Embed Size (px)
Citation preview

What is meant by Scraping?According to the Dictionary, scraping refers to removing (an outer layer, for example) from a surface by forceful strokes of an edged or rough instrument. While Web scraping is referred in Wikipedia as a computer software technique of extracting information from websites. Web scraping is the process of automatically collecting information from the World Wide Web in order to minimize the need for human’s manual examination and copy-and-paste from websites.
Thus, Scraping describes the method to extract data hidden in documents – such as Web Pages and PDFs and make it useable for further processing. It is among the most useful skills if you set out to investigate data – and most of the time it’s not especially challenging. For the simplest ways of scraping you don’t even need to know how to write code.
A short Introduction to HTML.Knowing the structure of a website is the first step towards extracting and using the data. That’s why it is useful to learn a bit about HTML.
Getting data from websites might seem a little complicated at first – but rest assured, once you’ve done it a couple of times it will be similar. To extract data from websites we need to peek under the hood and look at the underlying HTML code. Don’t worry you don’t need to understand every detail of it just to be able to do so.
HTML is the acronym for Hypertext Markup Language and is the language used to describe (markup) web pages. It is the underlying language to structure web-page content. HTML itself does not determine the way things look – it only helps to classify and structure content. So let’s peek at some websites.
Walkthrough: Exploring HTML with Google Chrome
1. Open the website listing all MPs for the UK Parliament at http://www.parliament.uk/mps-lords-and-offices/mps/ in Chrome
2. Scroll down to the list of MPs

3. Right click on one of the entries4. Select “Inspect Element”
1. Chrome will open a second area on the bottom of the page showing the underlying HTML code – focused on the element you clicked.
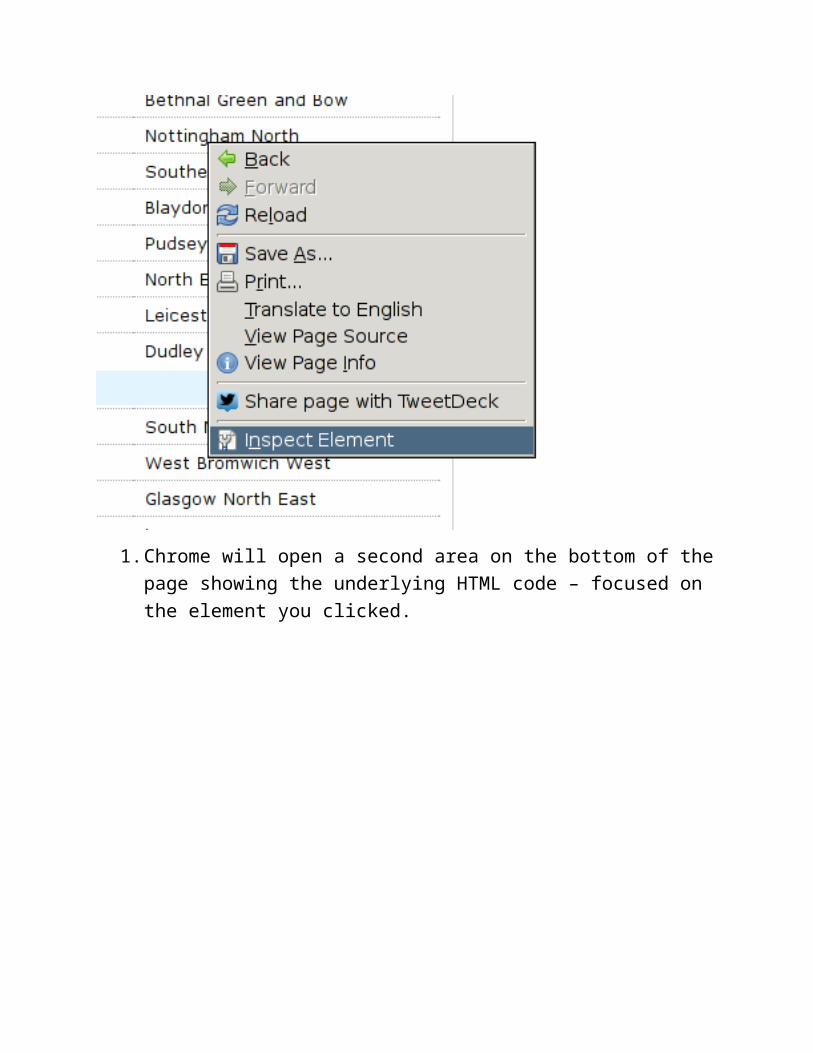
1. The pointy brackets are the HTML tags.2. Now move your mouse up and down and notice how chrome tells you
which element is which3. You can expand and collapse certain sections by clicking on the triangles4. Did you notice something? Every row in the long list of MPs is within one
<tr></tr> section. <tr> indicates a table row.5. The names and the constituency are in <td></td> tags – td indicates table
data. So we’re dealing with a table here?6. If you scroll up the list you’ll notice a <table> element, followed by a
<tbody> element – so yes this is a proper HTML table.
1. Go ahead and explore!
HTML is no mystery. If you want to know more about it and how to build webpages with it – visit the School of Webcraft for a gentle introduction.
Other browsers
To do the same thing in other browsers, try the following approaches.
● Firefox: Install Firebug plugin (http://getfirebug.com/)● Safari: Preferences > Advanced > Show Develop Menu > Show Web
Inspector● Internet Explorer 7: Install Developer toolbar
HTML Elements
Elements are identified by ‘tags’, their name. They can have an inner text and “attributes” (named properties): <tag attribute=”value”>text</tag>
● <html> – the whole document● <body> – the human-readable part of the web page● <table> – the frame of a table element● <tr> – a row in a table● <td> – a cell of content inside a row● <th> – a table header cell inside a row
Extracting a table from a webpage using Google SpreadsheetsLet’s get our data into a spreadsheet - so we can use it further. An easy way to do this is provided by a special formula in Google Spreadsheets.
The Google spreadsheet formula:
=importHTML("","table",N)
will scrape a table from an HTML web page into a Google spreadsheet. The URL of the target web page, and the target table element both need to be in double quotes. The number N identifies the N’th table in the page (counting starts at 1) as the target table for data scraping.
Walkthrough: Importing HTML tables into Google Spreadsheets.

1. Go to http://drive.google.com, log in and create a new spreadsheet2. Edit cell A1 (the top left cell)
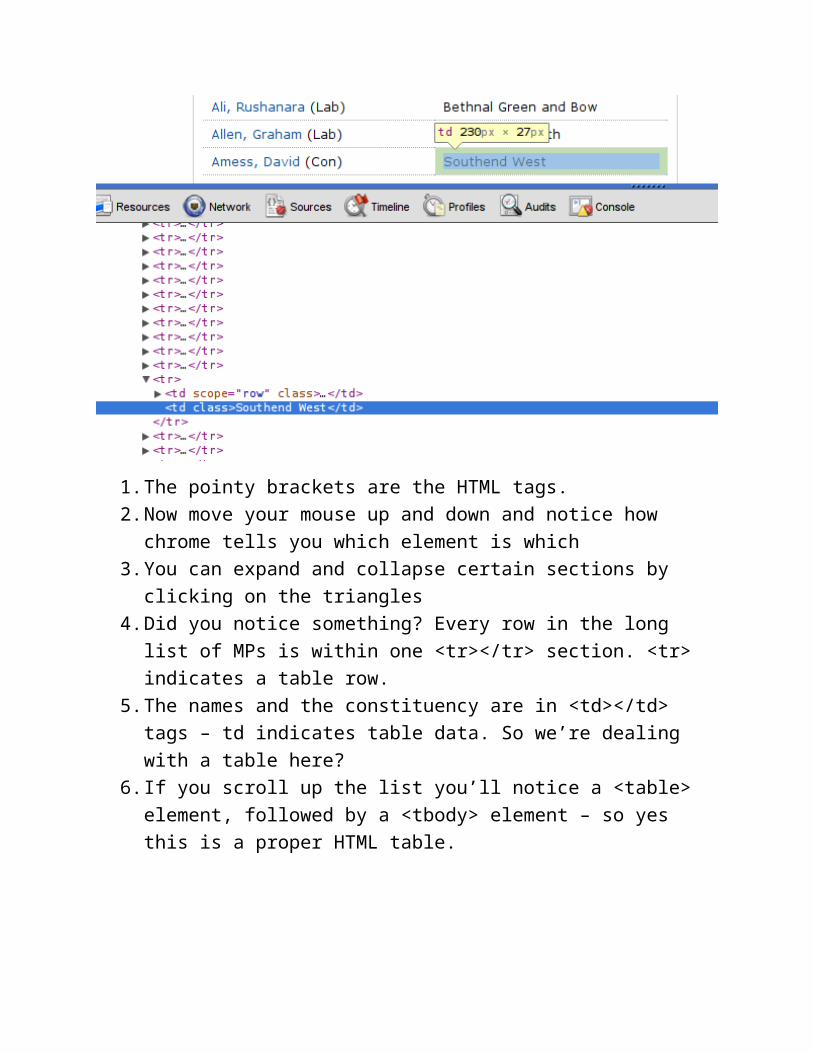
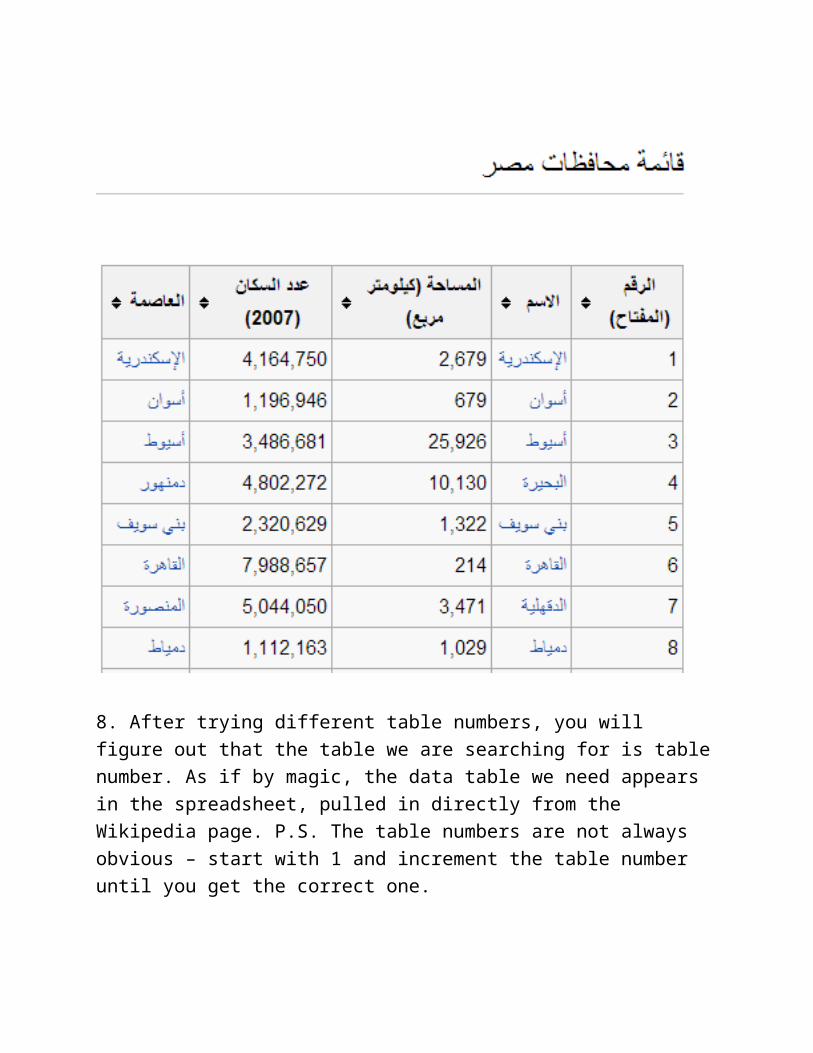
3. Let’s import the table of Egypt’s governorates in Arabic:
http :// ar . wikipedia . org / wiki / مصر
4. Enter the following formula into the cell:
=ImportHTML("http://ar.wikipedia.org/wiki/مصر", "table", 1)
(The last number indicates the number of the table in the document, just try them out and find the matching one...)
5. Press Enter
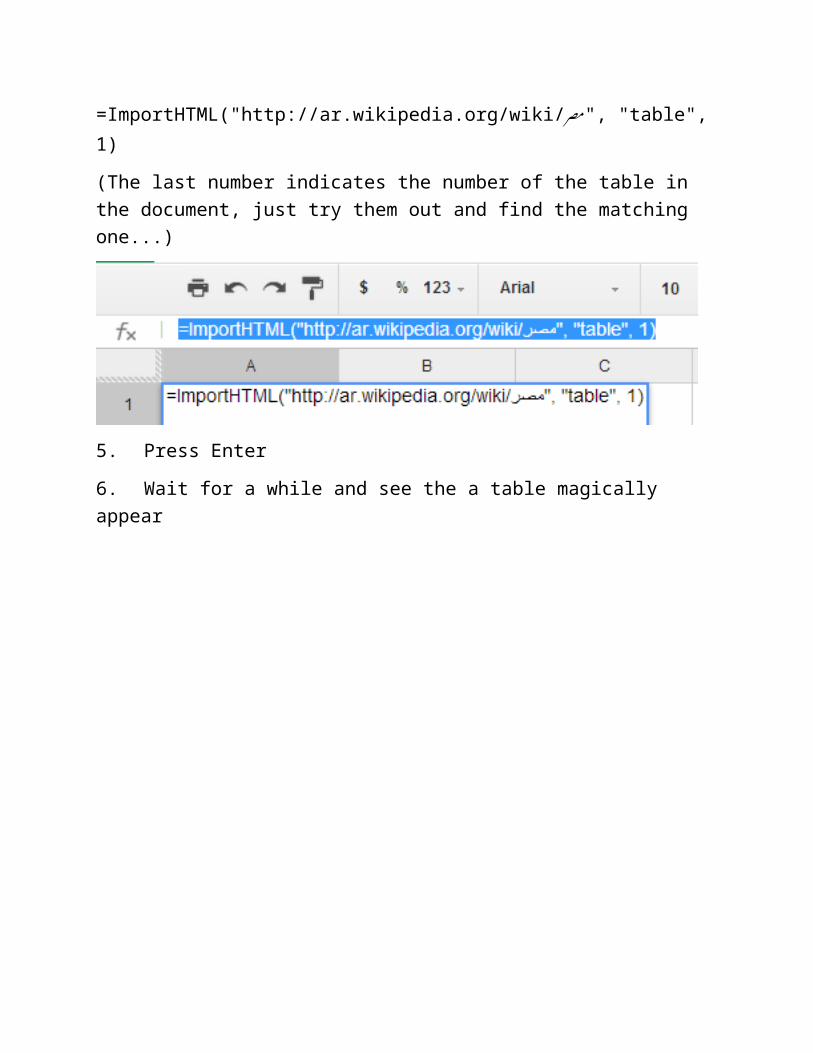
6. Wait for a while and see the a table magically appear

7. Wait this is not the table we expected right? This is because there are multiple tables on the page and google docs just picked the first one (the 1 in the end of our formula told it to do this). - Simply change it to 2 or three until you get the right table. (Remember, we are trying to get the table of Egyptian’s governorates).
8. After trying different table numbers, you will figure out that the table we are searching for is table number. As if by magic, the data table we need appears in the spreadsheet, pulled in directly from the Wikipedia page. P.S. The table numbers are not always obvious – start with 1 and increment the table number until you get the correct one.
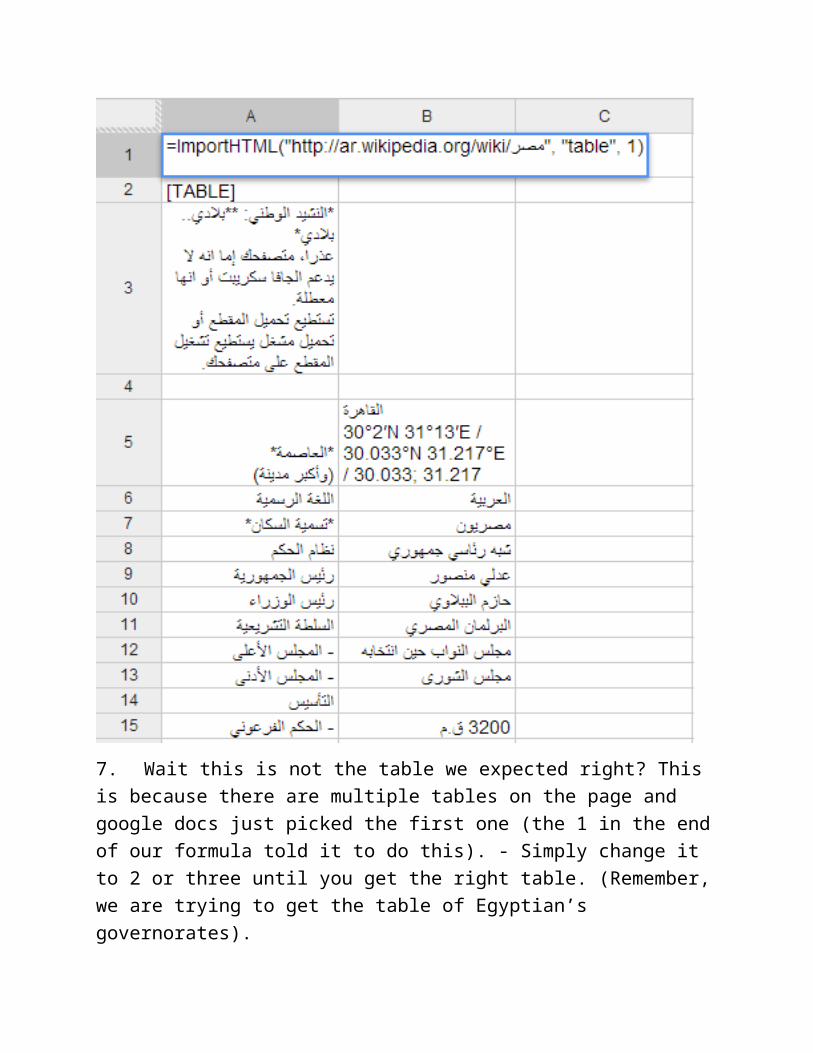
9. Congratulations: you scraped your first dataset!
It’s beyond the scope of this course to teach how to scrape, our aim here is to help you understand whether it is worth investing your time to learn, and to point you at some useful resources to help you on your way!
When should I make the investment to learn how to scrape?A few reasons (non-exhaustive list!):
1. If you regularly have to extract data where there are numerous tables in one page.2. If your information is spread across numerous pages.3. If you want to run the scraper regularly (e.g. if information is released every week or
month).4. If you want things like email alerts if information on a particular webpage changes.…And you don’t want to pay someone else to do it for you!
Summary:In this course we’ve covered Web scraping and how to extract data from websites. The main function of scraping is to convert data that is semi-structured into structured data and make it easily useable for further processing. While this is a relatively simple task with a bit of programming – for single webpages it is also feasible without any programming at all. We’ve introduced =importHTML and the Scraper extension for your scraping needs.
Further Reading● Scraping for Journalism: A Guide for Collecting Data: ProPublica Guides● Scraping for Journalists (ebook): Paul Bradshaw● Scrape the Web: Strategies for programming websites that don’t expect it : Talk from
PyCon● An Introduction to Compassionate Screen Scraping: Will Larson
Walkthrough: Extracting data from PDF tablesPDFs can be all forms and shapes – if you’re facing a nicely formatted PDF that is not scanned give Tabula a shot to extract the information. How? Read the short walkthrough below:
You’ll need:
● Tabula http://tabula.nerdpower.org/● PDF document.
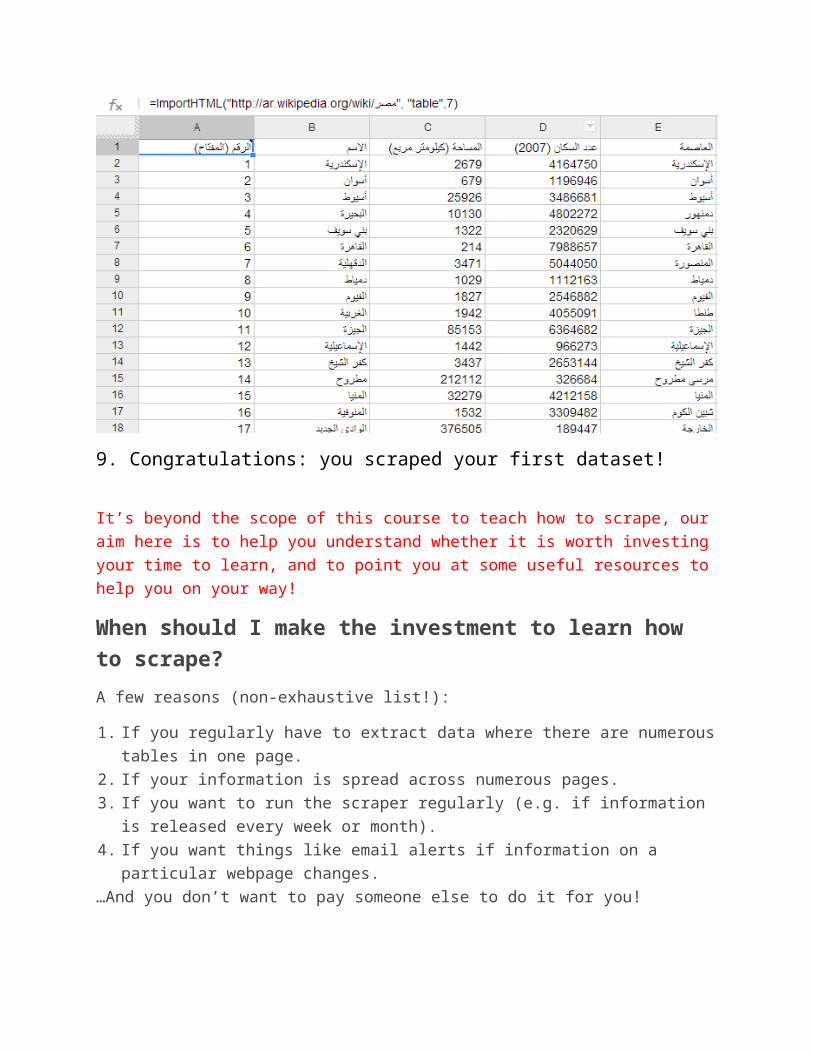
1. Download the PDF at:: http://datahub.io/dataset?q=egypt2. Start Tabula (most likely by double clicking on the tabula icon)3. point your browser to http://127.0.0.1:80804. Choose the file you want to upload and click Submit.
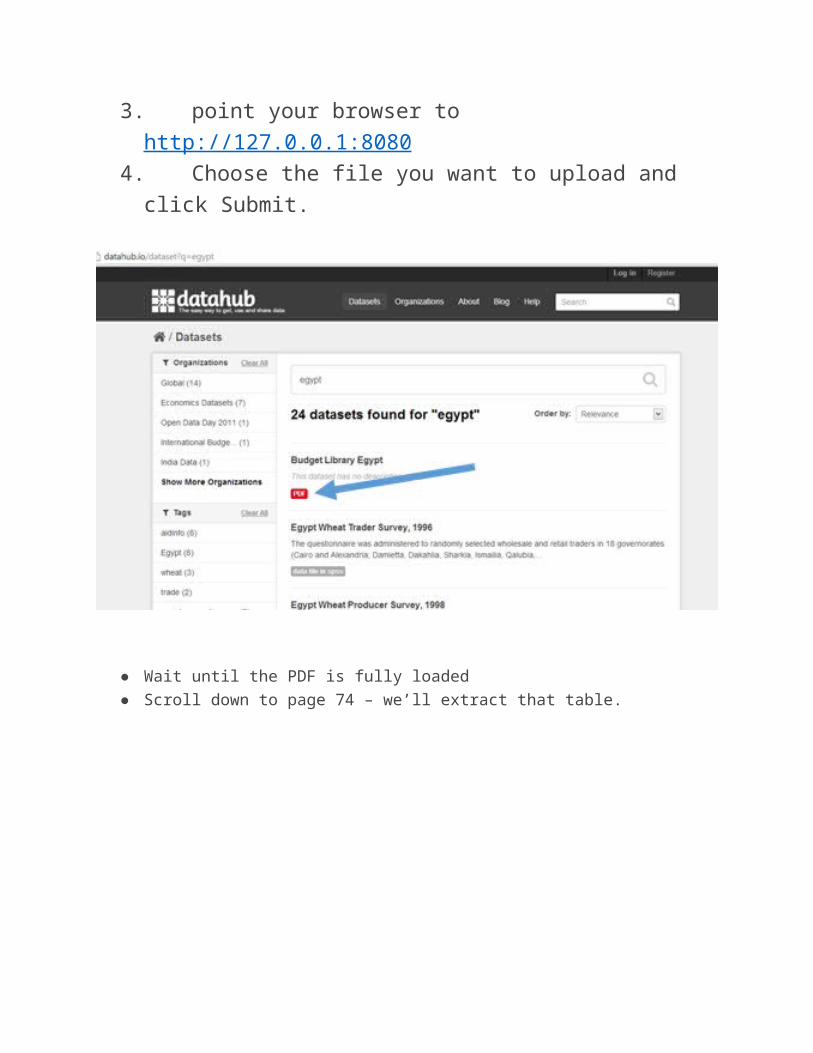
● Wait until the PDF is fully loaded● Scroll down to page 74 – we’ll extract that table.
Click and pull a selection box over the table

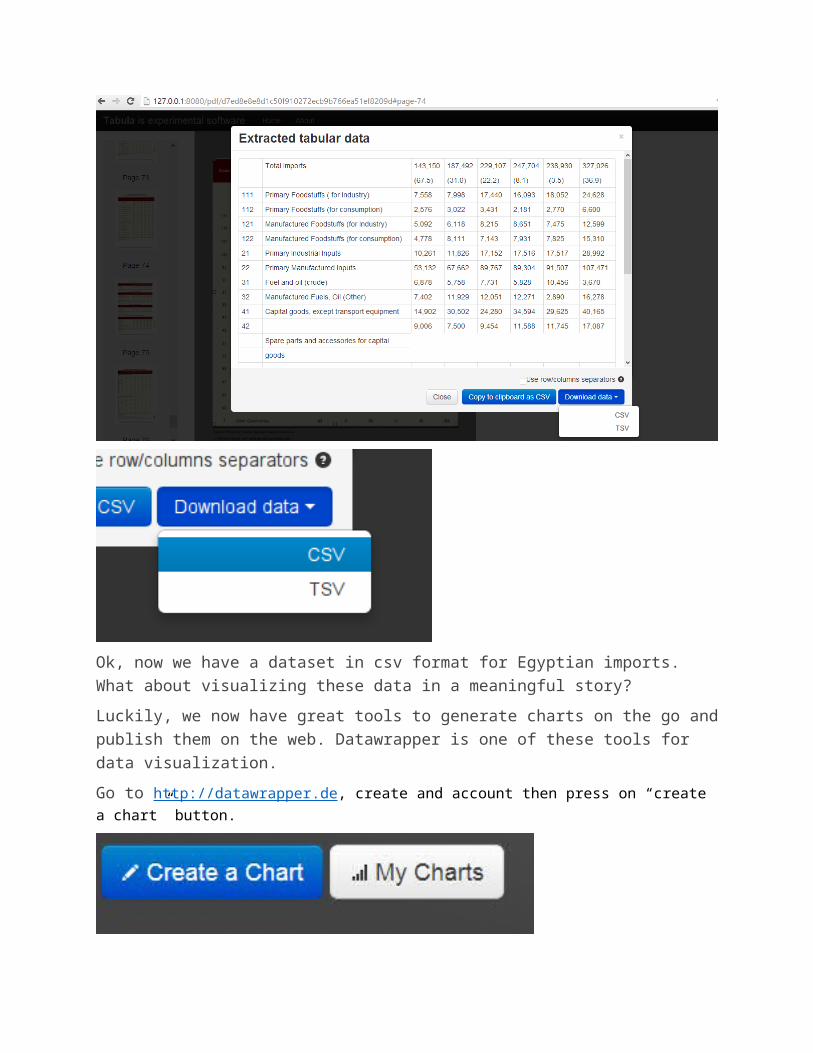
● A window will pop up to show how Tabula would extract the data.Now download the Data as CSV
Ok, now we have a dataset in csv format for Egyptian imports. What about visualizing these data in a meaningful story?
Luckily, we now have great tools to generate charts on the go and publish them on the web. Datawrapper is one of these tools for data visualization.
Go to http://datawrapper.de, create and account then press on “create a chart” button.
Here, you can credit your data source and edit the data. You can also transpose the data which means switching rows and columns in order to get the rows you want to visualize as column headers.
After you click visualize, you can select the chart type, refine the chart by changing colors, adding title and description. The best chart for the type of data we have here is the bar chart because our goal from visualization this data is to show comparisons of Egypt Imports through-out the last 5 years.
After you click publish, you will get a link for your visualization and HTML code to embed it in your website.
Voila! Now you can click the link and play with this cool chart: http://cf.datawrapper.de/11mKD/2/





























