Embed Size (px)
DESCRIPTION
From Sequences of Dependent Instructions to Functions: A Complexity- E ffective Approach for Improving Performance Without ILP or Speculation. Sami YEHIA and Olivier TEMAM LRI, Paris South University France. Scaling Up Processors. - PowerPoint PPT Presentation
Citation preview

From Sequences of Dependent Instructions to Functions: A
Complexity-Effective Approach for Improving Performance Without ILP
or Speculation
Sami YEHIA and Olivier TEMAMLRI, Paris South University
France
2/18
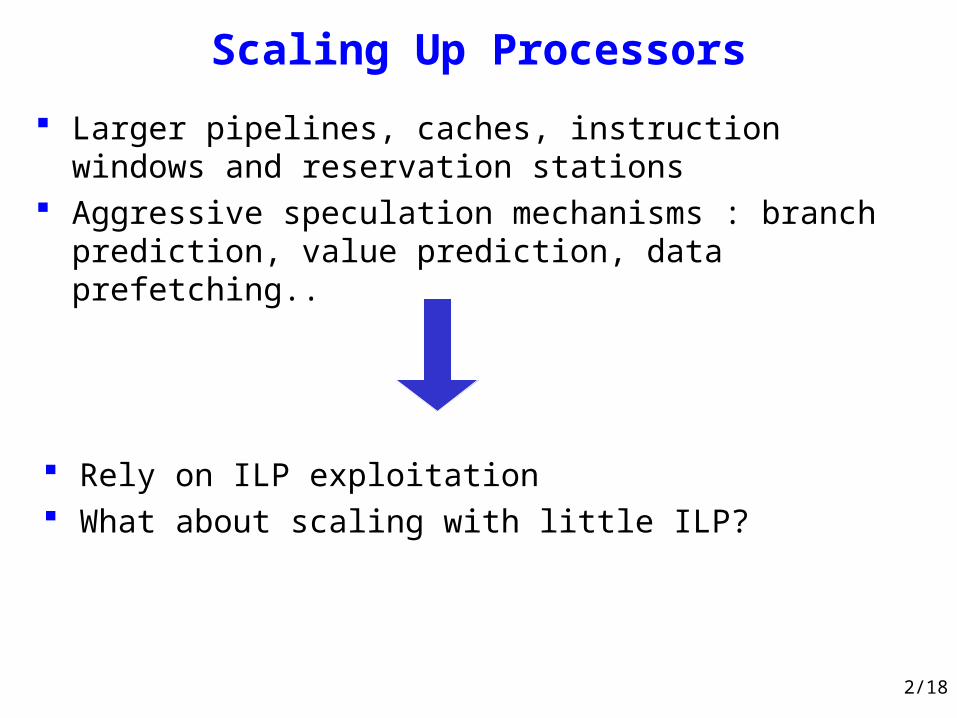
Scaling Up Processors
Larger pipelines, caches, instruction windows and reservation stations
Aggressive speculation mechanisms : branch prediction, value prediction, data prefetching..
Rely on ILP exploitation What about scaling with little ILP?
3/18
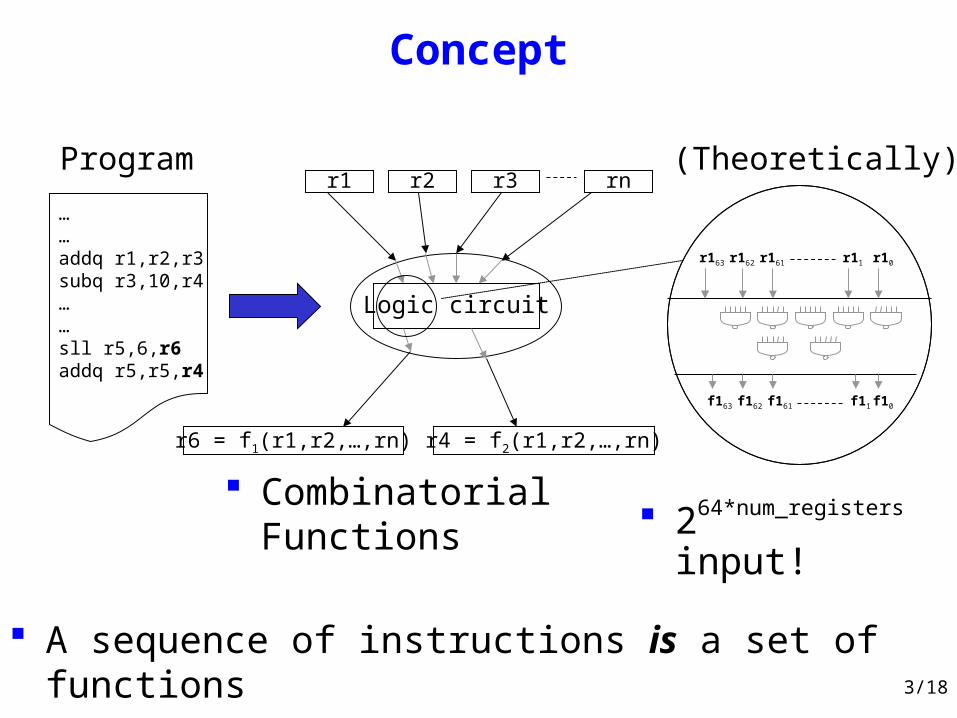
Concept
264*num_registers input!
(Theoretically)
……addq r1,r2,r3subq r3,10,r4……sll r5,6,r6addq r5,r5,r4
Programr1 r2 r3 rn
r6 = f1(r1,r2,…,rn) r4 = f2(r1,r2,…,rn)
Logic circuit
r163 r162 r161 r11 r10
f163 f162 f161 f11 f10
Combinatorial Functions
A sequence of instructions is a set of functions
4/18
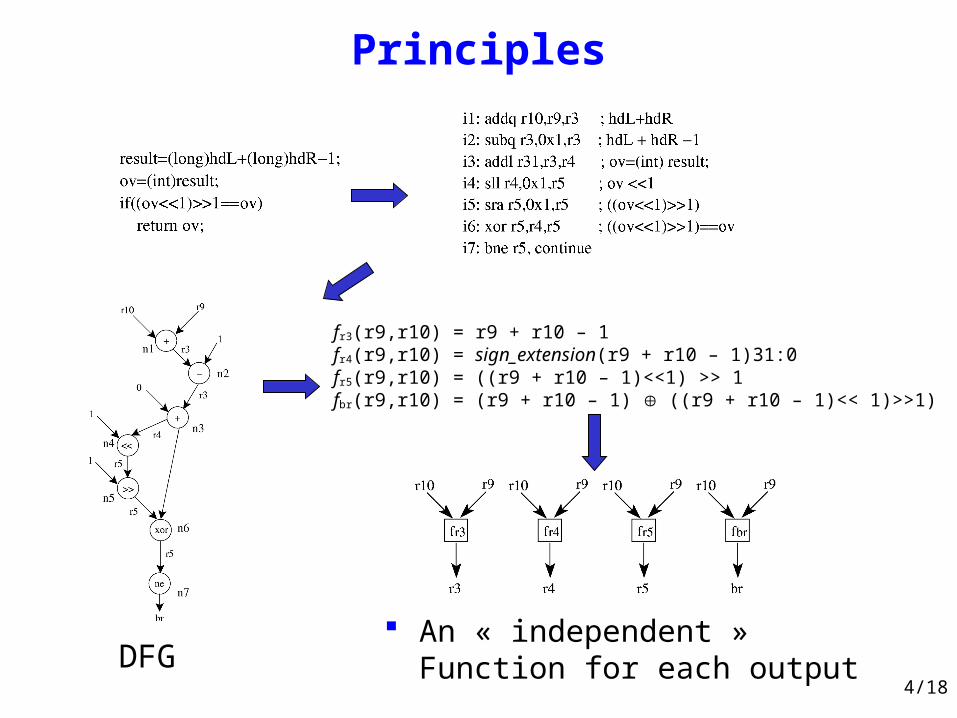
Principles
An « independent » Function for each output
fr3(r9,r10) = r9 + r10 – 1fr4(r9,r10) = sign_extension(r9 + r10 – 1)31:0fr5(r9,r10) = ((r9 + r10 – 1)<<1) >> 1fbr(r9,r10) = (r9 + r10 – 1) ((r9 + r10 – 1)<< 1)>>1)
DFG
5/18
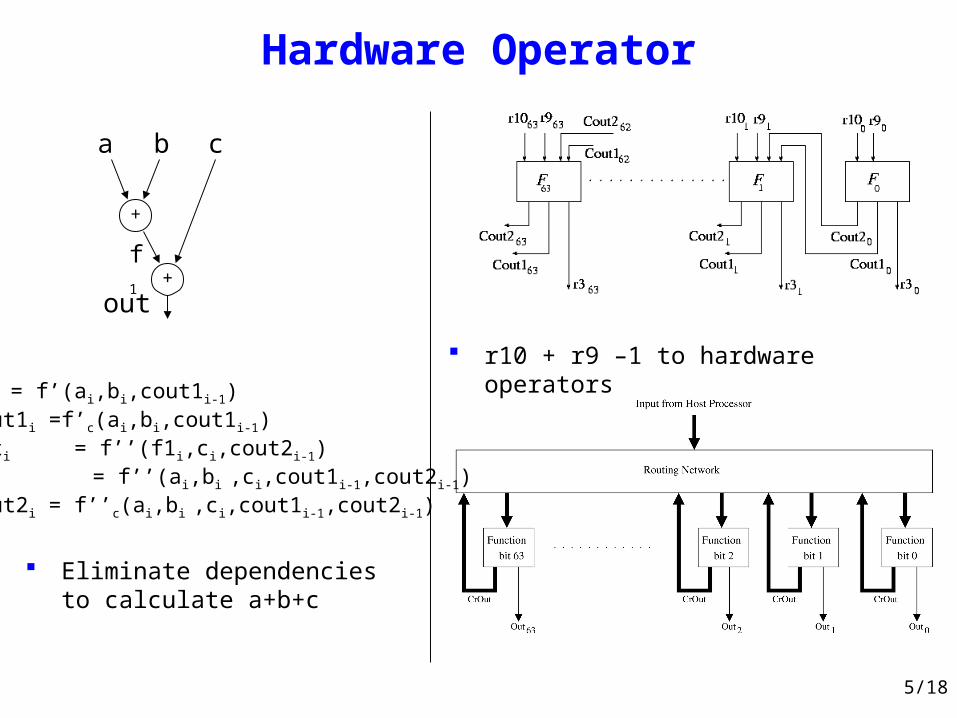
Hardware Operator
+
+
a b
out
c
f1
f1i = f’(ai,bi,cout1i-1)cout1i =f’c(ai,bi,cout1i-1)outi = f’’(f1i,ci,cout2i-1) = f’’(ai,bi ,ci,cout1i-1,cout2i-1)cout2i = f’’c(ai,bi ,ci,cout1i-1,cout2i-1)
Eliminate dependencies to calculate a+b+c
r10 + r9 –1 to hardware operators

6/18
Complexity Effectiveness
Scalability of ILP Vs. Functions
Complexity
Performance
ILP exploitation
Functions
7/18
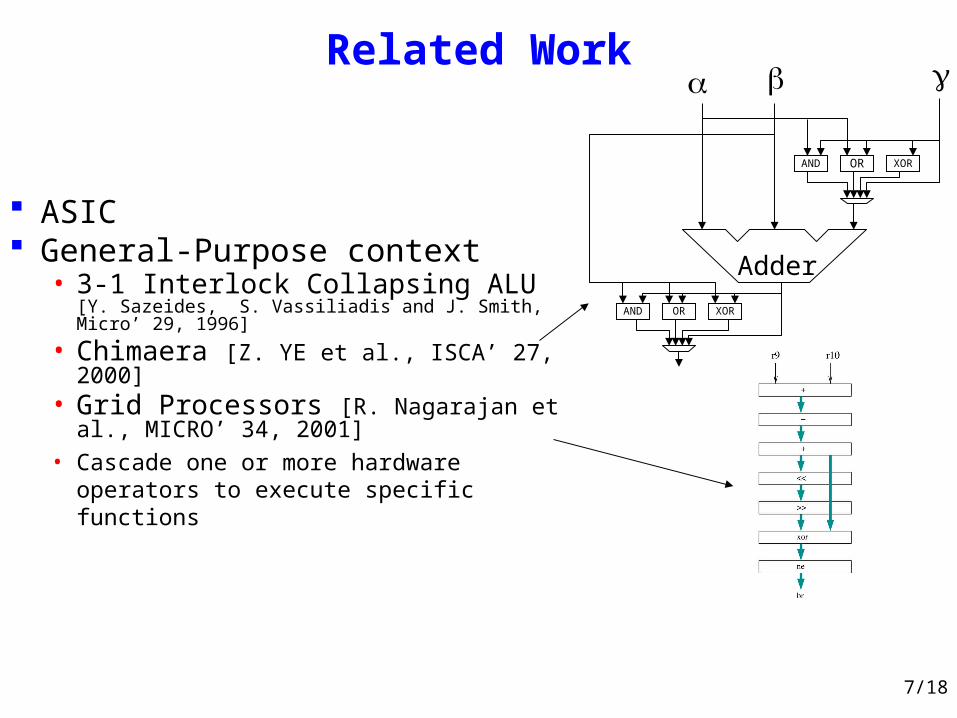
Related Work
ASIC General-Purpose context
• 3-1 Interlock Collapsing ALU [Y. Sazeides, S. Vassiliadis and J. Smith, Micro’ 29, 1996]
• Chimaera [Z. YE et al., ISCA’ 27, 2000]
• Grid Processors [R. Nagarajan et al., MICRO’ 34, 2001]
• Cascade one or more hardware operators to execute specific functions
AND OR XOR
AND OR XOR
Adder
8/18
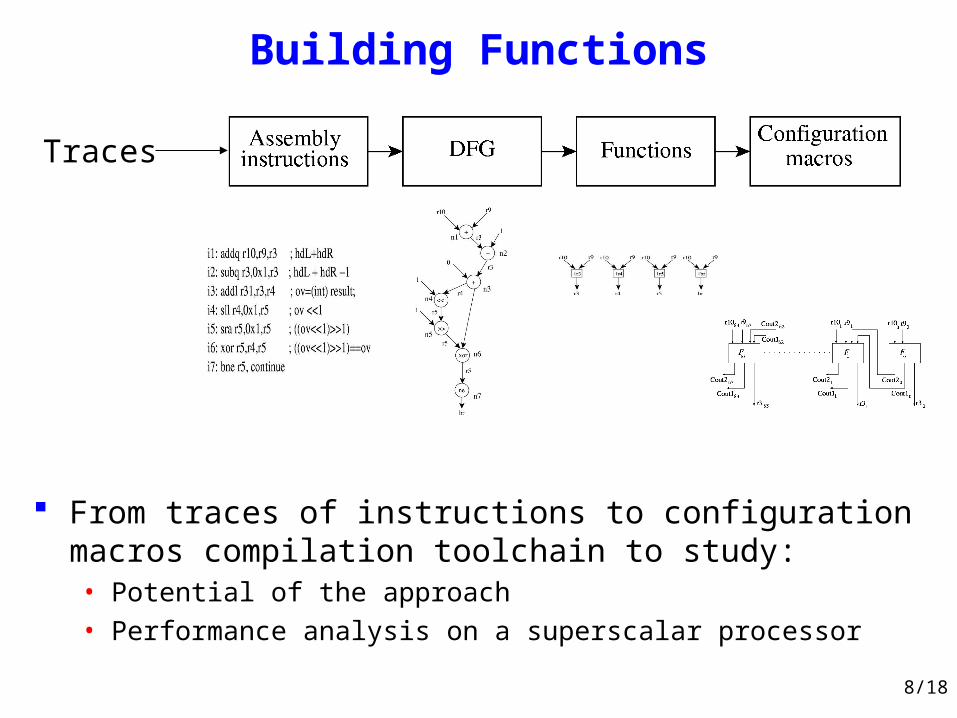
Building Functions
From traces of instructions to configuration macros compilation toolchain to study:• Potential of the approach• Performance analysis on a superscalar processor
Traces
9/18
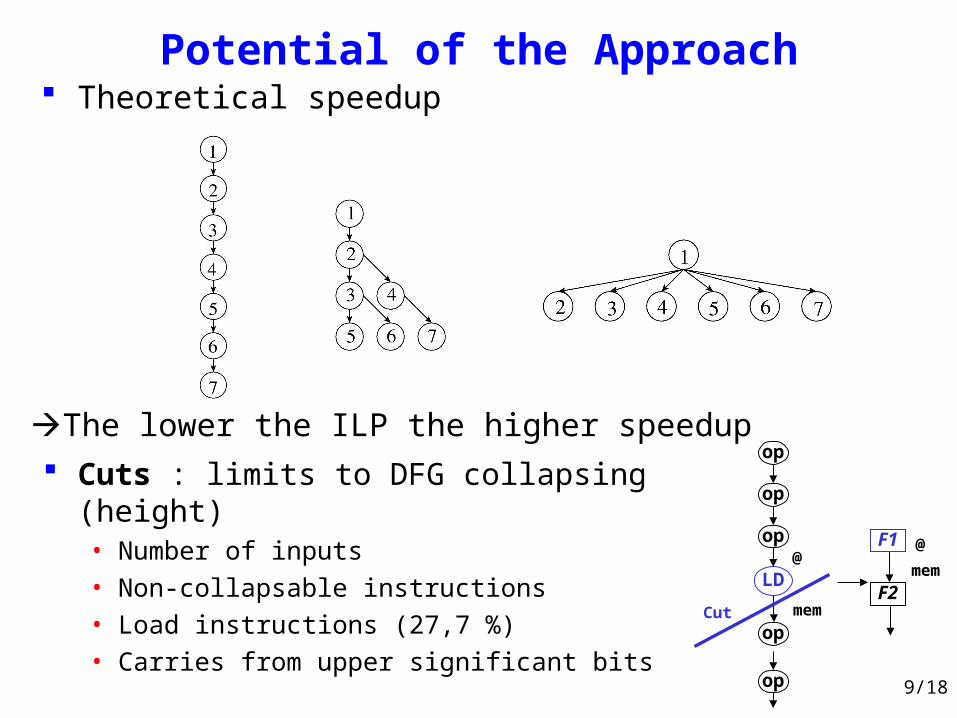
Potential of the Approach
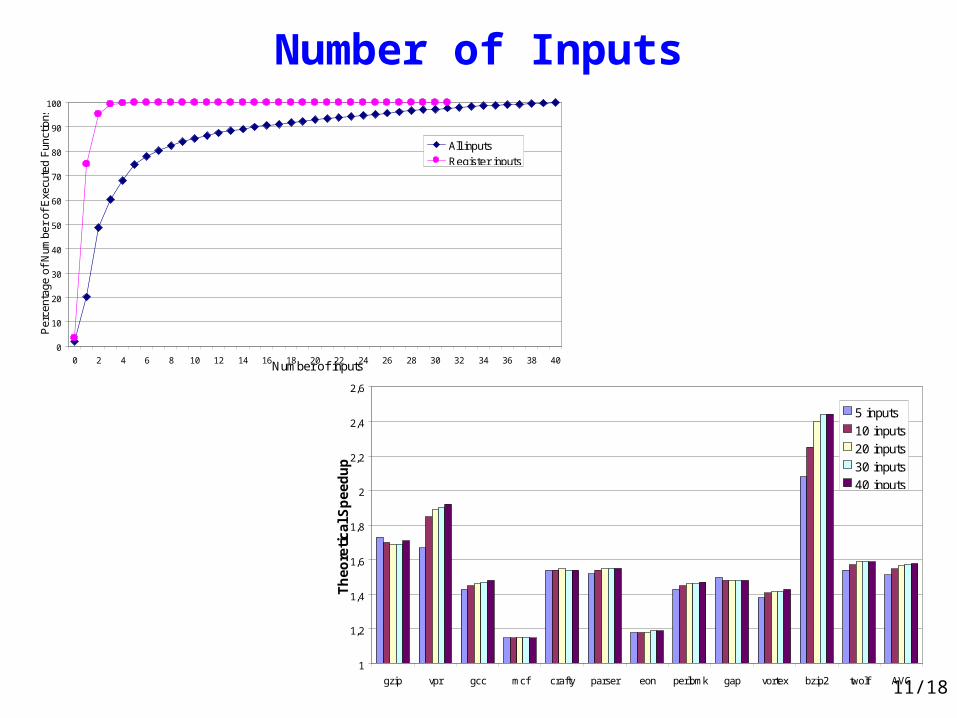
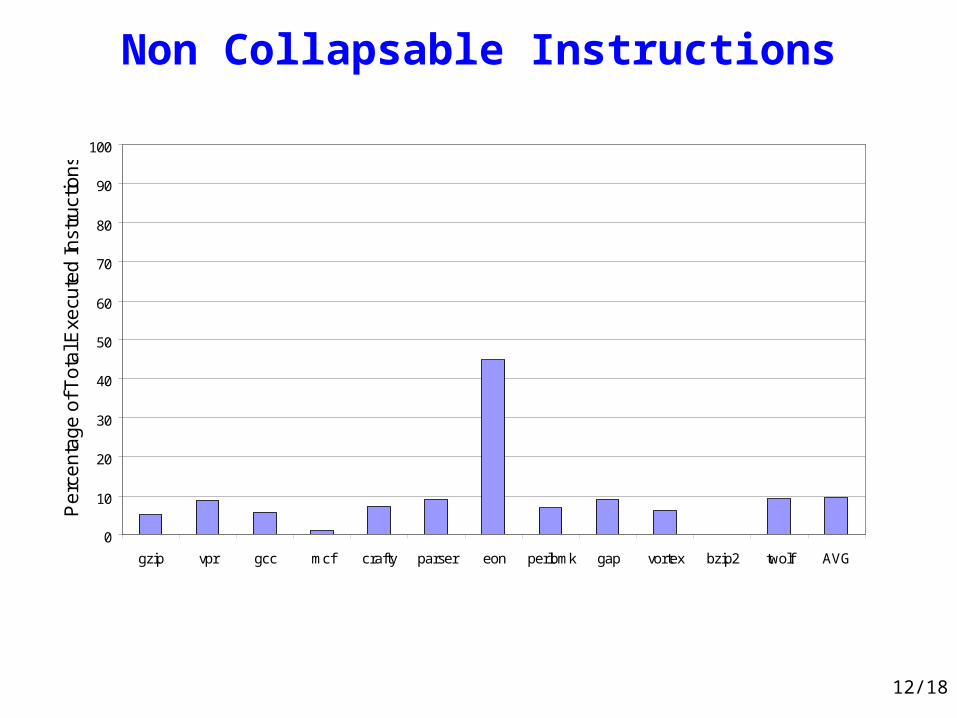
Cuts : limits to DFG collapsing (height)• Number of inputs• Non-collapsable instructions• Load instructions (27,7 %)• Carries from upper significant bits
Theoretical speedup
The lower the ILP the higher speedup
op
op
LD
op
op
memF2
mem
F1@
op
Cut
@
10/18
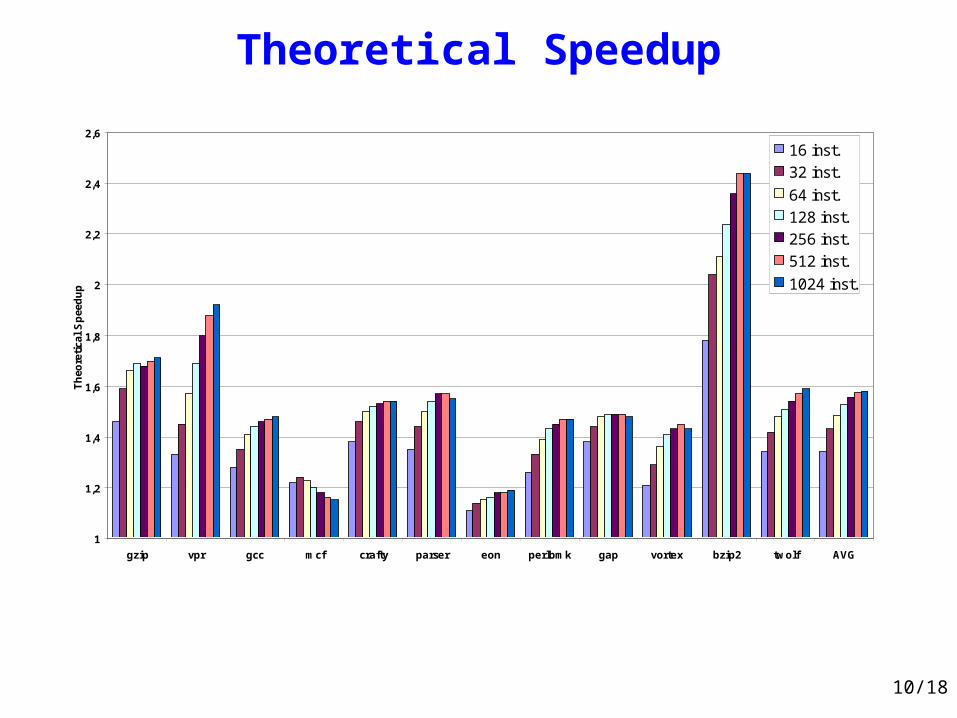
Theoretical Speedup
1
1,2
1,4
1,6
1,8
2
2,2
2,4
2,6
gzip vpr gcc mcf crafty parser eon perlbmk gap vortex bzip2 twolf AVG
Th
eore
tica
l S
pee
du
p
16 inst.
32 inst.
64 inst.
128 inst.
256 inst.
512 inst.
1024 inst.
11/18
Number of Inputs
0
10
20
30
40
50
60
70
80
90
100
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40Number of inputs
Per
cent
age
of N
umbe
r of
Exe
cute
d F
unct
ions
All inputs
Register inputs
1
1,2
1,4
1,6
1,8
2
2,2
2,4
2,6
gzip vpr gcc mcf crafty parser eon perlbmk gap vortex bzip2 twolf AVG
Th
eo
reti
ca
l Sp
ee
du
p
5 inputs
10 inputs
20 inputs
30 inputs
40 inputs
12/18
Non Collapsable Instructions
0
10
20
30
40
50
60
70
80
90
100
gzip vpr gcc mcf crafty parser eon perlbmk gap vortex bzip2 twolf AVG
Pe
rce
nta
ge
of T
ota
l Exe
cute
d In
stru
ctio
ns
13/18
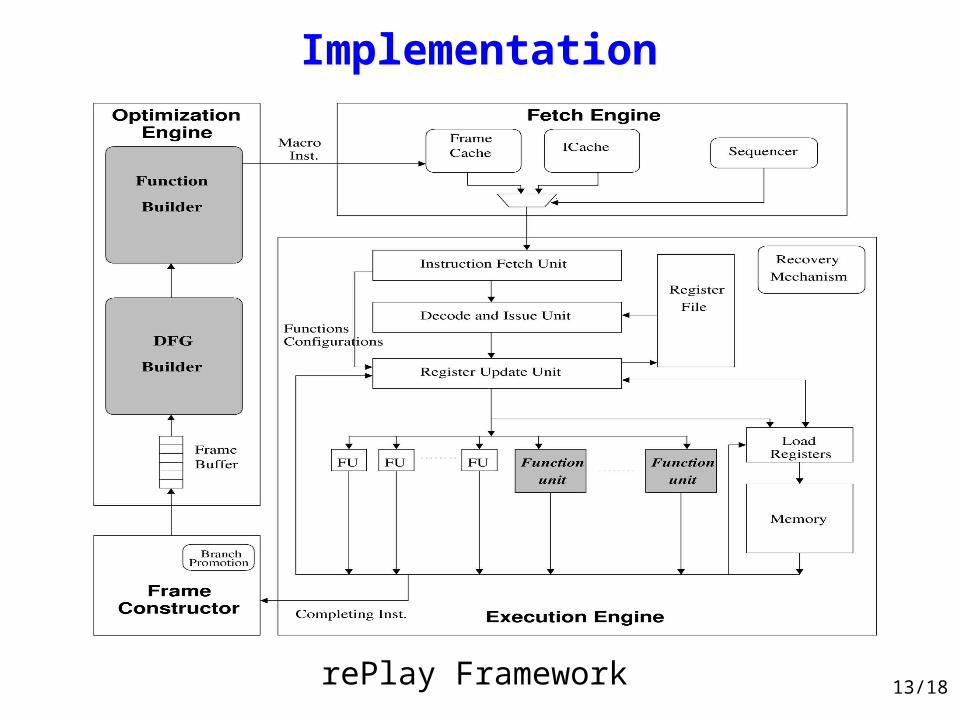
Implementation
rePlay Framework
14/18
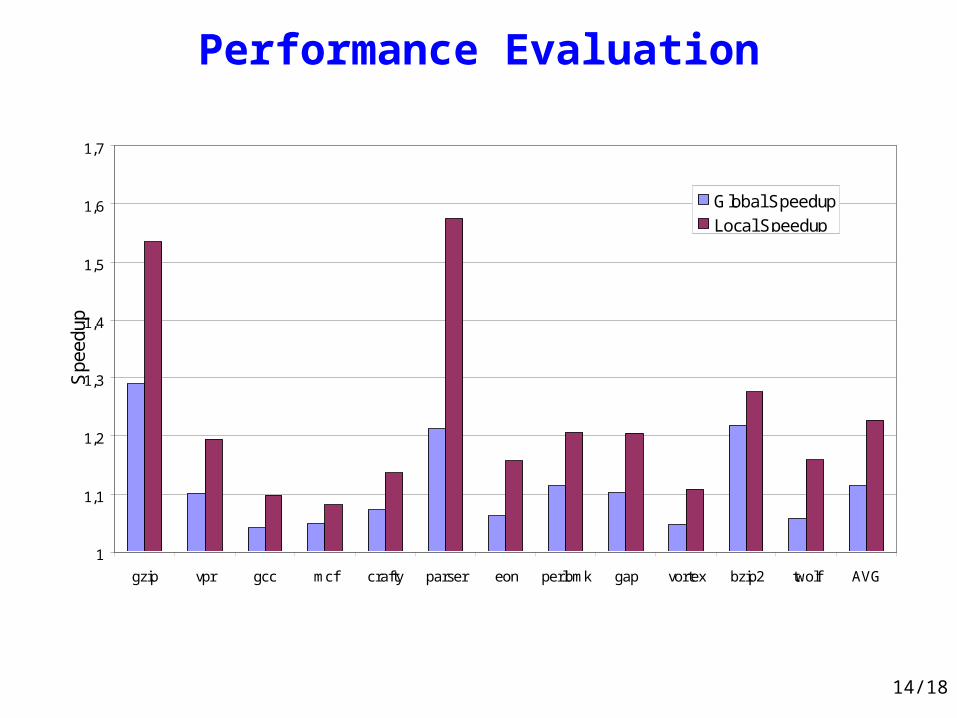
Performance Evaluation
1
1,1
1,2
1,3
1,4
1,5
1,6
1,7
gzip vpr gcc mcf crafty parser eon perlbmk gap vortex bzip2 twolf AVG
Spe
edup
Global Speedup
Local Speedup
15/18
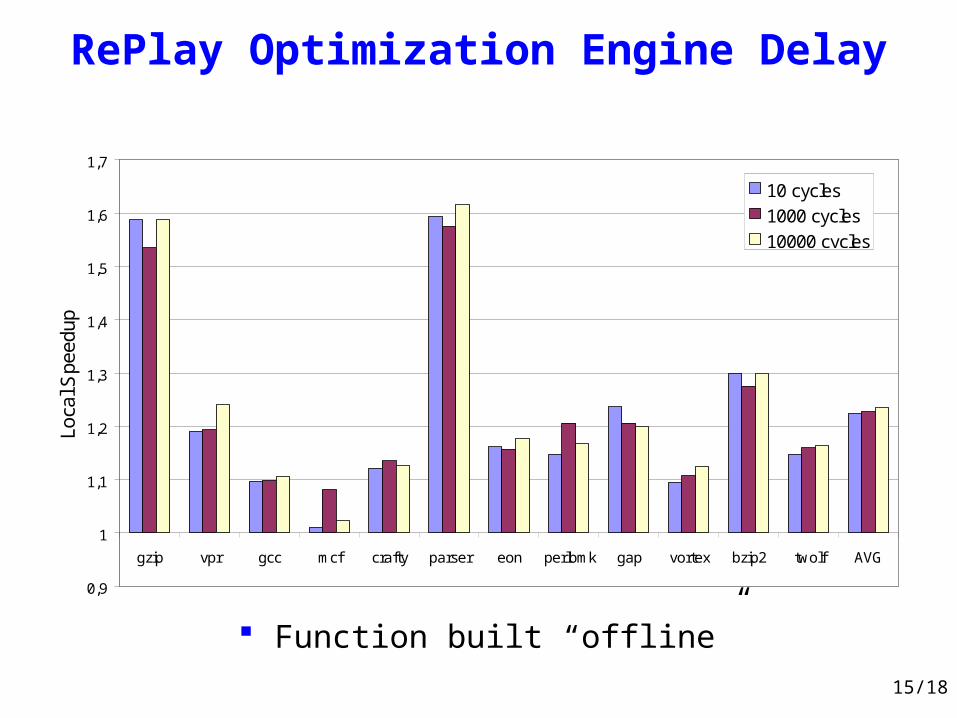
RePlay Optimization Engine Delay
0,9
1
1,1
1,2
1,3
1,4
1,5
1,6
1,7
gzip vpr gcc mcf crafty parser eon perlbmk gap vortex bzip2 twolf AVG
Loca
l Spe
edup
10 cycles
1000 cycles
10000 cycles
Function built “offline”
16/18
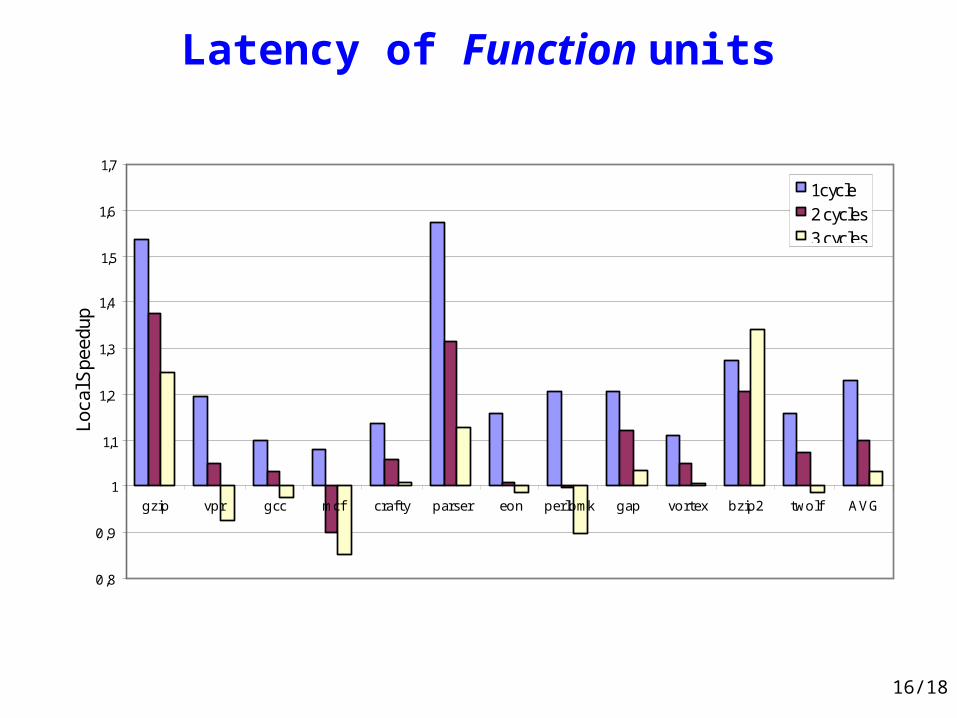
Latency of Function units
0,8
0,9
1
1,1
1,2
1,3
1,4
1,5
1,6
1,7
gzip vpr gcc mcf crafty parser eon perlbmk gap vortex bzip2 twolf AVG
Loca
l Spe
edup
1 cycle2 cycles3 cycles
17/18
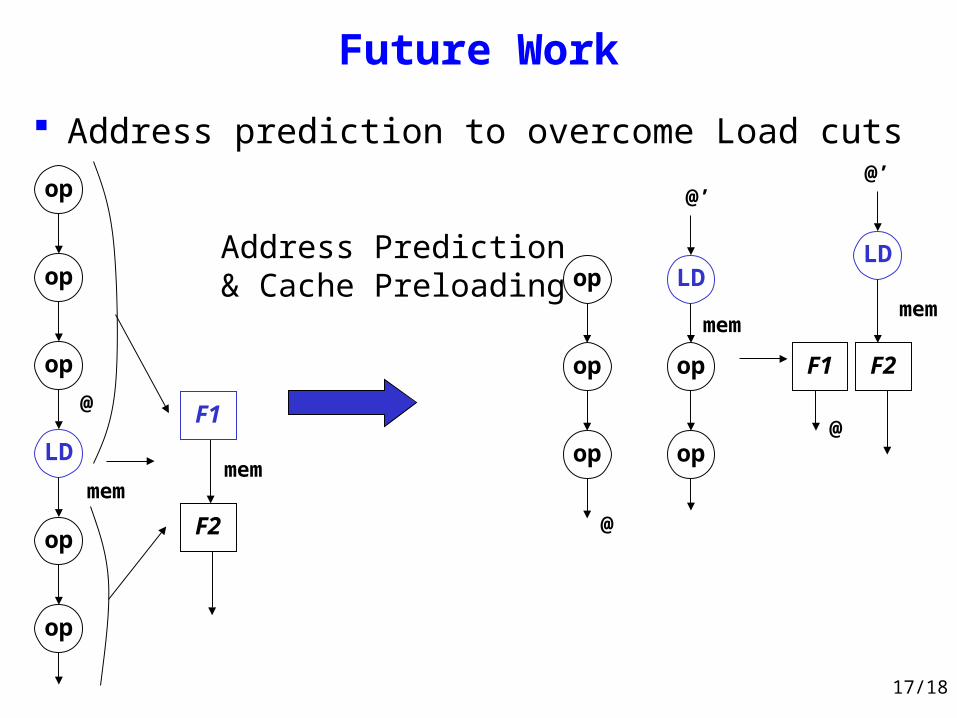
Future Work
Address prediction to overcome Load cuts
Address Prediction& Cache Preloadingop
op
LD
op
op
mem
F2
mem
F1@
op
op
op
LD
op
op
mem
@
op
@’
F1
@
LD
@’
F2
mem

18/18
Q & A
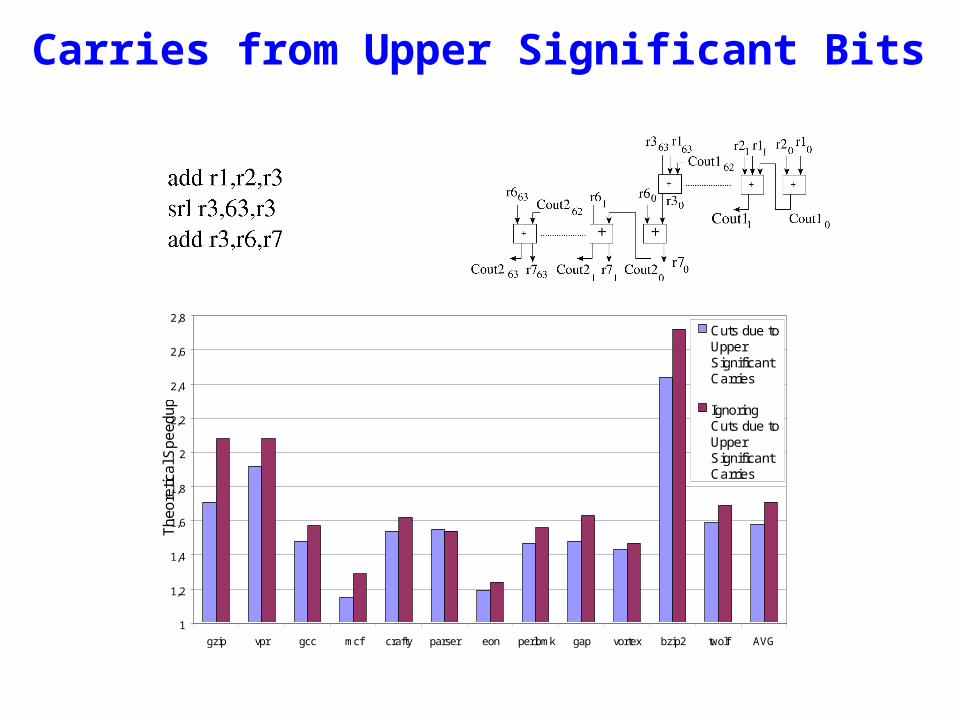
Carries from Upper Significant Bits
1
1,2
1,4
1,6
1,8
2
2,2
2,4
2,6
2,8
gzip vpr gcc mcf crafty parser eon perlbmk gap vortex bzip2 twolf AVG
Th
eo
retic
al S
pe
ed
up
Cuts due toUpperSignificantCarries
IgnoringCuts due toUpperSignificantCarries
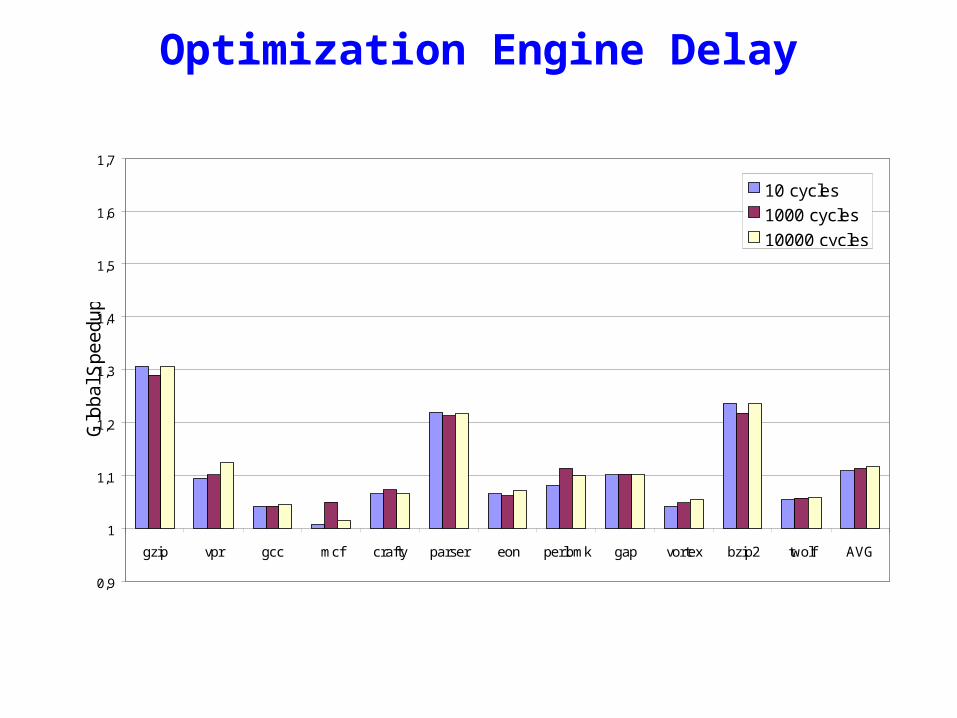
Optimization Engine Delay
0,9
1
1,1
1,2
1,3
1,4
1,5
1,6
1,7
gzip vpr gcc mcf crafty parser eon perlbmk gap vortex bzip2 twolf AVG
Glo
ba
l Sp
ee
du
p
10 cycles
1000 cycles
10000 cycles
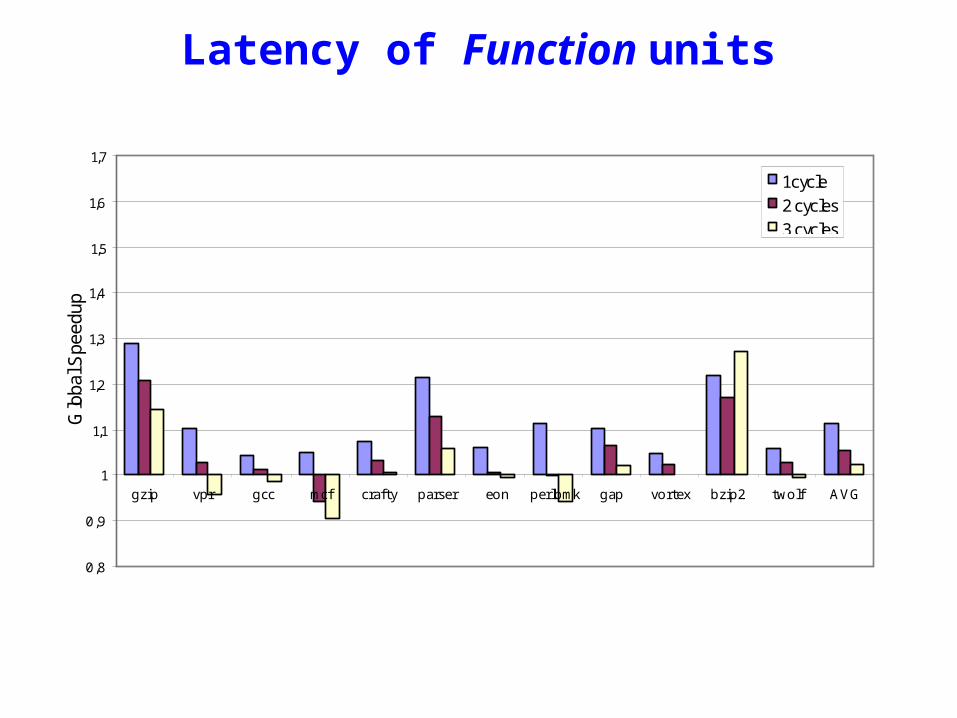
Latency of Function units
0,8
0,9
1
1,1
1,2
1,3
1,4
1,5
1,6
1,7
gzip vpr gcc mcf crafty parser eon perlbmk gap vortex bzip2 twolf AVG
Glo
bal S
peed
up
1 cycle2 cycles3 cycles





























