de Proteínas, como o
Escravo de Busca por Proteínas foram desenvolvidos em Delphi 7.0. A fase de implementação foi
dividida em rotinas de busca em banco de dados protéicos e uso remoto de ferramentas de
proteômica, inclusão de resultados no banco de dados e comunicação entre a aplicação principal e a
aplicação escrava.

59
O código fonte das principais funções e procedimentos de ambas as aplicações podem ser
vistos no Anexo I e II deste mesmo documento.
3.4.1. Componentes e Funções Utilizadas
Na implementação das aplicações principal e escrava, além dos componentes já citados
anteriormente, foram utilizados:
ClientDataSet: O componente ClientDataSet permite trazer na memória um conjunto de
registros de cada vez, não importa tão grande seja o resultado da consulta. É utilizado na
armazenagem dos resultados obtidos pela busca e criação da lista de proteínas a serem buscadas.
Zeos: Suíte de componentes para comunicação entre o banco de dados MySQL e o Delphi.
Na implementação das aplicações foram utilizadas funções já desenvolvidas por terceiros, a
fim de se evitar o re-trabalho.
3.4.1.1. Função de Leitura de Arquivo .ini
A função LeIni( ) faz a leitura de um arquivo .ini, atribuindo os valores lidos a variáveis do
sistema.
A função LeIni( ) é utilizada na inicialização do sistema, após o login do usuário. É através
dela que o banco de dados do usuário é selecionado.
3.4.1.2. Função de Criação de Lista com IPs da Rede
A função GetIPs quando executada retorna uma lista com os IPs dos computadores
conectados a rede em que a aplicação principal está sendo executada.
Na busca automática por escravos na rede é utilizada a função GetIPs para a criação da lista
de IPs que serão verificados afim de se identificar os escravos ativos na rede.

60
3.4.1.3. Função de Download de Arquivos na Internet
A função URLDownloadToCacheFile, desenvolvida pela Microsoft, parte componente da
biblioteca UrlMon.dll efetua o download de um documento ou arquivo na internet e o armazena em
cache (MICROSOFT, 2004).
Essa função é amplamente utilizada nas classes de busca de informações de básicas de
proteínas, domínios e motivos.
3.4.2. Busca em Banco de Dados Protéico
Para a criação da lista de proteínas a serem buscadas, foi desenvolvida uma rotina que de
acordo com a palavra-chave que o usuário informou é criada uma lista contendo Nome do Registro,
Accession Number (código de acesso) e uma breve descrição das proteínas a serem buscadas. Essa
lista é gerada através de acesso e uso remoto da ferramenta de busca UniProt Knowledgebase que
pode ser acessada através da URL http://www.expasy.org/cgi-bin/sprot-search-
ful?SEARCH=*&S=on onde o caractere “*” é substituído pela palavra-chave.
Como resultado do acesso a essa URL tem-se um documento Html que através do uso do
componente HtmlParser é convertido em um documento texto sem as Tag`s da linguagem HTML,
ou seja, somente o texto visto quando se acessa a URL pelo browser. De posse desse documento
texto é realizada uma busca, onde cada linha corresponde a um registro. Sabe-se que por padrão
desse documento o Nome de Registro da proteína é a primeira palavra de cada linha, Acession
Number é a primeira palavra entre colchetes e a descrição se inicia após o Acession Number e
termina no final da linha.
Para a busca de domínios e motivos segue-se o mesmo conceito, mudando-se apenas a URL
padrão e a localização dos registros necessários.

61
Para busca no banco de dados PFam (domínios) a URL passa a ser:
http://pfam.wustl.edu/cgi-bin/getswisspfam?key=*, onde o caractere “*” é substituído pelo nome de
registro da proteína e a localização dos registros inicia-se na linha “Pfam-A Domains” onde as
próximas linhas são o nome do domínio, inicio e término.
Para busca no banco de dados Prosite (motivos) a URL passa a ser: http://us.expasy.org/cgi-
bin/prosite/PSScan.cgi?form=theForm&seq=* onde o caractere “*” é substituído pelo nome de
registro da proteína e a localização dos registros inicia-se na linha com nome de registro onde as
próximas linhas são o nome do motivo, inicio e término.
3.4.3. Comunicação entre a Aplicação Principal e a Aplicação Servidora
A partir do momento que o usuário executa o sistema e escolhe o método de inclusão de
clientes (manual ou automática) uma porta TCP é aberta através do componente IdTcpServer
aguardando a conexão de novos clientes. À medida que os clientes vão conectando-se, é exibida
uma lista com os clientes ativos na rede.
A comunicação entre a aplicação principal e a aplicação escrava é feita através de troca de
mensagens via TCP, onde a mensagem é identificada de acordo com o seu tipo. Os campos das
mensagens são separados pelo caractere “|“ e são formatadas de acordo com o seu tipo, que pode
ser: mensagem de solicitação de conexão, solicitação de desconexão, solicitação de busca, retorno
com informações de busca e confirmação de recebimento de registros.
Ao se inserir manualmente ou de forma automática uma nova aplicação escrava, através de
um endereço IP, é criada uma mensagem do tipo: 1|ip_do_servidor, onde o campo tipo de
mensagem é definido como “1” é o segundo campo é o endereço IP que quem solicitou a conexão.
Na aplicação escrava a responsabilidade de recepção de mensagens fica por conta do
componente TcpServer que ao receber uma mensagem do tipo “1” (solicitação de conexão) deve
verificar se ela já não esta conectada a outra aplicação, caso não esteja, a aplicação escrava se
conecta a aplicação servidora através do componente IdTcpClient, dando inicio à comunicação
entre as aplicações.

62
Uma vez iniciada a comunicação a aplicação escrava está pronta para receber mensagens do
tipo solicitação de registros, que são formatadas da seguinte forma: 3|nome_de_registro,
onde o campo “3” identifica o tipo de mensagem e o campo nome_de_registro identifica o nome de
registro da proteína solicitada. Após o recebimento e leitura da mensagem é iniciada a busca pela
proteína através do nome de registro da mesma, e que quando concluída, as informações sobre a
proteína são armazenadas em um StringList e enviadas a aplicação principal que solicitou o registro.
Ao concluir o recebimento de registros enviados pela aplicação escrava, a aplicação
principal envia uma mensagem do tipo confirmação de recebimento de registros a aplicação escrava
que efetuou a busca, essa mensagem é formata da seguinte forma: 5|nome_de_registro, onde
o campo “5” identifica o tipo de mensagem e o campo nome_de_registro identifica o nome de
registro da proteína recebida. A aplicação escrava ao receber uma mensagem do tipo “5” encerra as
atividades de busca pela proteína “nome_de_registro”. Caso a aplicação escrava não receba uma
confirmação de recebimento de registros a mensagem contendo as informações sobre a proteína é
enviada novamente a aplicação principal. O tempo entre o envio e o recebimento da confirmação de
recebimento é configurado através de um campo de timeout na aplicação escrava. O número de
tentativas de envio de registro até que a operação seja considerada não concluída é configurado
através do campo tentativas de envio de registro.
3.4.4. Inclusão de Resultados no Banco de Dados
A partir do momento em que a aplicação principal envia a mensagem de confirmação de
recebimento de registro à aplicação escrava, inicia-se o processo de inclusão dos registros no banco
de dados.
A rotina de inclusão de resultados no banco de dados recebe como parâmetro um StringList,
onde cada elemento dessa StringList é uma instrução SQL pronta para ser executada por uma
Query, ao término da execução os dados estão gravados no banco de dados local.

63
3.5. VALIDAÇÃO E TESTES
A validação da aplicação se deu através da escolha de um grupo protéico, onde o nome do
mesmo serviu de palavra-chave para a busca. O grupo protéico escolhido e indicado pelo Prof.
André Lima foi o “ABC Transporters”. A validação foi dividida em cinco partes, que são: criação
da lista com proteínas a serem buscadas; busca de informações básicas da proteína, busca por
motivos, busca por domínios e busca por estrutura secundária.
Conforme a ferramenta de busca UniProt Knowledgebase (EXPASY, 2004), a busca pela
palavra-chave “ABC Transporters” deverá resultar em uma lista com 80 (oitenta proteínas),
conforme Figura 37.
Figura 37. Busca por ABC Transporters através da ferramenta UniProt Knowledgebase
Executando-se a mesma consulta através da aplicação tem-se como resultado o mesmo
número de proteínas, ou seja, 80 (oitenta). A Figura 38 exibe o resultado da consulta.

64
Figura 38. Resultado da busca por ABC Transporters através da aplicação.
Após a criação da lista de proteínas resultantes da busca através de palavra-chave. Escolheu-
se a proteína ABCCD_HUMAN. A validação se dá através da comparação entre os dados do
arquivo no formato Flat disponibilizado pelo banco de dados UniProt e os dados obtidos pela
aplicação.
A Figura 39 mostra o arquivo no formato Flat da proteína ABCCD_HUMAN e a Figura 40
mostra a tela Sistema de Busca de Informações de Proteínas com o resultado a busca pela mesma
proteína.

65
Figura 39. Arquivo no formato Flat da proteína ABCCD_HUMAN.
Figura 40. Tela informações básicas da proteína ABCCD_HUMAN.

66
Após a visualização das informações básicas da proteína se faz necessária a validação da
estrutura da proteína, ou seja, estrutura primária, estrutura secundária, motivos e domínios da
proteína.
A Figura 41 mostra o arquivo em formato Flat disponibilizado pelo banco de dados UniProt
onde se encontram as estruturas primárias e secundárias da proteína ABCCD_HUMAN.
Figura 41. Estrutura secundária fornecida pelo banco de dados Uniprot.
A Figura 42 mostra os resultados obtidos pela ferramenta PrositeScan, que tem como
objetivo disponibilizar os motivos da proteína.

67
Figura 42. Motivos na proteína ABCCD_HUMAN, conforme a ferramenta PrositeScan.
A Figura 43 mostra o resultados obtidos na busca pelos domínios da proteína através da
ferramenta de busca do banco de dados PFam.
Figura 43. Domínios na proteína ABCCD_HUMAN conforme banco de dados PFam.

68
A Figura 44 mostra os resultados obtidos pelo Sistema de Busca e Estruturação de
Informações de Proteínas, onde são exibidas as estruturas primária e secundária, os motivos e
domínios da proteína ABCCD_HUMAN.
Figura 44. Estrutura secundária, motivos e domínios encontrados através da aplicação.
Após a visualização dos resultados obtidos através das ferramentas citadas acima e análise
dos resultados obtidos pelo sistema apresentado, pode-se chegar a conclusão que os resultados
obtidos são positivos, ou seja, os dados disponibilizados pelas ferramentas utilizadas são iguais aos
obtidos pelo sistema apresentado.
[FIM DE SEÇÃO. Não remova esta quebra de seção]

4. CONCLUSÕES
Ao se definir o tema para o desenvolvimento deste trabalho levou-se em consideração que o
mesmo possa servir de base para projetos futuros que objetivam identificar novas proteínas com
base em características já conhecidas, fazendo uso de novas ferramentas a serem desenvolvidas nos
dados obtidos por esse trabalho.
Apesar de existirem ferramentas que acessem banco de dados biológicos, não foi encontrada
uma ferramenta que reunisse todas as etapas, desde a busca de dados protéicos (informações
básicas, motivos, domínios, etc.) até sua manipulação através de ferramentas de proteômica. Os
fatores a favor do desenvolvimento de tal ferramenta são:
• O uso das informações armazenadas de um banco de dados local, o que torna mais
rápido o seu acesso e manipulação.
• Possibilidade de se utilizar o banco de dados criado em outras aplicações.
• Criação de um banco de dados exclusivo para cada usuário.
Os objetivos deste trabalho iam desde pesquisa e compreensão de proteínas no que se diz
respeito a sua formação, estrutura, propriedades físico-químicas, características e suas funções até o
uso ferramentas de proteômica já desenvolvidas, bem como o acesso a banco de dados biológicos
fazendo uso da ferramenta desenvolvida para a criação de um banco de dados local com
informações sobre proteínas.
O uso da ferramenta de busca do banco de dados Swiss-Prot é o primeiro passo para a busca
de informações sobre proteínas, pois é através dela que é gerada a lista de proteínas a serem
pesquisadas, de acordo com as palavras-chave que o usuário informou. A princípio o acesso a essa
ferramenta seria feito através do preenchimento remoto de formulários em páginas web (rotina essa
desenvolvida durante a primeira etapa desse trabalho) onde por meio de rotinas era obtida a lista de
proteínas para busca. Esse método se comportou de maneira adequada durante os primeiros testes,
onde o número de proteínas era consideravelmente pequeno, mas com o incremento do número de
proteínas o sistema simplesmente deixava de responder, onde foi constatado que o componente que
estava sendo utilizado, o TWebBrowser que é distribuído juntamente com a linguagem de

70
programação escolhida, não suportava a navegação em uma página com tamanho número de
registros.
Com a constatação da origem do problema, o preenchimento remoto de formulários e o
componente o TWebBrowser foram dispensados, chegando-se a um novo método de acesso a
formulários em páginas web, o uso direto da ferramenta de busca, onde as palavras chave são
passadas como parâmetros, tendo como resultado, uma página web em formato HTML, é
processado através de uma biblioteca chamada HTMLParser que gera um documento texto sem os
tags da linguagem HTML. Depois disso o documento é novamente processado, tendo como
resultado a lista de proteínas para busca.
Durante a fase de implementação sugiram novas barreiras que tiveram que ser superadas,
sendo necessário algumas modificações no que foi planejado na primeira etapa do desenvolvimento.
Uma delas é o uso de documentos XML para captura de informações, já que o componente que
seria utilizado para realizar o processamento XML, o XMLTransformProvider, possui algumas
restrições quanto ao número de possíveis valores que um campo possa ter. Esse componente da
forma que estava sendo usada admite que um campo possa ter apenas um valor, restringindo
campos a exemplo da tabela proteínas, onde uma proteína pode ter mais de um nome cadastrado, ou
da tabela referencias, onde uma publicação pode ter mais que um autor.
Com o surgimento do problema do uso de XML, iniciou-se a busca de novas alternativas,
chegando-se ao uso de documentos em formato Flat (texto plano), sendo necessária a criação de
uma rotina que identificasse cada tipo de registro.
Inicialmente o banco de dados de domínio de proteínas escolhido foi o Prodom. Embora
tenham sido desenvolvidas e testadas as rotinas para recuperação de seus dados, o uso desse banco
de dados foi descartado devido o seu baixo desempenho na recuperação de dados. Novas
alternativas foram necessárias, onde foi encontrado o banco de dados Pfam, que além de ter um
maior número de registro se sobressaiu ao Prodom em relação ao desempenho na recuperação de
seus dados.
Durante o desenvolvimento desse trabalho verificou-se estar construindo uma ferramenta
que cumpriu os objetivos propostos e que seria de grande utilidade. Como se trata de um projeto
que objetiva servir de base para trabalhos futuros, tem suas limitações, dentre elas podem ser
citadas: atualização dos dados já existentes no banco de dados; possibilidade de criação de mais de

71
um banco de dados por usuário, onde o mesmo possa gerenciar projetos divididos por grupo
protéico; a não existência de relatórios; dependência de ferramentas desenvolvidas mantidas por
terceiros.
Diante das limitações citadas, sugere-se a continuidade do desenvolvimento da ferramenta
considerando os avanços alcançados durante o desenvolvimento do trabalho, ficando como sugestão
a correção das limitações já citadas e melhorias, tais como:
• Acesso direto a bancos de dados biológicos, sem o uso de ferramentas
disponibilizadas pelos mesmos;
• Uso de ferramentas que façam alinhamentos entre as proteínas; e
• Possibilidade de criação de projetos do usuário, onde os projetos seriam divididos
de acordo com a proteína ou grupo protéico estudado;
[FIM DE SEÇÃO. Não remova esta quebra de seção]

REFERÊNCIAS BIBLIOGRÁFICAS
ALBERTS, B., BRAY, D., LEWIS, J. Biologia Molecular da Célula. 3ª ed., Porto Alegre, Ed.
Artes Médicas, 1997.
BIBLIOMED. DNA: A Linguagem da vida. São Paulo, 2002. Disponível em:
<http://boasaude.uol.com.br/lib/ShowDoc.cfm?LibDocID=3831&ReturnCatID=1798>. Acesso em
10 nov. 2002.
BIOESFERA. DNA Goes to School: Os Banco de Dados Genéticos, 2001. Disponível em:
<http://www.eldnavaalaescuela.com/banco.htm>. Acesso em: 01 nov. 2004.
BIOMANIA. 1998-2002. Apresenta conteúdo sobre ciências biológicas. Disponível em:
<http://www.biomania.com.br>. Acesso em: 23 out. 2002.
BUYYA, R. High Performance Cluster Computing: Architecture and Systems, vol 1. pags 3-
45, New Jersey: Prentice Hall, 1999.
CARVALHO, F. F. Delphi 6: Programação Orientada a Objetos. 1ª ed., São Paulo: Érica, 2001.
CATES, S. Expasy Proteonics Tools 1, Mar. 2004. Disponível em:
<http://cnx.rice.edu/content/m11082/latest/>. Acesso em: 02 mar. 2004.
EMBOSS. European Molecular Biology Open Software Suíte. Disponível em:
<http://bioinfo.pbi.nrc.ca:8090/EMBOSS/>. Acesso em: 12 out. 2004.
EXPASY. Molecular Biology Server. Disponível em: <http://us.expasy.org>. Acesso em: 25 jul.
2006.
FALCÃO, P. K., et al. Sting Millennium Suite: ferramentas para análise estrutural de
proteínas. Disponível em: <http://www.comciencia.br/>. Acesso em: 23 mar 2004.
FARAH, S. B. DNA Segredos & Mistérios. São Paulo: SARVIER, 1997. 276p.

73
GENTIL, P. Ingestão de Proteínas. GEASE – Grupo de Estudo Avançados em Exercícios e
Saúde, Brasília, jan 2002.
GRIFFITHS, A., MILLER, J., SUZIKI, D. Introdução a Genética. 7a ed., Rio de janeiro:
Guanabara Koogan, 2001.
HORTON, H. R., MORAN, L. A., OCHS, R. S. Principles of Biochemistry. 3a ed., Toronto:
Prentice Hall, 1995.
JACINTO, D. S. Conceitos básicos para o desenvolvimento de algoritmos paralelos utilizando bibliotecas de passagem de mensagem. Linuxchix Brasil. Disponível em: <http://midia.linuxchix.org.br/artigos/programacao.pdf>. Acesso em 15 de mai. 2006.
LaCPaD. Laboratório de Computação Paralela e Distribuída. Florianópolis: UFSC. Disponível em: <http://www.lacpad.inf.ufsc.br/>. Acesso em: 15 mai. 2006.
LBMP. Laboratório de Bioquímica de Microrganismos e Plantas. Departamento de Tecnologia -
FCAV/UNESP. Jaboticabal. Disponível em: <http://lbmp.fcav.unesp.br/>. Acesso em 29 set. 2004.
LEHNINGER, A. L, NELSON, D. L., COX, M. M. Principles of Biochemistry, 2a ed., New York:
Worth Publishers, 1998.
LODISH, H., BERK, A., ZIPURSKY, S. L. Molecular Cell Biology. 4a ed., New York: W H
Freeman & Co., 1999.
LOURENÇO, A. P. Two Sequence Alignment. Disponível em:
<http://www.rge.fmrp.usp.br/cursos/topicosiii/paginas/web25/trabalho25.html>. Acesso em: 12 de
out. de 2004.
MELEIRO, R., FONSECA, C. O Genoma Humano. CiênciaJ, n. 23, set. 2001. Disponível em:
<http://www.ajc.pt/cienciaj/n23/avulvo9.php>
MELO, A. C. Desenvolvendo aplicações com UML 2.0: do conceitual à implementação. 2a ed.,
Rio de Janeiro: Brasport, 2004.

74
MICROSOFT. URLDownloadToCacheFile Function. Disponível em:
<http://msdn.microsoft.com/library/default.asp?url=/workshop/networking/moniker/reference/functi
ons/urldownloadtocachefile.asp>. Acesso em: 20 set. 2004.
MOTTA, V. T. Bioquímica Básica: Aminoácidos e Proteínas. Porto Alegre, 2004.
PIMENTA, A. M de C. Desafio do Proteona. Ciência Hoje, Belo Horizonte, n. 192. Disponível em:
<http://www2.uol.com.br/cienciahoje/chmais/pass/ch192/proteoma.pdf>. Acesso em: 19 mar. 2004.
PRODOM. The ProDom Database. Disponível em: <http://prodes.toulouse.inra.fr/prodom/current/html/home.php>. Acesso em: 30 set. 2004.
PROSDOCIMI, F., CERQUEIRA, G. C. BINNECK, E. Bioinformática: O manual do usuário.
Disponível em: <http://www.bionet.pucpr.br/tutoriais.php> . Acesso em: 18 out. 2004.
QMCWEB. O Mundo das Proteínas. QMCWEB Revista eletrônica. Florianópolis, Universidade
Federal de Santa Catarina, Departamento de Química, 1998. Diponível em:
<http://www.qmc.ufsc.br/qmcweb/artigos/proteinas.html/>. Acesso em: 29 out. 2004.
SANTANA, R., SOUZA, M., PIEKARSKI, A. E. Computação Paralela. São Carlos, 1997.
STAUFFER, A. O., FRANCO, J. M. CGI e Formulários HTML. [S.l., 2000]. Disponível em:
<http://equipe.nce.ufrj.br/adriano/c/apostila/cgi/#form>. Acesso em: 29 out. 2004.
SWISS-PROT. Swiss-Prot Protein Knowledgebase. Disponível em:
<http://www.expasy.org/sprot/>. Acesso em: 20 ago. 2004.
TANENBAUM A. S. Sistemas Operacionais Modernos, Rio de Janeiro: Prentice-Hall do
Brasil Ltda, 1995.
THOMPSON, M., MCINNES, R., WILLARD, H. Genética Médica. [ca 2000]. Rio de Janeiro:
GUANABARA KOOGAN, 1998. p. 23-25.
W3 CONSORTIUM. Extensible Markup Language (XML): activity statement. Disponível em: <http://www.w3c.org.>. Acesso em: 25 set. 2001.

75
_______. Extensible Markup Language (XML): W3C recommendation 6. 2ª ed., 2000. Disponível em: <http://www.w3c.org.>. Acesso em: 24 set. 2001. WIKIPEDIA. Wikipédia, a enciclopédia livre. RNA. Disponível em: <http://pt.wikipedia.org/wiki/RNA>. Acesso em: 18 out. 2006.
YANGENE BIOTECNOLOGIC COMPANY. Biotech Molecular Biology. [nl.] 2000. Dispinivel
em: <www.yangene.com/ content22_10.htm>. Acesso em 19 nov. 2002.
[FIM DE SEÇÃO. Não remova esta quebra de seção]

76
APÊNDICE A – DICIONÁRIO DE DADOS
Tabela 7. Dicionário de Dados da Tabela Autor
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
refid inteiro Código identificador da referência (FK)
idautor inteiro Código identificador do autor (PK)
nome char(50) Nome do autor
Tabela 8. Dicionário de Dados da Tabela Datas
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
iddata Inteiro Código identificador da referência (PK)
nomeregistro char(20) Código identificador da proteína (FK)
comentario char(100) Comentário da data
data char(50) Data
Tabela 9. Dicionário de Dados da Tabela Domínio.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
iddominio inteiro Código identificador do domínio (PK)
tamanho inteiro Tamanho do domínio
inicio inteiro Inicio do domínio
fim inteiro Fim do domínio
nomeregistro char(20) Nome de registro da proteína (FK)
nome char(20) Nome do dominio
Tabela 10. Dicionário de Dados da Tabela EstruturaSecundária.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
idestruturasecundaria inteiro Código identificador da estrutura secundária (PK)
nomeregistro char(20) Código identificador da proteína (FK)
inicio inteiro Início da estrutura secundária
fim inteiro Fim da estrutura secundária
tipoestrutura char(20) Tipo da estrutura secundaria

77
Tabela 11. Dicionário de Dados da Tabela Gene
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
idgene Inteiro Código identificador do Gene (PK)
nomeregistro char(20) Nome de Registro da proteína (FK)
tipo char(32) Tipo do Gene
gene char(32) Gene
Tabela 12. Dicionário de Dados da Tabela Motivo.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
idmotivo inteiro Código identificador do motivo (PK)
nomeregistro char(20) Nome de Registro da proteína (PK)
acmotivo char(20) Accession number do motivo
nome char(50) Nome do motivo
inicio char(5) Inicio do motivo
fim char(5) Fim do motivo
descricao char(150) Descrição do motivo
Tabela 13. Dicionário de Dados da Tabela Organismo.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
nomecientifico char(50) Nome científico do organismo (PK)
nomevulgar char(50) Nome vulgar do organismo
Tabela 14. Dicionário de Dados da Tabela Organismo_Proteína.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
nomecientifico char(50) Nome científico do organismo (FK)
nomeregistro char(20) Nome de registro da proteína (FK)
Tabela 15. Dicionário de Dados da Tabela Proteína.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
nomeregistro char(20) Nome do registro da proteína (PK)
funcao char(250) Função da proteína

78
Tabela 16. Dicionário de Dados da Tabela Referência.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
refid inteiro Código identificador da referencia (PK)
nomeregistro char(20) Nome de registro da proteína (FK)
titulo char(250) Título da referência
tissue char(25) Tissue da referência
publicacao char(50) Publicação da referência
citacao char(50) Citação da referência
escopo char(250) Escopo da referência
Tabela 17. Dicionário de Dados da Tabela Seqüência.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
idsequencia inteiro Código identificador da seqüência (PK)
idproteina inteiro Código identificador da proteína (FK)
tamanho inteiro Tamanho da seqüência
peso char(10) Peso da seqüência
sequencia texto Seqüência da proteína
Tabela 18. Dicionário de Dados da Tabela Taxonomia.
NOME DO ATRIBUTO TIPO/TAMANHO DESCRIÇÃO
nomecientifico char(50) Código identificador do organismo (PK)
taxonomia char(50) Nome da taxonomia (PK)
[FIM DE SEÇÃO. Não remova esta quebra de seção]

ANEXO I – CÓDIGO FONTE DA APLICAÇÃO PRINCIPAL
PClient = ^TClient; TClient = record PeerIP : string[15]; { Ip do client (servidor) } HostName : String[40]; { Nome do Client } Busca : boolean; NumeroProteina : integer; EntryName : string[20]; Connected, { Tempo conectado } LastAction : TDateTime; { Ultima atividade } Thread : Pointer; { Ponteiro para a thread } end; type TBuscaEN = class ListaEN: TStrings; ListaAC: TStrings; procedure BuscaSP(var Argumento: string); procedure AtualizaLista; procedure CriaLista; end; function LeIni: Boolean; var ArqIni : TIniFile; begin ArqIni := tIniFile.Create('c:\windows\temp\proteina.Ini'); Try hostname := ArqIni.ReadString('Dados', 'HostName', 'Main'); database := ArqIni.ReadString('Dados', 'database', 'Main' ); usuariodb := ArqIni.ReadString('Dados', 'usuario', 'Main' ); senha := ArqIni.ReadString('Dados', 'senha', 'Main' ); Finally ArqIni.Free; end; result := true; end; function getIPs: Tstrings; type TaPInAddr = array[0..10] of PInAddr; PaPInAddr = ^TaPInAddr; var phe: PHostEnt; pptr: PaPInAddr; Buffer: array[0..63] of Char; I: Integer; GInitData: TWSAData; begin WSAStartup($101, GInitData); Result := TstringList.Create; Result.Clear; GetHostName(Buffer, SizeOf(Buffer)); phe := GetHostByName(buffer); if phe = nil then Exit; pPtr := PaPInAddr(phe^.h_addr_list); I := 0; while pPtr^[i] <> nil do begin Result.Add(inet_ntoa(pptr^[i]^)); Inc(I); end; WSACleanup; end; procedure TBuscaEN.BuscaSP(var Argumento: string); var HTML : TStrings; Server, EN : String; i, j, inicio, k : integer; temp, temp2, DESCtemp, Base, AC : string; flag : integer; FileName: string; HtmlParser: THtmlParser; HtmlDoc: TDocument; Formatter: TBaseFormatter; primeiro, segundo : integer; begin

HTML := TStringList.Create; inicio := 0; primeiro := 0; Server := 'http://www.expasy.org/cgi-bin/sprot-search-ful?SEARCH=*&S=on'; Server := AnsiReplaceStr(Server,'*',Argumento); Server := AnsiReplaceStr(Server,' ','+'); SetLength(FileName, MAX_PATH + 1); if URLDownloadToCacheFile(nil, pchar(Server), PChar(FileName), MAX_PATH, 0, bsc) = S_OK then begin SetLength(FileName, StrLen(PChar(FileName))); HTML.LoadFromFile(FileName); end; HtmlParser := THtmlParser.Create; try HtmlDoc := HtmlParser.parseString(HTML.Text) finally HtmlParser.Free end; Formatter := TTextFormatter.Create; try HTML.Text := Formatter.getText(HtmlDoc) finally Formatter.Free end; Base := 'Search in Swiss-Prot: There are matches to'; for i := 0 to HTML.Count-1 do begin temp := HTML.Strings[i]; if copy(temp, 0, length(base)) = base then begin inicio := i+1; break; end; end; flag := 0; for i := inicio to HTML.count-1 do begin temp := HTML.Strings[i]; for j := 0 to length(temp)-1 do begin if temp[j] = ' ' then begin temp2 := copy(temp, j+1, 4); if temp2 = 'http' then begin for k := j+1 to length(temp)-1 do begin if temp[k] = '?' then primeiro := k; if temp[k] = '(' then begin segundo := k; EN := copy(temp, 0, j-1); ac := copy(temp, k+1, length(temp)-k-1); flag := 1; break; end; end; break; end else begin if flag = 0 then DESCtemp := DESCtemp + temp; if flag = 1 then begin DESCtemp := DESCtemp + temp; frmMain.CDS.insert; frmMain.Cds.Fields[2].Value := true; frmMain.Cds.Fields[0].Value := en; frmMain.Cds.Fields[1].Value := desctemp; frmMain.Cds.Fields[3].Value := false; frmMain.Cds.Fields[4].Value := ac; frmMain.CDS.Post; DESCtemp := ''; flag := 0; end; break; end; end; end; end; frmMain.Cds.IndexFieldNames := 'EN'; CriaLista;

frmMain.lb_numeroproteinas.Caption := 'Foram encontradas '+inttostr(ENList.Count)+' proteínas através da palavra-chave: '+frmMain.Edit1.text; frmMain.pnl_avancar.Visible := true; end; procedure TBuscaEN.AtualizaLista; var i : integer; begin frmMain.CDS.First; for i := 0 to ENLIst.Count-1 do ENList.Delete(0); while not frmMain.CDS.Eof do begin for i := 0 to frmMain.CDS.RecordCount-1 do begin if frmMain.CDS.fields[2].Value then begin ENList.Add(frmMain.CDS.fields[0].Value); frmMain.CDS.Next; end else frmMain.CDS.Next; end end; end; procedure TBuscaEN.CriaLista; begin frmMain.CDS.First; while not frmMain.CDS.Eof do begin if frmMain.CDS.fields[2].Value then begin ENList.Add(frmMain.CDS.fields[0].Value); ACList.Add(frmMain.CDS.fields[4].Value); frmMain.CDS.Next; end else frmMain.CDS.Next; end; end; procedure TFrmMain.btn_avancarClick(Sender: TObject); var ListItem: TListItem; begin btn_avancar.Enabled := false; pnl_avancar.Visible := false; PaginaControle.ActivePageIndex := 2; BuscaEN.AtualizaLista; ProgressBar.MaxValue := ENList.Count; lb_total.Caption := 'Buscando por '+inttostr(ENList.count)+' proteínas.'; NumThreads := 0; CDS.First; while not CDS.Eof do begin if CDS.fields[2].Value = False then CDS.Delete else CDS.Next; end; CDS.First; with lv_progresso do begin ViewStyle := vsReport; while not CDS.Eof do begin ListItem := Items.Add; ListItem.Caption := CDS.fields[0].Value; ListItem.SubItems.Add(CDS.fields[4].Value); ListItem.SubItems.Add('Não Iniciado'); ListItem.SubItems.Add(' '); ListItem.SubItems.Add(' '); CDS.Next; end; end; CDS.EmptyDataSet; if ENList.Count > 0 then Busca; end; procedure TFrmMain.btn_buscaClick(Sender: TObject); var BuscaEN: TBuscaEN; Argumento: string; begin // se existir dados no ClientDataSet - CDS, os dados são excluídos

if CDS.DataSize <> 0 then begin CDS.First; while not CDS.Eof do begin CDS.First; CDS.Delete; CDS.First; end; end else begin CDS.CreateDataSet; CDS.Open; end; BuscaEN := TBuscaEN.Create; ACList := TStringList.Create; Argumento := Edit1.Text; Label3.Caption := ''; BuscaEN.BuscaSP(Argumento); ProgressBar.MaxValue := 0; ProgressBar.Progress := 0; btn_avancar.Enabled := true; pnl_avancar.Visible := true; t := 0; end; procedure TFrmMain.Busca; var EntryName : string; NumeroHosts : integer; SelClient : PClient; ListItem : TListItem; begin NumeroHosts := LBIPAtivos.count-1; MaxThreads := LBIPAtivos.count; while (NumThreads < MaxThreads) and (t <= ENList.Count-1) do begin if HostN = NumeroHosts then HostN := 0 else inc(HostN); EntryName := ENList[t]; LBIPAtivos.ItemIndex := HostN; if LBIPAtivos.ItemIndex = -1 then begin Exit; end; try SelClient := PClient(Clients.LockList.Items[HostN]); SelClient.Busca := True; SelClient.EntryName := EntryName; SelClient.NumeroProteina := t; inc(NumThreads); with lv_progresso do begin ListItem := Items.Item[SelClient.NumeroProteina]; ListItem.SubItems.Strings[1] := 'Iniciado'; ListItem.SubItems.Strings[2] := SelClient.HostName; ListItem.SubItems.Strings[3] := SelClient.PeerIP; ListItem.SubItems.Strings[4] := TimeToStr(SelClient.LastAction); end; finally Clients.UnLockList end; inc(t); end; end; function TFrmMain.VerificaAtividade(ip: string) : boolean; var connec : boolean; msg : string; begin msg := Concat('1|',lbl_meuip.caption); // msg enviada para o client. 1 = código para teste de atividade. TCPClient.RemoteHost := ip; TCPClient.RemotePort := '1000'; Connec := TcpClient.Connect; if not Connec then begin lbl_atividade.Caption := 'Servidor não ativo.'; lbl_atividade.Caption := ''; end else

begin TcpClient.SendLn(msg); TcpClient.Disconnect; end; result := true; end; procedure TFrmMain.TCPServerConnect(AThread: TIdPeerThread); var NewClient: PClient; begin GetMem(NewClient, SizeOf(TClient)); NewClient.PeerIP := AThread.Connection.Socket.Binding.PeerIP; NewClient.HostName := GStack.WSGetHostByAddr(NewClient.PeerIP); NewClient.Busca := False; NewClient.EntryName := ''; NewClient.Connected := Now; NewClient.LastAction := NewClient.Connected; NewClient.Thread := AThread; AThread.Data := TObject(NewClient); try Clients.LockList.Add(NewClient); finally Clients.UnlockList; end; Protocol.Lines.Add(TimeToStr(Time)+' Conexão com "' + NewClient.HostName + '" com o IP ' + NewClient.PeerIP); RefreshListDisplay; if ENList.Count > 0 then Busca; end; procedure TFrmMain.TCPServerExecute(AThread: TIdPeerThread); var Client : PClient; Command, TempPathName, Msg, Ha, Hi, a3, NroMsg : string; Size : integer; ftmpStream : TFileStream; sql : Tstrings; ListItem : TListItem; HoraAtual, a1, a2 : TDateTime; Gravador : TGravador; connected: boolean; begin if not AThread.Terminated and AThread.Connection.Connected then begin Client := PClient(AThread.Data); Client.LastAction := Now; Gravador := TGravador.Create; if Client.Busca = True then begin Client.Busca := False; sql := tstringlist.Create; msg := concat('3|',Client.EntryName); AThread.Connection.WriteLn(msg); TempPathName := ExtractFileDir(ParamStr(0)) + '\' + Client.HostName + '_' + Client.EntryName +'.txt'; if FileExists (TempPathName) then DeleteFile(TempPathName); ftmpStream := TFileStream.Create(TempPathName,fmCreate); Size := AThread.Connection.ReadInteger; AThread.Connection.ReadStream(fTmpStream,Size,False); FreeAndNil(fTmpStream); sql.LoadFromFile(TempPathName); NroMsg := SQL.Strings[0]; EnviaMsg(NroMsg, Client.PeerIP); Gravador.GravaSQL(sql); if FileExists (TempPathName) then DeleteFile(TempPathName); with lv_progresso do begin ListItem := Items.Item[Client.NumeroProteina]; HoraAtual := Time; Ha := timetostr(HoraAtual); Hi := ListItem.SubItems.Strings[4]; a1 := StrToTime(Ha); a2 := StrToTime(Hi); a3 := TimeToStr(a2-a1); ListItem.SubItems.Strings[1] := 'Concluído'; ListItem.SubItems.Strings[5] := TimeToStr(HoraAtual); ListItem.SubItems.Strings[6] := a3; ProgressBar.Progress := ProgressBar.Progress + 1; end; AThread.Connection.WriteLn('DONE'); ClientsListBoxClick(nil);

dec(NumThreads); Busca; end end; end;

ANEXO II – CÓDIGO FONTE DA APLICAÇÃO ESCRAVA
type TBuscaDOMINIO = class ListaEN: TStrings; function Busca(var EN: string): TStrings; public HtmlParser, HtmlParser2 : THtmlParser; end; type TBuscaPROSITE = class ListaEN: TStrings; function Busca(var EN: string): TStrings; end; type TGravador = class function ParserFlat(FlatProt : WideString): TStrings; function GravaSQL(SQL: TStrings): Boolean; end; type TBuscaESTRUTURASEC = class ListaEN: TStrings; function Busca(var EN: string; SEQ: string; proteina: TStrings ): TStrings; end; function lemsg(campo : integer; msg: string): string; var npv, pvant, pvatual, i : integer; c : string; begin pvant := 0; npv := 0; for i := 1 to length(msg) do begin c := msg[i]; if (c = '|') or (i = length(msg)) then begin inc(npv); pvatual := i; if i = length(msg) then begin result := copy(msg,pvant+1,pvatual-pvant); break; end; if npv = campo then begin result := copy(msg,pvant+1,pvatual-pvant-1); break; end; pvant := pvatual; end; end; end; function GetLocalIPAddress : string; var wsdata : TWSAData; he : PHostEnt; ss : pchar; ip : TInAddr; i : cardinal; co : string; begin i := MAX_COMPUTERNAME_LENGTH + 1; SetLength(co,i); GetComputerName(PChar(co),i); WSAStartup(MakeWord(1, 1), wsdata); he := gethostbyname(pchar(co)); if he <> nil then begin ip.S_addr := integer(pointer(he^. h_addr_list^)^); ss := inet_ntoa(ip); Result := string(ss); end; WSACleanup(); end;

function BuscaInformacao(var EntryName: string): Tstrings; var Gravador : TGravador; BuscaDOMINIO : TBuscaDOMINIO; BuscaPROSITE : TBuscaProsite; BuscaESTRUTURASEC : TBuscaESTRUTURASEC; Argumento, Seq: string; FlatProt : widestring; HTTP: TIEHTTP; SQL, SQLDOMINIO, SQLPROSITE, SQLPROT, SQLSEC, Proteina : TStrings; Temp: TStrings; begin HTTP := TIEHTTP.Create(nil); Proteina := TStringList.Create; SQL := TStringList.Create; SQLPROT := TStringList.Create; SQLPROSITE := TStringList.Create; SQLDOMINIO := TStringList.Create; SQLSEC := TStringList.Create; BuscaDOMINIO := TBuscaDOMINIO.Create; BuscaPROSITE := TBuscaProsite.Create; BuscaESTRUTURASEC := TBuscaESTRUTURASEC.Create; HTTP.URL := 'http://www.ebi.uniprot.org/entry/'+EntryName+'?format=flat&ascii'; HTTP.Execute; FlatProt := AdjustLineBreaks(HTTP.sl.text); HTTP.Free; Proteina.Text := FlatProt; SQLPROT := Gravador.ParserFlat(FlatProt); SQLPROSITE := BuscaPROSITE.Busca(EntryName); SQLDOMINIO := BuscaDOMINIO.Busca(EntryName); SQLSEC := BuscaESTRUTURASEC.Busca(EntryName, Seq, Proteina); SQL.AddStrings(SQLPROT); SQL.AddStrings(SQLPROSITE); SQL.AddStrings(SQLDOMINIO); SQL.AddStrings(SQLSEC); result := SQL; end; procedure TfrmMain.TimerTimer(Sender: TObject); var Stream : TMemoryStream; pic : TBitmap; sCommand : string; proteina, tipo, en : string; buffer : pchar; sql : tstrings; ListItem: TListItem; Msg : PMsg; begin if not idTCPClient.Connected then Exit; Timer.Enabled := False; sCommand := idTCPClient.ReadLn; if SCommand = 'BYE' then idTCPClient.Disconnect; Tipo := LeMsg(1,sCommand); if Tipo = '3' then begin sql := tstringlist.create; EN := lemsg(2,sCommand); with lv_progresso do begin ViewStyle := vsReport; begin ListItem := Items.Add; ListItem.Caption := idTCPClient.LocalName; ListItem.SubItems.Add(EN); ListItem.SubItems.Add('Não Iniciado'); end; end; Log.Lines.Insert(0,'Iniciando busca por:' + EN + ' às: ' + DateTimeToStr(Now)); sql := buscainformacao(EN); ListItem.SubItems.Add('Concluído'); Stream := TMemoryStream.Create; sql.SaveToStream(Stream); Log.Lines.Insert(0,'Enviando dados...'); idTCPClient.WriteInteger(Stream.Size); idTCPClient.OpenWriteBuffer; idTCPClient.WriteStream(Stream); idTCPClient.CloseWriteBuffer; FreeAndNil(Stream); Log.Lines.Insert(0,'Concluído'); end; Timer.Enabled := True;

end; {**************************************************************** Function AllTrim Remove os espaços em branco de ambos os lados da string ****************************************************************} function Alltrim(const Search: string): string; const blackspace = [#33..#126]; var index : byte; begin index := 1; while (index <= length(search)) and not (search[index] in blackspace) do begin index := index + 1; end; result := copy(search, index, 255); index := length(result); while (index > 0) and not (result[Index] in blackspace) do begin index := index - 1; end; result := copy(result, 1, index); end; { Fim Function AllTrim } {**************************************************************** Function Busca da Classe TBuscaProsite Função que recebe como parametro o nome de registro da proteína e que através de acesso a ferramenta PrositeScan retorna uma StringList com instruções SQL para inclusão dos motivos dessa proteína no banco de dados. *****************************************************************} function TBuscaPROSITE.Busca(var EN: string): TStrings; var Html, Lista : TStrings; final, i, j, l, k, inicio, flag, primeiro, segundo: integer; scan, linha, Base, Server, temp, temp2, iniciomotivo, fimmotivo, nomemotivo, idmotivo, descricao : string; SQL : TStrings; HtmlDoc: TDocument; Formatter: TBaseFormatter; HtmlParser: THtmlParser; FileName: string; begin SQL := TStringList.Create; HTML := TStringList.Create; Lista := TStringList.Create; flag := 0; inicio := 0; primeiro := 0; // inicialização de variáveis server := 'http://us.expasy.org/cgi-bin/prosite/PSScan.cgi?form=theForm&seq='+EN; SetLength(FileName, MAX_PATH + 1); if URLDownloadToCacheFile(nil, pchar(Server), PChar(FileName), MAX_PATH, 0, nil) = S_OK then begin SetLength(FileName, StrLen(PChar(FileName))); HTML.LoadFromFile(FileName); HtmlParser := THtmlParser.Create; try HtmlDoc := HtmlParser.parseString(HTML.Text) finally HtmlParser.Free end; Formatter := TTextFormatter.Create; try HTML.Text := Formatter.getText(HtmlDoc) finally Formatter.Free end; end; HtmlDoc.Free; Base := 'document.getElementById'; for i := 0 to HTML.Count-1 do begin linha := HTML.strings[i]; temp := copy(linha,0, length(base)); if temp = base then for j:=0 to length(linha)-1 do if linha[j] = '?' then begin scan := copy(linha,j+1, length(linha)-j-2); break; end; end;

Server := 'http://us.expasy.org/cgi-bin/prosite/ScanView.cgi?'+scan; SetLength(FileName, MAX_PATH + 1); if URLDownloadToCacheFile(nil, pchar(Server), PChar(FileName), MAX_PATH, 0, nil) = S_OK then begin SetLength(FileName, StrLen(PChar(FileName))); HTML.LoadFromFile(FileName); HtmlParser := THtmlParser.Create; try HtmlDoc := HtmlParser.parseString(HTML.Text) finally HtmlParser.Free end; Formatter := TTextFormatter.Create; try HTML.Text := Formatter.getText(HtmlDoc) finally Formatter.Free end; for i := 0 to Html.Count-1 do begin temp := Html.Strings[i]; temp2 := copy(temp, 0, 2); if temp2 = 'PS' then begin inicio := i; break; end; end; for i := inicio to Html.Count-1 do begin temp := Html.Strings[i]; for j:=0 to length(temp) do if copy(temp, j, 3) = 'PS0' then begin Lista.add(copy(temp, j, 7)); break; end end; for i := inicio to HTML.count-1 do begin temp := Html.Strings[i]; for j := 0 to length(temp)-1 do begin if (temp[j] = ' ') and (flag = 1) then begin segundo := j; Html.Strings[i] := copy(temp, 0, primeiro-1) + ' ' + copy(temp, segundo+1, length(temp)-segundo-1); flag := 0; break; end; if (temp[j] = ' ') and (temp[j] <> '') then begin flag := 1; primeiro := j; end; end; end; j := 0; final := HTML.Count-1; for i := 0 to Lista.Count-1 do while (j <= HTML.Count-1) do begin if j > final then begin inc(j); break; end; temp := Html.Strings[j]; if copy(temp,0,2) = 'PS' then begin for k := 9 to length(temp)-1 do begin idmotivo := copy(temp,0,7); if (temp[k] = ' ') and (temp[k] <> '') then begin primeiro := k; nomemotivo := copy(temp, 9, primeiro-9); descricao := copy(temp, primeiro+1, length(temp)-primeiro-1); break; end; end; inc(j); temp := Html.Strings[j]; while copy(Html.Strings[j],0,2) <> 'PS' do begin inc(j); temp := Html.Strings[j]; if copy(temp, 0, 10) = 'horizontal' then

begin final := j; break; end; for l := 0 to length(temp)-1 do begin if temp[l] = ' ' then begin iniciomotivo := copy(temp, 0, l-1); fimmotivo := copy(temp, l+1, length(temp)); SQL.ADD('insert into motivo (acmotivo, nome, inicio, nomeregistro, descricao, fim) values("' + idmotivo + '","' + nomemotivo + '","' + iniciomotivo + '","' + EN + '","' + descricao + '","' + fimmotivo + '")'+';'); inc(j); break; end; end; inc(j); inc(j); inc(j); if copy(Html.Strings[j],0,2) = 'PS' then begin dec(j); break; end; dec(j); end; end; inc(j); end; end; Html.free; lista.free; result := SQL; end; {**************************************************************** Function Busca da Classe TBuscaDominio Função que recebe como parametro o nome de registro da proteína e que através de acesso ao banco de dados PFam retorna uma StringList com instruções SQL para inclusão dos domínios dessa proteína no banco de dados. *****************************************************************} function TBuscaDOMINIO.Busca(var EN: string): TStrings; var Base, temp,tempo, temp2, dominio, iniciodom, fimdom, server, nome: String; HtmlDoc,HtmlDoc2: TDocument; Html,Html2 : TStrings; Formatter,Formatter2: TBaseFormatter; i, j, k, inicio, fim, aux, tamanho : integer; HTTP2: TIEHTTP; Buffer: pchar; SQL : TStrings; FileName : string; begin SQL := TStringlist.Create; HTML := TStringList.Create; inicio := 0; fim := 0; tamanho := 0; Server := 'http://pfam.wustl.edu/cgi-bin/getswisspfam?key=*'; Server := AnsiReplaceStr(server,'*',EN); SetLength(FileName, MAX_PATH + 1); if URLDownloadToCacheFile(nil, pchar(Server), PChar(FileName), MAX_PATH, 0, nil) = S_OK then begin SetLength(FileName, StrLen(PChar(FileName))); HTML.LoadFromFile(FileName); HtmlParser := THtmlParser.Create; try HtmlDoc := HtmlParser.parseString(HTML.Text) finally HtmlParser.Free end; Formatter := TTextFormatter.Create; try HTML.Text := Formatter.getText(HtmlDoc) finally Formatter.Free end; HtmlDoc.Free; Base := 'Accession number:'; for i := 0 to Html.Count-1 do begin if (Html.Strings[i] = 'Pfam-A Domains') and (Html.Strings[i+2] = 'Domain') and (Html.Strings[i+4] = 'Start') then inicio := i+8;

if (Html.Strings[i] = 'Pfam-B Domains') or (Html.Strings[i] = 'Other Regions') then fim := i-2; end; if fim = 0 then fim := html.count-5; aux := 0; for i := inicio to fim do begin temp := html.Strings[i]; inicio := 0; if html.Strings[i] <> '' then begin temp2 := copy(temp,inicio, length(temp)); for j := 0 to length(temp)-1 do if (temp[j] = '/') then begin inicio := j+2; break; end; temp2 := copy(temp,inicio, length(temp)); inc(aux); case aux of 1: dominio := temp2; 2: iniciodom := temp2; 3: begin fimdom := temp2; aux := 0; Server := 'http://pfam.wustl.edu/cgi-bin/getdesc?name=*'; Server := AnsiReplaceStr(server,'*',dominio); HTTP2 := TIEHTTP.Create(nil); HTTP2.URL := Server; HTTP2.Execute; tempo := PChar(AdjustLineBreaks(HTTP2.sl.text)); Buffer := PChar(tempo); HtmlParser2 := THtmlParser.Create; try HtmlDoc2 := HtmlParser2.parseString(Buffer) finally HtmlParser2.Free end; Formatter2 := TTextFormatter.Create; try HTML2 := TStringList.Create; HTML2.Text := Formatter2.getText(HtmlDoc2); finally Formatter2.Free end; for k:= 0 to HTML2.Count-1 do begin nome := HTML2.Strings[k]; tempo := copy(nome, 0, 17); if tempo = Base then begin nome := copy(HTML2.Strings[k+1], 0,length(HTML2.Strings[k+1])); HTTP2.Free; HTML2.Free; SQL.ADD('insert into dominio (nomeregistro, dominio, nome, fim, inicio, tamanho) values("' + EN + '","' + dominio + '","' + nome + '","' + FimDom + '","' + InicioDom + '","' + inttostr(tamanho) + '")'+';'); break; end; end; end; end; end; end; end; HTML.Free; result := SQL; end; {**************************************************************** Function ParserFlat da Classe TGravador Função que recebe uma string contendo as informações básicas de uma proteína no formato Flat. Retorna uma StringList contendo as instruções para inclusão das informações básicas da proteína no banco de dados. *****************************************************************} function TGravador.ParserFlat(FlatProt: WideString): TStrings; var flag, i, j, k, l, q, m, ultimo, fim, inicio, indice, aux2 : integer; funcao,ultimochar, funcaotemp, temp5, tipo, dominio, valor, nome, accession, comentario, pesoseq, gene,taxonomia,tamanhoseq, Sequencia, citacao, autor, CCtemp, OCtemp, RTtemp, RLtemp, SQtemp, titulo, temp2,publicacao, temp3, temp4, aux, DEtemp, scopo, tissue, temp, refid, EN, nomecientifico, nomevulgar,nomegene, data : string;

ListaTitulo, ListaAutores, ListaPublicacoes, ListaIndices, ListaAC, ListaNomes, ListaSinonimo, ListaSynonimsGene, ListaTaxonomia : TStrings; TempQuery : string; Proteina, SQL : TStrings; F : textfile; datasql : string; begin Proteina := TStringList.Create; SQL := TStringList.Create; ListaIndices := TStringList.Create; flag := 0; //inicialização de variáveis Proteina.Text := FlatProt; for i:= 0 to Proteina.Count-1 do begin temp := Proteina.Strings[i]; if copy(temp,0,2) = 'CC' then begin ultimochar := copy(temp,length(temp), 1); if (ultimochar = '.') and (flag = 1) then begin funcao := funcaotemp + copy(temp, 9, length(temp)-2); for l := 0 to length(funcao)-1 do begin if (funcao[l] = #39) or (funcao[l] = #34) then funcao[l] := ' '; end; break; end else if copy(temp,0, 17) = 'CC -!- FUNCTION' then begin funcaotemp := funcaotemp + copy(temp, 20, length(temp)-1); flag := 1; end else begin funcaotemp := funcaotemp + copy(temp, 9, length(temp)-1); end; end; end; for i:=0 to Proteina.Count-1 do begin temp := Proteina.Strings[i]; if copy(temp,0,2) = 'ID' then begin for j := 6 to length(temp) do if temp[j] = ' ' then begin break; end; EN := copy(temp, 6, j-6); SQL.ADD('insert into proteina (nomeregistro, funcao) values("' + EN + '","' + funcao + '")'+';'); end; if copy(temp,0,2) = 'AC' then begin inicio := 4; for j := inicio to length(temp) do if temp[j] = ';' then begin fim := j; accession := copy(temp, inicio+2, fim-inicio-2); SQL.ADD('insert into ac (nomeregistro, accession) values("' + EN + '","' + accession + '")'+';'); inicio := fim; end; end; if copy(temp,0,2) = 'DT' then begin for j := 0 to length(temp) do begin if temp[j] = ',' then begin data := copy(temp, 6, j-6); comentario := copy(temp, j+2, length(temp)); SQL.ADD('insert into datas (nomeregistro, data, comentario) values("' + EN + '","' + data + '","' + comentario + '")'+';'); end; end; end; if copy(temp,0,2) = 'DE' then begin flag := 0; inicio := 0; if temp[length(temp)] = '-' then temp := copy(temp,6, length(temp)-1) else temp := copy(temp,6, length(temp));

DEtemp := DEtemp + temp; if temp[length(temp)] = '.' then for j := inicio to length(DEtemp) do begin if (DEtemp[j] = '(') and (flag = 0) then begin inicio := j; nome := copy(DEtemp, 0, inicio-2); tipo := 'Name'; SQL.ADD('insert into nome (nomeregistro, nome, tipo) values("' + EN + '","' + nome + '","' + tipo + '")'+';'); flag := 1; end; if (DEtemp[j] = '(') and (flag = 1) then begin inicio := j; end; if DEtemp[j] = ')' then begin fim := j; nome := copy(DEtemp, inicio+1, fim-inicio-1); tipo := 'Synonyms'; SQL.ADD('insert into nome (nomeregistro, nome, tipo) values("' + EN + '","' + nome + '","' + tipo + '")'+';'); end; end; end; if copy(temp,0,2) = 'GN' then begin inicio := 4; flag := 0; for j := inicio to length(temp) do if temp[j] = ';' then begin fim := j; temp2 := copy(temp, inicio+2, fim-inicio-1); for k := 0 to length(temp2) do begin if temp2[k] = '=' then begin if copy(temp2, 0, k-1) = 'Name' then begin gene := copy(temp2, k+1, length(temp2)-k-1); nomegene := 'Name'; SQL.ADD('insert into gene (nomeregistro, tipo, gene) values("' + EN + '","' + nomegene + '","' + gene + '")'+';'); end; if copy(temp2, 0, k-1) = 'Synonyms' then begin temp3 := copy(temp2,k+1, length(temp2)-k); inicio := 0; for l := 0 to length(temp3) do begin temp4 := temp3[l]; if temp4 = ',' then begin fim := l; nomegene := 'Synonyms'; gene := copy(temp3, inicio+1, fim-inicio-1); SQL.ADD('insert into gene (nomeregistro, tipo, gene) values("' + EN + '","' + nomegene + '","' + gene + '")'+';'); inicio := fim+1; flag := 1; end; if (temp4 = ';') and (flag = 1) then begin nomegene := 'Synonyms'; gene := copy(temp3,fim+3,length(temp3)-fim-3); SQL.ADD('insert into gene (nomeregistro, tipo, gene) values("' + EN + '","' + nomegene + '","' + gene + '")'+';'); end; if (temp4 = ';') and (flag = 0) then begin nomegene := 'Synonyms'; gene := copy(temp3,0,length(temp3)-1); SQL.ADD('insert into gene (nomeregistro, tipo, gene) values("' + EN + '","' + nomegene + '","' + gene + '")'+';'); end; end; end; end; end; inicio := fim; end; end;

if copy(temp,0,2) = 'OS' then begin for j := 0 to length(temp) do begin if temp[j] = '(' then begin nomecientifico := copy(temp, 6, j-7); nomevulgar := copy(temp, j+1, length(temp)-j-2); break; end; if temp[j] = '.' then begin nomecientifico := copy(temp, 6, length(temp)-2); nomevulgar := ''; end; end; SQL.ADD('insert into organismo (nomecientifico, nomevulgar) values("' + nomecientifico + '","' + nomevulgar + '")'+';'); SQL.ADD('insert into organismo_has_proteina (nomecientifico, nomeregistro) values("' + nomecientifico + '","' + EN + '")'+';'); end; if copy(temp,0,2) = 'OC' then begin temp := copy(temp,6, length(temp)); OCtemp := OCtemp + temp; if temp[length(temp)] = '.' then begin inicio := 0; for j := 0 to length(OCtemp) do begin if OCtemp[j] = ';' then begin fim := j; taxonomia := alltrim(copy(OCtemp, inicio+1, fim-inicio-1)); SQL.ADD('insert into organismo_has_taxonomia (nomecientifico, taxonomia) values("' + nomecientifico + '","' + taxonomia + '")'+';'); inicio := fim; end; if OCtemp[j] = '.' then begin taxonomia := alltrim(copy(OCtemp, inicio+1, length(OCtemp)-inicio-1)); SQL.ADD('insert into organismo_has_taxonomia (nomecientifico, taxonomia) values("' + nomecientifico + '","' + taxonomia + '")'+';'); end; end; end; end; end; i := 0; while i < Proteina.Count-1 do begin temp := Proteina.Strings[i]; if copy(temp,0,2) = 'RN' then begin ListaIndices.Add(inttostr(i)); end; if copy(temp,0,2) = 'CC' then begin ListaIndices.Add(inttostr(i)); Break; end; inc(i); end; i := 0; while i < Proteina.Count do begin temp := Proteina.Strings[i]; inicio := 16; flag := 0; if copy(temp,0,2) = 'SQ' then begin for m := 0 to length(temp) do begin if (temp[m] = ';') and (flag = 1) then begin pesoseq := copy(temp, inicio+2, m-inicio-2); end; if (temp[m] = ';') and (flag = 0) then begin tamanhoseq := copy(temp, inicio, m-inicio); inicio := m; flag := 1; end; end;

end; if copy(temp,0,2) = ' ' then begin temp2 := copy(Proteina.strings[i], 6, length(Proteina.strings[i])); temp2 := copy(temp2, 1, length(temp)); SQtemp := SQtemp + temp2; end; if copy(temp,0,2) = '//' then begin Sequencia := copy(SQtemp, 1, length(SQtemp)-1); Sequencia := AllTrim(Sequencia); SQL.ADD('insert into sequencia (nomeregistro, tamanho, peso, sequencia) values("' + EN + '","' + tamanhoseq + '","' + pesoseq + '","' + sequencia + '")'+';'); RTtemp := ''; end; inc(i); end; for i:=0 to ListaIndices.Count-2 do begin indice := strtoint(ListaIndices.Strings[i]); j := indice; refid := copy(Proteina.strings[j], 7, length(Proteina.strings[j])-7); while j < strtoint(ListaIndices.Strings[i+1]) do begin temp := Proteina.strings[j]; if copy(temp,0,2) = 'RP' then begin scopo := copy(Proteina.strings[j], 6, length(Proteina.strings[j])-6); end; if copy(temp,0,2) = 'RC' then begin tissue := copy(Proteina.strings[j], 13, length(Proteina.strings[j])-13); end; if copy(temp,0,2) = 'RX' then begin publicacao := copy(Proteina.strings[j], 6, length(Proteina.strings[j])-6); end; if copy(temp,0,2) = 'RA' then begin temp2 := copy(Proteina.strings[j], 6, length(Proteina.strings[j])-5); inicio := 0; for k := inicio to length(temp2) do begin if temp2[k] = ',' then begin fim := k; autor := copy(temp2, inicio+1, fim-inicio-1); SQL.ADD('insert into referencia_has_autor (nomeregistro, refid, nome) values("' + EN + '","' + refid + '","' + autor + '")'+';'); inicio := fim; end; end; end; if copy(temp,0,2) = 'RL' then begin temp2 := copy(Proteina.strings[j], 6, length(Proteina.strings[j])); if temp2[length(temp)] = '-' then temp2 := copy(temp2,1, length(temp)-1) else temp2 := copy(temp2,1, length(temp)); RLtemp := RLtemp + ' ' + temp2; if temp2[length(temp2)] = '.' then begin citacao := copy(RTtemp, 1, length(RTtemp)-1); RLtemp := ''; end; end; if copy(temp,0,2) = 'RT' then begin temp2 := copy(Proteina.strings[j], 6, length(Proteina.strings[j])); if temp2[length(temp)] = '-' then temp2 := copy(temp2,1, length(temp)-1) else temp2 := copy(temp2,1, length(temp)); RTtemp := RTtemp + ' ' + temp2; if temp2[length(temp2)] = ';' then begin Titulo := copy(RTtemp, 3, length(RTtemp)-4); for l :=0 to length(Titulo)-1 do begin if titulo[l] = #39 then titulo[l] := ' '; end;

SQL.ADD('insert into referencia (nomeregistro, refid, escopo, tissue, titulo, citacao, publicacao) values("' + EN + '","' + refid + '","' + scopo + '","' + tissue + '","' + titulo + '","' + citacao + '","' + publicacao + '")'+';'); tissue := ''; RTtemp := ''; end; end; inc(j); end; end; ListaTitulo.free; ListaAutores.free; ListaPublicacoes.free; ListaIndices.free; ListaAC.free; ListaNomes.free; ListaSinonimo.free; ListaSynonimsGene.free; ListaTaxonomia.free; Proteina.Free; result := SQL; end; {**************************************************************** Function GravaSQL da Classe TGravador Função que recebe como parametro uma StringList com instruções SQL resultante das funções TBuscaProsite.Busca, TBuscaDominio.Busca, TGravador.ParseFlat e TBuscaESTRUTURASEC.Busca Antes da execução de cada instrução, realiza a uma consulta a fim de verificar se existe duplicidade de registros. *****************************************************************} function TGravador.GravaSQL(SQL: TStrings): Boolean; var flag, aux2, i, fim, inicio, q : integer; TempQuery, valor : string; inicio_sec, final_sec, tipo, gene, dominio, acmotivo, iniciomotivo, EN, refid, nome, nomecientifico, taxonomia, sequencia, accession : string; ZQuery : TZQuery; Connection : TZConnection; begin Leini; Connection := TZConnection.Create(nil); Connection.Protocol := 'mysql'; Connection.HostName := HostName; Connection.Database := Database; Connection.User := Usuario; Connection.Password := senha; ZQuery := TZQuery.Create(nil); Zquery.Connection := Connection; inicio := 0; //inicialização de variáveis for q := 0 to SQL.Count-1 do begin TempQuery := SQL.Strings[q]; flag := 0; // verificação da existencia ou não do registro no banco // verificação para cada tipo de registro, // após verificação, registro é inserido no banco. if copy(TempQuery, 0, 32) = 'insert into referencia_has_autor' then begin aux2 := 0; for i := 0 to length(TempQuery)-1 do begin if (TempQuery[i] = #34) and (aux2 = 1) then begin fim := i; valor := copy(TempQuery, inicio+1, fim-inicio-1); inc(flag); aux2 := 0; end; if (TempQuery[i] = #34) then begin aux2 := 1; inicio := i; end; case flag of 1 : EN := valor; 3 : refid := valor; 5 : nome := valor; end; end; flag := 0; zQuery.SQL.Clear; zQuery.SQL.ADD('select * from referencia_has_autor'); zQuery.sql.ADD('where nomeregistro like "' + EN + '" and refid like "' + refid + '" and nome like "' + nome + '"'); zQuery.Open; if zQuery.IsEmpty then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL;

end; end; if copy(TempQuery, 0, 21) = 'insert into taxonomia' then begin aux2 := 0; for i := 0 to length(TempQuery)-1 do begin if (TempQuery[i] = #34) and (aux2 = 1) then begin fim := i; valor := copy(TempQuery, inicio+1, fim-inicio-1); inc(flag); aux2 := 0; end; if (TempQuery[i] = #34) then begin aux2 := 1; inicio := i; end; case flag of 1 : taxonomia := valor; end; end; flag := 0; zQuery.SQL.Clear; zQuery.SQL.ADD('select * from taxonomia'); zQuery.sql.ADD('where taxonomia like "' + taxonomia + '"'); zQuery.Open; if zQuery.IsEmpty then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL; end; end; if copy(TempQuery, 0, 35) = 'insert into organismo_has_taxonomia' then begin aux2 := 0; for i := 0 to length(TempQuery)-1 do begin if (TempQuery[i] = #34) and (aux2 = 1) then begin fim := i; valor := copy(TempQuery, inicio+1, fim-inicio-1); inc(flag); aux2 := 0; end; if (TempQuery[i] = #34) then begin aux2 := 1; inicio := i; end; case flag of 1 : nomecientifico := valor; 3 : taxonomia := valor; end; end; flag := 0; zQuery.SQL.Clear; zQuery.SQL.ADD('select * from organismo_has_taxonomia'); zQuery.sql.ADD('where taxonomia like "' + taxonomia + '" and nomecientifico like "' + nomecientifico + '"'); zQuery.Open; if zQuery.IsEmpty then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL; end; end; if copy(TempQuery, 0, 21) = 'insert into sequencia' then begin aux2 := 0; for i := 0 to length(TempQuery)-1 do begin if (TempQuery[i] = #34) and (aux2 = 1) then begin fim := i; valor := copy(TempQuery, inicio+1, fim-inicio-1); inc(flag); aux2 := 0; end; if (TempQuery[i] = #34) then begin aux2 := 1;

inicio := i; end; case flag of 1 : EN := valor; 7 : sequencia := valor; end; end; flag := 0; zQuery.SQL.Clear; zQuery.SQL.ADD('select * from sequencia'); zQuery.sql.ADD('where nomeregistro like "' + EN + '" and sequencia like "' + sequencia + '"'); zQuery.Open; if zQuery.IsEmpty then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL; end; end; if copy(TempQuery, 0, 20) = 'insert into proteina' then begin aux2 := 0; for i := 0 to length(TempQuery)-1 do begin if (TempQuery[i] = #34) and (aux2 = 1) then begin fim := i; valor := copy(TempQuery, inicio+1, fim-inicio-1); inc(flag); aux2 := 0; end; if (TempQuery[i] = #34) then begin aux2 := 1; inicio := i; end; case flag of 1 : EN := valor; end; end; flag := 0; zQuery.SQL.Clear; zQuery.SQL.ADD('select * from proteina'); zQuery.sql.ADD('where nomeregistro like "' + EN + '"'); zQuery.Open; if zQuery.IsEmpty then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL; end; end; if copy(TempQuery, 0, 23) = 'insert into organismo (' then begin aux2 := 0; for i := 0 to length(TempQuery)-1 do begin if (TempQuery[i] = #34) and (aux2 = 1) then begin fim := i; valor := copy(TempQuery, inicio+1, fim-inicio-1); inc(flag); aux2 := 0; end; if (TempQuery[i] = #34) then begin aux2 := 1; inicio := i; end; case flag of 1 : nomecientifico := valor; end; end; flag := 0; zQuery.SQL.Clear; zQuery.SQL.ADD('select * from organismo'); zQuery.SQL.ADD('where nomecientifico = "' + nomecientifico + '"'); zQuery.ExecSQL; zQuery.Open; if zQuery.IsEmpty then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL;

end; end; if copy(TempQuery, 0, 34) = 'insert into organismo_has_proteina' then begin aux2 := 0; for i := 0 to length(TempQuery)-1 do begin if (TempQuery[i] = #34) and (aux2 = 1) then begin fim := i; valor := copy(TempQuery, inicio+1, fim-inicio-1); inc(flag); aux2 := 0; end; if (TempQuery[i] = #34) then begin aux2 := 1; inicio := i; end; case flag of 1 : nomecientifico := valor; 3 : EN := valor; end; end; flag := 0; zQuery.SQL.Clear; zQuery.SQL.ADD('select * from organismo_has_proteina'); zQuery.sql.ADD('where nomecientifico like "' + nomecientifico + '" and nomeregistro like "' + EN + '"'); zQuery.Open; if zQuery.IsEmpty then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL; end; end; if copy(TempQuery, 0, 16) = 'insert into nome' then begin aux2 := 0; for i := 0 to length(TempQuery)-1 do begin if (TempQuery[i] = #34) and (aux2 = 1) then begin fim := i; valor := copy(TempQuery, inicio+1, fim-inicio-1); inc(flag); aux2 := 0; end; if (TempQuery[i] = #34) then begin aux2 := 1; inicio := i; end; case flag of 1 : EN := valor; 3 : nome := valor; end; end; flag := 0; zQuery.SQL.Clear; zQuery.SQL.ADD('select * from nome'); zQuery.sql.ADD('where nomeregistro like "' + EN + '" and nome like "' + nome + '"'); zQuery.Open; if zQuery.IsEmpty then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL; end; end; if copy(TempQuery, 0, 17) = 'insert into datas' then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL; end; if copy(TempQuery, 0, 14) = 'insert into ac' then begin aux2 := 0; for i := 0 to length(TempQuery)-1 do begin if (TempQuery[i] = #34) and (aux2 = 1) then begin

fim := i; valor := copy(TempQuery, inicio+1, fim-inicio-1); inc(flag); aux2 := 0; end; if (TempQuery[i] = #34) then begin aux2 := 1; inicio := i; end; case flag of 1 : EN := valor; 3 : accession := valor; end; end; flag := 0; zQuery.SQL.Clear; zQuery.SQL.ADD('select * from ac'); zQuery.sql.ADD('where nomeregistro like "' + EN + '" and accession like "' + accession + '"'); zQuery.Open; if zQuery.IsEmpty then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL; end; end; if copy(TempQuery, 0, 24) = 'insert into referencia (' then begin aux2 := 0; for i := 0 to length(TempQuery)-1 do begin if (TempQuery[i] = #34) and (aux2 = 1) then begin fim := i; valor := copy(TempQuery, inicio+1, fim-inicio-1); inc(flag); aux2 := 0; end; if (TempQuery[i] = #34) then begin aux2 := 1; inicio := i; end; case flag of 1 : EN := valor; 3 : refid := valor; end; end; flag := 0; zQuery.SQL.Clear; zQuery.SQL.ADD('select * from referencia'); zQuery.sql.ADD('where nomeregistro = "' + EN + '" and refid = "' + refid + '";'); zQuery.Open; if zQuery.IsEmpty then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL; end; end; if copy(TempQuery, 0, 18) = 'insert into motivo' then begin aux2 := 0; for i := 0 to length(TempQuery)-1 do begin if (TempQuery[i] = #34) and (aux2 = 1) then begin fim := i; valor := copy(TempQuery, inicio+1, fim-inicio-1); inc(flag); aux2 := 0; end; if (TempQuery[i] = #34) then begin aux2 := 1; inicio := i; end; case flag of 1 : acmotivo := valor; 3 : nome := valor; 5 : iniciomotivo := valor; 7 : EN := valor; end;

end; flag := 0; zQuery.SQL.Clear; zQuery.SQL.ADD('select * from motivo'); zQuery.sql.ADD('where nomeregistro like "' + EN + '" and acmotivo like "' + acmotivo + '" and nome like "' + nome + '" and inicio like "' + iniciomotivo + '"'); zQuery.Open; if zQuery.IsEmpty then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL; end; end; if copy(TempQuery, 0, 19) = 'insert into dominio' then begin aux2 := 0; for i := 0 to length(TempQuery)-1 do begin if (TempQuery[i] = #34) and (aux2 = 1) then begin fim := i; valor := copy(TempQuery, inicio+1, fim-inicio-1); inc(flag); aux2 := 0; end; if (TempQuery[i] = #34) then begin aux2 := 1; inicio := i; end; case flag of 1 : EN := valor; 3 : dominio := valor; 5 : nome := valor; end; end; flag := 0; zQuery.SQL.Clear; zQuery.SQL.ADD('select * from dominio'); zQuery.sql.ADD('where nomeregistro like "' + EN + '" and dominio like "' + dominio + '" and nome like "' + nome + '"'); zQuery.Open; if zQuery.IsEmpty then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL; end; end; if copy(TempQuery, 0, 16) = 'insert into gene' then begin aux2 := 0; for i := 0 to length(TempQuery)-1 do begin if (TempQuery[i] = #34) and (aux2 = 1) then begin fim := i; valor := copy(TempQuery, inicio+1, fim-inicio-1); inc(flag); aux2 := 0; end; if (TempQuery[i] = #34) then begin aux2 := 1; inicio := i; end; case flag of 1 : EN := valor; 3 : tipo := valor; 5 : gene := valor; end; end; flag := 0; zQuery.SQL.Clear; zQuery.SQL.ADD('select * from gene'); zQuery.sql.ADD('where nomeregistro like "' + EN + '" and gene like "' + gene + '" and tipo like "' + tipo + '";'); zQuery.Open; if zQuery.IsEmpty then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL; end;

end; if copy(TempQuery, 0, 31) = 'insert into estruturasecundaria' then begin aux2 := 0; for i := 0 to length(TempQuery)-1 do begin if (TempQuery[i] = #34) and (aux2 = 1) then begin fim := i; valor := copy(TempQuery, inicio+1, fim-inicio-1); inc(flag); aux2 := 0; end; if (TempQuery[i] = #34) then begin aux2 := 1; inicio := i; end; case flag of 1 : EN := valor; 3 : tipo := valor; 5 : inicio_sec := valor; 7 : final_sec := valor; end; end; zQuery.SQL.Clear; zQuery.SQL.ADD('select * from estruturasecundaria'); zQuery.sql.ADD('where nomeregistro = "' + EN + '" and tipoestrutura = "' + tipo + '" and inicio = "' + inicio_sec + '" and fim = "' + final_sec + '";'); zQuery.Open; if zQuery.IsEmpty then begin zQuery.SQL.Clear; zQuery.SQL.Add(TempQuery); zQuery.ExecSQL; end; end; end; result := true; end; {**************************************************************** Function Busca da Classe TBuscaESTRUTURASEC Função que recebe como parametro o nome de registro da proteína, Sequencia a proteína e uma string contendo informações da proteina no formato Flat. Verifica se existe estrutura secundaria para essa proteína nas informações básicas, senão utiliza a ferramenta EMBOSS para a predição da mesma. *****************************************************************} function TBuscaESTRUTURASEC.Busca(var EN: string; SEQ: string; proteina: TStrings ): TStrings; var Html : TStrings; i, j, flag, inicio, fim: integer; linha, Server, temp: string; SQL : TStrings; HtmlDoc: TDocument; Formatter: TBaseFormatter; HtmlParser: THtmlParser; ieHTTP: TIEHTTP; sec, tipo : string; FT, inicio_sec, final_sec : string; begin ieHttp := TIEHTTP.Create(nil); SQL := TStringList.Create; html := TStringList.Create; Server := 'http://npsa-pbil.ibcp.fr/cgi-bin/secpred_gor4.pl?notice='+SEQ; html.Text := iehttp.get_url(Server); HtmlParser := THtmlParser.Create; try HtmlDoc := HtmlParser.parseString(HTML.Text) finally HtmlParser.Free end; Formatter := TTextFormatter.Create; try HTML.Text := Formatter.getText(HtmlDoc) finally Formatter.Free end; i := 0; while i <= HTML.Count-1 do begin linha := HTML.Strings[i]; if length(linha) >= 10 then

if linha[10] = '|' then begin i := i + 2; seq := HTML.Strings[i]; break; end; inc(i); end; inicio := 0; flag := 1; while i <= length(seq)-1 do begin if (seq[i] = ' ') and (flag = 0) then begin flag := 1; inicio := i; inc(i); end; if (seq[i] = ' ') and (flag = 1) then begin flag := 0; sec := sec + copy(seq, inicio, i-inicio); inicio := i; end; inc(i); end; sec := sec + copy(seq, inicio, i-inicio); i:=0; while i <= length(sec)-1 do begin if tipo = copy(sec,i,1) then else inicio := i; tipo := copy(sec,i,1); if (sec[i+1] <> tipo) and (tipo <> ' ') then begin fim := i; if tipo = 'c' then tipo := 'RANDOM COIL'; if tipo = 'e' then tipo := 'EXTENDED STRAND'; if tipo = 'b' then tipo := 'BETA'; if tipo = 'h' then tipo := 'ALFA HELIX'; if tipo = 'i' then tipo := 'PI HELIX'; if tipo = 's' then tipo := 'BRAND REGION'; if tipo = 't' then tipo := 'BETA TURN'; if tipo = '?' then tipo := 'AMBIGOUS STATES'; if tipo = 'g' then tipo := '30x10 HELIX'; SQL.ADD('insert into estruturasecundaria (nomeregistro, tipoestrutura, inicio, fim) values("' + EN + '","' + tipo + '","' + inttostr(inicio) + '","' + inttostr(fim) + '");'); end; inc(i); end; for i := 0 to proteina.count-1 do begin linha := copy(proteina.Strings[i], 0, length(proteina.Strings[i])); linha := linha; FT := copy(linha, 0, 2); if FT = 'FT' then begin // FT CHAIN j := 7; tipo := ''; temp := ''; while j <= length(linha) do begin if (linha[j] = ' ') and (tipo = '') then begin tipo := copy(linha, 5, j-5); end; if (linha[j] <> ' ') and (tipo <> '') then begin temp := temp + copy(linha, j, 1); flag := 1; end;

if (linha[j] = ' ') or (j = length(linha)) and (tipo <> '') and (flag = 1) then begin if (final_sec = '') and (inicio_sec <> '') then begin final_sec := temp; end; if (inicio_sec = '') then begin inicio_sec := temp; temp := ''; end; end; inc(j); end; end; alltrim(tipo); if (copy(tipo, 2, 1) <> ' ') then if (final_sec <> '') and (inicio_sec <> '') then SQL.ADD('insert into estruturasecundaria (nomeregistro, tipoestrutura, inicio, fim) values("' + EN + '","' + tipo + '","' + inicio_sec + '","' + final_sec + '");'); inicio_sec := ''; final_sec := ''; tipo := ''; end; result := SQL; end;
[FIM DE SEÇÃO. Não remova esta quebra de se