Embed Size (px)
Citation preview

Tema 6Extensiones y aplicaciones
(Maquinas de vectores soporte, SVM)
Jose R. Berrendero
Departamento de MatematicasUniversidad Autonoma de Madrid

Contenidos del tema 6
El problema de clasificacion supervisada: un ejemplo
SVM para datos separables linealmente.
SVM para datos no separables linealmente.
Reglas de clasificacion no lineales: el truco del nucleo.

Diagnostico por imagen del cancer de mama
Puncion con aguja fina.
La muestra se tine pararesaltar los nucleos de lascelulas.
Se determinan los lımitesexactos de los nucleos.
Las variablescorresponden a distintosaspectos de su forma.

Variables
nombre descripcionradius radio del nucleotexture varianza de los niveles de gris en el interior del nucleo
perimeter perımetro del nucleoarea area del nucleo
smoothness suavidad medida mediante la variacion del radiocompactness el perımetro al cuadrado dividido por el area
concavity medida de la importancia de las concavidadesconcavepoints numero de concavidades
symmetry medida de la simetrıa del nucleofractal dimension fractal de la frontera
Mas informacion sobre estos datos

Grafico de estrellas

Variables smoothness y concavepoints
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●●
●
●
● ●
●
●
●
●
●● ● ●
●
●
●
●
●
●
●
● ● ●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
● ●
●
● ●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●
●●
●
●● ●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
● ●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●●●
●
●
●
●
●●
●
●
●
●●●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●●
●
● ●
● ●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
● ●
●
●
●
●
●
●
●●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●●
●●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
● ●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
● ●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
0.06 0.08 0.10 0.12 0.14 0.16
0.00
0.05
0.10
0.15
0.20
smoothness
conc
avep
oint
s

Clasificacion supervisada
Disponemos de una muestra de datos bien clasificados (training data):
(x1, y1), . . . , (xn, yn)
donde xi ∈ Rd son las variables observadas e yi ∈ {−1, 1} es la etiquetaque representa la clase a la que pertenecen las observaciones.
Se observa ahora un nuevo vector x independiente de los anteriores.El objetivo es determinar a que clase pertenece la observacion x .
La regla optima (regla Bayes) consiste en asignar a x el valor y = 1 si ysolo si
P(y = 1|x) > P(y = −1|x)
No es aplicable en la practica.

SVM para datos separables linealmente
Suponemos que las muestras de ambos grupos son separablesmediante un hiperplano.
8. Maquinas de vectores soporte
Caso 1: Existe un hiperplano separador
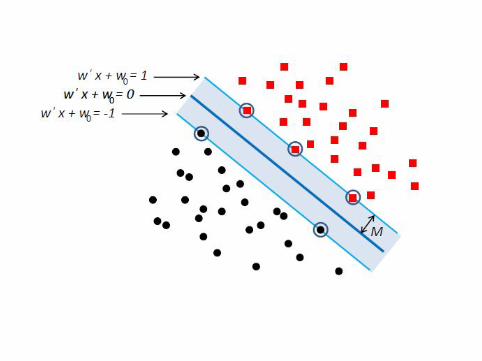
El margen, M, de un hiperplano separador es la distancia mınimadel hiperplano a los datos. El hiperplano separador optimo esaquel que maximiza el margen.
M
M
¿Como se calcula el margen de un hiperplano separador?
Jose Ramon Berrendero & Javier Carcamo Clasificacion supervisada 57El margen de un hiperplano separador viene dado por la menordistancia de los puntos al hiperplano.
El hiperplano optimo es aquel que maximiza el margen.

Distancia de un punto a un hiperplano
Distancia de un punto x al hiperplano w ′x + w0 = 0.
Sea x el punto del hiperplano mas cercano a x . Entonces,
x = x + rw
‖w‖⇒ w ′x + w0 = (w ′x + w0) + r‖w‖ = r‖w‖.
La distancia de un punto x al hiperplano es:
d = |r | =|w ′x + w0|‖w‖
.

Margen
Disponemos de una muestra de datos clasificados (xi , yi ),i = 1, . . . , n.
La clase es yi ∈ {−1, 1}.
Un hiperplano separador verifica yi (w′xi + w0) > 0, para todo
i = 1, . . . , n.
Siempre podemos definir w y w0 de manera que
mini{yi (w ′xi + w0)} = 1.
El margen es
Margen = mini
yi (w′x + w0)
‖w‖=
1
‖w‖.

Hiperplano separador optimo
Buscamos el hiperplano separador que maximiza el margen.
Tenemos que resolver el problema convexo
minimizar ‖w‖2/2s.a. yi (w
′xi + w0) ≥ 1, i = 1, . . . , n
La funcion lagrangiana de este problema es
L(w ,w0) =‖w‖2
2−
n∑i=1
ui [yi (w′xi + w0)− 1]

Condiciones KKT
Las condiciones de Karush-Kuhn-Tucker que debe satisfacer la solucion deeste problema son:
El gradiente de la funcion lagrangiana se anula
Se cumplen las restricciones del problema
Los multiplicadores no son negativos.
Se cumplen las condiciones de holgura complementaria.
Estas condiciones permiten deducir algunas propiedades importantes de lasolucion.

Condiciones KKT
∇L(w , w0) = 0⇒ w =n∑
i=1
uiyixi yn∑
i=1
uiyi = 0.
Para i = 1, . . . , n,yi (w
′xi + w0) ≥ 1, ui ≥ 0
ui(yi (w
′xi + w0)− 1)
= 0
El hiperplano optimo solo depende de aquellos puntos de los que esta mascerca (yi (w
′xi + w0) > 1⇒ ui = 0).
Tıpicamente son pocos. Se llaman vectores soporte.

Problema dual
Funcion dual (se obtiene minimizando la funcion lagrangiana en w yw0):
g(u) =n∑
i=1
ui −1
2
n∑i=1
n∑j=1
uiujyiyjx′i xj
si∑n
i=1 uiyi = 0, y g(u) = −∞ en caso contrario.
Problema dual:
maximizar g(u)s.a.
∑ni=1 uiyi = 0.
ui ≥ 0, i = 1, . . . , n.

Problema dual
En forma matricial, si 1n = (1, . . . , 1)′ ∈ Rn, y = (y1, . . . , yn)′ y H es lamatriz cuyas entradas son hij = yiyjx
′i xj ,
maximizar u′1n − 12u
′Hus.a. u′y = 0
u ≥ 0.
Es un problema de optimizacion convexo (la matriz H es definidapositiva).
La solucion depende de x1, . . . , xn unicamente a traves de losproductos escalares x ′i xj .

Calculo del hiperplano optimo
Resolvemos el problema dual mediante algun metodo deprogramacion convexa estandar.
A partir de la solucion del dual, u, aplicamos w =∑n
i=1 uiyixi paraobtener w .
Sean S = {i : ui > 0} los ındices de los vectores soporte. Por lascondiciones de holgura complementaria, para cada i ∈ S ,
w0 =1− yi w
′xiyi
= yi − w ′xi .
En la practica, es numericamente mas estable usar el promedio deestos valores. Si #S = ns .
w0 =1
ns
∑i∈S
(yi − w ′xi ).

Regla de clasificacion
Resulta una regla de clasificacion lineal: asignamos a x el valor y = 1 si ysolo si w ′x + w0 > 0.
w0 + w ′x > 0⇔ w0 +
[∑i∈S
yi uixi
]′x > 0
Si αi = yi ui , tambien podemos escribir la regla de clasificacion como:
y = 1⇔ w0 +∑i∈S
αi (x′i x) > 0
¿Como afecta a la clasificacion una rotacion de los datos?

SVM para datos no separables linealmente
En la practica, la mayorıa de los datos no son separables linealmente.
Se introducen unas variables de holgura ξ1, . . . , ξn de manera que:
se relajan las restricciones con el fin de permitir errores declasificacion,
se cambia el objetivo para penalizar estos errores.
minimizar ‖w‖2/2 + C∑n
i=1 ξis.a. yi (w
′xi + w0) + ξi ≥ 1, i = 1, . . . , nξi ≥ 0, i = 1, . . . , n
La constante C > 0 es seleccionada por el usuario y determina si loserrores se penalizan mas o menos.

SVM para datos no separables linealmente

Condiciones KKT
L(w ,w0, u, v) =‖w‖2
2+C
n∑i=1
ξi −n∑
i=1
ui [yi (w′xi +w0) + ξi − 1]−
n∑i=1
viξi
Gradiente de L igual a cero:
w =n∑
i=1
uiyixi ;n∑
i=1
uiyi = 0.
Factibilidad primal y dual:
yi (w′xi + w0) + ξi ≥ 1; ξi ≥ 0; 0 ≤ ui ≤ C .
Holgura complementaria:
ui [yi (w′xi + w0) + ξi − 1] = 0; (C − ui )ξi = 0.

Cuestiones
Escribe la funcion y el problema dual. ¿Que diferencias se observanrespecto al caso en que los datos son separables linealmente?
¿Que condicion deben verificar en este caso los vectores soporte?
Si ui , i = 1, . . . , n es la solucion del problema dual, ¿como se calculanw y w0
Escribe la regla de clasificacion.

Ejemplo. SVM para datos no separables linealmente
0.06 0.08 0.10 0.12 0.14 0.16
0.0
00
.05
0.1
00
.15
0.2
0
smoothness
con
cave
po
ints
C=10C=1000

Extension a reglas no lineales

Extension a reglas no lineales
Es posible que una regla de clasificacion lineal no sea apropiada paralos datos originales x1, . . . , xn pero sı para los datos transformadosφ(x1), . . . , φ(xn), donde φ : Rd → H para un espacio de Hilbert H.
Basta sustituir x ′i xj por 〈φ(xi ), φ(xj)〉H en el problema dual.
Tıpicamente H = RN con N >> d o H es un espacio de funciones(dimension infinita).
En la practica, puede ser difıcil calcular los productos escalares〈φ(xi ), φ(xj)〉H.

El truco del nucleo (the kernel trick)
Teorema: Una funcion k : Rd × Rd → R es simetrica y semidefinidapositiva (SDP) si y solo si existe un espacio de Hilbert H y unatransformacion φ : Rd → H tal que k(x , y) = 〈φ(x), φ(y)〉H.
Estas funciones simetricas y SDP se llaman nucleos.
En la practica, en lugar de elegir H y φ, se elige un nucleo y sesustituye x ′i xj por k(xi , xj).
Ası se obtienen reglas de clasificacion de la forma:
y = 1⇔ w0 +∑i∈S
αik(xi , x) > 0.

Algunos nucleos muy utilizados
Polinomios de grado m:
k(x , y) = (x ′y + c)m.
Gaussiano:
k(x , y) = exp
(−‖x − y‖2
2σ2
)Laplaciano:
k(x , y) = exp
(−‖x − y‖
σ
)Para cada problema concreto hay que usar un nucleo apropiado.Un polinomio de grado pequeno o el nucleo gaussiano suelen ser buenasprimeras opciones.

Regla de clasificacion con nucleo cuadratico
−4 −2 0 2 4
−4
−2
02
46
x1
x2
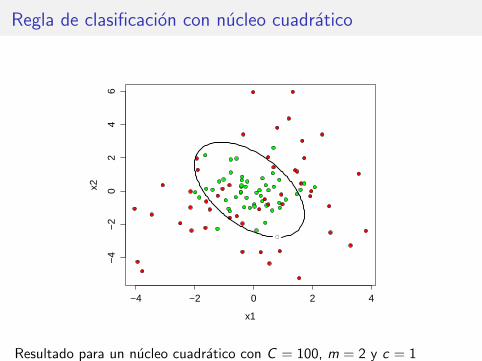
Regla de clasificacion con nucleo cuadratico
−4 −2 0 2 4
−4
−2
02
46
x1
x2
Resultado para un nucleo cuadratico con C = 100, m = 2 y c = 1

Regla de clasificacion con nucleo cuadratico
0.00 0.05 0.10 0.15 0.20
0.00
0.10
0.20
smoothness
conc
avep
oint
s
Resultado para un nucleo cuadratico con C = 100000, m = 2 y c = 1





























