Embed Size (px)
Citation preview

International Criticality Benchmark Comparison for Nuclear Data Validation
Isabelle Duhamel,1 J. L. Alwin,2 F. B. Brown,2 M. E. Rising,2 K. Y. Spencer,2 D. Heinrichs,3S. Kim,3 B. J. Marshall,4 E. M. Saylor
4
1IRSN, Fontenay-aux-Roses, France, [email protected]
2Los Alamos National Laboratory, Los Alamos, USA, [email protected], [email protected],
[email protected], [email protected] 3Lawrence Livermore National Laboratory, Livermore, USA, [email protected], [email protected]
4Oak Ridge National Laboratory, Knoxville, USA, [email protected], [email protected]
https://dx.doi.org/10.13182/T30859
INTRODUCTION
Under a collaborative effort between the US
Department of Energy (DOE) Nuclear Criticality Safety
Program (NCSP) and the French Institut de Radioprotection
et de Sûreté Nucléaire (IRSN), IRSN is leading a
benchmark intercomparison effort using a large selection of
criticality safety benchmarks.
This task is carried out by using the IRSN MORET
Monte Carlo code [ref. 1] together with various nuclear data
libraries, namely JEFF-3.3, ENDF/B-VII.1 and
ENDF/B-VIII.0. IRSN collates its results together with
those from Lawrence Livermore National Laboratory
(LLNL), Los Alamos National Laboratory (LANL) and Oak
Ridge National Laboratory (ORNL) using respectively the
COG [ref. 2], MCNP [ref. 3] and KENO (SCALE package)
[ref. 4] Monte Carlo codes associated with ENDF/B-VII.1
library. LLNL also shared in 2019 their COG results using
ENDF/B-VIII.0 and JEFF-3.3. Due to the large number of
benchmarks involved (about 3000), this effort is envisioned
to take three years and is currently focused on High
Enriched Uranium (HEU) and Plutonium systems (PU).
About 760 HEU and 500 PU benchmarks taken from
the ICSBEP handbook [ref. 5] covering a large energy
spectra range (from thermal to fast) and a wide range of
isotopes are considered.
METHODOLOGY
The benchmark development has been performed
independently with most of the cases being taken from each
codes validation suites. Results were provided with Monte
Carlo standard deviation of about 10 pcm for all the codes.
Table I gives the number of HEU and PU benchmarks
calculated with the different Monte Carlo codes.
TABLE I. Calculated benchmarks in validation suites
MORET 5
(IRSN)
COG
(LLNL)
MCNP
(LANL)
KENO
(ORNL)
HEU systems 447 761 378 102
PU systems 215 526 261 93
Despite the huge number of calculated benchmarks,
only 35 configurations for HEU and 33 for PU systems were
common to the four codes. Thus, it was decided to focus
first on the common benchmarks and also to perform code
to code comparison. This paper discusses mainly the results
obtained for these 68 common benchmarks, which are
briefly described in Table II.
TABLE II. Main characteristics of the common benchmarks
HST HMF PST PMF
Number of
experiments
14 21 26 7
Isotopic
composition
93% 235U 235U>
89%
239Pu > 95% 239Pu >
94%
Concentration 20 to 360 g/l - 25 to 140 g/l -
Moderator Water None, Be,
BeO
Water None
Poison None or
boron
None None None
Reflector None None, Mo,
Be, BeO,
CH2, V,
Steel,
Depleted
uranium
Water None,
Unat,
Th, Be,
W, Steel
RESULTS
Preliminary analysis
When analyzing the calculation results using the same
nuclear data libraries for these common benchmarks,
discovery of discrepant results helped to highlight modeling
errors, which were reported to the codes validation teams.
Transactions of the American Nuclear Society, Vol. 121, Washington, D.C., November 17–21, 2019
873Recent Nuclear Criticality Safety Program Technical Accomplishments
Moreover, rigorous cross-checking of results using the
same nuclear data evaluations has also revealed modeling
interpretation user’s misunderstanding, as well as some
inconsistencies in the DICE database, that will be gathered
and reported to the ICSBEP working group.
An important issue when performing a benchmark
intercomparison is to be sure to model exactly the same
configurations. Indeed, in the ICSBEP handbook, among the
225 evaluations available for HEU systems (95 for PU), 77
(45 for PU) have been revised (some of them having been
revised 4 times). In most of the cases, the revision of the
evaluation could have a small, but non negligible impact, on
the keff and could explain small observed discrepancies
between calculation results. For example, the well-known
JEZEBEL benchmark experiment, which is used worldwide
for Plutonium cross sections validation and adjustment, was
revised 4 times, the last one being in 2016, leading to
modifications of the sphere mass and density (implying a
modification of the radius of the sphere). Looking at the
benchmark keff and its associated uncertainty in the different
validation suites, one can conclude that COG and MORET
calculations considered the last revision of the JEZEBEL
benchmark, whereas MCNP and KENO calculations were
performed considering revision 2. It results in a difference
of about 40 pcm for the JEZEBEL experiment but it could
rise up to few hundreds of pcm for some benchmark’s
revision depending on the changes in the model.
Some observed discrepancies could also be explained
by the use of the simplified model described in the ICSBEP
handbook. Indeed, it was not always specified in the
validation suites whether the simplified or the detailed
model was considered. This could lead to small but not
negligible discrepancies between codes. A detailed analysis
is currently underway to examine the input files to
determine which model was used.
Finally, one might also face numbering issues. Indeed,
in a whole experimental program, some experiments could
not reach the critical state or were not considered as
acceptable for a benchmark. Some validation teams had then
considered the experiment number (referred as to the case
label in DICE), whereas some others used the case ID.
PU-SOL-THERM-007 experiments are a good example of
this issue with experiments 1, 4 and 11 being considered as
unacceptable. Thus the fifth case of the benchmark
corresponds to the experiment n°3. As the benchmark keff
and their associated uncertainties are the same for all the
experiments, this issue was not easily detected and the
discrepant results could have been attributed to modeling
errors.
Feedback on nuclear data
Once confident in the benchmark modeling, the
comparison of the results obtained with various libraries
allows validating the nuclear data of various isotopes of
interest for criticality safety.
ENDF/B-VII.1 results
Although, it was planned to compare both ENDF/B-
VII.1 and ENDF/B-VIII.0 results during 2019, only
ENDF/B-VII.1 results are currently available for the four
codes.
Table III presents the mean values of the calculation –
experiment discrepancies obtained for the plutonium
experiments in fast spectra by the 4 Monte Carlo codes, all
giving similar results. Calculations using ENDF/B-VII.1
nuclear data library lead to results within the experimental
uncertainties except for the PU-MET-FAST-008.001
benchmark, which is a thorium reflected plutonium sphere
and shows a small underestimation.
TABLE III. Benchmark keff and Calculation-experiment
discrepancies for plutonium metallic systems.
Benchmark
keff
Sigma Average of
C-E (pcm)
PMF-001-001
Revision 2
1.00000 0.00200 0
PMF-001-001
Revision 4
1.00000 0.00110 40
PMF-005-001 1.00000 0.00130 105
PMF-006-001 1.00000 0.00300 113
PMF-008-001 1.00000 0.00060 -191
PMF-010-001 1.00000 0.00180 -34
PMF-018-001 1.00000 0.00300 -72
PMF-026-001 1.00000 0.00240 -238
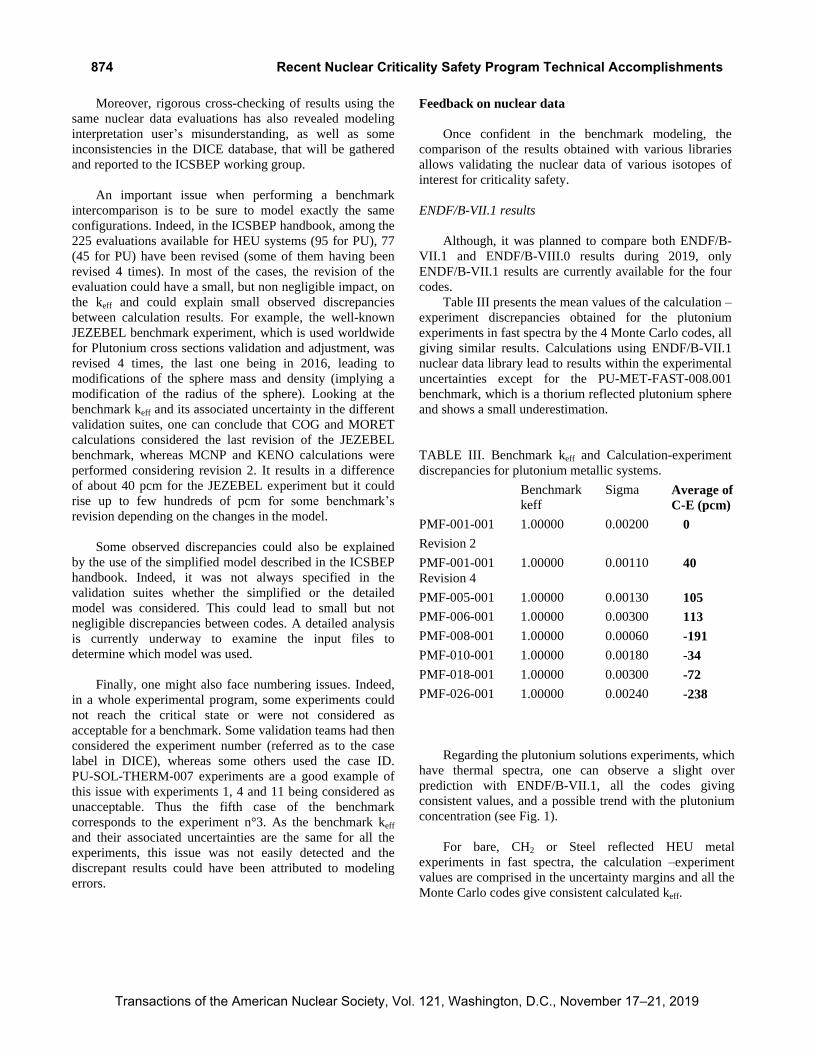
Regarding the plutonium solutions experiments, which
have thermal spectra, one can observe a slight over
prediction with ENDF/B-VII.1, all the codes giving
consistent values, and a possible trend with the plutonium
concentration (see Fig. 1).
For bare, CH2 or Steel reflected HEU metal
experiments in fast spectra, the calculation –experiment
values are comprised in the uncertainty margins and all the
Monte Carlo codes give consistent calculated keff.
Transactions of the American Nuclear Society, Vol. 121, Washington, D.C., November 17–21, 2019
874 Recent Nuclear Criticality Safety Program Technical Accomplishments
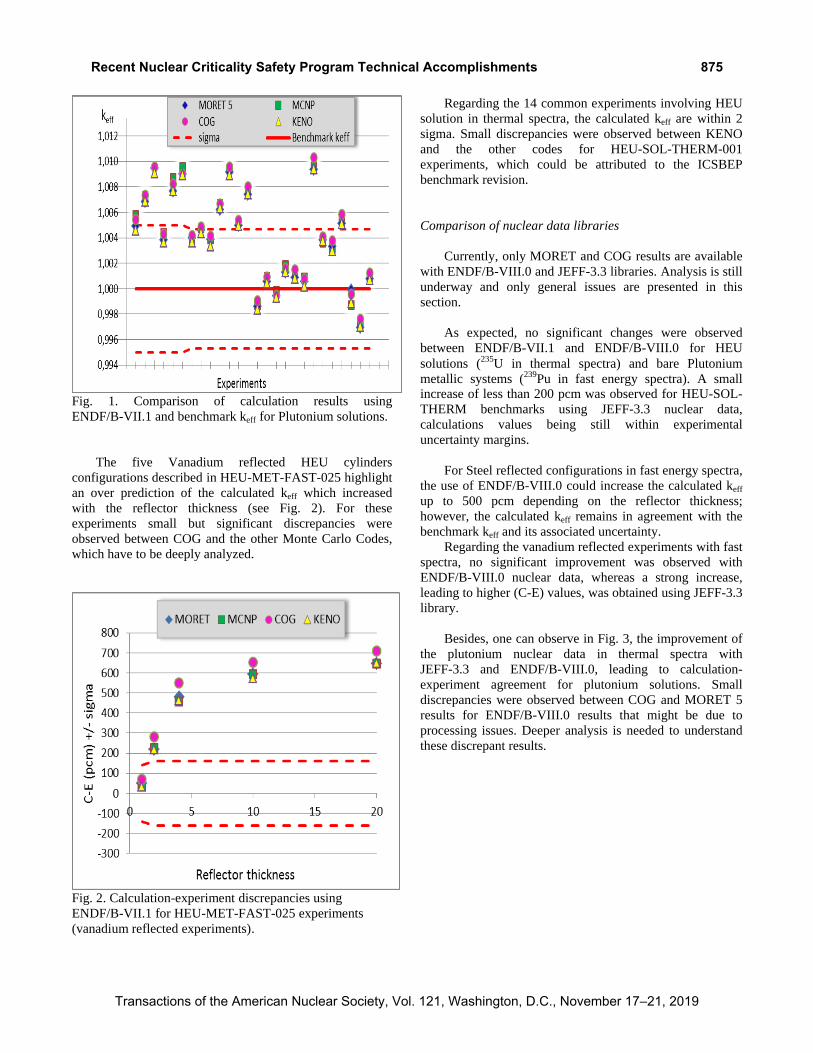
Fig. 1. Comparison of calculation results using
ENDF/B-VII.1 and benchmark keff for Plutonium solutions.
The five Vanadium reflected HEU cylinders
configurations described in HEU-MET-FAST-025 highlight
an over prediction of the calculated keff which increased
with the reflector thickness (see Fig. 2). For these
experiments small but significant discrepancies were
observed between COG and the other Monte Carlo Codes,
which have to be deeply analyzed.
Fig. 2. Calculation-experiment discrepancies using
ENDF/B-VII.1 for HEU-MET-FAST-025 experiments
(vanadium reflected experiments).
Regarding the 14 common experiments involving HEU
solution in thermal spectra, the calculated keff are within 2
sigma. Small discrepancies were observed between KENO
and the other codes for HEU-SOL-THERM-001
experiments, which could be attributed to the ICSBEP
benchmark revision.
Comparison of nuclear data libraries
Currently, only MORET and COG results are available
with ENDF/B-VIII.0 and JEFF-3.3 libraries. Analysis is still
underway and only general issues are presented in this
section.
As expected, no significant changes were observed
between ENDF/B-VII.1 and ENDF/B-VIII.0 for HEU
solutions (235
U in thermal spectra) and bare Plutonium
metallic systems (239
Pu in fast energy spectra). A small increase of less than 200 pcm was observed for HEU-SOL-
THERM benchmarks using JEFF-3.3 nuclear data,
calculations values being still within experimental
uncertainty margins.
For Steel reflected configurations in fast energy spectra,
the use of ENDF/B-VIII.0 could increase the calculated keff
up to 500 pcm depending on the reflector thickness;
however, the calculated keff remains in agreement with the
benchmark keff and its associated uncertainty.
Regarding the vanadium reflected experiments with fast
spectra, no significant improvement was observed with
ENDF/B-VIII.0 nuclear data, whereas a strong increase,
leading to higher (C-E) values, was obtained using JEFF-3.3
library.
Besides, one can observe in Fig. 3, the improvement of
the plutonium nuclear data in thermal spectra with
JEFF-3.3 and ENDF/B-VIII.0, leading to calculation-
experiment agreement for plutonium solutions. Small
discrepancies were observed between COG and MORET 5
results for ENDF/B-VIII.0 results that might be due to
processing issues. Deeper analysis is needed to understand
these discrepant results.
Transactions of the American Nuclear Society, Vol. 121, Washington, D.C., November 17–21, 2019
875Recent Nuclear Criticality Safety Program Technical Accomplishments
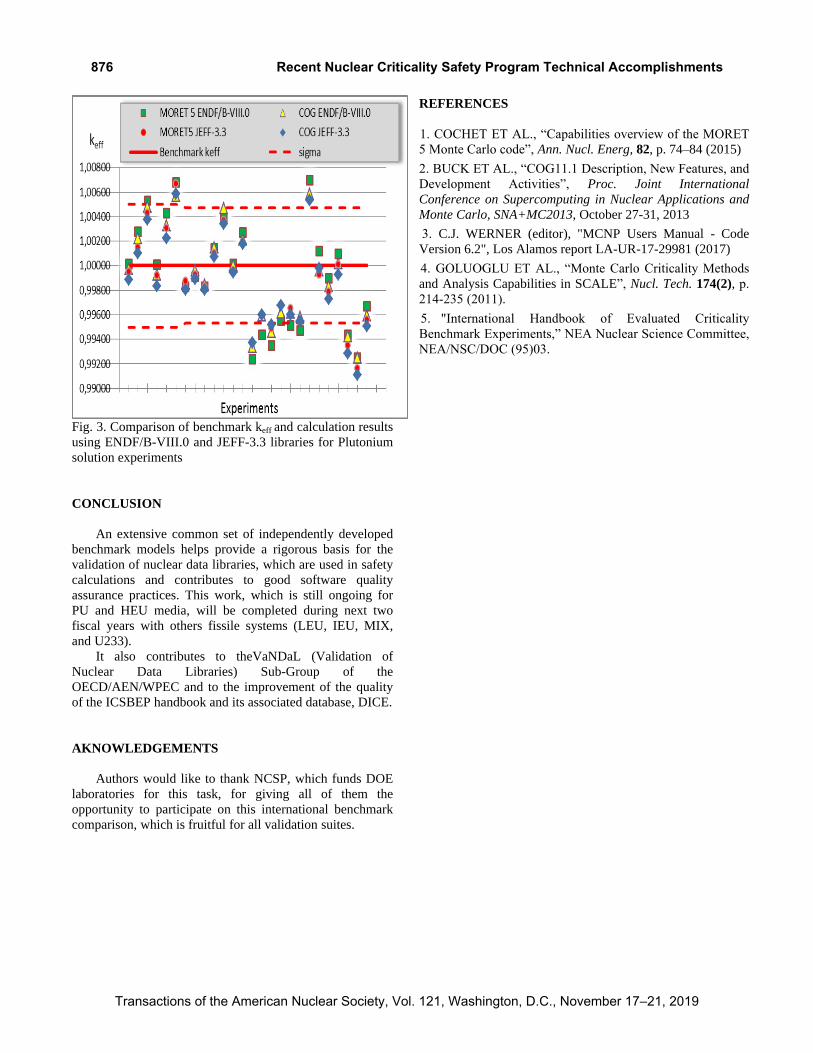
Fig. 3. Comparison of benchmark keff and calculation results
using ENDF/B-VIII.0 and JEFF-3.3 libraries for Plutonium
solution experiments
CONCLUSION
An extensive common set of independently developed
benchmark models helps provide a rigorous basis for the
validation of nuclear data libraries, which are used in safety
calculations and contributes to good software quality
assurance practices. This work, which is still ongoing for
PU and HEU media, will be completed during next two
fiscal years with others fissile systems (LEU, IEU, MIX,
and U233).
It also contributes to theVaNDaL (Validation of
Nuclear Data Libraries) Sub-Group of the
OECD/AEN/WPEC and to the improvement of the quality
of the ICSBEP handbook and its associated database, DICE.
AKNOWLEDGEMENTS
Authors would like to thank NCSP, which funds DOE
laboratories for this task, for giving all of them the
opportunity to participate on this international benchmark
comparison, which is fruitful for all validation suites.
REFERENCES
1. COCHET ET AL., “Capabilities overview of the MORET
5 Monte Carlo code”, Ann. Nucl. Energ, 82, p. 74–84 (2015)
2. BUCK ET AL., “COG11.1 Description, New Features, and
Development Activities”, Proc. Joint International
Conference on Supercomputing in Nuclear Applications and
Monte Carlo, SNA+MC2013, October 27-31, 2013
3. C.J. WERNER (editor), "MCNP Users Manual - Code
Version 6.2", Los Alamos report LA-UR-17-29981 (2017)
4. GOLUOGLU ET AL., “Monte Carlo Criticality Methods
and Analysis Capabilities in SCALE”, Nucl. Tech. 174(2), p.214-235 (2011).5. "International Handbook of Evaluated CriticalityBenchmark Experiments,” NEA Nuclear Science Committee,NEA/NSC/DOC (95)03.
Transactions of the American Nuclear Society, Vol. 121, Washington, D.C., November 17–21, 2019
876 Recent Nuclear Criticality Safety Program Technical Accomplishments





























