Embed Size (px)
Citation preview

Text Summarisation based on Human Language Technologies and its Applications
Elena Lloret PastorSupervisor: Dr. Manuel
PalomarSeminar - June 2011

Outline•Introduction•State of the Art•COMPENDIUM Text Summarisation Tool
•Evaluation and Experiments•COMPENDIUM in HLT Applications•Conclusion
2

IntroductionMOTIVATION
•Human Language Technologies (HLT)▫Allow people to communicate with
machines by using natural language (Cole, 1997)
•Intelligent applications based on HLT▫Information retrieval▫Question Answering▫Text Classification▫Opinion Mining▫Text Summarisation
3

IntroductionMOTIVATION
•Why is Text Summarization (TS) needed?▫To condense information, keeping at the
same time, the most relevant one▫Help users to manage and process large
amounts of information
4
The 2008 Summer Olympics took place in Beijing, China, from August 8 to August 24, 2008. A total of 11,028 athletes from 204 National Olympic Committees (NOCs) competed in 28 sports and 302 events. It was the third time that the Summer Olympic Games were held in Asia, after Tokyo, Japan in 1964 and Seoul, South Korea in 1988. The program for the Beijing Games was quite similar to that of the 2004 Summer Olympics held in Athens. There were 28 sports and 302 events. Moreover, there were 43 new world records and 132 new Olympic records set at the 2008 Summer Olympics. Chinese athletes won the most gold medals, with 51, and 100 medals altogether, while the United States had the most medals total with 110. There were many memorable champions but it was Michael Phelps and Usain Bolt who stole the headlines.
Source documents: http://en.wikipedia.org/wiki/2008_Summer_Olympicshttp://en.beijing2008.cn/#http://www.olympic.org/beijing-2008-summer-olympics
17.500.000 results
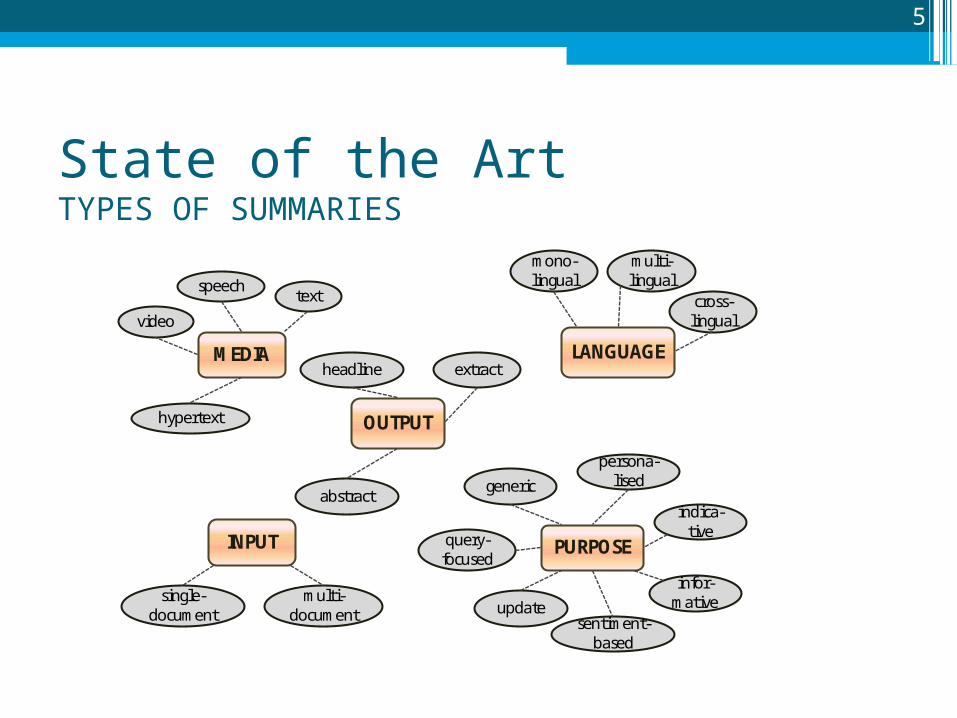
State of the ArtTYPES OF SUMMARIES
5
MEDIA
textspeech
video
hypertext
LANGUAGE
mono-lingual
multi-lingual
cross-lingual
INPUT
single-document
multi-document
PURPOSE
generic
persona-lised
query-focused
updatesentiment-
based
indica-tive
infor-mative
OUTPUT
extract
abstract
headline

State of the ArtTEXT SUMMARISATION PROCESS
•Topic identification▫What the document is about
•Interpretation or topic fusion▫Important topics are expressed using new
formulation
•Summary generation▫Natural Language Generation is applied to
build the final summary
6
Topic identification Interpretation Summary
generation
THE PROCESS OF SUMMARISATION

State of the ArtGENERATION OF SUMMARIES
•Approaches▫Statistical-based tf, tf*idf (e.g. Orăsan, 2009)▫Topic-based event words (e.g. Kuo & Chen,
2008)▫Graph-based LexRank (e.g. Erkan & Radev,
2004)▫Discourse-based lexical chains (e.g. Barzilay
& Elhadad, 1999)▫Machine learning-based neuronal nets (e.g.
Svore et al., 2007)
7

State of the ArtGENERATION OF SUMMARIES
•New types of summaries▫Personalised summaries user profiles (e.g.
Díaz & Gervás, 2007)▫Update summaries “history” (e.g. Li et al.,
2008)▫Sentiment-based summaries multi-aspect
rating model (e.g. Titov, & McDonald, 2008)▫Surveys summaries Wikipedia articles (e.g.
Sauper & Barzilay, 2009)▫Abstractive summaries sentence compression
(e.g. Filippova, 2010)
8

State of the ArtGENERATION OF SUMMARIES
•New scenarios ▫Literary text books (e.g. Ceylan &
Mihalcea, 2009)▫Patent claims (e.g. Trappey et al., 2009)▫Image captioning (e.g. Aker & Gaizauskas,
2010)▫Web 2.0 textual genres blogs (e.g. Balahur
et al., 2009)
9

State of the ArtEVALUATION OF SUMMARIES
10
•Types of evaluation▫Intrisic evaluate the summary on its own
Informativeness assessment
Quality assessment
▫Extrinsic evaluate how good the summaries are to perform other tasks
Pyramid QARLA ROUGEBasic Elements
Indicativeness Grammaticality Coherence Non-redundancy
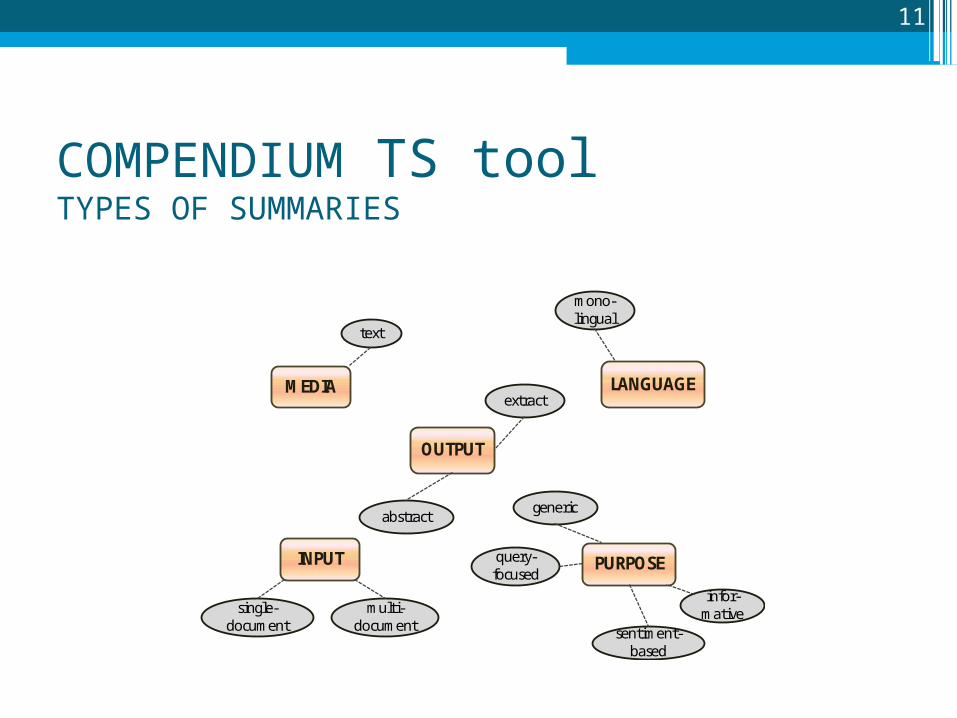
COMPENDIUM TS toolTYPES OF SUMMARIES
11
MEDIA
text
LANGUAGE
mono-lingual
INPUT
single-document
multi-document
PURPOSE
generic
query-focused
sentiment-based
infor-mative
OUTPUT
extract
abstract
12
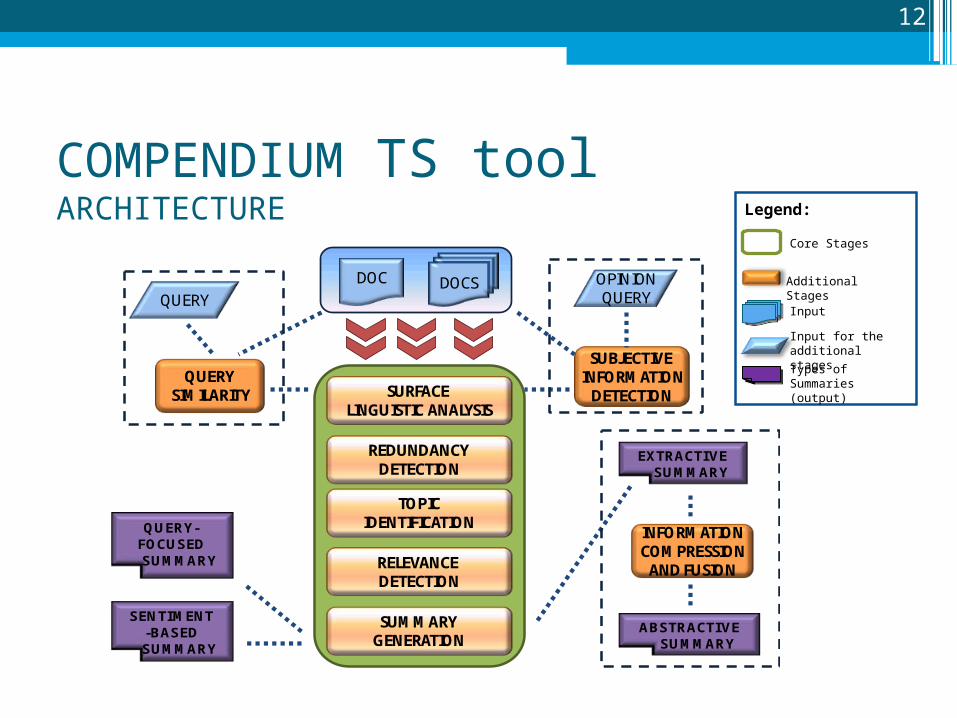
Legend:
Additional Stages
Types of Summaries (output)
Core Stages
Input for the additional stages
Input
COMPENDIUM TS toolARCHITECTURE
SURFACE LINGUISTIC ANALYSIS
TOPICIDENTIFICATION
RELEVANCE DETECTION
SUMMARY GENERATION
EXTRACTIVESUMMARY
QUERYOPINIONQUERY
REDUNDANCY DETECTION
QUERY SIMILARITY
SUBJECTIVE INFORMATION
DETECTION
QUERY-FOCUSED SUMMARY
SENTIMENT-BASEDSUMMARY
INFORMATIONCOMPRESSION
AND FUSION
ABSTRACTIVESUMMARY
DOC DOCS

•Suface Linguistic Analysis▫Pre-process the input text by employing state-of-the-art tools
Sentence segmentation Tokenisation Part-of-Speech tagging Stemming Stop word identification
13
COMPENDIUM TS toolCORE STAGES
SURFACE LINGUISTIC ANALYSIS
TOPICIDENTIFICATION
RELEVANCE DETECTION
SUMMARY GENERATION
EXTRACTIVESUMMARY
REDUNDANCY DETECTION
DOC DOCS
SURFACE LINGUISTIC ANALYSIS

•Redundancy Detection▫Identify and removerepeated information
Textual Entailment (Ferrández, 2009)
▫ The main idea behind the use of TE for detecting redundancy is that those sentences whose meaning is already contained in other sentences can be discarded, as
the information has been previously mentioned
14
COMPENDIUM TS toolCORE STAGES
SURFACE LINGUISTIC ANALYSIS
TOPICIDENTIFICATION
RELEVANCE DETECTION
SUMMARY GENERATION
EXTRACTIVESUMMARY
REDUNDANCY DETECTION
DOC DOCS
T: The man was killed last weekH: The man is dead
T: The man was shot in his shoulderH: The man is dead
TRUE FALSE
REDUNDANCY DETECTION

•Topic Identification▫Identify the most relevant topics
Term frequency (Luhn, 1958)
▫Most frequent words (without considering stop words) can be considered the main topics of a document
15
COMPENDIUM TS toolCORE STAGES
SURFACE LINGUISTIC ANALYSIS
TOPICIDENTIFICATION
RELEVANCE DETECTION
SUMMARY GENERATION
EXTRACTIVESUMMARY
REDUNDANCY DETECTION
DOC DOCS
TOPIC IDENTIFICATION

•Relevance Detection▫Compute a weight for each sentence, depending on itsimportance
The Code Quantity Principle (Givón, 1990) Coding element noun phrase
▫Sentences containing a noun phrase including high frequent words will be considered more important
▫Score for each sentence
16
COMPENDIUM TS toolCORE STAGES
SURFACE LINGUISTIC ANALYSIS
TOPICIDENTIFICATION
RELEVANCE DETECTION
SUMMARY GENERATION
EXTRACTIVESUMMARY
REDUNDANCY DETECTION
DOC DOCS
RELEVANCE DETECTION

•Summary Generation▫Summary size
number of words compression rate
▫The highest scored sentences up to a desired length are selected and extracted
▫Sentences are ordered as they appear in the document
•Type of summaries (output)▫Generic extracts COMPENDIUME
17
COMPENDIUM TS toolCORE STAGES
SURFACE LINGUISTIC ANALYSIS
TOPICIDENTIFICATION
RELEVANCE DETECTION
SUMMARY GENERATION
EXTRACTIVESUMMARY
REDUNDANCY DETECTION
DOC DOCS
SUMMARYGENERATION
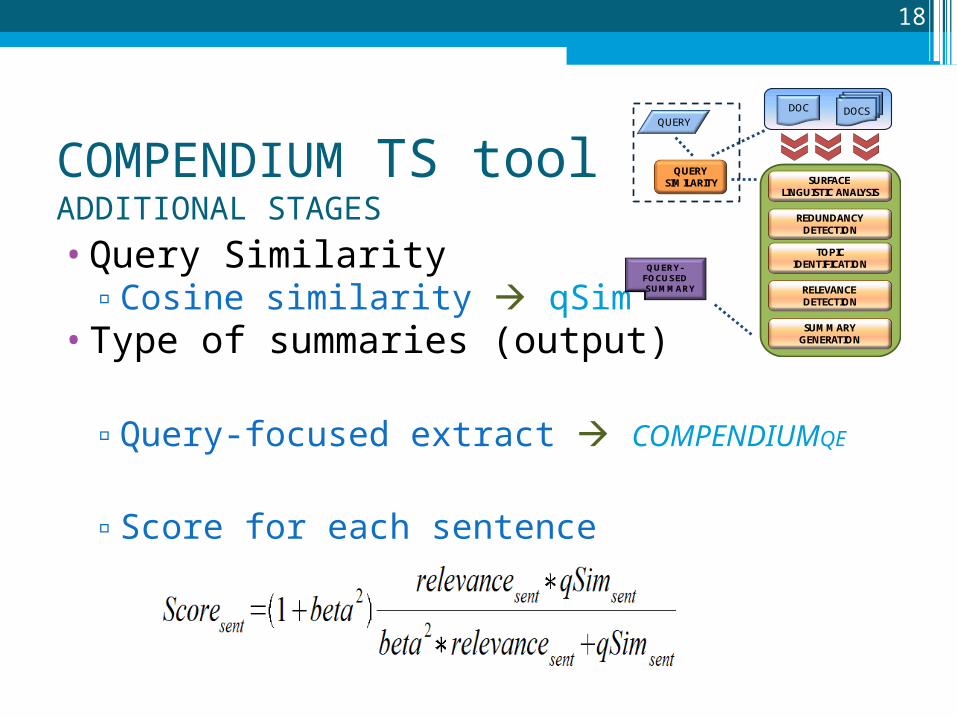
•Query Similarity▫Cosine similarity qSim
•Type of summaries (output)
▫Query-focused extract COMPENDIUMQE
▫Score for each sentence
18
COMPENDIUM TS toolADDITIONAL STAGES
SURFACE LINGUISTIC ANALYSIS
TOPICIDENTIFICATION
RELEVANCE DETECTION
SUMMARY GENERATION
QUERY
REDUNDANCY DETECTION
QUERY SIMILARITY
QUERY-FOCUSED SUMMARY
DOC DOCS

•Subjective Information Detection▫Opinion mining techniques (Balahur-Dobrescu et al., 2009)
•Type of summaries (output)▫Sentiment-based extract COMPENDIUMSE ▫Select the highest relevant sentences
among the subjective ones
19
COMPENDIUM TS toolADDITIONAL STAGES
SURFACE LINGUISTIC ANALYSIS
TOPICIDENTIFICATION
RELEVANCE DETECTION
SUMMARY GENERATION
OPINIONQUERY
REDUNDANCY DETECTION
SUBJECTIVE INFORMATION
DETECTION
SENTIMENT-BASEDSUMMARY
DOC DOCS

•Information compressionand fusion
▫Word graphs
•Type of summaries (output)▫Abstractive-oriented summary
COMPENDIUME-A ▫Combine extractive and new information
20
COMPENDIUM TS toolADDITIONAL STAGES
SURFACE LINGUISTIC ANALYSIS
TOPICIDENTIFICATION
RELEVANCE DETECTION
SUMMARY GENERATION
EXTRACTIVESUMMARY
REDUNDANCY DETECTION
INFORMATIONCOMPRESSION
AND FUSION
ABSTRACTIVESUMMARY
DOC DOCS

21
EVALUATION AND EXPERIMENTSEVALUATION METHODOLOGY
•Type of evaluation ▫intrinsic
•What are we going to assess?▫COMPENDIUM in different domains and
contexts•Which criteria are we going to use for the
evaluation?▫Content (automatically) ROUGE (Lin, 2004)▫Quality (manually) readability & user
satisfaction

• Newswire▫ Single-document generic extracts: ~ 45% (F-measure, ROUGE-
1)
▫ Multi-document: ~ 30% (F-measure, ROUGE-1)
• Blogs▫ Multi-document sentiment-based summaries: ~ 64% (F-
measure, Pyramid)
• Image captions▫ Multi-document query-focused summaries: ~36% (F-
measure, ROUGE-1)
• Medical research papers▫ Single-document abstractive-oriented summaries: ~ 42%
(F-measure, ROUGE-1)
22
EVALUATION AND EXPERIMENTSRESULTS

23
•Question answering▫ Allows users to formulate questions in
natural language and provide them with the exact information required
•Objective ▫Integrate COMPENDIUM with a Web-based
question answering approach COMPENDIUMQE
COMPENDIUM in HLT APPLICATIONS QUESTION ANSWERING

24
COMPENDIUM in HLT QUESTION ANSWERING
•Proposed approach • Question analysis▫ Question type, focus and
keywords • Information retrieval
▫ Retrieve the first 20 documents in Google
• Summarisation▫ COMPENDIUMQE
▫ Summary size length of snippets
• Answer extraction▫ Named Entities▫ Semantic roles

25
•Data ▫100 factual questions
Person Location Temporal Organization
•Evaluation▫Correct▫Incorrect▫Non-answered
Question(temporal)
When was the first Barbie produced?
Answer 1959
Question (location)
Where is the pancreas located?
Answer abdomen
COMPENDIUM in HLT QUESTION ANSWERING
F-measure (%)
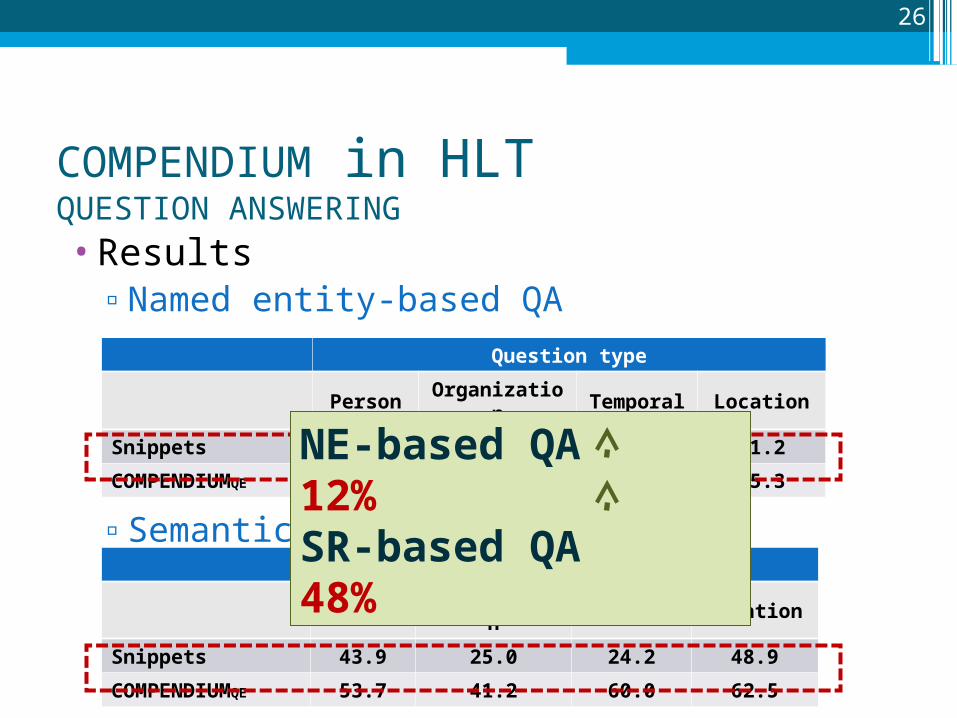
•Results▫Named entity-based QA
▫Semantic role-based QA
Question type
PersonOrganizatio
nTempora
lLocation
Snippets 53.3 52.2 48.9 61.2
COMPENDIUMQE 56.5 53.3 66.7 65.3
26
COMPENDIUM in HLT QUESTION ANSWERING
Question type
PersonOrganizatio
nTempora
lLocation
Snippets 43.9 25.0 24.2 48.9
COMPENDIUMQE
53.7 41.2 60.0 62.5
NE-based QA 12%SR-based QA 48%

•The proposed techniques are appropriate for TS▫Textual entailment appropriate to tackle
redundancy▫Code Quantity Principle detecting relevant
information▫Word graph-based algorithms compress and
merge information•Summaries, although imperfect in their nature,
can improve the performance of other HLT tasks▫Question Answering
27
CONCLUSION

Text Summarisation based on Human Language Technologies and its Applications
Elena Lloret PastorSupervisor: Dr. Manuel
PalomarSeminar - June 2011





























