Embed Size (px)
Citation preview

User Guide
Prepared by:
Iman Sugema
Beni Kapri
Ade Holis
Bintang Dwitya
Wahyu Purnamahadi
Farhana Zahrotunnisa

Chapter 1
Loading the data
The basic
Introduction
You must have data on your hand before estimating regression via the software. There are four
important things that you have to keep in mind:
1. Trickytreex can only read data from Excel. No other format is allowed.
2. The data is read by column. For instance, if you have four variables: GDP, Invest,
Consump, and Govex, you have to put them in four different columns. Each column
should be labeled according to the name of the data. The label should be put in the
‘first’ row of your data set. If, there is no label, then the first row would be read as the
label, and that would confuse you.
3. The data you put from Excel may be saved as a WKX file, which is a Trickytreex
workfile. Once you have that, it may be retrieved any time you need it. In that case,
you do not have to use the Excel file.
4. You can work with three types of data: time series, cross-section, and panel data.
Times series has a natural ordering based on time and you have to prepare the correct
ordering in Excel. Note that Excel has very excellent and easy to use time and date
formatting. Cross-section data do not have any natural ordering, and that is why you
do not have to put series ID on it. But if you wish, say name of the respondents, you
can treat it as “text ID label”. In panel data, you have two ID’s: time series and cross-
section, and both should be uniformly formatted. This will be clear by example.
The following sections show you how to manage your data
Three steps of having data in Trickytreex
First step, prepare everything correctly in Excel. Trickytreex do have “facility” to edit the data.
You just do it in Excel everything about data management. Trickytreex will capture anything
you specify in Excel.
Second step, upload the data from Excel to Trickytreex after making sure the data is correctly
specified. We will give you the examples, in the following sections.

Third step, use and save the data. After uploading the data, you can use it for any estimation
techniques available in the Trickytreex. Alternatively you can just save it for future use.
Dealing with time series data For simplicity, you may just follow the three step described below. You have to keep in mind
that time series mean that you order the data by time interval.
First step, prepare the data correctly in Excel. If you have data with other format, please make
sure that it can be read properly by Excel. Tricky can only read Excel formatted data!
Moreover, you have to put time series ID label. It can be yearly, bi-annually, quarterly,
monthly, weekly, daily, or even hourly. You have to learn by yourself how to make consistent
time formatting in Excel. If you have any difficulty, just click the help menu. However, if you
are comfortable with Excel format, you can make your own “text format”. For instant for
quarterly data you can have 2001Q1, 2001Q2, 2001Q3, 2001Q4, 2002Q1 ….. and so on. As long
as it is created within Excel, customized time format can be read by Trickytreex. The following
figure presents the distinction between time-series format and text format.
Figure 1.1. Time series format and text format

Please have a look at Figure 1 with great care. Observe that you have 5 time series data named
as XA, XB, XC, XD, and XE (from column C to G). The first rows always contain the name of the
series. You can name them as you wish. Column A contains what we call as “text label”
indicating year and month. Column B is the “time-series label”, which you can generate by using
Excel date format. You can use either one of them, but you cannot have both.
Second step upload the data from Excel to Trickytreex by clicking “Trickytreex” and click “From
Excel”. This dialog box will appear in the screen.
Figure 1.2. Uploading time-series data
In this example, you have 5 variables with 244 observations. So in the “Data Source” you must
type or highlight cells C1:G245. If you choose time series label then in the “Time Series ID
Label” you must highlight cells B2:B245, and then click “Date” and “Monthly” in the dialog box.
Note that this is just an example. Practically speaking, the cells you highlight will depend on the
number of variables and the time span.
In the case that you choose “text label” then you must highlight cells A2:A245 and click “Text”.
It should appear like this.
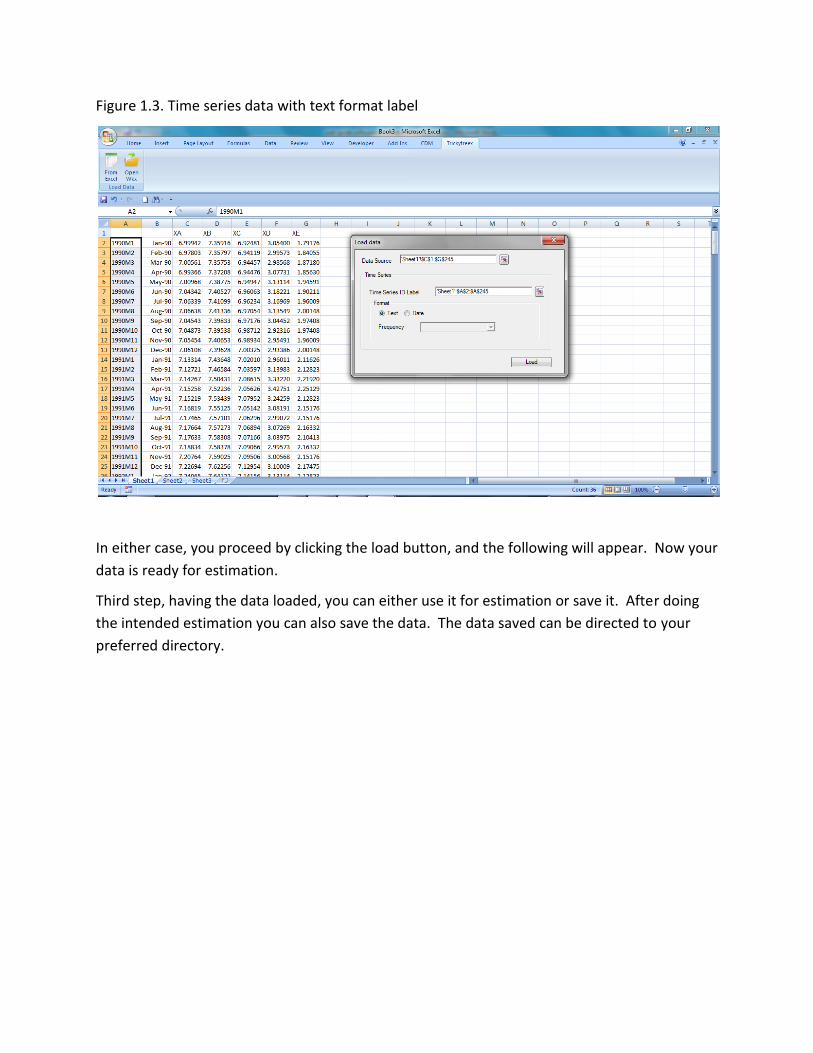
Figure 1.3. Time series data with text format label
In either case, you proceed by clicking the load button, and the following will appear. Now your
data is ready for estimation.
Third step, having the data loaded, you can either use it for estimation or save it. After doing
the intended estimation you can also save the data. The data saved can be directed to your
preferred directory.

Figure 1.4. Loaded time series data
Dealing with cross-section data Cross-section data do not have natural time ordering and therefore time series ID label is not
needed. Suppose that four data set YA, YB, YC and YD. To upload the data from excel to
Trickytreex, you just follow the step discussed in the previous section (Dealing with time-series
data) all the procedures are the same except that you need not to specify the “time series
label” in the dialog box. So what you have to do is specifying which data you are going to
upload. In the example, the dialog box should appear like this.

Figure 1.5. Loading cross-section data from Excel
Dealing with panel data Panel data means you have two ID for each data set: time series ID and cross-section ID.
Suppose you have three countries to analyze, Indonesia, Australia and Germany and two series
for each country, X and Y. Therefore you must have 6 data series which should be organized
like in the following screen. XIndonesia means variable X that belongs to Indonesia, while
YAustralia means variable Y that belongs to Australia.
Note that Trickytreex can only deal with un-stacked panel data. The stacking itself is done
automatically with in Trickytreex. The rest of the step is exactly the same with the previous
section. The resulting operation should appear like in Figure 1.7.

Figure 1.6. Preparing panel data
Figure 1.7. Loaded panel data

Chapter 2
Single Equation
Untuk melakukan estimasi regresi pada Trickytreex maka pilih Single Equation kemudian OLS
Tuliskan model yang akan diestimasi GOV_NET[spasi]INV[spasi]LY[spasi]CONS[spasi]c
kemudian tekan pada Full Observation–j ika data yang digunakan merupakan keseluruhan data
dari data yang dientry kemudian tekan OK.
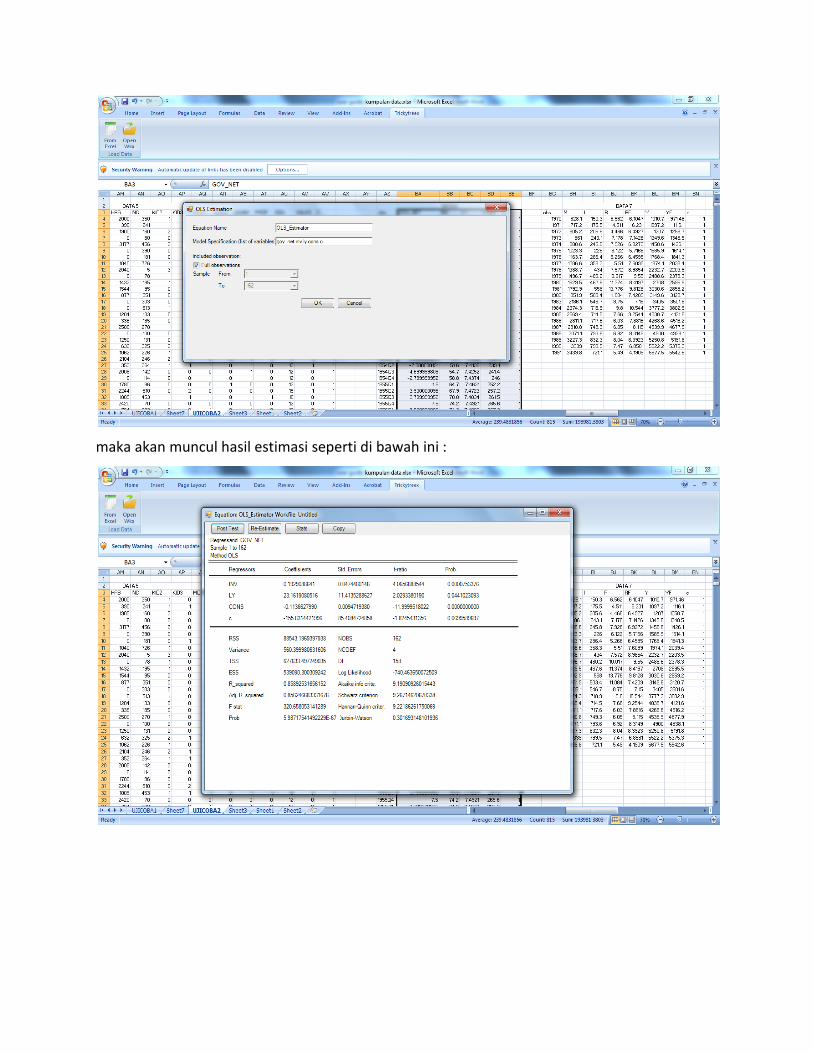
maka akan muncul hasil estimasi seperti di bawah ini :

Pelanggaran Terhadap Pelanggaran Asumsi OLS (Residual Tests)
Untuk melakukan pengujian asumsi-asumsi OLS maka tekan Post test kemudian pilih uji asumsi
mana yang ingin dilakukan terlebih dahulu uji autokorelasi atau heteroskedastisitas.
Untuk menguji autokorelasi :
Setelah hasil estimasiOLS keluar tekan Post Test kemudian Serial Correlation kemudian isi
kolom Lag of residual included misal 2.
maka hasil estimasi yang akan muncul sebagai berikut :

Untuk menguji heteroskedastisitas :
Setelah hasil estimasi OLS keluar tekan Post Test kemudian Heteroskedasticity– Uji
heteroskedastisitas yang di inginkan contoh :Breusch Pagan Godfrey

maka hasil estimasi yang akan muncul sebagai berikut :

Estimasi Weighted Least Square Dengan Trickytreex
Untuk melakukan estimasi regresi pada Trickytreex maka pilih Single Equation kemudian WLS
Tuliskan model yang akan diestimasi GOV_NET[spasi]INV[spasi]LY[spasi]CONS[spasi]c
kemudian tekan pada Full Observation–jika data yang digunakan merupakan keseluruhan data
dari data yang dientry – jangan lupa untuk mengisi kolom weight dengan pembobot yang telah
ditentukan missal 1/inv kemudian tekan OK.

Hasil estimasi Weighted Least Square akan muncul seperti pada gambar berikut ini
Dalam estimasi Weighted Least Square kita dapat juga melakukan pengujian asumsi
autokorelasi dan heteroskedastisitas dengan cara seperti yang dilakukan pada OLS.

Estimasi IV/2 SLS Dengan Trickytreex
Untuk melakukan estimasi IV/2SLS pada Trickytreex maka pilih Single Equation kemudian
IV/2SLS
Kemudian masukan model yang akan diestimasi pada kolom Equation Specification contoh
M[spasi]I[spasi]R[spasi]C, kemudian isi kolom Instrument dengan contoh
R[spasi]I[spasi]Y[spasi]C– jangan lupa untuk memasukan constant dalam kolom instrument,
kemudian tekan OK

Maka hasil estimasi akan muncul sebagai berikut :
Dalam estimasi IV/2SLS kita dapat juga melakukan pengujian asumsi autokorelasi dan
heteroskedastisitas dengan cara seperti yang dilakukan pada OLS.

Chapter 3
Binary Choice Model
Probit Estimate Xl
Masukan data yang ingindiestimasi – dependent variable berupa dummy yang
merepresentasikan suatu kejadian atau pilihan diantara dua alternatif. Lihat data 4

Setelah data yang ingin diestimasi dientry, Pilih Other - Probit
Pada kolom Model isi dengan model yang akan di estimasi contoh
GRADE[spasi]GPA[spasi]TUCE[spasi]PSI[spasi]c, kemudian tekan all observation – jika ingin

menggunakan keseluruhan time series dari data yang di entry atau sample – jika menggunakan
sebagian time series dari data yang di entry, kemudian tekan OK.
kemudian hasil estimasi akan muncul sebagai berikut :
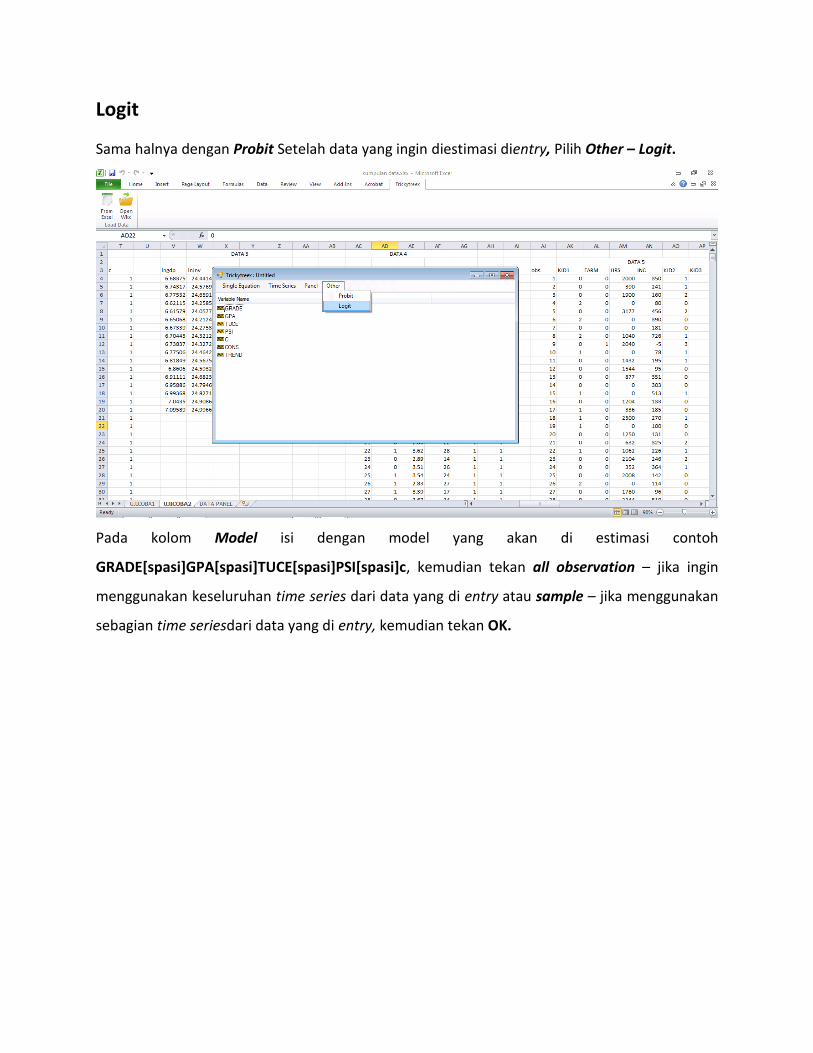
Logit
Sama halnya dengan Probit Setelah data yang ingin diestimasi dientry, Pilih Other – Logit.
Pada kolom Model isi dengan model yang akan di estimasi contoh
GRADE[spasi]GPA[spasi]TUCE[spasi]PSI[spasi]c, kemudian tekan all observation – jika ingin
menggunakan keseluruhan time series dari data yang di entry atau sample – jika menggunakan
sebagian time seriesdari data yang di entry, kemudian tekan OK.

kemudian hasil estimasi akan muncul seperti pada gambar berikut :

Chapter 4
Time Series
Pengujian Kestasioneritasan Data
Untuk menguji kestasioneritasan data, pilih Time Series kemudian Unit Root Test.
Muncul 2 pilihan uji kestasioneritas data yaitu Augmented Dicky Fuller (ADF) dan Phillips –
Perron (PP)
Pengujian Stasioneritas Augmented Dickey Fuller:
Klik Augmented Dicky Fuller (ADF), muncul

Isikan kolom Series dengan salah satu variabel yang akan diuji kestasioneritasannya.
Catatan : Isikan hanya satu variabel, jika lebih dari satu akan muncul pesan Error “Jumlah
series harus satu”.
Pada menu lag length, isikan panjang lag yang diinginkan dikolom Fixed at atau beri tanda
cek pada menu toolbox Automatic Selection dan pilih kriteria yang diinginkan. Kemudian
isikan panjang lag maksimum yang ingin diikutkan dalam perhitungan pada kolom Maximum
Lag.
Pada menu observation, cek pilihan All Observation jika ingin memproses seluruh range
data yang ada atau isikan sample pada kolom from dan to untuk memproses sebagian data.
Kemudian Klik OK, maka akan muncul output seperti berikut:
Pada tampilan output muncul nilai 4 model pengujian unit root berdasarkan tipe trend
deterministic yang digunakan, yaitu:
Tanpa konstanta dan tanpa tren
Dengan konstanta
Dengan konstanta dan tren linier
Dengan konstanta dan tren kuadratik.

Nilai ADF-Stat dibandingkan dengan critical value pada tingkat α yang diinginkan untuk
menentukan apakah variabel yang diuji mengandung unit root atau tidak.
Pengujian Stasioneritas Phillips-Perron (PP):
Pada tab Time Series pilih Unit Root Test kemudian klik Phillips-Perron (PP), muncul
Isikan variabel yang akan diuji kestasioneritasannya pada kolom Series.
Catatan : Isikan hanya satu variabel, jika lebih dari satu akan muncul pesan Error “Jumlah series
harus satu”.
Pada menu lag length, isikan panjang lag yang diinginkan dikolom Fixed at atau beri tanda cek
pada menu toolbox Automatic Selection.
Pada menu observation, cek pilihan All Observation jika ingin memproses seluruh range data
yang ada atau isikan sample pada kolom from dan to untuk memproses sebagian data.
Kemudian Klik OK, maka akan muncul output seperti berikut:

Pada tampilan output muncul nilai 4 model pengujian unit root berdasarkan tipe trend
deterministic yang digunakan, yaitu:
Tanpa konstanta dan tanpa tren
Dengan konstanta
Dengan konstanta dan tren linier
Dengan konstanta dan tren kuadratik.
Nilai PP-Stat dibandingkan dengan critical value pada tingkat α yang diinginkan untuk
menentukan apakah variabel yang diuji mengandung unit root atau tidak.

Vector Auto Regression (VAR)
Untuk melakukan pengujian VAR pilih menu Time Series kemudian pilih Vector Autoregression
Klik menu Vector Autoregression, muncul
Pada kolom Endogenus Variables ketik seluruh variabel yang akan dimodelkan dalam VAR.
Isikan panjang lag yang diinginkan pada kolom Lag Length. Ketik “cons” pada kolom Exogenus

Variable untuk menambahkan konstanta pada model dan tambahkan variabel eksogen lainnya
jika ada. Apabila tidak terdapat variabel eksogen didalam model, kolom ini dapat dikosongkan.
Pada menu observation, cek pilihan All Observation jika ingin memproses seluruh range data
yang ada atau isikan sample pada kolom from dan to untuk memproses sebagian data.
Kemudian Klik OK, maka akan muncul output seperti berikut:
Nilai di kolom atas merupakan nilai koefisien estimasi dari masing-masing variabel didalam
model disertai nilai t-statistiknya didalam kurung. Simbol L1, L2, dan seterusnya merupakan
koefisien untuk lag pertama, kedua dan seterusnya (t-1, t-2,…dst).
Pada kolom dibawahnya terdapat nilai statistik regresi untuk masing-masing variabel, seperti
RSS, TSS, R2, Adj R2, F-stat, dan seterusnya. Sedangkan pada kolom yang paling bawah disajikan
ringkasan statistik untuk model VAR secara keseluruhan.
Pengujian Lag Optimal
Penentuan lag optimal dilakukan dengan menggunakan tiga kriteria, yaitu Akaike Information
Criterion (AIC), Schwarz Based Criterion(SBC), dan Hannan-Quinn Criterion (HQC). Langkah-
langkah pengujiannya adalah sebagai berikut:

Pada tampilan output VAR terdapat beberapa tab dibagian atasnya. Klik tab Lag Length, maka
muncul kotak dialog Maximum Lag.
Selanjutnya isikan nilai lag maksimal yang akan diikutkan dalam pengujian model. Klik OK.
Muncul tampilan output Lag Selection. Untuk menentukan lag optimal pilih nilai AIC, SBC, atau
HQC yang paling kecil (minimum).

Pengujian Residual
Trickytreex menyediakan berbagai pengujian residual, seperti variance-covariance and Cross-
correlation matrix, correlogram, Portmanteau autocorrelation test, dan non-normality test.
Langkah untuk melakukan pengujian residual adalah :
Klik Tab Residual pada tampilan output VAR yang telah ada. Akan muncul pilihan menu sesuai
dengan pengujian yang ingin dilakukan.
Pilih Get Residual untuk menampilkan nilai residual dari model VAR.
Pilih variance-covariance and Cross-correlation matrix untuk menampilkan matriks
varians kovarian dan matriks korelasi silang.
Pilih Correlogram untuk melakukan pengujian correlogram.
Pilih Portmanteau autocorrelation test untuk melakukan pengujian autokorelasi
Portmanteau.
Pilih Non-normality test untuk melakukan test normalitas pada residual.
Impulse Response Function (IRF) Model VAR
Impulse Response Function atau IRF digunakan untuk melihat bagaimana respon suatu variabel
akibat adanya perubahan/shok dari variabel itu sendiri atau variabel lainnya dalam kurun waktu

tertentu. Untuk menghitung Impulse Response Function pada model VAR, klik tab Impulse pada
tampilan output VAR.
Pilih salah satu jenis shock yang diinginkan pada menu toolbox yang ada, kemudian pada kolom
Number of periods isikan jumlah periode yang ingin dilihat perubahannya, kolom ini wajib
terisi. Kita juga dapat memilih cek Accumulated Shock jika ingin melihat akumulasi shok pada
seluruh periode.
Jika kita memilih menu toolbox Cholesky, isikan urutan variabel yang akan dihitung pada kolom
ordering.

Selanjutnya Klik OK.
Forecast Error Variance Decompotion (FEVD)
Analisis FEVD bertujuan untuk memprediksi kontribusi persentase varian setiap variabel karena
adanya perubahan variabel tertentu dalam sistem VAR. Analisis FEVD digunakan untuk
menggambarkan relatif pentingnya setiap variabel dalam sistem karena adanya shock.
Untuk menghitung nilai FEVD, klik tab FEVD pada tampilan output VAR. Muncul kotak dialog
FEVD seperti berikut.
Pada kolom Cholesky ordering isikan urutan variabel yang akan dianalisis dengan FEVD dan
isikan pula jumlah periode yang diinginkan, kemudian klik OK.
Untuk kembali ke menu VAR dapat meng-klik tab Re-estimate.
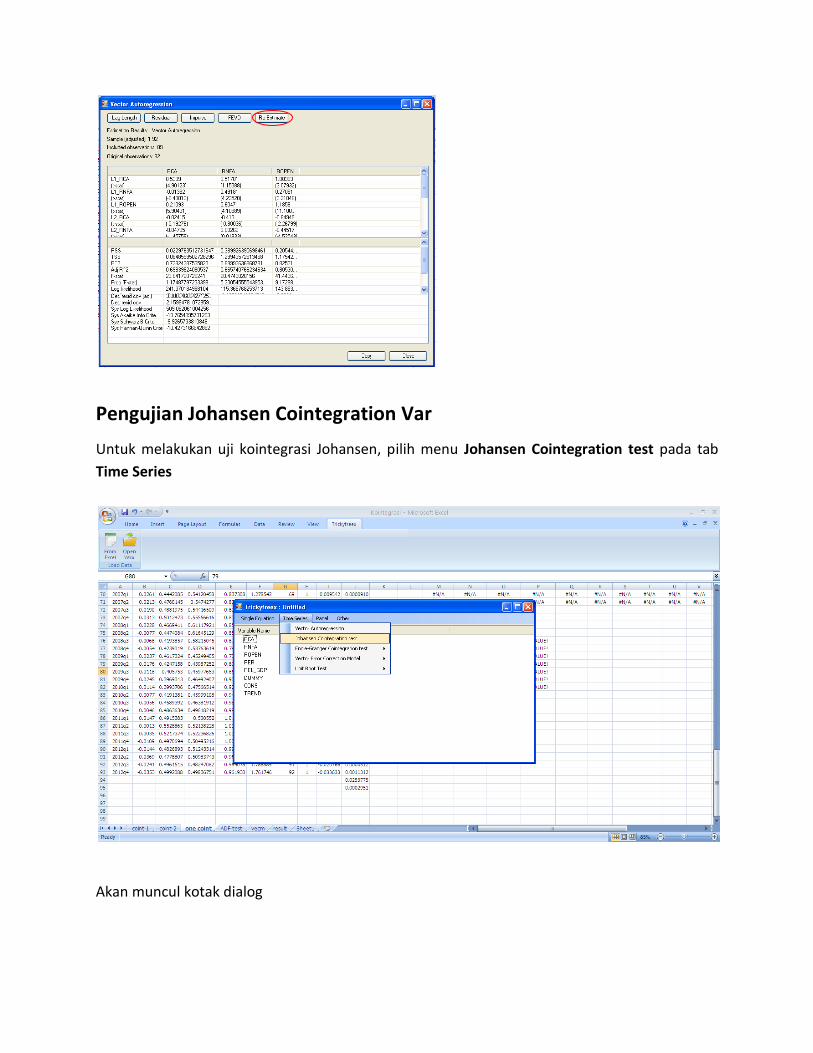
Pengujian Johansen Cointegration Var
Untuk melakukan uji kointegrasi Johansen, pilih menu Johansen Cointegration test pada tab
Time Series
Akan muncul kotak dialog

Ketik variabel endogen dan eksogen pada kolom yang tersedia. Jangan memasukan konstanta
dan atau trend di kolom Exogenus Variable, jika tidak ada variabel eksogen maka kolom ini
dapat dikosongkan. Kemudian isikan nilai lag maksimal pada kolom Maximum Lag.
Pada menu observation, cek pilihan All Observation jika ingin memproses seluruh range data
yang ada atau isikan sample pada kolom from dan to untuk memproses sebagian data.
Kemudian Klik OK, maka akan muncul output seperti berikut:
Dari output tersebut kita dapat memperoleh model trend deterministik yang terbaik
berdasarkan kriteria AIC, SBC, dan HQC.
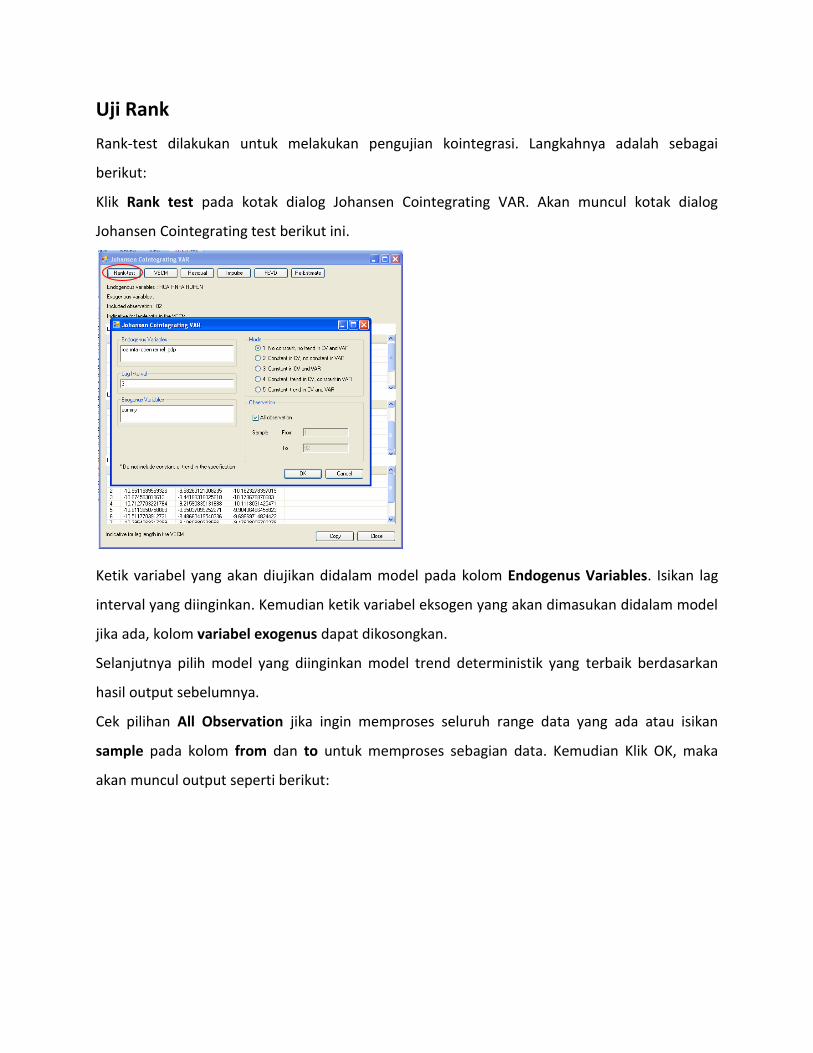
Uji Rank
Rank-test dilakukan untuk melakukan pengujian kointegrasi. Langkahnya adalah sebagai
berikut:
Klik Rank test pada kotak dialog Johansen Cointegrating VAR. Akan muncul kotak dialog
Johansen Cointegrating test berikut ini.
Ketik variabel yang akan diujikan didalam model pada kolom Endogenus Variables. Isikan lag
interval yang diinginkan. Kemudian ketik variabel eksogen yang akan dimasukan didalam model
jika ada, kolom variabel exogenus dapat dikosongkan.
Selanjutnya pilih model yang diinginkan model trend deterministik yang terbaik berdasarkan
hasil output sebelumnya.
Cek pilihan All Observation jika ingin memproses seluruh range data yang ada atau isikan
sample pada kolom from dan to untuk memproses sebagian data. Kemudian Klik OK, maka
akan muncul output seperti berikut:

Nilai lambda Eigenvalue dan nilai trace dibandingkan dengan critical value-nya masing-masing
untuk mendapatkan banyaknya persamaan kointegrasi.
Vector Error Correction Model (VECM)
Setelah diperoleh nilai lag optimal VAR dan jumlah persamaan kointegrasi serta model trend
determistik yang terbaik, kita dapat menghitung model VECM.
Klik VECM pada kotak dialog Johansen Cointegrating VAR. Muncul kotak dialog VECM.
Ketik variabel endogen pada kolom Endogenus Variables. Ketik variabel eksogen jika ada, kolom
ini dapat dikosongkan. Kemudian isikan lag optimal VECM pada kolom Lag in VECM dan isikan

jumlah persamaan kointegrasi pada kolom Number of Cointegrating vector. Selanjutnya pilih
model trend deterministik terbaik berdasarkan uji sebelumnya.
Cek pilihan All Observation jika ingin memproses seluruh range data yang ada atau isikan
sample pada kolom from dan to untuk memproses sebagian data. Kemudian Klik OK, maka
akan muncul output seperti berikut:
Terdapat empat kolom pada tampilan output VECM.
Kolom pertama atau yang paling atas merupakan nilai koefisien estimasi dari vektor kointegrasi
disertai nilai standard error-nya masing-masing dibawahnya. Simbol L1, L2, dan seterusnya
merupakan koefisien untuk lag pertama, kedua dan seterusnya (t-1, t-2,…dst).
Kolom kedua merupakan nilai koefisien estimasi dari model VECM.
Kolom ketiga merupakan nilai statistik regresi untuk masing-masing variabel, seperti RSS, TSS,
R2, Adj R2, F-stat, dan seterusnya.
Sedangkan pada kolom keempat disajikan ringkasan statistik untuk model VECM secara
keseluruhan.

Pengujian Residual
Pada model VECM juga disediakan berbagai pengujian residual.
Klik Tab Residual pada tampilan output VECM yang telah ada. Akan muncul pilihan menu sesuai
dengan pengujian yang ingin dilakukan.
Pilih Get Residual untuk menampilkan nilai residual dari model VAR.
Pilih Covariance and Cross-correlation matrix untuk menampilkan matriks kovarian dan
matriks korelasi silang.
Pilih Correlogram untuk melakukan pengujian correlogram.
Pilih Portmanteau autocorrelation test untuk melakukan pengujian autokorelasi
Portmanteau.
Pilih Non-normality test untuk melakukan test normalitas pada residual.
Impulse Response Function (IRF) Model VECM
Impulse Response Function atau IRF digunakan untuk melihat bagaimana respon suatu variabel
akibat adanya perubahan/shok dari variabel itu sendiri atau variabel lainnya dalam kurun waktu

tertentu. Untuk menghitung Impulse Response Function pada model VAR, klik tab Impulse pada
tampilan output VECM.
Pilih salah satu jenis shock yang diinginkan pada menu toolbox yang ada, kemudian pada kolom
Number of periods isikan jumlah periode yang ingin dilihat perubahannya, kolom ini wajib
terisi. Kita juga dapat mengklik cek Accumulated Shock jika ingin melihat akumulasi shok pada
seluruh periode.
Jika kita memilih menu toolbox Cholesky, isikan urutan variabel yang akan dihitung pada kolom ordering.
Selanjutnya Klik OK.

Forecast Error Variance Decompotion (FEVD)
Analisis FEVD bertujuan untuk memprediksi kontribusi persentase varian setiap variabel karena
adanya perubahan variabel tertentu dalam sistem VECM. Analisis FEVD digunakan untuk
menggambarkan relatif pentingnya setiap variabel dalam sistem karena adanya shock.
Untuk menghitung nilai FEVD, klik tab FEVD pada tampilan output VECM. Muncul kotak dialog
FEVD seperti berikut.
Pada kolom Cholesky ordering isikan urutan variabel yang akan dianalisis dengan FEVD dan
isikan pula jumlah periode yang diinginkan, kemudian klik OK.
Untuk kembali ke kotak dialog Johansen Cointegrating test dapat meng-klik tab Re-estimate.
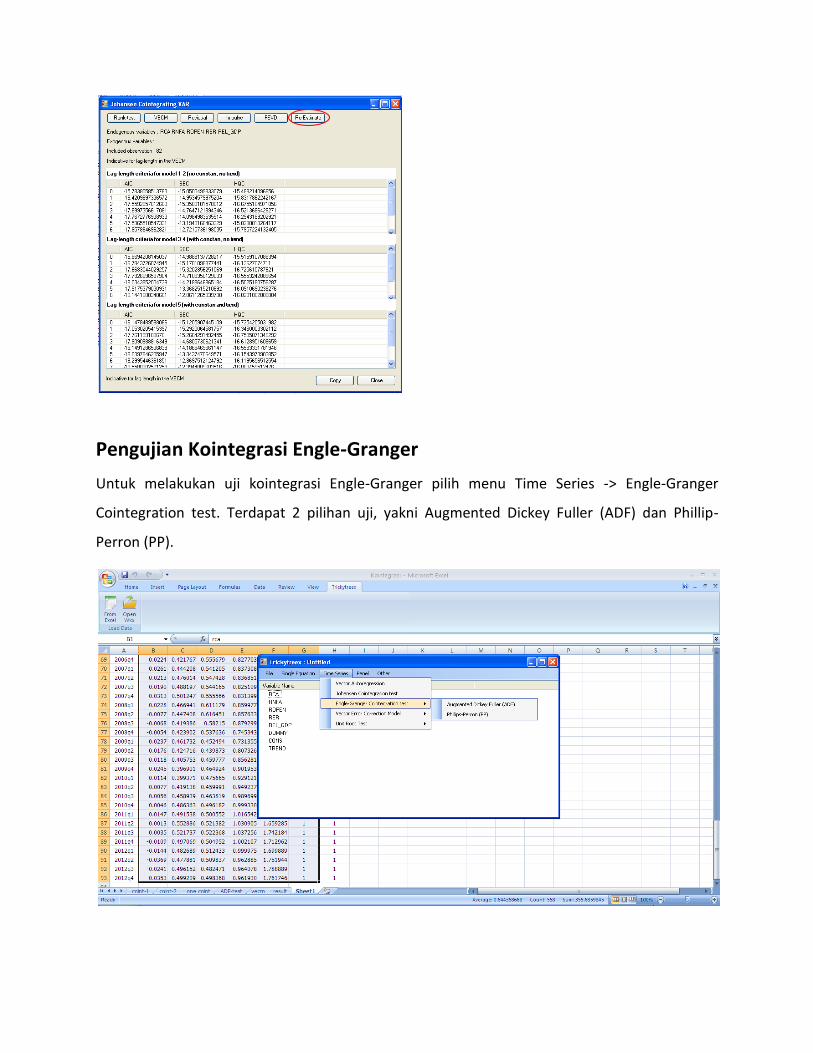
Pengujian Kointegrasi Engle-Granger
Untuk melakukan uji kointegrasi Engle-Granger pilih menu Time Series -> Engle-Granger
Cointegration test. Terdapat 2 pilihan uji, yakni Augmented Dickey Fuller (ADF) dan Phillip-
Perron (PP).

Augmented Dickey Fuller Test
Pilih Augmented Dickey Fuller (ADF) untuk menghitung kointegrasi dengan metode ADF. Akan
muncul kotak dialog berikut.
Isikan variabel dalam model yang akan diuji kointegrasi. Pada menu Lag Selection Method pilih
lag yang diinginkan di kolom Fixed at atau cek pada menu toolbox Automatic Selection untuk
memerintahkan software mencari lag yang sesuai.
Jika memilih automatic selection -> klik pilihan kriteria dan isikan maksimum lag yang diikutkan
dalam pengujian.
Pada menu Observation, cek pilihan All Observation jika ingin memproses seluruh range data
yang ada atau isikan sample pada kolom from dan to untuk memproses sebagian data.
Kemudian Klik OK, maka akan muncul output seperti
berikut:

Terdapat empat kolom pada tampilan output Engle-Granger Cointegrating test. Pada setiap
kolom terdapat 3 pilihan output yang disajikan berdasarkan model trend deterministiknya.
Kolom pertama menampilkan nilai statistik ADF. Nilai ADF-Stat tersebut dibandingkan
dengan critical value pada tingkat α yang diinginkan untuk menentukan apakah model
tersebut terkointegrasi atau tidak.
Kolom kedua menyajikan nilai koefisien estimasi dari masing-masing model vektor
kointegrasi.
Kolom ketiga merupakan nilai t-ratio dari koefisien estimasi masing-masing variabel.
Sedangkan pada kolom keempat menyajikan nilai statistik regresi untuk masing-masing
variabel, seperti RSS, TSS, R2, Adj R2, F-stat, dan seterusnya.
Phillips-Perron Test
Pilih Phillips-Perron (PP) untuk menghitung kointegrasi dengan metode Phillips-Perron.

Selanjutnya akan muncul kotak dialog berikut ini.
Pada kolom Variables ketik variabel-variabel yang akan diuji kointegrasi. Kemudian pada menu
Lag Selection Method isikan lag yang diinginkan atau cek pada menu toolbox Automatic
Selection untuk memerintahkan software memilihkan lag.
Pada menu Observation, cek pilihan All Observation jika ingin memproses seluruh range data
yang ada atau isikan sample pada kolom from dan to untuk memproses sebagian data.
Selanjutnya klik Ok.
Akan muncul output berikut ini.

Terdapat empat kolom pada tampilan output Phillips-Perron test. Pada setiap kolom terdapat 3
pilihan output yang disajikan berdasarkan model trend deterministiknya, meliputi dengan
konstanta, dengan konstanta dan trend linier, dan dengan konstanta dan trend kuadratik.
Kolom pertama menampilkan nilai statistik Phillips-Perron. Nilai PP-Stat tersebut
dibandingkan dengan critical value pada tingkat α yang diinginkan untuk menentukan
apakah model tersebut terkointegrasi atau tidak.
Kolom kedua menyajikan nilai koefisien estimasi dari masing-masing model vektor
kointegrasi.
Kolom ketiga merupakan nilai t-ratio dari koefisien estimasi masing-masing variabel.
Sedangkan pada kolom keempat menyajikan nilai statistik regresi untuk masing-masing
variabel, seperti RSS, TSS, R2, Adj R2, F-stat, dan seterusnya.
Pengujian Two-Step Engle-Granger
Untuk melakukan pengujian Two-Step Engle-Granger pilih menu Time Series -> Vector Error
Correction Model -> Two-step Engle-Granger
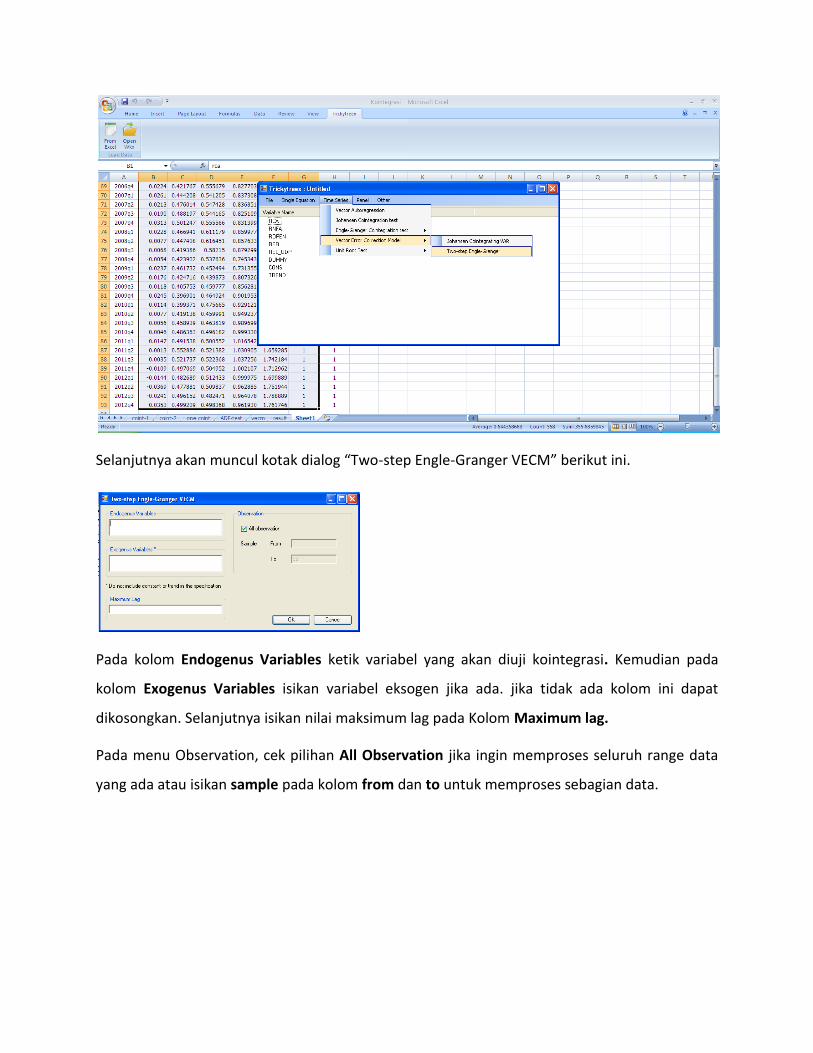
Selanjutnya akan muncul kotak dialog “Two-step Engle-Granger VECM” berikut ini.
Pada kolom Endogenus Variables ketik variabel yang akan diuji kointegrasi. Kemudian pada
kolom Exogenus Variables isikan variabel eksogen jika ada. jika tidak ada kolom ini dapat
dikosongkan. Selanjutnya isikan nilai maksimum lag pada Kolom Maximum lag.
Pada menu Observation, cek pilihan All Observation jika ingin memproses seluruh range data
yang ada atau isikan sample pada kolom from dan to untuk memproses sebagian data.

Selanjutnya klik Ok. Akan muncul tampilan output sebagai berikut.
Dari output tersebut kita dapat memperoleh model trend deterministik yang terbaik
berdasarkan kriteria AIC, SBC, dan HQC.
Selanjutnya kita dapat melakukan uji kointegrasi dengan metode ADF dan Phillips-Perron
melalui pilihan menu Coint test yang tersedia.
Klik Coint test
Akan muncul pilihan Metode Augmented Dickey Fuller (ADF) dan Phillips-Perron (PP) seperti
gambar berikut ini.

Selanjutnya untuk membentuk model VECM, pilih menu VECM pada tab yang tersedia dan akan
muncul kotak dialog seperti berikut.
Pada kolom Endogenus Variables ketik variabel yang akan dimasukkan kedalam model VECM.
Kemudian pada kolom Exogenus Variables isikan variabel eksogen jika ada. jika tidak ada kolom
ini dapat dikosongkan. Selanjutnya isikan nilai maksimum lag VECM pada Kolom Lag in VECM.

Pada menu CV List isikan variabel yang terdapat dalam vektor kointegrasi. Jumlah vektor
kointegrasi dapat lebih dari 1.
Pada menu Observation, cek pilihan All Observation jika ingin memproses seluruh range data
yang ada atau isikan sample pada kolom from dan to untuk memproses sebagian data.
Seperti pada contoh pengisian berikut ini.
Klik Ok.
Akan muncul output berikut
Terdapat empat kolom pada tampilan output Engle-Granger Cointegrating VAR (VECM).
Kolom pertama atau yang paling atas merupakan nilai koefisien estimasi dari vektor
kointegrasi disertai nilai standard error-nya masing-masing dibawahnya.

Kolom kedua merupakan nilai koefisien estimasi dari model VECM.
Kolom ketiga merupakan nilai statistik regresi untuk masing-masing variabel, seperti RSS,
TSS, R2, Adj R2, F-stat, dan seterusnya.
Sedangkan pada kolom keempat disajikan ringkasan statistik untuk model VECM secara
keseluruhan.
Pada output Two-step Engle-Granger VECM, kita juga dapat langsung melakukan pengujian
residual, menghitung IRF dan FEVD seperti pada metode VAR sebelumnya.

Chapter 5
Panel Data Analysis
Input Data Panel dalam Tricky-Treex
Tahap pertama adalah siapkan data panel ke dalam Ms. Excel. Dalam software tricky-treex, data
panel disusun kesamping untuk setiap cross-sectionper masing-masing variabel. Setiap cross-
section untuk masing-masing variabel dipisahkan dengan tanda under line (_). Contoh:
CPI_Brasil, CPI_Canada, dan lain-lain.

Melakukan Estimasi
Estimasi Fix Effect Model (FEM)
Setelah kita memasukan seluruh data ke dalam tricky-treex, maka tahap selanjutnya adalah melakukan
estimasi model panel. Untuk melakukan hal itu maka kita memilih pada menu panel fix effect model.
Setelah memilih fix effect model, maka berikutnya kita akan dihadapkan pada berbagai menu. Dalam
kolom regressand kita masukan variabel terikatnya, dalam hal ini adalah variabel CPI, sehingga kita
ketikan “CPI_?”. Kemudian pada kolom commond slope, kita masukan variabel bebasnya, caranya sama
dengan kolom regressand yakni “fx_? index? neer? reer_?”. Untuk kolom individual specific slope dan
time specific slope kita kosongkan. Selanjutnya untuk menu toolboxmethod kita klik keduanya apabila
kita ingin melakukan perhitungan fix effect model untuk two way. Namun jika tidak kita dapat memilih
salah satu.
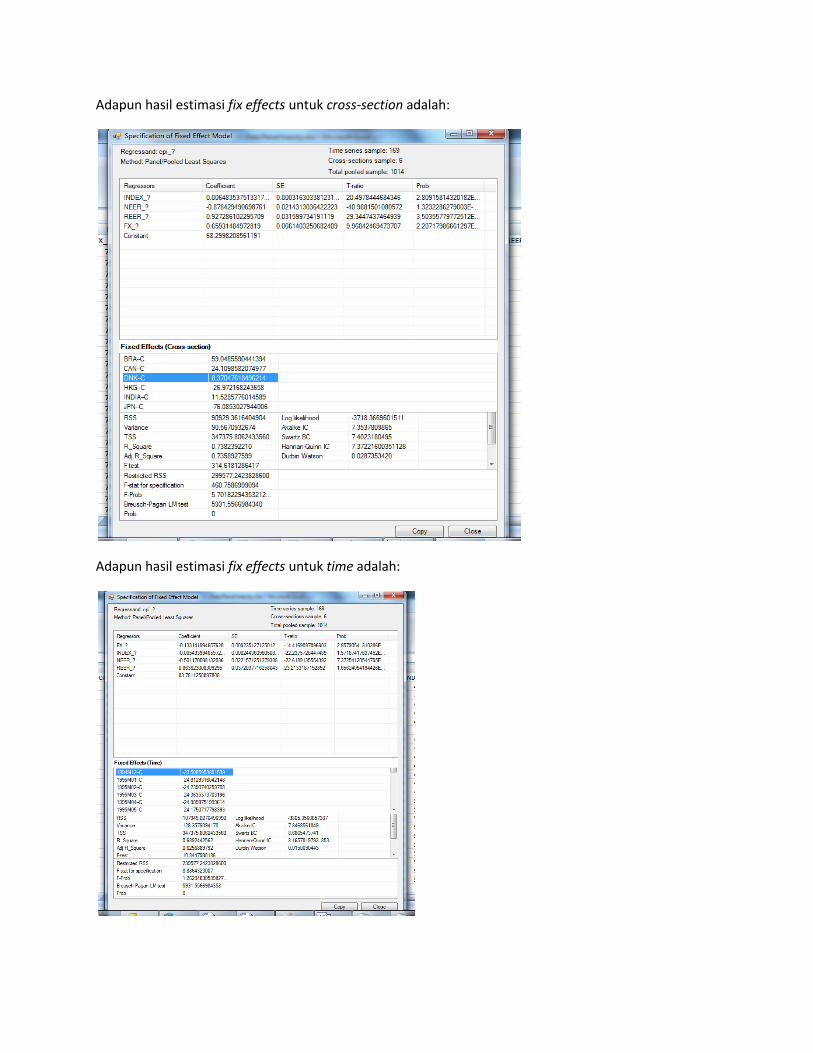
Adapun hasil estimasi fix effects untuk cross-section adalah:
Adapun hasil estimasi fix effects untuk time adalah:

Kemudian hasil estimasi fix effect untuk cross-section dan time adalah:
Estimasi Random Effect Model (REM)
Kembali pada menu awal data panel, untuk mengestimasi random effect model (REM) maka kita klik
pada pilihan random effect model.

Setelah masuk pada menu estimasi random effect model, maka pada kolom regressand kita ketikan
variabel terikatnya, yakni cpi_?. Kemudian pada kolom regressor kita ketikan variabel bebasnya, yakni
“fx_? Index_? Neer_? Reer_?. Selanjutnya untuk menu toolboxmethod kita klik keduanya apabila kita
ingin melakukan perhitungan random effect model untuk two way. Tetapi jika tidak kita dapat memilih
salah satunya.
Adapun hasil estimasi random effect model untuk cross-section adalah:

Adapun hasil estimasi random effect model untuk time adalah:
Sedangkan hasil estimasi random effect model untuk cross-section dan time adalah:

Estimasi Random Coefficient Model (REM)
Selain memiliki kemampuan untuk menjalankan model panel standard, softwaretricky-treex ini juga
memiliki kemampuan untuk malakukan analisis random coefficient model. Untuk melakukan hal
tersebut maka kita pilih menu random coefficient model.

Selanjutnya setelah kita masuk pada menu random coefficient model, maka kita masukan kolom
regressand dengan variabel terikat, yakni “cpi_?”, dan kemudian kolom regressor dengan variabel
bebas, yakni “fx_? index_? neer_? reer_?”.

Adapun hasil estimasi random coefficient model adalah:

Estimasi Non-Stationer Panel
Dalam menu non-stationer panel, terdapat dua menu utama, yakni: 1) panel unit root dan 2)
cointegration test.
Panel Unit Root Test
Yang pertama akan dibahas mengenai panel unit root test. Dalam panel unit root test terdapat dua
metode yang dapat digunakan, yakni im-pesaran-shin (IPS) dan Breitung. Contoh berikut ini adalah panel
unit root test dengan menggunakan metode IPS.

Adapaun hasil panel unit root dengan metode IPS adalah:
Selanjutnya cara melakukan panel unit root dengan menggunakan metode Brietung

Dan hasil panel unit root dengan metode Brietung adalah:
Cointegrated Panel Test
Kedua adalah menu cointegration test.Dalam menu terdapat kolom regressand yang kita isikan dengan
variable bebas, yakni “cpi_?”.Kemudian kolom regressor kita isi dengan variable bebasnya, yakni: “fx_?
Index_?Neer_?Reer_?”.

Ada pun perhitungan tricky-treexter dapat dua tab, yakni tab “cointegration test” dan “cointegrating
vector”.

Sedangkan output cointegrating vector
















![Full page photo - Central Railway · 2018. 5. 1. · DHRUV DOORWAR ANKUJSH KAPRI RANJAN AJAY KUMAR Div/HQ BSWBSI. BSWBSL BSL/BSL BSI]BSL BSI./BSL BSWBSL BSI]BSL Grou D No No No No](https://img.pdfslide.net/doc/110x75/60ccef348d05ab24d06b8f1c/full-page-photo-central-2018-5-1-dhruv-doorwar-ankujsh-kapri-ranjan-ajay.jpg)












