Embed Size (px)
Citation preview

Università degli Studi della Calabria FACOLTÀ DI INGEGNERIA
Corso di Diploma in Ingegneria Informatica
TESI DI DIPLOMA
UNA IMPLEMENTAZIONE DISTRIBUITA DELLA
PROGRAMMAZIONE GENETICA IN AMBIENTE PEER-TO-PEER
RELATORI CANDIDATI
Prof. Giandomenico Spezzano Castelfranco Antonino
Toscano Cosma Christian
_________________________________________________
ANNO ACCADEMICO 2002/2003

7.1
7.2
7.3
7.4 Introduzione
L’esigenza sempre più crescente di potenza di calcolo ha portato alla realizzazione di reti
informatiche, per risolvere il problema di risorse limitate, che vengono fornite da macchine
parallele, comunque sempre più prestanti ed economiche. Negli ultimi anni si sono fatte
strada, il grid computing e l’architettura peer-to-peer, che inizialmente si sono evolute in
maniera indipendente e che adesso sembrano trovare un naturale punto di convergenza: la
condivisione delle risorse di calcolo. Da qui nasce l’esigenza di parallelizzare o distribuire il
calcolo, creando applicazioni che abbiano tali caratteristiche. Un paradigma che ha in se il
concetto di parallelismo è rappresentato dagli algoritmi evolutivi e, nel caso che andremo
esaminare, la programmazione genetica.
Il nostro obiettivo è quello di realizzare un’implementazione distribuita della
programmazione genetica in ambiente peer-to-peer, ispirandoci a CAGE che ne è
un’implementazione parallela.

Dopo aver descritto la programmazione genetica e messo in evidenza le sue caratteristiche
nel capitolo 1, descriveremo la filosofia peer-to-peer cercando una diretta correlazione con
essa (capitolo 2).
Nel terzo capitolo analizzeremo la piattaforma JXTA che fornisce gli strumenti per
sviluppare applicazioni peer-to-peer e vedremo i dettagli implementativi del nostro prototipo,
nel quarto e nel quinto capitolo.

7.5
7.6
7.7
7.8
7.9
7.10
7.11 Capitolo 1
Programmazione genetica
1.1 L’Intelligenza Artificiale
"L’intelligenza artificiale è la capacita di un computer o di un dispositivo controllato da
computer di eseguire compiti comunemente associati con i più elevati processi intellettuali,
caratteristici dell’uomo, quali l’abilità di ragionare, scoprire significati, generalizzare o
imparare dalla passata esperienza."

L'intelligenza artificiale, inoltre, si occupa, fra l'altro, di risolvere problemi utilizzando
algoritmi che imitano o si ispirano all'intelligenza umana.
L'utilizzo di metodologie di AI(Artificial Intelligence) consente di affrontare problemi
non facilmente risolvibili con le tecniche tradizionali.
1.2 Gli algoritmi evolutivi
Gli algoritmi evolutivi sono strategie euristiche, che si ispirano all'evoluzione naturale
teorizzata da Darwin nel suo libro sull'evoluzione della specie, per risolvere problemi, trattati
dall’Intelligenza Artificiale, che ricercano un minimo o un massimo globale in un dominio
limitato.
Definizione 1.2.1: consideriamo un elemento D x ∈ , dove e D è un particolare
dominio, spesso chiamato spazio di ricerca. Se consideriamo D come uno spazio
cartesiano, allora la cardinalità di D sarà uguale a n e x sarà un vettore. Data una
funzione f : D�R detta funzione obiettivo, allora la ricerca dell'ottimo globale
corrisponde a trovare un x* che massimizza tale funzione, cioè: D *x ∈ e
f(x*) f(x) :D x ≤∈∀ .
La ricerca diventa molto difficoltosa, se la funzione presenta più punti di massimo locale,
vincoli sul dominio D, non linearità, ecc.
L’utilizzo degli algoritmi evolutivi permette di ottimizzare i tempi di ricerca, che altrimenti
non sarebbero accettabili se si risolvessero i problemi attraverso l’uso di tecniche esatte,
malgrado essi risolvano il problema con un certo grado d'incertezza, oppure non assicurino la
convergenza della ricerca alla soluzione se non in casi particolari. Essi sono classificati fra i
metodi di ricerca "deboli", chiamati così perchè riescono a risolvere una grande varietà di

problemi utilizzando poche informazioni sul domino particolare, in contrapposizione a quelli
"forti" che sfruttano la maggior parte delle conoscenze del dominio applicativo.
I metodi di ricerca "deboli" sono stati spesso ispirati dall'imitazione di metodi di
risoluzione utilizzati dall'uomo o da analogie con il mondo naturale. Fra i più conosciuti si
ricordano hill-climbing, depth-first e breadth-first-search.
Angeline, ha introdotto una nuova tipologia di metodi di ricerca, i metodi deboli
evolutivi, che meglio permette di classificare questo tipo di algoritmi.
Essi sono, infatti, metodi che inizialmente hanno poca conoscenza del dominio, ma durante
la loro evoluzione acquistano più consapevolezza del problema, diventando in tal modo
metodi forti. Si parla in questo caso di "intelligenza emergente", cioè si ha una comprensione
del dominio che emerge durante 1'evoluzione stessa, per cui si riescono a risolvere in modo
efficace anche problemi con domini particolari.
Come nella teoria dell’evoluzione naturale concepita da Darwin, nel suo libro “On the
Origin of Species by Means of Natural Selection” del 1859 sull’evoluzione della specie, gli
algoritmi evolutivi orientano la ricerca verso gli elementi piu "adatti", che hanno maggiore
possibilità di sopravvivere e di trasmettere le loro caratteristiche ai successori: in pratica, si ha
una popolazione di individui che evolvono di generazione in generazione attraverso
meccanismi simili alla riproduzione sessuale e alla mutazione dei geni.
Gli algoritmi evolutivi sono tecniche che vengono definite euristiche, perché conducono ad
una ricerca che privilegia le zone del dominio della funzione obiettivo, dove maggiormente è
possibile trovare soluzioni migliori, non trascurando altre zone a più bassa probabilità di
successo in cui saranno impiegate un minor numero di risorse.
Gli algoritmi evolutivi si possono classificare in algoritmi genetici e programmazione
genetica: entrambi hanno avuto un’importante diffusione nella comunità scientifica, nelle
strategie evolutive e nella programmazione evolutiva.

1.3 Gli algoritmi genetici
Nel 1975 John Holland propone la pionieristica formulazione matematica degli Algoritmi
Genetici, nel seguito indicati come AG: si tratta di un semplice modello computazionale
dell’evoluzione naturale e del meccanismo dell’ereditarietà basato su una popolazione di
stringhe binarie che, in analogia con il DNA biologico, codificano convenientemente la
struttura e le caratteristiche di una possibile soluzione per il problema considerato.
Si utilizzano per semplicità sequenze di bit di lunghezza prestabilita e su queste si
definiscono le operazioni genetiche di mutazione (riproduzione asessuale) e ricombinazione
o crossover (riproduzione sessuale).
In termini biologici, ogni stringa rappresenta un genotipo, cioè la formula basilare per la
costruzione dell’organismo manipolata dai processi genetici:
il genotipo è quindi decodificato per formare il fenotipo dell’individuo, corrispondente alla
possibile soluzione che viene valutata per determinarne la distanza dall’ottimo cercato, cioè il
suo grado di adattamento all’ambiente indicato solitamente con il termine fitness.
Considerato un generico problema da risolvere, un AG è costituito da cinque componenti
basilari:
� una codifica delle possibili soluzioni, la popolazione, tale da essere facilmente
manipolabile dagli operatori genetici: il metodo classico è l’uso di una stringa binaria
di lunghezza fissata M;
� una funzione di adattamento o fitness, in grado di assegnare ad ogni possibile
elemento dello spazio di ricerca un valore numerico corrispondente alla distanza dalla
soluzione desiderata;

� un insieme di operatori genetici che forniscano un modo per generare stocasticamente
i nuovi individui, a partire da uno o più genitori selezionati nella popolazione
esistente: si utilizzano in genere le sole operazioni di mutazione e crossover;
� un insieme di parametri di sistema che caratterizzano il comportamento dell’algoritmo
durante l’esecuzione: ad esempio la dimensione della popolazione, o le percentuali di
utilizzo degli operatori genetici durante la fase di riproduzione;
� un criterio di terminazione, che stabilisce quando l'algoritmo si può fermare.
Figura 1.3.1: Uno schema classico di algoritmo genetico

In figura 1.3 è rappresentato un semplice schema di funzionamento di un algoritmo
genetico:
1. si crea in maniera casuale una popolazione di individui, dove ogni individuo è
rappresentato da una stringa di lunghezza prefissata, tipicamente binaria;
2. si valuta la fitness;
3. si verifica se è soddisfatto il criterio di terminazione e in caso contrario si passa alla
nuova generazione.
Figura 1.3.2: pseudo codice per i passi fondamentali di un AG
La nuova popolazione sarà costruita, applicando alla vecchia i principali operatori genetici:

� il crossover che, dati due elementi selezionati nella popolazione, detti "genitori",
genera due "figli", cioè due individui con caratteristiche ereditate da entrambi i
parenti;
� la mutazione che altera un singolo "gene" (bit) di un individuo;
� la riproduzione che copia un individuo nella nuova popolazione.
Questi operatori che, insieme al numero di generazioni massime e alla dimensione della
popolazione, costituiscono i parametri fondamentali dell'algoritmo, sono applicati con diverse
probabilità fino a che la nuova popolazione non ha raggiunto la dimensione desiderata.
1.3.1 La popolazione
Un elemento molto importante degli algoritmi genetici è la popolazione, che è costituita da
un numero prefissato di individui ed è generata in modo casuale all'inizio dell'algoritmo.
Esistono diverse varianti di algoritmo genetico, le cui caratteristiche dipendono dalla
gestione della popolazione:
� si parla di popolazione generazionale se 1'intera popolazione è sostituita interamente
dai nuovi elementi;
� in caso contrario si ha 1'algoritmo genetico steady-state (a stato fissato);
� si ha un modello elitarista se 1'elemento o gli elementi migliori sono conservati
durante 1'evoluzione della popolazione.

� si ha un modello a isole, invece, se si hanno una serie di popolazioni che evolvono in
maniera autonoma, con occasionali migrazioni di individui da una "isola" all'altra.
Ogni individuo della popolazione è rappresentato, in genere, da una stringa di lunghezza
prefissata di bit.
Nel caso più diretto, tali stringhe rappresentano la concatenazione delle rappresentazioni
binarie dei parametri numerici di una funzione da minimizzare o di una funzione che codifica
la soluzione ad un problema in termini numerici.
La scelta di utilizzare prevalentemente un alfabeto binario è dovuto ad alcuni importanti
risultati teorici, quali il teorema degli schemi di Holland, che indica questa come una
rappresentazione molto vicina all'ottimo. Recenti studi indicano, però, in questa scelta alcuni
svantaggi, quali aggiungere multimodalità e complessità alla funzione obiettivo, il che
rende il problema più difficile da affrontare.
In generale, data l'universalità della rappresentazione binaria, il genoma può comunque
rappresentare virtualmente qualunque tipo di informazione (segnali, immagini, forme,
relazioni di tipo strutturale o topologico, ecc.).
Per impostare un esperimento con un algoritmo genetico è quindi necessario definire in
modo esatto la struttura del genoma, stabilendone quindi la lunghezza ed il significato dei
singoli bit.
1.3.2. Gli operatori genetici
Negli algoritmi genetici si utilizzano principalmente tre operatori: la riproduzione, 1a
mutazione e il crossover. I primi due metodi si applicano ad un solo individuo, mentre il
crossover ha bisogno di due individui. Prima di applicare uno di questi operatori è necessario
selezionare uno o due individui della popolazione, a seconda del caso.

I più popolari metodi di selezione sono:
� il fitness proporzionate, che assegna ad ogni elemento della popolazione una
probabilità di essere scelto, proporzionata al valore della sua fitness;
� il K-tournament, che sceglie K elementi a caso nella popolazione, indice un torneo
fra questi individui e quello che risulta vincente sarà quello selezionato.
Ovviamente, con entrambi i metodi, gli individui con fitness migliore hanno maggiori
probabilità di essere selezionati e, quindi, di trasmettere i propri geni alla generazione
successiva, rispettando i meccanismi evolutivi di sopravvivenza dei più adatti.
7.11.1 Figura 1.3.3: Due semplici operatori genetici
La riproduzione ricopia semplicemente 1'individuo nella nuova popolazione, lasciando
intatto tutto il suo patrimonio genetico.
La mutazione inverte un bit, scelto casualmente con una distribuzione uniforme, del
genotipo dell'individuo e inserisce in tal modo diversità nella popolazione, portando la ricerca
verso nuovi spazi o recuperando alleli che erano andati perduti in precedenza.

Il crossover combina i patrimoni genetici dei due genitori in modo da costruire due "figli",
che possiedono parte dei geni di uno e parte dell'altro. Esistono diverse tipologie di crossover:
� il crossover ad un punto, in cui le stringhe che codificano i due genitori vengono
"tagliate" in uno stesso punto. Si opera poi uno scambio della parte destra (o sinistra)
delle stringhe (figura 1.3.3), per ottenere due figli in cui il genotipo del primo è
costituito dalla concatenazione della parte destra del genotipo del primo genitore con
la parte sinistra (destra) di quello del secondo, mentre il genotipo del secondo figlio è
costituito dalla concatenazione della parte destra (sinistra) del genotipo del secondo
genitore con la parte sinistra (destra) di quello del primo;
� nel crossover a due punti, la stringa è considerata "circolare" (l'ultimo bit si
immagina concatenato al primo) (figura 1.3.4) e quindi il genotipo, "tagliato" in due
punti, viene suddiviso in due parti che, nella rappresentazione lineare della stringa,
corrispondono alla sottostringa interna ai due tagli e alle due sottostringhe esterne ad
essi che, tuttavia, come detto, si immaginano concatenate fra loro in una unica stringa.
Lo scambio avviene quindi in modo del tutto analogo al crossover singolo punto;
Figura 1.3.4: Crossover a due punti

� il crossover uniforme, invece, prevede che, per ogni posizione all'interno della stringa
(figura 1.3.5), i bit corrispondenti dei due genitori vengano assegnati uno ad un figlio
e l'altro all'altro figlio in modo casuale.
Figura 1.3.5: Crossover uniforme
Il crossover è la forza trainante dell'algoritmo genetico ed è 1'operatore che maggiormente
influenza la convergenza, anche se un suo utilizzo troppo spregiudicato potrebbe portare ad
una convergenza prematura della ricerca su qualche massimo locale.
I parametri che regolano la minore o maggiore influenza di un operatore su un altro sono
identificati come la probabilità di crossover, di mutazione e di riproduzione; la cui somma
deve essere uguale ad uno; bisogna comunque aggiungere che esistono varianti di algoritmi
genetici, che realizzano in ogni caso la mutazione anche dopo il crossover, per mantenere
maggiore diversità nella popolazione. In realtà, la scelta dei parametri e del tipo particolare di
operatore usato dipendono fortemente dal dominio del problema, perciò non è possibile, a
priori, stabilire le specifiche di un algoritmo genetico. Addirittura sono stati sviluppati con
buon successo algoritmi ibridi the sostituiscono la mutazione con un algoritmo fortemente
dipendente dal dominio.
1.3.3 Alcuni cenni teorici

Esiste pochissima teoria sul funzionamento effettivo degli algoritmi genetici; in
particolare, Holland ha tentato di spiegare la distribuzione delle risorse nello spazio di ricerca
con il suo famoso teorema degli schemi. Tale teorema è la prima rigorosa spiegazione del
perché gli algoritmi genetici funzionino.
Uno schema è un modello di valori del gene che possono essere rappresentati, nella
codifica binaria, da una stringa di caratteri dell'alfabeto {0,1,*}. Un cromosoma contiene gli
schemi ottenuti sostituendo col simbolo "*" uno o più dei suoi bit.
Per esempio, il cromosoma"1010", contiene tra gli altri gli schemi 10**, *0*0, **10 e
**1*. L'ordine di uno schema è il numero di simboli diversi da "*" che contiene e la
lunghezza definita è la distanza tra i simboli diversi da "*" più esterni (nell'esempio 2,3,1,3,
rispettivamente).
Il teorema degli schemi spiega la potenza di un GA in termini di quanti schemi sono
processati. Agli individui della popolazione viene data la possibilità di riprodursi, spesso
chiamata prove di riproduzione (reproduce trials), e producono figli. Il numero di opportunità
che ogni individuo riceve è in proporzione al suo fitness (selezione di tipo fitness-
proportionate), quindi i migliori individui contribuiscono maggiormente ai geni della
generazione successiva. Si presuppone che un alto valore di fitness sia dovuto al fatto che
l'individuo possiede buoni schemi. Passando i migliori schemi alla generazione successiva,
aumenta la probabilità di trovare soluzioni migliori. Holland ha dimostrato che la cosa
migliore è assegnare prove di riproduzione in numero sempre maggiore agli individui che
hanno il fitness più elevato rispetto al resto della popolazione, in modo che gli schemi buoni
abbiano un numero di prove crescente in modo esponenziale nelle generazioni successive
(teorema degli schemi). Ha mostrato inoltre che poichè ogni individuo contiene un gran
numero di schemi diversi, il numero degli schemi che devono essere effettivamente processati
è dell'ordine di n3, dove n è il numero di individui. Questa proprietà è detta parallelismo
implicito ed è una delle motivazioni del buon funzionamento dei GA.

Il crossover e la mutazione alterano gli schemi definiti e possono introdurne di nuovi.
Ricapitolando, il teorema degli schemi dimostra che, utilizzando una selezione di tipo
fitness-proportionate, la distribuzione degli schemi di ricerca, cioè l'aumento o la diminuzione
di un particolare schema, avviene in modo molto vicino all'ottimo matematico ed è
indipendente dal problema.
Numerose critiche sono state mosse a questo teorema, alcune delle quali sulla reale
applicabilità in casi pratici; sono stati sviluppati, infatti, GA (Genetic Algorithm) che non
soddisfano le condizioni del teorema, ma ottengono risultati simili all'algoritmo classico.
Altre critiche sono state mosse sugli aspetti teorici, in particolare si è notato che il teorema
degli schemi non esplica le correlazioni esistenti fra i padri e i figli.
Il teorema di Price spiega meglio queste relazioni ed asserisce che il funzionamento e
1'efficienza di un GA dipende maggiormente dalle correlazioni fra genitore a figlio che non
dagli schemi stessi.
1.4 Le strategie e la programmazione evolutiva
Le strategie evolutive sono state sviluppate all'Università di Berlino da Rechenberg,
Bienert, Schwefel, Bäck, Hoffmeister.
Diversamente dagli algoritmi genetici, la popolazione è costituita da vettori di numeri reali
di lunghezza prefissata e la popolazione iniziale è generata in modo casuale in un certo
intervallo e utilizzando una distribuzione uniforme.
Una nuova popolazione è costituita dai migliori M individui di quella precedente e i
rimanenti sono scelti applicando dei particolari operatori.
I principali sono:
� la ricombinazione discreta, che genera i figli con distribuzione uniforme rispetto ai
genitori;

� la ricombinazione intermedia, che fa la media dei valori dei due genitori;
� la ricombinazione intermedia casuale, che determina in modo casuale i pesi da
attribuire ai genitori;
� la mutazione che aggiunge un valore casuale, preso da una distribuzione gaussiana
con varianza scelta dal programmatore in modo appropriato a ogni elemento del
vettore.
Il principale vantaggio derivante dall'usare queste strategie è che elementi della
popolazione con piccole diversità, dovrebbero presentare poca differenza nei comportamenti.
Questo è vero, ma non sempre si riescono a generare figli con caratteristiche sufficientemente
simili a quelle dei genitori.
La programmazione evolutiva è stata introdotta da Fogel, Owens e Walsh.
Ogni individuo della popolazione costituisce una FSM (macchina a stati finiti), ed è
formato da una serie di stati interni facenti parte di un alfabeto finito.
La caratteristica principale di una FSM è che riceve in input una serie di simboli e
restituisce in output una serie di stati, basandosi solo sugli stati correnti e 1'input.
Ebbene, 1'obiettivo della programmazione evolutiva è predire la prossima configurazione
del sistema.
L'operatore usato è quello di mutazione, che altera lo stato iniziale, modifica la transizione
o cambia uno stato interno.
La caratteristica fondamentale di questo tipo di algoritmi è che i figli hanno un
comportamento simile a quello dei genitori.

1.5 La programmazione genetica
La programmazione genetica (PG) è un’estensione degli AG, in cui gli individui che
compongono la popolazione sono costituiti non più da strutture, che codificano le
caratteristiche delle possibili soluzioni, ma da veri e propri programmi, che una volta eseguiti
calcolano tali soluzioni.
Diversi tentativi sono stati fatti per adattare gli AG all’utilizzo di un linguaggio di
programmazione tradizionale, ma è con John Koza che arriviamo ad un paradigma applicato
con successo ad una grande varietà di problemi: l’algoritmo da lui definito è quello che
chiameremo canonico, per distinguerlo dalle numerose varianti che sono state proposte
successivamente.
I programmi utilizzati possono variare dinamicamente la loro struttura e vengono
rappresentati tramite alberi di derivazione o di parsing (Figura 1.5.1), che esplicitano
l’ordine di valutazione delle primitive del linguaggio implementato.
Eseguire il programma significa quindi partire dall’operatore presente nella radice e
valutare gli argomenti che questo utilizza, cioè i nodi figli, i quali a loro volta richiederanno il
calcolo dei propri argomenti, e così via, in un processo ricorsivo che provoca una visita
anticipata dell’albero.
L’uso della sintassi del linguaggio LISP (Figura 1.5.1), dovuta all’implementazione
originaria di Koza, pur non essendo necessaria, risulta però conveniente, sia per rappresentare
gli alberi in modo lineare attraverso la notazione prefissa e le parentesi, sia per il requisito
fondamentale di chiusura delle funzioni:

Figura 1.5.1: Notazione prefissa in stile LISP ed albero di derivazione
tutte le primitive del linguaggio definito devono restituire un valore del medesimo tipo, in
modo che, generando combinazioni casuali di codice, sia sempre garantita la correttezza
sintattica del programma. Stabilito che ad ogni nodo deve sempre corrispondere un numero di
figli pari a quello dei parametri usati dall’operatore corrispondente, il requisito di chiusura
implica che si possono utilizzare come argomenti i valori restituiti da qualsiasi altra primitiva,
consentendo quindi l’inserimento di sottoalberi in un punto qualunque del programma senza
alcuna verifica di correttezza.
Lo spazio di ricerca dell’algoritmo è quindi dato dai soli alberi di derivazione col corretto
numero di figli per nodo, ed ha una dimensione finita poiché si impone a questi una
profondità massima prestabilita dai parametri di sistema: in questo modo si evita la crescita
illimitata della lunghezza dei programmi, e quindi anche della rispettiva complessità, per
evitare ovvi problemi computazionali.
La popolazione dei programmi evolve utilizzando una funzione di fitness, che definisce la
bontà di un programma, e gli operatori genetici di crossover e mutazione adattati alla
rappresentazione ad albero.
1.5.1 I parametri principali

La programmazione genetica si presenta strutturalmente più complessa rispetto agli
algoritmi genetici, dal momento che ci sono molti più parametri da considerare nella
progettazione.
Le principali scelte che devono essere valutate sono:
� la generazione della popolazione iniziale;
� l'insieme di funzioni e terminali di base;
� il tipo di selezione;
� la dimensione della popolazione e il numero massimo di generazioni;
� il criterio di terminazione.
La procedura di creazione della popolazione iniziale richiede ora di generare delle strutture
ad albero in modo casuale, con il vincolo di introdurre tanti figli per nodo quanti sono gli
argomenti dell’operatore del linguaggio a questo associato: vengono quindi introdotti nuovi
parametri di sistema che specificano la profondità minima e massima degli alberi nella
generazione iniziale ed il metodo utilizzato per la loro costruzione.
Esistono principalmente tre metodi di generazione che danno luogo ad alberi di dimensione
e forma differenti:

� utilizzando il metodo full si creano solo alberi perfettamente bilanciati dalla
profondità massima prestabilita, cioè tali che ogni ramo dello stesso livello abbia
sempre la stessa lunghezza;
� nel metodo grow si utilizza il solo vincolo delle profondità minima e massima e si
generano casualmente alberi anche sbilanciati;
� infine, si possono combinare queste due procedure in modo da creare metà
popolazione col primo metodo e l’altra metà con il secondo, facendo in modo che gli
alberi risultino anche equidistribuiti rispetto alla profondità, da quella minima a quella
massima, garantendo così un’alta diversità nella loro struttura (metodo ramped-half-
and-half).
Usando questa tecnica si riesce a creare una varietà di alberi per forma e dimensione,
instaurando un buon grado di diversità nella popolazione.
Infatti, sperimentalmente, in un gran numero di casi, con questo metodo di generazione si
sono ottenuti i risultati migliori che con gli altri due.
Un'operazione aggiuntiva utile per aumentare la diversità nella popolazione è quella di
controllare, durante la creazione, se un individuo esiste già e in caso affermativo sostituirlo
con uno nuovo.
Un programma per computer è costituito da funzioni a cui sono passati argomenti che
possono essere altre funzioni o simboli terminali (costanti, variabili, numeri random, ecc..).
Nella programmazione genetica la fase iniziale prevede la definizione dell'insieme di base
di funzioni e terminali, da cui creare la popolazione iniziale.

La scelta di questi insiemi dipende fortemente dal dominio particolare del problema; per
esempio se si vuole ricercare un'espressione matematica intera, i simboli di funzione
potrebbero essere {+, *, - , \} e i terminali {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}.
Le funzioni scelte devono soddisfare la proprietà di chiusura, già descritto, e inoltre, avere
la proprietà di sufficienza, cioè è necessario che le funzioni, unite ai simboli terminali, siano
in grado di generare una soluzione del problema.
Perciò, la scelta di un insieme di funzioni e terminali, appropriate ad un particolare
dominio, risulta essere un punto critico nella riuscita di un algoritmo di programmazione
genetica; infatti, non sempre si conosce 1'insieme di funzioni sufficienti alla risoluzione di un
problema e, del resto, sceglierne un insieme ridondante può degradare in maniera significativa
le prestazioni del sistema.
La selezione degli elementi, su cui applicare gli operatori, influenza la convergenza
dell'algoritmo; infatti, una maggiore pressione selettiva comporta una più veloce convergenza
dell'algoritmo, però può portare ad una perdita della diversità della popolazione e la soluzione
ottima potrebbe non essere mai raggiunta.
I metodi più usati sono:
� fitness proportionate selection, in cui la probabilità che ogni individuo sia
selezionato è pari alla sua fitness normalizzata;
� rank selection, in cui gli elementi sono ordinati e scelti in base alla loro fitness
relativa e non assoluta;
� tournament selection, in cui un numero fissato di elementi è estratto in modo casuale
dalla popolazione, e quello fra di essi che possiede la fitness migliore viene
selezionato.

Fra questi metodi, il primo è quello che, generalmente, comporta una minor pressione
selettiva.
La dimensione della popolazione è un altro dei parametri che influenzano la convergenza
dell'algoritmo, insieme al numero massimo di generazioni; infatti un sottodimensionamento
potrebbe portare al non raggiungimento dell'ottimo cercato e del resto, al loro aumentare,
1'algoritmo diventa computazionalmente troppo espansivo.
1.5.2 Mutazione, crossover ed altri operatori
Il passaggio da una generazione all'altra avviene attraverso 1'applicazione di definiti
operatori unari o binari ad elementi della popolazione selezionati con i metodi descritti nel
precedente paragrafo.
I suddetti operatori sono applicati in modo esclusivo con una certa probabilità; ovviamente
la somma delle probabilità sarà uguale ad uno.
8
9 FIGURA 1.5.2: UN ESEMPIO DI CROSSOVER

Nella programmazione genetica la forza trainante dell'algoritmo è costituita dall'operatore
di crossover, di gran lunga più usato rispetto agli altri operatori quali mutazione,
permutazione, editing, incapsulamento e decimazione.
L’operazione genetica di crossover (Figura 1.5.2) consiste nello scambio incrociato di
interi sottoalberi appartenenti a due programmi: selezionati i genitori, su entrambi si sceglie
un nodo con procedura casuale, quindi i relativi sottoalberi vengono scambiati tra loro
ottenendo due nuovi individui.
È importante notare che se i due genitori sono identici, i figli ottenuti tramite crossover
risultano solitamente differenti da questi, grazie al fatto che i nodi per lo scambio dei
sottoalberi sono presi in modo casuale su entrambi gli alberi.
La scelta del punto di crossover avviene con una preferenza per i nodi con figli stabilita da
un parametro di sistema, in modo da evitare il rischio di effettuare troppo spesso semplici
scambi di foglie, presumibilmente poco significativi, e favorire modifiche più incisive nella
struttura dell’albero: lo standard utilizzato prevede una preferenza del 90% sui nodi interni.
Un secondo parametro, di importanza molto minore, stabilisce il comportamento del
sistema quando gli alberi generati superano il limite di profondità massima stabilito: si può
riprovare a scegliere i punti di crossover o ripartire da una nuova selezione, o ancora si
possono restituire le copie immutate degli stessi genitori.
Di norma è utilizzato quest’ultimo comportamento, sia perché non richiede un ulteriore
peso computazionale, e sia perché la ripetizione del tentativo non porta in generale a sensibili
differenze nelle prestazioni, dal momento che può comunque capitare che il crossover
produca delle copie dei genitori, il che avviene quando sono scelti per lo scambio sottoalberi
tra loro identici.

Figura 1.5.3: Un esempio di mutazione
L’operatore genetico di mutazione (Figura 1.5.3) consiste nell’inserire del nuovo codice
nel programma: selezionato il genitore, si sceglie in modo completamente casuale un suo
nodo, quindi il relativo sottoalbero viene sostituito da un altro generato sempre con procedura
casuale. La mutazione può essere implementata in modo che, nel caso il nuovo albero superi
il limite massimo di profondità, venga restituita una copia del genitore oppure sia ripetuta da
capo l’operazione; un ulteriore parametro specifica la profondità massima del nuovo
sottoalbero da inserire, il quale verrà creato con la stessa procedura casuale utilizzata per la
generazione iniziale. In generale si può considerare la mutazione come una specializzazione
del crossover per cui solitamente non è usata nell’algoritmo canonico: a differenza del
comportamento osservato per il crossover negli AG, la sua implementazione sugli alberi non è
legata alla perdita di diversità, ed in particolare è assai poco probabile che una primitiva
sparisca completamente e necessiti di essere reintrodotta tramite mutazione. In realtà, però, la
dinamica evolutiva può portare comunque a vistose cadute del tasso di diversità e l’uso della

mutazione, in una delle tante varianti proposte, è un possibile metodo per attenuare questo
processo.
La permutazione è attuata scegliendo un nodo interno (una funzione) a caso dell'albero; se
la funzione ha k argomenti, è estratta una delle k! permutazioni e gli argomenti sono
arrangiati di conseguenza. Ovviamente, se la funzione è commutativa l'operatore non ha
nessun effetto.
L'editing permette di semplificare un sottoalbero valutando 1'espressione risultante: ad
esempio, (OR X X) può essere sostituita con X.
L'operazione può essere effettuata durante la fase di run con una certa frequenza (ogni
generazione o più raramente) o sul risultato finale.
Nel primo caso, il suo utilizzo potrebbe causare una prematura convergenza dato che le
espressioni semplificate sono più soggette ad un effetto distruttivo del crossover.
Con 1'incapsulamento, un sottoalbero, che parte da un nodo interno di un albero
selezionato, è scelto e compilato; quindi tale sottoalbero va a far parte dei terminali e non è
soggetto perciò all'effetto distruttivo del crossover. In tal modo sono salvate le funzioni più
interessanti.
La decimazione seleziona una certa percentuale (ad esempio il 20%) della popolazione in
una determinata generazione, in base ai valori della fitness, senza permettere duplicati; il resto
della popolazione è cancellata.
Questo risulta utile per mantenere la diversità in quei casi dove pochi elementi hanno una
fitness molto più elevata degli altri e questi avrebbero il sopravvento in poche generazioni.
Come accennato in precedenza, fra i vari operatori, il più usato è senz'altro il crossover
che, diversamente dagli algoritmi genetici, basta da solo a garantire il mantenimento della
diversità; in genere è usato in congiunzione con la mutazione che ha una probabilità minore;
gli altri operatori sono usati solo in casi particolari, nei quali è possibile sfruttare uno dei
vantaggi descritti in precedenza.

Gli operatori sopracitati garantiscono la correttezza sintattica degli alberi generati, grazie
alla proprietà di chiusura, ma non la correttezza semantica. Sarà la fitness, penalizzando gli
alberi che non rispettano le regole semantiche, a favorire la crescita di alberi semanticamente
corretti.
1.5.3 L’aumento della complessità nella programmazione genetica
La complessità di un programma generato cresce con il passare delle generazioni, se non si
adottano strategie per limitarla, producendo effetti negativi, in quanto il programma risulta di
difficile interpretazione e non generalizza bene, in accordo al principio del rasoio di Occam,
che sostiene che le soluzioni più semplici sono da preferire in quanto evitano 1'aggiunta del
superfluo e, quindi, sono applicabili ad una casistica più generale.
Il fenomeno del bloating è una delle cause dell’aumento di complessità dei programmi;
esso indica 1'utilizzo di una quantità di simboli in eccesso rispetto a quelli effettivamente
necessari a esprimere un concetto,ad esempio:
log e + log e + log e al posto della semplice espressione 3 * log e.
Fra le cause scatenanti del bloating hanno particolare rilievo i cosiddetti introns, che
prendono il nome da quella parte del DNA che non viene trascritta nelle proteine.
In GP, gli introns sono definiti come una parte dell'albero del programma che non altera il
fenotipo, cioè non è utilizzato nel calcolo della fitness, come ad esempio i1 blocco (X AND
X) che non modifica la semantica del risultato.
Eliminare questa parte superflua del codice potrebbe sembrare la soluzione migliore per
ovviare ai problemi sopracitati, ma ciò potrebbe comportare effetti collaterali negativi. Vari
studi ed esperimenti hanno evidenziato un effetto positivo di questo fenomeno, nel preservare
soluzioni interessanti dagli effetti distruttivi del crossover.
Infatti, se un programma contiene parti non utilizzabili per il calcolo della fitnesss, sarà più
probabile che il crossover non alteri la fitness di tale programma. Perciò, 1'eliminazione o

meno degli introns deve essere attentamente considerata nel ridurre la complessità del
sistema.
In genere, per ottenere soluzioni più semplici, si agisce sui parametri del sistema fissando
la profondità massima degli alberi o si aggiunge alla fitness una funzione di parsimonia che
favorisca gli alberi più corti o, ancora, si modificano gli operatori genetici in modo da ridurre
le ridondanze. Limitare la profondità massima può essere difficoltoso se non si conosce la
dimensione della soluzione del problema, rischiando così di escluderla perché fuori dal limite
accettato. Ancora, aggiungere la funzione di penalizzazione alla fitness (parsimonia) non
favorisce lo sviluppo naturale del sistema e può penalizzare la ricerca della soluzione ottima.
In definitiva, la scelta di utilizzare alberi più o meno complessi resta un problema aperto,
dal momento che la riduzione dell'albero se da una parte genera soluzioni più compatte e
generali, dall'altra può portare ad una prematura convergenza e al non raggiungimento della
soluzione ottimale, cosa che non può prescindere dal dominio particolare.
1.5.4 Differenze e analogie fra GP e GA
Il genotipo degli algoritmi genetici è, in genere, rappresentato con una stringa di lunghezza
prefissata di bit, mentre nella programmazione genetica esso è costituito da un albero formato
da funzioni e terminali, di lunghezza variabile, anche se, solitamente, è fissata una profondità
massima che ne limita la dimensione. Niente vieterebbe, quindi, di rappresentare un albero di
GP, sicuramente limitato in dimensione da una profondità massima o da necessità di
implementazione, con una stringa di bit di lunghezza fissata pari a quella massima dell'albero,
cioè di utilizzare un algoritmo genetico.
Necessità di ordine pratico rendono più facile e naturale usare GP per far evolvere
programmi per computer che non GA. Da non sottovalutare il fascino naturale, che far
evolvere programmi per computer, invece che innaturali stringhe di bit senza significato,
esercita sull'uomo e rende più spontaneo la scelta della programmazione genetica.

L'operatore prevalente è, in entrambi i casi, quello di crossover, ma mentre in GP esso è
sufficiente da solo a mantenere la diversità nella popolazione, in GA è la mutazione che si
sobbarca questo compito, in modo da evitare una prematura convergenza, con 1'introduzione
di nuovi elementi per la ricerca o il recupero di elementi precedentemente persi. Nella
programmazione genetica, il crossover fra più alberi può introdurre una nuova semantica negli
alberi generati, spostando la ricerca verso un'altra zona, più di quanto possa fare l'analogo
operatore degli algoritmi genetici rendendo superflua la mutazione.
Un altro fattore importante di differenza fra i due metodi è la sensibilità ai parametri che
sono spesso di fondamentale importanza per la convergenza di un algoritmo genetico, mentre
non influenzano di molto il raggiungimento di una soluzione ottima per 1a GP; per essa 1a
fase di tuning dei parametri risulta più semplice e non necessita di molto sforzo.
Un altro punto da tenere in considerazione è che 1'interpretazione di un allele dipende
fortemente dalla sua posizione nella stringa di bit, mentre un istruzione per computer ha lo
stesso significato indipendentemente dalla posizione anche se, ovviamente, può generare
comportamenti semantici diversi; perciò questo aspetto facilita l'emergere di dinamiche
naturali insite nel processo evolutivo della programmazione genetica.
1.6 I modelli per la programmazione genetica
Prima di cominciare a descrivere la programmazione genetica, vediamo alcune definizioni
che possono tornare utili allo scopo:
Definizione 1.6.1: Lo speedup di un algoritmo parallelo è il rapporto fra il tempo
ottenuto dal miglior algoritmo sequenziale e quello impiegato dall'algoritmo parallelo
fatto girare su p processori; il caso ideale è quello di speedup lineare.

Definizione 1.6.2: L'efficienza è data dal rapporto fra lo speedup e il numero di
processori ed è un indice della frazione di tempo utilmente speso dai processori.
Definizione 1.6.3: Un sistema parallelo si dice scalabile se 1'efficienza può essere
mantenuta costante, all'aumentare dei processori, aumentando anche la dimensione del
problema. Se variando in modo lineare il numero di processori, basta variare in modo
lineare anche la dimensione del problema e 1'efficienza rimane costante, allora il sistema
si dice altamente scalabile.
La programmazione genetica e gli algoritmi evolutivi in genere hanno bisogno di grandi
popolazioni per ottenere una buona convergenza; questo aspetto, unito al fatto che calcolare la
fitness di un singolo individuo richiede la valutazione su un certo training set, porta ad uno
sforzo computazionale notevole.
Inoltre, nel caso particolare della programmazione genetica, l'albero del programma può
anche essere molto complesso e può quindi dare problemi di complessità spaziale, oltre a
quelli di complessità temporale, in quanto può superare la capacità di memorizzazione di una
singola macchina.
Una soluzione al problema della memoria insufficiente è quella di realizzare
un’implementazione parallela di questo tipo di algoritmi.
Questo compito risulta facilitato dal fatto che la programmazione genetica è
implicitamente parallela, in quanto la fase più dispendiosa dell’algoritmo, che è la valutazione
della fitness di ogni individuo, è indipendente e può avvenire su processori diversi. Il
problema, invece, è la selezione degli individui più adatti all’interno della popolazione, la

quale ha bisogno di accessi remoti che riducono la possibilità di avere speed-up lineari
dell’algoritmo parallelo.
I metodi per parallelizzare un algoritmo evolutivo, possono essere classificati in tre
tipologie: modello globale , modello a isole e modello diffusivo o cellulare.
� Il modello globale, in cui si ha sempre una singola popolazione, come nella versione
sequenziale, ma la valutazione della fitness degli individui è eseguita in parallelo,
dividendo il carico fra i processori disponibili, mentre il crossover e gli altri operatori
sono applicati in sequenziale. La selezione è quella classica che agisce su tutta la
popolazione, da qui il nome globale. Questo tipo di modello ha il vantaggio di
preservare il comportamento dell'algoritmo sequenziale anche in parallelo, ma la fase
di selezione richiede frequenti accessi all'intera popolazione e il conseguente overhead
di comunicazione risulta inaccettabile a meno che non ci siano funzioni di fitness
particolarmente pesanti da valutare.
� Un'alternativa al modello precedente è il modello ad isole, che utilizza un diverso
meccanismo di selezione limitato agli individui posti su un unico processore; la
popolazione è suddivisa in sottopopolazioni, dette isole, che sono distribuite, di solito,
una per processore. L'implementazione di tale modello prevede la creazione di
sottopopolazioni random all'interno di ogni singolo nodo; i vari operatori genetici e la
valutazione della fitness vengono eseguiti a livello locale. In tal modo l'algoritmo
presenta una scalabilità quasi lineare e risulta di facile implementazione: infatti, è
sufficiente lanciare un processo dell'algoritmo per ogni nodo. Una variante di tale
modello prevede la migrazione di elementi da una sottopopolazione all'altra, affinché
si introduca diversità nelle isole e si garantisca una convergenza migliore. Un aspetto

ancora non ben compreso di questo modello è se, in effetti, riesca a mantenere la
stessa convergenza di quello sequenziale classico.
� Nel modello diffusivo, ogni individuo k è sostituito, nella successiva generazione, da
un nuovo elemento generato applicando l'operatore di crossover o mutazione ad
elementi appartenenti al vicinato di k stesso. La selezione ristretta ad un vicinato
locale rende l'implementazione parallela molto efficiente, dal momento che le
comunicazioni sono limitate solo ai vicini e, di conseguenza, non c'è un overhead
eccessivo. Inoltre, soluzioni sub-ottime non si diffondono velocemente all'interno
dell'intera popolazione, favorendo lo svilupparsi di nicchie in cui si esplorano diverse
porzioni dello spazio di ricerca e viene evitata una prematura convergenza. Inoltre,
rispetto al modello ad isole, si può notare una maggiore stabilità riguardo ai parametri
di progettazione.
Dal momento che un modello di questo tipo è equivalente ad un automa cellulare,
esso è detto anche modello cellulare.
1.6.1 L'automa cellulare
Dalla sezione precedente si evince che 1'automa cellulare si presenta come il modello
ristretto più adatto per 1'implementazione di un modello diffusivo.
Gli automi cellulari sono stati introdotti da John Von Neumann e Stan Ulam, nel 1950 e,
in origine, sono stati utilizzati per lo studio di sistemi di autoriproduzione.
Un automa cellulare è formato da un insieme di elementi, detti celle, che sono disposti in
una qualche forma geometrica, a una, due o tre dimensioni.
Ad ogni cella è associato uno stato che possiede un valore compreso in un insieme finito.
Ogni cella evolve, secondo istanti discreti di tempo, da un certo valore dello stato ad un altro,
secondo una regola locale, detta funzione di transizione.

Il valore dello stato di una singola cella, al tempo T+1, dipende solamente dai valori dello
stato delle adiacenti e della cella stessa, al tempo T.
9.1.1 Figura 1.6.1: Evoluzione di un semplice automa cellulare monodimensionale
L'insieme delle celle che influenzano lo stato di una cella c vengono dette vicinato della
cella c.
La figura 1.6.1 esemplifica il funzionamento di un automa cellulare.
Quello visibile in figura è monodimensionale, come si può vedere, e le adiacenti di ogni
cella sono le due più vicine.
Lo stato di una cella è un intero e viene aggiornato facendo la somma del valore della cella
stessa e delle adiacenti, come si può notare dall'illustrazione.
La topologia è toroidale, cioè 1'adiacente della prima cella è 1'ultima e viceversa.
Gli automi cellulari sono usati per simulare fenomeni fisici e lo stato di una cella
rappresenta alcune caratteristiche (per esempio temperatura, pressione, ecc..) della zona di
spazio corrispondente alla cella stessa.
Diamo, di seguito, alcune definizioni formali di automa cellulare.
Definizione 1.6.1: Un automa cellulare è una quadrupla A = (E n, X, S, f) dove:
� E n è l' insieme delle celle appartenenti a uno spazio euclideo a n dimensioni e
ciascuna di esse può essere rappresentata come un punto a coordinate intere.

� X è l'indice di vicinato, cioè un insieme finito di vettori a n dimensioni che
rappresentano le coordinate di una cella; esso permette di definire l'insieme
N(X,i) dei vicini della cella i = < i1, i2, i3, … , in > in questo modo: sia X = { x1, x2,
x3 , … xm-1 } dove m è la cardinalità di X; allora N(X,i) = { i + x0 , i + x1 , i + x2 ,
... , i + xm-1) e x0 è il vettore nullo che permette di definire la cella stessa.
� S è l' insieme degli stati dell'automa: esso è costituito dal prodotto cartesiano S1 x
S2 x S3 x ... x Sk dove ciascun Si è l'insieme dei valori che ciascun sottostato può
assumere.
� f: Sm � S è la funzione di transizione dell'automa.
Definizione 1.6.2: La funzione ct : En � S, dove c(i) è lo stato della cella i, è detta
configurazione dell'automa cellulare.
La particolare struttura dell'automa cellulare consente un'efficiente implementazione
parallela ed è perciò stato scelto come modello per la realizzazione dell'ambiente parallelo di
programmazione genetica.
Nel caso della programmazione genetica, ogni cella dell'automa cellulare corrisponde ad
un individuo della popolazione.
La funzione di transizione di una cella applica uno dei classici operatori genetici agli
individui della popolazione nei modi visti in precedenza; gli elementi selezionati sono, però,
la cella stessa e (nel caso di operatori binari) uno dei suoi vicini, scelto secondo un criterio
opportuno. Inoltre restituisce 1'individuo prodotto dall'operatore (o uno dei due individui
prodotti nel caso di operatore binario) che, quindi, diventa il sostituito alla cella stessa nella
nuova popolazione.

1.7 CAGE ( CellulAr GEnetic programming tool )
CAGE è un’applicazione parallela per lo sviluppo della programmazione genetica basata sul
modello cellulare.
La popolazione degli individui è organizzata in una matrice a due dimensioni ed è suddivisa
tra i vari processori (Figura 1.7.1) in sezioni longitudinali, in modo che il carico di lavoro sia
bilanciato tra le parti. Inoltre, ogni processore ha due bordi, contenenti un numero di individui
pari alla larghezza della matrice, che conterranno il vicinato sinistro e destro del processore.
Figura 1.7.1: La griglia della popolazione divisa tra tre processi
La scelta di questa suddivisione è dettata da problemi di efficienza, dal momento che, su
calcolatori reali paralleli, con elevati tempi di startup delle comunicazioni, è quella che
garantisce maggiore scalabilità. La creazione degli individui, l’applicazione degli operatori
genetici e la valutazione della fitness avviene localmente su ogni processore, relativamente
alla porzione di popolazione presente in esso.
1.7.1 Architettura software di CAGE

L’architettura dell’ambiente è formata da una serie di processori disposti logicamente ad
anello (Figura 1.7.2), in cui le comunicazioni sono ristrette ai processori vicini localmente e
l’ultimo processore costituisce il vicino del primo; quindi tale struttura è adatta ad essere
gestita come una topologia ad anello, che, comunque, è abbastanza efficiente su un fat-tree.
Figura 1.7.2: Architettura software di CAGE
Ogni processore è uno slave ( valuta la fitness della sua porzione di popolazione, applica i
vari operatori, ecc.), mentre uno di essi, detto master, oltre a queste funzioni ne deve svolgere
altre aggiuntive ( scrive i report per ogni generazione e il report finale,manda in output la
messaggistica di errore, ecc.).
Lo schema di funzionamento dell’algoritmo parallelo è il seguente:
1. Ogni processore legge i parametri dell'algoritmo da file e da riga di comando.
2. Ogni processore alloca e inizializza le strutture di base, quindi crea la propria porzione
di popolazione secondo i parametri specificati e ne valuta la fitness iniziale.

3. Per ogni generazione fino alla finale o al soddisfacimento del criterio di terminazione
sono eseguite le seguenti operazioni da ogni processore (se non specificato altrimenti):
� sono caricati e scambiati i bordi dei processori vicini, in modo che la fase di
selezione locale possa avvenire senza ulteriori comunicazioni, anche negli
individui appartenenti alla striscia verticale di confine fra i processori;
� ad ogni individuo appartenente al processore, a secondo della probabilità
specificata è applicato un determinato operatore selezionando, nel caso di operatori
binari, anche un altro individuo, scelto fra quelli appartenenti al vicinato di Moore
(quello che presenta la fitness migliore);
� l'elemento risultante dall'applicazione dell'operatore è inserito nella nuova
popolazione; nel caso del crossover, che genera due figli, la scelta dell'elemento da
sostituire dipende dal parametro specificato a verrà descritto dopo;
� viene caricata la nuova popolazione;
� è valutata la fitness della nuova popolazione;
� gli slave valutano 1'elemento della popolazione avente fitness minima e il master
riceve l'elemento minimo di tutti i processori a stampa il report della generazione.
4. Il master genera il report dell'intero run dell'algoritmo, quindi vengono liberate tutte le
strutture dati.

CAGE si basa su SGPC (Simple Genetic Programming in C), uno dei migliori tool
relativi alla programmazione, in quanto ad efficienza, portabilità, leggibilità del codice e
facilità d’uso. SGPC è stato scritto da Aviram Carmi e Walter Alden Tackett in linguaggio C,
il che rende l’ambiente altamente compatibile ed efficiente e permette di definire le funzioni e
i terminali della programmazione genetica in un file denominato setup.c, mentre in un altro
file, chiamato fitness.c, è possibile definire la funzione di fitness dell’algoritmo e un
eventuale criterio di terminazione prima del raggiungimento del numero massimo di
generazioni. Il makefile rende possibile il linkaggio di tutti i file e costruisce l’eseguibile. I
parametri, se diversi da quelli indicati per default, possono essere scritti in un file definito
dall’utente, specificato a tempo di esecuzione. L’ambiente supporta la maggior parte dei
parametri utilizzati nella programmazione genetica classica, in particolare segnaliamo i
seguenti:
� seed (il seme random utilizzato per generare i numeri casuali, laddove sia
necessario);
� population_size (la dimensione della popolazione);
� steady-state (introduce la possibilità di avere un algoritmo a stato fissato);
� max_depth_for_new_tree (la profondità massima dei nuovi alberi creati);
� max_depth_after_crossover (la profondità massima degli alberi generati dal
crossover);

� max_mutant_depth (la profondità massima degli sottoalberi creati per l’operazione
di mutazione);
� grow_method (il metodo di creazione della popolazione: sono supportati il GROW, il
RAMPED e il FULL);
� selection_method (i metodi per la selezione della popolazione: è possibile utilizzare
FITNESSPROP oppure TOURNAMENT);
� tournament_k (il numero degli individui che partecipano al torneo, nel caso il
metodo di selezione sia il k-tournament);
� crossover_func_pt_fraction ( la probabilità di crossover che sceglie solo punti
interni degli alberi) ;
� crossover_func_any_fraction ( la probabilità di crossover che sceglie fra qualsiasi
punto degli alberi, anche un terminale);
� fitness_prop_repro_fraction ( la probabilità di riproduzione);
� parsimony_factor (un fattore di parsimonia che è aggiunto, moltiplicato per la
dimensione dell’albero soluzione, alla funzione di fitness definita dall’utente, in modo
da facilitare l’evoluzione di soluzioni più semplici).
E’ possibile specificare il numero massimo di generazioni eseguite e il numero di isole;
infatti SGPC consente di simulare il funzionamento di un algoritmo di GP distribuito secondo
il metodo ad isole, però su di un singolo processore. Inoltre, il tool rende possibile l’utilizzo di

costanti random secondo quanto descritto da Koza e consente di definire oltre alle normali
funzioni, anche macro, il che rende il codice molto efficiente.
CAGE conserva tutte le caratteristiche di SGPC, con l’aggiunta di alcune modifiche. Il tool
CAGE è basato su una griglia a due dimensioni. Inoltre, per ogni computazione locale vi sono
due buffer in più e le comunicazioni sono state implementate tramite le librerie di MPI. Per di
più CAGE supporta una differente strategia di selezione e sostituzione, specificate nel
parametro selection_method. Per l’operatore di crossover ci sono le seguenti strategie:
� EVERCHANGE seleziona il miglior individuo del vicinato di Moore e sostituisce
sempre il vecchio individuo con uno dei figli a caso.
� GREEDY sostituisce il vecchio individuo solo se il migliore dei due figli presenta una
fitness migliore del padre.
� SA adotta una strategia di sostituzione di tipo simulated annealing, tuttora non
implementata.
E’ possibile poi specificare i parametri width e height, che rappresentano rispettivamente la
larghezza e l’altezza della matrice dell’automa sotto il vincolo che il loro prodotto sia pari alla
dimensione della popolazione.
1.7.3 Dettagli dell’implementazione

La popolazione dell’automa è implementata come una matrice bidimensionale di alberi, ed
è divisa fra i processori secondo la dimensione longitudinale come illustrato in Figura 1.7.2.
Questa scelta, alternativa a quella di implementare l’automa come un vettore, rende più
naturale la programmazione delle varie funzioni, dal momento che rende l’accesso ad un
determinato elemento della popolazione immediato.
Si è scelto di decomporre la popolazione in una dimensione per motivi di efficienza.
Infatti, con una decomposizione a due dimensioni si hanno un numero di messaggi inviati alto
con una dimensione piccola, mentre con una decomposizione a una dimensione si hanno un
numero di messaggi piccolo con dimensione grande. Considerando che il tempo di startup è
più grande del tempo di trasferimento, il secondo approccio è più efficiente rispetto al primo.
L’operazione cruciale dell’implementazione parallela è la selezione dell’elemento su cui
applicare l’operazione di crossover che avviene a livello locale, in modo da minimizzare le
comunicazioni tra i processori; in pratica tale elemento viene scelto fra i vicini di raggio
unitario della cella stessa. Se la cella è interna alla porzione di automa contenuta nel singolo
nodo non vi sono problemi, ma se essa si trova sul bordo ha bisogno di accedere ad individui
che si trovano su altri nodi. Si è scelto, allora, di aggiungere alla matrice una coppia di bordi
(destro e sinistro) che contenga i vicini delle celle situate ai confini con gli altri nodi. Allora,
all’inizio di ogni generazione, in maniera sincrona, i bordi sono riempiti con gli individui
provenienti dai processori vicini. In questo modovi è un aumento, anche se limitato, della
memoria necessaria alle strutture dati, ma si riducono notevolmente gli overhead temporali
delle comunicazioni, dal momento che si scambiano tutti gli individui in una sola
comunicazione minimizzando il tempo di startup.
CAGE è basato su SPMD (Single Program Multiple Data). SPMD è lo stile dominante
dei programmi paralleli,dove ogni processore usa lo stesso programma benché ciascuno abbia
i propri relativi dati. Per un’effettiva implementazione, i dati sono partizionati in modo che le

comunicazioni siano locali e il carico computazionale sia condiviso tra gli elementi
processanti con una determinata strategia di bilanciamento. In questo approccio non si
assegna solo un individuo ad un processore, ma gli individui sono raggruppati in “fette” e
viene assegnata una “fetta” (slice) della popolazione a un nodo.
Il programma concorrente che implementa l’architettura di CAGE è composto da un set di
identici processi slice. Non è richiesta nessuna coordinazione perché il modello di
computazione è completamente decentralizzato. Ogni processo slice gira su una singola unità
elaborativi della macchina parallela.
La dimensione della sottopopolazione di ogni processo slice è calcolata dividendo la
popolazione per il numero di processori su cui CAGE è eseguito. Le variabili weight e height
definiscono la grandezza dei bordi della sottogriglia 2D.
Le comunicazioni sono state implementate adoperando le primitive della libreria MPI, che
non prevedono la possibilità di utilizzare strutture predefinite a puntatori.
Perciò, per inviare i bordi, che sono costituiti da una serie di alberi, si possono seguire due
strade alternative:
� Creare una particolare struttura, che preveda di mandare i puntatori in forma di
numeri e poi ricostruirla in fase di ricezione.
� Trasformare opportunamente un albero in un array di un tipo predefinito.
Si è scelto di seguire questa seconda strada, realizzando un pack dell’albero prima della
spedizione e un unpack a ricezione avvenuta.
Si è scelta questa seconda possibilità perché non si introduce ridondanza nell’informazione
da trasferire e inoltre i tempi per realizzare il pack e l’unpack sono trascurabili. L’operazione

di pack viene realizzata visitando l’albero in ampiezza e assegnando a locazioni successive
del vettore un carattere corrispondente ad una particolare funzione o terminale; gli alberi sono
posti in un unico array di caratteri, uno di seguito all’altro senza buchi, con associato un altro
array, che memorizza le lunghezza in sequenza degli alberi,in modo che sia possibile
ricostruire la sequenza originaria degli alberi. In questo modo si riesce, con due sole
comunicazioni, a trasferire un bordo dell’automa, minimizzando i tempi di startup e non
introducendo un eccessivo aumento di informazione. I processori sono connessi in accordo
all’architettura ad anello: ogni processo ha due buffers per inviare (SRbuf, SLbuf) e due
buffers per ricevere (RRbuf, RLbuf). Lo scambio dei dati avviene con due operazioni di invio
asincrone seguiti da due operazioni di ricevimento asincrone da destra a sinistra tra processi
vicini. L’esecuzione di un programma parallelo è composto da due fasi: computazione e
comunicazione; durante la computazione vengono manipolati i dati locali da parte dei
processi, questi dati possono essere variabili locali o dati ricevuti dai bordi vicini; durante la
computazione non sono scambiati dati.
Per poter eseguire una distribuzione computazionale equilibrata tra i nodi in CAGE è
introdotta una intelligente partizione della griglia. La strategia di partizione è basata su una
decomposizione block-cycling. L’idea è di dividere la griglia virtuale in un numero di campi
e assegnare uguali parti di ogni campo a ognuno dei processi (come illustrato in Figura
1.7.3).

Figura 1.7.3: Strategia di bilanciamento del carico
1.7.4 Esempi di programmazione genetica applicati al modello cellulare
Per verificare la bontà del modello cellulare per la programmazione genetica e per studiare
la scalabilità del sistema con problemi di diversa complessità, utilizzeremo tre esempi: la
regressione simbolica, il cosiddetto even-4-parity e la classificazione, descritti in Koza.
Il problema della regressione simbolica, ha come obiettivo la produzione di una funzione
che si adatti ad un insieme di punti.
Cioè, dato un insieme di punti del tipo (x,y), bisogna trovare una funzione che, per ogni
valore di x, restituisca il valore di y appropriato.
Nel nostro esempio, abbiamo utilizzato un insieme di 20 punti scelti in modo casuale
nell'intervallo [-1,1], come ascissa, e come ordinata abbiamo preso il valore della funzione y =
2.178 x2 + 3.1416 x applicata ai punti dell'intervallo:

� come insieme di funzioni della programmazione genetica abbiamo preso le funzioni
classiche {+,*,-,%}, dove % sta per la divisione protetta, cioè una divisione fra due
argomenti che ritorna il valore 1 se il denominatore è zero, per rispettare la proprietà
di chiusura;
� i terminali sono costituiti dalla variabile x e da una costante random, che permette di
generare i coefficienti che approssimano 1'equazione da ricavare;
� la funzione di fitness è data dalla somma delle differenze fra il valore dato dalla
funzione generata e quello della funzione esatta, calcolato su tutti i 20 punti scelti.
La even-4-parity è una funzione di tipo booleano che riceve in input quattro argomenti
(d0, dl, d2, d3) e ritorna un valore di verità solo se un numero pari di questi argomenti è vero,
altrimenti restituisce un valore di falsità.
Per addestrare il nostro algoritmo utilizziamo tutte le 16 combinazioni vero, falso possibili
con i 4 argomenti suddetti e la soluzione esatta dovrebbe verificare tutte le combinazioni:
� l'insieme delle funzioni è dato da {AND, OR, NAND, NOR} che consente di
rappresentare qualsiasi funzione booleana esistente;
� il set di terminali è dato, ovviamente, dagli argomenti di input { d0, d1, d2, d3};
� la funzione di fitness è data dalla somma, su tutte le combinazioni, della distanza di
Hamming fra il programma generato a il valore booleano corretto.

Il processo della classificazione consiste nell'assegnare differenti oggetti (tuple) di una
base di dati ad alcuni gruppi predeterminati, detti classi, a seconda del valore degli attributi.
Uno dei metodi per realizzare questo compito è quello di costruire alberi di decisione, che
permettano di assegnare un oggetto ad una determinata classe, semplicemente visitando
1'albero stesso.
Con la programmazione genetica è possibile costruire questo tipo di alberi, utilizzando
come:
� funzioni di base gli attributi degli oggetti;
� come simboli terminali le classi predefinite;
� la fitness sarà data dalla somma del numero di tuple non classificate correttamente su
un insieme di esempi, detto training set, di cui si conosce già la classificazione
corretta.
PARAMETRI DI PCGP 9.1.1.1 PROBLEMA 9.1.1.1.1 REG 9.1.1.1.2 EVEN-4-
9.2 CLASSIFICAZISimboli terminali {X, R} {d0, dl, d2, d3} classi Funzioni {+, - , * , %} {AND, OR, NAND, attributi Population_size 800 800 800 Width 40 40 40 Height 20 20 20 Max_depth_for_new_tree 5 5 5 Max_depth_after_crossove 6 6 6 Grow_method RAMPED RAMPED RAMPED selection_method EVERCHANG EVERCHANGE EVERCHANGE Crossover_func_pt_fractio 0.1 0.1 0.1 Crossover_any_pt_fraction 0.8 0.8 0.8 Fitness_prop_repro_fractio 0.1 0.1 0.1 Parsimony_factor 0.0 0.0 0.0

9.2.1 Tabella 1.7.1: I parametri usati negli esperimenti
Gli esperimenti sono stati condotti usando i parametri descritti nella tabella 1.7.1 e facendo
eseguire 1'algoritmo per 200 generazioni. In tabella 1.7.2 sono riportati i tempi di esecuzione
per gli esperimenti descritti sopra, variando il numero di processori (l, 2, 4, 8, 10) e mediando
su 5 prove, con seme random diverso.
La terminazione dell'algoritmo con un numero di generazioni fissate e non con il
raggiungimento di una soluzione ottima o subottima, ci permette di calcolare la scalabilità del
sistema in maniera indipendente da variazioni casuali che si avrebbero se le prove
raggiungessero la soluzione in un numero di generazioni differenti l’una dall'altra.
NUMERO DI PROBLEMA PROCESSORI REGRESSIONE EVEN-4-PARITY CLASSIFICAZIONE Tempo di esecuzione
1 179.37 182.24 1216.9 2 94.35 93.62 652.6 4 47.87 49.90 334.3 8 24.75 26.70 174.1 10 20.18 19.27 131.5
Tabella 1.7.2: Tempi di esecuzione dei tre esperimenti
I risultati sperimentali, effettuati su questi tre esempi hanno mostrato speed-up quasi lineari
che confermano l'elevata scalabilità di questo tipo di implementazione.
1 I test sono stati svolti su macchina parallela CS-2, di tipo MIMD, costituita da 6 nodi; ciascun nodo è formato da due processori
HyperSparc a 200 Mhz e una memoria RAM da 256 Mbyte. La rete di interconnessione è un fat-tree con larghezza di banda di 50 Mbytes/s
per ogni direzione.

Uno studio teorico della scalabilità e della complessità del sistema è stato portato avanti,
applicando il metodo della funzione di isoefficienza di Kumar ad un calcolatore reale,
sfruttando le misure e i modelli ricavati per le primitive MPI sulla CS-2 e si è ottenuta
un'espressione dello speed-up e dell'efficienza in funzione della dimensione del problema e
del numero di processori. L'utilizzo di tale modello permette di stabilire a priori il numero di
processori realmente utilizzabili per un'applicazione e verificarne l'efficienza, soltanto
stimando empiricamente alcuni parametri del sistema.
1.8 Un’ implementazione distribuita della programmazione genetica
Come abbiamo già notato gli algoritmi di programmazione genetica godono delle seguenti
proprietà:
� parallelismo implicito: il carico della computazione può essere suddiviso fra vari
processori, che fanno evolvere la popolazione autonomamente, introducendo diversità
più o meno frequentemente, per non avere una convergenza precoce, a seconda che si
usi il modello globale, a isole o diffusivo;
� efficienza: i modelli di parallelizzazione dell’elaborazione, danno enormi vantaggi per
quanto riguarda i tempi di esecuzione, rispetto a quelli sequenziali;
� scalabilità: l’efficienza rimane costante all’aumentare dei processori e della
dimensione del problema.
Abbiamo anche visto che un’implementazione parallela della programmazione genetica,
oltre che dividere il notevole sforzo computazionale fra diversi processori, risolve il problema

della memorizzazione degli alberi di programma, che possono essere anche molto complessi e
quindi richiedere una capacità di memorizzazione che va oltre quella di una singola macchina.
Tuttavia, i modelli di parallelizzazione possono essere utilizzati anche su architetture
distribuite, cioè nel caso in cui l’elaborazione della fitness avviene su macchine diverse
collegate in rete; in questo caso, però, si accentua ancora di più il problema dell’overhead sul
tempo di elaborazione, dovuto ai tempi di latenza delle comunicazioni lungo la rete.
Per questo occorre fare una scelta oculata del modello di elaborazione, in modo da rendere
trascurabile il problema.
Per rendere ininfluenti tali ritardi nell’elaborazione, e nello stesso tempo mantenere le
caratteristiche di parallelismo, efficienza e scalabilità, si deve scegliere un’architettura che sia
esente da sincronizzazione2, non è necessario quindi che sia centralizzata come,ad esempio, il
client-server, e che sia robusta, cioè resistente ai cambiamenti che sono frequenti in una rete
come Internet, per garantire che l’elaborazione sia portata a termine con successo.
Da qui nasce l’idea di un’implementazione distribuita peer to peer della
programmazione genetica, di cui noi vogliamo mostrare i vantaggi.
2 La sincronizzazione va bene nel caso di un’architettura parallela, ma è inaccettabile nel caso di architetture distribuite.

CAPITOLO 2
IL PEER-TO-PEER:
UNA NATURALE SOLUZIONE PER LA PROGRAMMAZIONE GENETICA
2.1 Cos'è il peer-to-peer?
E' l'acronimo di Peer-to-Peer, dove i peer non sono altro che normali PC usati da normali
utenti per navigare su Internet, inviare e ricevere E-mail, scrivere documenti, ecc.
L'architettura peer-to-peer e' una architettura nella quale i computer connessi ad Internet
possono condividere capacità di calcolo, spazio su disco e ogni tipo di risorsa in genere,
senza l'utilizzo di un server centrale. Proprio l'assenza di un server centrale che amministri
le connessioni e le risorse è la chiave di volta. La tecnologia Peer-to-Peer evolve l'ambiente di
elaborazione centralizzato pre-esistente ad un nuovo livello di infrastruttura software, creando
una rete "point-to-multipoint" tra host equivalenti (livello utente/applicazione) che si
comportano, a seconda della situazione, da server o da client. Riflettiamo, ad esempio, sulle

possibilità offerte alle funzioni di immagazzinamento e/o di condivisione dati di un sistema o
di una rete. In una architettura tradizionale, un server può fornire le informazioni presenti sui
propri hard-disk.
Di quanto stiamo parlando? Cinquanta dischi da cento gigabyte? Qualunque sia l'effettiva
capacità di immagazzinamento gestita da un server, non sarà mai paragonabile alle possibilità
offerte da una architettura p2p, nella quale ogni PC domestico condivide tutto o parte del suo
hard-disk.
Centinaia e centinaia di terabyte accessibili da tutti o da solo chi ne abbia i giusti privilegi;
senza i ritardi causati dalle migliaia di connessioni al minuto che un server deve gestire; senza
un luogo centralizzato che tenga traccia delle nostre connessioni e con la possibilità di
eseguire ricerche sugli hard-disk di altri peer come se le facessimo sul nostro; con
l'opportunità di avere la più recente versione di un prodotto prelevandola direttamente dal pc
del realizzatore e sfruttando al meglio la banda disponibile nella connessione tra i due peer.
Napster, con la sua architettura p2p ibrida (ovvero basata su un server centrale che
indirizza le connessioni, e il download tra i PC che avviene in modalita p2p), è uno degli
esempi più noti di filesharing. Grazie alla sua straordinaria facilità d'uso, alla semplicità
nell'effettuare ricerche ed all'efficacia nel determinare i risultati, ha iniziato una vera e propria
rivoluzione su Internet. Ecco, per quanto riguarda l'aspetto dell'architettura p2p che permette
la condivisione di risorse e nell'ottica di avere un quadro completo delle potenzialità, si
immagini un "fenomeno Napster" a 360 gradi.
Ma non si pensi che il p2p permetta solo una efficiente gestione delle risorse condivise. I
settori che traggono vantaggio dalle possibilità che questa architettura offre sono realmente
molteplici. Si pensi ai milioni di peer nel mondo che contribuiscono alla ricerca di
intelligenze extraterrestri con il progetto S.E.T.I. o ai milioni di utenti di portali che utilizzano
la comunicazione realtime.

2.2 L’essenza del peer to peer
In una rete peer to peer, si possono distinguere i seguenti punti cardine:
� Il sistema è basato sull’interazione fra peer;
� Il sistema non ha servizi o risorse operative centralizzate;
� Si possono verificare cambiamenti radicali sulla composizione della rete;
� Si va verso una topologia non deterministica;
� Può esservi un massiccio uso concorrente delle risorse.
Per comprendere meglio, cerchiamo di analizzare singolarmente i punti su riportati.
2.1.1 Sistema basato sull’interazione fra i peer
Non c’è nulla in comune fra i mega-siti su internet e l’architettura client-server, queste
dipendono strettamente da un robusto server che deve gestire tutti i loro utenti.
In figura è riportato un esempio di architettura centralizzata.

Figura 2.1.1: Un sistema centralizzato
Anche se il clustering o le altre tecnologie locali distribuite sono utilizzate al posto dei
server, c’è ancora un gruppo di server centralizzati che devono essere avviati per far lavorare
il sistema. Il client, malgrado tutto, leggero o pesante che sia, non è capace di svolgere il
lavoro richiesto senza connettersi al server centralizzato.
Tipicamente, il cuore della rete consiste di un mega-server e di un sofisticato routing e di
infrastrutture per il caching che assicurano che la parte più esterna della rete (client, web
browser) possa accedere a queste informazioni centralizzate nella maniera più efficiente.
Questa è la più esplicativa raffigurazione di internet dei nostri giorni, senza il peer to peer.
Il comportamento di questa sorta di sistemi è ben conosciuto. Con l’aumentare degli
utilizzatori, la potenza computazionale, la risorse di memorizzazione, e la larghezza di banda

associata ai server centralizzati, devono aumentare proporzionalmente. Contemporaneamente
il software e l’hardware devono essere capaci di “scalare” per supportare l’incremento di
risorsa richiesta all’aumentare degli utilizzatori. Normalmente, così come la scalabilità
permette di gestire decine di migliaia di utenti, i costi raggiungono livelli stratosferici.
Un sistema peer-to-peer si poggia unicamente sull’interazione fra peer. In figura è
rappresentato un sistema centralizzato che mette in evidenza il motivo per cui questo sistema,
è conosciuto come sistema con azione “ai bordi della rete”.
Figura 2.2.2: Sistema centralizzato in cui è evidente l’azione sul bordo rete
In figura si può notare come il peer-to-peer è basato sull’interazione client-client, senza il
server centrale. Quindi ogni peer interagisce direttamente con un altro peer; se vogliamo però

continuare a vedere l’architettura di una rete con la vecchia visione, vorrà dire che ogni peer
dovrà assumere contemporaneamente sia la funzione di client che di server.
In questa maniera ogni peer può gestire una porzione della rete, svolgendo quindi una parte
del lavoro che nei sistemi centralizzati, viene svolto dal server, in questo modo in molte
applicazioni, è possibile ridurre il carico di lavoro legato ad una gestione centralizzata, inoltre
è possibile gestire la rete con i peer correntemente connessi. Questo rappresenta il sogno di
molti professionisti del calcolo distribuito e parallelo.
2.3 Nessun appoggio su server o risorse centralizzate
Un sistema interamente basato sul peer-to-peer non necessita dell’esistenza di alcun server
o risorsa centralizzata. Quindi, un sistema puramente basato su tecnologia peer-to-peer non
deve contare su sistema di naming o indirizzamento centralizzato. Ciò significa che il nostro
risolutore di indirizzi predefinito, DNS, non è indicato a modellare il peer-to-peer. Mentre la
tabella DNS è replicata in molti server distribuiti, l’unica gerarchia centrale dei nomi è gestita,
dalla sua radice, da una autority centrale. Le esperienze fatte, insegnano che quando i name
server per un dominio non sono attivi, non vi è modo di accedere ad un sito web attraverso il
suo nome. Questo è sicuramente un problema che un sistema peer-to-peer evita – la caduta di
alcuni peer effettivamente non compromette il buon funzionamento dell’intero sistema o rete.
Un sistema di indirizzamento peer-to-peer, invece, deve essere completamente
decentralizzato. Se ci sono centinaia di migliaia di peer in una rete peer-to-peer, ognuno di
essi deve essere capace di trovare ogni altro peer connesso e stabilire una comunicazione.
Anche nel caso di una quasi completa distruzione di una rete, e nel caso in cui solamente due
peer rimangano connessi, esso sono ancora capaci di comunicare fra di loro.

2.4 Resistenza ai cambiamenti profondi nella composizione di una rete
Nel precedente paragrafo si è evidenziata la necessità di adattamento di un sistema peer-
to-peer ai cambiamenti profondi della composizione di una rete. Essenzialmente, un sistema
peer-to-peer progettato in modo coerente dovrebbe permettere la comunicazione fra due peer
per tutto il tempo in cui vengono spedite informazioni fra essi. In una rete completamente
connessa di peer, ci dovrebbero essere molte scelte durante la selezione del protocollo di rete
e mezzo di comunicazione fra peer. Un buon sistema peer-to-peer implementa alcune
ottimizzazioni per trarre vantaggio da ciò, e sceglie la più efficiente.
2.5 Una rete con topologia non deterministica
In un sistema peer-to-peer, i primi “clients” formano la rete e svolgono tutto il lavoro. Una
macchina client, come sappiamo, non è tipicamente una macchina super robusta o sempre in
attività. Ciò significa che le macchine possono essere accese o spente dall’utente in qualunque
momento, possono avere malfunzionamenti e quindi non riapparire più sulla rete, i loro dischi
e memoria non danno garanzia su backup o su protezioni, i loro contenuti dovrebbero essere
considerati volatili. In qualunque istante la topologia della rete peer-to-peer è imprevedibile. I
nodi che formano la rete sono costantemente variabili in base a quando un utente decide di
accedervi o uscirne. Proprio su questa variabilità si fonda la robustezza del peer-to-peer, che
riesce ad adattarsi a qualunque situazione.
2.6 Ottima scalabilità
L’essere completamente decentralizzata, permette alle reti peer-to-peer di avere un’ottima
scalabilità. Infatti, attraverso applicazioni che distribuiscono i processi lavorativi sui peer, un
buon sistema peer-to-peer dovrebbe avere, come unico limite al numero di utenti che possono
farvi parte, la larghezza di banda esistente fra i peer. Se pensiamo al fatto che comunque la

larghezza di banda va verso un incremento nel prossimo futuro, non dovrebbero addirittura
esservi limitazioni.
In effetti contrariamente a ciò che ci si potrebbe aspettare, le prestazioni della rete
aumentano con l’aumentare del numero di utenti, che è certamente una buona qualità.
2.7 Il peer to peer e la programmazione genetica: connubio perfetto
Nei precedenti paragrafi abbiamo potuto vedere le qualità del peer to peer. Riassumendo,
possiamo dire che il peer to peer è:
� Un sistema completamente decentralizzato;
� Caratterizzato da topologia non deterministica;
� Capace di resistere a cambiamenti radicali della rete;
� Ottimamente scalabile.
L’insieme di queste caratteristiche permettono l’individuazione di altri aspetti molto
importanti quali robustezza, parallelismo e asincronia.
La robustezza è intesa come la capacità da parte delle reti peer to peer di resistere a
cambiamenti improvvisi e radicali della rete dovuti ad esempio a crash di un sistema o
semplicemente alla disconnessione di un nodo. Questa qualità rende possibile la realizzazioni
di applicazioni che non sono strettamente legate alla composizione della rete. Immaginiamo
per esempio dei processi stocastici per cui non è necessario sapere da chi provengano i dati di
input da elaborare.
L’aspetto successivo, il parallelismo, è una proprietà intrinseca poiché ogni nodo è
completamente indipendente dagli altri. Le reti peer to peer, permettono di elaborare problemi
che necessitano di grande potenza di calcolo, l’osservazione è giustificata dalle risorse che il
peer to peer offre. Un algoritmo, che serva per la risoluzione di un dato problema, può essere

suddiviso in tanti sotto problemi, che a loro volta vengono affidati ai nodi della rete, ogni
nodo è così capace di procedere indipendentemente dagli altri durante l’elaborazione..
L’ultimo dei tre aspetti, l’asincronia, è comprensibile se si consideriamo i nodi della rete in
base alla loro diversità: differente potenza di calcolo e differenti tempi di elaborazione. La
possibilità di realizzare comunicazioni tramite primitive non bloccanti, permette alle
applicazioni a cui non necessiti scambiare obbligatoriamente dati, di lavorare autonomamente
e non essere influenzate da altri nodi che, disponendo di una potenza di calcolo minore,
richiedano un tempo di elaborazione maggiore.
A questo punto, se pensiamo alle conclusioni fatte nel precedente capitolo, si capisce
chiaramente come l’architettura peer to peer, sia una scelta naturale per l’implementazione
distribuita di algoritmi di programmazione genetica.
2.8 Java per il supporto peer to peer
L’ambiente che si è scelto per la realizzazione della piattaforma supporta applicazioni che:
� Sono massicciamente parallelizzabili;
� Sono asincrone;
� Hanno poche comunicazioni fra sottoprocessi;
� Richiedono molte risorse;
� Sono robuste.
Si potrebbe a questo punto pensare che la lista su menzionata sia molto restrittiva, ma vi
sono diverse applicazioni interessanti che si adattano a questa descrizione.
Buoni esempi sono rappresentati da processi indipendenti con carichi bilanciati, modelli ad

isole nella programmazione genetica, ottimizzazione euristica, e così via.
Le assunzioni su riportate permettono di dare minore importanza al requisito di affidabilità, al
requisito di sincronia e di controllo dei sottoprocessi. In altre parole sotto questi presupposti è
possibile applicare le tecnologie peer to peer. L’approccio peer to peer permette di avere
grande potenza di calcolo poiché è realizzato su reti come le WAN, inoltre come già
ampiamente evidenziato, un ulteriore vantaggio è la scalabilità quindi l’adattabilità in base
alle risorse presenti sulla rete senza ulteriori investimenti.
Nella piattaforma Java troviamo una naturale possibilità di distribuire i processi attraverso
in linkaggio dinamico del codice eseguibile di un’applicazione. Java fornisce sicurezza e una
completa indipendenza della piattaforma che la rendono un’ovvia scelta per la nostra
applicazione.
In altre parole essa può essere vista come una macchina distribuita virtuale fatta di
computer sparsi su internet. La configurazione delle macchine può costantemente cambiare e
crescere verso un limite teorico molto ampio. Ognuno che abbia accesso a Internet può unirsi
al gruppo di lavoro ed offrire la propria risorsa o utilizzare le risorse offerte per risolvere il
proprio problema.

10 CAPITOLO 3
DESCRIZIONE DELLA PIATTAFORMA JXTA
3.1 Architettura e servizi JXTA
Project JXTA ha definito una serie di sei protocolli, il cui scopo è quello di creare una rete
“virtuale” che nasconda le reti esistenti in particolare internet. Al di sopra di questa rete
possono essere creati servizi e applicazioni in modo semplice grazie alle primitive fornite. Le

specifiche dei protocolli descrivono come i peer comunicano e interagiscono, senza dire nulla
su come sono poi implementati o su come scrivere un’applicazione Peer-to-Peer.
L’uso dei protocolli JXTA permette ai peer di collaborare nella formazione di una
comunità auto-configurante, che non ha dipendenze dalla loro posizione sulla rete e non
necessita di particolari infrastrutture di supporto.
Nell’architettura JXTA, si è cercato di creare un set di protocolli con il minor overhead
possibile, senza fare delle assunzioni circa i meccanismi di trasporto propri di ogni rete e i
bisogni di un ambiente paritario. Attraverso un approccio di questo genere è possibile
realizzare molteplici servizi e applicazioni peer-to-peer, anche in presenza di ambienti di rete
fortemente mutevole e non affidabile.
L’uso dei protocolli JXTA permettono ai peer di propagare informazioni sulle loro risorse, di
scoprire le risorse di rete (servizi, pipe, ecc) che altri peer mettono a disposizione.
Un aspetto importante di questa architettura è la possibilità da parte dei peer di formare
PeerGroup in cui effettuare il routing dei messaggi e intrattenere speciali relazioni fra di
loro. Ogni messaggio porta con se una lista ordinata completa o parziale di gateway peer
attraverso i quali il messaggio può essere indirizzato.
Nell’eventualità che un’informazione di routing sia scorretta, è possibile trovare
dinamicamente un’altra strada che permetta di consegnare a destinazione le informazioni.
L’architettura JXTA è composta da sei protocolli che lavorano insieme per permettere: la
scoperta, l’organizzazione, il monitoraggio e la comunicazione tra peer. Tutti questi
protocolli sono implementati utilizzando un comune strato di messaggi. Questo strato di
messaggi è quello che lega i protocolli JXTA alle varie reti di trasporto. Ogni protocollo
JXTA è indipendente dagli altri, e un peer può non implementare tutti e sei i protocolli.
Per esempio, se un dispositivo ha tutti gli advertisement che usa pre-memorizzati, allora
non c’è bisogno che implementi il Peer Discovery Protocol.

Un peer può usare un set pre-configurato di peer router per instradare a tutti i suoi
messaggi, quindi non deve implementare il Peer Revolver Protocol e così via per gli altri
protocolli.
Nella seguente figura è riportato lo stack di protocolli JXTA:
Fig. 3.1.1: I protocolli JXTA
I protocolli JXTA non richiedono messaggi di alcun genere che ad alcun livello siano
mandati per la rete. Per esempio, JXTA non richiede il polling periodico, il controllo sullo
stato dei link, o il segnale per la scoperta dei vicini.

Un peer può decidere se memorizzare in cache gli advertisement scoperti via Peer
Discovery Protocol per un uso successivo. E’ importante segnalare che il caching non è
richiesto dall’architettura JXTA, ma che tuttavia può essere un’importante via di
ottimizzazione.
Il caching di advertisement da parte di un peer evita di dover effettuare una nuova scoperta
ogni volta che un peer accede a una risorsa di rete. In un ambiente altamente transitorio,
compiere la scoperta è la sola soluzione possibile, mentre in ambiente statico, il caching
risulta molto più efficiente. I peer possono ottenere informazioni dai peer vicini che hanno
memorizzato informazioni nella cache.
Ogni peer diviene quindi un provider per tutti gli altri.
3.2 Perché utilizzare JXTA?
Il progetto JXTA è una piattaforma open source progettata per il peer-to-peer computing.
Il protocollo JXTA standardizza il modo in cui i peer:
� scoprono altri peer;
� si auto-organizzano in un PeerGroup;
� annunciano e scoprono le risorse;
� comunicano con gli altri peer;
� tengono sotto controllo ogni altro peer.
Il protocollo JXTA invece non richiede:
� l’uso di un particolare linguaggio di programmazione o sistema operativo;
� l’uso di una particolare topologia di rete o di un particolare meccanismo di trasporto;
� l’utilizzo di un particolare metodo di autenticazione o di sicurezza.

L’architettura JXTA utilizza il paradigma del peer-to-peer, da inoltre la possibilità al
programmatore di creare e usare applicazioni e servizi interoperabili. Quest’architettura
fornisce una semplice e generica piattaforma peer to peer per ospitare ogni tipo di servizio di
rete.
In particolare l’architettura JXTA:
� è definita da un piccolo numero di protocolli. Ogni protocollo è semplice da
implementare e da integrare nelle applicazioni e nei servizi peer to peer. Così i servizi
offerti da un particolare utente possono essere usati in maniera trasparente da un
utente di un’altra comunità;
� è definita indipendentemente dal linguaggio di programmazione. Infatti può essere
implementato in C++, Java, Perl, ecc. Dispositivi eterogenei con uno stack di software
completamente differenti possono interoperare con i protocolli JXTA;
� è stata progettata indipendentemente dal protocollo di trasporto. Infatti può essere
implementato sullo stack di protocolli TCP/IP,http, Bluetooth, HomePNA, e molti altri
protocolli.
3.3 Il progetto JXTA
Project JXTA è una piattaforma per lo sviluppo di applicazioni di networking rivolta al
peer-to-peer. Jxta è nato inizialmente all’interno di Sun Microsystem, come piccolo progetto
di ricerca per cercare di analizzare e sfruttare le enormi potenzialità del peer-to-peer.
L’architettura che lo caratterizza è mostrata in figura.

Fig. 3.3.1: Architettura di Jxta
Il più basso livello, quello di Core, contiene le funzioni essenziali per ogni soluzione p2p,
cioè quelle di comunicazione, quelle di discovery, sia dei peer che delle altre risorse e di altre
funzioni di basso livello come ad esempio il routing dei messaggi.
Il livello intermedio contiene invece servizi di più alto livello e che sono desiderabili mo
non necessari ad ogni applicazione p2p, come ad esempio la ricerca e la condivisione di file,
l’autenticazione dei peer, o altri servizi implementati dalla comunità di programmatori JXTA.
Al livello più in alto infine troviamo le applicazioni peer-to-peer che sfruttano i livelli
sottostanti, ad esempio applicazioni Istant Messaging e di Auction-on-line.
JXTA è quindi un insieme di protocolli generici per il peer-to-peer che consente a qualsiasi
dispositivo connesso in qualche modo ad una rete(cioè dal cellulare ad un palmare) da un PC
ad un server, di comunicare e collaborare in modo paritario. I protocolli JXTA sono
indipendenti sia dall’ambiente hardware che dal linguaggio di programmazione, esistono
infatti implementazioni diverse, chiamate bindings. Oltre a Java, progetto originario ed
attualmente più completo, esistono anche quelle in linguaggio C, sia sotto linux che sotto
Windows, e ci sono progetti in corso per il porting in Perl, Objective C, Ada ecc.
3.4 Gli elementi di JXTA

3.4.1 Peer
Un peer è ogni dispositivo di rete (sensore, telefono, PDA, PC, server, supercomputer,
etc.) che implementi uno o più protocolli JXTA. Ogni peer opera indipendentemente e in
maniera asincrona dagli altri peer, ed è univocamante identificato da un Peer ID.
Un peer pubblica una o più interfacce di rete per utilizzarle con il protocollo JXTA. Ogni
interfaccia pubblicata è notificata come un peer endpoint che identifica univocamente
l’interfaccia di rete. I peer endpoint sono utilizzati dai peer per stabilire connessioni punto a
punto fra essi. I peer non devono essere necessariamente connessi direttamente per
intraprendere una comunicazione. Quando due peer devono comunicare fra loro e non sono
commessi direttamente, i peer che sono collocati fra di esse, fungono da intermediari, per
inoltrare sulla rete i messaggi. I peer scoprono spontaneamente gli altri peer presenti sulla rete
per formare eventualmente dei PeerGroup. I peer tipicamente interagiscono con un limitato
numero di peer (detti peer vicini o amici).
3.4.2 PeerGroup
Un PeerGroup è una collezione di peer che svolgono un un insieme di servizi in comune.
Ogni PeerGroup è univocamente identificato da un PeerGroupId, i peer si organizzano
automaticamente al suo interno. Ogni peer group può stabilire la propria politica di
appartenenza, (membership policy) da un accesso libero, ad un accesso con identificazione.
Un peer può appartenere a più peer group simultaneamente. Inizialmente, il primo gruppo
istanziato è il Net Peer Group.
Il protocollo JXTA non impone, come, quando, e perché un PeerGroup debba essere creato.
JXTA descrive solamente come un peer possa pubblicare, scoprire, fare il “join”, e monitorare
un PeerGroup.
JXTA riconosce tre motivazioni principali per creare un PeerGroup:

� Per creare un ambiente sicuro. All’interno di tale gruppo, viene stabilita una politica
di appartenenza che va da una semplice username/password, a chiavi criptate. I
partecipanti al PeerGroup permettono ai membri di accedere e pubblicare contenuti
protetti. Un PeerGroup forma uno spazio logico in cui i limitanti limitano l’accesso
alle risorse del gruppo.
� Per creare un ambiente visibile. Un PeerGroup è tipicamente formato e auto-
organizzato sopra i mutevoli interessi dei peer. Non sono imposte particolari regole su
come formare un PeerGroup, poiché i peer con gli stessi interessi tendono ad unirsi
allo stesso PeerGroup. I PeerGroup servono a suddividere la rete in regioni astratte
provvedendo ad un esplicito meccanismo di visibilità. I partecipanti al PeerGroup
definiscono l’ambito di visibilità delle ricerche dove ricercare gli argomenti del
gruppo.
� Per creare un ambiente monitorato. Un PeerGroup permette ai peer di monitorare
un set di peer per qualche speciale scopo (controllo del traffico, etc.). Un PeerGroup
fornisce un set di servizi chiamati PeerGroup services. JXTA definisce un set base di
servizi. Il protocollo JXTA specifica il formato guida per questi servizi di base.
Servizi aggiuntivi possono essere sviluppati per far fronte a specifiche esigenze.
In un peer gruop si hanno una serie di servizi chiamati peer group service. JXTA definisce
un nucleo di servizi di peer group. I servizi di questo nucleo sono i seguenti:
� Discovery Service: questo servizio è utilizzato dai peer per cercare le risorse del peer
group, peer, peer group, pipes e servizi.

� Membership Service: il servizio di membership è usato dai membri correnti per
accettare o respingere una nuova applicazione. I peer che desiderano unirsi al peer
group devono prima ricercare un membro è quindi richiedere l’accesso.
� Access Service: il servizio di accesso è usato per convalidare le richieste fatte da un
peer ad un altro. Il peer riceve la richiesta, ottiene le credenziali del peer che fa la
richiesta, inoltra informazioni circa la richiesta e infine determina se l’accesso al
servizio richiesto è permesso. Non tutte le azioni di un PeerGroup devono essere
controllate con l’Access Service, solo quelle azioni in cui a non tutti i peer è concesso
l’uso.
� Pipe Service: il servizio di pipe è usato per gestire e creare connessioni pipe tra
differenti membri di un PeerGroup.
� Revolver Service: questo servizio è usato per spedire query ai peer per cercare
informazioni su di un peer, un peer-group, un servizio o una pipe.
� Monitoring Service: il servizio di monitoraggio è usato per permettere ad un peer di
monitorare altri membri dello stesso PeerGroup.
Non tutti questi servizi devono essere necessariamente implementati da un PeerGroup.
Ogni servizio può implementare uno o più protocolli JXTA. Un servizio tipicamente
implementa un protocollo per ragioni di semplicità e modularità, ma un servizio può anche
non implementare alcun protocollo.

3.4.3 Network Services
I peer cooperano e comunicano per pubblicare, scoprire e invocare servizi di rete. I peer
scoprono i vari servizi via Peer Discovery Protocol.
Il protocollo JXTA riconosce due livelli di servizi di rete:
� Peer Services. Un peer service è accessibile unicamente dal peer che pubblica questo
servizio. Se il peer cade, cadrà con esso anche il servizio. Istanze multiple del
medesimo servizio, possono essere avviate su differenti peer, ma ogni istanza del
servizio pubblica il proprio dvertisement.
� PeerGroup Services. Un peer group service è composto di una collezione di istanze
che girano sui membri multipli del peer group. Se un qualunque peer cade il servizio
del peer group non cessa.
3.4.4 Pipe JXTA
I peer JXTA utilizzano le pipe per inoltrare messaggi ad altri peer. Le pipe sono asincrone
e unidirezionali, sono meccanismi per il trasferimento di messaggi utilizzate per il servizio di
comunicazione.
Le pipe non sono tipizzate; esse supportano il trasferimento di ogni oggetto, incluso
codice binario, stringhe, e qualunque oggetto basato su tecnologia Java.
Le pipe si differenziano in input pipe, su cui ricevere messaggi, e output pipe, su cui inviare
messaggi.
I peer endpoint, vengono collegati dinamicamente per poter ricercare a tempo di
esecuzione altri peer endpoint. Gli endpoint corrispondono ai canali disponibili su di un peer,
che possono essere usati per ricevere ed inviare messaggi da un altro peer. Come già è stato

detto in precedenza, per intraprendere una comunicazione, i peer non devono necessariamente
essere connessi direttamente; i peer endpoint intermediari, sono utilizzati per propagare il
messaggio.
Le Pipe offrono fondamentalmente due differenti modi per comunicare, poin-to-poit e
propagate, inoltre il nucleo di JXTA offre pipe secure unicast una variante delle point-to-poit
pipe.
� Point to Point. Una pipe point to point connette esattamente due pipe endpoint
insieme, una pipe di input che riceve messaggi da una pipe di output. Non sono
supportati messaggi di acknoledgement o verifica. Informazioni addizionali nel
payload del messaggio, come un id univoco, sono richieste qualora i messaggi
vengano inviati in sequenza. Il payload del messaggio può anche contenere un pipe
advertisement, che può essere usato per aprire una pipe di risposta al mittente.
� Propagate Pipe. Una Propagate Pipe connette insieme una pipe di output con più pipe
di input. Il flusso di messaggi nella pipe di input dalla pipe di output. Un propagate
message è mandato a tutte le input pipe in attesa. Questo processo può creare più copie
del messaggio che deve essere inviato. Sul TCP/IP,l’IP multicast può essere usato
come una implementazione per propagare. La propagazione può essere implementata
usando comunicazioni punto a punto su meccanismi di trasporto che non prevedono il
multicast come ad esempio HTTP.

Fig. 3.4.1: Le pipe Jxta
Come mostrato nella figura precedente le pipe possono connettere due peer che non hanno
una connessione fisica diretta. Uno dei molti peer endpoint intermediari è usato per effettuare
il routing del messaggio tra i due pipe endpoint.
3.4.5 Message JXTA
Un messaggio è l’unità di base di dati che viene scambiata fra due peer. I messaggi
vengono spediti e ricevuti attraverso il Pipe-Service e dall’Endpoint Service. Tipicamente
questi servizi vengono utilizzati da applicazioni per creare, spedire e ricevere messaggi.
Un messaggio è identificato da una sequenza ordinata di nomi e contenuti tipizzati
chiamati elementi del messaggio. Così un messaggio è essenzialmente un insieme di coppie
nomi/valori. Il contenuto può essere un tipo arbitrario. Vi sono due possibili rappresentazioni
per i messaggi: XML e binario.
Il protocollo JXTA è specificato come un set di messaggi XML scambiati tra peer. Ogni
piattaforma software descrive come un messaggio è convertito, per e da una struttura dati
nativa, come un oggetto Java o una struct C. L’uso di messaggi XML per definire protocolli

permette a differenti tipi di peer di comunicare tra di loro. Ogni peer è libero di implementare
il protocollo in una maniera meglio adatta al suo scopo.
3.4.6 Advertisement JXTA
Tutte le risorse di rete, come peer, PeerGroup, pipe e servizi, sono rappresentate degli
advertisement. Gli advertisement sono strutture di metadati rappresentati da un documento
XML. Il protocollo JXTA, utilizza gli advertisement per la descrizione e la pubblicazione
delle risorse disponibili. Inoltre i peer scoprono le risorse appunto ricercando gli
advertisement corrispondenti, e questo advertisement può essere depositato nella cahce locale
del peer. Ogni advertisement possiede un tempo di vita che specifica la durata della risorsa
associato. In questa maniera gli advertisement obsoleti possono essere eliminati senza nessun
controllo centralizzato. Per estendere la durata di un servizio, un advvertisement può essere
ripubblicato.
L’architettura JXTA definisce i seguenti tipi di advertisement:
� Peer Advertisement;
� PeerGroup Advertisement;
� Pipe Advertisemen;
� Service Advertisement;
� Content Advertisement;
� Endpoint Advertisement;
Peer Advertisement
Un Peer Advertisement descrive le risorse di un peer.
L’utilizzo principale di questo advertisement è quello di fornire informazioni sul peer,
come nome, peer id, servizi disponibili ed endpoint attivi.

Di seguito viene mostrata la struttura di un Peer Advertisement:
Un peer
advertisemet
contiene
quindi i
seguenti
campi:
� Name
:
nome
del
peer.
� Keywords: è un stringa opzionale da utilizzare per indicizzare e per effetture ricerche
sul peer.
� Peer id: l’identificatore che univocamente identifica un peer sulla rete.
� Service: sono dei Service Advertisement, uno per ogni servizio che il peer mette a
disposizione.
� Endpoint: gli endpoint attivi del peer sono degli URI del tipo http://127.0.0.1:9789.
� Initial App: applicazione opzionale che viene avviata al boot del peer.
PeerGroup Advertisement
���������� �������� ���� ����������� �
����� !������"���� "� �
�#$��� � ��������%���&#$��� �
�'�()��� � %$���� *"���++$"�� � � �$�� ��� ����$�
�&'�()��� �
�!��� ��������%����&!��� �
�,������ �
�� � ����� ,���������"���� "� �
������������������
�&����� ,���������"���� "� �
�&,������ �
�- �%�� "� �

Un PeerGroup advertisement descrive le risorse specifiche di un peer group, inoltre
raccoglie informazioni quali nome, peer group ID, descrizione, specifiche, e parametri di
servizio.
Analizziamo la struttura di un PeerGroup advertisement:
Un
PeerGroup
advertisem
ent
contiene
quindi i
seguenti
campi :
� Name : nome del PeerGroup.
� Keywords : è un stringa opzionale da utilizzare per indicizzare e per effetture ricerche
sul PeerGroup.
� PeerGroup id: l’identificatore che univocamente identifica un peer sulla rete.
� Service: sono dei Service Advertisement, uno per ogni servizio che il PeerGroup
mette a disposizione.
� Initial App: applicazione opzionale che viene avviata quando un nuovo peer effettua
il join al gruppo.
Pipe Advertisement
Un Pipe Advertisement, Descrive il canale di comunicazione di una pipe, utilizzato dal
pipe service per la creazione dell’endpoint associato alla pipe di input e a quella di output.
���������� �.���.�� ���� ��.�����.�� �
����� !��/ �*%����"���� "� �
�#$��� � ���������*%%���&#$��� �
�'�()��� �%$����*"���++$"��� ��$���������$��&'�()��� �
�/ ��� �!��/ �*%�0���&/ ��� �
�,������ �
����� ,���������"���� "� �
� � ������������������
�&���� ,���������"���� "� �

Ogni pipe advertisement contiene un ID simbolico opzionale, specifica il tipo della pipe, ed
un pipe ID univoco.
Vediamo la struttura di un pipe advertisement:
Analizziamo i campi della struttura:
� Name: E’ un elemento opzionale che può essere associato alla pipe. Il nome non deve
per forza essere univoco;
� Pipe Id: E’ un campo assolutamente indispensabile in quanto identifica univocamente
una pipe;
� Type: E’ un campo opzionale che specifica il tipo di pipe. Sono disponibili i seguenti
tipi:
1. RELIABLE (garantisce l’ordine di invio e che il messaggio sia inviato una sola volta).
2. UNRELIABLE (può non arrivare a destinazione o se si tratta di più messaggi possono
arrivare in un ordine diverso)
���������� �.���.�� ���� ��.�����.�� �
����� !�%�����"���� "� �
�#$��� � ��������$�%�%��&#$��� �
�0�� �!�%��0���&0�� �

3. SECURE (combina le funzionalità della pipe di tipo reliable e in più utilizza la
crittografia dei messaggi).
Service Advertisement
Il service advertisement contiene la descrizione di come creare ed invocare un servizio.
L’associazione del flusso dei messaggi del servizio con le relative pipe, è compito dei campi
pipe advertisement e metodo di accesso. Un service advertisement può avere più tipologie di
metodi di invocazione ognuna delle quali deve essere specificata.
Vediamo la struttura di un service advertisement:
Analizzi
amo i
campi della
struttura:
� Na
me:
è un campo opzionale che può essere associato al servizio e non deve per forza essere
univoco;
� Keywords: una stringa che può essere utilizzata per indicizzare il servizio in modo da
ritrovarlo in caso di ricerca. Questa stringa non è garantito sia unica, infatti più servizi
posso avere la stessa keyword;
� Service Id: questo è il campo che identifica univocamente il servizio;
� Version: questo campo identifica la versione del servizio;
� Provider: questo campo da informazioni sul fornitore del servizio;
���������� �.���.�� ���� ��.�����.�� �
����� ,���������"���� "� �
�#$��� � �����������+���&#$��� �
�1��� � �0���1��� ���&1��� � �
�'�()��� �%$����*"���++$"��� ��$���������$��&'�()��� �
�0�� �0���,���+����&0�� �
�!�%�� �!�%��$���"���� "�&!�%�� �
�!$$�� �%$$��"������� 2��*$+�� ���������+����&!$$�� �

� Pipe: questo è un campo opzionale che permette di creare un pipe di output da
associare al servizio. Non è detto che tutti i servizi utilizzino le pipe;
� Params: questo campo specifica i parametri di ingresso al servizio, in particolare si
tratta di una lista di stringhe;
� URI: questo campo opzionale specifica la posizione del codice che implementa il
servizio;
� Access Methods: almeno un metodo di accesso è richiesto per poter utilizzare il
servizio. Per esempio ilmetodo di accesso potrebbe essere specificato in un documento
WSDL che appunto specifica che il metodo di accesso è quello dei web service.
Content Advertisement
Un content advertisement descrive un come un contenuto (file o lo stato di un processo)
che può essere condiviso in un gruppo. Non ci sono restrizioni sui tipi di contenuto che
possono essere condivisi.
Vediamo la struttura di un content advertisment:
Analizziamo i campi della struttura:
� Mimetype: Il mime type del contenuto, può anche essere sconosciuto;
���������� �.���.�� ���� ��.�����.�� �
����� 3� "� "����"���� "� �
�4 ���"(%�� � ��������$�%�%��&4 ���"(%�� �
�,�+�� ��* �5�++$�&,�+�� �
�- ���� �� �"�%���������2��$��&- ���� �� �

� Id: E’ un campo richiesto che identifica univocamente un contenuto;
� Size: Le dimensioni totali del contenuto. Se il campo contiene il valore –1 allora
significa che non è nota la dimensione;
� Encoding: Specifica il tipo di codifica usata;
� RefId: Se il contenuto è stato propagato questo campo specifica chi originariamente
aveva il contenuto.
EndPoint Advertisement
Un Endpoint Advertisement descrive un protocollo di trasporto utilizzabile da un peer. Un
peer tipicamente può utilizzare più protocolli di trasporto. Solitamente si ha bisogno di un
endpoint per ogni tipo di protocollo di trasporto utilizzato (TCP/IP, HTTP, ecc). Un peer può
avere più interfacce di rete. Ogni interfaccia può avere un suo set di endpoint. L’endpoint
advertisement è presente nel peer advertisement per descrivere gli endpoint raggiungibili su di
un peer. Gli endpoint sono rappresentati come indirizzi virtuali che permettono di creare
dinamicamente un canale di comunicazione.
Per esempio “tcp://123.123.20.20:1002” o “http://133.125.23.10:6002” sono degli URI che
rappresentano indirizzi di endpoint.
Vediamo la struttura di un endpoint advertisement:
Analizziamo i campi della struttura:
<?xml version="1.0" encoding="UTF-8"?>
<JXTA:EndpointAdvertisement>
<Name> nome dell’endpoint</Name>
<Keywords> keywords</Keywords>

� Name: E’ un campo opzionale che può essere associato all’endpoint;
� Keywords: E’ una stringa opzionale che permette di indicizzare l’endpoint e di
ritrovarlo agevolmente in caso venga ricercato;
� Address: E’ un URI che indica la posizione globale dell’endpoint.
3.5 JXTA Credentials
Le reti P2P dinamiche come la rete JXTA, hanno la necessità di supportare differenti
livelli di accesso alle risorse. Ciò fa si che i peer JXTA operano in politiche di trusting, in cui
un peer individuale agisce sotto l’autorità concessagli da un altro peer sottoposto alla
medesima politica per realizzare una particolare operazione.
Le relazioni tra i peer, come si può immaginare, possono cambiare molto rapidamente, per
questo motivo l’architettura JXTA ha bisogno di meccanismi di accesso alle risorse, che
rapidamente concedano o neghino l’accesso ad un servizio.
A tale scopo esistono quattro tipologie di accesso alle risorse:
� Confidentiality: garantisce che il contenuto di un particolare messaggio non sia
intercettato da individui non autorizzati;
� Authorization: garantisce che il mittente sia autorizzato a spedire un messaggio;
� Data Integrity: garantisce che il messaggio non sia stato modificato accidentalmente
o deliberatamente durante la trasmissione;
� Refutability: garantisce che il messaggio sia stato trasmesso da un mittente
propriamente identificato e che non sia stato già spedito in precedenza.
I messaggi XML permettono di aggiungere una varietà di informazioni sotto forma di
metadati come ad esempio: credenziali, certificati digitali, chiavi pubbliche, etc. Le
credenziali sono costituite da un token che è presente nel body di un messaggio per

identificare il mittente, e che possono essere utilizzate per verificare che il messaggio sia
indirizzato verso il giusto endpoint.
Quindi le credenziali rappresentate da questo token sono trasparenti all’utente e devono
essere presenti in ogni messaggio trasmesso. Inoltre i protocolli JXTA hanno come obbiettivo,
l’assoluta compatibilità con gli odierni meccanismi di trasporto sicuro come IPSec o SSL.
3.6 ID JXTA
Gli ID sono un sistema canonico che permette di identificare univocamente tutte le risorse
di JXTA. Correntemente, esistono sei tipi di entità JXTA che hanno un ID JXTA definito:
peer, peer group, pipes, contenuti, moduli, specificazioni.
Gli URNs sono utilizzati per esprimere gli ID JXTA.
Un esempio di JXTA peer ID è il seguente:
urn:jxta:uuid-59616261646162614A78746150325033F3BC76FF13C2414CBC0AB663666DA53903
3.7 L’Architettura di una rete JXTA
Una rete JXTA consiste in una serie di peer connessi tra di loro. Le connessioni possono
essere fortemente transitorie, e il routing dei messaggi attraverso i peer è non deterministico.
Un peer può entrare ed uscire dalla rete in ogni momento e il routing tra due peer può
cambiare molto frequentemente.
L’organizzazione della rete non è affidata alla struttura di JXTA, ma in pratica sono utilizzati
3 tipi di peer:
� Minimal peer: Sono quei peer che mandano e ricevono messaggi, ma non
mantengono in cache advertisement relativi ad altri peer, ne tanto meno messaggi di

routing. Un minimal peer è quindi un peer con risorse molto limitate come ad esempio
un PDA o un cellulare;
� Simple peer: Un simple peer può mandare e ricevere messaggi e tipicamente
mantiene nella cache degli advertisement. Un simple peer risponde a richieste di
scoperta provenienti da altri peer, ma non inoltra le richieste di scoperta. La maggior
parte dei peer sono simple peer;
� RendezVous peer: Un RendezVous peer è un peer come gli altri, solo che mantiene
nella cache degli advertisement. Inoltre un RendezVous peer può anche inoltrare le
richieste che gli arrivano da altri RendezVous peer per aiutare altri peer nella scoperta
di risorse. Ogni simple peer può configurare se stesso come RendezVous peer o può
inizializzare una lista di RendezVous peer da utilizzare. Un RendezVous peer inoltre
mantiene una lista di tutti i peer che attualmente sono connessi a lui, per richiedere
informazioni su particolari risorse sullo stato del gruppo per ciò che riguarda le
presenze. I peer inviano le richieste di scoperta ai RendezVous peer, che a loro volta
inoltrano la richiesta ad altri RendezVous peer che conoscono. Il processo di inoltro
delle richieste continua fino a che il campo TTL del messaggio di scoperta non
raggiunge il valore zero. Tutti i messaggi di scoperta hanno come valore del TTL 7. I
cicli sono eliminati facendo si che venga mantenuta una lista di tutti i peer a cui è stato
già mandato il messaggio. Un esempio di utilizzo dei RendezVous peer è mostrato
nella seguente figura:
Fig. 3.7.1:
Scoperta

tramite RendezVous
� Relay peer: Un relay peer mantiene informazioni di routing verso altri peer ed inoltra
i messaggi verso questi peer. Un peer controlla prima nella sua cache se possiede già
le informazioni di routing e in caso non le possieda si rivolge al relay peer. I relay peer
servono anche nel caso su una rete siano presenti NAT o Firewall.
Nella seguente figura è mostrata la consegna di un messaggio ad un peer che è
posto in una rete con firewall:
Fig. 3.7.2: Consegna di messaggi attraverso i relay peer
10.1 3.8 Protocolli di JXTA
JXTA definisce una serie di formati di messaggi XML, o protocolli, per comunicazione tra
peer. I peer usano questi protocolli per scoprire altri peer, inviare advertisement e scoprire
risorse di rete, comunicazione e messaggi di routing.
Ci sono sei protocolli di JXTA:
� Peer Discovery Protocol (PDP): usato dai peer per rendere note le loro proprie
risorse (p.e., peer, peer groups, pipe, o servizi) e scopre risorse da altri peer;

� Peer Information Protocol (PIP): usato dai peer ottenere informazioni sullo stato
(uptime, state, recent traffic, ecc.) dagli altri peer;
� Peer Revolver Protocol (PRP): abilita i peer a spedire query generiche a uno o più i
peer e riceve una risposta (o risposte multiple) ad esse. Diversamente da PDP e PIP,
che sono usati per richiedere informazioni specifiche predefinite, questo protocollo
permette ai peer services di definire e scambiare tutte le informazioni di cui hanno
bisogno;
� Pipe Binding Protocol (PBP): usato dai peer per stabilire un canale di
comunicazione virtuale, o pipe, tra uno o più i peer;
� Endpoint Routing Protocol (ERP): usato dai peer per cercare routes(percorsi) verso
le porte di destinazione su altri peer. Le informazioni sui percorsi includono una
sequenza ordinata di relay peer IDs che possono essere usati per spedire un messaggio
a destinazione. (Per esempio, il messaggio può essere consegnato tramite la sua
spedizione ad un peer A che lo invia ad un peer B che lo inoltra alla destinazione
finale);
� Rendezvous Protocol (RVP): usato dai peer per propagare messaggi in un peer
group.
Tutti i protocolli JXTA sono asincroni, e sono basati su un modello query/response. Un
peer JXTA usa uno dei protocolli per spedire una query ad uno o più peer nel suo peer group.
Esso può ricevere zero, uno, o più risposte alla sua query.

Per esempio, un peer può usare PDP per spedire una discovery query che chiede tutti i peer
noti in una Net Peer Group di default. In questo caso, peer multipli risponderanno
probabilmente con una discovery response. In un altro esempio, un peer può spedire una
discovery request che chiede una pipe specifica chiamata “l'aardvark”. Se questa pipe non è
trovata, allora non verrà spedita in risposta alcuna discovery response.
Non è necessario che nei peer JXTA siano implementati tutti e sei i protocolli; è necessario
implementare solamente i protocolli che verranno usati. La corrente piattaforma Project
JXTA J2SE supporta tutti i sei protocolli di JXTA. Le API del linguaggio di programmazione
Java sono usate per accedere alle operazioni supportate da questi protocolli, come scoperta
dei peer o congiunzione di peer group.
3.9 Peer Discovery Protocol
Il Peer Discovery Protocol (PDP) è usato per scoprire tutte le risorse pubblicate dai peer.
Le risorse sono rappresentate come advertisement. Una risorsa può essere un peer, peer
group, pipe, servizi, o qualsiasi altra risorsa che ha un advertisement. PDP consente a un peer
di cercare advertisement su altri peer. Il PDP è il protocollo di scoperta di default per tutti gli
utenti definiti peer group e la net peer group di default.
I discovery service utilizzati possono scegliere di influenzare il PDP. Se un peer group non
ha il proprio discovery service, il PDP è usato per esaminare i peer alla ricerca di
advertisement. Ci sono modi multipli per scoprire informazioni distribuite.
La corrente piattaforma ProjectJXTA J2SE usa una combinazione fra indirizzi IP multicast
e l'uso di rendezvous peers all’interno della subnet locale, una tecnica basata sul
networkcrawling.
I rendezvous peers forniscono il meccanismo per spedire richieste da un peer noto al
prossimo (“strisciando” per la rete), per scoprire dinamicamente informazioni. Un peer può
essere pre-configurato con un set predefinito di rendezvous peers. Un peer può così scegliere

di avviare se stesso localizzando dinamicamente i rendezvous peers o di risorse di rete nella
prossimità del suo ambiente.
Altre tecniche, come le Content Addressable Networks (CANs), potrebbero essere
aggiunte per migliorare la scoperta delle risorse.
I peer generano messaggi di richiesta di tipo discovery query per scoprire advertisement
all’interno di un peer group. Questi messaggi contengono le credenziali del peer analizzato e
lo identificano al destinatario della comunicazione.
I messaggi possono essere spediti a qualsiasi peer all’interno di una regione o a un
rendezvous peer. Un peer può ricevere zero, uno, o più risposte a una richiesta di tipo
discovery query. Il messaggio di risposta restituisce uno o più advertisement.
3.10 Peer Information Protocol
Una volta localizzato un peer, possono essere consultate le sue risorse.
Il Peer Information Protocol (PIP) fornisce un set di messaggi per ottenere informazioni
sullo stato del peer. Queste informazioni possono essere usate per sviluppi interni o
commerciali delle applicazioni JXTA. Per esempio negli sviluppi commerciali le
informazioni possono essere usate per quantificare l'uso di un peer service e accreditare ai
consumatori l’uso del servizio.
All’interno di uno sviluppo IT, le informazioni possono essere usate dal reparto IT per
monitorare il comportamento di un nodo e dirottare il traffico della rete peer migliorare le
prestazioni complessivo. Questi ganci possono essere estesi per fornire al reparto IT il
controllo del peer node in aggiunta alle informazioni sullo stato.
Il messaggio ping di PIP è spedito ad un peer per controllare se il peer è attivo e ottenere
informazioni su di esso. Il messaggio ping specifica se deve essere restituita un’intera risposta
(peer advertisement) o un semplice acknoledgment (riconoscimento: alive ed uptime).
Il messaggio di peer info è usato per spedire un messaggio in risposta ad un ping.

Esso contiene le generalità del mittente, il peer ID del mittente e il peer ID del destinatario,
uptime, e peer advertisement.
3.11 Peer Revolver Protocol
Il Peer Revolver Protocol (PRP) consente ai peer di spedire query request generiche ad
altri peer. Le query request possono essere spedite ad un peer specifico, o possono essere
propagate all’interno di un peer group tramite i rendezvous services. Il PRP è un foundation
protocol che supporta query request generiche. Sia il PIP che il PDD sono fatti usando PRP, e
forniscono specifiche query/requests: il PIP è usato per consultare specifiche informazioni
sullo stato e PDP è usato per scoprire le peer resources. Il PRP può essere usato per ogni
query generica di cui un’applicazione può aver bisogno.
Per esempio, il PRP permette ai peer di definire e scambiare query per trovare o cercare
informazioni sullo stato del servizio, lo stato di un pipe endpoint, ecc. Il messaggio di
revolver query è usato per spedire una richiedere un servizio ad un altro membro di un peer
group. Il messaggio di resolver query contiene l’identificazione del mittente, un query ID
unico, uno specifico service handler e la query.
Ciascun servizio può registrare un handler nel resolver service del peer group che processa
la specifica richiesta di revolver query e genera le risposte. Il messaggio resolver response è
usato per spedire una risposta ad un messaggio di revolver query; esso contiene le generalità
del mittente, un query ID unico, uno specifico service handler e la risposta. Possono essere
spediti messaggi di revolver query multipli. Un peer può ricevere zero, uno, o più risposte a
una query request.
3.12 Pipe Binding Protocol
Il Pipe Binding Protocol (PBP) è usato dai membri del peer group per associare un pipe
advertisement ad un pipe endpoint.

Il pipe virtual link (percorso virtuale) può essere stratificato su qualsiasi numero di link di
trasporto di reti fisiche come TCP/IP. Ciascuna parte finale di una pipe lavora per mantenere
il link virtuale e ristabilirli, se necessario, legando o trovando i pipe endpoints che si trovano
attualmente sul confine.
Una pipe può essere vista come una coda astratta di messaggi e che supporta la creazione,
open/resolve (bind), chiusura (unbind), cancellazione, spedizione, e ricezione delle
operazioni. Le implementazioni attuali delle pipe possono differire, ma tutte le
implementazioni conformi al protocollo usano PBP per legare le pipe ad un endpoint.
Durante l’operazione astratta di creazione, un peer locale lega un pipe endpoint ad un pipe
transport.
La query PBP viene spedita attraverso la pipe endpoint del peer per trovare una pipe
endpoint di confine sullo stesso pipe advertisement. La query può richiedere informazioni
non ottenute dal cache. Questo è usato per ottenere le informazioni più recenti da un peer. La
query può contenere anche un peer ID opzionale che, se presente, indica che solamente il peer
specificato potrebbe rispondere. La richiesta del PBP è rispedita al peer richiedente attraverso
ogni peer di confine sulla pipe.
Il messaggio contiene il Pipe ID, il peer dove è stata creata la corrispondente InputPipe e
un valore boolean che indica se esiste l’InputPipe sul peer specificato.
3.13 Endpoint Routing Protocol
L'Endpoint Routing Protocol (ERP) definisce un set di messaggi request/query che sono
usati trovare informazioni di routing. Queste informazioni di instradamento sono mecessarie
per spedire un messaggio da un peer (sorgente) ad un altro (destinazione).
Quando a un peer è richiesto di spedire un messaggio ad un determinato endpoint address,
per prima cosa guarda nella sua cache locale per determinare se esiste una strada per arrivare
al peer. Se non trova un percorso, spedisce una route resolver query ai peer ad esso collegati

per ottenere informazioni di risoluzione del percoso. Quando un relay peer riceve una route
query, controlla se conosce il percorso; se non lo conosce restituisce le informazioni di route
come un’enumerazione di salti.
Qualsiasi peer può consultare un relay peer per ottenere informazioni di routing, ed ogni
peer può diventare un relay all’interno di un peer group. I relay peer tipicamente conservano
nella cache informazioni di routing; esse includono il peer ID del mittente, il peer ID del
destinatario, un campo TTL per il routing, e una sequenza ordinata di peer ID di gateway.
La sequenza di peer ID potrebbe non essere completo, ma deve contenere almeno il primo
relay. Le richieste di instradamento sono spedite da un peer ad un peer relay per richiedere
informazioni di routing.
La query può indicare una preferenza per aggirare il contenuto della del router e cercare
dinamicamente un nuovo percorso. Le query di routing sono spedite da un relay peer in
risposta ad una richieste di informazioni di routing. Questo messaggio contiene il peer ID
della destinazione, il peer ID e il peer advertisement di un router che conosce il percorso per
raggiungere la destinazione, e una sequenza ordinata di uno o più relay.
3.14 Rendezvous Protocol
Il Rendezvous Protocol (RVP) è il responsabile della propagazione di messaggi in un peer
group. Mentre differenti peer groups possono avere differenti metodi per propagare
comunicazioni, l’RVP definisce un semplice protocollo che permette:
� di connettere peers a server (essere capaci di propagare e ricevere messaggi) ;
� di controllare la propagazione dei messaggi (TTL, ricerca del loopback ecc.).
L’RPV è usato dal PRP e dal PBP per propagare messaggi.

10.2 3.15 Un semplice esempio che avvia una piattaforma JXTA
Questo paragrafo discute i passi necessari per far girare un semplice esempio includendo:
� Requisiti del sistema ;
� Accesso alla documentazione on-line;
� Downloading dei file binari del Progetto JXTA;
� Compilazione del codice della tecnologia JXTA;
� Esecuzione delle applicazioni della tecnologia JXTA;
� Configurazione dell'ambiente JXTA ;
3.15.1 Requisiti del sistema
Il seguente Project JXTA J2SE Platform Binding richiede una piattaforma che supporta la
JRE di Java o il JDK 1.3.1 e successive. Questo ambiente è attualmente disponibile per
Solaris, Microsoft Windows 95/98/2000/ME/NT 4.0, Linux, e Macintosh.
3.15.2 Esempio HelloWorld
Questo esempio illustra come un’applicazione può avviare la piattaforma di JXTA.
L'applicazione istanzia la piattaforma JXTA e poi stampa un messaggio visualizzando:
� il nome del peer group;
� il peer group ID;
� il nome del peer;
� il peer ID.

Figura 3.15.1: Output: SimpleJxtaApp
3.15.3 La classe SimpleJxtaApp
Definiamo una sola classe, SimpleJxtaApp con una variabile di classe:
� PeerGroup netPeerGroup // il nostro peerGroup (il peerGroup di default)
e due metodi:
� public static void main( ) //metodo principale: stampa informazioni sul peer e il
PeerGroup;
� public void startJxta( ) //inizializza la piattaforma JXTA e crea la net peer group
3.15.4 startJxta ( )
Il metodo startJxta( ) usa una sola chiamata per instanziare la piattaforma JXTA [linea
35]:
netPeerGroup = PeerGroupFactory.newNetPeerGroup( );
Questo chiamata istanzia l'oggetto “piattaforma di default”, quindi crea e restituisce un
oggetto PeerGroup contenente il net peer group di default. Questo oggetto contiene le
realizzazioni delle referenze di default dei vari servizi di JXTA (DiscoveryService,

MembershipService, RendezvousService ecc.). Inoltre contiene il peer group ID e il nome del
peer group, così come il nome e l’ID del peer sul quale gira l’applicazione.
3.15.5 main( )
Questo metodo innanzitutto chiama startJxta() per instanziare la piattaforma JXTA.
Successivamente, questo metodo stampa varie informazioni sul nostro netPeerGroup:
� Group name: il nome del net group di default, NetPeerGroup [linea 19]:
System.out.println ("Hello from JXTA group " +
netPeerGroup.getPeerGroupName( ) );
� Peer Group ID: l’ID del peer group del net peer group di default [linea 21]:
System.out.println (" Group ID = " + netPeerGroup.getPeerGroupID(
).toString());
� Peer Name: il nostro nome; tutto ciò che noi abbiamo fornito durante la
configurazione di base del JXTA[linea 23]:
System.out.println (" Peer name = " + netPeerGroup.getPeerName( ));
� Peer ID: il peer ID univoco che è stato assegnato al nostro peer JXTA quando
abbiamo avviato l’applicazione [linea 25]:
System.out.println (" Peer ID = " + netPeerGroup.getPeerID( ).toString( ));
Dopo avere stampato queste informazioni, la nostra applicazione termina.
3.15.6 Esecuzione di “Hello World”

La prima volta che SimpleJxtaApp è avviato, è visualizzato il tool di autoconfigurazione.
Dopo aver inserito le informazioni di configurazione e cliccato OK, l’applicazione continua a
stampare informazioni circa il peer JXTA e il peer group. Quando l’applicazione ha finito, si
può esaminare i vari file e subdirectories che sono stati creati nella directory corrente:
� PlatformConfig: il file di configurazione creato dal tool di autoconfigurazione;
� cm: la directory di cache locale; essa contiene subdirectories per ciascuno gruppo che
è stato individuato. Nel nostro esempio, noi dovremmo vedere la subdirectory
chiamata jxta-NetGroup;
� cm\jxta-NetPeerGroup\Peers: subdirectory che contiene advertisement (documenti
XML) per ogni peer che è stato individuato nel NetPeerGroup. Nel nostro esempio,
noi abbiamo creato un singolo peer JXTA, e dovremmo quindi vedere in questa
directory un solo file. Un esempio di peer advertisement è mostrato nella figura in
basso;
� pse: subdirectory che contiene i nostri peer certificati (usati per la sicurezza).

10.3 Figura 3.15.2: Esempio di peer advertisement JXTA
3.15.7 Codice sorgente: SimpleJxtaApp

3.16 Programmare con JXTA
Questo parte del capitolo presenta diversi esempi di programmazione JXTA che eseguono
task comuni come scoperta di peer e peer group, creare e pubblicare advertisement, creare e
legare un peer group e usare pipe.
3.17 Scoperta di un peer ( Peer Discovery )

Il seguente esempio di programmazione illustra come scoprire altri peer JXTA nella rete.
L’applicazione istanzia una piattaforma JXTA, quindi spedisce una Discovery Query al net
peer group di default, cercando ogni peer JXTA. Per ogni Discovery Response3 ricevuto,
l’applicazione stampa il nome del peer che ha spedito la risposta e anche il nome di ogni peer
che è stato scoperto.
Figura 3.17.1: Esempio di output: esempio di scoperta di peer
3.17.1 Il servizio di scoperta ( Discovery Service)
Il JXTA Discovery Service fornisce un meccanismo sincrono per scoprire peer, peer
group, pipe e il servizio advertisement. Gli advertisement sono memorizzati in una cache
locale persistente (la directory cm).
3 Nota: Poiché le Discovery Responses sono spedite in modo asincrono è necessario aspettare che siano spedite molte
Discovery Request prima di ricevere qualche risposta.
Se non si riceve alcuna Discovery Response, quando si avvia questa applicazione, significa che JXTA non è stato configurato
correttamente. Si dovrà specificare, tipicamente, almeno un rendezvous peer. Se il peer è localizzato dietro un firewall o un NAT, sarà
necessario specificare un relay peer. Rimuovere il file Platform Config che era stato creato nella directory corrente e riavviare l’applicazione.
Quando appare il configuratore JXTA inserire la configurazione corretta.

Quando un peer si avvia, la stessa cache è referenziata. Un peer può usare il metodo
getLocalAdvertisements( ) per recuperare advertisement che si trovano nella sua cache
locale. Se esso vuole scoprire altri advertisement può usare getRemotedAdvertisements( )
per spedire una Discovery Query ad altri peer.
La Discovery Query può essere spedita ad un peer specifico o propagato sulla rete JXTA.
Nella piattaforma J2SEE le Discovery Query, non intesi per uno specifico peer, sono
propagati nella sottorete locale, utilizzando l’IP multicast, ed inoltre propagato ai peer
rendezvous configurati. Un peer include il proprio advertisement in una Discovery Query,
eseguendo una notifica o un meccanismo di scoperta automatico.
Ci sono due modi per ricevere una Discovery Response. Ci si può aspettare che uno o più
peer rispondano ad una Discovery Response, e che facciano una chiamata al metodo
getLocalAdvertisements( ) per ricevere il risultato che è stato trovato e aggiunto alla cache
locale. Alternativamente, notifiche asincrone di scoperta dei peer possono essere completate
aggiungendo un Discovery Listener, che richiama il metodo discoveryEvent( ) ,quando è
ricevuto un evento di scoperta.
Se si sceglie di aggiungere un Discovery Listener si hanno due opzioni:
� si può invocare addDiscoveryListener( ) per registrare un listener;
� si può passare un listener come argomento al metodo getRemotedAdvertisements( ).
Il DiscoveryService è così usato per pubblicare advertisements. Tutto ciò è discusso in
maniera più dettagliata nel paragrafo “Creazione di peer group e pubblicazione di
advertisements”.
In tale esempio sono utilizzate le seguenti classi:

� net.jxta.discovery.DiscoveryService: meccanismo asincrono per scoprire peer ,peer
group, pipe e service advertisements e pubblicare advertisements;
� net.jxta.discovery.DiscoveryListener: l’interfaccia che descrive il listener, che serve
ad ascoltare gli eventi DiscoveryService;
� net.jxta.DiscoveryEvent: contiene le tipologie di Discovery Response;
� net.jxta.protocol.DiscoveryResponseMsg: definisce le Discovery Service
“response”.
3.17.2 Discovery Demo
Questo esempio usa l’interfaccia DiscoveryListener per ricevere eventi di notifica
asincroni.
Si definisce una singola classe, chiamata DiscoveryDemo, che implementa l’interfaccia
DiscoveryListener. Così si definisce una variabile di classe:
� PeerGroup netPeerGroup: il nostro peer group (peer group di default) [linea 27]
e quattro metodi:
� public void startJxta( ): inizializza la piattaforma JXTA [linea 35];
� public void esegui( ): thread per spedire una DiscoveryRequest [linea 58];
� public void discoveryEvent(DiscoveryEvent ev): gestisce le DiscoveryResponse
ricevute [linea 96];
� public static void main( ): metodo principale [linea 150]

3.17.2.1 Metodo startJxta( )
Il metodo startJxta( ) istanzia la piattaforma JXTA e crea il net peer group di default
[linea 37]:
gruppo = PeerGroupFactory.newNetPeerGroup( );
Successivamente, il nostro servizio di scoperta è ricevuto dal nostro peer group, il
netPeerGroup [linea 50]:
servizioDiScoperta = gruppo.getDiscoveryService( );
Questo servizio di scoperta sarà utilizzato successivamente per aggiungere il nostro peer
come DiscoveryListener per un evento di DiscoveryResponse e per spedire
DiscoveryRequest.
3.17.2.2 Metodo esegui( )
Il metodo esegui( ) aggiunge, per prima cosa, l’oggetto chiamante come un
DiscoveryListener per eventi DiscoveryResponse [linea 66]:
servizioDiScoperta.addDiscoveryListener(this);
Ora, quando è ricevuta una Discovery Response, il metodo discoveryEvent( ) sarà
chiamato su questo oggetto. Questo abilita la nostra applicazione a essere notificata
asincronamente ogni volta che questo peer riceve una Discovery Response.

Successivamente il metodo esegui( ) cicla all’infinito, spedendo Discovery Request
attraverso il metodo getRemoteAdvertisements( ).
Quest’ultimo riceve sei argomenti:
� java.lang.String peerID: ID del peer a cui spedire la query; se è null propaga una
query request.
� Int type: DiscoveryService.PEER, DiscoveryService.GROUP,
DiscoveryService.ADV.
� java.lang.String attribute: il nome dell’attributo su cui restringere la ricerca.
� java.lang.String value: valore dell’attributo per delimitare il campo di ricerca.
� int threshold: il limite superiore di risposte che devono giungere da un peer.
� net.jxta.discovery.DiscoveryListener listener: servizio di Discovery Listener.
Ci sono due principali modi per inviare una Discovery Request attraverso il Discovery
Service.
1. Se è specificato un peer ID nell’invocazione del metodo getRemoteAdvertisements(
), il messaggio viene spedito solo a tale peer. In questo caso l’endpoint router prova a
risolvere localmente l’endpoint del peer di destinazione.

2. Se è specificato un peer ID null, il messaggio è propagato nella sottorete locale
utilizzando l’IP multicast, e viene anche propagato ai rendezvous peer. Risponderanno
a tale richiesta solo i peer appartenenti allo stesso peer group.
Il parametro type specifica quali tipi di advertisement bisogna vagliare.
La classe DiscoveryService definisce tre costanti:
� DiscoveryService.PEER: cerca i peer advertisements.
� DiscoveryService.GROUP: cerca un group advertisement.
� DiscoveryService.ADV: cerca tutti gli altri tipi di advertisement, come i pipe
advertisement e module class advertisement.
L’area di ricerca può essere ristretta specificando la coppia attribute e value; solo gli
advertisement che corrispondono a tali valori verranno restituiti. La variabile attribute deve
avere un valore uguale ad un elemento nel documento XML associato. La stringa value usa
caratteri jolly (ad esempio, *) per effetturare il confronto. Per esempio le seguenti chiamate
limiteranno la ricerca ai peer, il cui nome contiene esattamente la stringa “test1”:
discovery.getRemoteAdvertisements (null, DiscoveryService.PEER, “Name”, “test1”, 5, null);
Un secondo esempio è quello per cui la chiamata del metodo getRemoteAdvertisements(
) restituisca ogni peer il cui nome contiene la stringa “test”:
discovery.getRemoteAdvertisements (null, DiscoveryService.PEER, “Name”, “*test*”, 5, null);

La ricerca può così essere limitata specificando il valore della variabile threshold, che
indica il limite superiore di risposte da un peer. Nel nostro esempio [linea 73], abbiamo
spedito una Discovery Request alla sottorete locale e ai rendezvous peer, alla ricerca di ogni
peer. Dando alla variabile threshold il valore 5, il nostro peer riceverà un massimo di cinque
risposte (peer advertisements) in ogni Recovery Response.
Se il peer ha più risultati rispetto al numero specificato, il numero esatto di risposte sarà
selezionato casualmente. Poiché il nostro peer è già un DiscoveryListener è stato specificato il
valore null per il parametro finale (DiscoveryListener).
discovery.getRemoteAdvertisements (null, DiscoveryService.PEER, null, null, 5, null);
Non c’è alcuna garanzia che vi sarà risposta ad una Discovery Request, in altre parole un
peer potrebbe ricevere nessuna, una o più risposte.
3.17.2.3 Metodo discoveryEvent( )
Poiché le nostre classi implementano l’interfaccia DiscoveryListener, si deve avere un
metodo discoveryEvent( ) [linea 96]:
public void discoveryEvent(DiscoveryEvent ev)
Il Discovery Service invoca questo metodo ogni volta che è ricevuto una Discovery
Response. I peer scoperti sono addizionati automaticamente alla cache locale (./cm/jxta-
NetGroup/peers). La prima parte di questo metodo stampa un messaggio che contiene il peer
che ci invia la risposta. Al metodo discoveryEvent( ) è passato un singolo argomento di
classe DiscoveryEvent.

Il metodo getResponse( ) restituisce la risposta associata a questo evento e lo memorizza
nella variabile risposta di classe DiscoveryResponseMsg [linea 98]:
DiscoveryResponseMsg risposta = ev.getResponse( );
Ogni oggetto DiscoveryResponseMsg contiene il peer advertisements del peer che ci invia
la risposta, un contatore del numero di risposte restituite, ed un elenco di peer
advertisement(uno per ogni peer scoperto).
Il nostro esempio riceve l’advertisement del peer che risponde al messaggio [linea 102]:
String testoAdvertisement = risposta.getPeerAdv( );
e usa tale stringa contenente l’advertisement del peer per costruire un PeerAdvertisement.
Il metodo statico AdvertisementFactory.newAdvertisement( ) è utilizzato per creare
advertisements [linea 108]:
InputStream inputStream = new ByteArrayInputStream( testoAdvertisement.getBytes( ) );
advertisement = (PeerAdvertisement) AdvertisementFactory.newAdvertisement (new MimeMediaType(
"text/xml" ), inputStream);
I due argomenti passati al metodo AdvertisementFactory.newAdvertisement( ) sono un
oggetto di classe MimeMediaType nel quale si riversano i byte del flusso di input
inputStream di classe ByteArrayInputStream, ottenuto dalla stringa testoAdvertisement
tramite il metodo getBytes( ).
Ottenuto così il peer advertisement, si può stampare una statistica delle risposte ricevute ed
il nome dei peer che hanno risposto [linea 112]:

System.out.println("[Ho ricevuto una Discovery Response che mi informa della presenza di [" +
risposta.getResponseCount() + " peer nella rete] dal peer : " + advertisement.getName()+ " ]" );
La seconda parte di questo metodo stampa il nome di ogni peer scoperto.Le risposte sono
restituite sottoforma di elenco, e possono essere ricevute dal DiscoveryResponseMsg [linea
124]:
Enumeration elenco = risposta.getResponses( );
Per ogni elemento dell’elenco noi creiamo un peer advertisement, quindi riceviamo e
stampiamo il nome del peer [linea 116]:
nuovoAdvertisement = (PeerAdvertisement) AdvertisementFactory.newAdvertisement (new
MimeMediaType( "text/xml" ), new ByteArrayInputStream (stringa.getBytes( )));
System.out.println( " Peer name = " + nuovoAdvertisement.getName());
3.17.2.4 Metodo main( )
Il metodo main( ) [linea 150] crea innanzitutto un nuovo oggetto di classe
DiscoveryDemo. Successivamente invoca il metodo startJxta( ) [linea 152] che istanzia la
piattaforma Jxta. Infine, invoca il metodo esegui( ) [linea 153] che cicla continuamente
spedendo Discovery Request.
3.18 La scoperta di un peer group (Peer Group Discovery)

Questo è molto simile a quello precedendente; la principale differenza è che invece di
spedire DiscoveryRequest per cercare peer, vengono spedite DiscoveryRequest per cercare
peer groups. Ogni DiscoveryRequest ricevuta contiene peer group advertisements piuttosto
che peer advertisements.
Come l’esempio precedente, viene istanziata una piattaforma JXTA e quindi spedita una
DiscoveryRequest al netPeerGroup di default alla ricerca di peer group. Per ogni
DiscoveryResponse ricevuta, l’applicazione stampa il nome del peer che spedisce la risposta,
così come ogni peer group scoperto.
Figura 3.18.1: Esempio di output: esempio di peer group discovery
3.18.1 Il metodo run( )
L’unica differenza, rispetto all’esempio precedente, è che si spedisce la DiscoveryRequest
alla ricerca di peer groups piuttosto che peers [linea 68]:
servizioDiScoperta.getRemoteAdvertisements (null, DiscoveryService.GROUP, null, null, 5, null);
3.18.2 Il metodo discoveryEvent( )

La prima parte di questo metodo è identica all’esempio precedente: noi riceviamo un
DiscoveryResponseMsg, estraiamo gli advertisement dei peer che rispondono (una stringa),
successivamente crea un oggetto peer advetisement usando la stringa.
Una volta che si è in possesso del peer advertisement, si può stampare il messaggio
contenente il nome del peer rispondente ed il numero di risposte. Le differenze si trovano
nella seconda parte del metodo, che stampa il nome di ogni peer group scoperto.
Come l’esempio di Peer Discovery, le risposte sono restituite sottoforma di elenco e sono
ricevute da DiscoveryResponseMsg [linea 92]:
Enumeration elenco = risposta.getResponses( );
Ora, invece di creare peer advertisements, noi creiamo peer group advertisements [linea
128]:
newAdv = (PeerGroupAdvertisement) AdvertisementFactory.newAdvertisement (new MimeMediaType (
"text/xml" ), new ByteArrayInputStream (str.getBytes( )));
System.out.println( " Peer Group = " + newAdv.getName());
3.19 Creare Peer Groups e pubblicare advertisements
Questo esempio crea un nuovo peer group e stampa il suo nome e il suo ID, quindi
pubblica il suo advertisement.
In figura è riportato l’output dell’applicazione:

Figura 3.19.1: Esempio output: creazione e pubblicazione di peergroup
Dopo il completamento di questo programma, si può verificare che l’ advertisement del
peer group sia stato aggiunto alla cache locale ./cm. L’advertisement del nuovo gruppo è
aggiunto al gruppo genitore, il mioGruppo creato dal nostro esempio: (jxta-
NetGroup/Groups directory). Inoltre, viene creata una nuova directory che ha lo stesso nome
del peer group ID, che contiene sottodirectory destinate a contenere peer, peer groups e altri
advertisement scoperti nella rete.
Un advertisement per il nostro peer è aggiunto alla sottodirectory corrispondente, dove
saranno aggiunti gli advertisement per ogni peer addizionale scoperto nel nuovo peer group.
� .cm/jxta-NetGroup/Groups/1D5E451AF1B243C1AD49B9D331AE858C02:
advertisement per il nuovo gruppo.
� .cm/1D5E451AF1B243C1AD49B9D331AE858C02: directory per il nuovo peer
group.
� .cm/1D5E451AF1B243C1AD49B9D331AE858C02/Peers/<peer id>: il nostro peer
advertisement.

3.19.1 Il metodo main( )
Questo metodo invoca startJxta( ) per avviare la piattaforma JXTA e creare un
mioGruppo di default. Inoltre invoca creaGruppo( ), per creare un nuovo peer group e
pubblicare il suo advertisement.
3.19.2 Il metodo startJxta( )
Questo metodo è identico agli esempi precedenti. Esso istanzia la piattaforma JXTA ed
estrae informazioni necessarie nel resto dell’applicazione:
� istanzia la piattaforma JXTA e crea il net peer group di default [linea 43];
mioGruppo = PeerGroupFactory.newNetPeerGroup();
� estrae il discovery service dal peer group; questo è usato successivamente per
pubblicare l’advertisement del nuovo gruppo [linea 58]
servizioDiScoperta = mioGruppo.getDiscoveryService();
3.19.3 createGroup( )
Questo metodo è utilizzato per creare un nuovo peer group è pubblicare i suoi
advertisement. La prima parte di questo metodo[linea 73] crea il nuovo peer group.

Inizialmente, si invoca getAllPurposePeerGroupImpleAdvertisement( ) per creare un
ModuleImplAdvertisement, che contiene voci per tutti i peer group services del core [linea
71]
ModuleImplAdvertisement implAdv = mioGroup.getAllPurposePeerGroupImplAdvertisement( );
Successivamente utilizziamo newGroup( ) per creare un nuovo peer group [linea 73].
PeerGroup nuovoPeerGroup = mioGruppo.newGroup(null, implAdv, "Gruppo Tesi", "Gruppo per la prova
della creazione di nuovi peer group");
Passiamo quattro argomenti al metodo newGroup( ):
� PeerGroupID gid: il peer group ID del gruppo che verrà creato; se è null, viene
creato un nuovo peer group ID.
� Advertisement implAdv: l’implementazione dell’advertisement.
� String name: il nome del nuovo gruppo.
� String description: una descrizione del gruppo.
Quando viene creato un nuovo gruppo tramite newGroup( )4, il suo advertisement è
sempre aggiunto alla cache locale. Esso usa il valore di default per la scadenza
4 Dal momento in cui il metodo newGroup( ) crea un nuovo gruppo esso è anche pubblicato, non è quindi necessario
invocare esplicitamente il metodo DiscoveryService.publish( )

dell’advertisement; il tempo di vita locale è di 365 giorni (il tempo di vita dell’advertisement
è memorizzato localmente dal peer che lo genera), ed un tempo di vita remoto di due ore (il
tempo dell’advetisement è mantenuto nella cache del peer che ha richiesto e ricevuto
l’advertisement). Dopo la creazione del gruppo, stampiamo il nome del gruppo è il suo peer
group ID.
La seconda parte del metodo pubblica in remoto il nuovo peer group advertisement [linea
102].
servizioDiScoperta.remotePublish(adv, DiscoveryService.GROUP);
Questo metodo riceve due argomenti: l’advertisement da pubblicare e il tipo di
advertisement; utilizza il tempo di scadenza di default.
La sua invocazione usa il discovery service per spedire messaggi alla sottorete locale e così
a tutti i rendezvous peers.
3.20 Unire un peer group
Questo esempio crea e pubblica un nuovo peer, unisce il peer group, e stampa le sue
credenziali di autorizzazione.
In figura è mostrato l’output di quando l’applicazione è in esecuzione:

Figura 3.20.1: Esempio di output: creare e unire un peer group
Questo esempio si costruisce sul precedente esempio che crea e pubblica un nuovo gruppo.
Il nuovo codice in questo esempio e nel metodo joinGroup( ), che illustra come fare per
appartenere ad un gruppo e quindi unirlo.
Questo esempio utilizza il meccanismo di default per unire un gruppo.
3.20.1 Servizio di appartenenza ad un gruppo (Membership Service)
In JXTA, il Membership Service è usato per fare in modo di appartenere ad un gruppo,
unire un peer group e abbandonare un peer group.
Il Membership Service permette ad un peer di assumere un’identità in un peer group.
Quando è stata stabilita la sua identità, sono disponibili delle credenziali che permettono al
peer di essere stato identificato correttamente. Le identità sono utilizzate dai servizi per
determinare i permessi che possono essere concessi al peer. Quando un peer group è
istanziato su un peer, il Membership Service per questo peer group assegna al peer un’identità

temporanea di default. Quest’identità temporanea , per convenzione, consente solo al peer di
stabilire la sua vera identità.
La sequenza per l’assegnazione dell’identità ad un peer in un peer group è la seguente:
� Apply: Il peer fornisce al Membership Servise le credenziali iniziali che possono
essere utilizzate dal servizio, per determinare quale metodo di autenticazione deve
essere usato per determinare l’identità di questo peer. Se il servizio concede
l’autenticazione usando il meccanismo richiesto, allora è restituito un’appropriato
oggetto autenticatore. Si suppone che il peer group sappia come interagire con
l’oggetto autenticatore (si ricordi che prima di applicare il processo è richiesto il
metodo di autenticazione).
� Join: l’autenticazione completa è restituita al Membership Service e l’identità di
questo peer è adattata in base alle credenziali fornite dall’autenticatore. L’identità del
peer rimane così come era, fino a quando non viene completata l’operazione di Join.
� Resign. È scartata qualsiasi identità esistente stabilita per questo peer, e l’identità
corrente ritorna all’identità nobody.
Le credenziali di autenticazione sono utilizzate dai servizi Membership Service come base
per le applicazioni per l’apparteneza al peer group.
Le AutenticationCredential forniscono due importanti pezzi di informazione: il metodo
di autenticazione richiesto e le informazioni di identità che saranno fornite a questo metodo di
autenticazione.

Non tutti i metodi di autenticazione utilizzano le informazioni sull’identità.
3.20.2 main( )
Questo metodo chiama i seguenti tre metodi:
� startJxta( ): per istanziare la piattaforma e creare il net peer group di default( ) [linea
35];
� createGroup( ): per creare e pubblicare un nuovo peer group [linea 36];
� joinGroup( ): per unire il nuovo gruppo [linea 38].
3.20.3 startJxta( )
Questo metodo è uguale a quello dell’esempio precedente.
3.20.4 createGroup( )
Questo metodo [linea 66] è quasi identico a quello dell’esempio precedente. Esso è usato
un nuovo peer group e pubblicare il suo advertisement. La sola differenza significativa e che
se il gruppo è creato con successo esso restituisce il nuovo peer group. Se si verifica un errore
durante la creazione del nuovo peer group il metodo restituisce null.
3.20.5 joinGroup( )
Il metodo è utilizzato per unire il peer group che è passato come argomento [linea 108]:
private void joinGroup(PeerGroup gruppo)

Nel codice di esempio il metodo joinGroup( ) inizialmente genera le credenziali di
autenticazione per il peer nel peer group specificato [linea 116]:
AuthenticationCredential authCred = AuthenticationCredential(gruppo, null, credenziali);
Questo costruttore prende tre argomenti:
� PeerGroup peerGroup: il peer group in cui vengono create queste credenziali di
autenticazione (il peer group che vogliamo unire).
� java.lang.String metodo: il metodo di autenticazione che sarà richiesto quando le
credenziali di autenticazione è fornita al servizio di MemberShipService del peer
group.
� Element identifyInfo: informazione aggiuntiva opzionale riguardante l’identità
richiesta, utilizzata dal metodo di autenticazione. Quest’informazione è passata al
metodo di autenticazione durante l’operazione di apply( ) del Membership Service.
Le credenziali di autenticazione sono create nel contesto di un peer group. Tuttavia, sono
generalmente indipendenti dal peer group. L’intenzione è di passare le credenziali di
autenticazione al Membership Service dello stesso peer group. Successivamente il nostro
esempio estrae il MemberShip Service dal peer group che noi vogliamo unire [linea 121]:
MembershipService appartenenza = gruppo.getMembershipService( );

e usa il metodo MembershipService.apply( ) per applicare l’appartenenza al gruppo [linea
125]:
Authenticator autenticatore = appartenenza.apply( authCred );
Le credenziali di autenticazione create precedentemente sono passate al metodo apply( ).
Nelle credenziali è inclusa l’informazione riguardante il nostro peer group ID, il nostro
peer ID e la nostra identità da utilizzare quando uniamo questo gruppo.
Il metodo apply( ) restituisce un oggetto Authenticator, che è utilizzato per verificare che
l’autenticazione sia stata completata correttamente. Il meccanismo per completare l’oggetto di
autenticazione è unico per ogni metodo di autenticazione. La sola operazione comune è
isReadyForJoin( ), che fornisce informazioni se sia stato o meno completato correttamente il
processo di autenticazione.
Dopo essere riusciti ad applicare l’appartenenza, il passo successivo è l’unione del gruppo.
Per prima cosa, il metdo Authenticator.isReadyForJoin( ) è invocato per verificare il
processo di autenticazione. Questo metodo restituisce true se l’oggetto autenticatore è
completo e pronto ad essere sottoposto al Memebership Service per l’unione; altrimenti esso
restituisce false. Se tutto è andato a buon fine nell’unire il group, il metodo
MembershipService.join( ) è invocato per unire il gruppo [linea 129]:
if (autenticatore.isReadyForJoin( )){
Credential miaCredenziale = appartenenza.join(autenticatore);

Il metodo MembershipService.join( ) restituisce un oggetto Credential.
3.21 Scambio di messaggi fra due peer
Questo esempio illustra come usare le pipe per spedire messaggi tra due peer JXTA.
In questo esempio sono usate due applicazioni separate:
� PipeListener: legge in un pipe advertisement contenuto in un file (examplepipe.adv),
crea un input pipe e ascolta i messaggi su di essa.
� PipeExample: legge un pipe advertisement contenuto in un file (examplePipe.adv),
crea un outputPipe e manda un messaggio su di essa.
Le figure in basso mostrano l’output quando sono avviate le applicazioni PipeListener e
PipeExample5:
Figura 3.21.1: Esempio di output: PipeListener
5 se si avviano entrambe le applicazioni sullo stesso sistema, sarà necessario avviare ogni applicazione da una sottodirectory
separata, cosicché può essere configurate ad usare orte separate.

Figura 3.21.2: Esempio di output: PipeExample
La seguente sezione fornisce le informazioni di fondo su pipe service, input pipe e output
pipe.
3.21.1 JXTA Pipe Service
La classe PipeService definisce un set di interfacce per creare e accedere alle pipe in un
peer group. Le pipe sono il cuore del meccanismo di scambio messaggi fra due applicazioni o
servizi JXTA. Le pipe forniscono un canale di comunicazione fra due peer semplice,
unidirezionale e asincrono. I messaggi sono scambiati fra input pipe e output pipe.
Un’applicazione, che vuole aprire una comunicazione in ricezione con altri peer, crea un
input pipe e la lega ad un pipe advertisement specifico. L’applicazione quindi pubblica il pipe
advertisement, cosicché le altri applicazioni o servizi possono ottenere l’advertisement e
creare output pipes corrispondenti per spedire messaggi all’input pipe. Le pipe sono
univocamente identificate in tutto l’ambiente JXTA da un PipeId (UUID) racchiuso in un pipe
advertisement. Questo PipeId unico è utilizzato per creare l’associazione fra input e output
pipes.
Le pipe sono canali di comunicazione non localizzati che non sono limitate ad un peer
specifico. Questa è una caratteristica unica delle pipe JXTA. Il meccanismo per risolvere la

locazione delle pipe ad un peer fisico è fatto in una maniera completamente decentralizzata,
attraverso il JXTA Pipe Binding Protocol
Il PBP non si poggia su un protocollo centralizzato come un DNS per legare un pipe
advertisement (nome simbolico) ad un’istanza di una pipe in un peer fisico (indirizzo IP).
Invece il protocollo di risoluzione utilizza un meccanismo di ricerca dinamico e adattabile
che tenta sempre di trovare i peer dove è in esecuzione un’istanza di questa pipe.
Le seguenti classi sono usate nelle applicazioni PipeListener e PipeExample:
� net.jxta.pipe.PipeService: definisce le api del pipe service.
� net.jxta.pipe.InputPipe: definisce l’interfaccia per ricevere messaggi da un pipe
service. Un’applicazione che desideri recevere un messaggio da un pipe creerà un
input pipe. Un’ InputPipe è creata e restituita dal pipe service.
� net.jxta.pipe.PipeMsgListener: l’interfaccia ascoltatore per ricevere PipeMsgEvent.
� net.jxta.pipe.PipeMsgEvent: contiene gli eventi ricevuti da una pipe.
� net.jxta.pipe.OutputPipe: definisce l’interfaccia per spedire messaggi da un
PipeService. Le applicazioni che vogliono spedire messaggi su una pipe devono
innanzitutto ottenere una OutputPipe dal PipeService.
� net.jxta.pipe.OutputPipeListener: l’interfaccia ascoltatore per ricevere eventi di
risoluzione OutputPipe.

� net.jxta.pipe.OutputPipeEvent: contiene gli eventi ricevuti quando è risolta una
OutputPipe.
� net.jxta.endpoint.Message: definisce l’interfaccia di messaggi spediti a pipe o
ricevuti da pipe usando le API PipeService. Un messaggio contiene un set di
MessageElements.
3.21.2 Pipe listener
Questa applicazione crea un ascoltatore per i messaggi su una input pipe. Definisce una
singola classe, PipeListener, che implementa le interfacce Runnable e PipeMsgListener.
Due costanti di classe contengono informazioni sulle pipe da creare:
� String FILENAME: il file XML contenente la rappresentazione testuale del nostro
pipe advertisement (questo file deve esistere, e deve contenere un pipe advertisement
valido, affinché la nostra applicazione venga eseguita correttamente).
� String TAG: il nome del messaggio, o tag che ci aspettiamo in ogni messaggio che
riceviamo.
Definiamo quindi quattro variabili:
� PeerGroup netPeerGroup: il nostro peer group, quello di default.
� PipeService pipeService: il pipe service che usiamo per creare le input pipe ed
ascoltare se arrivano messaggi.

� PipeAdvertisement pipeAdvertisement: il pipe advertisement che usiamo per creare
le nostre input pipe.
� InputPipe pipeIn: l’input pipe che creiamo.
3.21.2.1 main( )
Il metodo [linea 39] crea un nuovo oggetto PipeListener, invoca startJxta( ) per istanziare
la piattaforma JXTA, crea il net peer group di default ed invoca il metdo run( ) che crea
l’input pipe e registra questo oggetto come un PipeMsgListener (quest’applicazione non
termina mai, a causa di un thread Java “invisibile” che agisce inviando input pipe event).
3.21.2.2 startJxta( )
Questo metodo istanzia la piattaforma JXTA e crea il net peer group di default [linea 53]]:
netPeerGroup = PeerGroupFactory.newNetPeerGroup( );
A questo punto riceve il PipeService dal net peer group di default [linea 65]. Questo
servizio è utilizzato successivamente quando creiamo una input pipe:
pipeService = netPeerGroup.getPipeService( );
Successivamente, creiamo un pipe advertisement leggendolo da un file esistente
examplepipe.adv [linea 69]:

FileInputStream fileInputStream = new FileInputStream(FILENAME);
Il file examplepipe.adv deve esistere e deve essere un documento XML valido, contenente
un pipe advertisement, altrimenti viene sollevata un eccezione dalla piattaforma Jxta.
Questa applicazione (che crea una input pipe) e l’applicazione associata (che crea l’output
pipe) leggono il loro pipe advertisement dallo stesso file. Il contenuto del file
examplepipe.adv è presentato in figura 4.5.4.1. Il metodo
AdvertisementFactory.newAdvertisement( ) è invocato per creare un nuovo pipe
advertisement [linea 70]:
pipeAdvertisement = (PipeAdvertisement) AdvertisementFactory.newAdvertisement(new
MimeMediaType("text/xml"),
fileInputStream);
I due argomenti di questo metodo sono il MIME type (“text/xml” in questo esempio), da
associare al documento strutturato risultante (per esempio l’advertisement) e l’InputStream
contenente il corpo (body) dell’advertisement. Il tipo dell’advertisement è determinato dalla
lettura dell’InputStream.
Infine viene creato il pipe advertisement, viene chiuso l’InputStream [linea 73] e il metodo
termina:
fileInputStream.close( ).
3.21.2.3 run( )

Questo metodo utilizza il metodo PipeService.createInputPipe( ) per creare una nuova
input pipe per la nostra applicazione [linea 91]:
pipeIn = pipeService.createInputPipe(pipeAdvertisement, this);
Poiché vogliamo leggere un evento da una input pipe, invochiamo createInputPipe( ) con
due argomenti:
� PipeAdvertisement adv: l’advertisement della pipe che è stata creata;
� PipeMsgListener listener: l’oggetto che riceverà gli eventi generati dai messaggi
sulla input pipe;
Registrando il nostro oggetto come ascoltatore, quando noi creiamo l’input pipe, il nostro
metodo pipeMsgEvent( ) sarà invocato asincronamente ogni volta che si verifica su questa
pipe un PipeMsgEvent (per esempio: ogni volta che viene ricevuto un messaggio).
3.21.2.4 pipeMsgEvent( )
Questo metodo [linea 111] è invocato asincronamente ogni volta che si verifica un pipe
event sulla nostra input pipe.
A questo metodo viene passato un argomento:
� PipeMsgEvent event: l’evento che si verifica sulla pipe.

Inizialmente il nostro metodo invoca PipeMsgEvent.getMessage( ) per ricevere il
messaggio associato con l’evento [linea 116]:
messaggio = event.getMessage( );
Ogni messaggio contiene zero o un elemento, ognuno con un nome di elemento associato
(tag) e una stringa corrispondente. Il nostro metodo invoca messaggio.getString( ) per estrarre
la stringa corrispondente al messaggio identificato dal tag passato come argomento [linea
128]:
String testoMessaggio = messaggio.getString(TAG);
Se il tag non è presente nel messaggio, il metodo restituisce null.
Si ricordi che sia l’input pipe che l’output pipe devono essere in accordo con il tag
utilizzato nel messaggio. Nel nostro esempio, noi impostiamo nella classe PipeListener una
costante per riferirci al tag [linea 32]:
private final static String TAG = "Ascoltatore di messaggi sulla pipe";
Infine, il nostro metodo stampa il messaggio che ha ricevuto [linea 133]:
System.out.println("Il messaggio ricevuto è: " + testoMessaggio);

3.21.3 PipeExample
Questo esempio crea una output pipe sulla quale spedisce un messaggio. Definisce una
singola classe, PipeExample, che implementa le interfacce Runnable e OutputPipeListener.
Come la classe corrispondente, PipeListener, definisce due costanti per contenere
informazioni sulle pipe da creare:
� String FILENAME: il file XML contenente la rappresentazione testuale del nostro
PipeAdvertisement.
� String TAG: il nome del tag, che vogliamo includere in ogni messaggio che
spediamo.
3.21.3.1 main( )
Questo metodo [linea 36] crea un nuovo oggetto PipeExample, invoca startJxta( ) per
istanziare la piattaforma Jxta e crea il net peer group di default, e quindi chiama il metodo
run( ), che crea una output pipe.
3.21.3.2 startJxta( )
Questo metodo istanzia la piattaforma Jxta e crea il netPeerGroup di default [linea 103]:
netPeerGroup = PeerGroupFactory.newNetPeerGroup( );
Quindi ottiene il PipeService e il DiscoveryService dal net peer group di default [linea
118]. Questi servizi sono utilizzati successivamente, quando creeremo una input pipe:

pipeService = netPeerGroup.getPipeService( );
discoveryService = netPeerGroup.getDiscoveryService( );
Successivamente, creiamo un pipe advertisement, leggendolo da un file XML esistente
[linea 123]:
FileInputStream fileInputStream = new FileInputStream(FILENAME);
Il file examplepipe.adv deve esistere e deve essere un documento XML valido, contenente
un pipe advertisement, o sarà generata un’eccezione dalla piattaforma Jxta. Si ricordi che
l’applicazione che crea l’input pipe, legge il suo pipe advertisement dallo stesso file. Il
contenuto di examplepipe.adv si può vedere in figura 3.22.1.
Come nel precedente esempio, PipeListener, il metodo
AdvertisementFactory.newAdvertisement( ) è invocato per creare un nuovo pipe
advertisement [linea 124]:
pipeAdv = (PipeAdvertisement) AdvertisementFactory.newAdvertisement (new
MimeMediaType("text/xml"),
fileInputStream);
Poi viene creato il pipe advertisement, viene chiuso l’input stream [linea 127] e il metodo
termina:
fileInputStream.close( );

3.21.3.3 run( )
Questo metodo utilizza PipeService.createOutputPipe( ) per creare una nuova output pipe
per l’applicazione [linea 58]:
pipeService.createOutputPipe(pipeAdv, this);
Poichè noi vogliamo essere notificati quando i pipe endpoint sono risolti, invochiamo
createOuputPipe( ) passando due argomenti:
� PipeAdvertisement adv: l’advertisement della pipe da creare;
� OutputPipeListener listener: l’ascoltatore che deve essere invocato quando viene
determinata la pipe.
Registrando il nostro oggetto come ascoltatore, quando creiamo una output pipe, il nostro
metodo outputPipeEvent( ) sarà invocato asincronamente quando viene determinato il pipe
endpoint.
3.21.3.4 outputPipeEvent( )
Poiché abbiamo implementato l’interfaccia OutputPipeListener, dobbiamo definire il
metodo OutputPipe( ). uesto metodo [linea 74] è invocato asincronamente dalla piattaforma
Jxta, quando viene determinato il nostro pipe endpoint.
A questo metodo è passato un argomento:

� OutputPipeEvent event: l’evento che avviene su questa pipe;
Il nostro metodo per prima cosa chiama OuputPipeEvent.getOutputPipe( ) per creare
l’output pipe , ottenendola dall’evento [linea 77]:
OutputPipe op = event.getOutputPipe( );
Dopo, invochiamo PipeService.createMessage( ) per creare un nuovo messaggio [linea 82]:
Message msg = pipeService.createMessage( );
Ogni messaggio zero o un elemento, ognuno dei quali ha un tag associato e una stringa
corrispondente. ia l’input pipe che l’outpup pipe devono accettare lo stesso tag usato nel
messaggio. Si ricordi che settiamo una costante in entrambe le classi, PipeListener e
PipeExample, per contenere il TAG [linea 30]:
private final static String TAG = "Ascoltatore di messaggi sulla pipe";
Noi usiamo il metodo msg.setString( ) per aggiungere questo nuovo elemento al messaggio
[linea 83]:
msg.setString(TAG, myMsg);

Adesso che è stato creato il messaggio e contiene il testo, lo spediamo sulla output pipe
con l’invocazione di op.send(msg) [linea 84]. Dopo la spedizione di questo messaggio,
chiudiamo l’output pipe e terminiamo questo metodo.
3.21.4 Pipe Advertisement: il file examplepipe.adv
Il file XML contenente il pipe advertisement, example.adv, è riportato in figura. Questo
file è letto da entrambe le classi PipeListener e PipeExample6, per creare l’input pipe e la
output pipe. Entrambe le classi devono usare lo stesso pipe-id, in modo da comunicare tra di
loro.
Figura 3.21.1: il file example.adv

CAPITOLO 4
6 Entrambe le classi leggono dalla stesso file che si trova nella directory corrente. Se questo file non esiste, o contiene un piep advertisement non valido, l’applicazione genera un’eccezione

CAGE PEER–TO-PEER: L’IMPLEMENTAZIONE
Introduzione
CAGE peer to peer è un’applicazione distribuita su una rete di nodi, ognuno di essi è
completamente indipendente ed equivalente. Nessun nodo possiede informazioni o funzioni
speciali; in altre parole non esistono server. Inoltre ogni nodo deve possedere sufficienti
informazioni sul resto della rete, in modo da restare connesso e a sua volta fornire
informazioni.
Ogni nodo possiede una cache locale che contiene informazioni sui peer facenti parte della
rete, questa cache viene aggiornata periodicamente.
Poiché le caratteristiche della programmazione genetica si adattano in modo naturale alla
filosofia peer-to-peer, si è assunto che ogni applicazione avviata su ciascun nodo, sia formata
da un certo numero di task che possano lavorare in modo del tutto indipendente rispetto ai
task su altri nodi, con velocità differenti che dipendono dall’architettura della macchina su cui
sono eseguiti. Le uniche interazioni che si verificano fra i nodi sono le comunicazioni che, di
tanto in tanto, servono per diversificare le popolazioni elaborate su ciascun nodo.
L’approccio che è stato utilizzato per la realizzazione dell’applicazione si è ispirato al
modello a isole e a quello cellulare.
La piattaforma utilizzata per la realizzazione del software è JXTA, che abbiamo visto in
dettaglio nel capitolo 3. L’interfaccia è realizzata in modo da far si che possa gestire l’accesso
di tre differenti tipologie di utenti (figura 4.1):

Fig. 4.1: Architettura di CAGE peer to peer
� Utente A: utente che non desidera utilizzare l’applicativo per eseguire calcoli, ma
vuole semplicemente mettere a disposizione la potenza di calcolo della propria CPU;
� Utente B: questa tipologia di utenti comprende coloro che pur non essendo
programmatori, hanno intenzione di utilizzare l’applicazione per condurre esperienze
che sono già a disposizione;
� Utente C: utenti capaci di programmare la piattaforma e quindi eseguire esperimenti
specifici.
4.1 Le classi della nostra applicazione
Sono state sviluppate le seguenti classi:
� CanaleDiInput: implementa un canale di input unidirezionale asincrono;
� CanaleDiOutput: implementa un canale di output unidirezionale asincrono;
� Esploratore: fornisce i servizi per la ricerca dei vicini e per la configurazione
dell’anello;

� GruppoProgrammazioneGenetica: classe per la formazione del gruppo di lavoro per
la programmazione genetica;
� Peer: implementa un nodo e i suoi servizi;
� Utilità: fornisce le utilità per l’utilizzo degli advertisement.
4.2 La classe CanaleDiInput
Questa classe implementa l’interfaccia PipeMsgListener, che serve per l’ascolto degli
eventi generati dai messaggi ricevuti sulla pipe di input. Gli attributi della classe sono i
seguenti:
� private final static String TAG: contiene il nome del tag in cui è contenuto il
messaggio ricevuto;
� private Utility util;
� private PeerGroup gruppo: serve a memorizzare il gruppo di lavoro;
� private PipeService pipeService: variabile utilizzata per memorizzare il servizio per
l’utilizzo delle pipe;
� private Message message: buffer che contiene il messaggio momentaneamente
ricevuto;
� InputPipe pipeIn: variabile su cui verrà aperta la pipe di input.
Questa classe è fornita di un costruttore, che prende come parametro il gruppo di lavoro, e
dei seguenti metodi:
� public byte[] restituisciMessaggio(): restituisce il messaggio, codificato come array
di byte;

� public byte[] ricevibile(String nomeFile): restituisce il contenuto del file, il cui
nome è passato come argomento, codificato come array di byte;
� public void ascoltaSu(PeerID pID): apre la pipe di input per ricevere i messaggi dal
peer specificato;
� public void chiudi(): chiude la pipe di input;
� public void pipeMsgEvent(PipeMsgEvent event): ascoltatore degli eventi generati
dalla ricezione dei messaggi.
4.3 La classe CanaleDiOutput
Questa classe implementa l’interfaccia OutputPipeListener, che serve per l’ascolto degli
generati dai messaggi inviati sulla pipe di output. Gli attributi della classe sono i seguenti:
� private final static String TAG: contiene il nome del tag in cui è contenuto il
messaggio ricevuto;
� private Utility util;
� private PeerGroup gruppo: serve a memorizzare il gruppo di lavoro;
� private PipeService pipeService: variabile utilizzata per memorizzare il servizio per
l’utilizzo delle pipe;
� private Message message: buffer che contiene il messaggio momentaneamente
ricevuto;
� OutputPipe pipeOut: variabile su cui verrà aperta la pipe di output.

Questa classe è fornita di un costruttore, che prende come parametro il gruppo di lavoro, e
dei seguenti metodi:
� public void apri(PeerID pID): crea una pipe di output per inviare il messaggio al
peer specificato;
� public void invia(byte[] msg): questo metodo invia il messaggio specificato al peer
verso cui è stata aperta la pipe di output;
� public void inviaFile(String nomeFile, byte[] msg): questo metodo invia il
contenuto del file specificato nella lista dei parametri;
� public void chiudi(): chiude la pipe di output;
� public void outputPipeEvent(OutputPipeEvent event): ascoltatore degli eventi
generati dalla spedizione dei messaggi.
4.4 La classe Esploratore
Questa classe implementa l’interfaccia DiscoveryListener, che serve per l’utilizzo dei
servizi relativi alla scoperta dei peer sulla rete. Gli attributi della classe sono i seguenti:
� public static PeerID peerDestro;
� public static PeerID peerSinistro;
� public static PeerID auxDestro;
� public static PeerID auxSinistro;
� public static PeerID peerR;
� public static PeerID peerL.
Queste variabili contengono l’id dei peer vicini, con cui si dobrà creare il link logico per
formare l’anello.

� private PeerGroup gruppo: serve a memorizzare il gruppo di lavoro;
� private DiscoveryServiceservizioDiScoperta: serve a memorizzare il servizio di
scoperta per il gruppo di lavoro.
Questa classe è fornita di un costruttore, che prende come parametro il gruppo di lavoro, e
dei seguenti metodi:
� public void aggiornaCacheLocale(): è un metodo che viene utilizzato per
l’aggiornamento della cache locale di ogni peer;
� private Vector ordinaCacheLocale(): il metodo viene utilizzato per ordinare in
modo crescente le voci della cache locale, in base al peerID.
� public void individuaVicini(): la funzione di questo metodo è l’individuazione dei
peer destro e sinistro con cui si effettuerà lo scambio delle informazioni.
4.5 La classe GruppoProgrammazioneGenetica
Questa classe modella il gruppo di lavoro di cui tutti i peer dovranno far parte, per
partecipare all’elaborazione degli algoritmi di programmazione genetica. Gli attributi della
classe sono i seguenti:
� private final static String NOME: contiene il nome del gruppo di lavoro;
� private final static String DESCRIZIONE: contiene informazioni sul gruppo di
lavoro;
� private static PeerGroup netPeerGroup: memorizza il netPeerGroup di default, a
cui appartengono tutti i peer JXTA mondiali;

� private static PeerGroup gruppoProgrammazioneGenetica: serve per
memorizzare il peerGroup creato con i servizi all’interno di questa classe;
� private PeerGroupID PGID: la variabile contiene l’identificativo in formato
esadecimale del gruppo creato.
Questa classe è fornita di un costruttore, che prende come parametro il gruppo di lavoro, e
dei seguenti metodi:
� private void creaGruppo(): crea il gruppo di lavoro;
� private void uniscimiAlGruppo(): effettua il join del peer richiedente al gruppo di
lavoro;
� public PeerGroup get(): restituisce il gruppo di lavoro.
4.6 La classe Peer
Questa è la classe base che utilizza tutti i servizi offerti dalla piattaforma; in essa viene
avviata la piattaforma JXTA per il peer in questione, viene effettuato il join con il gruppo di
lavoro ed estratti il DiscoveryService.
A questo punto viene inizializzata la cache per eliminare eventuali voci inconsistenti e
vengono inizializzate tutti gli attributi della classe, che sono:
� private GruppoProgrammazioneGenetica gruppo: contiene il gruppo di lavoro;
� private Esploratore explorer: entità necessaria per la scoperta dei vicini e la
configurazione dell’anello;
� private DiscoveryService servizioDiScoperta: memorizza il servizio di scoperta
estratto per il gruppo di programmazione genetica;
� public Utility util: utilità di gestione degli advertisement;

� private CanaleDiInput inR: canale di input per la ricezione dei messaggi dal vicino
di destra;
� private CanaleDiInput inL: canale di input per la ricezione dei messaggi dal vicino
di sinistra;
� private CanaleDiOutput outR: canale di output per l’invio dei messaggi al vicino di
destra;
� private CanaleDiOutput outL: canale di output per l’invio dei messaggi al vicino di
sinistra;
� private Thread inviaADestra: thread che permette di inviare messaggi al peer di
destra, parallelamente all’esecuzione del resto del programma;
� private Thread inviaASinistra: thread che permette di inviare messaggi al peer di
sinistra, parallelamente all’esecuzione del resto del programma;
� private String arrayParametri[]: questo array è necessario per riceverei parametri
da passare al processo C che realizza l’infrastruttura per l’esecuzione di algoritmi di
programmazione genetica;
� private byte[] bufferDiTrasmissioneDestro: variabile che memorizza l’albero da
spedire al peer di destra;
� private byte[] bufferDiTrasmissioneSinistro: variabile che memorizza l’albero da
spedire al peer di sinistra;
� private byte[] bufferDiRicezioneDestro: variabile che memorizza l’albero ricevuto
dal peer di destra;
� private byte[] bufferDiRicezioneSinistro: variabile che memorizza l’albero ricevuto
dal peer di sinistra;
� private MetodiNativi m: entità che fornisce i servizi per invocare i metodi nativi;
� public boolean pronto[]: array di booleani per memorizzare lo stato di elaborazione,
per la sincronizzazione della fase di configurazione dell’anello;

� private boolean inviatoSx e private boolean inviatoDx: booleani che memorizzano
lo stato di ricezione dei messaggi;
Questa classe è fornita di un costruttore, che non riceve alcun parametro e avvia la
piattaforma:
� public void startJxta(): effettua le azioni descritte all’inizio del paragrafo;
� private inizializzaCache: inizializza la cache del peer;
� public PeerGroup getGruppo(): restituisce il gruppo di lavoro;
� public void ConfiguraAnello(): metodo che realizza la configurazione dell’anello.
� public void attendi(): realizza l’attesa dell’avvio dell’elaborazione, da parte di un
qualunque altro peer appartenente al gruppo di lavoro;
� public void estraiParametri(): metodo che carica nell’arrayParametri, i valori da
passare al processo C.
� public void ricevi(): realizza la ricezione dei file di configurazione dell’algoritmo di
programmazione genetica, inviati dal peer che ha avviato l’elaborazione.
� public void run(): azioni eseguite da ogni peer;
� private void riceviR(): riceve il messaggio inviato dal peer di destra;
� private void riceviL(): riceve il messaggio inviato dal peer di sinistra.
4.7 La classe Utility
Questa classe fornisce tutti i servizi per la gestione degli advertisement.Gli attributi della
classe sono i seguenti:
� private static PeerGroup gruppo memorizza il gruppo di lavoro;

� private DiscoveryService servizioDiScoperta: memorizza il servizio di scoperta
estratto per il gruppo di programmazione genetica.
Questa classe è fornita di un costruttore, che prende come parametro il gruppo di lavoro, e
dei seguenti metodi:
� public void creaPipeAdvertisement(String nome, String tipo): crea un pipe
advertisement per canali del tipo passato come argomento;
� public void creaPeerGroupAdvertisement(String nome): crea un peer group
advertisement con il nome specificato;
� public void creaConfigurationAdvertisement(): crea un advertisement che viene
utilizzato durante la configurazione dell’anello;
� public void token(String mioID, String peerID): realizza il token che percorre
l’anello a fine elaborazione, per la raccolta dei risultati;
� public int contaAdvertisement(int tipo, String tag, String val): metodo che conta
gli advertisement nella cache locale, che corrispondono ai valori passati come
parametro;
� public PipeAdvertisement estraiPipeAdvertisement(String nome, int tipo):
metodo che viene utilizzato per l’estrazione di un pipe advertisement dalla cache
locale, con il nome e il tipo specificato;
� public PipeAdvertisement estraiFileAdvertisement(String nome): estrae
l’advertisement che ha il contenuto del file di configurazione della programmazione
genetica, spedito dal peer che ha avviato l’elaborazione.
4.8 La realizzazione dei canali di comunicazione

JXTA fornisce l’implementazione di canali di comunicazione, di input e di output,
unidirezionali e asincroni, nella classe PipeService. Considerata la scelta della topologia ad
anello, per la realizzazione di comunicazioni veloci e che non appesantiscano la rete, abbiamo
realizzato un servizio che costruisce un canale bidirezionale, unendo in una sola entità i
canali di input e di output.
Visto che per aprire una pipe, bisogna creare un pipe advertisement con lo stesso nome su
entrambi i peer che intendono comunicare, abbiamo creato un naming ad hoc, che garantisce
la dinamicità della creazione e della distruzione dei canali di comunicazione e che mantenga
decentralizzata l’assegnazione dei nomi, in linea con la filosofia peer-to-peer.
Ogni peer durante la configurazione dell’anello, crea due pipe advertisement per il peer di
destra e due per il peer di sinistra, rispettivamente per l’apertura dei canali di input e di
output, con i nomi che rispettano la sintassi riportata nella tabella 4.8.1.
Tipo di canale Nome PipeAdvertisement
Canale di input per ricevere dal peer PeerIdDestro.in
Canale di output per inviare al peer destro PeerIdDestro.out
Canale di input per ricevere dal peer MyPeerId.out
Canale di output per ricevere dal peer MyPeerId.in
Tabella 4.8.1: Naming degli advertisement per l’apertura delle pipe
L’idea è simile a quella di un cavo incrociato, utilizzato per la connessione di due
computer in rete. A destra i canali di input e di output si aprono sui PipeAdvertisement
corrispondenti (.in per il canale di input, .out per il canale di output), mentre a sinistra il
matching è invertito.
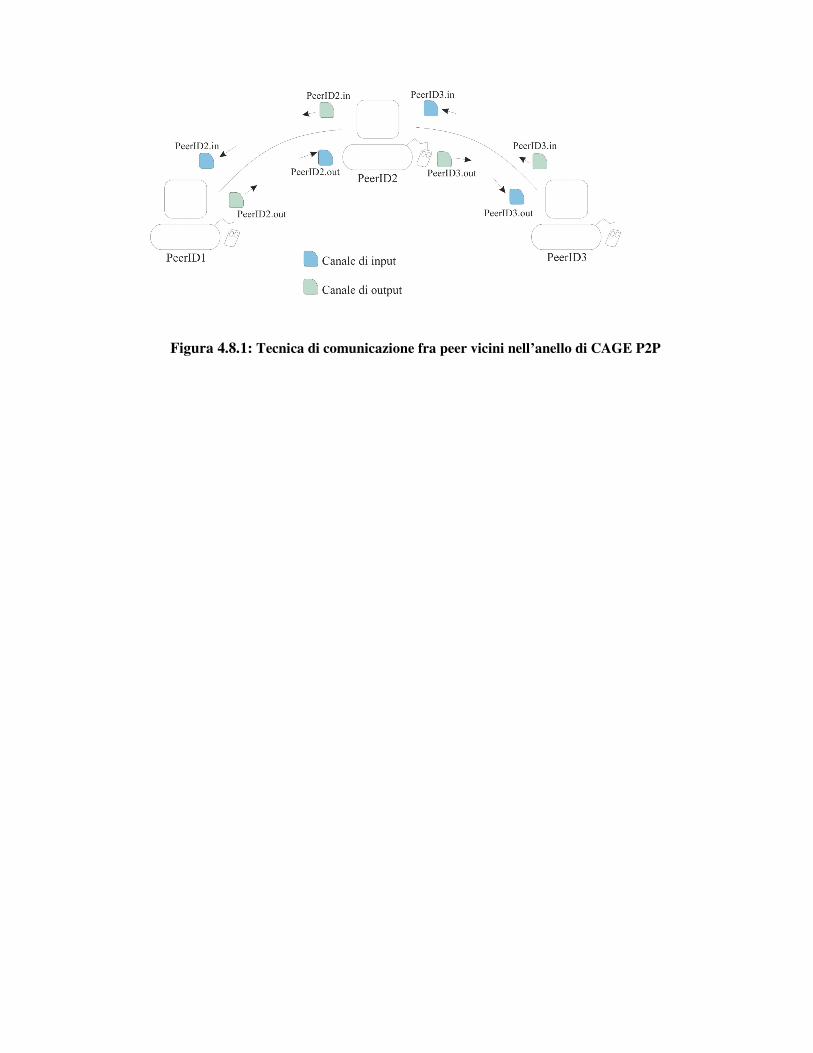
Figura 4.8.1: Tecnica di comunicazione fra peer vicini nell’anello di CAGE P2P

CAPITOLO 5
LA JAVA NATIVE INTERFACE
5.1 Cos'è JNI e quando serve
In generale, Java fornisce allo sviluppatore tutto quello di cui ha bisogno nei vari settori, e
in alcuni di questi (programmazione distribuita, applicazioni per Internet, etc.) permette di
ottenere ottimi risultati in tempo significativamente inferiore ad altri linguaggi. Tuttavia,
esistono casi in cui è indispensabile che un’applicazione Java interagisca a basso livello con il
sistema in cui viene eseguita, cioè con la sua parte nativa. Per questo l’ambiente di sviluppo di
Java (cioè il JDK in una sua qualunque versione) contiene la libreria JNI, o Java Native
Interface.
Si tratta di una collezione di librerie che permettono l’interazione e lo scambio di dati tra
una qualunque macchina virtuale Java (JVM) e il sistema in cui essa è installata.
Tipicamente, l’interazione con le parti a basso livello del sistema operativo è realizzata con
linguaggi che la consentano, e tra questi primeggiano sicuramente il C e il C++.

L’interazione a basso livello con il sistema, come regola, dovrebbe essere evitata,
soprattutto nello sviluppo di nuove applicazioni, che possono essere disegnate da zero con
certi criteri progettuali che tengano conto di tali problematiche; tuttavia, esistono casi dove
essa può rendersi estremamente utile.
Fra i più comuni, possiamo annoverare:
� interfacciamento di nuove applicazioni Java con software già esistente e non
convertibile per le più disparate ragioni, quali fattibilità, costi, vincoli di carattere
tecnico (es. sistemi di acquisizione dati sul campo);
� aggiunta ai propri programmi di funzionalità che non sono messe a disposizione da
Java;
� necessità di disporre di particolari performance in alcune funzionalità che Java,
malgrado i recenti ed importanti progressi, non è in grado di fornire.
La principale conseguenza dell’uso di JNI in un’applicazione è che questa, ovviamente,
non può più definirsi “100% Pure Java”, per cui viene naturale chiedersi se è consigliabile o
meno utilizzare la Java Native Interface.
Per dare una risposta a questa domanda consideriamo la seguente figura (5.1.1):

Figura 5.1.1: interazione di applicazioni Java con l'ambiente in cui operano
In figura, le frecce bidirezionali più scure rappresentano le normali interazioni di visibilità
che si realizzano fra i diversi strati di un sistema software; quelle più chiare, invece,
rappresentano le interazioni che si potrebbero realizzare tra un’applicazione scritta in Java nei
confronti delle parti di sistema più a basso livello o di software già esistente in casi come
quelli elencati poco sopra. Tali interazioni sono possibili proprio grazie all’utilizzo della
libreria JNI.
In certi casi di tali interazioni non si può fare a meno, e quindi si mina la portabilità delle
applicazioni. Ci sono due possibilità, a seconda dell’obiettivo che ci si prefigga:
� La nuova applicazione è stata scritta in Java per sfruttare le sue caratteristiche e il suo
particolare approccio ai concetti di OOP/OOD, ma deve funzionare solo su una certa
piattaforma;

� La nostra nuova applicazione è stata scritta in Java non solo per quanto detto sopra,
ma deve anche funzionare su piattaforme diverse e ovviamente fornire le stesse
funzionalità.
Nel primo caso non c’è alcun problema, mentre nel secondo, l’unico modo per assicurare
la portabilità di una applicazione è quello di sviluppare la parte di software (in particolare
modo una libreria condivisa) che interagisce a basso livello, per tutti i sistemi operativi su
cui intendiamo eseguire il nostro applicativo. In questo modo, anche se non potremo più
affermare di aver scritto un’applicazione solo in Java, di esso potremmo comunque sfruttare
tutti i vantaggi, e la portabilità è garantita.
Nel caso della nostra implementazione, abbiamo sfruttato la parte implementata della
versione parallela di CAGE, privata della parte delle primitive MPI per la comunicazione fra
processori; in questo modo si è ottenuto un’algoritmo sequenziale da utilizzare su ogni peer.
A questo punto per unire l’architettura di comunicazione, sviluppata interamente in Java
utilizzando la piattaforma JXTA, si è utilizzata la Java Native Interface: per mantenere la
portabilità si compilerà la libreria libgcp.so per ogni sistema operativo.
5.2 Struttura di JNI: vista d'insieme delle funzionalità
Come si è visto nel paragrafo precedente, JNI è un po’ il tramite tra i due “mondi” del
codice nativo e di una qualunque JVM (figura 5.1.2).; tale interazione è in qualche modo
speculare. Infatti è possibile chiamare e interagire con la parte a basso livello, implementando
in codice nativo metodi di classi Java (§ 5.1), e fare esattamente il cammino inverso, creando
una JVM e invocarne i metodi di classi di sistema o anche definite dall’utente.

Figura 5.2.1: Dettaglio del rapporto tra Java e il mondo nativo attraverso JNI
I metodi forniti da JNI consentono una grande flessibilità, in quanto è possibile:
� avere completo accesso alle classi Java, sia di sistema, sia definite dall’utente,
esaminandone gli attributi, chiamandone i metodi, etc;
� definire e dichiarare intere classi con tutte le loro caratteristiche, in maniera analoga a
quanto è possibile in Java puro con la Reflection API;
� creare nuovi oggetti di cui è stata già data completa definizione in Java attraverso uno
dei costruttori;
� creare array e stringhe di tipi primitivi o di qualsiasi altro oggetto;
� creare e sollevare eccezioni.

Java e il C/C++ sono linguaggi che, come si sa, hanno una matrice in comune. Siccome in
Java il trattamento dei tipi base (interi, booleani, numeri in virgola mobile, etc.) non è
altrettanto flessibile che in C/C++, esiste una corrispondenza standard di tali tipi nel passaggio
fra i due ambienti. Ad esempio, gli interi in Java sono soltanto con segno, e di questo bisogna
tenere conto (ad es. un numero intero a 32 bit in C/C++ senza segno maggiore di 231-1
(2147483647), se passato ad un programma Java, dev’essere contenuto in un intero lungo a 64
bit).
In tabella 5.2.1 e figura 5.2.2 sono riportate rispettivamente le mappature tra i tipi primitivi
e quelli complessi tra Java e C/C++.
Java Type Native Type Description
boolean jboolean unsigned 8 bits
byte jbyte signed 8 bits
char jchar unsigned 16 bits
short jshort signed 16 bits
int jint signed 32 bits
long jlong signed 64 bits
float jfloat 32 bits
double jdouble 64 bits
void void N/A
Tabella 5.2.1: Tipi primitivi tra Java e C/C++

Figura 5.2.2: I tipi complessi di Java nel mondo del codice nativo
Nel caso dei tipi rappresentati in Figura 5 se una procedura Java ad esempio ha come
parametro una String, nella corrispondente implementazione nativa quel parametro sarà
dichiarato di tipo jstring e così via.
Un’altra cosa importante sono le cosiddette type signatures (“firme”), riportate in tabella
5.2.2, che indicano con un codice convenzionale il tipo di parametri e il tipo di ritorno di una
qualunque funzione nella sua controparte Java; tali firme servono alle istruzioni in C/C++ per
attribuire alla controparte nativa di un oggetto Java il suo tipo corretto, ed inoltre di esplorare
le classi definite in Java in modo analogo a quanto avviene grazie al package
java.lang.reflection.

Tabell
a 5.2.2:
“Firme”
dei tipi di
Java
Per
esempio,
supponia
mo di
avere due metodi di una classe così definiti:
1. void pippo(int x, String s, double y);
2. byte[] topolino(com.foo.bar.Minni x, boolean b)
Le due firme diventano rispettivamente:
1. (Iljava/lang/String;D)V;
2. (Lcom/foo/bar/Minni;Z)[B;
il tipo restituito da una funzione va in fondo a tutto, mentre i parametri formali vanno
inseriti tra parentesi e in sequenza senza alcun separatore (es. spazio) interposto.
5.3 L’uso della JNI nella nostra applicazione
7 Dopo la L va inserito l’intero classpath della classe (es. String – Ljava/lang/String)
Field Descriptor Java Language
Z boolean
B byte
C char
S short
I int
J long
F float
D double
Lclass7 class
[type8 type[]
([type] || [Lclass] || [type) [type] || [Lclass] || [type method
([type] || [Lclass] || [type)V constructor

Nei paragrafi precedenti ci siamo limitati a descrivere gli aspetti principali e la simbologia
della JNI, che risultano fondamentali per capire la filosofia che sta dietro a tutto questo
discorso, nonché per rendere immediatamente comprensibile la nostra implementazione.
Il meccanismo per l’utilizzo della libreria nativa libgpc.so, che contiene i metodi che
implementano i servizi per gli algoritmi di programmazione genetica, è abbastanza semplice:
la classe Java MetodiNativi definisce i metodi detti nativi, che non vengono implementati.
Nella stessa classe viene introdotta una particolare istruzione in cui si specifica dove la JVM
può trovare a runtime l’implementazione di questi metodi che è realizzata a basso livello
tramite la libreria di sistema libgpc.so, detta shared library. Basta compilare questa libreria
per ogni sistema operativo, ospitante la nostra applicazione, per renderla indipendente da
esso, mantenendo così la portabilità.
5.3.1 I metodi nativi
I metodi della classe MetodiNativi che non sono implementati, ma sono già stati
implementati per la versione parallela di CAGE, devono avere nell’intestazione la parola
chiave native9. La struttura sintattica di un metodo nativo ricorda molto da vicino quella
seguita dai metodi definiti nelle interfacce: vengono dichiarate solo le intestazioni dei metodi,
mentre l’implementazione viene destinata alle classi che le implementano. Il compilatore
controlla se all’interno di queste sono implementati tutti i metodi dell’interfaccia, segnalando
un errore in caso contrario.
Allo stesso modo, in una classe vengono implementate soltanto le intestazioni dei metodi
nativi; la parola chiave native informa il compilatore Java che non deve cercare all’interno
8 Al posto di type viene inserita la firma del tipo (es. int – I ) 9 Nel listato 5.3.1 prendiamo in considerazione le righe di codice 5-10

della classe l’implementazione di tale metodo, ma che essa verrà effettuata dal compilatore di
un altro linguaggio di programmazione, che nel nostro caso è il C.
Listato 5.3.1 – L’implementazione della classe metodi nativi

5.3.2 Shared library
Solo al momento dell’esecuzione del programma verrà caricata l’implementazione del
metodo all’interno della classe. Per fare ciò, il sistema andrà a cercare tale implementazione
dentro una libreria condivisa esterna, che nel nostro caso è libgpc.so. L’estensione *.so indica
che è una libreria condivisa per il s.o. Linux, mentre per Windows abbiamo l’estensione *.dll.
Questa libreria è segnalata mediante la classe stessa, utilizzando il metodo
System.loadLibrary(String)10 inserito dentro un blocco di codice statico: durante il
caricamento della classe a runtime, la Java Virtual Machine utilizzerà le istruzioni contenute
nel blocco statico per effettuare l’inizializzazione e se non dovesse trovare alcun riferimento
alla shared library da utilizzare, genererà un’eccezione di tipo
java.lang.UnsatisfiedLinkError.
5.3.3 Compilazione
Appena la classe Java è pronta è possibile passare alla fase successiva, la compilazione del
codice. Questa fase è in realtà composta da due passi:
� Nel primo bisogna convertire il sorgente in bytecode mediante una compilazione
classica usando il comando javac;
� Nel secondo passo si procede alla generazione dell’header file(con estensione *.h),
necessario per la costruzione della shared library, mediante l’esecuzione del comando
javah:
javah –jni NomeClasse
10 Il nome da passare al metodo loadLibrary() deve essere il nome della libreria escluso il prefisso 'lib' e l'estensione '.so'

L’esecuzione del comando genererà il file MetodiNativi.h; è possibile assegnare
un nome diverso da quello del bytecode processato, specificandolo mediante l’opzione
“-o” nel comando di generazione; per lanciare javah senza parametri per avere
l’elenco delle opzioni possibili.
5.3.4 Header file
Nel codice dell’header file così ottenuto troviamo un’avvertenza sotto forma di commento,
con la quale veniamo avvertiti di non modificare in alcun modo il sorgente.
Questo file contiene la traduzione in linguaggio C dell’intestazione dei metodi nativi Java
(listato 5.3.2): non avrebbe senso, quindi, alterarlo, perché altrimenti si perderebbe il reale
significato delle intestazioni.
Listato 5.3.2: Il file header contenente le intestazioni dei metodi nativi

La conversione dell’intestazione dei metodi nativi seguono un preciso standard: la
funzione nel linguaggio nativo avrà un nome composto dal prefisso Java, seguito dal nome
del package contenente la classe Java, dal nome della classe Java, dal nome della classe ed
infine dal nome del metodo nativo, ognuno intervallato dal carattere underscore ‘_’.
Prendiamo ad esempio il metodo Java startup(String[ ]) (listato 5.3.1): seguendo la
convenzione e tenendo conto che la classe non è stata definita dentro un particolare package,
il nome della corrispondente funzione sarà quindi Java_MetodiNativi_startup (listato 5.3.2).
5.3.5 Parametri aggiuntivi
Osservando il codice precedente si nota che tra i parametri di entrambe le funzioni, oltre a
quelli dei metodi nativi opportunamente convertiti, ne troviamo altri due di tipo particolare. Il
primo parametro è un puntatore i tipo JNIEnv (listato 5.3.2): tramite esso è possibile accedere
ad una serie di informazioni, come ad esempio i parametri e gli oggetti contenuti nell’istanza
della classe Java. Il secondo parametro è un jobject: esso può assumere diversi significati. Se
è un metodo di istanze esso assume lo stesso significato della variabile “this” in Java, cioè
corrisponde al riferimento all’istanza dell’oggetto. Se il metodo è invece di classe, il jobject
corrisponderà al riferimento al metodo Java della classe. Ad esempio, tramite il puntatore
JNIEnv* env e il parametro jobject obj è possibile ottenere la classe Java dell’istanza su cui è
stato chiamato il metodo nativo:
jclass cls = (*env)field = (*env)�GetObjectClass(env,obj)
5.3.6 L’implementazione

L’header file è utilizzato per costruire il sorgente C (o C++), da cui ricavare tramite
compilazione la shared library finale, o è importato allorquando il codice C è già esistente,
come nel caso della nostra applicazione.
I metodi utilizzati nelle modifiche ai metodi dell’implementazione parallela di CAGE,
opportunamente sequenzializzata, sono i seguenti:
� (*env)����NewByteArray(JNIEnv,jint): questo metodo, come ogni altro metodo della
JNI, esistente per tutti i tipi predefiniti di java, compreso Object, inizializza un’array
del tipo corrispondente, in questo caso jbyte11: al metodo vanno passati l’oggetto env e
la lunghezza dell’array.
� (*env)����SetByteArrayRegion(JNIEnv, jbyte*, jint, jint, jbyte*): questo metodo
permette di riempire l’array passato come secondo parametro, con gli elementi
dell’array passato come ultimo parametro. Al metodo vanno inoltre passati, l’oggetto
env e gli indici di inizio e fine array;
� (*env)����GetArrayLenght(JNIEnv,jbyte*): questo metodo restituisce la dimensione
l’array passato come argomento;
� (*env)����GetObjectArrayElement(JNIEnv,jbyte*,jint): questo metodo estrae
l’oggetto corrente, identificato dall’indice passato come parametro, dall’array di
oggetti generici;
11 I tipi, corrispondenti ai tipi java, nelle implementazioni C/C++ conservano lo stesso nome preceduto dal carattere j

� (*env)����GetByteArrayElements(JNIEnv,jbyte*,jint): questo metodo estrae gli
elementi dell’array passato come parametro, dall’indice jint.
� (*env)�GetStringUTFChars(JNIEnv, jobject, jint): con questo metodo si converte
l’oggetto passato come parametro, in un array di caratteri;
� (*env)�ReleaseStringUTFChars(JNIEnv, jobject, jbyte*): Rilascia la memoria
per l’oggetto passato come argomento.
Bisogna sempre ricordarsi di includere in ogni file che implementa i metodi nativi, sia
l’header file generato che il file jni.h contenente l’API JNI di Java. Questo file, insieme ad
altri ad esso collegati, si trovano nella directory include presente nel JDK distribuito dalla
SUN: affinché il compilatore trovi questo file bisogna specificare il percorso da seguire per
trovare questa directory.
5.3.7 Compilare i sorgenti
Implementate tutte le funzioni dichiarate nell’header file, non rimane altro che compilare i
sorgenti per ottenere la shared library.
Su sistemi Linux la libreria si costruisce nel seguente modo:
gcc <nomefile> -o libgpc.so -shared -I$DIR_JDK+"include" -I$DIR_JDK+"include/linux"
mentre su Windows, usando Microsoft Visual C++, la sintassi è la seguente:
cl –Ic:\java\include –Ic:\java\include\win32 –LD <nomefile> -Felibgpc.dll

10.4
10.5
10.6
10.7 Conclusioni e sviluppi futuri
Abbiamo visto come il peer-to-peer e in particolar modo JXTA, la piattaforma che Sun
Microsystem ha proposto nel tentativo di creare uno standard per lo sviluppo di questo tipo di
applicazioni distribuite, si adattano perfettamente all’implementazione di applicazioni di
programmazione genetica. L’obiettivo di sviluppare un’implementazione distribuita di CAGE
è stato raggiunto, costruendo attraverso l’uso di JXTA una topologia ad anello per la
comunicazione fra i peer, utilizzando primitive asincrone.

La scelta è stata orientata su JXTA perché attraverso i suoi servizi, si è in grado di costruire
applicazioni, robuste, scalabili e altamente parallelizzabili, proprietà fondamentali per la
programmazione genetica.
Il nostro prototipo si è ispirato, per l’evoluzione della popolazione, ai modelli a isole e
diffusivo, nel tentativo di dirigere l’attenzione verso lo studio di un modello ibrido, che
promuova l’autonomia di evoluzione delle isole e che nello stesso tempo permetta di
scambiare poche, ma necessarie, informazioni per evitare una prematura convergenza della
fitness.
Gli sviluppi di questo applicativo potrebbero essere orientati verso:
� La creazione di un gruppo per ogni tipo di elaborazione, in modo da permettere il
contemporaneo uso del peer, come risorsa disponibile ad eseguire problemi lanciati da
altri, che come mezzo per risolverne uno proprio.
� La visualizzazione dei processi attivi e delle risorse allocate.
� Il bilanciamento del carico computazione, in quanto in una rete JXTA si possono
trovare dispositivi eterogenei (workstation, cluster, pc, pda, cellulari).
� Diritti di computazione: accettare o meno la cessione della propria risorsa.
� Sicurezza: gruppi con username e password (gestione di una eventuale registrazione).
� Creazione di advertisement di servizio XML personalizzati (dovrebbe essere
disponibile la funzionalità dalla versione 2.1).

� Inserimento dei grafici per visualizzare l’andamento della fitness
� I file .cfg e default.in verranno implementati come file XML.
� Rendere disponibili gli editor del sistema operativo, su cui viene installata
l’applicazione, costruendo una funzione simile ad apri con… di Windows
� Gestione di eventuali crash dei nodi, e di nuovi ingressi per incrementare la potenza di
calcolo.
� Migliorare la politica di ricerca dei vicini, spostandola a più basso livello.
Abbiamo elencato solo una parte dei possibili sviluppi dell’applicazione; inoltre la
piattaforma ha dimostrato grandi potenzialità ed è adatta a diversi scopi, che vanno oltre il
semplice scambio file.

10.8
10.9
10.10
10.11
10.12
10.13
10.14 Appendice A
Tool di configurazione JXTA
11
12
13 INTRODUZIONE
La prima volta che un’applicazione è avviata sul sistema, un tool di auto-configurazione
(Jxta Configurator) è visualizzato per configurare la piattaforma JXTA per la rete.
Questo tool è utilizzato per specificare informazioni sulla configurazione del peer JXTA in
esame, configurazione TCP/IP e HTTP, rendezvous e relay peer, informazioni di sicurezza.

13.1 A.1 Processo di configurazione
Due file di configurazione sono usati durante il processo di configurazione JXTA,
PlatformConfig e reconf:
� PlatformConfig: informazioni specifiche sul peer. Contiene tutte le informazioni di
configurazione necessarie per configurare la piattaforma JXTA ed avviare il
NetPeerGroup di default.
� reconf: se questo file esiste, sarà avviata la schermata di configurazione, inoltre dovrà
esistere contemporaneamente il file PlatformConfig.
All’avvio, la piattaforma JXTA cerca il file PlatformConfig nella directory corrente
� se esso esiste i suoi parametri verranno utilizzati per configurare la piattaforma.
� se non esiste viene visualizzato il tool di configurazione JXTA e l’utente può inserire
le informazioni di configurazione per il peer JXTA.
Quando l’utente e chiude il tool di configurazione, esso crea nella directory corrente le
seguenti directory e file di configurazione.
� PlatformConfig;
� cm (directory): contiene la cache locale degli advertisement JXTA;
� pse (directory): memorizza username e password.

Se la directory pse non esiste, quando si avvia l’applicazione JXTA, viene visualizzato il
configuratore JXTA. Le informazioni di configurazione dal file PlatformConfig saranno
reinseriti sui vari pannelli. L’utente può selezionare il pannello Security per inserire una
nuova username e password.
Un esempio del file PlatformConfig è visualizzato nella seguente figura: questo file è un
documento XML contenente informazioni riguardo il PeerID, il nome del peer e qualche
informazione sulla configurazione di TCP/IP e HTTP per il peer in questione.
13.1.1 Figura A.1.1: Esempio file PlatformConfig
13.2 A.2 Descrizione del tool
Quando il configuratore di JXTA viene visualizzato per la prima volta, invita l’utente ad
inserire i dati nel pannello Basics. Pannelli addizionali possono essere visualizzati,
selezionando advanced, Rendezvous/Router e Security nella parte superiore della finestra. In
molti casi solo i settaggi nel pannello Basics e Security necessitano di modifiche. Bisogna
specificare almeno il Peer Name (nel primo), username e password (nel secondo).

13.2.1.1.1 A.3 Basic Settings
Il pannello Basic Settings è visualizzato come primo pannello dal configuratore JXTA. Il
campo Peer Name può accogliere qualsiasi stringa. Se il peer JXTA è dietro un firewall,
bisogna selezionare la casella “Use a proxy server” e inserire il nome host e il numero di
porta per il proprio proxy server.
Se non si inseriscono nessuna delle impostazioni avanzate o di quelle rendezvous/relay,
può essere cliccare il tasto OK in basso alla finestra per continuare la configurazione.
Se è necessario specificare impostazioni di configurazione addizionali si deve cliccare
advanced o Rendezvous/Router.

13.2.1.2 Figura A.3.1: Configuratore JXTA: pannello Basic
13.2.1.2.1
13.2.1.2.2 A.4 Advanced settings
Questo pannello permette di specificare il Trace Level, le impostazioni TCP/IP e le
impostazioni HTTP (vedi figura A.4.1).
Di default Trace Level è settato a “error” e sia TCP/IP che HTTP sono abilitati.
Se il peer è dietro un firewall o NAT, esso deve usare HTTP; inoltre può essere anche
usato il TCP/IP.
Viceversa HTTP non è obbligatorio.
13.2.1.3 Figura A.4.1: Configuratore JXTA: Advanced settings
13.2.1.3.1 A.5 Trace level
Il trace level può essere settato in base alle opzioni presenti nel menu:

� error: visualizza solo gli errori JXTA;
� warn: visualizza gli errori JXTA e gli avvisi;
� info: visualizza messaggi di informazione addizionali;
� debug: visualizza lunghi messaggi di aiuto durante il debugging delle applicazioni
JXTA;
� user default: visualizza messaggi definiti dall’utente (da usare con log4j e event
tracing).
A.6 TCP settings
Il TCP è abilitato di default sulla porta 9701.
Quando TCP è abilitato, ogni istanza della piattaforma JXTA è limitata ad uno specifico
numero di porte TCP di un dato peer.
� Network interface: un peer può avere interfacce di rete multiple. Si può selezionare
quale interfaccia di rete deve essere usata per JXTA, scegliendo l’interfaccia
desiderata dal menu;
� Port number: si può cambiare la porta usata dal TCP/IP inserendo un valore
differente nel campo destro dell’indirizzo IP, di default 9701.
Nota: istanze multiple della piattaforma JXTA possono essere avviate da un singolo peer
cambiando il numero del TCP e legando ogni istanza ad una differerente porta.
Affinché le impostazioni di configurazione siano memorizzate nella directory locale,
ogni istanza deve essere avviata in una directory specifica.

� Public NAT address: se il peer è localizzato dietro un NAT si deve specificare il
public nat address per questo nodo.
� Manual configuration: se si seleziona l’opzione manual, sarà visualizzato un box
addizionale, always manual. Se si seleziona questo box, la schermata di
configurazione sarà visualizzata e l’utente dovrà selezionare manualmente
l’interfaccia di rete per il TCP, ogni volta che il peer sarà avviato. Questa opzione è
necessaria per nodi che usano DHCP, quando l’indirizzo IP può cambiarte. Se il box
always manual non è selezionato, il valore selezionato sarà salvato nel file di
configurazione e l’utente non sarà invitato a selezionare l’interfaccia di rete la volta
successiva.
13.2.1.3.2 A.7 HTTP settings
Di default, HTTP è abilitato ed è configurato sulla porta 9700. HTTP deve essere abilitato
se il peer si trova dietro un firewall o un NAT. Se si vuole usare una porta differente, bisogna
selezionare dal menu l’interfaccia desiderata. Si può cambiare la porta usata da HTTP
fornendo un valore diverso nel campo a destra dell’indirizzo IP. Se un peer ha più di una
interfaccia di rete si può cliccare sul box manual per esplicitare le specifiche che l’interfaccia
di rete dovrebbe usare per l’HTTP. Se si seleziona l’opzione manual, sarà visualizzato un box
addizionale, always manual. Se si seleziona questo box, la schermata di configurazione sarà
visualizzata e l’utente dovrà selezionare manualmente l’interfaccia di rete per il HTTP, ogni
volta che il peer sarà avviato.
13.2.1.3.3 A.8 Rendezvous and Relay Settings
Il pannello Rendezvous/Router setting permette di specificare le impostazioni di
Rendezvous e HTTP (vedi figura A.8.1).
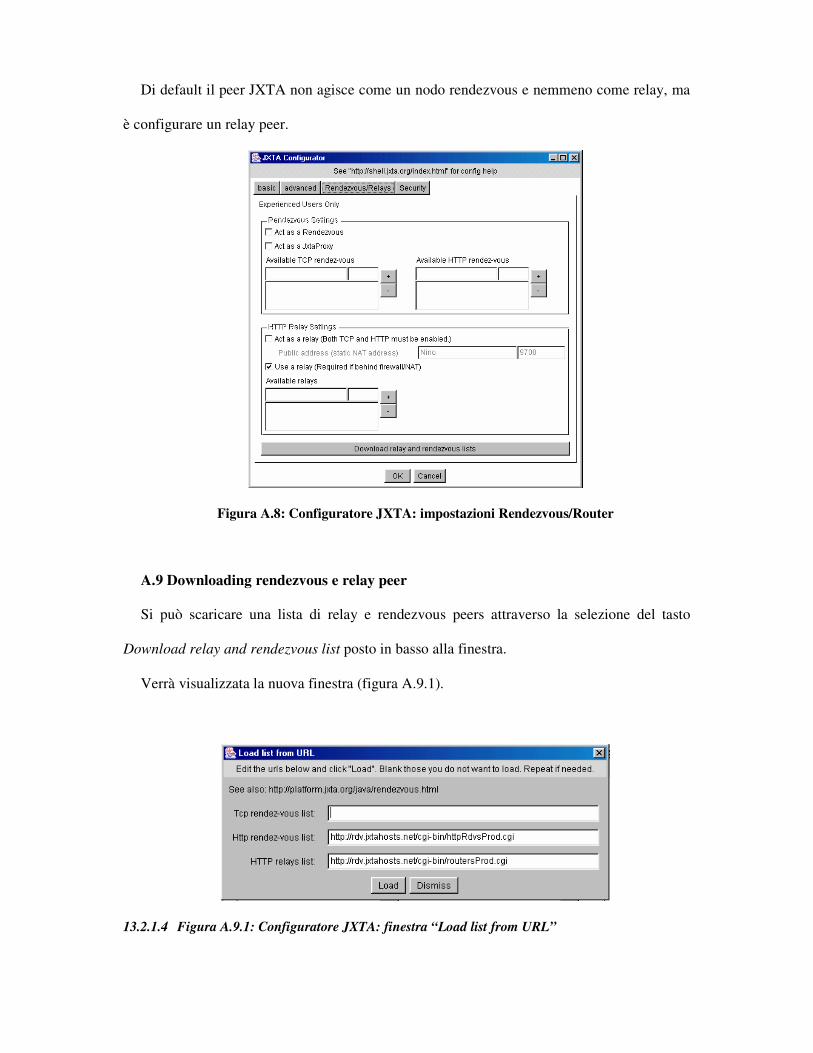
Di default il peer JXTA non agisce come un nodo rendezvous e nemmeno come relay, ma
è configurare un relay peer.
Figura A.8: Configuratore JXTA: impostazioni Rendezvous/Router
A.9 Downloading rendezvous e relay peer
Si può scaricare una lista di relay e rendezvous peers attraverso la selezione del tasto
Download relay and rendezvous list posto in basso alla finestra.
Verrà visualizzata la nuova finestra (figura A.9.1).
13.2.1.4 Figura A.9.1: Configuratore JXTA: finestra “Load list from URL”

Cliccando sul tasto Load verranno scaricati uno più rendezvous e relay peer.
Una volta terminato si clicca Dismiss per chiudere questa finestra e ritornare al pannello
Rendezvous/Router.
13.2.1.5 Figura A.9.2 – Configuratore JXTA: aggiornamento rendezvous router settings
A.10 Rendezvous Settings
È possibile aggiugere un peer rendezvous fornendo l’indirizzo IP e il numero di porta, e
selezionando il tasto “+”. Per rimuovere un rendezvous peer, selezionare il suo indirizzo e
premere il tasto “-“. Se si desidera che il peer in questione agisca come rendezvous,
selezionare il box Act as a rendezvous.
A.11 HTTP Relay Settings
Il box Use a relay è selezionato di default. Si può addizionare un relay peer fornendo
l’indirizzo IP e il numero di porta, e ciccando il tasto”+”. Per rimuovere un relay peer bisogna

selezionare l’indirizzo e premere il tasto “-”. Se si desidera che il peer agisca come relay
selezionare il box Act as a relay.
Sia TCP che HTTP devono essere abilitati prima di agire come un relay.
Inoltre, deve essere specificato l’indirizzo pubblico (Static Nat Address).
A.12 HTTP Security Settings
La piattaforma JXTA richiede che siano create username e password la prima volta quando
viene configurata. Nei successivi avvii della piattaforma verranno richieste username e
password. Il pannello Security Settings invita l’utilizzatore a fornire username e password.
La password deve essere lunga almeno 8 caratteri.

13.2.1.6 Figura A.12.1: Configuratore JXTA: Security Settings
Le applicazioni possono saltare la finestra sulla sicurezza settando le seguenti System
Properties:
� net.jxta.tls.principal;
� net.jxta.tls.password;
Indice
Introduzione ......................................................................................................... I
Capitoto 1............................................................................................................ 1
1.1 L’Intelligenza Artificiale ......................................................................... 1
1.2 Gli algoritmi evolutivi.............................................................................. 2
1.3 Gli algoritmi genetici ............................................................................... 4
1.3.1 La popolazione.................................................................................... 8
1.3.2. Gli operatori genetici ......................................................................... 9
1.3.3 Alcuni cenni teorici ........................................................................... 13
1.4 Le strategie e la programmazione evolutiva ......................................... 15
1.5 La programmazione genetica ................................................................ 17
1.5.1 I parametri principali........................................................................ 19
1.5.2 Mutazione, crossover ed altri operatori............................................. 22

1.5.3 L’aumento della complessità nella programmazione genetica ........... 27
1.5.4 Differenze e analogie fra GP e GA .................................................... 28
1.6 I modelli per la programmazione genetica ........................................... 30
1.6.1 L'automa cellulare ............................................................................ 33
1.7 CAGE ( CellulAr GEnetic programming tool ) ................................... 36
1.7.1 Architettura software di CAGE ......................................................... 37
1.7.3 Dettagli dell’implementazione........................................................... 42
1.7.4 Esempi di programmazione genetica applicati al modello cellulare .. 46
1.8 Un’ implementazione distribuita della programmazione genetica ...... 50
Capitolo 2.......................................................................................................... 53
2.1 Cos'è il peer-to-peer? ............................................................................. 53
2.2 L’essenza del peer to peer...................................................................... 55
2.1.1 Sistema basato sull’interazione fra i peer ......................................... 55
2.3 Nessun appoggio su server o risorse centralizzate ................................ 59
2.4 Resistenza ai cambiamenti profondi nella composizione di una rete... 60
2.5 Una rete con topologia non deterministica ........................................... 60
2.6 Ottima scalabilità................................................................................... 61
2.7 Il peer to peer e la programmazione genetica: connubio perfetto ....... 61
2.8 Java per il supporto peer to peer........................................................... 63
Capitolo 3.......................................................................................................... 65
3.1 Architettura e servizi JXTA .................................................................. 65
3.2 Perché utilizzare JXTA?........................................................................ 68
3.3 Il progetto JXTA.................................................................................... 70
3.4 Gli elementi di JXTA ............................................................................. 71

3.4.1 Peer .................................................................................................. 71
3.4.2 PeerGroup ........................................................................................ 72
3.4.3 Network Services.............................................................................. 75
3.4.4 Pipe JXTA ......................................................................................... 75
3.4.5 Message JXTA .................................................................................. 77
3.4.6 Advertisement JXTA .......................................................................... 78
3.5 JXTA Credentials .................................................................................. 87
3.6 ID JXTA ................................................................................................. 88
3.7 L’Architettura di una rete JXTA .......................................................... 89
3.8 Protocolli di JXTA ................................................................................. 91
3.9 Peer Discovery Protocol......................................................................... 93
3.10 Peer Information Protocol................................................................... 94
3.11 Peer Revolver Protocol ........................................................................ 95
3.12 Pipe Binding Protocol .......................................................................... 96
3.13 Endpoint Routing Protocol.................................................................. 97
3.14 Rendezvous Protocol............................................................................ 98
3.15 Un semplice esempio che avvia una piattaforma JXTA ..................... 99
3.15.1 Requisiti del sistema........................................................................ 99
3.15.2 Esempio HelloWorld ......................................................................100
3.15.3 La classe SimpleJxtaApp ................................................................100
3.15.4 startJxta ( ).....................................................................................101
3.15.5 main( ) ...........................................................................................101
3.15.6 Esecuzione di “Hello World” .........................................................102
3.15.7 Codice sorgente: SimpleJxtaApp ....................................................105
3.16 Programmare con JXTA ....................................................................105
3.17 Scoperta di un peer ( Peer Discovery ) ...............................................106

3.17.1 Il servizio di scoperta ( Discovery Service).....................................106
3.17.2 Discovery Demo.............................................................................108
3.18 La scoperta di un peer group (Peer Group Discovery) .....................116
3.18.1 Il metodo run( ) ..............................................................................117
3.18.2 Il metodo discoveryEvent( ) ............................................................117
3.19 Creare Peer Groups e pubblicare advertisements .............................118
3.19.1 Il metodo main( )............................................................................119
3.19.2 Il metodo startJxta( ) ......................................................................120
3.19.3 createGroup( ) ...............................................................................120
3.20 Unire un peer group............................................................................122
3.20.1 Servizio di appartenenza ad un gruppo (Membership Service)........123
3.20.2 main( ) ...........................................................................................125
3.20.3 startJxta( )......................................................................................125
3.20.4 createGroup( ) ...............................................................................125
3.20.5 joinGroup( ) ...................................................................................126
3.21 Scambio di messaggi fra due peer ......................................................128
3.21.1 JXTA Pipe Service..........................................................................130
3.21.2 Pipe listener ...................................................................................132
3.21.3 PipeExample ..................................................................................137
3.21.4 Pipe Advertisement: il file examplepipe.adv ...................................142
Capitolo 4.........................................................................................................144
Introduzione................................................................................................144
4.1 Le classi della nostra applicazione .......................................................146
4.2 La classe CanaleDiInput.......................................................................146
4.3 La classe CanaleDiOutput ....................................................................147

4.4 La classe Esploratore ............................................................................149
4.5 La classe GruppoProgrammazioneGenetica .......................................150
4.6 La classe Peer ........................................................................................151
4.7 La classe Utility .....................................................................................154
4.8 La realizzazione dei canali di comunicazione........................................155
Capitolo 5.........................................................................................................157
5.1 Cos'è JNI e quando serve......................................................................157
5.2 Struttura di JNI: vista d'insieme delle funzionalità ............................160
5.3 L’uso della JNI nella nostra applicazione ............................................165
5.3.1 I metodi nativi ..................................................................................166
5.3.2 Shared library ..................................................................................168
5.3.3 Compilazione ...................................................................................168
5.3.4 Header file .......................................................................................169
5.3.5 Parametri aggiuntivi ........................................................................171
5.3.6 L’implementazione ...........................................................................171
5.3.7 Compilare i sorgenti ........................................................................173
Conclusioni e sviluppi futuri.............................................................................174
Appendice A ....................................................................................................177
Introduzione................................................................................................177
A.1 Processo di configurazione...................................................................178
A.2 Descrizione del tool ..............................................................................180
A.3 Basic Settings........................................................................................180
A.4 Advanced settings.................................................................................181

A.5 Trace level ............................................................................................182
A.6 TCP settings .........................................................................................183
A.7 HTTP settings ......................................................................................184
A.8 Rendezvous and Relay Settings ...........................................................185
A.9 Downloading rendezvous e relay peer.................................................185
A.10 Rendezvous Settings...........................................................................187
A.11 HTTP Relay Settings..........................................................................187
A.12 HTTP Security Settings …………………………………………………...187
Bibliografia…………………………………………………………...………………..189

Bibliografia
A. David e J. R. Koza, “Exploiting the fruits of parallelism”: An implementation of
parallel genetic programming that achieves super-linear performance”, Information science
Jurnal, Elsevier, 1997.
P. J. Angeline, “Genetic Programming and Emergent Intelligent”, Advances in Genetic
Programming, K. Kinnear, Cambridge MA: MIT Press, pp. 75-96.
E. Cantù-Paz, “Designing Efficient Master-Slave Parallel Genetic Algorithms”, Technical
Report IlliGAI 9704, Dept. Comp. Science, University of Illinois at Urbana-Champaign,
1997.
E. Cantù-Paz, “Migration Policies and Takeover Times in Parallel Genetic Algorithms” ,
GECC-99: Proceedings of the Genetic and Evolutionary Competition Conference, San
Francisco, July 1999.
E. Cantù-Paz, “Migration policies, selection pressure, and parallel evolutionary
algorithms” , Technical Report IlliGAI 99015, Dept. Comp. Sciencs, University of Illinois at
Urbana-Champnign, 1999.
A. G. Deakin e D. F. Yates, “Genetic Programming tool Avaible on the Web: A First
Encounter” , Genetic Programming 1996, Proceedings of the First Annual Conference, MIT
Press, Stanford University, July 1996.

Enrique Alba, Marco Tomassini, “Parallelism and Evolutionary Algorithms”, IEEE
Transaction on evolutionary computation, vol. 6, n°5, Ottobre 2002
G. Folino, C. Pizzuti, G. Spezzano, “A tool for Parallel Genetic programming
Applications” , Proc. Of the European Genetic Programming Conference EuroGP01, Como,
15-16 April, to appears.
J. Holland, “Adaptation in Natural and Artificial Systems”, University of Michigan Press,
1975.
J. R. Koza, “Genetic Programming: On the Programming of Computers by means of
Natural Selection” , MIT Press, Cambridge, 1992.
C. E. Leiserson, “Fat-Trees: Universal Networks for Hardware-Efficient Supercomputing”
, IEEE Transaction on Computers, Vol. C-34, N. 10, October 1985.
P. Nordin e W. Banzhaf, “Complexity Compression and Evolution” , Proceedings of the
Fourth International Conference on Genetic Algorithms, Morgan Kaufmann Publishars Inc.,
1995.
P. Nordin, F. Francone e W. Banzhaf, “Explictly Defined Intros and Destructive Crossover
in Genetic Programming” Advances in Genetic Programming: Volume 2, P. Angeline and K.
Kinnear, MIT Press, Cambridge, 1996, pp. 111-134.
M. Oussaiden, B. Chopard, O. Picted and M. Tommasini, “Parallel Genetic Programming
and its Application to Trading Model Induction”, Parallel Computing....

C. C. Pettey, “Diffusion (cellular) models”, Handbook of Evolutionary Computation,
Institute of Phisics Publishing and Oxford University Press,1997, C 6.4.
E. Rich, “Artificial Intelligence”, McGraw-Hill, NewYork, 1983.
M. Snipper, “The Emergence of cellular Computing”, Computer, IEEE Computer Society,
July 1999.
Stephen Wolfram, “Cellular Automata and Complexity”, Addison Wesley Publishing
Company, 1994.
Antonio Pelleriti, “JXTA: il vero peer-to-peer”, Io Programmo Dicembre 2002
Antonino Panella, “JNI: dare accesso alle funzionalità del sistema operativo”, Io
Programmo Dicembre 2002
M.G. Arenas, Pierre Collèt, A.E. Eiben, Mark Jelasity, J.J. Merelo, Ben Paechter, Mike
Preu�, Marc Schoenauer, “A framework for distributed evolutionary algorithms”
Mark Jelasity, Mike Preu�, Ben Paetcher, “A scalable and robust framework for
distributed applications”
Daniel Brookshier, Darren Govoni, Navaneeth Krishnan, “JXTA: Java P2P
Programming”, SAMS Publishing, 2002

Sing Li, “JXTA Peer-to-Peer Computing with Java”, Wrox Press Ltd. 2001
Cay S. Horstmann, Gary Cornell, “Java2 volume1: fondamenti”, McGrawHill 2001
Cay S. Horstmann, Gary Cornell, “Java2 volume 2: tecniche avanzate”, McGrawHill 2000
www.java.sun.com
www.jxta.org
www.linuxvalley.com





























