Embed Size (px)
Citation preview

Using Error-Correcting Codes For Text Classification
Rayid [email protected]
Center for Automated Learning & Discovery,Carnegie Mellon University
This presentation can be accessed at http://www.cs.cmu.edu/~rayid/icmltalk

Outline Review of ECOC Previous Work Types of Codes Experimental Results Semi-Theoretical Model Drawbacks Conclusions & Work in Progress

Overview of ECOC Decompose a multiclass problem
into multiple binary problems The conversion can be independent
or dependent of the data (it does depend on the number of classes)
Any learner that can learn binary functions can then be used to learn the original multivalued function

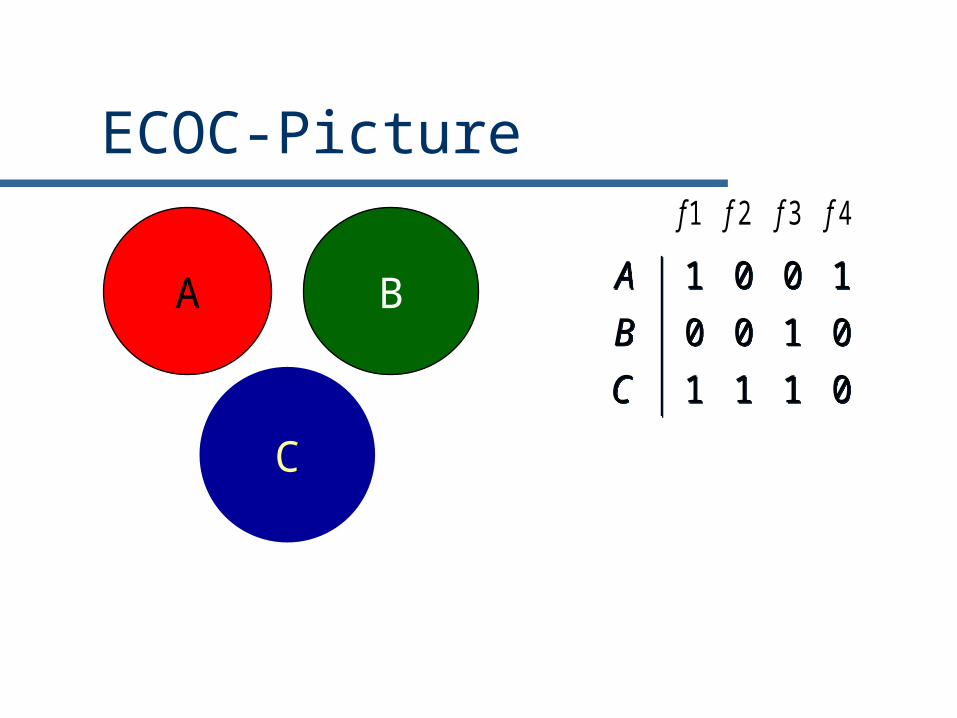
Training ECOC
Given m distinct classes
Create an m x n binary matrix M.
Each class is assigned ONE row of M.
Each column of the matrix divides the classes into TWO groups.
Train the Base classifiers to learn the n binary problems.

Testing ECOC To test a new instance
Apply each of the n classifiers to the new instance
Combine the predictions to obtain a binary string(codeword) for the new point
Classify to the class with the nearest codeword (usually hamming distance is used as the distance measure)
ECOC-Picture
0111
0100
1001
C
B
A
0111
0100
1001
C
B
A
4321 ffff
A B
C

Previous Work Combine with Boosting –
ADABOOST.OC (Schapire, 1997), (Guruswami & Sahai, 1999)
Local Learners Text Classification (Berger, 1999)

Experimental Setup Generate the code
BCH Codes Choose a Base Learner
Naive Bayes Classifier as used in text classification tasks (McCallum & Nigam 1998)

Dataset Industry Sector Dataset
Consists of company web pages classified into 105 economic sectors
Standard stoplist No Stemming Skip all MIME headers and HTML tags Experimental approach similar to
McCallum et al. (1998) for comparison purposes.
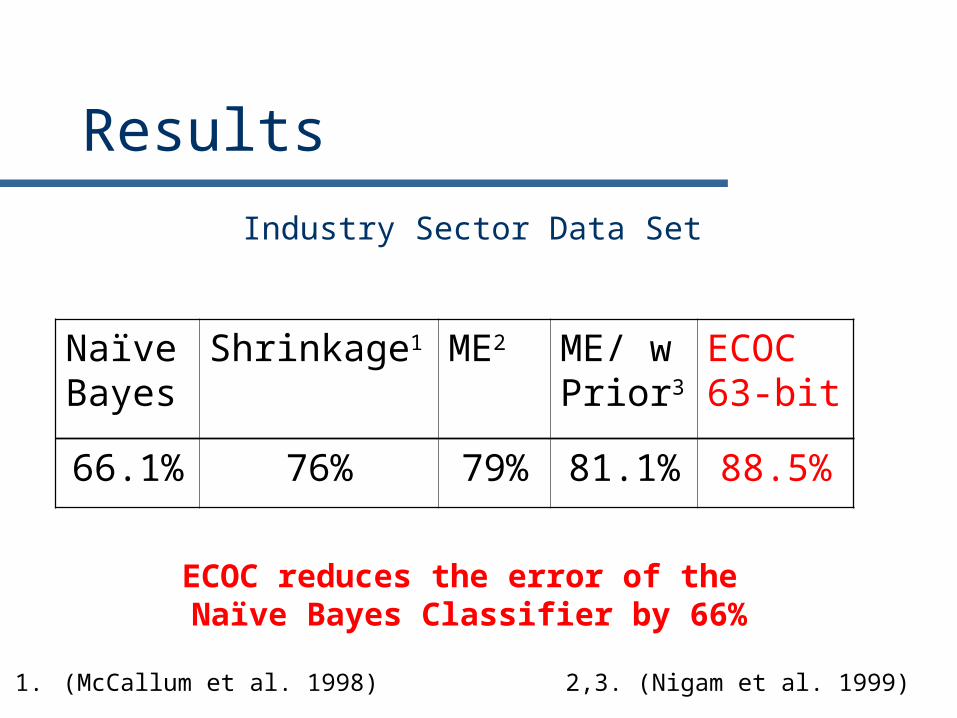
Results
Industry Sector Data Set
Naïve Bayes
Shrinkage1 ME2 ME/ w Prior3
ECOC 63-bit
66.1% 76% 79% 81.1% 88.5%
ECOC reduces the error of the Naïve Bayes Classifier by 66%
1. (McCallum et al. 1998) 2,3. (Nigam et al. 1999)

The Longer the Better!Naive Bayes Classifier15-bit ECOC 31-bit ECOC 63-bit ECOC
Accuracy(%) 65.3 77.4 83.6 88.1
Table 2: Average Classification Accuracy on 5 random 50-50 train-test splits of the Industry Sector dataset with a vocabulary size of 10000 words selected using Information Gain.
Longer codes mean larger codeword separation
The minimum hamming distance of a code C is the smallest distance between any pair of distance codewords in C
If minimum hamming distance is h, then the code can correct (h-1)/2 errors
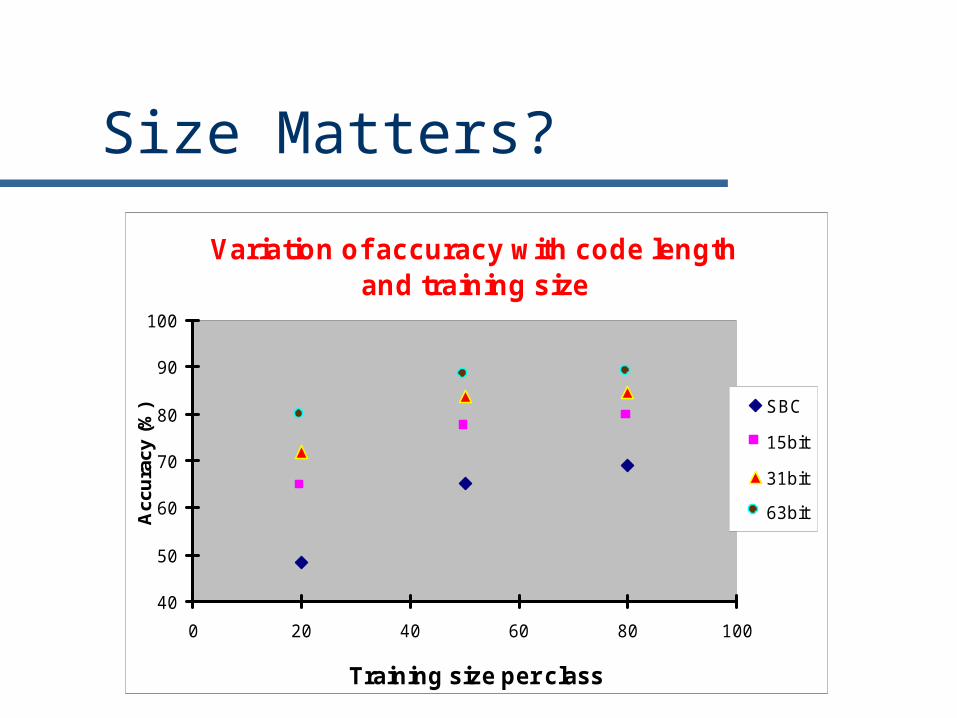
Size Matters?
Variation of accuracy with code length and training size
40
50
60
70
80
90
100
0 20 40 60 80 100
Training size per class
Acc
ura
cy (
%) SBC
15bit
31bit
63bit
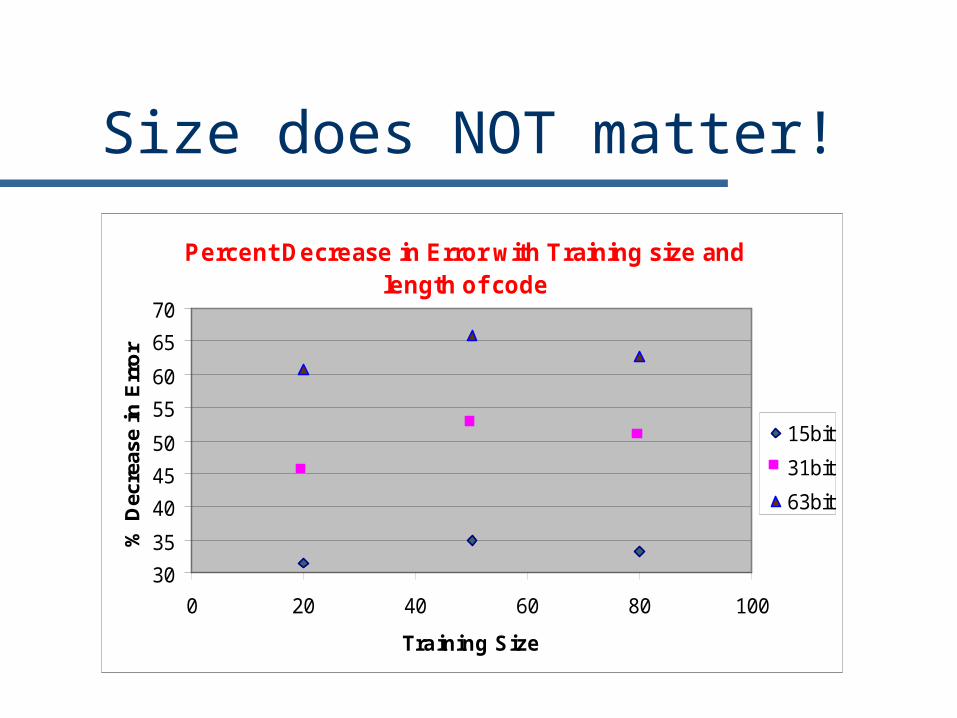
Size does NOT matter!
Percent Decrease in Error with Training size and length of code
30
35
40
45
50
55
60
65
70
0 20 40 60 80 100
Training Size
% D
ecre
ase
in E
rro
r
15bit
31bit
63bit
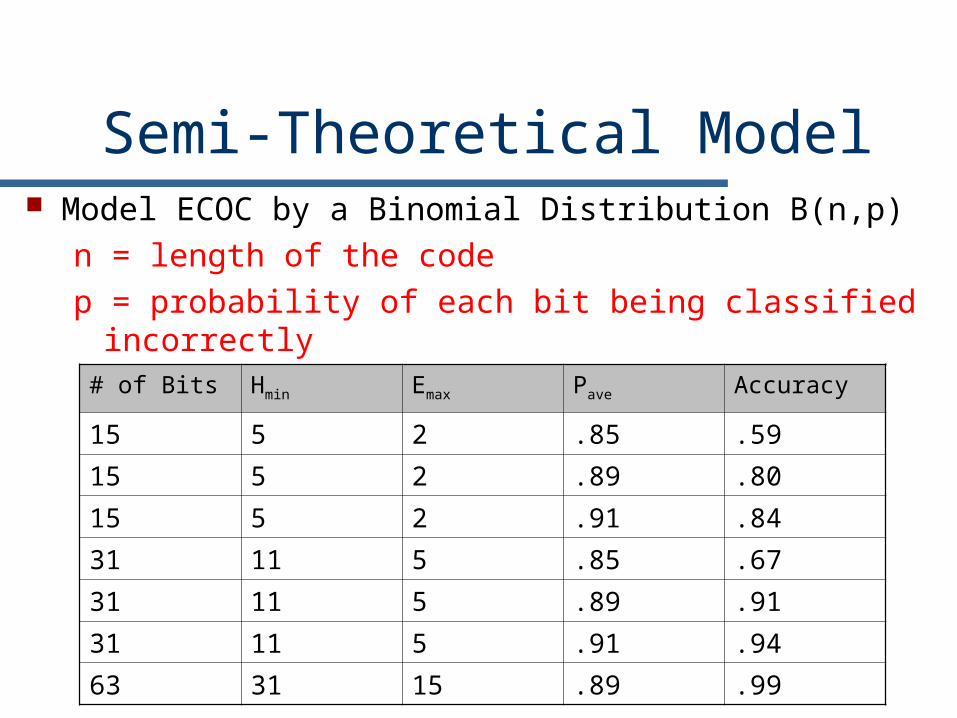
Semi-Theoretical Model Model ECOC by a Binomial Distribution B(n,p)
n = length of the codep = probability of each bit being classified
incorrectly# of Bits Hmin Emax Pave Accuracy
15 5 2 .85 .59
15 5 2 .89 .80
15 5 2 .91 .84
31 11 5 .85 .67
31 11 5 .89 .91
31 11 5 .91 .94
63 31 15 .89 .99
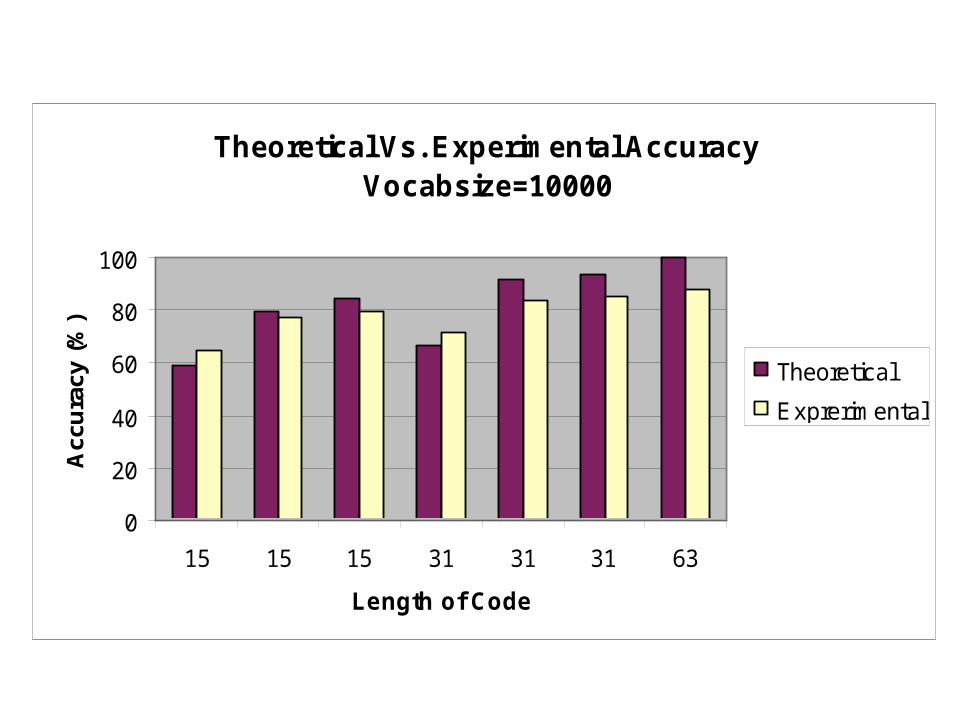
Theoretical Vs. Experimental AccuracyVocabsize=10000
0
20
40
60
80
100
15 15 15 31 31 31 63
Length of Code
Acc
ura
cy (
%)
Theoretical
Exprerimental
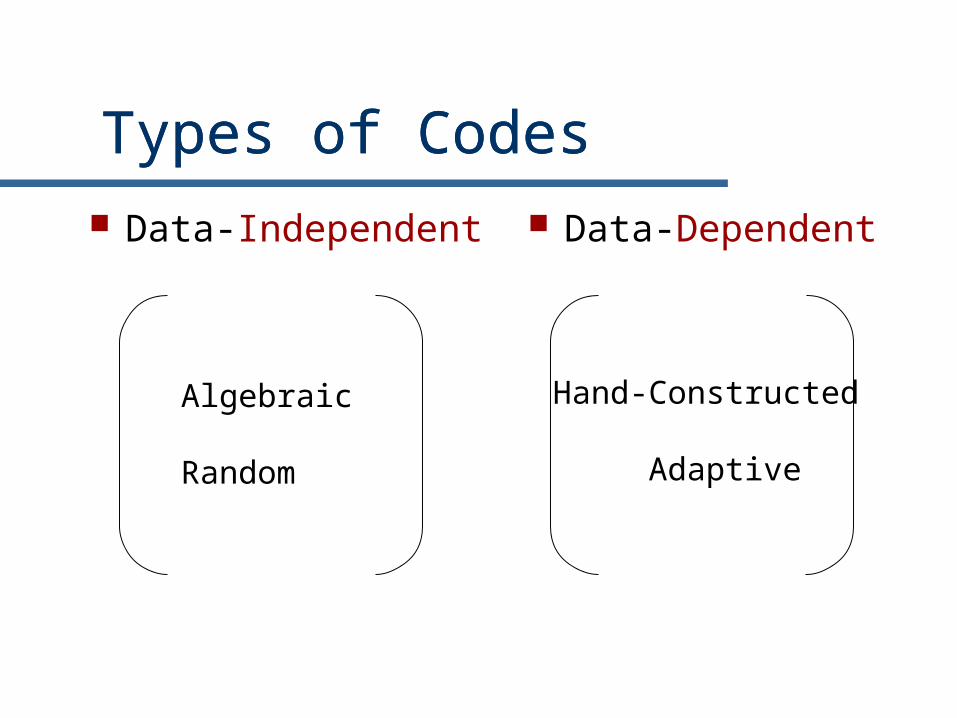
Types of CodesTypes of Codes Data-Independent Data-Dependent
Algebraic
Random
Hand-Constructed
Adaptive

What is a Good Code? Row Separation Column Separation (Independence
of errors for each binary classifier) Efficiency (for long codes)
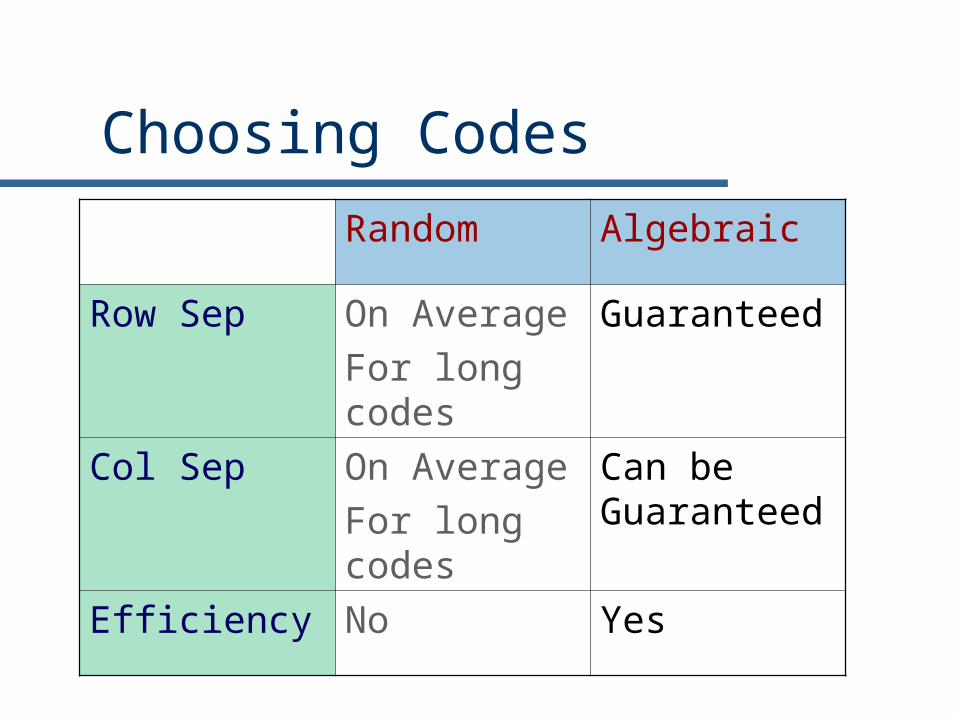
Choosing Codes
Random Algebraic
Row Sep On AverageFor long codes
Guaranteed
Col Sep On AverageFor long codes
Can be Guaranteed
Efficiency No Yes
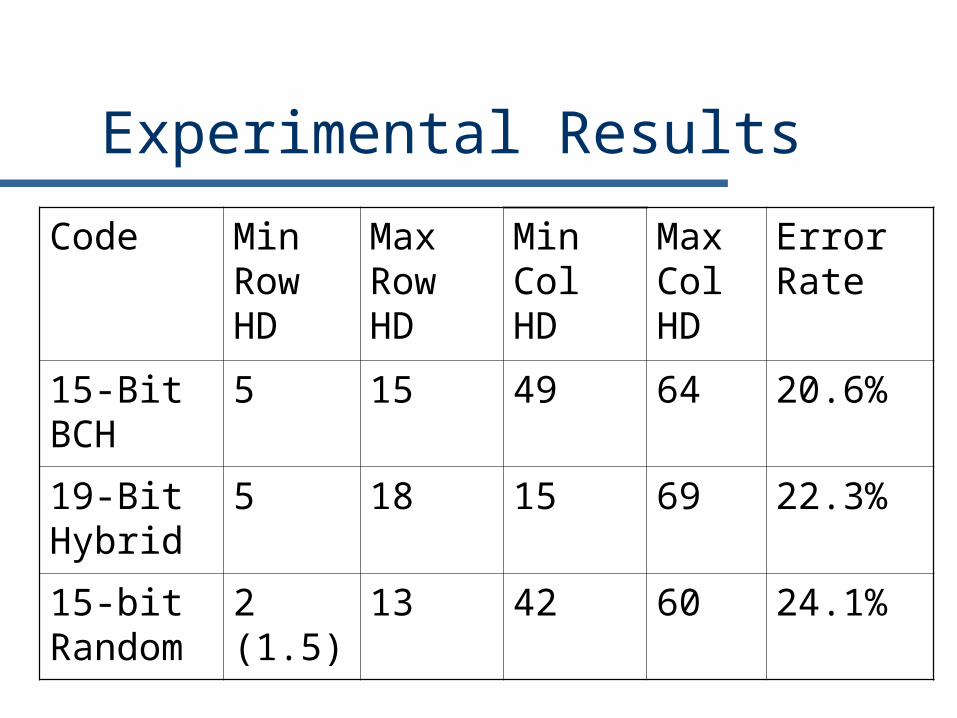
Experimental Results
Code Min Row HD
Max Row HD
Min Col HD
Max Col HD
Error Rate
15-Bit BCH
5 15 49 64 20.6%
19-Bit Hybrid
5 18 15 69 22.3%
15-bit Random
2 (1.5)
13 42 60 24.1%

Drawbacks Can be computationally expensive Random Codes throw away the real-
world nature of the data by picking random partitions to create artificial binary problems

Conclusion Improves Classification Accuracy
considerably! Can be used when training data is
sparse Algebraic codes perform better than
random codes for a given code lenth Hand-constructed codes are not the
answer

Conclusion Improves Classification Accuracy
considerably! Can be used when training data is sparse Algebraic codes perform better than
random codes for a given code lenth Hand-constructed codes are not the
answer

Future Work Combine ECOC with Co-Training Automatically construct optimal /
adaptive codes Sufficient and Necessary conditions
for optimal behavior

Future Work Combine ECOC with Co-Training or
Shrinkage Methods Sufficient and Necessary conditions
for optimal behavior





























