
Big Data: Hive on Spark mit Jedox nutzen
Autoren: Alexander Keidel, Michael Deuchert und Phillip Musch
Getestet mit:Jedox: 6.0, 6.0 SR1Cloudera CDH: 5.4.8
Research Paper
it-novum.com

1. Big Data-Datenbestände mit Jedox und Hive on Spark auswerten 3
2. KonfigurationvonHiveonSparkmitHilfedesClouderaClusterManager 4
3. Testen von Hive on Spark 7
4. Einrichten von Hive on Spark in Jedox 8
5. Hive on Spark mit Jedox 10
6. Messungen 11
7. Fazit 17
Inhalt
2

it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
1. Big Data-Datenbestände mit Jedox und Hive on Spark auswerten
Mit dem Release von Hive 1.1 im Januar 2015 hat Apache Spark in Hive Einzug gehalten. Bei
Apache Spark handelt es sich um ein Open Source-Projekt aus dem Bereich Cluster Computing
zur Verarbeitung von großen Datenmengen.
Im Gegensatz zu Map-Reduce über Hadoop versucht Spark, viele Operationen bei der Datenver-
arbeitungimArbeitsspeicherdurchzuführen(In-Memory)undZugriffeaufdasHDFSgeringzu
halten.FüreinigeAnwendungsfälleistesdaherbiszu100-malschnelleralsMap-Reduce.Das
betrifftinsbesondereAnwendungenmitvielenReduce-Schrittenwiesiez.B.beiderÜbersetzung
vonkomplexenQueriesoderimBusinessIntelligence-UmfeldanderTagesordnungsind.
Bislangwaresnichtmöglich,SparkinderBusinessIntelligence-PlattformvonJedoxzunutzen
undsovondenPerformancegewinnenzuprofitieren.AusdiesemGrundhabenwirdieseUn-
tersuchung gestartet: wir möchten zeigen, wie Spark in Verbindung mit Hive und mit einigen
EinschränkungenauchfürJedoxgenutztwerdenkann.Unddies,ohnedassAnpassungenan
den Queries oder in Jedox vorgenommen werden müssen.
3
it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
2. Konfiguration von Hive on Spark mit Hilfe des Cloudera Cluster Manager
DiekomfortabelsteMöglichkeit,demNutzerHive on Spark zu bieten, ist der Einsatz des Cloudera
SoftwareStacks,wieerauchbeiit-novumintensivgenutztwird.DieKonfigurationkannbequem
überdieOberflächedesClouderaClusterManagerserfolgen.Zubeachtenistallerdings,dass
Hive on SparkerstabVersion5.4.xenthaltenistundvonClouderanochnichtfürdenProduktiv-
betriebfreigegebenwurde.Dasheißt,dassesvonClouderanochkeinenSupportfürdenEinsatz
von Hive on Spark gibt.
FürunsereTestshabenwirdieneuesteClouderaVersion(CDH5.4.8)eingesetzt.UmCloudera
entsprechendzukonfigurieren,müssenfolgendeSchrittedurchgeführtwerden:
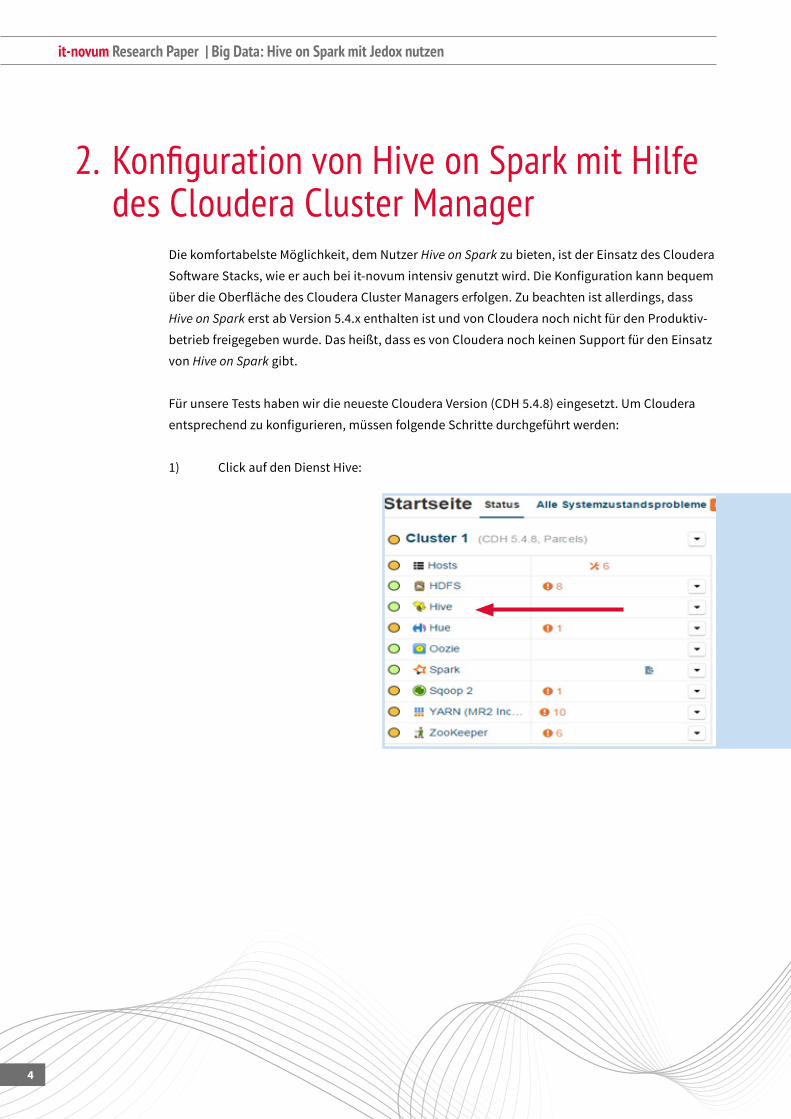
1) ClickaufdenDienstHive:
4
it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
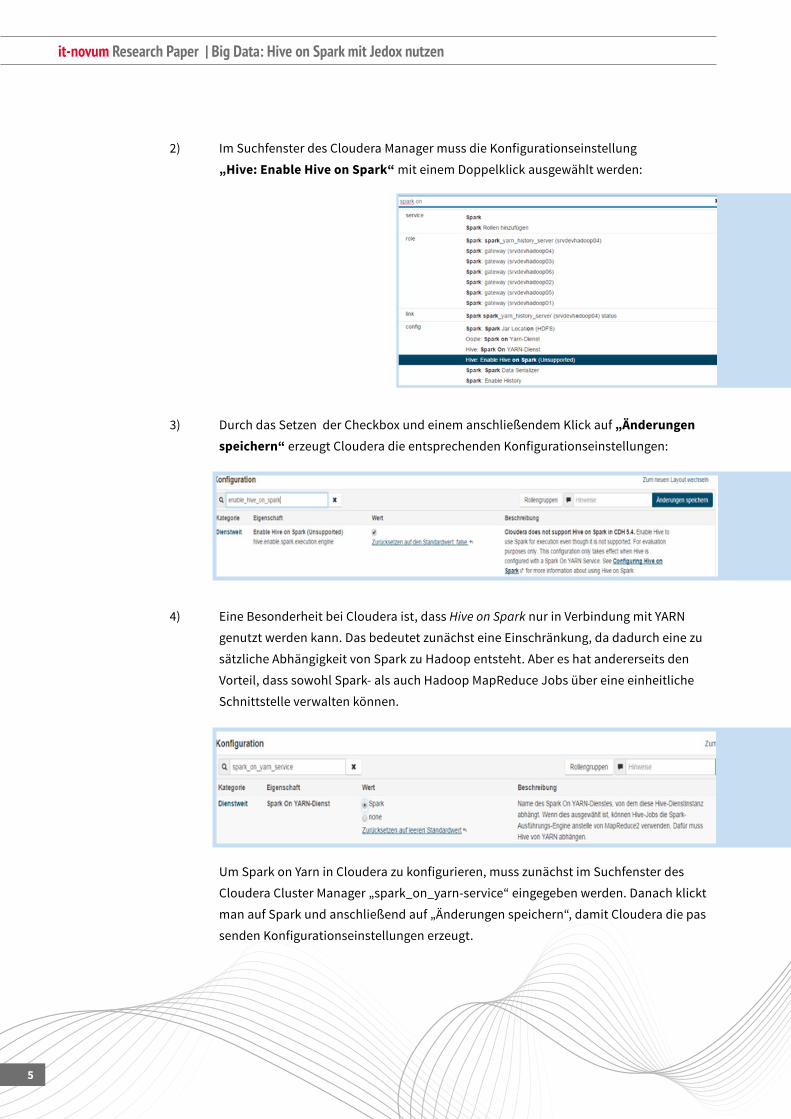
2) ImSuchfensterdesClouderaManagermussdieKonfigurationseinstellung
„Hive: Enable Hive on Spark“ mit einem Doppelklick ausgewählt werden:
3) DurchdasSetzenderCheckboxundeinemanschließendemKlickauf„Änderungen speichern“erzeugtClouderadieentsprechendenKonfigurationseinstellungen:
4) EineBesonderheitbeiClouderaist,dassHive on SparknurinVerbindungmitYARN
genutzt werden kann. Das bedeutet zunächst eine Einschränkung, da dadurch eine zu
sätzliche Abhängigkeit von Spark zu Hadoop entsteht. Aber es hat andererseits den
Vorteil, dass sowohl Spark- als auch Hadoop MapReduce Jobs über eine einheitliche
Schnittstelle verwalten können.
UmSparkonYarninClouderazukonfigurieren,musszunächstimSuchfensterdes
ClouderaClusterManager„spark_on_yarn-service“eingegebenwerden.Danachklickt
manaufSparkundanschließendauf„Änderungenspeichern“,damitClouderadiepas
sendenKonfigurationseinstellungenerzeugt.
5
it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
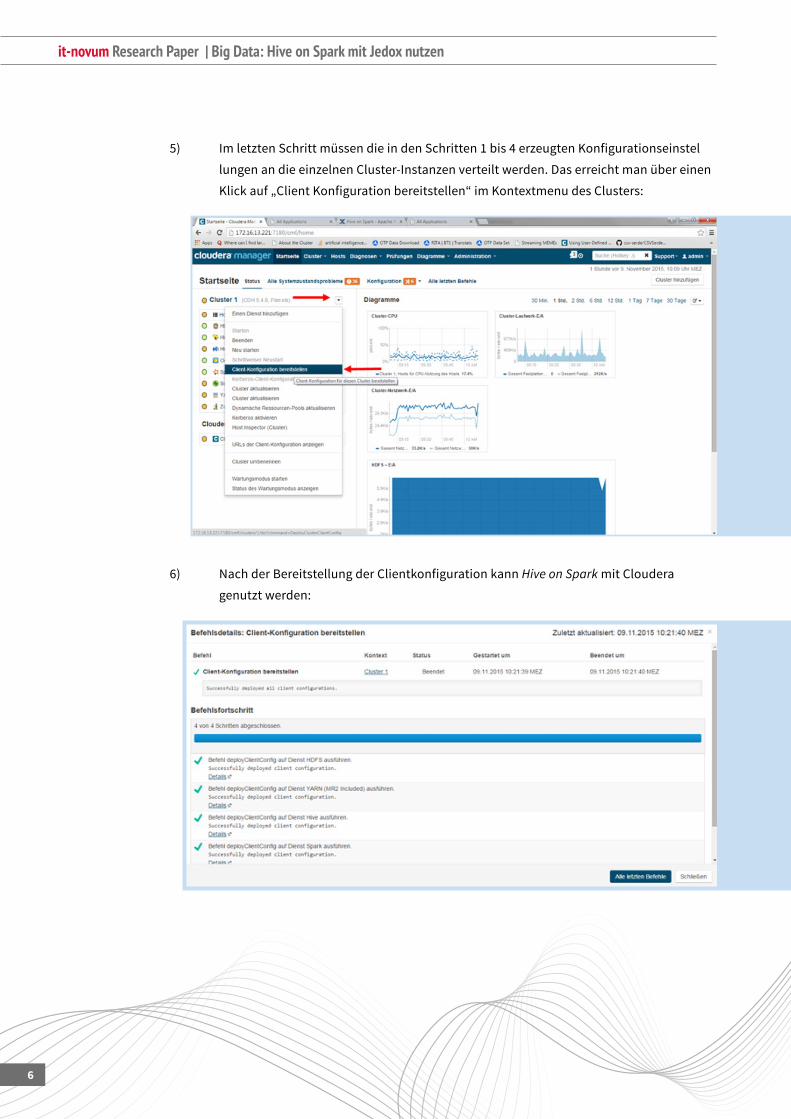
5) ImletztenSchrittmüssendieindenSchritten1bis4erzeugtenKonfigurationseinstel
lungen an die einzelnen Cluster-Instanzen verteilt werden. Das erreicht man über einen
Klickauf„ClientKonfigurationbereitstellen“imKontextmenudesClusters:
6) NachderBereitstellungderClientkonfigurationkannHive on Spark mit Cloudera
genutzt werden:
6

it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
3. Testen von Hive on SparkDasTestenderunterAbschnitt1erzeugtenKonfigurationerfolgtameinfachstenüberdieHive
Shell.DazumusstzunächstdieHiveExecutionEnginegeändertwerden;dieseistalsDefaultauf
MapReduceüberHadoopeingestellt.DerBefehl„sethive.execution.engine=spark“inderShell
ändertdiehive.executionenginefürdiejeweiligeSessionaufSpark:
hive>set hive.execution.engine=spark;
EineQuery,wiebeispielsweisezumAnzeigenderZeilenanzahl:
hive> select count (*) as num_row from mytable;
erzeugt nun einen Spark Job, der im Yarn Job Tracker angezeigt wird.
Hinweis:Querieswiez.B.Select*Frommy_tableerzeugeninHivekeinenMapReduceoder
SparkJob,dasietechnischgesehenlediglicheinLesenderHDFS-Dateidarstellen,diefürdie
Tabelle hinterlegt ist.
7
it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
4. Einrichten von Hive on Spark in JedoxUm Hive on Spark mit Jedox nutzen zu können, benötigen wir zusätzlich den Jedox Hadoop
Connector. In Version 6 von Jedox muss er als zusätzliches Package installiert werden. Es kann
nuneineStandardHiveVerbindung(überMapReduce)mitdemneuenVerbindungstyp„Hive“
angelegt werden. In Jedox stellen wir zunächst im ersten Schritt eine Verbindung zu Hive her
undsetzenanschließenddieHiveExecutionEngineaufSpark.DasistinJedoxmomentannur
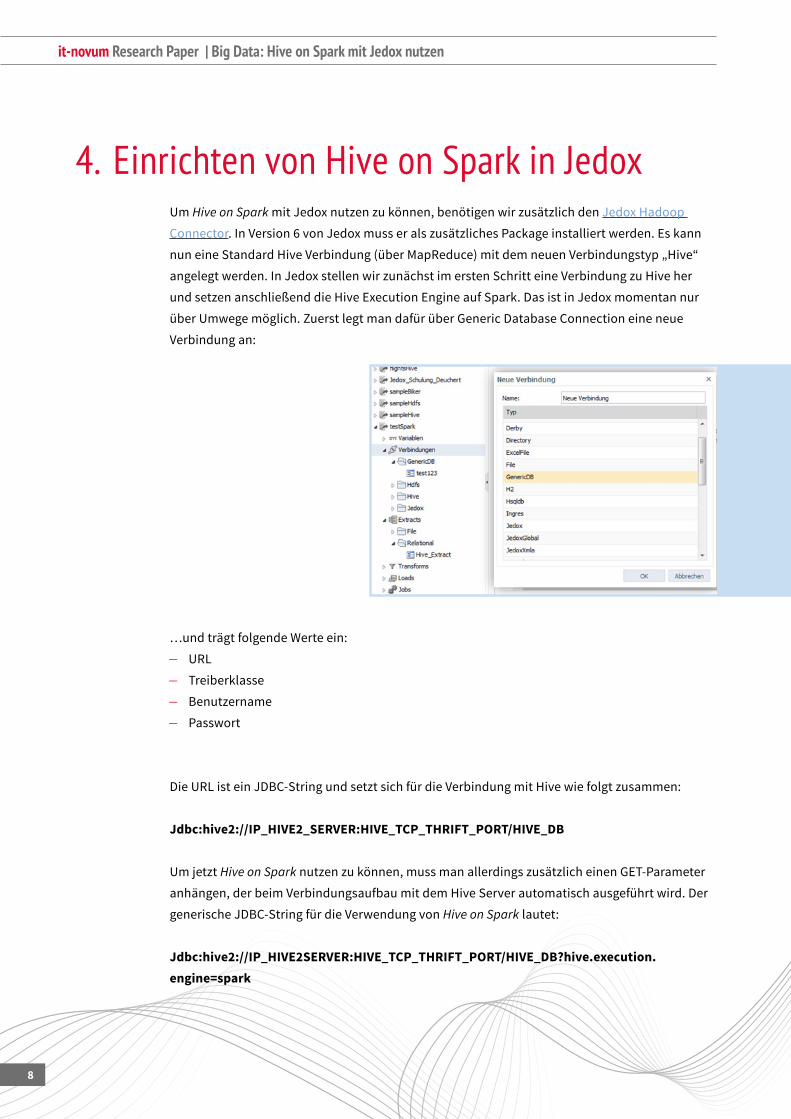
überUmwegemöglich.ZuerstlegtmandafürüberGenericDatabaseConnectioneineneue
Verbindung an:
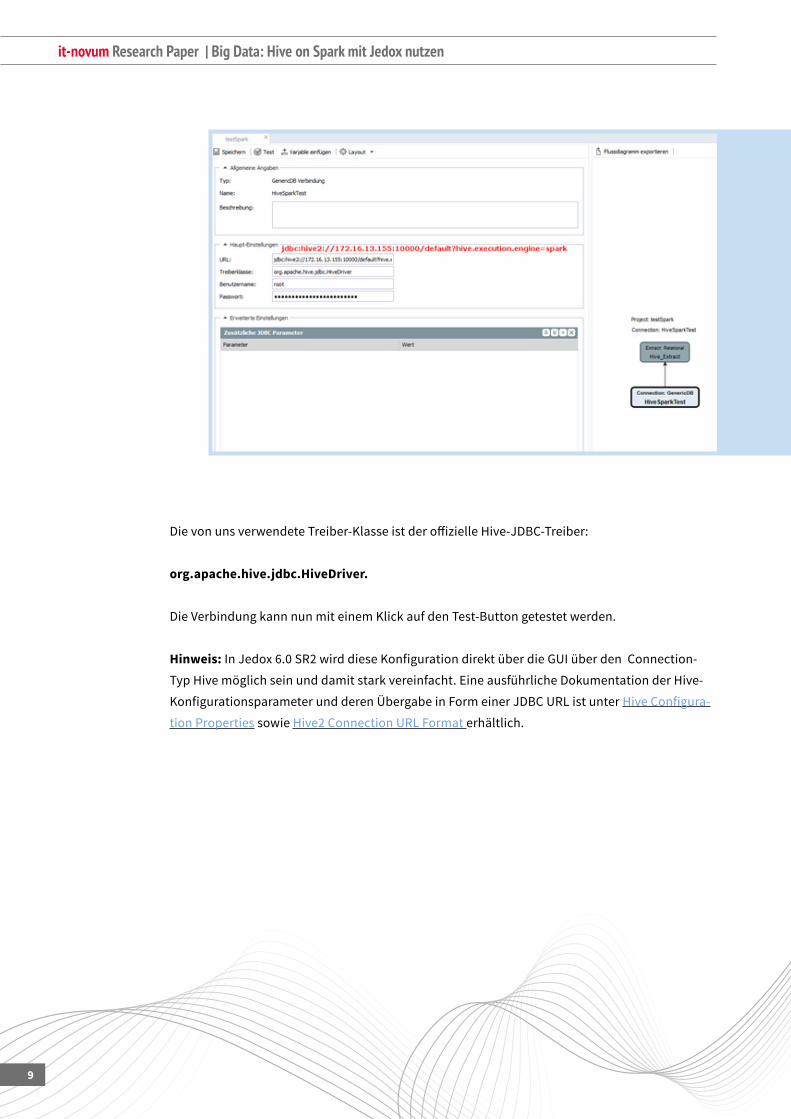
…undträgtfolgendeWerteein:
и URL
и Treiberklasse
и Benutzername
и Passwort
DieURListeinJDBC-StringundsetztsichfürdieVerbindungmitHivewiefolgtzusammen:
Jdbc:hive2://IP_HIVE2_SERVER:HIVE_TCP_THRIFT_PORT/HIVE_DB
Um jetzt Hive on Spark nutzen zu können, muss man allerdings zusätzlich einen GET-Parameter
anhängen,derbeimVerbindungsaufbaumitdemHiveServerautomatischausgeführtwird.Der
generischeJDBC-StringfürdieVerwendungvonHive on Spark lautet:
Jdbc:hive2://IP_HIVE2SERVER:HIVE_TCP_THRIFT_PORT/HIVE_DB?hive.execution.engine=spark
8
it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
DievonunsverwendeteTreiber-KlasseistderoffizielleHive-JDBC-Treiber:
org.apache.hive.jdbc.HiveDriver.
DieVerbindungkannnunmiteinemKlickaufdenTest-Buttongetestetwerden.
Hinweis:InJedox6.0SR2wirddieseKonfigurationdirektüberdieGUIüberdenConnection-
TypHivemöglichseinunddamitstarkvereinfacht.EineausführlicheDokumentationderHive-
KonfigurationsparameterundderenÜbergabeinFormeinerJDBCURListunterHiveConfigura-
tion Properties sowie Hive2 Connection URL Format erhältlich.
9
it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
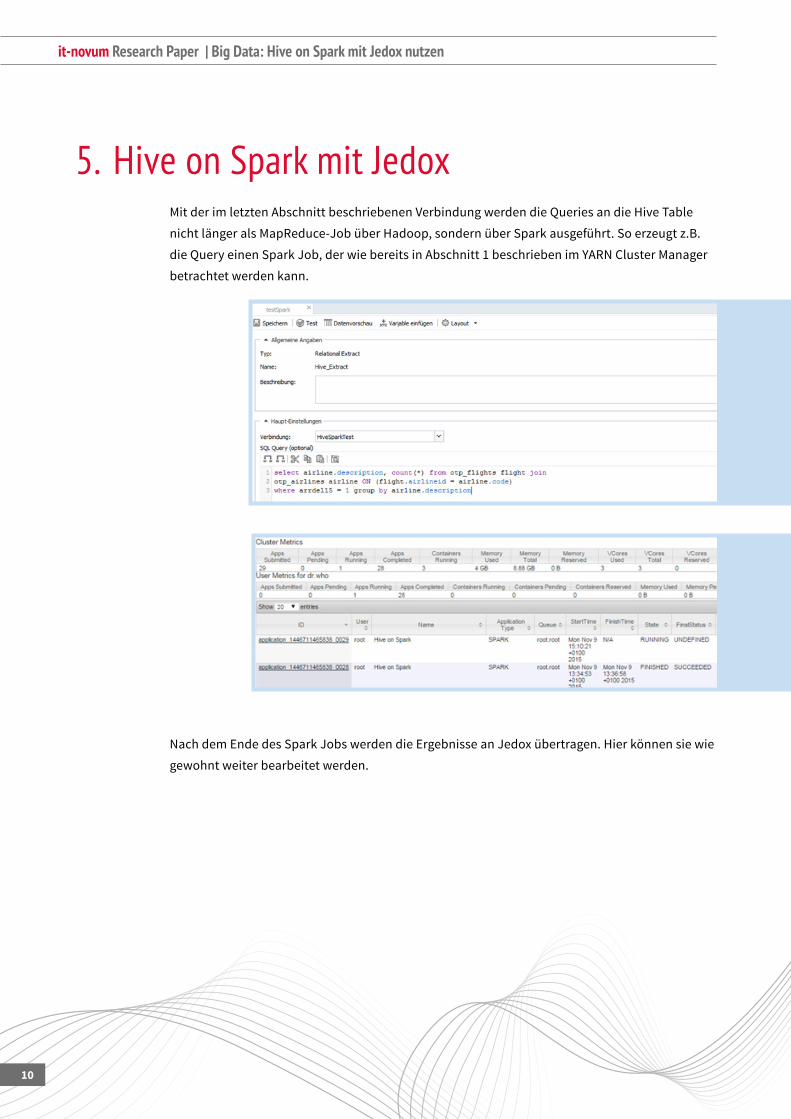
5. Hive on Spark mit JedoxMit der im letzten Abschnitt beschriebenen Verbindung werden die Queries an die Hive Table
nichtlängeralsMapReduce-JobüberHadoop,sondernüberSparkausgeführt.Soerzeugtz.B.
dieQueryeinenSparkJob,derwiebereitsinAbschnitt1beschriebenimYARNClusterManager
betrachtet werden kann.
NachdemEndedesSparkJobswerdendieErgebnisseanJedoxübertragen.Hierkönnensiewie
gewohnt weiter bearbeitet werden.
10
it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
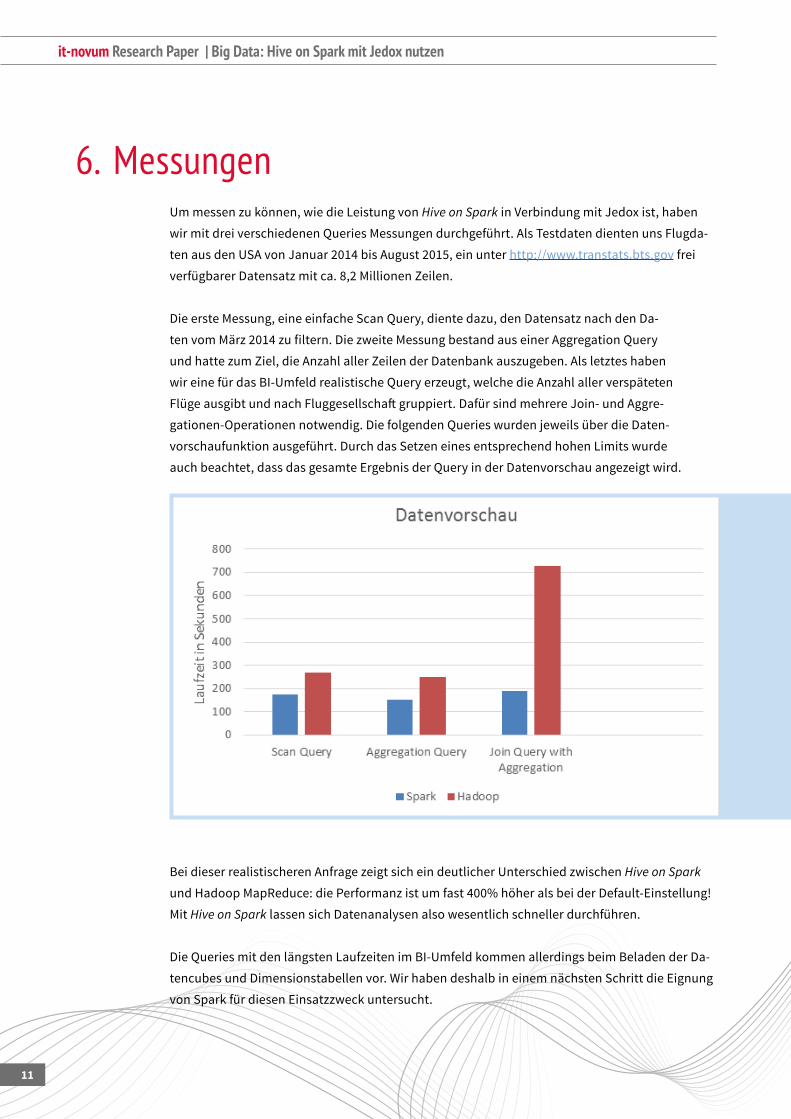
6. MessungenUm messen zu können, wie die Leistung von Hive on Spark in Verbindung mit Jedox ist, haben
wirmitdreiverschiedenenQueriesMessungendurchgeführt.AlsTestdatendientenunsFlugda-
ten aus den USA von Januar 2014 bis August 2015, ein unter http://www.transtats.bts.govfrei
verfügbarerDatensatzmitca.8,2MillionenZeilen.
DieersteMessung,eineeinfacheScanQuery,dientedazu,denDatensatznachdenDa-
tenvomMärz2014zufiltern.DiezweiteMessungbestandauseinerAggregationQuery
undhattezumZiel,dieAnzahlallerZeilenderDatenbankauszugeben.Alsletzteshaben
wireinefürdasBI-UmfeldrealistischeQueryerzeugt,welchedieAnzahlallerverspäteten
FlügeausgibtundnachFluggesellschaftgruppiert.DafürsindmehrereJoin-undAggre-
gationen-Operationennotwendig.DiefolgendenQuerieswurdenjeweilsüberdieDaten-
vorschaufunktionausgeführt.DurchdasSetzeneinesentsprechendhohenLimitswurde
auchbeachtet,dassdasgesamteErgebnisderQueryinderDatenvorschauangezeigtwird.
BeidieserrealistischerenAnfragezeigtsicheindeutlicherUnterschiedzwischenHive on Spark
undHadoopMapReduce:diePerformanzistumfast400%höheralsbeiderDefault-Einstellung!
Mit Hive on SparklassensichDatenanalysenalsowesentlichschnellerdurchführen.
DieQueriesmitdenlängstenLaufzeitenimBI-UmfeldkommenallerdingsbeimBeladenderDa-
tencubesundDimensionstabellenvor.WirhabendeshalbineinemnächstenSchrittdieEignung
vonSparkfürdiesenEinsatzzweckuntersucht.
11
it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
DazuhabenwirdiverseLoad-TypenwieDimension-Load,Cube-LoadundeineKombinationder
beidenVariantenuntersucht.ZusätzlichhabenwirdieVerarbeitungsgeschwindigkeitenbeim
Schreiben in eine Datei betrachtet. Dadurch werden eventuelle Bottlenecks z.B. durch den Lade-
prozessindieIn-memoryDBausgeschlossen.
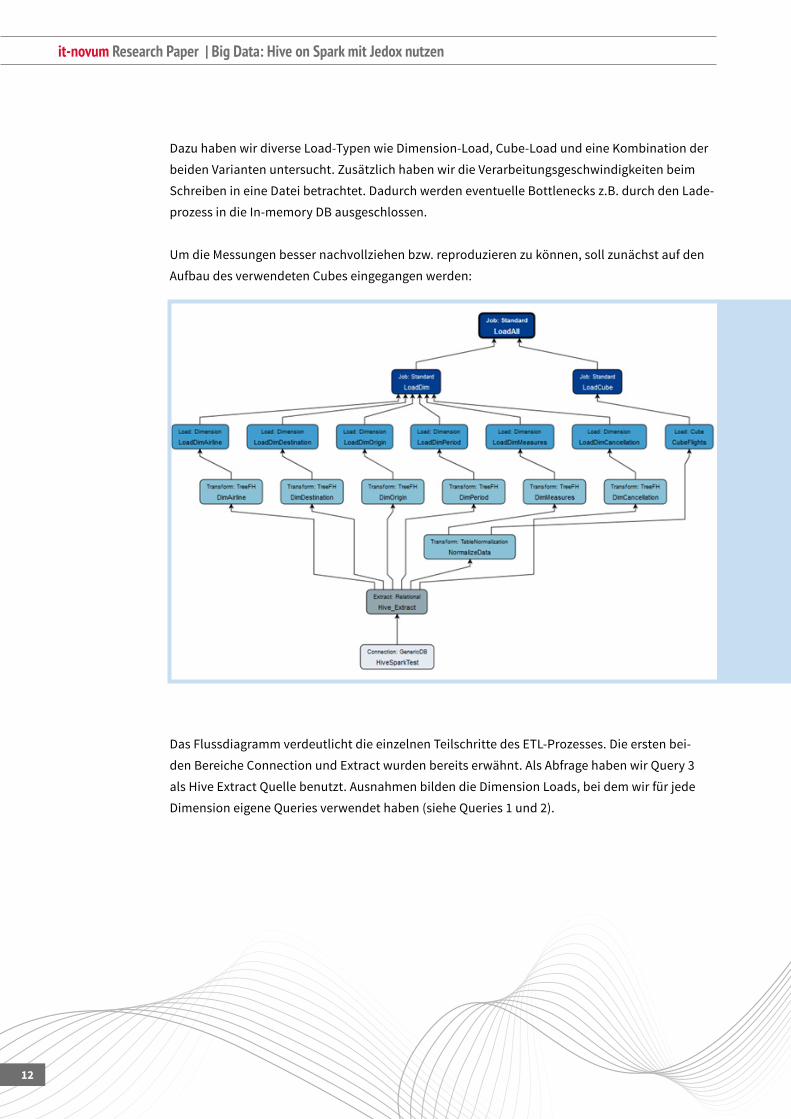
UmdieMessungenbessernachvollziehenbzw.reproduzierenzukönnen,sollzunächstaufden
AufbaudesverwendetenCubeseingegangenwerden:
Das Flussdiagramm verdeutlicht die einzelnen Teilschritte des ETL-Prozesses. Die ersten bei-
denBereicheConnectionundExtractwurdenbereitserwähnt.AlsAbfragehabenwirQuery3
alsHiveExtractQuellebenutzt.AusnahmenbildendieDimensionLoads,beidemwirfürjede
DimensioneigeneQueriesverwendethaben(sieheQueries1und2).
12
it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
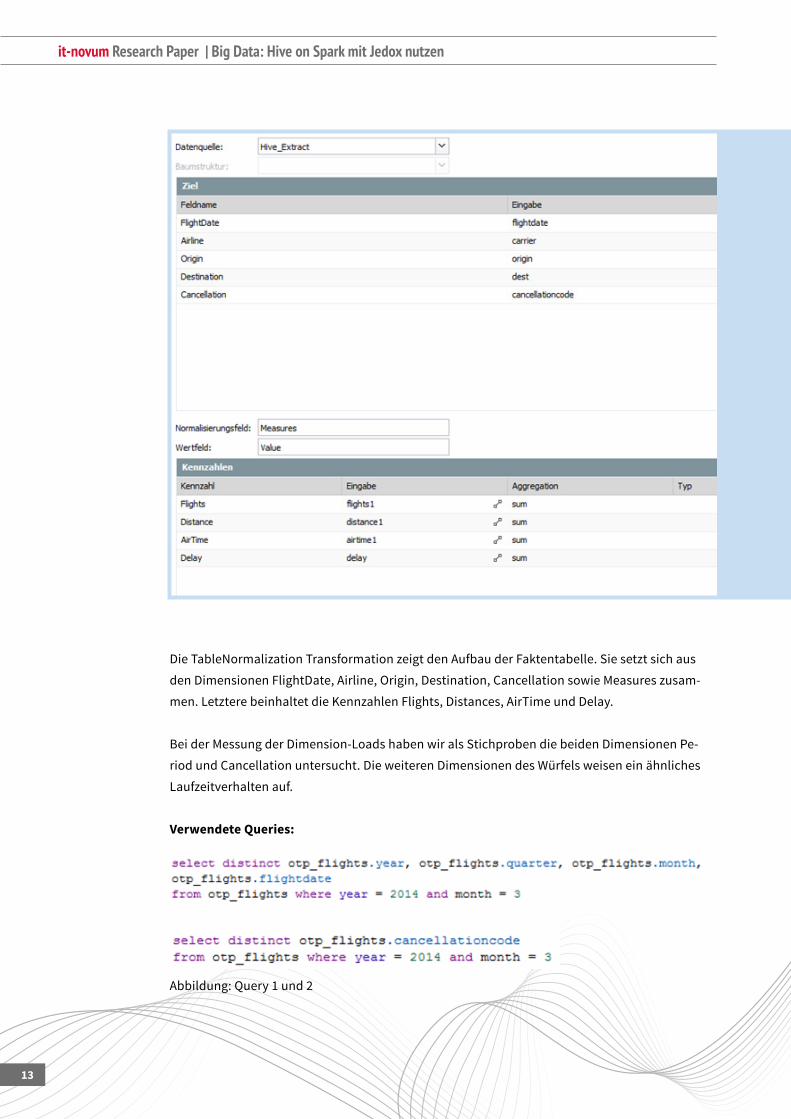
DieTableNormalizationTransformationzeigtdenAufbauderFaktentabelle.Siesetztsichaus
den Dimensionen FlightDate, Airline, Origin, Destination, Cancellation sowie Measures zusam-
men.LetzterebeinhaltetdieKennzahlenFlights,Distances,AirTimeundDelay.
Bei der Messung der Dimension-Loads haben wir als Stichproben die beiden Dimensionen Pe-
riodundCancellationuntersucht.DieweiterenDimensionendesWürfelsweiseneinähnliches
Laufzeitverhaltenauf.
Verwendete Queries:
Abbildung:Query1und2
13
it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
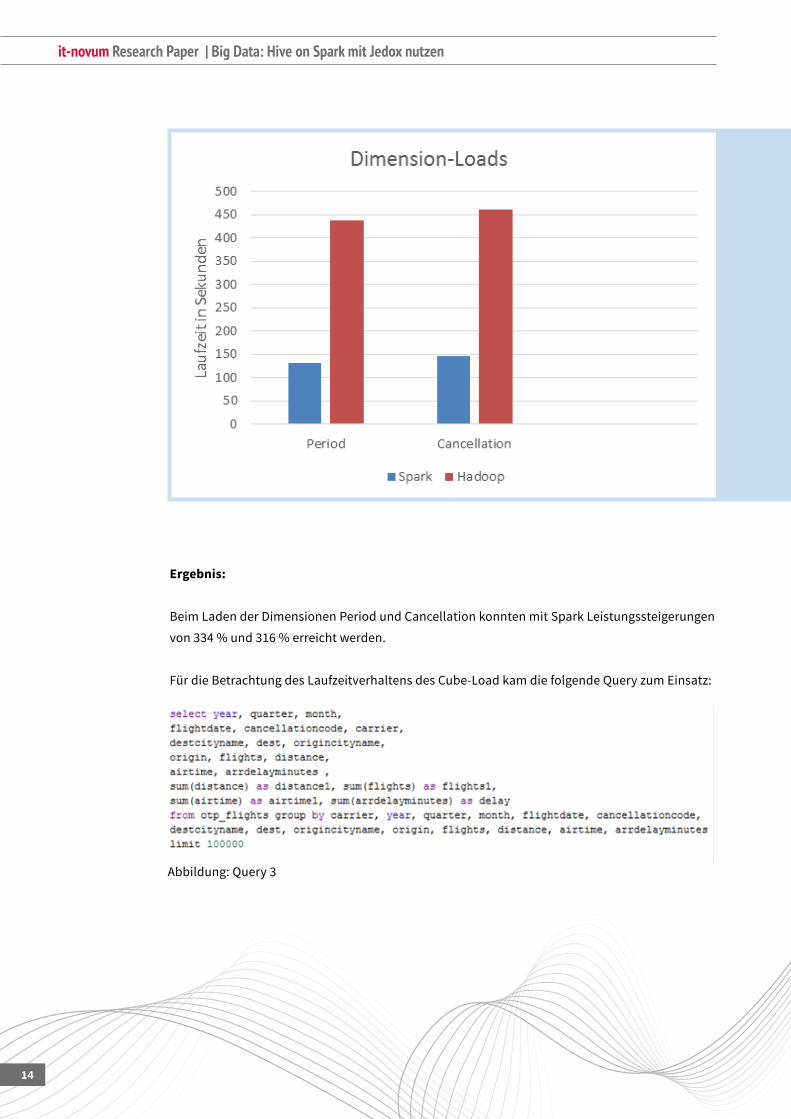
Ergebnis:
Beim Laden der Dimensionen Period und Cancellation konnten mit Spark Leistungssteigerungen
von334%und316%erreichtwerden.
FürdieBetrachtungdesLaufzeitverhaltensdesCube-LoadkamdiefolgendeQueryzumEinsatz:
Abbildung:Query3
14
it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
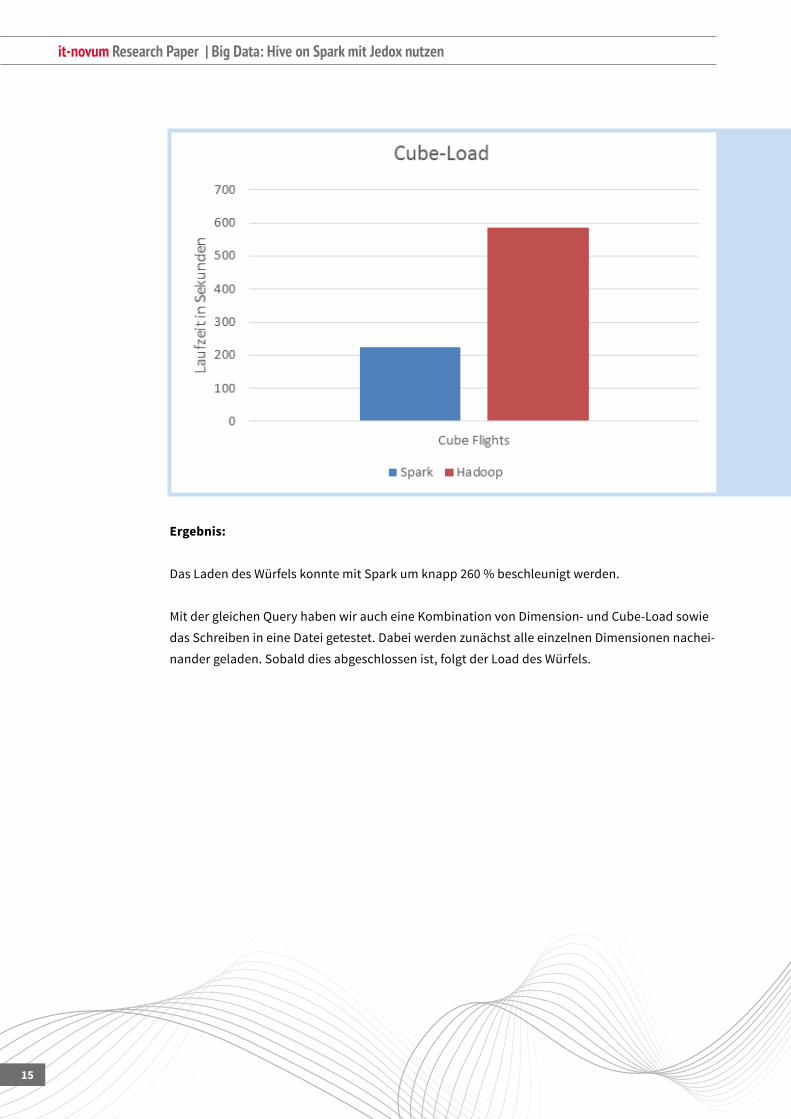
Ergebnis:
DasLadendesWürfelskonntemitSparkumknapp260%beschleunigtwerden.
MitdergleichenQueryhabenwiraucheineKombinationvonDimension-undCube-Loadsowie
das Schreiben in eine Datei getestet. Dabei werden zunächst alle einzelnen Dimensionen nachei-
nandergeladen.Sobalddiesabgeschlossenist,folgtderLoaddesWürfels.
15
it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
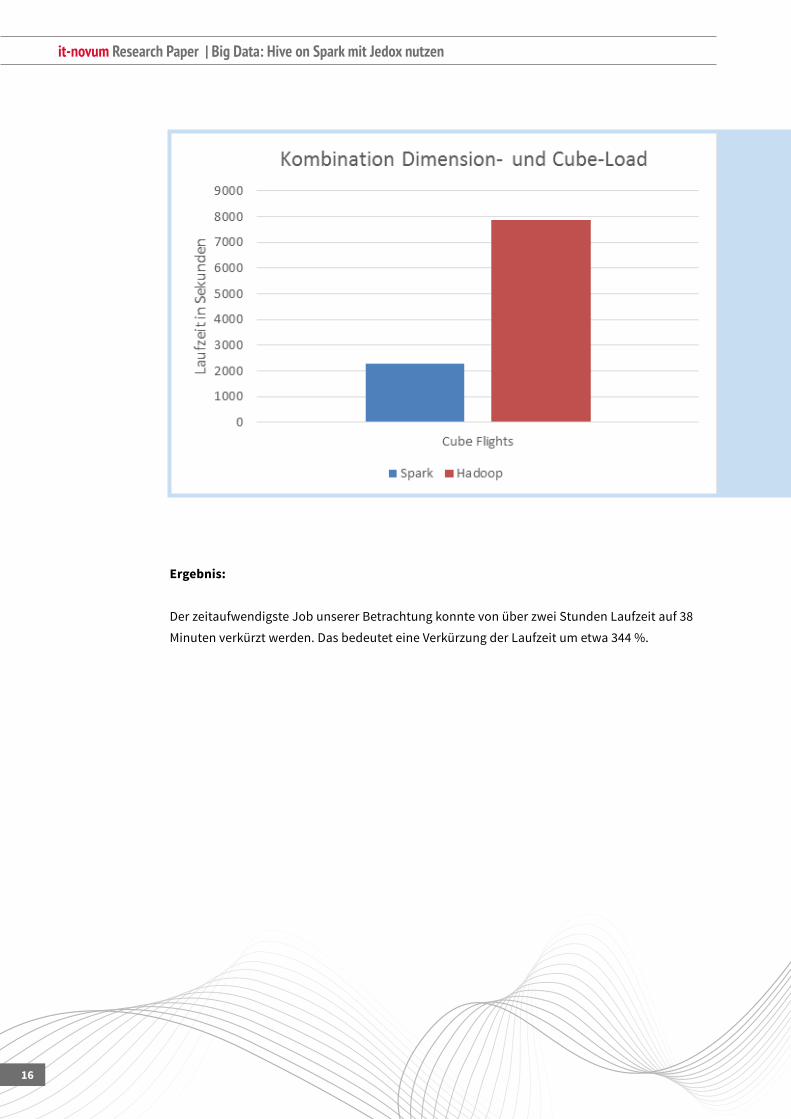
Ergebnis:
DerzeitaufwendigsteJobunsererBetrachtungkonntevonüberzweiStundenLaufzeitauf38
Minutenverkürztwerden.DasbedeuteteineVerkürzungderLaufzeitumetwa344%.
16

it-novum Research Paper | Big Data: Hive on Spark mit Jedox nutzen
7. FazitDieNutzungvonHive on SparkinVerbindungmitJedoxeröffnetganzneueMöglichkeitenfürdie
AufbereitungundAuswertungvonBigData-Datenbeständen.ObwohldievorgestellteLösung
miteinigenEinschränkungenverbundenist,zeigenunsereTests,dassmitgeringemAufwand
die Integration von Hive on SparkinJedoxmöglichist.DadurchlassensichPerformancegewinne
vonbiszu400%fürBigDataQuerieserreichen.DasbetrifftinsbesonderekomplexeQueriesmit
vielenJoinsundAggregationenwiesieoftimUmfeldvonBusinessIntelligenceundBusiness
Analyticsvorkommen.
Insbesondere die Ladeprozesse der Dimensionstabellen und Cubes durch Spark werden um
biszu344%erheblichbeschleunigt.DadieseArtvonLadeprozesseninjedemJedoxRoll-out
vorkommt, sollte unserer Meinung nach ein Hive on Spark Einsatz grundsätzlich in Betracht ge-
zogenwerden-auchwennsichdieSpark-UnterstützungzumaktuellenZeitpunktnochineinem
experimentellenStatusbefindet.ZukünftigistbeieinerWeiterentwicklungvonHive on Spark mit
noch größeren Leistungssteigerungen zu rechnen.
Trotz der deutlichen Vorteile von Hive on SparkgibtesleideraucheinenkleinenWermutstrop-
fen:KonfigurationseinstellungenfürHive on Spark können immer nur pro Verbindung als zusätz-
licherGET-ParameterinderJDBCURLangelegtwerden.DasÜberschreibenvonParameternpro
QueryunddamiteinmöglichesTuningistindervonunsbenutzenJedox-Versionnichtmöglich.
17

it-novum Profil
Ihr Ansprechpartner für Business Intelligence und Big Data: Stefan Müller DirectorBigDataAnalytics
+49(0)661103942
Führend in Business Open Source-Lösungen und -Beratungit-novumistdasführendeIT-BeratungsunternehmenfürBusinessOpenSourceimdeutschsprachigenMarkt.
Gegründet 2001 ist it-novum heute eine Konzerntochter der börsennotierten KAP Beteiligungs-AG.
Mitunseren85MitarbeiternbetreuenwirvomHauptsitzinFuldaunddenNiederlassungeninDüsseldorf,Dortmund,
WienundZürichausvorwiegendgroßeMittelstandskundensowieGroßunternehmenimdeutschsprachigenRaum.
WirsindzertifizierterSAPBusinessPartnerundlangjährigerakkreditierterPartnerzahlreicherOpenSource-
Produkte. Unsere Schwerpunkte sind die Integration von Open Source mit Closed Source und die Entwicklung
kombinierterOpenSource-Lösungenund-Plattformen.
MitseinerISO9001Zertifizierunggehörtit-novumzudenwenigenOpenSource-Spezialisten,
diedieBusinesstauglichkeitihrerLösungenauchdurcheinQualitätssicherungssystembelegen.
Über 15 Jahre Open Source-Projekterfahrung ▶ Unser Portfolio umfasst die vielfältige Bandbreite von Open Source-Lösungen im Applications- und
Infrastruktur-Bereichsowieeigene,imMarktetablierteProduktentwicklungen.
▶ AlsIT-BeratungshausmitprofundertechnischerExpertiseimBusinessOpenSource-Bereichgrenzenwirunsvon
den Standardangeboten der großen Lösungsanbieter ab. Denn unsere Lösungen sind nicht nur skalierbar und
flexibelanpassbar,sondernfügensichauchnahtlosinIhrebestehendeIT-Infrastrukturein.
▶ Wir stellen fachübergreifende Projektteams zur Verfügung, bestehend aus Entwicklern, Consultants und
Wirtschaftsinformatikern. So verbinden wir Business Know-how mit Technologieexzellenz und schaffen
nachhaltigeGeschäftsprozesse.
▶ UnserZielistes,IhneneinequalitativhochwertigeBeratunginallenProjektphasenzubieten–vonderAnalyse,
über die Konzeption bis hin zu Umsetzung und Support.
▶ AlsEntscheidungshilfevorProjektbeginnbietenwirIhneneinenProof-of-Conceptan.DurchdiePraxissimulation
unddenerstelltenPrototypenkönnenSiesichrisikofreifüreineneueSoftwareentscheidenundprofitierenvon
SicherheitundPlanbarkeit,klareProjektmethodikundvernünftigeKalkulation.
it-novum GmbH DeutschlandHauptsitz Fulda: Edelzeller Straße 44 · 36043 FuldaTelefon:+49(0)661103333NiederlassungeninDüsseldorf&Dortmund
it-novum Schweiz GmbHHotelstrasse 1 ·8058ZürichTelefon:+41(0)445676207
it-novum Zweigniederlassung ÖsterreichAusstellunsstraße50/ZugangC·1020WienTelefon:+4312057741041
Recommended

















