Embed Size (px)
Citation preview

The Processor – Pipelining
Alexander Nelson
March 17, 2021
University of Arkansas - Department of Computer Science and Computer Engineering
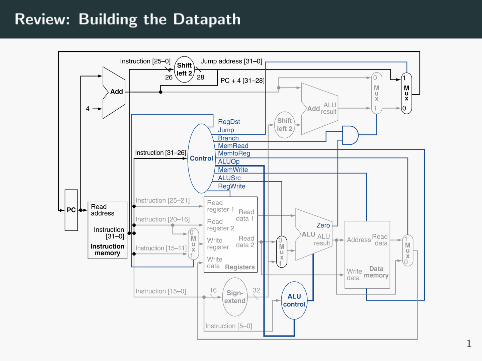
Review: Building the Datapath
1
Pipelining
What is a pipeline?
Pipeline – A state of development, preparation, or production
A not very helpful analogy
2
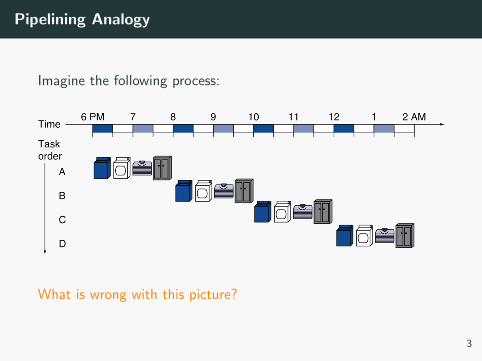
Pipelining Analogy
Imagine the following process:
What is wrong with this picture?
3
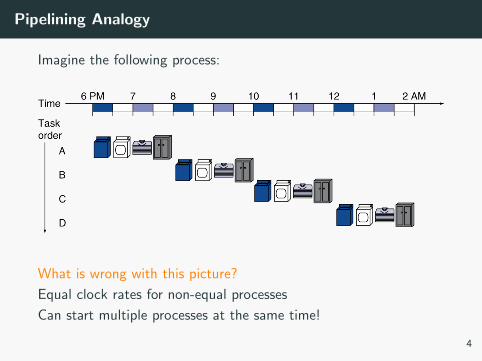
Pipelining Analogy
Imagine the following process:
What is wrong with this picture?
Equal clock rates for non-equal processes
Can start multiple processes at the same time!
4
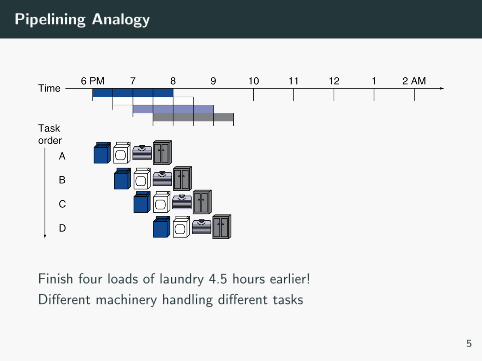
Pipelining Analogy
Finish four loads of laundry 4.5 hours earlier!
Different machinery handling different tasks
5
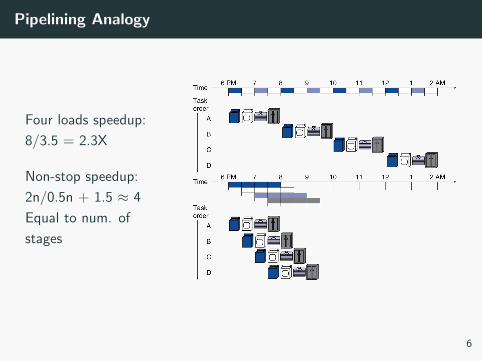
Pipelining Analogy
Four loads speedup:
8/3.5 = 2.3X
Non-stop speedup:
2n/0.5n + 1.5 ≈ 4
Equal to num. of
stages
6
MIPS Pipeline
How do we pipeline MIPS instructions?
7

MIPS Pipeline
How do we pipeline MIPS instructions?
Review:
1. Instruction Fetch – Memory Read from address
2. Instruction Decode – Determine operation type
3. Instruction Execute – ALU Calculation, write to memory,
write to register
8

MIPS Pipeline
MIPS five stage pipeline
1. IF – Instruction fetch from memory
2. ID – Instruction decode & register read
3. EX – Execute operation or calculate address
4. MEM – Access memory operand
5. WB – Write result back to register
9

MIPS Pipeline
How will this implementation perform?
Under ideal circumstances
i.e. completely balanced states, no extra overhead:
Time between instructionspipelined =Time between instructionsnonpipelined
Number of pipe stages
Speed up should be ≈5X
For 800ps single-cycle machine, 5-stage pipeline should be ≈160ps
10

MIPS Pipeline
Let’s look at an example:
Assume register read/write = 100ps execution time
Assume any other stage = 200ps
11

MIPS Pipeline
Speedup = 800ps200ps = 4X
12

Pipeline Speedup
Pipeline performance gain depends on balanced stages
i.e. All stages should take approx. the same time
What is the speedup for the first instruction?
13

Pipeline Speedup
Pipeline performance gain depends on balanced stages
i.e. All stages should take approx. the same time
What is the speedup for the first instruction?
No benefit to first instruction
Speedup due to increased throughput!
Latency (time for a given instruction) does not decrease (may
increase!)
14

Pipelining and ISA Design

Pipelining and ISA Design
MIPS ISA designed for pipelining
• All instructions are 32-bits
• Easier to fetch and decode in one cycle
• Compare to x86 1-17 bytes/instruction
• Few and regular instruction formats
• Can decode and read registers in one step
• Load/store addressing
• Can calculate address in 3rd stage, access memory in fourth
stage
• Alignment of memory operands
• Memory access takes only one cycle
15

Hazards
Hazard – Situation that prevents starting next instruction
Types of hazards:
• Structure Hazard – A required resource is busy
• Data Hazard – Need to wait for previous instruction to
complete its read/write
• Control Hazard – Deciding on control action depends on
previous instruction
16

Hazards – Structure Hazards
Structure Hazards – Conflict for use of a resource
MIPS pipeline with a single memory:
• Load/store requires data access
• Instruction fetch would have to stall for that cycle
• Would cause a pipeline “bubble”
Pipelined datapaths require separate instruction/data memories
• Separate instruction/data caches
17

Hazards – Data Hazards
Data Hazard – Instruction depends on completion of previous
instruction
e.g.
add $s0, $t0, $t1
sub $t2, $s0, $t3
Can we speed this up?
18
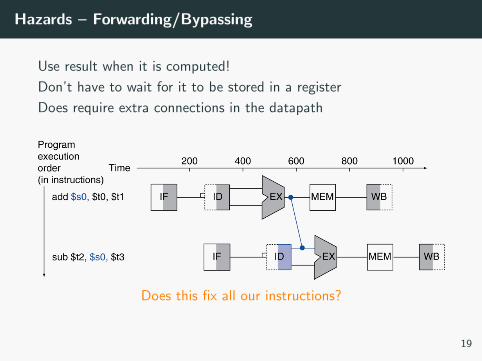
Hazards – Forwarding/Bypassing
Use result when it is computed!
Don’t have to wait for it to be stored in a register
Does require extra connections in the datapath
Does this fix all our instructions?
19

Hazards – Load-Use Data Hazard
Load-Use Data Hazard – Can’t always avoid stalls by forwarding
Any way we can get rid of this stall?
20

Hazards – Code Scheduling
May be possible to reorder code to reduce stalls
Assume the following C Code, where all variables are 32-bit
integers in memory, offset from $t0
a = b + e; c = b + f;
lw $t1, 0($t0)
lw $t2, 4($t0)
add $t3, $t1, $t2 -- STALL
sw $t3, 12($t0)
lw $t4, 8($t0)
add $t5, $t1, $t4 -- STALL
sw $t5, 16($t0)
13 cycles = 7 instructions + 4 pipeline load + 2 stalls
What can we do better?21

Hazards – Code Scheduling
May be possible to reorder code to reduce stalls
Assume the following C Code, where all variables are 32-bit
integers in memory, offset from $t0
a = b + e; c = b + f;
lw $t1, 0($t0)
lw $t2, 4($t0)
lw $t4, 8($t0)
add $t3, $t1, $t2
sw $t3, 12($t0)
add $t5, $t1, $t4
sw $t5, 16($t0)
11 cycles = 7 instructions + 4 pipeline load + 0 stalls
22
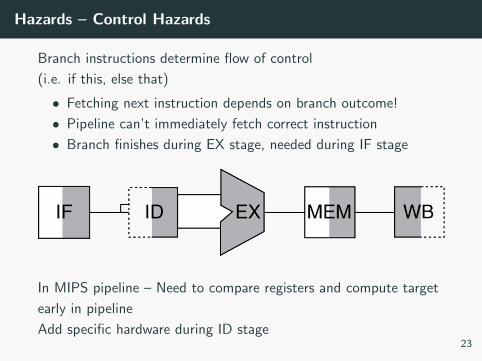
Hazards – Control Hazards
Branch instructions determine flow of control
(i.e. if this, else that)
• Fetching next instruction depends on branch outcome!
• Pipeline can’t immediately fetch correct instruction
• Branch finishes during EX stage, needed during IF stage
In MIPS pipeline – Need to compare registers and compute target
early in pipeline
Add specific hardware during ID stage23

Hazards – Stall on Branch
Wait until branch outcome determined before fetching
24

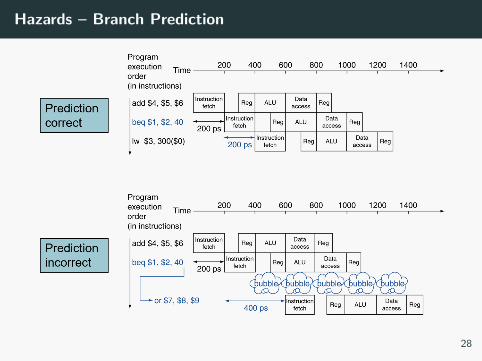
Hazards – Branch Prediction
Our MIPS pipeline has just 5 stages
Stalling causes one empty cycle, not a huge performance hit
However, longer pipelines can’t determine branch outcome early
Stall penalty may become large
Solution: Predict the branch!
25

Hazards – Branch Prediction
Naıve solution – Predict branch never taken
Fetch next instruction with no delay
What is the problem with this approach?
26

Hazards – Branch Prediction
Naıve solution – Predict branch never taken
Fetch next instruction with no delay
What is the problem with this approach?
What happens if the branch condition is true?
Flush the results of the previous instruction
27
Hazards – Branch Prediction
28
Hazards – Branch Prediction
Can we do better?
29
Hazards – Branch Prediction
Can we do better?
While/for loop – better to take or ignore branch?
If statement – better to take or ignore?
Case statement – better to take or ignore?
30

Hazards – Branch Prediction
Can we do better?
While/for loop – better to take or ignore branch?
If statement – better to take or ignore?
Case statement – better to take or ignore?
Static analyses show better to predict take backward branches, but
not forward branches
31
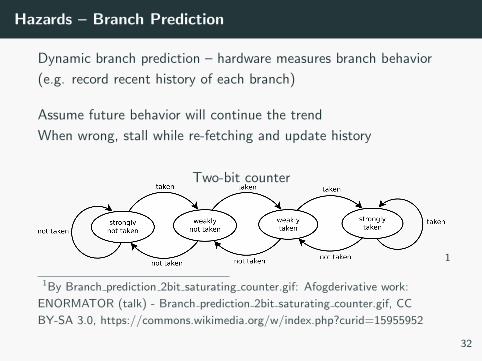
Hazards – Branch Prediction
Dynamic branch prediction – hardware measures branch behavior
(e.g. record recent history of each branch)
Assume future behavior will continue the trend
When wrong, stall while re-fetching and update history
Two-bit counter
1
1By Branch prediction 2bit saturating counter.gif: Afogderivative work:
ENORMATOR (talk) - Branch prediction 2bit saturating counter.gif, CC
BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=15955952
32
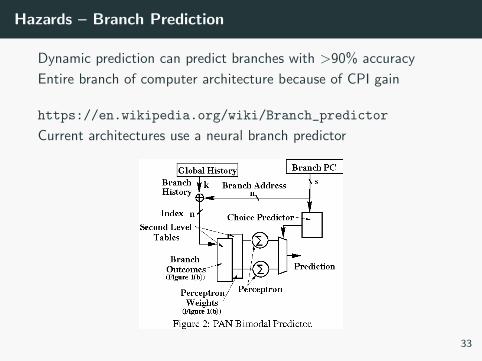
Hazards – Branch Prediction
Dynamic prediction can predict branches with >90% accuracy
Entire branch of computer architecture because of CPI gain
https://en.wikipedia.org/wiki/Branch_predictor
Current architectures use a neural branch predictor
33

Pipelining Summary
Pipelining improves performance through increasing throughput
• Execute multiple instructions in parallel
• Each instruction has same latency
Mostly invisible to programmer!
Subject to hazards – structural, data, control
ISA affects complexity of pipeline implementation
34

Pipeline Datapath
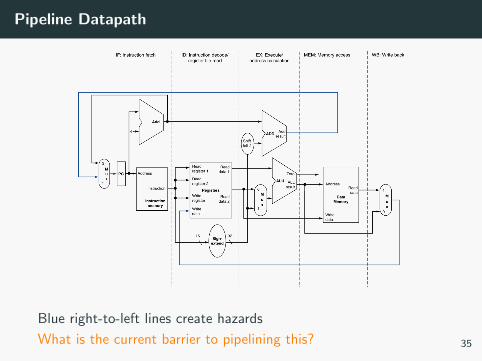
Pipeline Datapath
Blue right-to-left lines create hazards
What is the current barrier to pipelining this? 35
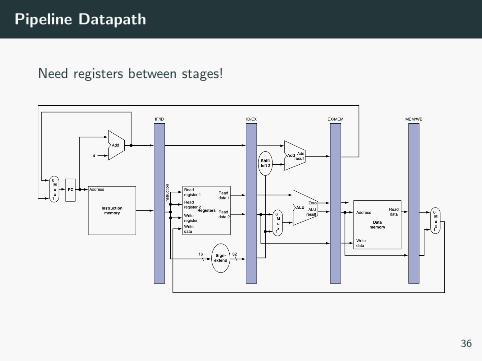
Pipeline Datapath
Need registers between stages!
36
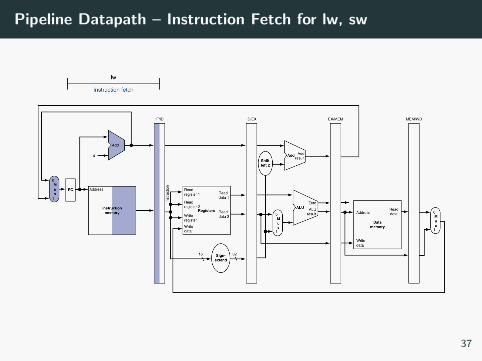
Pipeline Datapath – Instruction Fetch for lw, sw
37
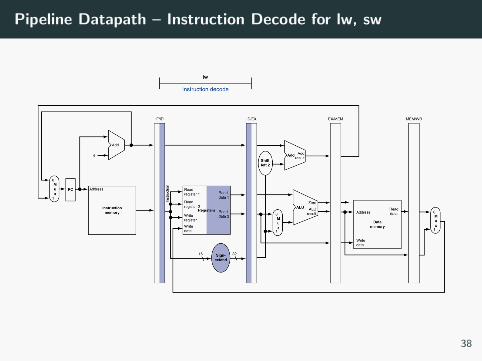
Pipeline Datapath – Instruction Decode for lw, sw
38
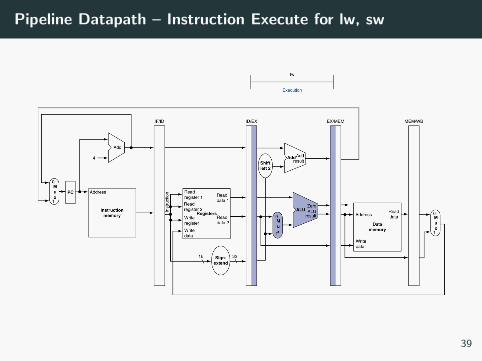
Pipeline Datapath – Instruction Execute for lw, sw
39
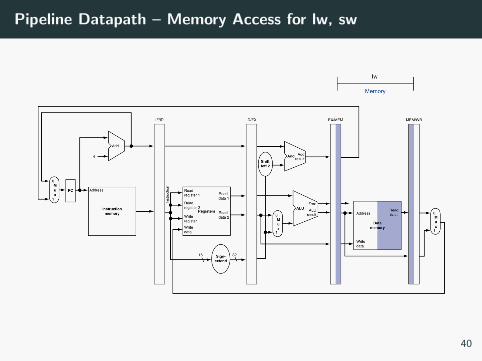
Pipeline Datapath – Memory Access for lw, sw
40
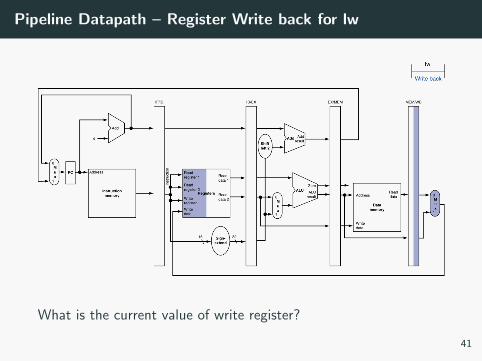
Pipeline Datapath – Register Write back for lw
What is the current value of write register?
41
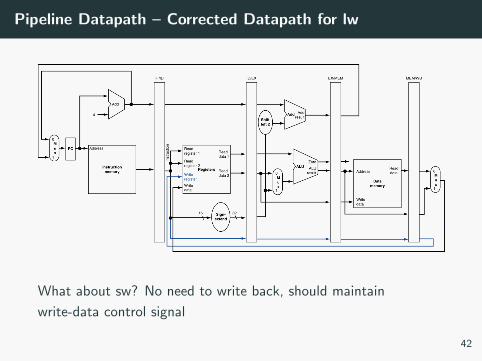
Pipeline Datapath – Corrected Datapath for lw
What about sw? No need to write back, should maintain
write-data control signal
42

Multi-Cycle Pipeline Diagrams
Resource Usage multi-cycle diagram
43
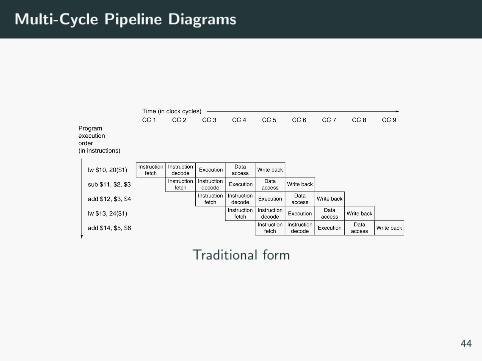
Multi-Cycle Pipeline Diagrams
Traditional form
44
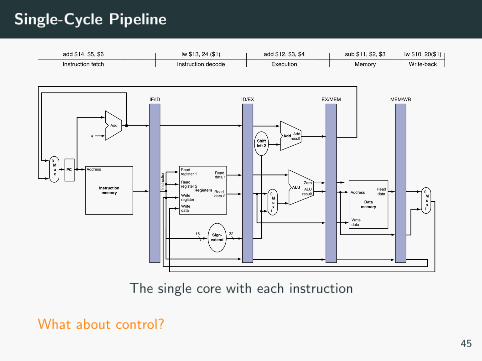
Single-Cycle Pipeline
The single core with each instruction
What about control?45

Pipeline Control – Simple
Still need the main control unit
46

Pipeline Control – Main Control Unit
Derive control signals from instruction and pass along to registers
47
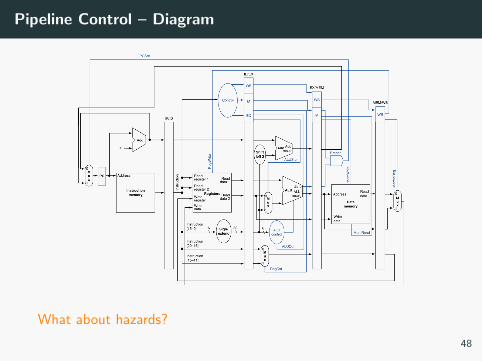
Pipeline Control – Diagram
What about hazards?
48

Hazards & Datapath

Data Hazards
Data Hazard – Need to wait for previous instruction to complete
its read/write
So consider:
sub $2, $1, $3
and $12, $2, $5
or $13, $6, $2
add $14, $2, $2
sw $15, 100($2)
What data hazards exist?
How do we detect when to forward these data?
49
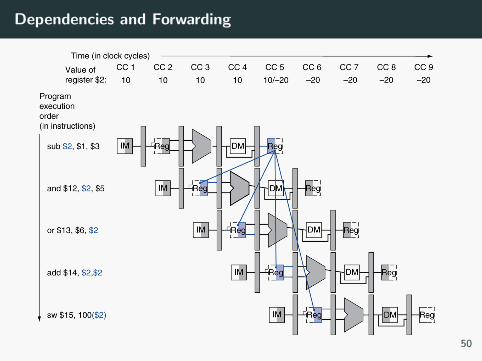
Dependencies and Forwarding
50

Detecting Need to Forward
How? Pass register numbers along pipeline!
• e.g. ID/EX.RegisterRs = Register number for Rs sitting in
ID/EX Pipeline register
ALU Operand register numbers in EX stage are given by
• ID/EX.RegisterRs, ID/EX.RegisterRt
Then, Data hazards exist when:
• EX/MEM.RegisterRd = ID/EX.RegisterRs
• EX/MEM.RegisterRd = ID/EX.RegisterRt
• MEM/WB.RegisterRd = ID/EX.RegisterRs
• MEM/WB.RegisterRd = ID/EX.RegisterRt
51

Detecting Need to Forward
Do we always need to forward these cases?
52
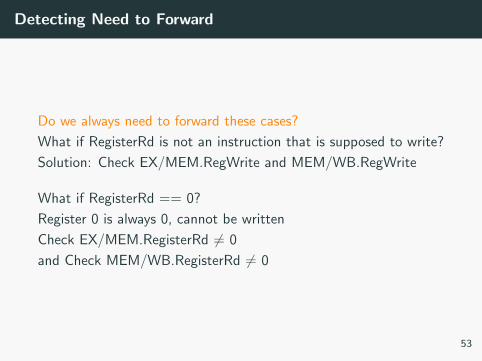
Detecting Need to Forward
Do we always need to forward these cases?
What if RegisterRd is not an instruction that is supposed to write?
Solution: Check EX/MEM.RegWrite and MEM/WB.RegWrite
What if RegisterRd == 0?
Register 0 is always 0, cannot be written
Check EX/MEM.RegisterRd 6= 0
and Check MEM/WB.RegisterRd 6= 0
53
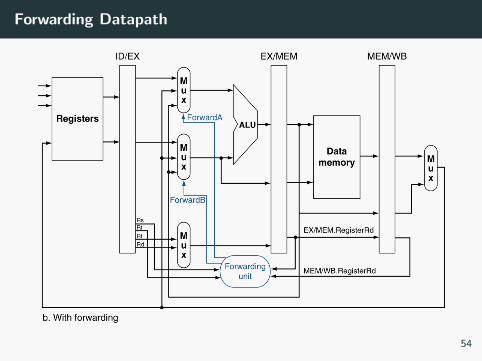
Forwarding Datapath
54

Forwarding Conditions
EX hazard:
• if (EX/MEM.RegWrite and (EX/MEM.RegisterRead 6=0)
AND (EX/MEM.RegisterRd = ID/EX.RegisterRs))
then ForwardA = 10
• if (EX/MEM.RegWrite and (EX/MEM.RegisterRd 6=0)
AND (EX/MEM.RegisterRd = ID/EX.RegisterRt))
then ForwardB = 10
MEM hazard:
• if (MEM/WB.RegWrite and (MEM/WB.RegisterRead 6=0)
AND (MEM/WB.RegisterRd = ID/EX.RegisterRs))
then ForwardA = 01
• if (MEM/WB.RegWrite and (MEM/WB.RegisterRd 6=0)
AND (EX/MEM.RegisterRd = ID/EX.RegisterRt))
then ForwardB = 0155

Double Data Hazard
What if there are more than 1 hazard?
Consider:
add $1, $1, $2
add $1, $1, $3
add $1, $1, $4
Then BOTH hazards would occur...
Must choose most recent
Therefore, revise MEM hazard condition
Only forward if EX hazard isn’t true
56

Revised Forwarding Condition
MEM hazard:
• if (MEM/WB.RegWrite and (MEM/WB.RegisterRead 6=0)
and not (EX/MEM.RegWrite and (EX/MEM.RegisterRd6=0)
and (EX/MEM.RegisterRd = ID/EX.RegisterRs))
AND (MEM/WB.RegisterRd = ID/EX.RegisterRs))
then ForwardA = 01
• if (MEM/WB.RegWrite and (MEM/WB.RegisterRd 6=0)
and not (EX/MEM.RegWrite and (EX/MEM.RegisterRd6=0)
and (EX/MEM.RegisterRd = ID/EX.RegisterRt))
AND (EX/MEM.RegisterRd = ID/EX.RegisterRt))
then ForwardB = 01
57

Datapath with Forwarding
58
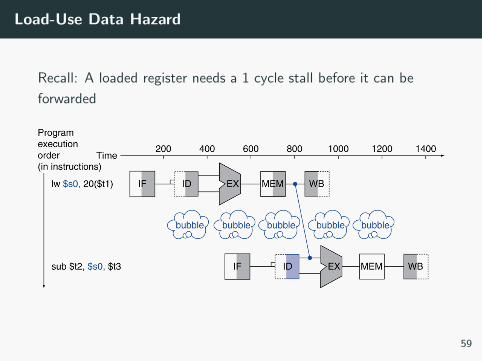
Load-Use Data Hazard
Recall: A loaded register needs a 1 cycle stall before it can be
forwarded
59
Load-Use Data Hazard
How do we detect this hazard?
60

Load-Use Hazard Detection
Check when using instruction is decoded in ID stage
ALU operand register numbers in ID stage are given by:
IF/ID.RegisterRs, IF/ID.RegisterRt
Load-use hazard when: (Breakout Groups)
61

Load-Use Hazard Detection
Check when using instruction is decoded in ID stage
ALU operand register numbers in ID stage are given by:
IF/ID.RegisterRs, IF/ID.RegisterRt
Load-use hazard when: ID/EX.MemRead and
((ID/EX.RegisterRt == IF/ID.RegisterRs) or
(ID/EX.RegisterRt == IF/ID.RegisterRt))
If detected, stall and insert a bubble
62

Stalling the Pipeline
When load-use hazard detected, must stall pipeline
Force control values in ID/EX register to 0
• EX, MEM, and WB do no-operation (nop/noop)
Prevent update of PC and IF/ID register
• Using instruction is decoded again
• Following instruction is fetched again
• 1-cycle stall allows mem to read data for lw
• Can subsequently forward to EX stage
63
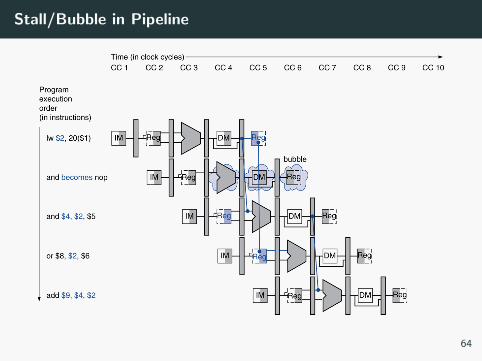
Stall/Bubble in Pipeline
64
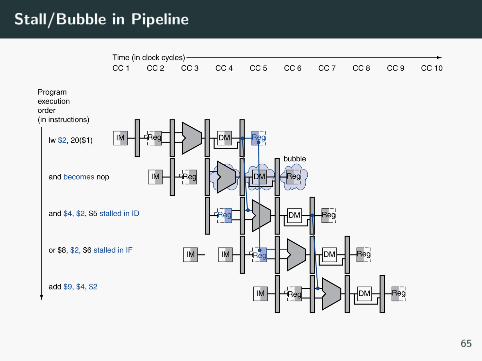
Stall/Bubble in Pipeline
65
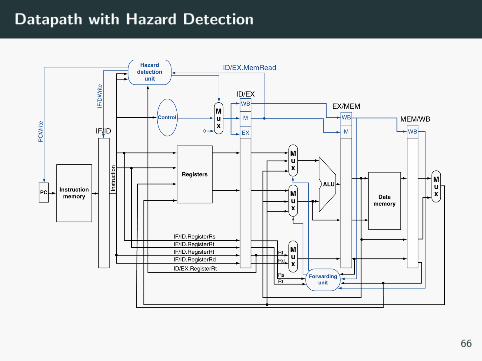
Datapath with Hazard Detection
66

Stalls and Performance
Stalls reduce performance
Required to obtain correct results
Compiler can re-arrange code to avoid hazards/stalls
Must know the pipeline structure – there are some general rules
that can be applied
67
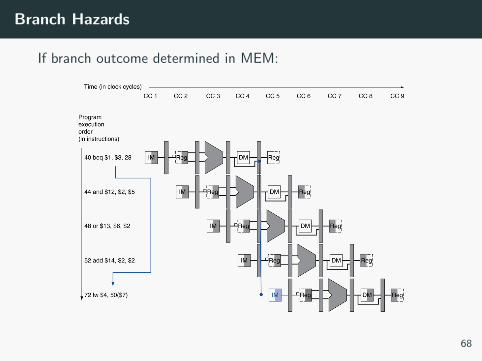
Branch Hazards
If branch outcome determined in MEM:
68
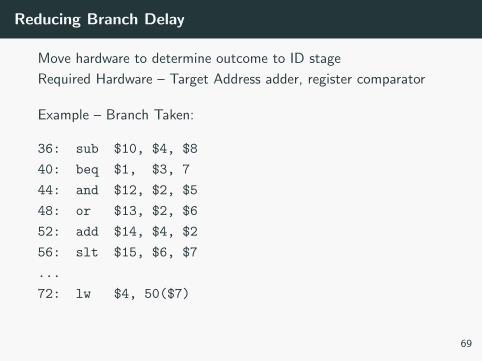
Reducing Branch Delay
Move hardware to determine outcome to ID stage
Required Hardware – Target Address adder, register comparator
Example – Branch Taken:
36: sub $10, $4, $8
40: beq $1, $3, 7
44: and $12, $2, $5
48: or $13, $2, $6
52: add $14, $4, $2
56: slt $15, $6, $7
...
72: lw $4, 50($7)
69
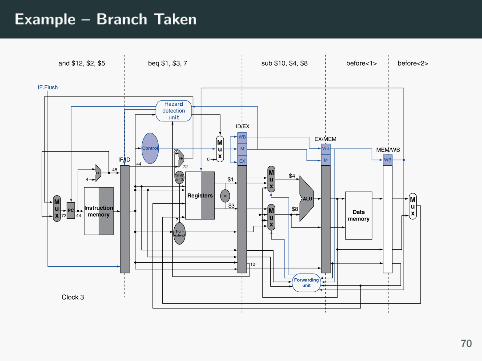
Example – Branch Taken
70

Example – Branch Taken
71

Data Hazards for Branches
If a comparison register is a destination register of 2nd or 3rd
preceding ALU instruction:
Can resolve using forwarding
72

Data Hazards for Branches
If comparison register is a destination of preceding ALU instruction
or 2nd preceding load instruction – need 1 stall cycle:
73

Data Hazards for Branches
What if comparison is destination of immediately preceding load
instruction?
74

Data Hazards for Branches
What if comparison is destination of immediately preceding load
instruction?
Need 2 stall cycles:
75

Calculating the Branch Target
Even with good prediction, still need to calculate target address
• 1-cycle penalty for taken branch
Branch Target Buffer
• Cache of target addresses
• Indexed by PC when instruction fetched – if hit and instruction
branch predicted taken, can fetch target immediately!
76






















![Untitled-1 [files.cluster2.hostgator.co.in]files.cluster2.hostgator.co.in/hostgator103813/file/dgi...Processors AM3358 1GHz ARM Cortex-A8 processor TI AM3358 Sitara Processor Pipelining](https://img.pdfslide.net/doc/110x75/5fa46f15d24acd25ea7584f2/untitled-1-files-files-processors-am3358-1ghz-arm-cortex-a8-processor-ti.jpg)





