Embed Size (px)
Citation preview

READING BETWEEN THE LINES: OBJECT LOCALIZATION USING IM-PLICIT CUES FROM IMAGE TAGS
Sung Ju Hwang and Kristen Grauman
University of Texas at Austin

Image tagged with keywords clearly tell us Which object to search for
Detecting tagged objects
DogBlack labJasperSofaSelfLiving roomFedoraExplore#24

3
Previous work using tagged images fo-cuses on the noun ↔ object correspon-dence.
Duygulu et al. 2002
Fergus et al. 2005
Berg et al. 2004
Vijayanarasimhan & Grauman 2008
Detecting tagged objects
Image tagged with keywords clearly tell us Which object to search for
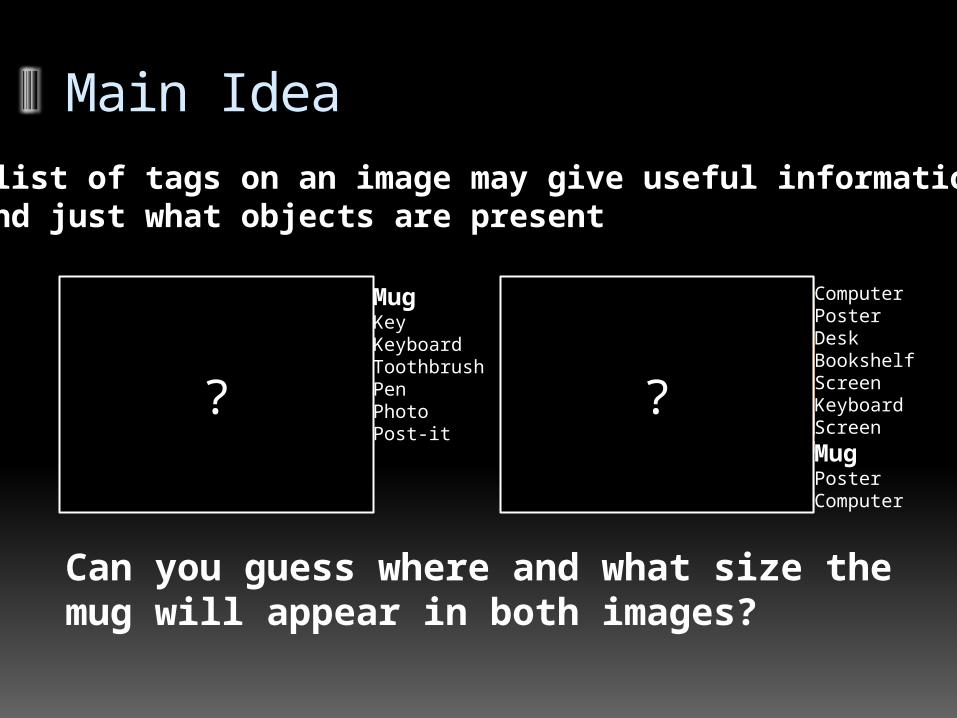
MugKeyKeyboardToothbrushPenPhotoPost-it
ComputerPosterDeskBookshelfScreenKeyboardScreen
MugPosterComputer
? ?
Can you guess where and what size the mug will appear in both images?
Main Idea
The list of tags on an image may give useful information Beyond just what objects are present

Main Idea
MugKeyKeyboardToothbrushPenPhotoPost-it
ComputerPosterDeskBookshelfScreenKeyboardScreen
MugPosterComputer
Mug is named the first Mug is named later in the list
Absence of larger objectsPresence of larger objects
Tag as context

Feature: word presence/ab-sence
MugKeyKeyboardToothbrushPenPhotoPost-it
ComputerPosterDeskBookshelfScreenKeyboardScreen
MugPosterComputer
Presence/absence of some other ob-jects, and the number of those objects affects the scene layout
Presence of smaller objects, such as key, and the absence of larger objects hints that it might be a close-up scene
Presence of the larger objects such as desk and book-shelf hints that the image describes a typical office scene

Feature: word presence/ab-sence
MugKeyKeyboardToothbrushPenPhotoPost-it
ComputerPosterDeskBookshelfScreenKeyboardScreen
MugPosterComputer
Word Mug Com-puter
Screen Keyboard Desk Book-shelf
Poster Photo Pen Post-it Tooth-brush
Key
W1 1 0 0 1 0 0 0 1 1 1 1 1
W2 1 2 2 1 1 1 2 0 0 0 0 0
Blue Larger objects Red Smaller objects
Plain bag-of-words fea-ture describing word frequency.
Wi = word

Feature: tag rank
MugKeyKeyboardToothbrushPenPhotoPost-it
ComputerPosterDeskBookshelfScreenKeyboardScreenMugPosterComputer
People tag the ‘important’ objects ear-lier
If the object is tagged the first, there is a high chance that it is the main object: large, and cen-tered
If the object is tagged later, then it means that the object might not be salient: either it might be far from the center or small in scale

Feature: tag rank
Blue High relative rank (>0.6)
Red Low relative rank(<0.4)
Percentile of the ab-solute rank of the tag compared against its typical rank.
ri = percentile of the rank for tag i
MugKeyKeyboardToothbrushPenPhotoPost-it
ComputerPosterDeskBookshelfScreenKeyboardScreenMugPosterComputer
Word Mug Com-puter
Screen Keyboard Desk Book-shelf
Poster Photo Pen Post-it Tooth-brush
Key
W1 0.80 0 0 0.51 0 0 0 0.28 0.72 0.82 0 0.90
W2 0.23 0.62 0.21 0.13 0.48 0.61 0.41 0 0 0 0 0
Green Medium relative rank (0.4~0.6)

Feature: proximity
1) Mug2) Key3) Keyboard4) Toothbrush5) Pen6) Photo7) Post-it
1) Computer2) Poster3) Desk4) Bookshelf5) Screen6) Keyboard7) Screen
8) Mug9) Poster10) Computer
People tend to move their eyes to the objects nearby
Objects that are close to each other in the tag list are likely to be close in the image
1
23
45
6
7
1
2
3
45
6
7
8
9
10

Feature: proximityEncoded as the inverse of the average rank differ-ence between tag words.
Pi,j = rank difference between tag i and j
1) Mug2) Key3) Keyboard4) Toothbrush5) Pen6) Photo7) Post-it
1) Computer2) Poster3) Desk4) Bookshelf5) Screen6) Keyboard7) Screen
8) Mug9) Poster10) Computer
1
23
45
6
7
1
2
3
45
6
7
8
9
10
Word Mug ScreenKey-
boardDesk
Book-shelf
Mug 1 0 0.5 0 0Screen 0 0 0 0Key-
board 1 0 0
Desk 0 0Book-shelf 0
Word Mug ScreenKey-
boardDesk
Book-shelf
Mug 1 1 0.5 0.2 0.25Screen 1 1 0.33 0.5Key-
board 1 0.33 0.5
Desk 1 1Book-shelf 1Blue Objects close to
each other
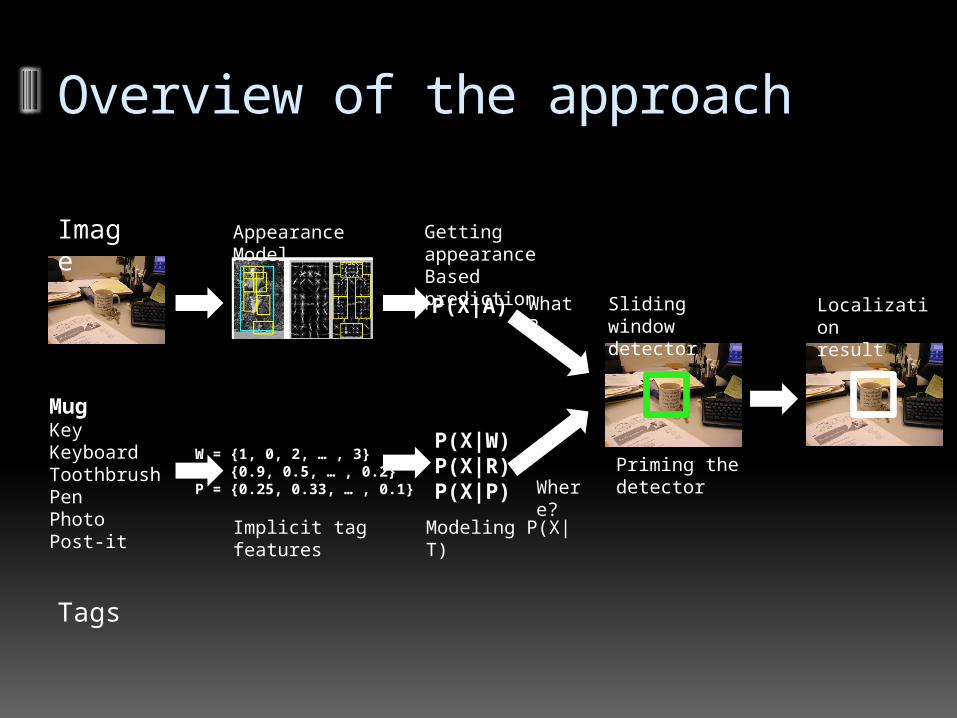
Overview of the approach
MugKeyKeyboardToothbrushPenPhotoPost-it
Im-age
Tags
W = {1, 0, 2, … , 3}R = {0.9, 0.5, … , 0.2}P = {0.25, 0.33, … , 0.1}
Appearance Model
Implicit tag fea-tures
P(X|W)P(X|R)P(X|P)
P(X|A) Sliding window detector
What?
Where?
Localizationresult
Priming the detector
Getting appear-ance Based predic-tion
Modeling P(X|T)
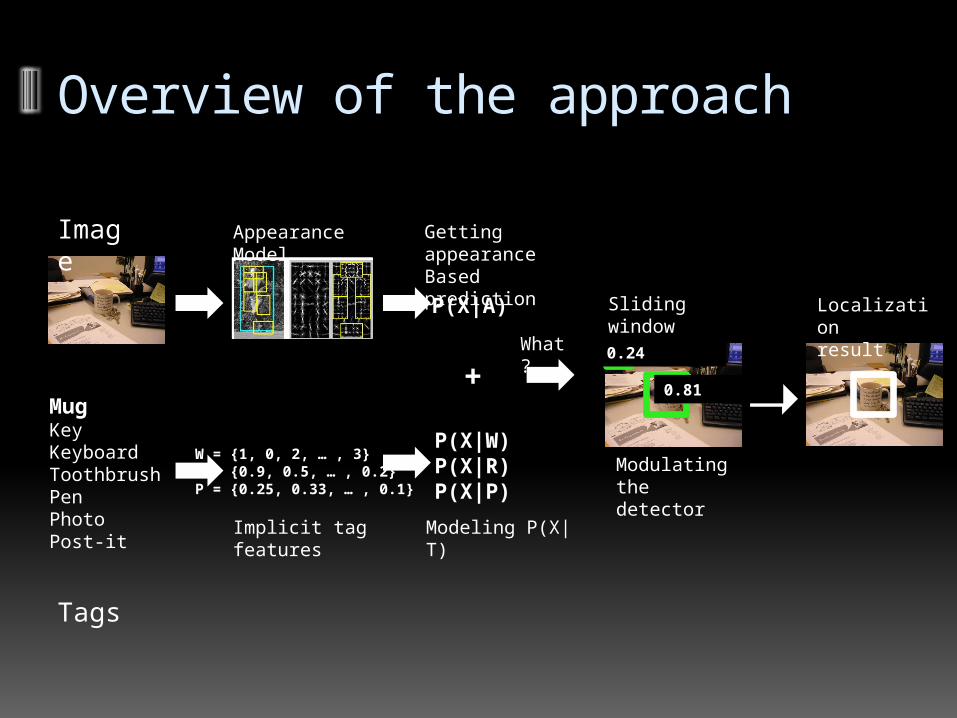
Overview of the approach
MugKeyKeyboardToothbrushPenPhotoPost-it
Im-age
Tags
W = {1, 0, 2, … , 3}R = {0.9, 0.5, … , 0.2}P = {0.25, 0.33, … , 0.1}
Appearance Model
Implicit tag fea-tures
P(X|W)P(X|R)P(X|P)
P(X|A) Localizationresult
+What?
Modulating thedetector
Sliding window detector
Getting appear-ance Based predic-tion
Modeling P(X|T)
0.24
0.81

Approach: modeling P(X|T)
We modeled this condi-tional PDF P(X|T) directly without calculating the joint distribution P(X,T), using the mixture density network (MDN)
We wish to know the conditional PDF of the location and scale of the target object, given the tag features: P(X|T) (X = s,x,y, T = tag feature)Lamp
CarWheelWheelLight
WindowHouseHouseCarCarRoadHouseLightpole
CarWindowsBuildingManBarrelCarTruckCar
BoulderCar
Top 30 mostly liked posi-tions for class car. Bounding box sampled according to P(X|T)

Approach: Priming the detector
Region to search
Ignored
Ignored
Most proba-blescale
Unlikely scale
33000
38600 1) Rank the detec-tion
results based on thelearned P(X|T)
5
Then how can we make use of this learned dis-tribution P(X|T)?
1) Use it to speed the detection process2) Use it to modulate the detection confidence
score
2) Search only theprobable region and
thescale, following the
rank

Approach: Modulating the de-tector Then how can we make use of this learned dis-
tribution P(X|T)?
1) Use it to speed the detection process2) Use it to modulate the detection confidence
scoreP(X|A)
Detector
P(X|W)P(X|R)P(X|P)
Logistic regressionClassifier
We learn the weights for each prediction,P(X|A), P(X|W), P(X|R), and P(X|P)
LampCarWheelWheelLight
Image tags

Approach: Modulating the de-tector Then how can we make use of this learned dis-
tribution P(X|T)?
1) Use it to speed the detection process2) Use it to modulate the detection confidence
score
0.70.8
Prediction based on theoriginal detector score
0.9

Approach: Modulating the de-tector Then how can we make use of this learned dis-
tribution P(X|T)?
1) Use it to speed the detection process2) Use it to modulate the detection confidence
score
0.70.8
Prediction based on theoriginal detector score
0.9
Prediction based on the tag fea-tures
0.3
0.9
0.2

Approach: Modulating the de-tector Then how can we make use of this learned dis-
tribution P(X|T)?
1) Use it to speed the detection process2) Use it to modulate the detection confidence
score
0.630.24
0.18

Experiments
We compare the following two Detection Speed
Number of windows to search Detection Accuracy
AUROC AP
On three methods Appearance-only Appearance + Gist Appearance + tag features (ours)
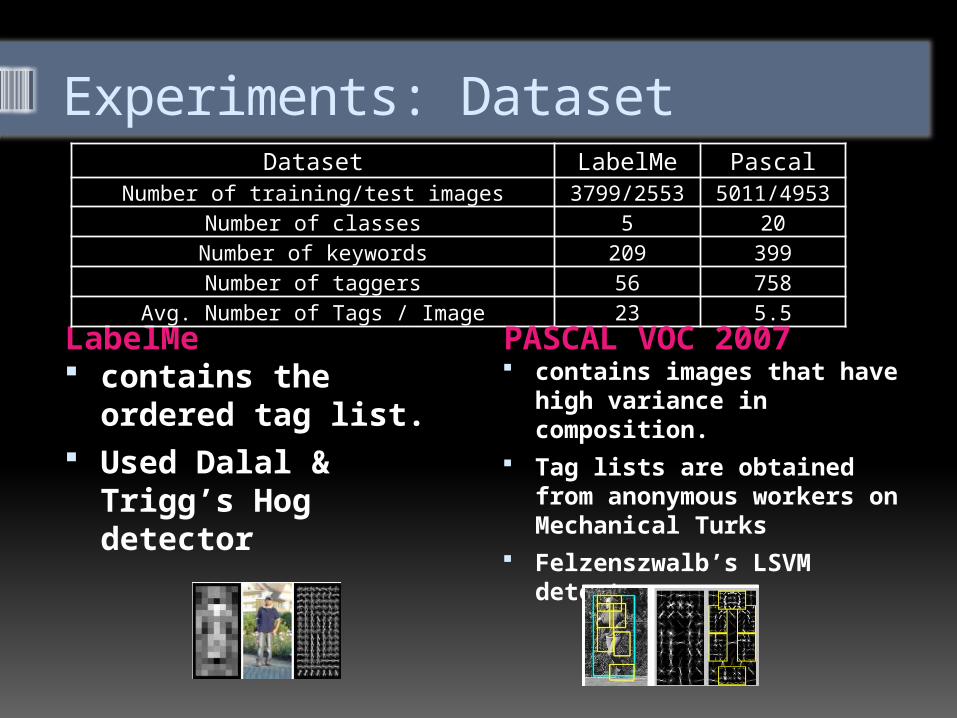
LabelMe contains the or-
dered tag list. Used Dalal &
Trigg’s Hog detec-tor
contains images that have high variance in composi-tion.
Tag lists are obtained from anonymous workers on Mechanical Turks
Felzenszwalb’s LSVM de-tector
Dataset LabelMe PascalNumber of training/test images 3799/2553 5011/4953
Number of classes 5 20Number of keywords 209 399Number of taggers 56 758
Avg. Number of Tags / Image 23 5.5
Experiments: Dataset
PASCAL VOC 2007

LabelMe: Performance Evaluation
More accurate de-tection,
Because we know which
hypotheses to trust most.
Modified version of the HOG detector by Dalal and Triggs.
Faster detection, because
we know where to look first

Results: LabelMe
SkyBuildingsPersonSidewalkCarCarRoad
CarWindowRoadWindowSkyWheelSign
HOG HOG+Gist HOG+Tags
Gist and Tags are likely to predict the same position, but
different scale. Most of the accuracy gain us-ing the tag
features comes from accurate scale predic-tion

Results: LabelMe
DeskKeyboardScreen
BookshelfDeskKeyboardScreen
MugKeyboardScreenCD
HOG HOG+Gist HOG+Tags

PASCAL VOC 2007: Performance Evaluation
Need to test less number
of windows to achieve the
same detection rate.
Modified Felzenszwalb’s LSVM detector
9.2% improvement in
accuracy over all classes
(Average Precision)
65%
25%
77%70%
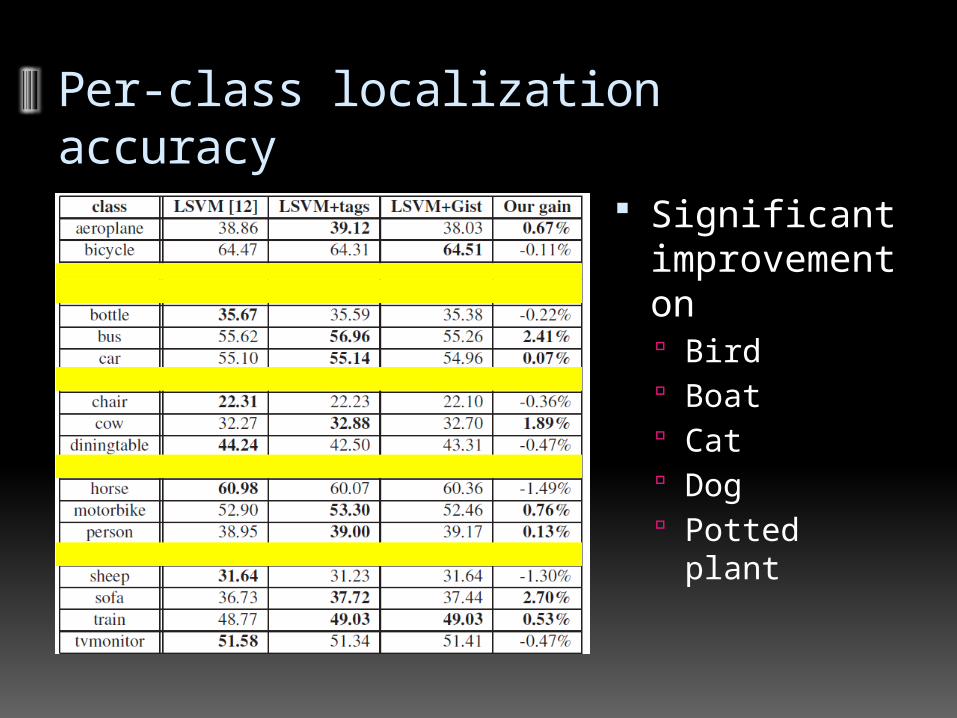
Per-class localization accu-racy
Significant improvement on Bird Boat Cat Dog Potted plant

PASCAL VOC 2007 (examples)
Aeroplane
BuildingAeroplaneSmoke
AeroplaneAeroplaneAeroplaneAeroplaneAeroplane
LampPersonBottleDogSofaPaintingTable
Bottle
PersonTableChairMirrorTableclothBowlBottleShelfPaintingFood
Ours
LSVM base-line

PASCAL VOC 2007 (examples)
Dog
DogFloorHairclip
DogDogDogPersonPersonGroundBenchScarf
Person
PersonMicrophoneLight
HorsePersonTreeHouseBuildingGroundHurdleFence

PASCAL VOC 2007 (Failure case)
AeroplaneSkyBuildingShadow
PersonPersonPoleBuildingSidewalkGrassRoad
DogClothesRopeRopePlantGroundShadowStringWall
BottleGlassWineTable

Some Observations
We find that often implicit features predict:- scale better for indoor objects- position better for outdoor objects
We find Gist usually better for y position, while tags are generally stronger for scale- agrees with previous experiments using Gist
In general, need to have learned about target objects in variety of ex-amples with different contexts

Conclusion
We showed how to exploit the im-plicit information present in human tagging behavior, on improving ob-ject localization performance in both speed and accuracy.

Future Work
Joint multi-object detection
From tags to natural language sen-tences
Image retrieval
Using Wordnet to group words with similar meanings

Conclusion
We showed how to exploit the im-plicit information present in human tagging behavior, on improving ob-ject localization performance in both speed and accuracy.


















![arXiv:1608.05148v2 [cs.CV] 7 Jul 2017 · Nick Johnston nickj@google.com Sung Jin Hwang sjhwang@google.com David Minnen dminnen@google.com Joel Shor joelshor@google.com Michele Covell](https://img.pdfslide.net/doc/110x75/5ee12c7aad6a402d666c2605/arxiv160805148v2-cscv-7-jul-2017-nick-johnston-nickj-sung-jin-hwang-sjhwang.jpg)










