Design of Scalable Dense Linear Algebra Librariesfor Multicore Processors and Multi-GPU Platforms
Enrique S. Quintana-Ortı[email protected]
High Performance Computing & Architectures GroupUniversidad Jaime I de Castellon (Spain)
Braunschweig – July, 2008
Dense Linear Algebra on Parallel Architectures 1

Joint work with:
Sergio Barrachina Ernie ChanMaribel Castillo Robert van de GeijnFrancisco D. Igual Field G. Van ZeeRafael MayoGregorio Quintana-OrtıRafael Rubio
Universidad Jaime I (Spain) The University of Texas at Austin
Supported by:
National Science Foundation (NSF)Spanish Office of ScienceNational InstrumentsNVIDIA. . .
Dense Linear Algebra on Parallel Architectures 2

General Motivation
Who has a multicore processor on the desktop/laptop?
Are you using more than 1 core?
Who has a recent graphics card on the desktop/laptop?
Are you using it for something else than games? ;-)
Dense Linear Algebra on Parallel Architectures 3

General Motivation
Who has a multicore processor on the desktop/laptop?
Are you using more than 1 core?
Who has a recent graphics card on the desktop/laptop?
Are you using it for something else than games? ;-)
Dense Linear Algebra on Parallel Architectures 4

Outline
Part I: Multicore processors
Part II: GPUs
Dense Linear Algebra on Parallel Architectures 5

Motivation
New dense linear algebra libraries for multicore processors
Scalability for manycore
Data locality
Heterogeneity?
Dense Linear Algebra on Parallel Architectures 6

Motivation
LAPACK (Linear Algebra Package)
Fortran-77 codes
One routine (algorithm) per operation in the library
Storage in column major order
Parallelism extracted from calls to multithreaded BLAS
Extracting parallelism only from BLAS limits the amount ofparallelism and, therefore, the scalability of the solution!
Column major order does hurt data locality
Dense Linear Algebra on Parallel Architectures 7

Motivation
FLAME (Formal Linear Algebra Methods Environment)
Libraries of algorithms, not codes
Notation reflects the algorithm
APIs to transform algorithms into codes
Systematic derivation procedure (automated usingMathematica)
Storage and algorithm are independent
Parallelism dictated by data dependencies, extracted atexecution time
Storage-by-blocks
Dense Linear Algebra on Parallel Architectures 8

Outline
Part I: Multicore processors
1 Motivation
2 Cholesky factorization (Overview of FLAME)
3 Parallelization
4 Other matrix factorizations: LU & QR
5 Experimental results
6 Concluding remarks
Part II: GPUs
Dense Linear Algebra on Parallel Architectures 9

The Cholesky Factorization
Definition
Given A→ n× n symmetric positive definite, compute
A = L · LT ,
with L→ n× n lower triangular
Dense Linear Algebra on Parallel Architectures 10

The Cholesky Factorization: Whiteboard Presentation
done
done
done
A(partially
updated)
?
α11 ?
a21 A22
?
α11:=√α11
?
a21:=a21/α11
A22:=
A22−a21aT21
?
done
done
done
A(partially
updated)
Dense Linear Algebra on Parallel Architectures 11

FLAME Notation
done
done
done
A(partially
updated)
?
α11 aT12
a21 A22
Repartition„ATL ATR
ABL ABR
«
→
0BB@A00 a01 A02
aT10 α11 aT
12
A20 a21 A22
1CCAwhere α11 is a scalar
Dense Linear Algebra on Parallel Architectures 12

FLAME Notation
Algorithm: [A] := Chol unb(A)
Partition A→“
AT L AT R
ABL ABR
”where ATL is 0× 0
while n(ABR) 6= 0 do
Repartition„ATL ATRABL ABR
«→
0@ A00 a01 A02
aT10 α11 aT12
A20 a21 A22
1Awhere α11 is a scalar
α11 :=√α11
a21 := a21/α11
A22 := A22 − a21aT21
Continue with„ATL ATRABL ABR
«←
0@ A00 a01 A02
aT10 α11 aT12
A20 a21 A22
1Aendwhile
Dense Linear Algebra on Parallel Architectures 13

FLAME/C Code
From algorithm to code. . .
FLAME notationRepartition„ATL ATR
ABL ABR
«→
0@ A00 a01 A02
aT10 α11 aT12
A20 a21 A22
1Awhere α11 is a scalar
FLAME/C codeFLA_Repart_2x2_to_3x3(
ATL, /**/ ATR, &A00, /**/ &a01, &A02,
/* ************** */ /* *************************** */
&a10t, /**/ &alpha11, &a12t,
ABL, /**/ ABR, &A20, /**/ &a21, &A22,
1, 1, FLA_BR );
Dense Linear Algebra on Parallel Architectures 14

(Unblocked) FLAME/C Code
int FLA_Cholesky_unb( FLA_Obj A )
{
/* ... FLA_Part_2x2( ); ... */
while ( FLA_Obj_width( ATL ) < FLA_Obj_width( A ) ){
FLA_Repart_2x2_to_3x3(
ATL, /**/ ATR, &A00, /**/ &a01, &A02,
/* ************* */ /* ************************** */
&a10t, /**/ &alpha11, &a12t,
ABL, /**/ ABR, &A20, /**/ &a21, &A22,
1, 1, FLA_BR );
/*------------------------------------------------------------*/
FLA_Sqrt( alpha11 ); /* a21 := sqrt( alpha11 ) */
FLA_Inv_Scal( alpha11, a21 ); /* a21 := a21 / alpha11 */
FLA_Syr ( FLA_MINUS_ONE,
a21, A22 ); /* A22 := A22 - a21 * a21t */
/*------------------------------------------------------------*/
/* FLA_Cont_with_3x3_to_2x2( ); ... */
}
}
Dense Linear Algebra on Parallel Architectures 15

Blocked FLAME/C Code
int FLA_Cholesky_blk( FLA_Obj A, int nb_alg )
{
/* ... FLA_Part_2x2( ); ... */
while ( FLA_Obj_width( ATL ) < FLA_Obj_width( A ) ){
b = min( FLA_Obj_length( ABR ), nb_alg );
FLA_Repart_2x2_to_3x3(
ATL, /**/ ATR, &A00, /**/ &A01, &A02,
/* ************* */ /* ******************** */
&A10, /**/ &A11, &A12,
ABL, /**/ ABR, &A20, /**/ &A21, &A22,
b, b, FLA_BR );
/*------------------------------------------------------------*/
FLA_Cholesky_unb( A11 ); /* A21 := Cholesky( A11 ) */
FLA_Trsm_rltn( FLA_ONE, A11,
A21 ); /* A21 := A21 * inv( A11 )’*/
FLA_Syrk_ln ( FLA_MINUS_ONE, A21,
A22 );/* A22 := A22 - A21 * A21’ */
/*------------------------------------------------------------*/
/* FLA_Cont_with_3x3_to_2x2( ); ... */
}
}
Dense Linear Algebra on Parallel Architectures 16

FLAME Code
Visit http://www.cs.utexas.edu/users/flame/Spark/. . .
C code: FLAME/C
M-script code formatlab: FLAME@lab
Other APIs:
FLATEXFortran-77LabViewMessage-passingparallel:PLAPACKFLAG: GPUs
Dense Linear Algebra on Parallel Architectures 17

Outline
1 Motivation
2 Cholesky factorization (Overview of FLAME)
3 Parallelization
4 Other matrix factorizations: LU & QR
5 Experimental results
6 Concluding remarks
Part II: GPUs
Dense Linear Algebra on Parallel Architectures 18

Parallelization on Multithreaded Architectures
LAPACK parallelization: kernels in multithread BLASA11 ?
A21 A22
, A11 is b× b
Advantage: Use legacy code
Drawbacks:
Each call to BLAS is a synchronization point for threadsAs the number of threads increases, serial operations with costO(nb2) are no longer negligible compared with O(n2b)
Dense Linear Algebra on Parallel Architectures 19

Parallelization on Multithreaded Architectures
FLAME parallelization: SuperMatrix
Traditional (and pipelined) parallelizations are limited by thecontrol dependencies dictated by the code
The parallelism should be limited only by the datadependencies between operations!
In dense linear algebra, imitate a superscalar processor:dynamic detection of data dependencies
Dense Linear Algebra on Parallel Architectures 20

FLAME Parallelization: SuperMatrix
int FLA_Cholesky_blk( FLA_Obj A, int nb_alg )
{
/* ... FLA_Part_2x2( ); ... */
while ( FLA_Obj_width( ATL ) < FLA_Obj_width( A ) ){
b = min( FLA_Obj_length( ABR ), nb_alg );
/* ... FLA_Repart_2x2_to_3x3( ); ... */
/*------------------------------------------------------------*/
FLA_Cholesky_unb( A11 ); /* A21 := Cholesky( A11 ) */
FLA_Trsm_rltn( FLA_ONE, A11,
A21 ); /* A21 := A21 * inv( A11 )’*/
FLA_Syrk_ln ( FLA_MINUS_ONE, A21,
A22 );/* A22 := A22 - A21 * A21’ */
/*------------------------------------------------------------*/
/* FLA_Cont_with_3x3_to_2x2( ); ... */
}
}
The FLAME runtime system “pre-executes” the code:
Whenever a routine is encountered, a pending task isannotated in a global task queue
Dense Linear Algebra on Parallel Architectures 21

FLAME Parallelization: SuperMatrix
(A00 ? ?
A10 A11 ?
A20 A21 A22
)Runtime→
1 FLA Cholesky unb(A00)
2 A10 := A10 tril (A00)−T
3 A20 := A20 tril (A00)−T
4 A11 := A11 −A10AT10
5 . . .
SuperMatrix
Once all tasks are annotated, the real execution begins!
Tasks with all input operands available are runnable; othertasks must wait in the global queue
Upon termination of a task, the corresponding thread updatesthe list of pending tasks
Dense Linear Algebra on Parallel Architectures 22

FLAME Storage-by-Blocks: FLASH
Algorithm and storage are independent
Matrices stored by blocks are viewed as matrices of matrices
No significative modification to the FLAME codes
Dense Linear Algebra on Parallel Architectures 23

Outline
1 Motivation
2 Cholesky factorization (Overview of FLAME)
3 Parallelization
4 Other matrix factorizations: LU & QR
5 Experimental results
6 Concluding remarks
Part II: GPUs
Dense Linear Algebra on Parallel Architectures 24

LU factorization
Pivoting for stability limits the amount of parallelismA11 A12
A21 A22
, A11 is b× b
All operations on A22 must wait till
(A11
A21
)is factorized
Algorithms-by-blocks for the Cholesky factorization do notpresent this problem
Is it possible to design an algorithm-by-blocks for the LUfactorization while maintaining pivoting?
Dense Linear Algebra on Parallel Architectures 25

LU factorization with incremental pivoting
A11 A12 A13
A21 A22 A23
A31 A32 A33
, Aij is t× t
1 Factorize P11A11 = L11U11
2 Apply permutation P11 and factor L11:
L−111 P11A12 L−1
11 P11A13
3 Factorize P21
(A11
A21
)= L21U21,
4 Apply permutation P21 and factor L21:
L−121 P21
„A12
A22
«L−1
21 P21
„A13
A23
«5 Repeat steps 2–4 with A31
Dense Linear Algebra on Parallel Architectures 26

LU factorization with incremental pivoting
A11 A12 A13
A21 A22 A23
A31 A32 A33
, Aij is t× t
Different from LU factorization with column pivoting
To preserve structure, permutations only applied to blocks onthe right!
To obtain high performance a blocked algorithm with blocksize b� t, is used in the factorization and application offactors
To maintain the computational cost, the upper triangularstructure of A11 is exploited during the factorization
Dense Linear Algebra on Parallel Architectures 27

LU factorization with incremental pivoting
Stability? Element growth with random matrices:
Dense Linear Algebra on Parallel Architectures 28

QR factorization
Same problem as with LU: proceeding by blocks of columnslimits the amount of parallelism
A11 A12
A21 A22
, A11 is b× b
All operations on A22 must wait till
(A11
A21
)is factorized
Is it possible to design an algorithm-by-blocks for the QRfactorization while maintaining pivoting?
Dense Linear Algebra on Parallel Architectures 29

QR factorization by blocks
A11 A12 A13
A21 A22 A23
A31 A32 A33
, Aij is t× t
1 Factorize Q11A11 = R11
2 Apply factor Q11:QT
11A12 QT11A13
3 Factorize Q21
(A11
A21
)= R21,
4 Apply factor Q21:
QT21
„A12
A22
«QT
21
„A13
A23
«5 Repeat steps 2–4 with A31
Dense Linear Algebra on Parallel Architectures 30

Outline
1 Motivation
2 Cholesky factorization (Overview of FLAME)
3 Parallelization
4 Other matrix factorizations: LU & QR
5 Experimental results
6 Concluding remarks
Part II: GPUs
Dense Linear Algebra on Parallel Architectures 31

Experimental Results
General
Platform Specs.
set CC-NUMA with 16 Intel Itanium-2 processors
neumann SMP with 8 dual-core Intel Pentium4 processors
Implementations
LAPACK 3.0 routine + multithreaded MKL
Multithreaded routine in MKL
AB + serial MKL
AB + serial MKL + storage-by-blocks
Dense Linear Algebra on Parallel Architectures 32

Experimental Results
0
10
20
30
40
50
60
70
80
90
0 2000 4000 6000 8000 10000
GF
LOP
S
Matrix size
Cholesky factorization on 16 Intel Itanium [email protected]
ABMKLLAPACK
Dense Linear Algebra on Parallel Architectures 33

Experimental Results
0
10
20
30
40
50
60
70
0 2000 4000 6000 8000 10000
GF
LOP
S
Matrix size
Cholesky factorization on 8 dual AMD [email protected]
ABMKLLAPACK
Dense Linear Algebra on Parallel Architectures 34

Experimental Results
0
10
20
30
40
50
60
70
80
90
0 2000 4000 6000 8000 10000
GF
LOP
S
Matrix size
LU factorization on 16 Intel Itanium [email protected]
ABMKLLAPACK
Dense Linear Algebra on Parallel Architectures 35

Experimental Results
0
10
20
30
40
50
60
70
0 2000 4000 6000 8000 10000
GF
LOP
S
Matrix size
LU factorization on 8 dual AMD [email protected]
ABMKLLAPACK
Dense Linear Algebra on Parallel Architectures 36

Experimental Results
0
10
20
30
40
50
60
70
80
90
0 2000 4000 6000 8000 10000
GF
LOP
S
Matrix size
QR factorization on 16 Intel Itanium [email protected]
ABMKLLAPACK
Dense Linear Algebra on Parallel Architectures 37

Experimental Results
0
10
20
30
40
50
60
70
0 2000 4000 6000 8000 10000
GF
LOP
S
Matrix size
QR factorization on 8 dual AMD [email protected]
ABMKLLAPACK
Dense Linear Algebra on Parallel Architectures 38

Experimental Results
0
5
10
15
20
25
30
35
40
45
200 400 600 800 1000 1200
GF
LOP
S
Bandwidth (kd)
Band Cholesky factorization on 16 Intel Itanium [email protected] GHz; n=5,000
LAPACK (4 proc.)AB
Dense Linear Algebra on Parallel Architectures 39

Experimental Results
0
5
10
15
20
25
30
200 400 600 800 1000 1200
GF
LOP
S
Bandwidth (kd)
Band Cholesky factorization on 8 dual AMD [email protected] GHz; n=5,000
LAPACKAB
Dense Linear Algebra on Parallel Architectures 40

Outline
1 Motivation
2 Cholesky factorization (Overview of FLAME)
3 Parallelization
4 Experimental results
5 Concluding remarks
Part II: GPUs
Dense Linear Algebra on Parallel Architectures 41

Concluding Remarks
More parallelism is needed to deal with the large number ofcores of future architectures and data locality issued:traditional dense linear algebra libraries will have to berewritten
Some operations require new algorithms to better exposeparallelism: LU with incremental pivoting, tiled QR,. . .
The FLAME infrastructure (FLAME/C API, FLASH, andSuperMatrix) reduces the time to take an algorithm fromwhiteboard to high-performance parallel implementation
Dense Linear Algebra on Parallel Architectures 42

Outline
Part I: Multicore processorsPart II: GPUs
Dense Linear Algebra on Parallel Architectures 43

Motivation
The power and versatility of modern GPU have transformed theminto the first widely extended HPC platform
Dense Linear Algebra on Parallel Architectures 44

Outline
Part I: Multicore processorsPart II: GPUs
1 Motivation
2 Introduction
3 LAPACK on 1 GPU
4 LAPACK on multiple GPUs
5 FLAG@lab
6 Concluding remarks
Dense Linear Algebra on Parallel Architectures 45

Outline
Part I: Multicore processorsPart II: GPUs
1 Motivation
2 Introduction
3 LAPACK on 1 GPU
4 LAPACK on multiple GPUs
5 FLAG@lab
6 Concluding remarks
Dense Linear Algebra on Parallel Architectures 46
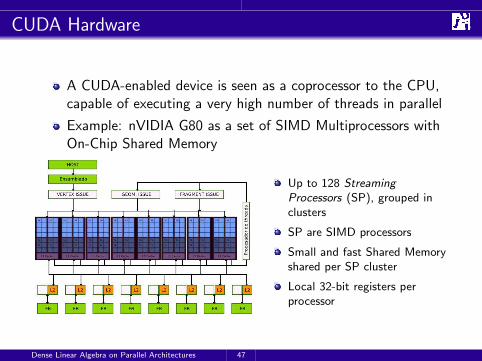
CUDA Hardware
A CUDA-enabled device is seen as a coprocessor to the CPU,capable of executing a very high number of threads in parallel
Example: nVIDIA G80 as a set of SIMD Multiprocessors withOn-Chip Shared Memory
Up to 128 StreamingProcessors (SP), grouped inclusters
SP are SIMD processors
Small and fast Shared Memoryshared per SP cluster
Local 32-bit registers perprocessor
Dense Linear Algebra on Parallel Architectures 47

CUDA Software
The CUDA API provides a simple framework for writing Cprograms for execution on the GPU
Consists of:
A minimal set of extensions to the C languageA runtime library of routines for controlling the transfersbetween video and main memory, run-time configuration,execution of device-specific functions, handling multipleGPUs,. . .
CUDA libraries
On top of CUDA, nVIDIA provides two optimized libraries:CUFFT and CUBLAS
Dense Linear Algebra on Parallel Architectures 48

CUBLAS Example
i n t main ( vo id ){. . .f l o a t∗ h v e c t o r , ∗ d v e c t o r ;
h v e c t o r = ( f l o a t ∗) m a l l o c (M∗ s i z e o f ( f l o a t ) ) ;
. . . // I n i t i a l i z e v e c t o r o f M f l o a t sc u b l a s A l l o c (M, s i z e o f ( f l o a t ) ,
( vo id ∗∗) &d v e c t o r ) ;
c u b l a s S e t V e c t o r (M, s i z e o f ( f l o a t ) , h v e c t o r ,d v e c t o r , 1 ) ;
c u b l a s S s c a l (M, ALPHA, d v e c t o r , 1 ) ;c u b l a s G e t V e c t o r (M, s i z e o f ( f l o a t ) , d v e c t o r ,
h v e c t o r , 1 ) ;
c u b l a s F r e e ( d v e c t o r ) ;. . .}
A typical CUDA (andCUBLAS) program has 3phases:
1 Allocation and transfer ofdata to GPU
2 Execution of the BLASkernel
3 Transfer of results back tomain memory
Dense Linear Algebra on Parallel Architectures 49

Outline
Part I: Multicore processorsPart II: GPUs
1 Motivation
2 Introduction
3 LAPACK on 1 GPU
4 LAPACK on multiple GPUs
5 FLAG@lab
6 Concluding remarks
Dense Linear Algebra on Parallel Architectures 50

Cholesky factorization. Blocked variants
Algorithm: A := Chol blk(A)
Partition . . .where . . .
while m(ATL) < m(A) doDetermine block size bRepartition„
ATL ATRABL ABR
«→
0@ A00 A01 A02
A10 A11 A12
A20 A21 A22
1Awhere A11 is b× b
Variant 1:A11 := Chol unb(A11)
A21 := A21tril (A11)−T
A22 := A22 −A21AT21
Variant 2:
A10 := A10tril (A00)−T
A11 := A11 −A10AT10
A11 := Chol unb(A11)
Variant 3:A11 := A11 −A10AT
10A11 := Chol unb(A11)A21 := A21 −A20AT
10
A21 := A21tril (A11)−T
Continue with. . .
endwhile
Dense Linear Algebra on Parallel Architectures 51

Cholesky factorization. Experimental results
0
5
10
15
20
25
30
35
40
0 1000 2000 3000 4000 5000
GF
LOP
S
Matrix dimension
Cholesky factorization. Blocked variants
CPU Variant 1CPU Variant 2CPU Variant 3GPU Variant 1GPU Variant 2GPU Variant 3
Dense Linear Algebra on Parallel Architectures 52

Cholesky padding. Experimental results
0
5
10
15
20
25
30
35
40
0 1000 2000 3000 4000 5000
GF
LOP
S
Matrix dimension
Cholesky factorization. Blocked variants with padding
GPU Variant 1 + paddingGPU Variant 2 + paddingGPU Variant 3 + paddingGPU Variant 1GPU Variant 2GPU Variant 3
Dense Linear Algebra on Parallel Architectures 53

Cholesky hybrid and recursive. Experimental results
0
10
20
30
40
50
0 1000 2000 3000 4000 5000
GF
LOP
S
Matrix dimension
Cholesky factorization. Recursive and hybrid variants
GPU Variant 1GPU Variant 1. HybridGPU Variant 1. Recursive+Hybrid
Dense Linear Algebra on Parallel Architectures 54

Iterative refinement for extended precision
Compute the Cholesky factorization A = LLT and solve(LLT )x = b in the GPU
→ 32 bits of accuracy!
i← 1repeat
r(i) ← b−A · x(i)
r(i)(32) ← r(i)
z(i)(32) ← L−T(32)(L
−1(32)r
(i)(32))
z(i) ← z(i)(32)
x(i+1) ← x(i) + z(i)
i← i+ 1until ‖r(i)‖ <
√ε‖x(i)‖
Dense Linear Algebra on Parallel Architectures 55

Iterative refinement. Experimental results
0
1
2
3
4
5
6
0 1000 2000 3000 4000 5000
Tim
e (s
)
Problem size
Solution of a linear system - Cholesky
LAPACK - Double precisionVariant 1 - Mixed precisionVariant 1 - Single precision
Dense Linear Algebra on Parallel Architectures 56

Outline
Part I: Multicore processorsPart II: GPUs
1 Motivation
2 Introduction
3 LAPACK on 1 GPU
4 LAPACK on multiple GPUs
5 FLAG@lab
6 Concluding remarks
Dense Linear Algebra on Parallel Architectures 57

What if multiple GPUs are available?
Already here:
Multiple ClearSpeed boards
Multiple NVIDIA cards
nVIDIA Tesla series
How are we going to program these?
Dense Linear Algebra on Parallel Architectures 58

What if multiple GPUs are available?
Already here:
Multiple ClearSpeed boards
Multiple NVIDIA cards
nVIDIA Tesla series
How are we going to program these?
Dense Linear Algebra on Parallel Architectures 58

Porting SuperMatrix to multiple GPUs
Employ the equivalence: 1 core ≡ 1 GPU
Difference: Transference from RAM to video memory
Run-time system (scheduling), storage, and code areindependent
No significative modification to the FLAME codes: Interfacingto CUBLAS
A software effort of two hours!
Dense Linear Algebra on Parallel Architectures 59

Experimental setup
CPU GPU
Processor 16 x Intel Itanium2 nvidia Tesla s870 (4 G80)Clock frequency 1.5 GHz 575 MHz
Dense Linear Algebra on Parallel Architectures 60

Porting SuperMatrix. Experimental results
0
20
40
60
80
100
120
140
0 2048 4096 6144
GF
LOP
S
Matrix size
Cholesky factorization on 4 GPU of NVIDIA S870
AB + no 2dAB + 2d
AB + 2d + block cacheAB + 2d + block cache + page-locked
Dense Linear Algebra on Parallel Architectures 61

Porting SuperMatrix. Experimental results
A more elaborate port required for high-performance:
2-D work distribution
Memory/cache coherence techniques to reduce transferencesbetween RAM and video memory: write-back andwrite-invalidate
Dense Linear Algebra on Parallel Architectures 62
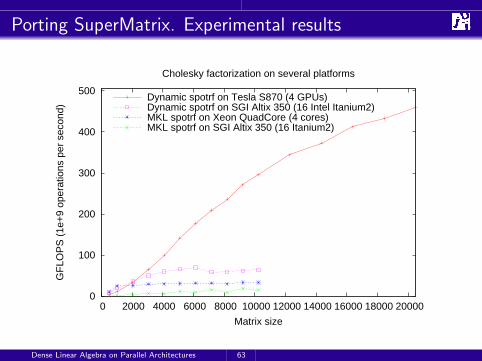
Porting SuperMatrix. Experimental results
0
100
200
300
400
500
0 2000 4000 6000 8000 10000 12000 14000 16000 18000 20000
GF
LOP
S (
1e+
9 op
erat
ions
per
sec
ond)
Matrix size
Cholesky factorization on several platforms
Dynamic spotrf on Tesla S870 (4 GPUs)Dynamic spotrf on SGI Altix 350 (16 Intel Itanium2)MKL spotrf on Xeon QuadCore (4 cores)MKL spotrf on SGI Altix 350 (16 Itanium2)
Dense Linear Algebra on Parallel Architectures 63

Outline
Part I: Multicore processorsPart II: GPUs
1 Motivation
2 Introduction
3 LAPACK on 1 GPU
4 LAPACK on multiple GPUs
5 FLAG@lab
6 Concluding remarks
Dense Linear Algebra on Parallel Architectures 64

FLAG@lab
Assorted flavours:
FLAG: A M-script API for GPU computing fromMatlab/Octave
FLAGOOC: A M-script API for Out-of-Core GPU computingfrom Matlab/Octave
Dense Linear Algebra on Parallel Architectures 65

High-level APIs: FLAG
function [ A ] = FLAG_Chol( A )
% [ ... ] = FLAG_Part_2x2( ... );
while ( FLAG_Obj_length( ATL, 1 ) < FLAG_Obj_length( A, 1 ) )
b = min( FLAG_Obj_length( ABR, 1 ), nb_alg );
% [ ... ] = FLAG_Repart_2x2_to_3x3( ... );
%------------------------------------------------------------%
FLAG_Chol_unb( A11 ); % A11 = Chol( A11 )
FLAG_Trsm_rltn( 1.0, A11,
A21 ); % A21 = A21 * tril( A11 )^-T
FLAG_Syrk_ln( -1.0, A21,
1.0, A22 ); % A22 = A22 - A21 * A21’;
%------------------------------------------------------------%
% [ ... ] = FLAG_Cont_with_3x3_to_2x2( ... );
end
Just replace FLA in FLAME@lab by FLAG !
Dense Linear Algebra on Parallel Architectures 66

Concluding Remarks
Simple precision may not be enough. Double precision iscoming, but at the expense of speed?
Overlap transferences and computation is also needed (close?)
Programming dense linear algebra using CUBLAS on NVIDIAhardware is easy
Programming at CUDA level?I’ll need to ask my student Francisco...
Dense Linear Algebra on Parallel Architectures 67

Concluding Remarks
Simple precision may not be enough. Double precision iscoming, but at the expense of speed?
Overlap transferences and computation is also needed (close?)
Programming dense linear algebra using CUBLAS on NVIDIAhardware is easy
Programming at CUDA level?I’ll need to ask my student Francisco...
Dense Linear Algebra on Parallel Architectures 67

Related Publications
E. Chan, E.S. Quintana-Ortı, G. Quintana-Ortı, R. van de Geijn. SuperMatrixout-of-order scheduling of matrix operations for SMP and multicorearchitectures. 19th ACM Symp. on Parallelism in Algorithms and Architectures– SPAA’2007.
E. Chan, F. Van Zee, R. van de Geijn, E.S. Quintana-Ortı, G. Quintana-Ortı.Satisfying your dependencies with SuperMatrix. IEEE Cluster 2007.
E. Chan, F.G. Van Zee, P. Bientinesi, E.S. Quintana-Ortı, G. Quintana-Ortı, R.van de Geijn. SuperMatrix: A multithreaded runtime scheduling system foralgorithms-by-blocks. Principles and Practices of Parallel Programming –PPoPP’2008.
E.S. Quintana-Ortı, R. van de Geijn. Updating an LU factorization withpivoting. ACM Trans. on Mathematical Software, 2008.
Dense Linear Algebra on Parallel Architectures 68

Related Publications
S. Barrachina, M. Castillo, Francisco D. Igual, R. Mayo, E. S. Quintana-Ort´ i.Evaluation and tuning of the level 3 CUBLAS for graphics processors. Workshopon Parallel and Distributed Scientific and Engineering Computing,– PDSEC’2008.
S. Barrachina, M. Castillo, F. Igual, R. Mayo, E. S. Quintana. Solving denselinear systems on graphics processors. Euro-Par’2008.
M. Castillo, F. Igual, R. Mayo, R. Rubio, E. S. Quintana, G. Quintana, R. vande Geijn. Out-of-Core Solution of Linear Systems on Graphics Processors.Parallel/High-Performance Object-Oriented Scientific Computing – POOSC’08 .
Dense Linear Algebra on Parallel Architectures 69

Related Approaches
Cilk (MIT) and CellSs (Barcelona SuperComputing Center)
General-purpose parallel programming
Cilk → irregular problemsCellSs → for the Cell B.E.
High-level language based on OpenMP-like pramas +compiler + runtime system
Moderate results for dense linear algebra
PLASMA (UTK – Jack Dongarra)
Traditional style of implementing algorithms: Fortran-77
Complicated coding
Runtime system + ?
Dense Linear Algebra on Parallel Architectures 70

For more information. . .
Visit http://www.cs.utexas.edu/users/flame
Support. . .
National Science Foundation awards CCF-0702714 andCCF-0540926 (ongoing till 2010)
Spanish CICYT project TIN2005-09037-C02-02
Dense Linear Algebra on Parallel Architectures 71
Recommended