1/19/08 CS 461, Winter 2008 1
CS 461: Machine LearningLecture 3
Dr. Kiri [email protected]
Dr. Kiri [email protected]

1/19/08 CS 461, Winter 2008 2
Questions?
Homework 2 Project Proposal Weka Other questions from Lecture 2

1/19/08 CS 461, Winter 2008 3
Review from Lecture 2
Representation, feature types (continuous, discrete, ordinal)
Model selection, bias, variance, Occam’s razor
Noise: errors in label, features, or unobserved
Decision trees: nodes, leaves, greedy, hierarchical, recursive, non-parametric
Impurity: misclassification error, entropy Turning trees into rules Evaluation: confusion matrix, cross-
validation

1/19/08 CS 461, Winter 2008 4
Plan for Today
Decision trees Regression trees, pruning
Evaluation One classifier: errors, confidence intervals,
significance Comparing two classifiers
Support Vector Machines Classification
Linear discriminants, maximum margin Learning (optimization) Non-separable classes
Regression
1/19/08 CS 461, Winter 2008 5
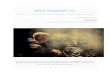
Remember Decision Trees?

1/19/08 CS 461, Winter 2008 6
Algorithm: Build a Decision Tree
[Alpaydin 2004 The MIT Press]

1/19/08 CS 461, Winter 2008 7
Building a Regression Tree
Same algorithm… different criterion Instead of impurity, use Mean Squared
Error(in local region) Predict mean output for node Compute training error (Same as computing the variance for the node)
Keep splitting until node error is acceptable;then it becomes a leaf Acceptable: error < threshold
1/19/08 CS 461, Winter 2008 8
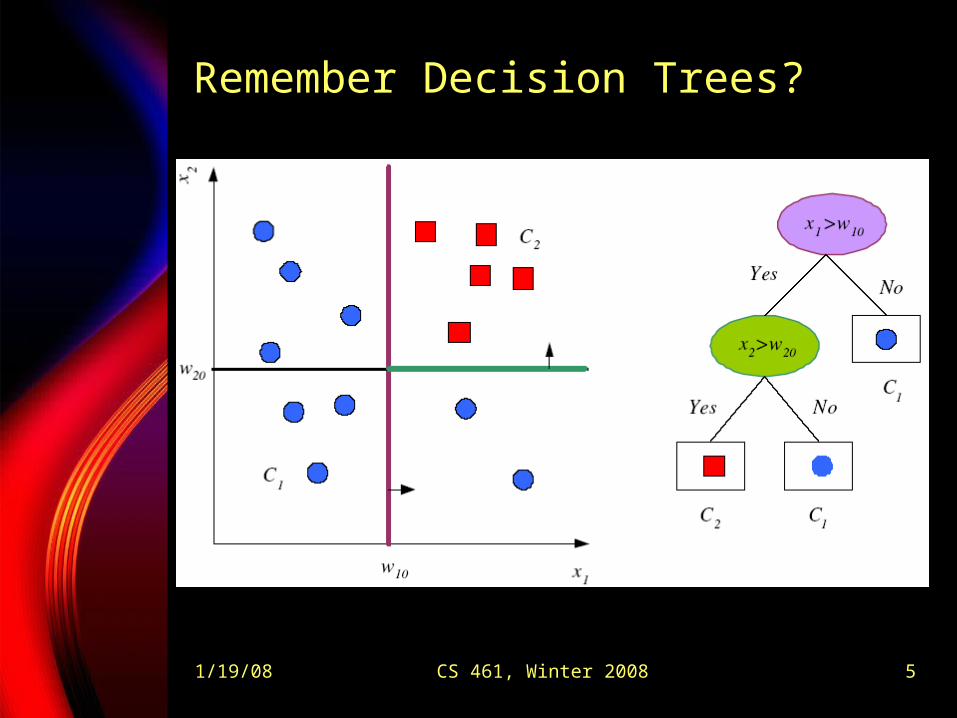
Bias and Variance
[http://www.aiaccess.net/e_gm.htm]
Linear:
High bias, low variance
Data Set 1 Data Set 2
Polynomial:
Low bias, high variance

1/19/08 CS 461, Winter 2008 9
Evaluating a Single Algorithm
Chapter 14Chapter 14
1/19/08 CS 461, Winter 2008 10
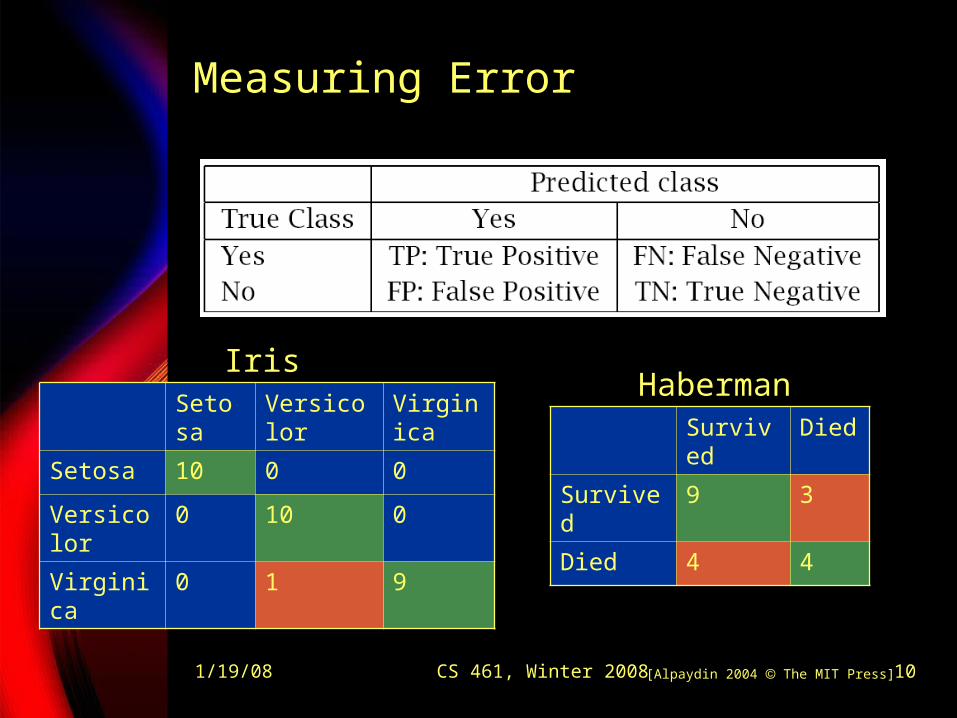
Measuring Error
[Alpaydin 2004 The MIT Press]
Setosa
Versicolor
Virginica
Setosa 10 0 0
Versicolor
0 10 0
Virginica 0 1 9
Survived
Died
Survived 9 3
Died 4 4
IrisHaberman
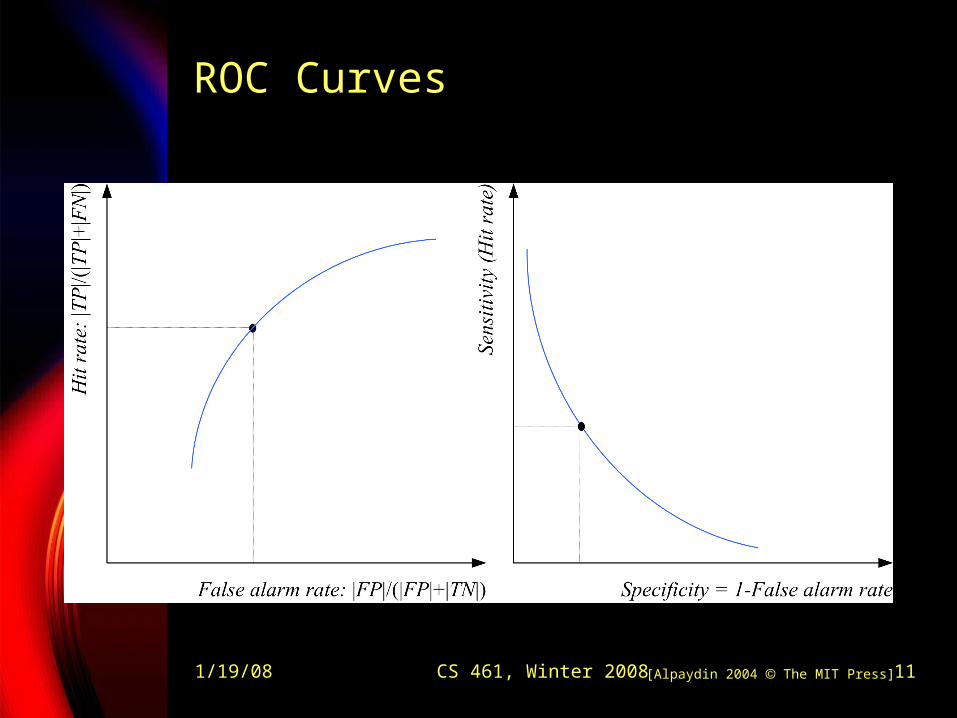
1/19/08 CS 461, Winter 2008 11
ROC Curves
[Alpaydin 2004 The MIT Press]

1/19/08 CS 461, Winter 2008 12
Example: Finding Dark Slope Streaks on Mars
Marte Vallis, HiRISE on MRO
Output of statistical landmark detector: top 10%
Results
TP: 13
FP: 1
FN: 16
Recall = 13/29 = 45%
Precision = 13/14 = 93%

1/19/08 CS 461, Winter 2008 13
Evaluation Methodology
Metrics: What will you measure? Accuracy / error rate TP/FP, recall, precision…
What train and test sets? Cross-validation LOOCV
What baselines (or competing methods)? Are the results significant?

1/19/08 CS 461, Winter 2008 14
Baselines
Simple rule “Straw man” If you can’t beat this… don’t bother!
Imagine:
vs.

1/19/08 CS 461, Winter 2008 15
Statistics
Confidence intervals Significant comparisons Hypothesis testing
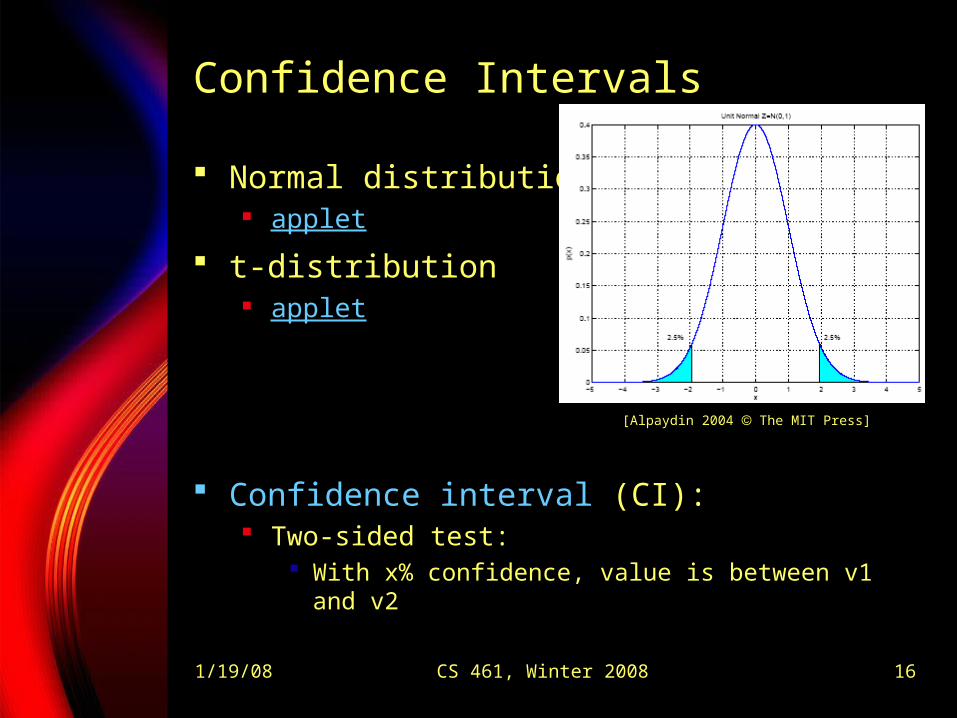
1/19/08 CS 461, Winter 2008 16
Confidence Intervals
Normal distribution applet
t-distribution applet
Confidence interval (CI): Two-sided test:
With x% confidence, value is between v1 and v2
[Alpaydin 2004 The MIT Press]

1/19/08 CS 461, Winter 2008 17
CI with Known Variance
Known variance (use normal dist): CI applet( )
( )
α−=⎭⎬⎫
⎩⎨⎧ σ
+<μ<σ
−
=⎭⎬⎫
⎩⎨⎧ σ
+<μ<σ
−
=⎭⎬⎫
⎩⎨⎧ <
σμ−
<−
σμ−
αα 1
950961961
950961961
22N
zmN
zmP
.N
.mN
.mP
..m
N.P
~m
N
//
Z
[Alpaydin 2004 The MIT Press]

1/19/08 CS 461, Winter 2008 18
CI with Unknown Variance
Unknown variance (use t-dist): CI applet
( ) ( ) ( )
α−=⎭⎬⎫
⎩⎨⎧ +<μ<−
μ−−−=
−α−α
−∑
1
1
1212
1
22
N
Stm
N
StmP
t~SmN
N/mxS
N,/N,/
Nt
t
[Alpaydin 2004 The MIT Press]
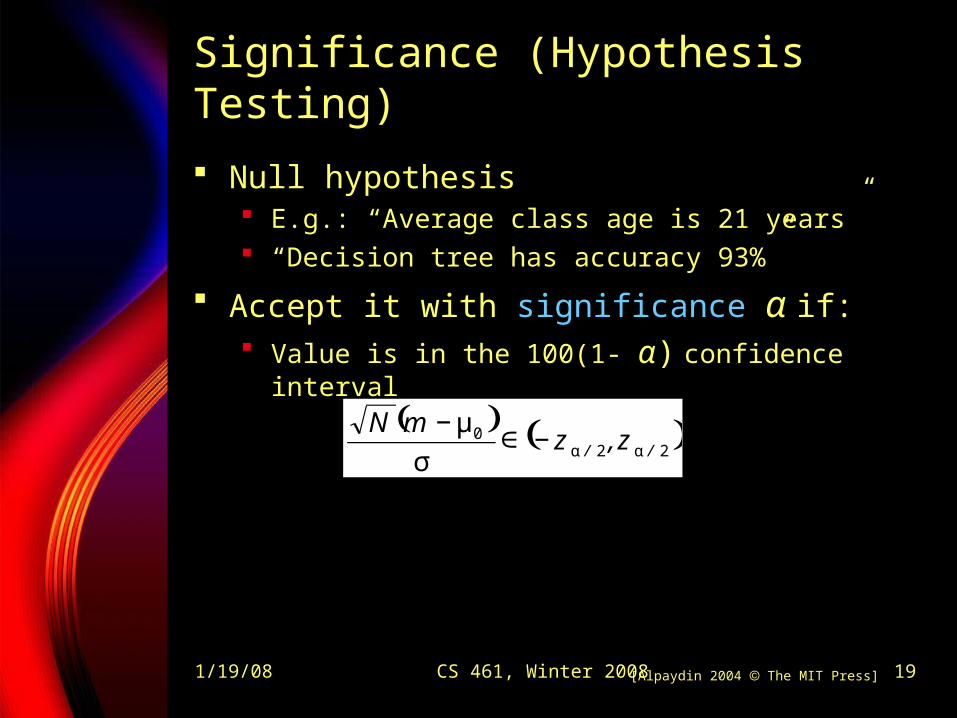
1/19/08 CS 461, Winter 2008 19
Significance (Hypothesis Testing)
Null hypothesis E.g.: “Average class age is 21 years” “Decision tree has accuracy 93%”
Accept it with significance α if: Value is in the 100(1- α) confidence interval
[Alpaydin 2004 The MIT Press]
( ) ( )220
// z,zmN
αα−∈σ
μ−

1/19/08 CS 461, Winter 2008 20
Significance with Cross-Validation: t-test K folds = K train/test pairs
m = mean error rate S = std dev of error rate p0 = hypothesized error rate
Accept with significance α if:
is less than tα,K-1
( )1
0−
−Kt~
SpmK

1/19/08 CS 461, Winter 2008 21
Comparing Two Algorithms
Chapter 14Chapter 14

1/19/08 CS 461, Winter 2008 22
Machine Learning Showdown!
McNemar’s Test
Under H0, we expect e01= e10=(e01+ e10)/2
( ) 21
1001
2
1001 1X~
ee
ee
+
−−Accept if < X2
α,1
[Alpaydin 2004 The MIT Press]

1/19/08 CS 461, Winter 2008 23
K-fold CV Paired t-Test
Use K-fold CV to get K training/validation folds
pi1, pi
2: Errors of classifiers 1 and 2 on fold i
pi = pi1 – pi
2 : Paired difference on fold i
The null hypothesis is whether pi has mean 0
[Alpaydin 2004 The MIT Press]
( )
( ) ( )12121
1
2
21
00
inif Accept0
1
0 vs.0
−−−
==
−⋅
=−
−
−==
≠=
∑∑
K,/K,/K
K
i i
K
i i
t,tt~s
mKsmK
K
mps
K
pm
:H:H
αα
μμ
Note: this tests whether they are the same!

1/19/08 CS 461, Winter 2008 24
Support Vector Machines
Chapter 10Chapter 10

1/19/08 CS 461, Winter 2008 25
Linear Discrimination Model class boundaries (not data
distribution) Learning: maximize accuracy on labeled
data Inductive bias: form of discriminant used
€
g x |w,b( ) = wTx + b = wii=1
d
∑ x i + b
( )⎩⎨⎧ >
otherwise
0if choose
2
1
C
gC x
[Alpaydin 2004 The MIT Press]
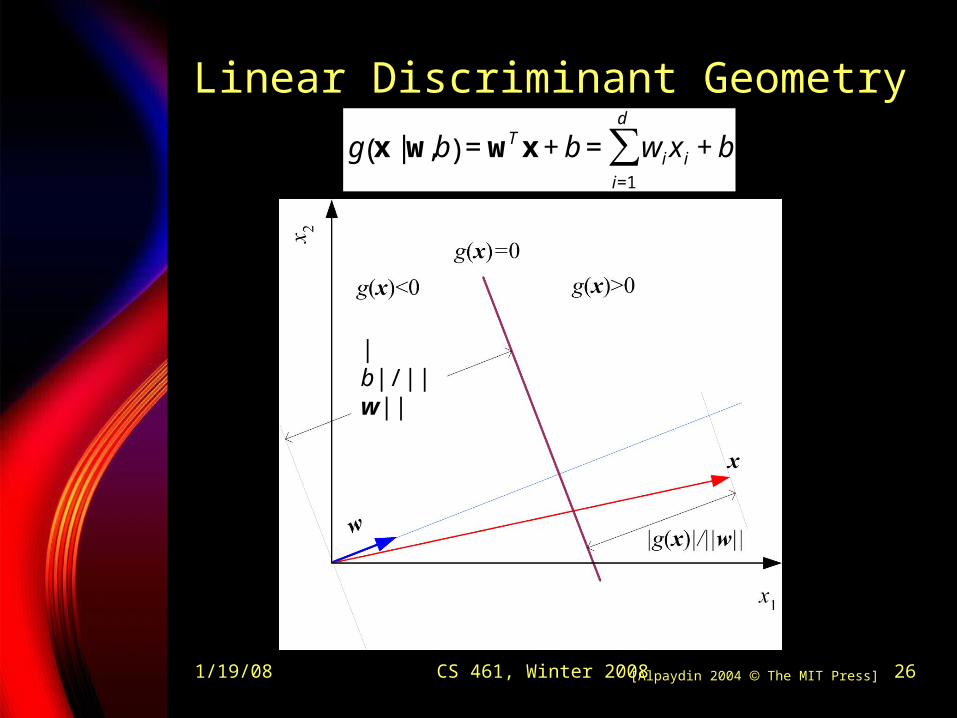
1/19/08 CS 461, Winter 2008 26
Linear Discriminant Geometry
[Alpaydin 2004 The MIT Press]
€
g x |w,b( ) = wTx + b = wii=1
d
∑ x i + b
|b|/||w||

1/19/08 CS 461, Winter 2008 27
Multiple Classes
€
gi x |wi,bi( ) = wiTx + bi
Classes arelinearly separable
( ) ( )xx j
K
ji
i
gg
C
1max
if Choose
==
[Alpaydin 2004 The MIT Press]

1/19/08 CS 461, Winter 2008 28
Multiple Classes, not linearly separable
… but pairwise linearly separable Use a one-vs.-one (pairwise) approach
€
gij x |wij ,bij( ) = wijTx + bij
( )⎪⎩
⎪⎨
⎧∈≤∈>
=otherwisecare tdon'
if 0
if 0
j
i
ij C
C
g x
x
x
( ) 0
if choose
>≠∀ xij
i
g,ij
C
[Alpaydin 2004 The MIT Press]

1/19/08 CS 461, Winter 2008 29
How to find best w, b?
E(w|X) is error with parameters w on sample X
w*=arg minw E(w | X) Gradient
Gradient-descent: Starts from random w and updates w iteratively in the negative direction of gradient
T
dw w
E,...,
wE
,wE
E ⎥⎦
⎤⎢⎣
⎡
∂∂
∂∂
∂∂
=∇21
[Alpaydin 2004 The MIT Press]
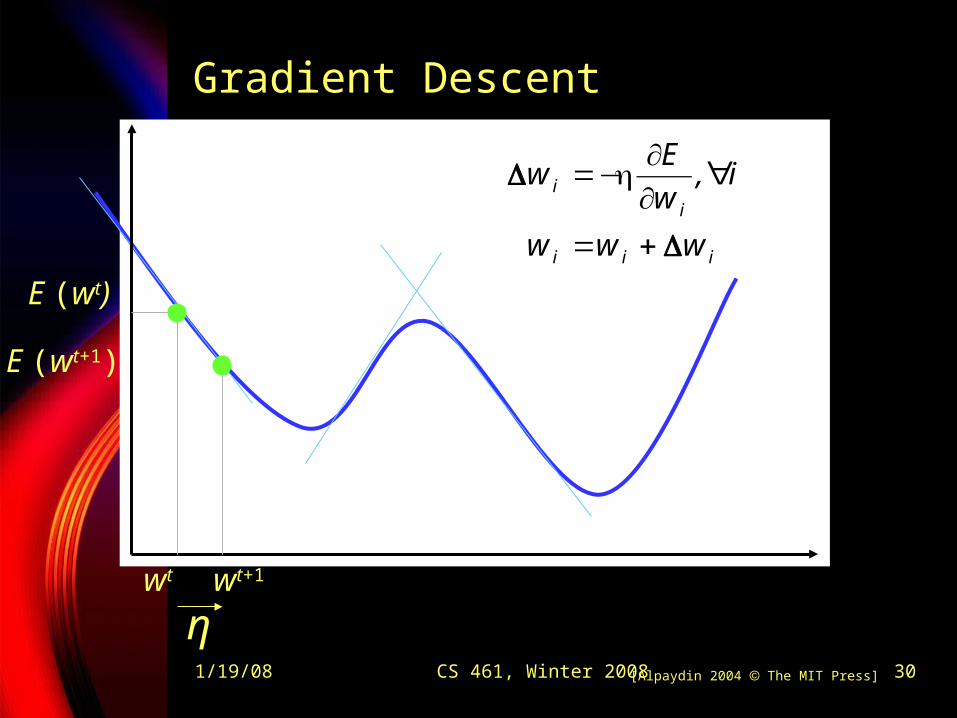
1/19/08 CS 461, Winter 2008 30
Gradient Descent
[Alpaydin 2004 The MIT Press]
wt wt+1
η
E (wt)
E (wt+1)
iii
ii
www
i,wE
w
Δ
Δ
+=
∀∂∂
η−=

1/19/08 CS 461, Winter 2008 31
Support Vector Machines
Maximum-margin linear classifiers [Andrew Moore’s slides]
How to find best w, b? Quadratic programming:
€
min 1
2w
2 subject to y t wTx t + b( ) ≥ +1,∀ t

1/19/08 CS 461, Winter 2008 32
Optimization (primal formulation)
Must get training data right!
N + d +1 parameters
[Alpaydin 2004 The MIT Press]
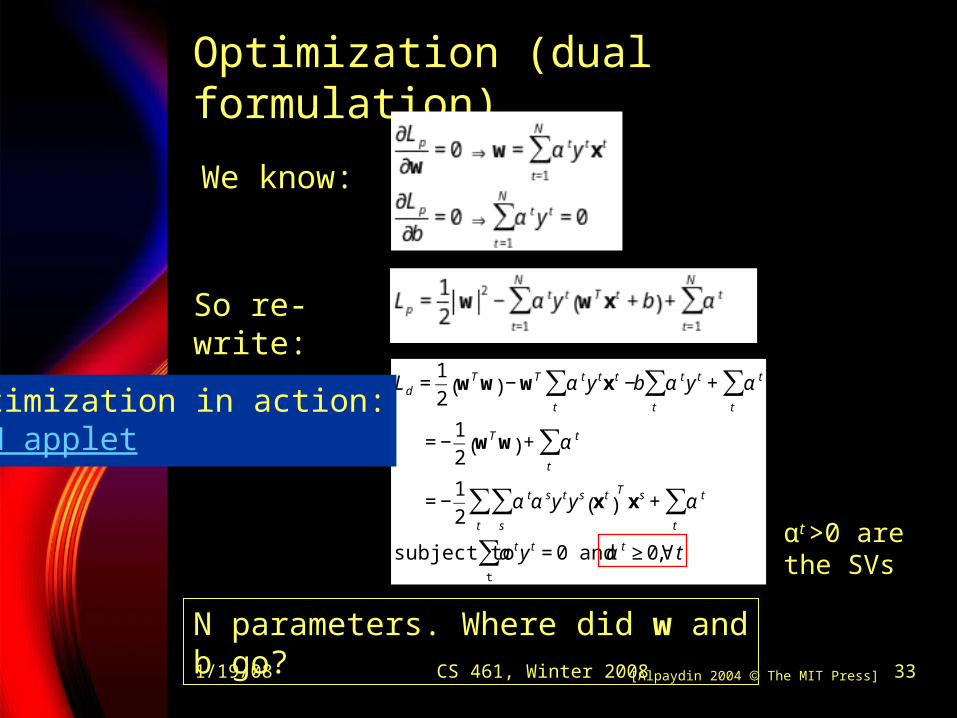
1/19/08 CS 461, Winter 2008 33
Optimization (dual formulation)
€
Ld =1
2wTw( ) −wT α ty tx t −
t
∑ b α ty t + α t
t
∑t
∑
= −1
2wTw( ) + α t
t
∑
= −1
2α tα s
s
∑t
∑ y ty s x t( )Tx s + α t
t
∑
subject to α ty t = 0 and α t ≥ 0,∀ tt
∑
[Alpaydin 2004 The MIT Press]
N parameters. Where did w and b go?
We know:
So re-write:
αt >0 are the SVs
Optimization in action:SVM applet

1/19/08 CS 461, Winter 2008 34
What if Data isn’t Linearly Separable?
1. Add “slack” variables to permit some errors [Andrew Moore’s slides]
2. Embed data in higher-dimensional space Explicit: Basis functions (new features) Implicit: Kernel functions (new dot product) Still need to find a linear hyperplane

1/19/08 CS 461, Winter 2008 35
SVM in Weka
SMO: Sequential Minimal Optimization Faster than QP-based versions Try linear, RBF kernels

1/19/08 CS 461, Winter 2008 36
Summary: Key Points for Today
Decision trees Regression trees, pruning
Evaluation One classifier: errors, confidence intervals,
significance Comparing two classifiers
Support Vector Machines Classification
Linear discriminants, maximum margin Learning (optimization) Non-separable classes

1/19/08 CS 461, Winter 2008 37
Next Time
Neural Networks (read Ch. 11.1-11.8)
Questions to answer from the reading Posted on the website (calendar)
Recommended