Embed Size (px)
Citation preview

Speech Recognition

What makes speech recognition hard?

Speech Recognition
• Task: Identify sequence of words uttered by speaker, given acoustic waveform.
• Uncertainty introduced by noise, speaker error, variation in pronunciation, homonyms, etc.
• Thus speech recognition is viewed as problem of probabilistic inference.

Example: “I’m firsty, um, can I haf somefing to dwink?”
From Russell and Norvig, Artificial Intelligence
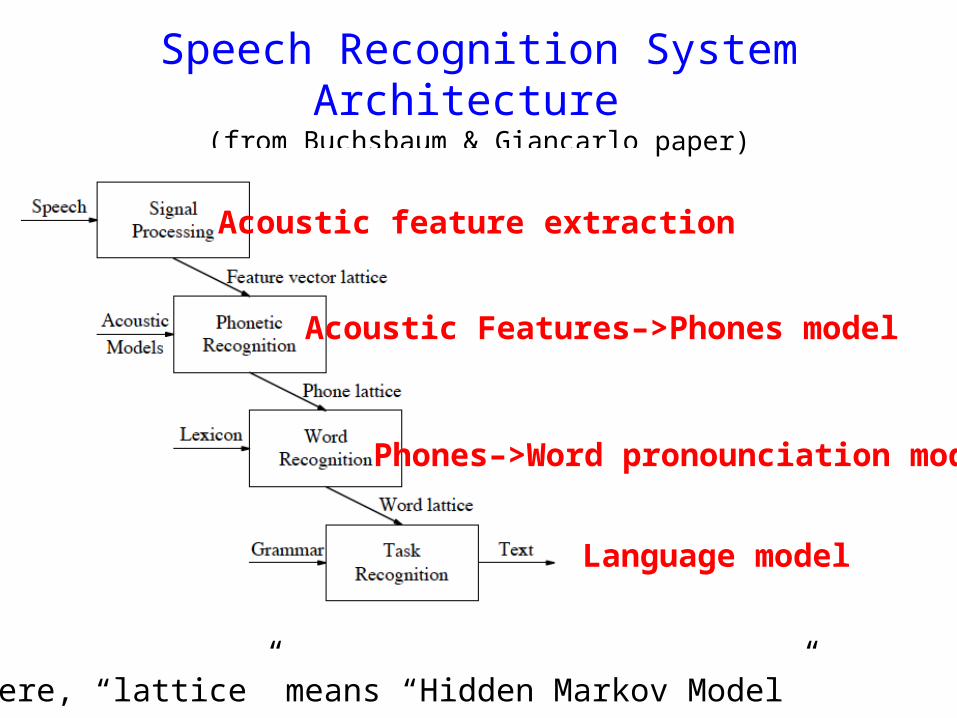
Speech Recognition System Architecture (from Buchsbaum & Giancarlo paper)
Here, “lattice” means “Hidden Markov Model”
Acoustic feature extraction
Acoustic Features–>Phones model
Phones–>Word pronounciation model
Language model
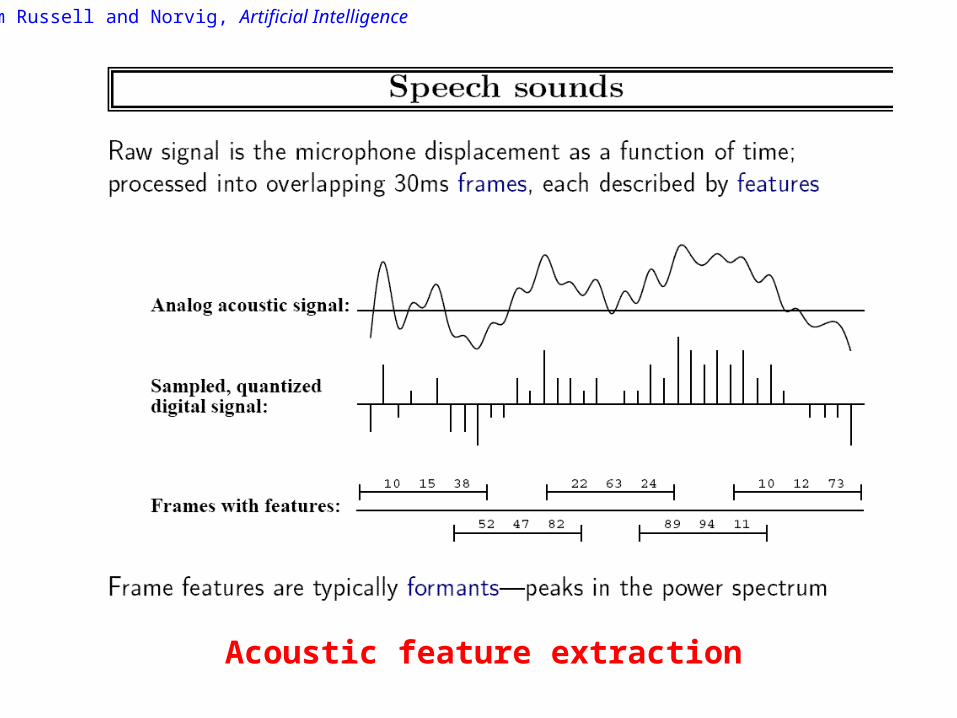
Acoustic feature extraction
From Russell and Norvig, Artificial Intelligence
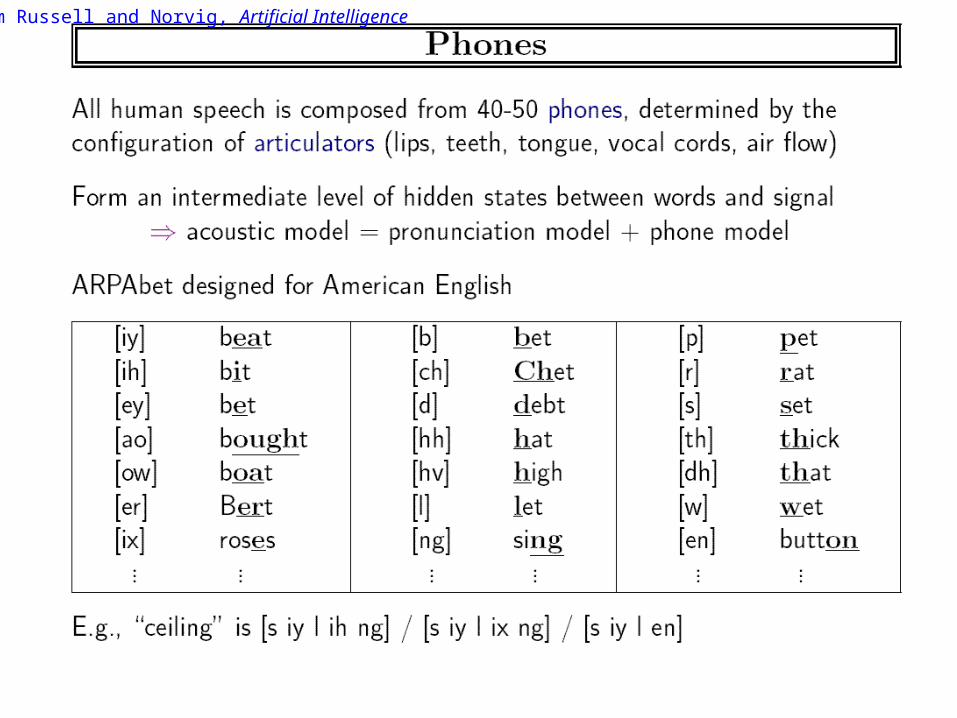
From Russell and Norvig, Artificial Intelligence

Hidden Markov Models
• Markov model: Given state Xt, what is probability of transitioning to next state Xt+1 ?
• E.g., word bigram probabilities give P (wordt+1 | wordt )
• Hidden Markov model: There are observable states (e.g., signal S) and “hidden” states (e.g., Words). HMM represents probabilities of hidden states given observable states.

Phone model
P( phone | frame features) = P(frame features| phone) P(phone)
P(frame features| phone) often represented by Gaussian mixture model
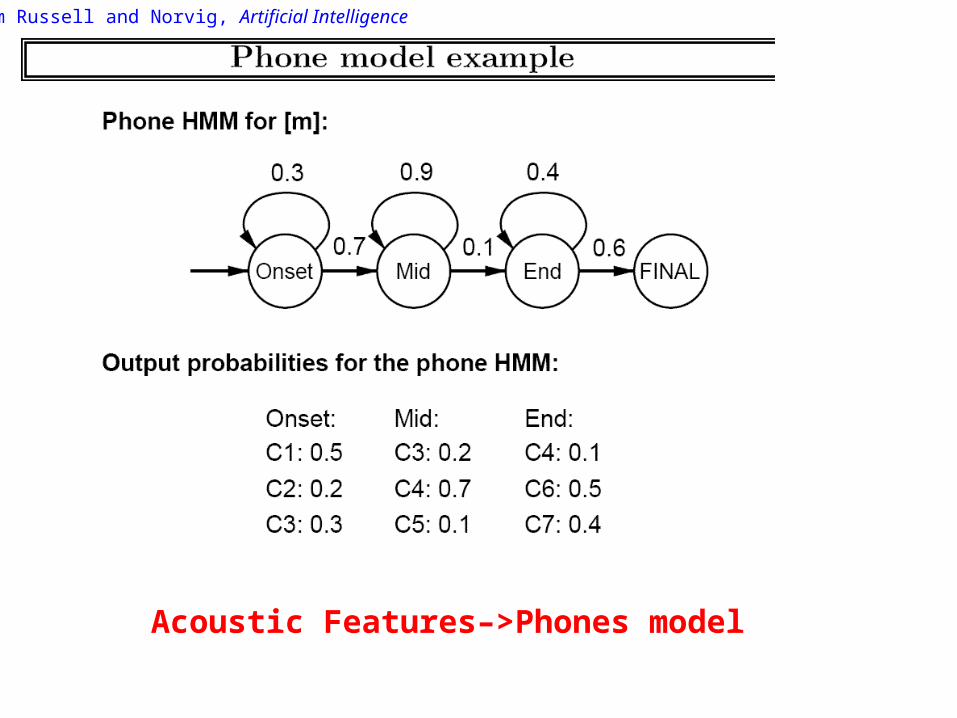
From Russell and Norvig, Artificial Intelligence
Acoustic Features–>Phones model

Word Pronunciation model
Now we want
P (words|phones1:t ) = P(phones1:t | words) P(words)
Represent P(phones1:t | words) as an HMM
Phones–>Word pronounciation model
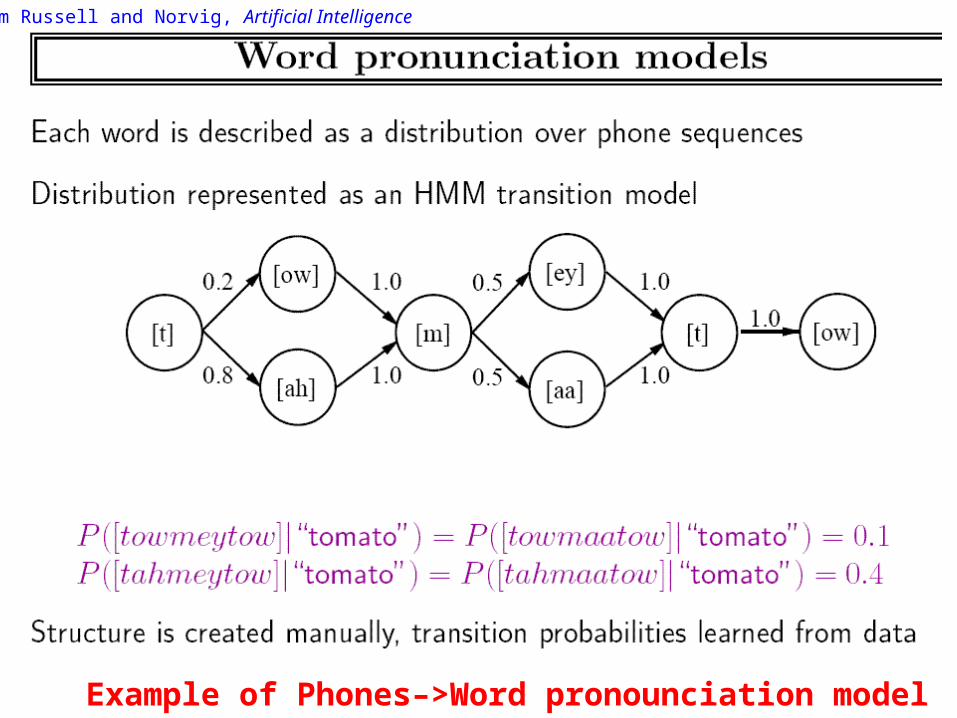
Example of Phones–>Word pronounciation model
From Russell and Norvig, Artificial Intelligence

From Russell and Norvig, Artificial Intelligence
Language model

To build a speech recognition system, need: • Lots of data
• Acoustic signal processing tools
• Methods for learning various probability models
• Methods for “maximum likelihood” calculation (i.e., search or “decoding”):
Suppose we have observations (features from acoustic signal) O= (o1 o2 o3 … on).
We want to find W* = (w1 w2 w3 … wn) such that
€
W* = argmaxW∈L
P(W |O)
= argmaxW∈L
P(O |W)P(W)

To build a speech recognition system, need: • Lots of data
• Acoustic signal processing tools
• Methods for learning various probability models
• Methods for “maximum likelihood” calculation (i.e., search or “decoding”):
Suppose we have observations (features from acoustic signal) O= (o1 o2 o3 … on).
We want to find W* = (w1 w2 w3 … wn) such that
€
W* = argmaxW∈L
P(W |O)
= argmaxW∈L
P(O |W)P(W)
Language model
Combine phone models, segmentation models, word pronunciation models
Search or “decoding” method

To build a speech recognition system, need: • Lots of data
• Acoustic signal processing tools
• Methods for learning various probability models
• Methods for “maximum likelihood” calculation (i.e., search or “decoding”):
Suppose we have observations (features from acoustic signal) O= (o1 o2 o3 … on).
We want to find W* = (w1 w2 w3 … wn) such that
€
W* = argmaxW∈L
P(W |O)
= argmaxW∈L
P(O |W)P(W)
Language model
Combine phone models, segmentation models, word pronunciation models
Search or “decoding” method

Emotion recognition in speech(by OES high-school students!)
http://www.youtube.com/watch?v=NnbsGyViN3Y













