Embed Size (px)
Citation preview

Semantic Parsing with Weak Supervision
Slides by Ben Bogin
Learning Dependency-Based compositional SemanticsPercy Liang, Michael I. Jordan, Dan KleinUC Berkeley
Semantic Parsing on Freebase from Question-Answer PairsJonathan Berant, Andrew Chou, Roy Frostig, Percy LiangStanford University

What we’ve done so far:
Learning from annotated training data – data with logical forms.

What we’ve done so far:
Learning from annotated training data – data with logical forms.
What is the state with the largest population density?answer(A,largest(B,(state(A),density(A,B)))))

What we’ve done so far:
Learning from annotated training data – data with logical forms.
What is the state with the largest population density?answer(A,largest(B,(state(A),density(A,B)))))
Sacramento is the capital of which state?answer(A,(const(B,cityid(sacramento,_)),
capital(B),loc(B,A),state(A))))

What we’ve done so far:
Learning from annotated training data – data with logical forms.
What is the state with the largest population density?answer(A,largest(B,(state(A),density(A,B)))))
Sacramento is the capital of which state?answer(A,(const(B,cityid(sacramento,_)),
capital(B),loc(B,A),state(A))))
(New Jersey)
(California)

What we’ll see next:
Learning from unannotated training data
What is the state with the largest population density?
Sacramento is the capital of which state?
New Jersey
California

Why learn directly from answers?
• Easier to get than annotated logical forms
• Allowing to scale up
• Representation independent
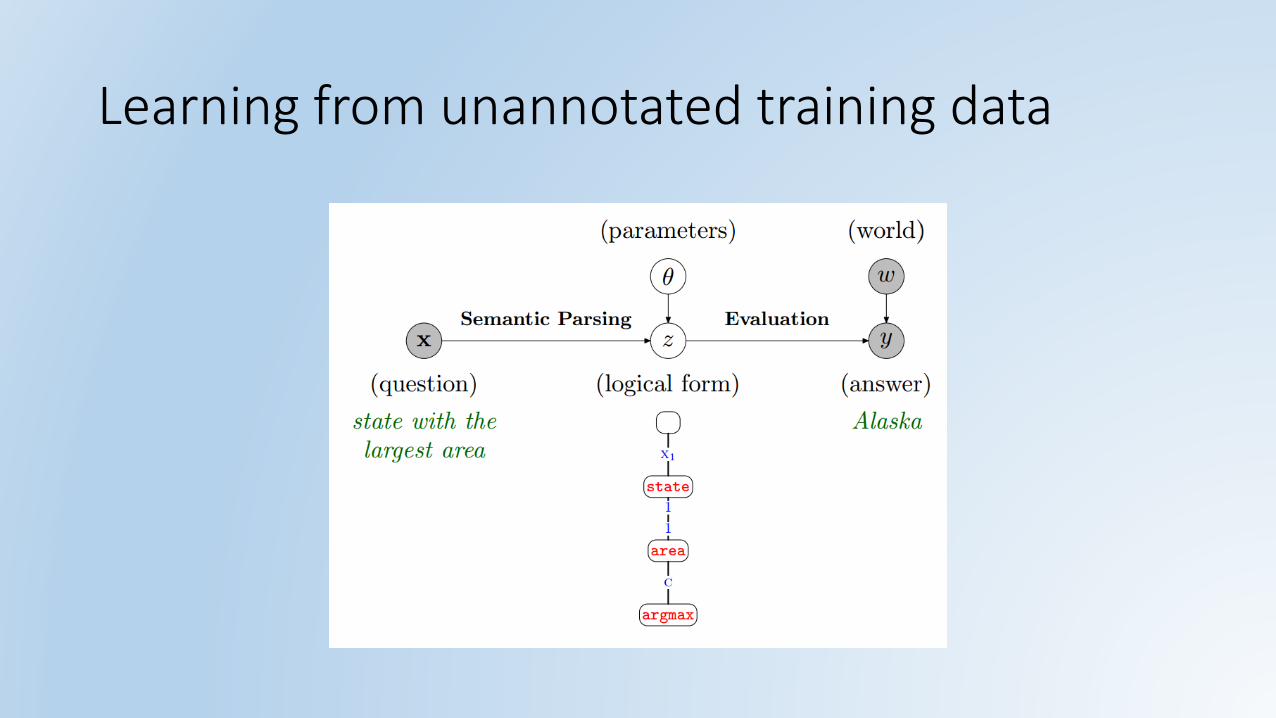
Learning from unannotated training data

Challenges
• Choosing our representation:
We want a representation that is both expressive and simple.
(CCG can become quite complex)

Challenges
• Computational: How to efficiently search exponential space?
• Statistical: How to parameterize mapping from sentence to logical
form?

Challenges
• Computational: How to efficiently search exponential space?
• Statistical: How to parameterize mapping from sentence to logical
form?
What is the most populous city in California?
𝑎𝑟𝑔𝑚𝑎𝑥 𝜆𝑥. 𝑐𝑖𝑡𝑦 𝑥 ∧ 𝑙𝑜𝑐 𝑥, 𝐶𝐴 , 𝜆𝑥. 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛(𝑥)
Los Angeles

Challenges
• Computational: How to efficiently search exponential space?
• Statistical: How to parameterize mapping from sentence to logical
form?
What is the most populous city in California?
𝑎𝑟𝑔𝑚𝑎𝑥 𝜆𝑥. 𝑐𝑖𝑡𝑦 𝑥 ∧ 𝑙𝑜𝑐 𝑥, 𝐶𝐴 , 𝜆𝑥. 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛(𝑥)
Los Angeles
What is the most populous city in California?

Challenges
• Computational: How to efficiently search exponential space?
• Statistical: How to parameterize mapping from sentence to logical
form?
What is the most populous city in California?
𝑎𝑟𝑔𝑚𝑎𝑥 𝜆𝑥. 𝑐𝑖𝑡𝑦 𝑥 ∧ 𝑙𝑜𝑐 𝑥, 𝐶𝐴 , 𝜆𝑥. 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛(𝑥)
Los Angeles
What is the most populous city in California? 𝑎𝑟𝑔𝑚𝑎𝑥 𝜆𝑥. 𝑐𝑖𝑡𝑦 𝑥 ∧ 𝑙𝑜𝑐 𝑥, 𝐶𝐴 , 𝜆𝑥. 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛(𝑥)

Dependency Based Compositional Semantics (DCS)
Major city in California
CA
1
1
major
2
1
1
city
1
loc

Dependency Grammar

Dependency Grammar
Major city in California
CA
1
1major
2
1
1
city
1loc

Dependency Grammar
Number (of) major cities

Dependency Parsing
Number of major cities

Basic DCS Trees
A DCS tree encodes a constraint satisfaction problem (CSP)
City in California
CA
2
1
1
city
1
loc
DCS Tree
𝑐 ∈ 𝑐𝑖𝑡𝑦
𝑐1 = ℓ1
ℓ ∈ 𝑙𝑜𝑐
ℓ2 = 𝑠1
𝑠 ∈ 𝐶𝐴
Constraints Database
city
San Francisco
Chicago
Bostin
…
loc
CaliforniaMount Shasta
CaliforniaSan Francisco
MassachusettsBoston
…
(Join example)

Basic DCS Trees

Basic DCS Trees

Basic DCS Trees: Denotation

Basic DCS Trees: Denotation

Basic DCS Trees: Denotation
A world 𝓌 is a mapping from each predicate 𝑝to a set of tuples.
For example, 𝓌 𝑠𝑡𝑎𝑡𝑒 = 𝐶𝐴 , 𝑂𝑅 ,…

Basic DCS Trees – Another example
A city that's located in a state that borders California, and in the city also traverses a major river that goes through Arizona.

Basic DCS Trees – Another example
riverstate
1
1
loc
1
1
1
city
2
traverse
border
CA
2
1
2
1
1
1
traverse
1
1
major
1
1
AZ
2
1
A city that's located in a state that borders California, and in the city also traverses a major river that goes through Arizona.

Basic DCS Trees: Aggregators
To represent aggregators such as count or average we introduce a new
aggregate relation, notated Σ.

Basic DCS Trees: Aggregators
To represent aggregators such as count or average we introduce a new
aggregate relation, notated Σ.
Number of major cities Average population of major cities The denotation of Σ is a
singleton containing the
set of its children.
Formally:
Σ: 𝑐 𝓌 = 𝑐 𝓌

Full DCS Trees
Basic DCS trees cover a core subset of language, but let’s consider more cases.

Full DCS Trees
Basic DCS trees cover a core subset of language, but let’s consider more cases.
Syntax
Californiamost
populous
city
in

Full DCS Trees
Basic DCS trees cover a core subset of language, but let’s consider more cases.
Syntax
Californiamost
populous
city
in
Semantics
𝑎𝑟𝑔𝑚𝑎𝑥 𝜆𝑥. 𝑐𝑖𝑡𝑦 𝑥 ∧ 𝑙𝑜𝑐 𝑥, 𝐶𝐴 , 𝜆𝑥. 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛 𝑥

Full DCS Trees
Basic DCS trees cover a core subset of language, but let’s consider more cases.
Syntax
Californiamost
populous
city
in
Semantics
𝑎𝑟𝑔𝑚𝑎𝑥 𝜆𝑥. 𝑐𝑖𝑡𝑦 𝑥 ∧ 𝑙𝑜𝑐 𝑥, 𝐶𝐴 , 𝜆𝑥. 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛 𝑥
Problem: Syntactic scope is lower then semantic scope

Scope diversion solution: Mark-Execute
𝑎𝑟𝑔𝑚𝑎𝑥 𝜆𝑥. 𝑐𝑖𝑡𝑦 𝑥 ∧ 𝑙𝑜𝑐 𝑥, 𝐶𝐴 , 𝜆𝑥. 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛 𝑥
most populous city in California
CA
1
1
population
2
1
1
city
1
loc
argmax
C
𝑋1

Scope diversion solution: Mark-Execute
𝑎𝑟𝑔𝑚𝑎𝑥 𝜆𝑥. 𝑐𝑖𝑡𝑦 𝑥 ∧ 𝑙𝑜𝑐 𝑥, 𝐶𝐴 , 𝜆𝑥. 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛 𝑥
most populous city in California
CA
1
1
population
2
1
1
city
1
loc
argmax
C
𝑋1
Mark at syntactic scope

Scope diversion solution: Mark-Execute
𝑎𝑟𝑔𝑚𝑎𝑥 𝜆𝑥. 𝑐𝑖𝑡𝑦 𝑥 ∧ 𝑙𝑜𝑐 𝑥, 𝐶𝐴 , 𝜆𝑥. 𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛 𝑥
most populous city in California
CA
1
1
population
2
1
1
city
1
loc
argmax
C
𝑋1
Mark at syntactic scope
Execute at semantic scope

Mark-Execute example
California borders which states?

Mark-Execute example
California borders which states?
Semantics
1
1
CA
2
border
1
state
𝑋1
E
Syntax
CA
border
state

Full DCS Trees denotation
Denotation for basic trees: 𝓏 𝓌 = 𝑆𝐹, 𝐿𝐴,…
But since mark-execute acts non-locally, we must augment 𝓏 𝓌 to include
information about marked nodes in 𝓏 that can be accessed later on.

Full DCS Trees denotation
Denotation for basic trees: 𝓏 𝓌 = 𝑆𝐹, 𝐿𝐴,…
But since mark-execute acts non-locally, we must augment 𝓏 𝓌 to include
information about marked nodes in 𝓏 that can be accessed later on.

Full DCS Trees denotation

Full DCS Trees denotation
𝑋12 ⋅

Full DCS Trees: ambiguity
some river traverses every city

Full DCS Trees: ambiguity
some river traverses every city

DCS trees compared to CCG

DCS trees compared to CCG
CCG Lexicon entries DCS lexical trigger

From natural language to logical form
𝒵
𝑦𝓌 Sacramento
CA
2
1
1
1
capital
database

From natural language to logical form
𝑥
𝒵
𝑦𝓌
𝜃
capital of California?
Sacramento
CA
2
1
1
1
capital
database
parameters

From natural language to logical form
𝑥
𝒵
𝑦𝓌
𝜃
capital of California?
Sacramento
CA
2
1
1
1
capital
database
parameters
• What’s possible? 𝓏 ∈ 𝒵 𝑥
• What’s probable? 𝑝 𝓏 𝑥, 𝜃
• Learning 𝜃 from (𝑥, 𝑦) data

From words to predicates
What is the most populous city in CA ?

From words to predicates
What is the most populous city in CA ?
1. Domain-independent triggers
To narrow down the search, a basic lexicon is used, made of three types of entries:

From words to predicates
What is the most populous city in CA ?
1. Domain-independent triggers 2. World (database) values
“Boston” ⇒ Boston: City
To narrow down the search, a basic lexicon is used, made of three types of entries:

From words to predicates
What is the most populous city in CA ?
1. Domain-independent triggers 2. World (database) values
“Boston” ⇒ Boston: City
3. Domain dependent POS triggers
To narrow down the search, a basic lexicon is used, made of three types of entries:

From words to predicates
What is the most populous city in CA ?
1. Domain-independent triggers 2. World (database) values
“Boston” ⇒ Boston: City
3. Domain dependent POS triggers
To narrow down the search, a basic lexicon is used, made of three types of entries:
argmax

From words to predicates
What is the most populous city in CA ?
1. Domain-independent triggers 2. World (database) values
“Boston” ⇒ Boston: City
3. Domain dependent POS triggers
To narrow down the search, a basic lexicon is used, made of three types of entries:
argmax CA

From words to predicates
What is the most populous city in CA ?
1. Domain-independent triggers 2. World (database) values
“Boston” ⇒ Boston: City
3. Domain dependent POS triggers
To narrow down the search, a basic lexicon is used, made of three types of entries:
argmax CApopulation
state
river
city

From words to predicates
What is the most populous city in CA ?
1. Domain-independent triggers 2. World (database) values
“Boston” ⇒ Boston: City
3. Domain dependent POS triggers
To narrow down the search, a basic lexicon is used, made of three types of entries:
argmax CApopulation
state
river
city
population
state
river
city

From predicates to DCS Trees
𝐶𝑖,𝑗 = 𝑠𝑒𝑡 𝑜𝑓 𝑝𝑜𝑠𝑠𝑖𝑏𝑙𝑒 𝐷𝐶𝑆 𝑡𝑟𝑒𝑒𝑠 𝑓𝑜𝑟 𝑠𝑝𝑎𝑛 𝑖, 𝑗
𝒵 𝑥 = 𝐶0,𝑛

From predicates to DCS Trees𝐶𝑖,𝑗 is recursively built from combinations of the trees of two sub-spans
𝑎 ∈ 𝐶𝑖,𝑘 and 𝑏 ∈ 𝐶𝑘′,𝑗 (where 𝑖 ≤ 𝑘 ≤ 𝑘′ < 𝑗).

From predicates to DCS Trees𝐶𝑖,𝑗 is recursively built from combinations of the trees of two sub-spans
𝑎 ∈ 𝐶𝑖,𝑘 and 𝑏 ∈ 𝐶𝑘′,𝑗 (where 𝑖 ≤ 𝑘 ≤ 𝑘′ < 𝑗).

From predicates to DCS Trees𝐶𝑖,𝑗 is recursively built from combinations of the trees of two sub-spans
𝑎 ∈ 𝐶𝑖,𝑘 and 𝑏 ∈ 𝐶𝑘′,𝑗 (where 𝑖 ≤ 𝑘 ≤ 𝑘′ < 𝑗).

From predicates to DCS Trees
(Start of) formal definition: Single-nodes trees with each predicate from lexicon.
𝐶𝑖,𝑗 = 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗

From predicates to DCS Trees
(Start of) formal definition: Single-nodes trees with each predicate from lexicon.
𝐶𝑖,𝑗 = 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗

From predicates to DCS Trees
(Start of) formal definition: Added recursive combinations of trees
𝐶𝑖,𝑗 = 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗 ∪ ራ
𝑖≤𝑘≤𝑘′<𝑗𝑎∈𝐶𝑖,𝑘𝑏∈𝐶𝑘′,𝑗
𝑇 𝑎, 𝑏

From predicates to DCS Trees
(Start of) formal definition: Added recursive combinations of trees
𝐶𝑖,𝑗 = 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗 ∪ ራ
𝑖≤𝑘≤𝑘′<𝑗𝑎∈𝐶𝑖,𝑘𝑏∈𝐶𝑘′,𝑗
𝑇 𝑎, 𝑏
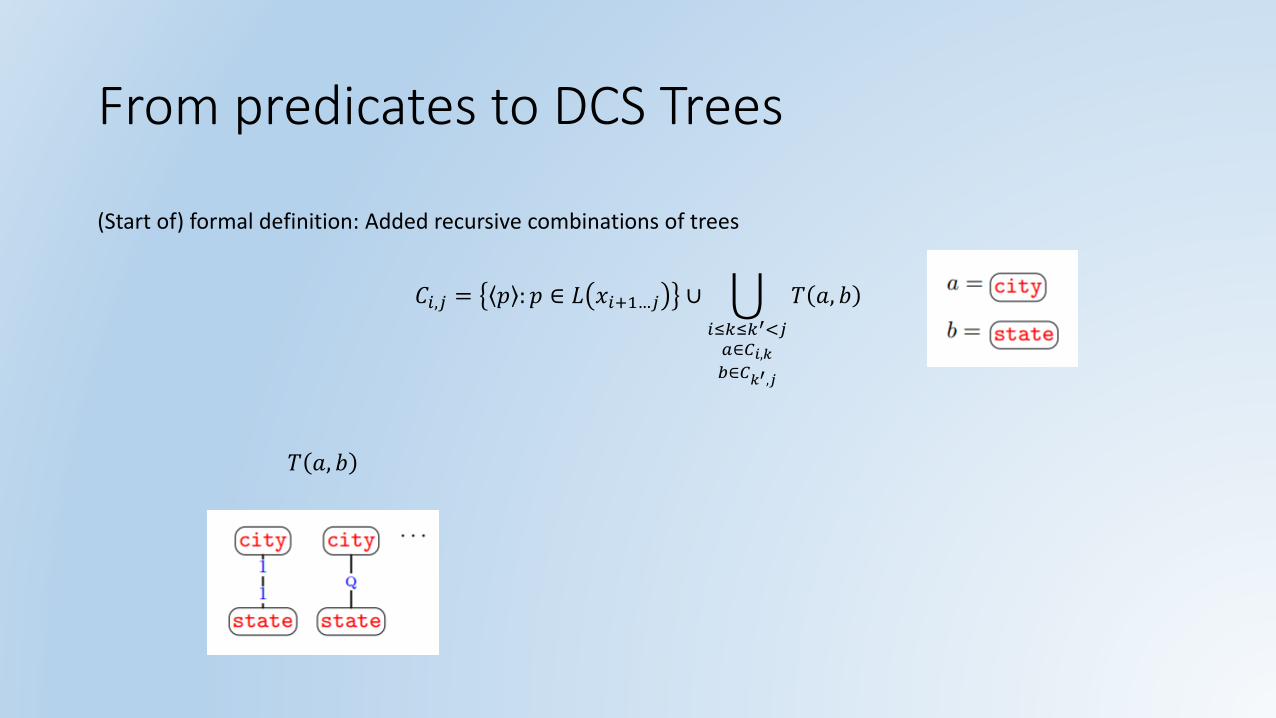
From predicates to DCS Trees
(Start of) formal definition: Added recursive combinations of trees
𝐶𝑖,𝑗 = 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗 ∪ ራ
𝑖≤𝑘≤𝑘′<𝑗𝑎∈𝐶𝑖,𝑘𝑏∈𝐶𝑘′,𝑗
𝑇 𝑎, 𝑏
𝑇 𝑎, 𝑏

From predicates to DCS Trees
(Start of) formal definition: Added recursive combinations of trees, different root each time
𝐶𝑖,𝑗 = 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗 ∪ ራ
𝑖≤𝑘≤𝑘′<𝑗𝑎∈𝐶𝑖,𝑘𝑏∈𝐶𝑘′,𝑗
𝑇 𝑎, 𝑏 ∪ 𝑇 𝑏, 𝑎

From predicates to DCS Trees
(Start of) formal definition: Added recursive combinations of trees, different root each time
𝐶𝑖,𝑗 = 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗 ∪ ራ
𝑖≤𝑘≤𝑘′<𝑗𝑎∈𝐶𝑖,𝑘𝑏∈𝐶𝑘′,𝑗
𝑇 𝑎, 𝑏 ∪ 𝑇 𝑏, 𝑎
𝑇 𝑎, 𝑏
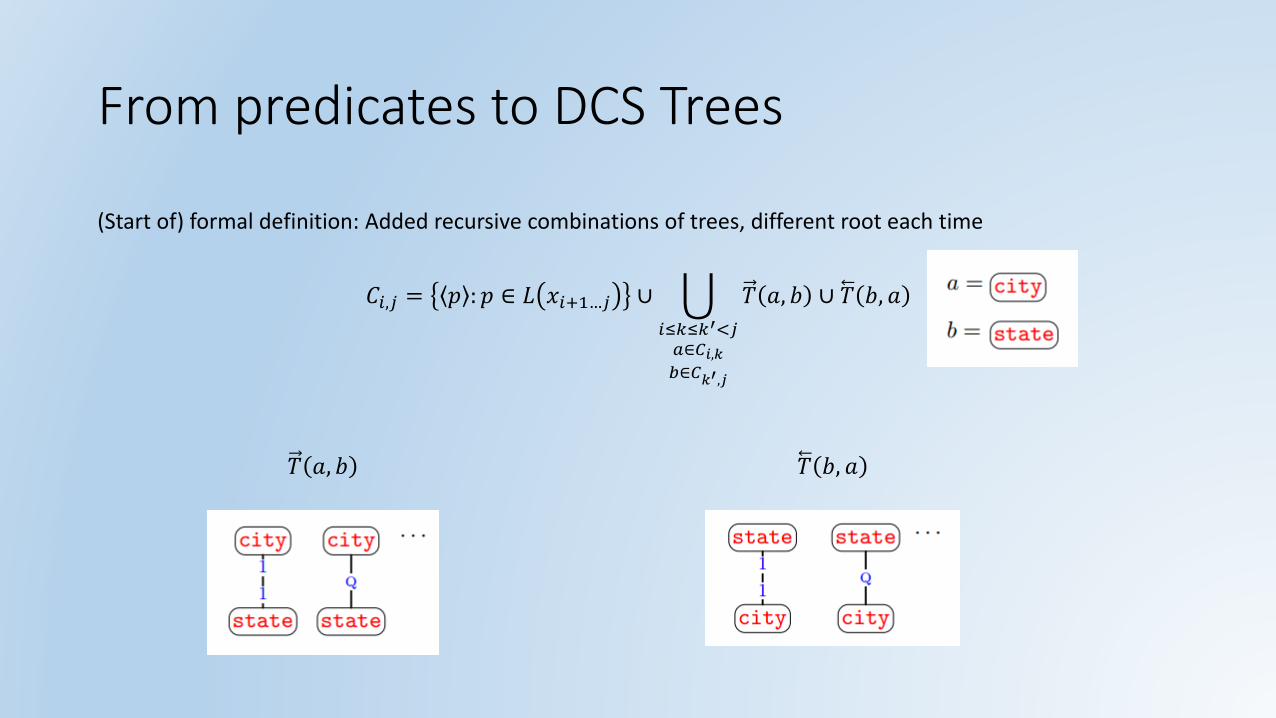
From predicates to DCS Trees
(Start of) formal definition: Added recursive combinations of trees, different root each time
𝐶𝑖,𝑗 = 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗 ∪ ራ
𝑖≤𝑘≤𝑘′<𝑗𝑎∈𝐶𝑖,𝑘𝑏∈𝐶𝑘′,𝑗
𝑇 𝑎, 𝑏 ∪ 𝑇 𝑏, 𝑎
𝑇 𝑎, 𝑏 𝑇 𝑏, 𝑎

From predicates to DCS Trees
(Start of) formal definition: Allow trace predicates (predicates not triggered by any natural word)
𝐶𝑖,𝑗 = 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗 ∪ ራ
𝑖≤𝑘≤𝑘′<𝑗𝑎∈𝐶𝑖,𝑘𝑏∈𝐶𝑘′,𝑗
𝑇2 𝑎, 𝑏 ∪ 𝑇2 𝑏, 𝑎

From predicates to DCS Trees
(Start of) formal definition: Allow trace predicates (predicates not triggered by any natural word)
𝐶𝑖,𝑗 = 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗 ∪ ራ
𝑖≤𝑘≤𝑘′<𝑗𝑎∈𝐶𝑖,𝑘𝑏∈𝐶𝑘′,𝑗
𝑇2 𝑎, 𝑏 ∪ 𝑇2 𝑏, 𝑎
𝑇2 𝑎, 𝑏 𝑇2 𝑏, 𝑎
𝐿 𝜖 =

From predicates to DCS Trees
(Start of) formal definition: Augment 𝐸 and 𝑋1 relations
𝐶𝑖,𝑗 = 𝐴 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗 ∪ ራ
𝑖≤𝑘≤𝑘′<𝑗𝑎∈𝐶𝑖,𝑘𝑏∈𝐶𝑘′,𝑗
𝑇2 𝑎, 𝑏 ∪ 𝑇2 𝑏, 𝑎

From predicates to DCS Trees
(Start of) formal definition: Augment 𝐸 and 𝑋1 relations
𝐶𝑖,𝑗 = 𝐴 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗 ∪ ራ
𝑖≤𝑘≤𝑘′<𝑗𝑎∈𝐶𝑖,𝑘𝑏∈𝐶𝑘′,𝑗
𝑇2 𝑎, 𝑏 ∪ 𝑇2 𝑏, 𝑎

From predicates to DCS Trees
(Start of) formal definition: Augment 𝐸 and 𝑋1 relations
𝐶𝑖,𝑗 = 𝐴 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗 ∪ ራ
𝑖≤𝑘≤𝑘′<𝑗𝑎∈𝐶𝑖,𝑘𝑏∈𝐶𝑘′,𝑗
𝑇2 𝑎, 𝑏 ∪ 𝑇2 𝑏, 𝑎

From predicates to DCS Trees
Formal definition: Filter impossible combinations
𝐶𝑖,𝑗 = 𝐹 𝐴 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗 ∪ ራ
𝑖≤𝑘≤𝑘′<𝑗𝑎∈𝐶𝑖,𝑘𝑏∈𝐶𝑘′,𝑗
𝑇2 𝑎, 𝑏 ∪ 𝑇2 𝑏, 𝑎

From predicates to DCS Trees
Formal definition: Filter impossible combinations
𝐶𝑖,𝑗 = 𝐹 𝐴 𝑝 : 𝑝 ∈ 𝐿 𝑥𝑖+1…𝑗 ∪ ራ
𝑖≤𝑘≤𝑘′<𝑗𝑎∈𝐶𝑖,𝑘𝑏∈𝐶𝑘′,𝑗
𝑇2 𝑎, 𝑏 ∪ 𝑇2 𝑏, 𝑎
𝑇2 𝑎, 𝑏 𝑇2 𝑏, 𝑎

Probability of DCS trees
We now have the set of 𝓏 ∈ 𝒵 𝑥 . What’s most probable?

Probability of DCS trees
We now have the set of 𝓏 ∈ 𝒵 𝑥 . What’s most probable?
city in California
CAcity loc
1 1 2 1
𝓏:𝑥:

Probability of DCS trees
We now have the set of 𝓏 ∈ 𝒵 𝑥 . What’s most probable?
city in California
CAcity loc
1 1 2 1
𝓏:𝑥:
𝑠𝑐𝑜𝑟𝑒 𝑥, 𝓏 = 𝑓𝑒𝑎𝑡𝑢𝑟𝑒𝑠 𝑥, 𝓏 ⋅ 𝜃
𝑓𝑒𝑎𝑡𝑢𝑟𝑒𝑠 𝑥, 𝓏 = ∈ ℝ𝑑
𝑝 𝓏|𝑥, 𝜃 =𝑒𝑠𝑐𝑜𝑟𝑒 𝑥,𝑧
σ𝑧′∈𝒵 𝑥 𝑒𝑠𝑐𝑜𝑟𝑒 𝑥,𝑧
in - loc
city loc
…
: 1
: 1

The features: example

Learning 𝜃 from (𝑥, 𝑦) data
Our regularized objective we want to maximize:
𝒪 𝜃 =
𝑥,𝑦
𝑧∈𝒵 𝑥 : 𝑧 𝑤=𝑦
log 𝑝𝜃 𝑧 − 𝜆 𝜃 22
Which sums over all DCS trees 𝑧 that evaluate to the target answer 𝑦.

Learning algorithm
The problem: 𝒵 𝑥 grows exponentially with the length of 𝑥.
Therefore, we want to approximate it by using beam search.

Learning algorithm
The problem: 𝒵 𝑥 grows exponentially with the length of 𝑥.
Therefore, we want to approximate it by using beam search.
parameters 𝜃 Enumerate/score DCS trees
0,0, … , 0

Learning algorithm
The problem: 𝒵 𝑥 grows exponentially with the length of 𝑥.
Therefore, we want to approximate it by using beam search.
parameters 𝜃 Enumerate/score DCS trees K-best listtree1tree2tree3tree4…
0,0, … , 0

Learning algorithm
The problem: 𝒵 𝑥 grows exponentially with the length of 𝑥.
Therefore, we want to approximate it by using beam search.
parameters 𝜃 Enumerate/score DCS trees K-best listtree1tree2tree3tree4…
Numerical optimization
0,0, … , 0

Learning algorithm
The problem: 𝒵 𝑥 grows exponentially with the length of 𝑥.
Therefore, we want to approximate it by using beam search.
parameters 𝜃 Enumerate/score DCS trees K-best listtree1tree2tree3tree4…
Numerical optimization0.3, −1.4, …
0,0, … , 0

Learning algorithm
The problem: 𝒵 𝑥 grows exponentially with the length of 𝑥.
Therefore, we want to approximate it by using beam search.
parameters 𝜃 Enumerate/score DCS trees K-best listtree1tree2tree3tree4…
Numerical optimization0.3, −1.4, …
0,0, … , 0

Learning algorithm

Learning intuition
When the weights are zero, the beam search is unguided, and only the simplest of the training examples can be answered (around 29%).
As 𝜃 improves, beam searching is leading to more trees with correct answers, and vice-versa.

Results
Results show competitive results without using annotations.

Results
When using a richer lexicon:

Results
When using a richer lexicon:

Results
When using a richer lexicon:

Results (Effect of beam size)

Scaling up the problem: Freebase
What if we had a much bigger amount of predicates?

Scaling up the problem: Freebase
who plays Hermione Granger? “Emma Watson”
what kind of money in Aruba? “Aruban florin”
when was the civil war in Libya? 2011
what airport fly into for Maui? “Hana Airport”
What if we had a much bigger amount of predicates?

Scaling up the problem: Freebase
who plays Hermione Granger? “Emma Watson”
what kind of money in Aruba? “Aruban florin”
when was the civil war in Libya? 2011
what airport fly into for Maui? “Hana Airport”
What if we had a much bigger amount of predicates?
Freebase: a large collaborative knowledge base, containing 41M entities, 19K
properties and 596M property-value tuples.

Scaling up the problem: Freebase
who plays Hermione Granger? “Emma Watson”
what kind of money in Aruba? “Aruban florin”
when was the civil war in Libya? 2011
what airport fly into for Maui? “Hana Airport”
What if we had a much bigger amount of predicates?
Freebase: a large collaborative knowledge base, containing 41M entities, 19K
properties and 596M property-value tuples. BarackObama, PlaceOfBirth, HonoluluDonaldTrump, PlaceOfBirth, NewYork

Short introduction to simple 𝜆-DCS
As in DCS, the motivation for 𝜆-DCS was to produce logical forms that
are simpler than lambda calculus.
For example,
𝜆𝑥. ∃𝑎. 𝑝1 𝑥, 𝑎 ∧ ∃𝑏. 𝑝2 𝑎, 𝑏 ∧ 𝑝3 𝑏, 𝑒
Is expressed compactly as
𝑝1. 𝑝2. 𝑝3. 𝑒

Short introduction to simple 𝜆-DCS
Basic 𝜆-DCS logical forms 𝑧 and their denotations 𝑧 𝒦 are defined
recursively:
• Unary base case. For an entity 𝑒 ∈ ℰ such as Seattle, 𝑧 𝒦 = 𝑒
• Binary base case. For a propery 𝑝 ∈ 𝒫 such as PlaceOfBirth, p is a
binary logical form with 𝑝 𝒦 = 𝑒1, 𝑒2 : 𝑒1, 𝑝, 𝑒2 ∈ 𝒦
For example, PlaceOfBirth 𝒦 =
{ BarackObama,Honolulu , DonaldTrump,NewYork , …}

Short introduction to simple 𝜆-DCS
• Join: if 𝑏 is a binary and 𝑢 is a unary, then 𝑏. 𝑢 (e.g.
PlaceOfBirth.Seattle) is a unary:
𝑏. 𝑢 𝒦 = 𝑒1 ∈ ℰ: ∃𝑒2. 𝑒1, 𝑒2 ∈ 𝑏 𝒦 ∧ 𝑒2 ∈ 𝑢 𝒦
For example, PlaceOfBirth.Seattle 𝒦 =
{JimiHendrix, ChrisCornell, BillGates, …}

Short introduction to simple 𝜆-DCS
• Intersection: if 𝑢1 and 𝑢2 are both unaries, then 𝑢1 ⊓ 𝑢2 (e.g.
Profession.Scientist⊓ PlaceOfBirth.Seattle is the
set intersection:
𝑢1 ⊓ 𝑢2 𝒦 = 𝑢1 𝒦 ∩ 𝑢2 𝒦
For example, Profession.Scientist ⊓ PlaceOfBirth.Seattle 𝒦 =
{GeorgeHHitchings, …}

Short introduction to simple 𝜆-DCS
• Aggregation: if 𝑢 is a unary, then count 𝑢 denotes the cardinality
𝑐𝑜𝑢𝑛𝑡(𝑢) 𝒦 = 𝑢 𝒦

Short introduction to simple 𝜆-DCS
As a final example, the representation of
“number of dramas starring Tom Cruise” in lambda calculus would be:
count(λ𝑥.Genre(𝑥,Drama)∧ ∃𝑦.Performance(𝑥, 𝑦) ∧
Actor(𝑦,TomCruise))
In 𝜆-DCS, it is simply:
count(Genra.Drama ⊓ Performance.Actor.TomCruise)

Mapping words to predicates
Since we now have more then 19,000 predicates, we can no longer
search all possibilities nor can we use hand-crafted rules.
Two strategies are proposed:
• Alignment: Learning a lexicon by aligning a large text corpus to
Freebase
• Bridging: Generating new logical predicates by neighboring predicates

Aligning words and predicates
A large set of (𝑒1, 𝑟, 𝑒2) triplets were used, already aligned with KB
entities and their types.

Aligning words and predicates
A large set of (𝑒1, 𝑟, 𝑒2) triplets were used, already aligned with KB
entities and their types.
BarackObama, “was also born in”, August1961
[Person, Date]
BillClinton, “married in”, Fayetteville
[Person, Location]
…

Aligning words and predicates
For every such phrase 𝑟, we look at its extension ℱ 𝑟 : The pair of co-
occurring entities.

Aligning words and predicates
For every such phrase 𝑟, we look at its extension ℱ 𝑟 : The pair of co-
occurring entities.
“born in” [Person, Date]
“married in”,[Person, Location]
…
𝑟 ∈ ℛ1

Aligning words and predicates
For every such phrase 𝑟, we look at its extension ℱ 𝑟 : The pair of co-
occurring entities.
“born in” [Person, Date]
“married in”,[Person, Location]
…
𝑟 ∈ ℛ1
{(BarackObama, Honolulu),…}
{(BillClinton, Fayetteville),…}
…
ℱ 𝑟

Aligning words and predicates
We can than compare ℱ 𝑟1 constructed from the text phrases to
ℱ 𝑟2 constructed from predicates.

Aligning words and predicates
We can than compare ℱ 𝑟1 constructed from the text phrases to
ℱ 𝑟2 constructed from predicates.
“born in”
{(BarackObama, Honolulu), …}
…
ℱ 𝑟1

Aligning words and predicates
We can than compare ℱ 𝑟1 constructed from the text phrases to
ℱ 𝑟2 constructed from predicates.
“born in”
{(BarackObama, Honolulu), …}
…
ℱ 𝑟1
PlaceOfBirth
{(BarackObama, Honolulu), …}
…
ℱ 𝑟2

Aligning words and predicates
We can than compare ℱ 𝑟1 constructed from the text phrases to
ℱ 𝑟2 constructed from predicates.
“born in”
{(BarackObama, Honolulu), …}
…
ℱ 𝑟1
PlaceOfBirth
{(BarackObama, Honolulu), …}
…
ℱ 𝑟2
We will be interested in ℱ 𝑟1 ∩ ℱ 𝑟2 .

Aligning words and predicates

Aligning words and predicates
Non-zero overlap doesn’t guarantees mapping –
Since the data is noisy, even the phrase “born in” and the property
Marriage.EndDate co-occur 4 times.
Instead, we learn mapping by defining features.

Aligning words and predicates

Bridging
In some cases, alignment is hard or even impossible.

Bridging
In some cases, alignment is hard or even impossible.
“What government does Chile have?”

Bridging
In some cases, alignment is hard or even impossible.
“What government does Chile have?”
“What actors are in Top Gun?”

Bridging
In some cases, alignment is hard or even impossible.
“What government does Chile have?”
“What actors are in Top Gun?”
“What is Italy money?”

Bridging
In some cases, alignment is hard or even impossible.
“What government does Chile have?”
“What actors are in Top Gun?”
“What is Italy money?”
How can we generate a manageable set of candidate logical forms?

Bridging
The approach: Types of other unaries can be helpful.

Bridging
The approach: Types of other unaries can be helpful.
“What government does Chile have?”

Bridging
The approach: Types of other unaries can be helpful.
“What government does Chile have?”
ChileType.FormOfGovernment
𝑧1 of type 𝑡1

Bridging
The approach: Types of other unaries can be helpful.
“What government does Chile have?”
ChileType.FormOfGovernment
𝑧1 of type 𝑡1 𝑧2 of type 𝑡2

Bridging
The approach: Types of other unaries can be helpful.
“What government does Chile have?”
ChileType.FormOfGovernment
𝑧1 of type 𝑡1 𝑧2 of type 𝑡2
We can now search for all binaries b with type signature 𝑡1, 𝑡2 and generate a logical form 𝑧1 ⊓ 𝑏. 𝑧2
Type.FormOfGovernment ⊓ GovernmentTypeOf.Chile

Another example

WebQuestions Dataset
The dataset FREE917 based on FreeBase contains logical forms, so it is difficult to scale up.
Therefore WebQuestions was created – to allow training and testing on a bigger dataset, that still contains natural questions.
Questions were collected by a breadth-first search over questions using the Google Suggest API, answered manually by workers at Amazon Mechanical Turk.

The results
Free917: 62% accuracy, outperforming the 59% accuracy reported by
Cai and Yates(2013), that trained on full logical forms. When used
without bridging (on dev set), accuracy dropped from 71.3% to 38.0%.
WebQuestions: 31.4% accuracy. When used without bridging, accuracy
received was 26.9%.

Any questions?





























