変換ログを用いた仮名漢字変換精度の向上
山口洋平 森信介 河原達也京都大学情報学研究科
2011 年 3 月 10 日
2011 年 3 月 10 日 @ 豊橋技術科学大学 言語処理学会第 17 回年次大会 (NLP 2011)
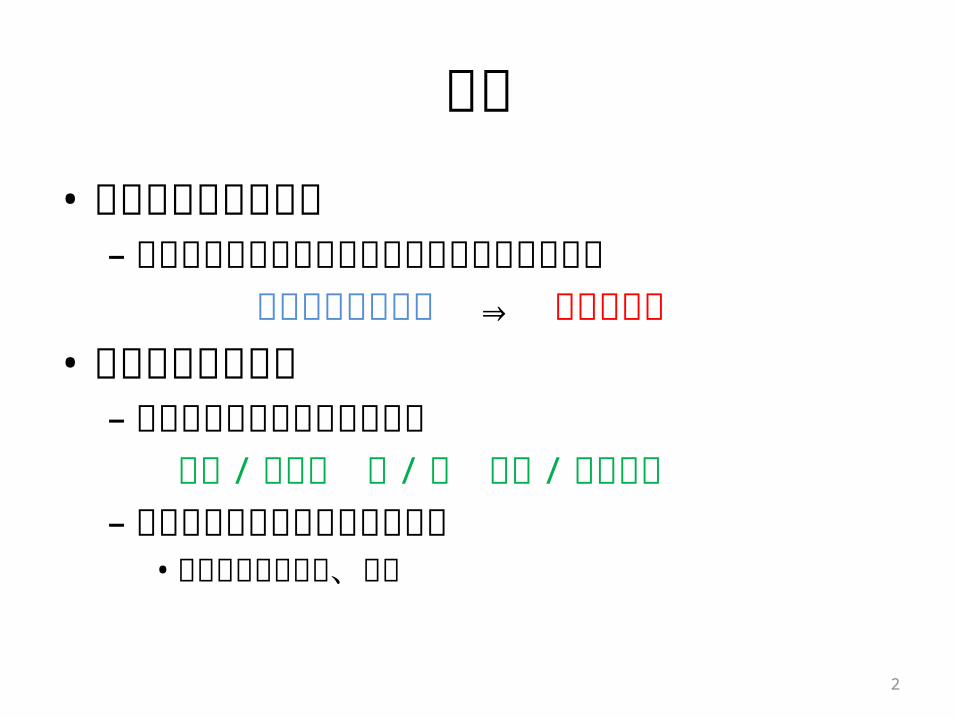
背景• 統計的仮名漢字変換– ひらがな文を仮名漢字混じり文に変換して出
力 きかんしぜんそく ⇒ 気管支喘息
• 仮名漢字変換ログ–変換システムの入出力の履歴
気管 / きかん 支 / し 喘息 / ぜんそく–ユーザの言語活動の特性を反映• よく変換する単語、表現
2
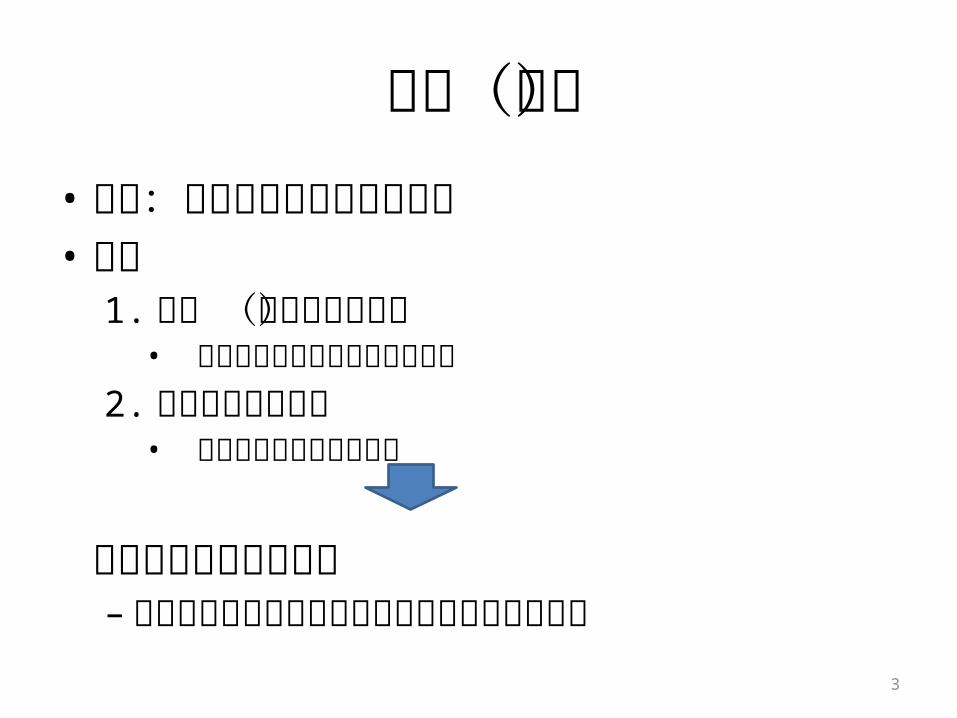
背景(続)• 目的:ユーザの特性の自動学習• 問題
1. 語彙 (未知語の問題)• 語彙にない単語は出力できない
2. 言語モデルの傾向• 同音異義語の選択を誤る
変換ログの活用の提案– ユーザの特性を反映した語彙と文脈情報の追加
3
先行研究• 統計的仮名漢字変換– [ 森他 , 情処論 , 98] [Chen et al., ACL, 00]
• テキストの部分文字列を変換候補に挙げる仮名漢字変換– [Mori et al. Coling, 06]– 未知語であっても変換候補に列挙– 文脈情報を考慮
4

統計的仮名漢字変換(単語と読み)• 入力: y 出力: w• モデル: P(w|y)• w* = argmaxw P(w|y) =
argmaxw P(w, y)– 確率が最大となる単語列を求める– 解探索: Viterbi アルゴリズム
• 言語モデル P(w, y)– 単語と読みの組が単位の n-gram モデル
• [ 森他 , 情処論 , 10]
– 単語に読みがついたコーパスからパラメータ推定 5

テキストの部分文字列の利用 (1/2)
1. テキストすべての部分文字列に対してすべての可能な読みを辞書に追加(単漢字辞書を活用)
文字列表記:関手可能な読み: かんて、せきて、かんしゅ、かんで、せ
きしゅ2. テキスト中の全ての部分文字列を語彙とする
n-gram を構築– テキストの各文字の間の単語境界確率を推定– テキストから文脈情報も得ている
6

テキストの部分文字列の利用 (2/2)
• 実際は計算量が膨大• 近似– 擬似確率的単語分割
テキストを乱数で揺らしながら単語に分割– 擬似確率的読み付与
乱数で揺らしながら読みを付与• 乱数の発生回数が多いと、より良い近似に
7

擬似確率的単語分割
8
確率的単語分割コーパス+乱数= 揺れのある単語分割済みコーパス( × 倍率)
≒ 確率的単語分割コーパス
試行 結果1 単項 イデアル 整 域上 の2 単項 イデ アル 整域 上 の3 単項 イデアル 整域上 の4 単 項 イデアル 整域 上 の
の上域整ルアデイ項例)単 9.03.03.09.01.01.01.09.02.0各文字間で1. 単語境界となる確率を推定2. 0~1の乱数に従って境界かどうかを判定
確率は KyTea で推定
倍率4
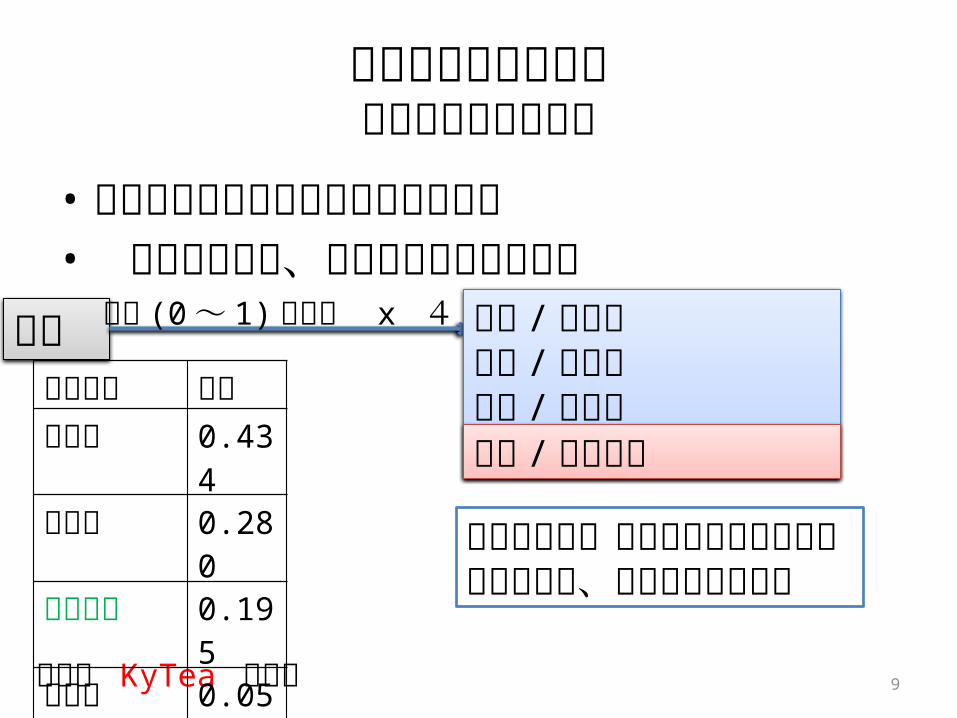
擬似確率的読み付与読み付与誤りに対処
• 単語の可能の読みとその確率を推定• 乱数に従って、付与する読みを揺らす
9
関手
確率は KyTea で推定
読み候補 確率せきて 0.434
かんて 0.280
かんしゅ 0.195
かんで 0.050
せきしゅ 0.041
乱数 (0 ~ 1) を発生 x 4 関手 / せきて関手 / かんて関手 / せきて
未知語でも1つでも正しい読みが付与されれば、変換候補に挙がる
関手 / かんしゅ
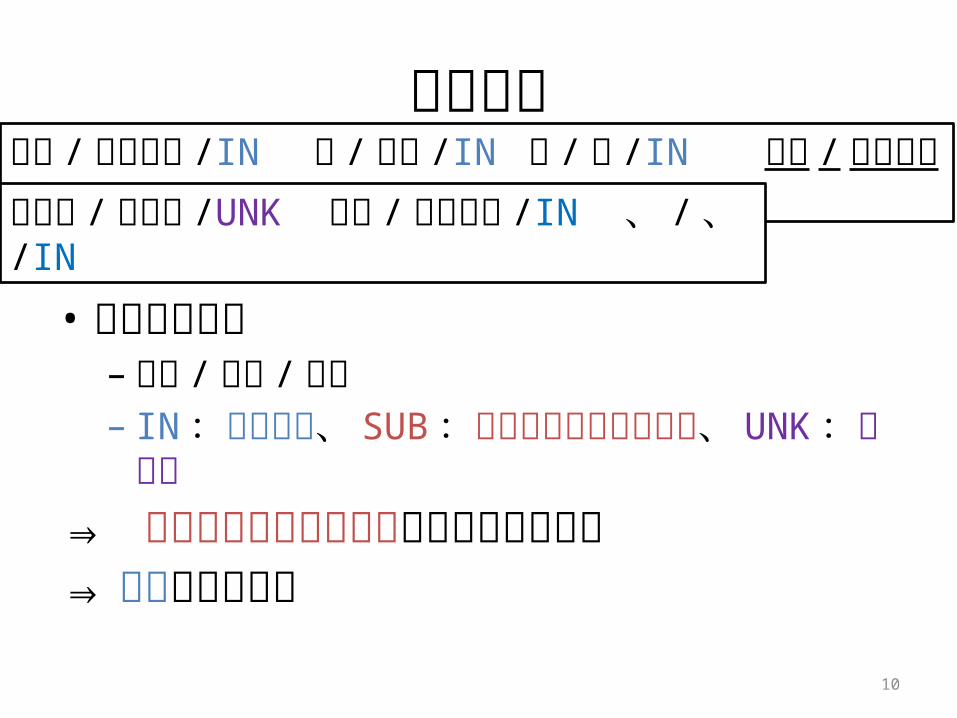
変換ログ
• フォーマット– 表記 / 読み / 出典– IN :内部語彙、 SUB :テキストの部分文字列、
UNK :未知語⇒ テキストの部分文字列が変換ログに出現⇒ 語彙として獲得
10
難溶 / なんよう /IN 性 / せい /IN の / の /IN 製剤 / せいざい /SUBエンゲ / えんげ /UNK 困難 / こんなん /IN 、 / 、 /IN
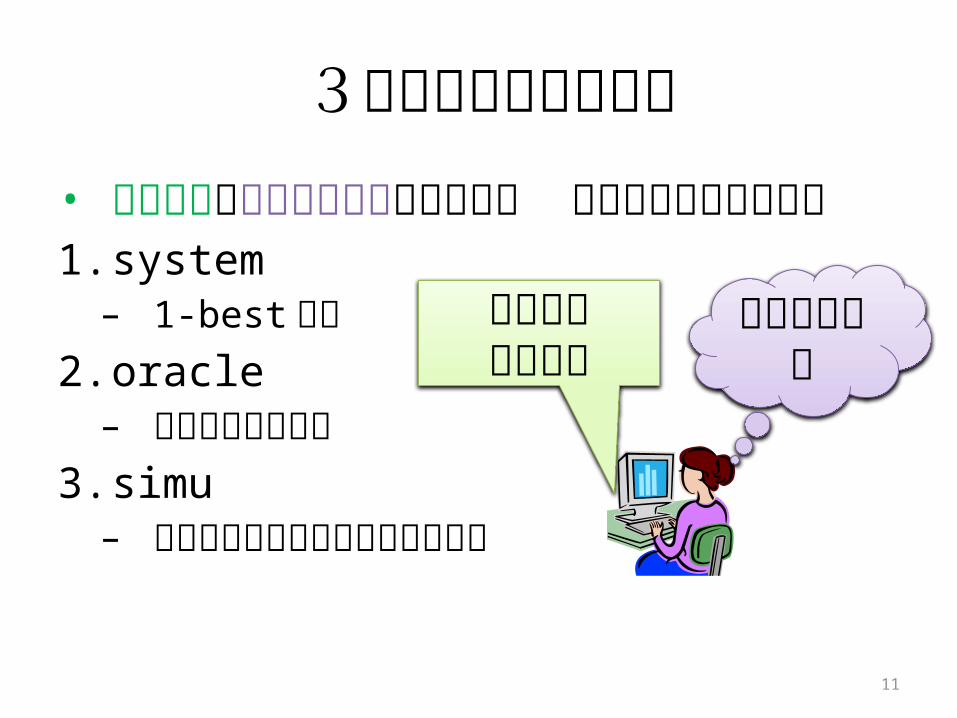
3種類のユーザモデル• 変換出力とユーザの意図が異なる時 ユー
ザはどう振舞うか1.system– 1-best 出力
2.oracle– ユーザの意図通り
3.simu– 現実のユーザのシミュレーション
11
ユーザの意図
IMEの変換出力
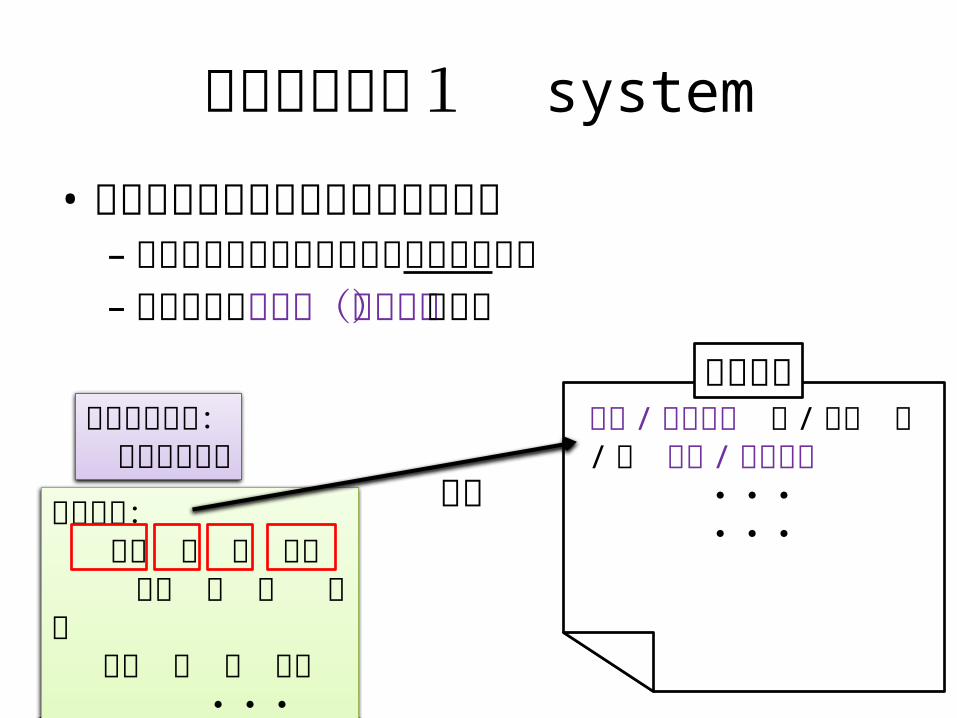
ユーザモデル1 system
• 仮名漢字変換エンジンの出力を選択– 誤分割や誤変換があってもそのまま確定– 変換ログは誤変換(ノイズ)も含む
南陽 / なんよう 性 / せい の / の 製材 / せいざい
・・・・・・
変換出力: 南陽 性 の 製材 難溶 正 ノ 政財 南洋 聖 野 製剤 ・・・
確定
変換ログユーザの意図: 難溶性の製剤
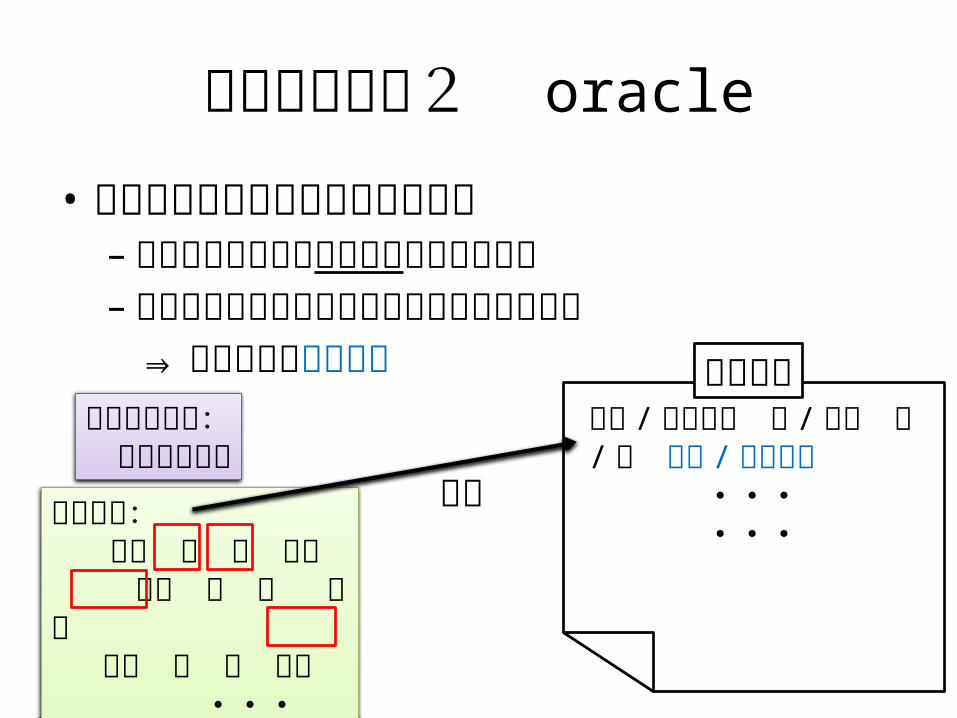
ユーザモデル2 oracle
• 必ずユーザの意図した結果を選択– 誤分割や誤変換を必ず修正してから確定– 変換ログは正しく修正された結果のみを含む
⇒ 未知語なら語彙獲得
1313
難溶 / なんよう 性 / せい の / の 製剤 / せいざい
・・・・・・
変換出力: 南陽 性 の 製材 難溶 正 ノ 政財 南洋 聖 野 製剤 ・・・
ユーザの意図: 難溶性の製剤
変換ログ
確定

ユーザモデル3 simu
• 現実のユーザのシミュレーション– system と oracle の中間–個人の入力の傾向、状況に依存
• 振る舞い–システムの出力とユーザの意図が異なる時1. 割合 α で誤変換を確定2. 誤確定箇所を消去3. 再入力し正しい変換結果を選択
14

実験• 変換ログを用いた仮名漢字変換精度の評価– 3種類のユーザを想定
• 評価基準–カバー率
• 語彙 V = V 学習コーパス ∪ V 変換ログ がテストコーパスの語彙をどれだけカバーしているか
• SUB は語彙ではなく単語候補– 変換精度
• F値(文単位)
15
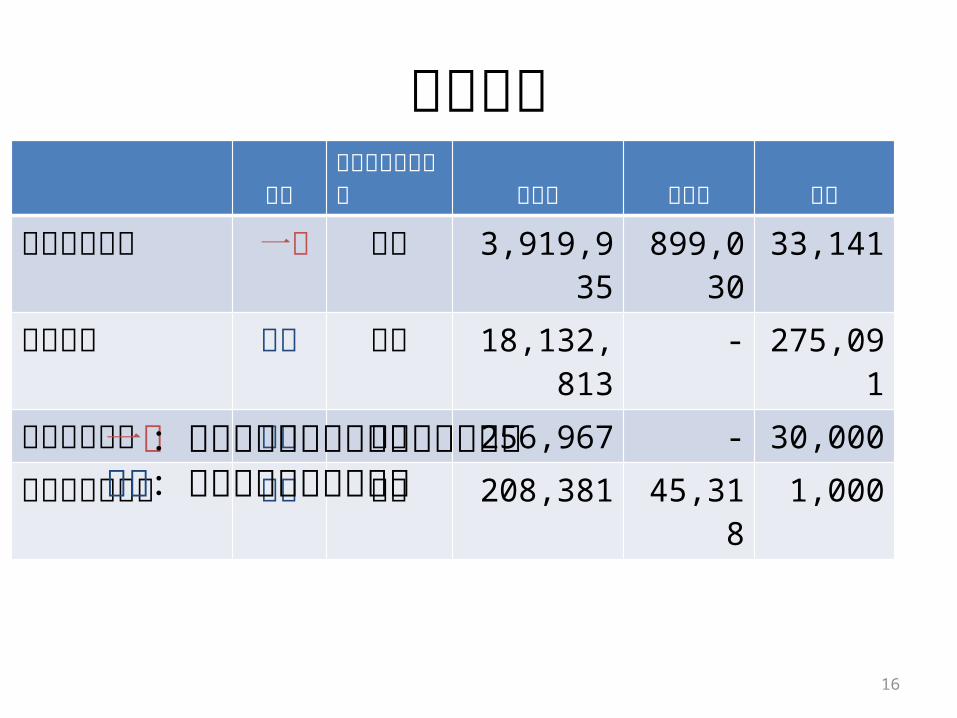
言語資源
16
分野単語境界入力記号 文字数 単語数 文数
学習コーパス 一般 人手 3,919,935 899,030 33,141
テキスト 医薬 自動 18,132,813 - 275,091
ユーザの入力 医薬 自動 256,967 - 30,000
テストコーパス
医薬 人手 208,381 45,318 1,000一般:現代日本語書き言葉均衡コーパス医薬:日本医薬情報センター
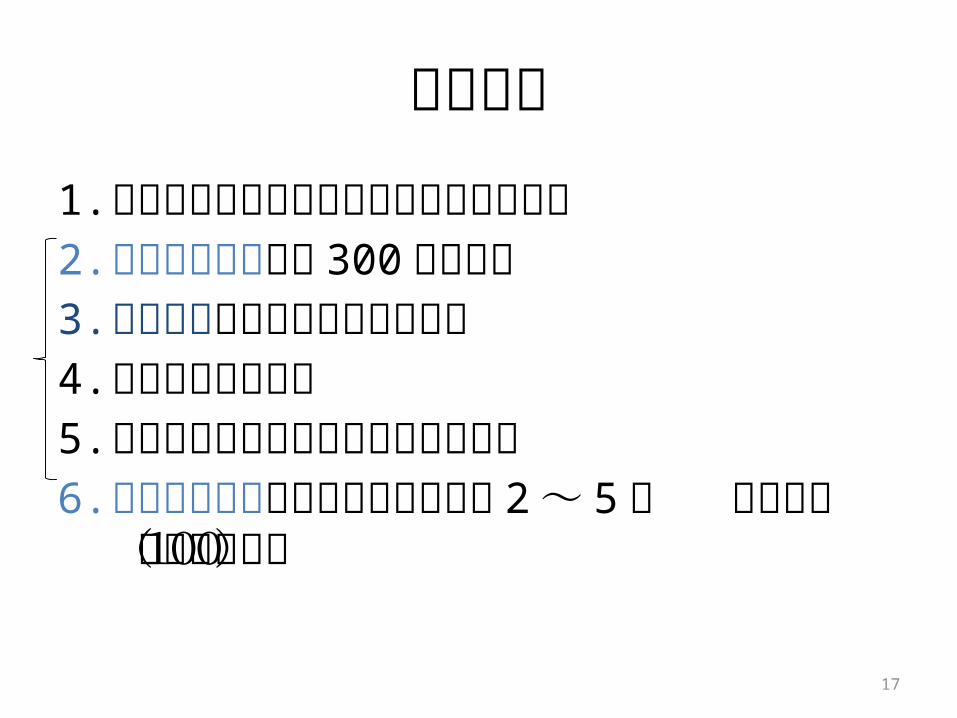
実験手順1. 学習コーパスから初期言語モデルを構築2. ユーザの入力から 300 文を変換3. 変換ログを学習コーパスに追加4. 言語モデルを更新5. テストコーパスに対する精度を計算6. ユーザの入力全てに行き渡るまで 2 ~ 5
の 繰り返し(全100回)
17

ユーザの変換ログの作り方• system : 1-best を変換ログに追加• oracle : 正解を変換ログに追加• simu– 誤変換の割合: α = 13/200 = 0.065
• あるユーザの変換ログから推定a. system と oracle が同じなら system の方を追
加b. そうでないとき、
1. 乱数( 0 ~ 1 )を発生α以下なら system の変換ログも追加
2. oracle の変換ログを追加18
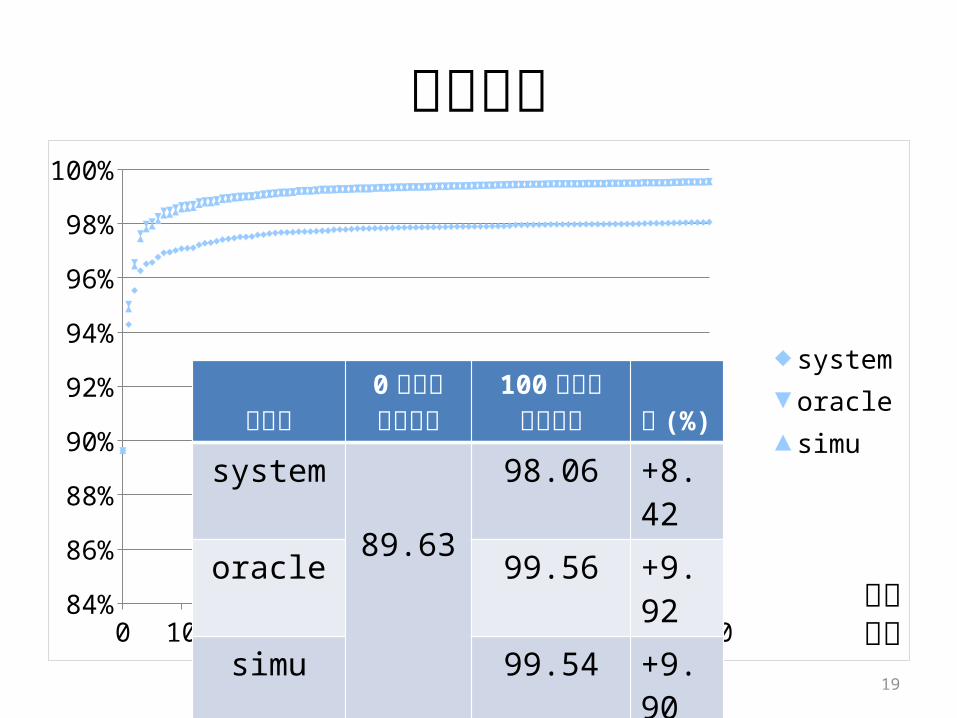
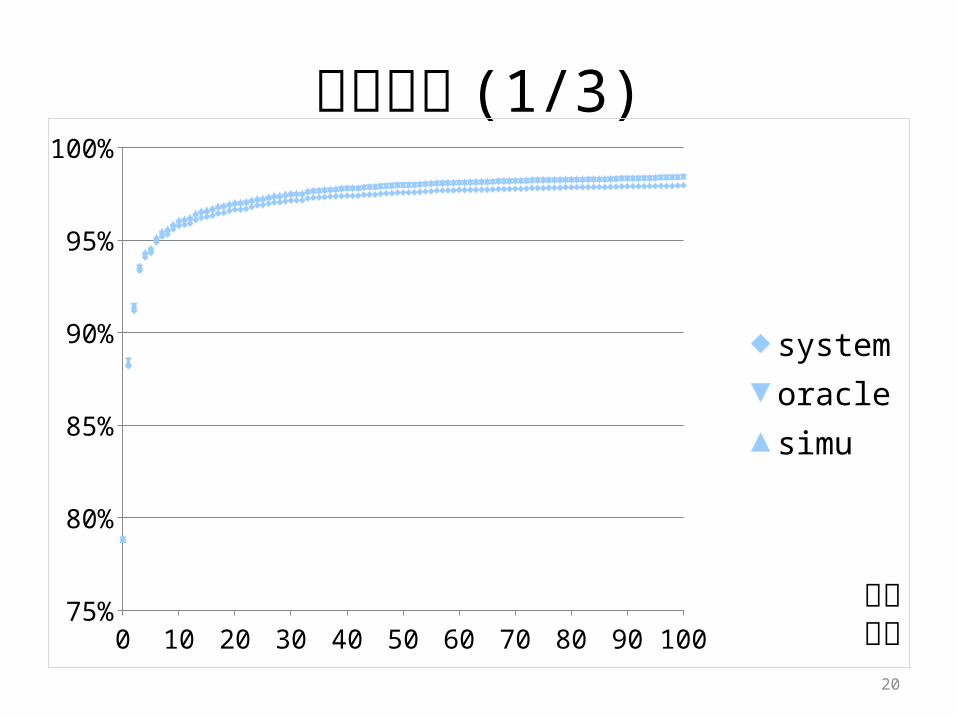
カバー率
19
0 10 20 30 40 50 60 70 80 90 10084%
86%
88%
90%
92%
94%
96%
98%
100%
systemoraclesimuユーザ
0回目のカバー率
100回目のカバー率 差 (%)
system
89.63
98.06 +8.42oracle 99.56 +9.92simu 99.54 +9.90
追加回数
変換精度 (1/3)
20
0 10 20 30 40 50 60 70 80 90 10075%
80%
85%
90%
95%
100%
systemoraclesimu
追加回数
変換精度 (2/3)
21
0 10 20 30 40 50 60 70 80 90 10094%
95%
96%
97%
98%
99%
systemoraclesimu
追加回数
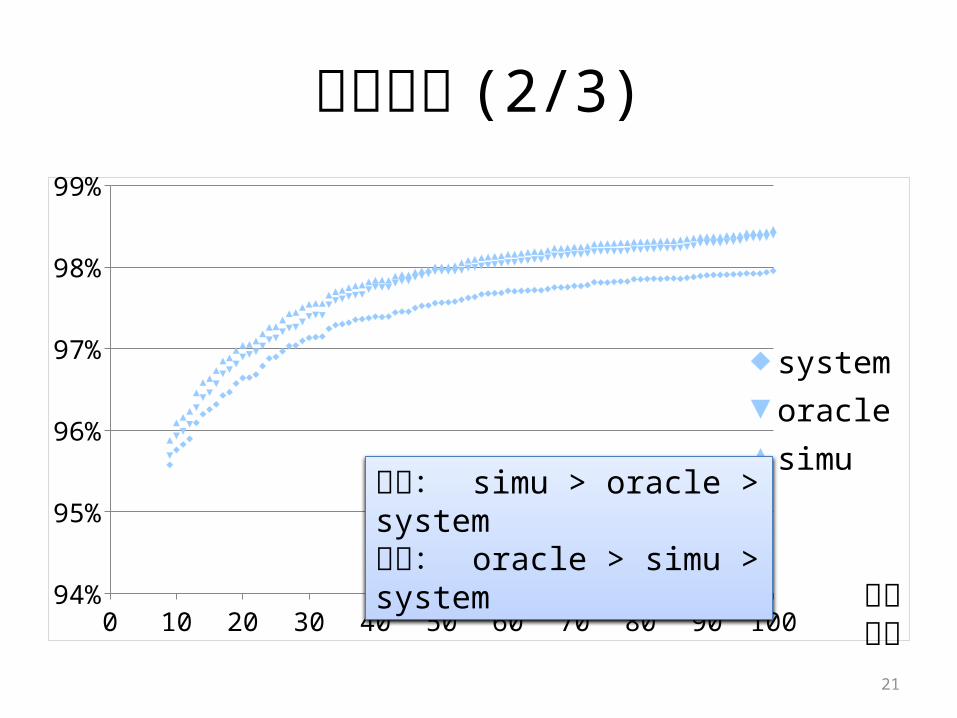
結果: simu > oracle > system期待: oracle > simu > system

変換精度 (3/3)
22
• 精度が向上– 理由1:未知語である単語候補が語彙としてとれた– 理由2:言語モデルがよくなった
• 100 回目のF値: simu > oracle > system– 理由1:simu の変換ログの量は oracle の (1+α) 倍– 理由2:ユーザの入力とその正解データを自動で分割
ユーザ0回目のF値 (%)
100回目のF値 (%)
100回目の再現率 (%)
100回目の適合率 (%) F値の差
(%)
system
78.1497.95 98.07 97.84 +19.81
oracle 98.39 98.38 98.40 +20.25simu 98.46 98.45 98.46 +20.32

まとめと今後の課題• ユーザの特性を動的に学習– 変換ログの活用• 語彙とその文脈情報の言語モデルへの追加
– 3種類のユーザモデルによる実験• 今後の課題– 変換ログの活用方法の工夫• 補間• ノイズ有りデータからの学習
– 文断片(文節程度)単位での実験
23

24
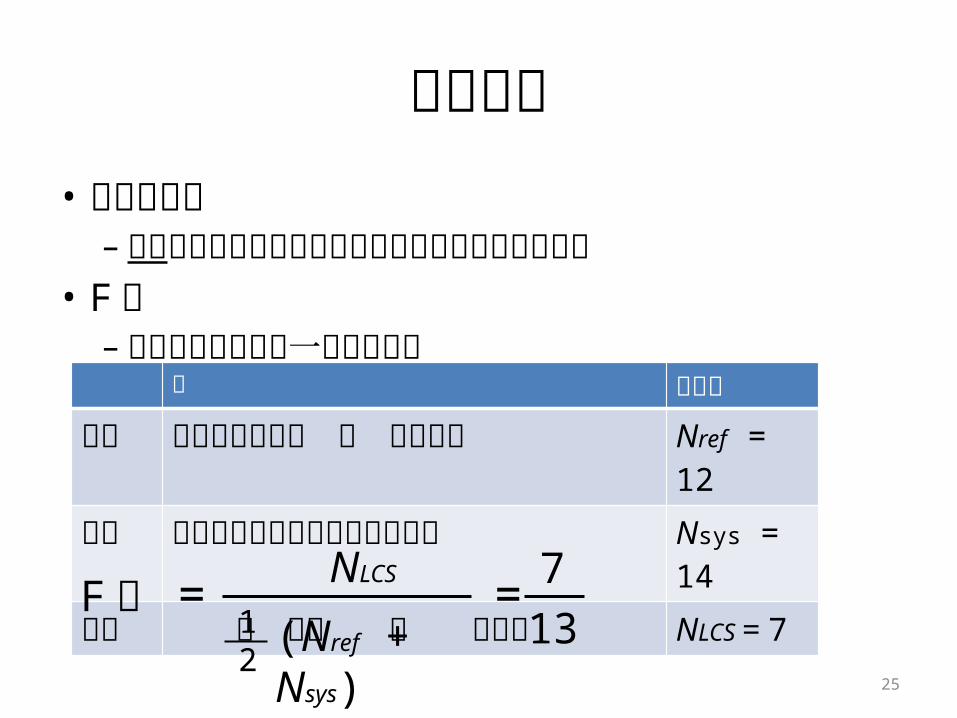
評価基準• カバレージ– 語彙がテストコーパスをどれだけカバーできてるか
• F値– 仮名漢字変換の第一候補の精度
25
文 文字数
正解 警官の厚い人垣 に 傍まれた Nref = 12
出力 景観の熱い人が気にはばまれた Nsys = 14
共通 の い人 に まれた NLCS = 7NLCS
(Nref + Nsys)F値 =
12
= 713
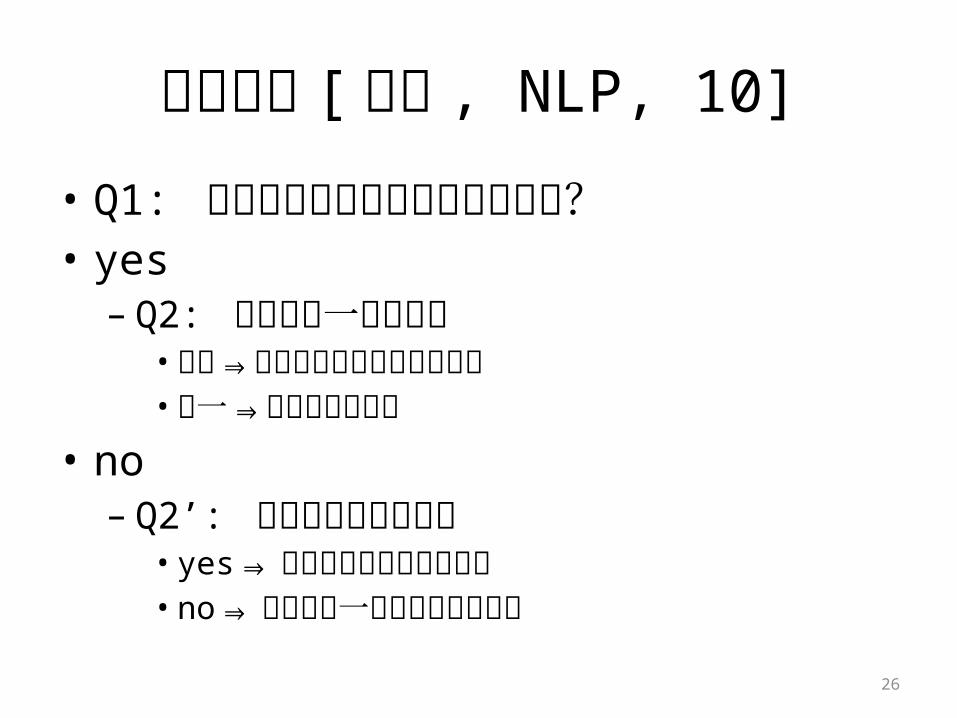
読み推定 [ 森他 , NLP, 10]
• Q1: 学習コーパスに出現しているか?• yes – Q2: 読みが唯一か複数か• 複数⇒分類器を用いて読みを選択• 唯一⇒その読みを選択
• no– Q2’: 辞書に入っているか• yes⇒ 最初の項目の読みを選択• no⇒ 各文字の一般的な読みの連接
26
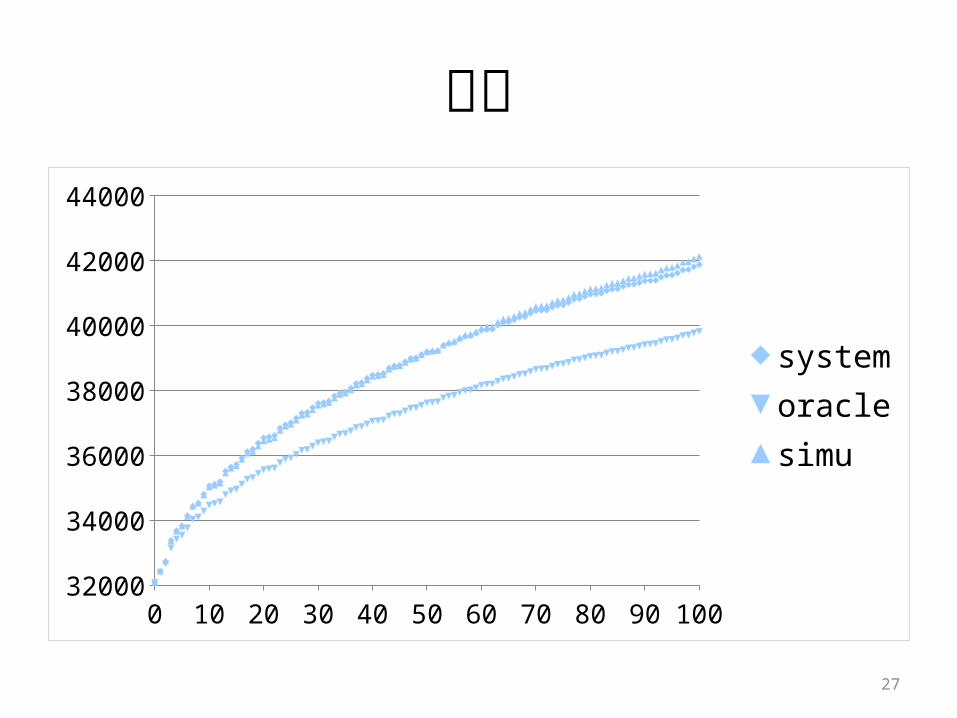
語彙
27
0 10 20 30 40 50 60 70 80 90 10032000
34000
36000
38000
40000
42000
44000
systemoraclesimu
Recommended

















