Embed Size (px)
Citation preview

Reducing Cache Misses5.1 Introduction
5.2 The ABCs of Caches
5.3 Reducing Cache Misses
5.4 Reducing Cache Miss Penalty
5.5 Reducing Hit Time
5.6 Main Memory
5.7 Virtual Memory
5.8 Protection and Examples of Virtual Memory
– Compulsory—The first access to a block is not in the cache, so the block must be brought into the cache. Also called cold start misses or first reference misses.(Misses in even an Infinite Cache)
– Capacity—If the cache cannot contain all the blocks needed during execution of a program, capacity misses will occur due to blocks being discarded and later retrieved.(Misses in Fully Associative Size X Cache)
– Conflict—If block-placement strategy is set associative or direct mapped, conflict misses (in addition to compulsory & capacity misses) will occur because a block can be discarded and later retrieved if too many blocks map to its set. Also called collision misses or interference misses.(Misses in N-way Associative, Size X Cache)
Classifying Misses: 3 Cs

Cache Size (KB)
Mis
s R
ate
per
Ty
pe
0
0.02
0.04
0.06
0.08
0.1
0.12
0.141 2 4 8
16
32
64
12
8
1-way
2-way
4-way
8-way
Capacity
Compulsory
3Cs Absolute Miss Rate (SPEC92)
Conflict
Compulsory vanishingly
small
Reducing Cache Misses Classifying Misses: 3 Cs

Cache Size (KB)
Mis
s R
ate
per
Ty
pe
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
1 2 4 8
16
32
64
12
8
1-way
2-way
4-way
8-way
Capacity
Compulsory
2:1 Cache Rule
Conflict
miss rate 1-way associative cache size X = miss rate 2-way associative cache size X/2
Reducing Cache Misses
Classifying Misses: 3 Cs

3Cs Relative Miss Rate
Cache Size (KB)
Mis
s R
ate
per
Typ
e
0%
20%
40%
60%
80%
100%1 2 4 8
16 32 64
128
1-way
2-way4-way
8-way
Capacity
Compulsory
Conflict
Reducing Cache Misses Classifying Misses: 3 Cs
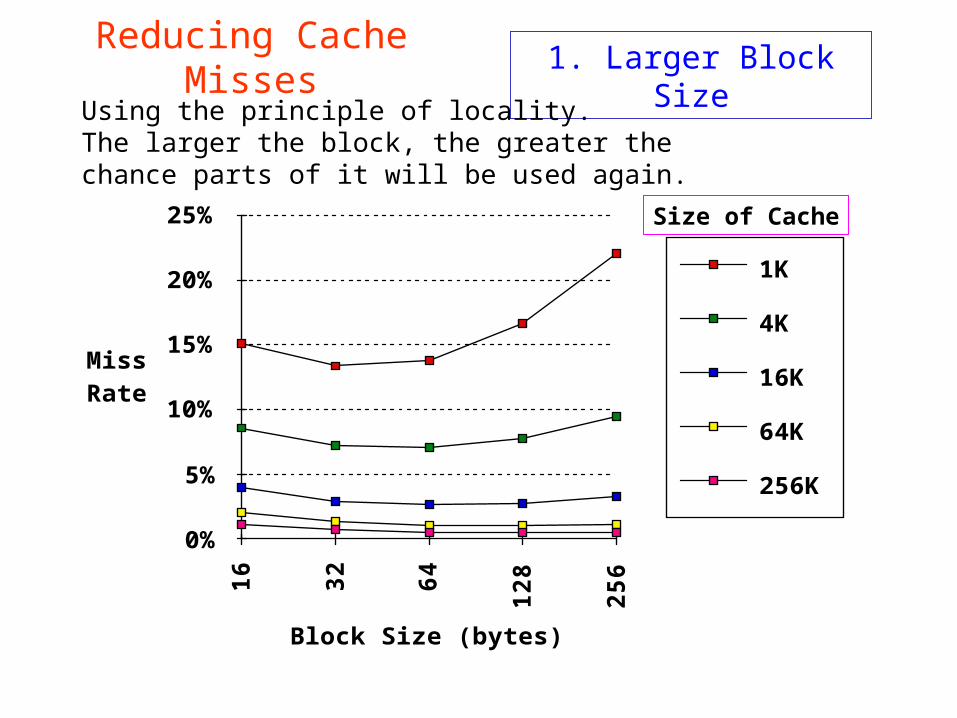
Block Size (bytes)
Miss
Rate
0%
5%
10%
15%
20%
25%16 32 64
128
256
1K
4K
16K
64K
256K
Reducing Cache Misses 1. Larger Block Size
Size of Cache
Using the principle of locality.The larger the block, the greater thechance parts of it will be used again.

• 2:1 Cache Rule: Miss Rate Direct Mapped cache size N = Miss Rate 2-way cache size N/2
• But Beware: Execution time is the only final measure we can believe!
– Clock Cycle time increase as a result of having a more complicated cache.
– Hill [1988] suggested hit time for 2-way vs. 1-way is: external cache +10%internal + 2%
2. Higher Associativity
Reducing Cache Misses
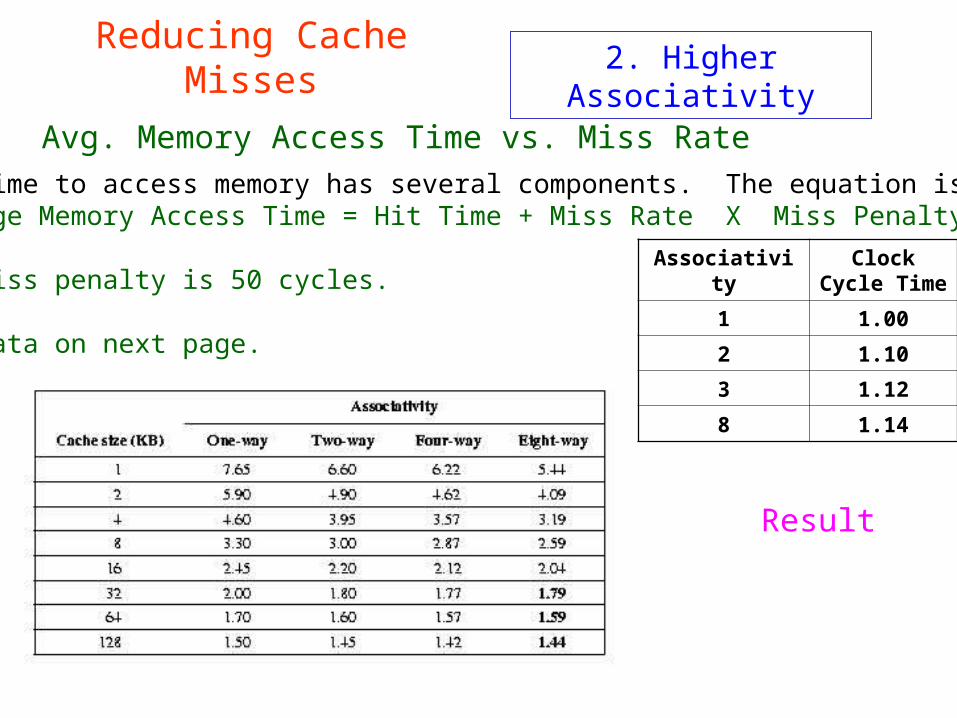
Avg. Memory Access Time vs. Miss Rate
2. Higher Associativity
Reducing Cache Misses
The time to access memory has several components. The equation is:Average Memory Access Time = Hit Time + Miss Rate X Miss Penalty
The miss penalty is 50 cycles.
See data on next page.
Associativity
Clock Cycle Time
1 1.00
2 1.10
3 1.12
8 1.14
Result
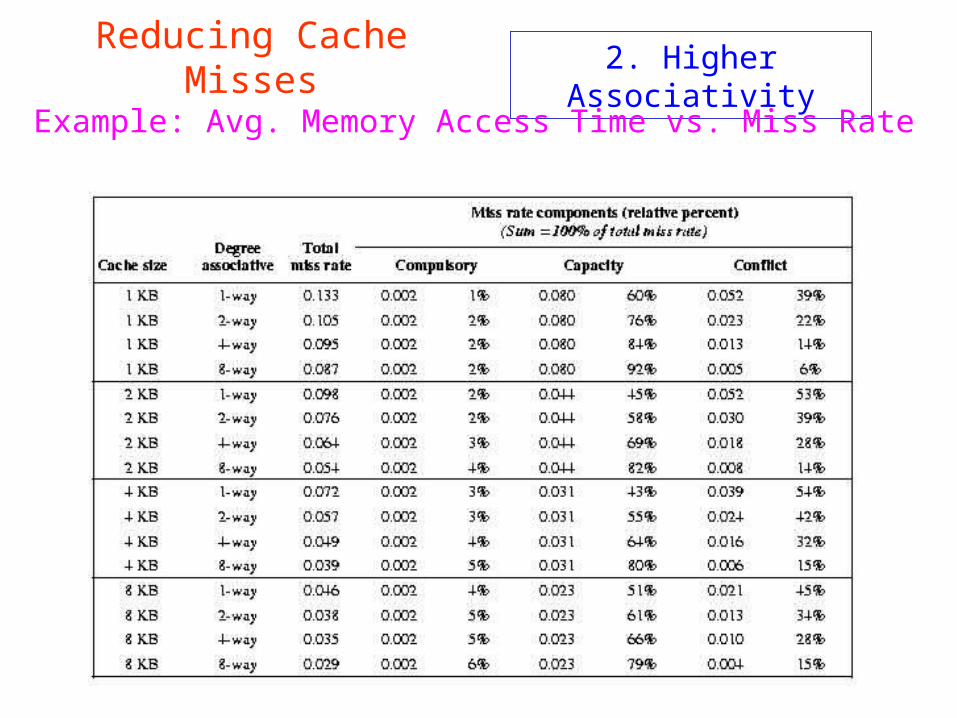
2. Higher Associativity
Reducing Cache Misses
Example: Avg. Memory Access Time vs. Miss Rate

• How to combine fast hit time of direct mapped yet still avoid conflict misses?
– Add buffer to place data discarded from cache
– A 4-entry victim cache removed 20% to 95% of conflicts for a 4 KB direct mapped data cache
– Used in Alpha, HP machines.
– In effect, this gives the same behavior as associativity, but only on those cache lines that really need it.
Reducing Cache Misses 3. Victim Caches

Reducing Cache Miss Penalty
Time to handle a miss is becoming more and more the controlling factor. This is because of the great improvement in speed of processors as compared to the speed of memory.
5.1 Introduction
5.2 The ABCs of Caches
5.3 Reducing Cache Misses
5.4 Reducing Cache Miss Penalty
5.5 Reducing Hit Time
5.6 Main Memory
5.7 Virtual Memory
5.8 Protection and Examples of Virtual Memory
Average Memory Access Time
= Hit Time + Miss Rate * Miss Penalty

• Write through with write buffers offer RAW conflicts with main memory reads on cache misses
• If simply wait for write buffer to empty, might increase read miss penalty (old MIPS 1000 by 50% )
• Check write buffer contents before read; if no conflicts, let the memory access continue
• Write Back?– Read miss replacing dirty block– Normal: Write dirty block to memory, and then do the
read– Instead copy the dirty block to a write buffer, then do
the read, and then do the write– CPU stall less since restarts as soon as do read
Reducing Cache Miss Penalty
Prioritization of Read Misses over Writes

• Don’t have to load full block on a miss• Have valid bits per subblock to indicate valid
Valid BitsSubblocks
Reducing Cache Miss Penalty
Sub Block Placement for Reduced Miss
Penalty

• Don’t wait for full block to be loaded before restarting CPU– Early restart—As soon as the requested word of
the block arrives, send it to the CPU and let the CPU continue execution
– Critical Word First—Request the missed word first from memory and send it to the CPU as soon as it arrives; let the CPU continue execution while filling the rest of the words in the block. Also called wrapped fetch and requested word first
• Generally useful only in large blocks, • Spatial locality a problem; tend to want next
sequential word, so not clear if benefit by early restart block
Reducing Cache Miss Penalty
Early Restart and Critical Word First

• L2 Equations Average Memory Access Time = Hit TimeL1 + Miss RateL1 x Miss PenaltyL1
Miss PenaltyL1 = Hit TimeL2 + Miss RateL2 x Miss PenaltyL2
Average Memory Access Time = Hit TimeL1
+ Miss RateL1 x (Hit TimeL2 + Miss RateL2 + Miss PenaltyL2)
• Definitions:– Local miss rate— misses in this cache divided by the total number of memory
accesses to this cache (Miss rateL2)– Global miss rate—misses in this cache divided by the total number of memory
accesses generated by the CPU (Miss RateL1 x Miss RateL2)
– Global Miss Rate is what matters
Reducing Cache Miss Penalty
Second Level Caches
Reducing Hit Time
This is about how to reduce time to access data that IS in the cache.
What techniques are useful for quickly and efficiently finding out if data is in the cache, and if it is, getting that data out of the cache.
5.1 Introduction
5.2 The ABCs of Caches
5.3 Reducing Cache Misses
5.4 Reducing Cache Miss Penalty
5.5 Reducing Hit Time
5.6 Main Memory
5.7 Virtual Memory
5.8 Protection and Examples of Virtual Memory
Average Memory Access Time = Hit Time + Miss Rate * Miss
Penalty

Reducing Hit Time
• Why Alpha 21164 has 8 KB Instruction and 8 KB data cache + 96 KB second level cache?– Small data cache and clock rate
• Direct Mapped, on chip
Small and Simple Caches

• Pipeline Tag Check and Update Cache as separate stages; current write tag check & previous write cache update
• Only STORES in the pipeline; empty during a miss
Store r2, (r1) Check r1Add --Sub --Store r4, (r3) M[r1]<-r2&
• In shade is “Delayed Write Buffer”; must be checked on reads; either complete write or read from buffer
Reducing Hit Time Pipelining Writes for Fast Write Hits
Check r3

Chap. 5 - Memory 18

Chap. 5 - Memory 19
Way prediction to reduce Hit time
Reduce conflict-miss in associative caches.
Predict which of the block within the set contains the current data.
The multiplexor is preset to this predicted value so that the delay caused by multiplexer is avoided.
If error, correct block is chosen and prediction is updated.
One-bit history can be used for prediction.

Chap. 5 - Memory 20
Trace caches to reduce Hit time
• used in Pentium 4.
• idea is to use dynamic trace of memory access pattern to fetch a sequence of instructions.
• complex to implement.
• high overhead.

Chap. 5 - Memory 21
Nonblocking cache
•Most caches can only handle one outstanding request at a time. If a request is made to the cache and there is a miss, the cache must wait for the memory to supply the value that was needed, and until then it is "blocked".
•A non-blocking cache has the ability to work on other requests while waiting for memory to supply any misses.
• The Intel Pentium Pro and Pentium II processors use this technology for their level 2 caches, which can manage up to four simultaneous requests.
• This is done by using a transaction-based architecture, and a dedicated "backside" bus for the cache that is independent of the main memory bus. Intel calls this "dual independent bus" (DIB) architecture.






![Fighting latency - events.static.linuxfound.org · L1-dcache-prefetches [Hardware cache event] L1-dcache-prefetch-misses [Hardware cache event] L1-icache-loads [Hardware cache event]](https://img.pdfslide.net/doc/110x75/5f0b8a857e708231d4310611/fighting-latency-l1-dcache-prefetches-hardware-cache-event-l1-dcache-prefetch-misses.jpg)






















