Embed Size (px)
Citation preview

Journal of Information Processing Vol.26 768–778 (Nov. 2018)
[DOI: 10.2197/ipsjjip.26.768]
Regular Paper
Towards Automatic Evaluation of Customer-HelpdeskDialogues
Zhaohao Zeng1,a) Cheng Luo2,b) Lifeng Shang3,c) Hang Li4,d) Tetsuya Sakai1,e)
Received: March 7, 2018, Accepted: July 2, 2018
Abstract: We attempt to tackle the problem of evaluating textual, multi-round, task-oriented dialogues between thecustomer and the helpdesk, such as those that take the form of online chats. As an initial step towards automaticevaluation of helpdesk agent systems, we have constructed a test collection comprising 3,700 real Customer-Helpdeskmulti-round dialogues by mining Weibo, a major Chinese microblogging media. Each dialogue has been annotatedwith multiple subjective quality annotations and nugget annotations, where a nugget is a minimal sequence of posts bythe same utterer that helps towards problem solving. In addition, 34% of the dialogues have been manually translatedinto English. We first propose a nugget-based dialogue quality evaluation measure called Utility for Customer andHelpdesk (UCH), where a nugget is a manually identified utterance within a dialogue that helps the Customer advancetowards problem solving. In addition, we propose a simple neural network-based approach to predicting the dialoguequality scores from the entire dialogue, which we call Neural Evaluation Machine (NEM). According to our experi-ments with DCH-1, UCH correlates better with the appropriateness of utterances than with customer satisfaction. Incontrast, as NEM leverages natural language expressions within the dialogue, it correlates relatively well with customersatisfaction.
Keywords: Helpdesk, dialogue, evaluation, nugget, neural network
1. Introduction
Whenever a user of a commercial product or a service encoun-ters a problem, an effective way to solve it would be to contact thehelpdesk. Efficient and successful dialogues are desirable bothfor the customer and the company that sells the product/service.Recent advances in artificial intelligence suggest that, in the not-too-distant future, these human-human Customer-Helpdesk dia-logues may soon be replaced by human-machine ones.
To enable researchers and engineers to build and tune intelli-gent helpdesk agent systems efficiently, reliable automatic eval-uation measures need to be established. However, as there cur-rently is no standard framework for evaluating textual, dyadic(i.e., between two utterers), multi-round, task-oriented dialogues,we propose two approaches to evaluating such dialogues in thispaper. An example of a Customer-Helpdesk dialogue is shown inFig. 1: this is a two-round dialogue (i.e., there are two Customer-Helpdesk exchanges). It can be observed that it is initiated byCustomer’s report of a particular problem she is facing, whichwe call a trigger. This is an example of a successful dialogue,for Helpdesk provides an actual solution to the problem and Cus-tomer acknowledges that the problem has been solved.
1 Waseda University, Shinjuku, Tokyo 169–8555, Japan2 Tsinghua University, P.R. China3 Huawe Noah’s Ark Lab, HongKong4 Toutiao AI Lab, P.R. Chinaa) [email protected]) [email protected]) [email protected]) [email protected]) [email protected]
Evaluating Customer-Helpdesk dialogues is related but verydifferent from the traditional closed-domain spoken dialogue sys-tems where the task boils down to slot filling. For example, for aticket booking task, the system can utilise a pre-defined schemaand converse with the customer to fill the necessary slots suchas “depart-city” and “arrival-city” [1]. In contrast, Customer-Helpdesk dialogues discuss diverse problems about products andservices and therefore required slots cannot be listed up exhaus-tively in advance.
As a first step towards evaluating Customer-Helpdesk dia-logues, we constructed a test collection comprising 3,700 realcustomer-helpdesk multi-round dialogues by mining Weibo *1, amajor Chinese microblogging website. Each dialogue has beenannotated with subjective quality annotations as well as nugget
annotations. Subjective quality annotations comprise task ac-
complishment, customer satisfaction, helpdesk appropriateness,and customer appropriateness scores, which can be regarded asthe gold standard by researchers seeking ways to automaticallyevaluate the quality of a given dialogue. Nugget annotationscomprise nugget type labels for each nugget within a dialogue,where a nugget is defined to be a minimal sequence of posts bythe same utterer that helps the customer advance towards prob-lem solving. Examples of nugget types include Customer’s trig-
ger nuggets (i.e., nuggets that clarify the problem the Customer isfacing) and Helpdesk’s goal nuggets (i.e., nuggets that provide thesolution to the Customer’s problem). Our premise is that nuggetsidentified within a dialogue are useful clues for estimating theoverall quality of a dialogue, and for close diagnosis of specific
*1 http://www.weibo.com
c© 2018 Information Processing Society of Japan 768

Journal of Information Processing Vol.26 768–778 (Nov. 2018)
Fig. 1 An example of a dialogue between Customer (C) and Helpdesk (H). The left part is the translateddialogue and the right part is the screenshot of the original dialogue on Weibo.
parts within the dialogue, as we shall discuss later in our proposalof a nugget-based dialogue evaluation measure. In addition, 34%of the dialogues have been manually translated into English. Asour first contribution in the present study, we have made our testcollection DCH-1 (Dialogues between Customer and Helpdesk)publicly available for research purposes, along with a smaller pi-lot collection DCH-0, which contains 234 dialogues *2.
Our second contribution in the present study is a proposal ofa simple nugget-based evaluation measure for task-oriented dia-logue evaluation, which we call UCH (Utility for Customer andHelpdesk). Using DCH-1, we examine how our measure corre-lates with the subjective quality annotations.
Our third contribution in the present study is the proposal of analternative approach to estimating the subjective quality scoresfor a given dialogue, which we call Neural Machine Evaluation(NEM). While UCH is purely nugget-based and therefore onlytakes into account pieces of useful information conveyed in theutterances, NEM is an end-to-end neural network designed to takeinto account aspects of a dialogue not covered by nuggets, suchas context and sentiment. For example, if the Helpdesk keeps re-peating utterances such as “We will have your problem recorded”this will probably have a negative impact on the Customer’s satis-faction; if the Customer actually utters “I am not happy with yourservice” this is a strong negative signal. NEM can directly makeuse of these signals.
Our main findings on UCH and NEM based on the DCH-1 col-lection are as follows.
(1) Averaging UCH scores based on individual annotatorsachieves higher correlation with subjective ratings than a singleUCH score computed by consolidating nuggets from multiple an-notations. (2) UCH correlates better with subjective ratings thatreflect the appropriateness of utterances than with customer satis-faction. (3) The patience parameter of UCH, which considersthe positions of nuggets within a dialogue, is a useful featurefor enhancing the correlation with customer satisfaction. (4) For
*2 http://waseda.box.com/DCH-0-1
the majority of our subjective annotation criteria, customer ut-terances play a much more important role for UCH to achievehigh correlations with subjective ratings than helpdesk utterancesdo. (5) NEM, which does not require any nugget annotations andtakes the entire dialogue as input, correlates well with all subjec-tive ratings, especially with customer satisfaction.
We start off by discussing related work in Section 2. In Sec-tion 3, the construction and statistics of the dataset DCH will bedetailed. The aforementioned methods UCH and NEM will bedetailed in Section 4 and Section 5. The experimental results ofUCH and NEM will be discussed in Section 6. We conclude thispaper and discuss future work for evaluating customer-helpdeskdialogues in Section 7.
2. Related Work
2.1 Evaluating Non-Task-Oriented DialoguesThis section discusses some recent studies on evaluating tex-
tual, non-task-oriented dialogues. While these are differentfrom our work that handles task-oriented Customer-Helpdesk di-alogues, how to evaluate generated texts is a problem commonacross dialogue evaluation tasks, and is worth mentioning here.
Galley et al. [2] proposed Discriminative BLEU, a variant ofthe popular machine translation evaluation measure BLEU whichis based on n-gram-based precision [3]. They mined a corpus ofconversations to obtain multiple gold standard responses, and hadthe assessors rate the quality of these responses to define positiveand negative weights for them.
The Dialogue Breakdown Detection Challgenge (DBDC) [4]is an evaluating task that leverages Human-System dialogue cor-pora in Japanese and English. To each system utterance, a groupof annotators independently annotate one of the following la-bels: “NB” (not a breakdown), “PB” (possible breakdown), or“B” (breakdown). Participating systems are required to estimatethe distribution annotators over these labels; the participating sys-tems are evaluated by comparing the gold distribution and the es-timated distribution by means of Jensen-Shannon Divergence and
c© 2018 Information Processing Society of Japan 769

Journal of Information Processing Vol.26 768–778 (Nov. 2018)
Mean Squared Error.The Second Short Text Conversation task (STC-2) at NTCIR-
13, which attracted 22 participating teams, addressed the prob-lem of evaluating single-round Chinese Weibo conversations.Given a Weibo post, participating systems either retrieved pastWeibo posts or generated their own responses. The ranked listof responses were evaluated using information retrieval mea-sures, where each response was judged based on four criteria:coherence, topical relevance, non-repetitiveness, and context-
independence [5].At Alexa Prize 2017 [6], 16 teams were challenged to build
conversational agents. The users’ daily ratings and conversationdurations were used to evaluate the participating systems. More-over, a sample of dialogues was manually annotated to computeresponse error rate.
Like Alexa Prize, we would like to evaluate the entire dialogue;like DBDC and STC-2, we would like to establish off-line evalua-tion methods. On the other hand, unlike the above studies, we ad-dress the problem of task-oriented Customer-Helpdesk dialogues.
2.2 Evaluating Task-Oriented DialoguesThis section discusses task-oriented dialogue evaluation; while
these studies are primarily for spoken dialogues, their approachesare generally applicable to textual dialogues once transcribed.
Two decades ago, Walker et al. [1] proposed the PARADISE(PARAdigm for DIalogue System Evaluation) framework forclosed-domain, slot-filling spoken dialogue tasks. As we havediscussed earlier, slot-filling approaches are not adequate forevaluating Customer-Helpdesk dialogues as they discuss diversetopics.
Kiyota et al. [7] proposed a dialogue based QA system to an-swer customers’ questions based on a large textual KnowledgeBase (KB). To evaluate this system, they let annotators manu-ally check if the system could retrieve relevant documents whenthe KB had relevant documents, and if the system could avoidreturning irrelevant documents when the KB had no relevant doc-uments.
There are also some attempts at applying machine learningmodels to automatically evaluate spoken task-oriented dialogues.Walker et al. [8] proposed to train a binary classifier to automati-cally identify problematic situations in human-machine helpdeskdialogues. The dialogue corpus was collected with AT&T’s How
May I help You spoken dialogue system, and the classifier learntto distinguish two classes for each dialogue: tasksuccess andproblematic. Recently, Ando et al. [9] proposed to utilise hierar-chical Long Short-Term Memory (LSTM) to estimate customersatisfaction from contact center calls.
The most straightforward approach to evaluating dialogues isto collect subjective assessments from the user who actually expe-rienced the dialogue. Hone and Graham [10] used a large ques-tionnaire to evaluate an in-car speech interface. Hartikainenet al. [11] applied a service quality assessment from market-ing to the evaluation of telephone-based email application; theirmethod is known as SERVQUAL. Paek [12] discussed SASSI,SERVQUAL and PARADISE in a survey paper that discussesspoken dialogue evaluation, along with his Wizard-of-Oz ap-
proach.
2.3 Evaluating Textual Information AccessOur proposed dialogue evaluation measure UCH was inspired
by work in textual information access evaluation: summarisationevaluation, in particular. Hence this section briefly discusses priorart in this area.
While BLEU and related measures such as ROUGE [13] ba-sically computes precision, recall, and F-measure based on au-tomatically extracted textual units such as n-grams, manually-devised nuggets have been used instead as the basic units inboth summarisation evaluation [14] and question answering eval-uation. For example, in the TREC Question Answering (QA)tracks, a nugget was defined as “a fact for which the annotator
could make a binary decision as to whether a response contained
that nugget” [15].In the aforementioned evaluation approaches based on small
textual units (whether they are automatically or manually de-fined), note that system responses are treated as a mere set ofthese units. In contrast, Sakai et al. [16] introduced a nugget-based evaluation measure called S-measure for evaluating textualsummaries for mobile search, by incorporating a decay factor fornugget weights based on nugget positions. Just like informa-tion retrieval for ranked retrieval defines a decay function overranks of documents, S-measure defines a linear decay functionover the text, using offset positions of the nuggets. This reflectsthe view that important nuggets should be presented first and thatwe should minimise the amount of text that the user has to read.Sakai and Dou [17] generalised the idea of S-measure to handlevarious textual information access tasks, including web search.Their measure, known as U-measure, constructs a string calledtrailtext, which is a concatenation of all the texts that the userhas read (obtained by observation or by assuming a user model).Then, over the trailtext, a linear decay function is defined (seeSection 4). Our proposed measure UCH builds on this approach.
3. Data Collection
3.1 OverviewOur ultimate goal is automatic evaluation of human-machine
Customer-Helpdesk dialogues. As a first step towards it, we builta test collections based on real (i.e., human-human) Customer-Helpdesk dialogues, which we call DCH-1. Prior to DCH-1, wealso built a preliminary small-sized dataset DCH-0, which is usedto establish an efficient and reliable test collection constructionprocedure. Note that the present study utilises only the originalChinese part of DCH-1 collection.
Table 1 provides some statistics of DCH-0 and DCH-1. Asshown in the table, DCH-1 consists of 3,700 dialogues. We usedthe turn as the basis for measuring the length of a dialogue inDCH-1, formed by merging all consecutive posts by the sameutterer. For example, if each Customer post is denoted by pC
and each helpdesk post is denoted by pH , a dialogue of the form[pC , pC , pC , pH , pH , pH , pC , pC] will be regarded as three turns,[bC , bH , bC], where bC is a Customer turn and bH is a Helpdeskone. This dialogue is considered as a three-turn dialogue whenwe sample dialogues by length.
c© 2018 Information Processing Society of Japan 770

Journal of Information Processing Vol.26 768–778 (Nov. 2018)
Table 1 Data collection statistics.
DCH-0 DCH-1Source www.weibo.comLanguage ChineseData timestamps Jan. 2013 - Sep. 2016#Dialogues 234 3,700#English translations 40 1,264#Helpdesk accounts 16 161Avg. #posts/dialogue 13.402 4.512Avg. #turns/dialogue 12.021 4.162Avg. post length (#chars) 35.011 44.568Avg. turn length 39.031 48.313#annotators/dialogue 2 3Subjective annotation TS, TA, CS, HA, CAcriteria (see Section 3.4)Nugget types CNUG0, CNUG, HNUG,
CNUG∗, HNUG∗(see Section 3.5)
Below, we discuss the construction and validation of DCH-1.
3.2 Dialogue MiningThe 3,700 Helpdesk dialogues contained in the DCH-1 test col-
lection were mined from Weibo in September 2016 as follows.( 1 ) We collected an initial set of Weibo accounts by searching
Weibo account names that contained keywords such as “as-sistant” and “helper” (in Chinese). We denote this set by A0.
( 2 ) For each account name a in A0, we added a prefix “@” to a
and used the string as a query for searching up to 40 conver-sational threads (i.e., initial post plus comments on it) thatcontain a mention of the official account *3. We then filteredout accounts that did not respond to over one half of thesethreads. As a result, we obtained 41 active account names.We denote the filtered set of “active” accounts as A.
( 3 ) For each account a in A, we retrieved all threads that containa mention of a from January 2013 to September 2016, andextracted Customer-Helpdesk dyadic dialogues from them.We then kept those that consist of at least one turn by Cus-tomer and one by Helpdesk. As a result, 21,669 dialogueswere obtained. This collection is denoted as D0. Note thatalthough we used account names in A as seeds for search-ing the dialogue corpus, we obtained dialogues involvingnot only these accounts but also subaccounts of these ac-counts. For example, when the customer mentions “ABCDCompany Helpdesk,” a subaccount called “ABCD CompanyHelpdesk Beijing” might actually respond to it. Such dia-logues are also included in DCH-1; thus it actually covershelpdesk accounts that are outside A.
( 4 ) As D0 is too large for annotation, we sampled 3,700 dia-logues from it as follows. For i = 2, 3, . . . , 6, we randomlysampled 700 dialogues that contained i turns. In addition, werandomly sampled 200 that contained i = 7 turns; we couldnot sample 700 dialogues for i = 7 as D0 did not containenough dialogues that are very long.
The final number of accounts included in DCH-1 is 161, asshown in Table 1. In addition, thirty-four percent (1,264) of theChinese Dialogues in DCH-1 were manually translated into En-
*3 Weibo’s interface for conversational threads is somewhat different fromTwitter’s: comments to a post are not displayed on the main timeline;they are displayed under each post only if the “comments” button isclicked.
glish by a professional translation company for researchers inter-ested in English dialogue evaluation. Note that the present studyutilises only the original Chinese part of the test collection.
3.3 AnnotatorsWe hired 16 Chinese undergraduate students from the Faculty
of Science and Engineering at Waseda University so that eachChinese dialogue was annotated independently by three annota-tors. The assignment of dialogues to annotators was randomised;given a dialogue, each annotator first read the entire dialoguecarefully, and then gave it ratings according to the five subjec-tive annotation criteria described in Section 3.4; finally, he/sheidentified nuggets within the same dialogue, where nuggets weredefined as described in Section 3.5. An initial face-to-face in-struction and training session for the annotators was organised bythe first author of this paper at Waseda University; subsequently,the annotators were allowed to do their annotation work onlineusing a web-browser-based tool at their convenient location andtime. The number of dialogues assigned to each annotator was3,700 ∗ 3/16 = 693.75 on average; all of them completed theirwork within two weeks as they were initially asked to do. Theactual annotation time spent by each annotator was 18–20 hours.Each annotator was paid 1,200 Japanese Yen per hour.
3.4 Subjective AnnotationBy subjective annotation, we mean manual quantification of
the quality of a dialogue as a whole. As there are two playersinvolved in a Customer-Helpdesk dialogue, we wanted to accom-modate the following two viewpoints:Customer’s viewpoint Does Helpdesk solve Customer’s prob-
lem efficiently? Customer may want a solution quickly whileproviding minimal information to Helpdesk.
Helpdesk’s viewpoint Does Customer provide accurate andsufficient information so that Helpdesk can provide the rightsolution? Helpdesk also wants to solve Customer’s problemthrough minimal interactions, as these interactions translatedirectly into cost for the company.
Moreover, we wanted to assess customer satisfaction as this isof utmost importance for both parties. While customer satisfac-tion ratings should ideally be collected from the real customer atthe time of dialogue termination, we had no choice but to collectsurrogate, post-hoc ratings by the annotators instead.
By considering the above points and manually examining someactual dialogues from the smaller DCH-0 collection, we finallydevised the following five subjective annotation criteria:Task Statement Whether the task (i.e., the problem to be
solved) is clearly stated by Customer (denoted by TS);Task Accomplishment Whether the task is actually accom-
plished (denoted by TA);Customer Satisfaction Whether Customer is likely to have
been satisfied with the dialogue, and to what degree (denotedby CS);
Helpdesk Appropriateness Whether Helpdesk provided ap-propriate information (denoted by HA);
Customer Appropriateness Whether Customer provided ap-propriate information (denoted by CA).
c© 2018 Information Processing Society of Japan 771

Journal of Information Processing Vol.26 768–778 (Nov. 2018)
Fig. 2 Subjective annotation criteria.
Table 2 Inter-annotator agreement of the subjective annotations for DCH-1(3,700 dialogues, three annotators per dialogue). Note that Fleiss’κ and Randolph’s κfree treat the ratings as nominal categories. 2+agree means the proportion of dialogues for which at least two an-notators agree; 3 agree means the proportion of dialogues for whichall three annotators agree. For CS, 2 and 1 were treated as 1, and−2 and −1 were treated as −1.
#labels/category 2+ agree 3 agree Fleiss’ κ κfree
(1/0/−1)TS 692/9/1 .981 .729 .301 .719TA 154/219/329 .925 .361 .273 .324CS 191/284/227 .938 .349 .276 .318HA 420/142/140 .873 .309 .197 .245CA 631/49/22 .857 .288 .141 .216
We neither claim nor assume that these criteria are orthogonal.For example, if the task is not clearly stated by the customer (i.e.,low TS), then the Customer probably did not provide appropri-ate information (i.e., low CA); if the task was accomplished (i.e.,high TA), then the customer is likely to be satisfied with the dia-logue (i.e., high CS), but not always. The actual instructions forannotators is shown in Fig. 2: note that CS is on a five-point scale(−2 to 2), while the other four are on a three-point scale (−1 to1).
Table 2 shows the distributions of subjective ratings and in-dicators of inter-annotator agreement for DCH-1. For simplic-ity, the five-point scale of CS has been collapsed into three-pointscale. For example, the row for TS shows that the ratings arequite heavily skewed towards 1 (“Does Customer communicatethe problem clearly to Helpdesk?: Yes). As an indicator of inter-annotator agreement, the table shows Fleiss’ κ values [18], but itshould be noted that κ is for nominal categories: for example, itdoes not take into account the fact that “Category 0” is closer to“1” than “−1.” However, it does show, for example, that the inter-annotator agreement for TS is substantially higher than that forCA *4. “2+ agree” means the proportion of dialogues for whichat least two annotators agree, e.g., (−1,−1); “3 agree” means theproportion of dialogues for which all three annotators agree, e.g.,(−1,−1,−1).
Table 2 also shows an indicator similar to κ, known as Ran-dolph’s κfree [19]. Unlike Fleiss’ κ, this indicator does not dependon the skewed distributions such as the ones shown in the table,and is recommended when annotators have freedom as to howmany items must be assigned to each category. It can be observed
*4 The 95% CI of Fleiss’ κ for TS is [.287, .316]; that for CA is [.127, 155].
Fig. 3 Task accomplishment as state transitions, and the role of a nugget.
that the agreement among the three assessors is low, except per-haps for TS, which reflects the highly subjective nature of thislabelling task. While it may be possible to improve the inter-assessor agreement a little in our future work by revising the la-belling instructions, note that the labelling task may be inherentlymore subjective than well-established tasks such as document rel-evance assessments.
3.5 Nugget AnnotationWe had three annotators independently identified nuggets for
each dialogue as follows. At the instruction and training session,annotators were given the diagram shown in Fig. 3, which reflectsour view that accumulating nuggets will eventually solve Cus-tomer’s problem, together with a written definition of nuggets:(1) A nugget is a post, or a sequence of consecutive posts by thesame utterer (i.e., either Customer or Helpdesk); (2) It can neitherpartially nor wholly overlap with another nugget; (3) It shouldbe minimal: that is, it should not contain irrelevant posts at thestart, the end or in the middle. An irrelevant post is one that doesnot contribute to the Customer transition (see Fig. 3); (4) It helpsCustomer transition from Current State (including Initial State)towards Target State (i.e., when the problem is solved).
Note that we utilise Weibo posts as the atomic building blocksfor forming nuggets; This takes into account the remark by Wanget al. [20]: “Experience from question answering evaluations has
shown that users disagree about the granularity of nuggets—for
example, whether a piece of text encodes one or more nuggets and
how to treat partial semantic overlap between two pieces of text.”Note also that according to our definition, a turn (i.e., maximalconsecutive posts by the same utterer) generally subsumes one ormore nuggets.
Compared to traditional nugget-based information access eval-uation that was discussed in Section 2.3, there are two uniquefeatures in nugget-based helpdesk dialogue evaluation:• A dialogue involves two parties, Customer and Helpdesk;• Even within the same utterer, nuggets are not homogeneous,
by which we mean that some nuggets may play specialroles. In particular, since the dialogues we consider are task-oriented (but not closed-domain, which makes slot filling ap-proaches infeasible), there must be some nuggets that repre-sent the state of identifying the task and those that representthe state of accomplishing it.
Based on the above considerations, we defined the following
c© 2018 Information Processing Society of Japan 772

Journal of Information Processing Vol.26 768–778 (Nov. 2018)
Table 3 Rating distributions and inter-annotator agreement of the nugget annotations for DCH-1 (3,700dialogues, 3 annotators per dialogue). 2+ agree means the proportion of nuggets for which atleast two annotators agree; 3 agree means the proportion of dialogues for which all three anno-tators agree. NAN means “not a nugget.” 95% CI for κ are also shown.
total ratings #labels/category 2+ agree 3 agree Fleiss’κ κfree
Helpdesk (#total posts) (HNUG/HNUG* /NAN) 7,155 11,410/4,025/6,030 .907 .299 .174[.165, .184] .253Customer (#total posts) (CNUG0/CNUG/CNUG*/NAN) 9,539 10,228/9,434/1,274/7,681 .959 .491 .488 [.481, .496] .529
four mutually exclusive nugget types:CNUG0 Customer’s trigger nuggets. These are nuggets that
define Customer’s initial problem, which directly causedCustomer to contact Helpdesk.
HNUG Helpdesk’s regular nuggets. These are nuggets inHelpdesk’s utterances that are useful from Customer’s pointof view.
CNUG Customer’s regular nuggets. These are nuggets in Cus-tomer’s utterances that are useful from Helpdesk’s point ofview.
HNUG∗ Helpdesk’s goal nuggets. These are nuggets inHelpdesk’s utterances which provide the Customer with asolution to the problem.
CNUG∗ Customer’s goal nuggets. These are nuggets in Cus-tomer’s utterances which tell Helpdesk that Customer’sproblem has been solved.
Each nugget type may or may not be present in a dialogue. Mul-tiple nuggets of the same type may be present in a dialogue.
Using a pull-down menu on our web-browser-based tool, as-sessors categorised each post into CNUG0, CNUG, HNUG,CNUG∗, HNUG∗, or NAN (not a nugget). Then, consecutiveposts with the same label (e.g., CNUG followed by CNUG) wereautomatically merged to form a nugget.
Table 3 shows the inter-annotator agreement of the nugget an-notations, where the posts are used as the basis for comparison.The 3,700 dialogues in DCH-1 contains a total of 7,155 Helpdeskposts, all of which were annotated independently by three annota-tors, producing a total of 21,465 annotations, A direct comparisonwith the subjective annotation agreement shown in Table 2 wouldbe difficult, since both the annotation unit (dialogues vs. nuggets)and the annotation schemes (numerical ratings vs. nugget types)are different. However, it can be observed that the agreement forCustomer nuggets is substantially higher than for the Helpdesknuggets. A possible explanation for this would be that it is easierfor annotators to judge the contribution of Customer’s utterancesfor reaching his/her target state than to judge that of Helpdesk, atleast for regular nuggets: while Helpdesk often asks Customer formore information regarding the problem context, it is Customer’sutterances that actually provide that information.
While directly comparing the inter-annotator agreement ofsubjective annotation and nugget annotation seems difficult, wewould like to compare the intra-annotator consistency by mak-ing each annotator process the same dialogue multiple times inour future work.
4. UCH: A Nugget Based Approach
In this section, we detail the two methods we proposed to eval-uate Customer-Helpdesk dialogues.
4.1 UC, UH and UCHBy extending U-measure [17], we propose Utility for Customer
and Helpdesk (UCH), which is a measure that leverages nuggetsfor quantifying the quality of Customer-Helpdesk dialogues. Inthe U-measure framework, a trailtext is the text read by the user toreach a piece of useful information, which is defined as a nuggetin our case. By discounting the value of each nugget based on thelength of the corresponding trailtext, user effort can be taken intoaccount to better evaluate the system.
By considering Customer-Helpdesk dialogue as a kind of in-formation retrieval behaviour that both customer and helpdeskneed to retrieve enough useful information from the utterancesuttered by the other side to solve the problem, U-measure canbe extended to our scenario: evaluating Customer-Helpdesk dia-logues. Let pos denote the position of a nugget; for ideographiclanguages such as Chinese and Japanese, we use the number ofcharacters to define the offset position. Given a patience param-
eter L, we define a decay function over the trailtext as [17]:
D(pos) = max(0, 1 − pos
L
). (1)
This is for discounting the value of a nugget that appear laterin the dialogue; just like Discounted Cumulative Gain [21] dis-counts the value of a document at low ranks. At position L, thevalue of any nugget wears out completely. In our experiments, welet L = Lmax = 916 as this is the number of (Chinese) charactersin the longest dialogue from the DCH-1 collection. In practice, ifwe have a requirement that each dialogue has to terminate withinT minutes, and if we have an estimate of the average typing speeds (characters per minute) in an online chat, it might be useful tolet L be T × s. Note that traditional N-gram- and nugget-basedmeasures are position-unaware: they evaluate systems based onsets of N-grams or nuggets. The benefit of introducing L is dis-cussed in Section 6.1.2.
Let N and M denote the number of Customer’s non-goal (i.e.,trigger or regular) nuggets and Helpdesk’s non-goal (i.e., regular)nuggets identified within a dialogue, respectively; for simplicity,let us assume that there is at most one Customer’s goal nugget (c∗)and at most one Helpdesk’s goal nugget (h∗) in a dialogue. Let{c1, . . . , cN , c∗} denote the set of nuggets from Customer’s posts,and let {h1, . . . , hM , h∗} denote that from Helpdesk’s posts. Letpos(ci) (i ∈ {1, . . . ,N, ∗}) be the position of nugget ci; pos(h j)( j ∈ {1, . . . ,M, ∗}) is defined similarly.
Given the gain value of each nugget g(ci), a simple evaluationmeasure based solely on Customer’s utterances can be computedas:
UC =∑
ci∈{c1 ,...,cN ,c∗}g(ci) D(pos(ci)) . (2)
In the present study, we define the gain value of non-goal nugget
c© 2018 Information Processing Society of Japan 773

Journal of Information Processing Vol.26 768–778 (Nov. 2018)
(i.e. CNHG and CNUG0) as one and goal nugget CNUG∗ asg(c∗) = 1 +
∑Ni=1 g(ci). This is an attempt at reflecting the view
that task accomplishment is what matters most. To be more spe-cific, when the discounting function is ignored and dialogues areregarded as sets of nuggets, then having only the goal nugget isbetter than having all the non-goal nuggets. This is because, bydefinition, a set of non-goal nuggets cannot solve the customer’sproblem *5.
Similarly, given the gain value of each nugget g(h j), a measuresolely based on Helpdesk’s utterances can be computed as:
UH =∑
h j∈{h1 ,...,hM ,h∗}g(h j) D(pos(h j)) , (3)
where g(h∗) = 1 +∑M
j=1 g(h j) and g(h j) = 1 when 1 ≤ j ≤ M.Finally, for a given parameter α (0 ≤ α ≤ 1) that specifies thecontribution of Helpdesk’s utterances relative to Customer’s, wecan define the following combined measure:
UCHα = (1 − α)UC + αUH . (4)
By default, we use α = 0.5. Note that UCH0.5 is equivalent tocomputing a single U-measure score without distinguishing be-tween Customer’s and Helpdesk’s nuggets. The choice of α isdiscussed in Section 6.1.3.
Like U-measure, UCH is an unnormalised measure: it doesnot have the [0, 1] score range. However, we do not considernormalisation in the present study since we are not comparingone dialogue with another. Also, note that if score standardisa-
tion is applied to evaluation measure scores, then normalisationbecomes redundant [22], [23]. While variants of UCH are possi-ble *6, Section 6.1 examines the basic properties of this simple,pilot measure.
4.2 UCH with Multiple Nugget AnnotatorsSince we have three independent nugget annotations per di-
alogue, we tried the following two approaches to computing asingle score for a given dialogue.Average UCH (AUCH) Calculate a UCH score for each anno-
tator, then take the average.Consolidated UCH (CUCH) First, merge the three lists of
nugget annotations as follows. For each post with three in-dependent annotations, if it received at least two votes forthe same nugget type (e.g., <CNUG, CNUG, NAN>), thenassign that nugget type to the post. Otherwise let the nuggettype be NAN. Merge consecutive posts to form nuggets asdescribed in Section 3.5. Let the gain value of each non-goal nugget be the number of votes it received: for example,if two consecutive posts with annotations <CNUG, CNUG,NAN> and <CNUG, CNUG, CNUG> were merged to forma CNUG nugget, its weight would be five. Finally, computea single UCH score based on the consolidated nuggets with
*5 While it is not impossible that multiple non-goal nuggets can serve as asolution to the Customer’s problem only when taken together, we havenot witnessed such a case in our data.
*6 For example, we could use nonlinear discount functions, and possiblydifferent discount functions for Customer and Helpdesk. Also, we couldemploy a Time-Biased-Gain [24] based measure, which explicitly utilisesthe timestamps associated with the Weibo posts.
weights.
5. NEM: An End-to-End Neural NetworkBased Approach
UCH is purely nugget-based and therefore only takes into ac-count pieces of useful information conveyed in the utterances.For example, if the Helpdesk keeps repeating utterances such as“We will have your problem recorded” this will probably have anegative impact on the Customer’s satisfaction; if the Customeractually utters “I am not happy with your service” this is a strongnegative signal. UCH cannot handle these signals because it doesnot use the dialogue text directly as input. Moreover, nugget-based approaches require annotators to provide nugget annota-tions. To address these problems, we aimed to construct an end-to-end evaluation model that: (1) can be utilised without anymanual annotation, and (2) understands the context-rich interac-tion in multi-round dialogues. In this section, we introduce theproposed model that learns to evaluate Customer-Helpdesk dia-logues, which we call Neural Evaluating Machine (NEM). Wefirst formalise the problem, and then describe the architecture ofthe NEM model.
5.1 Problem FormalisationSuppose that we are given a Customer-Helpdesk dialogue D =
(p1,p2, . . . , pT ), where pt is a post uttered by st ∈ {C,H} as weonly have two possible speakers: Customer (C) and Helpdesk(H). Each post consists of a list of tokens pt = (xt
1, xt2, . . . , x
tmt
),where mt denotes the length of the t-th post. We use one-hotencoding to represent the i-th token of the t-th post xt
i ∈ RV×1
and V is the vocabulary size. For each dialogue, we predicttheir subjective labels: Task Statement (TS), Task Accomplish-ment (TA), Customer Satisfaction (CS), Helpdesk Appropriate-ness (HA), and Customer Appropriateness (CA). We use thesame architecture for all of them, but the model was trained withthe five different label types separately.
5.2 ModelIn this subsection, we detail the architecture of the NEM
model, which is shown in Fig. 4. Converting a one-hot repre-sentation into a distributed representation has became a standardmethod in NLP tasks to ease the curse of dimensionality prob-lem [25]. Here, we follow the standard way of using an em-bedding matrix weight A ∈ Rd×V to convert the one-hot wordvector xt
i ∈ RV×1 into the distributed word vector xti′ ∈ Rd×1:
xti′= Axt
i. To differentiate between the customer’s post andthe helpdesk’s post, we further convert xt
i′ into xt
i ∈ R2d×1 as:xt
i = [xti′ · 1{st=H}, xt
i′ · 1{st=C}] where [·, ·] denotes concatenation
and 1 denotes indicator function. For each post, we use Bag ofWords to encode it into et by summing the word embedding vec-tors to get its representation et: et =
∑mt
i=1 xti.
Recurrent Neural Networks (RNNs) with Long Short-TermMemory (LSTM) units [26] have been successfully applied tomany NLP tasks. By encompassing memory cells that can storeinformation, LSTM eases the problem of gradient vanishing andexploding to make long distance dependency possible. We em-ploy LSTM to map each post encoding et to a vector ht. For
c© 2018 Information Processing Society of Japan 774
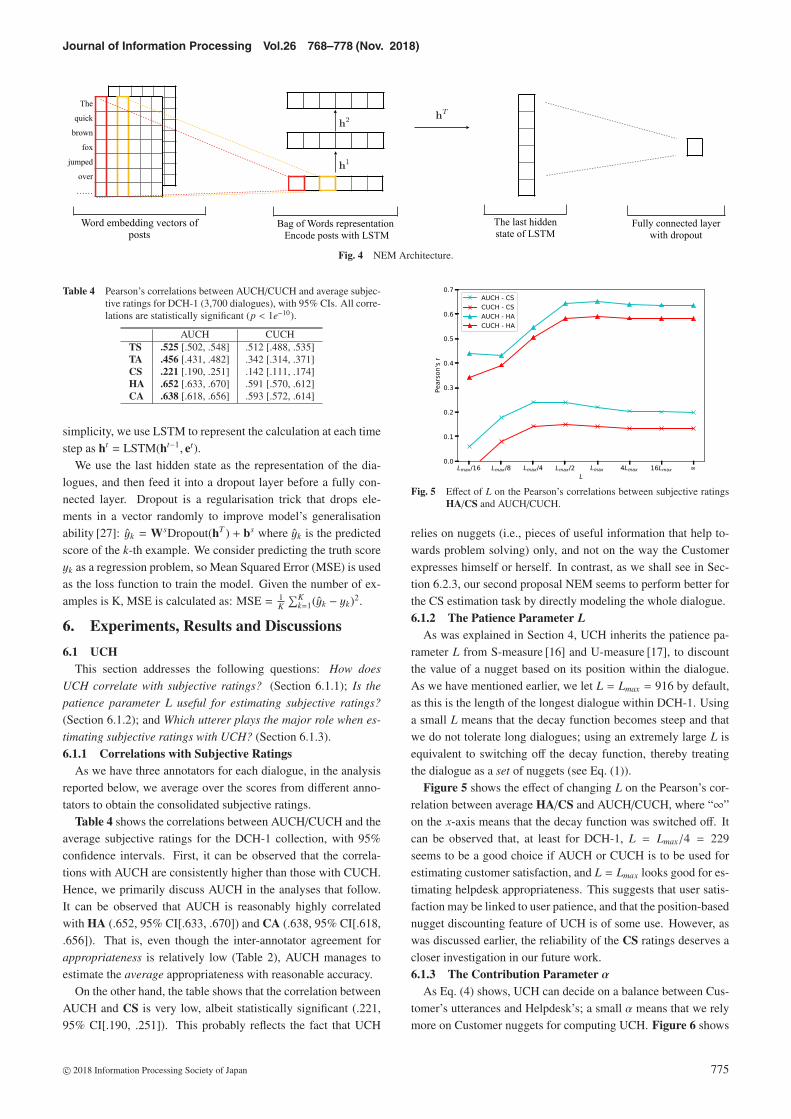
Journal of Information Processing Vol.26 768–778 (Nov. 2018)
Fig. 4 NEM Architecture.
Table 4 Pearson’s correlations between AUCH/CUCH and average subjec-tive ratings for DCH-1 (3,700 dialogues), with 95% CIs. All corre-lations are statistically significant (p < 1e−10).
AUCH CUCHTS .525 [.502, .548] .512 [.488, .535]TA .456 [.431, .482] .342 [.314, .371]CS .221 [.190, .251] .142 [.111, .174]HA .652 [.633, .670] .591 [.570, .612]CA .638 [.618, .656] .593 [.572, .614]
simplicity, we use LSTM to represent the calculation at each timestep as ht = LSTM(ht−1, et).
We use the last hidden state as the representation of the dia-logues, and then feed it into a dropout layer before a fully con-nected layer. Dropout is a regularisation trick that drops ele-ments in a vector randomly to improve model’s generalisationability [27]: yk = WsDropout(hT ) + bs where yk is the predictedscore of the k-th example. We consider predicting the truth scoreyk as a regression problem, so Mean Squared Error (MSE) is usedas the loss function to train the model. Given the number of ex-amples is K, MSE is calculated as: MSE = 1
K
∑Kk=1(yk − yk)2.
6. Experiments, Results and Discussions
6.1 UCHThis section addresses the following questions: How does
UCH correlate with subjective ratings? (Section 6.1.1); Is the
patience parameter L useful for estimating subjective ratings?
(Section 6.1.2); and Which utterer plays the major role when es-
timating subjective ratings with UCH? (Section 6.1.3).6.1.1 Correlations with Subjective Ratings
As we have three annotators for each dialogue, in the analysisreported below, we average over the scores from different anno-tators to obtain the consolidated subjective ratings.
Table 4 shows the correlations between AUCH/CUCH and theaverage subjective ratings for the DCH-1 collection, with 95%confidence intervals. First, it can be observed that the correla-tions with AUCH are consistently higher than those with CUCH.Hence, we primarily discuss AUCH in the analyses that follow.It can be observed that AUCH is reasonably highly correlatedwith HA (.652, 95% CI[.633, .670]) and CA (.638, 95% CI[.618,.656]). That is, even though the inter-annotator agreement forappropriateness is relatively low (Table 2), AUCH manages toestimate the average appropriateness with reasonable accuracy.
On the other hand, the table shows that the correlation betweenAUCH and CS is very low, albeit statistically significant (.221,95% CI[.190, .251]). This probably reflects the fact that UCH
Fig. 5 Effect of L on the Pearson’s correlations between subjective ratingsHA/CS and AUCH/CUCH.
relies on nuggets (i.e., pieces of useful information that help to-wards problem solving) only, and not on the way the Customerexpresses himself or herself. In contrast, as we shall see in Sec-tion 6.2.3, our second proposal NEM seems to perform better forthe CS estimation task by directly modeling the whole dialogue.6.1.2 The Patience Parameter L
As was explained in Section 4, UCH inherits the patience pa-rameter L from S-measure [16] and U-measure [17], to discountthe value of a nugget based on its position within the dialogue.As we have mentioned earlier, we let L = Lmax = 916 by default,as this is the length of the longest dialogue within DCH-1. Usinga small L means that the decay function becomes steep and thatwe do not tolerate long dialogues; using an extremely large L isequivalent to switching off the decay function, thereby treatingthe dialogue as a set of nuggets (see Eq. (1)).
Figure 5 shows the effect of changing L on the Pearson’s cor-relation between average HA/CS and AUCH/CUCH, where “∞”on the x-axis means that the decay function was switched off. Itcan be observed that, at least for DCH-1, L = Lmax/4 = 229seems to be a good choice if AUCH or CUCH is to be used forestimating customer satisfaction, and L = Lmax looks good for es-timating helpdesk appropriateness. This suggests that user satis-faction may be linked to user patience, and that the position-basednugget discounting feature of UCH is of some use. However, aswas discussed earlier, the reliability of the CS ratings deserves acloser investigation in our future work.6.1.3 The Contribution Parameter α
As Eq. (4) shows, UCH can decide on a balance between Cus-tomer’s utterances and Helpdesk’s; a small α means that we relymore on Customer nuggets for computing UCH. Figure 6 shows
c© 2018 Information Processing Society of Japan 775

Journal of Information Processing Vol.26 768–778 (Nov. 2018)
Fig. 6 Effect of α on the Pearson’s correlations between average subjectiveratings and AUCH.
the effect of α on the Pearson’s correlations between AUCH anddifferent average subjective ratings. The trends are the same forTS, TA, CS, and CA: the smaller the α, the higher the correlation.That is, to achieve the highest correlation, it is best to rely entirelyon Customer utterances, i.e., to completely ignore Helpdesk ut-terances. Interestingly, however, the trend is different for HA: thecurve for HA suggests that α = 0.8 is in fact the best choice. Thatis, to achieve the highest correlation with Helpdesk Appropriate-ness, both Customer’s and Helpdesk’s nuggets are helpful. Whileit is obvious that Helpdesk’s utterances need to be taken into ac-count in order to estimate Helpdesk Appropriateness, the curveimplies that Customer’s utterances also play at least as impor-tant a part in the estimation. These results suggest that differentsubjective annotation criteria require different balances betweenCustomer’s and Helpdesk’s utterances.
6.2 NEM6.2.1 Experiment Setup
We focus on the DCH-1 dataset to train and evaluate the NeuralEvaluation Machine (NEM) model. Recall that we had three in-dependent annotators to provide five different subjective ratings(TS, TA, CS, CA, HA) for each dialogue. Similar to the UCHexperiment, we use the average subjective ratings from differentannotators to generate true labels to train and evaluate NEM forsimplicity. DCH-1 was randomly partitioned into three collec-tions: a training set (70%), a development set (15%) and a testset (15%). The training set was for training the parameters of themodel, the development set was for model selection and hyper-parameter tuning, and the test set was for measuring the model’sperformance.6.2.2 Implementation Details
We used the open-sourced Chinese HMM based tokeniserJieba *7 to preprocess posts. For word embedding, we usedpre-trained Chinese Word2Vec embedding vectors provided byBaidu PaddlePaddle project *8. The vectors have 256 dimen-sions and were trained using the skip-gram architecture [28]. Weused zero vectors to represent padding and all out-of-vocabularywords. The word embedding vector was fixed during training. Weutilised three layers of unidirectional LSTM to encode posts. The
*7 https://github.com/fxsjy/jieba*8 https://github.com/PaddlePaddle/Paddle
Table 5 NEM’s Performance on DCH-1 Test Collection (555 dialogues)with 95% CI. All correlations are statistically significant (p <1e−10).
NEM AUCH (test)MSE Pearson’s r
TS .130 .632 [.579, .680] .480 [.413, .541]TA .254 .628 [.574, .675] .436 [.366, .501]CS .329 .710 [.666, .749] .268 [.190, .344]CA .286 .524 [.460, .582] .615 [.561, .665]HA .241 .624 [.570, .672] .579 [.521, .632]
hidden units of LSTM was set to 150 for all layers. The dropoutrate was set to 0.2. The model was optimised by ADAM [29] withthe default hyper-parameters.6.2.3 Results and Discussions
Table 5 shows the performance of NEM and AUCH on DCH-1 test collection (555 dialogues). Similar to UCH, we mainlyuse Pearson’s correlation to measure the performance of NEM.In addition, Mean Squared Error (MSE) is used as an alternativemetric for NEM. This is because, unlike UCH which is basicallya sum of weighted nuggets, NEM aims to directly estimate thetarget ratings.
For the CS estimation task, it can be observed that NEM re-sulted in a strong correlation in terms of Pearson’s correlation(.710, 95% CI[.666, .749]), which suggests that the correlationis indeed substantial. This result suggests that NEM model maybe good at estimating CS since NEM can utilise semantic andsyntactic features directly from the whole dialogue.
Interestingly, while NEM resulted in a strong correlation withHA (.624, 95% CI[.570, .672]), it did not correlate well with CA(.524, 95% CI[.460, .582]). This observation is also differentfrom what we obtained in UCH since UCH resulted in a bettercorrelation with CA than with HA. Also, the correlation of NEMin the CA estimation task is worse than with CS.
The comparison result between UCH and NEM on DCH-1 testcollection, which is shown in Table 5, suggests that UCH andNEM may be good at different estimation tasks: NEM may cap-ture the semantic and syntactic features (e.g., customer’s emo-tional reaction in the dialogue) to infer customer satisfaction, butNEM underperformed UCH in the customer appropriateness es-timation task.
7. Conclusion and Future Work
As an initial step towards evaluating automatic dialogue sys-tems, we have constructed and released DCH-1, which contains3,700 real Customer-Helpdesk multi-round dialogues mined fromWeibo. We have annotated each dialogue with subjective qual-ity annotations (TS, TA, CS, HA, and CA) and nugget annota-tions, with three annotators per dialogue. In addition, 34% ofthe dialogues have been manually translated into English. Wedescribed how we constructed the test collection and the phi-losophy behind it. We also proposed UCH, a simple nugget-based evaluation measure for task-oriented dialogue evaluation,and NEM, a neural network based automatic evaluation model.Our main findings on UCH based on the DCH-1 collection areas follows. (1) Averaging UCH scores based on individual anno-tators achieves higher correlation with subjective ratings than asingle UCH score computed by consolidating nuggets from mul-
c© 2018 Information Processing Society of Japan 776

Journal of Information Processing Vol.26 768–778 (Nov. 2018)
tiple annotations; (2) UCH correlates better with subjective rat-ings that reflect the appropriateness of utterances (HA and CA)than with customer satisfaction (CS); (3) The patience parameterL of UCH, which considers the positions of nuggets within a dia-logue, may be a useful feature for enhancing the correlation withcustomer satisfaction; (4) For the majority of our subjective an-notation criteria, customer utterances seem to play a much moreimportant role for UCH to achieve high correlations with subjec-tive ratings than helpdesk utterances do, according to our analysison the parameter α; (5) NEM, which does not require any nuggetannotations and takes the entire dialogue as input, correlates wellwith all subjective ratings, especially with Customer Satisfaction.
Our future work includes the following:• Comparing subjective annotation and nugget annotation in
terms of intra-annotator agreement.• Investigating the reliability of offline customer satisfaction
ratings by comparing them with real customer ratings col-lected right after the termination of a helpdesk dialogue.
• Collecting subjective and nugget annotations for the Englishsubcollection of DCH-1, and comparing across Chinese andEnglish.
• Devising ways for automatic nugget identification and auto-matic categorisation of nuggets into different nugget types.
• Building more sophisticated neural models to improveNEM.
• Collecting more data from the same helpdesk accounts cov-ered in DCH-1 to investigate if UCH and NEM can provideenough discriminative power [30] at both the system leveland at the dialogue level.
The NTCIR-14 Short Text Conversation task (STC-3) will fea-ture a new subtask that is based on the present study: given adialogue, participating systems are required to estimate the distri-bution of subjective scores such as user satisfaction over multipleannotators, as well as the distribution of nugget types (e.g., trig-ger, regular, goal, not-a-nugget) over multiple assessors for eachturn [31]. We will be serving both as organisers of this task and asa participant, and will apply improved models of NEM to submitour results.
Acknowledgments We thank the metareviewer Dr.Masayuki Okamoto and the two anonymous reviewers fortheir constructive comments which helped us improve this paper.This work was supported by JSPS KAKENHI Grant Number17H01830.
References
[1] Walker, M.A., Litman, D.J., Kamm, C.A. and Abella, A.: PARADISE:A Framework for Evaluating Spoken Dialogue Agents, Proc. ACL1997, pp.271–280 (1997).
[2] Galley, M., Brockett, C., Sordoni, A., Ji, Y., Auli, M., Quirk, C.,Mitchell, M., Gao, J. and Dolan, B.: ΔBLEU: A Discriminative Met-ric for Generation Tasks with Intrinsically Diverse Targets, Proc. ACL2015, pp.445–450 (2015).
[3] Papineni, K., Roukos, S., Ward, T. and Zhu, W.-J.: BLEU: A Methodfor Automatic Evaluation of Machine Translation, Proc. ACL 2002,pp.311–318 (2002).
[4] Higashinaka, R., Funakoshi, K., Inaba, M., Tsunomori, Y., Takahashi,T. and Kaji, N.: Overview of Dialogue Breakdown Detection Chal-lenge 3, Proc. DSTC6 (2017).
[5] Shang, L., Sakai, T., Li, H., Higashinaka, R., Miyao, Y., Arase, Y.and Nomoto, M.: Overview of the NTCIR-13 Short Text Conversa-
tion Task, Proc. NTCIR-13 (2017).[6] Ram, A., Prasad, R., Khatri, C., Venkatesh, A., Gabriel, R., Liu, Q.,
Nunn, J., Hedayatnia, B., Cheng, M., Nagar, A., King, E., Bland,K., Wartick, A., Pan, Y., Song, H., Jayadevan, S., Hwang, G. andPettigrue, A.: Conversational AI: The Science Behind the Alexa Prize,CoRR, Vol.abs/1801.03604 (2017).
[7] Kiyota, Y., Kurohashi, S. and Kido, F.: Dialog navigator: A questionanswering system based on large text knowledge base, Proc. COLING2002 (2002).
[8] Walker, M.A., Langkilde-Geary, I., Wright, J.H., Gorin, A.L. andLitman, D.J.: Learning to Predict Problematic Situations in a SpokenDialogue System: Experiments with How May I Help You?, Proc.NAACL 2000, pp.210–217 (2000).
[9] Ando, A., Masumura, R., Kamiyama, H., Kobashikawa, S. and Aono,Y.: Hierarchical LSTMs with Joint Learning for Estimating CustomerSatisfaction from Contact Center Calls, Proc. INTERSPEECH 2017,pp.1716–1720 (2017).
[10] Hone, K.S. and Graham, R.: Towards a Tool for the Subjective Assess-ment of Speech System Interfaces (SASSI), Natural Language Engi-neering, Vol.6, No.3-4, pp.287–303 (2000).
[11] Hartikainen, M., Salonen, E.-P. and Turunen, M.: Subjective Evalua-tion of Spoken Dialogue Systems Using SERVQUAL Method, Proc.INTERSPEECH 2004-ICSLP (2004).
[12] Paek, T.: Toward Evaluation that Leads to Best Practices: ReconcilingDialog Evaluation in Research and Industry, Proc. Bridging the Gap:Academic and Industrial Research in Dialogue Technologies Work-shop, pp.40–47 (2007).
[13] Lin, C.-Y.: ROUGE: A Package for Automatic Evaluation of Sum-maries, Proc. Workshop on Text Summarization Branches Out, pp.74–81 (2004).
[14] Nenkova, A., Passonneau, R. and McKeown, K.: The PyramidMethod: Incorporating Human Content Selection Variation in Sum-marization Evaluation, ACM Trans. Speech and Language Processing,Vol.4, No.2 (2007).
[15] Lin, J. and Demner-Fushman, D.: Will Pyramids Built of NuggetsTopple Over?, Proc. HLT/NAACL 2006, pp.383–390 (2006).
[16] Sakai, T., Kato, M.P. and Song, Y.-I.: Click the Search Button and BeHappy: Evaluating Direct and Immediate Information Access, Proc.ACM CIKM 2011, pp.621–630 (2011).
[17] Sakai, T. and Dou, Z.: Summaries, Ranked Retrieval and Sessions:A Unified Framework for Information Access Evaluation, Proc. ACMSIGIR 2013, pp.473–482 (2013).
[18] Fleiss, J.L.: Measuring Nominal Scale Agreement among ManyRaters, Psychological Bulletin, Vol.76, No.5, pp.378–382 (1971).
[19] Randolph, J.J.: Free-marginal Multirater Kappa (Multirater κfree):An Alternative to Fleiss’ Fixed Marginal Multirater Kappa, JoensuuLearning and Instruction Symposium 2005 (2005).
[20] Wang, Y., Sherman, G., Lin, J. and Efron, M.: Assessor Differencesand User Preferences in Tweet Timeline Generation, Proc. ACM SI-GIR 2015, pp.615–624 (2015).
[21] Jarvelin, K. and Kekalainen, J.: Cumulated Gain-Based Evaluation ofIR Techniques, ACM TOIS, Vol.20, No.4, pp.422–446 (2002).
[22] Sakai, T.: A Simple and Effective Approach to Score Standardisation,Proc. ACM ICTIR 2016 (2016).
[23] Webber, W., Moffat, A. and Zobel, J.: Score Standardization for Inter-Collection Comparison of Retrieval Systems, Proc. ACM SIGIR 2008,pp.51–58 (2008).
[24] Smucker, M.D. and Clarke, C.L.A.: Time-Based Calibration of Effec-tiveness Measures, Proc. ACM SIGIR 2012, pp.95–104 (2012).
[25] Bengio, Y., Ducharme, R., Vincent, P. and Jauvin, C.: A neuralprobabilistic language model, Journal of Machine Learning Research,Vol.3, No.Feb, pp.1137–1155 (2003).
[26] Hochreiter, S. and Schmidhuber, J.: Long short-term memory, NeuralComputation, Vol.9, No.8, pp.1735–1780 (1997).
[27] Srivastava, N., Hinton, G.E., Krizhevsky, A., Sutskever, I. andSalakhutdinov, R.: Dropout: A simple way to prevent neural networksfrom overfitting., Journal of Machine Learning Research, Vol.15,No.1, pp.1929–1958 (2014).
[28] Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S. and Dean, J.: Dis-tributed representations of words and phrases and their composition-ality, Advances in Neural Information Processing Systems, pp.3111–3119 (2013).
[29] Kingma, D. and Ba, J.: Adam: A method for stochastic optimization,Proc. ICLR 2015 (2015).
[30] Sakai, T.: Evaluation with Informational and Navigational Intents,Proc. ACM WWW 2012, pp.499–508 (2012).
[31] Sakai, T.: Towards Automatic Evaluation of Multi-Turn Dialogues: ATask Design that Leverages Inherently Subjective Annotations, Proc.EVIA 2017, pp.24–30 (2017).
c© 2018 Information Processing Society of Japan 777

Journal of Information Processing Vol.26 768–778 (Nov. 2018)
Zhaohao Zeng is a first-year Ph.D stu-dent at the Department of Computer Sci-ence and Engineering, Waseda University.
Cheng Luo is a postdoc researcher atTsinghua University, Beijing, China. Heis also a co-PI at NExT++ center foundedby National University of Singapore andTsinghua University. His research inter-ests include Web search, user behavioranalysis and search evaluation. He has re-ceived reveral research award, including
Best Paper Honorable Mention at AIRS 2016 and Best Short Pa-per Honorable Mention at SIGIR 2018.
Lifeng Shang is a principal researcher ofHuawei Noah’s Ark Lab. He obtained hisPhD degree in computer science from theUniversity of Hong Kong in 2012. Be-fore joining Huawei, he was a postdoc-toral research fellow at the City Universityof Hong Kong. His research interests in-clude machine learning, computer vision,
and natural language processing.
Hang Li is a director of AI Lab,Bytedance Technology (also known asToutiao), adjunct professors of PekingUniversity and Nanjing University. Heis an IEEE Fellow and an ACM Distin-guished Scientist. His research areas in-clude natural language processing, infor-mation retrieval, machine learning, and
data mining. Hang graduated from Kyoto University in 1988 andearned his PhD from the University of Tokyo in 1998. He workedat NEC Research as researcher from 1990 to 2001, Microsoft Re-search Asia as senior researcher and research manager from 2001to 2012, and chief scientist and director of Huawei Noah’s ArkLab from 2012 to 2017. He joined Bytedance in 2017.
Tetsuya Sakai is a professor and the headof department at the Department of Com-puter Science and Engineering, WasedaUniversity, Japan. He is also a visitingprofessor at the National Institute of In-formatics. His previous employment in-clude Microsoft Research Asia. He is aneditor-in-chief of Springer’s Information
Retrieval Journal. He has received several research awards, in-cluding an IPSJ SIG Research Award (2006), IPSJ Best PaperAwards (2006, 2007), and a FIT Funai Best Paper Award (2008).
c© 2018 Information Processing Society of Japan 778





























