Embed Size (px)
Citation preview

RobustnessMeetsAlgorithms
AnkurMoitra(MIT)
ICML2017Tutorial,August6th

CLASSICPARAMETERESTIMATIONGivensamplesfromanunknowndistributioninsomeclass
e.g.a1-DGaussian
canweaccuratelyestimateitsparameters?

CLASSICPARAMETERESTIMATIONGivensamplesfromanunknowndistributioninsomeclass
e.g.a1-DGaussian
canweaccuratelyestimateitsparameters? Yes!

CLASSICPARAMETERESTIMATIONGivensamplesfromanunknowndistributioninsomeclass
e.g.a1-DGaussian
canweaccuratelyestimateitsparameters?
empiricalmean: empiricalvariance:
Yes!

Themaximumlikelihoodestimatorisasymptoticallyefficient(1910-1920)
R.A.Fisher

Themaximumlikelihoodestimatorisasymptoticallyefficient(1910-1920)
R.A.Fisher J.W.Tukey
Whatabouterrors inthemodelitself?(1960)

ROBUSTSTATISTICS
Whatestimatorsbehavewellinaneighborhood aroundthe model?

ROBUSTSTATISTICS
Whatestimatorsbehavewellinaneighborhood aroundthe model?
Let’sstudyasimpleone-dimensionalexample….

ROBUSTPARAMETERESTIMATIONGivencorrupted samplesfroma1-DGaussian:
canweaccuratelyestimateitsparameters?
=+idealmodel noise observedmodel

Howdoweconstrainthenoise?

Howdoweconstrainthenoise?
Equivalently:
L1-normofnoiseatmostO(ε)

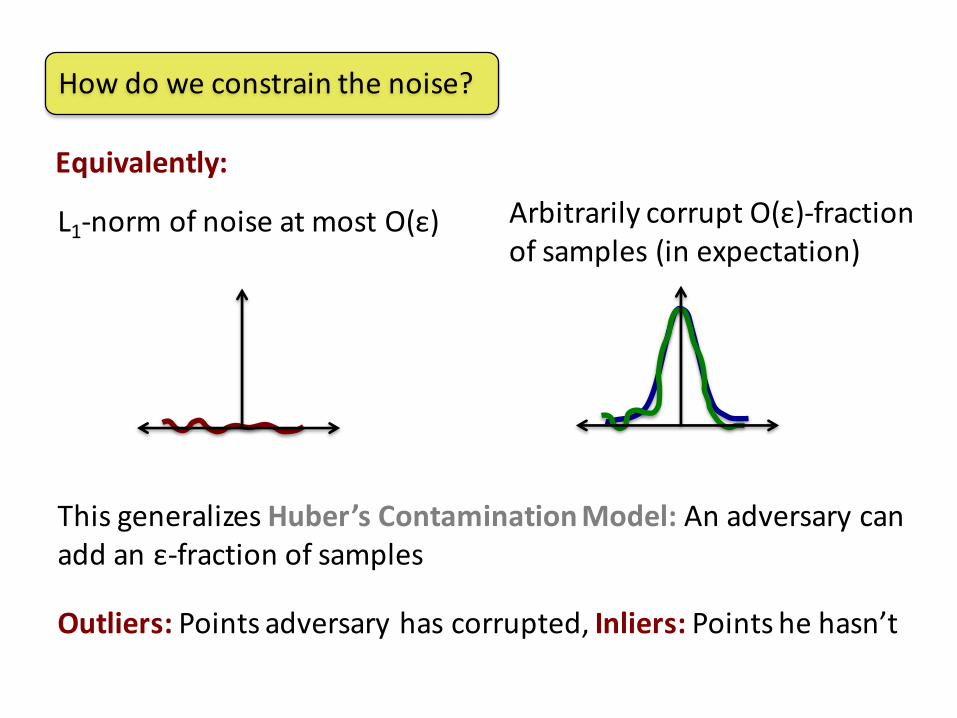
Howdoweconstrainthenoise?
Equivalently:
L1-normofnoiseatmostO(ε) ArbitrarilycorruptO(ε)-fractionofsamples(inexpectation)

Howdoweconstrainthenoise?
Equivalently:
ThisgeneralizesHuber’sContaminationModel:Anadversarycanadd anε-fractionofsamples
L1-normofnoiseatmostO(ε) ArbitrarilycorruptO(ε)-fractionofsamples(inexpectation)
Howdoweconstrainthenoise?
Equivalently:
ThisgeneralizesHuber’sContaminationModel:Anadversarycanadd anε-fractionofsamples
L1-normofnoiseatmostO(ε) ArbitrarilycorruptO(ε)-fractionofsamples(inexpectation)
Outliers:Pointsadversaryhascorrupted,Inliers:Pointshehasn’t

Inwhatnormdowewanttheparameterstobeclose?

Inwhatnormdowewanttheparameterstobeclose?
Definition:Thetotalvariationdistancebetweentwodistributionswithpdfs f(x)andg(x)is

Inwhatnormdowewanttheparameterstobeclose?
FromtheboundontheL1-normofthenoise,wehave:
observedideal
Definition:Thetotalvariationdistancebetweentwodistributionswithpdfs f(x)andg(x)is

Inwhatnormdowewanttheparameterstobeclose?
Definition:Thetotalvariationdistancebetweentwodistributionswithpdfs f(x)andg(x)is
estimate ideal
Goal:Finda1-DGaussianthatsatisfies

Inwhatnormdowewanttheparameterstobeclose?
estimate observed
Definition:Thetotalvariationdistancebetweentwodistributionswithpdfs f(x)andg(x)is
Equivalently,finda1-DGaussianthatsatisfies

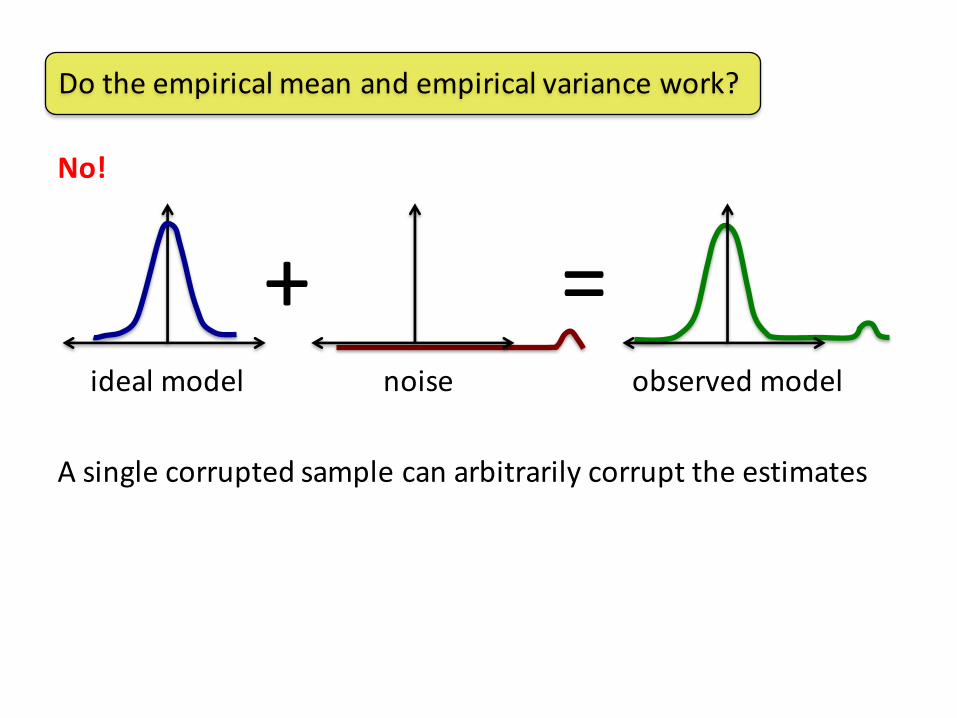
Dotheempiricalmeanandempiricalvariancework?

Dotheempiricalmeanandempiricalvariancework?
No!

Dotheempiricalmeanandempiricalvariancework?
No!
=+idealmodel noise observedmodel
Dotheempiricalmeanandempiricalvariancework?
No!
=+idealmodel noise observedmodel
Asinglecorruptedsamplecanarbitrarilycorrupttheestimates

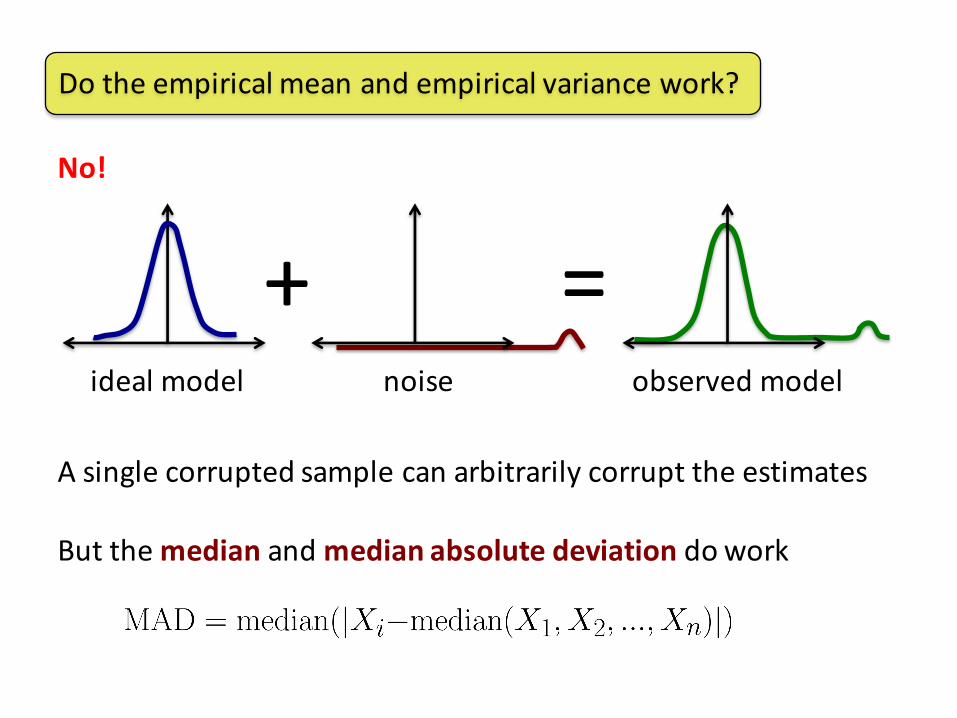
Dotheempiricalmeanandempiricalvariancework?
No!
=+idealmodel noise observedmodel
Asinglecorruptedsamplecanarbitrarilycorrupttheestimates
Butthemedian andmedianabsolutedeviationdowork
Dotheempiricalmeanandempiricalvariancework?
No!
=+idealmodel noise observedmodel
Asinglecorruptedsamplecanarbitrarilycorrupttheestimates
Butthemedian andmedianabsolutedeviationdowork

Fact[Folklore]:Givensamplesfromadistributionthatareε-closeintotalvariationdistancetoa1-DGaussian
themedianandMADrecoverestimatesthatsatisfy
where

Fact[Folklore]:Givensamplesfromadistributionthatareε-closeintotalvariationdistancetoa1-DGaussian
themedianandMADrecoverestimatesthatsatisfy
where
Alsocalled(properly)agnosticallylearninga1-DGaussian

Fact[Folklore]:Givensamplesfromadistributionthatareε-closeintotalvariationdistancetoa1-DGaussian
themedianandMADrecoverestimatesthatsatisfy
where
Whataboutrobustestimationinhigh-dimensions?

Whataboutrobustestimationinhigh-dimensions?
e.g.microarrayswith10kgenes
Fact[Folklore]:Givensamplesfromadistributionthatareε-closeintotalvariationdistancetoa1-DGaussian
themedianandMADrecoverestimatesthatsatisfy
where

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

MainProblem:Givensamplesfromadistributionthatareε-closeintotalvariationdistancetoad-dimensionalGaussian
giveanefficientalgorithmtofindparametersthatsatisfy

MainProblem:Givensamplesfromadistributionthatareε-closeintotalvariationdistancetoad-dimensionalGaussian
giveanefficientalgorithmtofindparametersthatsatisfy
SpecialCases:
(1)Unknownmean
(2)Unknowncovariance

ACOMPENDIUMOFAPPROACHES
ErrorGuarantee
RunningTime
UnknownMean

ACOMPENDIUMOFAPPROACHES
ErrorGuarantee
RunningTime
TukeyMedian
UnknownMean

ACOMPENDIUMOFAPPROACHES
ErrorGuarantee
RunningTime
TukeyMedian
UnknownMean
O(ε)

ACOMPENDIUMOFAPPROACHES
ErrorGuarantee
RunningTime
TukeyMedian
UnknownMean
O(ε) NP-Hard

ACOMPENDIUMOFAPPROACHES
ErrorGuarantee
RunningTime
TukeyMedian
UnknownMean
O(ε) NP-Hard
GeometricMedian

ACOMPENDIUMOFAPPROACHES
ErrorGuarantee
RunningTime
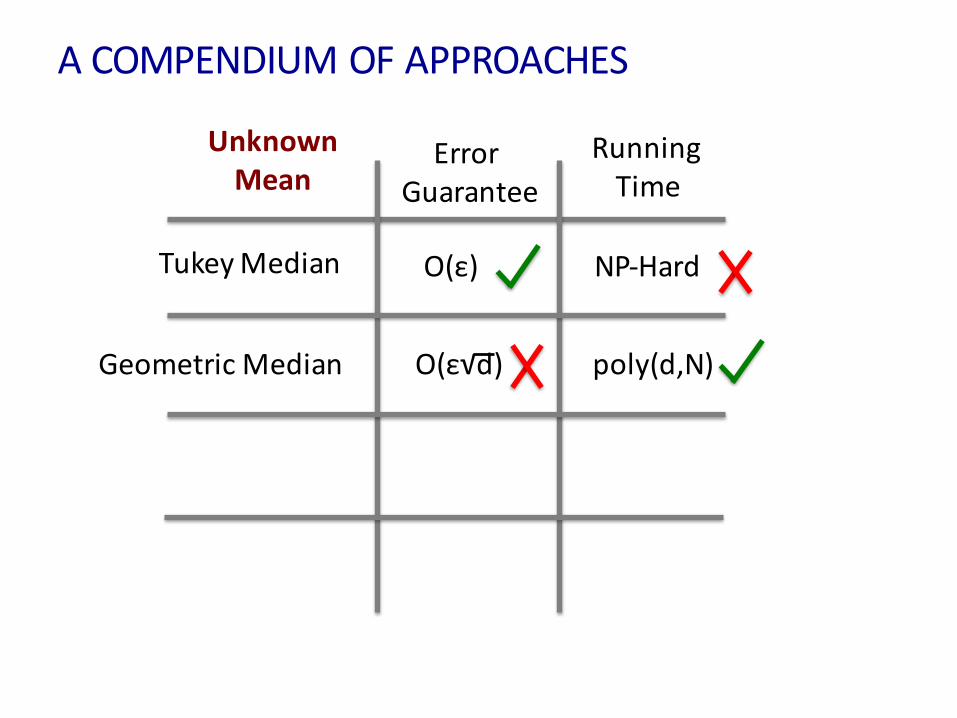
TukeyMedian
UnknownMean
O(ε) NP-Hard
GeometricMedian poly(d,N)
ACOMPENDIUMOFAPPROACHES
ErrorGuarantee
RunningTime
TukeyMedian
UnknownMean
O(ε) NP-Hard
GeometricMedian poly(d,N)O(ε√d)

ACOMPENDIUMOFAPPROACHES
ErrorGuarantee
RunningTime
TukeyMedian
UnknownMean
O(ε) NP-Hard
GeometricMedian poly(d,N)O(ε√d)
Tournament O(ε) NO(d)

ACOMPENDIUMOFAPPROACHES
ErrorGuarantee
RunningTime
TukeyMedian
UnknownMean
O(ε) NP-Hard
GeometricMedian poly(d,N)O(ε√d)
Tournament O(ε) NO(d)
O(ε√d)Pruning O(dN)

ACOMPENDIUMOFAPPROACHES
ErrorGuarantee
RunningTime
TukeyMedian O(ε) NP-Hard
GeometricMedian O(ε√d) poly(d,N)
Tournament O(ε) NO(d)
O(ε√d)Pruning O(dN)
UnknownMean
…

ThePriceofRobustness?
Allknownestimatorsarehardtocomputeorlosepolynomial factorsinthedimension

ThePriceofRobustness?
Allknownestimatorsarehardtocomputeorlosepolynomial factorsinthedimension
Equivalently:Computationallyefficientestimatorscanonlyhandle
fractionoferrorsandgetnon-trivial(TV<1)guarantees

ThePriceofRobustness?
Allknownestimatorsarehardtocomputeorlosepolynomial factorsinthedimension
Equivalently:Computationallyefficientestimatorscanonlyhandle
fractionoferrorsandgetnon-trivial(TV<1)guarantees

ThePriceofRobustness?
Allknownestimatorsarehardtocomputeorlosepolynomial factorsinthedimension
Equivalently:Computationallyefficientestimatorscanonlyhandle
fractionoferrorsandgetnon-trivial(TV<1)guarantees
Isrobustestimationalgorithmicallypossibleinhigh-dimensions?

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

RECENTRESULTS
Theorem[Diakonikolas,Li,Kamath,Kane,Moitra,Stewart‘16]:Thereisanalgorithmwhengivensamplesfromadistributionthatisε-closeintotalvariationdistancetoad-dimensionalGaussianfindsparametersthatsatisfy
Robustestimationishigh-dimensionsisalgorithmicallypossible!
Moreoverthealgorithmrunsintimepoly(N,d)

RECENTRESULTS
Theorem[Diakonikolas,Li,Kamath,Kane,Moitra,Stewart‘16]:Thereisanalgorithmwhengivensamplesfromadistributionthatisε-closeintotalvariationdistancetoad-dimensionalGaussianfindsparametersthatsatisfy
Robustestimationishigh-dimensionsisalgorithmicallypossible!
Moreoverthealgorithmrunsintimepoly(N,d)
Alternatively:CanapproximatetheTukeymedian,etc,ininterestingsemi-randommodels

Independentlyandconcurrently:
Theorem[Lai,Rao,Vempala ‘16]:Thereisanalgorithmwhengivensamplesfromadistributionthatisε-closeintotal
variationdistancetoad-dimensionalGaussianfindsparametersthatsatisfy
Moreoverthealgorithmrunsintimepoly(N,d)

Independentlyandconcurrently:
Theorem[Lai,Rao,Vempala ‘16]:Thereisanalgorithmwhengivensamplesfromadistributionthatisε-closeintotal
variationdistancetoad-dimensionalGaussianfindsparametersthatsatisfy
Moreoverthealgorithmrunsintimepoly(N,d)
Whenthecovarianceisbounded,thistranslatesto:

AGENERALRECIPE
Robustestimationinhigh-dimensions:
� Step#1:Findanappropriateparameterdistance
� Step#2:Detectwhenthenaïveestimatorhasbeencompromised
� Step#3:Findgoodparameters,ormakeprogressFiltering:FastandpracticalConvexProgramming:Bettersamplecomplexity

AGENERALRECIPE
Robustestimationinhigh-dimensions:
� Step#1:Findanappropriateparameterdistance
� Step#2:Detectwhenthenaïveestimatorhasbeencompromised
� Step#3:Findgoodparameters,ormakeprogressFiltering:FastandpracticalConvexProgramming:Bettersamplecomplexity
Let’sseehowthisworksforunknownmean…

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

PARAMETERDISTANCE
Step#1:FindanappropriateparameterdistanceforGaussians

PARAMETERDISTANCE
Step#1:FindanappropriateparameterdistanceforGaussians
ABasicFact:
(1)

PARAMETERDISTANCE
Step#1:FindanappropriateparameterdistanceforGaussians
ABasicFact:
(1)
ThiscanbeprovenusingPinsker’s Inequality
andthewell-knownformulaforKL-divergencebetweenGaussians

PARAMETERDISTANCE
Step#1:FindanappropriateparameterdistanceforGaussians
ABasicFact:
(1)

PARAMETERDISTANCE
Step#1:FindanappropriateparameterdistanceforGaussians
ABasicFact:
(1)
Corollary:Ifourestimate(intheunknownmeancase)satisfies
then

PARAMETERDISTANCE
Step#1:FindanappropriateparameterdistanceforGaussians
ABasicFact:
(1)
Corollary:Ifourestimate(intheunknownmeancase)satisfies
then
OurnewgoalistobecloseinEuclideandistance

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

DETECTINGCORRUPTIONS
Step#2:Detectwhenthenaïveestimatorhasbeencompromised

DETECTINGCORRUPTIONS
Step#2:Detectwhenthenaïveestimatorhasbeencompromised
=uncorrupted=corrupted
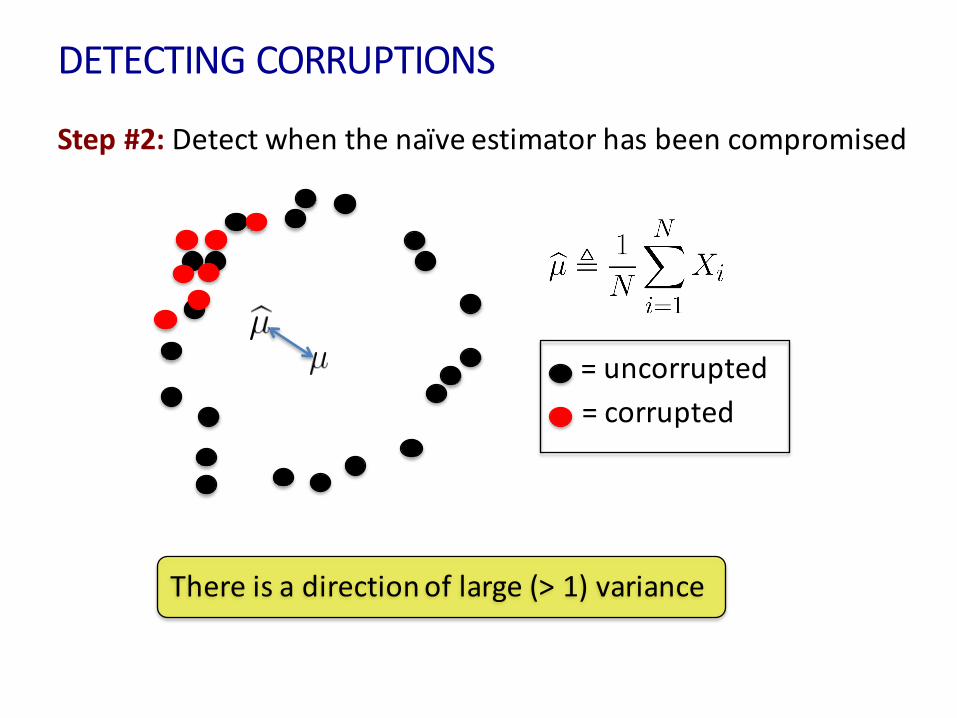
DETECTINGCORRUPTIONS
Step#2:Detectwhenthenaïveestimatorhasbeencompromised
=uncorrupted=corrupted
Thereisadirectionoflarge(>1)variance

KeyLemma:IfX1,X2,…XN comefromadistributionthatisε-closetoandthenfor
(1) (2)
withprobabilityatleast1-δ

KeyLemma:IfX1,X2,…XN comefromadistributionthatisε-closetoandthenfor
(1) (2)
withprobabilityatleast1-δ
Take-away:Anadversaryneedstomessupthesecondmomentinordertocorruptthefirstmoment

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

AWIN-WINALGORITHM
Step#3:Eitherfindgoodparameters,orremovemanyoutliers

AWIN-WINALGORITHM
Step#3:Eitherfindgoodparameters,orremovemanyoutliers
FilteringApproach:Supposethat:

AWIN-WINALGORITHM
Step#3:Eitherfindgoodparameters,orremovemanyoutliers
FilteringApproach:Supposethat:
Wecanthrowoutmorecorruptedthanuncorruptedpoints:
v
wherevisthedirectionoflargestvariance

AWIN-WINALGORITHM
Step#3:Eitherfindgoodparameters,orremovemanyoutliers
FilteringApproach:Supposethat:
Wecanthrowoutmorecorruptedthanuncorruptedpoints:
v
wherevisthedirectionoflargestvariance,andThasaformula

AWIN-WINALGORITHM
Step#3:Eitherfindgoodparameters,orremovemanyoutliers
FilteringApproach:Supposethat:
Wecanthrowoutmorecorruptedthanuncorruptedpoints:
v
T
wherevisthedirectionoflargestvariance,andThasaformula

AWIN-WINALGORITHM
Step#3:Eitherfindgoodparameters,orremovemanyoutliers
FilteringApproach:Supposethat:
Wecanthrowoutmorecorruptedthanuncorruptedpoints

AWIN-WINALGORITHM
Step#3:Eitherfindgoodparameters,orremovemanyoutliers
FilteringApproach:Supposethat:
Wecanthrowoutmorecorruptedthanuncorruptedpoints
Ifwecontinuetoolong,we’dhavenocorruptedpointsleft!

AWIN-WINALGORITHM
Step#3:Eitherfindgoodparameters,orremovemanyoutliers
FilteringApproach:Supposethat:
Wecanthrowoutmorecorruptedthanuncorruptedpoints
Ifwecontinuetoolong,we’dhavenocorruptedpointsleft!
Eventuallywefind(certifiably)goodparameters

AWIN-WINALGORITHM
Step#3:Eitherfindgoodparameters,orremovemanyoutliers
FilteringApproach:Supposethat:
Wecanthrowoutmorecorruptedthanuncorruptedpoints
Ifwecontinuetoolong,we’dhavenocorruptedpointsleft!
Eventuallywefind(certifiably)goodparameters
RunningTime: SampleComplexity:

AWIN-WINALGORITHM
Step#3:Eitherfindgoodparameters,orremovemanyoutliers
FilteringApproach:Supposethat:
Wecanthrowoutmorecorruptedthanuncorruptedpoints
Ifwecontinuetoolong,we’dhavenocorruptedpointsleft!
Eventuallywefind(certifiably)goodparameters
RunningTime: SampleComplexity:ConcentrationofLTFs

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

AGENERALRECIPE
Robustestimationinhigh-dimensions:
� Step#1:Findanappropriateparameterdistance
� Step#2:Detectwhenthenaïveestimatorhasbeencompromised
� Step#3:Findgoodparameters,ormakeprogressFiltering:FastandpracticalConvexProgramming:Bettersamplecomplexity

AGENERALRECIPE
Robustestimationinhigh-dimensions:
� Step#1:Findanappropriateparameterdistance
� Step#2:Detectwhenthenaïveestimatorhasbeencompromised
� Step#3:Findgoodparameters,ormakeprogressFiltering:FastandpracticalConvexProgramming:Bettersamplecomplexity
Howaboutforunknowncovariance?

PARAMETERDISTANCE
Step#1:FindanappropriateparameterdistanceforGaussians

PARAMETERDISTANCE
Step#1:FindanappropriateparameterdistanceforGaussians
AnotherBasicFact:
(2)

PARAMETERDISTANCE
Step#1:FindanappropriateparameterdistanceforGaussians
AnotherBasicFact:
Again,provenusingPinsker’s Inequality
(2)

PARAMETERDISTANCE
Step#1:FindanappropriateparameterdistanceforGaussians
AnotherBasicFact:
Again,provenusingPinsker’s Inequality
(2)
Ournewgoalistofindanestimatethatsatisfies:

PARAMETERDISTANCE
Step#1:FindanappropriateparameterdistanceforGaussians
AnotherBasicFact:
Again,provenusingPinsker’s Inequality
(2)
Ournewgoalistofindanestimatethatsatisfies:
Distanceseemsstrange,butit’stherightonetousetoboundTV

UNKNOWNCOVARIANCE
Whatifwearegivensamplesfrom?

UNKNOWNCOVARIANCE
Whatifwearegivensamplesfrom?
Howdowedetectifthenaïveestimatoriscompromised?

UNKNOWNCOVARIANCE
Whatifwearegivensamplesfrom?
Howdowedetectifthenaïveestimatoriscompromised?
KeyFact:Let and
Thenrestrictedtoflattenings ofdxdsymmetricmatrices

UNKNOWNCOVARIANCE
Whatifwearegivensamplesfrom?
Howdowedetectifthenaïveestimatoriscompromised?
KeyFact:Let and
Thenrestrictedtoflattenings ofdxdsymmetricmatrices
ProofusesIsserlis’s Theorem

UNKNOWNCOVARIANCE
needtoprojectout
Whatifwearegivensamplesfrom?
Howdowedetectifthenaïveestimatoriscompromised?
KeyFact:Let and
Thenrestrictedtoflattenings ofdxdsymmetricmatrices

KeyIdea: Transformthedata,lookforrestrictedlargeeigenvalues

KeyIdea: Transformthedata,lookforrestrictedlargeeigenvalues

KeyIdea: Transformthedata,lookforrestrictedlargeeigenvalues
Ifwerethetruecovariance,wewouldhaveforinliers

KeyIdea: Transformthedata,lookforrestrictedlargeeigenvalues
Ifwerethetruecovariance,wewouldhaveforinliers,inwhichcase:
wouldhavesmallrestrictedeigenvalues

KeyIdea: Transformthedata,lookforrestrictedlargeeigenvalues
Ifwerethetruecovariance,wewouldhaveforinliers,inwhichcase:
wouldhavesmallrestrictedeigenvalues
Take-away:Anadversaryneedstomessupthe(restricted)fourthmomentinordertocorruptthesecondmoment

ASSEMBLINGTHEALGORITHM
Givensamplesthatareε-closeintotalvariationdistancetoad-dimensionalGaussian

ASSEMBLINGTHEALGORITHM
Givensamplesthatareε-closeintotalvariationdistancetoad-dimensionalGaussian
Step#1:Doublingtrick

ASSEMBLINGTHEALGORITHM
Givensamplesthatareε-closeintotalvariationdistancetoad-dimensionalGaussian
Step#1:Doublingtrick
Nowusealgorithmforunknowncovariance

ASSEMBLINGTHEALGORITHM
Givensamplesthatareε-closeintotalvariationdistancetoad-dimensionalGaussian
Step#1:Doublingtrick
Nowusealgorithmforunknowncovariance
Step#2:(Agnostic)isotropicposition

ASSEMBLINGTHEALGORITHM
Givensamplesthatareε-closeintotalvariationdistancetoad-dimensionalGaussian
Step#1:Doublingtrick
Nowusealgorithmforunknowncovariance
Step#2:(Agnostic)isotropicposition
rightdistance,ingeneralcase

ASSEMBLINGTHEALGORITHM
Givensamplesthatareε-closeintotalvariationdistancetoad-dimensionalGaussian
Step#1:Doublingtrick
Nowusealgorithmforunknowncovariance
Step#2:(Agnostic)isotropicposition
Nowusealgorithmforunknownmeanrightdistance,ingeneralcase

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

SYNTHETICEXPERIMENTS
Errorratesonsyntheticdata(unknownmean):
+10%noise

SYNTHETICEXPERIMENTS
Errorratesonsyntheticdata(unknownmean):
100 200 300 400
0
0.5
1
1.5
dimension
excess` 2
error
Filtering
LRVMean
Sample mean w/ noise
Pruning
RANSAC Geometric Median
100 200 300 400
0.04
0.06
0.08
0.1
0.12
0.14
dimension
excess` 2
error

SYNTHETICEXPERIMENTS
Errorratesonsyntheticdata(unknowncovariance,isotropic):
+10%noise
closetoidentity
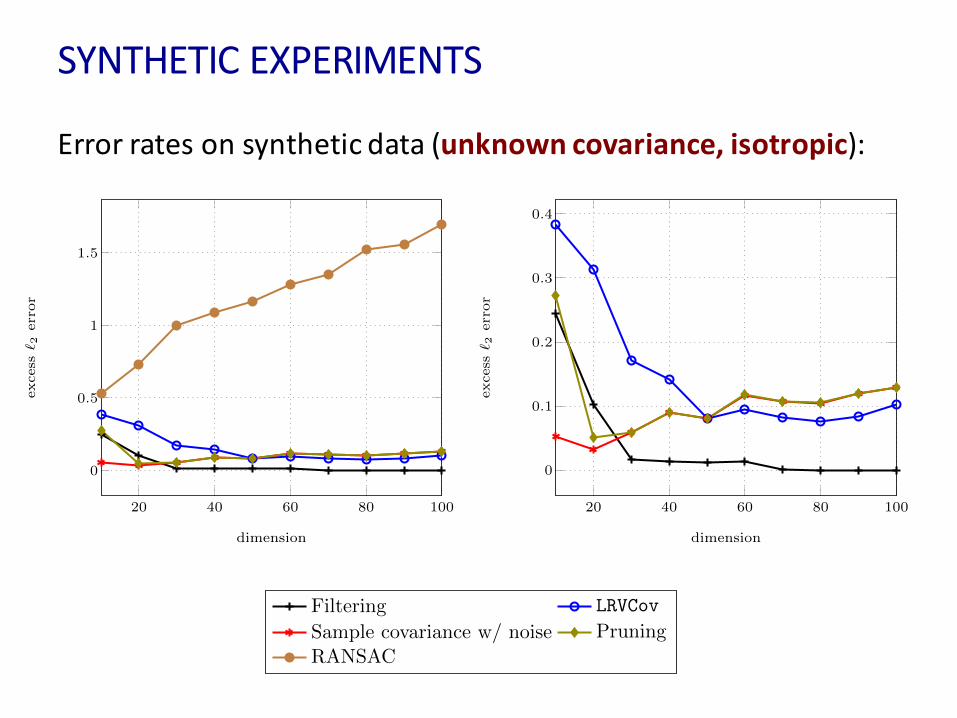
SYNTHETICEXPERIMENTS
20 40 60 80 100
0
0.5
1
1.5
dimension
excess` 2
error
Filtering
LRVCov
Sample covariance w/ noise
Pruning
RANSAC
20 40 60 80 100
0
0.1
0.2
0.3
0.4
dimension
excess` 2
error
Errorratesonsyntheticdata(unknowncovariance,isotropic):

SYNTHETICEXPERIMENTS
Errorratesonsyntheticdata(unknowncovariance,anisotropic):
+10%noise
farfromidentity

SYNTHETICEXPERIMENTS
20 40 60 80 100
0
50
100
150
200
dimension
excess` 2
error
Filtering
LRVCov
Sample covariance w/ noise
Pruning
RANSAC
20 40 60 80 100
0
0.5
1
dimension
excess` 2
error
Errorratesonsyntheticdata(unknowncovariance,anisotropic):

REALDATAEXPERIMENTS
Famousstudyof[Novembre etal.‘08]:TaketoptwosingularvectorsofpeoplexSNPmatrix(POPRES)
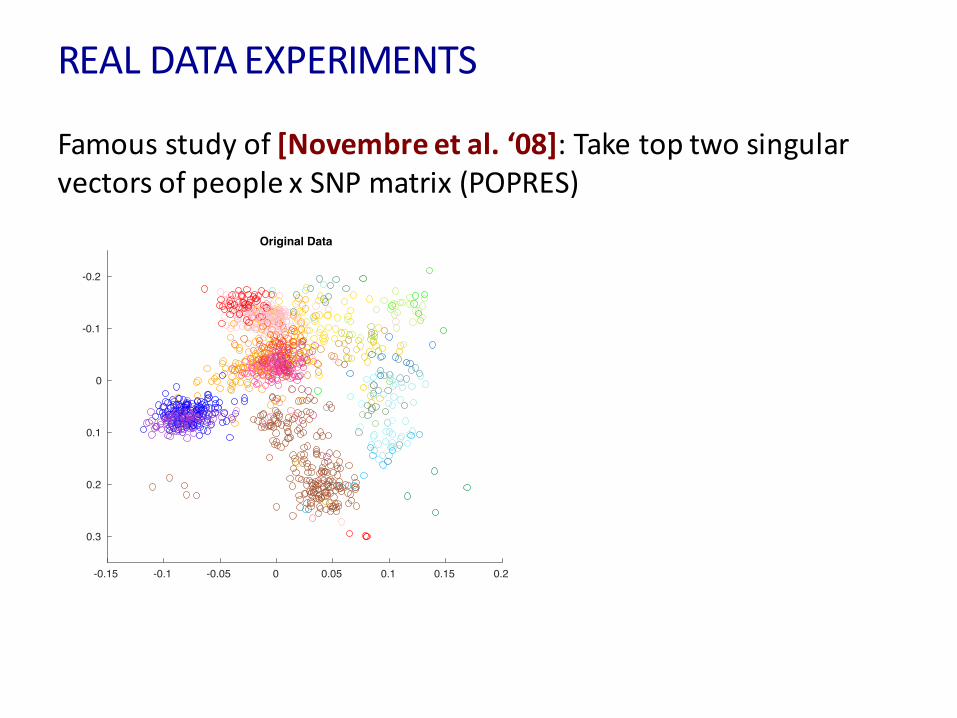
REALDATAEXPERIMENTS
Famousstudyof[Novembre etal.‘08]:TaketoptwosingularvectorsofpeoplexSNPmatrix(POPRES)
-0.2
-0.1
0
0.1
0.2
0.3
-0.15 -0.1 -0.05 0 0.05 0.1 0.15 0.2
Original Data
REALDATAEXPERIMENTS
Famousstudyof[Novembre etal.‘08]:TaketoptwosingularvectorsofpeoplexSNPmatrix(POPRES)
-0.2
-0.1
0
0.1
0.2
0.3
-0.15 -0.1 -0.05 0 0.05 0.1 0.15 0.2
Original Data

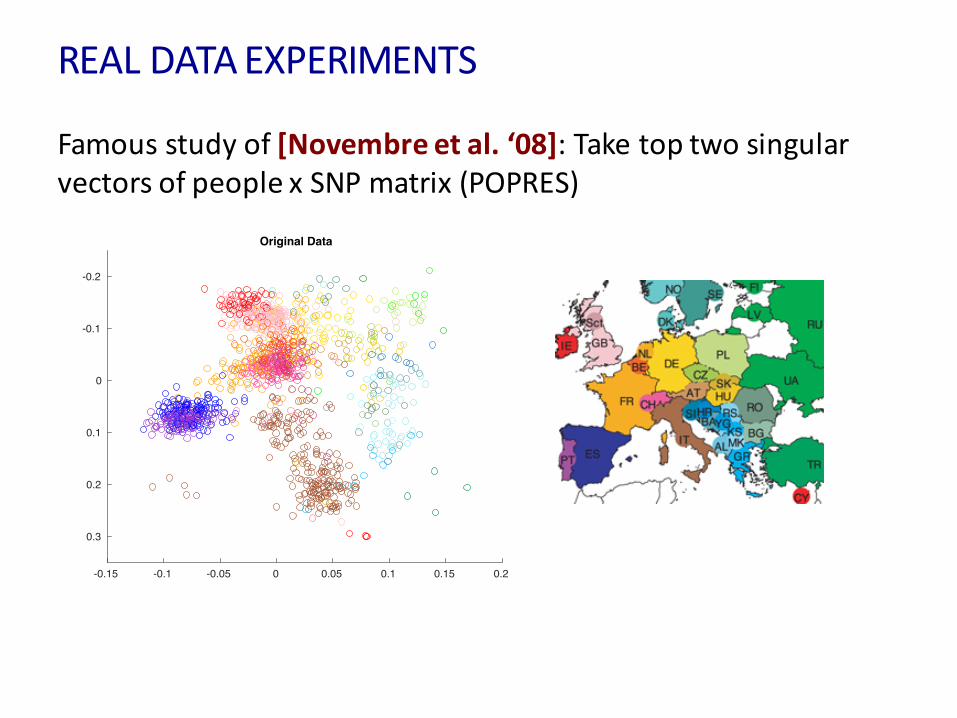
REALDATAEXPERIMENTS
Famousstudyof[Novembre etal.‘08]:TaketoptwosingularvectorsofpeoplexSNPmatrix(POPRES)
-0.2
-0.1
0
0.1
0.2
0.3
-0.15 -0.1 -0.05 0 0.05 0.1 0.15 0.2
Original Data
“GenesMirrorGeographyinEurope”

REALDATAEXPERIMENTS
Canwefindsuchpatternsinthepresenceofnoise?

REALDATAEXPERIMENTS
Canwefindsuchpatternsinthepresenceofnoise?
-0.2 -0.1 0 0.1 0.2 0.3-0.15
-0.1
-0.05
0
0.05
0.1
0.15
0.2Pruning Projection
10%noise
WhatPCAfinds
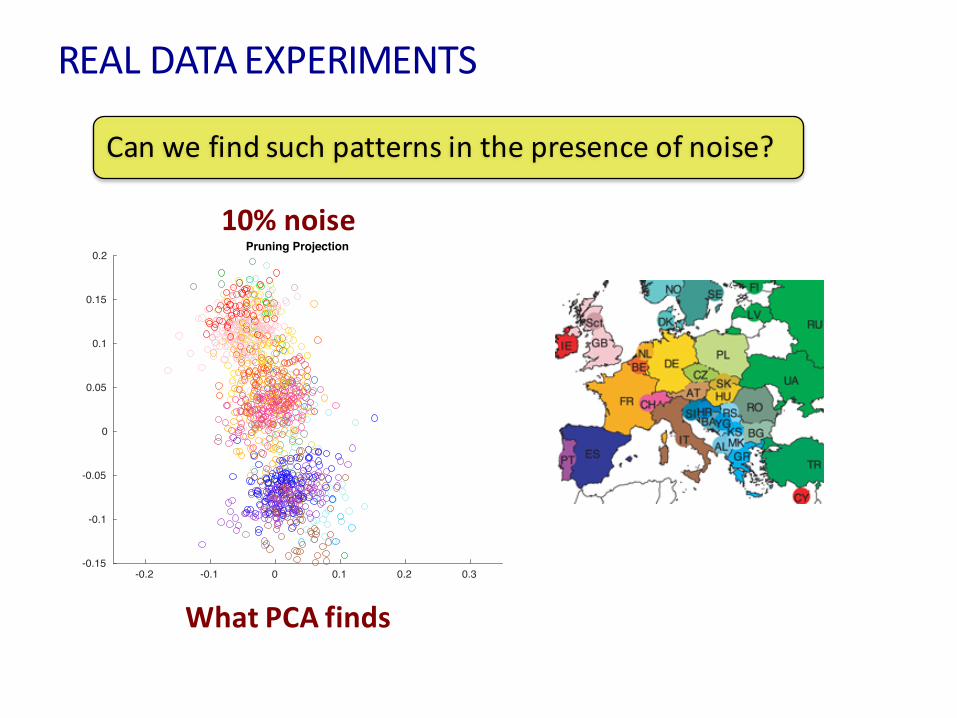
REALDATAEXPERIMENTS
Canwefindsuchpatternsinthepresenceofnoise?
-0.2 -0.1 0 0.1 0.2 0.3-0.15
-0.1
-0.05
0
0.05
0.1
0.15
0.2Pruning Projection
10%noise
WhatPCAfinds
-0.2 -0.1 0 0.1 0.2 0.3
-0.15
-0.1
-0.05
0
0.05
0.1
0.15
0.2RANSAC Projection
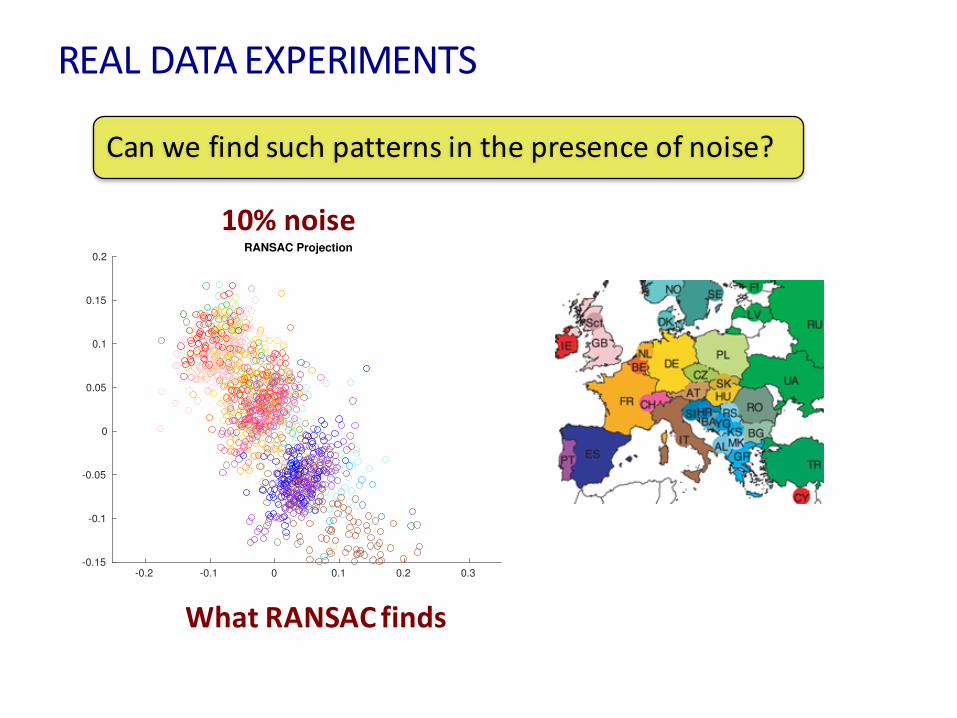
REALDATAEXPERIMENTS
Canwefindsuchpatternsinthepresenceofnoise?
10%noise
WhatRANSACfinds
-0.2
-0.1
0
0.1
0.2
0.3
-0.15 -0.1 -0.05 0 0.05 0.1 0.15 0.2
XCS Projection
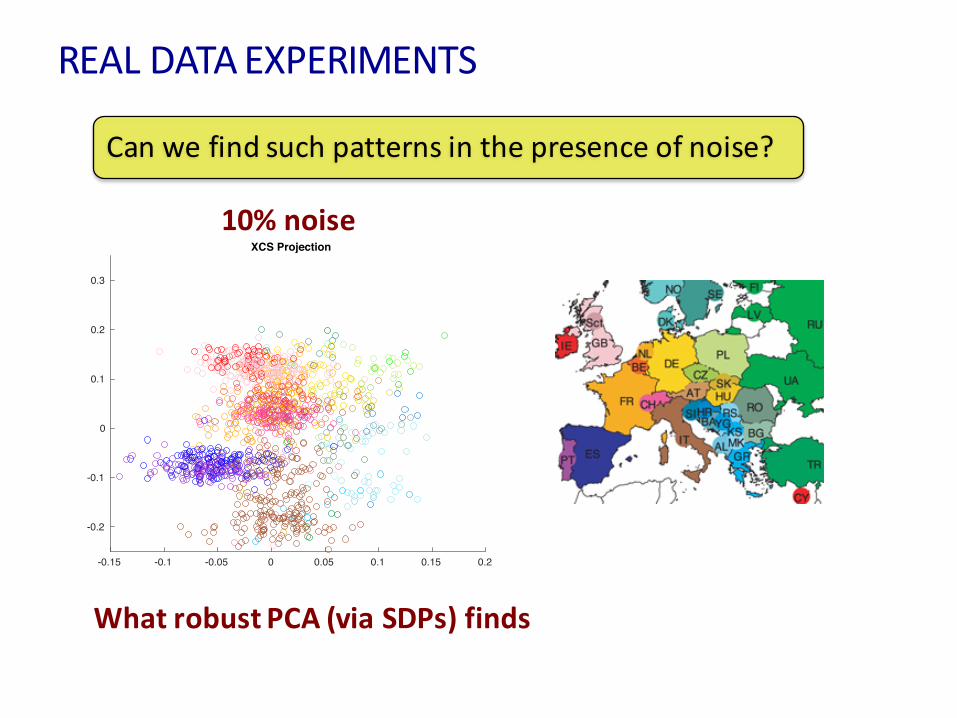
REALDATAEXPERIMENTS
Canwefindsuchpatternsinthepresenceofnoise?
10%noise
WhatrobustPCA(viaSDPs)finds

-0.2
-0.1
0
0.1
0.2
0.3
-0.15-0.1-0.0500.050.10.150.2
Filter Projection
REALDATAEXPERIMENTS
Canwefindsuchpatternsinthepresenceofnoise?
10%noise
Whatourmethodsfind
-0.2
-0.1
0
0.1
0.2
0.3
-0.15-0.1-0.0500.050.10.150.2
Filter Projection
-0.2
-0.1
0
0.1
0.2
0.3
-0.15 -0.1 -0.05 0 0.05 0.1 0.15 0.2
Original Data
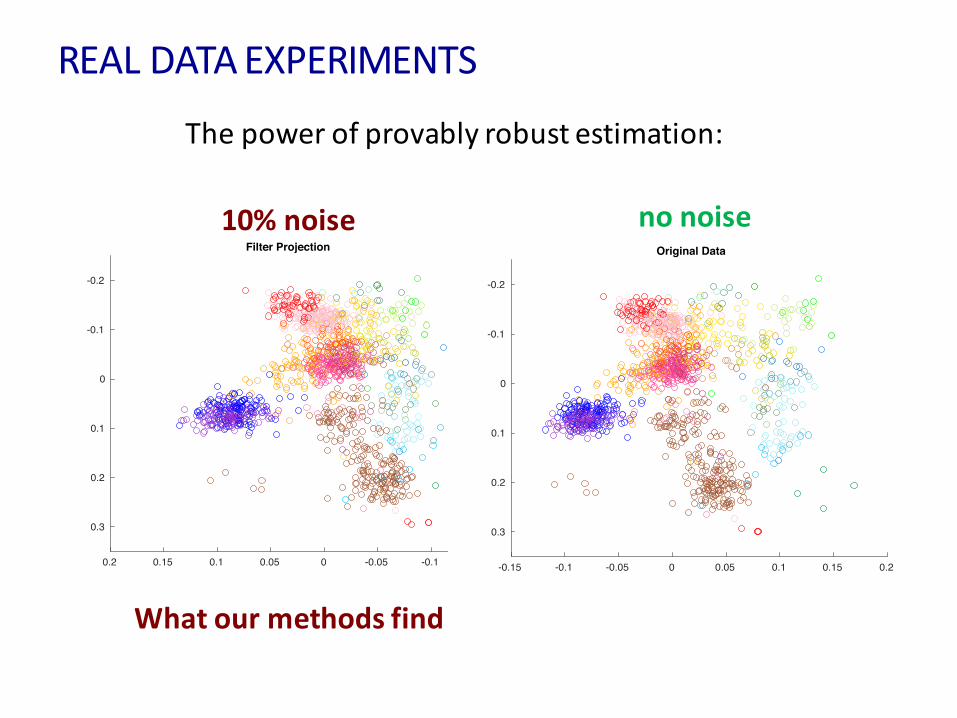
REALDATAEXPERIMENTS
10%noise
Whatourmethodsfind
nonoise
Thepowerofprovablyrobustestimation:

LOOKINGFORWARD
CanalgorithmsforagnosticallylearningaGaussianhelpinexploratorydataanalysisinhigh-dimensions?

LOOKINGFORWARD
CanalgorithmsforagnosticallylearningaGaussianhelpinexploratorydataanalysisinhigh-dimensions?
Isn’tthiswhatwewouldhavebeendoingwithrobuststatisticalestimators,ifwehadthemallalong?

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

OUTLINE
PartI:Introduction
� RobustEstimationinOne-dimension� Robustnessvs.HardnessinHigh-dimensions
� RecentResults
PartII:AgnosticallyLearningaGaussian
� ParameterDistance� DetectingWhenanEstimatorisCompromised
� AWin-WinAlgorithm� UnknownCovariance
PartIII:Experiments PartIV:Extensions

LIMITATIONSTOROBUSTESTIMATION
Theorem[Diakonikolas,Kane,Stewart‘16]:Anystatisticalquerylearning* algorithminthestrongcorruptionmodel
thatmakeserrormustmakeatleastqueries
insertionsanddeletions

LIMITATIONSTOROBUSTESTIMATION
Theorem[Diakonikolas,Kane,Stewart‘16]:Anystatisticalquerylearning* algorithminthestrongcorruptionmodel
thatmakeserrormustmakeatleastqueries
*Insteadofseeingsamplesdirectly,analgorithmqueriesafnctn
andgetsexpectation,uptosamplingnoise
insertionsanddeletions

LIMITATIONSTOROBUSTESTIMATION
Theorem[Diakonikolas,Kane,Stewart‘16]:Anystatisticalquerylearning* algorithminthestrongcorruptionmodel
thatmakeserrormustmakeatleastqueries
*Insteadofseeingsamplesdirectly,analgorithmqueriesafnctn
andgetsexpectation,uptosamplingnoise
Thisisapowerfulbutrestrictedclassofalgorithms
insertionsanddeletions

HANDLINGMORECORRUPTIONS
Whatifanadversaryisallowedtocorruptmorethanhalfofthesamples?

HANDLINGMORECORRUPTIONS
Theorem[Charikar,Steinhardt,Valiant‘17]:Givensamplesfromadistributionwithmeanandcovariancewherehavebeencorrupted,thereisanalgorithmthatoutputs
Whatifanadversaryisallowedtocorruptmorethanhalfofthesamples?
with thatsatisfies

HANDLINGMORECORRUPTIONS
Whatifanadversaryisallowedtocorruptmorethanhalfofthesamples?
Thisextendstomixturesstraightforwardly
Theorem[Charikar,Steinhardt,Valiant‘17]:Givensamplesfromadistributionwithmeanandcovariancewherehavebeencorrupted,thereisanalgorithmthatoutputs
with thatsatisfies

SPARSEROBUSTESTIMATION
Canweimprovethesamplecomplexitywithsparsity assumptions?
Theorem[Li‘17] [Du,Balakrishnan,Singh’17]:Thereisanalgorithm,intheunknownk-sparsemeancaseachieveserror
withsamples

SPARSEROBUSTESTIMATION
Theorem[Li‘17] [Du,Balakrishnan,Singh’17]:Thereisanalgorithm,intheunknownk-sparsemeancaseachieveserror
withsamples
[Li‘17] alsostudiedrobustsparsePCA
Canweimprovethesamplecomplexitywithsparsity assumptions?

SPARSEROBUSTESTIMATION
Theorem[Li‘17] [Du,Balakrishnan,Singh’17]:Thereisanalgorithm,intheunknownk-sparsemeancaseachieveserror
withsamples
[Li‘17] alsostudiedrobustsparsePCA
Isitpossibletoimprovethesamplecomplexitytooraretherecomputationalvs.statisticaltradeoffs?
Canweimprovethesamplecomplexitywithsparsity assumptions?

LOOKINGFORWARD
CanalgorithmsforagnosticallylearningaGaussianhelpinexploratorydataanalysisinhigh-dimensions?
Isn’tthiswhatwewouldhavebeendoingwithrobuststatisticalestimators,ifwehadthemallalong?

LOOKINGFORWARD
CanalgorithmsforagnosticallylearningaGaussianhelpinexploratorydataanalysisinhigh-dimensions?
Isn’tthiswhatwewouldhavebeendoingwithrobuststatisticalestimators,ifwehadthemallalong?
Whatotherfundamentaltasksinhigh-dimensionalstatisticscanbesolvedprovablyandrobustly?

Summary:� DimensionindependenterrorboundsforrobustlylearningaGaussian
� Generalrecipeusingrestrictedeigenvalueproblems� SQLlowerbounds,handlingmorecorruptionsandsparserobustestimation
� Ispractical,robuststatisticswithinreach?

Thanks!AnyQuestions?
Summary:� DimensionindependenterrorboundsforrobustlylearningaGaussian
� Generalrecipeusingrestrictedeigenvalueproblems� SQLlowerbounds,handlingmorecorruptionsandsparserobustestimation
� Ispractical,robuststatisticswithinreach?





























