Embed Size (px)
Citation preview

SupervisedandUnsupervisedLearning
CiroDonalekAy/Bi199–April2011

Summary• KDDandDataMiningTasks• Findingtheop?malapproach• SupervisedModels
– NeuralNetworks– Mul?LayerPerceptron– DecisionTrees
• UnsupervisedModels– DifferentTypesofClustering– DistancesandNormaliza?on– Kmeans– SelfOrganizingMaps
• Combiningdifferentmodels– CommiOeeMachines– IntroducingaPrioriKnowledge– SleepingExpertFramework
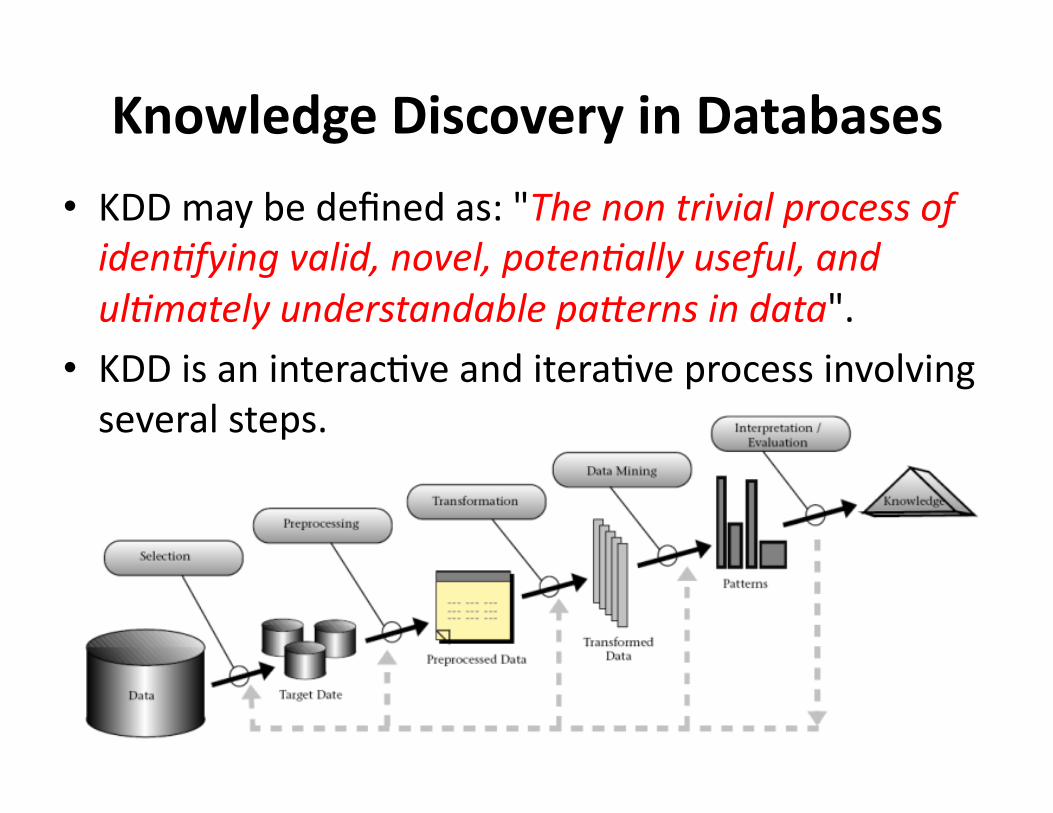
KnowledgeDiscoveryinDatabases
• KDDmaybedefinedas:"Thenontrivialprocessofiden2fyingvalid,novel,poten2allyuseful,andul2matelyunderstandablepa9ernsindata".
• KDDisaninterac?veanditera?veprocessinvolvingseveralsteps.

Yougotyourdata:what’snext?
Whatkindofanalysisdoyouneed?Whichmodelismoreappropriateforit?…
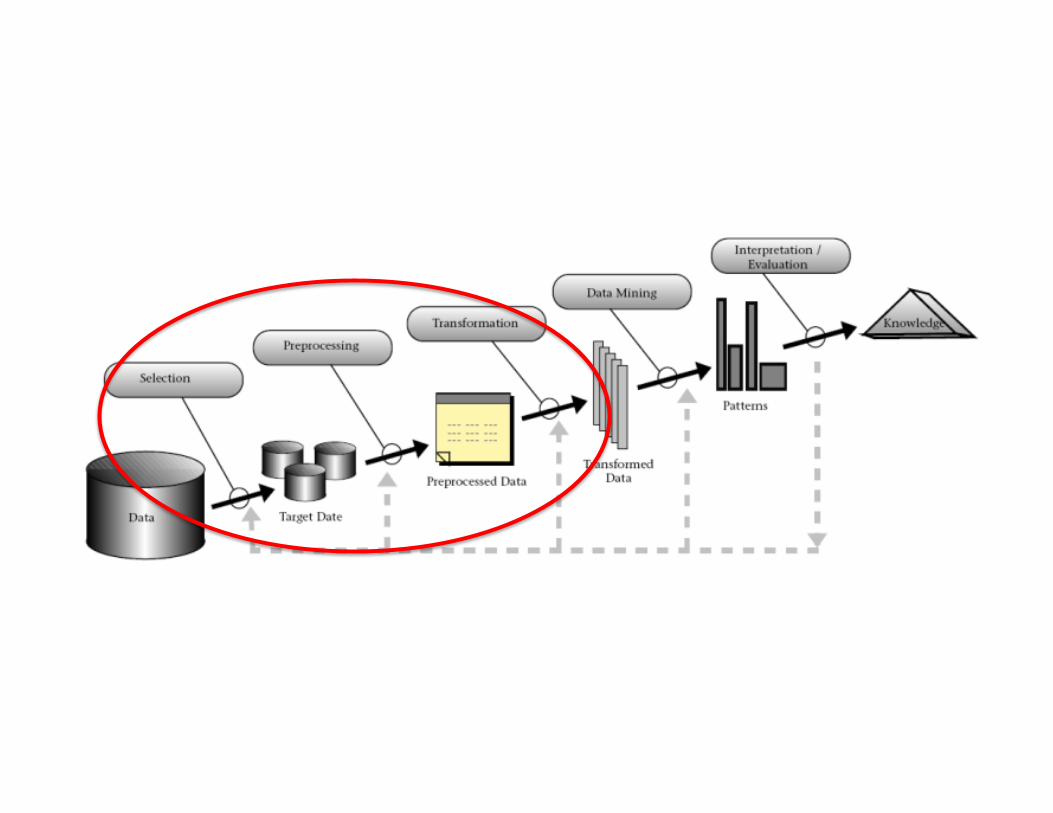

Cleanyourdata!• Datapreprocessingtransformstherawdataintoaformatthatwillbemoreeasilyandeffec?velyprocessedforthepurposeoftheuser.
• Sometasks• sampling:selectsarepresenta?vesubset
fromalargepopula?onofdata;• Noisetreatment• strategiestohandlemissingdata:some?mes
yourrowswillbeincomplete,notallparametersaremeasuredforallsamples.
• normaliza2on• featureextrac2on:pullsoutspecifieddata
thatissignificantinsomepar?cularcontext.
Usestandardformats!

MissingData• Missingdataareapartofalmostallresearch,andweallhaveto
decidehowtodealwithit.• CompleteCaseAnalysis:useonlyrowswithallthevalues• AvailableCaseAnalysis• Subs?tu?on
– MeanValue:replacethemissingvaluewiththemeanvalueforthatpar?cularaOribute
– RegressionSubs?tu?on:wecanreplacethemissingvaluewithhistoricalvaluefromsimilarcases
– MatchingImputa?on:foreachunitwithamissingy,findaunitwithsimilarvaluesofxintheobserveddataandtakeitsyvalue
– MaximumLikelihood,EM,etc• SomeDMmodelscandealwithmissingdatabeOerthanothers.• Whichtechniquetoadoptreallydependsonyourdata
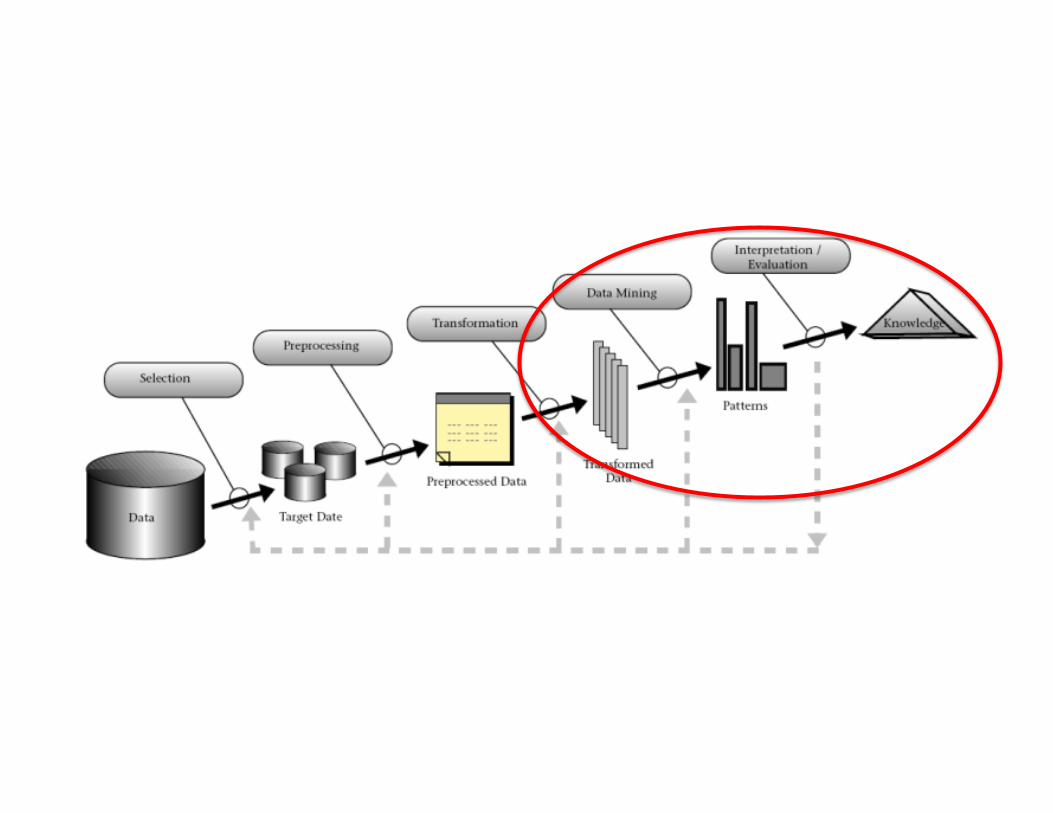

DataMining• CrucialtaskwithintheKDD• DataMiningisaboutautoma?ngtheprocessofsearchingforpaOernsinthedata.
• Moreindetails,themostrelevantDMtasksare:– associa?on– sequenceorpathanalysis– clustering– classificaDon– regression– visualiza?on

FindingSoluDonviaPurposes• Youhaveyourdata,whatkindofanalysisdoyouneed?
• Regression– predictnewvaluesbasedonthepast,inference– computethenewvaluesforadependentvariablebasedonthevaluesofoneormoremeasuredaOributes
• Classifica?on:– dividesamplesinclasses– useatrainedsetofpreviouslylabeleddata
• Clustering– par??oningofadatasetintosubsets(clusters)sothatdataineachsubsetideallysharesomecommoncharacteris?cs
• Classifica?onisinasomewaysimilartotheclustering,butrequiresthattheanalystknowaheadof?mehowclassesaredefined.

ClusterAnalysis
Howmanyclustersdoyouexpect?




SearchforOutliers

ClassificaDon• Dataminingtechniqueusedtopredictgroupmembershipfordatainstances.Therearetwowaystoassignanewvaluetoagivenclass.
• CrispyclassificaDon– givenaninput,theclassifierreturnsitslabel
• ProbabilisDcclassificaDon– givenaninput,theclassifierreturnsitsprobabili?estobelongtoeachclass
– usefulwhensomemistakescanbemorecostlythanothers(givemeonlydata>90%)
– winnertakeallandotherrules• assigntheobjecttotheclasswiththehighestprobability(WTA)
• …butonlyifitsprobabilityisgreaterthan40%(WTAwiththresholds)


Regression/ForecasDng
• Datatablesta?s?calcorrela?on– mappingwithoutanypriorassump?ononthefunc?onalformofthedatadistribu?on;
– machinelearningalgorithmswellsuitedforthis.
• Curvefigng– findawelldefinedandknownfunc?onunderlyingyourdata;
– theory/exper?secanhelp.

MachineLearning
• Tolearn:togetknowledgeofbystudy,experience,orbeingtaught.
• TypesofLearning• Supervised• Unsupervised

UnsupervisedLearning
• Themodelisnotprovidedwiththecorrectresultsduringthetraining.
• Canbeusedtoclustertheinputdatainclassesonthebasisoftheirsta?s?calproper?esonly.
• Clustersignificanceandlabeling.• Thelabelingcanbecarriedoutevenifthelabelsareonlyavailableforasmallnumberofobjectsrepresenta?veofthedesiredclasses.

SupervisedLearning
• Trainingdataincludesboththeinputandthedesiredresults.
• Forsomeexamplesthecorrectresults(targets)areknownandaregivenininputtothemodelduringthelearningprocess.
• Theconstruc?onofapropertraining,valida?onandtestset(Bok)iscrucial.
• Thesemethodsareusuallyfastandaccurate.• Havetobeabletogeneralize:givethecorrectresultswhennewdataaregivenininputwithoutknowingapriorithetarget.

GeneralizaDon
• Referstotheabilitytoproducereasonableoutputsforinputsnotencounteredduringthetraining.
Inotherwords:NOPANICwhen"neverseenbefore"dataaregivenininput!
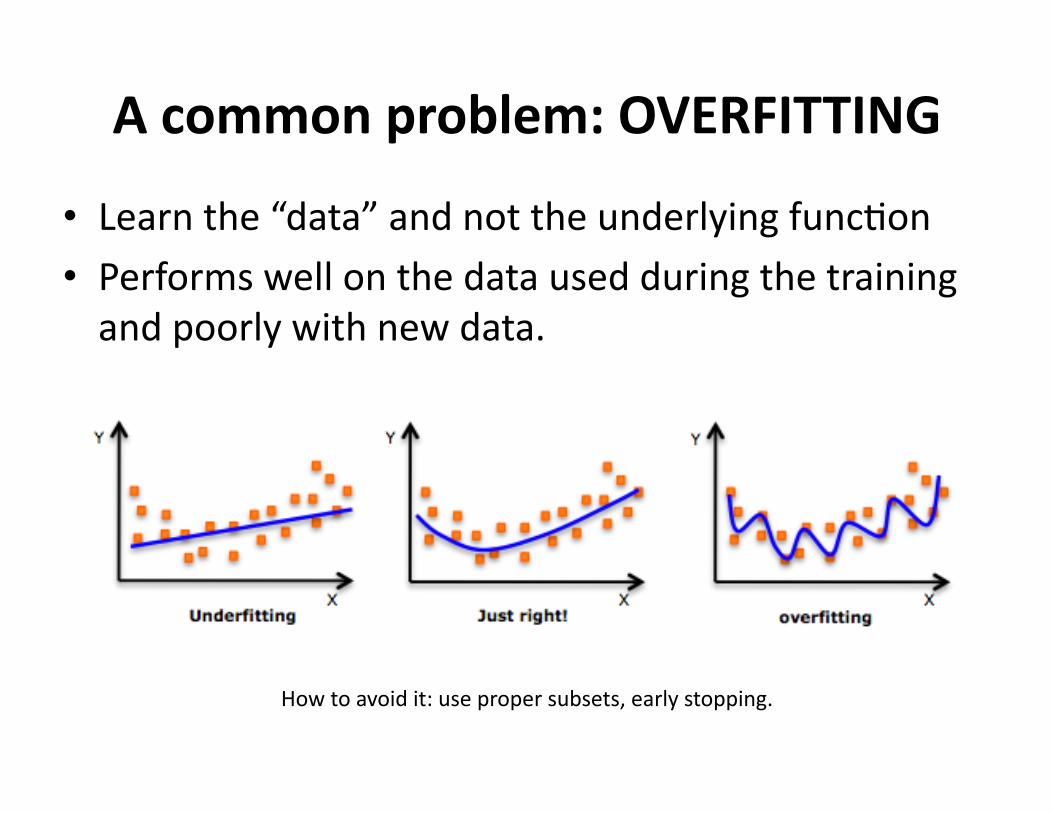
Acommonproblem:OVERFITTING
• Learnthe“data”andnottheunderlyingfunc?on• Performswellonthedatausedduringthetrainingandpoorlywithnewdata.
Howtoavoidit:usepropersubsets,earlystopping.

Datasets• Trainingset:asetofexamplesusedforlearning,wherethetargetvalueisknown.
• ValidaDonset:asetofexamplesusedtotunethearchitectureofaclassifierandes?matetheerror.
• Testset:usedonlytoassesstheperformancesofaclassifier.Itisneverusedduringthetrainingprocesssothattheerroronthetestsetprovidesanunbiasedes?mateofthegeneraliza?onerror.

IRISdataset
• IRIS– consistsof3classes,50instanceseach– 4numericalaOributes(sepalandpetallengthandwidthincm)
– eachclassreferstoatypeofIrisplant(Setosa,Versicolor,Verginica)
– thefirstclassislinearlyseparablefromtheothertwowhilethe2ndandthe3rdarenotlinearlyseparable
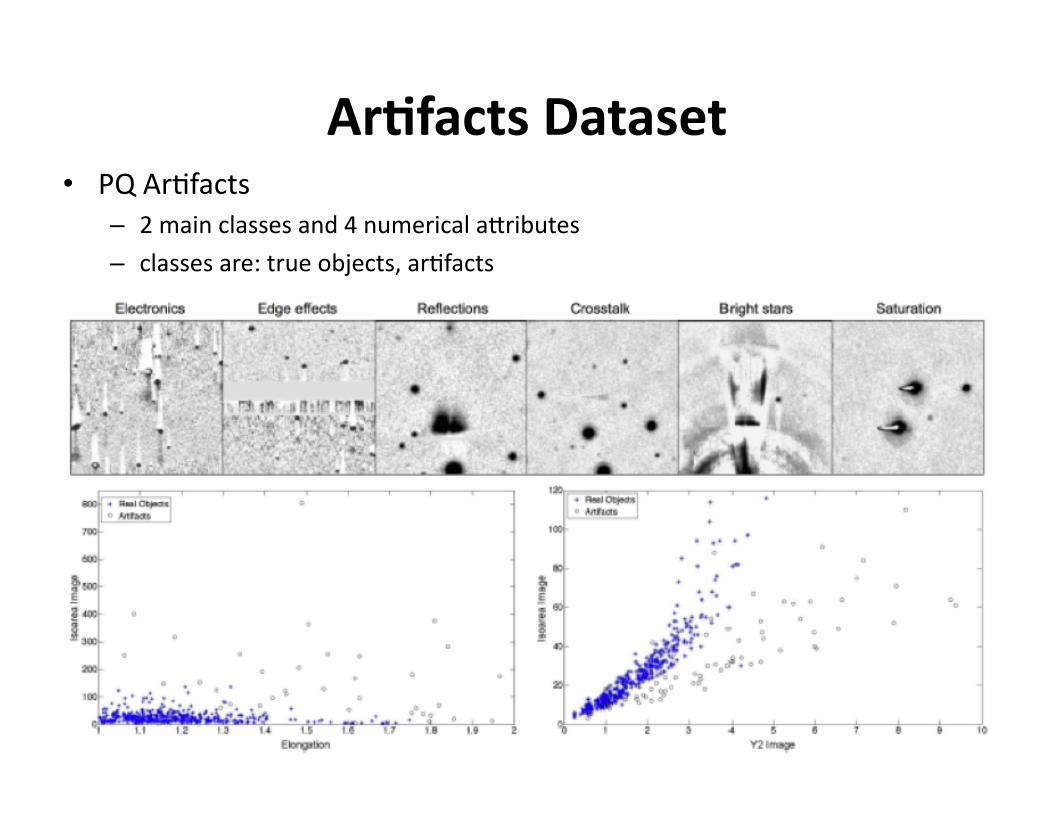
ArDfactsDataset• PQAr?facts
– 2mainclassesand4numericalaOributes
– classesare:trueobjects,ar?facts

DataSelecDon
• “Garbagein,garbageout”:training,valida?onandtestdatamustberepresenta?veoftheunderlyingmodel
• Alleventuali?esmustbecovered• Unbalanceddatasets– sincethenetworkminimizestheoverallerror,thepropor?onoftypesofdatainthesetiscri?cal;
– inclusionofalossmatrix(Bishop,1995);– onen,thebestapproachistoensureevenrepresenta?onofdifferentcases,thentointerpretthenetwork'sdecisionsaccordingly.
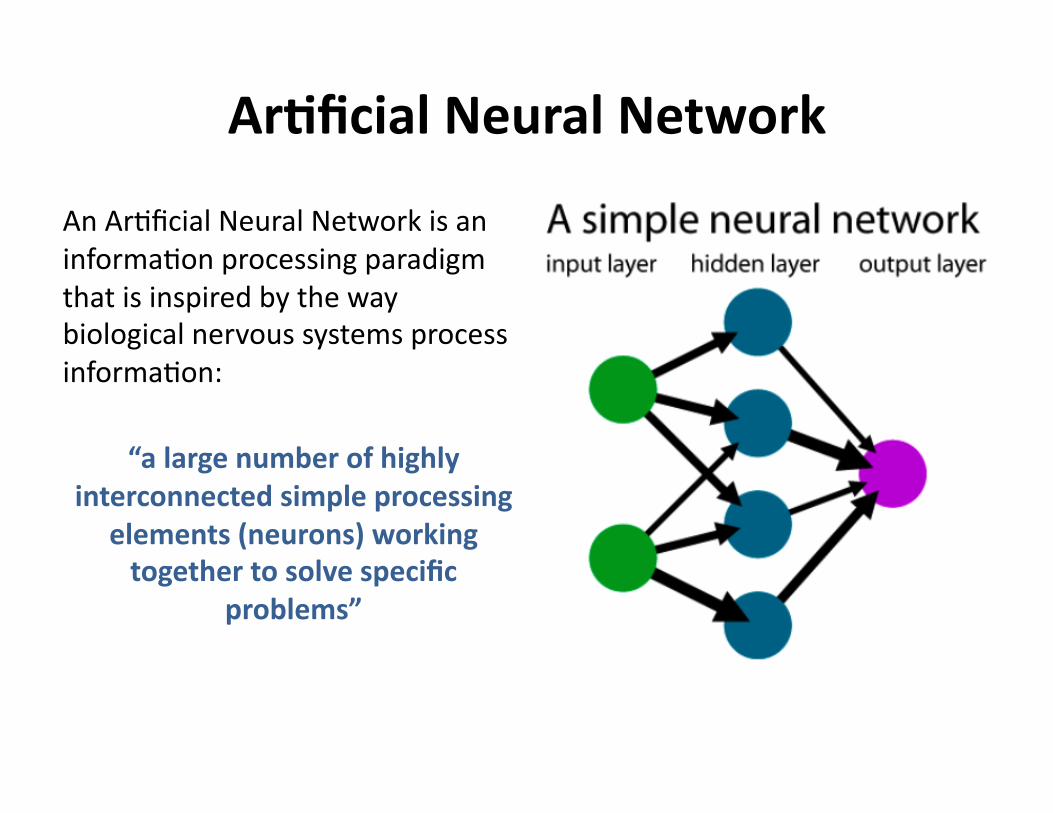
ArDficialNeuralNetwork
AnAr?ficialNeuralNetworkisaninforma?onprocessingparadigmthatisinspiredbythewaybiologicalnervoussystemsprocessinforma?on:
“alargenumberofhighlyinterconnectedsimpleprocessing
elements(neurons)workingtogethertosolvespecific
problems”
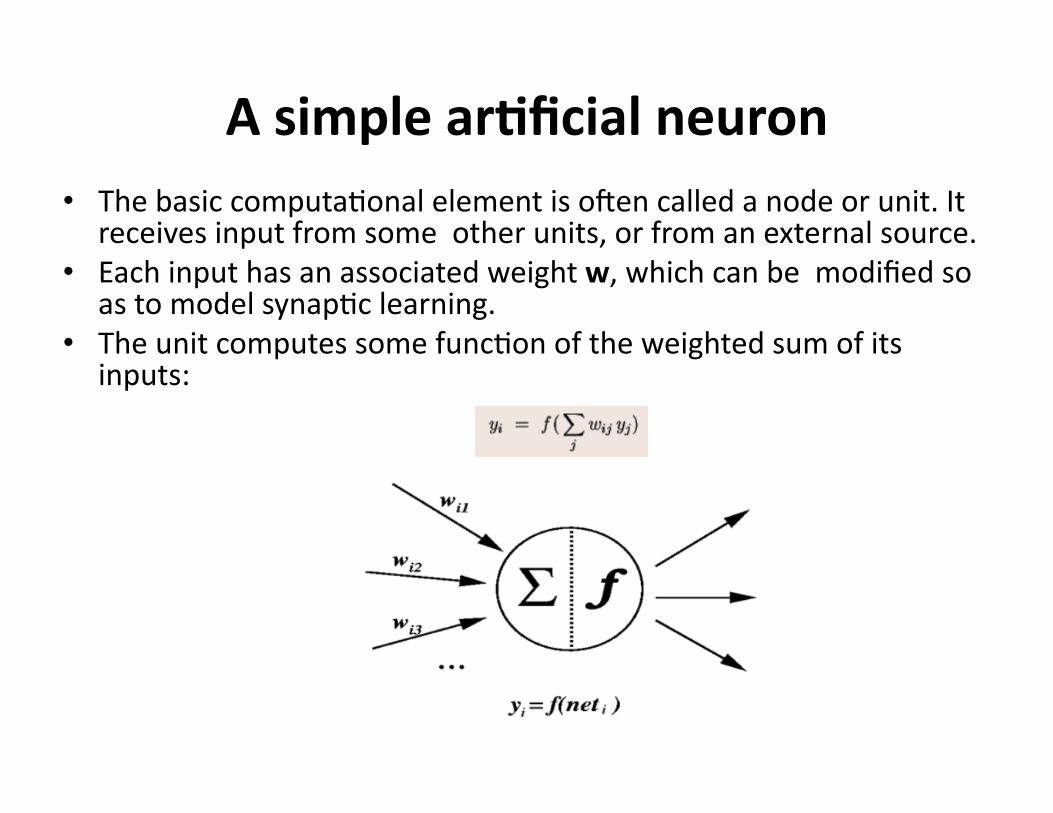
AsimplearDficialneuron• Thebasiccomputa?onalelementisonencalledanodeorunit.It
receivesinputfromsomeotherunits,orfromanexternalsource.• Eachinputhasanassociatedweightw,whichcanbemodifiedso
astomodelsynap?clearning.• Theunitcomputessomefunc?onoftheweightedsumofits
inputs:
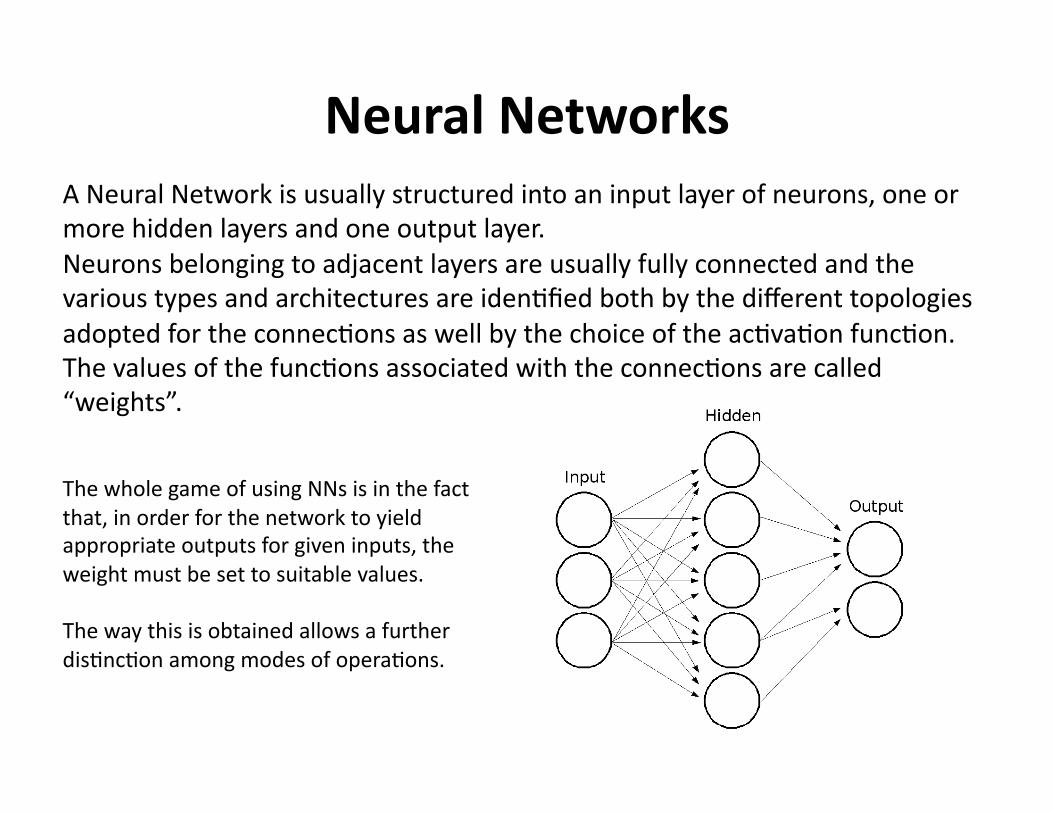
NeuralNetworksANeuralNetworkisusuallystructuredintoaninputlayerofneurons,oneormorehiddenlayersandoneoutputlayer.Neuronsbelongingtoadjacentlayersareusuallyfullyconnectedandthevarioustypesandarchitecturesareiden?fiedbothbythedifferenttopologiesadoptedfortheconnec?onsaswellbythechoiceoftheac?va?onfunc?on.Thevaluesofthefunc?onsassociatedwiththeconnec?onsarecalled“weights”.
ThewholegameofusingNNsisinthefactthat,inorderforthenetworktoyieldappropriateoutputsforgiveninputs,theweightmustbesettosuitablevalues.
Thewaythisisobtainedallowsafurtherdis?nc?onamongmodesofopera?ons.
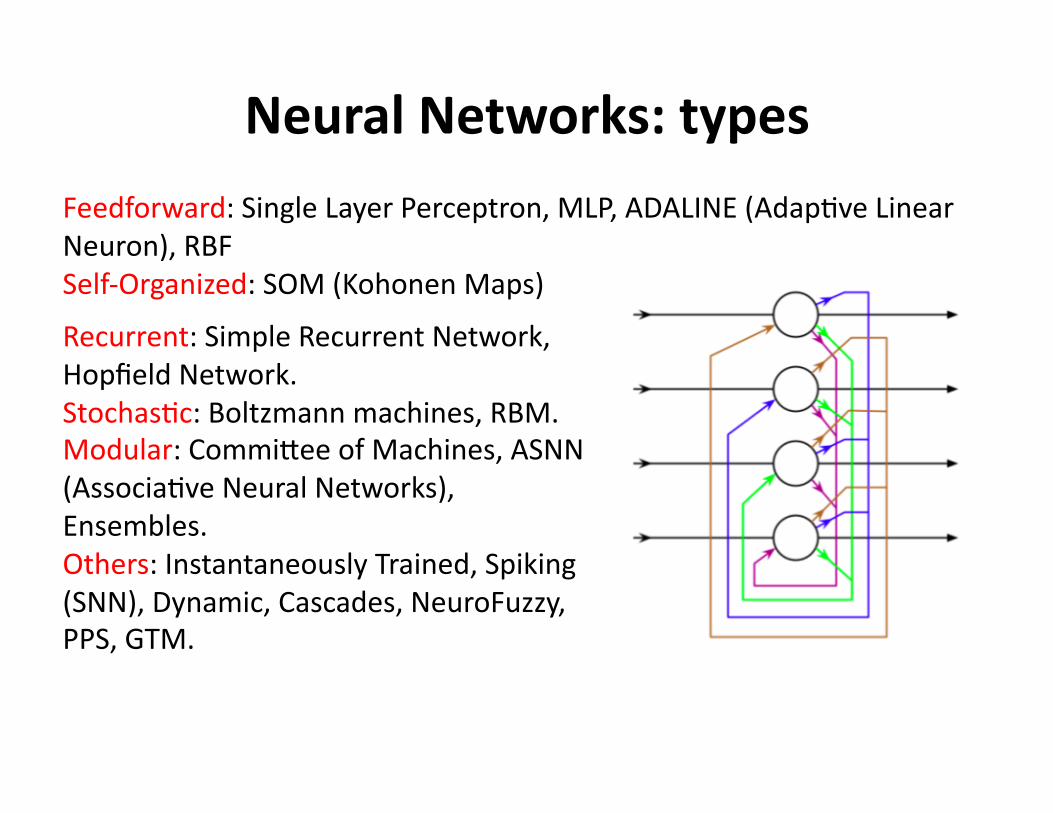
NeuralNetworks:types
Feedforward:SingleLayerPerceptron,MLP,ADALINE(Adap?veLinearNeuron),RBFSelf‐Organized:SOM(KohonenMaps)
Recurrent:SimpleRecurrentNetwork,HopfieldNetwork.Stochas?c:Boltzmannmachines,RBM.Modular:CommiOeeofMachines,ASNN(Associa?veNeuralNetworks),Ensembles.Others:InstantaneouslyTrained,Spiking(SNN),Dynamic,Cascades,NeuroFuzzy,PPS,GTM.
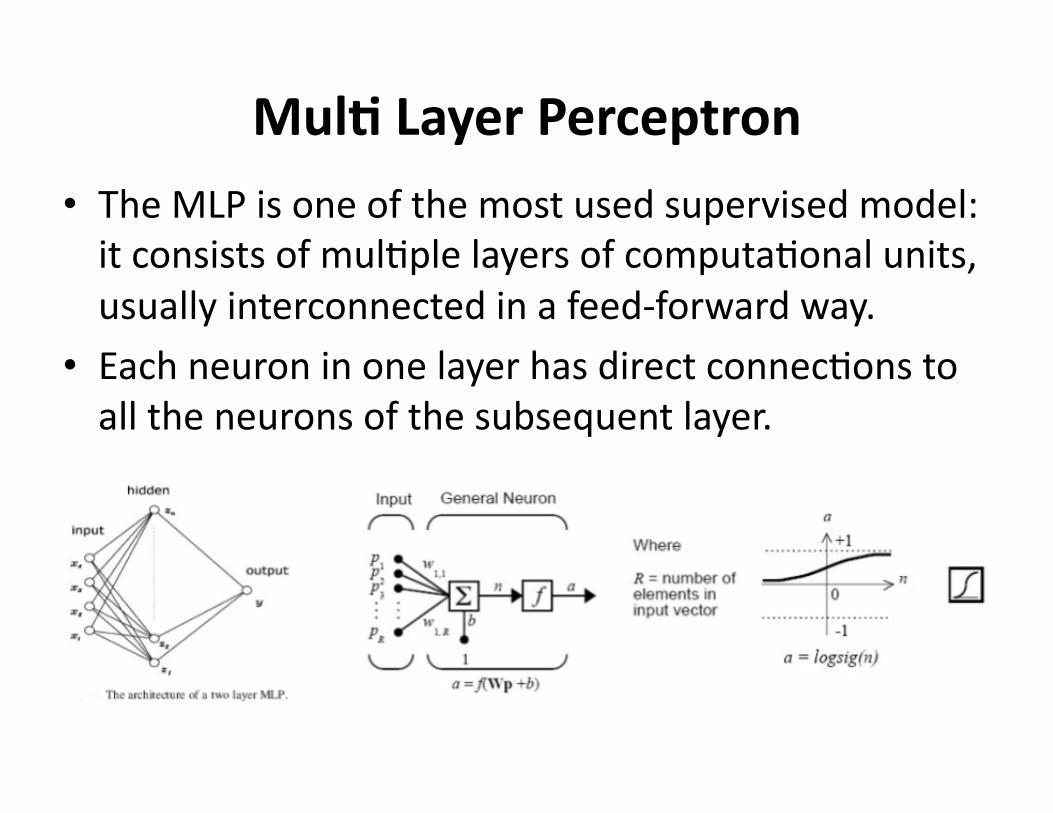
MulDLayerPerceptron• TheMLPisoneofthemostusedsupervisedmodel:itconsistsofmul?plelayersofcomputa?onalunits,usuallyinterconnectedinafeed‐forwardway.
• Eachneuroninonelayerhasdirectconnec?onstoalltheneuronsofthesubsequentlayer.
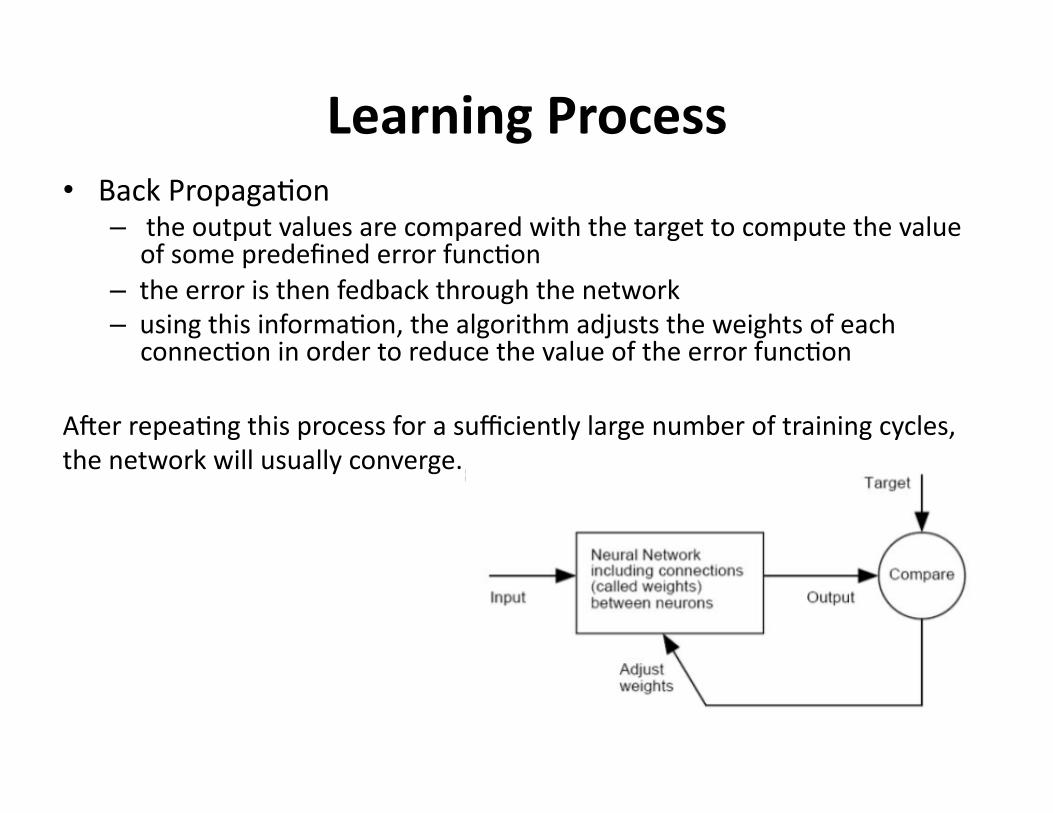
LearningProcess• BackPropaga?on
– theoutputvaluesarecomparedwiththetargettocomputethevalueofsomepredefinederrorfunc?on
– theerroristhenfedbackthroughthenetwork– usingthisinforma?on,thealgorithmadjuststheweightsofeach
connec?oninordertoreducethevalueoftheerrorfunc?on
Anerrepea?ngthisprocessforasufficientlylargenumberoftrainingcycles,thenetworkwillusuallyconverge.

HiddenUnits• Thebestnumberofhiddenunitsdependon:
– numberofinputsandoutputs
– numberoftrainingcase– theamountofnoiseinthetargets
– thecomplexityofthefunc?ontobelearned
– theac?va?onfunc?on
• Toofewhiddenunits=>hightrainingandgeneraliza?onerror,duetounderfigngandhighsta?s?calbias.
• Toomanyhiddenunits=>lowtrainingerrorbuthighgeneraliza?onerror,duetooverfigngandhighvariance.
• Rulesofthumbdon'tusuallywork.

AcDvaDonandErrorFuncDons
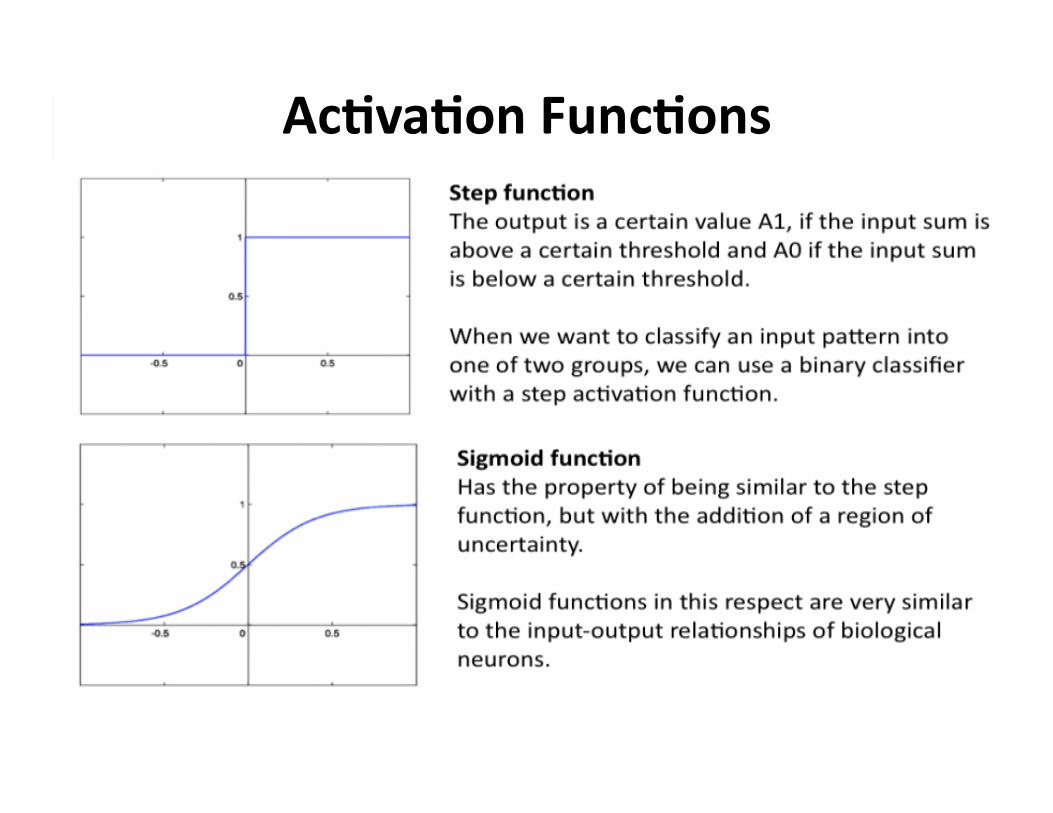
AcDvaDonFuncDons
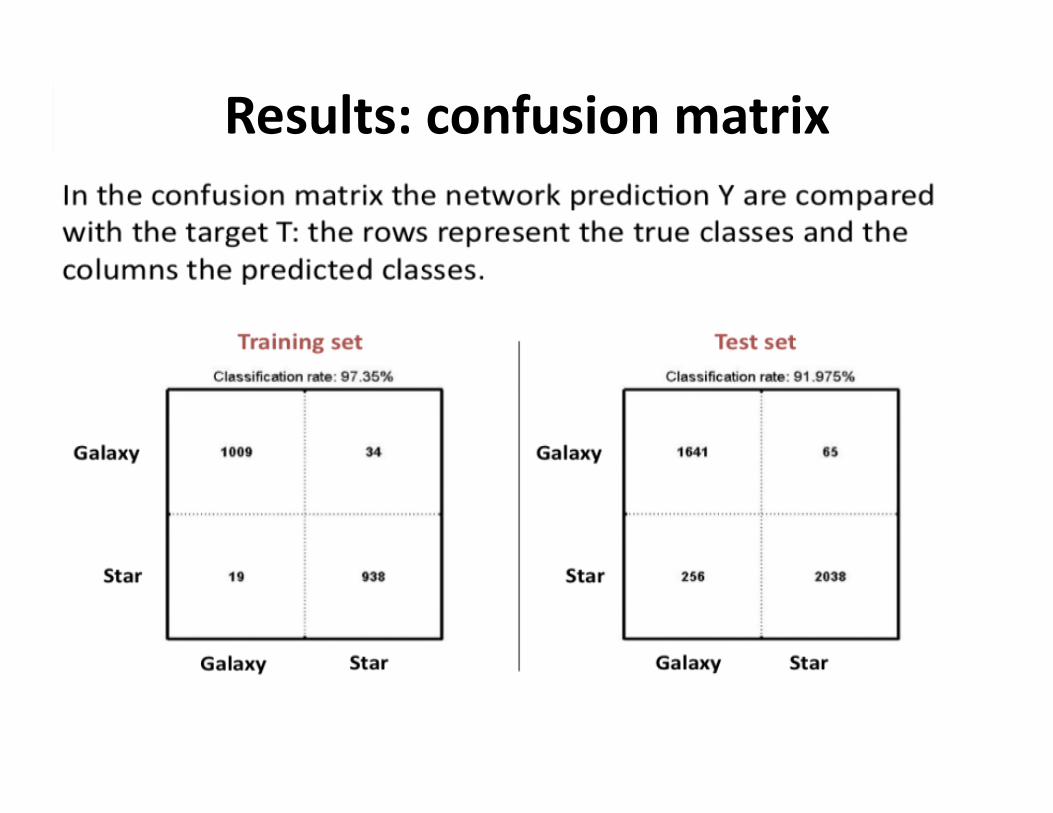
Results:confusionmatrix

Results:completenessandcontaminaDon
Exercise:computecompletenessandcontamina?onforthepreviousconfusionmatrix(testset)

DecisionTrees• Isanotherclassifica?onmethod.• Adecisiontreeisasetofsimplerules,suchas"ifthesepallengthislessthan5.45,classifythespecimenassetosa."
• Decisiontreesarealsononparametricbecausetheydonotrequireanyassump?onsaboutthedistribu?onofthevariablesineachclass.

Summary• KDDandDataMiningTasks• Findingtheop?malapproach• SupervisedModels
– NeuralNetworks– Mul?LayerPerceptron– DecisionTrees
• UnsupervisedModels– DifferentTypesofClustering– DistancesandNormaliza?on– Kmeans– SelfOrganizingMaps
• Combiningdifferentmodels– CommiOeeMachines– IntroducingaPrioriKnowledge– SleepingExpertFramework

UnsupervisedLearning
• Themodelisnotprovidedwiththecorrectresultsduringthetraining.
• Canbeusedtoclustertheinputdatainclassesonthebasisoftheirsta?s?calproper?esonly.
• Clustersignificanceandlabeling.• Thelabelingcanbecarriedoutevenifthelabelsareonlyavailableforasmallnumberofobjectsrepresenta?veofthedesiredclasses.
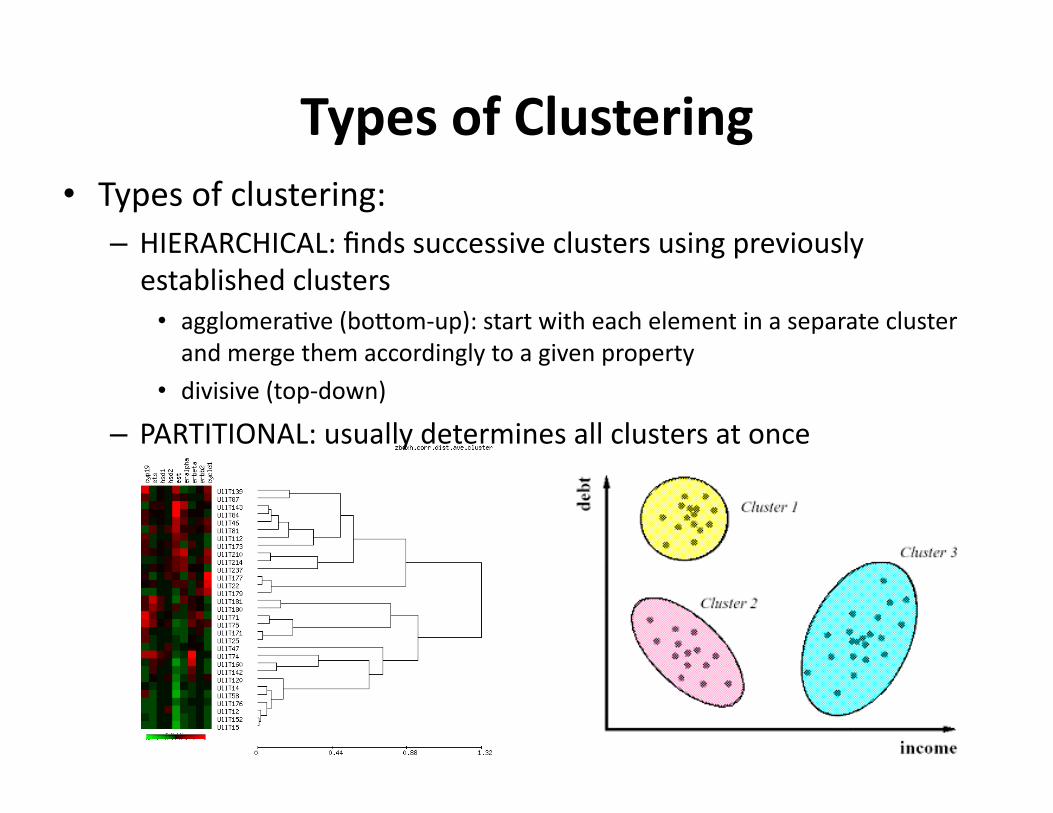
TypesofClustering• Typesofclustering:
– HIERARCHICAL:findssuccessiveclustersusingpreviouslyestablishedclusters• agglomera?ve(boOom‐up):startwitheachelementinaseparateclusterandmergethemaccordinglytoagivenproperty
• divisive(top‐down)– PARTITIONAL:usuallydeterminesallclustersatonce
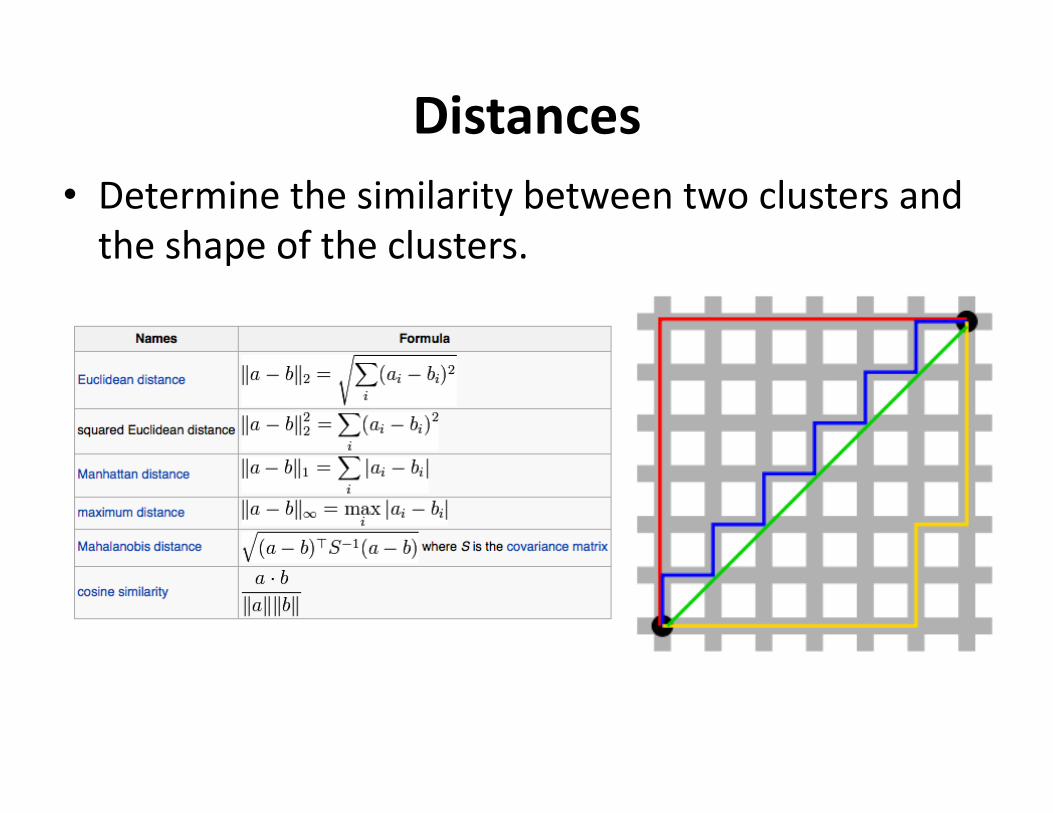
Distances• Determinethesimilaritybetweentwoclustersandtheshapeoftheclusters.

Incaseofstrings…• TheHammingdistancebetweentwostringsofequallengthisthenumberofposi?onsatwhichthecorrespondingsymbolsaredifferent.– measurestheminimumnumberofsubs2tu2onsrequiredtochangeonestringintotheother
• TheLevenshtein(edit)distanceisametricformeasuringtheamountofdifferencebetweentwosequences.– isdefinedastheminimumnumberofeditsneededtotransformonestringintotheother.
10010011000100HD=3
LD(BIOLOGY,BIOLOGIA)=2BIOLOGY‐>BIOLOGI(subsDtuDon)BIOLOGI‐>BIOLOGIA(inserDon)

NormalizaDon
VAR:themeanofeachaOributeofthetransformedsetofdatapointsisreducedtozerobysubtrac?ngthemeanofeachaOributefromthevaluesoftheaOributesanddividingtheresultbythestandarddevia?onoftheaOribute.
RANGE(Min‐MaxNormalizaDon):subtractstheminimumvalueofanaOributefromeachvalueoftheaOributeandthendividesthedifferencebytherangeoftheaOribute.Ithastheadvantageofpreservingexactlyallrela?onshipinthedata,withoutaddinganybias.
SOFTMAX:isawayofreducingtheinfluenceofextremevaluesoroutliersinthedatawithoutremovingthemfromthedataset.Itisusefulwhenyouhaveoutlierdatathatyouwishtoincludeinthedatasetwhiles?llpreservingthesignificanceofdatawithinastandarddevia?onofthemean.
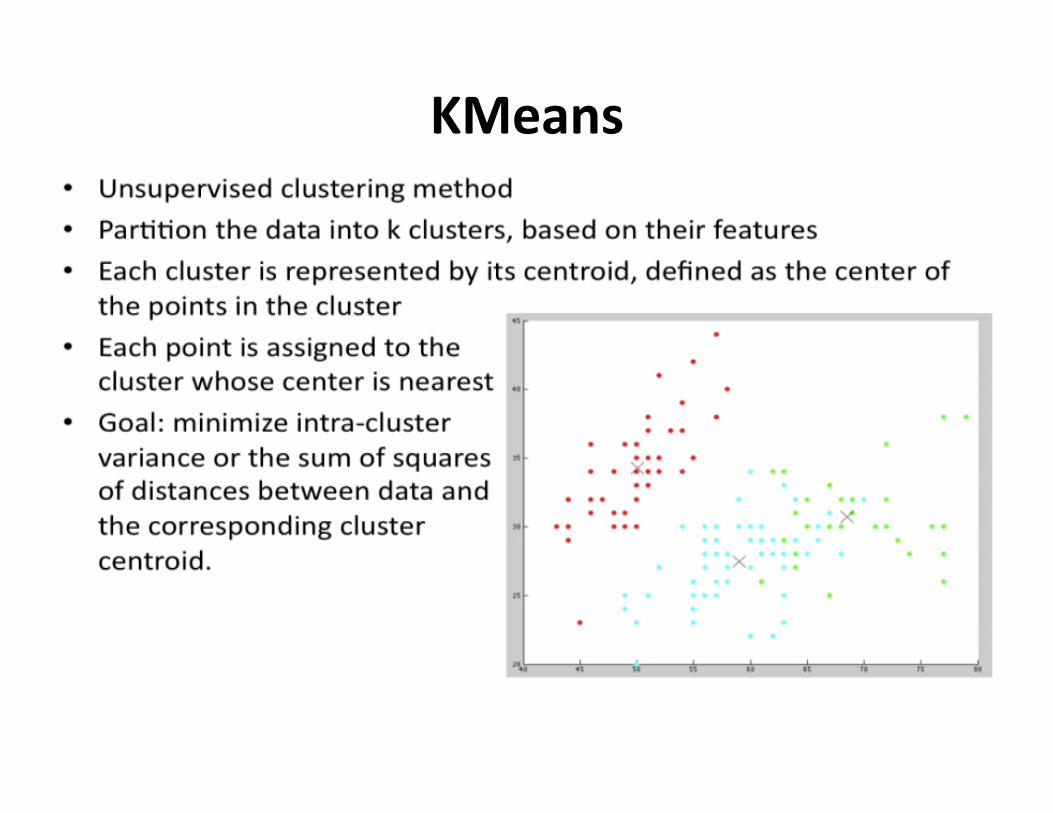
KMeans
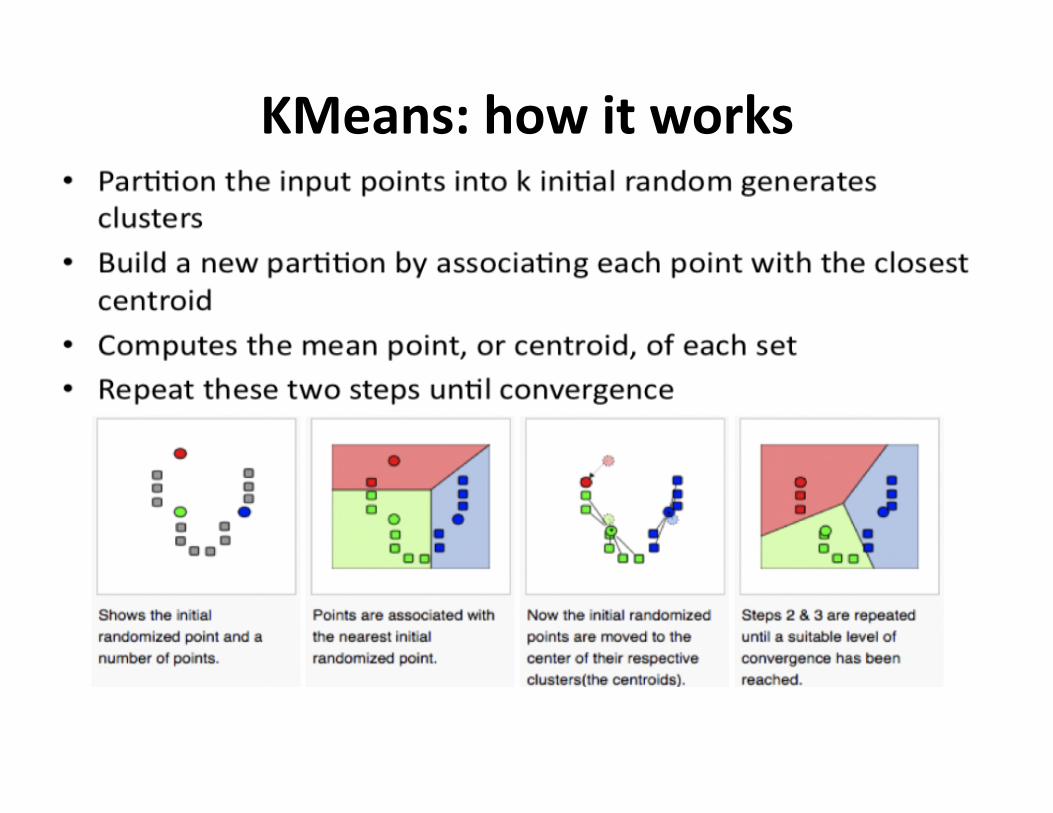
KMeans:howitworks

Kmeans:ProandCons

LearningK• Findabalancebetweentwovariables:thenumberofclusters(K)andtheaveragevarianceoftheclusters.
• Minimizebothvalues
• Asthenumberofclustersincreases,theaveragevariancedecreases(uptothetrivialcaseofk=nandvariance=0).
• Somecriteria:– BIC(BayesianInforma?onCriteria)– AIC(AkaikeInforma?onCriteria)– Davis‐BouldinIndex– ConfusionMatrix
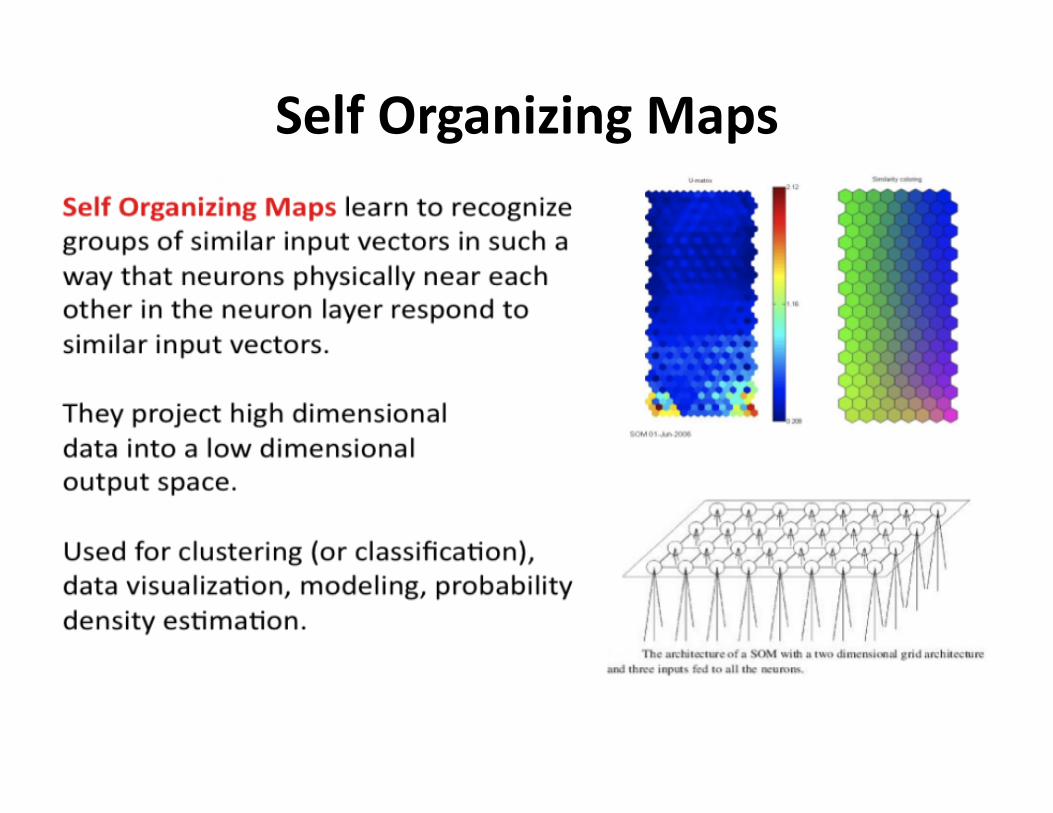
SelfOrganizingMaps
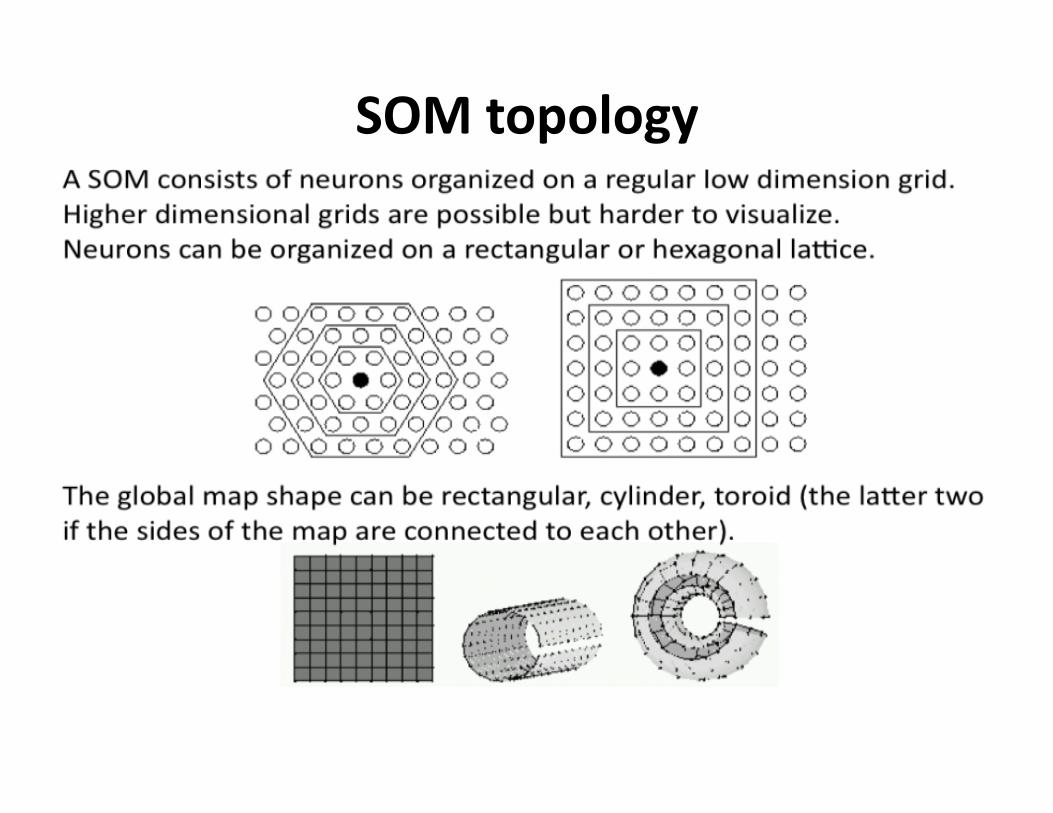
SOMtopology
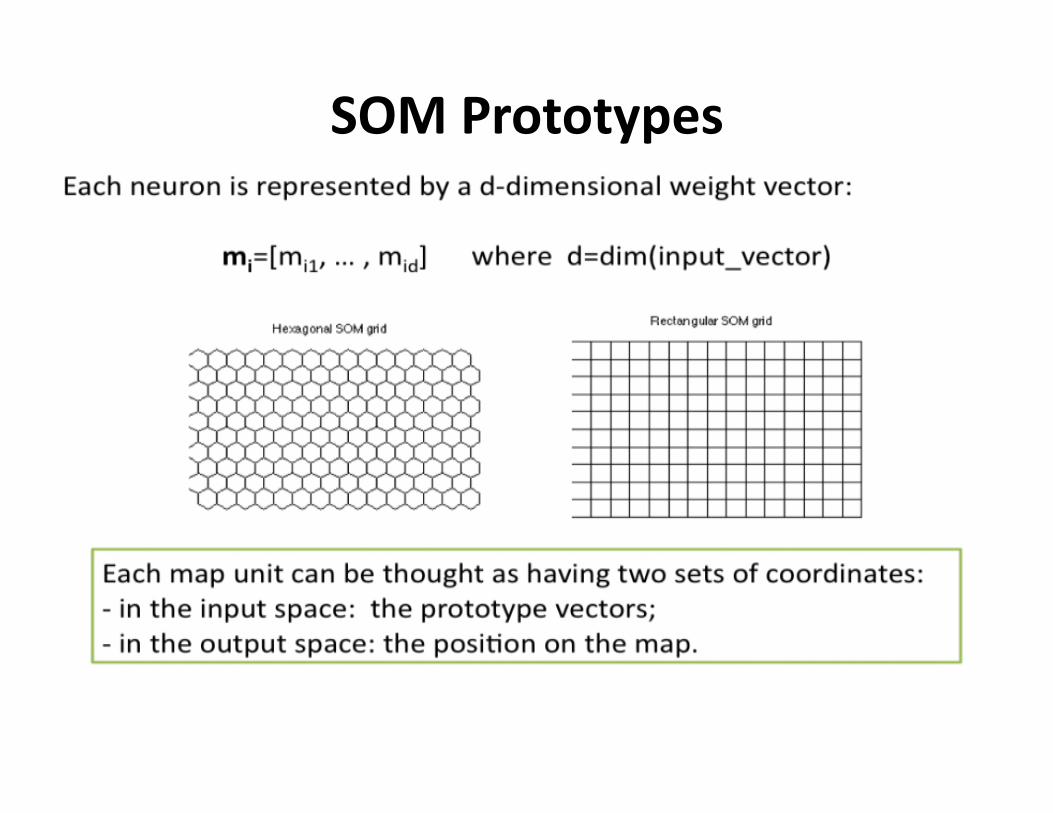
SOMPrototypes

SOMTraining
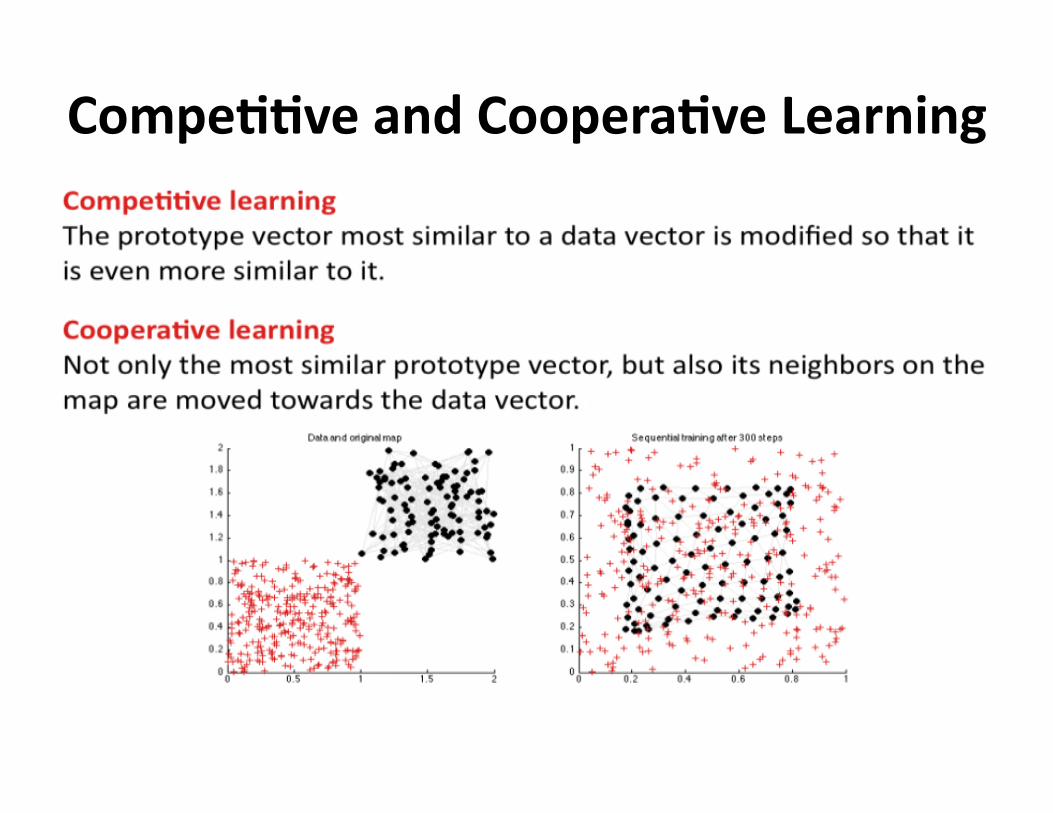
CompeDDveandCooperaDveLearning

SOMUpdateRule

Parameters

DMwithSOM
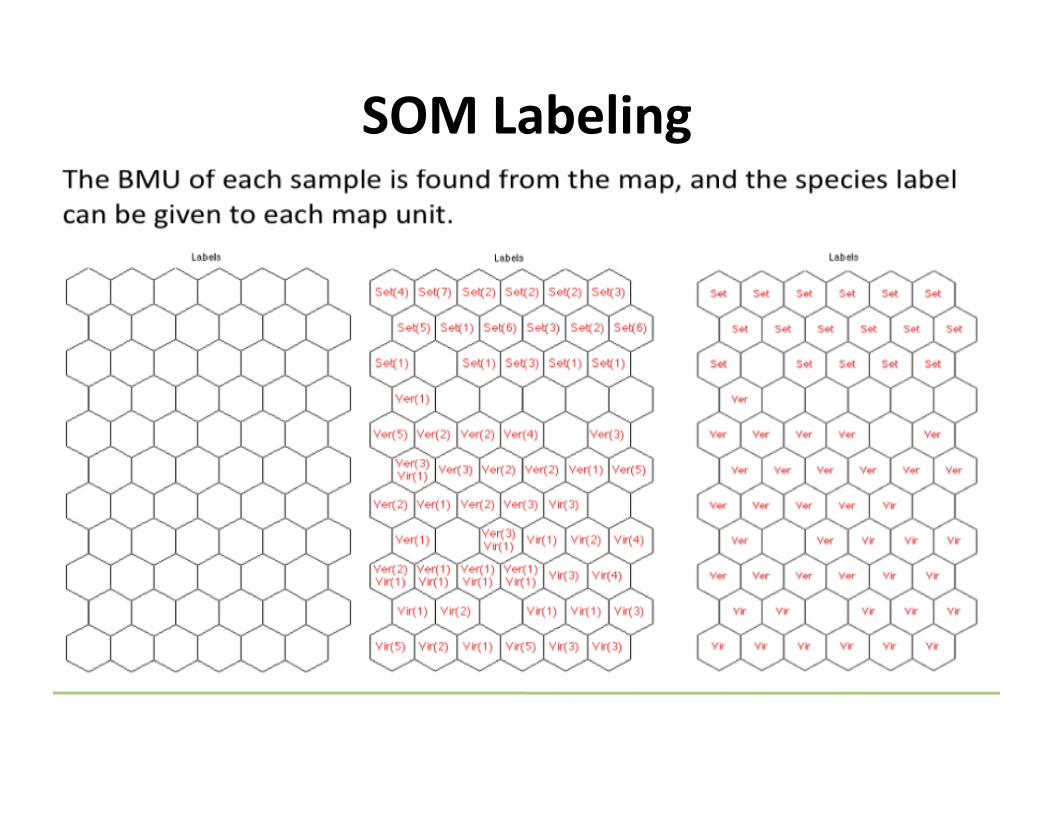
SOMLabeling

LocalizingData
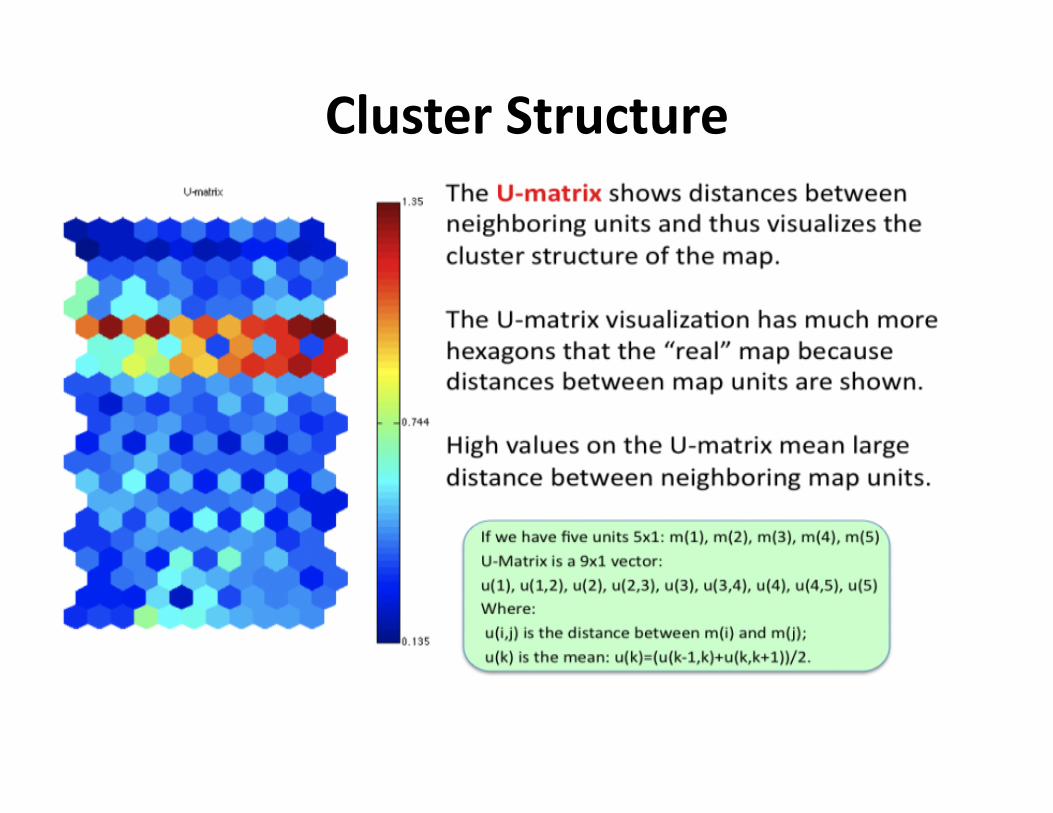
ClusterStructure
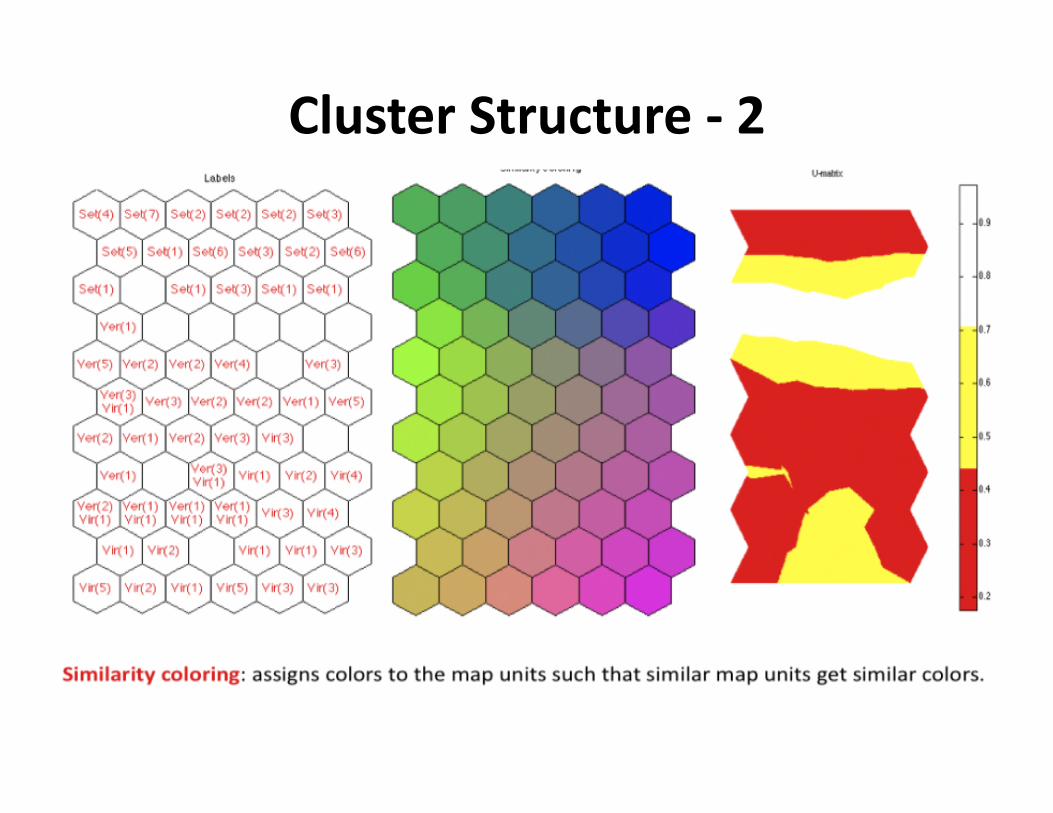
ClusterStructure‐2
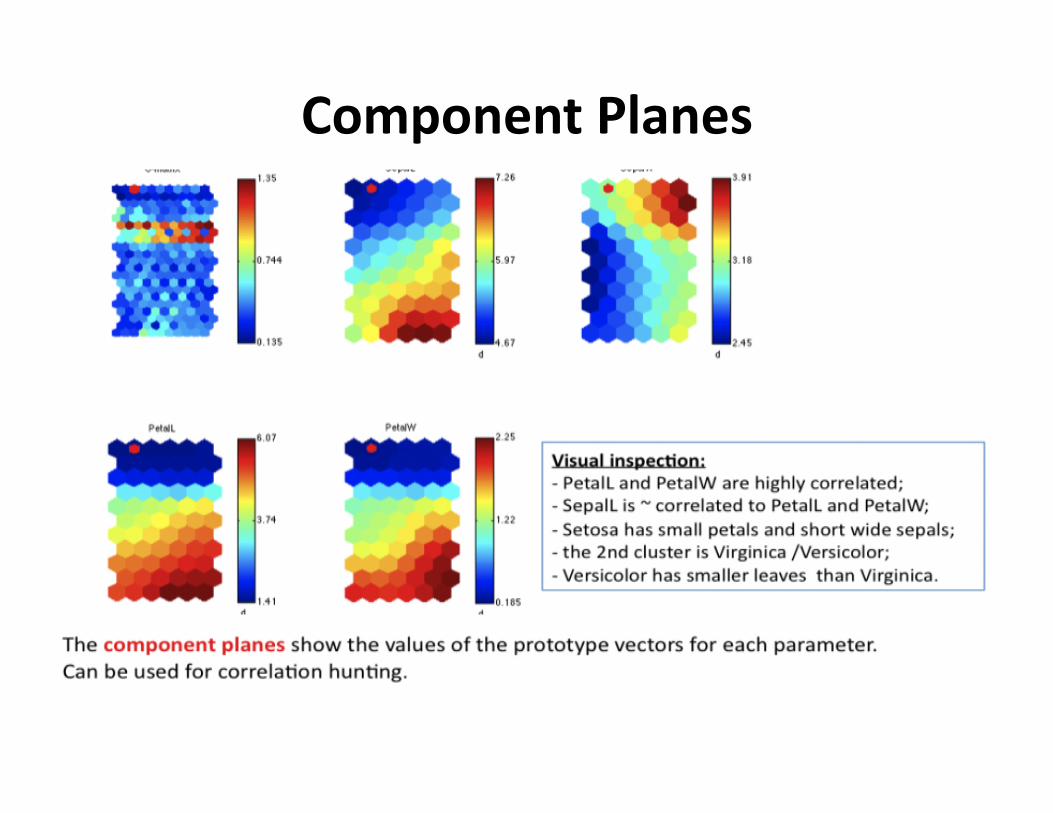
ComponentPlanes
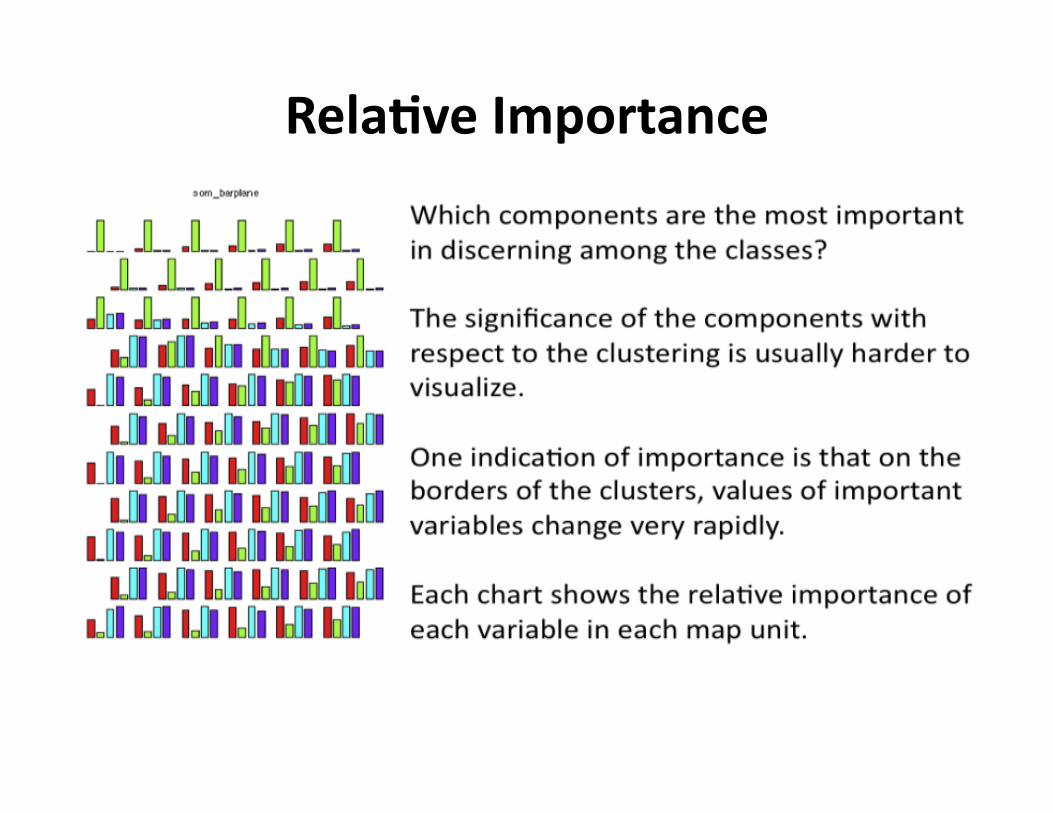
RelaDveImportance

Howaccurateisyourclustering
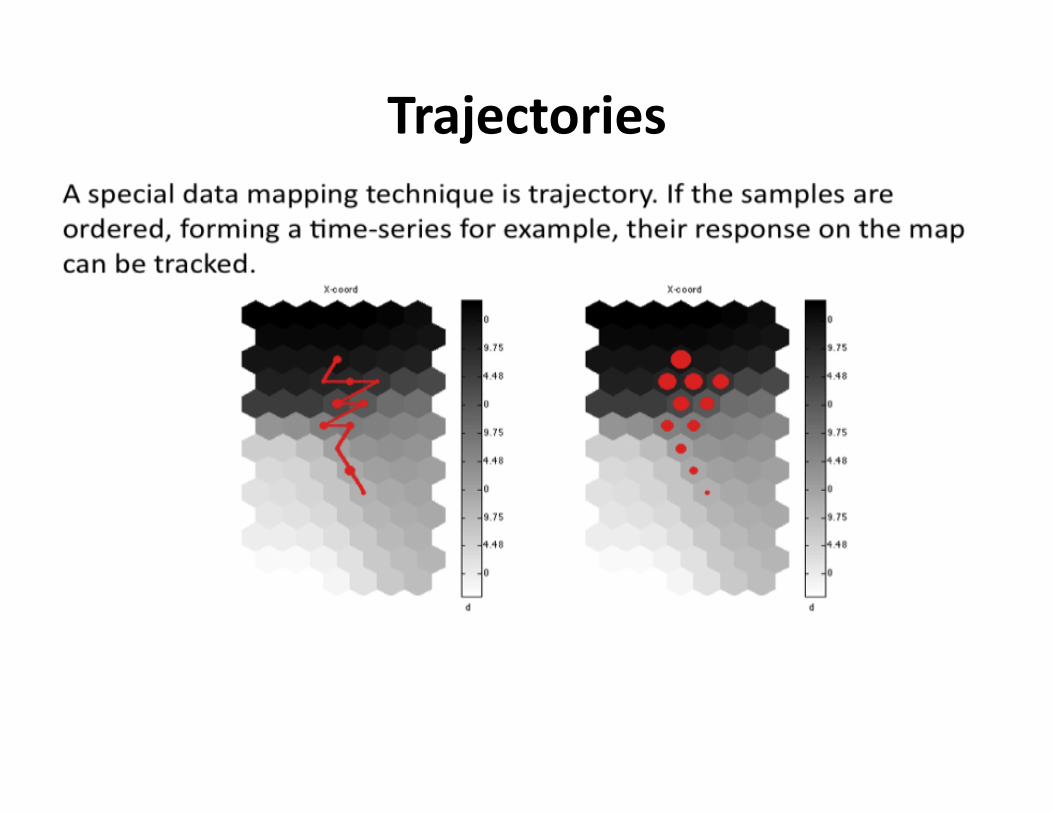
Trajectories

CombiningModels
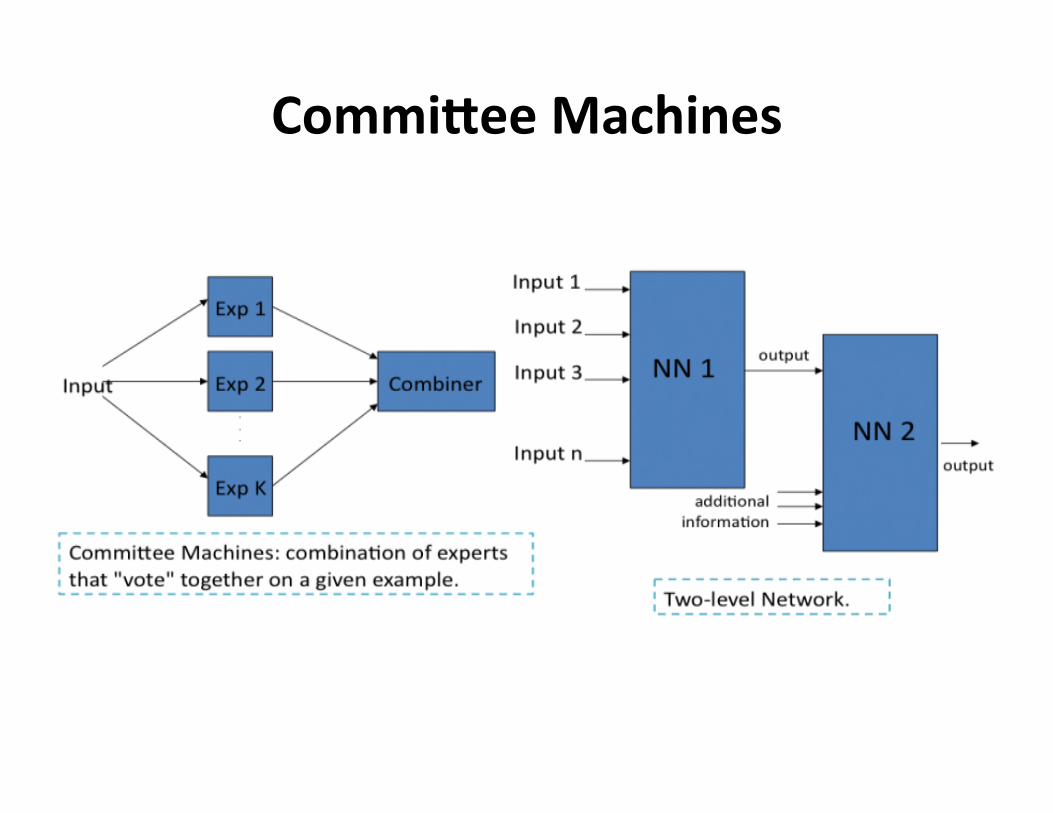
CommideeMachines
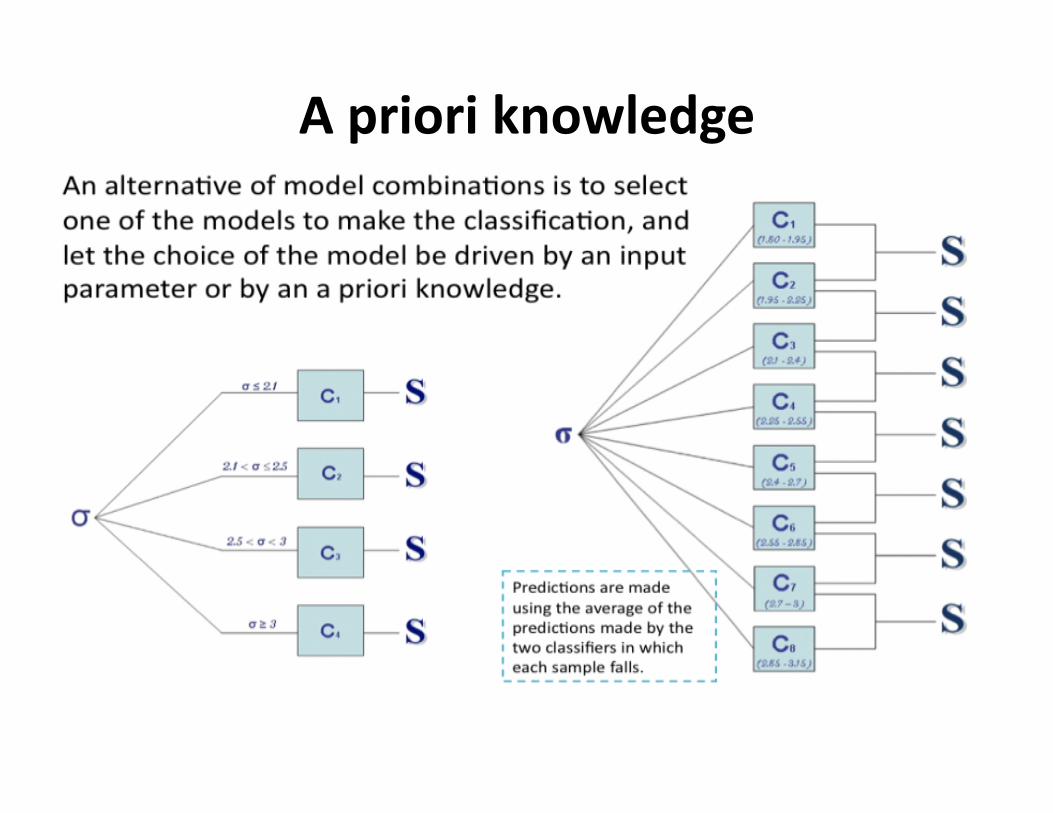
Aprioriknowledge
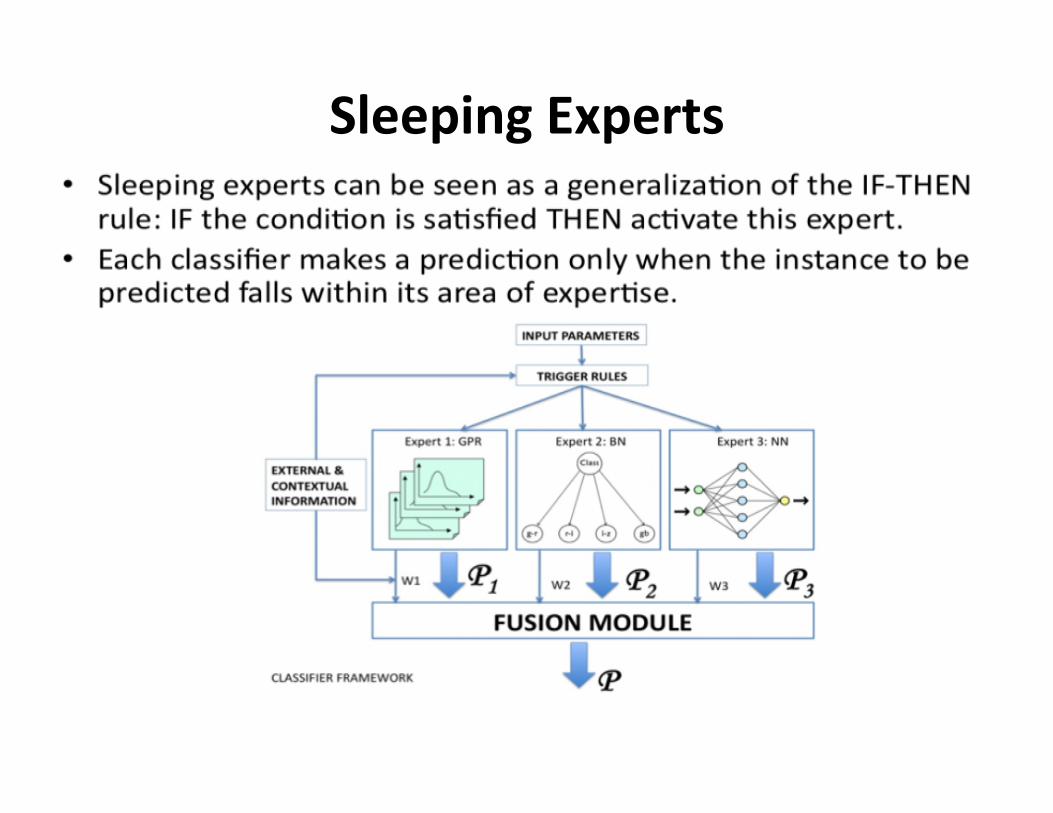
SleepingExperts





























