
Natural Language
Engineering
Daniela GÎFU
http://profs.info.uaic.ro/~daniela.gifu/
“ALEXANDRU IOAN CUZA” UNIVERSITATY OF IAŞI
FACULTY OF COMPUTER SCIENCE

2
Laboratory 5 Word Sense Disambiguation

What is this lab. about?
Meaning and Natural Language Processing (NLP)
Computational Semantics
Computational Pragmatics
3
Familiarization with relevant Terminology
• Semantics
• Pragmatics
• Natural language
• Computational Linguistics
• Natural Language Processing
…
4
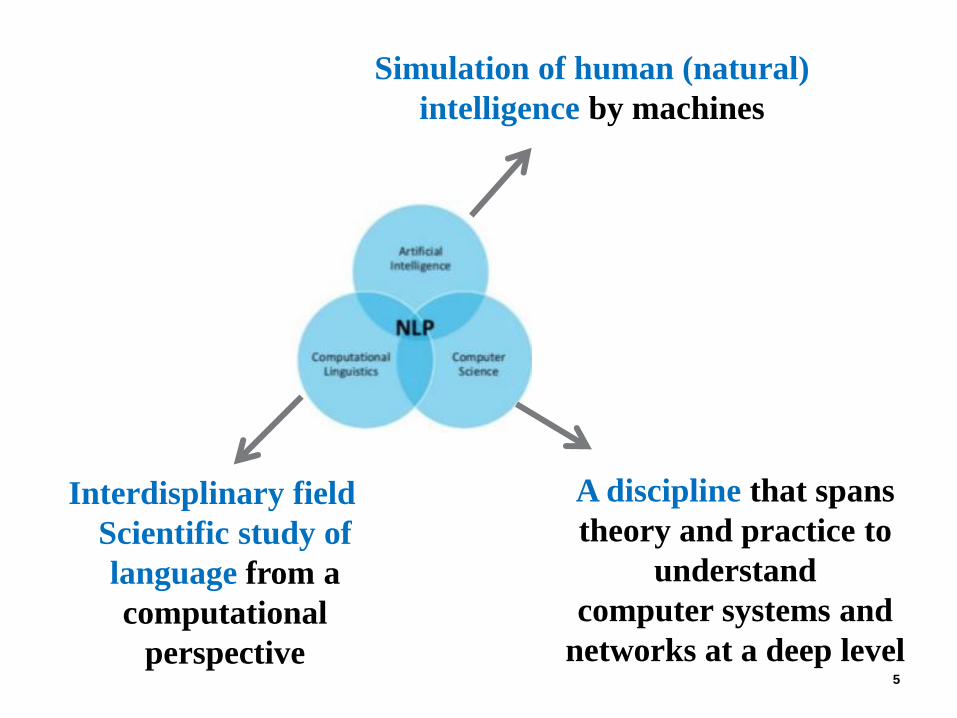
Simulation of human (natural)
intelligence by machines
Interdisplinary field ~
Scientific study of
language from a
computational
perspective
A discipline that spans
theory and practice to
understand
computer systems and
networks at a deep level 5

- Covers computer understanding and manipulation of human language.
Ex: printing press
- A way for computers to analyze, understand, and derive meaning from human language.
Ex: automatic summarization, translation, named entity recognition, relationship extraction, sentiment analysis, speech recognition, and topic segmentation.
- Considers the hierarchical structure of language.
Ex: several words = a clause
several clauses = a sentence/phrase
several sentences = an idea
NLP – intersection of CS, AI and CL
NLP systems = correcting
grammar, converting
speech to text, etc.

CL = gives theoretical background (computational
theories on language), linguistics models.
NLP = applied CL, including:
- natural language technology (NLT)
- human language technology (HLT)
7
The research domain

Spoken language
- speech processing (from speech to text to syntax and
semantics to speech)
Written language – my area of interest
Language in correlation with other modalities
(multimodality)
- speech
- intonation
- image
8
Natural language technology

Document segmentation and interpretation
– cleaning (elimination of dots, enhancing contrast,
etc.)
– separation of text from image, curved lines...
– recognizing printed, semi-uncial characters, etc.
• Optical Character Recognition (OCR)
~ 100% accuracy in scanning printed Latin script
based material
Challenge in OCR
9
Written language technologies
Students?
10
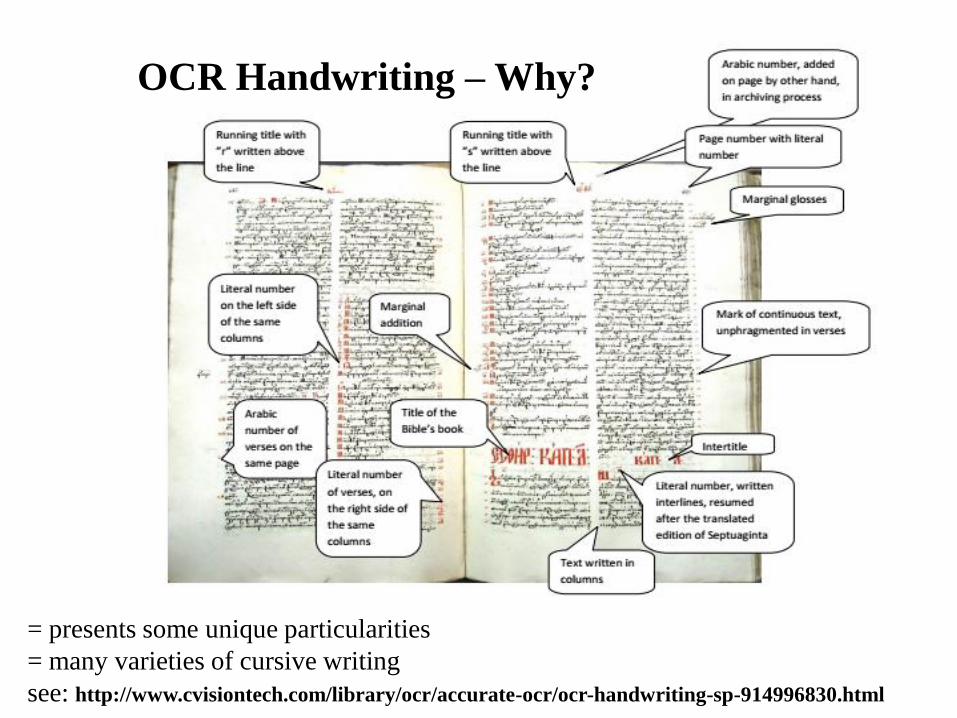
OCR Handwriting – Why?
= presents some unique particularities
= many varieties of cursive writing
see: http://www.cvisiontech.com/library/ocr/accurate-ocr/ocr-handwriting-sp-914996830.html

•Analysis and understanding of written language
– sub-syntactic processing
• lexical units
• sentence splitting
• clause borders
• part of speech and morphological information
• lemmas
• entity names
• groups (nominal, verbal, prepositional, etc.) and
-lexical attractions (ex. collocations – verbal: “verb +
complement”, “noun + verb”) to make (WordNet 3.1):
1st sense: (v) make#1, do#1 (engage in) "make love, not war"; "make an effort";
"do research"; "do nothing"; "make revolution".
2nd sense: (v) make#16 (perform or carry out) "make a decision"; "make a move";
"make advances"; "make a phone call". 11
Written language technologies

• Language analysis and understanding
- semantic and discourse processing
• semantic disambiguation → word senses
• semantic roles labeling
• rhetorical structure of discourse and dialogue
• anaphora resolution
• text summarization
12
Written language technologies

13
NLP – a subdomain of Artificial Intelligence and
Linguistics
1. Thematic Areas
- Linguistics - mathematical linguistics - computational
linguistics
- Formal Language
- Linguistic and Language Processing
- The grammatical structure of utterances: the sentence,
constituents, phrase, classifications and structural rules,
syntactic processing ...
- Parser
- Semantics (meaning) & Pragmatics
(understanding)

14
Linguistic and Language Processing
1. Linguistics = science of language.
Includes:
Sounds (phonology)
Word formation (morphology)
Sentence structure (syntax)
Meaning (semantics) and understanding (pragmatics)…
2. Levels of linguistic analysis
- Higher level → Speech Recognition (SR)
- Lower levels → Natural Language Processing (NLP)

15
Levels of Linguistic Analysis
NLP
Letters - strings
Morphemes
Words
Phrases & sentences
Meaning out of context
Meaning in context
Phones
Acoustic signal
SR
Phonetics – production and perception of speech
Phonology – Sound patterns of language
Lexicon – Dictionary of words in a language
Morphology – Word formation and structure
Syntax – Sentence structure
Semantics – Intended meaning
Pragmatics – Understanding from external info

16
A semantic scope ambiguity….
Big challenge – Ambiguity!
Every woman loves a man.
∀x(woman(x)→ ∃y(man(y)∧loves(x,y))) ∃y(man(y)∧ ∀x(woman(x)→loves(x,y)))
… and its interaction with anaphora = NP (pronoun, definite NP,
proper name)
Every team worked on a project. It was about computational
semantics.
The politician made a speech. It was about terrorism.
Students?
17
Steps of NLP - 1 1. Semantic Analysis
- Derives an absolute (dictionary definition) meaning from the
context
- The structure created by the syntactic analyzer are assigned
meaning. A mapping is made between the syntactic structure
and objects in the task domain.
Ex: “Colourless green ideas sleep furiously” – correct? (Noam
Chomsky, 1957).

18
Steps of NLP - 2
2. Discourse Integration
- The meaning of an individual sentence may depend on the
sentences that precede it and may influence the meaning of
the sentences that follow it.
Ex: the word “it” in the sentence, “you wanted it” depends on the
prior discourse context.

19
Steps of NLP - 3
3. Pragmatic analysis
- Derives knowledge from the external commonsense
information
- Means understanding the purposeful use of language in
situations particularly those aspects pf language which
require world knowledge
- What was said is reinterpreted to determine what was
actually meant.
Ex: “Do you know what time it is” – should be interpreted
as a request.

20
Semantics and pragmatics (S & P)

21
Word Sense Disambiguation – Lesk algorithm
(M.E. Lesk, 1986) (Vasilescu et al., 2004) https://en.wikipedia.org/wiki/Lesk_algorithm (adapted for WordNet)
function SIMPLIFIED LESK(word,sentence) returns best sense of word
best-sense <- most frequent sense for word
max-overlap <- 0
context <- set of words in sentence
for each sense in senses of word do
signature <- set of words in the gloss and examples of sense
overlap <- COMPUTEOVERLAP (signature,context)
if overlap > max-overlap then
max-overlap <- overlap
best-sense <- sense
end return (best-sense)
COMPUTEOVERLAP function returns the number of words in
common between two sets, ignoring function words or other words
on a stop list.

22
Word Sense Disambiguation – Example
the context “pine cone” (using following dictionary definitions):
PINE
1. kinds of evergreen tree with needle-shaped leaves
2. waste away through sorrow or illness
CONE
1. solid body which narrows to a point
2. something of this shape whether solid or hollow
3. fruit of certain evergreen trees
_________________________
The best intersection is Pine #1 ⋂ Cone #3 = 2.

23
Final project: SEMEVAL 2019
Groups structured by “n” students:
- Choose a task/ data set from SEMEVAL-2019 based to their
research supervised constantly - for Lab. 5 WSD using Lesk
algorithm:
http://alt.qcri.org/semeval2019/index.php?id=tasks
Methodology:
1. Extract all common nouns from a sentence;
2. Identify the correct sense of each noun in a given context;
3. Identify for each of noun the proper synonym;
4. Add new instance <synonym>…</synonym> in your XML/
JSON file for each common noun.

24
Projects steps – next time
1. Form a team...
2. Choose a task
3. Define the teamwork
4. Establish the modular structure
5. Edit a report

25
SEMEVAL-2019 - TASKS http://alt.qcri.org/semeval2019/index.php?id=tasks
Frame Semantics and Semantic Parsing
• Task 1 - Cross-lingual Semantic Parsing with UCCA (Universal
Conceptual Cognitive Annotation) = (with pilot annotation projects on
Czech, Russian and Hebrew)
Data set (training and development) – English, French, German
Useful for defining semantic evaluation measures for text-to-text generation
tasks, including: machine translation, text simplification and grammatical
error correction.
UCCA supports rapid annotation by non-experts, assisted by an accessible
annotation interface.
Use the final parsing text according to the UCCA semantic annotation and
add a new attribute: entities and relation type between entities using
triggers (could verbs a good example?).

26
SEMEVAL-2019 - TASKS
Frame Semantics and Semantic Parsing
• Task 2 - Unsupervised Lexical Semantic Frame Induction Task
Data set (training and development) – must agree to "SemEval 2019 Task 2
Evaluation Agreement" as set by LDC (Linguistics Data Consortium) to
access the Penn Treebank 3.0 (2,499 stories from a three year Wall Street
Journal (WSJ) collection of 98,732 stories for syntactic annotation).
Useful for : temporal relations based on temporal connectives or extract the
events
Homework: Extract Temporal and/ or Causal Relations between Events.

27
SEMEVAL-2019 - TASKS
Opinion, emotion and abusive language detection
• Task 3 - EmoContext: Contextual Emotion Detection in Text =
Understanding Emotions in Textual Conversations
Data set (training) – 15K records for emotion classes i.e., Happy, Sad and
Angry combined. It also contains 15K records not belonging to any of the
aforementioned emotion classes. Test Data will be released as well. Data set
can be accessed by joining LinkedIn group
(https://www.linkedin.com/groups/12133338/).
Homework: given a textual dialogue i.e. a user utterance along with two
turns of context, classifying the emotion of user utterance as one of the
emotion classes: Happy, Sad, Angry or Others.

28
SEMEVAL-2019 - TASKS
Opinion, emotion and abusive language detection
• Task 4 - Hyperpartisan News Detection
Data set (training and validation) – https://zenodo.org/record/1489920
Homework: deciding whether it follows a hyperpartisan argumentation, i.e.,
whether it exhibits blind, prejudiced, or unreasoning allegiance to one party,
faction, cause, or person.

29
SEMEVAL-2019 - TASKS
Opinion, emotion and abusive language detection
• Task 5 - Shared Task on Multilingual Detection of Hate speech against
immigrants and women in Twitter (hatEval).
Hate Speech = any communication that disparages a person or a group on
the basis of some characteristic such as: race, color, ethnicity, gender,
sexual orientation, nationality, religion, or other characteristics.
Data set (training and development) –Twitter, featured by two specific
different targets, immigrants and women, in a multilingual perspective, for
Spanish and English - https://goo.gl/forms/UPD2m8isvXMTvXV73
Homework: (a) identifying if the target of hate is a single human or a group
of persons (women or immigrants) ;
(b) identifying if the message author intends to be aggressive, harmful, or
even to incite, in various forms, to violent acts against the target.

30
SEMEVAL-2019 - TASKS
Opinion, emotion and abusive language detection
• Task 6 - OffensEval: Identifying and Categorizing Offensive Language in
Social Media
Data set (OffensEval's training, test, gold) –
https://competitions.codalab.org/competitions/20011#learn_the_details-
additional-datasets.
Useful for : temporal relations based on temporal connectives or extract the
events
Homework: (a) identifying offense, aggression, and hate speech in user-
generated content (e.g. posts, comments, microblogs, etc.);
(b) automatic classification of offense types;
(c) offense target identification.

31
SEMEVAL-2019 - TASKS
Fact vs. fiction
• Task 7 - RumourEval 2019: Determining Rumour Veracity and Support
for Rumours
Data set (training and development) – tweets -
https://groups.google.com/forum/#!forum/rumoureval.
Homework: (a) responses to a rumourous post are classified according to
stance (introduce a label with the type of interaction between a given
statement (rumourous post) and a reply post (the latter can be either direct
or nested replies using the tree-structured with 4 categories: support, deny,
query, comment) ; (b) the statements themselves are classified for veracity
(using only true/false labels for rumours using a score between 0-1).

32
SEMEVAL-2019 - TASKS
Fact vs. fiction
• Task 8 - Fact Checking in Community Question Answering Forums
Data set (training and development) – Intra-forum (from the QatarLiving).
Old threads in the forum may contain enough information to estimate the
factuality of the answers. Download an archive with QL threads:
http://alt.qcri.org/semeval2016/task3/data/uploads/QL-unannotated-data-
subtaskA.xml.zip.
Example uses of such sources are described:
https://arxiv.org/pdf/1803.03178.pdf
Homework: verifying in community question answering forums (1. decide
whether a question asks for a factual information, an opinion/advice or is
just socializing; 2. decide whether an answer to a factual question is true,
false, or does not constitute a proper answer).

33
SEMEVAL-2019 - TASKS
Information extraction and question answering
• Task 9 - Suggestion Mining from Online Reviews and Forums =
expressions of tips, advice, recommendations
Data set (training and development) – evaluating suggestion mining
systems for two domains, suggestion forums and hotel reviews.
Datasets are available at:
https://github.com/Semeval2019Task9?tab=repositories.
Use Stanford's parser for automatically splitting text into sentences.
Homework: classifying given sentences into suggestion and non-suggestion
classes using supervising machine learning or a suggestion lexicon (e.g.
recommend; recommendation; specify, etc.) .
Synonyms of suggestions: proposal, proposition, recommendation, advice,
hint, tip, clue, etc.

34
SEMEVAL-2019 - TASKS Information extraction and question answering
• Task 10 - Math Question Answering
Data set (training questions = 3000-4000 and test = over 1000) –
unabridged practice exams from various study guides, for the (now retired)
exam format administered from 2005 to 2016. Tagged questions into three
broad categories (A majority of the questions are 5-way multiple choice,
and a minority have a numeric answer. Only the Geometry subset contains
diagrams):
(a) Closed-vocabulary algebra
Ex: "Suppose 3x + y = 15, where x is a positive integer. What is the
difference between the largest possible value of y and the smallest possible
value of x, assuming that y is also a positive integer?"
(b) Open-vocabulary algebra
Ex: "At a basketball tournament involving 8 teams, each team played 4
games with each of the other teams. How many games were played at this
tournament?"
(c) Geometry
Ex: "The lengths of two sides of a triangle are (x-2) and (x+2), where x >
2. Which of the following ranges includes all and only the possible values
of the third side y?"

35
SEMEVAL-2019 - TASKS
NLP for scientific applications
• Task 12 - Toponym Resolution (or geoparsing, geo-grounding or place
name resolution) in Scientific Papers
Data set (training and development) – 150 full text journal articles in open
access and downloaded from PubMed Central (PMC); scientific domain
where the resolution of the names of places is a crucial knowledge:
epidemiology.
Useful for: (a) toponym disambiguation tackles ambiguities existing
between different toponyms using GeoNames (http://www.geonames.org/.,
Google Maps and Wikipedia.
Ex: Manchester, NH USA vs. Manchester, UK (Geo-Geo ambiguities)
(b) or between toponyms and other entities,
Ex: names of people or daily life objects (Geo-NonGeo ambiguities).

Thank you!
Recommended

















