Embed Size (px)
Citation preview

Development Impact Evaluation
Field Coordinator Training Washington, DC
April 22-25, 2013
Randomization “how to” in
Stata (plus other random stuff)
Aidan Coville

Overview
Putting sample size in perspective (what ICC and MDE really imply for sample size)
How to randomize in Stata (SRS, Multiple treatment arms, Stratification, Clustering)
Practical notes for the field

SAMPLE SIZE IN PERSPECTIVE

Sample size (implications of MDE and ICC)
Great to get a precise estimate, but this comes at a cost
Need to reflect on the full set of options to make a reasonable decision
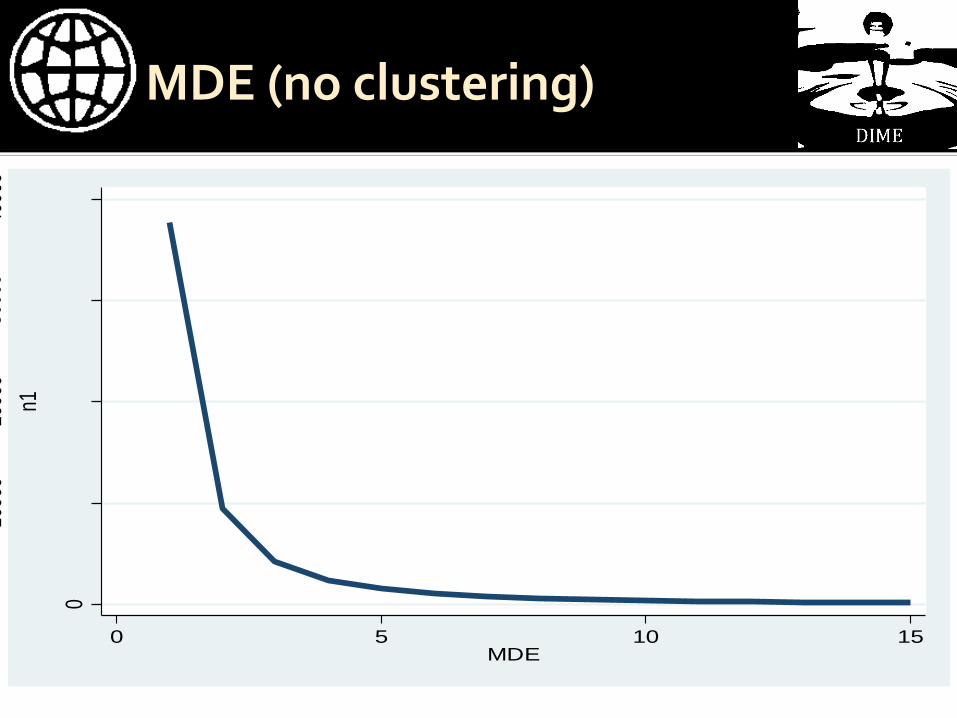
MDE (no clustering)
0
1000
020
000
3000
040
000
n1
0 5 10 15MDE
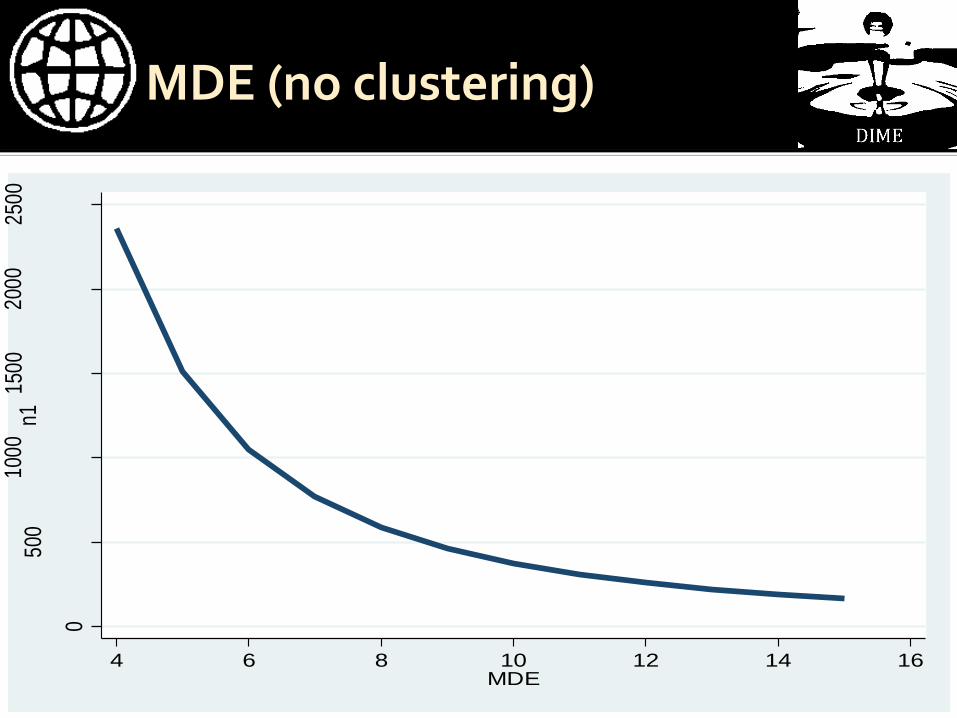
MDE (no clustering)
0
500
1000
1500
2000
2500
n1
4 6 8 10 12 14 16MDE
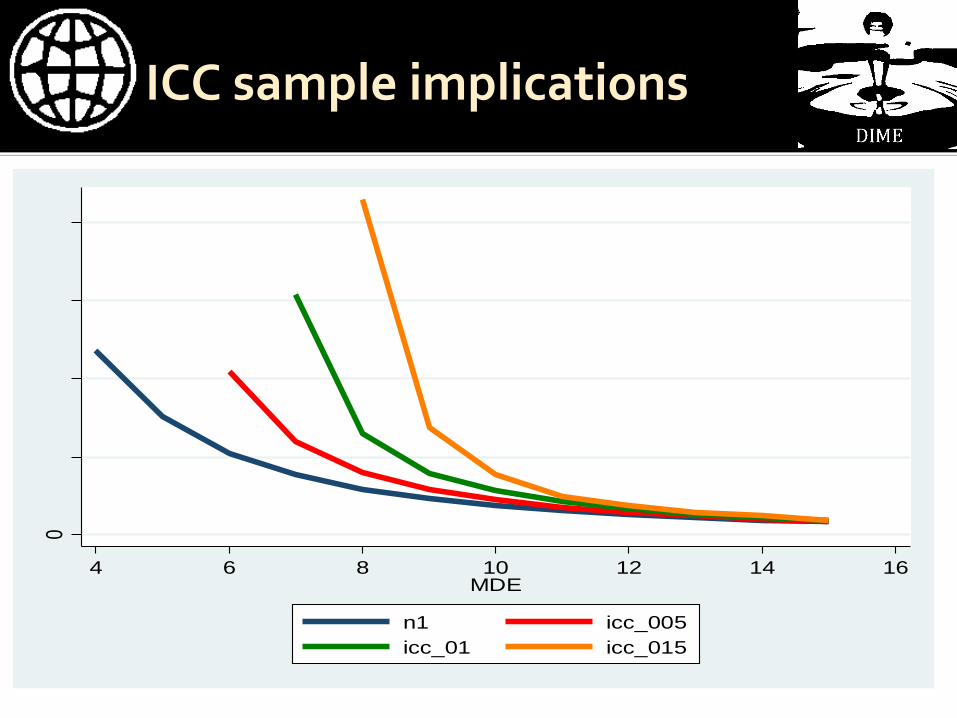
ICC sample implications
0
1000
2000
3000
4000
4 6 8 10 12 14 16MDE
n1 icc_005
icc_01 icc_015

Improving accuracy (within the realms of reality)
Multiple rounds of data collection on key variables (McKenzie, 2012)
Stratify ex ante on variables most associated with outcomes (Bruhn & McKenzie, 2008)
At the extreme this includes pairwise matching
Focus on more homogenous groups…? (McKenzie, 2009)

RANDOMIZATION (ACTUALLY DOING IT)

Randomization in Stata
Choose a “seed” to start from – eg. from your token ID (this ensures replicability)
set seed 838 448
Generate random numbers for each obs
gen rand_num = uniform()
Rank numbers from smallest to largest egen ordering = rank(rand_num)
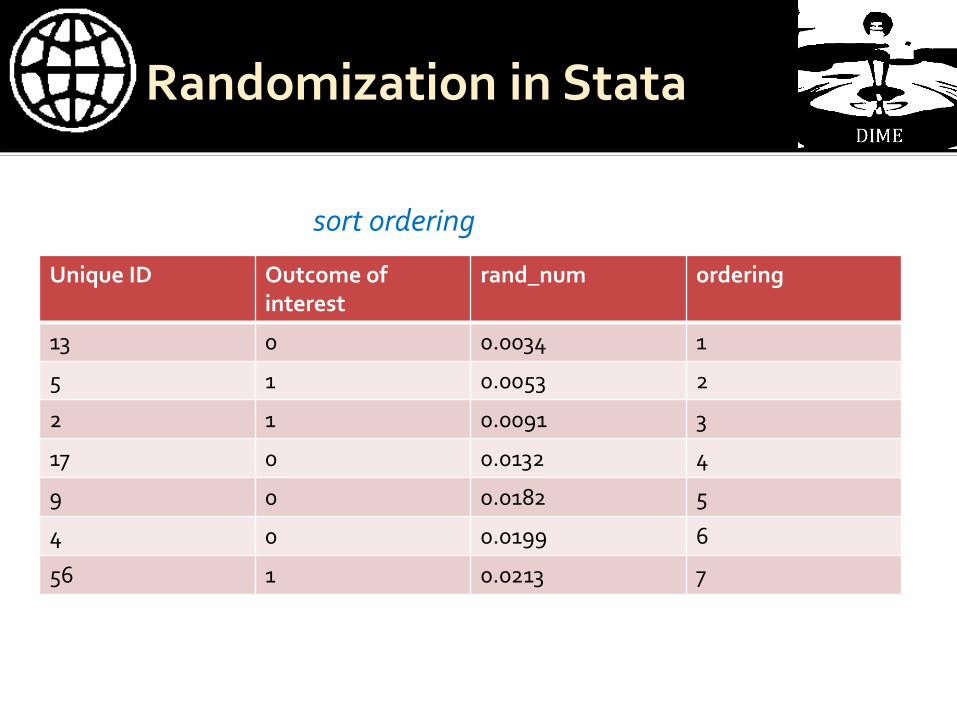
Unique ID Outcome of interest
rand_num ordering
13 0 0.0034 1
5 1 0.0053 2
2 1 0.0091 3
17 0 0.0132 4
9 0 0.0182 5
4 0 0.0199 6
56 1 0.0213 7
sort ordering
Randomization in Stata

For one treatment, 1 control, assign treatment status by giving 1st half to control and second half to treatment
gen group = ""
replace group = "T" if ordering <= _N/2 replace group = "C" if ordering > _N/2
Randomization in Stata
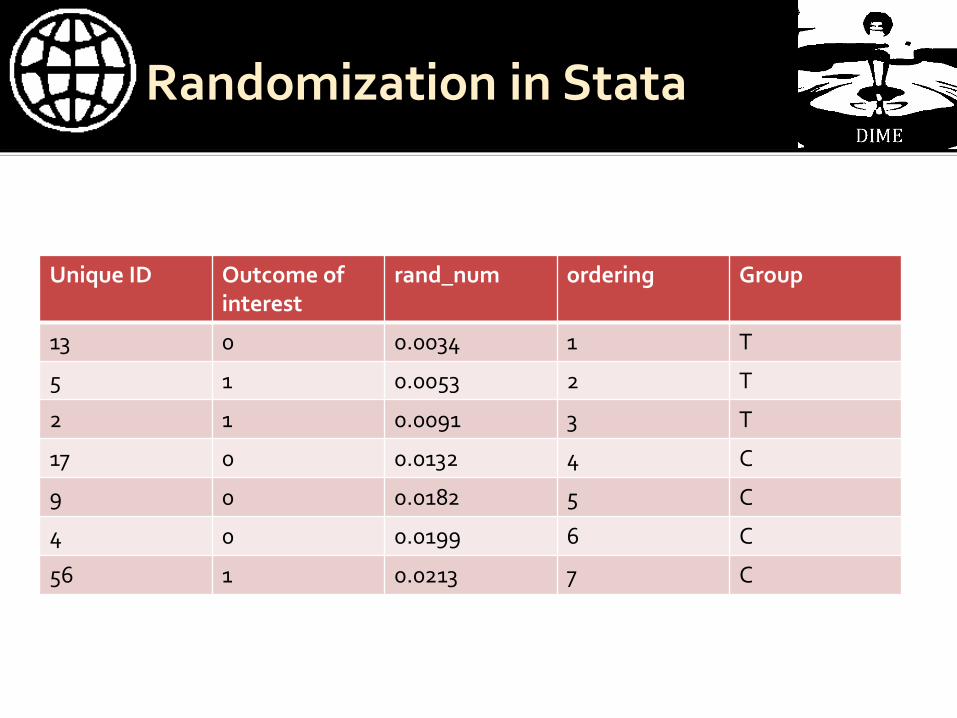
Unique ID Outcome of
interest rand_num ordering Group
13 0 0.0034 1 T
5 1 0.0053 2 T
2 1 0.0091 3 T
17 0 0.0132 4 C
9 0 0.0182 5 C
4 0 0.0199 6 C
56 1 0.0213 7 C
Randomization in Stata

Taking it further
What about:
multiple treatment arms
Stratification
Clustering

Multiple treatment arms
Basically, just create random numbers and instead of splitting into 2, split into 6 gen group2 = "" replace group2 = "C" if ordering <= _N/6 forvalues i = 1/5 { replace group2 = "T`i'" if ordering <= (`i'+1)*_N/6 & ordering > `i'*_N/6 }
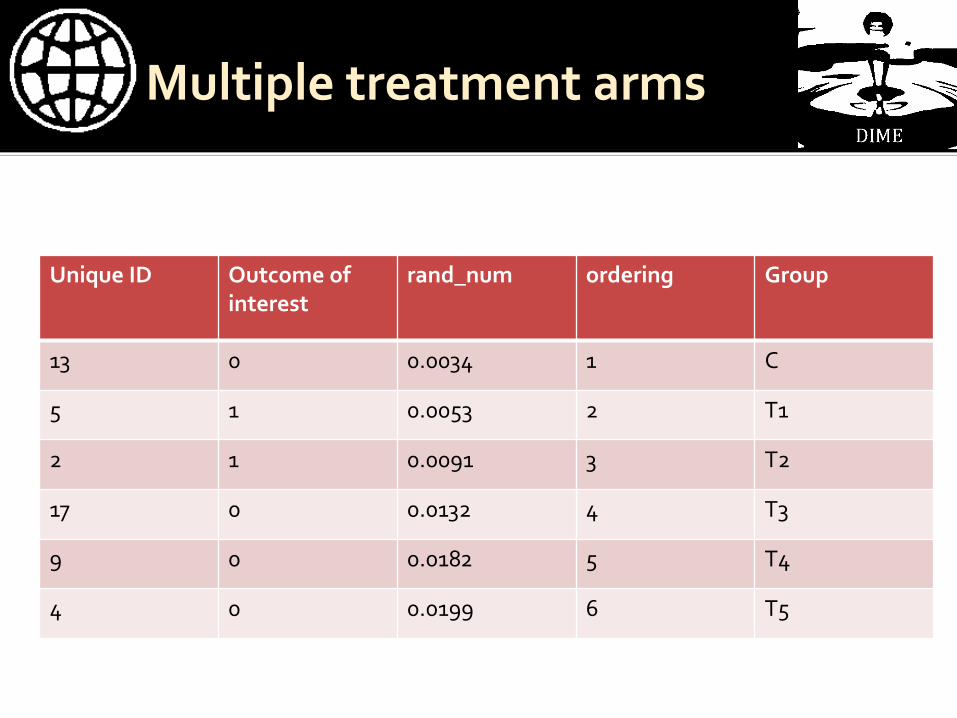
Unique ID Outcome of
interest rand_num ordering Group
13 0 0.0034 1 C
5 1 0.0053 2 T1
2 1 0.0091 3 T2
17 0 0.0132 4 T3
9 0 0.0182 5 T4
4 0 0.0199 6 T5
Multiple treatment arms

Stratification
Define all strata, eg if stratifying by gender and urban/rural you have 4 groups
Randomize within each group
Urban Rural
Male 20 60
Female 40 30

gen group3 = "" egen strata=group(gender urban) *creates 4 groups bysort strata: egen ordering2=rank(random_num) bysort strata: replace group3 = "T" if ordering2 <= _N/2 bysort strata: replace group3 = "C" if ordering2 > _N/2
Stratification

Clustering
See accompanying handout. Randomize at the cluster level then apply all (or a sample of) observations to treatment or control.
What if observations don’t fit neatly into strata? What if we have multiple strata and multiple treatment arms?
Review Miriam Bruhn and David McKenzie’s blog post on this:
http://blogs.worldbank.org/impactevaluations/tools-of-the-trade-doing-stratified-randomization-with-uneven-numbers-in-some-strata

IN THE FIELD

Confirming treatment assignment
For valid RCT, we need to have compliance, or at least a good understanding of the level of compliance in the field (how much deviation was there from the treatment assignment.
Assess availability of project monitoring data
Independent audit
Self-reported exposure in follow up questionnaire (include falsification questions to assess accuracy)

Dealing with survey companies
How do we deal with replacement? How do we keep track of non-response?
Missing at random vs. systematic non-response How do we make sure that survey company
sticks to sampling frame? All causal inference relies on the assumption that
the sample method was as stated in the methodology
Use ToR templates to make sure these issues are unambiguous

Important for the field
1. Always keep record of do file for replication purposes
2. Never provide implementers with control list unless you have to
3. Best not to provide survey company with treatment status if possible (blind study)

References
Bruhn, M., & McKenzie, D. (2008). In pursuit of balance: Randomization in practice in development field experiments. World Bank Policy Research Working Paper Series, Vol. McKenzie, D. (2010). Impact Assessments in Finance and Private Sector Development: What have we learned and what should we learn?. The World Bank Research Observer, 25(2), 209-233. McKenzie, D. (2012). Beyond baseline and follow-up: The case for more T in experiments. Journal of Development Economics, 99(2), 210-221.





























