Embed Size (px)
Citation preview

Topics Topics Speedup Amdahl’s law Execution time
ReadingsReadings
January 10, 2012
CSCE 713 Computer Architecture

– 2 –CSCE 713 Spring 2012
OverviewOverviewReadings for todayReadings for today
Landscape of Parallel Computing Research Berkeley View EECS-2006-183
Parallel Benchmarks Inspired by Berkeley Dwarfs Ka10_7dwarfsOfSymbolicComputation
NewNew Topics overview Syllabus and other course pragmatics
Website (not shown)Dates
Power wall, ILP wall, to multicore Seven Dwarfs Amdahl’s Law, Gustaphson’s law

– 3 –CSCE 713 Spring 2012
Copyright © 2012, Elsevier Inc. All rights reserved.
Single Processor PerformanceSingle Processor PerformanceIn
trod
uctio
n
RISC
Move to multi-processor

– 4 –CSCE 713 Spring 2012
Power WallPower Wall
Note both of dynamic power and energy have voltageNote both of dynamic power and energy have voltage22 as dominant termas dominant term
So lower voltage improves both; 5V So lower voltage improves both; 5V 1V over period 1V over period of time, but then can’t continue without errorsof time, but then can’t continue without errors
witchedFrequencySVoltageLoadCapacitivePowerdynamic 2
2
1
2_ VoltageLoadCapacitiveEnergydynamic

– 5 –CSCE 713 Spring 2012
Static PowerStatic Power
CMOS chip have power loss due to current leakage CMOS chip have power loss due to current leakage even when the transistor is offeven when the transistor is off
In 2006 the goal for leakage is 25%In 2006 the goal for leakage is 25%
VoltageCurrentPower staticstatic

– 6 –CSCE 713 Spring 2012
Single CPU Single Thread Programming ModelSingle CPU Single Thread Programming Model

– 7 –CSCE 713 Spring 2012
Berkeley Conventional WisdomBerkeley Conventional Wisdom
Old CWOld CW: Power is free, but transistors are expensive.: Power is free, but transistors are expensive.
· · New CW New CW is the “is the “Power wallPower wall”: Power is expensive, but ”: Power is expensive, but transistors are “free”. That is, we can put more transistors transistors are “free”. That is, we can put more transistors on a chip than we have the power to turn on.on a chip than we have the power to turn on.
2. 2. Old CWOld CW: If you worry about power, the only concern is : If you worry about power, the only concern is dynamic power.dynamic power.
· · New CWNew CW: For desktops and servers, static power due to : For desktops and servers, static power due to leakage can be 40% of total power. leakage can be 40% of total power.
3. 3. Old CWOld CW: Monolithic uniprocessors in silicon are reliable : Monolithic uniprocessors in silicon are reliable internally, with errors occurring only at the pins.internally, with errors occurring only at the pins.
· · New CWNew CW: As chips drop below 65 nm feature sizes, they will : As chips drop below 65 nm feature sizes, they will have high soft and have high soft and hard error rates. [Borkar 2005] hard error rates. [Borkar 2005] [Mukherjee et al 2005][Mukherjee et al 2005]

– 8 –CSCE 713 Spring 2012
Old CWOld CW: By building upon prior successes, we can continue : By building upon prior successes, we can continue to raise the level of abstraction and hence the size of to raise the level of abstraction and hence the size of hardware designs.hardware designs.
· · New CWNew CW: Wire delay, noise, cross coupling (capacitive : Wire delay, noise, cross coupling (capacitive and inductive), manufacturing variability, reliability (see and inductive), manufacturing variability, reliability (see above), clock jitter, design validation, and so on conspire above), clock jitter, design validation, and so on conspire to stretch the development time and cost of large designs to stretch the development time and cost of large designs at 65 nm or smaller feature sizes.at 65 nm or smaller feature sizes.

– 9 –CSCE 713 Spring 2012
Old CWOld CW: Researchers demonstrate new architecture ideas : Researchers demonstrate new architecture ideas by building chips.by building chips.
· · New CWNew CW: The cost of masks at 65 nm feature size, the : The cost of masks at 65 nm feature size, the cost of Electronic Computer Aided Design software to cost of Electronic Computer Aided Design software to design such chips, and the cost of design for GHz clock design such chips, and the cost of design for GHz clock rates means researchers can no longer build believable rates means researchers can no longer build believable prototypes.prototypes.
Thus, an alternative approach to evaluating architectures Thus, an alternative approach to evaluating architectures must be developed.must be developed.

– 10 –CSCE 713 Spring 2012
Old CWOld CW: Performance improvements yield both lower : Performance improvements yield both lower latency and higher bandwidth.latency and higher bandwidth.
· · New CWNew CW: Across many technologies, bandwidth improves : Across many technologies, bandwidth improves by at least the squareof the improvement in latency. by at least the squareof the improvement in latency. [Patterson 2004][Patterson 2004]
7. 7. Old CWOld CW: Multiply is slow, but load and store is fast.: Multiply is slow, but load and store is fast.
· · New CW New CW is the “is the “Memory wallMemory wall” [Wulf and McKee 1995]: ” [Wulf and McKee 1995]: Load and store is slow, but multiply is fast. Load and store is slow, but multiply is fast.
Modern microprocessors can take 200 clocks to access Modern microprocessors can take 200 clocks to access Dynamic Random Access Memory (DRAM), but even Dynamic Random Access Memory (DRAM), but even floating-point multiplies may take only four clock cycles.floating-point multiplies may take only four clock cycles.
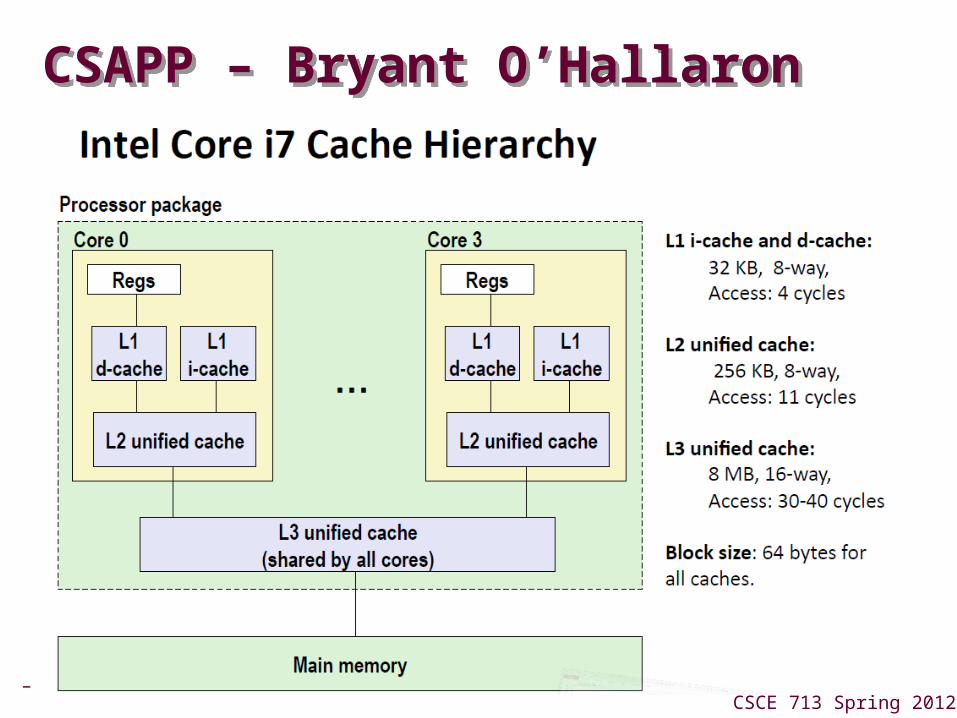
– 11 –CSCE 713 Spring 2012
CSAPP – Bryant O’HallaronCSAPP – Bryant O’Hallaron
..

– 12 –CSCE 713 Spring 2012
Topics CoveredTopics Covered
The needs for gains in The needs for gains in performanceperformance
The need for The need for ParallelismParallelism
Amdahl’s and Amdahl’s and Gustaphson’s lawsGustaphson’s laws
Various Problems: the Various Problems: the 7 Dwarfs and …7 Dwarfs and …
Various ApproachesVarious Approaches
Bridges betweenBridges between
MultithreadedMultithreaded• Multicore• Posix pthreads• Intel’s TTB
• Distributed – MPIDistributed – MPI
• Shared Memory – Shared Memory – OpenMPOpenMP
• GPUsGPUs
• Grid ComputingGrid Computing
• Cloud ComputingCloud Computing

– 13 –CSCE 713 Spring 2012
Top 10 challenges in parallel computingTop 10 challenges in parallel computing
By By Michael Wrinn (Intel) In priority order: In priority order:
1.1. Finding concurrency in a program - how to help programmers Finding concurrency in a program - how to help programmers “think parallel”?“think parallel”?
2.2. Scheduling tasks at the right granularity onto the processors of Scheduling tasks at the right granularity onto the processors of a parallel machine.a parallel machine.
3.3. The data locality problem: associating data with tasks and The data locality problem: associating data with tasks and doing it in a way that our target audience will be able to use doing it in a way that our target audience will be able to use correctly.correctly.
4.4. Scalability support in hardware: bandwidth and latencies to Scalability support in hardware: bandwidth and latencies to memory plus interconnects between processing elements.memory plus interconnects between processing elements.
5.5. Scalability support in software: libraries, scalable algorithms, Scalability support in software: libraries, scalable algorithms, and adaptive runtimes to map high level software onto platform and adaptive runtimes to map high level software onto platform details.details.
http://www.multicoreinfo.com/2009/01/wrinn-top-10-challenges/

– 14 –CSCE 713 Spring 2012
6.6. Synchronization constructs (and protocols) that Synchronization constructs (and protocols) that enable programmers write programs free from enable programmers write programs free from deadlock and race conditions.deadlock and race conditions.
7.7. Tools, API’s and methodologies to support the Tools, API’s and methodologies to support the debugging process.debugging process.
8.8. Error recovery and support for fault tolerance.Error recovery and support for fault tolerance.
9.9. Support for good software engineering practices: Support for good software engineering practices: composability, incremental parallelism, and code composability, incremental parallelism, and code reuse.reuse.
10.10. Support for portable performance. What are the right Support for portable performance. What are the right models (or abstractions) so programmers can write models (or abstractions) so programmers can write code once and expect it to execute well on the code once and expect it to execute well on the important parallel platforms?important parallel platforms?
http://www.multicoreinfo.com/2009/01/wrinn-top-10-challenges/

– 15 –CSCE 713 Spring 2012
Berkeley Conventional WisdomBerkeley Conventional Wisdom
1. 1. Old CWOld CW: Power is free, but transistors are expensive.: Power is free, but transistors are expensive.
· · New CW New CW is the “is the “Power wallPower wall”: Power is expensive, but ”: Power is expensive, but transistors are “free”. That is, we can put more transistors are “free”. That is, we can put more transistors on a chip than we have the power to turn on.transistors on a chip than we have the power to turn on.
2. 2. Old CWOld CW: If you worry about power, the only concern is : If you worry about power, the only concern is dynamic power.dynamic power.
· · New CWNew CW: For desktops and servers, static power due to : For desktops and servers, static power due to leakage can be 40% of total power.leakage can be 40% of total power.
http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html

– 16 –CSCE 713 Spring 2012
Old CWOld CW: Monolithic uniprocessors in silicon are reliable : Monolithic uniprocessors in silicon are reliable internally, with errors occurring only at the pins.internally, with errors occurring only at the pins.
· · New CWNew CW: As chips drop below 65 nm feature sizes, they : As chips drop below 65 nm feature sizes, they will have high soft and will have high soft and hard error rates. [Borkar 2005] hard error rates. [Borkar 2005] [Mukherjee et al 2005][Mukherjee et al 2005]
4. 4. Old CWOld CW: By building upon prior successes, we can : By building upon prior successes, we can continue to raise the level of abstraction and hence the continue to raise the level of abstraction and hence the size of hardware designs.size of hardware designs.
· · New CWNew CW: Wire delay, noise, cross coupling (capacitive : Wire delay, noise, cross coupling (capacitive and inductive), manufacturing variability, reliability (see and inductive), manufacturing variability, reliability (see above), clock jitter, design validation, and so on conspire above), clock jitter, design validation, and so on conspire to stretch the development time and cost of large designs to stretch the development time and cost of large designs at 65 nm or smaller feature sizes.at 65 nm or smaller feature sizes.http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html

– 17 –CSCE 713 Spring 2012
5. 5. Old CWOld CW: Researchers demonstrate new architecture : Researchers demonstrate new architecture ideas by building chips.ideas by building chips.
· · New CWNew CW: The cost of masks at 65 nm feature size, the : The cost of masks at 65 nm feature size, the cost of Electronic Computer Aided Design software to cost of Electronic Computer Aided Design software to design such chips, and the cost of design for GHz clock design such chips, and the cost of design for GHz clock rates means researchers can no longer build believable rates means researchers can no longer build believable prototypes.prototypes.
Thus, an alternative approach to evaluating architectures Thus, an alternative approach to evaluating architectures must be developed.must be developed.
http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html

– 18 –CSCE 713 Spring 2012
6. 6. Old CWOld CW: Performance improvements yield both lower : Performance improvements yield both lower latency and higher bandwidth.latency and higher bandwidth.
· · New CWNew CW: Across many technologies, bandwidth improves : Across many technologies, bandwidth improves by at least the square of the improvement in latency. by at least the square of the improvement in latency. [Patterson 2004][Patterson 2004]
7. 7. Old CWOld CW: Multiply is slow, but load and store is fast.: Multiply is slow, but load and store is fast.
· · New CW New CW is the “is the “Memory wallMemory wall” [Wulf and McKee 1995]: ” [Wulf and McKee 1995]: Load and store is slow, but multiply is fast. Modern Load and store is slow, but multiply is fast. Modern microprocessors can take 200 clocks to accessmicroprocessors can take 200 clocks to access
Dynamic Random Access Memory (DRAM), but even Dynamic Random Access Memory (DRAM), but even floating-point multiplies may take only four clock cycles.floating-point multiplies may take only four clock cycles.
http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html

– 19 –CSCE 713 Spring 2012
8. 8. Old CWOld CW: We can reveal more instruction-level : We can reveal more instruction-level parallelism (ILP) via compilers and architecture parallelism (ILP) via compilers and architecture innovation. Examples from the past include branch innovation. Examples from the past include branch prediction, out-of-order execution, speculation, and Very prediction, out-of-order execution, speculation, and Very Long Instruction Word systems.Long Instruction Word systems.
· · New CW New CW is the “is the “ILP wallILP wall”: There are diminishing returns on ”: There are diminishing returns on finding more ILP.finding more ILP.
http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html

– 20 –CSCE 713 Spring 2012
Old CWOld CW: Uniprocessor performance doubles every 18 : Uniprocessor performance doubles every 18 months.months.
· · New CW New CW is is Power Wall + Memory Wall + ILP Wall = Brick Power Wall + Memory Wall + ILP Wall = Brick WallWall. Figure 2 plots processor performance for almost 30 . Figure 2 plots processor performance for almost 30 years. In 2006, performance is a factor of three below the years. In 2006, performance is a factor of three below the traditional doubling every 18 months that we enjoyed traditional doubling every 18 months that we enjoyed between 1986 and 2002. The doubling of uniprocessor between 1986 and 2002. The doubling of uniprocessor performance may now take 5 years.performance may now take 5 years.
http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html

– 21 –CSCE 713 Spring 2012
Old CWOld CW: Don’t bother parallelizing your application, as you : Don’t bother parallelizing your application, as you can just wait a little while and run it on a much faster can just wait a little while and run it on a much faster sequential computer.sequential computer.
· · New CWNew CW: It will be a very long wait for a faster sequential : It will be a very long wait for a faster sequential computer computer
http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html

– 22 –CSCE 713 Spring 2012
Old CWOld CW: Increasing clock frequency is the primary method : Increasing clock frequency is the primary method of improving processor performance.of improving processor performance.
· · New CWNew CW: Increasing parallelism is the primary method of : Increasing parallelism is the primary method of improving processor performance. improving processor performance.
12. 12. Old CWOld CW: Less than linear scaling for a multiprocessor : Less than linear scaling for a multiprocessor application is failure.application is failure.
· · New CWNew CW: Given the switch to parallel computing, any : Given the switch to parallel computing, any speedup via parallelism is a success.speedup via parallelism is a success.
http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html
– 23 –CSCE 713 Spring 2012
..

– 24 –CSCE 713 Spring 2012
Amdahl’s LawAmdahl’s Law
])1[(
1
enhanced
enhancedenhanced
overall
Speedup
FracFrac
Speedup
Suppose you have an enhancement or improvement in Suppose you have an enhancement or improvement in a design component.a design component.
The improvement in the performance of the system is The improvement in the performance of the system is limited by the % of the time the enhancement can be limited by the % of the time the enhancement can be usedused

– 25 –CSCE 713 Spring 2012
Exec Time of Parallel ComputationExec Time of Parallel Computation

– 26 –CSCE 713 Spring 2012
Gustafson’s Law: Scale the problemGustafson’s Law: Scale the problem
http://en.wikipedia.org/wiki/Gustafson%27s_lawhttp://en.wikipedia.org/wiki/Gustafson%27s_law

– 27 –CSCE 713 Spring 2012
Matrix Multiplication – scaling the problemMatrix Multiplication – scaling the problem
Note we would really scale a model of a “real problem,” Note we would really scale a model of a “real problem,” but matrix multiplication might be one step requiredbut matrix multiplication might be one step required

– 28 –CSCE 713 Spring 2012

– 29 –CSCE 713 Spring 2012
High-end simulation in the physical sciences = 7 numerical methods:High-end simulation in the physical sciences = 7 numerical methods:
1.1. Structured Grids (including Structured Grids (including locally structured grids, locally structured grids, e.g. Adaptive Mesh e.g. Adaptive Mesh Refinement)Refinement)
2.2. Unstructured GridsUnstructured Grids
3.3. Fast Fourier TransformFast Fourier Transform
4.4. Dense Linear AlgebraDense Linear Algebra
5.5. Sparse Linear Algebra Sparse Linear Algebra
6.6. ParticlesParticles
7.7. Monte CarloMonte Carlo
Well-defined targets from algorithmic, software, and architecture standpoint
Phillip Colella’s “Seven dwarfs”
If add 4 for embedded, covers
all 41 EEMBC benchmarks
8. Search/Sort 9. Filter
10. Combinational logic11. Finite State Machine
Note: Data sizes (8 bit to 32 bit)
and types (integer,
character) differ, but algorithms the
same Slide from “Defining Software
Requirements for Scientific Computing”, Phillip Colella, 2004
www.eecs.berkeley.edu/bears/presentations/06/Patterson.ppt

– 30 –CSCE 713 Spring 2012
Seven Dwarfs - Dense Linear Algebra Seven Dwarfs - Dense Linear Algebra
Data are dense matrices or vectors. Data are dense matrices or vectors.
• Generally, such applications use unit-stride memory Generally, such applications use unit-stride memory accesses to read data from rows, andaccesses to read data from rows, and
• strided accesses to read data from columns.strided accesses to read data from columns.
• Communication patternCommunication pattern• Black is no communication
http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html

– 31 –CSCE 713 Spring 2012
Seven Dwarfs -Sparse Linear Algebra Seven Dwarfs -Sparse Linear Algebra
..
http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html
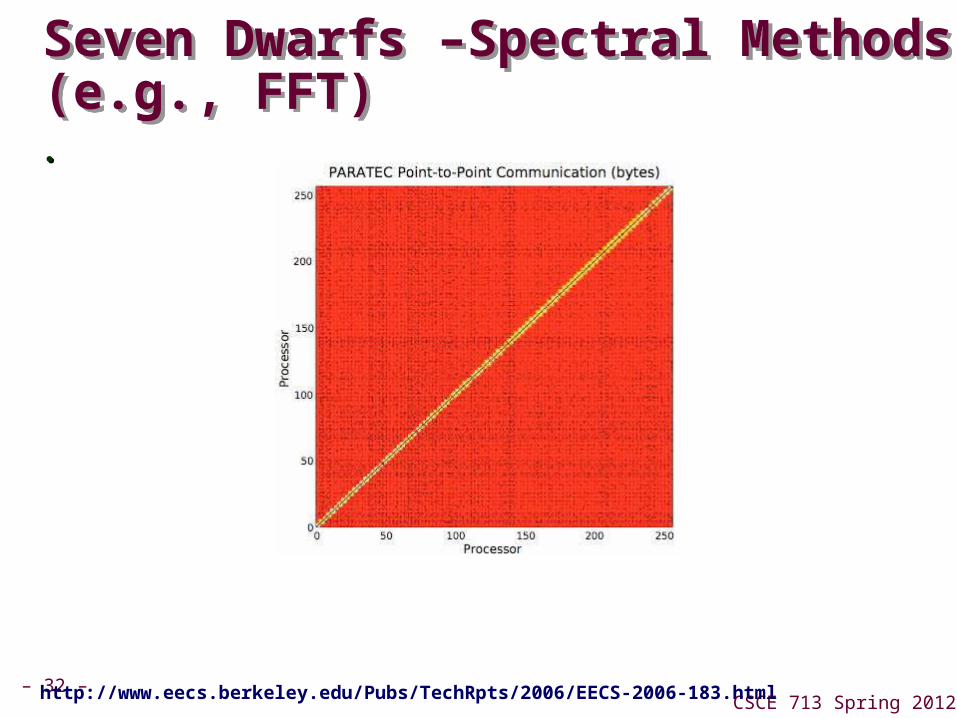
– 32 –CSCE 713 Spring 2012
Seven Dwarfs –Spectral Methods(e.g., FFT) Seven Dwarfs –Spectral Methods(e.g., FFT) ..
http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html

– 33 –CSCE 713 Spring 2012
Seven Dwarfs - N-Body Methods Seven Dwarfs - N-Body Methods
Depends on interactions between many discrete points. Depends on interactions between many discrete points. Variations include particle-particle methods, where every Variations include particle-particle methods, where every point depends on all others, leading to an O(N2) point depends on all others, leading to an O(N2) calculation, and hierarchical particle methods, which calculation, and hierarchical particle methods, which combine forces or potentials from multiple points to combine forces or potentials from multiple points to reduce the computational complexity reduce the computational complexity to O(N log N) or to O(N log N) or O(N).O(N).
http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html
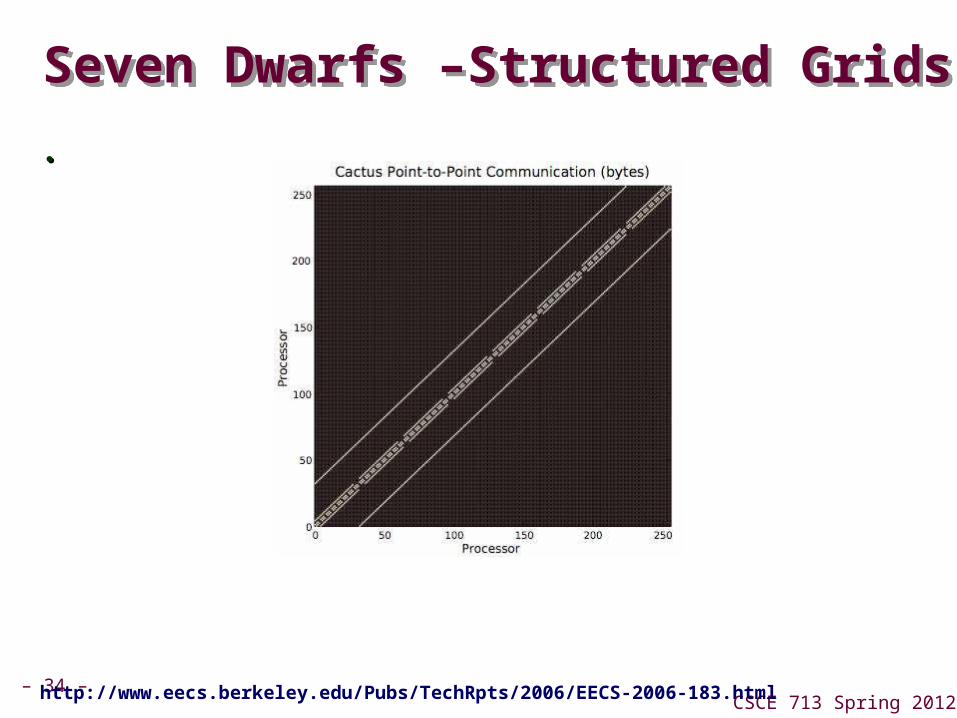
– 34 –CSCE 713 Spring 2012
Seven Dwarfs –Structured Grids Seven Dwarfs –Structured Grids
..
http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html

– 35 –CSCE 713 Spring 2012
Seven Dwarfs – Unstructured Grids Seven Dwarfs – Unstructured Grids
An irregular grid where data locations are selected, usually An irregular grid where data locations are selected, usually by underlying characteristics of the application.by underlying characteristics of the application.
http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html

– 36 –CSCE 713 Spring 2012
Seven Dwarfs - Monte Carlo Seven Dwarfs - Monte Carlo
Calculations depend on statistical results of repeated Calculations depend on statistical results of repeated random trials. Considered embarrassingly parallel.random trials. Considered embarrassingly parallel.
Communication is typically not dominant in Monte Carlo Communication is typically not dominant in Monte Carlo methods.methods.
EmbarrassinglyParallel / NSF TeragridEmbarrassinglyParallel / NSF Teragrid
http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html

– 37 –CSCE 713 Spring 2012
Principle of LocalityPrinciple of Locality
Rule of thumb – Rule of thumb –
A program spends 90% of its execution time in only A program spends 90% of its execution time in only 10% of the code.10% of the code.
So what do you try to optimize?So what do you try to optimize?
Locality of memory referencesLocality of memory references
Temporal localityTemporal locality
Spatial localitySpatial locality

– 38 –CSCE 713 Spring 2012
Taking Advantage of ParallelismTaking Advantage of Parallelism
Logic parallelism – carry lookahead adderLogic parallelism – carry lookahead adder
Word parallelism – SIMDWord parallelism – SIMD
Instruction pipelining – overlap fetch and executeInstruction pipelining – overlap fetch and execute
Multithreads – executing independent instructions at Multithreads – executing independent instructions at the same timethe same time
Speculative execution - Speculative execution -

– 39 –CSCE 713 Spring 2012
Linux – Sytem InfoLinux – Sytem Info
saluda> lscpusaluda> lscpuArchitecture: i686Architecture: i686CPU op-mode(s): 32-bit, 64-bitCPU op-mode(s): 32-bit, 64-bitCPU(s): 4CPU(s): 4Thread(s) per core: 1Thread(s) per core: 1Core(s) per socket: 4Core(s) per socket: 4CPU socket(s): 1CPU socket(s): 1Vendor ID: GenuineIntelVendor ID: GenuineIntelCPU family: 6CPU family: 6Model: 15Model: 15Stepping: 11Stepping: 11CPU MHz: 2393.830CPU MHz: 2393.830Virtualization: VT-xVirtualization: VT-xL1d cache: 32KL1d cache: 32KL1i cache: 32KL1i cache: 32KL2 cache: 4096KL2 cache: 4096Ksaluda> saluda>
– 40 –CSCE 713 Spring 2012
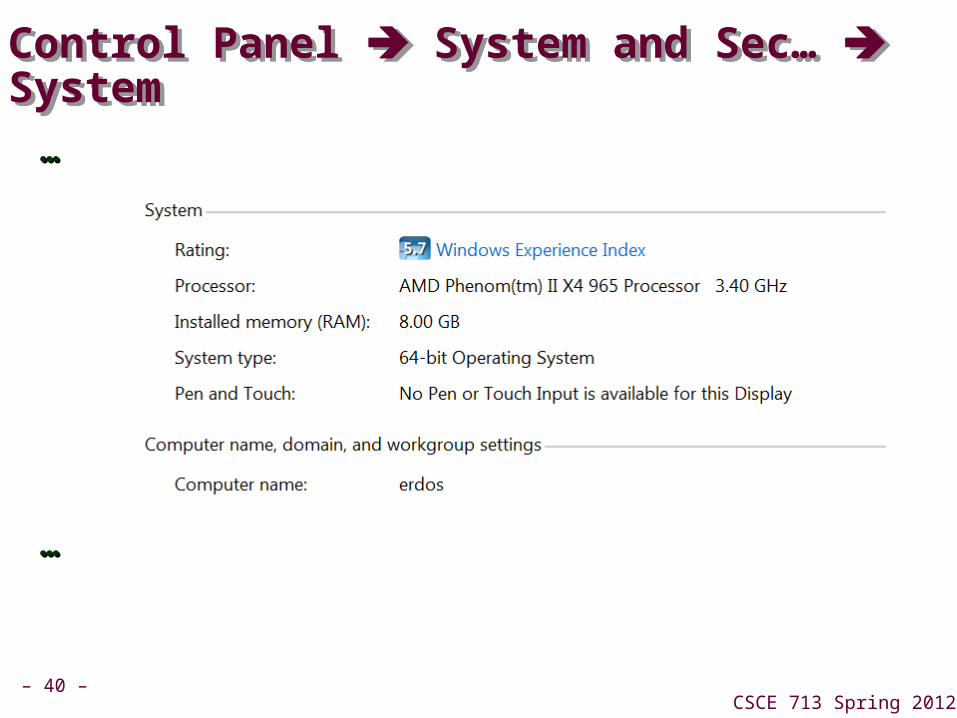
Control Panel System and Sec… SystemControl Panel System and Sec… System
……
……
– 41 –CSCE 713 Spring 2012
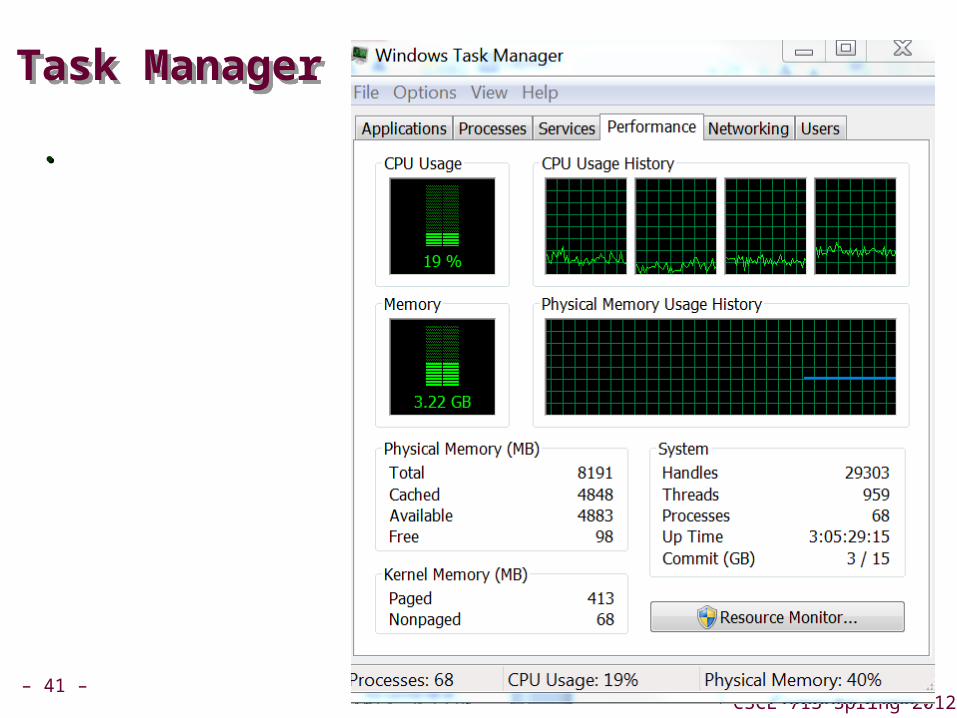
Task ManagerTask Manager
..





![Installation of PROOF-lite and ROOT on NERSC systems · A. Amdahl’s Law Amdahl’s law [2] is one method to determine the speedup for a problem of fixed size, but variant time](https://img.pdfslide.net/doc/110x75/5fc658bba5169a0f0715295f/installation-of-proof-lite-and-root-on-nersc-systems-a-amdahlas-law-amdahlas.jpg)























