The fMRI experiment: Start Point One Scanner ; One Brain ; One
Experiment ???
Slide 4
An fMRI experiment Condition 1: Word Generation Scanner Bed
Healthy Volunteer Jellyfish Screen Noun is presented Verb is
generated Catch
Slide 5
An fMRI experiment Condition 1: Word Generation Scanner Bed
Healthy Volunteer Burger Screen Noun is presented Verb is generated
Fry
Slide 6
An fMRI experiment Condition 2: Word Shadowing Scanner Bed
Healthy Volunteer Swim Screen Verb is presented Verb is shadowed
Swim
Slide 7
An fMRI experiment Condition 2: Word Shadowing Scanner Bed
Healthy Volunteer Strut Screen Verb is presented Verb is shadowed
Strut
Slide 8
An fMRI experiment Baseline No Stimuli Scanner Bed Healthy
Volunteer + Screen Cross-hair presented
Slide 9
Example Experiment 12 slices * 64 voxels x 64 voxels = 49,152
voxels 1 voxel = 136 time points 1 run = 6.7 million data points 1
experiment = multiple runs; 6.7 million * ? An fMRI experiment 1 st
TR 2 nd TR 3 rd TR etc. 4 th TR Time Series Note: if your TR was
sec; then this run would have had a duration of approximately 4 and
a half minutes -> 6.7 million data points every 4.5 mins!!
Slide 10
We could, in principle, analyze data by voxel surfing: move the
cursor over different areas and see if any of the time courses look
interesting Slice 9, Voxel 0, 0 Even where theres no brain, theres
noise Slice 9, Voxel 9, 27 Heres a voxel that responds well in
condition 1 and condition 2 Slice 9, Voxel 13, 41 Slice 9, Voxel
22, 7 The signal is much higher where there is brain, but theres
still noise Option 1 Heres one that responds well to condition 1
stimuli only
Slide 11
View 2: A multiple voxel time series Standard hypothesis-driven
statistical analysis (e.g. GLM) goes with view 2 since it is
applied independently for each voxel time course (voxel-wise
statistical analysis). View 1: A series of volumes (scans, 3D
images) GLM: Voxel x Voxel Time-Series Analysis Brainvoyager
Innovation BV
Slide 12
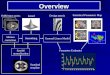
fMRI Analysis: Overview of SPM RealignmentSmoothing
Normalisation General linear model Statistical parametric map (SPM)
Image time-series Parameter estimates Design matrix Template Kernel
Gaussian field theory p
The GLM models the expected signal time courses for individual
conditions. The Design Matrix > A model consists of a set of
assumptions about what these time series look like for each of the
specific conditions or categories of data. We therefore have
various knows which we can put into our model: 1. The expected
signal time course for each of our individual conditions 2. The
expected signal time course of confounds in the data
Slide 29
fMRI signal residuals Time The Design Matrix Y: Observed Data =
+ 1 2 3 + X1X1 X2X2 X3X3 X: Predictors / Design Matrix + Error A
linear combination of the predictors y 1 = x 1 * 1 + x 2 * 2 + x 3
* 3 + 1 Brainvoyager Innovation BV
Slide 30
Aside
Slide 31
fMRI signal residuals Time Y: Observed Data = + 1 2 3 + X1X1
X2X2 X3X3 X: Predictors / Design Matrix + Error Hemodynamic
response function
Slide 32
Neural pathwayHemodynamics MR scanner Hemodynamic response
function HRF basic function -> Reshape (convolve) regressors to
resemble HRF
Slide 33
fMRI signal = data = + residuals = error design matrix = model
Time The Design Matrix 1 1 + 2 x + 3 x So far, we have only
included (in our design matrix) the predicted signal time series
for our effects of interest. We also have information about
confounds in our data (i.e. effects of NO interest such as head
movement). We need to add these additional predictor time courses
in order to improve our model of the data (& thus reduce the
error) X1X1 X2X2 X3X3
Slide 34
The Design Matrix We therefore have various knows which we can
put into our model: 1. The expected signal time course for each of
our individual conditions 2. The expected signal time course of
confounds in the data The Design Matrix Needs to Model the Expected
Signal Time Course for: Effects of Interest each individual
condition (X 1, X 2 ) a constant predictor (X 3 ) Effects of No
Interest (i.e. confounds): each physiological confounds head
movement.. each psychological confounds stress, attention Scanner
Drift The Design Matrix thus embodies all available knowledge about
experimentally controlled factors and potential confounds
Slide 35
X: The Design Matrix The design matrix should include
everything that might explain the data. Subjects Global activity or
movement Conditions: Effects of interest More complete models make
for lower residual error, better stats, and more accurate estimates
of the effects of interest.
Slide 36
The observed fMRI time course in a specific voxel (dependent
variable) The GLM in Matrix Notation y = X + Observed data
Slide 37
The General Linear Model y = X + Observed data The observed
fMRI time course in a specific voxel (dependent variable) =
Predictors (the design matrix) A set of specified predictors (each
of which has a unique expected signal time course) Model is
specified by: 1.Design matrix X 2.Assumptions about e Embodies all
available knowledge about experimentally controlled factors and
potential confounds
Slide 38
The General Linear Model y = X + Observed data The observed
fMRI time course in a specific voxel (dependent variable) A set of
specified predictors (each of which has a unique expected signal
time course) = Predictors = Everything that we know But what about
everything that we DONT know??? The Unknowns: 1.The Beta Values
2.The Error (Residuals) Model is specified by: 1.Design matrix X
2.Assumptions about e
Slide 39
1 1 2 2 3 3 estimate The General Linear Model -> Each
predictor time course gets an associated coefficient or beta
weight. y = X + -> The beta weight of a condition predictor
quantifies the contribution of its time course (X 1 ; X 2 ; X 3 )
in explaining the voxels time course (y). fMRI signal = data = +
residuals = error design matrix = model Time 1 1 + 2 x + 3 x X1X1
X2X2 X3X3
Slide 40
Generation Shadowing Baseline Measured X1X1 X2X2 X3X3 Known We
have our set of hypothetical time-series The Model + 3 * Unknown
parameters + 2 * 1*1* The estimation entails finding the parameter
values such that the linear combination of these hypothetical time
series best fits the data.
Slide 41
Generation Shadowing Baseline Finding the best parameter values
For a given voxel (time-series) we try to figure out just what type
that is by modelling it as a linear combination of the hypothetical
time-series. Parameter Estimation 432 + 3 * 10 1*1* 210 10 + 2
*
Slide 42
Generation Shadowing Baseline + 3 * Finding the best parameter
values For a given voxel (time-series) we try to figure out just
what type of voxel this is by modelling it as a linear combination
of the hypothetical time- series. Parameter Estimation 432 10 1*1*
Not brilliant 210 003 10 + 2 *
Slide 43
Generation Shadowing Baseline + 3 * Parameter Estimation 10
1*1* 210 104 10 + 2 * Neither that 432 Finding the best parameter
values For a given voxel (time-series) we try to figure out just
what type of voxel this is by modelling it as a linear combination
of the hypothetical time- series.
Slide 44
Generation Shadowing Baseline Parameter Estimation 432 Cool!
SSE = (y i i ) 2 = (y i X ) 2 + 2 *+ 1 * 10 0*0* + 3 * 10 1*1* 10 +
2 * 210 0.830.162.98 Finding the best parameter values For a given
voxel (time-series) we try to figure out just what type of voxel
this is by modelling it as a linear combination of the hypothetical
time- series.
Slide 45
Generation Shadowing Baseline + 2 *+ 1 * Finding the best
parameter values And the nice thing is that the same model fits all
the time-series, only with different parameters. Parameter
Estimation 3*3* 321 In other words: + 2 *+ 1 * 10 0*0* + 3 * 10
1*1* 10 + 2 * 210 0.680.822.17
Slide 46
Generation Shadowing Baseline + 2 *+ 1 * Finding the best
parameter values And the nice thing is that the same model fits all
the time-series, only with different parameters. Parameter
Estimation 0*0* 321 Doesnt care: + 2 *+ 1 * 10 0*0* + 3 * 10 1*1*
10 + 2 * 210 0.030.062.04
Slide 47
Parameter Estimation... Time-series beta_0001.img beta_0002.img
beta_0003.img Same model for all voxels. Different parameters for
each voxel. Plots the estimated beta 1s over the whole brain
Slide 48
So far
Slide 49
The observed fMRI time course in a specific voxel (dependent
variable) The GLM in Matrix Notation y = X + Observed data Model is
specified by: 1.Design matrix X 2.Assumptions about e
Slide 50
The General Linear Model y = X + Observed data The observed
fMRI time course in a specific voxel (dependent variable) =
Predictors (the design matrix) A set of specified predictors (each
of which has a unique expected signal time course) Model is
specified by: 1.Design matrix X 2.Assumptions about e Effects of
Interest each individual condition (X 1, X 2 ) a constant predictor
(X 0 ) The Design Matrix thus embodies all available knowledge
about experimentally controlled factors and potential confounds
Effects of No Interest (i.e. confounds): each physiological
confounds head movement.. each psychological confounds stress,
attention Scanner Drift The Design Matrix Needs to Model the
Expected Signal Time Course for:
Slide 51
The General Linear Model y = X + Observed data The observed
fMRI time course in a specific voxel (dependent variable) =
Predictors (the design matrix) A set of specified predictors (each
of which has a unique expected signal time course) Model is
specified by: 1.Design matrix X 2.Assumptions about e * Parameters
Quantifies how much each predictor contributes to the observed data
i.e. the voxels time course (y) Referred to as association
coefficients or beta weights () 1.Each predictor time course (X)
gets an estimated beta weight. 2. This weight attempts to quantify
the specific predictors contribution to the specific voxels time
course (Y).
Slide 52
The General Linear Model y = X + Observed data The observed
fMRI time course in a specific voxel (dependent variable) =
Predictors (the design matrix) A set of specified predictors (each
of which has a unique expected signal time course) Model is
specified by: 1.Design matrix X 2.Assumptions about e * Parameters
Quantifies how much each predictor contributes to the observed data
i.e. the voxels time course (y) + Error Variance in the data not
explained by the model (Represents the mismatch between the
observed data and the described Model).
Slide 53
Error y = X + Model is specified by: 1.Design matrix X
2.Assumptions about e We assume that the errors are normally
distributed: Assumes we have the same error/uncertainty in each and
every measurement point And that there is no correlation between
the errors in the different voxels.
Slide 54
Error y = X + Model is specified by: 1.Design matrix X
2.Assumptions about e 1.Get the parameter estimates for each and
every regressor/predictor (beta weights) ; 2.Get an estimate of the
residual error; 3.Enables you to estimate the variance in the data
(for that particular time series)
Slide 55
fMRI Analysis: Overview of SPM RealignmentSmoothing
Normalisation General linear model Statistical parametric map (SPM)
Image time-series Parameter estimates Design matrix Template Kernel
Gaussian field theory p