Embed Size (px)
Citation preview

Elaboración de redes neuronales artificiales para pronóstico de
escurrimiento en cuencas hidrográficas
Elaboración de redes neuronales artificiales para pronóstico de
escurrimiento en cuencas hidrográficas
SEMINARIO INSTITUTO DE AUTOMATICA
Expositor: Oscar Raúl Dölling
Universidad Nacional de San Juan -Argentina
Departamento de Hidráulica
Universidad Nacional de San Juan -Argentina
Departamento de Hidráulica

SiguienteAnterior
Planteo del Problema Planteo del Problema
Desarrollar un modelo de pronóstico de escurrimien tossuperficiales en cuencas de régimen pluvio-nival cap az de:
• Capturar la naturaleza “no lineal” de los
fenómenos dinámicos involucrados.
• Hacer predicciones en situación de escasez de información

SiguienteAnterior
Alcances de la presentaciAlcances de la presentacióónn
Describir la técnica de redes neuronales artificiales aplicada a la predicción de caudales de deshielo en cuencas pluvio-nivales con información escasa.
Describir la metodología de diseño y validación de un modelo de red neuronal artificial que permita encontrar aquel modelo que arroje la mejor respuesta en la predicción del deshielo entre distintos modelos candidatos.
Presentar ejemplos de aplicación de la metodología descrita al pronóstico de escurrimiento en las cuencas: 1) cuenca del río Maule, Chile.2) cuenca del río San Juan, Argentina.

SiguienteAnterior
Redes neuronales Redes neuronales Artificiales (ANNs)Artificiales (ANNs)
DefiniciónUna red neuronal artificial, es un modelo matemátic o del tipo
conexionista “grafo dirigido”, formado por “unidad es o neuronas” y “conexiones o enlaces” entre ellas que poseen un “pe so” o valor de ponderación asociado al enlace.
EL procesamiento de la información entre las unidad es es modelado a través de elementos computacionales básicos (suma, multiplicación, umbral).
Una neurona está formada básicamente por una “funci ón de activación” y una “función umbral o de salida” dichas funciones pueden ser funciones lineales o no lineales, contin uas y diferenciables.
A la entrada cada neurona puede poseer elementos a dicionales llamados “sites” los cuales permiten un tratamiento diferencial de las señales de ingreso a la neurona.
Columnash i j k z
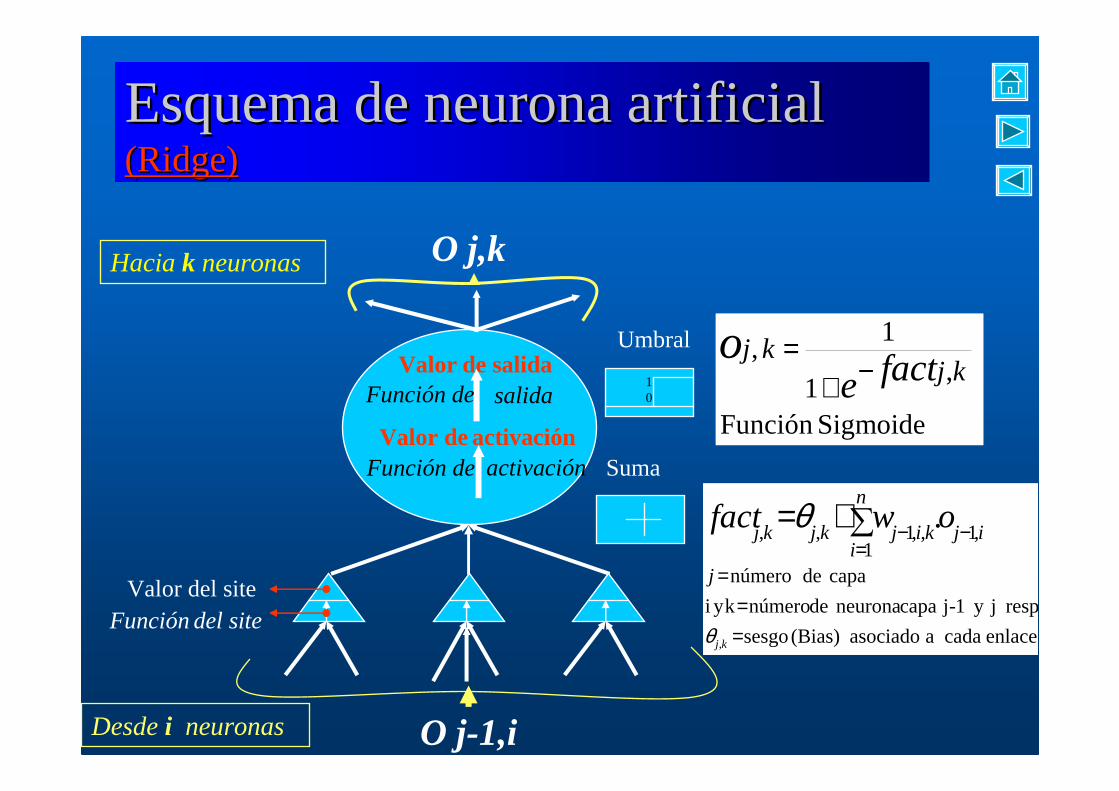
Esquema de neurona artificial Esquema de neurona artificial ((RidgeRidge))
Hacia k neuronas
Valor de salidasalidaFunción de
Función deValor de activación
activación
Valor del siteFunción del site
Umbral
Suma
10
SigmoideFunción
,
1
1,
kjkj
facteo
−+=
enlace cada a asociado (Bias) sesgo
resp. jy 1-j capa neurona de número k y i
capa de número1
,1,,1,,
,
.
==
==
−−∑+=
kj
j
n
iijkijkjkj
owfact
θ
θ
O j-1,i
O j,k
Desde i neuronas

DiseDiseñño de o de ANNsANNs con fines de con fines de predicciprediccióónn
Para desarrollar un modelo de predicción basado en redes neuronales, primero deben ser definidos los siguientes aspectos.
1) Que tipo de fenómeno estoy modelando?2) Cuantas neuronas de salida son necesarias?3) Cuantas neuronas de entrada voy a utilizar?4) Cuantas capas ocultas y cuantas neuronas por capa son necesarias y . suficientes?5) Que tipo de enlaces y cuantos son adecuados para armar la red?6) Cuales son los valores de los pesos en los enlaces?7) Es el modelo desarrollado valido?
Dependen del tipo de problema de predicción y de los datos disponibles

Aspectos principales a resolverAspectos principales a resolverAjuste de pesos Tratamiento de
información
Nro. Neuronasde entrada
Nro. Neuronasde salida
Evaluación del pronóstico
Nro. neuronasocultas
wij cij

MetodologMetodologíía utilizada para la elaborar a utilizada para la elaborar ANNsANNs para prediccipara prediccióón de caudalesn de caudalesPara cubrir convenientemente todos los
aspectos mencionados, se elaboró una metodología constituida por las siguientes etapas fundamentales:
� Análisis de Información� Identificación de modelos candidatos� Validación de modelos candidatos� Selección del modelo óptimo

Identificación de la estructura de la capa oculta. Proposición de modelos candidatos
Aprendizaje de modelos candidatos. Selección de estrategia de entrenamiento
Cálculo de estadísticos y Análisis de Residuos
Evaluación de la capacidad predictiva de los modelos candidatos
Comparación de resultados de lavalidación. Pautas de selección .
Modelo óptimo
Identificación de la estructura de la capa de entrada
Series de Datos de caudales y variablesexplicativas
Tratamiento estadístico de datos
Selección de la estructura de la capa de salida
Armado de duplas entrada-salida
sets de entrenamiento-validación y test
Análisis de Información
Selección del
Modelo óptimo
Validación de candidatos
Identificación de candidatos
�
�
�
�

SiguienteAnterior
Identificación de laestructura de la capa de entrada
Obtención Datos de caudales y variables explicativas
Tratamiento estadístico de datos
Selección de la estructurade la capa de salida
Armado de duplasentrada-salida
sets de entrenamiento-validación y test
Análisis de Información

Análisis de Información�
Tratamiento estadTratamiento estadíístico de la stico de la informaciinformacióónnLas series de datos deben recibir el siguiente tratamiento previo:
•Análisis de homogeneidad •(Análisis de tendencias diferenciación)
•Análisis de consistencia •(Análisis de saltos Test de Fisher)
•Estandarización periódica

Tratamiento de información
Se aconseja realizar el siguiente tratamiento de datos :
1) Clasificar el conjunto de datos en clases según su escurrimientototal anual dentro de cada período hidrológico, asignándole a cada año o período hidrológico un número de clase ej. 1,2,3,4 (normal, pobre, rico, torrencial).
3) Armar un set de tantos ejemplos como ciclos hidrológicos observados se disponga (ver planilla ejemplo)
2) Si se usa Función de Activación Sigmoide, escalar los datos de todas las variables a una escala conveniente por ejemplo entre-0.7 y 0.7 mediante la fórmula:Xescalado = X/[maximo(X) *1,5]
Análisis de Información 2222�

SiguienteAnterior
Clasificación de datos
Método propuesto: Red feedforward con método de aprendizaje supervisado
4) Entrenar una red que aprenda a pronosticar el número de clase de año hidrológico presente.
�

Esquema: Capa de entrada Capa oculta Capa de salida
Esquema:
SelecciSeleccióón Estructura de la capa de salidan Estructura de la capa de salida
Análisis de Información
2
1
:
:
Caudal mes
pronóstico
M.I.S.O.
5
2
3
4
67
1
:20
1
2
:::
30
1
2
J
A
SO
N
E
D
M.I.M.O.

SiguienteAnterior
Métodos:
Análisis de Regresión
Análisis de componentes principales
Análisis de Información
IdentificaciIdentificacióón de las neuronas de la n de las neuronas de la capa de entrada (red PCA)capa de entrada (red PCA)
�

SiguienteAnterior
Análisis de Información
Armado de duplas de Armado de duplas de entrenamiento validacientrenamiento validacióón y testn y test
Objeto: Dividir el conjunto de duplas entrada-salida en tres: Entrenamiento, Validación y Test.
Método Cross Validation: Seleccionar las duplas que formaran cada uno
de los conjuntos de tal manera de que los mismos no representen en forma sesgada el espacio de escenarios hidrológicos factibles .
(propuesta para datos escasos)
�

SiguienteAnterior
Armado de duplas en situaciArmado de duplas en situacióón de n de Datos escasosDatos escasosSi uno tiene un set muy pequeño, de N ejemplos:
Análisis de Información�
1) Crear N diferentes sets de entrenamiento de tamaño N-1 ejemplos cada uno, los que están formados por los mi smos ejemplos del set original pero se ha extraído un ejemplo distinto en cada uno de ellos.
2) Entrenar N redes con cada uno de estos N sets de entrenamiento y determinar cuantos ciclos de entrenami ento hacen falta para predecir correctamente el ejemplo que se ha extraído de cada uno de los set de entrenamiento.
3) Promediar estos números de ciclos así obtenidos y entrenar la red con el set completo con dicho número d e ciclos (ver ejemplo de armado de duplas)
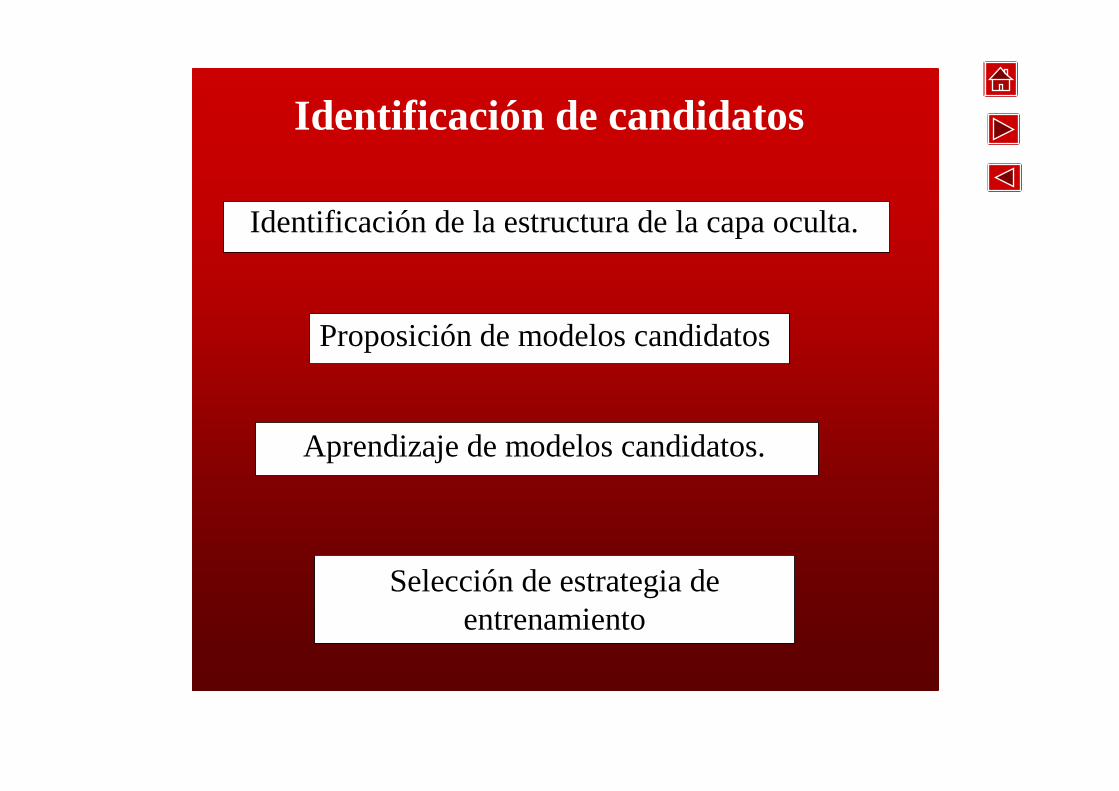
Identificación de la estructura de la capa oculta.
Aprendizaje de modelos candidatos.
Selección de estrategia de entrenamiento
Proposición de modelos candidatos
Identificación de candidatos

MMéétodos de identificacitodos de identificacióón de n de capa ocultacapa oculta
Existen numerosos métodos que sirven para orientar en la identificación del número de neuronas de la capa oculta, entre ellos:
� Prueba y error.� Cascade Correlation.� Podado de pesos.� Skeletonización.� Algoritmos Genéticos.

Modelos candidatos Modelos candidatos Si denominamosF= red diseñada y entrenada (función modelo) f = función a modelarF-f = el error entre modelo y función real
Objetivo: Transformar el ajuste de la red en un problema de aproximación de funciones, para lo cual se deben definir 3 componentes escenciales:
• Función • Norma• Forma
Identificación de Candidatos�

FunciFuncióónn
[ ]2/1
1
2 )()(
−=− ∑=
m
l
ll xfxFfF
Norma (medida de la aproximación)Norma (medida de la aproximación)
f(xl) puede ser especificada como un conjunto de datos continuo o discreto {x1,...xm} que corresponden a m conjuntos de s variables de entrada.
Identificación de Candidatos��

FormaForma
Forma general n cj parámetros
F(x) = ∑∑∑∑ c j.ΦΦΦΦj(x) Φj(x) funcionesj=1 básicas.
Existen distintas formas de aproximación, las mas usadas en ANNs son:
Radial Basis Function (multivariada)
Función Cresta (Ridge) (entrenamiento)
∑=
−Φ+=n
jjjjo wxccF
1
)(
∑=
+Φ=n
jj
Tjjj xwcF
1
)( θ
Identificación de Candidatos��

Modelos Modelos Feed ForwardFeed ForwardCapa de entrada Capa oculta Capa de sali da
i=1,.....,l j=1,....,n k=1,....,p w ij c j
k
Capa oculta redes Función cresta (Ridge) Función Radial Basis
1 1
2
p
2
2
1
n
1
w1j
w2j
wlj
∑ Φ+= )( jjiijjj zxwz θ
w1j
w2j
wlj
cj2
cj1
cjp
F1
F2
Fp
cj2
cj1
cjp
F1
F2
Fp∑
=
Φ=n
jjj
kjk ZcF
1
)(
2)(
)( 2
jjij
ijij z
wxz Φ
−= ∑
σ
∑=
Φ+=n
jjj
kj
kok ZccF
1
)(
2
Identificación de Candidatos�

Estrategia de EntrenamientoEstrategia de Entrenamiento
Identificación de Candidatos
La estrategia de entrenamiento se especifica en base a la definición de los siguientes aspectos:
� Algoritmo de Aprendizaje :(Backpropagation mom.)� Actualización de pesos: (on line)� Inicialización de pesos:(aleatorio)� Variación de parámetros de aprendizaje:(manual)� Presentación de duplas de entrenamiento:(en orden)� Criterio de Término del aprendizaje:(Punto de Término)

Aprendizaje Aprendizaje -- EntrenamientoEntrenamiento
El aprendizaje de redes neuronales artificiales feedforward se basa en los principios del método del gradiente descendente y la regla de la cadena con el objeto de , minimizar la función de desempeño:
∑ ∑
−−=s z
oszdszP 2)(
dondeP= es el desempeño medidos = es un índice que fluctúa entre las muestrasz = es un índice que fluctúa entre todos los nodos de salidadsz = es la salida deseada para la muestra de entrada s en el nodo z-ésimoosz = es la salida calculada para la muestra de entrada s en el nodo z-ésimo
Identificación de Candidatos

AprendizajeAprendizajeBackpropagationBackpropagation
El objetivo es minimizar y luego de aplicar la regla de la
cadena y escribir β=∂∂
o
P
wij
P∂∂
deducir las fórmulas para el cambio de
gradientedemétododeliaconvergenc
laacelerar adestinadamomentumllamadaconstante
donde
)1(.).1(..
=
−∆+−=∆
α
αβ twijjojojoirWij(t)
Identificación de Candidatos
pesos, base para el desarrollo del método Backpropagation Error:
ver heurística del método
SiguienteAnterior
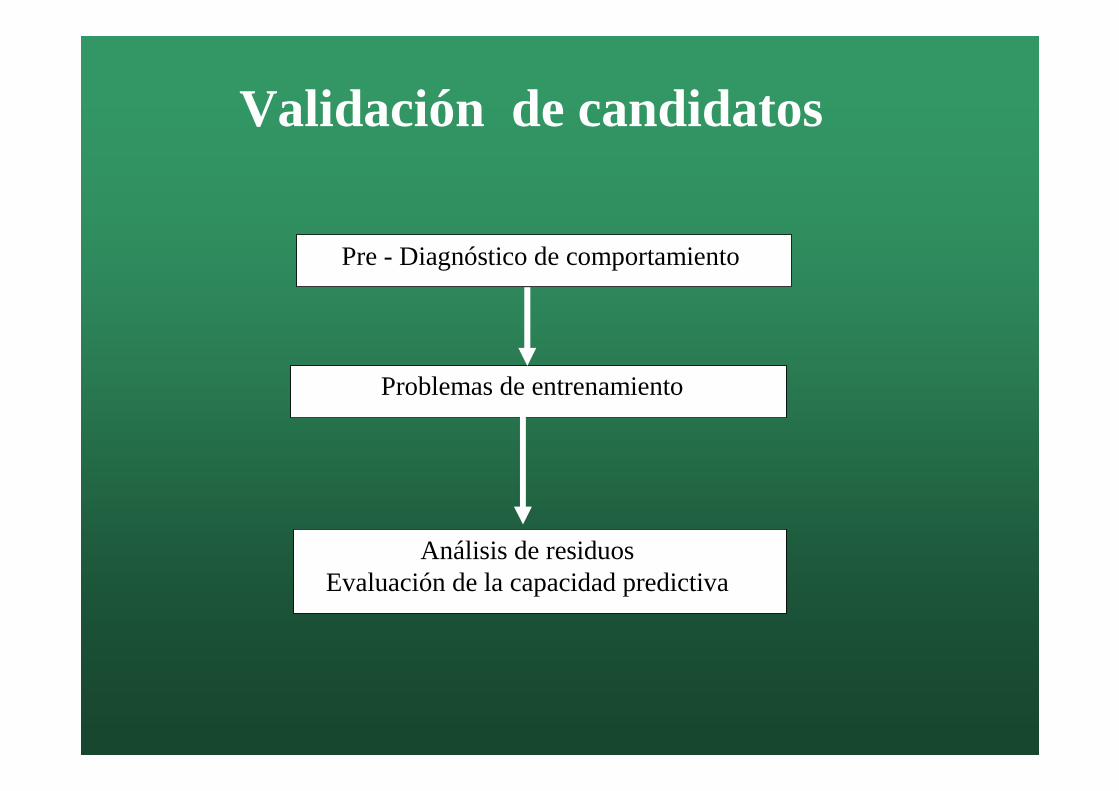
Análisis de residuosEvaluación de la capacidad predictiva
Validación de candidatos
Pre - Diagnóstico de comportamiento
Problemas de entrenamiento

PrePre-- diagndiagnóóstico stico -- Curvas de entrenamientoCurvas de entrenamientoCausas comunes de problemas de convergencia:
A) Problemas Estructurales� incorrecta asignación de nodos de entrada
� inconsistencia en los datos
� insuficientes nodos ocultos
� Demasiados nodos ocultos
B) Mala estrategia de entrenamiento
� Overfitting�Selección parámetros de entrenamiento y/o pesos
iniciales
Validación de Candidatos

Inconsistencia en los Datos.Inconsistencia en los Datos.
Set entrenamiento incluyendo datos inconsistentes
Set entrenamiento extrayendo datos inconsistentes
Análisis curva SSE del set de validación
SSE
ciclos
Validación de Candidatos�
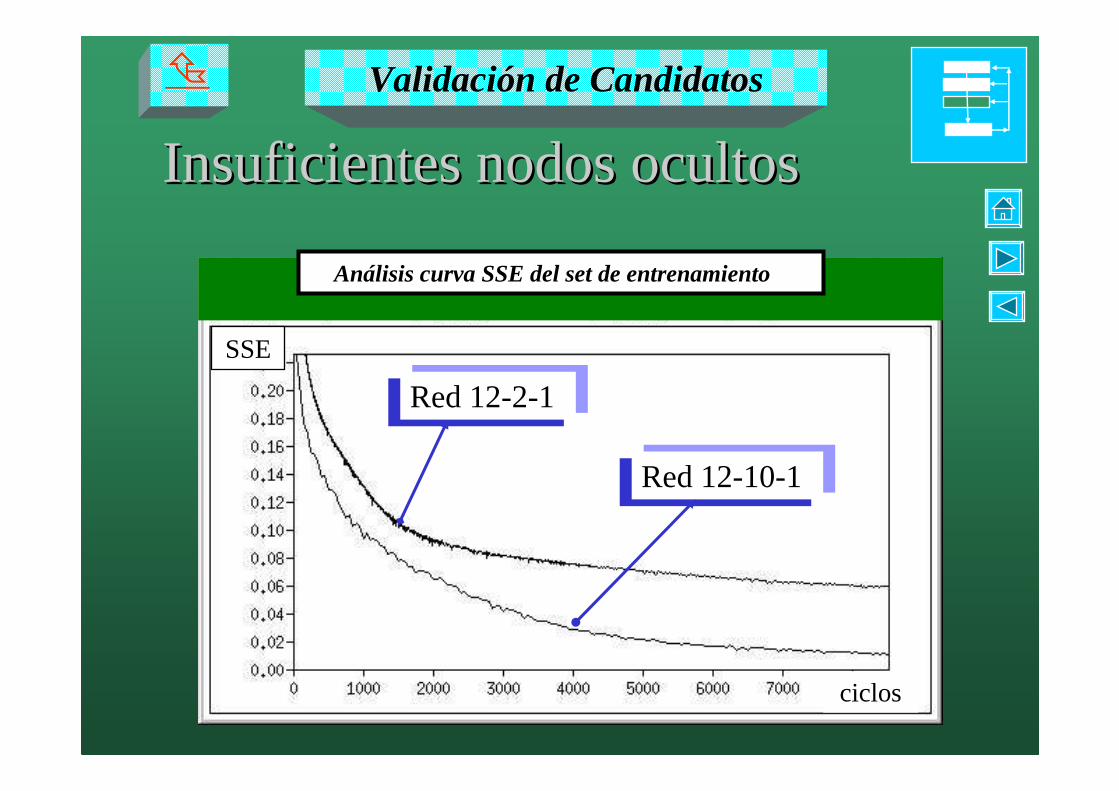
Insuficientes nodos ocultosInsuficientes nodos ocultos
Red 12-2-1
Red 12-10-1
SSE
ciclos
Validación de Candidatos�
Análisis curva SSE del set de entrenamiento

Demasiados nodos ocultosDemasiados nodos ocultos
Red 12-10-10-1
Red 12-10-1
ciclos
SSE
Validación de Candidatos�
Análisis curva SSE del set de entrenamiento

Set de entrenamiento
Set de validación
Problema deProblema deOverfittingOverfitting
SSE
ciclos
Validación de Candidatos�
Análisis curva SSE del set de entrenamiento y validación superpuestos
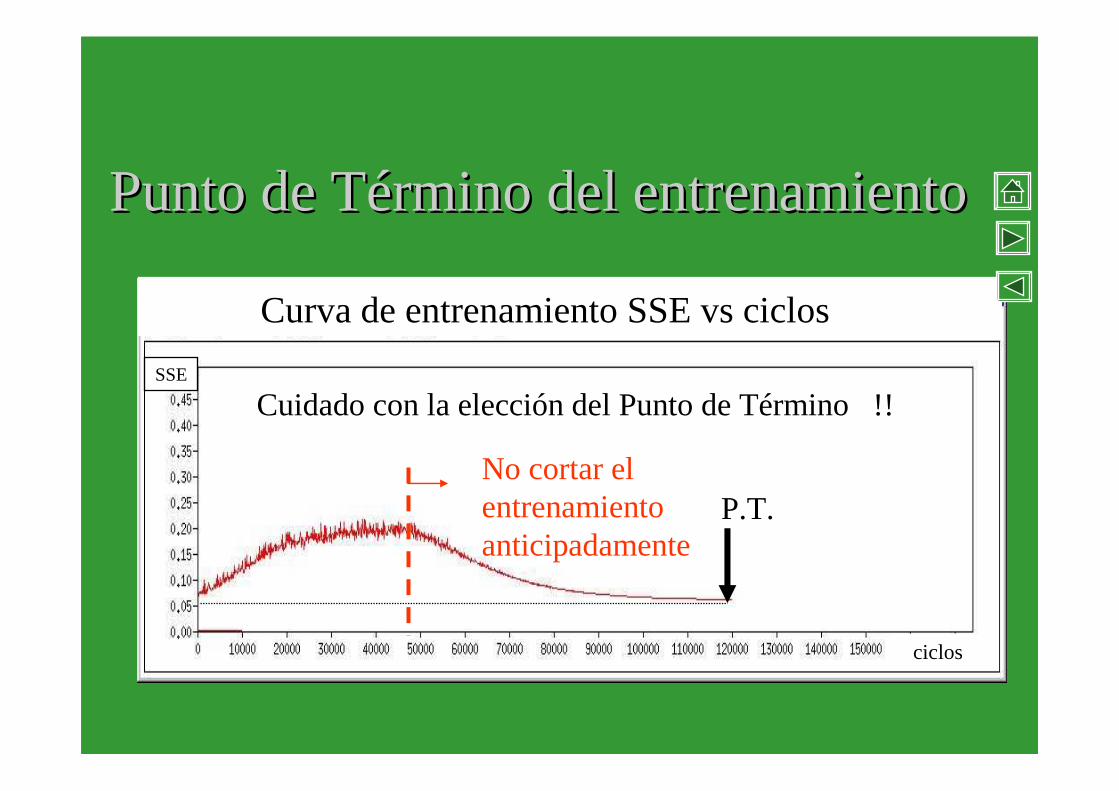
Punto de TPunto de Téérmino del entrenamientormino del entrenamiento
P.T.
Cuidado con la elección del Punto de Término !!
No cortar el entrenamiento anticipadamente
Curva de entrenamiento SSE vs ciclos
ciclos
SSE

Problemas con la selecciProblemas con la seleccióón de parn de paráámetros de metros de rapidez, rapidez, momentum momentum y valor de pesos inicialesy valor de pesos iniciales
P.T.
Influencia del valor inicial de pesos
Influencia valor de los parámetros de entrenamiento.
P.T.
r=0.9 α= 0.1
r=0.4 α= 0.1
Análisis curva SSE del set de validación
Ver Método Montecarlo
Validación de Candidatos

Curva de entrenamiento para Curva de entrenamiento para distintos pardistintos paráámetros de rapidezmetros de rapidez
r = 0.2
r = 0.8
Curva de entrenamiento SSE vs ciclos
SSE
ciclos
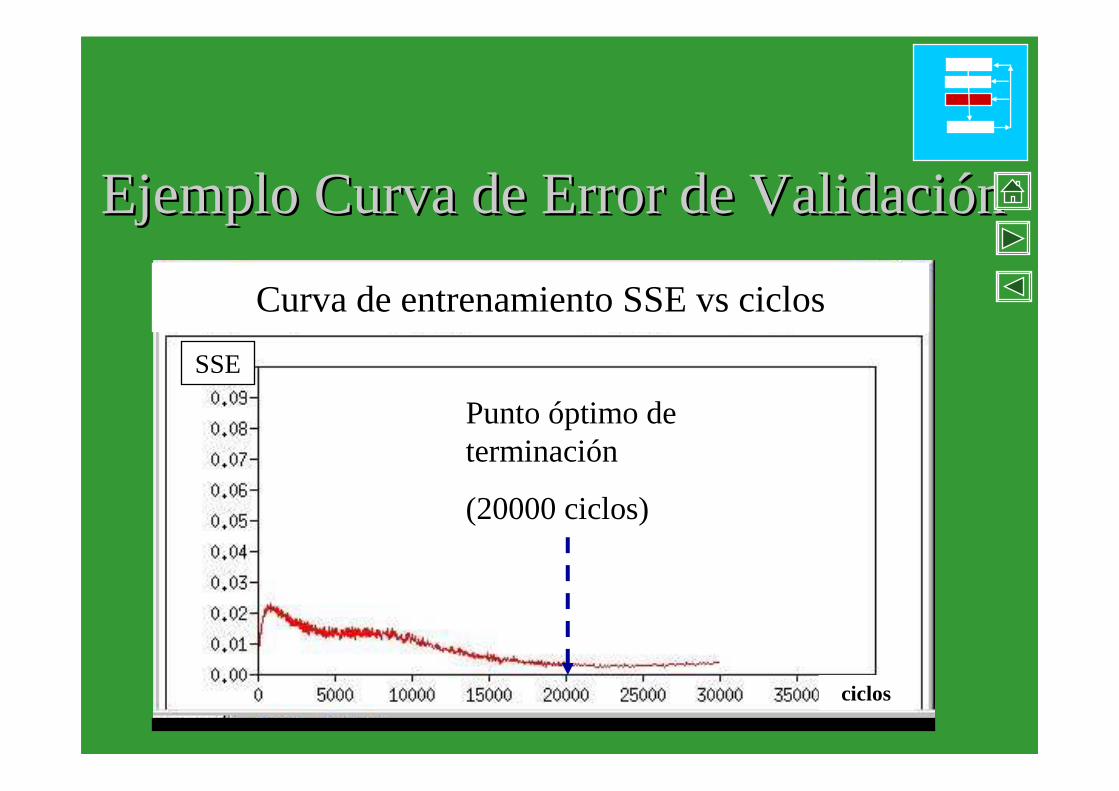
Ejemplo Curva de Error de ValidaciEjemplo Curva de Error de Validacióón n
Punto óptimo de terminación
(20000 ciclos)
Curva de entrenamiento SSE vs ciclos
SSE
ciclos

Pesos InicialesPesos Iniciales
Monte Carlo: Es la manera mas fácil de determinar los pesos y sesgos (bias) en una red. Para cada ciclo de aprendizaje, todos los pesos son cambiados en forma aleatoria entre (min,max). Se calcula el SSE, si es menor que el mejor anterior, estos pesos son almacenados. No es muy eficiente, pero puede usarse para encontrar un buen conjunto de pesos iniciales para el entrenamiento.
Validación de Candidatos�

EvaluaciEvaluacióón de capacidad n de capacidad predictivapredictiva
N
Validación de Candidatos 2222
SSE vs ciclos
S4E vs ciclos
MAE vs ciclos
RMSE vs ciclos
COE vs ciclos
SSE vs ciclos
R2 vs ciclos

*
*
Qcalc
Qobs0
VerificaciVerificacióón del grado de ajusten del grado de ajuste
*
*
Qcalc
Qobs0
*
*
Qcalc
Qobs0
*
*
Qcalc
Qobs0
*
**
*
*
*
*
*
***
**
*
**
*
**
*
*
*
*
* *
* *
*
*
*
*
*
*
*
**
*
*
*
* **
* *
*
* *
*
**
*
*
*
*
****
*
*
*
*
*
** *
*
*
*
*
*
**
**
*
**
*
*
*
**
*
**
*
*
Validación de Candidatos 2222�

VisualizaciVisualizacióón de resultadosn de resultados
QANN
Qobs
0
Qm(m3/s)
Tiempo (meses)
Validación de Candidatos 2222�

DiagnDiagnóóstico de problemas en la stico de problemas en la estructura del modelo estructura del modelo (f(fóórmulas)rmulas)
+1 Φεε(τ)
+20-20-1
+1 Φε2´
ε2(τ)
+20-20-1
+1 Φε(εu)(τ)
+20-20-1
+1 Φu2´
ε(τ)
+20-20-1
+1 Φuε(τ)
+20-20-1
Validación de Candidatos�
FAS
FAC2
FCC FCC
FCC+ 1.96 √ N
-1.96√ N

ValidaciValidacióón de Modelos Candidatosn de Modelos CandidatosUna vez pasada la etapa de pre-diagnóstico se propo ne realizar el test de Billings and Voon (1986) para l a diagnosis de ajuste de modelos NARMAX. Los test básicos se refieren al análisis de la independencia de los residuos los cuales debe demostrarse correspon den a un proceso de “ruido blanco” por lo que deben cumplir las condiciones: (fund. del Contraste)
( )( )
0 0)]1().1().([)(
0)](.)()(([)(
0)](.)()(([)(
0)]().([)(
)()]().([)(
)(
222
22
2´2
´2
≥=−−−−=Φ
∀=−−=Φ
∀=−−=Φ
∀=−=Φ∀=−=Φ
−
−
τττεεττεττ
τετττεττττρετετ
εε
ε
ε
ε
εε
tuttE
ttutuE
ttutuE
ttuE
ttE
u
u
u
u
Validación de Candidatos�
Ref: P.J.AntsaklisRef: P.J.Antsaklis

ValidaciValidacióón de Modelos Candidatosn de Modelos CandidatosYt = Y*t + ft + at
Validación de Candidatos�
Efecto de las variables explicativasEfecto sistemático de la
estructura temporal de las variables excluidas
Multitud de pequeñas perturbaciones sinestructura temporal
Modelo de inercia Ф(B)
Modelo de transferencia Л(B)
Yt = Л(B) xt + Ф(B) a*t modelo verdadero
Yt = Л(B) xt + Ф(B) at modelo estimado^^ ^at = Л(B) -Л(B) xt + Ф(B)a*t
Ф(B) Ф(B)
^ ^
^ ^
Л(B) = Л(B)^Л(B) = Л(B)^
Л(B) = Л(B)^
Ф(B) = Ф(B)^Ф(B) = Ф(B)^
Ф(B) = Ф(B)^

SelecciSeleccióón del Modelo n del Modelo óóptimoptimo
Las propiedades deseables para el modelo óptimo se refieren a aquel que presente:
�Menos problemas de convergencia en el entrenamiento.�Mejor capacidad de generalización.�Una serie de residuos con propiedades de “ruido blanco”.�Menor número de parámetros a ajustar .(parsimonia)�Menor número de ciclos de entrenamiento.�Mejor respuesta en situaciones extremas.
Validación de Candidatos
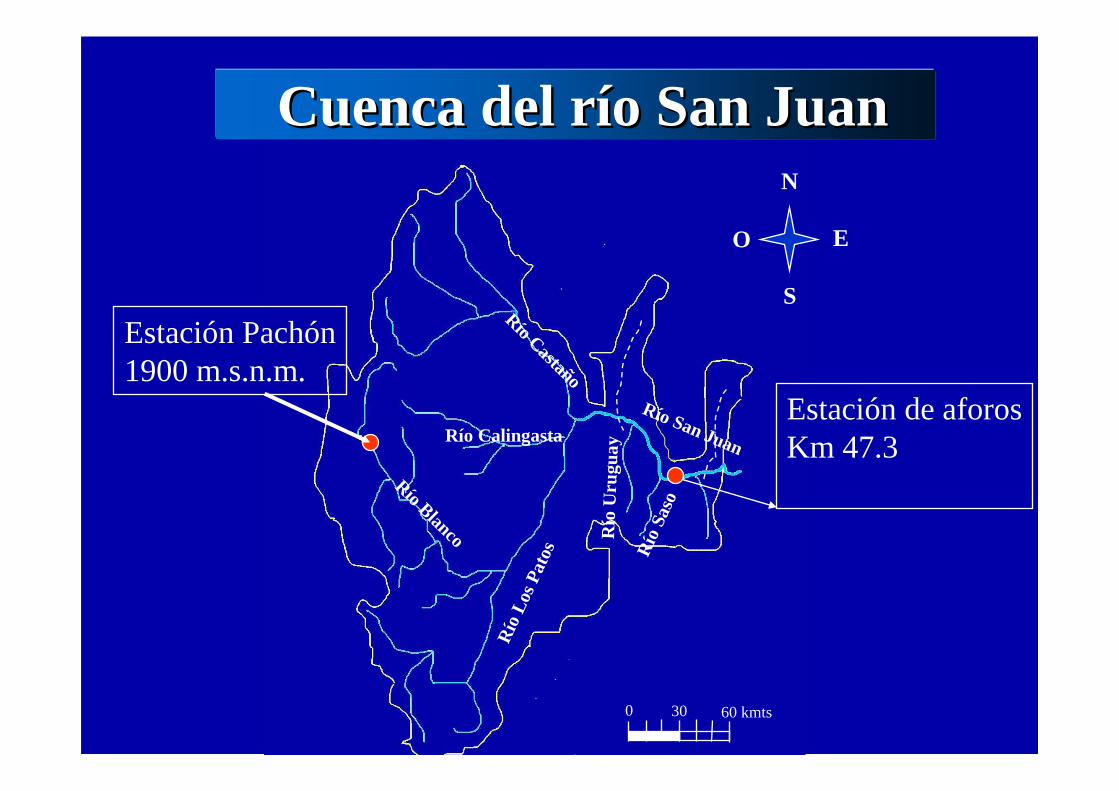
Cuenca del rCuenca del ríío San Juano San Juan
Río San Juan
Río Blanco
Río Calingasta
Río
Los
Pat
os
Río Castaño
Río
Uru
guay
Río
Sas
o
0 30 60 kmts
N
O E
S
Estación Pachón1900 m.s.n.m.
Estación de aforosKm 47.3

Datos disponibles para el estudioDatos disponibles para el estudioSe contó para esta investigación con datos climáticos observados agregados mensualmente del período 1981-1997 de la estación Pachón ubicada a 1900 msnm en la cuenca del río San Juan -Argentina.
Variables Utilizadas
•Q = Caudales medios mensuales a la salida de la cuenca (m3/seg)•P = Precipitación mensual Acumulada (mm)•T= Temperatura promedio mensual•R = Ruta de nieve promedio (equivalente de agua en mm)•H=Humedad relativa promedio mensual•V= Viento promedio mensual•He= Heliofanía efectiva promedio•D= Días de Nublado Total al mes•N = Anomalías de Temperatura en el Pacífico Ecuatorial Zona 3• n = número indicador del mes del año
� Análisis de Información

ParParáámetros estadmetros estadíísticos sticos VolumenesVolumenesde escurrimiento (Hm3/mes) de escurrimiento (Hm3/mes)
rríío San Juan Estacio San Juan Estacióón n KmKm 47.347.3MES MEDIA Desv.Est. LONGITUD CHI^2 G.Libertad N.Significac.
Julio 107.504 37.2197 87 7.70115 5 0.173493Agosto 104.0645 35.103 87 2.93968 5 0.709285Setiembre 104.619 34.8538 86 1.28417 4 0.864055Octubre 142.7717 64.6993 86 7.44464 6 0.281676Noviembre 236.495 170.915 86 3.32291 7 0.853611Diciembre 349.33 356.188 86 2.05837 4 0.72502Enero 309.492 282.344 86 2.19718 3 0.5325Febrero 199.157 140.66 86 2.1947 2 0.333742Marzo 153.079 84.4826 86 14.465 3 0.0023358Abril 115.045 51.3736 86 8.23832 5 0.14358Mayo 116.511 46.1706 86 9.6275 5 0.0865Junio 110.186 38.9449 86 2.85593 3 0.414376

Ejemplo Datos de entrenamiento escalados entre Ejemplo Datos de entrenamiento escalados entre --07 y 0.707 y 0.7
Análisis de Información
Añomes DIAS T. NUB. mes(n-1) mes(n-2) Vol km 47.3 Vol n-1 Vol n-2junio 1981 0.03684211 0.47894737 0.18421053 0.07200979 0.08258331 0.08535715junio 1982 0.70000000 0.33157895 0.14736842 0.04943464 0.04767696 0.04284335junio 1983 0.47894737 0.25789474 0.25789474 0.10628448 0.12072488 0.13380309junio 1984 0.40526316 0.36842105 0.03684211 0.07695326 0.08786183 0.09442016junio 1985 0.36842105 0.11052632 0.03684211 0.08420367 0.09739723 0.10595491junio 1986 0.58947368 0.51578947 0.22105263 0.06475938 0.06163950 0.05800331junio 1987 0.14736842 0.51578947 0.11052632 0.08337976 0.08479689 0.08667540junio 1988 0.18421053 0.33157895 0.03684211 0.11567706 0.13213330 0.14929261junio 1990 0.22105263 0.11052632 0.29473684 0.05899200 0.05976648 0.05750896junio 1991 0.47894737 0.55263158 0.25789474 0.05569636 0.05108246 0.04679813junio 1993 0.36842105 0.36842105 0.22105263 0.09293712 0.10642180 0.08848801junio 1994 0.22105263 0.22105263 0.33157895 0.06096939 0.06283143 0.06195808junio 1995 0.33157895 0.03684211 0.22105263 0.05338941 0.05993676 0.05619071
Armado de duplas de entrenamiento validación y test
Datos de Entrada

Validación de Candidatos 2222
Modelo ANN de pronModelo ANN de pronóósticosticocuenca Rcuenca Ríío San Juano San Juan
5
2
3
4
6
7
1
:
20
1
2
:
:
:
30
1
2
J
A
S
O
N
E
D

Red Red Neuronal Neuronal ANN 30ANN 30--2020--77
Variables de entrada xi, i= 1,.....,30
Valor de salida nodos capa entrada xi, i= 1,.....,30
30Valor de salida nodos capa oculta 1 yj= g(a0j+∑ aij . xi) j=1,......,20
i=1
20
Valor de salida nodos capa de salida ym= g(c0m+ ∑ ckm. yk) m=1,......,7k=1
Función de activación sigmoide limitada entre 0 y +1 g(u) = 1 .
1+e - u
escurrimientos V.escurrimiento(x1,....,x7) = ym(x1,....,x7)

DispersiDispersióón del pronn del pronóósticosticoANN 30ANN 30--2020--77
Validación de Candidatos 2222
DIspersión del pronóstico
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8
Observado
Pro
nost
icad
o
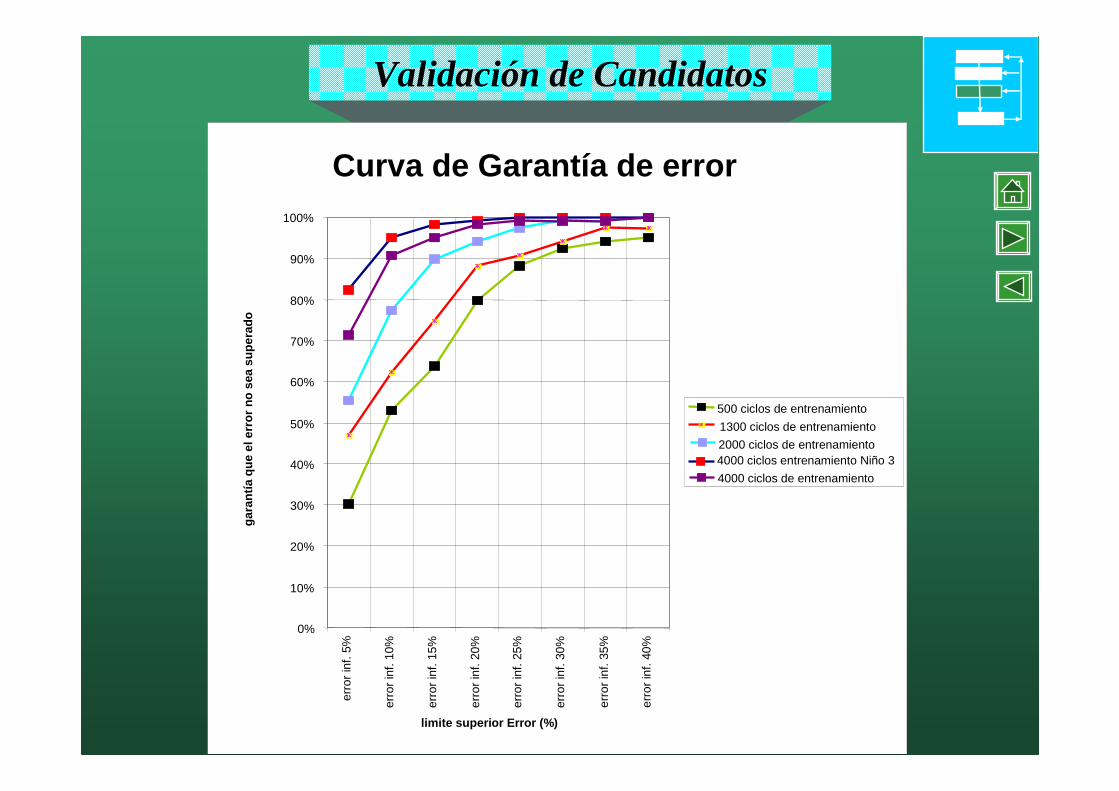
Curva de Error Curva de Error -- ANN (30ANN (30--2020--7)7)
Validación de Candidatos
Curva de Garantía de error
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
erro
rin
f. 5%
erro
rin
f. 10
%
erro
rin
f. 15
%
erro
rin
f. 20
%
erro
rin
f. 25
%
erro
rin
f. 30
%
erro
rin
f. 35
%
erro
rin
f. 40
%
limite superior Error (%)
gara
ntía
que
el e
rror
no
sea
supe
rado
500 ciclos de entrenamiento
1300 ciclos de entrenamiento
2000 ciclos de entrenamiento4000 ciclos entrenamiento Niño 3
4000 ciclos de entrenamiento

ACF y PACF de los residuosACF y PACF de los residuos
Validación de Candidatos�
VAR00001
Lag Number
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
AC
F
1.0
.5
0.0
-.5
-1.0
Confidence Limits
Coefficient
ACF Serie de Residuos VAR00001
Lag Number
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
Par
tial A
CF
1.0
.5
0.0
-.5
-1.0
Confidence Limits
Coefficient
PACF Serie de Residuos

AnAnáálisis de lisis de autocorrelaciautocorrelacióón n de de residuos red ANN 30residuos red ANN 30--2020--77
Análisis residuos red neuronal ANN 30-20-7 Rio San Juan
Lag Corr. Err. Lag Corr. Err.1 0.062 0.91 1 0.062 0.0922 -0.075 0.09 2 -0.079 0.0923 0.089 0.09 3 0.091 0.0924 0.029 0.089 4 -0.002 0.0925 0.061 0.089 5 0.092 0.0926 -0.037 0.089 6 -0.081 0.0927 -0.033 0.088 7 -0.014 0.0928 0.005 0.088 8 -0.031 0.0929 -0.005 0.087 9 0.012 0.09210 -0.045 0.087 10 -0.046 0.09211 -0.025 0.087 11 -0.004 0.09212 -0.027 0.086 12 -0.035 0.09213 -0.037 0.086 13 -0.021 0.09214 0.002 0.085 14 0.006 0.09215 0.005 0.085 15 0.017 0.09216 -0.001 0.085 16 0.008 0.092
Total cases: 119 Computable first lags: 118
Función Autocorrelación Parcial
Serie de residuos
Función Autocorrelación
Serie de residuos

Error de pronError de pronóóstico con stico con ANN (30ANN (30--2020--7)7)
Validación de Candidatos 2222
ANN 30-20-7 (4000 ciclos ENSO)
Mes Error rel (%) Maximo Minimo
Julio -0.57807989 4.88016888 -7.93289147Agosto 0.36926771 14.2258204 -11.2748139Septiembre -0.16767839 11.1940299 -7.96581718Octubre 0.62166082 21.8555273 -9.16590284Noviembre -0.48814821 0.88180431 -4.00824124Diciembre 0.63442424 3.84615385 -0.68052647Enero 0.70541988 17.4618538 -3.7921035

VisualizaciVisualizacióón de resultadosn de resultados
Validación de Candidatos
Volúmenes de Escurrimiento (julio año T - enero año T+1)
0
100
200
300
400
500
600
700
800
900
1000
1100
1200
Meses
Vol
úmen
es d
e E
scur
rimie
nto
KM
47.
3 (H
m3)
Observado Pronosticado -ANN
J E J E J E J E J E J E J E J E J EJ E J E J E J E J E J E J E J E19821981 1984 1985 19921986 1987 1988 1989 1990 1991 1993 1994 1995 1996 19971983
Niño 1982 a 1987 Niño 1997
Niña 1988 a 1996

SiguienteAnterior
xw y
Red PCA (AnRed PCA (Anáálisis de lisis de Componentes Principales)Componentes Principales)
Los pasos principales del Análisis de componentes principales es:
1) Obtener Matriz de covarianzas de las variables origina les.2) Obtener las raíces características de la matriz de v arianzas y covarianzas C resolviendo IC- λλλλ I=0 3) Obtener para cada λλλλi el vector característico de C.4) Normalizar el vector característico IIc iII=1 IIIII5) Obtener los (n) vectores independientes que son la s componentes principales : Y1=X.c1
Y2=X.c2..............Yn=X.cn

SiguienteAnterior
Cuenca alta delCuenca alta delMauleMaule (5600 km2)(5600 km2)
Est. fluviométrica Est. meteorológica
Laguna Dial
Calabozo
Lo Aguirre
Meseta Barroso
� Análisis de Información 2222

SiguienteAnterior
SetSetde Entrenamiento (sin el ade Entrenamiento (sin el añño 1976)o 1976)Curva de error para Curva de error para setsetde validacide validacióón an añño 1997o 1997
Entrena sin 1976
Entrena con 1976
Punto de Términos/método T.Mitchell
�

SiguienteAnterior
Red 12Red 12--1010--11Entrenamiento sin 1976Entrenamiento sin 1976ValidaciValidacióón an añño 1997o 1997
Pronóstico red setiembre = 493 m3/segEscurrimiento real setiembre = 499 m3/seg
P.T.
Nota: Ambos entrenamientos r= 0.2 pero configuración de pesos inicial distinta
�

SiguienteAnterior
Datos de entrenamiento ANN de Datos de entrenamiento ANN de pronpronóóstico de clasesstico de clases
Output Setiembre InputsClase Patrón Año Q-1 Q-2 Q-3 P-1 P-2 P-3 R-1 R-2 R-3 N-1 N-2 N-3 Q
3 1 1975 0.25977 0.4705 0.30304 0.19291 0.52594 0.46415 0.58238 0.47644 -0.2397 -0.2351 -0.2949 .3016042 2 1976 0.17607 0.15948 0.17174 0.12751 0.06316 0.37173 0.13952 0.12209 0.37828 0.33141 0.23077 0.241413 3 1977 0.40305 0.48148 0.19641 0.42572 0.54059 0.41923 0.58778 0.3233 -0.0824 0.04624 0.09295 0.4836324 4 1978 0.3342 0.66667 0.18378 0.11816 0.66667 0.31165 0.41254 0 -0.161 -0.1734 -0.1763 0.4614223 5 1979 0.66667 0.40042 0.11008 0 0.5024 0.03874 0.18952 0 0.08989 0.03083 0.1891 0.5559924 6 1980 0.42085 0.50751 0.44584 0.19049 0.25591 0.46599 0.30984 0.17017 -0.0337 0.07707 0.22436 0.3804453 7 1981 0.39858 0.31992 0.31091 0.44276 0.18862 0.08474 0.17921 0.1326 -0.2846 -0.1156 0.02244 0.3506414 8 1982 0.41842 0.5813 0.31424 0.44331 0.38617 0.66667 0.6131 0.66667 0.50936 0.42004 0.41667 0.6666672 9 1983 0.31847 0.28417 0.2087 0.2748 0.23915 0.28114 0.32603 0.29529 0.42322 0.50482 0.66667 0.313894 10 1984 0.26033 0.40342 0.13485 0.19445 0.5306 0.27489 0.66667 0.42502 -0.1236 -0.1541 -0.2468 0.4545042 11 1985 0.21664 0.35701 0.17309 0.04067 0.22675 0.15019 0.10219 0.10575 -0.1873 -0.2274 -0.1987 0.2738154 12 1986 0.45912 0.3765 0.66667 0.49651 0.11647 0.65647 0.17495 0.16866 0.08989 0.1079 0.02885 0.3813933 13 1987 0.43852 0.53888 0.18719 0.58137 0.59606 0.10744 0.36857 0.14733 0.66667 0.66667 0.50321 0.402282 14 1988 0.35981 0.21827 0.12515 0.66667 0.14073 0.32892 0.24524 0.18443 -0.5393 -0.6474 -0.5609 0.2788981 15 1989 0.259 0.15032 0.08858 0.41407 0.18497 0.26016 0.23151 0.08023 -0.0749 -0.0231 -0.0192 0.2801311 16 1990 0.22464 0.13169 0.09573 0.14608 0.08242 0.0789 0.09103 0.00716 0.09363 0.03468 0.11218 0.420583 17 1991 0.2873 0.4484 0.37156 0.04683 0.27488 0.29242 0.27175 0 0.22097 0.44316 0.39744 0.4308813 18 1992 0.25832 0.30084 0.33874 0.23424 0.08943 0.55889 0.51317 0.53832 -0.0225 0.06166 0.16026 0.3956333 19 1993 0.37498 0.37848 0.41133 0.23636 0.10461 0.50166 0.5319 0.42598 0.05243 0.158 0.28846 0.3768062 20 1994 0.29952 0.53489 0.21234 0.04331 0.39404 0.31437 0.36168 0.17359 -0.0524 -0.0809 0.08974 0.3887163 21 1995 0.31205 0.37213 0.30387 0.39406 0.32815 0.43337 0.48048 0.27678 -0.1798 -0.0039 -0.0192 0.521121 22 1996 0.23218 0.15792 0.16823 0.45217 0.06183 0.22779 0.14271 0.09819 -0.0712 0 -0.0801 0.2416964 23 1997 0.6364 0.32319 0.42725 0.28546 0.18439 0.77689 0.32571 0.33978 1.16105 1.04817 0.68269 0.751432
� Análisis de Información 2222

SiguienteAnterior
Capacidad de PredicciCapacidad de Prediccióónn
Valor real observado
0,751
Patrón de setiembre de 1997
Resultado red 11-10-1

SiguienteAnterior
Valores de entrada en las duplas de aValores de entrada en las duplas de añños os de similar escurrimiento total anualde similar escurrimiento total anual
-0.8
-0.6
-0.4
-0.2
0.0
0.2
0.4
0.6
0.8
Q-1
Q-2
Q-3
P-1
P-2
P-3
R-1
R-2
R-3
N-1
N-2
N-3
variable
valo
r nor
mal
izad
o (-0.
7-0.
7)
19761985198819891990

SiguienteAnterior
Propiedades de los datos Propiedades de los datos dsiponiblesdsiponibles

SiguienteAnterior
ReconstrucciReconstruccióón caudales del rn caudales del ríío o MauleMauleEn el escurrimiento real del río Maule en la estaci ón
Armerillo intervienen, desde distintas fechas:
� Derivación de caudal del río Melado hacia el río Ancoa, aguas arriba del embalse El Melado.
� La regulación de la laguna del Maule� La regulación de la laguna Invernada en uno de
sus afluentes� La derivación de caudal de riego para el canal
Maule Alto� La regulación del embalse El Melado en el río
Melado.
Análisis de Información 2222�

PronPronóósticos cuenca del sticos cuenca del MauleMaule
.
1) Estimación con datos hasta setiembre del volumen total (octubre a marzo) y posterior distribución mensual de la onda de derretimiento. Posterior modificación de la estimación con modelos de pronóstico a un mes plazo, en los cuales se incorporan mes a mes la nueva información
Se plantean dos esquemas complementarios
2) Se realizan Pronósticos en septiembre a uno, dos, hasta seis meses de plazo, con lo que se obtiene la curva de deshielo estimada.

Datos disponibles para el estudioDatos disponibles para el estudioSe contó para esta investigación con datos climáticos observados agregados mensualmente del período julio 1981 a noviembre de 1997 de la estación Pachón ubicada a 1900 msnm en la cuenca del río San Juan - Argentina.
Variables Utilizadas
•Q = Caudales medios mensuales a la salida de la cuenca (m3/seg)•P = Precipitación mensual Acumulada (mm)•T= Temperatura promedio mensual (°C)•A = Altura de nieve promedio (equivalente de agua en mm)•H=Humedad relativa promedio mensual (%)•V= Viento promedio mensual (Km/mes)•He= Heliofanía efectiva promedio (hs/día)•D= Días de Nublado Total al mes•N = Anomalías de Temperatura en el Pacífico Ecuatorial Zona 3
Análisis de Información

SelecciSeleccióón del Modelo n del Modelo óóptimoptimo
Las propiedades deseables para el modelo óptimo se refieren a aquel que presente:
�Menos problemas de convergencia en el entrenamiento.�Mejor capacidad de generalización.�Una serie de residuos con propiedades de “ruido blanco”.�Menor número de parámetros a ajustar .(parsimonia)�Menor número de ciclos de entrenamiento.�Mejor respuesta en situaciones extremas.
Validación de Candidatos

ConclusionesConclusiones
� Validar el Método de elaboración y validación de ANNs propuesto para redes entrenadas con datos escasos.
� Comprobar la mejora del comportamiento predictivo con la adición de indicadores de clima global como el IOS (zona 3).
� Pronosticar la onda completa de deshielo (julio a enero) con errores inferiores al 10% en el 95% de los casos a partir de datos de los meses de abril mayo y junio anteriores a los meses de maximas nevadas.
Validación de Candidatos 2222
Se logró en este proyecto:� Identificar, elaborar y validar un Modelo ANN con buena capacidad de predicción y generalización de los fenómenos involucrados en el fenómeno de deshielo en la cuenca del río San Juan.

ConclusionesConclusiones--ProyecciProyeccióón futuran futura
� Asegure la validez del Método de elaboración y validación de ANNspropuesto para redes entrenadas con datos escasos.
� Aporte a la hidrología un Método válido alternativo para la predicción de escurrimientos, además de brindar un marco comparativo de las futuras aplicaciones que se realicen con esta técnica computacional.
Validación de Candidatos 2222
Se espera que el proyecto:� Identifique, elabore y valide un Modelo ANN con buena capacidad de predicción y generalización de los fenómenos involucrados en el fenómeno de deshielo

ConclusionesConclusiones
� Validar el Método de elaboración y validación de ANNs propuesto para redes entrenadas con datos escasos.
� Comprobar la mejora del comportamiento predictivo con la adición de indicadores de clima global como el IOS (zona 3).
� Pronosticar la onda completa de deshielo (julio a enero) con errores inferiores al 10% en el 95% de los casos a partir de datos de los meses de abril mayo y junio anteriores a los meses de maximas nevadas.
Validación de Candidatos 2222
Se logró en este proyecto:� Identificar, elaborar y validar un Modelo ANN con buena capacidad de predicción y generalización de los fenómenos involucrados en el fenómeno de deshielo en la cuenca del río San Juan.

FIN PRESENTACIFIN PRESENTACIÓÓNN

ConclusionesConclusiones
� Validar el Método de elaboración y validación de ANNs propuesto para redes entrenadas con datos escasos.
� Comprobar la mejora del comportamiento predictivo con la adición de indicadores de clima global como el IOS (zona 3).
� Pronosticar la onda completa de deshielo (julio a enero) con errores inferiores al 10% en el 95% de los casos a partir de datos de los meses de abril mayo y junio anteriores a los meses de maximas nevadas.
Validación de Candidatos 2222
Se logró en este proyecto:� Identificar, elaborar y validar un Modelo ANN con buena capacidad de predicción y generalización de los fenómenos involucrados en el fenómeno de deshielo en la cuenca del río San Juan.

RelaciRelacióón con otros proyectos que n con otros proyectos que aplicaron aplicaron ANNsANNs en hidrologen hidrologííaa
Se analizaron 22 publicaciones recientes (1992-1999) que describen aplicaciones de ANNs a la predicción de caudales de escurrimiento en distintas cuencas. De ellos se han elegido las 15 mas relevantes y se han concluido los siguientes puntos: (ver cuadros)
Solo 1 de 15 trabajos se interesó por investigar distintas estructuras de salida.
Solo 1 de 15 trabajos realiza una optimización de variables de entrada pero no usa el método
de Análisis de componentes principales.
Solo 2 de 15 trabajos investiga la optimización de la capa oculta, de los 13 restantes solo 8
seleccionan la mejor configuración entre varias candidatas por prueba y error.
Solo 1 de 15 trabajos realiza podado de nodos y/o enlaces innecesarios.
Solo 2 de 15 trabajos investiga entre distintas funciones de activación y distintas topologías
de enlaces.
13 de los 15 trabajos utiliza la redFeedforward con Función de Activación
Sigmoide entrenada con el métodoBackpropagation.
Solo 6 de 15 trabajos propone distintos estadísticos para evaluar el comportamiento
de la red, los 9 restantes usan SSE como indicador de ajuste
Ningún trabajo analiza la bondad de la estructura de la red mediante un análisis de
FAS de los residuos ni las correlaciones cruzadas entre residuos y variables de entrada
En definitiva se concluye que ningún trabajo propone una metodología de identificación,
elaboración y validación de modelo ANNs mas completa en todas sus fases como la que se presenta en esta propuesta de investigación. Esta situación aumenta considerablemente las posibilidades de
éxito de la investigación propuesta.

SiguienteAnterior
RelaciRelacióón de esta propuesta con n de esta propuesta con otras investigaciones en el otras investigaciones en el áárearea
*

SiguienteAnterior
validación
aprendizaje
arquitectura

SiguienteAnterior
� Es una red neuronal que usa aprendizaje no supervisado con los conceptos de la regla de Hebb (1949) modificados por Oja (1982) ver regla.
� Asegura la convergencia a un estado con pesos w* que maximiza la varianza de las salidas E(y2 ) sujeta a la condición de que ||w||= 1.
� Se puede demostrar que el vector solución w* es un vector de pesos característico principal, el cual corresponde al mayor valor característico de la matriz de correlaciones cruzadas del vector de entrada x, C=xT.x, cuya diagonal son las autocorrelaciones x 2.
xw y
Análisis de Información
Red PCA (AnRed PCA (Anáálisis de lisis de Componentes Principales)Componentes Principales)
�

SiguienteAnterior
Red PCA (AnRed PCA (Anáálisis de lisis de CompoCompo--nentesnentesPrincipales)Principales)� La regla de Hebb (1949) modificada por Oja (1982) ase gura la
convergencia a un estado w* que maximiza la varianza de las salidas y 2 sujeta a la condición de que ||w||= 1.
� Se puede demostrar que la solución w* es un vector característico principal, el cual corresponde al mayor valor característico de la matriz de correlaciones cruzadas d el vector de entrada x, C=x T.x, cuya diagonal son las autocorrelaciones x 2
k paso elen unidades las de salidas lasson w)(x y
k paso elen unidades las a entradas lasson x
0
)(w
min)(max, entre aleatorio
kTkk
k
21k
1
=
>
−+=+
ρ
ρρdonde
wyxyw
wkkkkk
Reglade Oja(una
salida)
xw y
Decaimiento de pesos proporcional a y2
�

SiguienteAnterior
xw y
Red PCA (AnRed PCA (Anáálisis de lisis de CompoCompo--nentesnentesPrincipales)Principales)
Los pasos principales del Análisis de componentes principales es:
1) Obtener Matriz de covarianzas de las variables origina les.2) Obtener las raíces características de la matriz de v arianzas y covarianzas C resolviendo IC- λλλλ I=0 3) Obtener para cada λλλλi el vector característico de C.4) Normalizar el vector característico IIc iII=1 IIIII5) Obtener los (n) vectores independientes que son la s componentes principales : Y1=X.c1
Y2=X.c2..............Yn=X.cn
�

SiguienteAnterior
Esquema Regla de Esquema Regla de OjaOja
wjiyi
xj
j=1..n i=1..m
∑=
∑−=∆
==
n
jjijii
m
kkkjjij xwyyywxw
11. donde .ρ
�

SiguienteAnterior
Curvas de verificaciCurvas de verificacióón entrenamiento n entrenamiento
Entrenamiento- Regla de Oja
1
1.2
1.4
1.6
1.8
2
2.2
2.4
1 10 100 1000
iteraciones (k)
mag
nitu
d ve
ctor
wk
Regla de Oja
Entrenamiento- Regla de Oja
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1 10 100 1000
iteraciones (k)
Cos
θθ θθRegla de Oja
1995). (M.Hassoum siguiendo asiy c* wprincipal componente segunda la
encontrar podremos c a ortogonal seasolución vector wel que adicional
ntorequerimie elcon pero J(w) deón maximizaci esta repetimos Si . finito) real valor (a
definido positivo Hessiano al hace que a.c* wpara máximoun solo existe
que veremosJ(w) de Hessiano el Examinando.xJ(w) objetivo
función lamaximizar decir Es.1*w que a sujeto .w)(x varianzala
maximice *solución w la que talentrada de variableslas de lineal
suma una es que .w)(x proyección laencontrar es básica idea La
(2)2
(1)
(1)1
2T
2T
T
=
==
=
=
w
w �

SiguienteAnterior
Entrenamiento de la red PCAEntrenamiento de la red PCA
Entrenamiento- Regla de Oja
1
1.2
1.4
1.6
1.8
2
2.2
2.4
1 10 100 1000
iteraciones (k)
mag
nitu
d ve
ctor
wk
Regla de Oja
Entrenamiento- Regla de Oja
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1 10 100 1000
iteraciones (k)
Cos
θθ θθRegla de Oja
Durante el entrenamiento debe asegurarse que el valor de la magnitud del vector de pesos Wconverja a 1 (máxima var(Y) y una única solución). Además debe asegurarse que el coseno del angulo entre el vector de pesos y el vector propio principal de la matriz de correlacion C=XXT converja también a 1, esto asegura que el vector de pesos esta alineado con el vector principal. Esto debe hacerse para cada dirección principal.(Rubner y Tavan 1989)
�

SiguienteAnterior
Principio de parsimoniaPrincipio de parsimonia
Para asegurar la capacidad de generalización, debem os evaluar el grado de parsimonia del modelo de red ajustado, se proponen los siguientes indicadores:
N= número de ejemplosNw= número de pesosSSE= error cuadrático medio
( )( ) Error) Prediction (Final
2NSSE FPE
Akaike) den informació de (criterio .2)2
ln(
w
w
NN
NNNNw
NSSE
AIC
−+=
+=

SiguienteAnterior
Diferencias con modelos ARMADiferencias con modelos ARMA
� Las ANNs no necesitan conocer la distribución estadística de los datos, tampoco es necesario que sean estacionarios y de distribución normal.(Burke 1991)
� La no estacionariedad (tendencia, variaciones estacionales) está considerada en la estructura interna de los ANNs (Maier y Dandy 1996)
� No necesita conocer previamente las relaciones existentes entre las variables a ser modeladas.
� Tiene mayor habilidad para determinar las relaciones entrada-salida con una alta capacidad de generalización.

SiguienteAnterior
AlgoritmoAlgoritmo BackpropagationBackpropagation-- IVIVHeurística del método :
La idea global que yace tras la retropropagación es hacer un cambio grande a un peso en particular, w, si el peso conduce a una reducción grande de errores observados en los nodos de salida.
Para cada combinación de muestras de entrada, considere cada valor deseado de salida, d; su valor real, o; y la influencia de un
peso en particular, w, sobre el error, d-o.
Un cambio grande sobre w tiene sentido si tal cambio puede reducir un error grande de salida y si el tamaño de dicha reducción es considerable. Pero, si un cambio en w, no reduce ningún error grande de forma significativa, poco se le deberá hacer a tal peso.

SiguienteAnterior
AlgoritmoAlgoritmo BackpropagationBackpropagation-- VVColumnas
h i j k zwij
Un cambio en la entrada del nodo jtrae como resultado un cambio en su salida el cual depende de la pendiente de la función de umbral.
En consecuencia, hay que arreglarselas para que el cambio sobrewij dependa de la pendiente de la función de umbral en el nodo jsobre la base de que el cambio debe ser liberal sólo en aquellas partes en que haga mucho beneficio.
En las partes donde la pendiente es más pronunciada, un cambio en la entrada tiene el máximo efecto en el valor de salida.

SiguienteAnterior
AlgoritmoAlgoritmo BackpropagationBackpropagation-- VIVIColumnas
h i j k zwij
La pendiente de la funciónSigmoide está dada por una fórmula particularmente sencilla,
o(1-o)
Por lo tanto, el uso de esta función de umbral conduce a la siguiente heurística para realizar los cambios enwij:
1
-5.0
0.5
00.0 5.0
Función Sigmoide
xe−+11

SiguienteAnterior
BackpropBackprop--VIIVII
Columnash i j k z
2- El cambio en el peso dei a j ∆∆∆∆ wij debe ser proporcional aoi, la salida del nodoi. Debido a que un cambio en la entrada del nodo j , motivado por un cambio en el pesowij debe hacerse solo si la salida del nodoi es alta.
1- El cambio de peso dei a j ∆∆∆∆wij debe ser proporcional a la pendiente del umbral de salida del nodo j , oj(1-oj).
3- El cambio en el peso∆∆∆∆wij , debe ser proporcional a un factor, que llamaremos ββββ, que capte cuán benéfico en el resultado es cambiar la salida del nodo j .
Estas tres consideraciones combinadas conducen a que: ∆∆∆∆wij proporcional aoi.oj(1-oj).ββββj .

SiguienteAnterior
Backprop Backprop -- VIIIVIII
Columnash i j k z
∑ −=k
kkkjkj oow ββ ).1(.
Por supuesto que el nodo j está conectado a muchos nodos de la próxima capa. Por lo que el beneficio general obtenido al cambiaroj debe ser la suma de los efectos individuales. Así, el beneficio que se obtiene al cambiar la salida del nodo j se resume como sigue:
Imaginemos que el nodo j está conectado a sólo un nodo de la capa siguiente, a saber, el nodo k.
Entonces, el cambio aoj debe ser proporcional aok(1-ok), la pendiente de la función umbral en el nodo k.
Además, el cambio aoj debe ser proporcional awjk , el peso del enlace que conecta el nodoj con el nodo k, también lo debe ser a ok, la salida del nodo k y aββββk el beneficio que se obtiene de cambiar la salidaok.

SiguienteAnterior
BackpropBackprop-- IXIX
Columnash i j k z
Pero, cual es el beneficio que se obtiene al cambiar el valor de un nodo de salida?Este valor depende, por supuesto, de qué tan mal pueda estar el valor del nodo de salida. La regla a la salida sería:Dado:dz = la salida deseada en el nodo zoz = la salida real de dicho nodo (maestro)
Si (dz-oz) es pequeño, entonces el cambio enozdebe ser pequeño. Caso contrario el cambio enozdebe ser grande.
Es decir tendríamos ββββz= dz-oz

SiguienteAnterior
BackpropBackprop-- XX
salidadecapalaen nodospara
ocultascapasen nodospara).1(.
).1(..
ozdzz
kokokwjkj
jojojoirwij
k
−=
−=−=∆
∑
β
βββ
Al combinar todas las ecuaciones , se tienen las siguientesfórmulas de retropropagación:
Finalmente los cambios en los pesos deben depender directamente de un parámetro de rapidez r de aprendizaje.

Recomendaciones para encontrar Recomendaciones para encontrar el Punto de Tel Punto de Téérminormino
En general el Punto de Término del proceso de entrenamiento debe elegirse en el mínimo de error de la curva de error del set de validación, con lo cual se asegura el máximo de capacidad de generalización de la red.
En otros casos la curva de error del set de validación pasa por un mínimo local, luego sube para posteriormente bajar constantemente hasta el mínimo global, asegurando la convergencia de la red y su alta capacidad de generalización.
Por ello debe tenerse mucho cuidado cuando se define el punto determinación, para no llegar a una conclusión falsa al observar mínimos locales.

IdentificaciIdentificacióón de la capa ocultan de la capa oculta
Se propone emplear el meta-algoritmo Cascade Correlation (CC) desarrollado por Scott Falhman y Lebiere (1990).
El mismo parte de una arquitectura mínima (sin capa oculta) y combina la idea de ir incrementando el número de neuronas ocultas y el aprendizaje en el mismo proceso de entrenamiento analizando el mejoramiento producido en la suma de los errores cuadráticos (SSE) hasta que el problema se considere suficientemente aprendido.
Se propone entrenar los pesos de la red con el algoritmobackpropagation para minimizar el error SSE.
(podado de enlaces) (algoritmo CC) otros
Identificación de Candidatos�

Algoritmo Algoritmo Cascade CorrelationCascade Correlation
� Comenzar con solo dos capas completamente conectadas (I-O)
� Entrenar los pesos hasta que el SSE no disminuya mas .� Generar las unidades candidatas. Conectarlas con todas
las unidades de entrada y las ocultas existentes.� Tratar de maximizar la correlación entre la activación de las
unidades candidatas y el error residual de la red entrenando todos los enlaces que llegan a una unida d candidata. Detener el entrenamiento cuando no se mejo ra la correlación.
� Elegir la unidad candidata con la máxima correlación, congelar sus pesos de entrada y agregarla a la red y generar los enlaces con las unidades de salida.Volver al paso 2.
��

MatemMatemáática del algoritmo CCtica del algoritmo CC( )
( ) ( )
( )( ) ( )
y entren correlació la de signo
´ ;
ascendente gradiente de método
elpor maximiza seFahlman den correlació de eCoeficient
o"" salida de unay
i"" ocultau entrada de unidad una entre enlace del peso
p""patron un para i"" ocultau entrada de unidad una de valor
o"" unidad una de activación defunción la de derivada´
][ ; ´
p""patron el para o"" salida de unidad la de calculada salida
p""patron el para o"" unidad la de esperada salida
edescendent gradiente usandominimizar 21
o"" unidad de residualerror
2
ooop
pipi
po
jpoopo p
opoopo
io
ip
p
ppoippo
iooppopopo
po
po
opopo
p
eyIw
C
feeeeyyC
w
I
f
eIew
Enetftye
y
t
tyE
==∂∂
−=−−=
=
=
=
=∂∂−=
=
=
−=
∑
∑∑∑
∑
∑∑
=
σδ
σδ
�

Podado de enlaces innecesariosPodado de enlaces innecesarios
Existen métodos automáticos (desarrollados por Rumelhart 1988) para el podado de nodos innecesarios en la red, se propone utilizar el
Podado basado en Magnitud el cual, después de cada entrenamiento, elimina el enlace que tenga el menor peso y evalúa su influencia en el valor del SSE de las salidas.Esto se basa en que la importancia de un enlace está relacionada directamente al valor absoluto de su peso.
A pesar de que este método es muy simple, raramente conduce a peores resultados que los algoritmos mas complejos.
Identificación de Candidatos�

AprendizajeAprendizaje--Entrenamiento (Entrenamiento (RidgeRidge))
salidadecapalaen nodospara
ocultascapasen nodospara).1(.
).1(..
ozdzz
kokokwjkj
jojojoirwij
k
−=
−=−=∆
∑
β
βββ
Columnash i j k z
� Aprendizaje Backpropagation
1- Función Ridge (heurística)
1
-5.0
0.5
00.0 5.0
Función Sigmoide
facte−+1
1
Identificación de Candidatos�

Aprendizaje Aprendizaje -- Entrenamiento (RBF)Entrenamiento (RBF)2- Función Radial Basis
1
-5.0
0.5
00.0 5.0
Función Gaussiana
2
2
2)( jp
tjxj
etjxjh
−−
=−
( ) ( )
( )∑ ∑
∑∑
= =
==
−=
==
++−=
∂∂−=∆
∂∂−=∆
∂∂−=∆
m N
iikki
k
n
ikiki
k
jjkj
wc
xoy
xfbxdtxhcx
wj
Ewj
j
Ej
cj
Ecj
1k 1
2,
1,
1,k
)(E
m1,....,k )(()(o
; ;
r
rrrr σσ
ρσ
ρσρ σ
tn,k
tjxjh −
tjxjh −
x1
x2
xn
∑
t1,1
dn
d1
d2
c1
ck
t2,1
tn,1
o
Identificación de Candidatos�

Aprendizaje Aprendizaje estocestocáásticostico
Simulated Annealing (Kirkpatrick et al, 1983): Es un método de optimización mas sofisticado que los anteriores, permite encontrar un mínimo global en u na superficie de error. Solo un peso o sesgo (bias) es cambiado en cada ciclo de entrenamiento. El cambio en el parámetro es aceptado dependiendo de la evolución d el error y del coeficiente T del sistema.
ndisminuciófactor T.T parámetro elDisminuir .4
[0,1] aleatorio número p ; estados entre SSEerror elen cambio
e p adprobabilid unacon aumenta o disminuye SSE si cambioAceptar 3.
estado) de E(operador patrones los todospara SSECalcular 2.
min])[max, (aleatorio bias o pesoun Cambiar .1
===∆
≤
∆−
E
T
E
Identificación de Candidatos�

Programa entrenamiento Programa entrenamiento (Lenguaje (Lenguaje Batch Batch de SNNS)de SNNS)Programa para entrenar una redloadNet(“encoder.net”)loadPattern(“encoder.pat”)setInitFunc(“Randomize_Wegihts”, 1.0, -1.0)initNet()while SSE> 6.9 and CYCLES <1000 do
if CYCLES mod 10 == 0 thenprint (“ciclos = “, CYCLES, “ SSE = “, SSE) endif
trainNet()endwhilesaveResult ( “encoder.res”, 1, PAT, TRUE, TRUE, “cr eate”)saveNet (“encoder.trained.net”)print (“Ciclos de entrenamiento: “,CYCLES)print (“Entrenamiento termino para error: “, SSE)
Identificación de Candidatos�





























