Embed Size (px)
Citation preview

Techniques for Pseudogene Identification and Prediction of Gene
Conversion
University of IowaCenter for Bioinformatics and Computational Biology (CBCB)Coordinated Laboratory for
Computational Genomics (CLCG)http://genome.uiowa.edu
Jared Bischof, Todd Scheetz, Tom Casavant, Ed Stone, Val
Sheffield, Terry Braun

2

3
Overview
• Definition of pseudogenes and gene conversion
• Describe methods for identification of pseudogenes in the human genome
• Identify characteristics of pseudogenes that may implicate gene conversion
• Validate through sequence disablements• Rank pseudogenes as gene conversion
candidates• Examine candidates for potential
disease-causing mutations• Data available via the web

4
What are pseudogenes and how do they arise?

5
Why do we care about pseudogenes?
• Human genome• Estimated 30,000 genes• ? pseudogenes
• Genes encode a functional product --> protein
• Mutations in genes• Alters proteins• Disease, deficiencies
• Pseudogenes may be a source of mutations in genes

6
Gene Conversion
• The transformation of the sequence of one gene to that of another separate and distinct gene.
• The nonreciprocal transfer of genetic information between two similar but non-identical sequences.
• May result in gene mutations that affect and possibly delete the function of the gene.

7
Gene Conversion
Non-processed pseudogenesare the best candidates for gene conversion
Heteroduplex
5' 3'5'3'
Gene conversion
No gene conversion

8
meiosis I

9
prophase I
-chromosomes more spread out (relative to mitosis)

10
prophase I
-identical pairs matched

11
prophase I
-homologous pairs match up (called a bivalent)-crossing over can now occur

12
prophase I
-as chromatids shorten, and thicken, they are called “tetrads”-“chiasmata” – regions where crossover occurs-virtually all tetrads form at least one “chiasma”-thought to stabilize the tetrad

13
metaphase I
-tetrads line up-microtubules attach to sister chromosomes

14
anaphase I
–sister chromatids are pulled to the same pole (in mitosis, sister chromatids were pulled apart)

15
Telophase I
•cell divides
16
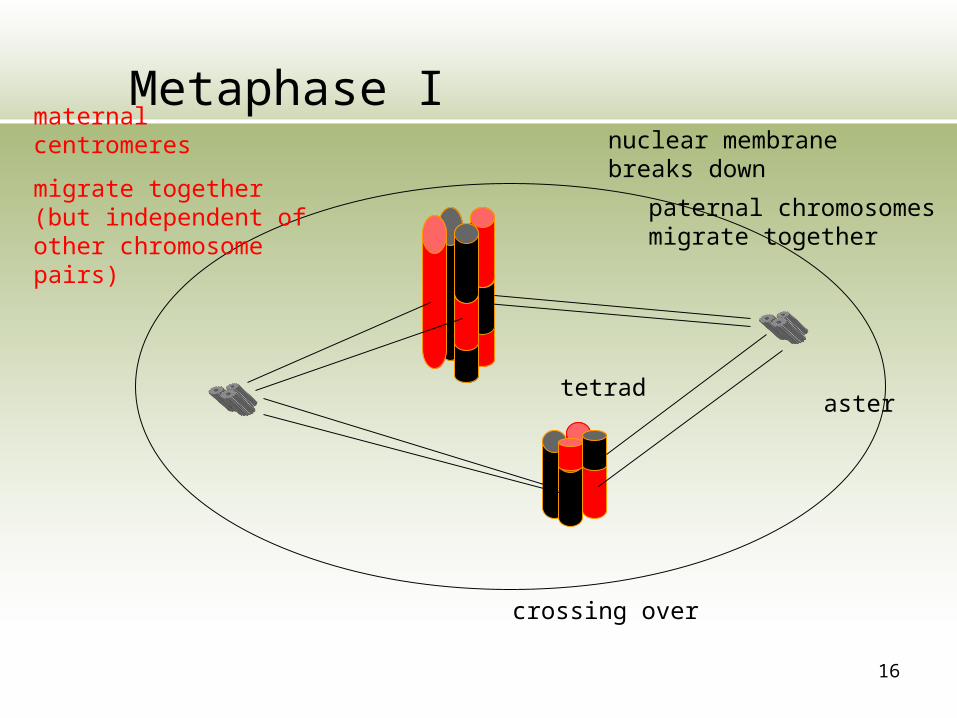
Metaphase Imaternal centromeres
migrate together (but independent of other chromosome pairs) paternal chromosomes
migrate together
crossing over
tetradaster
nuclear membrane breaks down

17
Anaphase II, Telophase II
-sister pairs are pulled apart - cell constricts and divides
18
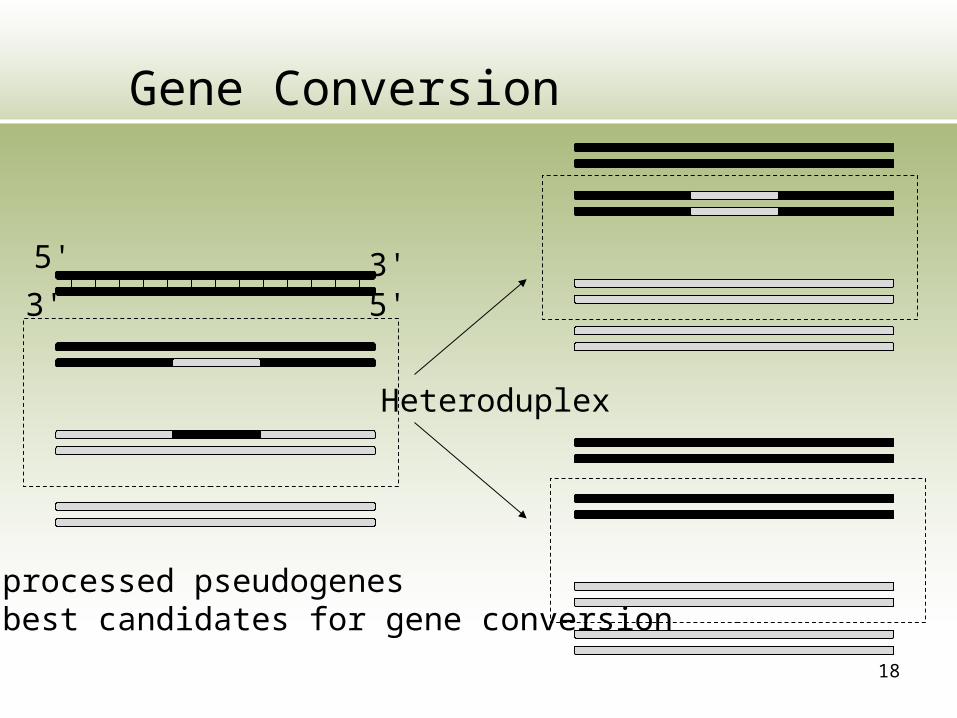
Gene Conversion
Heteroduplex
Non-processed pseudogenesare best candidates for gene conversion
5' 3'5'3'

19
Defining pseudogenes
1) Genomic DNA sequence that does not overlap known genes as defined by NCBI’s Reference Sequence gene set.* NCBI: National Center for
Biotechnology Information
AND
2) Genomic DNA sequence with sequence and gene structure similarity to genuine genes.

20
Pseudogenes and Gene Conversion
Gene Co-localized Pseudogene
Processed/Non Pseudogene
Deleterious effects
5/14.1 YES Non-processed B cell deficiency
ABCC6 YES Non-processed Pseudoxanthoma elasticum (PXE)
CRYBB2 YES Non-processed Autosomal dominant cataract
CYP21 YES Non-processed Congenital adrenal hyperplasia
FR YES Non-processed Neural tube defects
GBA YES Non-processed Type 2 Gaucher disease
IDS YES Non-processed Hunter syndrome
p47-phox YES Non-processed Chronic granulomatous disease
PKD1 YES Non-processed Autosomal dominant polycystic kidney disease
SBDS YES Non-processed Shwachman-Diamond syndrome
VWF NO Non-processed Type 3 von Willebrand disease

21
Pseudogene: Previous Work
1) Zhang and colleagues at Yale University• Identified processed and non-
processed• Non-processed are not available
2) Ohshima and colleagues in Japan• Identified processed pseudogenes
only
3) Torrents and colleagues at the European Molecular Biology Laboratory (EMBL)• Identified processed and non-
processed

22
Pseudogene Study by EMBL
• Searched for pseudogenes in the human genome using protein sequences from the SpTrEMBL database to query the genome.o 830,525 entries (September 2, 2003)
o Including at least 10 species
• Gene location is not available• Exon/Intron structure is not available

23

24

25

26
Pseudogene Search
UCSCHuman GenomeJuly 2003 (hg16)
UCSC annotationGenomic locationof refseq genes
Mask out RefSeq genes
Exons of refseq genes in FASTA
format
Human GenomeWith refseq genes
Masked out
BLAST exons vs. masked genome
BLAST results Candidate list of pseudogenes
UCSC human genome assembly masked for repeats
UCSC annotationGenomic alignments
of RefSeq genes
Exons of RefSeq genes in FASTA
format
Human genomewith RefSeq genes
masked out
BLAST results Identify pseudogenes
Pseudogenes, including
candidates for gene conversion

27
ReportPaths Program
• RefSeq Gene A has 3 exons
• The exons (blue) and the BLAST alignments (red) of those exons against a RefSeq gene-masked genome are shown below with their genomic indices:
Gene A Exon 1 Exon 2 Exon 3
BLAST alignments (e < 0.0001)
chr110,400 11,000
2,000 X X X
910 11,080
10,20010,000chr1chr1
10,600 10,800
2,200 2,520 2,650 3,120 3,320
730
109,100
chr1 chr1 chr1
990 11,140 109,140
790
chrX chr2 chr10
chr9 chr12,680 2,720
22,330 22,370chr12
50% coverage
cutoff
X
X
X

28
ReportPaths Program
• RefSeq Gene A has 3 exons
• The exons (blue) and the BLAST alignments (red) of those exons against a RefSeq gene-masked genome are shown below with their genomic indices:
2,000 X X X2,200 2,520 2,650 3,120 3,320chr1 chr1 chr1
chr12,680 2,720
BLAST alignments (e < 0.0001)
910 990chrX
X
Gene A Exon 1 Exon 2 Exon 3
chr110,400 11,00010,20010,000
chr1chr110,600 10,800
109,100 109,140chr10
11,080 11,140chr2X
730 790chr9
22,330 22,370chr12
X

29
Pseudogenes Identified
6,898
7,103
Overlap
1,0711,77816,68819,537EMBL
3,8783,3697,08914,336UI
AmbiguousNonProcessedAllStudyType
0.01
0.0001
E-value cutoff
0.30 %9.3 Mbp476 bpEMBL
0.39 %11.9 Mbp830 bpUI
Coverage of genome
Total base pairs of pseudogenes
Average length of pseudogenes
Category
Study
• UI -- 50% of one exon from the progenitor gene must be
represented in a pseudogene sequence

30
Classifying for Processing
Pseudogenes classified as processed ornon-processed
0
200
400
600
800
1000
1200
1400
-0.9 -0.6 -0.3 0 0.3 0.6 0.9 1.2 More
Percentage change of intronic sequence retained
Number of pseudogenes
7,098

31
Pseudogene Disablements Identified
UI Pseudogenes EMBL Pseudogenes
Number of disablement
s
Pseudogenes w/disablemen
t
Number of disablement
s
Pseudogenes w/disablemen
t
Early stops 29,724 7,951
(55.5%)
12,568 6,972
(35.7%)
Frameshifts 17,546 7,335
(51.2%)
20,064 8,968
(45.9%)
Early stops or Frameshifts
47,270 9,169
(64.0%)
32,632 11,293
(57.8%)

32
Bias of Co-localized Pseudogenes
• 1,945 (56.8%) of non-processed pseudogenes are on the same chromosome as the progenitor gene
• 375 (5.2%) of processed pseudogenes are on the same chromosome as the progenitor gene
33
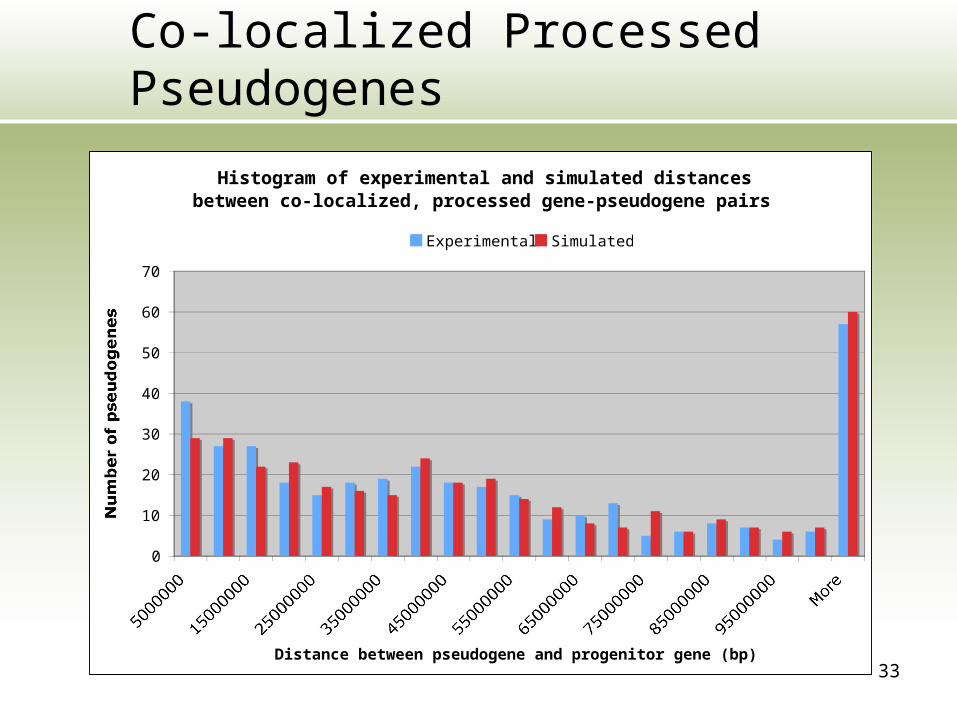
Co-localized Processed Pseudogenes
Histogram of experimental and simulated distances between co-localized, processed gene-pseudogene pairs
0
10
20
30
40
50
60
70
5000000150000002500000035000000450000005500000065000000750000008500000095000000
More
Distance between pseudogene and progenitor gene (bp)
Number of pseudogenes
Experimental Simulated

34
Co-localized Non-processed Pgenes
Histogram of experimental and simulated distances between co-localized, non-processed gene-pseudogene pairs
0
200
400
600
800
1000
1200
1400
5000000150000002500000035000000450000005500000065000000750000008500000095000000
More
Distance between pseudogene and progenitor gene (bp)
Number of pseudogenes
Experimental Simulated

35

36
Known Gene Conversion Cases
Gene Pgene ID
Co Chrom Dist Sim Len GC% GC3%
5/14.1 08894 YES 22 1.8M 96% 576 63% 77%
ABCC6 04734 YES 16 2.3M 99% 1198 61% 74%
CRYBB2 08798 YES 22 224k 95% 525 59% 78%
CYP21 11041 YES 6 29k 99% 2006 61% 81%
FR 02141 YES 11 30k 93% 714 55% 72%
GBA 00535 YES 1 7k 97% 2273 56% 65%
IDS 13690 YES X 20k 99% 237 50% 58%
p47-phox 11753 YES 7 369k 99% 1339 62% 82%
PKD1 04876-81 YES 16 5-10k 98% 6385-10155 67% 84%
SBDS 11923 YES 7 5.8M 97% 1578 42% 50%
VWF 02767 NO 12,22() NA 98% 2874 59% 73%
Note: All pseudogenes involved in known cases were identified as non-processed.

37
Known Gene Conversion Cases
Gene involved in known gene conversion case
Pseudogene identified by EMBL
5/14.1 Identified as processed pseudogene
ABCC6 Not identified
CRYBB2 Not identified
FR Identified as non-processed pseudogene
GBA Identified as non-processed pseudogene
IDS Identified as processed pseudogene
p47-phox Not identified
PKD1 Identified as processed pseudogene
SBDS Not identified
VWF Identified as processed pseudogene
Note: CYP21p is not present in the July 2003 genome release

38
Ranking Gene Conversion Candidates
• Non-processed, co-localized pseudogeneso 1,945 candidates
• Sequence characteristics (Score between 0 and 1)1. Similarity2. Pseudogene length/progenitor gene
length3. Pseudogene length/max pseudogene
length4. GC content5. GC3 content6. Distance from progenitor gene
1 - (distance/max distance)

39
Ranking Gene Conversion Candidates
• Six variableso a,b,c,d,e,f
(0.00 to 1.00)o Six weights (w1,w2, … w6)
0.40, 0.02, 0.05, 0.00, 0.80, 1.00o Assign weights and rank gene conversion candidates (gene-pseudogene pairs)
o Try all combinations1.00a + 0.00b + 0.00c + 0.00d + 0.00e + 0.00f
0.98a + 0.02b + 0.00c + 0.00d + 0.00e + 0.00f
…0.00a + 0.00b + 0.00c + 0.00d + 0.00e +1.00f

40
Ranking Gene Conversion Candidates
• Optimal weightso Best ranking of known cases (9 of 11) Sum of all rankings
2,228
2,228
SUM
5091055514546719218179126Rank
SBDSp47IDSGBAFRCYP21CRYBB2ABCC65/14.1Gene
39618688163Pubmed

41
Ranking Gene Conversion Candidates
• Optimal weightso Best ranking of known cases (9 of 11) Sum of all rankings
Variable Similarity Length/ gene length
Length/ maxlength
GC GC3 Distance
Weight 0.26 0.02 0.00 0.08 0.02 0.62
2,228

42
Publicly Available Data
• Web siteo http://genome.uiowa.edu/pseudogenes/
o Identified pseudogenes- July 2003- May 2004
o Gene conversion candidateso Statisticso Programs
- Reportpaths- Rank
- Looked closely at known retinal disease genes (155)- Novel gene conversion event

43
Disease-causing Candidates
• Retinal Information Networko 155 human genes related to inherited retinal disorders
o 25 of these intersect the UI pseudogenes
o 13 have a co-localized pseudogeneo 6 have a non-processed pseudogeneo 4 have a non-processed, co-localized pseudogene-ABCC6, OPN1LW, RP9, ALMS1-(in training set)

44
Disease-causing Candidates
• ABCC6 pseudogeneo Known case of pseudogene involvement in gene conversion has been linked with Pseudoxanthoma elasticum (PXE)
• OPN1LW pseudogeneo Involved in gene conversions with OPN1MW (24kb away) that can cause color blindness
• RP9 pseudogeneo Mutation (GAT-GGT) present in the Human Gene Mutation Database (HGMD) has been found to cause autosomal dominant retinitis pigmentosa
• ALMS1 pseudogeneo No literature to support gene conversion theory

45
Disease-causing Candidates
• Highest-ranked validating gene conversion candidateo HBZ gene and a pseudogene 8.5kb awayo Gene conversion activates pseudogene
• Processed, co-localized gene-pseudogene pairso IMPDH1 pseudogene
- (GAC-AAC) is associated with the RP10 form of autosomal dominant retinitis pigmentosa
o PGK1 pseudogene- (ATT-ACT) has been associated with a PGK deficiency
- Final thought: gene conversion may be transparent to linkage disequilibrium (give example of LD)

46
Repositories for mutations?• Pseudogenes may act as repositories for mutations -- where mutations may collect over time -- and then aberrantly be "gene converted" into the genuine gene.
• Conversely, perhaps the genuine gene actually helps maintain a copy of the p-gene, by continually "gene converting" a recognizable copy of the p-gene?

47
An in silico discovery"Among the pseudogenes identified is a
retinitis pigmentosa 9 (RP9) pseudogene that carries a c.509A>G mutation which produces a p.Asp170Gly substitution that is associated with the RP9 form of autosomal dominant retinitis pigmentosa (adRP). The c.509A>G mutation in RP9 is a previously unrecognized example of gene conversion between the progenitor gene and its pseudogene."

48
Questions?
Acknowledgements:
Jared BischofVal SheffieldEd StoneTodd ScheetzTom Casavant
CLCG

49
End

50
Gene Conversion
• The transformation of the sequence of one gene to that of another separate and distinct gene.
• The nonreciprocal transfer of genetic information between two similar but non-identical sequences.
• May result in gene mutations that affect and possibly delete the function of the gene.

51
Simulation of Co-localized Pairs
• N1, N2, … represents the number of gene-pseudogene pairs co-localized to Chromosome 1, 2, …
• N1, N2, … number of genes and their pseudogenes were each randomly distributed on Chromosome 1, 2, …
• The distributions of these gene-pseudogene pairs were then analyzed in two groups (processed and non-processed)

52
Final Thoughts
• 1,945 ranked candidates for gene conversion
• Similar analysis could be performedo OMIM - Online Mendelian Inheritance in Man
o HGMD - Human Gene Mutation Database

53
Gene Conversion
Heteroduplex
Non-processed pseudogenesare best candidates for gene conversion





























