Embed Size (px)
Citation preview

White Paper Series
THE ITALIANLANGUAGE IN
THE DIGITALAGE
Collana Libri Bianchi
LA LINGUAITALIANANELL’ERADIGITALE
Nicoletta CalzolariBernardo MagniniClaudia SoriaManuela Speranza


White Paper Series
THE ITALIANLANGUAGE IN
THE DIGITALAGE
Collana Libri Bianchi
LA LINGUAITALIANANELL’ERADIGITALE
Nicoletta Calzolari CNR-ILC
Bernardo Magnini FBK
Claudia Soria CNR-ILC
Manuela Speranza FBK
Georg Rehm, Hans Uszkoreit(curatori, editors)

PREFAZIONE PREFACE
uesto Libro Bianco fa parte di una collana che inten- is white paper is part of a series that promotesde promuovere la conoscenza in merito alle tecnologie knowledge about language technology and its poten-del linguaggio e al loro potenziale. Si rivolge, tra gli al- tial. It addresses journalists, politicians, language com-tri, ai giornalisti, i politici, gli educatori e le comuni- munities, educators and others. e availability andtà linguistiche. La disponibilità e l’uso delle tecnologie use of language technology in Europe varies betweendel linguaggio in Europa variano da lingua a lingua, e languages. Consequently, the actions that are requireddi conseguenza differiscono anche le azioni richieste to further support research and development of lan-per sostenere la ricerca e lo sviluppo di tali tecnologie. guage technologies also differ. e required actionsGli interventi necessari dipendono da molti fattori, tra depend on many factors, such as the complexity of ai quali la complessità di ciascuna lingua e le dimensioni given language and the size of its community.della comunità che vi fa riferimento. META-NET, a Network of Excellence funded by theMETA-NET, una Rete di Eccellenza finanziata dalla European Commission, has conducted an analysis ofCommissione Europea, con questa Collana di Libri current language resources and technologies in thisBianchi ha condotto un’analisi delle risorse e delle tec- white paper series (p. 69). e analysis focused on thenologie linguistiche attualmente esistenti (p. 69). L’a- 23 official European languages as well as other impor-nalisi si è concentrata sulle 23 lingue europee ufficiali tant national and regional languages in Europe. e re-e su altre importanti lingue nazionali e regionali d’Eu- sults of this analysis suggest that there are tremendousropa. I risultati di questa analisi indicano che per tut- deficits in technology support and significant researchte le lingue considerate esistono dei deficit tecnologi- gaps for each language. e given detailed expert anal-ci enormi e significative lacune nella ricerca. L’analisi ysis and assessment of the current situation will helpdettagliata che viene fornita, insieme a una valutazione maximise the impact of additional research.della situazione attuale, potrà consentire di massimiz- As of November 2011, META-NET consists of 54zare l’impatto delle ricerche future. research centres in 33 European countries (p. 65).A novembre 2011, META-NET è composta da 54 META-NET is working with stakeholders from econ-centri di ricerca, dislocati in 33 paesi europei (p. 65). omy (soware companies, technology providers andMETA-NET collabora con aziende commerciali, enti users), government agencies, research organisations,governativi, industrie, organizzazioni di ricerca, com- non-governmental organisations, language communi-pagnie produttrici di soware e università europee. In- ties and European universities. Together with thesesieme a queste comunità,META-NET sta creando una communities,META-NET is creating a common tech-visione comune sulla tecnologia e un’agenda di ricerca nology vision and strategic research agenda for multi-strategica condivisa per l’Europa multilingue del 2020. lingual Europe 2020.
III

META-NET – [email protected] – http://www.meta-net.eu
Gli autori di questo documento sono grati agli autori del LibroBianco sulla lingua tedesca per aver consentito di riutilizzarealcuni materiali selezionati dal loro documento [1].
uesto Libro Bianco è stato finanziato dal Settimo Program-ma uadro e dal Programma di sostegno alla politica in ma-teria di TIC (tecnologie dell’informazione e delle comunica-zioni) della Commissione Europea nell’ambito dei contrattiT4ME (accordo di finanziamento 249 119), CESAR (accor-do di finanziamento 271 022), METANET4U (accordo di fi-nanziamento 270 893) eMETA-NORD (accordo di finanzia-mento 270 899).
e authors of this document are grateful to the authors ofthe White Paper on German for permission to re-use selectedlanguage-independent materials from their document [1].
e development of this White Paper has been funded by theSeventh Framework Programme and the ICT Policy SupportProgramme of the European Commission under the contractsT4ME (Grant Agreement 249 119), CESAR (Grant Agree-ment 271 022), METANET4U (Grant Agreement 270 893)and META-NORD (Grant Agreement 270 899).
IV

INDICE CONTENTS
LA LINGUA ITALIANA NELL’ERA DIGITALE
1 Sommario 1
2 Le nostre lingue a rischio: Una sfida per le tecnologie del linguaggio 42.1 I confini linguistici frenano la società europea dell'Informazione . . . . . . . . . . . . . . . . . . . 52.2 Le nostre lingue a rischio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.3 La tecnologia del linguaggio è una tecnologia fondamentale . . . . . . . . . . . . . . . . . . . . 62.4 Le opportunità per le tecnologie linguistiche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.5 Le sfide delle tecnologie linguistiche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.6 L'acquisizione del linguaggio negli umani e nelle macchine . . . . . . . . . . . . . . . . . . . . . 8
3 La lingua italiana nella società europea dell'informazione 103.1 Aspetti generali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.2 Particolarità della lingua italiana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113.3 Sviluppi recenti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113.4 Iniziative per la promozione della lingua italiana . . . . . . . . . . . . . . . . . . . . . . . . . . 123.5 La lingua nel settore della formazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.6 L'italiano su Internet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4 Le tecnologie linguistiche per l'italiano 144.1 Architetture applicative . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144.2 Ambiti applicativi principali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154.3 Altre aree applicative . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224.4 Programmi formativi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244.5 Progetti e iniziative nazionali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244.6 Disponibilità di strumenti e risorse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.7 Confronto fra le lingue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 274.8 Conclusioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5 META-NET 32

THE ITALIAN LANGUAGE IN THE DIGITAL AGE
1 Executive Summary 33
2 Languages at Risk: a Challenge for Language Technology 362.1 Language Borders Hold back the European Information Society . . . . . . . . . . . . . . . . . . 372.2 Our Languages at Risk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372.3 Language Technology is a Key Enabling Technology . . . . . . . . . . . . . . . . . . . . . . . . 382.4 Opportunities for Language Technology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 382.5 Challenges Facing Language Technology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 392.6 Language Acquisition in Humans and Machines . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3 The Italian Language in the European Information Society 413.1 General Facts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413.2 Particularities of the Italian Language . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413.3 Recent Developments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 423.4 Official Language Protection in Italy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 433.5 Language in Education . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 433.6 Italian on the Internet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4 Language Technology Support for Italian 454.1 Application Architectures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.2 Core Application Areas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 464.3 Other Application Areas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 524.4 Educational Programmes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 544.5 National Projects and Initiatives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 544.6 Availability of Tools and Resources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 554.7 Cross-language comparison . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 574.8 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5 About META-NET 61
A Riferimenti bibliografici -- References 63
B Membri di META-NET -- META-NET Members 65
C La Collana Libri Bianchi META-NET -- The META-NET White Paper Series 69

1
SOMMARIO
Nel corso degli ultimi 60 anni, l’Europa è diventata unastruttura politica ed economica distinta, che si carat-terizza per la ricchezza e la varietà del suo patrimonioculturale e linguistico. Ciò significa che dal portogheseal polacco e dall’italiano all’islandese, la comunicazionequotidiana tra cittadini europei, così come la comunica-zione nella sfera degli affari e della politica, sono inevita-bilmente ostacolate da barriere linguistiche. Le istituzio-ni dell’UE spendono circa unmiliardo di euro l’annopermantenere la loro politica di multilinguismo, che consi-ste nella traduzione di testi scritti e nell’interpretariatodi comunicazioni orali. Secondo alcune stime, il merca-to europeo per la traduzione, l’interpretariato, la loca-lizzazione del soware e la globalizzazione dei siti web siaggira intorno a 8.4miliardi di euro e ci si aspetta che au-menti del 10% all’anno. Ma si tratta di una spesa davve-ro necessaria? Nonostante questo impegno economico,i testi tradotti rappresentano solo una parte dell’infor-mazione a disposizione della popolazione in paesi dovec’è una sola lingua predominante, come gli StatiUniti, laCina o il Giappone. Lemoderne tecnologie del linguag-gio e la ricerca linguistica possono dare un contributosignificativo per abbattere questi confini linguistici. Secombinate con dispositivi e applicazioni intelligenti, letecnologie del linguaggio in futuro saranno in grado diaiutare i cittadini europei a comunicare e fare affari facil-mente tra loro anche se non parlano una lingua comune.
L’economia italiana trae vantaggio dal mercato unicoeuropeo ma le barriere linguistiche possono portare aduna limitazione degli scambi, soprattutto per le PMI chenon hanno i mezzi finanziari per invertire la situazione.
L’unica (impensabile) alternativa a questo tipo di Euro-pamultilingue sarebbe quella di permettere a una singo-la lingua di acquisire una posizione dominante e finireper sostituire tutte le altre lingue.
Le tecnologie del linguaggio costruiscono pontiper il futuro dell’Europa.
Ilmodo più naturale per superare le barriere linguistichesarebbe certamente quello di imparare le lingue stranie-re. Eppure, considerando la quantità delle lingue d’Eu-ropa – circa ottanta, tra lingue ufficiali e non – l’appren-dimento delle lingue non basta da solo per le necessitàdella comunicazione, del commercio e del trasferimen-to dell’informazione tra tutti i confini linguistici. Senzail supporto della tecnologia, per esempio la traduzioneautomatica, la diversità linguistica dell’Europa rischia dirappresentare un ostacolo insormontabile per i cittadinieuropei e per l’economia, il dibattito politico e il progres-so scientifico.Le tecnologie del linguaggio hanno un ruolo chiave perfornire una soluzione sostenibile, economica e social-mente vantaggiosa al problema creato dalle barriere lin-guistiche.ueste tecnologie offriranno agli attori europei enormivantaggi, non solo all’interno del mercato comune eu-ropeo, ma anche nelle relazioni commerciali con i pae-si terzi, in particolare le economie emergenti. Le solu-zioni proposte dalle tecnologie del linguaggio finirannoper rappresentare un unico ponte tra le lingue d’Europa.Per raggiungere questo obiettivo e preservare la diversità
1

culturale e linguistica dell’Europa, è prima necessario ef-fettuare un’analisi sistematica delle particolarità lingui-stiche di tutte le lingue europee e dello stato attuale delletecnologie linguistiche per ciascuna di esse.Già alla fine degli anni Settanta l’UE aveva compreso lagrande importanza della tecnologia del linguaggio perguidare l’unità europea, quando cominciò a finanziarei primi progetti di ricerca (per esempio, EUROTRA).Dopo un lungo periodo in cui i finanziamenti venivanoconcessi in modo relativamente poco concertato, pochianni fa la Commissione Europea ha istituito un diparti-mento dedicato alle tecnologie del linguaggio e alla tra-duzione automatica.Al momento l’Unione Europea sostiene progetti comeEuroMatrix e EuroMatrixPlus (dal 2006) e iTranslate4(dal 2010), che conducono ricerca di base e applicata eproducono risorse per la creazione di tecnologie lingui-stiche di alta qualità per tutte le lingue europee. ue-sti sforzi hanno già portato un certo numero di risulta-ti notevoli. I servizi di traduzione dell’Unione Europea,per esempio, attualmente utilizzano il soware di tradu-zione automatica open-source MOSES, che è stato svi-luppato principalmente attraverso progetti di ricerca eu-ropei. Tuttavia, questi progetti non sono mai sfociati inuno sforzo coerente e coeso a livello europeo, che vedal’UE e i suoi stati membri perseguire in modo sistemati-co lo scopo comune di sostenere tecnologicamente tuttele lingue europee.
Le tecnologie del linguaggiosono la chiave per il futuro.
Invece di investire sui risultati dei suoi progetti di ricer-ca, l’Europa hamantenuto la tendenza a svolgere attivitàdi ricerca isolate, con un impatto sul mercato meno per-vasivo. Di conseguenza, questa pur intensa attività di fi-nanziamento non ha prodotto dei risultati sostenibili.Inmolti casi, la ricerca fatta in Europa ha prodotto risul-
tati considerevoli, ma fuori dai confini europei. I vinci-tori di questo sviluppo generale sonoGoogle eApple. Inrealtà, molti dei soggetti principali nel settore oggi sonoaziende private a scopo di lucro con sede nelNordAme-rica.Lamaggior parte dei sistemi di tecnologia del linguaggiosviluppati da queste aziende si basano su approcci stati-stici imprecisi, che non fanno uso di metodi linguisticipiù sofisticati. Per esempio, le frasi vengono tradotte au-tomaticamente mettendo a confronto una nuova frasecontro migliaia di frasi tradotte in precedenza da esse-ri umani. La qualità del risultato dipende in larga misu-ra dalla dimensione e dalla qualità del corpus campio-ne disponibile. Mentre la traduzione automatica di fra-si semplici in lingue con sufficienti quantità di materia-le testuale a disposizione può raggiungere risultati uti-li, detti metodi statistici poco profondi sono destinati afallire nel caso di lingue che dispongono di molto menomateriale campione, oppure nel caso di frasi con struttu-re complesse. Analizzare le proprietà strutturali più pro-fonde delle lingue è l’unica strada percorribile se voglia-mo creare applicazioni che funzionino bene per tutte lelingue d’Europa.
Le tecnologie linguisticheaiutano a unificare l’Europa.
In Europa ci sono condizioni ottimali per la ricerca: gra-zie ad iniziative comeCLARIN,META-NET e FLaRe-Net, la comunità di ricerca è ben coesa; in FLaReNet eMETA-NET sono state sviluppate delle agende di ricer-ca a lungo termine, e le tecnologie del linguaggio stannorafforzando il loro ruolo presso la Commissione Euro-pea inmodo lentoma costante. Tuttavia, da alcuni puntidi vista, la situazione europea è peggiore rispetto a quelladi altre società multilingui. A fronte di risorse finanzia-rie inferiori, paesi come l’India, con 22 lingue ufficiali, eil SudAfrica, con 11 lingue ufficiali, hanno recentemen-
2

te istituito programmi nazionali a lungo termine per laricerca linguistica e lo sviluppo tecnologico.uello che manca in Europa sono la consapevolezza, lavolontà politica e il coraggio di lottare per una posizio-ne di leader internazionale in questo settore tecnologicoattraverso uno sforzo concertato di finanziamento. Sullabase dei risultati ottenuti finora, sembra che la tecnolo-gia linguistica di oggi, definita ibrida in quanto combinai metodi statistici con un’analisi linguistica a livello piùprofondo, riuscirà a colmare il divario tra tutte le lingueeuropee.Come vienemostrato in questa collana di Libri Bianchi,c’è una notevole differenza tra i diversi paesi membri re-lativamente allo stato di preparazione rispetto alle solu-zioni tecnologiche linguistiche e allo stato della ricerca.L’italiano, in quanto una delle grandi lingue dell’UE, sitrova in una situazione migliore sia per quanto riguar-da la maturità della ricerca che il livello di sviluppo delletecnologie linguistiche. Tuttavia, l’italiano necessita an-cora di ulteriori ricerche prima di poter avere soluzionitecnologiche veramente efficaci pronte per l’uso quoti-diano.La percentuale di utenti Internet che parlano italianosubirà una diminuzione nel prossimo futuro e l’italia-no potrebbe andare incontro al problema di essere sottorappresentato nel Web, specialmente se paragonato al-l’inglese. È qui che le tecnologie del linguaggio possonosvolgere un ruolo fondamentale per vincere le sfide cheaspettano la lingua italiana nell’era digitale. La presenza“digitale” di una lingua in applicazioni e servizi basati suInternet è ormai un elemento cruciale per mantenere la
vitalità culturale di quella lingua. E, d’altra parte, appli-cazioni e servizi su Internet sono sostenibili solo in pre-senza di adeguate infrastrutture e tecnologie. La ricer-ca nel campo delle tecnologie del linguaggio è condottain Italia in oltre 15 laboratori (secondo quanto riporta-to dallo studio EUROMAP) e la presenza italiana nellacomunità di ricerca internazionale è attiva e rilevante.A partire dal 1997 è stato fatto uno sforzo considerevo-le in Italia nella ricerca sulle tecnologie del linguaggio,quando per questo settore è stata designata una politicadi ricerca nazionale. Sfortunatamente, i fiananziamentia livello nazionale sono molto limitati, e lo stato attualedelle tecnologie del linguaggio non è sufficiente a garan-tire all’italiano una dimensione digitale proporzionataalla richiesta delle applicazioni e dei servizi dell’Internetdel futuro. Per i prossimi decenni la comunità italianadeve fare uno sforzo sostanziale per creare risorse e stru-menti linguistici per l’italiano in grado di trainare la ri-cerca, l’innovazione e lo sviluppo in generale. In questovolume verrà presentata una introduzione alle tecnolo-gie linguistiche e alle relative prinicipali aree di applica-zione, corredata da una valutazione dello stato attualedelle tecnologie linguistiche disponibili per l’italiano.uesta collana di Libri Bianchi integra le altre azio-ni strategiche intraprese da META-NET (si veda l’ap-pendice per una panoramica). Informazioni aggiorna-te, come per esempio la versione attuale del vision pa-per di META-NET [2] o l’Agenda di Ricerca Strategi-ca (SRA) sono disponibili sul sito web di META-NET:http://www.meta-net.eu.
3

2
LE NOSTRE LINGUE A RISCHIO:UNA SFIDA PER LE TECNOLOGIE DELLINGUAGGIO
Siamo testimoni di una rivoluzione digitale che sta aven-doun impatto radicale sulla comunicazione e sulla socie-tà. I recenti sviluppi nella tecnologia dell’informazionedigitale e della comunicazione vengono talvolta parago-nati all’invenzione della stampa da parte di Gutenberg.Ma cosa puòdirci questa analogia sul futurodella societàdell’informazione europea e, in particolare, delle nostrelingue?
La rivoluzione digitale è paragonabileall’invenzione della stampa da parte di
Gutenberg.
In seguito all’invenzione di Gutenberg, furono compiu-ti grandi progressi nella comunicazione e nello scambiodi conoscenza attraverso opere quali la traduzione dellaBibbia in una lingua volgare da parte di Lutero. Nel cor-sodei secoli successivi, sono state sviluppate tecnichepergestire meglio l’elaborazione del linguaggio e lo scambiodi conoscenza:
‚ la standardizzazioneortografica e grammaticale dellelingue principali ha oermesso di disseminare nuoveidee scientifiche e intellettuali in modo rapido;
‚ lo sviluppo delle lingue ufficiali ha reso possibile aicittadini la comunicazione all’interno di determina-ti confini (spesso politici);
‚ l’insegnamento delle lingue e la traduzione ha resopossibili gli scambi tra persone che parlavano linguediverse;
‚ la creazione di linee guida editoriali e bibliograficheha assicurato la qualità e la disponibilità di materialestampato;
‚ la creazione di diversimezzi di comunicazione, comei giornali, la radio, la televisione e i libri, ha permes-so di soddisfare bisogni di comunicazione di naturadiversa.
Negli ultimi vent’anni, la tecnologia dell’informazioneha aiutato ad automatizzare e facilitare molti processi:
‚ i soware per il desktop publishing hanno sostituitola dattilografia e la composizione tipografica;
‚ PowerPoint di Microso ha sostituito i lucidi;
‚ con la posta elettronica si spediscono e si ricevonodocumenti più velocemente che utilizzando un fax;
‚ Skype offre la possibilità di fare chiamate telefonichesu Internet in modo economico e permette di orga-nizzare incontri virtuali;
‚ grazie a formati di codifica audio e video è possibilescambiarsi in maniera semplice contenuti multime-diali;
‚ i motori di ricerca forniscono un accesso alle pagineweb basato su parole chiave;
4

‚ servizi online comeGoogle Translate producono ve-loci traduzioni approssimate;
‚ le piattaforme di social media come Facebook, Twit-ter, e Google+ facilitano la comunicazione, la colla-borazione e la condivisione dell’informazione.
Sebbene queste applicazioni e questi strumenti sianoutili, essi non sono ancora in grado di supportare pie-namente una società europea multilingue in cui l’infor-mazione e le merci possano circolare liberamente.
2.1 I CONFINI LINGUISTICIFRENANO LA SOCIETÀEUROPEA DELL’INFORMAZIONENon siamo in grado di prevedere esattamente come saràla società dell’informazione del futuro. Tuttavia, esisteun’elevata probabilità che la rivoluzione nelle tecnolo-gie della comunicazione avvicinerà persone che parlanolingue diverse in nuovi modi. uesta tendenza inducegli individui a imparare nuove lingue e gli sviluppatori,in particolare, a creare nuove applicazioni tecnologicheper assicurare la comprensione reciproca e l’accesso allaconoscenza condivisa.In uno spazio economico e di informazione globale, unamaggiore quantità di lingue, di parlanti e di contenutiinteragiscono più velocemente con nuovi tipi di mez-zi di comunicazione. L’attuale popolarità dei social me-dia (Wikipedia, Facebook, Twitter, YouTube e, recente-mente, Google+) rappresenta soltanto la punta dell’ice-berg.
L’economia e lo spazio d’informazioneglobali ci mettono di fronte a lingue,
parlanti e contenuti diversi.
Oggi possiamo trasmettere gigabyte di testo in tutto ilmondo in pochi secondi prima di accorgerci che si trat-
ta di una lingua che non comprendiamo. Secondo un re-cente rapporto della Commissione Europea, il 57% de-gli utenti di Internet in Europa acquista merci e serviziin linguediverse dalla loro linguanativa; l’inglese è la lin-gua straniera più comune, seguito dal francese, dal tede-sco e dallo spagnolo. Il 55% degli utenti legge contenutiin una lingua straniera mentre il 35% usa un’altra linguaper scrivere e-mail o per spedire commenti sul Web [3].
Alcuni anni fa, l’inglese poteva essere considerato la lin-gua franca del Web – la grande maggioranza dei con-tenuti sul Web era in inglese – ma la situazione ora ècambiata sensibilmente. La quantità di contenuti onlinein altre lingue europee (così come per quelle asiatiche emedio-orientali) si è moltiplicata.
Sorprendentemente, questo onnipresente divario digi-tale dovuto ai confini linguistici non ha ricevuto mol-ta attenzione pubblica; eppure, esso solleva una doman-damolto pressante: quali lingue europee prospererannonella società dell’informazione e della conoscenza in re-te, e quali sono destinate a scomparire?
2.2 LE NOSTRE LINGUE ARISCHIOSe da un lato l’invenzione della stampa contribuì certa-mente ad intensificare lo scambio di informazioni in Eu-ropa, essa al contempoportò anche all’estinzionedimol-te lingue europee. Le lingue regionali e minoritarie ve-nivano stampate raramente e lingue come il cornico e ildalmatico vennero ridotte a forme di trasmissione orale,il che a sua volta restrinse gli ambiti d’uso di queste lin-gue. Internet avrà lo stesso impatto sulle nostre lingue?
L’ampia varietà di lingue esistentiin Europa rappresenta una delle
sue ricchezze più importanti.
5

Le circa 80 lingue dell’Europa costituiscono uno dei piùricchi e più importanti patrimoni culturali dell’Europa,e unaparte vitale del suomodello sociale unico [4].Men-tre lingue come l’inglese e lo spagnolo probabilmentesopravviveranno nel mercato digitale emergente, moltealtre lingue Europee potrebbero diventare irrilevanti al-l’interno di una società in rete. uesto porterebbe ad unindebolimento dello stato globale dell’Europa e andreb-be contro l’obiettivo strategico di assicurare un’ugualepartecipazione a tutti i cittadini europei indipendente-mente dalla lingua.Secondo un rapporto dell’UNESCO sul multilingui-smo, le lingue rappresentano un mezzo essenziale perpoter godere di diritti fondamentali come il diritto diespressione politica, il diritto all’educazione e alla parte-cipazione nella società [5].
2.3 LA TECNOLOGIA DELLINGUAGGIO È UNATECNOLOGIA FONDAMENTALEIn passato, gli sforzi di investimento nell’ambito dellaconservazione delle lingue si sono focalizzati sull’inse-gnamento delle lingue e sulla traduzione. Secondo unastima, il mercato europeo per la traduzione, l’interpre-tariato, la localizzazione di soware e di siti web è statodi 8,4 miliardi di euro nel 2008 e per il futuro è attesauna crescita del 10% all’anno [6]. Eppure questa cifra co-pre solo una piccola parte dei bisogni attuali e futuri perquanto riguarda la comunicazione tra lingue diverse. Lasoluzione più convincente per assicurare in futuro am-piezza e profondità nell’uso delle lingue in Europa con-siste nell’uso di una tecnologia appropriata, allo stessomodo in cui usiamo la tecnologia per risolvere le nostreesigenze di trasporto e di energia.Le tecnologie linguistiche (rivolte a tutte le forme di te-sti scritti e discorsi orali) aiutano le persone a collabo-rare, a fare affari, a condividere la conoscenza e a parte-
cipare al dibattito sociale e politico a prescindere dallebarriere linguistiche e dall’abilità nell’uso del computer.Spesso operano in maniera invisibile all’interno di siste-mi informatici complessi, per aiutarci a:
‚ trovare informazioni mediante un motore di ricercasu Internet;
‚ controllare errori di ortografia e di grammatica all’in-terno di un programma per l’elaborazione di testi;
‚ vedere, in un negozio online, le opinioni sui prodottiespresse da altri clienti;
‚ seguire, in automobile, le istruzioni vocali di un si-stema di navigazione;
‚ tradurre pagine web attraverso un servizio in rete.
La tecnologia del linguaggio consiste in un certo nume-ro di applicazioni di base che rendono possibili processiall’interno di un più ampio quadro applicativo. I LibriBianchi diMETA-NET si prefiggono l’obiettivo di veri-ficare che livello abbiano raggiunto queste tecnologie dibase per ciascuna lingua europea.
L’Europa ha bisogno di tecnologie linguisticherobuste ed economicamente accessibili per tutte
le lingue europee.
Al fine di mantenere la propria posizione in prima li-nea nell’innovazione globale l’Europa avrà bisogno, pertutte le lingue europee, di tecnologie linguistiche robu-ste, economicamente accessibili e saldamente integrateall’interno degli ambienti soware principali. Senza letecnologie del linguaggio, non saremo in grado di rag-giungere in un prossimo futuro un’esperienza utente in-terattiva, multimediale emultilingue realmente efficace.
6

2.4 LE OPPORTUNITÀ PER LETECNOLOGIE LINGUISTICHE
La rivoluzione tecnologica nel mondo della carta stam-pata fu la possibilit√† di duplicare rapidamente un’im-magine di un testo usando una macchina da stampa suf-ficientemente potente. Il duro lavoro di ricerca, lettura,traduzione e sintesi della conoscenza era appannaggiodegli uomini. Per registrare la lingua parlata si è dovu-to aspettare fino ad Edison e di nuovo la sua tecnolo-gia produceva semplicemente delle copie analogiche. Letecnologie linguistiche possono ora semplificare e auto-matizzare i processi stessi di traduzione, produzione dicontenuto e gestione della conoscenza per tutte le lin-gue europee. Possono anche arricchire interfacce intui-tive a base vocale per elettrodomestici, macchinari, vei-coli, computer e robot. Delle applicazioni commercialied industriali reali sono ancora agli stadi iniziali di svi-luppo, ma i progressi di R&S stanno creando una verafinestra di opportunità. Per esempio, la traduzione auto-matica è già ragionevolmente accurata in settori specifi-ci, ed alcune applicazioni sperimentali consentono la ge-stionemultilingue dell’informazione e della conoscenzae la produzione di contenuto in molte lingue europee.
Come accade per lamaggioranza delle tecnologie, le pri-me applicazioni linguistiche come le interfacce basatesulla voce e i sistemi di dialogo erano sviluppate per set-tori altamente specialistici, e spesso avevano prestazionilimitate. Ma l’integrazione delle tecnologie linguistichenei giochi, nei siti legati al patrimonio culturale, nei pac-chetti di edutainment, nelle biblioteche, negli ambientidi simulazione e nei programmi di training offre oppor-tunità di mercato enormi nell’industria dell’educazionee dell’intrattenimento. I servizi mobili di informazio-ne, il soware per l’apprendimento delle lingue assisti-to da computer, gli ambienti di eLearning, gli strumentidi auto-valutazione e il soware di rilevamento del pla-gio sono solo alcune delle aree applicative in cui le tec-
nologie linguistiche possono avere un ruolo importante.La popolarità delle applicazioni socialmedia comeTwit-ter e Facebook suggeriscono un ulteriore bisogno di tec-nologie linguistiche sofisticate che consentano di mo-nitorare i messaggi, sintetizzare le discussioni, suggeri-re andamenti di opinione, individuare risposte emotive,identificare violazioni di copyright o rintracciare usi im-propri. Le tecnologie linguistiche rappresentano un’op-portunità straordinaria per l’Unione Europea, in quan-to possono aiutare ad affrontare il complesso problemadel multilinguismo in Europa – il fatto che lingue diver-se coesistono naturalmente nel mondo degli affari, delleamministrazioni e delle scuole. I cittadini, tuttavia, han-no bisogno di comunicare al di là di questi confini lin-guistici che attraversano il Mercato Comune Europeo,e le tecnologie linguistiche possono aiutare a superarequest’ultima barriera pur continuando a supportare l’u-so libero e aperto delle singole lingue.
Le tecnologie linguistiche aiutano a superarequella forma di disabilità rappresentata dalla
diversità linguistica.
Guardando ancora più avanti, le tecnologie linguistichemultilingui innovative rappresenteranno un punto di ri-ferimento per i nostri partner globali quando le comu-nità multilingui cominceranno a dotarsene. Le tecnolo-gie linguistiche possono essere viste come una tecnolo-gia assistiva che aiuta a superare quella forma di disabi-lità rappresentata dalla diversità linguistica, rendendo lecomunità linguistiche ancora più accessibili le une ver-so le altre. Infine, un campo di ricerca attivo è l’uso del-le tecnologie linguistiche per operazioni di soccorso inaree colpite da emergenze, dove le prestazioni possonoessere una questione di vita o di morte: i robot intelli-genti del futuro con capacità trans-linguistiche hanno ilpotenziale di salvare vite umane.
7

2.5 LE SFIDE DELLETECNOLOGIE LINGUISTICHENonostante i considerevoli passi avanti compiuti dal-le tecnologie linguistiche negli ultimi anni, il ritmo delprogresso tecnologico e dell’innovazione produttiva ètroppo lento. Tecnologie ampiamente usate come i cor-rettori ortografici e grammaticali degli editori di testosono in genere monolingui, e sono disponibili per po-che lingue. I servizi di traduzione automatica on-line,sebbene utili per generare rapidamente una ragionevoleapprossimazione del contenuto di un documento, sonoirti di difficoltà quando siano richieste delle traduzionicomplete emolto accurate. A causa della complessità dellinguaggio umano,modellare le nostre lingue permezzodi un soware che sia poi testato in applicazioni reali èun processo troppo lungo e costoso che richiede un im-pegno finanziario costante. L’Europa, quindi, deveman-tenere il suo ruolo pionieristico nell’affrontare le sfidetecnologiche di una comunità multilingue, inventandonuovimetodi – tanto il progresso computazionale quan-to tecniche come il crowdsourcing –per accelerare lo svi-luppo a tutto campo.
Il ritmo del progresso tecnologicodeve essere accelerato.
2.6 L’ACQUISIZIONE DELLINGUAGGIO NEGLI UMANI ENELLE MACCHINEPer illustrare il modo in cui i computer gestiscono il lin-guaggio e il perché sia difficile programmarli ad usarlo,diamoun rapido sguardo almodo in cui gli umani acqui-siscono le lingue, e vediamo poi come lavorano le tecno-logie linguistiche.
Gli esseri umani acquisiscono le competenze linguisti-che in duemodi diversi. I bambini acquisiscono una lin-gua ascoltando delle interazioni reali che avvengono tragenitori, fratelli o membri della famiglia. A partire dacirca due anni, i bambini producono le loro prime pa-role e delle brevi frasi. uesto è possibile solo perché gliesseri umani hannouna predisposizione genetica ad imi-tare e poi razionalizzare i suoni che sentono.L’apprendimento di una seconda lingua ad un’età mag-giore richiede più sforzo, in gran parte perché il bambi-no non è immerso in una comunità linguistica di par-lanti nativi. A scuola, le lingue straniere di solito sonoacquisite studiando la struttura grammaticale, il vocabo-lario e l’ortografia con esercizi che descrivono la cono-scenza linguistica in termini di regole astratte, tabelle edesempi.
Gli esseri umani acquisiscono il linguaggioin due modi diversi: apprendendo dagli
esempi e apprendendo le regolelinguistiche che li governano.
I due tipi principali di sistemi di tecnologie linguistiche‚Äòacquisiscono‚Äô delle capacità linguistiche inmodosimile.Gli approcci statistici (o ‚Äòdata driven‚Äô) rica-vano la conoscenza linguistica da vaste raccolte di esem-pi testuali concreti. Mentre è sufficiente usare del testoin una sola lingua per addestrare un correttore ortogra-fico, per addestrare un sistema di traduzione automaticasono necessari dei testi paralleli in due (o più) lingue.L’algoritmo di machine learning poi “impara” dei mo-delli di come sono tradotte le parole, i gruppi di parolee le frasi complete.uesto approccio statistico può richiedere milioni difrasi e la qualità delle prestazioni aumenta con la quanti-tà di testo analizzato. uesto è uno dei motivi per cuii fornitori di motori di ricerca vogliono raccogliere ilmaggior numero possibile di materiale scritto. La cor-rezione ortografica negli editori di testo, e servizi come
8

Google Search e Google Translate si basano tutti su ap-procci statistici. Il grande vantaggio della statistica è chela macchina impara velocemente in serie continue di ci-cli di apprendimento, anche se la qualità può variare ar-bitrariamente.
Il secondo approccio alle tecnologie linguistiche – e al-la traduzione automatica in particolare – è quello di co-struire sistemi basati su regole. Esperti di linguistica, lin-guistica computazionale e informatica devono prima ditutto codificare delle analisi grammaticali (regole di tra-duzione) e compilare liste di vocaboli (lessici). uestolavoro è molto lungo e laborioso. Alcuni dei sistemi lea-der di traduzione automatica basati su regole sono statiin costante sviluppo da più di venti anni. Il grande van-taggio dei sistemi basati su regole è che gli esperti hannoun controllo più dettagliato sulla elaborazione del lin-guaggio. In questo modo è possibile correggere sistema-ticamente gli errori nel soware e fornire all’utente unfeedback dettagliato, soprattutto quando i sistemi basa-ti su regole vengono utilizzati per l’apprendimento dellelingue. Ma a causa del costo elevato di questo lavoro, letecnologie linguistiche basate su regole finora sono statesviluppate solo per le lingue principali.
Dal momento che i punti di forza e di debolezza dei si-stemi statistici e di quelli basati su regole tendono ad es-sere complementari, la ricerca attuale si concentra sugliapprocci ibridi che combinano le duemetodologie. Tut-tavia, questi approcci finora hanno avuto più successonei laboratori di ricerca che in applicazioni industriali.
I due tipi principali dei sistemidi tecnologie linguistiche acquisiscono
il linguaggio in modo simile.
Come abbiamo visto in questo capitolo, molte applica-zioni ampiamente usate nella società dell’informazionedi oggi si basanomolto sulla tecnologia linguistica. Gra-zie alla sua comunità multilingue, questo è vero in par-ticolar modo per lo spazio economico e di informazio-ne europeo. Sebbene le tecnologie linguistiche abbianofatto progressi notevoli negli ultimi anni, c’è ancora unospazio di miglioramento enorme per la qualità dei siste-mi di tecnologie linguistiche. Nei prossimi capitoli de-scriveremo il ruolo della lingua italiana nella società del-l’informazione europea e valuteremo lo stato attuale del-le tecnologie linguistiche per la lingua italiana.
9

3
LA LINGUA ITALIANA NELLA SOCIETÀEUROPEA DELL’INFORMAZIONE
3.1 ASPETTI GENERALILa lingua italiana conta circa 62milioni di parlanti nati-vi, il che la colloca tra le 20 lingue più parlate al mondo.125 milioni di persone la usano come seconda lingua.Diverse comunità di ex-emigranti, ciascuna costituita dapiù di 500.000 persone che ancora parlano italiano, sitrovano in Argentina, Brasile, Canada e Stati Uniti. Se-condo un’indagine realizzata nel 2006, con i suoi 56mi-lioni di parlanti nativi residenti in Italia l’italiano è la se-conda lingua nell’Unione Europea per numero di par-lanti, dopo il tedesco e alla pari con l’inglese.Nell’ambito di vari studi condotti in anni diversi, è statostimato che altri 280.000 parlanti di italiano come pri-ma lingua risiedano in Belgio, 70.000 in Croazia (pae-se candidato a entrare a far parte dell’Unione Europea),1.000.000 in Francia, 548.000 in Germania, 20.800 nelLussemburgo, 27.000 a Malta (esclusi 118.000 parlan-ti di italiano come seconda lingua), 2.560 in Romania,4.010 in Slovenia, 200.000 nel Regno Unito e 471.000in Svizzera.
La lingua italiana conta circa 62 milioni diparlanti nativi.
L’italiano si trova al sesto posto nell’Unione Europea trale lingue più parlate come lingua straniera dopo l’ingle-se, il francese, il tedesco, lo spagnolo e il russo. Per quan-to concerne il numero di traduzioni a livello mondiale,
l’italiano si trova al quinto posto come lingua di parten-za e all’undicesimo come lingua di arrivo.
Nell’Unione Europea l’italiano è parlato come secondalingua dal 3% della popolazione, cioè 14 milioni di per-sone; da uno studio effettuato nel 2005 è emerso che il61% dei maltesi, il 14% dei croati, il 12% degli sloveni,l’11% degli austriaci, l’8% dei romeni e il 6% dei francesie dei greci includono l’italiano tra le due lingue straniereche i bambini dovrebbero imparare. L’italiano è la lin-gua ufficiale della Repubblica Italiana (formalmente ciòè apparso nellaCostituzione soltanto a partire dal 2007)e della Repubblica di SanMarino. In Svizzera l’italiano èuna delle quattro lingue ufficiali, ed è parlato soprattut-to nel Canton Grigioni e nel Canton Ticino. A Cittàdel Vaticano è una delle lingue ufficiali (tutte le leggi e iregolamenti dello stato sono pubblicati in italiano).
L’italiano è una lingua ufficiale regionale in Slovenia(l’articolo 64 della Costituzione slovena concede all’I-stria, regione di lingua italiana, un’ampia libertà perquanto riguarda l’uso dell’italiano in aree quali l’istru-zione, la cultura, la scienza, l’economia e i mass media)e in Croazia.
Sebbene in Italia l’italiano sia la lingua di gran lunga piùparlata, e quasi tutti i media (per esempio, la televisio-ne, i giornali, i film, eccetera) siano prodotti in italiano,altre lingue sono co-ufficiali all’interno di alcune regio-ni: il francese in Val d’Aosta, il tedesco in Trentino-AltoAdige e il sardo in Sardegna.
10

3.2 PARTICOLARITÀ DELLALINGUA ITALIANALa lingua italiana deriva dal latino ed è la lingua nazio-nale ad esso più vicina. A differenza della maggior par-te delle altre lingue romanze, la lingua italiana mantie-ne il contrasto tra consonanti lunghe e consonanti breviche era presente in latino. Come nella maggior pare del-le lingue romanze, l’accento ha una funzione distintiva.In particolare la lingua italiana è la più vicina al latinotra le lingue romanze per quanto riguarda il lessico [7].La grammatica italiana è quella tipica delle lingue ro-manze in generale. I casi esistono per i pronomi (no-minativo, accusativo e dativo), ma non per i sostantivi.Ci sono due generi grammaticali (maschile e femmini-le). I sostantivi, gli aggettivi e gli articoli cambiano la de-sinenza in rapporto al genere e al numero (singolare eplurale). Gli aggettivi a volte si trovano prima del nomea cui si riferiscono e a volte dopo. I sostantivi che svol-gono la funzione di soggetto di solito sono posizionatiprima del verbo. I pronomi personali soggetto di solitovengono omessi in quanto la loro presenza è resa super-flua dalle desinenze verbali. I sostantivi con funzione dicomplemento oggetto seguono il verbo. I pronomi com-plemento oggetto in genere precedono il verbo, ma loseguono nel caso di verbi all’imperativo e all’infinito. Cisono numerosi casi di contrazioni di preposizioni e arti-coli (preposizioni articolate). Esistono infine numerosisuffissi molto produttivi per il diminutivo, l’accrescitivo,il peggiorativo e il vezzeggiativo, che possono anche dareorigine a dei neologismi.
Molti parlanti nativi dell’italiano in realtà sonoparlanti nativi bilingui, parlano cioè come lingua
nativa sia l’italiano sia il loro dialetto.
Una caratteristica peculiare dell’italiano è che moltiparlanti nativi residenti in Italia in realtà sono par-lanti nativi bilingui, parlano cioè come lingua nativa
sia l’italiano sia il loro dialetto. Alcuni dei dialetti ita-liani più parlati sono il lombardo (8.830.000 parlantinel 2000), il napoletano-calabrese (7.050.000 parlantinel 1976), il siciliano (4.830.000 parlanti nel 2000), ilpiemontese (3.110.000 parlanti nel 2000), il venezia-no (2.180.000 parlanti nel 2000), l’emiliano-romagnolo(2.000.000 parlanti nel 2003), il ligure (1.920.000 par-lanti nel 2000). Alcuni dialetti italiani sono sufficiente-mente distanti dall’italiano da essere considerati lingueseparate. I dialetti hanno svolto un ruolo significativonello sviluppo delle molteplici varietà regionali esisten-ti per l’italiano e tale influenza risulta particolarmenteevidente nella prosodia, nella fonetica e nel lessico del-l’italiano parlato da dialettofoni.
3.3 SVILUPPI RECENTINegli anni ’50, le serie televisive e i film americani inizia-rono a dominare il mercato italiano. Sebbene di solito leserie e i film stranieri siano doppiati in italiano, la for-te presenza del modo di vivere americano nei media hainfluenzato la cultura e la lingua italiana. In seguito altrionfo della musica inglese e americana a partire daglianni ’60, gli adolescenti italiani hanno subito una forteesposizione all’inglese per generazioni. L’inglese ha benpresto acquisito lo stato di lingua ‘in’ o ‘di moda’, statusche mantiene anche ai giorni nostri.Il mantenimento di questo status da parte della linguainglese si riflette nel numero dei prestiti dall’inglese (an-glicismi) presenti attualmente nella lingua. Uno studiorecente [8]mira a quantificare l’impatto degli anglicisminon adattati sulla base di conteggi relativi alla frequen-za d’uso. uesto studio si basa su una lista di esempi dianglicismi non adattati raccolti da un corpus italiano co-stituito da articoli di quotidiani. L’analisi mostra come,sebbene il numero di anglicismi nei dizionari italiani siaconsiderevole, la loro presenza all’interno dei quotidiani– un genere che i linguisti tradizionalmente considera-no incline all’inclusione di prestiti in generale e di an-
11

glicismi nello specifico – raggiunge percentuali moltopiù basse. L’autore sostiene che le strategie di marketingspingono gli editori e i curatori a massimizzare il nume-ro di lemmi nei dizionari includendo molti prestiti e, inparticolare, molti anglicismi; sarebbero invece da pren-dere in considerazione i conteggi relativi alla frequenza ebasati su corpora, in quanto capaci di attestare l’uso realedi una parola. L’autore suggerisce che dovrebbero essereintrodotte delle soglie di frequenza per determinare l’in-clusione degli anglicismi nei dizionari monolingui e neidizionari settoriali, sia per l’italiano che per altre lingue,e in questo la linguistica basata su corpora può offrireil suo contributo fornendo dati approssimati sulla fre-quenza d’uso delle parole.
3.4 INIZIATIVE PER LAPROMOZIONE DELLA LINGUAITALIANAUno dei principali punti di riferimento per le ricerchesulla lingua italiana, anche rispetto alle sue varietà regio-nali, è “l’Accademia della Crusca” [9], che fu fondata aFirenze nella seconda metà del XVI secolo. Il principalerisultato ottenuto dall’Accademia fu il “Vocabolario de-gli Accademici dellaCrusca” (1612), il primo dizionariodella lingua italiana. Attualmente, l’attività dell’Accade-mia mira a sostenere l’attività scientifica e la formazionedi nuovi ricercatori nel campo della linguistica e dellafilologia italiana e a collaborare con le omologhe istitu-zioni estere e con le istituzioni governative italiane e del-l’Unione Europea per la politica dell’Europa a favore delplurilinguismo.
L’Accademia della Crusca è uno deiprincipali punti di riferimento per le ricerche
sulla lingua italiana.
Infine, l’Accademia punta ad acquisire e diffondere nonsolo la conoscenza storica ma anche la coscienza criticadell’evoluzione dell’italiano nell’era della società dell’in-formazione.
In parte come reazione alla crescente importanza de-gli anglicismi nella lingua italiana, nel 2001 è stata pre-sentata un’iniziativa parlamentare che punta alla crea-zione di un “Consiglio Superiore della Lingua Italiana”(CSLI), allo scopo di contrastare l’impoverimento dellalingua italiana e la sua perdita di prestigio a livello euro-peo e internazionale (tale proposta non ha avuto ancoral’approvazione del Parlamento). Gli obiettivi del CLSIincluderebbero, tra gli altri, la difesa, la valorizzazionee la diffusione della cultura italiana, in particolar modoattraverso iniziative mirate alla promozione di un usocorretto della lingua italiana nelle scuole, nei mezzi dicomunicazione e negli scambi economici. Un obiettivoaggiuntivo sarebbe costituito dalla diffusione della lin-gua italiana all’estero, così come il suo uso ufficiale nelleistituzioni europee.
3.5 LA LINGUA NEL SETTOREDELLA FORMAZIONELe capacità linguistiche costituiscono una competenzafondamentale richiesta nella formazione scolastica e an-che per la comunicazione personale e professionale. Lostatus della lingua italiana come materia scolastica nellascuola di base sembra riflettere la necessità di dare prio-rità a questo aspetto. Il primo studio PISA, condottonel 2000, ha rivelato come gli studenti italiani ottenga-no risultati inferiori alla media OECD per quanto con-cerne le loro capacità nella lettura. Gli studenti con unbackground di migrazione ottengono risultati partico-larmente bassi. Il dibattito che ne è derivato ha avutol’effetto di aumentare nell’opinione pubblica la consape-volezza dell’importanza dell’apprendimento linguistico,specialmente nel contesto dell’integrazione sociale. Nel-
12

l’ultimo studio PISA (2009), gli studenti italiani hannoottenuto risultati simili a quelli ottenuti nel 2000, il chepuò essere valutato positivamente dal momento che lamedia OECD nello stesso periodo si è invece abbassata[10].
3.6 L’ITALIANO SU INTERNETSi stima che la penetrazione di Internet in Italia si attestial 51,7%, con 30 milioni di utenti su una popolazionetotale di 58 milioni; gli utenti di Internet in Italia sonocresciuti del 127,5% tra il 2000 e il 2010 e rappresenta-no circa il 6,3% degli utenti di Internet nell’Unione Eu-ropea. La percentuale di pagine web in italiano a livel-lo mondiale è raddoppiata passando dall’1,5% nel 1998al 3,05% nel 2005. È stato stimato che nel 2004 in tut-to il mondo ci fossero 30,4 milioni di parlanti italianionline. Al di fuori dei confini dell’Unione Europea, lestime parlano di 520.000 americani, 200.000 svizzeri e100.000 australiani che accedono a Internet in italiano.
Il numero di utenti di Internet italiani negli ultimi cin-que anni è rimasto relativamente stabile, mentre il nu-mero di nuovi utenti nei paesi in via di sviluppo è au-mentato notevolmente. La conseguenza è che la propor-zione di utenti Internet che parlano italiano subirà unadiminuzione nel prossimo futuro e l’italiano potrebbeandare incontro al problema di essere sotto rappresen-tato nel Web, specialmente se paragonato all’inglese. Èqui che le tecnologie del linguaggio possono svolgere unruolo fondamentale per vincere le sfide che aspettano lalingua italiana nell’era digitale.
L’uso massiccio di sistemi interattivi nell’Internetdel Futuro richiede tecnologie del linguaggiocon un alto livello di adattabilità a parlanti
di diverse varietà di italiano.
L’uso massiccio di sistemi interattivi nell’Internet delFuturo richiede tecnologie del linguaggio con un alto li-vello di adattabilità a parlanti di diverse varietà di italia-no. Ciò si ripercuote in primo luogo sulle tecnologie perla trascrizione automatica di dati audio, dal momentoche gli accenti regionali variano significativamente, mane sono interessate anche tutte le altre tecnologie del lin-guaggio, in quanto le varietà regionali sono caratterizza-te da differenze a tutti i livelli linguistici, dal lessico allasintassi. La disponibilità di sistemi in grado di suppor-tare le varietà regionali dell’italiano permetterebbe nonsolo un miglioramento in termini di prestazioni, ma an-che un’interazione più naturale tra umani e computer.L’applicazione web più comunemente usata è certamen-te la ricerca di contenuti, la quale richiede l’elaborazioneautomatica del linguaggio a vari livelli, come vedremopiù in dettaglio nella seconda parte di questo articolo.Essa richiede tecnologie linguistiche sofisticate che dif-feriscono da lingua a lingua (in italiano, ad esempio, ènecessario far corrispondere “città” e “citta’”). È anchepossibile, tuttavia, che gli utenti di Internet e coloro chepubblicano contenuti sul Web sfruttino le tecnologielinguistiche in unmodomeno esplicito, per esempio nelmomento in cui esse vengono impiegate per effettuare latraduzione automatica di contenuti web da una linguaall’altra. Considerando i costi della traduzione manualedi tali contenuti, può apparire sorprendente quanto sialimitata la quantità di tecnologie linguistiche effettiva-mente disponibili, specialmente se paragonata ai biso-gni.D’altra parte, questo risulta meno sorprendente se pren-diamo in considerazione la complessità della lingua ita-liana e la quantità di tecnologie richieste per una tipi-ca applicazione di tecnologie del linguaggio. Nel prossi-mo capitolo, presentiamo un’introduzione alle tecnolo-gie del linguaggio e ai loro ambiti applicativi principali;proponiamo inoltre una valutazione della situazione at-tuale di queste tecnologie per la lingua italiana.
13

4
LE TECNOLOGIE LINGUISTICHE PER L’ITALIANO
Le tecnologie linguistiche sono usate per sviluppare si-stemi soware progettati per gestire il linguaggio uma-no e di conseguenza sono spesso chiamate “tecnologiadel linguaggio umano”. Il linguaggio umano si presen-ta in forma orale o scritta. Mentre la voce è la forma dicomunicazione linguistica più antica e più naturale intermini evolutivi, l’informazione complessa e lamaggiorparte della conoscenza sono memorizzate e trasmesse intesti scritti. Le tecnologie vocali e testuali elaborano oproducono queste diverse forme di linguaggio usando idizionari, le regole della grammatica e della semantica.Ciò significa che la tecnologia linguistica (TL) collegail linguaggio a varie forme di conoscenza, indipenden-temente dal mezzo (discorso o testo) con cui è espressa.La Figura 1 illustra il panorama delle tecnologie lingui-stiche.uando comunichiamo, combiniamo il linguaggio conaltri modi di comunicazione e mezzi di informazione –per esempio il parlare può includere gesti ed espressionifacciali. I testi digitali sono collegati a immagini e suoni.I film possono contenere il linguaggio in forma parlata escritta. In altre parole, le tecnologie vocali e testuali si so-vrappongono e interagiscono con altre tecnologie dellacomunicazione multimodali e multimediali.In questo capitolo, presenteremo i campi principali diapplicazione delle tecnologie linguistiche, ovvero il con-trollo ortografico e grammaticale di una lingua, la ricercasuWeb, la tecnologia vocale, e la traduzione automatica.ueste applicazioni e tecnologie di base includono:
‚ correzione ortografica
‚ supporto alla creazione di documenti
‚ apprendimento linguistico assistito da computer
‚ information retrieval
‚ estrazione di informazione
‚ sommarizzazione automatica
‚ question answering
‚ riconoscimento vocale
‚ sintesi vocale
L’area di ricerca relativa alle tecnologie del linguaggio di-spone di un vasto insiemedi letteratura introduttiva; perun approfondimento si rimanda ai seguenti riferimentibibliografici: [11, 12, 13, 14, 15].Prima di discutere queste aree di applicazione, descrive-remo brevemente l’architettura di un tipico sistema ditecnologie del linguaggio.
4.1 ARCHITETTURE APPLICATIVELe applicazioni soware per l’elaborazione del linguag-gio generalmente sono costituite da più componenti cherispecchiano i diversi aspetti del linguaggio. Sebbene sitratti di applicazioni in genere molto complesse, la Fi-gura 2 mostra un’architettura altamente semplificata diun tipico sistema di elaborazione del testo. I primi tremoduli gestiscono la struttura e il significato del testo iningresso:
1. Pre-processing: prepara i dati, analizza o rimuove ilformato, rileva la lingua in ingresso, rileva gli accenti(“città” e “citta’”) e gli apostrofi (“dell’UE” e “dellaUE”) per l’italiano, e così via.
14

Tecnologie multimediali e multimodali
Tecnologie linguistiche
Tecnologie vocali
Tecnologie per l'elaborazione del testo
Tecnologie della conoscenza
1: Tecnologie linguistiche
2. Analisi grammaticale: riconosce il verbo, i suoi og-getti, modificatori e altre parti del discorso e inoltrerileva la struttura della frase.
3. Analisi semantica: esegue la disambiguazione (cioèassegna un significato appropriato alle parole in baseal contesto), risolve l’anafora (cioè quali pronomi siriferiscono a quali sostantivi nella frase) e le espres-sioni sostitutive, e rappresenta il significato della fra-se in un formato leggibile da una macchina.
Dopo aver analizzato il testo, deimoduli specifici per uncerto compito possono eseguire altre operazioni, comeil riassunto automatico e la ricerca in un database.Dopo aver introdotto le aree chiave della tecnologie lin-guistiche, nella parte restante di questo capitolo fornire-mo prima una breve panoramica dello stato attuale del-la ricerca e della formazione in questo campo e poi unquadro dei programmi di ricerca passati e attuali. Infine,presenteremo una stima esperta degli strumenti e dellerisorse che sono fondamentali per l’italiano da diversipunti di vista, quali la disponibilità, la maturità e la qua-lità. La situazione generale delle tecnologie linguisticheper l’italiano è infine riassunta in Figura 8 alla fine diquesto capitolo. uesta tabella elenca tutti gli strumen-ti e le risorse che sono evidenziati nel testo. Le tecno-logie linguistiche per l’italiano sono confrontate anchecon quelle per le altre lingue facenti parte di questa col-lana.
4.2 AMBITI APPLICATIVIPRINCIPALIIn questa sezione, ci concentriamo sugli strumenti e lerisorse più importanti per le tecnologie linguistiche, perpoi passare ad una panoramica delle attività legate alletecnologie del linguaggio in Italia.
4.2.1 Controllo ortografico egrammaticale
Chiunque abbia usato un editore di testo come Micro-so Word sa che dispone di un correttore ortograficoche evidenzia gli errori di ortografia e propone dellecorrezioni. I primi programmi di correzione ortograficaconfrontavano una lista di parole estratte con un dizio-nario di parole scritte correttamente. Oggi questi pro-grammi sono molto più sofisticati. Utilizzando algorit-mi dipendenti dalla lingua per l’analisi grammaticale,rilevano gli errori relativi alla morfologia (per esempio,la formazione del plurale), così come gli errori relativi al-la sintassi, come un verbomancante o un conflitto di ac-cordo verbo-soggetto contratto (ad esempio, lei *scriouna lettera). Ma la maggior parte dei correttori ortogra-fici non troverà alcun errore nel testo che segue [16]:
‚ *Per salire in casa occorre fare 15 scali
‚ (Per salire in casa occorre fare 15 gradini)
15

Testo in input
Pre-elaborazione Analisi grammaticale
Analisi semantica
Moduli specifici del compito
Output
2: Architettura tipica di un’applicazione per l’elaborazione del testo
La gestione di questo tipo di errori di solito richiedeun’analisi del contesto. uesto tipo di analisi deve at-tingere a delle grammatiche specifiche per una lingua,faticosamente codificate nel soware da parte di esper-ti, o ad un modello di linguaggio statistico. In quest’ul-timo caso, un modello calcola la probabilità di una cer-ta parola di comparire in una determinata posizione (adesempio, tra le parole che la precedono e la seguono). Adesempio: 15 gradini è una sequenza di parole più proba-bile di 15 scali. Un modello di linguaggio statistico puòessere creato automaticamente utilizzando una grandequantità di dati linguistici (corretti), un cosiddetto cor-pus testuale. La maggior parte di questi approcci sonostati sviluppati sulla base di dati per la lingua inglese.Nessuno dei due approcci può essere facilmente trasfe-rito all’italiano perché la lingua ha un ordine flessibiledelle parole e un sistema flessionale più ricco.
Il controllo ortografico e grammaticale non è limitatoagli editori di testo, ma è usato anche in “sistemi di sup-porto alla creazione di documenti”, cioè ambienti so-ware con cui sono scritti imanuali e altra documentazio-ne che segue standard particolari per le tecnologie del-l’informazione, i prodotti sanitari, l’ingegneria ed altro.Temendo lamentele da parte dei clienti circa l’uso scor-retto e richieste di risarcimento per danni dovuti a istru-zioni poco chiare, le aziende sono sempre più concentra-te sulla qualità della documentazione tecnica, puntandoal contempo al mercato internazionale (tramite tradu-
zioneo localizzazione). I progressi nella elaborazionedellinguaggio naturale hanno portato allo sviluppo di so-ware di supporto alla creazione di documenti, che aiu-tano l’autore di documentazione tecnica nell’uso di unvocabolario e di una costruzione della frase coerenti conle regole del settore e con le restrizioni terminologicheaziendali.
L’uso del controllo ortografico e grammaticalenon è limitato agli editori di testo ma è usato
anche nei sistemi di supporto alla creazione didocumenti.
Oltre ai correttori ortografici e ai supporti alla creazio-ne di documenti, il controllo grammaticale è importanteanchenel campodell’apprendimentodelle lingue assisti-to da computer. Le applicazioni di controllo grammati-cale correggono automaticamente le query dei motori diricerca, come ad esempio nei suggerimenti di Google.
4.2.2 Ricerca nel Web
La ricerca nel Web, nelle intranet o nelle biblioteche di-gitali è probabilmente l’applicazione di tecnologia dellinguaggio oggi più usata, anche se in gran parte anco-ra poco sviluppata. Il motore di ricerca di Google, cheha iniziato nel 1998, gestisce oggi circa l’80% di tutte lequery di ricerca [17]. L’interfaccia di ricerca di Google
16

Testo in input Controllo ortografico Controllo grammaticale Proposte di correzione
Modello statistico di linguaggio
3: Correttore ortografico e grammaticale (sopra: statistica, sotto: a regole)
e la pagina che mostra i risultati non sono significativa-mente cambiate rispetto alla prima versione. Tuttavia,nella versione attuale Google offre la correzione orto-grafica per le parole errate e di recente ha incorporatodelle funzionalità di base di ricerca semantica che pos-sonomigliorare la precisione della ricerca analizzando ilsignificato dei termini in un dato contesto di query di ri-cerca [18]. La storia del successo di Google mostra chegrandi quantità di dati unite a tecniche di indicizzazioneefficienti sono in grado di fornire risultati soddisfacentiusando un approccio basato sulla statistica.
Per richieste di informazioni più sofisticate, è essenzia-le integrare delle conoscenze linguistiche più approfon-dite che consentano l’interpretazione del testo. Espe-rimenti che hanno utilizzato delle risorse lessicali co-me thesauri elettronici o risorse linguistiche ontologi-che (ad esempio,WordNet per l’inglese o ItalWordNet eMultiWordNet per l’italiano) hanno dimostrato dei mi-glioramenti nella ricerca di pagine utilizzando dei sino-nimi dei termini di ricerca originali, come “energia” ato-mica e “energia nucleare”, o termini meno strettamenteconnessi.
La prossima generazione di motori di ricerca dovrà in-cludere una tecnologia linguistica molto più sofisticata,in particolare per affrontare querydi ricerca costituite dadomande o altri tipi di frase, piuttosto che da un elencodi parole chiave. Per la richiestaDammiun elenco di tuttele aziende che sono state rileate da altre società negli ul-timi cinque anni, è necessaria un’analisi semantica oltrea quella sintattica. Il sistema dovrà inoltre fornire un in-
dice per recuperare rapidamente i documenti rilevanti.Una risposta soddisfacente richiederà l’analisi sintatticaper analizzare la struttura grammaticale della frase e de-terminare che l’utente desidera conoscere le aziende chesono state acquisite, e non le società che hanno acquisi-to altre società. Per l’espressione gli ultimi cinque anni, ilsistema deve determinare gli anni in questione. E la que-ry deve essere confrontata con una quantità enorme didati non strutturati per trovare la o le informazioni per-tinenti che l’utente desidera. uesto processo si chiamainformation retrieval, e implica la ricerca e la classifica-zione dei documenti rilevanti. Per generare un elenco disocietà, il sistema deve anche riconoscere che una parti-colare stringa di parole in un documento è il nome del-la società, utilizzando un processo chiamato “riconosci-mento di entità nominate”.
La prossima generazione di motori di ricercadovrà includere una tecnologia linguistica molto
più sofisticata.
Una sfida ancora più impegnativa è far corrispondereuna query in una lingua con dei documenti in un’altralingua. Il cross-lingual information retrieval comportatradurre automaticamente la query in tutte le lingue diorigine possibili e poi di nuovo tradurre i risultati nellalingua di destinazione.Ora che i dati sono sempre più disponibili in formatinon testuali, sono necessari dei servizi che offrano il re-cupero di informazionemultimediale attraverso la ricer-
17

Query utente
Pagine web
Pre-elaborazione Analisi della query
Pre-elaborazione Elaborazione semantica Indicizzazione
Corrispondenza e
rilevanza
Risultati della ricerca
4: Ricerca su Web
ca di immagini, file audio e dati video. Nel caso di fileaudio e video, un modulo di riconoscimento vocale de-ve convertire il contenuto parlato in testo (o in una rap-presentazione fonetica) che possa poi essere confrontatocon una query dell’utente.In Italia, aziende come Expert System e CELI, tra le al-tre, sviluppano e applicano con successo le tecnologie diricerca semantica.
4.2.3 Interazione Vocale
L’interazione vocale è una delle molte aree applicati-ve che dipendono dalle tecnologie vocali, ovvero quellotecnologie che consentono l’elaborazione del linguaggioparlato. Le tecnologie per l’interazione vocale sono uti-lizzate per creare interfacce che consentono agli uten-ti di interagire in linguaggio parlato anziché usare undisplay grafico, tastiera e mouse. Oggi, queste interfac-ce utente vocali (Voice User Interfaces – VUI) vengonoutilizzate per servizi telefonici completamente o parzial-mente automatizzati che vengono forniti dalle società aiclienti, ai dipendenti o ai partner commerciali. I domini
applicativi che si basano massicciamente sulle VUI in-cludono banche, catene di distribuzione, trasporti pub-blici, e telecomunicazioni. Altri usi delle tecnologie perl’interazione vocale includono le interfacce dei sistemidi navigazione per auto e l’uso del linguaggio parlato co-me alternativa alle interfacce grafiche o touch-screen ne-gli smartphone.L’interazione vocale comprende quattro tecnologie:
1. Il riconoscimento vocale automatico (ASR), chedetermina quali parole sono effettivamente pronun-ciate in una data sequenza di suoni emessi da unutente.
2. La comprensione del linguaggio naturale analizza lastruttura sintattica dell’espressione di un utente e lainterpreta secondo il sistema in questione.
3. La gestione del dialogo determina l’azione da intra-prendere in base all’input dell’utente e le funzionalitàdel sistema.
4. La sintesi vocale (text-to-speech o TTS) trasforma larisposta del sistema in suoni per l’utente.
18

Input vocale Elaborazione del segnale
Output vocale Sintesi vocaleRicerca fonetica e
pianificazione dell'intonazione
Comprensione del linguaggio naturale
e dialogo
Riconoscimento
5: Sistema di dialogo parlato
La tecnologia vocale rappresenta la baseper creare delle interfacce che permettano
ad un utente di interagire tramite il linguaggioparlato anziché usare uno schermo grafico,
tastiera e mouse.
Una delle sfide principali dei sistemi di riconoscimentovocale consiste nel riconoscere con precisione le paro-le pronunciate da un utente. uesto significa limitare lagammadi espressioni possibili degli utenti ad un insiemelimitato di parole chiave, oppure creare manualmentedei modelli di linguaggio che coprano una vasta gammadi espressioni in linguaggio naturale. Utilizzando tecni-che di machine learning, dei modelli di linguaggio pos-sono essere generati anche automaticamente da corpo-ra di parlato, ovvero grandi raccolte di file audio voca-li e trascrizioni testuali. Limitare le espressioni di solitocostringe le persone a utilizzare l’interfaccia utente vo-cale in modo rigido e può pregiudicare l’accettazione daparte dell’utente, ma la creazione, l’adattamento e la ma-nutenzione di modelli di linguaggio ricchi aumentanosensibilmente i costi. Le interfacce vocali che utilizzanomodelli linguistici e permettono inizialmente all’utentedi esprimere le proprie intenzioni in modo più flessibile– per esempio tramite un saluto introduttivo come Co-me posso aiutarla? – tendono ad essere automatizzate esono accettate meglio dagli utenti.Le aziende tendono ad usare delle espressioni pre-registrate da attori professionisti per generare l’output
dell’interfaccia utente vocale. Per espressioni statiche incui la formulazione non dipende da contesti d’uso par-ticolari o da dati personali, questo può offrire un’espe-rienza più ricca per l’utente. Tuttavia, i contenuti più di-namici in un enunciato potrebbero essere compromes-si da un’intonazione innaturale derivante dalla semplicecombinazione di frammenti di file audio. I sistemi di sin-tesi vocale attuali sono in continuo miglioramento (an-che se possono essere ancora ottimizzati) nel produrreespressioni dinamiche che suonino naturali.
Nel mercato dell’interazione vocale le interfacce sonostate notevolmente standardizzate negli ultimi dieci an-ni in termini di componenti tecnologici vari. C’è statoanche un forte consolidamento nel mercato del ricono-scimento vocale e della sintesi vocale. Imercati nazionalidei paesi del G20 (paesi economicamente resilienti e in-tensamente popolati) sono stati dominati da sole cinquefigure di livellomondiale, conNuance (USA) eLoquen-do (Italia) a rappresentare le figure più importanti in Eu-ropa. Nel 2011, Nuance ha completato l’acquisizione diLoquendo, definendo così un ulteriore passo avanti nelconsolidamento del mercato.
Nel mercato del riconoscimento vocale automatico perla lingua italiana, ci sono anche aziende più piccole co-me PerVoice, Cedat85 e Synthema. Per quanto riguardala tecnologia e il know-how della gestione del dialogo, ilmercato è dominato da operatori nazionali per le PMI.In Italia, questi includono IMService Lab. Piuttosto che
19

fare affidamento su un modello produttivo basati su li-cenze soware, queste aziende sono posizionate princi-palmente come fornitori di servizi completi che creanointerfacce utente vocali come parte di un servizio di in-tegrazione di sistema. Nel settore della tecnologia inte-rattiva, non vi è ancora un vero mercato per tecnologiedi base basate su analisi sintattica e semantica.
Ladomandadi interfacce utente vocali in Italia è cresciu-ta rapidamente negli ultimi cinque anni, trainata dal-la richiesta crescente di servizi self-service da parte deiclienti e dalla crescente accettazione del linguaggio par-lato come mezzo per l’interazione uomo-macchina.
Guardando al futuro, ci saranno cambiamenti significa-tivi dovuti alla diffusione degli smartphone quale nuovapiattaforma per la gestione delle relazioni con i clientiin aggiunta ai telefoni fissi, Internet e posta elettronica.uesto influirà anche sulmodo in cui è usata la tecnolo-gia vocale. Nel lungo periodo, ci saranno sempre menointerfacce vocali basate sul telefono e il linguaggio par-lato avrà un ruolo molto più centrale come modalità diaccesso per gli smartphone.uesto sarà in granparte de-terminato dai miglioramenti intervenuti nell’accuratez-za del riconoscimento vocale indipendente dal parlanteattraverso i servizi di dettatura vocale già offerti comeservizi centralizzati agli utenti di smartphone.
4.2.4 Traduzione automatica
L’idea di utilizzare i computer per tradurre le lingue na-turali risale al 1946 ed è stata seguita da cospicui finan-ziamenti per la ricerca durante gli anni ’50 e nuovamentenegli anni ’80. Eppure la traduzione automatica (Ma-chine Translation, MT) non è ancora in grado dimante-nere la sua promessa iniziale.
Nella traduzione automatica, l’approccio più sempliceconsiste nel sostituire automaticamente le parole di untesto in una certa lingua naturale con parole in un’altralingua. uesto può essere utile in ambiti che hanno unlinguaggio molto limitato e stereotipato, come le previ-
sioni meteo. Ma per produrre una buona traduzione ditesti meno standardizzati, o per unità di testo più gran-di (come sintagmi, frasi o anche interi passaggi), devonoessere trovati gli omologhi migliori nella lingua di arri-vo.
Ad un livello base, la traduzione automaticaconsiste semplicemente nella sostituzione di
parole in una lingua con parole in un’altra lingua.
La difficoltàmaggiore è che il linguaggio umano è ambi-guo. L’ambiguità crea problemi su più livelli, ad esempioa livello lessicale (la parola inglese jaguar può essere tra-dotta come una marca di auto o come un animale) o alivello sintattico, per esempio:
‚ e chicken is ready to eat.
‚ [Il pollo è pronto a mangiare.]
‚ [Il pollo è pronto per essere mangiato.]
Un modo di costruire un sistema di MT consiste nel-l’utilizzare delle regole linguistiche. Per le traduzioni tralingue molto simili, una traduzione diretta basata sul-la sostituzione può essere fattibile in casi come quellodell’esempio precedente. Tuttavia, i sistemi basati su re-gole (o basati sulla conoscenza linguistica) spesso ana-lizzano il testo in input e creano una rappresentazionesimbolica intermedia da cui il testo può essere generatonella lingua di destinazione. Il successo di questi meto-di è fortemente dipendente dalla disponibilità di grandilessici dotati di informazioni morfologiche, sintattichee semantiche, e di grandi insiemi di regole grammatica-li attentamente progettate da linguisti esperti. uesto èun processo molto lungo e di conseguenza costoso.L’interesse per i modelli statistici nella traduzione auto-matica è cresciuto verso la fine degli anni ’80, quandola potenza di calcolo è aumentata ed è diventata menocostosa. I modelli statistici sono derivati dall’analisi di
20

Traduzione automatica
statistica
Testo originale
Testo finale
Analisi testuale (formattazione, morfologia, sintassi, ecc.)
Post-editing (formattazione, contesto, ecc.)
Regole di traduzione
6: Traduzione automatica (a sinistra: statistico, a destra: a regole)
corpora testuali bilingui, come il corpus parallelo Eu-roparl, che raccoglie gli atti del Parlamento europeo in21 lingue europee. Con una quantità sufficiente di dati,la traduzione automatica statistica funziona abbastanzabene da ricavare un significato approssimativo di un te-sto in una lingua straniera, elaborando versioni paralle-le e trovando delle sequenze di parole plausibili. Ma adifferenza dei sistemi basati sulla conoscenza, la tradu-zione automatica statistica (o data-driven) spesso gene-ra un risultato sgrammaticato. La traduzione automati-ca data-driven è vantaggiosa perché richiede uno sforzoumanominore, e può anche trattare particolarità specia-li del linguaggio (ad esempio, le espressioni idiomatiche)che possono essere ignorate da sistemi basati sulla cono-scenza.
I punti di forza e di debolezza della traduzione auto-matica basata sulla conoscenza e di quella data-driventendono ad essere complementari, di modo che al gior-no d’oggi i ricercatori si concentrano su approcci ibridiche combinano entrambe le metodologie. Un approc-cio particolare utilizza sia sistemi basati sulla conoscenzache data-driven, con un modulo di selezione che decidela migliore uscita per ogni frase. Tuttavia, i risultati perfrasi più lunghe di 12 parole saranno spesso ben lonta-ni dall’essere perfetti. Una soluzione più soddisfacenteconsiste nel combinare le parti migliori di ogni frase dapiù uscite diverse; la cosa può essere piuttosto comples-sa, in quanto non è sempre evidente quali siano le parti
corrispondenti di alternative multiple, che devono esse-re allineate.
La traduzione automatica è particolarmenteimpegnativa per la lingua italiana.
La traduzione automatica è particolarmente impegnati-va per la lingua italiana, che è morfologicamente com-plessa ed ha un ordine libero delle parole nella frase. Cisono alcune aziende in Italia attive nel settore della tra-duzione automatica, soprattutto nella fornitura di servi-zi per usi professionali (ad esempio, Translated).L’uso della traduzione automatica può aumentare la pro-duttività in modo significativo, ammesso che il sistemasia adattato in modo intelligente alla terminologia spe-cifica per l’utente e integrato nel flusso di lavoro. Sonostati sviluppati dei sistemi speciali per supportare la tra-duzione interattiva.Il potenziale di miglioramento della qualità dei sistemidi traduzione automatica è ancora enorme. Le sfide at-tuali riguardano l’adattamento delle risorse linguistichea un dominio o argomento determinato e l’integrazio-ne della tecnologia nei flussi di lavoro che dispongonogià di database di termini e memorie di traduzione. Unaltro problema è che la maggior parte dei sistemi attualisono incentrati sull’inglese e supportano solo alcune lin-gue da e verso l’italiano. uesto comporta una frizionenel flusso di lavoro di traduzione e costringe gli utenti
21

Lingua target – Target languageEN BG DE CS DA EL ES ET FI FR HU IT LT LV MT NL PL PT RO SK SL SV
EN – 40.5 46.8 52.6 50.0 41.0 55.2 34.8 38.6 50.1 37.2 50.4 39.6 43.4 39.8 52.3 49.2 55.0 49.0 44.7 50.7 52.0BG 61.3 – 38.7 39.4 39.6 34.5 46.9 25.5 26.7 42.4 22.0 43.5 29.3 29.1 25.9 44.9 35.1 45.9 36.8 34.1 34.1 39.9DE 53.6 26.3 – 35.4 43.1 32.8 47.1 26.7 29.5 39.4 27.6 42.7 27.6 30.3 19.8 50.2 30.2 44.1 30.7 29.4 31.4 41.2CS 58.4 32.0 42.6 – 43.6 34.6 48.9 30.7 30.5 41.6 27.4 44.3 34.5 35.8 26.3 46.5 39.2 45.7 36.5 43.6 41.3 42.9DA 57.6 28.7 44.1 35.7 – 34.3 47.5 27.8 31.6 41.3 24.2 43.8 29.7 32.9 21.1 48.5 34.3 45.4 33.9 33.0 36.2 47.2EL 59.5 32.4 43.1 37.7 44.5 – 54.0 26.5 29.0 48.3 23.7 49.6 29.0 32.6 23.8 48.9 34.2 52.5 37.2 33.1 36.3 43.3ES 60.0 31.1 42.7 37.5 44.4 39.4 – 25.4 28.5 51.3 24.0 51.7 26.8 30.5 24.6 48.8 33.9 57.3 38.1 31.7 33.9 43.7ET 52.0 24.6 37.3 35.2 37.8 28.2 40.4 – 37.7 33.4 30.9 37.0 35.0 36.9 20.5 41.3 32.0 37.8 28.0 30.6 32.9 37.3FI 49.3 23.2 36.0 32.0 37.9 27.2 39.7 34.9 – 29.5 27.2 36.6 30.5 32.5 19.4 40.6 28.8 37.5 26.5 27.3 28.2 37.6FR 64.0 34.5 45.1 39.5 47.4 42.8 60.9 26.7 30.0 – 25.5 56.1 28.3 31.9 25.3 51.6 35.7 61.0 43.8 33.1 35.6 45.8HU 48.0 24.7 34.3 30.0 33.0 25.5 34.1 29.6 29.4 30.7 – 33.5 29.6 31.9 18.1 36.1 29.8 34.2 25.7 25.6 28.2 30.5IT 61.0 32.1 44.3 38.9 45.8 40.6 26.9 25.0 29.7 52.7 24.2 – 29.4 32.6 24.6 50.5 35.2 56.5 39.3 32.5 34.7 44.3LT 51.8 27.6 33.9 37.0 36.8 26.5 21.1 34.2 32.0 34.4 28.5 36.8 – 40.1 22.2 38.1 31.6 31.6 29.3 31.8 35.3 35.3LV 54.0 29.1 35.0 37.8 38.5 29.7 8.0 34.2 32.4 35.6 29.3 38.9 38.4 – 23.3 41.5 34.4 39.6 31.0 33.3 37.1 38.0MT 72.1 32.2 37.2 37.9 38.9 33.7 48.7 26.9 25.8 42.4 22.4 43.7 30.2 33.2 – 44.0 37.1 45.9 38.9 35.8 40.0 41.6NL 56.9 29.3 46.9 37.0 45.4 35.3 49.7 27.5 29.8 43.4 25.3 44.5 28.6 31.7 22.0 – 32.0 47.7 33.0 30.1 34.6 43.6PL 60.8 31.5 40.2 44.2 42.1 34.2 46.2 29.2 29.0 40.0 24.5 43.2 33.2 35.6 27.9 44.8 – 44.1 38.2 38.2 39.8 42.1PT 60.7 31.4 42.9 38.4 42.8 40.2 60.7 26.4 29.2 53.2 23.8 52.8 28.0 31.5 24.8 49.3 34.5 – 39.4 32.1 34.4 43.9RO 60.8 33.1 38.5 37.8 40.3 35.6 50.4 24.6 26.2 46.5 25.0 44.8 28.4 29.9 28.7 43.0 35.8 48.5 – 31.5 35.1 39.4SK 60.8 32.6 39.4 48.1 41.0 33.3 46.2 29.8 28.4 39.4 27.4 41.8 33.8 36.7 28.5 44.4 39.0 43.3 35.3 – 42.6 41.8SL 61.0 33.1 37.9 43.5 42.6 34.0 47.0 31.1 28.8 38.2 25.7 42.3 34.6 37.3 30.0 45.9 38.2 44.1 35.8 38.9 – 42.7SV 58.5 26.9 41.0 35.6 46.6 33.3 46.6 27.4 30.9 38.9 22.7 42.0 28.2 31.0 23.7 45.6 32.2 44.2 32.7 31.3 33.5 –
7: Traduzione automatica tra 22 lingue dell’UE – Machine translation between 22 EU-languages [19]
dei sistemi di traduzione automatica ad apprendere l’u-so di strumenti diversi di codifica dei lessici per sistemidiversi.
Le campagne di valutazione aiutano a confrontare laqualità dei sistemi di traduzione automatica, i diversi ap-procci e lo stato dei sistemi per coppie di lingue diverse.La Figura 7 (p. 22), che è stata preparata durante il pro-getto europeo Euromatrix +, mostra le prestazioni otte-nute per coppie di lingue su 22 delle 23 lingue ufficialidell’UE (l’irlandese non è stato confrontato). I risultatisono classificati in base al punteggio BLEU, che assegnapunteggi più alti alle traduzioni migliori [20] (un tra-duttore umano raggiungerebbe un punteggio di circa 80punti).
I risultati migliori (in verde e blu) sono stati raggiuntida quelle lingue che beneficiano di un notevole sforzo diricerca in programmi coordinati e dell’esistenza di molticorpora paralleli (ad esempio, inglese, francese, olande-
se, spagnolo e tedesco). Le lingue con risultati inferiorisono contrassegnate in rosso. Per queste lingue manca-no sforzi di sviluppo analoghi oppure si tratta di linguestrutturalmente molto diverse dalle altre (ad esempio,l’ungherese, il maltese e il finlandese).
4.3 ALTRE AREE APPLICATIVELa creazione di applicazioni di tecnologia linguisticacomporta una serie di attività secondarie che non sem-pre affiorano al livello di interazione con l’utente, maforniscono funzionalità di servizio cruciali del sistemain questione. Tutte rappresentano importanti temi di ri-cerca che ora si sono evoluti in sotto-discipline indipen-denti della linguistica computazionale. Il question an-swering, per esempio, è un’area di ricerca molto attiva,per la quale sono stati costruiti dei corpora annotati esono state avviate delle competizioni scientifiche. L’idea
22

alla base del question answering è di andare oltre la ri-cerca basata su parole chiave (in cui il motore di ricer-ca risponde fornendo una raccolta di documenti poten-zialmente rilevanti) e consentire agli utenti di fare unadomanda concreta a cui il sistema fornisce una sola ri-sposta. Per esempio:
Domanda: uanti anni avevaNeil Armstrong quan-do andò sulla luna?
Risposta: 38.
Anche se il question answering è ovviamente correlatoal settore della ricerca sul web, oggi è considerato un ter-mine generico che ricomprende temi di ricerca quali idiversi tipi di domande possibili e come dovrebbero es-sere trattati, il modo di analizzare e confrontare un in-sieme di documenti che potenzialmente contengono larisposta (forniscono risposte contraddittorie?), e il mo-do per estrarre in modo attendibile delle informazionispecifiche (la risposta) da un documento senza ignorareil contesto.
Le applicazioni di tecnologia linguistica spessoforniscono delle funzionalità di servizio importanti
ricomprese in sistemi software più ampi.
Il question answering è a sua volta connesso con l’estra-zione di informazioni (information extraction, IE), unsettore estremamente popolare ed influente al momen-to della svolta statistica della linguistica computaziona-le, nei primi anni ’90. L’information extraction si propo-ne di identificare delle informazioni specifiche in speci-fiche classi di documenti, come ad esempio identificaregli attori-chiave in acquisizioni aziendali riportate in ar-ticoli di giornale. Un altro scenario comune che è statostudiato sono i rapporti sugli incidenti terroristici.ui ilproblema consiste nel far coincidere il testo con un mo-dello che specifica l’autore, l’obiettivo, l’ora, il luogo e i
risultati dell’incidente. Il riempimento di modelli cali-brato su un dominio specifico è la caratteristica centra-le dell’information extraction; questo la rende un altroesempio di quelle tecnologie “dietro le quinte” che co-stituiscono una ben delimitata area di ricerca che in pra-tica ha bisogno di essere integrata in un ambiente appli-cativo adatto. La sommarizzazione automatica e la ge-nerazione di testo sono due aree di confine che posso-no sia agire come applicazioni indipendenti che giocareun ruolo di supporto. La sommarizzazione tenta di pre-sentare gli elementi essenziali di un testo lungo in for-ma abbreviata, ed è una delle funzionalità disponibili inMicroso Word. Si utilizza per lo più un approccio sta-tistico per identificare le parole “importanti” in un testo(per esempio, parole che compaionomolto di frequentenel testo in questione,mameno di frequente nell’uso ge-nerale) e determinare quali frasi contengono la maggiorparte di queste parole “importanti”. ueste frasi vengo-no poi estratte e messe insieme per creare il riassunto. Inquesto scenario commerciale molto comune, la somma-rizzazione è semplicemente una forma di estrazione difrasi, e il testo è ridotto a un sottoinsieme delle sue fra-si. Un approccio alternativo, per il quale sono state svol-te alcune ricerche, consiste nel generare frasi nuove chenon esistono nel testo di partenza. uesto richiede unacomprensione più profonda del testo, il che significa chefino ad ora questo approccio è molto meno robusto. Ungeneratore di testo viene raramente utilizzato come ap-plicazione indipendente; il più delle volte è inserito inun ambiente soware più ampio, come ad esempio unsistema informativo clinico che raccoglie, memorizza edelabora i dati dei pazienti. La creazione di rapporti è so-lo una delle molte applicazioni della sommarizzazioneautomatica.
La ricerca nelle tecnologie di testo descritte è moltome-no sviluppata per la lingua italiana che per la lingua in-glese.Question answering, information extraction e som-marizzazione automatica sono stati al centro di nume-
23

rose competizioni negli Stati Uniti dal 1990, principal-mente organizzate da organizzazioni governative qualiDARPA e NIST.
Per la lingua italiana la ricerca nelle tecnologiedi testo descritte è molto meno sviluppata che
per la lingua inglese.
ueste competizioni hanno notevolmente miglioratolo stato dell’arte, ma la loro attenzione è stata principal-mente sulla lingua inglese. Come risultato, in italiano cisono meno corpora annotati o altre risorse speciali ne-cessarie per svolgere questi compiti. I sistemi di somma-rizzazione basati su metodi puramente statistici sono ingran parte indipendenti dalla lingua e sono disponibilialcuni prototipi di ricerca. Per la generazione del testo, icomponenti riutilizzabili sono tradizionalmente limita-ti ai moduli di realizzazione superficiale (grammatichedi generazione) e la maggior parte del soware disponi-bile è per la lingua inglese.
4.4 PROGRAMMI FORMATIVILe tecnologie linguistiche costituiscono un campo alta-mente interdisciplinare che include le competenze com-binate, fra gli altri, di linguisti, informatici, matematici,filosofi, psicolinguisti e neuroscienziati. Di conseguen-za, questo campo di studi non ha acquisito una esistenzachiara e indipendente nel sistema universitario italiano.Per quanto concerne i curricula universitari, segnaliamoil “Master Internazionale di secondo livello in Tecno-logie del Linguaggio Umano e Interfacce” presso l’U-niversità di Trento e il “Master Europeo in Tecnologiedel Linguaggio e della Comunicazione” presso la Libe-ra Università di Bolzano. Inoltre a livello di laurea e didottorato di ricerca sono attivi almeno altri 16 curricu-la collegati alle tecnologie del linguaggio (in particolarepresso le Università di Venezia, Torino, Pavia, Pisa, Ro-ma “TorVergata”,Napoli e Bari), per un totale di almeno
76 corsi universitari riguardanti questo campo in Italia,includendo quelli che fanno riferimento a percorsi di In-formatica Umanistica.
4.5 PROGETTI E INIZIATIVENAZIONALILa presenza “digitale” di una lingua in applicazioni e ser-vizi basati su Internet è ormai un elemento cruciale permantenere la vitalità culturale di quella lingua. E, d’altraparte, applicazioni e servizi su Internet sono sostenibilisolo in presenza di adeguate infrastrutture e tecnologie.Per quanto riguarda l’italiano, sebbene la situazione nonpossa essere paragonata a quella dell’inglese, a partire dal1997 è stato fatto uno sforzo considerevole in Italia nellaricerca sulle tecnologie del linguaggio, quando per que-sto settore è stata designata una politica di ricerca nazio-nale con il lancio di due progetti della durata di tre anni:
‚ TAL, Infrastruttura Nazionale per le risorse Lingui-stiche nel campo del Trattamento Automatico delLinguaggioNaturale Scritto e Parlato, finanziato dalgoverno italiano per circa 1,75 milioni di Euro;
‚ LRCMM, rivolto alla ricerca nel campo della lingui-stica computazionale, sia monolingue che multilin-gue, finanziato per circa 3 milioni di Euro.
I finanziamenti a livello nazionale però sono molto li-mitati. Il lancio dei due progetti sopra menzionati è sta-to seguito, recentemente, soltanto dal finanziamento didue progetti di dimensioni minori: MIUR-PARLI, perl’armonizzazione delle risorse computazionali esisten-ti per l’italiano, e MIUR-PAISÀ, per la realizzazionedi una piattaforma per l’apprendimento dell’italiano sucorpora annotati.La produzione di tecnologie per il linguaggio e di risor-se linguistiche per l’italiano è principalmente il risultatodi vari progetti di ricerca finanziati dall’Unione Euro-pea e di altre iniziative.Grazie a questi investimenti sono
24

ora disponibili diversi database lessicali, nonché corporadi linguaggio scritto e parlato con annotazioni a diversilivelli (caratteristiche fonetiche, categorie grammatica-li, costruzioni sintattiche, menzioni testuali di persone,organizzazioni e luoghi, ecc.) realizzate manualmente oautomaticamente. Lo stesso vale per strumenti sowarein grado di effettuare l’analisi linguistica di testi in ita-liano (ad esempio annotatori di categorie grammaticali,analizzatori sintattici e riconoscitori di entità nominate)di riconoscere il parlato o di tradurre automaticamentetesti da e verso l’italiano.
La ricerca nel campo delle tecnologie del linguaggio ècondotta in Italia in oltre 15 laboratori (secondo quantoriportato dallo studio EUROMAP) e la presenza italia-na nella comunità di ricerca internazionale è attiva e rile-vante. La comunità italiana ha ospitato alcuni importan-ti eventi, tra cui l’undicesima edizione della “Conferenceof the EuropeanChapter of theAssociation forCompu-tational Linguistics” (EACL 2006) a Trento, la dodice-sima “Annual Conference of the International SpeechCommunication Association” (Interspeech 2011) a Fi-renze, e nel 2006, a Genova, la quinta edizione della“International Conference on Language Resources andEvaluation”, nella cui organizzazione la comunità italia-na ha un ruolo di primo piano. Diversi gruppi italianisono attualmente coinvolti con ruoli di coordinamentoinprogetti di networking internazionale, in particolare alivello europeo: menzioniamoCLEF – Cross LanguageEvaluation Forum [21], e FLaReNet, una rete di eccel-lenza che promuove una rete internazionale per le risor-se linguistiche [22]. Secondo una recente indagine con-dotta da META-NET [23], sono attualmente in corsosette progetti nazionali e sei progetti europei coordina-ti da partner italiani. Dal 2003 è inoltre attivo CELCT[24], ilCentroper la valutazione delle tecnologie del lin-guaggio e della comunicazione, con sede a Trento. Nel-l’ambito dell’Associazione Italiana per l’Intelligenza Ar-tificiale (AI*IA) [25]), il gruppo di interesse sull’Elabo-
razione del Linguaggio Naturale è il punto di riferimen-to scientifico per la comunità di ricerca italiana. L’ita-liano è incluso in molte iniziative internazionali per lavalutazione delle tecnologie del linguaggio. CLEF, peresempio, ha reso disponibili dataset in lingue diverse perl’organizzazione di task multilingui che includono l’i-taliano (per esempio, sul Question Answering). Evalita[26], una campagna di valutazione delle tecnologie dellinguaggio sia parlato che scritto, specifica per la linguaitaliana, è stata organizzata ogni due anni a partire dal2007. La comunità che si occupa del linguaggio parla-to è rappresentata dalla Associazione Italiana di Scienzedella Voce (AISV) [27]. Infine, il ForumTal [28], che harealizzato il “Libro Bianco” sulle tecnologie del linguag-gio in Italia e organizzato tre edizioni della conferenzaTAL, svolge un ruolo importante nella promozione ediffusione di tali tecnologie, in particolare nei confrontidella Pubblica Amministrazione italiana. Nonostante isuccessi ottenuti nel campo delle tecnologie del linguag-gio per l’italiano, lo stato attuale delle tecnologie non èsufficiente a garantire all’italiano una dimensione digi-tale proporzionata alla richiesta delle applicazioni e daiservizi dell’Internet del Futuro. Nei prossimi decenni lacomunità italiana deve, da un lato, proseguire i proprisforzi nella ricerca di base, ma dall’altro ha la necessitàdi sviluppare tecnologie per l’italiano in grado di tenereil passo con le dimensioni dei dati disponibili sull’Inter-net del Futuro. Inoltre, tutti potranno potenzialmenteaccedere ai servizi web, perciò le tecnologie del linguag-gio coinvolte nel fornire questi servizi in lingua italianadovranno essere in grado di gestire le varianti di italianoregionale prodotte dai diversi parlanti.
4.6 DISPONIBILITÀ DISTRUMENTI E RISORSELa Figura 8 fornisce una valutazione delle tecnologie dellinguaggio esistenti per la lingua italiana. Esperti del set-
25

ua
ntità
Disp
onib
ilità
ua
lità
Cop
ertu
ra
Matur
itá
Sosten
ibili
tà
Ada
ttab
ilità
Tecnologie Linguistiche: Strumenti, Tecnologie e Applicazioni
Riconoscimento vocale 2 2 6 5 4.5 3 3
Sintesi vocale 3 3 5 5 4 3.5 4
Analisi grammaticale 3.5 3 4 5 4 3 2
Analisi semantica 2.5 2.5 3.5 4 3 2.5 2.5
Generazione di testo 0 0 0 0 0 0 0
Traduzione automatica 4 3.5 4 3 4 3.5 2.5
Risorse Linguistiche: Risorse, Dati e Basi di Conoscenza
Corpora testuali 2.5 2.5 4 3.5 3.5 2.5 2
Corpora di parlato 3 3 4 2.5 2.5 2 2
Corpora paralleli 2 2 4 3 4 3 2
Risorse lessicali 3.5 3.5 5 5 5 2.5 2.5
Grammatiche 2 2 4 4 3 2 2
8: Stato di avanzamento delle tecnologie linguistiche per l’italiano
tore hanno fornito delle stime basate su una scala da 0(molto basso) a 6 (molto alto) usando sette criteri.
I principali risultati per quanto riguarda le tecnologiedel linguaggio per l’italiano sono i seguenti:
‚ L’elaborazione del parlato attualmente sembra esse-re più matura rispetto all’elaborazione dello scritto.Le tecnologie del parlato infatti sono già state inte-grate con successo in molteplici applicazioni di usoquotidiano, quali sistemi di dialogo, interfacce basa-te sulla voce e sistemi di navigazione per i cellulari ele automobili.
‚ La ricerca ha portato con successo alla sviluppo disoware di qualità medio alta per l’analisi di base deltesto, come strumenti per l’analisi morfologica e sin-tattica. Tuttavia, le tecnologie avanzate che richiedo-no elaborazione linguistica sofisticata e conoscenza
semantica sono ancora agli inizi.
‚ Per quanto riguarda le risorse, per l’italiano esiste unvasto corpus di testi di riferimento (in cui sono pre-senti vari generi in proporzioni bilanciate), ma talecorpus non è accessibile facilmente per questioni dicopyright; risulta più facile accedere a corpora nonbilanciati. Sono disponibili diversi corpora annotaticon strutture sintattiche, con strutture semantiche,o anche con strutture del discorso. Anche in questocaso, però, non esiste un numero sufficiente di cor-pora contenenti il tipo di annotazione richiesta perfar fronte al crescente bisogno di informazione lin-guistica e semantica più complessa.
‚ In particolare, sono quasi assenti corpora paralleli,che costituiscono la base per gli approcci statistici eibridi per la traduzione automatica. Attualmente, latraduzione dall’italiano all’inglese è quella che fun-
26

ziona meglio, poiché per questa coppia di lingue esi-ste una quantità maggiore di testi paralleli.
‚ Molti degli strumenti, delle risorse e dei formati didati disponibili non raggiungono gli standard indu-striali e non possono essere sostenuti in modo effica-ce. Sono quindi necessari programmi concertati perstandardizzare i formati dei dati e le API.
‚ Una situazione legale non chiara pone limiti all’usodei testi digitali (per esempio, quelli pubblicati in re-te dai giornali) per la ricerca nel campo della lingui-stica empirica e della tecnologia del linguaggio, co-me per esempio l’addestramento dimodelli linguisti-ci statistici. Insieme ai politici e agli addetti al setto-re, i ricercatori dovrebbero cercare di stabilire leggi oregolamenti che diano la possibilità ai ricercatori diutilizzare i testi disponibili pubblicamente per atti-vità di ricerca e sviluppo relative al linguaggio.
‚ La cooperazione tra la comunità delle tecnologie dellinguaggio e quelle coinvolte nel Web Semantico enel movimento Linked Open Data dovrebbe essereintensificata allo scopo di realizzare una base di co-noscenza digitale che venga mantenuta in manieracollaborativa, e che possa essere usata sia nei sistemiinformativi basati sul web, sia come una base di co-noscenza semantica in applicazioni di tecnologie lin-guistiche. uesto sforzo dovrebbe essere indirizzatoin direzione multilingue su scala europea.
In diverse aree specifiche della ricerca sulla lingua italia-na, attualmente sono disponibili soware con funziona-lità limitate. Ovviamente, sono necessari ulteriori sforzida parte della ricerca per risolvere il deficit relativo all’a-nalisi del testo a un livello semantico più profondo e persopperire alla mancanza di risorse quali i corpora paral-leli, necessari per la traduzione automatica.
4.7 CONFRONTO FRA LELINGUELo stato attuale delle tecnologie linguistiche varia con-siderevolmente da una comunità linguistica ad un’altra.Al fine di paragonare la situazione tra le diverse lingue,inquesta sezionepresentiamounavalutazione a campio-ne basata su due aree applicative (la traduzione automa-tica e l’elaborazione del parlato), una tecnologia di base(l’analisi del testo), e le risorse di base necessarie per co-struire applicazioni di tecnologie linguistiche.
Le lingue sono state raggruppate in base ad una tabella acinque punti:
1. Supporto eccellente
2. Buon supporto
3. Supporto medio
4. Supporto frammentario
5. Supporto debole o assente
Il supporto per le tecnologie linguistiche è stato misu-rato in base ai criteri seguenti:
Elaborazione del parlato: qualità delle tecnologie di ri-conoscimento vocale esistenti, qualità delle tecnologiedi sintesi vocale esistenti, copertura dei domini, numeroe dimensioni dei corpora di parlato esistenti, quantità evarietà delle applicazioni vocali esistenti.
Traduzione automatica: qualità delle tecnologie di tra-duzione automatica esistenti, numero delle coppie dilingue trattate, copertura di fenomeni e domini lingui-stici, qualità e dimensioni dei corpora paralleli esistenti,quantità e varietà delle applicazioni di traduzione auto-matica disponibili.
Analisi del testo: qualità e copertura delle tecnologie dianalisi del testo esistenti (morfologia, sintassi, semanti-ca), copertura di fenomeni e domini linguistici, quantitàe varietà delle applicazioni disponibili, qualità e dimen-sioni dei corpora (annotati) esistenti, qualità e copertura
27

delle risorse lessicali (ad es.WordNet) e delle grammati-che esistenti.
Risorse: qualità e dimensioni dei corpora testuali, diparlato e paralleli esistenti, qualità e copertura delle ri-sorse lessicali e delle grammatiche esistenti.
Le Figure 9-12 mostrano come lo stato attuale delle tec-nologie linguistiche per la lingua italiana sia migliore ri-spetto alla maggior parte delle altre lingue, grazie ai fi-nanziamenti su larga scala ottenuti negli ultimi decen-ni. La situazione è paragonabile a quella di lingue conun numero di parlanti simile, come ad esempio il tede-sco. Tuttavia le risorse e gli strumenti per l’italiano sonoancora lontani dal raggiungere la qualità e la coperturadelle risorse e degli strumenti corrispondenti disponibiliper l’inglese. Inoltre, rispetto alle risorse linguistiche perl’inglese, esistono ancoramolte lacune anche per quantoriguarda le applicazioni di alta qualità.
Per l’elaborazione del parlato, le tecnologie disponibiliattualmente hanno prestazioni sufficientemente buoneper essere integrate con successo in diverse applicazioniindustriali, come ad esempio i dialoghi vocali e i sistemidi dettatura. I componenti e le risorse linguistiche perl’analisi testuale sono già in grado di coprire gran par-te dei fenomeni linguistici dell’italiano e sono utilizza-ti per molte applicazioni che includono principalmentel’elaborazione del linguaggio naturale di base, come peresempio la correzione ortografica e il supporto alla crea-zione di documenti.
Tuttavia, al fine di creare applicazioni più sofisticate co-me la traduzione automatica permane un evidente biso-gno di risorse e di tecnologie che coprano una più am-pia gamma di aspetti linguistici e che rendano possibileun’analisi semantica profonda del testo in input.Miglio-rando la qualità e la copertura di queste risorse di base,dovremo essere in grado di aprire nuove opportunità pertrattare uno spettro più ampio di aree applicative avan-zate, tra cui la traduzione automatica di alta qualità.
4.8 CONCLUSIONIIn questa collana di Libri Bianchi abbiamo cercato di va-lutare lo stato delle tecnologie del linguaggio per 30 lingueeuropee conontandole a liello generale. Una olta iden-tificate le lacune, le necessità e le mancanze, la comunitàeuropea delle tecnologie del linguaggio sarà ora in grado didelineare un programma di ricerca e di sviluppo su largascala che miri a creare una comunicazione davvero mul-tilingue in Europa, in grado di suttare appieno la tecno-logia disponibile.
I risultati di questa collana di Libri Bianchi mostranocome vi sia una differenza enorme nelle tecnologie dellinguaggio disponibili per le diverse lingue europee. Peralcune lingue e per alcune aree applicative esistono so-ware di buona qualità e sono disponibili molte risorselinguistiche, ma nel caso di altre lingue, di solito lingue‘minori’, sono state riscontrate considerevoli lacune. Permolte linguemancano sia le tecnologie di base per l’ana-lisi dei testi sia le risorse essenziali. Altre lingue possie-dono strumenti e risorse di base ma non sono tuttorain grado di investire, per esempio, nell’analisi semantica.Per questa ragione è necessario fare ancora uno sforzo sularga scala per poter raggiungere l’ambizioso obiettivo dioffrire tecnologie linguistiche di alta qualità per tutte lelingue europee.
Nel casodella lingua italiana, possiamoconsiderarci cau-tamente ottimisti per quanto riguarda lo stato attualedelle tecnologie del linguaggio. Grazie al contributo digrandi programmi di ricerca nel passato, oggi in Italiaesiste una vivace comunità di ricerca e sono state crea-te tecnologie allo stato dell’arte per l’italiano. Tuttavia,le risorse e gli strumenti sono ancora piuttosto limitatise paragonati all’inglese, e sono semplicemente insuffi-cienti come qualità e quantità per sviluppare il tipo ditecnologie richieste a supporto di una società della co-noscenza davvero multilingue.
Per gestire l’italiano non è nemmeno possibile trasferiretecnologie già sviluppate e ottimizzate per l’inglese. Si-
28

stemi per l’analisi sintattica e grammaticale basati sull’in-glese tipicamente ottengono prestazioni molto più bas-se su testi italiani a causa delle caratteristiche specifichedella lingua italiana.L’industria italiana delle tecnologie linguistiche è attual-mente frammentata e disorganizzata. La maggior partedelle grandi aziende ha interrotto gli sforzi nelle tecno-logie linguistiche o ha operato grossi tagli, lasciando ilcampo a piccole o medie imprese specializzate che nonhanno la forza necessaria per rivolgersi al mercato inter-no e globale con una strategia costante.In questo Libro Bianco siamo giunti alla conclusioneche sia necessario fare uno sforzo sostanziale per crearerisorse e strumenti linguistici per l’italianoper trainare laricerca, l’innovazione e lo sviluppo in generale. La neces-sità di grandi quantità di dati e l’estrema complessità deisistemi di tecnologie del linguaggio rendono indispen-
sabile sviluppare una nuova infrastruttura per stimolareuna maggiore condivisione e cooperazione.
Infine, vi è unamancanza di continuità nei finanziamen-ti per la ricerca e lo sviluppo. Programmi coordinati abreve termine si alternano a periodi con finanziamentiscarsi o del tutto assenti. Inoltre, vi è una generale man-canza di coordinamento con i programmi in altri paesidell’UE e a livello della Commissione Europea.
L’obiettivo a lungo termine di META-NET è quello diintrodurre tecnologie linguistiche di alta qualità per tut-te le lingue. Ciò richiede che tutti i soggetti interessati –nella politica, nella ricerca, negli affari e nella società –uniscano i propri sforzi. La tecnologia contribuirà ad ab-battere le barriere esistenti e a costruire ponti tra le lin-gue d’Europa, aprendo la strada verso l’unità politica edeconomica attraverso la diversità culturale.
29

Supporto Buon Supporto Supporto Supportoeccellente supporto medio frammentario debole o assente
Inglese CecoFinlandeseFranceseItalianoOlandesePortogheseSpagnoloTedesco
BascoBulgaroCatalanoDaneseEstoneGalizianoGrecoIrlandeseNorvegesePolaccoSerboSlovaccoSlovenoSvedeseUngherese
CroatoIslandeseLettoneLituanoMalteseRumeno
9: Elaborazione del parlato: stato delle tecnologie linguistiche per 30 lingue europee
Supporto Buon Supporto Supporto Supportoeccellente supporto medio frammentario debole o assente
Inglese FranceseSpagnolo
CatalanoItalianoOlandesePolaccoRumenoTedescoUngherese
BascoBulgaroCecoCroatoDaneseEstoneFinlandeseGalizianoGrecoIrlandeseIslandeseLettoneLituanoMalteseNorvegesePortogheseSerboSlovaccoSlovenoSvedese
10: Traduzione automatica: stato delle tecnologie linguistiche per 30 lingue europee
30
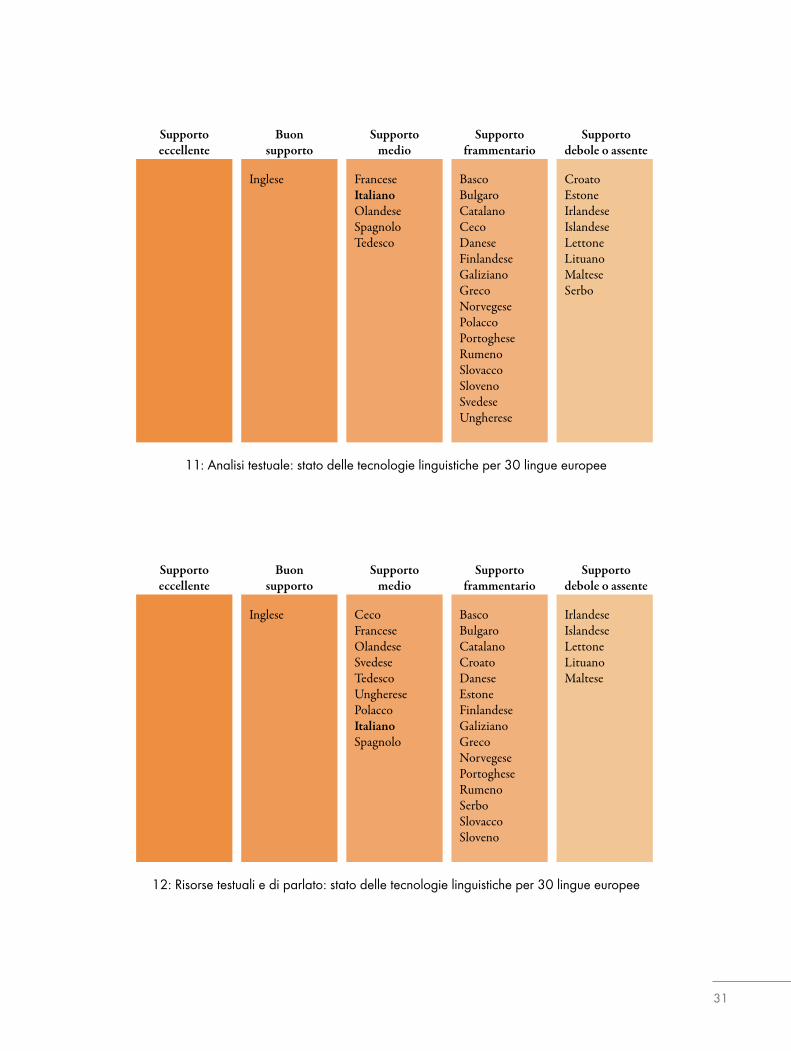
Supporto Buon Supporto Supporto Supportoeccellente supporto medio frammentario debole o assente
Inglese FranceseItalianoOlandeseSpagnoloTedesco
BascoBulgaroCatalanoCecoDaneseFinlandeseGalizianoGrecoNorvegesePolaccoPortogheseRumenoSlovaccoSlovenoSvedeseUngherese
CroatoEstoneIrlandeseIslandeseLettoneLituanoMalteseSerbo
11: Analisi testuale: stato delle tecnologie linguistiche per 30 lingue europee
Supporto Buon Supporto Supporto Supportoeccellente supporto medio frammentario debole o assente
Inglese CecoFranceseOlandeseSvedeseTedescoUngheresePolaccoItalianoSpagnolo
BascoBulgaroCatalanoCroatoDaneseEstoneFinlandeseGalizianoGrecoNorvegesePortogheseRumenoSerboSlovaccoSloveno
IrlandeseIslandeseLettoneLituanoMaltese
12: Risorse testuali e di parlato: stato delle tecnologie linguistiche per 30 lingue europee
31

5
META-NET
META-NET è una Rete di Eccellenza finanziata dallaCommissione Europea [29]. La rete è attualmente com-posta da 54 centri di ricerca in 33 paesi europei. META-NET sostiene lo sviluppo di META (Multilingual Eu-rope Technology Alliance), una comunità in espansioneche raccoglie inEuropa i professionisti e le organizzazio-ni che operano nel campo delle tecnologie linguistiche.META-NET intende porre le basi tecnologiche per unasocietà europea dell’informazione veramente multilin-gue, in modo da:
‚ rendere possibili la comunicazione e la cooperazionetra le lingue;
‚ fornire a tutti i cittadini europei pari accesso all’in-formazione e alla conoscenza, in qualsiasi lingua;
‚ migliorare le funzionalità della tecnologie dell’infor-mazione condivisa in rete.
La rete di META-NET vuole sostenere un’Europa uni-ta intorno ad un solo mercato digitale e un solo spaziodi informazione, stimolando e promuovendo le tecno-logie linguistiche per tutte le lingue Europee. Sono que-ste tecnologie che consentono la traduzione automatica,la produzione di contenuto, l’elaborazione dell’informa-zione e la gestione della conoscenza per un’ampia gam-ma di settori e domini applicativi, così come lo svilup-po di interfacce intuitive basate sul linguaggio per glistrumenti elettronici domestici, i macchinari, i veico-li, i computer e i robot. A partire dal 1 Febbraio 2010,META-NET ha già condotto molte iniziative nelle suetre linee di azione META-VISION, META-SHARE eMETA-RESEARCH.META-VISION vuole favorire la crescita di una comu-nità dinamica ed influente che condivida una visione
e un’Agenda di Ricerca Strategica comuni. L’obiettivoprincipale di questa attività è la costruzione in Europa diuna comunità coerente e coesa nel settore delle tecnolo-gie linguistiche, che riunisca rappresentanti provenientida gruppi diversificati. uesto Libro Bianco è stato pre-parato insieme ad altri 29 volumi per altrettante lingue.La visione condivisa delle tecnologie è stata sviluppata intre Vision Groups suddivisi per settore. Allo scopo di di-scutere e preparare l’Agenda di Ricerca Strategica, basatasulla visione in stretta interazione con l’intera comunitàdelle tecnologie linguistiche, è stato costituito un orga-nismo apposito, il META Technology Council.META-SHARE intende creare un ambiente aperto edistribuito per lo scambio e la condivisione di risorse,una rete P2Pdi depositi digitali che contiene dati lingui-stici, strumenti e web services, documentati con meta-dati di qualità e organizzati in categorie standardizzate.Le risorse sono facilmente accessibili ed è possibile ef-fettuare delle ricerche in modo uniforme. Le risorse di-sponibili includonomateriale libero da copyright e opensource così come materiale soggetto a licenze commer-ciali.META-RESEARCH si occupa di collegare settori tec-nologici affini. uesta attività vuole capitalizzare l’avan-zamento tecnologico e la ricerca innovativa in altri setto-ri che possono essere di beneficio alle tecnologie lingui-stiche. In particolare, questa linea d’azione si concentrasu condurre ricerca di frontiera nella traduzione auto-matica, raccogliere e preparare i dati, organizzare risorselinguistiche per scopi di valutazione, compilare inven-tari di strumenti e metodi, e organizzare workshop edeventi educativi per i membri della comunità.
[email protected] – http://www.meta-net.eu
32

1
EXECUTIVE SUMMARY
During the last 60 years, Europe has become a distinctpolitical and economic structure. Culturally and lin-guistically, it is rich and diverse. However, from Por-tuguese to Polish and Italian to Icelandic, everyday com-munication between Europe’s citizens, within businessand among politicians is inevitably confrontedwith lan-guage barriers. e EU’s institutions spend about onebillion Euros a year on maintaining their policy of mul-tilingualism, i. e., translating texts and interpreting spo-ken communication. e European market for trans-lation, interpretation, soware localisation and websiteglobalisation was estimated at 8.4 billion in 2008 and isexpected to grow by 10% per annum [1]. Are these ex-penses necessary and are they even sufficient? Despitethis high level of expenditure, the translated texts rep-resent only a fraction of the information that is avail-able to the whole population in countries with a singlepredominant language, like the USA, China or Japan.Language technology and linguistic research canmake asignificant contribution to removing the linguistic bor-ders. Combined with intelligent devices and applica-tions, language technology will help Europeans talk anddo business together even if they do not speak a com-mon language.
Language technology builds bridges.
eItalian economy takes advantage from theEuropeansinglemarket but language barriers can bring business toa halt, especially for SMEs who do not have the finan-cial means to reverse the situation. e only (unthink-
able) alternative to a multilingual Europe would be toallow a single language to take a predominant positionand replace all other languages in transnational commu-nication. Another way to overcome language barriers isto learn foreign languages. Yet, considering the multi-tude of European languages, including 23 official lan-guages of the European Union and some 60 other lan-guages, language learning alone is not sufficient to pro-vide for communication, trade and information transferacross all language borders. Without technological sup-port, e. g., machine translation, the European linguisticdiversity is an insurmountable obstacle for Europe’s cit-izens, economy, political debate, and scientific progress.
Language technology is a key enabling technology forsustainable, cost-effective and socially beneficial solu-tions to language problems. Language technologies willoffer European stakeholders tremendous advantages,not only within the common European market, but al-so in trade relations with non-European countries, espe-cially emerging economies. Language technology solu-tions will eventually serve as a unique bridge betweenEurope’s languages. An indispensable prerequisite fortheir development is first to carry out a systematic anal-ysis of the linguistic particularities of all European lan-guages, and the current state of language technologysupport for them. As early as the late 1970s, the EUrealised the profound relevance of language technolo-gy as a driver of European unity, and began fundingits first research projects, such as EUROTRA. Aer alonger period of sparse funding on the European level,the European Commission set up a department dedi-
33

cated to language technology andmachine translation afew years ago. Currently, the EU is supporting languagetechnological projects such as EuroMatrix and EuroMa-trix+ (since 2006) and iTranslate4 (since 2010), which,through basic and applied research, generate resourcesfor establishing high quality language technology solu-tions for all European languages.ese selective fundingefforts led to a number of valuable results. For example,the translation services of the European Union now usethe Moses open-source machine translation soware,which has been mainly developed in European researchprojects. However, these projects never led to a concert-ed European effort, where the EU and its member statessystematically pursue the common goal of technologi-cally supporting all European languages.
Language technology is a key for the future.
Rather than building on the outcomes of its researchprojects, Europe has tended to pursue isolated researchactivities with a less pervasive impact on the market.us, an intensive phase of funding has eventually notled to sustainable results. In many cases, research fund-ed in Europe turned out to bear fruit, but outside ofEurope. e winners of this general development in-clude Google and Apple. In fact, many of the predom-inant actors in the field today are privately-owned for-profit enterprises based in Northern America. Most oftheir language technology systems rely on imprecise sta-tistical approaches that do not make use of deeper lin-guistic methods and knowledge. For example, sentencesare oen automatically translated by comparing eachnew sentence against thousands of sentences previouslytranslated by humans. e quality of the output large-ly depends on the size and quality of the available da-ta. While the automatic translation of simple sentencesin languages with sufficient amounts of available textualdata can achieve useful results, shallow statistical meth-
ods are doomed to fail in the case of languages with amuch smaller body of sample data or in the case of newsentences with complex structures. Analysing the deep-er structural properties of languages is the only way for-ward if we want to build applications that perform wellacross the entire range of European languages.
Language Technology helps to unify Europe.
Concerning research in Europe, the prerequisites areoptimal: rough initiatives like CLARIN, META-NET, and FLaReNet, the research community is well-connected; in META-NET and FLaReNet a long-termresearch agenda is currently evolving, and language tech-nology is slowly but steadily strengthening its role with-in the EuropeanCommission. Still, in some respect, ourposition is worse compared to other multilingual soci-eties.Despite fewer financial resources, countries like In-dia (22 official languages) and South Africa (11 officiallanguages) have set up long-term national programmesfor language research and technology development.What is missing in Europe is the lack of awareness, po-litical will and the courage to strive for an internationalleading position in this technology area through a con-certed funding effort. Drawing on the insights gainedso far, today’s hybrid language technology mixing deepprocessing with statistical methods should be able tobridge the gap between all European languages and be-yond.However, as this series of white papers shows, there isa dramatic difference between Europe’s member statesin terms of both the maturity of the research and inthe state of readiness with respect to language solu-tions. Italian, as one of the bigger EU languages, is bet-ter equipped thanmany other languages, but further re-search is needed before truly effective language technol-ogy solutions will be ready for everyday use and in or-der not to lag behind themuch better resourced English
34

language. e percentage of global Internet users whospeak Italian can be expected to decrease in the near fu-ture.As a consequence, Italianmay experience in the up-coming decades the problem of being under representedon the web especially compared to English, a problemin which a fundamental role will be played by languagetechnologies. e capability of a language to be “digi-tally” present in Internet-based applications and serviceshas become a crucial element tomaintain the cultural vi-tality of the language itself.On the other hand, Internet applications and servicescan be sustained only if adequate infrastructures andtechnologies are present. In Italy, research on HLT iscarried on by more than 15 research labs, with an activeand relevant presence in the international research com-munity. Considerable effort has been invested in Lan-guage Technologies research in Italy since 1997, whenHumanLanguageTechnologywas designated aNation-al research policy. Unfortunately, funding at the nation-
al level is currently very limited, and little usable lan-guage technology is built in comparison to the antici-pated need.In spite of the accomplishments obtained in the fieldof language technologies for Italian, the current stateof technologies is not enough to guarantee a digital di-mension to Italian such as it is required by applicationsand services of the future Internet. In this volume, wewill present an introduction to language technology andits core application areas as well as an evaluation of thecurrent situation of language technology support forItalian. is white paper series complements the oth-er strategic actions taken by META-NET (see the ap-pendix for an overview). Up-to-date information suchas the current version of the META-NET vision pa-per [2] and the Strategic Research Agenda (SRA) canbe found on the META-NET web site: http://www.meta-net.eu.
35

2
LANGUAGES AT RISK: A CHALLENGE FORLANGUAGE TECHNOLOGY
We are witnesses to a digital revolution that is dramati-cally impacting communication and society. Recent de-velopments in information and communication tech-nology are sometimes compared to Gutenberg’s in-vention of the printing press. What can this analogy tellus about the future of the European information societyand our languages in particular?
The digital revolution is comparable toGutenberg’s invention of the printing press.
Aer Gutenberg’s invention, real breakthroughs incommunication were accomplished by efforts such asLuther’s translation of the Bible into vernacular lan-guage. In subsequent centuries, cultural techniques havebeen developed to better handle language processingand knowledge exchange:
‚ the orthographic and grammatical standardisationof major languages enabled the rapid disseminationof new scientific and intellectual ideas;
‚ the development of official languages made it possi-ble for citizens to communicate within certain (of-ten political) boundaries;
‚ the teaching and translation of languages enabled ex-changes across languages;
‚ the creationof editorial andbibliographic guidelinesassured the quality of printed material;
‚ the creation of different media like newspapers, ra-dio, television, books, andother formats satisfieddif-ferent communication needs.
In the past twenty years, information technology hashelped to automate and facilitate many processes:
‚ desktop publishing soware has replaced typewrit-ing and typesetting;
‚ Microso PowerPoint has replaced overhead projec-tor transparencies;
‚ e-mail allows documents to be sent and receivedmore quickly than using a fax machine;
‚ Skype offers cheap Internet phone calls and hostsvirtual meetings;
‚ audio and video encoding formatsmake it easy to ex-change multimedia content;
‚ web search engines provide keyword-based access;
‚ online services like Google Translate produce quick,approximate translations;
‚ social media platforms such as Facebook, Twitterand Google+ facilitate communication, collabora-tion, and information sharing.
Although these tools and applications are helpful, theyare not yet capable of supporting a fully-sustainable,multilingual European society in which informationand goods can flow freely.
36

2.1 LANGUAGE BORDERSHOLD BACK THE EUROPEANINFORMATION SOCIETYWe cannot predict exactly what the future informationsociety will look like. However, there is a strong likeli-hood that the revolution in communication technolo-gy is bringing together people who speak different lan-guages in new ways. is is putting pressure both on in-dividuals to learn new languages and especially on de-velopers to create new technologies to ensure mutualunderstanding and access to shareable knowledge. Inthe global economic and information space, there is in-creasing interaction between different languages, speak-ers and content thanks to new types of media. e cur-rent popularity of social media (Wikipedia, Facebook,Twitter, Google+) is only the tip of the iceberg.
The global economy and information spaceconfronts us with different languages,
speakers and content.
Today, we can transmit gigabytes of text around theworld in a few seconds before we recognise that it is ina language that we do not understand. According to areport from the European Commission, 57% of Inter-net users in Europe purchase goods and services in non-native languages; English is the most common foreignlanguage followedbyFrench,GermanandSpanish. 55%of users read content in a foreign language while 35%use another language to write e-mails or post commentson the Web [3].A few years ago, English might have been the linguafranca of the web – the vast majority of content on thewebwas inEnglish –but the situationhas nowdrastical-ly changed. e amount of online content in other Eu-ropean (as well as Asian and Middle Eastern) languageshas exploded.
Surprisingly, this ubiquitous digital linguistic dividehas not gained much public attention. Yet, it raises avery pressing question: Which European languages willthrive in the networked information and knowledge so-ciety, and which are doomed to disappear?
2.2 OUR LANGUAGES AT RISK
While the printing press helped step up the exchangeof information in Europe, it also led to the extinctionof many languages. Regional and minority languageswere rarely printed and languages such as Cornish andDalmatian were limited to oral forms of transmission,which in turn restricted their scope of use. Will the In-ternet have the same impact on our modern languages?
The variety of languages in Europe is one of itsrichest and most important cultural assets.
Europe’s approximately 80 languages are one of ourrichest and most important cultural assets, and a vitalpart of this unique social model [4]. While languagessuch as English and Spanish are likely to survive inthe emerging digitalmarketplace,many languages couldbecome irrelevant in a networked society. is wouldweaken Europe’s global standing, and run counter tothe goal of ensuring equal participation for every citizenregardless of language. According to aUNESCOreporton multilingualism, languages are an essential mediumfor the enjoyment of fundamental rights, such as polit-ical expression, education and participation in society[5].
37

2.3 LANGUAGE TECHNOLOGYIS A KEY ENABLINGTECHNOLOGYIn the past, investments in language preservation fo-cused primarily on language education and transla-tion. According to one estimate, the European marketfor translation, interpretation, soware localisation andwebsite globalisation was €8.4 billion in 2008 and isexpected to grow by 10% per annum [6]. Yet this fig-ure covers just a small proportion of current and futureneeds in communicating between languages. e mostcompelling solution for ensuring the breadth and depthof language usage in Europe tomorrow is to use appro-priate technology, just as we use technology to solve ourtransport and energy needs among others.Language technology targeting all forms of written textand spoken discourse can help people to collaborate,conduct business, share knowledge and participate insocial and political debate regardless of language barri-ers and computer skills. It oen operates invisibly insidecomplex soware systems to help us already today to:
‚ find information with a search engine;
‚ check spelling and grammar in a word processor;
‚ view product recommendations in an online shop;
‚ follow the spoken directions of a navigation system;
‚ translate web pages via an online service.
Language technology consists of a number of core ap-plications that enable processes within a larger applica-tion framework. e purpose of the META-NET lan-guage white papers is to focus on how ready these coreenabling technologies are for each European language.
Europe needs robust and affordable languagetechnology for all European languages.
Tomaintain our position in the frontline of global inno-vation, Europe will need language technology, tailoredto all European languages, that is robust and affordableand can be tightly integrated within key soware envi-ronments.Without language technology, wewill not beable to achieve a really effective interactive, multimediaand multilingual user experience in the near future.
2.4 OPPORTUNITIES FORLANGUAGE TECHNOLOGYIn the world of print, the technology breakthrough wasthe rapid duplication of an image of a text using a suit-ably powered printing press. Human beings had to dothe hard work of looking up, assessing, translating, andsummarising knowledge. We had to wait until Edisonto record spoken language – and again his technologysimply made analogue copies.
Language technology can now simplify and automatethe processes of translation, content production, andknowledge management for all European languages. Itcan also empower intuitive speech-based interfaces forhousehold electronics, machinery, vehicles, computersand robots. Real-world commercial and industrial ap-plications are still in the early stages of development,yet R&D achievements are creating a genuine windowof opportunity. For example, machine translation is al-ready reasonably accurate in specific domains, and ex-perimental applications provide multilingual informa-tion and knowledge management, as well as contentproduction, in many European languages.
As with most technologies, the first language applica-tions such as voice-based user interfaces and dialoguesystems were developed for specialised domains, andoen exhibit limited performance. However, there arehuge market opportunities in the education and enter-tainment industries for integrating language technolo-gies into games, edutainment packages, libraries, simu-
38

lation environments and training programmes. Mobileinformation services, computer-assisted language learn-ing soware, eLearning environments, self-assessmenttools and plagiarism detection soware are just someof the application areas in which language technolo-gy can play an important role. e popularity of socialmedia applications like Twitter and Facebook suggest aneed for sophisticated language technologies that canmonitor posts, summarise discussions, suggest opiniontrends, detect emotional responses, identify copyrightinfringements or track misuse.
Language technology helps overcome the“disability” of linguistic diversity.
Language technology represents a tremendous opportu-nity for the European Union. It can help to address thecomplex issue of multilingualism in Europe ‚Äì the factthat different languages coexist naturally in Europeanbusinesses, organisations and schools.However, citizensneed to communicate across the language borders of theEuropean Common Market, and language technologycan help overcome this final barrier, while supportingthe free and open use of individual languages. Lookingeven further ahead, innovative European multilinguallanguage technology will provide a benchmark for ourglobal partners when they begin to support their ownmultilingual communities. Language technology can beseen as a form of “assistive” technology that helps over-come the “disability” of linguistic diversity and makeslanguage communitiesmore accessible to each other. Fi-nally, one active field of research is the use of languagetechnology for rescue operations in disaster areas, whereperformance can be amatter of life and death: Future in-telligent robots with cross-lingual language capabilitieshave the potential to save lives.
2.5 CHALLENGES FACINGLANGUAGE TECHNOLOGYAlthough language technology has made considerableprogress in the last few years, the current pace of tech-nological progress and product innovation is too slow.Widely-used technologies such as the spelling and gram-mar correctors in word processors are typically mono-lingual, and are only available for a handful of languages.Onlinemachine translation services, althoughuseful forquickly generating a reasonable approximation of a doc-ument’s contents, are fraught with difficulties whenhighly accurate and complete translations are required.Due to the complexity of human language, modellingour tongues in soware and testing them in the realworld is a long, costly business that requires sustainedfunding commitments. Europe must therefore main-tain its pioneering role in facing the technological chal-lenges of a multiple-language community by inventingnewmethods to accelerate development right across themap. ese could include both computational advancesand techniques such as crowdsourcing.
Technological progress needs to be accelerated.
2.6 LANGUAGE ACQUISITIONIN HUMANS AND MACHINESTo illustrate how computers handle language andwhy itis difficult to program them toprocess different tongues,let’s look briefly at the way humans acquire first andsecond languages, and then see how language technolo-gy systems work.Humans acquire language skills in two different ways.Babies acquire a language by listening to the real inter-actions between their parents, siblings and other familymembers. From the age of about two, children produce
39

their first words and short phrases. is is only possi-ble because humans have a genetic disposition to imitateand then rationalise what they hear.Learning a second language at an older age requiresmore effort, largely because the child is not immersedin a language community of native speakers. At school,foreign languages are usually acquired by learning gram-matical structure, vocabulary and spelling using drillsthat describe linguistic knowledge in terms of abstractrules, tables and examples.
Humans acquire language skills in two differentways: learning from examples and learning the
underlying language rules.
Moving now to language technology, the two maintypes of systems ‚Äòacquire‚Äô language capabilities ina similar manner. Statistical (or ‚Äòdata-driven‚Äô) ap-proaches obtain linguistic knowledge from vast collec-tions of concrete example texts. While it is sufficient touse text in a single language for training, e. g., a spellchecker, parallel texts in two (or more) languages haveto be available for training amachine translation system.e machine learning algorithm then “learns” patternsof how words, short phrases and complete sentences aretranslated.is statistical approach can require millions of sen-tences to boost performance quality. is is one rea-son why search engine providers are eager to collect asmuchwrittenmaterial as possible. Spelling correction inword processors, and services such asGoogle Search andGoogle Translate all rely on statistical approaches. egreat advantage of statistics is that the machine learnsfast in continuous series of training cycles, even thoughquality can vary randomly.e second approach to language technology and ma-chine translation in particular is to build rule-based sys-
tems. Experts in the fields of linguistics, computation-al linguistics and computer science first have to encodegrammatical analyses (translation rules) and compilevocabulary lists (lexicons). is is very time consumingand labour intensive. Someof the leading rule-basedma-chine translation systems have been under constant de-velopment for more than 20 years. e great advantageof rule-based systems is that the experts have more de-tailed control over the language processing. is makesit possible to systematically correct mistakes in the so-ware and give detailed feedback to the user, especiallywhen rule-based systems are used for language learning.But due to the high cost of this work, rule-based lan-guage technology has so far only been developed for afew major languages.
The two main types of language technologysystems acquire language in a similar manner.
As the strengths and weaknesses of statistical and rule-based systems tend to be complementary, current re-search focuses on hybrid approaches that combine thetwo methodologies. However, these approaches have sofar been less successful in industrial applications than inthe research lab.As we have seen in this chapter, many applications wide-ly used in today’s information society rely heavily onlanguage technology. Due to its multilingual communi-ty, this is particularly true of Europe’s economic andinformation space. Although language technology hasmade considerable progress in the last few years, there isstill huge potential in improving the quality of languagetechnology systems. In the following, we will describethe role of Italian in European information society andassess the current state of language technology for theItalian language.
40

3
THE ITALIAN LANGUAGE IN THEEUROPEAN INFORMATION SOCIETY
3.1 GENERAL FACTSe Italian language counts 62 million native speakersworldwide, whichmakes it the 20thmost spoken nativelanguage in the world, and by 125 million speakers as asecond language. Very large emigrant communities eachconsisting of over 500,000 people still speaking Italianare found in Argentina, Brazil, Canada and the UnitedStates.A2006 survey showed that Italianhad the secondhighest number (tied with English) of native speakers inthe European Union aer German, with 56 million na-tive speakers of Italian residing in Italy. It has been es-timated at various dates that, additionally, 280,000 firstlanguage speakers of Italian reside in Belgium, 70,000in the candidate country Croatia, 1,000,000 in France,548,000 inGermany, 20,800 in Luxembourg, 27,000 inMalta (not including 118,000 second language speak-ers), 2,560 in Romania, 4,010 in Slovenia, 200,000 inthe United Kingdom and 471,000 in Switzerland.
The Italian language counts around 62 millionnative speakers.
Italian was listed as the 6th most spoken foreign lan-guage in the European Union aer English, French,German, Spanish and Russian. Regarding the numberof translations worldwide, Italian is ranked 5th as thesource language, and 11th as a target language.From a study conducted in 2005, it emerged that 61%of Maltese, 14% of Croatians, 12% of Slovenians, 11%
of Austrians, 8% of Romanians, and 6% of French andGreeks include Italian among the two foreign languagesthat children should learn.
Italian is the official language in Italy (it formally ap-pears in the Italian Constitution as the official languagestarting in 2007, although it has been considered the of-ficial language at least since the reunification of Italy)and SanMarino. In Switzerland, Italian is one of four of-ficial languages, spoken mainly in Canton Grigioni andCantonTicino. In the VaticanCity State, it is one of theofficial languages (all laws and regulations of the stateare published in Italian). It is an official regional lan-guage in Slovenia (article 64 of its constitution allowsextensive freedom in the Italian-speaking region of Istriafor the use of Italian in areas such as schooling, culture,science, the economy andmassmedia) and in the candi-date country Croatia.
In Italy, Italian is by far themost widely spoken languageand almost all media (television, newspapers, movies,etc.) in the country are produced in Italian. However,other languages are co-officialwithin certain regions, in-cluding French inVal d’Aosta, German inTrentino-AltoAdige, and Sardinian in Sardinia.
3.2 PARTICULARITIES OF THEITALIAN LANGUAGEItalian derives diachronically from Latin and is the clos-est national language to Latin. Unlike most other Ro-
41

mance languages, Italian retains Latin’s contrast be-tween short and long consonants. As in most Romancelanguages, stress is distinctive. In particular, among theRomance languages, Italian is the closest to Latin interms of vocabulary [7].Italian grammar is typical of the grammar of Romancelanguages in general. Cases exist for pronouns (nomi-native, accusative, dative), but not for nouns. ere aretwo genders (masculine and feminine). Nouns, adjec-tives, and articles inflect for gender and number (singu-lar and plural). Adjectives are sometimes placed beforetheir noun and sometimes aer. Subject nouns gener-ally come before the verb. Subject pronouns are usual-ly dropped, their presence implied by verbal inflections.Noun objects come aer the verb, as do pronoun objectsaer imperative verbs and infinitives, but otherwise pro-noun objects come before the verb. ere are numerouscontractions of prepositions with subsequent articles.ere are numerous productive suffixes for diminutive,augmentative, pejorative, attenuating etc., which are al-so used to create neologisms.
Many native speakers of Italian are actuallynative bilingual speakers of the Italian language
and an Italian dialect.
A peculiar characteristic of Italian is that many na-tive speakers of Italian residing in Italy are actual-ly native bilingual speakers of the Italian languageand an Italian dialect. Some of the most spokenItalian dialects are Lombard (8,830,000 speakers in2000), Napolitano-Calabrese (7,050,000 speakers in1976), Sicilian (4,830,000 speakers in 2000), Piemon-tese (3,110,000 speakers in 2000), Venetian (2,180,000in 2000), Emiliano-Romagnolo (2,000,000 speakers in2003), Ligurian (1,920,000 speakers in 2000), some ofwhich are mutually unintelligible. Some Italian dialectsare distinct enough from Italian to be considered as
separate languages. e different dialects played a sig-nificant role in the development of different varietiesof regional Italians. is influence mainly concerns theprosody, phonetics and lexicon of the Italian languageby speakers of dialects.
3.3 RECENT DEVELOPMENTSFrom the 1950s on, American television series andmovies began to dominate the Italian market. Eventhough foreign films and series are usually dubbed intoItalian, the strong presence of the American way of lifein themedia influenced the Italian culture and language.Due to the continuing triumph of English and Ameri-can music since the 1960s, Italians have been exposedto a lot of English during their adolescence for gener-ations. English soon acquired the status of a ‘cool/hip’language, which it has kept up to the present day.is continuing status is reflected by the sheer numberof present-day loan words from English (so-called an-glicisms). A recent study [8] aims at quantifying the im-pact of non-adapted anglicisms in Italian with the aidof frequency counts. e study is based on a sample listof non-adapted anglicisms retrieved from a vast Italiancorpus of newspaper texts.e analysis shows that, eventhough the number of anglicisms in Italian dictionar-ies may be regarded as considerable, the extent to whichthey are used in newspaper texts – a genre which hasbeen traditionally recognised by linguists as prone toincluding borrowings in general and specifically angli-cisms – amounts to much lower percentages. It is ar-gued that while marketing strategies force publishersand editors tomaximise the number of entries in dictio-naries of borrowings, especially anglicisms, only corpus-based frequency counts, which testify their actual usage,should be considered meaningful. e author suggeststhat threshold frequencies should determine which an-glicisms should be included inmonolingual general andspecial purpose dictionaries, both for Italian and other
42

languages; corpus linguistics may help to provide suchtentative frequency scores.
3.4 OFFICIAL LANGUAGEPROTECTION IN ITALYOne of the main points of reference for research on theItalian language, also in relation to its regional varieties,is the “Accademia della Crusca” [9], which was found-ed in Florence in the second half of the 16th century. Itsmain accomplishment was the “Vocabolario degli Acca-demici della Crusca” (1612), the first dictionary of theItalian language. At present, its activity is centered onsupporting scientific activity and the training of new re-searchers in Italian linguistics and philology, as well ason collaborating with foreign institutions and the Ital-ian and European Governments to support the causeof multilingualism. e historical academy strives to ac-quire and spread not only historical knowledge of theItalian language, but also awareness of the present evo-lution of Italian in the era of the information society.
One of the major points of reference forresearch on the Italian language is the
“Accademia della Crusca”.
Partially as a reaction to the increasing importance of an-glicisms in Italian, a proposal was submitted in 2001 tothe Italian Parliament to create the “Consiglio superioredella lingua italiana” (CSLI –HighCouncil for the Ital-ian Language), with the aim to counteract the impover-ishment of the Italian language and its lost of prestige atthe European and international level (this proposal hasyet to be approved by the Italian Parliament). Amongthe goals ofCLSIwould be the defense, valorisation anddiffusion of Italian culture, particularly through initia-tives aimed at promoting the correct use of the Italianlanguage, specifically in schools, communication media
and commerce. An additional goal would be the diffu-sion of the Italian language abroad, as well as its officialuse in European institutions.
3.5 LANGUAGE IN EDUCATIONLanguage skills are the key qualification needed in edu-cation as well as for personal and professional commu-nication.e status of Italian as a school subject in basicschool seems to reflect the need to give priority to this.e first PISA study, conducted in 2000, revealed thatItalian students performed below OECD average withrespect to reading literacy. Students with a migrationbackground received particularly low results. e ensu-ing debate has increased public awareness for the impor-tance of language learning, especially with respect to in-tegration. In the last PISA test (2009), Italianpupils per-form almost the same with respect to reading literacythan in 2000, which might be considered as a positiveresult, considering the fact that the OECD average hassunk since 2000 [10].
3.6 ITALIAN ON THE INTERNETInternet penetration in Italy is estimated to be at 51.7%(30 million out of a population of 58 million), hav-ing grown 127.5% from 2000 to 2010, and representing6.3% of Internet users in the European Union. e per-centage of web pages in Italianworldwide doubled from1.5% in1998 to 3.05% in2005.As of 2004, 30.4millionItalian speakers were estimated to be online worldwide.Outside of the European Union, an estimated 520,000Americans access the Internet in Italian, 200,000 Swissand 100,000 Australians.As the number of Italian Internet users has remained rel-atively stable over the last five years, while the numberof new users from developing countries has dramatical-ly increased, the percentage of global Internet users whospeak Italian can be expected to decrease in the near fu-
43

ture.As a consequence, Italianmay experience in the up-coming decades the problem of being under representedon the web especially compared to English, a problemin which a fundamental role will be played by languagetechnologies.
The massive use of interactive systems in thefuture Internet requires language technologies
with high adaptability to speakersof different variants of Italian.
e massive use of interactive systems in the future In-ternet requires language technologies with high adapt-ability to speakers of different variants of Italian. isaffects in the first place technologies for the automatictranscription of audio data, as regional accents of Italianspeakers show great variation across different regions,but all other language technologies as well, because re-gional variants are characterised by differences at all lin-guistic levels, from the lexicon to the syntax. e avail-ability of systems supporting regional variants of Italianwould allow not only for an improvement in terms of
performance, but also for a more natural interaction be-tween humans and computers.e most commonly used web application is certainlyweb search, which involves the automatic processing oflanguage on multiple levels, as we will see in more de-tail in the second part of this paper. It involves sophisti-cated language technology, differing for each language.For Italian, this comprises, for instance, matching “cit-tà” and “citta’”. But Internet users and providers of webcontent can also profit from language technology in lessobvious ways, for example, if it is used to automaticallytranslate web contents from one language into anoth-er. Considering the high costs associated with manuallytranslating these contents, it may be surprising how lit-tle usable language technology is built in comparison tothe anticipated need.However, it becomes less surprising if we consider thecomplexity of the Italian language and the number oftechnologies involved in typical language technologyapplications. In the next chapter, we will present an in-troduction to language technology and its core applica-tion areas as well as an evaluation of the current situa-tion of language technology support for Italian.
44

4
LANGUAGE TECHNOLOGY SUPPORTFOR ITALIAN
Language technology is used to develop soware sys-tems designed to handle human language and are there-fore oen called “human language technology”. Humanlanguage comes in spoken and written forms. Whilespeech is the oldest and in terms of human evolution themost natural form of language communication, com-plex information and most human knowledge is storedand transmitted through the written word. Speech andtext technologies process or produce these differentforms of language, using dictionaries, rules of grammar,and semantics. is means that language technology(LT) links language to various forms of knowledge, in-dependently of the media (speech or text) in which it isexpressed. Figure 2 illustrates the LT landscape.When we communicate, we combine language withother modes of communication and information media– for example speaking can involve gestures and facialexpressions. Digital texts link to pictures and sounds.Movies may contain language in spoken and writtenform. In otherwords, speech and text technologies over-lap and interact with other multimodal communicationand multimedia technologies.In this section, we will discuss the main applicationareas of language technology, i. e., language checking,web search, speech interaction, and machine transla-tion. ese applications and basic technologies include
‚ spelling correction
‚ authoring support
‚ computer-assisted language learning
‚ information retrieval
‚ information extraction
‚ text summarisation
‚ question answering
‚ speech recognition
‚ speech synthesis
Language technology is an established area of researchwith an extensive set of introductory literature. e in-terested reader is referred to the following references:[11, 12, 13, 14, 15].Before discussing the above application areas, we willshortly describe the architecture of a typical LT system.
4.1 APPLICATIONARCHITECTURESSoware applications for language processing typicallyconsist of several components that mirror different as-pects of language. While such applications tend to bevery complex, Figure 4 shows a highly simplified archi-tecture of a typical text processing system.efirst threemodules handle the structure and meaning of the textinput:
1. Pre-processing: cleans the data, analyses or re-moves formatting, detects the input language, de-tects accents (“città” and “citta’”) and apostrophes(“dell’UE” e “della UE”) for Italian, and so on.
45

Multimedia &MultimodalityTechnologies
LanguageTechnologies
Speech Technologies
Text Technologies
Knowledge Technologies
1: Language technologies
2. Grammatical analysis: finds the verb, its objects,modifiers and other sentence elements; detects thesentence structure.
3. Semantic analysis: performs disambiguation (i. e.,computes the appropriatemeaning of words in a giv-en context); resolves anaphora (i. e., which pronounsrefer to which nouns in the sentence) and substituteexpressions; represents the meaning of the sentencein a machine-readable way.
Aer analysing the text, task-specific modules can per-form other operations, such as automatic summarisa-tion and database look-ups.
In the remainder of this section, we firstly introducethe core application areas for language technology, andfollow this with a brief overview of the state of LT re-search and education today, and a description of pastand present research programmes. Finally, we present anexpert estimate of core LT tools and resources for Italianin terms of various dimensions such as availability, ma-turity and quality. e general situation of LT for theItalian language is summarised in figure 14 (p. 56) at theend of this chapter.is table lists all tools and resourcesthat are boldfaced in the text. LT support for Italian isalso compared to other languages that are part of thisseries.
4.2 CORE APPLICATION AREASIn this section, we focus on themost important LT toolsand resources, and provide an overview of LT activitiesin Italy.
4.2.1 Language Checking
Anyone who has used a word processor such as Mi-croso Word knows that it has a spelling checker thathighlights spelling mistakes and proposes corrections.e first spelling correction programs compared a list ofextracted words against a dictionary of correctly spelledwords. Today these programs are farmore sophisticated.Using language-dependent algorithms for grammaticalanalysis, they detect errors related tomorphology (e. g.,plural formation) as well as syntax-related errors, suchas a missing verb or a conflict of verb-subject agreement(e. g., she *write a letter). However, most spell checkerswill not find any errors in the following text: [16]:
I have a spelling checker,It came with my PC.It plane lee marks four my revueMiss steaks aye can knot sea.
Handling these kinds of errors usually requires an anal-ysis of the context. is type of analysis either needs todraw on language-specific grammars laboriously coded
46

Input Text
Pre-processing Grammatical Analysis Semantic Analysis Task-specific Modules
Output
2: A typical text processing architecture
into the soware by experts, or on a statistical languagemodel. In this case, a model calculates the probability ofa particular word as it occurs in a specific position (e. g.,between the words that precede and follow it). For ex-ample: I cannot is amuchmore probableword sequencethan aye can knot. A statistical languagemodel canbe au-tomatically created by using a large amount of (correct)language data (called a text corpus). Most of these twoapproaches have been developed around data from En-glish. Neither approach can transfer easily to Italian be-cause the language has a flexible word order and a richerinflection system.
Language checking is not limited to wordprocessors but also applies to authoring systems.
Language checking is not limited to word processors;it is also used in authoring support systems, i. e., so-ware environments in which manuals and other typesof technical documentation for complex IT, healthcare,engineering and other products, are written. To off-set customer complaints about incorrect use and dam-age claims resulting from poorly understood instruc-tions, companies are increasingly focusing on the qual-ity of technical documentation while targeting the in-ternational market (via translation or localisation) atthe same time. Advances in natural language process-ing have led to the development of authoring support
soware, which helps the writer of technical documen-tation to use vocabulary and sentence structures that areconsistentwith industry rules and (corporate) terminol-ogy restrictions.Besides spell checkers and authoring support, languagechecking is also important in the field of computer-assisted language learning. And language checkingapplications also automatically correct search enginequeries, as found in Google’s Did you mean... sugges-tions.
4.2.2 Web Search
Searching the web, intranets or digital libraries is proba-bly themostwidely used yet largely underdeveloped lan-guage technology application today. e Google searchengine, which started in 1998, now handles about 80%of all search queries [17]. e Google search interfaceand results page display has not significantly changedsince the first version. However, in the current version,Google offers spelling correction for misspelled wordsand incorporates basic semantic search capabilities thatcan improve search accuracy by analysing the meaningof terms in a search query context [18].eGoogle suc-cess story shows that a large volume of data and efficientindexing techniques can deliver satisfactory results us-ing a statistical approach to language processing.For more sophisticated information requests, it is essen-tial to integrate deeper linguistic knowledge for text in-terpretation. Experiments using lexical resources such
47

Input Text Spelling Check Grammar Check Correction Proposals
Statistical Language Models
3: Language checking (top: statistical; bottom: rule-based)
as machine-readable thesauri or ontological languageresources (e. g., WordNet for English or ItalWordNetand MultiWordNet for Italian) have demonstrated im-provements in finding pages using synonyms of the orig-inal search terms, such as energia atomica [atomic ener-gy] and energia nucleare [nuclear energy], or even moreloosely related terms.
The next generation of search engineswill have to include much more sophisticated
language technology.
e next generation of search engines will have to in-clude much more sophisticated language technology,especially to deal with search queries consisting of aquestion or other sentence type rather than a list of key-words. For the query, Give me a list of all companies thatwere taken over by other companies in the last five years,a syntactic as well as semantic analysis is required. esystem also needs to provide an index to quickly retrieverelevant documents. A satisfactory answer will requiresyntactic parsing to analyse the grammatical structureof the sentence and determine that the user wants com-panies that have been acquired, rather than companiesthat have acquired other companies. For the expressionlast five years, the systemneeds to determine the relevantrange of years, taking into account the present year. equery then needs to be matched against a huge amountof unstructured data to find the pieces of informationthat are relevant to the user’s request. is process
is called information retrieval, and involves searchingand ranking relevant documents. To generate a list ofcompanies, the system also needs to recognise a particu-lar string of words in a document represents a companyname, using a process called named entity recognition.A more demanding challenge is matching a query inone language with documents in another language.Cross-lingual information retrieval involves automati-cally translating the query into all possible source lan-guages and then translating the results back into the us-er’s target language.Now that data is increasingly found in non-textual for-mats, there is a need for services that deliver multime-dia information retrieval by searching images, audio filesand video data. In the case of audio and video files,a speech recognition module must convert the speechcontent into text (or into a phonetic representation)that can then be matched against a user query.In Italy, among the others, companies like Expert Sys-tem and CELI successfully develop and apply semanticsearch technologies.
4.2.3 Speech Interaction
Speech interaction is one of many application areas thatdependon speech technology, i. e., technologies for pro-cessing spoken language. Speech interaction technolo-gy is used to create interfaces that enable users to inter-act in spoken language instead of using a graphical dis-play, keyboard and mouse. Today, these voice user in-terfaces (VUI) are used for partially or fully automat-
48
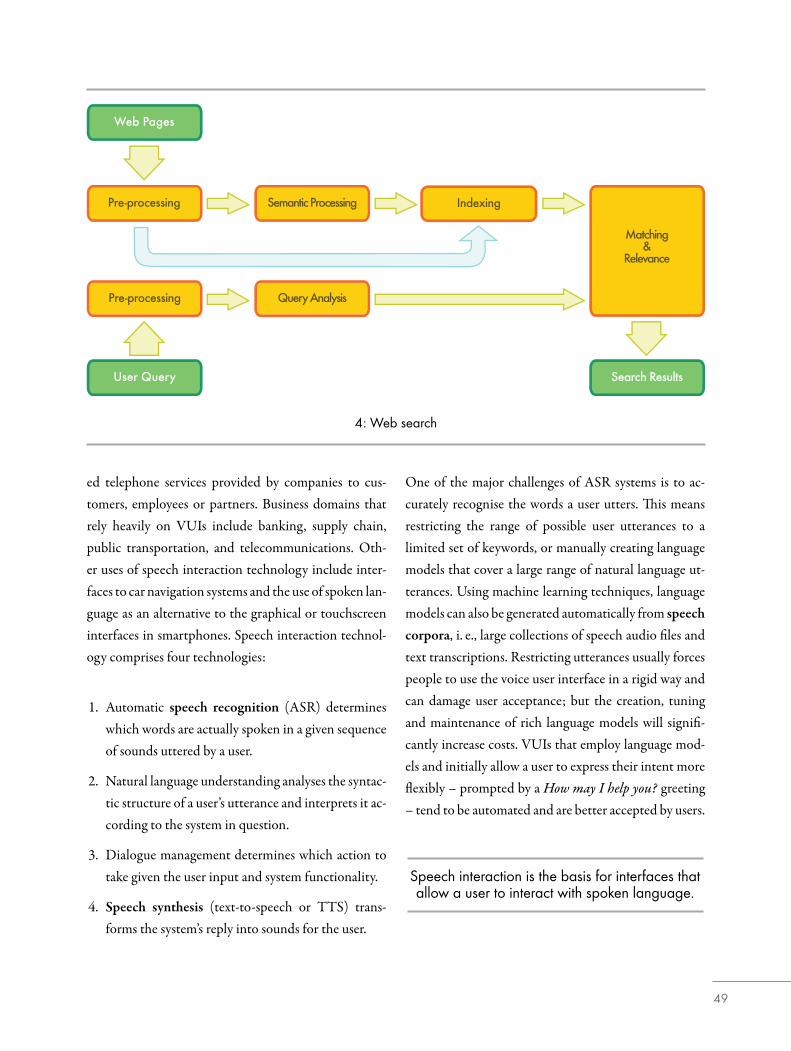
User Query
Web Pages
Pre-processing Query Analysis
Pre-processing Semantic Processing Indexing
Matching&
Relevance
Search Results
4: Web search
ed telephone services provided by companies to cus-tomers, employees or partners. Business domains thatrely heavily on VUIs include banking, supply chain,public transportation, and telecommunications. Oth-er uses of speech interaction technology include inter-faces to car navigation systems and the use of spoken lan-guage as an alternative to the graphical or touchscreeninterfaces in smartphones. Speech interaction technol-ogy comprises four technologies:
1. Automatic speech recognition (ASR) determineswhich words are actually spoken in a given sequenceof sounds uttered by a user.
2. Natural language understanding analyses the syntac-tic structure of a user’s utterance and interprets it ac-cording to the system in question.
3. Dialogue management determines which action totake given the user input and system functionality.
4. Speech synthesis (text-to-speech or TTS) trans-forms the system’s reply into sounds for the user.
One of the major challenges of ASR systems is to ac-curately recognise the words a user utters. is meansrestricting the range of possible user utterances to alimited set of keywords, or manually creating languagemodels that cover a large range of natural language ut-terances. Using machine learning techniques, languagemodels can also be generated automatically from speechcorpora, i. e., large collections of speech audio files andtext transcriptions. Restricting utterances usually forcespeople to use the voice user interface in a rigid way andcan damage user acceptance; but the creation, tuningand maintenance of rich language models will signifi-cantly increase costs. VUIs that employ language mod-els and initially allow a user to express their intent moreflexibly – prompted by a How may I help you? greeting– tend to be automated and are better accepted by users.
Speech interaction is the basis for interfaces thatallow a user to interact with spoken language.
49

Speech Input Signal Processing
Speech Output Speech Synthesis Phonetic Lookup & Intonation Planning
Natural Language Understanding &
Dialogue
Recognition
5: Speech-based dialogue system
Companies tend to use utterances pre-recorded by pro-fessional speakers for generating the output of the voiceuser interface. For static utterances where the wordingdoes not depend on particular contexts of use or per-sonal user data, this can deliver a rich user experience.But more dynamic content in an utterance may sufferfrom unnatural intonation because different parts of au-dio files have simply been strung together. Today’s TTSsystems are getting better (though they can still be op-timised) at producing natural-sounding dynamic utter-ances.
Interfaces in speech interaction have been considerablystandardised during the last decade in terms of theirvarious technological components. ere has also beenstrong market consolidation in speech recognition andspeech synthesis.enationalmarkets in theG20 coun-tries (economically resilient countries with high popu-lations) have been dominated by just five global play-ers, withNuance (USA) andLoquendo (Italy) being themost prominent players in Europe. In 2011, Nuance an-nounced the acquisition of Loquendo, which representsa further step in market consolidation.
In the Italian-language ASR market, there are small-er companies such as PerVoice, Cedat85 and Synthe-ma. With regard to dialogue management technologyand know-how, the market is dominated by nationalSME players. In Italy, this includes the IM Service Lab.Rather than relying on a soware license-drivenproduct
business, these companies are mainly positioned as full-service providers that create voice user interfaces as partof a system integration service. In the area of interactiontechnology, there is as yet no real market for syntacticand semantic analysis-based core technologies.
e demand for voice user interfaces in Italy has grownfast in the last five years, driven by increasing demandfor customer self-service, cost optimisation for automat-ed telephone services, and the increasing acceptance ofspoken language as amedia for human-machine interac-tion.
Looking ahead, there will be significant changes, due tothe spread of smartphones as a new platform for man-aging customer relationships, in addition to fixed tele-phones, the Internet and e-mail.iswill also affect howspeech interaction technology is used. In the long term,there will be fewer telephone-based VUIs, and spokenlanguage apps will play a far more central role as a user-friendly input for smartphones.is will be largely driv-en by stepwise improvements in the accuracy of speaker-independent speech recognition via the speech dicta-tion services already offered as centralised services tosmartphone users.
4.2.4 Machine Translation
e idea of using digital computers to translate naturallanguages goes back to 1946 and was followed by sub-stantial funding for research during the 1950s and again
50

Statistical Machine
Translation
Source Text
Target Text
Text Analysis (Formatting, Morphology, Syntax, etc.)
Text Generation
Translation Rules
6: Machine translation (left: statistical; right: rule-based)
in the 1980s. Yet machine translation (MT) still can-not deliver on its initial promise of providing across-the-board automated translation.
At its basic level, Machine Translation simplysubstitutes words in one natural language with
words in another language.
e most basic approach to machine translation is theautomatic replacement of the words in a text writtenin one natural language with the equivalent words ofanother language. is can be useful in subject do-mains that have a very restricted, formulaic languagesuch as weather reports. However, in order to produce agood translation of less restricted texts, larger text units(phrases, sentences, or even whole passages) need to bematched to their closest counterparts in the target lan-guage. e major difficulty is that human language isambiguous. Ambiguity creates challenges on multiplelevels, such as word sense disambiguation at the lexicallevel (a jaguar is a brand of car or an animal) or the as-signment of case on the syntactic level, for example:
‚ e chicken is ready to eat.
‚ [Il pollo è pronto a mangiare.]
‚ [Il pollo è pronto per essere mangiato.]
One way to build an MT system is to use linguisticrules. For translations between closely related languages,
a translation using direct substitution may be feasible incases such as the above example. However, rule-based(or linguistic knowledge-driven) systems oen analysethe input text and create an intermediary symbolic rep-resentation from which the target language text can begenerated.e success of thesemethods is highly depen-dent on the availability of extensive lexicons with mor-phological, syntactic, and semantic information, andlarge sets of grammar rules carefully designed by skilledlinguists.is is a very long and therefore costly process.
In the late 1980s when computational power increasedand became cheaper, interest in statistical models formachine translation began to grow. Statistical modelsare derived from analysing bilingual text corpora, paral-lel corpora, such as the Europarl parallel corpus, whichcontains the proceedings of the European Parliamentin 21 European languages. Given enough data, statis-tical MT works well enough to derive an approximatemeaning of a foreign language text by processing parallelversions and finding plausible patterns of words. Unlikeknowledge-driven systems, however, statistical (or data-driven) MT systems oen generate ungrammatical out-put. Data-driven MT is advantageous because less hu-man effort is required, and it can also cover special par-ticularities of the language (e. g., idiomatic expressions)that are oen ignored in knowledge-driven systems.
e strengths and weaknesses of knowledge-driven anddata-drivenmachine translation tend to be complemen-
51

tary, so that nowadays researchers focus on hybrid ap-proaches that combine both methodologies. One ap-proachuses both knowledge-driven anddata-driven sys-tems together with a selection module that decides onthe best output for each sentence. However, results forsentences longer than say 12wordswill oen be far fromperfect. A better solution is to combine the best parts ofeach sentence from multiple outputs; this can be fairlycomplex, as corresponding parts ofmultiple alternativesare not always obvious and need to be aligned.
Machine Translation is particularlychallenging for the Italian language.
Machine translation is particularly challenging for theItalian language due to the morphological complexityand the free word order of the Italian language. Somecompanies are active in the MT sector in Italy, mainlyproviding services for professional usages (for example,Translated).e use ofmachine translation can significantly increaseproductivity provided that the system is intelligentlyadapted to user-specific terminology and integrated in-to a workflow. Special systems for interactive translationsupport were developed.ere is still a huge potential for improving the quali-ty of MT systems. e challenges involve adapting lan-guage resources to a given subject domain or user area,and integrating the technology into workflows that al-ready have term bases and translation memories. An-other problem is that most of the current systems areEnglish-centred and only support a few languages fromand into Italian. is leads to friction in the translationworkflow and forcesMT users to learn different lexiconcoding tools for different systems.Evaluation campaigns help to compare the quality ofMT systems, the different approaches and the statusof the systems for different language pairs. Figure 7
(p. 22), whichwas prepared during theECEuromatrix+project, shows the pair-wise performances obtained for22 of the 23 official EU languages (Irish was not com-pared.) e results are ranked according to a BLEUscore, which indicates higher scores for better transla-tions [20]. A human translator would achieve a score ofaround 80 points.ebest results (in green andblue)were achievedby lan-guages that benefit froma considerable research effort incoordinated programs and from the existence of manyparallel corpora (e. g., English, French, Dutch, Span-ish and German). e languages with poorer results areshown in red. ese languages either lack such develop-ment efforts or are structurally very different from otherlanguages (e. g., Hungarian, Maltese and Finnish).
4.3 OTHER APPLICATION AREASBuilding language technology applications involves arange of subtasks that do not always surface at the levelof interaction with the user, but they provide significantservice functionalities “behind the scenes” of the sys-tem in question.ey all form important research issuesthat have now evolved into individual sub-disciplines ofcomputational linguistics.uestion answering, for example, is an active area of re-search for which annotated corpora have been built andscientific competitions have been initiated. e con-cept of question answering goes beyond keyword-basedsearches (in which the search engine responds by de-livering a collection of potentially relevant documents)and enables users to ask a concrete question towhich thesystem provides a single answer. For example:
Question: How old was Neil Armstrong when hestepped on the moon?
Answer: 38.
While question answering is obviously related to thecore area of web search, it is nowadays an umbrella term
52

for such research issues as which different types of ques-tions exist, and how they should be handled; how a setof documents that potentially contain the answer can beanalysed and compared (do they provide conflicting an-swers?); and how specific information (the answer) canbe reliably extracted from a document without ignoringthe context.
Language technology applications often providesignificant service functionalities “behind the
scenes” of larger software systems.
uestion answering is in turn related to information ex-traction (IE), an area that was extremely popular andinfluential when computational linguistics took a sta-tistical turn in the early 1990s. IE aims to identify spe-cific pieces of information in specific classes of docu-ments, such as the key players in company takeovers asreported in newspaper stories. Another common sce-nario that has been studied is reports on terrorist in-cidents. e task here consists of mapping appropriateparts of the text to a template that specifies the per-petrator, target, time, location and results of the in-cident. Domain-specific template-filling is the centralcharacteristic of IE, which makes it another exampleof a “behind the scenes” technology that forms a well-demarcated research area, which in practice needs to beembedded into a suitable application environment.Text summarisation and text generation are two bor-derline areas that can act either as standalone applica-tions or play a supporting role. Summarisation attemptsto give the essentials of a long text in a short form, and isone of the features available inMicrosoWord. It most-ly uses a statistical approach to identify the importantwords in a text (i. e., words that occur very frequently inthe text in question but less frequently in general lan-guage use) and determine which sentences contain themost of these importantwords.ese sentences are then
extracted and put together to create the summary. Inthis very common commercial scenario, summarisationis simply a form of sentence extraction, and the text isreduced to a subset of its sentences. An alternative ap-proach, for which some research has been carried out, isto generate brand new sentences that do not exist in thesource text.
For Italian, research in most text technologies ismuch less developed than for English.
is requires a deeper understanding of the text, whichmeans that so far this approach is far less robust. On thewhole, a text generator is rarely used as a stand-alone ap-plicationbut is embedded into a larger soware environ-ment, such as a clinical information system that collects,stores and processes patient data. Creating reports is justone of many applications for text summarisation.
For the Italian language, research in the text technolo-gies described above is much less developed than for theEnglish language. uestion answering, information ex-traction, and summarisation have been the focus of nu-merous open competitions in the USA since the 1990s,primarily organised by the government-sponsored or-ganisations DARPA and NIST.
ese competitions have significantly improved thestate-of-the-art, but their focus has mostly been on theEnglish language. As a result, there are fewer annotat-ed corpora or other special resources needed to performthese tasks in Italian.
When summarisation systems use purely statisticalmethods, they are largely language-independent anda number of research prototypes are available. Fortext generation, reusable components have traditionallybeen limited to surface realisation modules (generationgrammars) and most of the available soware is for theEnglish language.
53

4.4 EDUCATIONALPROGRAMMESLanguage technology is a very interdisciplinary fieldthat involves the combined expertise of linguists, com-puter scientists, mathematicians, philosophers, psy-cholinguists, and neuroscientists among others. As a re-sult, it has not acquired a clear, independent existence inthe Italian faculty system. As for university curricula wemention the second level International Master on Hu-man Language Technologies and Interface at the Uni-versity of Trento and the EuropeanMaster on Languageand Communication Technologies hosted by the FreeUniversity of Bolzano. In addition, at master and PhDlevel, there are at least 16 other curricula related toHLT(most notably at theUniversities ofVenice, Turin, Pavia,Pisa, Roma Tor Vergata, Naples, and Bari), for a total ofat least 76 university courses involving HLT topics in-cluding those related to Humanities Computing curric-ula.
4.5 NATIONAL PROJECTS ANDINITIATIVESe capability of a language to be “digitally” present inInternet-based applications and services has become acrucial element to maintain the cultural vitality of thelanguage itself.On the other hand, Internet applicationsand services can be sustained only if adequate infrastruc-tures and technologies are present. As for Italian, thesituation cannot be compared to that of English, yet aconsiderable effort has been invested in Language Tech-nologies research in Italy since 1997, whenHumanLan-guage Technology (hence forth HLT) was designated aNational research policy, with the launch of two three-year projects:
‚ TAL, National Infrastructure for Linguistic re-sources in the field of Automatic Treatment of Spo-
ken and Written Natural Language, funded by theItalian government for about 1.75M Euros;
‚ LRCMM, devoted to mono and multilingual re-search in computational linguistics, funded forabout 3M Euros.
Funding at the national level is very limited, howev-er. Since the two projects above were launched, onlytwo small-size projects have been recently funded, i. e.,MIUR-PARLI, for the harmonisation of existing com-putational resources for Italian, and MIUR-PAISÀ, forthe realisation of a platform for learning Italian from an-notated corpora.e majority of the production of language resourcesand technologies for Italian is the result of various EU-funded research projects and other initiatives.anks to these investments, several lexical databases aswell as spoken and written corpora with both manu-al and automatic annotations at different levels (gram-matical categories, syntactic constructions, textual men-tions of people, organisations and locations, etc.) arenow available.e same holds true for tools performinglinguistic analysis of Italian, e. g., part of speech taggers,syntactic parsers and named entity recognisers, speechrecognition or automatic translation from and into Ital-ian.Research onHLT is carried on bymore than 15 researchlabs (according to theEUROMAPstudy)with an activeand relevant presence in the international research com-munity. Some major events have been organised by theItalian community, among which the 11th Conferenceof the European Chapter of the Association for Com-putational Linguistics (EACL 2006) in Trento, the 5th
International Conference on Language Resources andEvaluation (LREC 2006) in Genova and the 12th An-nual Conference of the International Speech Commu-nication Association (Interspeech 2011) in Florence.Italian groups are involved, oen with coordinationroles, in international networking projects, particularly
54

at the European Level, for example in CLEF, the CrossLanguage Evaluation Forum [21], and in FLaReNet, aproject fostering an international network for languageresources [22]. According to a recent META-NET sur-vey [23], there are currently seven national projects run-ning and six European projects coordinated by Italianpartners.
Furthermore, 2003 witnessed the founding of CELCT[24], the Center for the Evaluation of Languageand Communication Technologies, located in Trento.Within the ItalianAssociation forArtificial Intelligence(AI*IA) [25], the special interest group onNatural Lan-guage Processing is the scientific point of reference forthe Italian research community in that field. Italian is in-cluded in several international initiatives for the evalu-ation of language technologies. CLEF, for example, hasmade available comparable tests in different languagesfor the organisation of cross language tasks (e. g., onuestion Answering), which include Italian.
Evalita [26], an evaluation campaign of language tech-nologies devoted exclusively to the Italian language,both spoken and written, has been organised every twoyears since 2007. e speech community is represent-ed by the Italian Association of Speech Science (AISV)[27]. Finally, the ForumTal [28] plays an important rolein the promotion and diffusion of language technolo-gies, in particular in Italian Public Administration, withone of itsmain achievements being the realisation of thewhite paper on language technologies in Italy.
In spite of the accomplishments obtained in the fieldof language technologies for Italian, the current state oftechnologies is not enough to guarantee a digital dimen-sion to Italian such as it is required by applications andservices of the future Internet. For the coming decades,the Italian community, while also going on with its ef-fort on basic research, needs to develop technologies forItalian able to keep up with the size of the data availableon the Internet of the future. In addition, all web-based
services will be accessed by potentially everyone, so thelanguage technologies involved in providing such ser-vices in Italian should support the different variants ofItalian produced by any speaker.
4.6 AVAILABILITY OF TOOLSAND RESOURCESFigure 14 provides a rating for language technology sup-port for the Italian language.is rating of existing toolsand resources was generated by leading experts in thefield who provided estimates based on a scale from 0(very low) to 6 (very high) using seven criteria.e key results for Italian language technology can besummed up as follows:
‚ Speech processing currently seems to be more ma-ture than the processing of written text. In fact,speech technology has already been successfully in-tegrated into many everyday applications, from spo-ken dialogue systems and voice-based interfaces tomobile phones and car navigation systems.
‚ Research has successfully led to the design of medi-um to high quality soware for basic text analysis,such as tools for morphological analysis and syntac-tic parsing. But advanced technologies that requiredeep linguistic processing and semantic knowledgeare still in their infancy.
‚ As to resources, there is a large reference text cor-pus with a balanced mix of genres for the Italian lan-guage, but it is difficult to access due to copyright is-sues; nonbalanced corpora are easier to access.ereare anumber of corpora annotatedwith syntactic, se-mantic and discourse structure mark-up, but again,there are not nearly enough language corpora con-taining the right sort of content tomeet the growingneed for deeper linguistic and semantic information.
‚ In particular, there is a lack of the sort of parallel cor-pora that form the basis for statistical and hybrid ap-
55

ua
ntity
Availabi
lity
ua
lity
Cov
erag
e
Matur
ity
Sustaina
bilit
y
Ada
ptab
ility
Language Technology: Tools, Technologies and Applications
Speech Recognition 2 2 6 5 4.5 3 3
Speech Synthesis 3 3 5 5 4 3.5 4
Grammatical analysis 3.5 3 4 5 4 3 2
Semantic analysis 2.5 2.5 3.5 4 3 2.5 2.5
Text generation 0 0 0 0 0 0 0
Machine translation 4 3.5 4 3 4 3.5 2.5
Language Resources: Resources, Data and Knowledge Bases
Text corpora 2.5 2.5 4 3.5 3.5 2.5 2
Speech corpora 3 3 4 2.5 2.5 2 2
Parallel corpora 2 2 4 3 4 3 2
Lexical resources 3.5 3.5 5 5 5 2.5 2.5
Grammars 2 2 4 4 3 2 2
7: State of language technology support for Italian
proaches to machine translation. Currently, transla-tion from Italian to English works best because forthere are large amounts of parallel text available forthis language pair.
‚ Many of these tools, resources and data formats donotmeet industry standards and cannot be sustainedeffectively. A concerted programme is required tostandardise data formats and APIs.
‚ An unclear legal situation restricts the use of dig-ital texts, e. g., those published online by newspa-pers, for empirical linguistic and language technol-ogy research, such as training statistical languagemodels. Together with politicians and policy mak-ers, researchers should try to establish laws or regula-tions that enable researchers to use publicly availabletexts for language-related R&D activities.
‚ e cooperation between the Language Technolo-gy community and those involved with the Seman-tic Web and the closely related Linked Open Da-ta movement should be intensified with the goal ofestablishing a collaboratively maintained, machine-readable knowledge base that can be used bothin web-based information systems and as semanticknowledge bases in LT applications. Ideally, this en-deavour should be addressed multilingually on theEuropean scale.
In a number of specific areas of Italian language research,we have sowarewith limited functionality available to-day. Obviously, further research efforts are required tomeet the current deficit in processing texts on a deepersemantic level and to address the lack of resources suchas parallel corpora for machine translation.
56

4.7 CROSS-LANGUAGECOMPARISONecurrent state of LT support varies considerably fromone language community to another. In order to com-pare the situation between languages, this section willpresent an evaluation based on two sample applica-tion areas (machine translation and speech processing)and one underlying technology (text analysis), as wellas basic resources needed for building LT applications.e languages were categorised using the following five-point scale:
1. Excellent support
2. Good support
3. Moderate support
4. Fragmentary support
5. Weak or no support
Language Technology support was measured accordingto the following criteria:
Speech Processing:uality of existing speech recogni-tion technologies, quality of existing speech synthesistechnologies, coverage of domains, number and size ofexisting speech corpora, amount and variety of availablespeech-based applications.
Machine Translation: uality of existing MT tech-nologies, number of language pairs covered, coverage oflinguistic phenomena and domains, quality and size ofexisting parallel corpora, amount and variety of availableMT applications.
Text Analysis: uality and coverage of existing textanalysis technologies (morphology, syntax, semantics),coverage of linguistic phenomena and domains, amountand variety of available applications, quality and size ofexisting (annotated) text corpora, quality and coverageof existing lexical resources (e. g., WordNet) and gram-mars.
Resources: uality and size of existing text corpora,speech corpora and parallel corpora, quality and cover-age of existing lexical resources and grammars.Figures 16 to 22 show that, thanks to large-scale LTfunding in recent decades, the Italian language is betterequipped than most other languages. It compares wellwith languages with a similar number of speakers, suchasGerman. But LT resources and tools for Italian clearlydo not yet reach the quality and coverage of comparableresources and tools for the English language, which is inthe lead in almost all LT areas. And there are still plen-ty of gaps in English language resources with regard tohigh quality applications.For speech processing, current technologies performwell enough to be successfully integrated into a numberof industrial applications such as spoken dialogue anddictation systems. Today’s text analysis components andlanguage resources already cover the linguistic phenom-ena of Italian to a certain extent and form part of manyapplications involving mostly shallow natural languageprocessing, e. g., spelling correction and authoring sup-port.However, for building more sophisticated applications,such as machine translation, there is a clear need for re-sources and technologies that cover a wider range of lin-guistic aspects and enable a deep semantic analysis ofthe input text. By improving the quality and coverageof these basic resources and technologies, we shall beable to open up new opportunities for tackling a broad-er range of advanced application areas, including high-quality machine translation.
4.8 CONCLUSIONSIn this series of white papers, we have provided thefirst high-leel comparison of language technology sup-port across 30 European languages. By identifying thegaps, needs and deficits, the European language technol-ogy community and its related stakeholders are now in
57

a position to design a large scale research and develop-ment programme aimed at building truly multilingual,technology-enabled communication across Europe.e results of this white paper series show that there is adramatic difference in language technology support be-tween European languages. While there are good qual-ity soware and resources available for some languagesand application areas, other (usually smaller) languageshave substantial gaps. Many languages lack basic tech-nologies for text analysis and the essential resources.Others have basic tools and resources, but there is littlechance of implementing semantic methods in the nearfuture. is means that a large-scale effort is needed toreach the ambitious goal of providing support for all Eu-ropean languages, for example through high qualityma-chine translation.In the case of the Italian language, we can be cautiouslyoptimistic about the current state of language technol-ogy support. ere is a viable LT research communityin Italy, which has been supported in the past by largeresearch programmes. And a number of large-scale re-sources and state-of-the-art technologies have been pro-duced for Italian. However, the scope of the resourcesand the range of tools are still very limited when com-pared to English, and they are simply not sufficient inquality and quantity to develop the kind of technolo-gies required to support a truly multilingual knowledgesociety.Nor can we simply transfer technologies already devel-oped and optimised for the English language to han-dle Italian. English-based systems for parsing (syntactic
and grammatical analysis of sentence structure) typical-ly perform far lesswell on Italian texts, due to the specificcharacteristics of the Italian language.e Italian language technology industry is current-ly fragmented and disorganised. Most large companieshave either stopped or severely cut their LT efforts, leav-ing the field to a number of specialised SMEs that arenot robust enough to address the internal and the glob-al market with a sustained strategy.Our findings lead to the conclusion that the only wayforward is tomake a substantial effort to create languagetechnology resources for Italian, as a means to drive for-ward research, innovation and development. e needfor large amounts of data and the extreme complexity oflanguage technology systems makes it vital to developan infrastructure and a coherent research organisationto spur greater sharing and cooperation.Finally there is a lack of continuity in research anddevel-opment funding. Short-term coordinated programmestend to alternate with periods of sparse or zero funding.In addition, there is an overall lack of coordination withprogrammes in other EU countries and at the EuropeanCommission level.e long term goal of META-NET is to enable the cre-ation of high-quality language technology for all lan-guages. is requires all stakeholders – in politics, re-search, business, and society – to unite their efforts.e resulting technology will help tear down existingbarriers and build bridges between Europe’s languages,paving theway for political and economic unity throughcultural diversity.
58

Excellent Good Moderate Fragmentary Weak/nosupport support support support support
English CzechDutchFinnishFrenchGermanItalianPortugueseSpanish
BasqueBulgarianCatalanDanishEstonianGalicianGreekHungarianIrishNorwegianPolishSerbianSlovakSloveneSwedish
CroatianIcelandicLatvianLithuanianMalteseRomanian
8: Speech processing: state of language technology support for 30 European languages
Excellent Good Moderate Fragmentary Weak/nosupport support support support support
English FrenchSpanish
CatalanDutchGermanHungarianItalianPolishRomanian
BasqueBulgarianCroatianCzechDanishEstonianFinnishGalicianGreekIcelandicIrishLatvianLithuanianMalteseNorwegianPortugueseSerbianSlovakSloveneSwedish
9: Machine translation: state of language technology support for 30 European languages
59

Excellent Good Moderate Fragmentary Weak/nosupport support support support support
English DutchFrenchGermanItalianSpanish
BasqueBulgarianCatalanCzechDanishFinnishGalicianGreekHungarianNorwegianPolishPortugueseRomanianSlovakSloveneSwedish
CroatianEstonianIcelandicIrishLatvianLithuanianMalteseSerbian
10: Text analysis: state of language technology support for 30 European languages
Excellent Good Moderate Fragmentary Weak/nosupport support support support support
English CzechDutchFrenchGermanHungarianItalianPolishSpanishSwedish
BasqueBulgarianCatalanCroatianDanishEstonianFinnishGalicianGreekNorwegianPortugueseRomanianSerbianSlovakSlovene
IcelandicIrishLatvianLithuanianMaltese
11: Speech and text resources: state of support for 30 European languages
60

5
ABOUT META-NET
META-NET is a Network of Excellence partially fund-ed by theEuropeanCommission [29].enetwork cur-rently consists of 54 research centres in 33 Europeancountries.META-NET forgesMETA, theMultilingualEurope Technology Alliance, a growing community oflanguage technology professionals and organisations inEurope. META-NET fosters the technological founda-tions for a truly multilingual European information so-ciety that:
‚ makes communication and cooperation possibleacross languages;
‚ grants all Europeans equal access to information andknowledge regardless of their language;
‚ builds upon and advances functionalities of net-worked information technology.
e network supports a Europe that unites as a sin-gle digital market and information space. It stimulatesand promotes multilingual technologies for all Euro-pean languages. ese technologies support automat-ic translation, content production, information process-ing and knowledge management for a wide variety ofsubject domains and applications. ey also enable in-tuitive language-based interfaces to technology rang-ing from household electronics, machinery and vehi-cles to computers and robots. Launched on 1 February2010,META-NEThas already conducted various activ-ities in its three lines of actionMETA-VISION,META-SHARE and META-RESEARCH.META-VISION fosters a dynamic and influentialstakeholder community that unites around a shared vi-sion and a common strategic research agenda (SRA).
e main focus of this activity is to build a coherentand cohesive LT community in Europe by bringing to-gether representatives from highly fragmented and di-verse groups of stakeholders. e present White Paperwas prepared together with volumes for 29 other lan-guages. e shared technology vision was developed inthree sectorial Vision Groups. e META TechnologyCouncil was established in order to discuss and to pre-pare the SRA based on the vision in close interactionwith the entire LT community.
META-SHARE creates an open, distributed facilityfor exchanging and sharing resources. e peer-to-peernetwork of repositories will contain language data,tools and web services that are documented with high-quality metadata and organised in standardised cate-gories. e resources can be readily accessed and uni-formly searched. e available resources include free,open sourcematerials as well as restricted, commerciallyavailable, fee-based items.
META-RESEARCH builds bridges to related tech-nology fields. is activity seeks to leverage advances inother fields and to capitalise on innovative research thatcan benefit language technology. In particular, the ac-tion line focuses on conducting leading-edge research inmachine translation, collecting data, preparing data setsand organising language resources for evaluation pur-poses; compiling inventories of tools and methods; andorganising workshops and training events for membersof the community.
[email protected] – http://www.meta-net.eu
61


A
RIFERIMENTIBIBLIOGRAFICI
REFERENCES
[1] Aljoscha Burchardt, Markus Egg, Kathrin Eichler, Brigitte Krenn, Jörn Kreutel, Annette Leßmöllmann,Georg Rehm, Manfred Stede, Hans Uszkoreit, and Martin Volk. Die Deutsche Sprache im Digitalen Zeital-ter – e German Language in the Digital Age. META-NET White Paper Series. Georg Rehm and HansUszkoreit (Series Editors). Springer, 2012.
[2] Aljoscha Burchardt, Georg Rehm, and Felix Sasaki. Die zukünige europäische mehrsprachige Information-sgesellscha – Aufsatz mit Visionen für einen strategische Forschungsagenda (e Future European Multi-lingual Information Society – Vision Paper for a Strategic Research Agenda), 2011. http://www.meta-net.eu/vision/reports/meta-net-vision-paper.pdf.
[3] Directorate-General Information Society&Media of the EuropeanCommission. User Language PreferencesOnline, 2011. http://ec.europa.eu/public_opinion/flash/fl_313_en.pdf.
[4] European Commission. Multilingualism: an Asset for Europe and a Shared Commitment, 2008. http://ec.europa.eu/languages/pdf/comm2008_en.pdf.
[5] Directorate-General of the UNESCO. Intersectoral Mid-term Strategy on Languages and Multilingualism,2007. http://unesdoc.unesco.org/images/0015/001503/150335e.pdf.
[6] Directorate-General for Translation of the European Commission. Size of the Language Industry in the EU,2009. http://ec.europa.eu/dgs/translation/publications/studies.
[7] Grimes, Barbara F. (October 1996). Barbara F. Grimes. ed. Ethnologue: Languages of the World. Con-sulting Editors: Richard S. Pittman and Joseph E. Grimes (thirteenth ed.) Dallas, Texas: Summer Institute ofLinguistics, Academic Pub. ISBN 1-55671-026-7.
[8] Roswitha Fischer and Hanna Pulaczewska (Eds.). Anglicisms in Europe: Linguistic Diversity in a Global Con-text. Cambridge Scholars Publishing, 2008.
[9] Accademia della Crusca. http://www.accademiadellacrusca.it.
[10] OECD. Summary of Results from PISA 2009. http://www.pisa.oecd.org/dataoecd/34/19/46619755.pdf.
[11] Kai-Uwe Carstensen, Christian Ebert, Cornelia Ebert, Susanne Jekat, Hagen Langer, and Ralf Klabunde, ed-itors. Computerlinguistik und Sprachtechnologie: Eine Einführung. Spektrum Akademischer Verlag, 2009.
63

[12] Daniel Jurafsky and James H. Martin. Speech and Language Processing (2nd Edition). Prentice Hall, 2009.
[13] Christopher D. Manning and Hinrich Schütze. Foundations of Statistical Natural Language Processing. MITPress, 1999.
[14] Language Technology World (LT World). http://www.lt-world.org.
[15] Ronald Cole, Joseph Mariani, Hans Uszkoreit, Giovanni Battista Varile, Annie Zaenen, and Antonio Zam-polli, editors. Survey of the State of the Art in Human Language Technology (Studies in Natural LanguageProcessing). Cambridge University Press, 1998.
[16] Jerrold H. Zar. Candidate for a Pullet Surprise. Journal of Irreproducible Results, page 13, 1994.
[17] Spiegel Online. Google zieht weiter davon (Google is still leaving everybody behind), 2009. http://www.spiegel.de/netzwelt/web/0,1518,619398,00.html.
[18] Juan Carlos Perez. Google Rolls out Semantic Search Capabilities, 2009. http://www.pcworld.com/businesscenter/article/161869/google_rolls_out_semantic_search_capabilities.html.
[19] Philipp Koehn, Alexandra Birch, and Ralf Steinberger. 462 Machine Translation Systems for Europe. InProceedings of MT Summit XII, 2009.
[20] Kishore Papineni, SalimRoukos, ToddWard, andWei-Jing Zhu. BLEU:AMethod forAutomatic Evaluationof Machine Translation. In Proceedings of the 40th Annual Meeting of ACL, Philadelphia, PA, 2002.
[21] e CLEF Initiative. Conference and Labs of the Evaluation Forum. http://www.clef-initiative.eu.
[22] FLaReNet. Fostering Language Resources Network. http://www.flarenet.eu.
[23] Claudia Soria and Joseph Mariani. Report on Existing Projects and Initiatives. META-NET DeliverableD11.3.
[24] CELCT. Center for the Evaluation of Language and Communication Technology. http://www.celct.it.
[25] AI*IA. Associazione Italiana per l’IntelligenzaArtificiale (ItalianAssociation forArtificial Intelligence). http://www.aixia.it.
[26] EVALITA. Evaluation of NLP and Speech Tools for Italian. http://www.evalita.it.
[27] AISV. Associazione Italiana di Scienze della Voce (ItalianAssociation for Speech Sciences). http://www.aisv.it.
[28] ForumTAL. Forum Permanente sul Trattamento Automatico del Linguaggio (Permanent Forum about Nat-ural Language Processing). http://www.forumtal.it.
[29] Georg Rehm and Hans Uszkoreit. Multilingual Europe: A challenge for language tech. MultiLingual,22(3):51–52, April/May 2011.
64

B
MEMBRI DI META-NET META-NET MEMBERS
Austria Austria Zentrum für Translationswissenscha, Universität Wien: Gerhard Budin
Belgio Belgium Computational Linguistics and Psycholinguistics Research Centre, University ofAntwerp: Walter Daelemans
Centre for Processing Speech and Images, University of Leuven:Dirk van Compernolle
Bulgaria Bulgaria Inst. for Bulgarian Language, Bulgarian Academy of Sciences: Svetla Koeva
Cipro Cyprus Language Centre, School of Humanities: Jack Burston
Croazia Croatia Inst. of Linguistics, Faculty of Humanities and Social Science, University of Zagreb:Marko Tadić
Danimarca Denmark Centre for Language Technology, University of Copenhagen:Bolette Sandford Pedersen, Bente Maegaard
Estonia Estonia Inst. of Computer Science, University of Tartu: Tiit Roosmaa, Kadri Vider
Finlandia Finland Computational Cognitive Systems Research Group, Aalto University:Timo Honkela
Department of Modern Languages, University of Helsinki: Kimmo Koskenniemi,Krister Lindén
Francia France Centre National de la Recherche Scientifique, Laboratoire d’Informatique pour laMécanique et les Sciences de l’Ingénieur and Inst. for Multilingual and MultimediaInformation: Joseph Mariani
Evaluations and Language Resources Distribution Agency: Khalid Choukri
Germania Germany Language Technology Lab, DFKI: Hans Uszkoreit, Georg Rehm
Human Language Technology and Pattern Recognition, RWTH Aachen Universi-ty: Hermann Ney
Department of Computational Linguistics, Saarland University: Manfred Pinkal
Grecia Greece R.C. “Athena”, Inst. for Language and Speech Processing: Stelios Piperidis
Irlanda Ireland School of Computing, Dublin City University: Josef van Genabith
Islanda Iceland School of Humanities, University of Iceland: Eiríkur Rögnvaldsson
Italia Italy Consiglio Nazionale delle Ricerche, Istituto di Linguistica Computazionale “Anto-nio Zampolli”: Nicoletta Calzolari
Human Language Technology Research Unit, Fondazione Bruno Kessler:Bernardo Magnini
65
Lettonia Latvia Tilde: Andrejs Vasiļjevs
Inst. of Mathematics and Computer Science, University of Latvia: Inguna Skadiņa
Lituania Lithuania Inst. of the Lithuanian Language: Jolanta Zabarskaitė
Lussemburgo Luxembourg Arax Ltd.: Vartkes Goetcherian
Malta Malta Department Intelligent Computer Systems, University of Malta: Mike Rosner
Norvegia Norway Department of Linguistic, Literary and Aesthetic Studies, University of Bergen:Koenraad De Smedt
Department of Informatics, Language Technology Group, University of Oslo:Stephan Oepen
Paesi Bassi Netherlands Utrecht Inst. of Linguistics, Utrecht University: Jan Odijk
Computational Linguistics, University of Groningen: Gertjan van Noord
Polonia Poland Inst. of Computer Science, Polish Academy of Sciences: Adam Przepiórkowski,Maciej Ogrodniczuk
University of Łódź: Barbara Lewandowska-Tomaszczyk, Piotr Pęzik
Department of Computer Linguistics and Artificial Intelligence, Adam MickiewiczUniversity: Zygmunt Vetulani
Portogallo Portugal University of Lisbon: António Branco, Amália Mendes
SpokenLanguage SystemsLaboratory, Inst. for SystemsEngineering andComputers:Isabel Trancoso
Regno Unito UK School of Computer Science, University of Manchester: Sophia Ananiadou
Inst. for Language, Cognition andComputation, Centre for SpeechTechnology Re-search, University of Edinburgh: Steve Renals
Research Inst. of Informatics and Language Processing, University of Wolverhamp-ton: Ruslan Mitkov
Repubblica Ceca Czech Republic Inst. of Formal and Applied Linguistics, Charles University in Prague: Jan Hajič
Romania Romania Research Inst. for Artificial Intelligence, Romanian Academy of Sciences: Dan Tufiș
Faculty ofComputer Science,UniversityAlexandru IoanCuza of Ia»ôi:DanCristea
Serbia Serbia University of Belgrade, Faculty of Mathematics: Duško Vitas, Cvetana Krstev,Ivan Obradović
Pupin Inst.: Sanja Vranes
Slovacchia Slovakia Ludovit Stur Inst. of Linguistics, Slovak Academy of Sciences: Radovan Garabík
Slovenia Slovenia Jozef Stefan Inst.: Marko Grobelnik
Spagna Spain Barcelona Media: Toni Badia, Maite Melero
Institut Universitari de Lingüistica Aplicada, Universitat Pompeu Fabra: Núria Bel
66

Aholab Signal Processing Laboratory, University of the Basque Country:Inma Hernaez Rioja
Center for Language andSpeechTechnologies andApplications,Universitat Politéc-nica de Catalunya: Asunción Moreno
Department of Signal Processing and Communications, University of Vigo:Carmen García Mateo
Svezia Sweden Department of Swedish, University of Gothenburg: Lars Borin
Svizzera Switzerland Idiap Research Inst.: Hervé Bourlard
Ungheria Hungary Research Inst. for Linguistics, Hungarian Academy of Sciences: Tamás Váradi
Department of Telecommunications andMedia Informatics, Budapest University ofTechnology and Economics: Géza Németh, Gábor Olaszy
Quasi 100 esperti di tecnologie linguistiche – in rappresentanza dei paesi e delle lingue rappresentate in META-NET – hanno discusso e messo a punto i principali messaggi e risultati della Collana Libri Bianchi durante unariunione di META-NET a Berlino, Germania, il 21 e 22 ottobre 2011. — About 100 language technology experts– representatives of the countries and languages represented in META-NET – discussed and finalised the keyresults and messages of the White Paper Series at a META-NET meeting in Berlin, Germany, on October 21/22,2011.
67


C
LA COLLANA LIBRIBIANCHI META-NET
THE META-NETWHITE PAPER SERIES
Basco Basque euskaraBulgaro Bulgarian българскиCatalano Catalan catalàCeco Czech češtinaCroato Croatian hrvatskiDanese Danish danskEstone Estonian eestiFinlandese Finnish suomiFrancese French françaisGaliziano Galician galegoGreco Greek εηνικάInglese English EnglishIrlandese Irish GaeilgeIslandese Icelandic íslenskaItaliano Italian italianoLettone Latvian latviešu valodaLituano Lithuanian lietuvių kalbaMaltese Maltese MaltiNorvegese Bokmål Norwegian Bokmål bokmålNorvegese Nynorsk Norwegian Nynorsk nynorskOlandese Dutch NederlandsPolacco Polish polskiPortoghese Portuguese portuguêsRumeno Romanian românăSerbo Serbian српскиSlovacco Slovak slovenčinaSloveno Slovene slovenščinaSpagnolo Spanish españolSvedese Swedish svenskaTedesco German DeutschUngherese Hungarian magyar
69

www.meta-net.eu
La
ngua
ge Users Society Research Communities In
dustries
www.meta-net.eu
In everyday communication, Europe’s citizens, businesspartners and politicians are inevitably confronted withlanguage barriers. Language technology has the po-tential to overcome these barriers and to provide inno-vative interfaces to technologies and knowledge. Thiswhite paper presents the state of language technolo-gy support for the Italian language. It is part of a se-ries that analyses the available language resources andtechnologies for 30 European languages. The analysiswas carried out by META-NET, a Network of Excellencefunded by the European Commission. META-NET con-sists of 54 research centres in 33 countries, who cooper-ate with stakeholders from economy, government agen-cies, research organisations and others. META-NET’s vi-sion is high-quality language technology for all Euro-pean languages.
Nella comunicazione quotidiana, i cittadini europei,i partner commerciali e i politici si trovano inevitabil-mente di fronte a delle barriere linguistiche. La tec-nologia linguistica ha il potenziale per superare que-ste barriere e fornire delle interfacce innovative alletecnologie e alla conoscenza. Questo Libro Biancopresenta lo stato del supporto alla tecnologia del lin-guaggio per la lingua italiana. Fa parte di una serieche analizza le risore linguistiche e le tecnologie di-sponibili per 30 lingue europee. L’analisi è stata con-dotta da META-NET, una rete di eccellenza finanzia-ta dalla Commisione Europea. META-NET è costituitoda 54 centri di ricerca in 33 paesi, che collaboranocon esponenti del mondo economico, agenzie gover-native, organizzazioni di ricerca e altri. La visione diMETA-NET è quella di raggiungere una tecnologialinguistica di alta qualità per tutte le lingue europee.
“E non ci si rende abbastanza conto che, se in Italia non verranno sviluppate le ricerche sulle tecnologie sullalingua – soprattutto il Trattamento Automatico del Linguaggio – la lingua italiana è destinata a diventare semprepiù marginale, fin quasi a scomparire. Se questa è la cattiva notizia, la buona notizia è che il TAL, nel mondodella ricerca italiano, gode di molte attenzioni.”— Prof. Giordano Bruno Guerri (Presidente, Fondazione Il Vittoriale degli Italiani)



























