Embed Size (px)
Citation preview

When Bad is Good: Effect When Bad is Good: Effect of Ebonics on Computational of Ebonics on Computational
Language ProcessingLanguage Processing
Tamsin MaxwellTamsin Maxwell5 November 20075 November 2007

Acknowledgment
• IP notice - some background slides thanks to:– Dan Jurafsky, Jim Martin, Bonnie Dorr
(Linguist180, 2007)– Mark Wasson, LexisNexis (2002)– Theresa Wilson (PhD work 2006)– Janyce Wiebe, U. Pittsburgh (2006)

OverviewPart 1• Comp Ling and ‘free text’• Ebonics in lyrics• Comp Ling approach to language• Example - part of speech (POS) tagging• Application - sentiment analysis
Part 2• Methodology• Results• The broader picture

Comp Ling and ‘free text’
• Just like people, Comp Ling relies on having lots of examples to learn from
• Most advances based on large text collections– Brown corpus: 1 million words, 15 genres (1961)
– GigaWord corpus…trillion word corpus
• Training data is generally ‘clean’ but real language is messy
• Can we successfully use techniques developed on clean data to understand ‘free text’?

• We’re dealing with language!– Text/speech may lack structure that traditional
processing and mining techniques can exploit– Information within text may be implicit – Ambiguity– Disfluency– Error, sarcasm, invention, creativity….
• Contrast with spreadsheets, databases, etc.– Well-defined structure
The trouble with text

• “Not enough focus on the data”– Collection– Cleansing– Scale– Completeness, including non-traditional sources– Structure
• “Too much focus on algorithms”
– Mark Wasson (LexisNexis):
Back to basics

What is ebonics?
• Ebonics, or AAVE (African American Vernacular English), differs from ‘regular’ English – Pronunciation: “tief” - steal / “dem” - them or those
– Grammar: “he come coming in here” - he comes in here
– Vocabulary: “kitchen” - kinky hair at nape of neck
– Slang: “yard axe” - preacher of little ability
• Many ebonics words, phrases, pronunciations have become common parlance– ain't, gimme, bro, lovin, wanna
Green, Lisa J. (2002). “African American English: A Linguistic Introduction”, Cambridge University Press

Source of ebonics
• Rooted in African tradition but very much American – Southern rural during slavery
– Slang 1900-1960 sinner-man black musician
– Street culture, rap and hip-hop
– Working class

Lyrics data
• 2392 popular song lyrics from 2002 • 496 artists, mostly pop/rock and some rap/hip-hop• From user-upload public websites, so very messy!
– Misspelling (e.g. dancning)
– Phonetic spelling (e.g. cit-aa-aa-aa-aaay)
– Annotation (e.g. feat xxx, [Dre])
– Abbreviation (e.g. chorus x2)
– Too much punctuation or none e.g. no line breaks
– Foreign language

Ebonics lexicon
Approximately 15% of all tokens
Ebonics• Phonetic translations (pronunciation)• Slang• Abbreviations
Also includes• Spelling errors• Unintended word conjunctions• Named entities (people, places, brands)

Lexicon examples

Lexicon examples

Ebonics frequency
Ebonics in red
‘Regular’ English in blue
Wo
rd c
oun
t
Dictionary word number

Ebonics in lyrics
• Red in curve suggests many frequent and differentiating words are ebonics terms
• These terms have largely replaced their regular English counterparts– Cos, coz, cuz and cause for because
– Wanna for want to
• Red streaks in the tail suggest certain artists have very high proportions of ‘ebonics’– Others may use only very common terms

Comp Ling ABC• Computer programmes have three basic tasks:
– Check conditions (if x=y, then…)
– Perform tasks in order (procedure)– Repeat tasks (iterate)
• This underlies Comp Ling analysis e.g.– Break text into chunks (words, clauses, sentences)
– Check if chunks meet specified conditions
– Represent conditions with numbers (e.g. counts, binary)
– Repeat for different conditions
– Use maths to find the most likely solution to all conditions

An example: POS tagging

An example
• Break text into chunks (words, clauses, sentences)• Check if chunks meet specified conditions• Represent results with numbers (e.g. counts, binary)• Repeat for different conditions• Use maths to find the most likely solution to all
conditions

Tokenise the data• Each line of lyrics tokenised into unique tokens (words)
• Punctuation split off by default– Where are you? Where / are / you / ?– It’s about time It / ‘s / about / time
• Very tricky: how to reattach punctuation?– U.S.A. U / . / S / . / A / .– Good lookin’ Good / lookin / ’ – Get / in / ‘ / cuz / we / ’re / ready / to / go
• “Get in because” ?• “Getting because” ?

An example
• Break text into chunks (words, clauses, sentences)• Check if chunks meet specified conditions• Represent results with numbers (e.g. counts, binary)• Repeat for different conditions• Use maths to find the most likely solution to all
conditions

Focus the problem• Convert language into metadata • In this example, convert tokens into POS tags• Words often have more than one POS: back
– The back door = JJ
– On my back = NN
– Win the voters back = RB
– Promised to back the bill = VB
• Tags constrained by conditions:– Condition: what tags are possible?
– Condition: what is the preceding/following word?

Most frequent tag
• Baseline statistical tagger – Create a dictionary with each possible tag for a word– Take a tagged corpus– Count the number of times each tag occurs for that
word– Pick the most frequent tag independent of
surrounding words (“unigram”)
• Around 90% accuracy on news text

An example
• Break text into chunks (words, clauses, sentences)• Check if chunks meet specified conditions• Represent results with numbers (e.g. counts, binary)• Repeat for different conditions• Use maths to find the most likely solution to all
conditions

Most frequent tag• Which POS is more likely in a corpus (1,273,000 tokens)?
NN VB Total race 400 600 1000
• P(NN|race) = P(race&NN) / P(race) by the definition of conditional probability– P(race) 1000/1,273,000 = .0008 – P(race&NN) 400/1,273,000 =.0003– P(race&VB) 600/1,273,000 = .0005
• And so we obtain:– P(NN|race) = P(race&NN)/P(race) = .0003/.0008 =.375– P(VB|race) = P(race&VB)/P(race) = .0004/.0008 = .625

An example
• Break text into chunks (words, clauses, sentences)• Check if chunks meet specified conditions• Represent results with numbers (e.g. counts, binary)• Repeat for different conditions• Use maths to find the most likely solution to all
conditions

POS tagging as sequence classification
• We are given a sentence ( a “sequence of observations”)– Secretariat is expected to race tomorrow
• What is the best sequence of tags which corresponds to this sequence of observations?
• Probabilistic view:– Consider all possible sequences of tags– Out of this universe of sequences, choose the tag
sequence which is most probable given the observations

Disambiguating “race”

An example
• Break text into chunks (words, clauses, sentences)• Check if chunks meet specified conditions• Represent results with numbers (e.g. counts, binary)• Repeat for different conditions• Use maths to find the most likely solution to all
conditions

Hidden Markov Models
• We want, out of all sequences of n tags t1…tn the single tag sequence such that P(t1…tn|w1…wn) is highest
• This equation is guaranteed to give us the best tag sequence
• Hat ^ means “our estimate of the best one”• Argmaxx f(x) means “the x such that f(x) is maximized”

The solution• P(NN|TO) = .00047• P(VB|TO) = .83• P(race|NN) = .00057• P(race|VB) = .00012• P(NR|VB) = .0027• P(NR|NN) = .0012• P(VB|TO)P(NR|VB)P(race|VB) = .00000027• P(NN|TO)P(NR|NN)P(race|NN)=.00000000032
• So we (correctly) choose the verb reading

But hang on a minute…
• Most-frequent-tag approach has a problem!• What about words that don’t appear in the training set?
– E.g. Colgate, goose-pimple, headbanger• New words added to (newspaper) language 20+ per
month• Plus many proper names …• “Out of vocabulary” (OOV) words increase tagging
error rates

Handling unknown words
• Method 1: assume they are nouns
• Method 2: assume the unknown words have a probability distribution similar to words only occurring once in the training set.
• Method 3: Use morphological information, e.g., words ending with –ed tend to be tagged VBN.

The bottom line
• POS tagging is widely considered a solved problem• Statistical taggers achieve about 97% per-word
accuracy - the same as inter-annotator agreement
Ongoing issues• Incorrect tags affect subsequent tagging decisions -
more likely to find strings of errors• OOV words (in the training corpus) cause most errors• Statistical taggers are state-of-the-art but may not be
as portable to new domains as rule-based taggers

What is POS tagging good for?• First step for vast number of Comp Ling tasks
• Speech synthesis:– How to pronounce “lead”?– INsult inSULT– OBject obJECT– OVERflow overFLOW
• Word prediction in speech recognition and etc– Possessive pronouns (my, your, her) followed by nouns– Personal pronouns (I, you, he) likely to be followed by
verbs

What is POS tagging good for?• Parsing: Need to know POS in order to parse
S
VP
DT NN VBD
NPNP
VP
The representative put chairs on the table
NNS IN DT NN
NP PP
S
VP
DT JJ NN
NP
The representative put chairs on the table
VBZ IN DT NN
PP

What is POS tagging good for?
• Chunking - dividing text into noun and verb groups – E.g. rules that permit optional adverbials and
adjectives in passive verb groups
• Was probably sent or was sent away
• Require that the tag for was be VBN or VBD (since POS taggers cannot reliably distinguish the two)
• Sentiment analysis - deciding when a word reflects emotion– “I like the way you walk”
– “Beat me like Better Crocker cake mix”

Sentiment detection
Opinion mining• Opinions, evaluations, emotions, speculations are
private states• Find relevant words, phrases, patterns that can be
used to express subjectivity• Determine the polarity of subjective expressions• Expressions directed towards an object
Emotion detection• All text reflects personal emotion• May be undirected

Polarity
• Focus on positive/negative and strong/weak emotions, evaluations, stances
I’m ecstatic the Steelers won!
She’s against the bill.
sentiment analysis

Prior and Contextual Polarity
Lexicon abhor: negative acrimony: negative . . . cheers: positive . . . beautiful: positive . . . horrid: negative . . . woe: negative wonderfully: positive
Prior polarity (out of context)
“Cheers to Timothy Whitfield for the wonderfully horrid visuals.”
“Cheers to Timothy Whitfield for the wonderfully horrid visuals.”

Shifting polarity
• Negation - flip or intensify– Not good
– Not only good but amazing
• Diminishers - flip– Little truth
– Lack of understanding
• Word sense - shift– The old school was condemned in April
– The election was condemned for being rigged
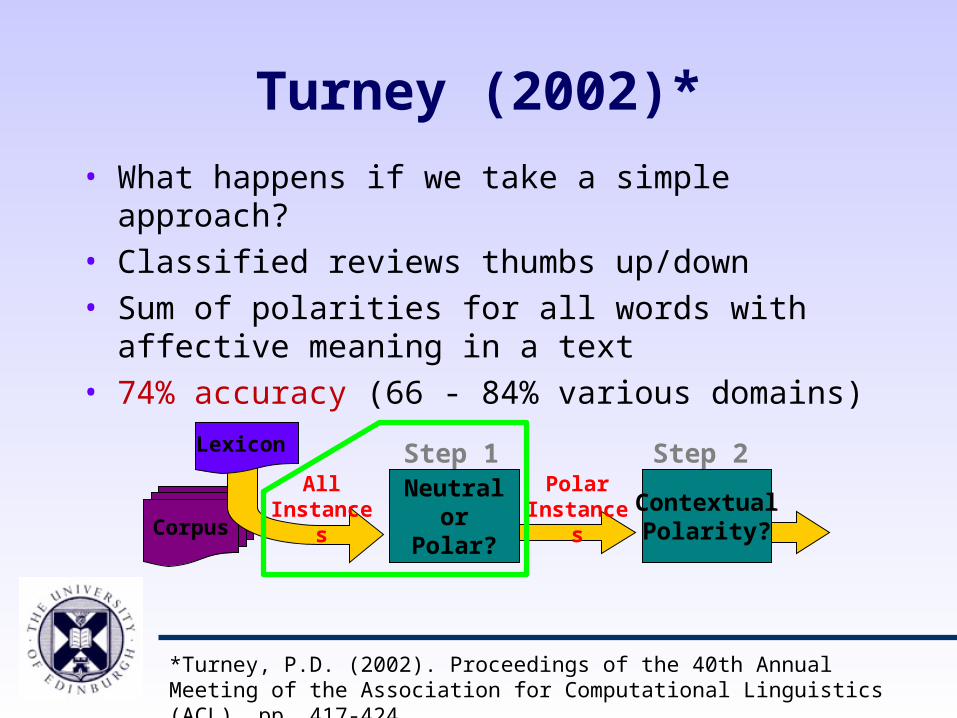
Turney (2002)*
• What happens if we take a simple approach?• Classified reviews thumbs up/down• Sum of polarities for all words with affective meaning
in a text• 74% accuracy (66 - 84% various domains)
*Turney, P.D. (2002). Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), pp. 417-424.
Corpus
Lexicon
Neutralor
Polar?
Step 1
ContextualPolarity?
Step 2All
InstancesPolar
Instances

Sentiment Lexicon
• Developed by Wilson et al (2005)– First two dimensions of Charles Osgood’s Theory of
Semantic Differentiation– Evaluation or prior polarity (positive/negative/both/neutral)– Potency or reliability (strong/weak subjective)– Does not include activity (passive/active)
• Over 8,000 words – Both manually and automatically identified– Positive/negative words from General Inquirer and
Hatzivassiloglou and McKeown (1997)
T. Wilson, J. Wiebe and P.Hoffmann (2005), “Recognizing contextual polarity in phrase-level sentiment analysis”. HLT '05, p 347--354.C.E. Osgood, G.J. , P.H. Tannenbaum (1957), “The Measurement of Meaning”, University of Illinois Press

Word entries• Adjectives1 (7.5% all text)
– Positive: honest, important, mature, large, patient– Negative: harmful, hypocritical, inefficient, insecure– Subjective: curious, peculiar, odd, likely, probable
• Verbs2
– positive: praise, love– negative: blame, criticize– subjective: predict
• Nouns2
– positive: pleasure, enjoyment– negative: pain, criticism– subjective: prediction
• Obscenities– Five slang words added to avoid obvious error
1. Hatzivassiloglou & McKeown 1997, Wiebe 2000, Kamps & Marx 2002, Andreevskaia & Bergler 2006
2. Turney & Littman 2003, Esuli & Sebastiani 2006
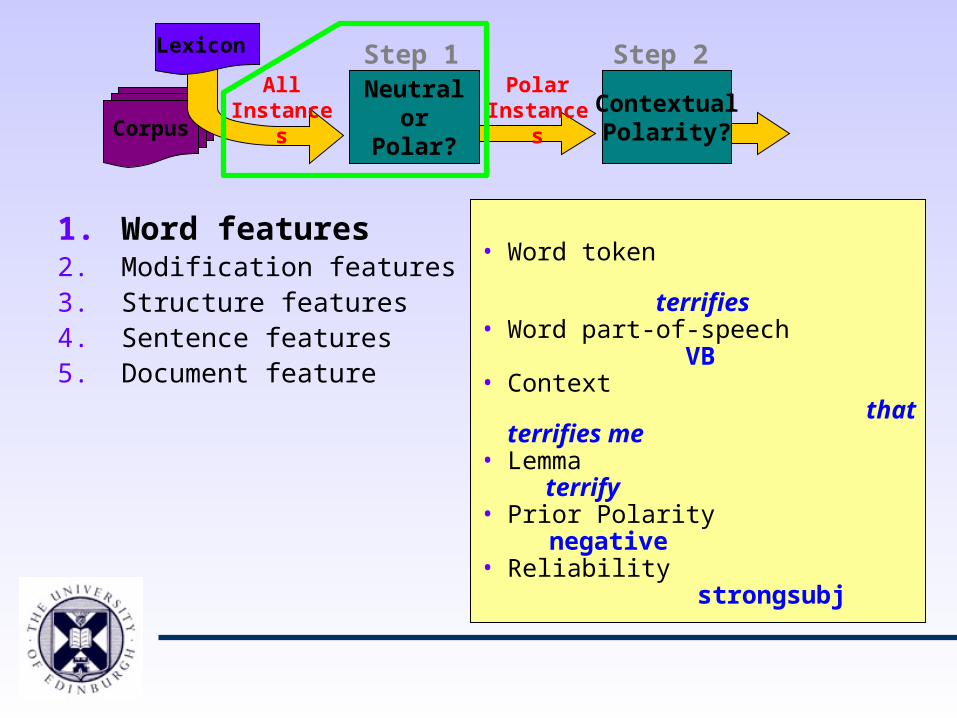
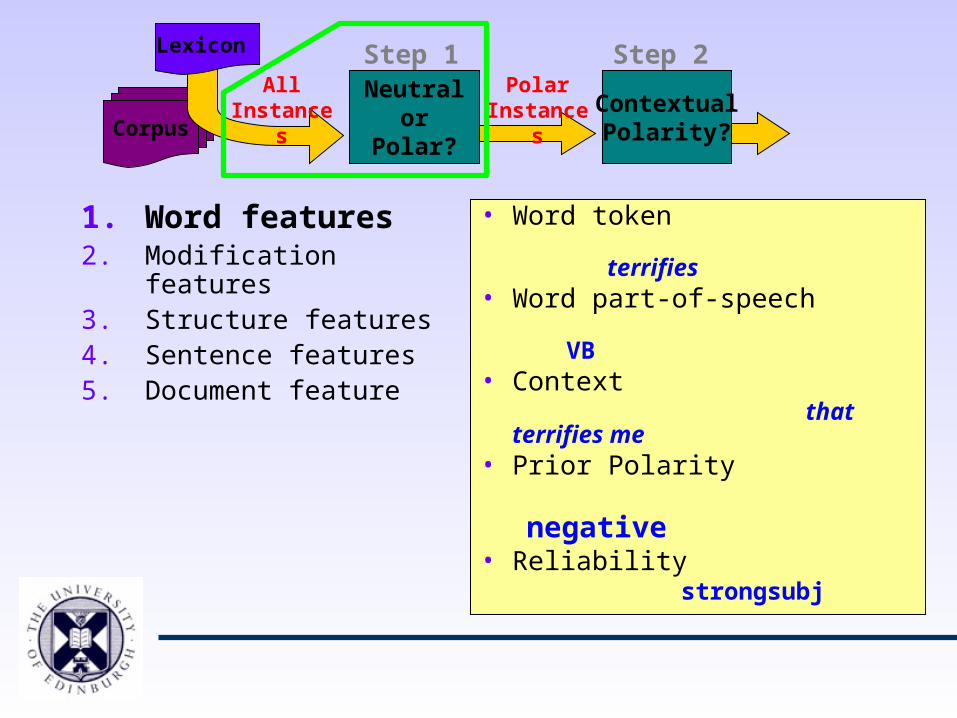
1. Word features2. Modification features3. Structure features4. Sentence features5. Document feature
• Word token terrifies• Word part-of-speech
VB• Context that terrifies me• Lemma
terrify• Prior Polarity
negative
• Reliability strongsubj
Corpus
Lexicon
Neutralor
Polar?
Step 1
ContextualPolarity?
Step 2All
InstancesPolar
Instances

Where does ebonics fit in?• Standardising ebonics terms in ‘free’ language may
improve accuracy of language processing tools e.g. POS taggers
• Also benefit subsequent analysis e.g. sentiment detection
• Possible application to:– User-generated web content (e.g. in chat rooms)
– Speech
– Creative writing

Methodology - ebonics• Check every token against the CELEX dictionary
– If not found, check the suffix• attempt correction and re-check CELEX (no errors)
– If still not found, write to ebonics lexicon
• Write dictionary translation by hand– Include stress pattern for rhythm analysis– Keep number of tokens and POS the same if possible
in / in’ ing runnin becomes runninga / a' (word length > 2) er brotha becomes brotherer re center becomes centreor our color becomes colour

Methodology - features• Extract features: POS, language, sentiment, repetition• POS tags
– Number of words for each UPenn tag – Number of words in tag categories {NN, VB, JJ, RB, PRP}
• Language – Number of regular abbreviations (e.g. don't)– Number of frontal contractions (e.g. 'cause)– Number of modal, passive and active verbs– Average, minimum and maximum line lengths
– Language formality = % formal words (NN, JJ, IN, DT) versus informal words (PRP, RB, UH, VB)
– Word variety = type to token ratio

Methodology - features
• Extract features: POS, language, sentiment, repetition• Sentiment
– Number of words strong/weak positive – Number of words strong/weak negative
• Repetition– Number of phrase repetitions– Phrase length– Number of lines repeated in full– Number of unique (non-repeated) lines
• Combination– Combined features from above categories, edited to
remove correlations

Methodology - corpus size
• Subsequent analyses use neural networks that prefer more data
• But ebonics lexicon is labor intensive• Want to observe impact of reduced data set
• Standardise ebonics for approximately half the data (1037 songs out of 2392)

Ebonics and POS• Stability within major tag categories
– Nouns most shift NN to NNP / NNPS to NNP
– High frequency of named entities
– “be my Yoko Ono”, “served like Smuckers jam”
• Some shift from NN to VBG/VBZ tags – “what's happ'ning”
• Increase in comparative adjectives – “a doper flow”
• Ebonics does not appear to be important for POS tagging unless text is from traditional ebonics source

Results

Ebonics and POS
• Most instances of ebonics don’t affect POS tagging– “grinders” meaning sandwiches
– “deco umbrella” meaning average uterus
• Some ebonics affects tag counts– “sloppy joe” meaning hamburger
• Phrasal tagging errors can be caused by surprising CELEX entries– “shama lama ding dong dip dip dip” all but two words
appear in CELEX
– Q: Which two? A: ding and dong

Ebonics and POS
• Most slang does not affect POS tagging• Phrasal slang does affect tagging - one to many
relation– “doing hunny in a sixty-five” meaning speeding
(recklessly, on an American freeway)

Ebonics and features
• Sentiment features responded most to ebonics edit– Before edit average 0-15 positive words, 1-13 negative
– After edit average 0-28 positive words, 0-21 negative
• Other features virtually no effect after edit
• Ebonics terms likely to be charged with sentiment• Text may benefit from ebonics editing prior to
sentiment analysis
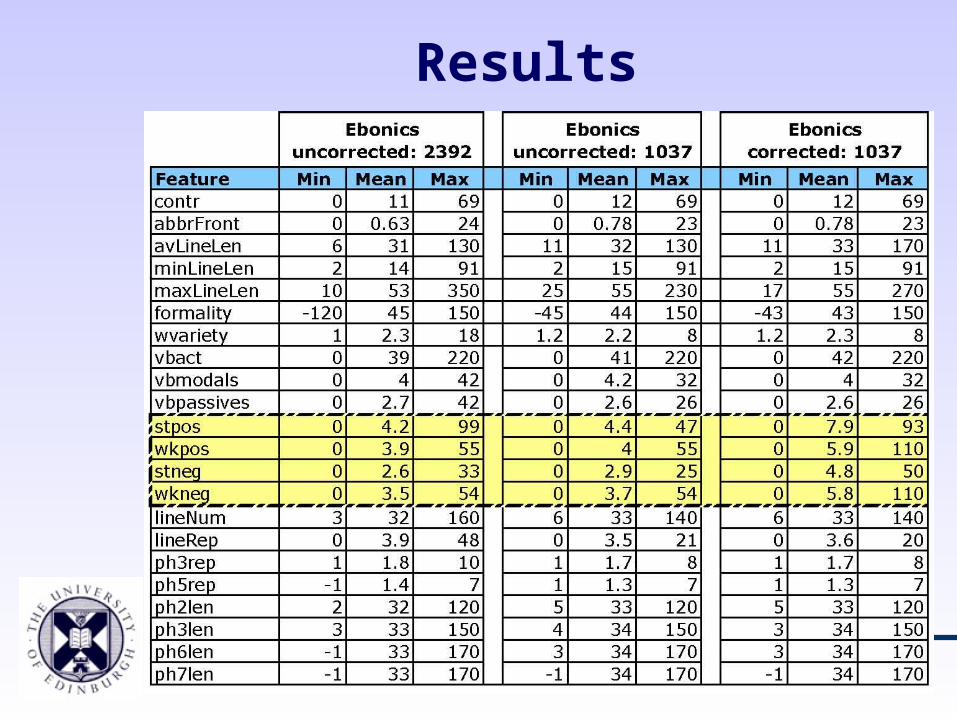
Results

Data distribution
• Doubling data did not substantially affect data distribution
• Effect on outliers - more data means more variety
• Ebonics edit makes data more consistent– Effect on machine learning
– More sensitive to small changes
– May be loosing useful information

Conclusions
• Ebonics does not appear to be important for POS tagging unless text is from traditional ebonics source– How do we identify these texts?
• Text may benefit from ebonics editing prior to sentiment analysis– Should we be watching for grammar changes too?
– Should we finesse sentiment or language analysis to improve results?

Thank you.
Questions?

The bigger picture
• Discovering the music genome: using heterogenous lyric features to classify music
Why?• Automatically fill music databases• Automate online playlists / radio• Retrieve relevant music in multimedia search• Better interface for your iPod• Might adding text-based information to existing data
mining applications make them better?

Knowledge discovery
• The non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data.– Support predictions or classification
– Explain existing data, not just describe it

Knowledge discovery methodology
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.

Self-organising maps
•som_show(M,'umat', 'all','comp','all');
•som_show(M,'empty','Labels')
•M=som_autolabel(M,D);
•som_show_add('label',M) •som_show(M,'color',{p{i},[int2str(i),' clusters']})

Gold data (prior to cleaning)
Distance matrix + hits Distance matrix

Language
All data Ebonic off: half data
Ebonic on: half data
The data problem

A B
C
A: ebonic off, full data
B: ebonic off, half data
C: ebonic on, half data
language
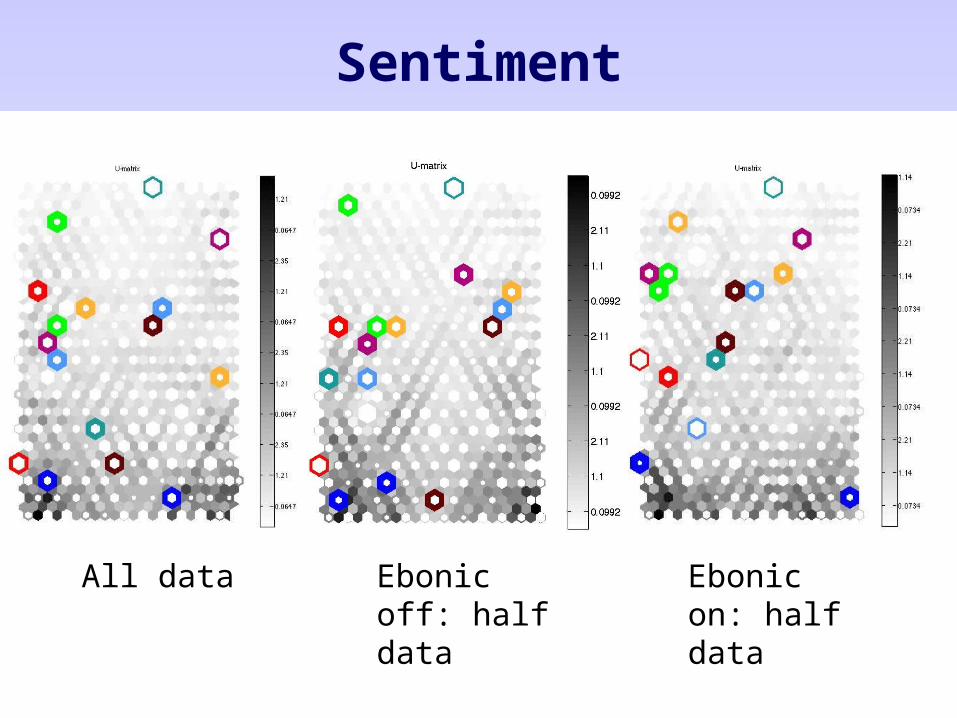
Sentiment
All data Ebonic off: half data
Ebonic on: half data
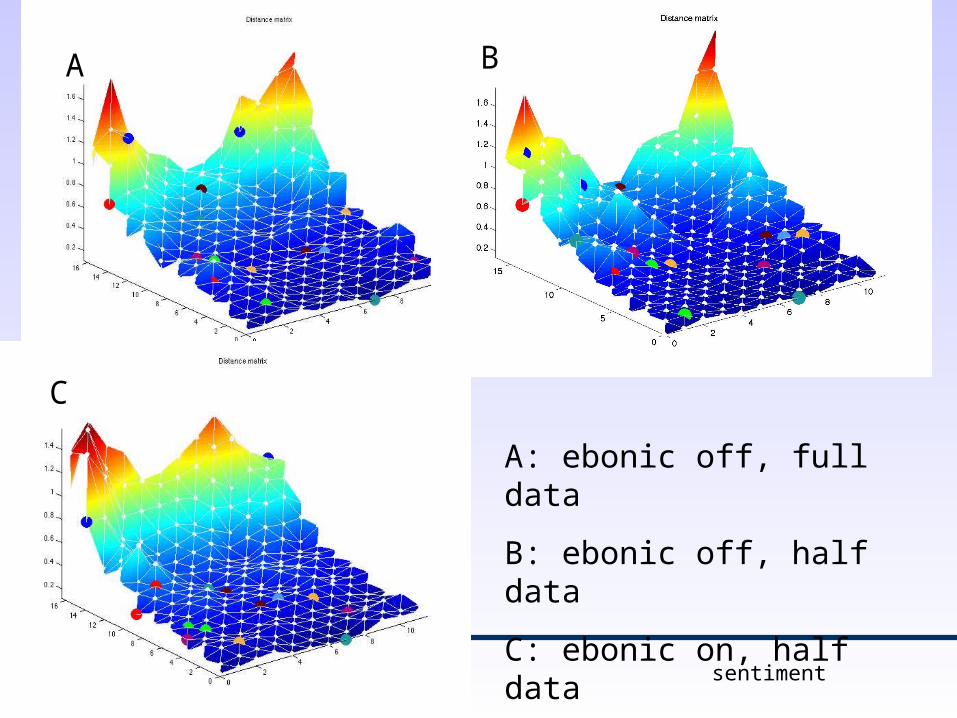
A B
C
A: ebonic off, full data
B: ebonic off, half data
C: ebonic on, half data
sentiment
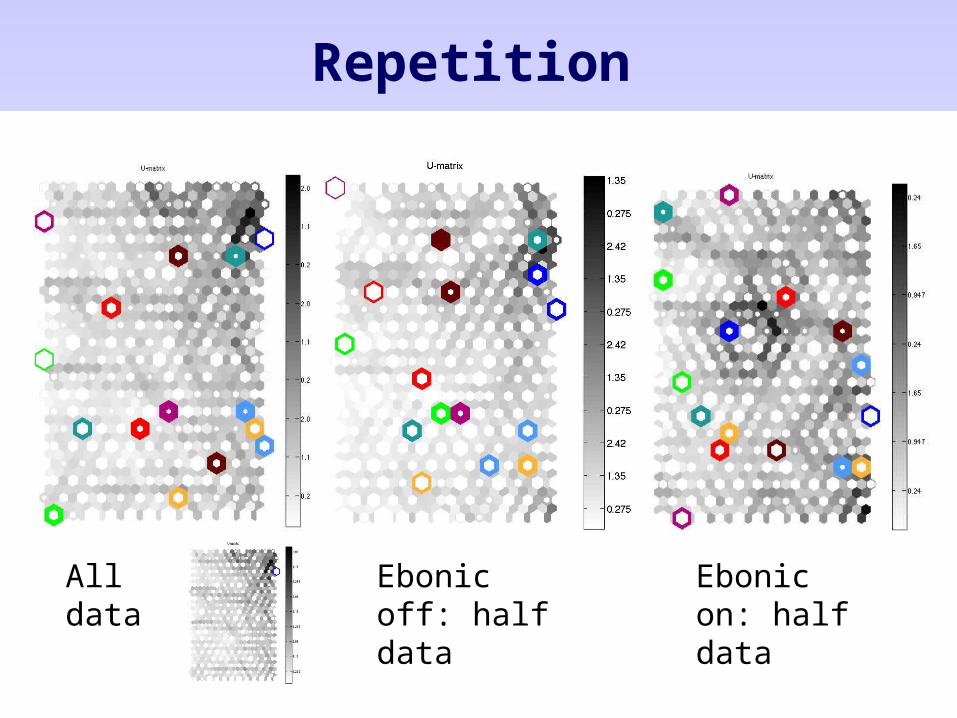
Repetition
All data Ebonic off: half data
Ebonic on: half data

A B
C
A: ebonic off, full data
B: ebonic off, half data
C: ebonic on, half data
repetition

Non-acoustic: all
All data Ebonic off: half data
Ebonic on: half data

A: ebonic off, full data
B: ebonic off, half data
C: ebonic on, half data
A B
C
Non-acoustic all

Ambiguity
1. Word features2. Modification features3. Structure features4. Sentence features5. Document feature
• Word token terrifies• Word part-of-speech
VB• Context that terrifies me• Prior Polarity
negative
• Reliability strongsubj
Corpus
Lexicon
Neutralor
Polar?
Step 1
ContextualPolarity?
Step 2All
InstancesPolar
Instances
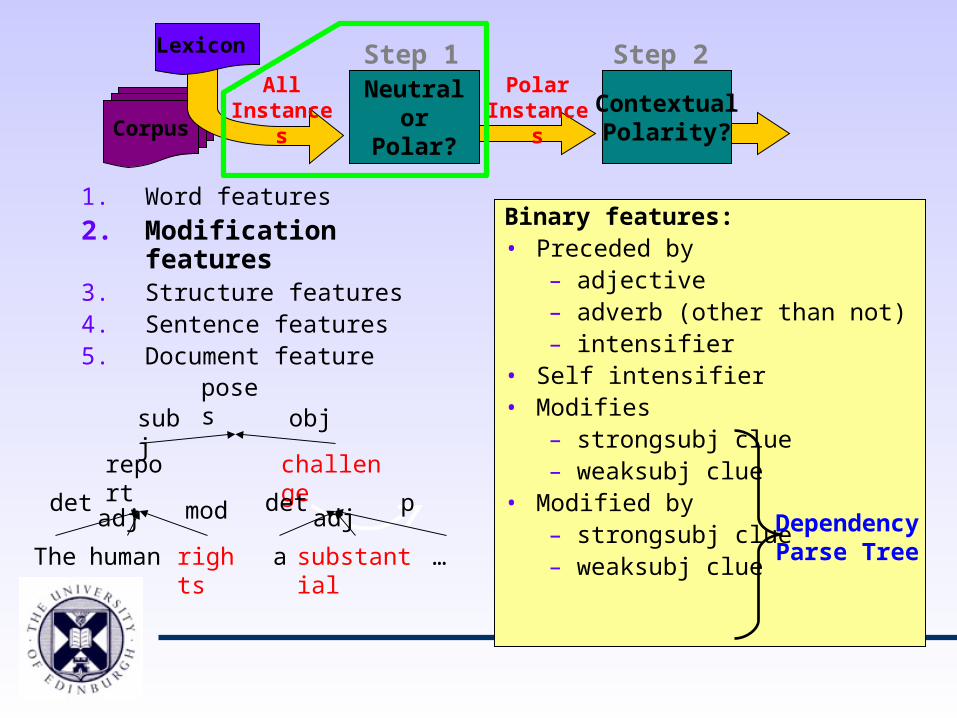
1. Word features
2. Modification features3. Structure features4. Sentence features5. Document feature
Binary features:• Preceded by
– adjective– adverb (other than not)– intensifier
• Self intensifier• Modifies
– strongsubj clue– weaksubj clue
• Modified by – strongsubj clue– weaksubj clue
Dependency Parse TreeThe human rights
report
poses
a substantial
challenge
…
detadj mod adj
det
subj obj
p
Corpus
Lexicon
Neutralor
Polar?
Step 1
ContextualPolarity?
Step 2All
InstancesPolar
Instances

1. Word features
2. Modification features
3. Structure features4. Sentence features
5. Document feature
Binary features:• In subject The human rights report poses
• In copular I am confident
• In passive voicemust be regarded
Corpus
Lexicon
Neutralor
Polar?
Step 1
ContextualPolarity?
Step 2All
InstancesPolar
Instances
The human rights
report
poses
a substantial
challenge
…
detadj mod adj
det
subj obj
p
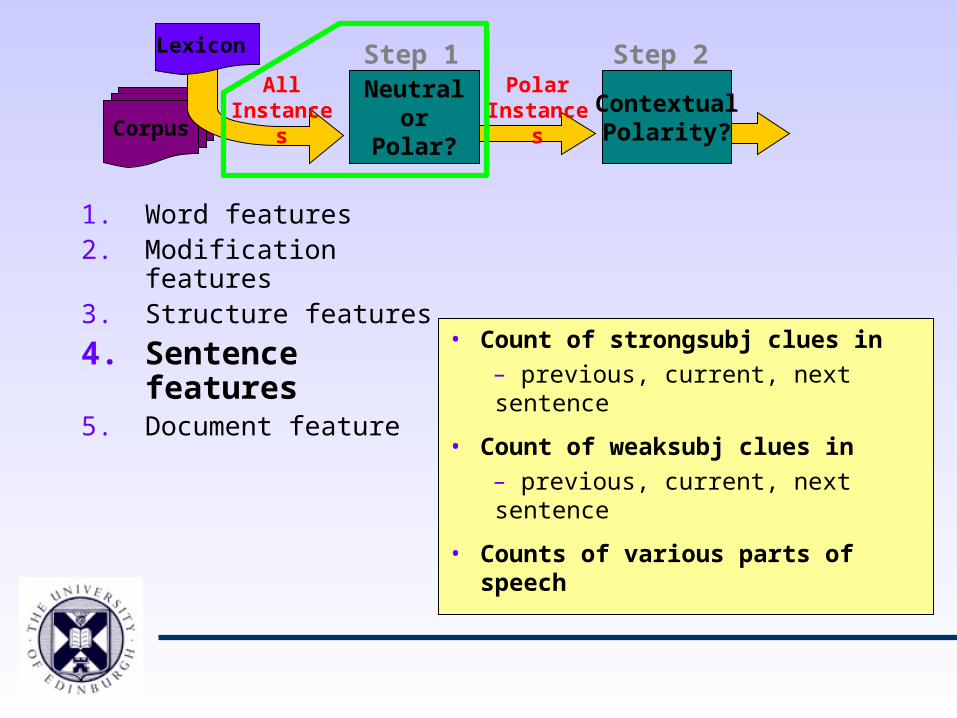
1. Word features2. Modification features3. Structure features
4. Sentence features5. Document feature
• Count of strongsubj clues in
– previous, current, next sentence
• Count of weaksubj clues in
– previous, current, next sentence
• Counts of various parts of speech
Corpus
Lexicon
Neutralor
Polar?
Step 1
ContextualPolarity?
Step 2All
InstancesPolar
Instances

1. Word features
2. Modification features
3. Structure features
4. Sentence features
5. Document feature
• Document topic (15)
– economics– health
– Kyoto protocol– presidential election in Zimbabwe
…
Example: The disease can be contracted if a person is bitten by a certain tick or if a person comes into contact with the blood of a congo fever sufferer.
Corpus
Lexicon
Neutralor
Polar?
Step 1
ContextualPolarity?
Step 2All
InstancesPolar
Instances





























