Embed Size (px)
Citation preview

Vision Based Deep Learning Approach for Dynamic Indian Sign Language Recognition in Healthcare
Aditya P Uchil1, Smriti Jha2, B G Sudha3
1The International School Bangalore (TISB), Bangalore [email protected]
2LNM Institute of Information Technology, Jaipur [email protected]
3Xelerate, Bangalore [email protected]
Abstract
Healthcare for the deaf and dumb can be significantly improved with a Sign Language Recognition (SLR) system capable of recognizing medical terms. This paper is an effort to build such a system. SLR can be modelled as a video classification problem and we have used vision based deep learning approach. The dynamic nature of sign language poses additional challenge to the classification. This work explores the use of OpenPose with convolutional neural network (CNN) to recognize the sign language video sequences of 20 medical terms in Indian Sign Language (ISL) which are dynamic in nature. All the videos are recorded using common smartphone camera. The results show that even without the use of recurrent neural networks (RNN) to model the temporal information, the combined system works well with 85% accuracy. This eliminates the need for specialized camera with depth sensors or wearables. All the training and testing was done on CPU with the support of Google Colab environment. Keywords: Indian sign language recognition, Convolutional neural network, OpenPose, Video classification, Pose estimation, Gesture recognition, Medical terms, Healthcare. 1 Introduction
India's National Association of the Deaf estimates that 1.8 to 7 million people in India are deaf [1]. To
assist the needs of the deaf and dumb community worldwide different sign language dictionaries have been developed with American Sign Language (ASL) being the most popular and common of all. A lot of work has been done for ASL recognition so that deaf people can easily communicate with others and others can easily interpret their signs. For Indian Sign language, recently researchers have started developing novel approaches which can handle static and dynamic gestures.
Signers have to communicate their conditions routinely at health care setups (hospitals). Signs of words used for conveying in health care settings comprise of a continuous sequence of gestures and are hence termed as dynamic gestures. A gesture recognition system that recognises the dynamic gestures and classifies the sequence of gestures (video of sign) needs to be developed. As sensor hand gloves or motion tracking devices are expensive and not common in rural health care outlets, we have focused on developing a vision based solution for sign language recognition. Our work is the first attempt to recognize medical terms in ISL. This will involve video of the signer captured from a regular smartphone camera as input. This paper is organised as follows: The next section lists the related work done on Indian and other sign language recognition followed by the proposed methodology, results and discussion. 2 Related works ISL: Ansari & Harit [2] achieved an accuracy of 90.68% in recognizing 16 alphabets of ISL. Using Microsoft Kinect camera, they recorded images of 140 static signs and devised a combination strategy using SIFT (Scale-Invariant Feature Transform), SURF (Speeded Up Robust Features), SURF neural network, Viewpoint Feature Histogram (VFH) neural network that gave highest accuracy. Tewari &Srivastava[3] used 2D-Discrete Cosine Transformation (2D-DCT) and Kohonen Self Organizing Feature Map neural network for image compression and recognition of patterns in static signs. Their dataset consisted of static signs of ISL numerals (0 to 5) and 26 alphabets captured on a 16.0 MP digital camera (Samsung DV300F). Implemented in MATLAB R2010a, their recognition rate was 80% for 1000 training epochs with least time to process. Their approach did not take non-manual features (body, arm, facial expression) into account and included only hand gesture information making it suitable for static signs only. Singha & Das[4] worked on live video recognition of ISL. They considered 24 different alphabets for 20 people (total of 480 images) in the video sequences and attained a success rate of 96.25%. Eigen values and Eigen vector were considered as features. For classification they used Euclidean distance weighed on Eigen values. Kishore & Kumar [5] used a wavelet based video segmentation technique wherein a fuzzy inference system was trained on features obtained from Discrete wavelet transformation and

Elliptical Fourier descriptors. To reduce feature vector size, they further processed the descriptor data using Principle component analysis (PCA). For the 80 signs dataset they achieved 96% accuracy. K Tripathi et al [6] used gradient based key frame extraction procedure to recognize a mixture of dynamic and static gestures. They created a database of ten sentences using a Canon EOS camera with 18 mega pixels, 29 frames per second. Feature extraction using Orientation Histogram with Principal Component Analysis was followed by classification based on Correlation and Euclidean distance. Dour & Sharma [7] acquired the input from an i-ball C8.0 web camera at a resolution of 1024 X 768 pixels and used adapted version of fuzzy inference systems (Sugeno-type and Adaptive-Neuro Fuzzy) to recognize the gestures. 26 signs from 5 different volunteers and 100 samples of each gesture were used for training purpose. So a total of around 2611 training samples was obtained. The classification of the input sign gesture was done by a voting scheme according to the clusters formed. The system was able to recognize for all alphabets. Most of the misclassified samples correspond to the gestures that are similar to each other like letters E and F.Rao & Kishore [8] used a smart phone front camera (5M pixel) to generate a database of 18 signs in continuous sign language by 10 different signers. Minimum Distance (MD) and Artificial Neural Network (ANN) classifiers were used to train the feature space. The average word matching score (WMS) of this selfie recognition system was around 85.58% for MD and 90% for ANN with minute difference of 0.3 s in classification times. They found that ANN outperformed MDC by an upward 5% of WMS on changing the train and test data. Other sign languages: N. Camgoz et al [9] approached the problem as a neural machine translation task. The dataset presented “RWTH-PHOENIX-Weather 2014T ” covered a vocabulary of 2887 different German words translated from 1066 different signs by 9 signers. Using sequence-to-sequence (seq2seq) learning method, the system learnt the spatio-temporal features, language model of the signs and their mapping to spoken language. They used different tokenization methods like state-of-the-art RNN-HMM (Hidden Markov Model) hybrids and tried to model conditional probability using attention-based encoder-decoders with CNNs. D. Konstantinidis et al [10] took the LSA64 dataset of Argentinian sign language consisting of 3200 RGB videos of 64 different signs by 10 subjects. For uniform video length, they processed the gesture video sequences to compose of 48 frames each. They extracted features using a pretrained ImageNet VGG-19 network. This network up toconv4_4 was used for hand skeleton detection and initial 10 layers of this network for detecting body skeleton. They concluded that non manual features like body skeletal joints contain important information that when combined with hand skeletal joints information gave a 3.25% increase inrecognition rate. Their proposed methodology classified both one-handed and two-handed signs of the LSA64 dataset and outperformed all variantsby around 65% irrespective of the type of classifier or features they employed. Mahmoud et al [11] extracted local features from each frame of the sign videos and created a Bag of features (BoFs) using clustering to recognize 23 words. Each image was represented by a histogram of visual words to generate a code book.They had further designed a two-phase classification model wherein the BoFs was used to identify postures anda Bag of Postures (BoPs) was used to recognize signs. M. Hassan et al [12] used Polhemus G4 motion tracker and a camera to generate two datasets of 40 Arabic sentences. Features were extracted using window- based statistical features and 2D-DCT transformation and classified using three approaches: modified KNN (MKNN)and two different HMM toolkits (RASR and GT2 K). Polhemus G4 motion tracker measuredhand position and orientation whereas the DG5-V Hand data gloves measured the hand position and configuration. They found that inspite of more precision in sensor-based data, vision-based data achievedgreater accuracy. Most of the approaches listed above either used
● Specialized camera like Microsoft Kinect which measures the depth information or motion tracker camera or
● Wearable like hand gloves with sensors and ● Extensive Image processing to extract and handcraft the features ● CNN + RNN for temporal information which is computationally expensive ● Static signs
Our proposed method models the problem based on computer vision and deep learning thus representing the sign language recognition as that of sequence of image classification. InceptionV3 model and OpenPose [13] are used to classify the image frames individually. A voting scheme is then applied which classifies the video based on the maximum vote for a particular category. The following are the contributions towards this paper:
● Created the medical dataset comprising of 80 videos of 19 dynamic and 1 static sign for medical terms each performed by two different volunteers.

● Studied the effect of using OpenPose with CNN to improve the accuracy of recognition of medical signs directly from RGB videos without specialized hardware or hand gloves and extensive image processing or computationally intensive RNN.
Table I shows the list of medical terms used for our study. Except the word ‘chest’, all the other words are dynamic in nature.
Table I. List of medical terms comprising our dataset
1. Allergy 2. Old 3. Heart Attack 4. Chest 5. Exercise 6. Bandage 7. Throat 8. Blood pressure 9. Pain 10. Choking
11. Common Cold 12. Cough 13. Diabetes 14. Ear 15. Eye 16. Chicken Pox 17. Forehead 18. Injection 19. Mumps 20. Blood
3 Proposed methodology
The sign language recognition system can be modelled as a video classification problem and can be
built using different approaches as mentioned in [14]. Both spatial and temporal information are used in most of the approaches for the classification to give the desired output. But the use of RNN for storing temporal information is a bottleneck as it is more computationally expensive and requires more storage. The two articles [15] and [16] support the same and it is proved that CNN is all that we need. Also researchers have now shifted focus to attention-based network and multi-task learning which formed the basis of OpenPose architecture. OpenPose [13] has proven its ability to identify human poses with face and hand key points which are very crucial for sign language recognition. Hence we have leveraged the power of CNN and OpenPose for recognising dynamic signs.
Fig. 1. Overall Architecture of the proposed CNN+OpenPose system
Algorithm: Training and Testing using OpenPose and CNN Input: Sign Video Output: Label for the Sign Recognised

Training 1. For each of the classes in training set 2. For each of the videos in class folders do
a) Pass the RGB video to OpenPose framework to get the video with stick figure embedded. b) Extract the frames from OpenPose videos and write the OpenPose frames to the images
folder under the class folder; c) Extract frames for each of the RGB videos and add it to the images folder d) Feed the Inception V3 model with all the images in all the class folders. e) Save the model built
Testing 1. Repeat steps 1 to 2 (b) of the training set for the test set 2. Feed the learnt CNN model with all the images in the test set. 3. Get the prediction of each of the frames for a particular video as a list 4. Use majority voting scheme on the list above to get the class prediction of the video.
Advantages of our proposed method:
● Specialized hardware like Kinect cameras that capture depth information is not required. A common smartphone camera is sufficient.
● All the models are trained and tested on CPU and hence no GPU is required. OpenPose is run online on Colab environment with GPU enabled and hence does not require GPU system.
● Previous works focus mainly on signs limited to the wrist whereas our system takes both manual (hand) and non-manual features (arm, body, face) of the sign into account. This is useful for recognition of sign language wherein complexity of the signs is greater.
● Removed the feature engineering part.
Experimental Setup: The sign language recognition system was implemented on an Intel Corei5 CPU (1.80 GHz × 2) with 8 GB
RAM. The system ran macOS Mojave (version 10.14.3). Lenovo-Intel Corei3 – UCPU with 4GB RAM running windows7 was also used. The programming language used for implementing the system was Python. OpenPose library was used for keypoint detection from the sign language videos. OpenCV was used for handling data and pre-processing. The recognition system took 10 minutes on the MacOS and 18 minutes on the windows system to complete training on the sign language dataset.
3.1 Data acquisition The sign videos are recorded in a controlled environment by a 12MP smartphone front camera having
frame resolution of 640x480 pixels captured at the rate of 30 frames per second. In the process initially we collected 20 signs of medical terms from Indian sign language.The dataset has been selected from the ISL general, technical and medical dictionaries. Indian Sign Language Research and Training Institute (ISLRTC), New Delhi, [17] has been taken as the standard source for Indian sign language. So, all the videos are performed based on observation from the ISLRTC YouTube channel. The ISLRTC videos were lengthier of the order of 30 seconds for every word on an average which is very long compared to other sign languages. For example, the Argentinian sign language [18] has words with video lengths of the order of 1 or 2 seconds.Hence we took only that portion of the video which essentially means the sign performed. So we have fixed 3 seconds for the signs. Inorder to standardise and simplify processing, the signs are performed with a uniform white background at a constant distance of 1m right in front of the camera. The signers wore black coloured clothes with sleeves to make sure that only the hands and face part are visible. Each sign is repeated 2-3 times depending on the complexity of the gesture. Due to different recording environments the lighting conditions vary slightly from subject to subject. The dataset hence forth referred to as ‘ISL Medical Dataset’, consists of 1 static and 19 dynamic signs handpicked from ISL. All volunteers were non-native to sign language. The videos were recorded for a period of three seconds consistently for all the signs. The frame rate of the videos captured was 30fps. Another Research Institute extensively working on building ISL dictionary – the Ramakrishna Mission Vivekananda Educational and Research Institute (RKMVERI), Coimbatore Campushas their ISL videos listed in [19]. The ISL videos given by RKMVERI were also used as reference by the signers.
3.2 Data pre-processing (i) Preparation of training set: The data pre-processing stage is also pictorially represented in Fig 1. The video acquired above was fed to
OpenPose. OpenPose requires GPU for processing. Hence Google Colab environment which is freely available

for academic use [20] was used to get the pose estimation of hands and face keypoints. Thus we get an equivalent video with the keypoints marked in the video. Each video consisted of 90 frames at a frame rate of 30fps. This key points video was fed to OpenCV for frame extraction to extract every 5th frame. Thus we get a total of 18 frames. Usually the first and last few fractions of a second do not contain useful information. The frames are then cropped on the sides to ensure that the signer is prominent in all the frames and also to reduce the dimensionality for training. Hence the first two and last two frames were omitted from the training set. Thus a total of 14 image frames for each video sequence comprise our training set. Thus for 20 classes, there were 1120 image frames.
To study the effect of using OpenPose with CNN, the training set was prepared in two phases. In
the first phase, the original videos without OpenPose pose estimations formed our training set. In the second phase, the training frames were extracted from the output of OpenPose pose estimation. Testing was done after each of these training phases. The results are shown later in the results section. (ii) Preparation of test set
To test the performance of our gesture recognition approach we collected videos of each sign from
the official YouTube channel of ISLRTC, New Delhi (Indian Sign Language Research and Training Centre). The signs performed by signers involved repetition of the same gesture multiple times in a video to clearly explain how the sign is performed. The videos also involved the signer explaining the context of the sign so each sign language reference video was observed to be around 30-40 seconds which was too lengthy for our model to detect features and recognise the gestures. Consequently, we clipped the videos to display the signer performing the key gesture once or twice at maximum and obtained our shortened test videos which were fed for frame extraction.
3.3 Fine Tuning Inception V3 model
The frames extracted from the two phases of pre-processing with and without OpenPose were fed to
the Inception V3 model with all other layers frozen except for the top layer. Hence fine tuning of the model was done using our training data for all the twenty categories. The number of training steps was 500 with a learning rateof 0.01.The cross entropy results and accuracy of the training set is shown is Fig 2 and Fig 3 with OpenPose frames.
Fig 2. Cross entropy results of training Fig 3. Training Accuracy of the model
Cross entropy was used for calculating loss and from Fig. 2 we can observe that the loss reduced when approaching 500 steps in training. The training accuracy with the augmentation of OpenPose frames was 99% as shown in figure 3.
3.4 Classification of Sign Video (i) Prediction of individual frames:
The test frames from ISLRTC videos were fed to the trained/ learnt model to classify each frame individually.The probability score of each frame is given as output. This is done by using the features learnt from the CNN model. The features are represented in Fig. 4 as stick figures from OpenPose embedded in the RGB frames. Thus these feature embedded frames give a body part mapping which is very useful in matching the frame to a corresponding frame with similar pose estimation in training set. The same is explained in Fig 4.

(ii) Prediction of sign video The predictions of each of the 14 frames are given as input to a majority voting scheme which give
the predicted label of the video sequence based on the probability scores of individual frames. The formula for majority voting is given in Eq. (1).
y =mode{C(X1), C(X2), C(X3),....,C(X14)} (1)
where ‘y’ is the class label of the sign video X1, X2,...X14 represent the frames extracted for a single sign video and C(X1), C(X2),... C(X14) represent the class label predicted for each frame.
Fig. 4. Data flow pipeline for prediction of class label The fig 4. shows an example of bandage class where the OpenPose video is fed to the model for testing. The individual frames are extracted and classified individually. Both OpenPose and RGB frames are combined for training. As it can be seen, all the frames are classified as ‘bandage’ class with a probability score of 0.75 on an average. Hence, the test video or the sign is recognised as ‘bandage’ with high confidence. 4 Results and Discussion The test results given in Table 2 show that without OpenPose key points, the CNN fails to recognise the class correctly. But with OpenPose, the results are amazing, given the large difference in probability score as seen below for the allergy class from 23.09 for old (wrong class) to allergy (correct class) with 87.81 for frame f5.
Table 2. Improvement in results with and without OpenPose trained samples
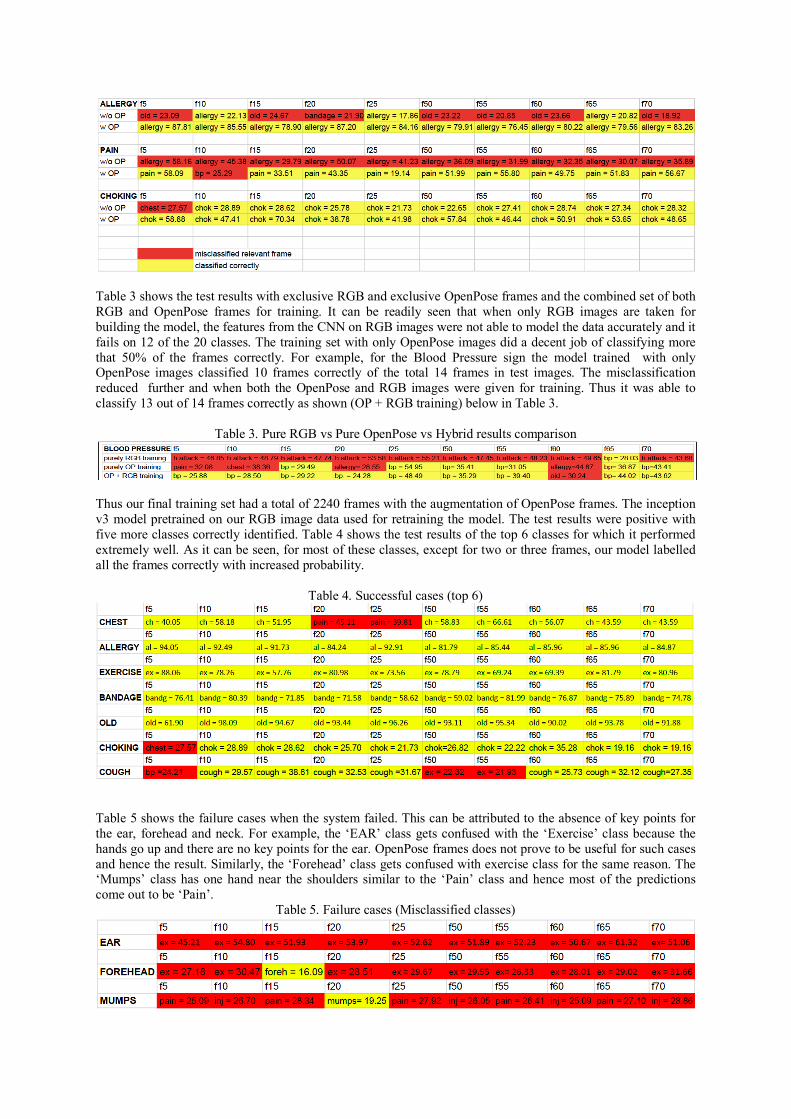
Table 3 shows the test results with exclusive RGB and exclusive OpenPose frames and the combined set of both RGB and OpenPose frames for training. It can be readily seen that when only RGB images are taken for building the model, the features from the CNN on RGB images were not able to model the data accurately and it fails on 12 of the 20 classes. The training set with only OpenPose images did a decent job of classifying more that 50% of the frames correctly. For example, for the Blood Pressure sign the model trained with only OpenPose images classified 10 frames correctly of the total 14 frames in test images. The misclassification reduced further and when both the OpenPose and RGB images were given for training. Thus it was able to classify 13 out of 14 frames correctly as shown (OP + RGB training) below in Table 3.
Table 3. Pure RGB vs Pure OpenPose vs Hybrid results comparison
Thus our final training set had a total of 2240 frames with the augmentation of OpenPose frames. The inception v3 model pretrained on our RGB image data used for retraining the model. The test results were positive with five more classes correctly identified. Table 4 shows the test results of the top 6 classes for which it performed extremely well. As it can be seen, for most of these classes, except for two or three frames, our model labelled all the frames correctly with increased probability.
Table 4. Successful cases (top 6)
Table 5 shows the failure cases when the system failed. This can be attributed to the absence of key points for the ear, forehead and neck. For example, the ‘EAR’ class gets confused with the ‘Exercise’ class because the hands go up and there are no key points for the ear. OpenPose frames does not prove to be useful for such cases and hence the result. Similarly, the ‘Forehead’ class gets confused with exercise class for the same reason. The ‘Mumps’ class has one hand near the shoulders similar to the ‘Pain’ class and hence most of the predictions come out to be ‘Pain’.
Table 5. Failure cases (Misclassified classes)

The test results show that of the 20 medical sign videos, 17 were classified correctly and the above three classes were misclassified. Thus our system has an overall accuracy of 85%. The confusion matrix for the test results is shown in Fig 4 below.
Fig 5. Test Accuracy of the proposed system shown as confusion matrix
The misclassification rate can be reduced if more keypoints are included as features. Also training set can be increased to give more variations in the data. Limitations
● Video classification is not performed in real time. ● Our system depends on OpenPose for improved accuracy.
Future enhancements
Currently our work involves classification of 20 medical terms (19 dynamic and 1 static). The training set can be increased with more videos performed by different signers. The Bag of visual featuresmodel can be used to classify each of the patches separately for every frame to capture the local information along with a global classifier. A mobile application can be developed toclassify the video in real-time. 5 Conclusion
Real time recognition of Indian sign Language in a healthcare setting is important and crucial for the improvement in quality of life for the deaf and dumb. But to realise this in a resource limited clinic is a challenge. We have addressed this challenge with minimal system requirements so that the computational and storage requirements are not a bottleneck. If this system could be made available in a smartphone, the applications are endless from condition monitoring to assisting the disabled. We have shown that OpenPose with CNN is all we need for a sign language recognition system. References
[1] National Public Radio (US). https://www.npr.org/sections/goatsandsoda/2018/01/14/575921716/a-mom-fights-to-get-an-education-for-her-deaf-daughters.
[2] Ansari, Zafar A, and Gaurav H.: Nearest neighbour classification of Indian sign language gestures using kinect camera. Sadhana 41, no. 2 (2016): 161-182.
[3] Tewari, Deepika, and Srivastava S.: A visual recognition of static hand gestures in indian sign language based on kohonen self-organizing map algorithm. In: International Journal of Engineering and Advanced Technology (IJEAT) 2, no. 2 (2012): 165-170.
[4] Singha J, and Das K.: Recognition of Indian sign language in live video. arXiv preprint arXiv:1306.1301 (2013).
[5] Kishore, P. V. V., and P. Rajesh Kumar.: A video based Indian sign language recognition system (INSLR) using wavelet transform and fuzzy logic. In: International Journal of Engineering and Technology 4, no. 5 (2012): 537.
[6] Tripathi, Kumud, and Baranwal N GC Nandi.: Continuous Indian sign language gesture recognition and sentence formation. In: Procedia Computer Science 54 (2015): 523-531.
A - Allergy B - Old C - Heart Attack D - Chest E - Exercise F - Bandage G -Throat H - Blood pressure I - Pain J – Choking
K - Common Cold L - Cough M - Diabetes N - Ear O - Eye P - Chicken Pox Q - Forehead R - Injection S - Mumps T - Blood

[7] Dour, Shweta, and Sharma M. M.: Review of Literature for the Development of Indian Sign Language Recognition System. In: International Journal of Computer Applications 132, no. 5 (2015): 27-34.
[8] Rao, G. Ananth, and P. V. V. Kishore.: Selfie video based continuous Indian sign language recognition system. In: Ain Shams Engineering Journal 9, no. 4 (2018): 1929-1939.
[9] CihanCamgoz, Necati, Hadfield S, Koller O, Ney H, and Bowden R.: Neural sign language translation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7784-7793. 2018.
[10] Konstantinidis D, Dimitropoulos K, and Daras P.: Sign language recognition based on hand and body skeletal data. In: 2018-3DTV-Conference: The True Vision-Capture, Transmission and Display of 3D Video (3DTV-CON), pp. 1-4. IEEE, 2018.
[11] Zaki, Mahmoud M., and Shaheen S I.: Sign language recognition using a combination of new vision based features. Pattern Recognition Letters 32, no. 4 (2011): 572-577.
[12] El-Soud, Abo M, Hassan A. E., Kandil M.S., and Shohieb S.M.: A proposed web based framework e-learning and dictionary system for deaf Arab students. In: IJECS2828 (2010): 106401.
[13] Cao, Zhe, Hidalgo G, Simon T, Wei S, and Sheikh Y.: OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields. arXiv preprint arXiv:1812.08008 (2018).
[14] Five video classification methods implemented in Keras and Tensorflow, https://blog.coast.ai/five-video-classification-methods-implemented-in-keras-and-tensorflow-99cad29cc0b5
[15] Chen, Qiming, and Wu R.: CNN is all you need. arXiv preprint arXiv:1712.09662 (2017). [16] Karpathy, Andrej, Toderici G, Shetty S, Leung T, Sukthankar R, and Li Fei-Fei.: Large-scale video
classification with convolutional neural networks. In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp. 1725-1732. 2014.
[17] Youtube ISLRTC, New Delhi, https://www.youtube.com/channel/UC3AcGIlqVI4nJWCwHgHFXtg/videos?disable_polymer=1
[18] Ronchetti, Franco, Quiroga F, Estrebou C E, Lanzarini L C, and Rosete A.: LSA64: an Argentinian sign language dataset. In: XXII CongresoArgentino de Ciencias de la Computación (CACIC 2016). 2016.
[19] Indian Sign Language || FDMSE, RKMVERI, CBE (Deemed University), http://www.indiansignlanguage.org/indian-sign-language/
[20] Openpose Colab Jupyter notebook, https://colab.research.google.com/github/tugstugi/dl-colabnotebooks/blob/master/notebooks/OpenPose.ipynb.





























