Embed Size (px)
DESCRIPTION
Sparse Matrix Solvers on the GPU: Conjugate Gradients and Multigrid. Jeffrey Bolz, Ian Farmer, Eitan Grinspun, Peter Schr öder Caltech ASCI Center. Actual. Possible. Why Use the GPU?. Semiconductor trends cost wires vs. compute Stanford streaming supercomputer Parallelism - PowerPoint PPT Presentation
Citation preview

Sparse Matrix Solvers on the GPU: Conjugate Gradients and Multigrid
Jeffrey Bolz, Ian Farmer, Eitan Grinspun, Peter Schröder
Caltech ASCI Center

Why Use the GPU?
• Semiconductor trends– cost– wires vs. compute– Stanford streaming supercomputer
• Parallelism– many functional units– graphics is prime example
• Harvesting this power– what application suitable?– what abstractions useful?
• History– massively parallel SIMD machines– media processing
1e-4
1e-3
1e-2
1e-1
1e+0
1e+1
1e+2
1e+3
1e+4
1e+5
1e+6
1e+7
1980 1990 2000 2010 2020
Perf (ps/Inst)
Linear (ps/Inst)
Cha
rt c
ourt
esy
Bill
Dal
ly
Possible
Actual
Imagine stream processor; Bill Dally, Stanford Connection Machine CM2; Thinking Machines

Contributions and Related Work
• Contributions– numerical algorithms on GPU
• unstructured grids: conjugate gradients• regular grids: multigrid
– what abstractions are needed?
• Numerical algorithms– Goodnight et al. 2003 (MG)– Hall et al. 2003 (cache)– Harris et al. 2002 (FD sim.)– Hillisland et al. 2003 (optimization)– Krueger & Westermann 2003 (NLA)– Strzodka (PDEs)

Streaming Model
• Abstract model– Purcell, et al. 2002– data structures: streams– algorithms: kernels
• Concrete model– render a rectangle– data structures: textures– algorithms: fragment programs
Kernelinput
recordstream
outputrecordstream
globals
Rasterizer(set up textureindices and all
associated data)
Fragmentprogram
(for all pixelsin parallel)
Textureas read-only
memory
Output goes totexture
Bind buffer to texture
Kernel
globals

Sparse Matrices: Geometric Flow
• Ubiquitous in numerical computing– discretization of PDEs: animation
• finite elements, difference, volumes
– optimization, editing, etc., etc.
• Example here:– processing of surfaces
• Canonical non-linear problem– mean curvature flow– implicit time discretization
• solve sequence of SPD systems
)(4
))cot()(cot(
iNj ijiii
ijijij
aAa
ta
)()()()( tntHttx iiiit
Velocity opposite meancurvature normal
ii xAx 1

Conjugate Gradients
• High level code– inner loop– matrix-vector
multiply– sum-reduction– scalar-vector
MAD
• Inner product– fragment-wise multiply– followed by sum-reduction– odd dimensions can be handled

y=Ax
Aj – off-diagonal matrix elements
R – pointers to segments

Row-Vector Product
X – vector elements
R – pointers to segments
Ai – diagonal matrix elements
J – pointers to xj
Aj – off-diagonal matrix elements
Fragment program

Apply to All Pixels
• Two extremes– one row at a time: setup overhead
– all rows at once: limited by worst row
• Middle ground– organize “batches” of work
• How to arrange batches?– order rows by non-zero entries
• optimal packing NP hard
• We choose fixed size rectangles– fragment pipe is quantized
– simple experiments reveal best size• 26 x 18 – 91% efficient
• wasted fragments on diagonal
Time
Area(pixels)

Packing (Greedy)
9 9 8 8 8 8 8 7 715 13 13 12 12 11 10 9 9 7 7 7 7 7 7 7 7 6 5 5 4
15 13 13
12 12 11
10 9 9
9 9 8
8 8 8
8 7 7
7 7 7
7 7 7
7 7 6
…
non-zero entriesper row
each batchbound to anappropriate
fragment program All this setup doneonce only at the
beginning of time.Depends only onmesh connectivity

Recomputing Matrix
• Matrix entries depend on surface– must “render” into matrix– two additional indirection textures
• previous and next

Results (NV30@500MHz)
• 37k elements – matrix multiply
• 33 instructions, 120 per second
• only 13 flops
• latency limited
– reduction• 7 inst/frag/pass, 3400 per second
– CG solve: 20 per second

Regular Grids
• Poisson solver as example– multigrid approach– this time variables on “pixel grid”
• e.g.: Navier-Stokes
buuuu
u
2)(
0
t
u p2after discretization:solve Poisson eq.at each time step

Poisson Equation
• Appears all over the place– easy to discretize on regular grid– matrix multiply is
stencil application– FD Laplace stencil:
• Use iterative matrix solver– just need application of stencil
• easy: just like filtering
• incorporate geometry (Jacobian)
• variable coefficients
(i,j)-4
1
1
1 1
0
0
0
0
jijiji
jijiji
XXX
XXX
,1,1,
,1,1,2
4

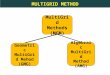
Multigrid
Relax
Relax
RelaxRelax
Relax
Projection Projection Interpolation Interpolation
• Fine to coarse to fine cycle– high freq. error removed quickly– lower frequency error takes longer
Relax, Project, Interpolate

Computations and Storage Layout
• Lots of stencil applications– matrix multiply: 3x3 stencil
– projection: 3x3 stencil
– interpolation: 2x2(!)• floor op in indexing
• Storage for matrices and DOFs– variables in one texture
– matrices in 9(=3x3) textures
– all textures packed• exploit 4 channels
• domain decomp.
• padded boundary
1/16
1 1
1 1
2
2
2 24
21,0 2 2/)(41
d hh dii vv
xy
zw

Coarser Matrices
• Operator at coarser level– needed for relaxation at all levels
• Triple matrix product…– work out terms and map to stencils
• exploit local support of stencils
• straightforward but t-e-d-i-o-u-s
Af
Ac
SP=
2
2
}1,0,1{,
}1,0,1{,
22
]2[]2[']['4/1
]2[4/1][
ge
gh
ge
gh
dgeedh
eiAdgeSeS
eiASSiA

Results (NV30@500MHz)
• 257x257 grid– matrix multiply - 27 instructions
• 1370 per second
– interpolation 10 inst.– projection 19 inst.
• Overall performance– 257x257 at 80 fps!

Conclusions
• Enhancements– global registers for reductions– texture fetch with offset– rectangular texture border– scalar versus vector problems
• Where are we now?– good streaming processor– twice as fast as CPU implementation– lots of room for improvement
• Scientific computing compiler– better languages! Brook? C*?– manage layout in a buffer