Embed Size (px)
Citation preview

Department of Computer Science and Engineering
University of Texas at Arlington
Arlington, TX 76019
Robust Content-based Image Indexing
Y. Alp Aslandogan, Ravishankar Mysore
Clement T. Yu, Bo Liu
Department of Computer Science, The University of Illinois at Chicago
Technical Report CSE-2003-29

Robust Content-based Image Indexing
Using Contextual Clues and Automatic Pseudo-Feedback
Y. Alp Aslandogan, Ravishankar Mysore Clement T. Yu, Bo Liu
Dept. of Computer Science and Engineering Dept. of Computer Science
The University of Texas at Arlington The University of Illinois at Chicago
[email protected] [email protected]
Abstract
In this paper we present a robust information integration approach to identifying images of per-
sons in large collections, such as the web. The underlying system relies on combining content anal-
ysis, which involves face detection and recognition, with context analysis which involves extraction
of text or HTML features. Two aspects are explored to test the robustness of this approach: Sen-
sitivity of the retrieval performance to the context analysis parameters and automatic construction
of a facial image database via automatic pseudo-feedback. For the sensitivity testing, we reevaluate
system performance while varying context analysis parameters. This is compared with a learning
approach where association rules among textual feature values and image relevance are learned via
the CN2 algorithm. A face database is constructed by clustering after an initial retrieval relying on
face detection and context analysis alone. Experimental results indicate that the approach is robust
for identifying and indexing person images.
1

1 Introduction
Automatic image and text analysis techniques have certain limitations when used alone in indexing
multimedia. One difficulty is bridging the so called semantic gap [11, 9, 23, 24, 5]. Semantic concepts
that are close to the user’s intent but away from the low-level, automatically extracted features are
hard to identify by relying on visual features alone. While textual context or descriptions can be
used to generate semantic metadata for the images, it is not possible to rely solely on context analysis
either. Since the textual context is essentially separate from the non-textual media content, there is
always the possibility of the descriptive information being inaccurate or insufficient. Furthermore,
the textual context is a single snapshot of a particular agent’s comments related to the media content,
hence it is very subjective. The combination of content and context analysis, when possible, provides
a richer environment for content indexing.
From the image analysis perspective, a major difficulty is having to deal with uncontrolled image
acquisition conditions. In the case of person images accessible over the web, there is no control over
the conditions of how the images are taken or processed. Many facial images have gross variations
in resolution, viewpoint, illumination and size, making most face recognizers unusable. Recently,
researchers have incorporated pre-processing and normalization steps to the recognition process in
order to account for the variations in images collected in uncontrolled environments [17]. However,
even these approaches assume an existing face database. When a known image database doesn’t
exist prior to retrieval, recognition can not be used initially.
In this work, we investigate the robustness of an information integration approach for dealing
with the aforementioned problems. The approach is to use the textual context in guiding the visual
analysis of the image contents. Currently available textual contexts for images and video include
the following: (1) The world wide web, (2) TV closed captions, (3) displayed text on TV and video,
(4) verbal annotations such as transcriptions of physicians’ impressions of medical images, and (5)
2

news stories accompanying photographs.
The integration technique was implemented in the image search agent Diogenes1 [2] where the
use of text analysis, face detection, face recognition with an existing face database and heuristically
set parameters produced an overall precision of 95% for twenty celebrity queries [1]. Two questions
arose in that context: Would the system be able to obtain similar results if the parameter values
were changed, and in the absence of a face database would the system be able to use recognition?
In the following we address these two issues. Specifically, we compare the performance of the search
agent under varying contextual analysis parameters and with parameter learning. This allows us to
examine the sensitivity of the context analysis to these parameters. The experimental results show
that the approach is fairly insensitive to fine tuning of these parameters. Secondly, we implement
a pseudo-feedback method for automatic face database construction via clustering. This allows us
to determine system performance in the absence of a known image database. A key contribution of
this paper is the demonstration of the automatic pseudo-feedback method in the context of content
based image retrieval.
The paper is organized as follows: In Section 2 we give an overview of the architecture of image
search agent Diogenes upon which the techniques described in this paper are built. Section 3
provides the background for the information integration approach we have implemented. In Section
4 we examine the sensitivity of the retrieval performance to context analysis parameters. We first
experiment with different sets of weights and then we describe a parameter learning experiment
where association rules between the contextual feature values and the image relevance are learned
via the CN2 algorithm. In Section 5 we describe an automatic pseudo-feedback method that is
facilitated by evidence combination and its evaluation. Section 6 reviews related work and finally,
section 7 gives a summary of the key points of the paper and discusses future research possibilities.
1After philosopher Diogenes of Sinope, d.c. 320 B.C. who is said to have gone about Athens with a lantern in daytime looking for an honest man.
3

2 Background
The information integration approach that is evaluated in the following sections are implemented
on top of the image search agent Diogenes. Diogenes is a web-based image search agent designed
for identifying and indexing person images. The user types in the first name and the last name of a
person as a query. The system returns images of that person ranked by their estimated relevance.
The query page on the web interface for Diogenes is shown in Figure 1. The results of the ”Abraham
Lincoln” query are depicted in Figure 2.
Figure 1: Image search query page of Diogenes.
2.1 Visual and Contextual Features
In analyzing web pages, Diogenes analyzes both the images themselves and the text/HTML context
around them. The content-based visual features are: (1) Whether a human face is present in the
image, and (2) whether the image matches one of the known images in the facial image database.
4
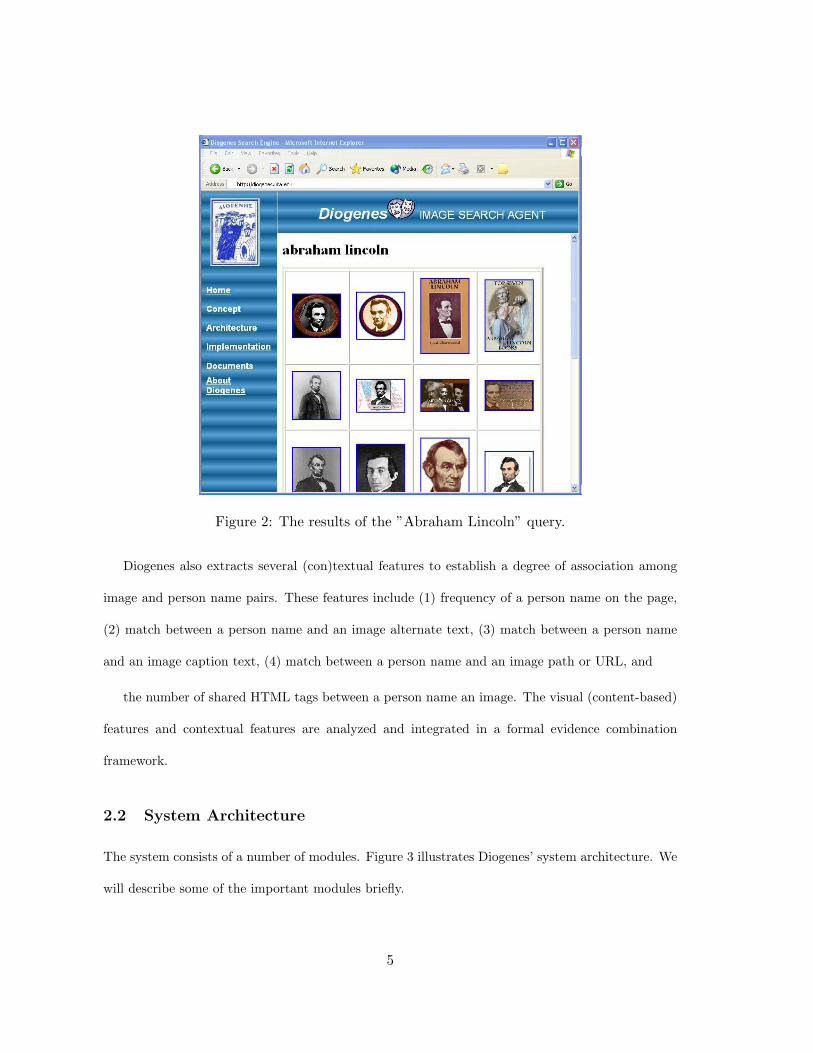
Figure 2: The results of the ”Abraham Lincoln” query.
Diogenes also extracts several (con)textual features to establish a degree of association among
image and person name pairs. These features include (1) frequency of a person name on the page,
(2) match between a person name and an image alternate text, (3) match between a person name
and an image caption text, (4) match between a person name and an image path or URL, and
the number of shared HTML tags between a person name an image. The visual (content-based)
features and contextual features are analyzed and integrated in a formal evidence combination
framework.
2.2 System Architecture
The system consists of a number of modules. Figure 3 illustrates Diogenes’ system architecture. We
will describe some of the important modules briefly.
5

Figure 3: Diogenes system architecture.
1. Search Engine Driver: This module interfaces with web text search engines and obtains a list of
URLs for a given name. The user types a query name in the form of first and last name. This
module then submits the query string according to the conventions of several different text
search engines and concatenates the results. The engines that were used for the experimental
results reported here included AltaVista, Lycos, Google, WebCrawler, and others.
2. Web Crawler: This module actually issues HTTP requests to visit each URL obtained by the
search engine driver. It retrieves the text of the URLs and then retrieves each of the images
referenced on those pages. It then saves all this information under a directory generated from
a unique time-stamp.
6

3. Face Detector: This neural-network based module [20] detects whether a human face exists in
an image. If one or more faces are present, it reports the locations of those faces in terms of
rectangular coordinates.
4. Face Recognizer: This module identifies new facial images by using a database of known facial
images. It computes distance values between the query image and a subset of the known
images. For the experiments reported in this paper, the face recognition module was only used
in the second stage to improve upon the detection/text analysis-only results.
5. HTML Analyzer: This module analyzes the HTML structure of the downloaded web pages. It
examines features such as common HTML tags, caption fields, and alternate fields.
6. Feedback Processor: This module processes the results of the initial retrieval, forms image
clusters and generates a face image database for use by face recognition. It then drives the
evidence combination module with the output of the context (text/HTML) analysis and the
face recognition modules. This pseudo-feedback process takes place without user interaction.
7. Evidence Combination Module: This module combines the evidences produced by context
analysis and face recognition modules using different combination mechanisms.
8. HTML Composer: This module prepares the results page based on the image links found in
the search.
3 Integrating Content-based and Contextual Information
The content-based visual evidence and the contextual evidence obtained from surrounding text are
integrated in the formal framework of Dempster-Shafer Theory of Evidence, also known as the Math-
ematical Theory Of Evidence [25]. The Dempster-Shafer theory is intended to be a generalization
of Bayesian theory of subjective probability. Since the details of this theory are beyond the scope
of this article we refer the interested reader to the relevant literature [10] and focus on Dempster’s
7

formula for evidence combination which we use for integrating context and content information.
3.1 Dempster’s Rule for Evidence Combination
Suppose we are interested in finding the combined evidence for a hypothesis C. We may think of
C as a class assignment in pattern recognition. C is a member of 2Θ, where Θ is our frame of
discernment, the set of hypotheses under consideration. Given two independent sources of evidence
m1 and m2, Dempster’s rule for their combination is as follows:
m1,2(C) =∑
A,B⊆Θ,A∩B=Cm1(A)m2(B)∑
A,B⊆Θ,A∩B 6=∅ m1(A)m2(B)
Here m1,2(C) is the combined Dempster-Shafer probability for C. m1 and m2 are the basic prob-
abilities assigned to sets A and B respectively by two independent sources of evidence. A and B
are supersets of C. A and B are not necessarily proper supersets and they may as well be equal to
C or to the frame of discernment Θ. The numerator accumulates the evidence which supports a
particular hypothesis and the denominator conditions it on the total evidence for those hypotheses
supported by both sources.
3.2 Using Dempster-Shafer Theory in Image Retrieval
The content-based visual feature, namely the relevance score obtained from the face detection/recognition
(FR) module, and the contextual feature, namely the relevance score obtained from the text/HTML
analysis module (TA) represent the two sources of evidence we have for image classification. We
assume that if more than one person appears in an image, identifying one of them is sufficient. We
designate the two pieces of evidence as mFR and mTA respectively. By default, these two modules
operate independently: The results of face recognition module does not affect the text/HTML score
and vice versa. Hence the independence assumption of the theory holds. The text/HTML analysis
8

module determines a degree of association between a personal name and facial image on the web
page. Similarly, the face detection/recognition module determines a degree of relevance for an image,
given a known image database. Let us assume that P represents the hypothesis that in the context
of a query ( a person name P) an image I is relevant. Using Dempster’s Rule for combination of
evidence we get the following:
mFR,TA(P ) =∑
A,B⊆Θ,A∩B=PmF R(A)mT A(B)∑
A,B⊆Θ,A∩B 6=∅ mF R(A)mT A(B)
Again, P designates a hypothesis which is an element of 2Θ. In the case of classification of personal
images, it is possible to simplify this formulation. Our face recognition and text/HTML analysis
modules give us information about the relevance of a particular image and the uncertainty of the
recognition/analysis. This means we have only beliefs for singleton classes (persons) and (m(Θ)),
the uncertainty in the body of the evidence. With this observation we can simplify the combined
evidence.
mFR,TA(P ) = mF R(P )mT A(P )+mF R(Θ)mT A(P )+mF R(P )mT A(Θ)∑A,B⊆Θ,A∩B 6=∅ mF R(A)mT A(B)
Since we are interested in the ranking of the hypotheses and the denominator is independent of any
particular hypothesis (i.e. same for all) we can ignore the denominator and compare the support
for hypotheses on the basis of the numerator only:
rank(I, P ) ∝ mFR(P )mTA(P ) + mFR(Θ) + mTA(P ) + mFR(P )mTA(Θ)
Here ∝ represents ‘is proportional to” relationship, mFR(Θ) and mTA(Θ) represent the uncertainty
in the bodies of evidence mFR and mTA respectively. Both face recognition and text analysis
uncertainties are obtained locally, i.e. for each retrieval and automatically without user interaction
in contrast to applications where the users provide the uncertainties [12].
9

3.3 Evidence from Content Analysis
Analysis of the image content yields two kinds of information: Whether a human face is present in
an image and the likely identity of this face. The first piece of information is obtained by a face
detector and is used for screening out pages that do not contain an facial images. The second piece is
obtained by a face recognition module and used in determining the rank of this image in the context
of a query. Suppose mFR(P ) is the evidence from face recognition module for the hypothesis that
the target image belongs to a person P named in the user’s query. It is computed by the following
formula:
mFR(P ) = CFR ∗ dFR(I, P )
and
dFR(I, P ) = 1− (minDistance(I, P )
distanceMAX)
where dFR(I, P ) is the degree of association, according to the face recognition module, between
person P named in the query and the image I. minDistance(I, P ) is the minimum distance among
the distances between the images of person P in the training database and image I. distanceMAX
is a global constant maximum distance which is set to 10000 for the eigen-face recognition module.
Any distance(I) that is greater than distanceMAX is set to be equal to distanceMAX .
The multiplier constant CFR is obtained as follows:
CFR =1−mFR(Θ)∑P∈Φ dFR(I, P )
mFR(Θ) represents the uncertainty in the body of evidence mFR and is obtained as follows: The
eigen-face based face recognition module used in our initial experiments provides a “distance from
face space” (DFFS) value for each recognition. This value is the distance of the target image to the
space of eigen-faces formed from the training images [31]. Diogenes uses the DFFS value to estimate
10

the uncertainty associated with face recognition. If the DFFS value is small, the recognition is good
(uncertainty is low) and vice versa. The following is Diogenes’ formula for the uncertainty in face
recognition:
mFR(Θ) = 1− (1
ln(e + DFFS))
3.4 Evidence from Context Analysis
The context analysis module of Diogenes assigns weights to the text/HTML features found on the
web pages. Some of these features are local while others are global. The local features are specific
features associating a personal name with a particular image. Global features are features of personal
names that are not related to any specific image. Weights associated with four of the important
features are the following:
• (wfreq) Name Frequency Weight: This is the weight associated with the global feature of
name frequency. When a person’s name occurs with a high frequency on a page, that name is
assumed to be related to the images that appear on that page.
• (wtag) Shared HTML Tags Weight: As the number of HTML tags that are shared by the
image and a name increases, the degree of association between the image and the name is also
assumed to increase.
• (wpath) Image Path Match Weight: If part of the image path matches part or all of the person
name, then it is assumed that there is an association between the image and the name.
• (walt) Alternate Text Match Weight: If a person’s name appears fully or in part in the alternate
text for an image, an association is assumed.
The text/HTML analysis process proceeds as follows: When a page is retrieved, a part-of-speech
tagger (Brill’s tagger[3]) tags all the words that are part of a proper name on the page. The
occurrence frequency of these words are recorded. For each such word, and for each image on the
11

page, a degree of association is established. The frequency of the word serves as the starting point
for this score. Then the HTML analysis module analyzes the HTML structure of the page. If an
image and a word share some common tags, their degree of association is increased. If the word is a
substring of the image name or if the word is part of the alternate text for the image, the association
is increased further. The formula for calculating the degree of association between a word w and
image I is
d(w, I) = ωfreq ∗ sfreq + ωtag ∗ stag + ωpath ∗ spath + ωalt ∗ salt
where d(w, I) is the degree of association between the word and the image; ωfreq, ωtag, ωpath,
and ωalt are the relative weights of word frequency, shared HTML tags, image name substring
property and image alternate text substring property respectively. The sfreq, stag, spath, salt are
the corresponding scores for word frequency, number of shared HTML tags, whether the word is
part of the image name, and whether the word is part of the alternate text, respectively. Since
the text/HTML analysis module assigns degrees of association to individual words, at the time of
evidence combination, a weighed combination of the scores of the two words (the first name and the
last name) that make up a personal name P is calculated to get a single text/HTML score.
d(I, P ) = α ∗ d(firstName(P ), I) + β ∗ d(lastName(P ), I)
For the experimental results reported here these coefficients were .25 and .75 respectively.
The contextual evidence mTA(P ) for the relevance of a particular image I in the context of a
person name P is obtained by normalizing d(I, P ).
mTA(P ) = CTA ∗ d(I, P )Dmax
12

where Dmax is a global normalization constant. The multiplier constant CTA is obtained as follows:
CTA =1−mTA(Θ)∑P∈Φ dTA(I, P )
For text analysis, uncertainty is assumed to be inversely proportional to the maximum value among
the set of degree of association values assigned to name-image combinations.
mTA(Θ) =1
ln(e + dmax)
Where dmax is the local maximum numeric “degree of association” value assigned to a personal
name with respect to a facial image among other names.
4 Sensitivity to Context Analysis Parameters
In testing the sensitivity of the retrieval accuracy to the particular weight values, we follow two
approaches. In the first approach, the weights associated with the four parameters are varied and
the overall retrieval precision is evaluated. In the second approach, instead of using fixed weights
associated with feature values, we employ the CN2 algorithm to learn association rules among feature
values and the image relevance. Tables 1, 2, and 4 show the results of the first set of experiments.
In these tables the average precision numbers are rounded after two decimal units.
In Table 1 the results of retrievals with twenty different weight sets are reported. The average
precision ranges from .89 to .95. The first observation is that there are multiple weight sets that
achieve the best or near-best results. Namely, weight set 10 produces the best average precision
of .95, weight sets 5 and 7 produce an average precision of .94, weight sets 3, 4, 8, 18, 19 and
20 produce an average precision of .93. These results suggest that the performance of the context
analysis module does not depend on fine tuning of these parameters. The next table shows the
13

aggregated average precision for individuals over 20 weight sets. Even averaged over 20 different
weight sets, some of which do not produce competitive results, the overall average precision is still a
competitive value of .92. In the next experiment we look at individual queries to confirm previous
Table 1: Different Weight Sets and Resulting Average Precision.
Weight Set Freq Tag Path Alt Avg. Precision1 0.6 0.1 0.2 0.1 .922 0.3 0.3 0.1 0.3 .913 0.1 0.1 0.35 0.45 .934 0.2 0.05 0.35 0.4 .935 0.1 0.15 0.4 0.35 .946 0.4 0.05 0.2 0.35 .927 0.5 0.05 0.4 0.05 .948 0.2 0.25 0.3 0.25 .939 0.1 0.35 0.25 0.3 .9110 0.05 0.45 0.45 0.05 .9511 0.25 0.5 0.05 0.2 .8912 0.2 0.6 0.1 0.1 .9113 0.1 0.7 0.1 0.1 .9114 0.05 0.8 0.05 0.1 .9015 0.02 0.9 0.02 0.06 .9016 0.1 0.1 0.1 0.7 .9217 0.25 0.25 0.15 0.35 .9218 0.15 0.1 0.25 0.5 .9319 0.35 0.3 0.15 0.2 .9320 0.15 0.05 0.4 0.4 .93
observations and to better understand why this is the case. The query names were obtained from
the Time magazine’s Top 100 most influential people list2. The weight sets are shown in Table 3.
In Table 3 the columns labelled with feature names show the weight for that feature. The ”Avg.
Precision” column shows the average precision over 20 queries with this weight set. The column
labelled ”Num. Best” shows how many times this particular weight set provided the best average
precision. Similarly, the column labelled ”Num Worst” shows the number of queries where this
particular weight set produced the worst result. Table 4 shows the results for individuals. The best
2http://www.time.com/time/time100/
14

Table 2: Average Precision Over 20 Weight Sets for Individual Queries.
Query Avg. PrecisionJay Leno .57Michael Jordan .85Dalai Lama .92Grant Hill .75Dick Cheney .93Pete Sampras .97Martina Hingis 1.0Martina Navratilova .91Albert Einstein .99Andre Agassi .98Diego Maradona .89Tiger Woods .88Tom Cruise 1.0Demi Moore 1.0Deng Xiaoping .82Julia Roberts .96Pamela Anderson Lee 1.0Brooke Shields 1.0Sharon Stone 1.0Sylvester Stallone .99Overall .92
precision(s) in each row is (are) shown in bold. A review of these results indicate that while the
system is not sensitive to small changes in individual weights, some textual features are indeed more
significant than others. For instance, the weight sets where the frequency and path match features
are assigned relatively higher weights than the other two features produce better results than others.
Similarly, the two weight sets where the weights for these features are set to 0.0 produce relatively
worse results. We have also looked at the textual feature values for the individual query results.
This analysis shows that for the top 20-40 results most images tend to have the majority of the
textual features. Therefore a variation of the textual weights does not produce a significant impact.
Below the top 40, however, certain features are less frequent, and weight sets emphasizing those
features are likely to produce more accurate results.
15

Table 3: Weight Sets for Individual Evaluation and Average Precision.
Weight Set Freq Tag Path Alt Avg. Precision Num. Best Num. Worst1 0.30 0.00 0.35 0.35 .91 9 32 0.00 0.35 0.35 0.30 .89 1 83 0.35 0.35 0.00 0.30 .90 2 44 0.35 0.35 0.30 0.00 .90 4 45 0.25 0.25 0.25 0.25 .89 2 76 0.30 0.20 0.30 0.20 .92 17 07 0.50 0.0 0.25 0.25 .89 2 9
Table 4: Impact of Different Weight Sets on Individual Queries.
Query Set1 Set2 Set3 Set4 Set5 Set6 Set7Lucille Ball 1.0 0.94 0.96 0.96 0.96 1.0 0.94Nelson Mandela 0.94 0.9 0.9 0.9 0.92 0.96 0.92Enrico Fermi 0.94 0.92 0.94 0.94 0.92 0.96 0.92Marilyn Monroe 0.92 0.88 0.92 0.92 0.92 0.94 0.94Oprah Winfrey 0.92 0.9 0.9 0.92 0.9 0.94 0.9Mahatma Gandhi 0.92 0.92 0.9 0.92 0.9 0.94 0.88Sigmund Freud 0.92 0.92 0.92 0.9 0.9 0.94 0.9Albert Einstein 0.89 0.92 0.9 0.88 0.9 0.92 0.86Mother Teresa 0.92 0.88 0.9 0.92 0.92 0.92 0.85Charlie Chaplin 0.88 0.88 0.9 0.9 0.92 0.92 0.88Frank Sinatra 0.9 0.84 0.88 0.9 0.88 0.9 0.86Mao Zedong 0.8 0.83 0.87 0.86 0.86 0.9 0.86Adolf Hitler 0.9 0.88 0.88 0.86 0.88 0.9 0.88Mikhail Gorbachev 0.93 0.89 0.9 0.92 0.9 0.9 0.9Henry Ford 0.92 0.9 0.9 0.88 0.88 0.9 0.88Marlon Brando 0.9 0.88 0.9 0.9 0.86 0.9 0.88Mikhail Gorbachev 0.9 0.86 0.86 0.88 0.86 0.9 0.86Louis Armstrong 0.88 0.88 0.9 0.88 0.88 0.9 0.86Bill Gates 0.92 0.89 0.88 0.88 0.87 0.88 0.85Theodore Roosevelt 0.86 0.87 0.86 0.88 0.86 0.88 0.88Average Precision 0.90 0.89 0.90 0.9 0.89 0.92 0.89
16

4.1 Automatic Parameter Learning
In our earlier experiments [1] we have reported results obtained with a heuristically selected set
of weights. In the previous section affects of varying the weight sets on the retrieval results were
examined. In this section, we report the results of an experiment where association rules are used
instead of weighting.
A set of examples are used to train the system. Each example includes a set of contextual
attribute values for an image and its relevance with respect to a query (a personal name). The
program then induces a set of rules based on this data. In our application, the attributes are the
values of the context features described above. The training sample was produced as follows: For
each person, 20 different sets of weights were used. For each set of weights, the relevance information
for the top 20 returned images were recorded. Thus for each person a set of 400 (20 times 20) sample
lines were produced. Each line has 4 double values and one discrete value. The double values are
the values of the context features and the discrete value is one of “Relevant” or “Irrelevant”. A
sample line from the example file is given below:
mfreq mtag mpath malt Relevance
.97 1.0 0.75 0.25 Relevant
where mfreq represents the frequency of the person name on a page divided by a global maximum
frequency, mtag represents the status of tag match (0 for no match, 0.25 for first name match, 0.75
for last name match, 1.0 for full name match); mpath represents person name match with image
path (one of 0, 0.25, 0.75 or 1.0 as in name match) , and finally malt represents person name match
with image alternate text. For ten-fold validation, the 20 persons were partitioned into 10 groups.
Each group contained 2 persons. Each group in turn was removed from the set of 20 person names
to form the test set. The remaining 18 persons’ sample files were merged to form the training set.
Rules learned from each of the training sets were saved in a file. These steps were executed ten
times to produce 10 sample (training) files and 10 sets of rules. An example rule could be of the
17

form:
if mfreq ≥ 0.50 ∧ mtag ≥ 0.50 ∧ mpath ≥ 0.50 ∧ malt ≥ 0.50 then relevant
During the screening of the rules that were produced, rules whose output were ”Irrelevant” were
removed as well as rules that were induced on fewer than 50 sample lines. Finally 10 sets of screened
rules were obtained. Each of the rules is an induction on the relationship of a particular set of
attribute values and the resulting images’ being relevant. These 10 sets of learned association rules
were then used to perform test runs for the test groups. Top 20 images returned on the test sets
were analyzed and the average precision over this top 20 were recorded. The total average precision
for each query is shown in Table 5. It can be observed that while the average precision remains
high, one particular person, namely Jay Leno, has low precision. This behavior is further explained
in Section 5.2. The table shows that the main retrieval mechanism of the system, namely context
Table 5: Learning Results.
Query Before Learning After LearningQ:Jay Leno .50 .55Q:Michael Jordan .90 .90Q:Dalai Lama .85 .80Q:Grant Hill .70 .75Q:Dick Cheney .95 .95Q:Pete Sampras 1.0 1.0Q:Martina Hingis 1.0 1.0Q:Martina Navratilova 1.0 0.95Q:Albert Einstein 1.0 1.0Q:Andre Agassi .95 .95Q:Diego Maradona .95 .95Q:Tiger Woods 0.80 0.85Q:Tom Cruise 1.0 1.0Q: Demi Moore 1.0 1.0Q: Deng Xiaoping 1.0 .75Q: Julia Roberts .95 1.0Q: Pamela Anderson Lee 1.0 1.0Q: Brooke Shields 1.0 1.0Q: Sharon Stone 1.0 1.0Q: Sylvester Stallone 1.0 1.0Average .9275 .92
18

analysis combined with face detection showed little sensitivity to particular parameters of context
analysis.
5 Automatic Visual Pseudo-Feedback
A pesudo-feedback mechanism is implemented in Diogenes to construct a facial image database
automatically without user input. Different forms of feedback have been used successfully in the
past to improve search results in both text and multimedia retrieval systems. In interactive feedback,
the user of an information retrieval system can provide feedback to the system by designating the
results returned in response to a query as relevant or irrelevant. This kind of feedback mechanism
has been demonstrated to improve retrieval performance in both text and image retrieval systems
[6, 30, 26, 30, 14, 21, 22, 15, 4, 33]. One drawback of interactive feedback is its need for involving
the user in the process after the initial query. Usage statistics of web-based search engines indicate
that users prefer very short queries and minimal interaction when searching for a document or a
multimedia element3.
The two modes of evidence used by Diogenes facilitate another type of feedback known as auto-
matic pseudo-feedback. This type of a feedback mechanism is considered pseudo feedback because
the user does not really go over the initial retrieval results and mark them as relevant or irrelevant.
The relevance of the images in the initial retrieval results are not known, instead certain assumptions
are made about the initial accuracy.
In this method a user can initiate a retrieval with a textual query without having any facial
images of a person. The system uses the face detector to filter out images without any faces and
then ranks the images containing faces based solely on their context score. The majority of the top
ranking images retrieved with this method are relevant. The system then does a similarity analysis
3From a presentation by a system engineer of Excite Inc. at the SIGIR ’97 conference. Also, see http://www.alexa.com.
19

by using a face recognition module and a clustering algorithm. The purpose of this step is to group
similar images into clusters. Images taken from relatively large clusters are then used as an initial
face database for the person. Since relevant images belong to the same person and irrelevant images
tend to belong to different persons, relevant images are expected to form larger clusters around them
while irrelevant images remain alone or form only small clusters.
Figure 4 illustrates this process. In Figure 4 the search process starts when the user issues a
User Query
Initial Ranking Preliminary
Results
Clustering
Face
Training Set
Combine
Evidences &
Reevaluate
Context
Analysis
Face Detection
Face
Recognition
Final
Results
Retrieved
Pages
1
3
2
4
5 6
Figure 4: Diogenes feedback process.
query (Step 1). The system retrieves an initial set of pages and analyzes them via face detection and
context analysis (Step 2). The initial ranking is based on context analysis, provided a facial image
is found (Step 3). The goal of the next step in the pseudo-feedback process is to cluster images from
this top set based on their visual similarity to each other. The idea is that the irrelevant images in
this set will not form large clusters since they typically do not belong to a single person. Instead,
they will remain solitary or form small clusters. In our experiments we have regarded a cluster size
20

of three or more as a relatively large cluster. To be able to cluster images based on their similarity
to each other, the distances are computed between pairs of images. Then these images are clustered
iteratively until there are N images in clusters of size three or more, where N is the size of the face
database we want to form. The hierarchical clustering algorithm used here is called the UPGMA
or Unweighted Pair-Group Method using Arithmetic Averages. We will present this method briefly
below. Details and references can be found in [8]. When the clustering is done, N images that belong
to clusters of size three or more are designated as the training set for face recognition (Step 4). If
there are more than N images in clusters of size three or more, first N of these are selected. The
size of the training set, N, is a number selected according to performance and precision trade off
parameters. For instance, initially as N gets bigger, the accuracy of the recognition increases, but
the recognition time gets longer as well. After a certain threshold point, increasing N doesn’t lead
to any further improvement in accuracy, instead the accuracy begins to degrade. One reason for this
behavior is that as more and more images from the top are included, they may contain an increasing
number of irrelevant images. Since the whole process is executed without any user interaction, it
is not possible to identify the irrelevant images a-priori. In our experiments we have found that a
training set of size 10 provided the best accuracy-performance trade-off with the wavelet-based face
recognition program we used.
After preparing the training set for face recognition, the system reevaluates all of the existing
images and gives them face recognition scores (Step 5). These visual scores are then combined with
the text scores via the combination mechanisms described earlier. This re-evaluation results in a
new ranking of the images (Step 6).
5.1 Clustering Using U.P.G.M.A.
The method starts by forming a cluster from each image (containing only one image) and proceeds
as follows:
21

1. Compute the distance between each pair of clusters. The distance between clusters consisting
of single images is the distance between those two images. The distance between two images
is obtained by wavelet-based face recognition module [18] and is explained further below. The
distance between two clusters which contain more than one image is the average of the pair-wise
image distances.
2. Find the pair of clusters Ci and Cj with the minimum distance among all possible pairs, and
merge them. If there is a tie, merge the first pair found.
3. Repeat steps 1 and 2 until an exit criteria is met.
In our application of the UPGMA algorithm, the exit criteria was to have a total of at least N
images in clusters of size three or more. This condition can be met in a number of ways, for instance
with one cluster of size N or with two clusters of size N/2 each.
The computational cost of the automatic pseudo-feedback process consist of three components:
The first component is the initial clustering, the second component is the face recognition and the
third component is the relevance score re-computation. The first process has a computational cost
O(M2) where M is the number of initial images to be clustered. This step can be performed in
parallel or distributed mode. The second step is O(N) where N is the number of images to be
reevaluated. This number is domain dependent. In our experience, for the general celebrity domain
a value between 60 and 120 is typically sufficient to obtain an average precision of above 90%. The
third component is also O(N) and is negligible. While the total computational cost of pseudo-
feedback is not excessive, it may be infeasible for online queries. In a distributed environment where
the indices are pre-generated, this cost can be mitigated.
5.2 Experimental Evaluation
The process outlined in Figure 4 was implemented to examine its feasibility. The results of these
experiments are summarized in Table 6 and Figure 5. In Table 6 the number in each cell shows the
22

Query No FB DioFB Ditto GoogleJay Leno .65 .80 .60 .80David Letterman .55 .80 .75 .65Michael Jordan .85 .90 .85 .70Dalai Lama .95 .95 .75 .80Grant Hill .85 .85 .50 .85Steve Forbes 1.0 1.0 1.0(4) .85Dick Cheney .90 .95 .25(4) .90Bill Gates 1.0 1.0 .80 .80Bill Clinton .95 .95 .95 .75Hillary Clinton .95 1.0 .80 .70Pete Sampras 1.0 1.0 1.0 .90Martina Hingis 1.0 1.0 .90 1.0Martina Navratilova .95 1.0 N/A 1.0Albert Einstein .95 .95 1.0 .90Andre Agassi .90 .90 .90 1.0Diego Maradona 1.0 1.0 .83(6) .95Tiger Woods 0.95 0.95 1.0 .90Tom Cruise 1.0 1.0 .85 .85Al Gore 1.0 1.0 .90 .95Princess Diana 1.0 1.0 .90 .70Average .92 .95 .82 .85
Table 6: Automatic Feedback Experimental Results.
average precision of the retrieval computed over the top 20 images. A value of .90 indicates that
18 of the top 20 images were relevant. As can be seen in Table 6, the feedback-enabled Diogenes
system achieved the best precision in 17 of the 20 queries. Its average precision is also higher than
both Ditto and Google, as well as its previous results not involving feedback. In Table 1, some
average precision numbers for Ditto are shown next to a number in parentheses. For these queries
Ditto returned fewer than 20 images. Hence, the average precision was computed over this smaller
total.
In Figure 9 the average precision of retrieval results before and after feedback are plotted as a
function of the number of images from the top. The values .92 and .95, which are also reported as the
average precision in Table 6, correspond to the average precision computed over the top 20 retrieved
23

0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
10 15 20 25 30 35 40
Num
ber
of r
elev
ant i
mag
es
Number of images from top
Before feedbackAfter feedback
Figure 5: Average precision plots of before and after feedback retrieval results for Diogenes as a functionof number of images from the top.
images4. If we assume ten images per page, then these results correspond to a user’s viewing two
result pages. A higher number of images from the top corresponds to a user’s viewing more pages of
retrieval results. The plot reflects the proportion of the images viewed by the user that are relevant.
Note that when the user views only the first page of results (top ten images), the average precision
of Diogenes, while using the automatic pseudo-feedback method, reaches .97.
The experimental results show that the automatic pseudo-feedback mechanism did provide an
improvement in average precision without any need for user interaction. The average precision was
improved in five queries and remained the same in others. Especially worthy of notice are the first
two queries: Jay Leno and David Letterman. These two queries posed the greatest challenge to our
context analysis module. Some of the heuristics used by the context module were invalidated by the
pages devoted to guests of these talk show hosts5. Image names, captions and alternate text fields
4In our earlier experiments, we were able to obtain a score of .95 for queries not involving talk show hosts. In thoseexperiments the system that came closest to Diogenes in terms of retrieval precision was Ditto with an average score of.79. Details of these experiments are reported in [1]
5Analysis of retrieval results by Ditto and Google showed that these search engines also suffered from similar problems.
24

provided misleading clues about the owners of images in those pages. An example of such an image
is in Figure 10. The image belongs to singer Shania Twain and was taken when she was a guest
Figure 6: Shania Twain as a guest on David Letterman’s show.
on David Letterman’s show. On the page containing the image, the words David and Letterman
have the highest frequency. The image is named “letterman18s.jpg” and the alternate text for the
image reads “Letterman”. According to the heuristics employed by the context module, this image
is highly likely to belong to David Letterman. Although to the human eye it is obvious that the
image doesn’t belong to David Letterman, it is not possible to confirm this without an existing face
database. As demonstrated by the above results, the combination strategy employed by Diogenes
was able to take advantage of the visual clues by forming a face database for David Letterman
automatically and then using this source of evidence to lower the score of the above image. Overall,
Diogenes was able to improve the context-only results without user interaction. Below we show four
additional example images from image search results of Google (top 20) where textual clues are
misleading. The first and the last images belong to people who are named Jenny Jones and Larry
King respectively. While in a context-free query these can be regarded as legitimate results, if the
user’s intent is known (e.g. talk show host) these can be eliminated with the method proposed in
this work. The second image has all the textual clues for Nelson Mandela (alternate text match,
path match, shared tags, frequency) but the image does not feature Mandela himself. The third
Ditto, for instance, had four guest images for Jay Leno in top twenty. Google had two guest images for David Lettermanin the top twenty.
25

image belongs to a public speaker who presented Henry Ford in an event. These two images could
also be easily eliminated with the proposed method.
Figure 7: Example images where (con)textual clues are misleading. Left to right: Jenny Jones, NelsonMandela, Henry Ford and Larry King.
6 Related Work
Multimedia content has an important role in the World Wide Web’s becoming a popular medium
of information exchange. The enormity of this content has created a challenge for effective and effi-
cient information access. A number of research projects and some commercial products have been
developed to help users locate relevant multimedia elements. Some of these systems incorporate
interactive feedback features. WebSEEk6 [29] was among the pioneers of content based indexing of
multimedia on the web. It provides access to images and videos on the web via keywords and sim-
ilarity queries. WebSEEk and Amore7 [19] categorize their images into conceptual categories such
as arts, sports, celebrities, movies etc. With WebSEEk, the user can start a querying session with a
random image and search by similarity; or he can type keywords to be used in conjunction with the
visual features such as color and shape. The user can also indicate the relative significance of those
features. ImageScape8, and ImageRover [30, 14] both use textual and visual information to classify
6http://www.ctr.columbia.edu/webseek7http://www.ccrl.com/amore/8http://www.liacs.nl/home/lim/image.scape.html
26

images. While ImageScape aims at indexing arbitrary images found on the web, ImageRover is fo-
cused on nature images. The relevance feedback mechanism in ImageRover is based on recomputing
the distance metrics that are used in determining image similarity based on user feedback. In [21]
the content based image retrieval system MARS is presented for retrieving images using automat-
ically extracted visual features. This system incorporates the term weighting approach developed
in the Information Retrieval field for reevaluating and hence improving image retrieval results. A
Bayesian approach is used in the feedback mechanism proposed in PicHunter [4]. In the partial
labelling approach described in [23] textual and visual information are integrated to label a portion
of an image database and serve as seeds to enable further visual searches. The pseudo-feedback
method employed by Diogenes is intended for applications where interactive feedback is infeasible.
Commercial search engines such as AltaVista9 and Lycos10 also provide image search capability
but no feedback mechanism. Another commercial image search engine Ditto11 emphasizes timely
celebrity image searches. A recent addition to the highly successful Google search engine is the
image search interface12. While none of these search engines provide any feedback mechanism, they
do provide the advanced search features offered for text searches. In the SIMPLICITY search engine
[32], region-based wavelet signatures are used for content based image retrieval and the detection of
various types of objects in images.
7 Conclusion and Future Work
Content-based indexing of multimedia in large collections is a challengin task. In this paper we have
presented a robust information integration (evidence combination) approach for indexing person
images. In the proposed approach contextual evidence is combined with content-based evidence to
9http://www.altavista.com/sites/search/simage10http://multimedia.lycos.com,11http://www.ditto.lycos.com,12http://images.google.com
27

achieve accurate identification of person images. In any retrieval and indexing system that relies
on a set of parameters and an existing database of known objects, two questions arise: Are the
system parameters fine-tuned for a particular set of queries; if so would the performance degrade
for another set of queries or for another set of weights? Secondly, in the absence of a known object
database, would recognition be possible? In the experiments reported here we have shown that face
detection combined with context analysis is a robust way to identify person images on the web.
Namely, we have shown that the approach is not sensitive to fine-tuning of textual feature weights,
and furthermore, in the absence of a known person image database, the system can construct a
database automatically and possibly improve previous retrieval results that did not make use of
recognition.
The proposed method was demonstrated in the domain of person image indexing. However,
a number of other applications are obvious. Replacing the face detector used in the system with
another object detector and replacing the contextual analysis module to reflect heuristics about that
object type would render a new system capable of handling a new object type. Neural networks
have been shown to be very effective in detecting a multitude of objects [7, 13, 16]. Region-based
wavelet signatures have also been shown to be effective in object detection in images [32].
An important problem in content based multimedia indexing and retrieval is that of the semantic
gap between the user’s intent in querying and what an automated indexing system can identify in
multimedia. The MPEG7 standard provides a common mechanism to describe the contents of video
data in terms closer to the users’ semantic concepts. However, generation of these high level concepts
is an open research problem [11]. Evidence combination and feedback are likely to be very useful
in enabling automated semantic content extraction for video as well as for other forms of media
such as radio archives, XML document archives, images and computer generated structured media
elements. The Transferable Belief Model (TBM) [27, 28] appears to be another good candidate for
evidence combination in addition to the Dempster-Shafer model used in the present system.
28

References
[1] Y. Alp Aslandogan and Clement Yu. Experiments in Using Visual and Textual Clues for ImageHunting on the Web. In Proceedings of VISUAL 2000, Lyon , France, pages 108–119, November2000.
[2] Y. Alp Aslandogan and Clement Yu. Multiple Evidence Combination in Image retrieval: Dio-genes Searches for People on the Web. In Proceedings of ACM SIGIR 2000, Athens, Greece,pages 88–95, July 2000.
[3] Eric Brill. Some advances in transformation-based part of speech tagging. In Proceedings ofthe Twelfth National Conference on Artificial Intelligence, pages 722–727, 1994.
[4] I. Cox, M. Miller, S. Omohundro, and P. Yianilos. Pichunter: Bayesian relevance feedback forimage retrieval. volume 3, pages 361–369, 1996.
[5] Chitra Dorai and Svetha Venkatesh. Bridging the semantic gap in content management systems:Computational media aesthetics. In Proceedings of COSIGN 2001: Computational Semioticsfor Games and New Media, pages 33–52, 2001.
[6] Faloutsos C., Barber R., Flickner M., Hafner J., Niblack W., Petkovic D., and Equitz W.Efficient and Effective Querying by Image Content. Journal of Intelligent Information Systems,3(1):231–262, 1994.
[7] B. A. Golomb, D. T. Lawrence, and T. J. Sejnowski. Sexnet: A Neural Network Identifies Sexfrom Human Faces. In Advances in Neural Information Processing Systems 3, 1991.
[8] Earl Gose, Richard Johnsonbaugh, and Steve Jost. Pattern Recognition and Image Analysis.Artech HousePrentice Hall, 1996.
[9] William I. Grosky and Rong Zhao. Negotiating the semantic gap: From feature maps tosemantic landscapes. In Conference on Current Trends in Theory and Practice of Informatics,pages 33–52, 2001.
[10] David L. Hall. Mathematical Techniques in Multisensor Data Fusion. Artech House, 1992.
[11] R. Jain and A. Hampapur. Metadata in video databases. SIGMOD Record (ACM SpecialInterest Group on Management of Data), 23(4):27–33, 1994.
[12] Joemon M. Jose, Jonathan Furner, and David J. Harper. Spatial Querying for Image Retrieval:A User Oriented Evaluation. In ACM SIGIR, pages 232–240, 1998.
[13] A. Katz and P. Thrift. Hybrid neural network classifiers for automatic target detection, 1993.
[14] Marco LaCascia, Saratendu Sethi, and Stan Sclaroff. Combining Textual and Visual Cues forContent-based Image Retrieval on the World Wide Web. In Proceedings of IEEE Workshop onContent-Based Access of Image and Video Libraries, June 1998.
[15] Christophe Meilhac and Chahab Nastar. Relevance feedback and category search in imagedatabases. In ICMCS, Vol. 1, pages 512–517, 1999.
[16] Tom M. Mitchell. Machine learning. McGraw Hill, New York, US, 1996.
[17] Baback Moghaddam and Alex Pentland. Face Recognition using View-Based and ModularEigenspaces. Automatic Systems for the Identification and Inspection of Humans, SPIE, 2277,July 1994.
[18] Xiaoyan Mu, Mehmet Artiklar, Metin Artiklar, Mohamad Hassoun, and Paul Watta. TrainingAlgorithms for Robust Face Recognition using a Template-matching Approach. In Proceedingsof the IJCNN ’01, July 2001.
[19] Sougata Mukherjea, Kyoji Hirata, and Yoshinori Hara. AMORE: A World Wide Web ImageRetrieval Engine. World Wide Web, 2(3):115–132, 1999.
29

[20] Henry A. Rowley, Shumeet Baluja, and Takeo Kanade. Neural Network-Based Face Detection.IEEE Transactions on Pattern Analysis and Machine Intelligence, 20(1):23–38, Jan 1998.
[21] Y. Rui, T. Huang, and S. Mehrotra. Content-based image retrieval with relevance feedback inmars. In Proceedings of IEEE Int. Conf. on Image Proc., 1997.
[22] Y. Rui, T. S. Huang, and S. Mehrotra. Relevance feedback techniques in interactive content-based image retrieval. In Storage and Retrieval for Image and Video Databases (SPIE), pages25–36, 1998.
[23] Simone Santini. The integration of textual and visual search in image databases. In FirstInternational Workshop on Intelligent Multimedia Computing and Networking, 2000.
[24] Simone Santini, Amarnath Gupta, and Ramesh Jain. Emergent semantics through interactionin image databases. Knowledge and Data Engineering, 13(3):337–351, 2001.
[25] Glenn Shafer. A Mathematical Theory of Evidence. Princeton University Press, 1976.
[26] Alan F. Smeaton and Ian Qigley. Experiments on Using Semantic Distances Between Wordsin Image Caption Retrieval. In Proceedings of ACM SIGIR Conference, 1996.
[27] Ph. Smets and R. Kennes. The transferable belief model. Artificial Intelligence, 66:191–234,1994.
[28] Ph. Smets and R. Kennes. The transferable belief model for quantified belief representation.Handbook of Defeasible Reasoning and Uncertainty Management Systems, 1:267–301, 1998.
[29] J. R. Smith and S. F. Chang. Visually Searching the Web for Content. IEEE Multimedia,4(3):12–20, July-September 1997.
[30] Leonid Taycher, Marco LaCascia, and Stan Sclaroff. Image Digestion and Relevance Feedbackin the ImageRover WWW Search Engine. In Proceedings of SPIE Visual 97, 1997.
[31] M. Turk and A. Pentland. Eigenfaces for Recognition. Cognitive Neuroscience, 3(1):71–86,1991.
[32] James Ze Wang, Jia Li, and Gio Wiederhold. Simplicity: Semantics-sensitive integrated match-ing for picture libraries. IEEE Transactions on Pattern Analysis and Machine Intelligence,23(9):947–963, 2001.
[33] M. E. J. Wood, N. W. Campbell, and B. T. Thomas. Iterative refinement by relevance feedbackin content-based digi tal image retrieval. In ACM Multimedia 98, pages 13–20, Bristol, UK,1998. ACM.
30




























