Embed Size (px)
Citation preview

Towards Richer and Self-SupervisedPerception in Robots
Sudeep [email protected]
April 28, 2017
1 Introduction
Robots need to be able to navigate through environments, perform manipulation tasks, andavoid obstacles, all while having a strong spatial and semantic understanding of its immediate en-vironment. This thesis focuses on endowing robots with richer perceptual models for improvednavigation and scene understanding. I focus on three fundamental elements that are imperative torobust perception in autonomous systems1. Through the concept of SLAM-supported object recogni-tion, we develop the ability for robots to be able to leverage their inherent localization and mappingcapabilities (spatial understanding) to better inform object recognition within scenes (semanticunderstanding). Inherent to the spatial and semantic understanding is the choice of map repre-sentation. Motivated by the need for a unified resource-aware map representation in vision-basedmapping and navigation we develop a High-performance and Tunable Stereo Reconstruction algorithmthat enable robots to quickly reconstruct their immediate surroundings and thereby maneuver athigh-speeds.
In order to robustly operate in their environments, robots are expected to maintain a strong se-mantic and geometric model of the world around them. By leveraging this combined understand-ing of their immediate world, robots should also be able to self-supervise themselves from previousexperiences and continuously adapt their models for improved task-performance and model effi-ciency. Towards this end, we motivate the need for self-supervision in vision-based autonomousrobots and introduce new capabilities in Self-supervised Visual Ego-motion Estimation and Weakly-Supervised Vision-based Re-localization. We envision that self-supervised and weakly-supervised so-lutions to task learning shall have far-reaching implications in several domains, especially in thecontext of life-long learning in autonomous systems. Furthermore, we expect these techniques toseamlessly operate under resource-constrained situations in the near future by leveraging exist-ing solutions in model reduction and dynamic model architecture tuning. With the availabilityof multiple sensors on these autonomous systems, we also foresee bootstrapped task learning topotentially enable robots to learn from experience, and use the new models learned from theseexperiences to encode redundancy and fault-tolerance all within the same framework.
1Selected publications: [1, 2, 3, 4, 5, 6, 7]
1

SLAM-Supported Semantic Scene Understanding Semantic scene understanding broadly en-compasses object-level detection and recognition along with scene-level understanding of contextand object relationships. We focus on the particular problem of object recognition in the domain ofautonomous systems, where scene and robot context is particularly beneficial to consider. Robotsperceive their environment through on-board cameras as a continuous image stream, observing thesame set of objects several times, and from multiple viewpoints, as it constantly moves around inits immediate environment. As expected, object detection and recognition can be further bolsteredif the robot were capable of simultaneously localizing itself and mapping (SLAM) its immediateenvironment by integrating object detection evidences across multiple views.
Considering both the camera (localization) and scene information (object labels, 3D reconstruc-tion) together presents several benefits especially while reasoning over occlusions, moving in-and-out of the field of view etc. Furthermore, the added benefit of object persistence allows one tomodel the object label likelihood given multiple views of the object, instead of relying purely onsingle view identification that may be prone to mis-classification. To this end, we develop a noveland rich model for object recognition by leveraging SLAM information that is typically consideredin autonomous systems. We introduce the notion of SLAM-supported object recognition [1] - a robot,spatially cognizant of its 3D environment and location, can outperform traditional frame-by-framedetection and recognition techniques, by incorporating its knowledge of the object from variousviewpoints.
Geometric Scene Representations and Tunable Reconstruction Following the need for stronggeometric understanding in mobile robots, we shift our focus towards the underlying representa-tions of the scene considered in modern autonomous systems. More specifically, we address theconcern of representational choice when it comes to maintaining metrically accurate maps for nav-igation purposes in mobile robots. We motivate the need for a unified representation for vision-based mapping and planning, and introduce a mesh-based stereo reconstruction algorithm thathas compelling properties geared towards mobile robots.
We propose a high-performance and tunable stereo disparity estimation method [2], with apeak frame-rate of 120Hz (1 CPU-thread with SIMD instructions), that enables robots to quicklyreconstruct their immediate surroundings and maneuver at high-speeds. Our key contributionis an iterative refinement step that approximates and refines the scene reconstruction via a piece-wise planar mesh representation, coupled with a fast depth validation step. The mesh is initiallyseeded with sparsely matched keypoints, and is recursively tessellated and refined as needed (viaa resampling stage), to provide the desired stereo disparity accuracy. The inherent simplicity andspeed of our approach, with the ability to tune it to a desired reconstruction quality and runtimeperformance makes it a compelling solution for applications in high-speed vehicles.
Self-Supervised Learning in SLAM-aware Robots Model-based perception algorithms haveenabled significant advances in mobile robot navigation, however, they are limited in their abil-ity to learn from new experiences and adapt accordingly. We envision robots to be able to learnfrom their previous experiences and continuously tune their internal model representations inorder to achieve improved task-performance and model efficiency. We investigate the concept ofself-supervised and weakly-supervised learning in mobile robots, whereby, robots can teach them-selves navigation-related tasks on newer sensors by bootstrapping its known internal model rep-resentation.
2

(i) Self-Supervised Visual Ego-motion Learning: Visual odometry (VO) [8], commonly referred toas ego-motion estimation, is a fundamental capability that enable robots to reliably navigate itsimmediate environment. While many visual ego-motion algorithm variants have been proposedin the past decade, each of these algorithms have been custom tailored for specific camera optics(pinhole, fisheye, catadioptric) and the range of motions observed by these cameras mounted onvarious platforms [9]. We envision that an adaptive and trainable solution for relative pose estima-tion or ego-motion can be especially advantageous for several reasons: (i) a common end-to-endtrainable model architecture that applies to a variety of camera optics including pinhole, fisheye,and catadioptric lenses (ii) simultaneous optimization over both ego-motion estimation and cam-era parameters (intrinsics and extrinsics) (iii) online calibration and parameter tuning is implicitlyencoded within the learning framework (iv) joint reasoning over resource-aware computation andaccuracy within the same architecture is amenable. We envision that such an approach is espe-cially beneficial in the context of bootstrapped (or weakly-supervised) learning in robots, wherethe supervision in ego-motion estimation for a particular camera can be obtained from the fusionof measurements from various other robot sensors (GPS, wheel encoders etc.).
Through recent work [3], we demonstrate the ability to self-supervise visual odometry (VO)estimation in mobile robots. We propose an end-to-end solution to visual ego-motion estimationfor varied camera optics, that maps observed optical flow vectors to an ego-motion density esti-mate via a Mixture Density Network (MDN). By modeling the architecture as a Conditional Vari-ational Autoencoder (C-VAE), our model is able to provide introspective reasoning and predictionfor scene-flow, conditioned on the ego-motion estimate and input feature location. Additionally,our proposed model is especially amenable to bootstrapped ego-motion learning in robots wherethe supervision in ego-motion estimation for a particular camera sensor can be obtained from thefusion of measurements from various other robot sensors (GPS, wheel encoders etc.). Further-more, we expect our method to seamlessly operate under resource-constrained situations in thenear future by leveraging existing solutions in model reduction and dynamic model architecturetuning. With the availability of multiple sensors on these autonomous systems, we also foresee ourapproach to bootstrapped task (visual ego-motion) learning to potentially enable robots to learnfrom experience, and use the new models learned from these experiences to encode redundancyand fault-tolerance all within the same framework.
(ii) Weakly-supervised Visual-SLAM Front-End: Critical to any vision-based SLAM front end is therobust operation of both visual odometry estimation and loop closure detection. As described ear-lier this section, we propose a self-supervised solution to visual ego-motion estimation in genericcameras thereby allowing robots to continually learn from visual experience. In on-going work,we propose to develop methods to self-supervise visual place recognition and classification. Ourinitial thrusts investigate weak-supervision in SLAM-aware systems by leveraging minimally su-pervised pose-graph optimized solutions to generate training data for loop-closure identification.Weak supervision in this case can come from various modalities including GPS, WiFi access-points,fiducial markers, human-annotations etc. Similar to [10], we explore whether the hypothesizedweakly-supervised place recognition method uncovers location-specific object saliency masks, thatcan be re-purposed for object-based landmark recognition and loop-closure detection.
In addition to this direction, we explore the topological SLAM problem where the discrete-continuous optimization [11] (discrete in the data association, and continuous in landmark andpose variables) is reformulated as a fully-continuous metric learning problem by lifting the dis-crete data associations to a higher-dimensional embedding [12]. This potentially relieves the issue
3

with discrete data association factors that makes the problem formulation combinatorially exhaus-tive from an optimization standpoint. Effectively, both these approaches enable scalable trainingof Visual-SLAM front-ends without having to use human-devised visual feature descriptors andhand-tuned hyper-parameters during deployment.
4

2 SLAM-Supported Semantic Scene Understanding
Object recognition is a vital component in a robot’s repertoire of skills. Traditional object recog-nition methods have focused on improving recognition performance (Precision-Recall, or meanAverage-Precision) on specific datasets [13, 14]. While these datasets provide sufficient variabilityin object categories and instances, the training data mostly consists of images of arbitrarily pickedscenes and/or objects. Robots, on the other hand, perceive their environment as a continuous im-age stream, observing the same object several times, and from multiple viewpoints, as it constantlymoves around in its immediate environment. As a result, object detection and recognition can befurther bolstered if the robot were capable of simultaneously localizing itself and mapping (SLAM)its immediate environment - by integrating object detection evidences across multiple views.
We refer to a “SLAM-aware” system as - one that has access to the map of its observable sur-roundings as it builds it incrementally and the location of its camera at any point in time. This is incontrast to classical recognition systems that are “SLAM-oblivious” - those that detect and recog-nize objects on a frame-by-frame basis without being cognizant of the map of its environment, thelocation of its camera, or that objects may be situated within these maps. In this work [1], we developthe ability for a SLAM-aware system to robustly recognize objects in its environment, using an RGB cameraas its only sensory input (Figure 1).
Cap
CoffeeMug
SodaCan
Bowl
Bowl
Figure 1: The proposed SLAM-aware object recognition system is able to robustly localize and recognize several objectsin the scene, aggregating detection evidence across multiple views. Annotations in white are provided for clarity andare actual predictions proposed by our system.
2.1 Related Work
Most classical object detection methods have focused their efforts on single-view-based recog-nition (Precision-Recall) performance [15, 16, 17, 18]. As robots operate in spatio-temporally con-tinuous and rich contexts, it is imperative that the algorithms they are equipped with are also ableto leverage this information in a holistic manner. This is particularly relevant in the context of mo-bile robots, where the agent can reason jointly over the underlying map and their corresponding
5

semantic labels. Furthermore, this form of reasoning can be extremely robust in the presence ofocclusions, or depth discontinuities, and by being able to reason over objects that come and go inand out of camera view. Moreover, modeling directly in 3D provides various contextual advan-tages over single frame or multi-frame videos.
While some of these recognition methods have been extended to video [19, 20], another obviousextension is to the multi-view case [21, 22], by aggregating object evidence across disparate framesand views. Lai et al. [23] proposed a multi-view-based approach for detecting and labeling objectsin a 3D environment reconstructed using an RGB-D sensor. Bao et al. [24, 25] proposed one ofthe first approaches to jointly estimate camera parameters, scene points and object labels usingboth geometric and semantic attributes in the scene. In their work, the authors demonstrate theimproved object recognition performance, and robustness by estimating the object semantics andSfM jointly. Other works [26, 27, 28, 29, 30] have also investigated object-based SLAM, SLAM-aware, and 3D object recognition architectures, however they have a few of glaring concerns: either(i) the system cannot scale beyond a finite set of object instances (generally limited to less than10), or (ii) they require RGB-D input to support both detection and pose estimation, or (iii) theyrequire rich object information such as 3D models in its database to match against object instancesin a brute-force manner. More specifically, we expect it to be especially advantageous for robotsto be equipped with the concept of SLAM-aware object recognition, where the spatio-temporalinformation, camera and map information are leveraged simultaneously to enable robust semanticscene understanding.
2.2 Contributions
We make the following contributions towards this end: Using state-of-the-art semi-dense mapreconstruction techniques in monocular visual SLAM as pre-processed input, we introduce thecapability to propose multi-view consistent object candidates, as the camera observes instancesof objects across several disparate viewpoints. Leveraging this object proposal method, we incor-porate some of the recent advancements in bag-of-visual-words-based (BoVW) object classifica-tion [31, 32, 33] and efficient box-encoding methods [34] to enable strong recognition performance.The integration of this system with a monocular visual-SLAM (vSLAM) back-end also enablesus to take advantage of both the reconstructed map and camera location to significantly bolsterrecognition performance. Additionally, our system design allows the run-time performance to bescalable to a larger number of object categories, with near-constant run-time for most practicalobject recognition tasks.
We present several experimental results validating the improved object proposition and recog-nition performance of our proposed system: (i) The system is compared against the current state-of-the-art [23, 35] on the UW-RGBD Scene [35, 36] Dataset. We compare the improved recogni-tion performance of being SLAM-aware, to being SLAM-oblivious (ii) The multi-view object pro-posal method introduced is shown to outperform single-view object proposal strategies such asBING [37] on the UW-RGBD dataset, that provide object candidates solely on a single-view. (iii)The run-time performance of our system is analysed, with specific discussion on the scalability ofour approach, compared to existing state-of-the-art methods [23, 35].
6

Figure 2: An illustration of the multi-view object proposal method and subsequent SLAM-aware object recognition.Given an input RGB image stream, a scale-ambiguous semi-dense map is reconstructed (a) via the ORB-SLAM-based [38]semi-dense mapping solution. The reconstruction retains edges that are consistent across multiple views, and is em-ployed in proposing objects directly from the reconstructed space. The resulting reconstruction is (b) filtered and (c)partitioned into several segments using a multi-scale density-based clustering approach that teases apart objects (whilefiltering out low-density regions) via the semi-dense edge-map reconstruction. Each of the clustered regions are then(d) projected on to each of individual frames in the original RGB image stream, and a bounded candidate region isproposed for subsequent feature description, encoding and classification. (e) The probabilities for each of the proposalsper-frame are aggregated across multiple views to infer the most likely object label.
Figure 3: Illustration of per-frame detection results provided by our object recognition system that is intentionally SLAM-oblivious (for comparison purposes only). Object recognition evidence is not aggregated across all frames, and detectionsare performed on a frame-by-frame basis. Only detections having corresponding ground truth labels are shown. Figureis best viewed in electronic form.
2.3 Extensions and Future Work
There are several extensions to this work that incorporate more recent and state-of-the-art objectrecognition tools such as Fast-RCNN [15], and Faster-RCNN [39]. With respect to object proposals,I would like to provide strong baselines for single-view object proposals (such as Geodesic ObjectProposals [40], DeepMask [41]) and show how their extension to 3D is accomplished by leveragingcamera localization. By leveraging these newer techniques, it becomes clear that datasets such as theUW-RGBD scenes [35] (14 scenes with short video sequences) may not be a good representativebenchmark for SLAM-aware recognition tasks. Instead we hope to introduce a large-scale datasetwith long camera trajectories and weakly-supervised annotations to encourage research in this
7

Figure 4: Illustration of the recognition capabilities of our proposed SLAM-aware object recognition system. Each ofthe object categories are detected every frame, and their evidence is aggregated across the entire sequence through theset of object hypothesis. In frame-based object recognition, predictions are made on an individual image basis (shownin gray). In SLAM-aware recognition, the predictions are aggregated across all frames in the image sequence to providerobust recognition performance. The green boxes indicate correctly classified object labels, and the gray boxes indicatebackground object labels. Figure is best viewed in electronic form.
Method View(s) Input Precision/RecallBowl Cap Cereal Box Coffee Mug Soda Can Background Overall
DetOnly [23] Single RGB 46.9/90.7 54.1/90.5 76.1/90.7 42.7/74.1 51.6/87.4 98.8/93.9 61.7/87.9Det3DMRF [23] Multiple RGB-D 91.5/85.1 90.5/91.4 93.6/94.9 90.0/75.1 81.5/87.4 99.0/99.1 91.0/88.8HMP2D+3D [35] Multiple RGB-D 97.0/89.1 82.7/99.0 96.2/99.3 81.0/92.6 97.7/98.0 95.8/95.0 90.9/95.6
Ours Single RGB 88.6/71.6 85.2/62.0 83.8/75.4 70.8/50.8 78.3/42.0 95.0/90.0 81.5/59.4Ours Multiple RGB 88.7/70.2 99.4/72.0 95.6/84.3 80.1/64.1 89.1/75.6 96.6/96.8 89.8/72.0
0.0 0.2 0.4 0.6 0.8 1.0
Recall
0.0
0.2
0.4
0.6
0.8
1.0
Pre
cisi
on
Frame-based vs. SLAM-aware Precision-Recall
Single view (Frame-based)10% views (SLAM-aware)30% views (SLAM-aware)All views (SLAM-aware)
Table 1 & Figure 5: Left: Object classification results using the UW RGB-D Scene Dataset [35, 36], providing mean-Average Precision (mAP) estimates for both Single-View, and Multi-View object recognition approaches. We compareagainst existing methods([23, 35]) that use RGB-D information instead of relying only on RGB images, in our case.Recognition for the single-view approach is done on a per-frame basis, where prediction performance is averaged acrossall frames across all scenes. For the multi-view approach, recognition is done on a per-scene basis, where predictionperformance is averaged across all scenes. Right: Performance comparison via precision-recall for the Frame-based vs.SLAM-aware object recognition. As expected, the performance of our proposed SLAM-aware solution increases withmore recognition evidence is aggregated across multiple viewpoints.
area. With each scene, we shall provide both images and their corresponding pose to motivate theneed for camera-based localization in object recognition and scene understanding tasks.
Recognition-Supported SLAM As shown earlier, semantic understanding in robots that con-tinuously observe its environment can be bolstered by using the geometric understanding of boththe map of its immediate environment and the trajectory the robot and camera followed. As onewould expect, the rich semantics inferred from these scenes can also be used to support SLAM viasparse, yet robust data associations. I hope to explore this capability further, and hope to have re-sults on this front very soon. More specifically, I will address the concern with current techniquesthat employ low-level bag-of-words based approaches for visual scene similarity search [42, 43]and show how such approaches do not scale very well in time.
Lifting the semantic embedding space In addition to exploring the object-driven data associa-tion efforts, I am currently also exploring the SfM/SLAM problem where the discrete-continuous
8

optimization [11] is reformulated as a fully-continuous metric learning problem by lifting the dis-crete data associations to a higher-dimensional embedding [12]. This potentially relieves the issuewith discrete data association factors that makes the problem formulation combinatorially exhaus-tive from an optimization standpoint. I would like to look into some recent efforts in lifted struc-tured feature embeddings [44] and try to find analogs that may help with reformulating data as-sociation problem, allowing far more powerful scalability compared to existing methods that dealwith robustness in pose-graph measurements [45, 46, 47].
2.4 Relevant Publications
1. Sudeep Pillai and John Leonard. Monocular SLAM Supported Object Recognition. In Pro-ceedings of Robotics: Science and Systems, Rome, Italy, July 2015. (Link)
9

3 Geometric Scene Representation and Reconstruction
Stereo disparity estimation has been a classical and well-studied problem in computer vision,with applications in several domains including large-scale 3D reconstruction, scene estimation andobstacle avoidance for autonomous driving and flight etc. Most state-of-the-art methods [48] havefocused its efforts on improving the reconstruction quality on specific datasets [49, 50], with the ob-vious trade-off of employing sophisticated and computationally expensive techniques to achievesuch results. Some recent methods, including Semi-Global Matching [51], and ELAS [52], haverecognized the necessity for practical stereo matching applications and their real-time require-ments. However, none of the state-of-the-art stereo methods today can provide meaningful scenereconstructions in real-time (≥ 25Hz) except for a few FPGA or parallel-processor-based meth-ods [53, 54, 55]. Other methods have achieved high-speed performance by matching fixed dispar-ities, fusing these measurements in a push-broom fashion with a strongly-coupled state estima-tor [56]. Most robotics applications, on the other hand, require real-time performance guaranteesin order for the robots to make quick decisions and maneuver their immediate environment in anagile fashion. Additionally, as requirements for scene reconstruction vary across robotics applica-tions, existing methods cannot be reconfigured to various accuracy-speed operating regimes.
A
B
C D
E
Figure 6: The proposed high-performance stereo matching method provides semi-dense reconstruction (E) of the scene,capable of running at a peak frame-rate of 120Hz (8.2 ms, VGA resolution). Our approach maintains a piece-wise planarrepresentation that enables the computation of disparities (semi-densely, and densely) for varied spatial densities overseveral iterations (B-2 iterations, C-1 iteration, D-4 iterations). Colors illustrate the scene depths, with green indicatingnear-field and red indicating far-field regions. Figure best viewed in digital format.
10

3.1 Related Work
Various map reconstruction representations have been considered for map reconstruction inthe past decade, including sparse feature-based reconstruction [57], dense pixel-level reconstruc-tion [58, 59], and more recently semi-dense reconstructions [60]. Other representations includingTruncated-Signed Distance Functions (TSDFs) [61, 62] and occupancy maps in the form of dis-cretized voxel-grids [63] or Gaussian Processes [64, 65], have all garnered wide interest in theirintended map reconstruction applications. While these representations attempt to specifically ad-dress the mapping problem, most of them are limited in their ability to apply to other tasks suchas planning and navigation that are typically required of mobile robots.
In typical vision-based solutions for obstacle avoidance, navigation and planning, current state-of-the-art methods have resorted to stereo-camera based dense disparity estimation and recon-struction. Even within the class of dense stereo algorithms, the run-time performance of 5-10Hzmay still be insufficiently slow especially in the context of fast maneuvering vehicles. Furthermore,these algorithms do not particularly offer any tunability of their operating regime in terms of run-time performance or accuracy.
Existing solutions also exacerbate the representational complexity when performing a varietyof tasks simultaneously such as mapping, navigation, and planning simultaneously. For planning,existing approaches convert dense reconstructions obtain to an intermediate voxel-grid based occu-pancy map to perform obstacle avoidance [66] and trajectory optimization [67]. However, mappingsolutions maintain a factor-graph based representation [68], constantly optimizing over the sparse3D map measurements and camera trajectory. This requires the robot to maintain inefficient inter-mediate representations that are redundant and computationally expensive, while adding morearchitectural complexity.
These inadequacies in vision-based mapping and planning motivate the need for a unified rep-resentation that can potentially leverage the same internal model to enable efficient mapping andnavigation. We argue for a mesh-based, any-time reconstruction algorithm that can be iteratively re-fined that has compelling properties geared towards fast-maneuvering mobile robots. In the contextof mapping and navigation, robots may need to map the world around them, in a slow but accu-rate manner, while also requiring the ability to avoid dynamic obstacles quickly and robustly. Suchsystems require the ability to dynamically change the accuracy requirements in order to achievetheir desired runtime performance, given a fixed compute budget; this work is an attempt to pro-vide such capability. Another potential application of this approach could be to generate rapidand high-fidelity reconstructions, given a sufficiently coarse trajectory plan or foveation. Given areasonable exploration-exploitation strategy, this approach can provide the flexibility in exploit-ing accurate and rich scene information, while also being able to adjust itself to rapidly handledynamic scenes during the exploration stage.
3.2 Contributions
In this work [2], we propose a high-performance, iterative stereo matching algorithm, capableof providing semi-dense disparities at a peak frame-rate of 120Hz (see Figure 6). An iterative stereodisparity hypothesis and refinement strategy is proposed that provides a tunable iteration parame-
11

ter to adjust the accuracy-versus-speed trade-off requirement on-the-fly. Through experiments, weshow the strong reliability of disparity estimates provided by our system despite the low compu-tational requirements. We provide several evaluation results comparing accuracies against currentstereo methods, and provide performance analysis for varied runtime requirements. We validatethe performance of our system on both publicly available datasets, and commercially availablestereo sensors for comparison. In addition to single view disparity estimates, we show qualitativeresults of large-scale stereo reconstructions registered via stereo visual odometry, illustrating theconsistent stereo disparities our approach provides on a per-frame basis.
We propose a tunable (and iterative) stereo algorithm that consists of four key steps: (i) Depthprior construction from Delaunay triangulation of sparse key-point stereo matches (ii) Disparityinterpolation using piece-wise planar constraint imposed by the tessellation with known depths(iii) Cost evaluation step that validates interpolated disparities based on matching cost threshold(iv) Re-sampling stage that establishes new support points from previously validated regions andvia dense epipolar search. The newly added support points are re-tessellated and interpolated tohypothesize new candidate planes in an iterative process. Since we are particularly interested incollision-prone obstacles and map structure in the immediate environment, we focus on estimatingthe piece-wise planar reconstruction as an approximation to the scene, and infer stereo disparitiesin a semi-dense fashion from this underlying representation. Unless otherwise noted, we considerand perform all operations on only a subset of image pixels that have high image gradients, andavoid reconstructing non-textured regions in this work.
Discussion Several robotics applications adhere to strict computational budgets and runtimerequirements, depending on their task domain. Some systems require the need to actively adapt tovarying design requirements and conditions, and adjust parameters accordingly. In the context ofmapping and navigation, robots may need to map the world around them, in a slow but accuratemanner, while also requiring the ability to avoid dynamic obstacles quickly and robustly. Suchsystems require the ability to dynamically change the accuracy requirements in order to achievetheir desired runtime performance, given a fixed compute budget; this work is an attempt to pro-vide such capability. We believe such capabilities can be especially useful in resource-constrainedsystems such as quadcopters, high-speed vehicles and agile robots that require fast and real-timeperception and planning.
3.3 Relevant Publications
1. Sudeep Pillai, Srikumar Ramalingam, and John Leonard. High-Performance and TunableStereo Reconstruction. In Robotics and Automation (ICRA), 2016 IEEE International Conferenceon. IEEE, 2016. (Link)
2. Srikumar Ramalingam, Michel Antunes, Dan Snow, Gim Hee Lee, and Sudeep Pillai. Line-sweep: Cross-Ratio for Wide-Baseline Matching and 3D Reconstruction. In Proc. IEEE Conf.on Computer Vision and Pattern Recognition (CVPR), 2015. (Link)
12

Figure 7: Illustrations of our proposed stereo disparity estimation method (Ours-2, row 2) on the KITTI dataset withcorresponding ground truth estimates (row 3) obtained from projecting Velodyne data on to the left camera. Despiteits short execution time, our approach shows accurate estimates of disparities for a variety of scenes. The ground truthestimates are provided as reference, and are valid points that fall below the horizon. Similar colors indicate similardepths at which points are registered.
Figure 8: Illustrated above are various scenes reconstructed using our proposed stereo matching approach. We use theground truth poses from the KITTI dataset to merge the reconstructions from multiple frames, qualitatively showingthe consistency in stereo disparity estimation of our approach.
13

4 Self-supervised Learning in SLAM-aware Robots
Model-based perception algorithms have enabled significant advances in mobile robot navi-gation, however, they are limited in their ability to learn from new experiences and adapt accord-ingly. We envision robots to be able to learn from their previous experiences and continuously tunetheir internal model representations in order to achieve improved task-performance and model ef-ficiency. This concept of life-long learning [69, 70] has been studied in various contexts, the mostrelevant of which originated with the works onNever-Ending Learning [71, 72]. The authors in thiswork propose fundamental concepts in enabling self-supervised learning in agents both for text-retrieval, language-understanding, and image retrieval. We would like to endow robots with thecapability to improve its task-specific performance as it continues to gather more experiences ofthe same task.
We envision robots to be able to leverage their previous experiences to improve upon theirability to perform tasks by considering these new experiences in hindsight. Specifically, we expectrobots to fine-tune their capabilities in such a way that admits seamless and gradually improvedperformance in its operating environment without any human supervision. Furthermore, withthe addition of new sensors we expect these agents to self-supervise the use of the newly introducedsensor towards existing tasks performed, if possible. For example, if the fused odometry estimateis available to the robot (via a combination of wheel encoder, and laser range finder estimates),it should also be available to self-supervise a bootstrapped regression using the newly introducedsensor whose intrinsics, extrinsics and visual odometry estimator is unknown.
One of the typical concerns with visual-SLAM front-ends is the ability to robustly provideframe-to-frame odometry estimates and data-association in the form of loop-closure relative poseconstraints. These measurements are typically extracted with the help of visual feature-baseddetectors and descriptors such as SIFT [73] or ORB [74]. In the case of frame-to-frame match-ing, visual features are matched and the relative pose between the frames are estimated via aRANSAC-enabled Nister’s 5-point algorithm [8]. For the problem of loop-closure identificationor commonly referred to as place recognition, typical implementations employ a vocabulary-treesupported visual bag-of-words matching for real-time visual scene description storage, indexingand retrieval [42]. Both these methods however still require fine-tuning to ensure real-time, long-term and robust operation in mobile robots [75, 76].
4.1 Self-Supervised Visual Ego-motion Learning in Robots
Visual odometry (VO) [8], commonly referred to as ego-motion estimation, is a fundamentalcapability that enable robots to reliably navigate its immediate environment. With the wide-spreadadoption of cameras in various robotics applications, there has been an evolution in visual odom-etry algorithms with a wide set of variants including monocular VO [8, 77], stereo VO [78, 79] andeven non-overlapping n-camera VO [80, 81]. Furthermore, each of these algorithms have been cus-tom tailored for specific camera optics (pinhole, fisheye, catadioptric) and the range of motionsobserved by these cameras mounted on various platforms [9].
With increasing levels of model specification for each domain, we expect these algorithms toperform differently from others while maintaining lesser generality across various optics, and cam-
14

era configurations. Moreover, the strong dependence of these algorithms on their model specifi-cation prevents being able to actively monitor and optimize their intrinsic model parameters in anonline fashion. In addition to these concerns, many autonomous systems today employ severalsensors with varied intrinsic and extrinsic properties that make system characterization extremelytedious. Furthermore, these algorithms and their parameters are fine-tuned on specific datasetswhile enforcing little guarantees on their generalization performance on new data.
4.1.1 Related Work
Recovering relative camera poses from a set of images is a well studied problem under thecontext of Structure-from-Motion (SfM) [82, 83]. Visual odometry, unlike incremental Structure-from-Motion, only focuses on determining the 3D camera pose from sequential images or videoimagery observed by a monocular camera. Most of the early work in VO was done primarily todetermine vehicle egomotion [84, 85, 86] in 6-DOF, especially in the Mars planetary rover. Over theyears several variants of the VO algorithm have been proposed, leading up to the work of Nisteret al. [8], where the authors proposed the first real-time and scalable VO algorithm. In their work,they developed a 3D-to-2D, 5-point minimal solver coupled with a RANSAC-based outlier rejectionscheme [87] that is still extensively used today. Other works [88] have extended this work to variouscamera types including catadioptric and fisheye lenses.
Constrained VO: While the classical VO objective does not impose any constraints regarding theunderlying motion manifold or camera model, it however is ridden several failure modes that makeit especially difficult to ensure robust operation under arbitrary scene and lighting conditions.Moreover, imposing egomotion constraints has been shown to considerably improve accuracy, ro-bustness, and run-time performance. One particularly popular strategy for VO estimation in ve-hicles is to enforce planar homographies during matching features on the ground plane [89, 90],thereby being able to robustly recover both relative orientation and absolute scale. For example,Scaramuzza et al. [9, 91] introduced a novel 1-point solver by imposing the vehicle’s non-holonomicmotion constraints, thereby speeding up the VO estimation up to 400Hz.
Data-driven VO: While several model-based methods have been developed specifically for theVO problem, a few have attempted to solve it with a data-driven approach. Typical approacheshave leveraged dimensionality reduction techniques by learning a reduced-dimensional subspaceof the optical flow vectors induced by the egomotion [92]. In their recent work, Ciarfuglia et al.[93] employ Support Vector Regression (SVR) to recover vehicle egomotion (3-DOF). The authorsfurther build upon their previous result with an end-to-end trainable CNN [94] while showingconsiderable improvements in performance on the KITTI odometry benchmark [50]. Recently,Clarke et al. [95] introduced an end-to-end trainable visual-inertial odometry solution. By pos-ing visual-inertial odometry (VIO) as a sequence-to-sequence learning problem, they developed aneural network architecture that combined CNNs with Long Short-Term Units (LSTMs) to fuse theindependent sensor measurements into a reliable 6-DOF pose estimate for ego-motion.
15

+Fused GPS/INS trajectory representation(Ground truth target poses)
Unsupervised feature tracking (KLT)in new camera sensor with synchronized target poses from fused GPS/INSBootstrapping visual ego-motion learningin new camera sensor
Synchronized camera sensor timestamps with GPS/INS timestamps
UNSUPERVISEDROBOT DATA COLLECTION BOOTSTRAPPEDGROUND TRUTH GENERATION
Figure 9: Bootstrapped learning for ego-motion estimation: An illustration of the bootstrap mechanism whereby arobot self-supervises the proposed ego-motion regression task in a new camera sensor by fusing information from othersensor sources including GPS and INS.
4.1.2 Contributions
We propose an end-to-end trainable architecture for visual odometry estimation in generic cam-eras with varied camera optics (pinhole, fisheye and catadioptric lenses) [3]. In this work, we takea pure geometric approach by posing the regression task of ego-motion as a density estimationproblem. By tracking salient features in the image induced by the ego-motion (via Kanade-Lucas-Tomasi/KLT feature tracking), we learn the mapping from these tracked flow features to a proba-bility mass that specifies the likelihood over a range of likely ego-motion. We make the followingcontributions:
• An end-to-end trainable ego-motion estimator We introduce a fully-differentiable densityestimation model (via a Mixture Density Network [96]) for visual ego-motion estimation thatrobustly captures the inherent ambiguity and uncertainty in relative camera pose estimation.
• Ego-motion for generic camera optics Without imposing any constraints on the type of cam-era optics, we propose an approach that is able to recover ego-motions for a variety of cameramodels including pinhole, fisheye and catadioptric lenses.
• Bootstrapped ego-motion training and refinement We propose a bootstrapping mechanismfor autonomous systems whereby a robot self-supervises the ego-motion regression task. Byfusing information from other sensor sources including GPS and INS (Inertial NavigationSystems), these indirectly inferred trajectory estimates serve as ground truth target poses forthe aforementioned regression task. Any newly introduced camera sensor can now lever-age this information to learn to provide visual ego-motion estimates without relying on anexternally provided ground truth source.
16
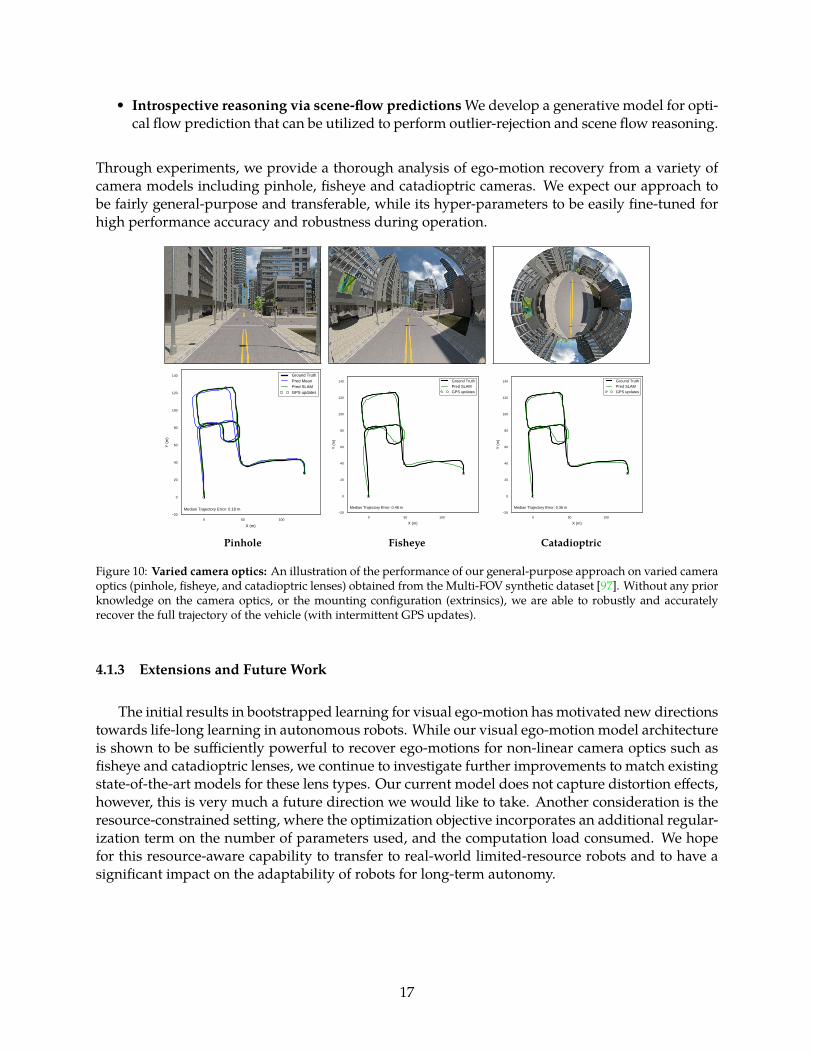
• Introspective reasoning via scene-flow predictions We develop a generative model for opti-cal flow prediction that can be utilized to perform outlier-rejection and scene flow reasoning.
Through experiments, we provide a thorough analysis of ego-motion recovery from a variety ofcamera models including pinhole, fisheye and catadioptric cameras. We expect our approach tobe fairly general-purpose and transferable, while its hyper-parameters to be easily fine-tuned forhigh performance accuracy and robustness during operation.
0 50 100
X (m)
20
0
20
40
60
80
100
120
140
Y (m
)
Median Trajectory Error: 0.18 m
Ground TruthPred MeanPred SLAMGPS updates
0 50 100
X (m)
20
0
20
40
60
80
100
120
140
Y (m
)
Median Trajectory Error: 0.48 m
Ground TruthPred SLAMGPS updates
0 50 100
X (m)
20
0
20
40
60
80
100
120
140
Y (m
)
Median Trajectory Error: 0.36 m
Ground TruthPred SLAMGPS updates
Pinhole Fisheye Catadioptric
Figure 10: Varied camera optics: An illustration of the performance of our general-purpose approach on varied cameraoptics (pinhole, fisheye, and catadioptric lenses) obtained from the Multi-FOV synthetic dataset [97]. Without any priorknowledge on the camera optics, or the mounting configuration (extrinsics), we are able to robustly and accuratelyrecover the full trajectory of the vehicle (with intermittent GPS updates).
4.1.3 Extensions and Future Work
The initial results in bootstrapped learning for visual ego-motion has motivated new directionstowards life-long learning in autonomous robots. While our visual ego-motion model architectureis shown to be sufficiently powerful to recover ego-motions for non-linear camera optics such asfisheye and catadioptric lenses, we continue to investigate further improvements to match existingstate-of-the-art models for these lens types. Our current model does not capture distortion effects,however, this is very much a future direction we would like to take. Another consideration is theresource-constrained setting, where the optimization objective incorporates an additional regular-ization term on the number of parameters used, and the computation load consumed. We hopefor this resource-aware capability to transfer to real-world limited-resource robots and to have asignificant impact on the adaptability of robots for long-term autonomy.
17

20 0 20 40 60 80 100 120 14020
0
20
40
60
80
100
120
140TruePred SLAMGPS updates
400 300 200 100 0
X (m)
0
100
200
300
400
500
600
Y (m
)
Median Trajectory Error: 0.52 m
Ground TruthPred SLAMGPS updates
0 100 200 300 400 500 600 700
X (m)
600
400
200
0
200
Y (m
)
Median Trajectory Error: 0.03 m
Ground TruthPred SLAMGPS updates
200 100 0 100 200 300
X (m)
0
100
200
300
400
Y (m
)
Median Trajectory Error: 0.19 m
Ground TruthPred SLAMGPS updates
(a) Multi-FOV Synthetic Dataset (b) Omnicam Dataset (c) Oxford 1000km (d) KITTI 00
200 100 0 100 200
X (m)
0
100
200
300
Y (m
)
Median Trajectory Error: 0.12 m
Ground TruthPred SLAMGPS updates
200 150 100 50 0
X (m)
100
50
0
50
100
Y (m
)
Median Trajectory Error: 0.18 m
Ground TruthPred SLAMGPS updates
400 300 200 100 0 100 200 300 400
X (m)
0
100
200
300
400
Y (m
)
Median Trajectory Error: 0.63 m
Ground TruthPred SLAMGPS updates
100 0 100 200 300
X (m)
0
100
200
300
400
500
Y (m
)
Median Trajectory Error: 0.30 m
Ground TruthPred SLAMGPS updates
(e) KITTI 05 (f) KITTI 07 (g) KITTI 08 (h) KITTI 09
Figure 11: Sensor fusion with learned ego-motion: On fusing our proposed VO method with intermittent GPS updates(every 150 frames, black circles), the pose-graph optimized ego-motion solution (in green) achieves sufficiently high ac-curacy relative to ground truth. We test on a variety of publicly-available datasets including (a) Multi-FOV syntheticdataset [97] (pinhole shown above), (b) an omnidirectional-camera dataset [98], (c) Oxford Robotcar 1000km Dataset [99](2015-11-13-10-28-08) (d-h) KITTI dataset [50]. Weak supervision such as GPS measurements can be especially advanta-geous in recovering improved estimates for localization, while simultaneously minimizing uncertainties associated withpure VO-based approaches.
4.1.4 Relevant Publications
1. Sudeep Pillai and John Leonard. Towards Visual Ego-motion Learning in Robots. Mar 2017.Submitted to IEEE/RSJ Intl. Conf. on Intelligent Robots and Systems (IROS) 2017 (Link)
4.2 Weakly-supervised Visual-SLAM Front-End
Place recognition or more commonly known as loop-closure detection is a critical componentin robot navigation that enables it to re-establish previously visited locations and simultaneouslyuse this information to correct the drift incurred in the dead-reckoned estimate. In the standardfactor graph construction, this is established by enforcing a constraint factor between the currentlatent node and the node that was identified as the revisited node. Constraints come in variousforms depending on the state representation of the robot, and is most commonly represented inSE(2) or SE(3) based on whether the robot experiences planar or full 6-DOF motion respectively.Identifying loop-closures, grows in complexity as the robot operating time continues to grow andis commonly established via specific sensor modalities such as cameras, lasers etc.
Loop-closure recognition is a well-studied topic [76] with several approaches leveraging sensor-specific hand-engineered features for the task at hand. However, even state-of-the-art methodstoday use hand-tuned features and matching techniques to implement their vision-based loop-closure mechanisms. However, with the growing sensor modalities on robotic systems, maintain-
18

ing several variants of the hand-engineered front-ends becomes increasingly tedious and difficult.To alleviate this growing concern, we envision robots to self-supervise or weakly-supervise the task ofvisual loop-closure recognition in newer sensors by bootstrapping their existing localization andmapping capabilities.
4.2.1 Related Work
Recently, there have been considerable improvements in visual tasks such as place recogni-tion [100] by re-training existing the popular AlexNet [101], and VGG Net [102] deep Convolu-tional Neural Network architectures on large-scale datasets of scenes. One particularly intriguingby-product of training these networks on a variety of scenes is the emergence and implicit devel-opment of scene-specific object detectors [10]. This suggests that the context of scenes are pre-dominantly identifiable by their objects contained within it. More recently, Sunderhauf et al. [103]employed these architectures to place recognition tasks by augmenting localization-capabilities viaEdge-Boxes [104] object proposals. In order to match and identify loop-closures, however, they stillresorted to a hand-specified cosine metric that enabled strong recognition performance. To furtherremedy this, the authors in [105] propose to learn a distance metric that appropriately maximizesthe place recognition objective.
In recent work, Kendall et al. [106] introduced PoseNet, where the re-localization task is castas a location regression problem. The authors show some preliminary results in re-localization byutilizing Structure-from-Motion estimates to supervise the location regression. However, it is stillunclear if such approaches generalize well to complex and larger scenes. For a detailed overviewof existing visual place recognition methods and their capabilities, we refer the reader to a recentliterature survey [76].
4.2.2 Proposed Work
Through this work, I would like to explore the use of weak-supervision via these constraints tosolve and optimize the underlying pose-graph, that can subsequently be used to generate train-ing samples for loop-closure detection. Weak supervision in this case can also come from variousmodalities including GPS, WiFi access-points, ground-truth fiducial markers, landmark recogni-tion etc. Furthermore, we realize that with most commonly occurring pose-graph optimization,these constraints can be minimal. I hope to look into metric-learning for this task, as I see it being anappropriate fit for the particular optimization of similarity metric learning for loop-closure detec-tion. With readily available training samples from the weakly supervised pose-optimized graphand their corresponding multi-modal sensor data, we expect to train a relevant metric for each ofthe modalities available to the robot. As a follow-up to this, I would like to look into incorporatingthe trained metric model in a probabilistic fashion with a sequential loop-closure model such asSeqSLAM [107].
19

5 Selected Publications
1. Sudeep Pillai and John Leonard. Monocular SLAM Supported Object Recognition. In Pro-ceedings of Robotics: Science and Systems, Rome, Italy, July 2015. (Link)
2. Sudeep Pillai, Srikumar Ramalingam, and John Leonard. High-Performance and TunableStereo Reconstruction. In Robotics and Automation (ICRA), 2016 IEEE International Conferenceon. IEEE, 2016. (Link)
3. Sudeep Pillai and John Leonard. Towards Visual Ego-motion Learning in Robots. Mar 2017.Submitted to IEEE/RSJ Intl. Conf. on Intelligent Robots and Systems (IROS) 2017 (Link)
4. Dehann Fourie, Sam Claassens, Sudeep Pillai, Roxana Mata, and John Leonard. SLAMinDB:Centralized Graph Databases for Mobile Robotics. In Robotics and Automation (ICRA), 2017IEEE International Conference on. IEEE, 2017. (Link)
5. Oscar Moll, Aaron Zalewski, Sudeep Pillai, Sam Madden, Michael Stonebraker, and VijayGadepally. Exploring big volume sensor data with Vroom. 2017. Submitted to Very Large DataBases (VLDB) 2017, Demo Track (Link)
6. Srikumar Ramalingam, Michel Antunes, Dan Snow, Gim Hee Lee, and Sudeep Pillai. Line-sweep: Cross-Ratio for Wide-Baseline Matching and 3D Reconstruction. In Proc. IEEE Conf.on Computer Vision and Pattern Recognition (CVPR), 2015. (Link)
7. Tzu-Kuan Chuang, Chun-Chih Teng, Sudeep Pillai, Chen-Hao Hung, Yi-Wei Huang, Chang-Yi Kuo, Teng-Yok Lee, Liam Paull, John Leonard, and Hsueh-Cheng Wang. Robust Deep TextSpotting for Resource-Constrained Mobile Robots. Mar 2017. Submitted to IEEE/RSJ Intl. Conf.on Intelligent Robots and Systems (IROS) 2017 (Link)
6 Timeline
Oct 2014 - July 2015 (Completed: RSS 2015) Through the concept of SLAM-supported objectrecognition, we develop the ability for robots to be able to leverage their inherent localization andmapping capabilities (spatial understanding) to better inform object recognition within scenes (se-mantic understanding). This work was submitted and presented paper on Monocular SLAM Sup-ported Object Recognition [1] at Robotics Science and Systems, 2015.
Jan 2015 - May 2016 (Completed: CVPR 2015, ICRA 2016) Following the need for strong geo-metric understanding in mobile robots, we shift our focus towards the underlying representationsof the scene considered in modern autonomous systems. More specifically, we address the concernof representational choice when it comes to maintaining metrically accurate maps for navigationpurposes in mobile robots. In preliminary work, we investigate sparse and semi-dense represen-tations for mapping in the multi-view reconstruction case. We explore the concept of line-sweepwhere we leverage cross-ratio constraints to reconstruct in wide-baseline scenarios where tradi-tional narrow-baseline matching methods fail. Along with Ramalingam et al. [4], we submittedand presented our work on Line-Sweep: Cross-Ratio for Wide-Baseline Matching and 3D Reconstructionat the IEEE Computer Vision and Pattern Recognition, 2015.
20

We motivate the need for a unified representation for vision-based mapping and planning,and introduce a mesh-based stereo reconstruction algorithm that has compelling properties gearedtowards mobile robots. We develop a High-performance and Tunable Stereo Reconstruction algorithmthat enable robots to quickly reconstruct their immediate surroundings and thereby maneuver athigh-speeds. Our key contribution is an iterative refinement step that approximates and refinesthe scene reconstruction via a piece-wise planar mesh representation, coupled with a fast depthvalidation step. This work submitted and presented at IEEE International Conference for Robotics andAutomation, 2016.
Jan 2016 - Sep 2016 (Completed: ICRA 2017) In order to support the SLAM-aware seman-tic scene understanding work, we collected datasets using two different sensor stacks. Using theGoogle Project Tango Tablet, we collected a large-scale dataset with long camera trajectories andweakly-supervised annotations to encourage research in this area. The dataset will contain longtrajectories of egocentric motion in both indoor and outdoor settings, along with associated seman-tic labels, and pose information. We foresee this dataset will help advance research in simultane-ous geometric and semantic-scene understanding and provide a benchmark for future works. Wehope to make this dataset available along with a journal submission that furthers the SLAM-awarerecognition state-of-the-art.
In order to support the notion of life-long autonomy, we introduce another dataset along witha fully-autonomous and 24x7 operational Turtlebot 2. Through this data collection tool, we hope toexplore strategies in life-long autonomy and experience-based learning for visual perception taskssuch as ego-motion and loop-closure detection or re-localization. We equip a Turtlebot 2 with sev-eral sensors including an RPlidar laser-range finder, Asus RGB-D Kinect, 4 PS3-Eye cameras, andtwo compute platforms (Sabre Laptop with an Intel Core-i7, and NVIDIA Jetson TK1). We en-able full 24x7 operation for the Turtlebot 2 by providing mechanisms for autonomous exploration,navigation and docking in order to support life-long operation. Through this work, we also sup-ported the development of SLAMinDB: Centralized Graph Databases for Mobile Robotics [5] that willbe presented at IEEE International Conference for Robotics and Automation, 2017.
Oct 2016 - Mar 2017 (Completed: IROS 2017 submission) In our submission Towards VisualEgo-motion Learning in Robots [3] to IEEE International Conference on Intelligent Robots and Systems2017, we propose techniques to enable self-supervised learning in autonomous systems. In partic-ular, we address the concern of growing sensor modalities in autonomous systems today, and theneed for a framework that allows for bootstrapped self-supervision for tasks such as ego-motionestimation. To this end, we propose a fully trainable end-to-end solution to visual ego-motion es-timation for varied camera optics (including pinhole, fisheye, and catadioptric lenses). Our proposedmodel is especially amenable to bootstrapped ego-motion learning in robots where the supervision inego-motion estimation for a particular camera sensor can be obtained from the fusion of measure-ments from other robot sensors such as GPS/INS, wheel encoders etc. We envision the capability ofrobots to self-supervise computer vision tasks such as visual ego-motion to be especially beneficialin the context of life-long perceptual learning in autonomous systems.
Jan-Apr 2017 (On-going, Journal Submission) I am currently working on extending our pre-viously published work on Monocular SLAM Supported Object Recognition [1], and submitting it to ajournal (AURO or IJRR). Through the submission, we argue the need for a larger object recognitiondataset involving a single-moving camera, as our proposed techniques achieve greater than 95%mAP on existing benchmarks [36]. In this work, we incorporate some of the more recent object de-
21

tection and recognition techniques (Fast-RCNN [15, 39]) coupled with the SLAM-aware recognitionbackend previously proposed to enable strong object recognition capability in robots. Addition-ally, we see this capability as a key enabler for future work in enabling robot localization and placerecognition using rich object and scene descriptions.
Mar - June 2017 (On-going, CoRL 2017 submission) Fundamental to any vision-based SLAMfront-end is the ability to perform a combination of visual odometry estimation, and visual loopclosure identification. As the previous submission [3] addresses the ability for robots to self-supervise ego-motion estimation, we now focus on the second component in vision-based SLAM.As previously addressed in Section 2.3, I would like to revisit the semantic pose-graph embeddingby leveraging its latent structure to improve the robustness in re-localization and place recogni-tion in the context of vision-based SLAM. Similar to [10], I would like to explore whether weakly-supervised SLAM-aware localization training uncovers location-specific object saliency masks thatcan be repurposed for object-based landmark recognition and loop-closure detection. For this, wehope to utilize the simulated environments we’ve developed for the Turtlebot to learn individualsensor characteristics before they are deployed and fine tuned on the physical Turtlebot. With theresults and insights obtained through this work, I hope to submit a draft to the Conference on RobotLearning2.
July - Aug 2017 Write, submit and defend thesis.
References[1] Sudeep Pillai and John Leonard. Monocular SLAM Supported Object Recognition. In Proceedings of
Robotics: Science and Systems, Rome, Italy, July 2015. (Link).
[2] Sudeep Pillai, Srikumar Ramalingam, and John Leonard. High-Performance and Tunable Stereo Re-construction. In Robotics and Automation (ICRA), 2016 IEEE International Conference on. IEEE, 2016.(Link).
[3] Sudeep Pillai and John Leonard. Towards Visual Ego-motion Learning in Robots. Mar 2017. Submittedto IEEE/RSJ Intl. Conf. on Intelligent Robots and Systems (IROS) 2017 (Link).
[4] Srikumar Ramalingam, Michel Antunes, Dan Snow, Gim Hee Lee, and Sudeep Pillai. Line-sweep:Cross-Ratio for Wide-Baseline Matching and 3D Reconstruction. In Proc. IEEE Conf. on Computer Visionand Pattern Recognition (CVPR), 2015. (Link).
[5] Dehann Fourie, Sam Claassens, Sudeep Pillai, Roxana Mata, and John Leonard. SLAMinDB: Central-ized Graph Databases for Mobile Robotics. In Robotics and Automation (ICRA), 2017 IEEE InternationalConference on. IEEE, 2017. (Link).
[6] Oscar Moll, Aaron Zalewski, Sudeep Pillai, Sam Madden, Michael Stonebraker, and Vijay Gadepally.Exploring big volume sensor data with Vroom. 2017. Submitted to Very Large Data Bases (VLDB) 2017,Demo Track (Link).
[7] Tzu-Kuan Chuang, Chun-Chih Teng, Sudeep Pillai, Chen-Hao Hung, Yi-Wei Huang, Chang-Yi Kuo,Teng-Yok Lee, Liam Paull, John Leonard, and Hsueh-Cheng Wang. Robust Deep Text Spotting forResource-Constrained Mobile Robots. Mar 2017. Submitted to IEEE/RSJ Intl. Conf. on Intelligent Robotsand Systems (IROS) 2017 (Link).
21st Annual Conference on Robot Learning (CoRL 2017) - Website
22

[8] David Nister, Oleg Naroditsky, and James Bergen. Visual odometry. In Computer Vision and PatternRecognition, 2004. CVPR 2004. Proceedings of the 2004 IEEE Computer Society Conference on, volume 1,pages I–652. IEEE, 2004.
[9] Davide Scaramuzza. 1-point-ransac structure from motion for vehicle-mounted cameras by exploitingnon-holonomic constraints. International journal of computer vision, 95(1):74–85, 2011.
[10] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Object detectorsemerge in deep scene CNNs. arXiv preprint arXiv:1412.6856, 2014.
[11] David Crandall, Andrew Owens, Noah Snavely, and Dan Huttenlocher. Discrete-continuous opti-mization for large-scale structure from motion. In Computer Vision and Pattern Recognition (CVPR),2011 IEEE Conference on, pages 3001–3008. IEEE, 2011.
[12] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representationsof words and phrases and their compositionality. In Advances in neural information processing systems,pages 3111–3119, 2013.
[13] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. ThePASCAL Visual Object Classes (VOC) Challenge. Int’l J. of Computer Vision, 88(2):303–338, 2010.
[14] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang,Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNetLarge Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 2015.
[15] Ross Girshick. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, pages1440–1448, 2015.
[16] RGJS Shaoqing Ren, Kaiming He, and RCNN Faster. Towards real-time object detection with regionproposal networks, arxiv preprint. arXiv preprint arXiv:1506.01497.
[17] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 779–788, 2016.
[18] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, andAlexander C Berg. Ssd: Single shot multibox detector. In European Conference on Computer Vision,pages 21–37. Springer, 2016.
[19] Kai Kang, Wanli Ouyang, Hongsheng Li, and Xiaogang Wang. Object detection from video tubeletswith convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and PatternRecognition, pages 817–825, 2016.
[20] Abhijit Kundu, Vibhav Vineet, and Vladlen Koltun. Feature space optimization for semantic videosegmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages3168–3175, 2016.
[21] Alexander Thomas, Vittorio Ferrar, Bastian Leibe, Tinne Tuytelaars, Bernt Schiel, and Luc Van Gool.Towards multi-view object class detection. In Proc. IEEE Conf. on Computer Vision and Pattern Recogni-tion (CVPR), volume 2. IEEE, 2006.
[22] Alvaro Collet and Siddhartha S Srinivasa. Efficient multi-view object recognition and full pose esti-mation. In Proc. IEEE Int’l Conf. on Robotics and Automation (ICRA). IEEE, 2010.
[23] Kevin Lai, Liefeng Bo, Xiaofeng Ren, and Dieter Fox. Detection-based object labeling in 3D scenes. InProc. IEEE Int’l Conf. on Robotics and Automation (ICRA). IEEE, 2012.
[24] Sid Yingze Bao and Silvio Savarese. Semantic structure from motion. In Proc. IEEE Conf. on ComputerVision and Pattern Recognition (CVPR). IEEE, 2011.
23

[25] Sid Yingze Bao, Mohit Bagra, Yu-Wei Chao, and Silvio Savarese. Semantic structure from motion withpoints, regions, and objects. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR).IEEE, 2012.
[26] Renato F Salas-Moreno, Richard A Newcombe, Hauke Strasdat, Paul HJ Kelly, and Andrew J Davi-son. SLAM++: Simultaneous localisation and mapping at the level of objects. In Proc. IEEE Conf. onComputer Vision and Pattern Recognition (CVPR). IEEE, 2013.
[27] Robert O Castle, Georg Klein, and David W Murray. Combining monoSLAM with object recognitionfor scene augmentation using a wearable camera. Image and Vision Computing, 28(11), 2010.
[28] Javier Civera, Dorian Galvez-Lopez, Luis Riazuelo, Juan D Tardos, and JMM Montiel. Towards se-mantic SLAM using a monocular camera. In Proc. IEEE/RSJ Int’l Conf. on Intelligent Robots and Systems(IROS). IEEE, 2011.
[29] Liefeng Bo, Xiaofeng Ren, and Dieter Fox. Hierarchical matching pursuit for image classification:Architecture and fast algorithms. In Advances in Neural Information Processing Systems (NIPS), 2011.
[30] Saurabh Gupta, Ross Girshick, Pablo Arbelaez, and Jitendra Malik. Learning rich features from RGB-D images for object detection and segmentation. In Proc. European Conf. on Computer Vision (ECCV).2014.
[31] Herve Jegou, Matthijs Douze, Cordelia Schmid, and Patrick Perez. Aggregating local descriptors intoa compact image representation. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR).IEEE, 2010.
[32] Jonathan Delhumeau, Philippe-Henri Gosselin, Herve Jegou, and Patrick Perez. Revisiting the VLADimage representation. In Proceedings of the 21st ACM international conference on Multimedia, 2013.
[33] Relja Arandjelovic and Andrew Zisserman. All about VLAD. In Proc. IEEE Conf. on Computer Visionand Pattern Recognition (CVPR). IEEE, 2013.
[34] Koen EA van de Sande, Cees GM Snoek, and Arnold WM Smeulders. Fisher and VLAD with FLAIR.In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). IEEE, 2014.
[35] Kevin Lai, Liefeng Bo, and Dieter Fox. Unsupervised feature learning for 3D scene labeling. In Proc.IEEE Int’l Conf. on Robotics and Automation (ICRA). IEEE, 2014.
[36] Kevin Lai, Liefeng Bo, Xiaofeng Ren, and Dieter Fox. A large-scale hierarchical multi-view RGB-Dobject dataset. In Proc. IEEE Int’l Conf. on Robotics and Automation (ICRA). IEEE, 2011.
[37] Ming-Ming Cheng, Ziming Zhang, Wen-Yan Lin, and Philip Torr. BING: Binarized normed gradientsfor objectness estimation at 300fps. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition(CVPR), 2014.
[38] Raul Mur-Artal, JMM Montiel, and Juan D Tardos. ORB-SLAM: a versatile and accurate monocularSLAM system. arXiv preprint arXiv:1502.00956, 2015.
[39] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detec-tion with region proposal networks. In Advances in neural information processing systems, pages 91–99,2015.
[40] Philipp Krahenbuhl and Vladlen Koltun. Geodesic object proposals. In European Conference on Com-puter Vision, pages 725–739. Springer, 2014.
[41] Pedro O Pinheiro, Ronan Collobert, and Piotr Dollar. Learning to segment object candidates. InAdvances in Neural Information Processing Systems, pages 1990–1998, 2015.
24

[42] Dorian Galvez-Lopez and Juan D Tardos. Bags of binary words for fast place recognition in imagesequences. IEEE Transactions on Robotics, 28(5):1188–1197, 2012.
[43] Mark Cummins and Paul Newman. Appearance-only slam at large scale with fab-map 2.0. The Inter-national Journal of Robotics Research, 30(9):1100–1123, 2011.
[44] Hyun Oh Song, Yu Xiang, Stefanie Jegelka, and Silvio Savarese. Deep metric learning via lifted struc-tured feature embedding. arXiv preprint arXiv:1511.06452, 2015.
[45] Niko Sunderhauf and Peter Protzel. Switchable constraints for robust pose graph slam. In 2012IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 1879–1884. IEEE, 2012.
[46] Yasir Latif, Cesar Cadena, and Jose Neira. Robust loop closing over time. Robotics: Science and SystemsVIII, page 233, 2013.
[47] Edwin Olson and Pratik Agarwal. Inference on networks of mixtures for robust robot mapping. TheInternational Journal of Robotics Research, 32(7):826–840, 2013.
[48] Jure Zbontar and Yann LeCun. Computing the stereo matching cost with a convolutional neuralnetwork. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2015.
[49] Daniel Scharstein and Richard Szeliski. A taxonomy and evaluation of dense two-frame stereo corre-spondence algorithms. Int’l J. of Computer Vision, 47(1-3), 2002.
[50] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the KITTIvision benchmark suite. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2012.
[51] Heiko Hirschmuller. Accurate and efficient stereo processing by semi-global matching and mutualinformation. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), volume 2. IEEE,2005.
[52] Andreas Geiger, Martin Roser, and Raquel Urtasun. Efficient large-scale stereo matching. In ComputerVision–ACCV 2010. Springer, 2011.
[53] Dominik Honegger, Helen Oleynikova, and Marc Pollefeys. Real-time and low latency embeddedcomputer vision hardware based on a combination of FPGA and mobile CPU. In Proc. IEEE/RSJ Int’lConf. on Intelligent Robots and Systems (IROS). IEEE, 2014.
[54] Christian Banz, Sebastian Hesselbarth, Holger Flatt, Holger Blume, and Peter Pirsch. Real-timestereo vision system using semi-global matching disparity estimation: Architecture and FPGA-implementation. In Embedded Computer Systems (SAMOS), 2010 International Conference on. IEEE, 2010.
[55] Stefan K Gehrig, Felix Eberli, and Thomas Meyer. A real-time low-power stereo vision engine usingsemi-global matching. In Computer Vision Systems. Springer, 2009.
[56] Andrew J Barry and Russ Tedrake. Pushbroom stereo for high-speed navigation in cluttered environ-ments. In Proc. IEEE Int’l Conf. on Robotics and Automation (ICRA). IEEE, 2015.
[57] Andrew J Davison, Ian D Reid, Nicholas D Molton, and Olivier Stasse. Monoslam: Real-time singlecamera slam. IEEE transactions on pattern analysis and machine intelligence, 29(6):1052–1067, 2007.
[58] Richard A Newcombe, Steven J Lovegrove, and Andrew J Davison. Dtam: Dense tracking and map-ping in real-time. In Computer Vision (ICCV), 2011 IEEE International Conference on, pages 2320–2327.IEEE, 2011.
[59] Matia Pizzoli, Christian Forster, and Davide Scaramuzza. Remode: Probabilistic, monocular densereconstruction in real time. In Robotics and Automation (ICRA), 2014 IEEE International Conference on,pages 2609–2616. IEEE, 2014.
25

[60] Jakob Engel, Thomas Schops, and Daniel Cremers. LSD-SLAM: Large-scale direct monocular SLAM.In Proc. European Conf. on Computer Vision (ECCV). Springer, 2014.
[61] Richard A Newcombe, Shahram Izadi, Otmar Hilliges, David Molyneaux, David Kim, Andrew J Davi-son, Pushmeet Kohi, Jamie Shotton, Steve Hodges, and Andrew Fitzgibbon. Kinectfusion: Real-timedense surface mapping and tracking. In Mixed and augmented reality (ISMAR), 2011 10th IEEE interna-tional symposium on, pages 127–136. IEEE, 2011.
[62] Thomas Whelan, Michael Kaess, Hordur Johannsson, Maurice Fallon, John J Leonard, and John Mc-Donald. Real-time large-scale dense rgb-d slam with volumetric fusion. The International Journal ofRobotics Research, 34(4-5):598–626, 2015.
[63] Armin Hornung, Kai M Wurm, Maren Bennewitz, Cyrill Stachniss, and Wolfram Burgard. Octomap:An efficient probabilistic 3d mapping framework based on octrees. Autonomous Robots, 34(3):189–206,2013.
[64] Simon T OâĂŹCallaghan and Fabio T Ramos. Gaussian process occupancy maps. The InternationalJournal of Robotics Research, 31(1):42–62, 2012.
[65] Fabio Ramos and Lionel Ott. Hilbert maps: scalable continuous occupancy mapping with stochasticgradient descent. The International Journal of Robotics Research, 35(14):1717–1730, 2016.
[66] Benjamin Charrow, Vijay Kumar, and Nathan Michael. Approximate representations for multi-robotcontrol policies that maximize mutual information. Autonomous Robots, 37(4):383–400, 2014.
[67] Charles Richter, Adam Bry, and Nicholas Roy. Polynomial trajectory planning for aggressive quadrotorflight in dense indoor environments. In Robotics Research, pages 649–666. Springer, 2016.
[68] Michael Kaess, Ananth Ranganathan, and Frank Dellaert. isam: Incremental smoothing and mapping.IEEE Transactions on Robotics, 24(6):1365–1378, 2008.
[69] Sebastian Thrun and Tom M Mitchell. Lifelong robot learning. Robotics and autonomous systems, 15(1-2):25–46, 1995.
[70] Sebastian Thrun and Lorien Pratt. Learning to learn. Springer Science & Business Media, 2012.
[71] Tom Mitchell. Never-ending learning. Technical report, DTIC Document, 2010.
[72] Tom M Mitchell, William Cohen, Estevam Hruschka, Partha Talukdar, Justin Betteridge, AndrewCarlson, Bhavana Dalvi Mishra, Matthew Gardner, Bryan Kisiel, Jayant Krishnamurthy, et al. Never-ending learning. In Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015.
[73] David G Lowe. Object recognition from local scale-invariant features. In Computer vision, 1999. Theproceedings of the seventh IEEE international conference on, volume 2, pages 1150–1157. Ieee, 1999.
[74] Ethan Rublee, Vincent Rabaud, Kurt Konolige, and Gary Bradski. ORB: an efficient alternative to SIFTor SURF. In Proc. Int’l. Conf. on Computer Vision (ICCV). IEEE, 2011.
[75] Davide Scaramuzza and Friedrich Fraundorfer. Visual odometry [tutorial]. IEEE robotics & automationmagazine, 18(4):80–92, 2011.
[76] Stephanie Lowry, Niko Sunderhauf, Paul Newman, John J Leonard, David Cox, Peter Corke, andMichael J Milford. Visual place recognition: A survey. IEEE Transactions on Robotics, 32(1):1–19, 2016.
[77] Kurt Konolige, Motilal Agrawal, and Joan Sola. Large-scale visual odometry for rough terrain. InRobotics research, pages 201–212. Springer, 2010.
[78] Andrew Howard. Real-time stereo visual odometry for autonomous ground vehicles. In 2008IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 3946–3952. IEEE, 2008.
26

[79] Bernd Kitt, Andreas Geiger, and Henning Lategahn. Visual odometry based on stereo image se-quences with RANSAC-based outlier rejection scheme. In Intelligent Vehicles Symposium, pages 486–492, 2010.
[80] Gim Hee Lee, Friedrich Faundorfer, and Marc Pollefeys. Motion estimation for self-driving cars witha generalized camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 2746–2753, 2013.
[81] Laurent Kneip, Paul Furgale, and Roland Siegwart. Using multi-camera systems in robotics: Efficientsolutions to the n-PnP problem. In Robotics and Automation (ICRA), 2013 IEEE International Conferenceon, pages 3770–3776. IEEE, 2013.
[82] Bill Triggs, Philip F McLauchlan, Richard I Hartley, and Andrew W Fitzgibbon. Bundle adjustmen-tâĂŤa modern synthesis. In International workshop on vision algorithms, pages 298–372. Springer, 1999.
[83] Richard Hartley and Andrew Zisserman. Multiple view geometry in computer vision. Cambridge uni-versity press, 2003.
[84] Hans P Moravec. Obstacle avoidance and navigation in the real world by a seeing robot rover. Tech-nical report, DTIC Document, 1980.
[85] Larry Henry Matthies. Dynamic stereo vision. 1989.
[86] Clark F Olson, Larry H Matthies, H Schoppers, and Mark W Maimone. Robust stereo ego-motion forlong distance navigation. In Computer Vision and Pattern Recognition, 2000. Proceedings. IEEE Conferenceon, volume 2, pages 453–458. IEEE, 2000.
[87] Martin A Fischler and Robert C Bolles. Random sample consensus: A paradigm for model fitting withapplications to image analysis and automated cartography. Communications of the ACM, 24(6):381–395,1981.
[88] Peter Corke, Dennis Strelow, and Sanjiv Singh. Omnidirectional visual odometry for a planetary rover.In Intelligent Robots and Systems, 2004.(IROS 2004). Proceedings. 2004 IEEE/RSJ International Conferenceon, volume 4, pages 4007–4012. IEEE, 2004.
[89] Bojian Liang and Nick Pears. Visual navigation using planar homographies. In Robotics and Automa-tion, 2002. Proceedings. ICRA’02. IEEE International Conference on, volume 1, pages 205–210. IEEE, 2002.
[90] Qifa Ke and Takeo Kanade. Transforming camera geometry to a virtual downward-looking camera:Robust ego-motion estimation and ground-layer detection. In Computer Vision and Pattern Recognition,2003. Proceedings. 2003 IEEE Computer Society Conference on, volume 1, pages I–390. IEEE, 2003.
[91] Davide Scaramuzza, Friedrich Fraundorfer, and Roland Siegwart. Real-time monocular visual odom-etry for on-road vehicles with 1-point RANSAC. In Robotics and Automation, 2009. ICRA’09. IEEE In-ternational Conference on, pages 4293–4299. IEEE, 2009.
[92] Richard Roberts, Christian Potthast, and Frank Dellaert. Learning general optical flow subspaces foregomotion estimation and detection of motion anomalies. In Computer Vision and Pattern Recognition,2009. CVPR 2009. IEEE Conference on, pages 57–64. IEEE, 2009.
[93] Thomas A Ciarfuglia, Gabriele Costante, Paolo Valigi, and Elisa Ricci. Evaluation of non-geometricmethods for visual odometry. Robotics and Autonomous Systems, 62(12):1717–1730, 2014.
[94] Gabriele Costante, Michele Mancini, Paolo Valigi, and Thomas A Ciarfuglia. Exploring Representa-tion Learning With CNNs for Frame-to-Frame Ego-Motion Estimation. IEEE Robotics and AutomationLetters, 1(1):18–25, 2016.
[95] Ronald Clark, Sen Wang, Hongkai Wen, Andrew Markham, and Niki Trigoni. VINet: Visual-Inertialodometry as a sequence-to-sequence learning problem. AAAI, 2016.
27

[96] Christopher M Bishop. Mixture density networks. 1994.
[97] Zichao Zhang, Henri Rebecq, Christian Forster, and Davide Scaramuzza. Benefit of large field-of-viewcameras for visual odometry. In IEEE International Conference on Robotics and Automation (ICRA). IEEE,2016.
[98] Miriam Schonbein and Andreas Geiger. Omnidirectional 3d reconstruction in augmented manhattanworlds. In Intelligent Robots and Systems (IROS 2014), 2014 IEEE/RSJ International Conference on, pages716–723. IEEE, 2014.
[99] Will Maddern, Geoffrey Pascoe, Chris Linegar, and Paul Newman. 1 year, 1000 km: The oxford robot-car dataset. The International Journal of Robotics Research, page 0278364916679498, 2016.
[100] Bolei Zhou, Agata Lapedriza, Jianxiong Xiao, Antonio Torralba, and Aude Oliva. Learning deep fea-tures for scene recognition using places database. In Advances in neural information processing systems,pages 487–495, 2014.
[101] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolu-tional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
[102] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale imagerecognition. arXiv preprint arXiv:1409.1556, 2014.
[103] Niko Sunderhauf, Sareh Shirazi, Adam Jacobson, Feras Dayoub, Edward Pepperell, Ben Upcroft, andMichael Milford. Place recognition with convnet landmarks: Viewpoint-robust, condition-robust,training-free. Proceedings of Robotics: Science and Systems XII, 2015.
[104] C Lawrence Zitnick and Piotr Dollar. Edge boxes: Locating object proposals from edges. In EuropeanConference on Computer Vision, pages 391–405. Springer, 2014.
[105] Zetao Chen, Stephanie Lowry, Adam Jacobson, Zongyuan Ge, and Michael Milford. Distance metriclearning for feature-agnostic place recognition. In Intelligent Robots and Systems (IROS), 2015 IEEE/RSJInternational Conference on, pages 2556–2563. IEEE, 2015.
[106] Alex Kendall, Matthew Grimes, and Roberto Cipolla. Posenet: A convolutional network for real-time6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, pages2938–2946, 2015.
[107] Michael J Milford and Gordon F Wyeth. Seqslam: Visual route-based navigation for sunny summerdays and stormy winter nights. In Robotics and Automation (ICRA), 2012 IEEE International Conferenceon, pages 1643–1649. IEEE, 2012.
28





























